


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于渐进式嵌套特征的融合网络
[孙君顶1  , 王金凯
, 王金凯1 , 唐朝生1 , 毋小省1 ]
, 王金凯, 唐朝生, 毋小省]
|
|



作者简介:

王金凯,硕士研究生,主要研究方向为显著性目标检测.E-mail:853865671@qq.com.

唐朝生,博士,讲师,主要研究方向为医学图像处理.E-mail:tcs@hpu.edu.cn.

毋小省,硕士,副教授,主要研究方向为图像处理、模式识别.E-mail:wuxs@hpu.edu.cn.
显著目标检测是指通过引入人类视觉注意力机制,使计算机能检测视觉场景中人们最感兴趣的区域或对象.针对显著性目标检测中存在检测边缘不清晰、检测目标不完整及小目标漏检的问题,文中提出基于渐进式嵌套特征的融合网络.网络采用渐进式压缩模块,将较深层特征不断向下传递融合,在降低模型参数量的同时也充分利用高级语义信息.先设计加权特征融合模块,将编码器的多尺度特征聚合成可访问高级信息和低级信息的特征图.再将聚合的特征分配到其它层,充分获取图像上下文信息及关注图像中的小目标对象.同时引入非对称卷积模块,进一步提高检测准确性.在6个公开数据集上的实验表明文中网络取得较优的检测效果.
About Author:
WANG Jinkai, master student. His research interests include salient object detection.
TANG Chaosheng, Ph.D., lecturer. His research interests include medical image processing.
WU Xiaosheng, master, associate professor. Her research interests include image processing and pattern recognition
In salient object detection, the computer detects the most interesting areas or objects in the visual scene by means of introducing the human visual attention mechanism. Aiming at the problems of unclear edge, incomplete object and missing detection of small objects in salient object detection, a fusion network based on progressive nested feature is proposed. Progressive compression module is adopted to continuously transfer and merge deeper features downward and make full use of advanced semantic information while the number of model parameters is reduced. A weighted feature fusion module is designed to aggregate the multi-scale features of the encoder into a feature map that can access both high-level and low-level information. Then, the aggregated features are allocated to other layers to fully obtain image context information and focus on small objects in the image. The asymmetric convolution block is introduced to further improve the detection accuracy. Experiments on six open datasets show that the proposed network achieves good detection results.
显著性目标检测(Salient Object Detection, SOD)旨在检测图像中吸引人类注意力的对象, 在计算机视觉任务中具有广泛应用.传统检测方法往往依赖图像局部细节和全局上下文信息, 由于缺乏高级语义信息, 在复杂场景上的检测能力较弱[1, 2].
近年来, 基于深度学习的方法在显著性目标检测方面取得较优性能[2], 尤其是基于特征金字塔网络(Feature Pyramid Network, FPN)[3]的检测框架.基于FPN的检测框架主要分为3种类型:自底向上编码流框架、多尺度特征预测框架和自顶向下解码流框架.
自底向上编码流框架基本原理是基于自底向上的编码器实现特征提取, 再在编码器的顶部附加一个简单的分类器, 预测像素的显著性映射.该框架往往设计一个或多个正向的网络路径以预测显著性目标图.Liu等[4]构建3种自底向上的编码器, 应对3种不同分辨率的输入图像.Li等[5]在设计三路径框架提取多尺度特征的基础上采用两个全连接层, 实现显著性目标的预测.Li等[6]使用共享的自底向上编码路径及2个并行预测头, 完成语义分割和显著性预测.
多尺度特征预测框架基本原理是在编码器的多个阶段进行预测.Hou等[7]在整体嵌套边缘检测的网络体系结构[8]中引入skip-layer结构, 用于增强多尺度特征.Zhao等[9]引入空间注意力机制和通道注意力机制, 分别实现低级特征和高级特征的增强.Gao等[10]提出gOctConv(Generalized Octave Convo-lution), 基于动态权值衰减方案减少表示冗余.Wu等[11]提出CPD(Cascaded Partial Decoder), 实现快速准确的显著性目标检测.之后, Wu等[12]提出SCRN(Stacked Cross Refinement Network), 通过堆叠交叉细化单元同时细化显著目标检测和边缘检测的多层次特征.
自顶向下解码流框架采用编码器-解码器体系结构, 由编码器特征图逐层融合得到解码器.Liu等[13]提出PoolNet, 设计基于池化的U型架构, 同时引入全局引导模块和特征聚合模块, 引导自顶向下的路径.Feng等[14]提出注意反馈模块, 较好地探索物体结构.Lee等[15]提出TRACER(Extreme Atten-tion Guided Salient Object Tracing Network), 合并注意引导跟踪模块, 检测具有显式边缘的显著对象.Liu等[16]提出PoolNet+, 设计特征聚合模块, 无缝融合低级语义信息与自上而下路径中的细粒度特征.Xie等[17]提出Pyramid Grafting Network, 利用Trans-former和卷积神经网络(Convolutional Neural Net-work, CNN)主干, 分别从不同分辨率图像中提取特征, 再将特征从Transformer分支移植到CNN分支.Fang等[18]设计渐进压缩快捷路径, 将编码器高级特征中的传播语义信息增强到解码器的底部卷积块, 形成密集嵌套的自上而下特征流.Zhao等[19]提出EGNet(Edge Guidance Network), 通过渐进融合的方式提取显著的对象特征, 并整合局部边缘信息和全局位置信息, 得到显著的边缘特征.
虽然基于上述检测框架的网络在显著性目标检测中都取得较优的检测效果, 但是在特征传递过程中往往存在语义信息被稀释的问题, 造成目标缺失、背景误判等现象.同时, 上述网络往往只是在最后的特征融合阶段才能访问图像的细粒度特征, 造成预测结果边缘不清晰的问题.针对上述问题, 本文提出基于渐进式嵌套特征的融合网络(Fusion Network Based on Progressive Nested Feature, PNFFNet).为了解决高级语义信息被逐渐稀释的问题, 设计渐进式压缩模块(Progressive Compression Module, PCM), 将由编码器得到的特征图逐步压缩传输到后续的解码器中, 从而充分利用图像高层特征.为了解决预测结果边缘不清晰的问题, 设计加权特征融合模块(Weighted Feature Fusion Module, WFFM), 通过动态生成权重与编码器各层特征图进行融合, 并映射到解码器的每个阶段, 使每个阶段都能访问到既包含全局信息又包含细粒度信息的特征图.在HKU-IS[5]、DUTS[20]、ECSSD[21]、PASCAL-S[22]、SOD[23]、DUT-O[24]这6个公开数据集上的实验表明本文网络取得较优的检测效果.
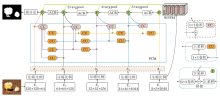
本文提出渐进式嵌套特征的融合网络(PNFFNet), 本质仍属于一种编码器-解码器结构, 具体网络结构如图1所示, 其中编码器可采用去掉全连接层的特征提取网络, 如ResNet[25]和Effi-cientNet[26]等.
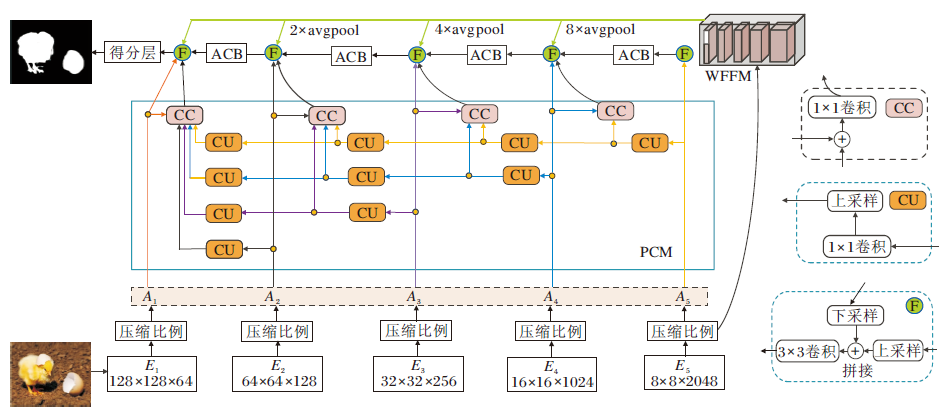 | 图1 PNFFNet结构图Fig.1 Architecture of PNFFNet |
图1以ResNet50作为编码器骨干网络为例说明.在图中, E1表示ResNet50中的第 1个7× 7的卷积模块, E2、E3、E4、E5分别对应ResNet50中其余4个模块, CU操作表示将输入特征图进行1× 1卷积后再使用双线性插值法进行上采样, CC操作表示将输入特征图拼接后进行1× 1卷积, F操作表示多个输入特征图拼接后进行3× 3卷积, 非对称卷积模块(Asymmetric Convolution Block, ACB)[27]实现对输入特征进行3条路径的卷积操作, 得分层表示对输入特征图进行1× 1卷积后将通道数调整为1并上采样到原图大小.
为了降低参数量和计算复杂度, 首先对编码器的编码结果{Ei}
为了避免高级语义信息被逐渐稀释导致检测目标不完整的问题, 基于残差连接, 本文设计渐进式压缩模块(PCM), 具体计算过程如图2所示.
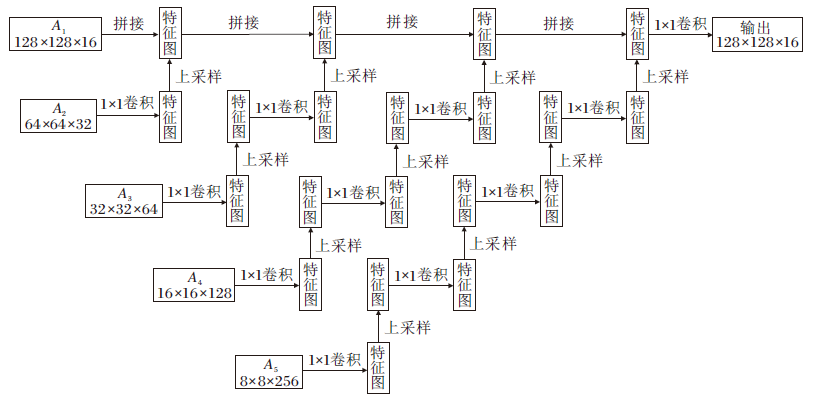 | 图2 PCM模块计算过程Fig.2 Calculation process of PCM |
较深的特征图能反映显著区域的位置信息, 却丢失细粒度特征; 较浅的特征图侧重于细粒度信息, 却缺少全局特征.PCM模块的基本思想就是通过深层特征图到浅层特征图的系列短连接, 融合深层特征图的全局特征与浅层特征图的细节特征, 得到稠密而准确的显著图.具体来说, PCM模块利用ResNet[25]的思想将语义信息使用残差连接进行传递, 在残差连接中采用1× 1卷积进行通道调整.在传统模型中, 往往采用多个3× 3卷积, 在解码器的每个阶段构造金字塔融合模块, PCM采用1× 1卷积, 目的是为了减少参数量.
PCM的具体操作分为4个阶段.第1阶段, A5经过CU操作得到与A4相同大小和通道数的特征图, 并与A4进行CC操作, 得到的特征图与A4一起传入解码器中.第2阶段, A5、A4分别经过2次、1次CU操作得到与A3相同大小和通道数的特征图, 并与A3进行CC操作, 得到的特征图与A3一起传入解码器中.第3阶段和第4阶段的过程可以以此类推.
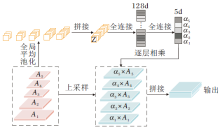
在FPN结构中:低级特征中包含有助于重建对象边界的空间结构信息, 但只是在最终融合阶段才被访问; 高级特征中包含有助于定位完整对象的语义信息, 但其渐进地被传递至浅层, 存在被稀释的问题.而且, 采用远距离层间的间接信息传递, 也会降低特征融合有效性, 造成输出边界不清晰、目标不完整的现象.为此本文设计加权特征融合模块(WFFM).该模块通过加权聚合后生成既包含全局信息又包含细粒度信息的特征图, 并将其分配到解码器的所有层中, 获得丰富的上下文信息.WFFM模块基本结构如图3所示.
 | 图3 WFFM模块结构图Fig.3 Architecture of WFFM |
具体来说, 首先对{Ai}
Z=‖
其中, ‖ 表示拼接操作函数, (i, j)表示每级特征图的坐标, Hn、Wn表示第n个特征图的高和宽, An表示第n个特征图.权重
α =W2(ReLU(W1(Z))),
其中, W1∈ RD× M、W2∈ RM× N表示两个全连接层, D表示Z的通道数, M表示转换后的维度, 本文设置为128.
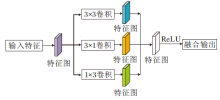
在ACNet(Asymmetric Convolutional Network)[27]中, 为了提升模型对图像翻转和旋转的鲁棒性, 强化特征提取能力, 提出ACB模块.为了进一步提高显著性目标检测性能, 在本文网络中也引入ACB模块, 结构如图4所示.
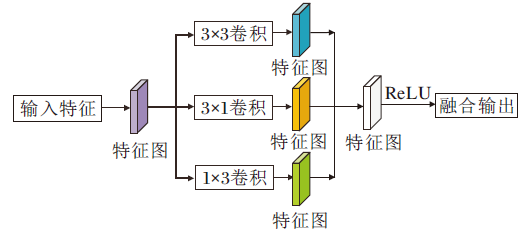 | 图4 ACB模块结构图Fig.4 Structure of ACB |
ACB模块对输入特征进行3条路径的卷积操作, 卷积核大小分别为3× 3、1× 3和3× 1, 融合3条路径的输出特征, 得到ACB模块的输出.本文使用ACB模块代替标准的方形卷积, 可提高网络训练的精度, 减少模型训练的参数和复杂度, 却不会引入额外的开销.
为了关注突出对象的边缘, 本文采用边缘加权二值交叉熵[28]作为损失函数, 定义如下:
Lwbce=
其中, BCE(· )表示交叉熵损失函数, γ 表示常数, H、W分别表示图像的高和宽, P表示预测图像, Y表示标签, Pi, j表示在(i, j)处预测值, Yi, j表示在(i, j)处标签值, β i, j表示在位置(i, j)处分配给损失的权重, δ 表示β i, j计算的窗口半径大小.
本文实验采用如下6个公开数据集:DUTS数据集[20]、ECSSD数据集[21]、HKU-IS数据集[5]、PAS-CAL-S数据集[22]、SOD数据集[23]及 DUT-O数据集[24].
评价指标选择F-measure[29]、平均绝对误差(Mean Absolute Error, MAE)、S-measure(S)[30]、PR(Precision-Recall)曲线.
编码骨干网络分别采用ResNet[25]和Efficient-Net[26].对于ResNet, 采用知识蒸馏策略[31]初始化网络参数.对于EfficientNet, 在ImageNet[32]上预训练并进行参数初始化.
初始学习速率设置为5e-5, 动量为0.9, 权重衰减为5e-4, 损失函数中的超参数设置为γ =3和δ =10, 优化器选择Adam优化器(Adaptive Mo-ment Estimation)[33].
实验中的所有模型均在公开的DUTS数据集上进行训练.
模型使用PyTorch实现, 采用48 GB的NVIDIA Quadro RTX 8000 GPU.
为了降低模型复杂度和参数量, 在编码阶段使用1× 1卷积进行r倍通道压缩, 为了选择合适的压缩比, 设计如下实验.
对于EfficientNet, 由于其本身为轻量级网络, 若采用较大的压缩比虽然会大幅降低参数量, 但导致模型性能下降较大, 为此在后续的实验中将其压缩比设置为2.
对于ResNet50, 当r=2, 4, 8, 16, 32, 指标值如表1所示.由表可看出, 随着压缩比的增大, 参数量和计算量迅速下降, 但效果也逐步降低.综合考虑, 在后面的实验中设置压缩比r=4.
| 表1 不同压缩比对网络性能的影响 Table 1 Effect of different compression ratios on network performance |
为了验证PCM模块和WFFM模块的有效性, 采用ResNet50作为骨干网络, DUTS数据集作为实验数据集, 共设计4组对比实验, 结果如表2所示.在表中, √ 表示使用该模块, × 表示未使用该模块.由表可看出, 分别加入PCM模块和WFFM模块后, 指标值均有所提升, 将二者都加入后, 取得最优效果.
| 表2 各模块消融实验结果 Table 2 Ablation experiment result of different modules |
各模块消融实验的可视化对比结果如图5所示, 图中Baseline表示没有添加PCM模块和WFFM模块的特征金字塔网络.由图可看到, 不采用PCM模块和WFFM模块时, 网络输出的显著性目标图像存在边缘不清晰及目标不完整的情况.当仅加入WFFM模块时, 网络会关注目标边缘, 但由于特征传递过程中高级语义逐步被稀释, 仍存在目标缺失的情况.当仅加入PCM模块时, 目标拥有一定的完整性, 但会忽略边缘信息及细节部分.同时加入PCM模块和WFFM模块后, 得到拥有清晰边界和完整目标的显著性目标图.
 | 图5 PCM模块和WFFM模块可视化效果对比Fig.5 Visualization result comparison of PCM and WFFM |
为了验证ACB模块对本文网络的影响, 分别使用ACB模块和3× 3卷积作为解码过程中的卷积块.解码器使用不同卷积块对本文网络的影响如表3所示.由表可看出, 相比直接使用3× 3卷积, 使用ACB模块后的网络性能更优.
| 表3 解码器使用不同卷积块对本文网络的影响 Table 3 Effect of decoder with different convolutional blocks on the proposed network |
为了进一步验证PNFFNet的性能, 本文选择如下显著性目标检测网络进行对比:BASNet(Boundary Aware Network)[2]、文献[7]网络、CPD[11]、SCRN[12]、TRACER[15]、 PoolNet+[16]、 EGNet[19]、 F3Net[28]、 ITSD(Lightweight Interactive Two-Stream Decoder)[34]、MINet[35].
各网络在DUTS、HKU-IS数据集上的实验结果如表4和表5所示, 表中黑体数字表示最优值, 表4采用的骨干网络为ResNet, 表5采用的骨干网络为EfficientNet.
| 表4 基于ResNet骨干网络的指标值对比 Table 4 Index value comparison of backbone network based on ResNet |
| 表5 基于EfficientNet骨干网络的指标值对比 Table 5 Index value comparison of backbone network based on EfficientNet |
由表4可看出, 当使用ResNet作为骨干网络时, 传统方法中EGNet效果较优, PNFFNet略优于EGNet, 但PNFFNet参数量却只有EGNet的1/4.
由表5可看出, 当使用EfficientNet-b3作为骨干网络时, PNFFNet虽然在参数量上略多于ITSD, 但检测效果在所有对比模型中明显更优.采用Effi-cientNet-b0作为骨干网络时, PNFFNet参数量明显少于其它模型, 而检测效果并未明显降低.
各网络在ECSSD、PASCAL-S、SOD、DUT-O数据集上的实验结果如表6所示, 表中黑体数字表示最优值, 除标明外, 其余网络使用EfficientNet-b3作为骨干网络.
| 表6 各网络在4个数据集上的指标值对比 Table 6 Index value comparison of different networks on 4 datasets |
由表6可看出, 在4个数据集上, PNFFNet也取得较优的检测效果.
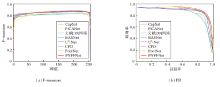
为了进一步验证PNFFNet的检测效果, 选择如下对比网络:BASNet[2]、CPD[11]、PoolNet[13]、PiCA-Net(Pixel-Wise Contextual Attention Network)[36]、U2-Net[37]、CapSal[38]、文献[39]网络.各网络在DUST数据集上的PR曲线和F-measure曲线如图6所示.PR曲线和F-measure曲线包围的面积越大, 说明该网络性能越优.网络均采用ResNet作为骨干网络.
 | 图6 各网络的F-measure曲线和PR曲线对比Fig.6 Comparison of F-measure curves and PR curves among different networks |
由图6可明显看出, PNFFNet以较少的参数量取得较优效果.
各网络在DUTS数据集上的检测结果的视觉对比如图7所示, 网络均采用ResNet作为骨干网络.由图可看出, 对于显著性目标与背景高度相似图像(第1幅和第7幅)、显著性目标较小(第5幅)和存在多个显著性目标图像(第6幅和第7幅), PNFFNet均能较好地检测显著性目标并给出较清晰的轮廓边界.
 | 图7 各网络在DUTS数据集上检测结果的视觉对比Fig.7 Visualization comparison of detection results among different networks on DUTS dataset |
针对显著性目标检测中存在的检测目标边缘模糊、目标不完整和小目标漏检的问题, 基于FPN检测框架, 本文提出基于渐进式嵌套特征的融合网络(PNFFNet).通过渐进式特征压缩模块(PCM), 将更高阶段的特征融入解码器的每个阶段, 从而充分利用高层语义特征, 提升检测性能和目标完整性.通过加权特征融合模块(WFFM), 在每个阶段均能融合图像的细粒度特征, 保证显著性目标的清晰边缘和对小目标的检测.在广泛应用的公开数据集上的实验验证PNFFNet的检测效果较优.今后将研究与伪装目标检测任务的联合学习, 进一步提高网络的检测精度.
本文责任编委 桑 农
Recommended by Associate Editor SANG Nong
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|