



{kind=link}
{kind=link}
{kind=link}
{kind=link}
融入事件知识的汉语-越南语跨语言事件检索
[黄于欣1, 2  , 邓同杰
, 邓同杰1, 2 , 余正涛1, 2 , 线岩团1, 2 ]
, 邓同杰, 余正涛, 线岩团]
|
|



作者简介:
黄于欣,博士,副教授,主要研究方向为自然语言处理、文本摘要.E-mail:huangyuxin@163.com.
邓同杰,硕士研究生,主要研究方向为自然语言处理、信息检索.E-mail:821986279@qq.com.
线岩团,博士,副教授,主要研究方向为自然语言处理、信息检索、机器翻译.E-mail:xianyt@kust.edu.cn.
汉语-越南语跨语言事件检索任务是指根据输入的汉语查询检索表达相同事件的越南语文档.现有的跨语言检索模型在汉语-越南语低资源检索上对齐效果不佳,并且单纯的语义匹配检索难以理解复杂查询的事件语义信息.针对目标问题,文中提出融入事件知识的汉语-越南语跨语言事件检索模型,构建汉语-越南语跨语言事件预训练模块,进行持续的预训练,改善模型在汉语-越南语低资源语言上的表征效果.并且基于对比学习,对事件知识的掩盖预测值与真实值进行差异判别,促使模型更好地理解和捕捉事件知识特征.在跨语言事件检索任务和问答任务上的实验表明,文中方法性能有所提升.
About Author:
HUANG Yuxin, Ph.D., associate profe-ssor. His research interests include natural language processing and text summarization.
DENG Tongjie, master student. His research interests include natural language processing and information retrieval
XIAN Yantuan, Ph.D., associate profe-ssor. His research interests include natural language processing, information retrieval and machine translation.
The goal of Chinese-Vietnamese cross-language event retrieval task is to retrieve Vietnamese documents expressing the same event based on the input Chinese query. Existing cross-language retrieval models exhibit poor alignment in Chinese-Vietnamese low-resource retrieval, and simple semantic matching retrieval struggles to comprehend the event semantic information of complex queries. To address this issue, a Chinese-Vietnamese cross-language event retrieval method incorporating event knowledge is proposed. A Chinese-Vietnamese cross-language event pre-training module is built for continuous pre-training to improve the representation performance of the model on Chinese-Vietnamese low-resource languages. The difference between the masked predicted values and the true values of the event is discriminated based on contrastive learning to encourage the model to better understand and capture the event knowledge features. Experiments on cross-language event retrieval tasks and cross-language question-and-answer tasks demonstrate the performance improvement of the proposed method.
汉语-越南语(下文简称汉越)跨语言事件检索任务是根据输入的源语言(如汉语)及蕴含的事件要素检索目标语言(如越南语)中表达相同事件的文档.和通用的信息检索任务不同, 跨语言事件检索不仅关注源语言和目标语言在语义上的相近, 更进一步要求查询和结果要表达同一个事件, 具有相同的事件要素.例如:当汉语查询为“ 成都大运会将于近期举办开幕仪式” , 内容包括事件主体(成都大运会)和事件要素(事件触发词“ 举办” 及时间触发词“ 本周” ).目标越南语文档事件检索结果译为“ 成都世界大学生运动会开幕式本周如期举办” , 结合查询事件要素, 和查询描述事件一致.
相比信息检索, 跨语言事件检索增强对查询中事件要素的关注, 确保目标检索事件与查询之间的一致性.在全球化背景下精准检索不同语言中的事件信息, 有助于更全面、准确、及时了解事件始末, 以支持舆情监测、紧急事件响应等应用场景中的决策制定、分析和研究工作.
汉越跨语言事件检索是一种特殊的跨语言信息检索任务.传统的跨语言检索通常有两类方法.1)利用机器翻译将查询文档或待查询文档翻译为同一语言进行检索, 将跨语言检索任务转换为同一语言的检索任务, 但其效果受限于机器翻译的性能.针对中文、英文等资源丰富语言, 翻译误差较小, 效果较优, 而针对越南语等低资源语言, 翻译性能受限, 人名、地名、组织机构名等事件的重要实体可能会译错, 检索性能不理想[1].2)利用多语言词嵌入或多语言预训练模型, 将不同语言表征到同一语义空间[2], 计算查询和文档之间的语义相似度, 实现跨语言信息检索.Bhattacharya等[3]通过多语言词嵌入, 将不同语言语义相近的词表示在一个分布空间, 微调实现在跨语言检索上的有效应用.Jiang等[4]基于多语言预训练模型, 构建深度相关性匹配建模任务, 微调原语言查询在高层语义空间检索目标语言文档的匹配方式, 改善模型在检索任务上的表现.
然而目前存在一些多语言预训练模型, 如mBERT(Multilingual Bidirectional Encoder Representations from Transformers)[5], 在不同语言之间的数据分布存在不平衡的情况.这种不平衡导致这些模型在处理资源丰富的语言, 如中文和英文时, 表现较强的表示能力, 实现良好的对齐效果[6], 然而对于汉越等低资源语言的表示效果却较差, 因此直接利用多语言预训练模型实现汉越的跨语言检索仍面临很大的挑战.
另外, 跨语言事件检索和传统信息检索不同, 传统信息检索仅考虑查询和文档在语义层面的相似度, 而事件检索更要考虑句子和查询是否在描述同一事件, 即是否具有相同事件主体、触发词及事件时间等要素信息.例如:汉语查询为“ 成都大运会将于近期举办开幕仪式” , 直接利用mBERT, 检索到越南语文档译为“ 成都大学开学典礼于今日稍早开幕” , 虽然语义与查询相近, 但是事件差异较大.因此跨语言事件检索任务需要改进mBERT等预训练模型, 在现有的文本表征基础上增加对事件的理解能力.
近年来, 随着单语预训练语言模型[5]的出现及模型在其基础上发展的RoBERTa(Robustly Optimi-zed Bidirectional Encoder Representations from Trans-formers Approach)[7]和XLNet[8]等, 对整个自然语言处理领域带来重大革新.以RoBERTa为例, 其应用于信息检索的方法主要有两种.1)单塔模型.首先将查询和文档打包成一个语言对, 使用[SEP]标记进行分隔, 然后输入RoBERTa编码器中.在编码过程中, 每个查询或文档的词元都可关注整个序列, 称为交叉注意力机制[9].最终, 通过预测[CLS]标记的输出表示进行排名得分的预测.2)双塔模型.与单塔模型不同, 双塔模型中查询和文档分别使用独立的RoBERTa编码器进行编码, 计算两个嵌入序列的余弦相似度, 得到匹配分数.双塔模型对查询和文档的向量表示更有效, 通常用于检索的第一阶段[9].而具有完全交叉注意力机制的单塔模型通常用于检索最后阶段, 对召回文档进行重排序[10, 11].研究表明, 在文档重排序任务中, 除了使用交叉注意力机制输出的[CLS]向量外, 结合上下文词嵌入提供的术语级匹配信息也可进一步改进性能.本文研究检索的重排序任务, 并为了简化, 采用单塔模型作为研究对象而非借助于术语级匹配信息.
跨语言预训练模型[12, 13]具备同时编码多种不同语言文本的能力.mBERT采用与BERT(Bidirec-tional Encoder Representations from Transformer)[5]相同的模型结构和预训练任务, 但其MLM(Masked Language Modeling)任务应用于来自100多种维基百科中不同语言的预训练数据上.除了MLM任务外, Conneau等[14]提出XLM(Cross-Lingual Language Model), 对并列语句中的内容进行MLM任务方式的预训练.XLM关注语句上下文和对齐的其它语言上下文, 预测被掩盖的内容, 而XLM-R(XLM-RoBERT)[5]提出另外两个单词和句子级任务, 对统一编码器进行预训练, 并结合更多的数据改进XLM.
在跨语言的背景下, 同样存在针对检索的跨语言迁移[15, 16, 17]和问答的跨语言迁移[18]研究.然而, 在使用单塔模型进行跨语言检索时, 需要模型在一次检索遍历中编码来自不同语言的两个序列, 如跨语言检索中的查询和文档及跨语言问答中的问题和答案.目前在单塔模型下进行跨语言检索的研究中, 仅有Jiang等[4]将查询解耦为术语, 将文档解耦为句子, 从而在BERT交叉注意力机制的基础上构建一种复杂的模型.然而, 该模型的复杂性使其实用性不高.
大型预训练语言模型的引入在事件时间推理任务上取得显著进展[19, 20].然而普通的预训练语言模型在捕捉与事件关系相关的事件知识方面并不专注, 这可能是由于MLM任务的训练方式导致, 模型在处理随机掩盖任务时对于时间触发词和事件触发词的关注不足.为了解决这个问题, Zhou等[21]提出TacoLM(Temporal Common Sense Language Model), 有针对性地掩盖预测事件频率和典型时间词, 实验表明, 相比普通的预训练语言模型, 在相关任务上取得性能提升.然而, 事件频率和典型时间词并不能直接帮助模型理解事件时间关系的对应性.此外, TacoLM在掩码预测损失上采用软交叉熵方法, 通过人工手动标注的外部知识得到标签, 这可能会在连续的预训练过程中引入噪声.而Zhao等[22]提出的预训练模型, 利用外部标注的成对的事件时态关系, 在预训练过程中掩盖事件时态触发的指示器, 并且仅应用在事件检测任务中.Pereira等[23]提出ALICE(Adversarial Training Algorithm for Commonsense Inference), 提前标注数据中的触发词, 但训练数据重复固定且仅应用在单语检索上.
基于上述分析, 本文提出融入事件知识的汉语-越南语跨语言事件检索模型, 构建汉越跨语言事件预训练模块, 改善模型在汉越低资源语言上的表征效果, 并基于对比学习, 对事件知识进行差异判别, 促使模型更好地理解和捕捉事件知识特征.具体来说, 一方面针对汉越低资源语言对齐效果不佳的问题, 构建汉越跨语言事件预训练模块, 对模型在汉越数据集上进行持续预训练, 在此过程中学习汉越在模型高层语义空间的共享表示.另一方面, 针对多语言预训练模型对事件理解能力较弱的缺陷, 通过预训练模块对事件知识进行不断掩盖预测, 以及基于对比学习, 对被掩盖预测值与真实值进行差异判别, 促使模型更好地理解和捕捉事件知识特征, 提升模型对事件知识的关注度.通过两种策略的融合, 提升模型在汉越跨语言事件检索等跨语言任务上的性能.
本文提出融入事件知识的汉语-越南语跨语言事件检索模型, 框架如图1所示.本文模型包括2个预训练任务模块:触发词掩盖预测模块(Trigger Words Mask Prediction, TMP)和检索建模排序模块(Retrieve Modeling Sort, RS), 对于不同的预训练模块采用不同的输入语言对.具体地, TMP将汉语言查询和越南语相关文档拼接建模, 构成汉越跨语言对.标注事件触发词和总结时间触发词分别构成触发词词表, 对汉语言查询进行对事件及时间触发词的针对性掩盖, 并结合越南语相关文档进行掩码和预测, 提升模型对事件知识的关注.RS将汉语言查询分别和越南语相关文档及越南语不相关文档拼接, 模拟查询文档排序, 不断优化排序结果, 更好地建模查询文档交互场景, 提升跨语言事件检索任务性能.
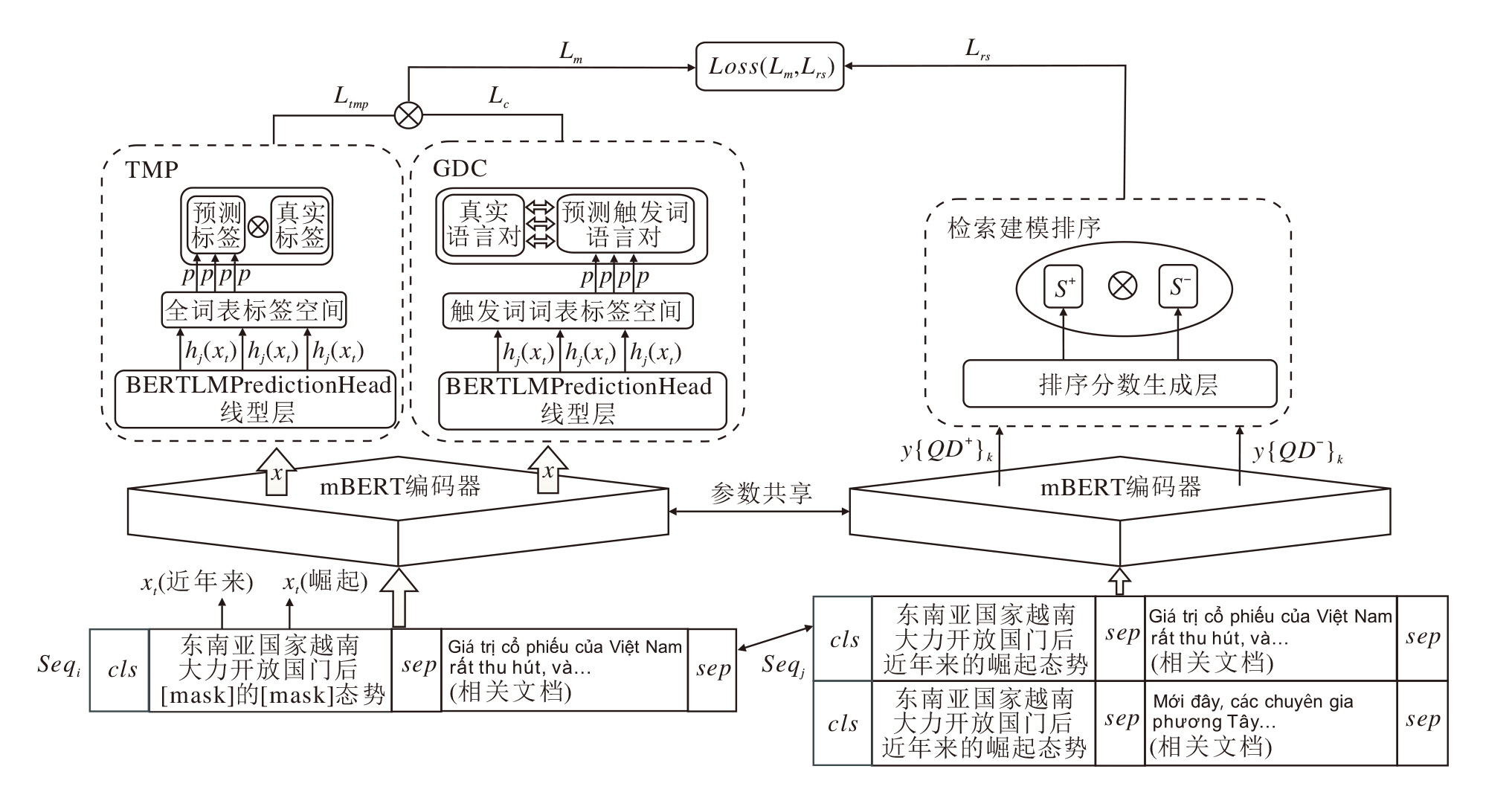 | 图1 本文模型框架图Fig.1 Framework of the proposed model |
在TMP的基础上, 本文构建基于对比学习的生成鉴别器模块(Generative Discriminator for Contras-tive Learning, GDC), 将预测结果映射到触发词表上, 和真实触发词对比纠正, 以此提升模型预测被掩盖触发词的正确率和模型对事件知识额外的关注.
与现有的XLM不同, 本文的目标是鼓励模型在不知道输入语言的情况下学习语言特征, 因此并未固定特定语言的嵌入表示, 而是直接将语言对作为输入, 让模型自行区分并学习输入序列的两个部分.这种设计旨在提升模型对语言特征的抽取能力, 从而更好地适应汉越跨语言事件检索任务的需求.
本文采用与BERT相同的输入长度限制.如图1所示, 具体根据预训练任务的不同, 模型输入如下.在TMP和GDC中, 对于本文构建的原始汉越查询-文档语言对, 按照一定比例μ , 通过触发词表对查询部分的触发词进行匹配, 替换为[mask]标记, 并与相关越南语文档进行拼接, 将最终处理的多个语言对打包为输入序列:
Seqi= (QC1DV1, QC2DV2, …, QCiDVi).
而对于RS, 本文将单个汉语查询QC和相关越南语文档
$Se{{q}_{j}}=(\{{{Q}_{C}}_{1}{{D}_{V}}_{1}, {{Q}_{C}}_{1}D_{V}^{-}\}, \{{{Q}_{C}}_{2}{{D}_{V}}_{2}, {{Q}_{C}}_{2}D_{V}^{-}\}, \ldots , \{{{Q}_{C}}_{j}{{Q}_{V}}_{j}, {{Q}_{C}}_{j}D_{V}^{-}\})$.
最终将序列集合通过编码器转化为词向量集合:
x=emb(Seqi), y=emb(Seqj),
其中, emb(· )使用模型中的编码器, 将打包好的汉越语言对序列嵌入到向量空间.
1.2.1 触发词掩盖预测模块
针对触发词掩盖预测模块(TMP)的输入序列x, 本文使用BERT[5]的MLM预训练任务中的BERT预测头(BERTLMPredictionHead)线型层组件, 预测被掩盖的触发词, 并将结果映射在全词表标签空间上, 通过softmax层获得最终全词表的标签预测概率分布:
p(xt|x)=Softmax(fδ (hJ(xt))),
其中, xt表示输入序列x中t位置索引语言对被屏蔽的触发词, hJ(x)表示BERT预测头的输出, fδ 表示线型层模块, 将被掩盖的词向量映射到全词表标签空间δ .本文使用交叉熵损失计算每个触发词掩码预测的目标:
${{l}_{tmp}}=-\underset{x_{t}^{\delta }\in {{x}^{\delta }}}{\mathop \sum }\, L[x_{t}^{\delta }={{x}_{t}}]\ln (p({{x}_{t}}|x))$,
其中,
任务使用一个额外的越南语文档, 辅助预测查询部分被掩盖的文本, 因此如果将掩盖比例μ 参照BERT设置在15%, TMP任务将要比传统的MLM任务更容易.并且按照总文本长度百分比掩盖可能会使触发词的掩盖不完整, 模型无法完整学习到事件知识.为此本文将掩盖的策略设定为:训练过程中按照6∶ 2∶ 2的随机概率, 从匹配到的触发词列表中随机采样一个、两个或三个触发词, 并掩盖在查询文本中.由于查询文本通常较短, 某些触发词的长度比例可能已经超过查询文本长度30%, 所以大多数情况下将掩盖触发词的数量设置为1.考虑到某些触发词可能较短, 以及某些查询文本中可能存在三个或更多触发词的情况, 因此在匹配掩盖的过程中, 仍有小部分概率将掩盖触发词的数量设置为2或3.
1.2.2 检索建模排序模块
检索建模排序模块(RS)任务类似于检索任务中的召回排序阶段, 但是相比一般检索任务的细粒度数据, 本文任务的数据语义具有更粗的粒度.对于RS输入序列y中不相关文档的选择, 为了避免模型陷入固定的梯度, 导致优化过程收敛于局部最优解, 本文在预训练数据采集处理阶段计算查询和文档之间的余弦相似度, 并选择相似度高于阈值的文档作为查询对应的不相关文档, 训练过程中对查询对应的不相关文档使用随机采样以匹配不相关文档
在排序分数生成层, 本文使用一个可学习的参数权重矩阵W乘以序列正负例编码输出的y{QD+}k和y{QD-}k, 分别得到排序分数:
S+=y{QD+}k* W,
S-=y{QD-}k* W.
并使用交叉熵损失优化模型.通过不断优化W和最小化交叉熵损失函数lrs, 提高对正例的排序分数S+, 并持续降低对负例的排序分数S-, 使模型在检索场景下对正负例进行更好的判断, 改进召回文档的排序过程.
为了进一步提高TMP的准确率和模型对事件知识的关注, 设计基于对比学习的生成鉴别器模块(GDC).具体地, 将真实语言对作为正样本, 在模型预测的触发词和真实触发词不一致时, 把预测触发词从全词表上映射到触发词词表标签空间η 上[19], 将生成的预测文本作为负样本.通过生成鉴别器将正负样本作为对比, 不断优化模型预测触发词的正确率.本节使用对比损失训练模型, 即
${{l}_{c}}=-\underset{{{x}_{t}}\in {{x}^{\eta }}}{\mathop \sum }\, y\ln (D({{x}_{t}}|x))+(1-y)\ln (1-D({{x}_{t}}|x))$,
其中
D(xt|x)=Sigmoid(fη (hD(xt))),
y表示判断模型预测是否正确的二进制标签, fη 表示线型层模块, 将被掩盖的词向量映射到触发词词表标签空间η , hD和TMP的hJ是共用的BERT模型预测头.
鉴别器的预测主要集中在时间触发词和事件触发词上生成掩码预测, 因此这个任务更容易完成.然而一个好的对比学习鉴别器需要相对平衡的正样本数据和负样本数据.为了解决这个问题, 在生成正负例的过程中, 有p%的概率不使用模型预测的触发词, 而是先对时间触发词预测任务和事件触发词预测任务进行分类, 再从触发词表中随机抽取相同长度的触发词替换它们.本节将p设置为50, 保证正负样本的相对均衡.
混合3个损失函数ltmp, lc, lrs, 进行模型训练优化, 观察到:1)混合3个损失函数需要更多的GPU内存用于计算和存储, 导致训练时间相应延长; 2)TMP和GDC相互关联, 对比损失函数可以对预测提供额外的反馈信息, 而RS相对较独立.3)在实际实验中, 将全部损失函数混合后的模型在特定下游任务上的性能反而有所下降.
本节选择一种组合方案Loss(lm, lrs), 即将TMP得到的交叉熵损失和对比损失相加:
lm=ltmp+lc.
再将两个损失函数信息整合在lm损失函数中, 并通过前向传播层对模型进行迭代和优化.而对于RS输出的交叉熵损失lrs, 单独在训练结束后通过前向传播层, 不与其它损失函数混合.
通过选择混合不同损失函数并将它们作为模型训练的目标, 可在多任务学习中充分利用任务间的相关性.这种组合策略有助于促进模型在特定下游任务中的性能提升, 并更好地适应任务之间的差异性和关联性.
2.1.1 预训练数据集
为了获取包含事件知识的汉越文本组成查询-文档语言对, 依据:1)拼接得到的查询部分能作为摘要, 很好地概括原文本; 2)从检索概念上说, 匹配检索的最低预期下限是两个部分是同一实体的不同方面, 这对于检索结果预期来说是可接受的[29].
本文先后从维基百科和越南新闻网获取相应数据, 维基百科查询-文档语言对数量为13 786, 越南新闻网查询-文档语言对数量为95 082.
对于维基百科, 本文从汉语和越南语维基页面编年史中提取具有相同月份的文档数据DocC和DocV.只通过超链接拼接汉语文档数据DocC, 得到汉语查询文档 QueC(i), 并针对汉语查询文档QueC(i)和越南语文档DocV(j)在跨语言词嵌入上使用余弦相似度, 计算两个文档之间的相似度, 如果结果大于预设阈值β , 视为相似语言对.这种方法实现汉语和越南语相关语言对的对齐.
对于新闻网数据, 在越南语新闻文本ArtV中选取段首文本SentV(i)作为语言对文档部分, 通过汉越跨语言摘要生成模型输出生成的汉语摘要SentC, 作为语言对的查询部分.
2.1.2 评估数据集
为了评估本文模型在汉越跨语言事件检索任务上的性能, 同时为了测试本文模型对其它语种的跨语言事件检索任务的性能是否产生积极影响, 在针对汉越跨语言事件检索任务进行评估的同时, 同样考虑在越南语-英语(下面简称越英)、英语-汉语(下面简称英汉)等语言的零样本学习任务上进行跨语言事件检索的评估.考虑到MLQA数据集[14]在多语言上经过广泛扩充和标注以确保不同语言内容之间的高度对齐, 同时提供相同的实体和事件信息, 这有助于跨语言问答系统准确理解和回答与这些实体或事件相关的问题.本文处理数据集上汉语、越南语和英语部分的开发集和测试集, 构建用于模型性能评估的开发集和测试集.
具体地, 本文将问答数据集上的问题部分用作事件检索任务的查询部分, 将问题的标准答案及通过问答任务生成的前三个预测答案作为检索中的相关文档.剩下的、由问答任务生成的分数较低的预测答案和其它问题的答案作为查询的不相关文档.相关文档包括与查询相关的事件信息, 同时引入分数较低的生成答案, 模拟事件检索中存在高语义相似度但精确事件匹配不完全的情境, 从而增加检索任务难度.
此外, 为了进一步验证事件检索性能, 对评估数据集上的查询和相关文档进行额外的事件标注, 这些标注有助于后续事件表征任务, 并更全面地评估事件检索的准确性和效果.最终得到不同语言的查询和相关与不相关文档的评估数据集, 具体组成如表1所示.
| 表1 检索评估数据集 Table 1 Retrieval evaluation dataset |
本文采用平均准确率(Mean Average Preci-sion, MAP)评估模型在检索任务中的性能:
$MAP=\frac{1}{N}\overset{N}{\mathop{\underset{i=1}{\mathop \sum }\, }}\, \left( \frac{i}{position\left( i \right)} \right)$,
其中, N表示相关文档的总数, position(i)表示第i个相关文档在检索结果列表中的位置.MAP是多个查询平均正确率(AP)的均值, 作为检索任务的通常评价指标, 能从整体上反映模型的检索性能.
本文以mBERT作为基线模型, 考虑到具体跨语言事件检索任务, 同时引入其它表现良好的跨语言预训练模型作为对比模型, 具体如下.
1)mBERT[5].广泛应用的多语言预训练模型之一, 具有卓越的跨语言能力.
2)XLM-R[6].基于RoBERTa架构的多语言预训练模型, 在大规模跨语言的数据集上进行自监督学习, 具备在多语言环境下进行理解和生成任务的能力, 在多语言任务上表现出色.
3)LaBSE[24].基于双语嵌入的跨语言模型, 在大规模跨语言数据上进行自监督学习, 能生成具有语言无关性的句子嵌入表示, 广泛应用于跨语言信息检索任务.
4)使用汉越语料进一步训练mBERT(简记为mBER(MLM)).为了深入探究本文提出的提升关注事件知识的思想对事件检索性能的影响, 对mBERT使用与训练汉越跨语言事件检索模型相同的汉越预训练数据集进行进一步的预训练.这样可以排除预训练语料的影响, 研究当训练数据相同时不同预训练任务对模型性能的影响.
本节在汉语、越南语和英语三种语言交叉的查询-文档检索数据集上进行跨语言检索性能的评估实验, 并采用MAP作为评估指标.实验使用4种基线模型同本文模型进行对比.本文已通过RS优化检索场景, 所以在微调过程中仅微调最后三个编码层以避免过度匹配.在评估过程利用交叉熵损失优化模型, 最大训练次数设置为20.当模型在开发集上获得最佳MAP时, 程序在测试集上进行评估并记录相应的MAP, 最终选择最佳值作为结果保存.
各模型的MAP值如表2所示.由表可见, 尽管XLM-R和mBERT具有相似的模型结构和预训练目标, 并且使用更多的训练数据进行预训练, 但XLM-R在3种跨语言检索任务上的性能远不及mBERT.本文推测原因可能是由于预训练数据输入模型的方式造成的.XLM-R预训练任务接受词元级别的输入, 这种输入方式可能适用于单词级任务, 但对于需要对齐表示长文本的任务, 如跨语言事件检索, 可能会导致模型混淆.LaBSE在英汉跨语言任务上表现优于其它基线模型, 在越南语跨语言任务上表现不佳, 这可能是在模型预训练的过程中, 预训练数据中越南语的缺乏导致.而重新使用汉越数据进行预训练后的mBERT, 在汉越跨语言事件检索上取得4个基线模型中的最优值, 这说明使用汉越跨语言文本进行预训练对汉越语言在模型高层语义空间的对齐有一定的改善和促进作用.
| 表2 各模型在跨语言事件检索任务上的MAP值对比 Table 2 MAP comparison of different models on cross-language event retrieval task |
本文模型在汉越跨语言事件检索这一下游任务上的MAP值比最佳基线模型提升32%, 表明本文提出的预训练策略和生成鉴别器对于汉越跨语言事件检索任务具有显著改进.同时在英汉、越英等未经跨语言训练的零样本学习任务上, 使用汉越跨语言事件检索预训练方法后的本文模型在事件检索任务上的分数也均高于其它模型.通过零样本任务的评估, 观察到本文的预训练方法不仅提升模型在汉越事件检索任务中的性能, 还在模型的跨语言能力方面取得显著进展, 这表明本文模型可以扩展到其它语言组合的事件检索任务和更多跨语言下游任务中, 从而为广泛的模型跨语言能力和事件检索等领域提供一定帮助.
为了进一步验证本文模型的有效性, 进行消融实验.针对TMP、GDC、RS, 重新训练多个去除单个模块的模型, 研究每个预训练模块对模型及下游任务性能的影响, 具体MAP值如表3所示.由表可见, 新的预训练策略对下游任务性能提升起到积极作用, 但是两个预训练模块对模型性能的影响存在差异性.RS和TMP都为汉越跨语言事件检索提供积极收益, 而RS比TMP更有效.
| 表3 各模块的消融实验结果 Table 3 Ablation experiment results of different modules |
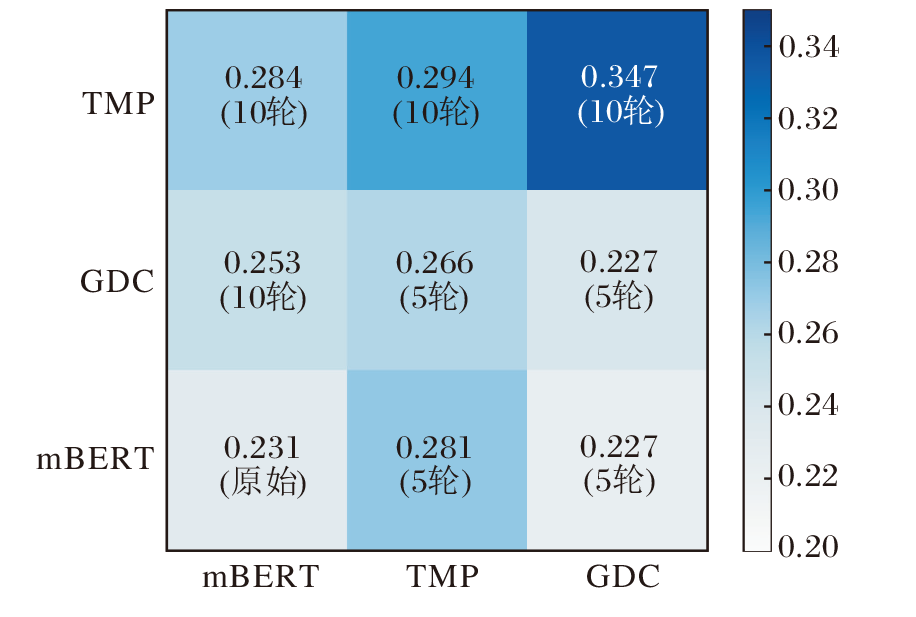
考虑到RS在设计时参照建模使用语言模型进行检索任务的场景, 这可能是RS在检索上更有效的原因.而在零样本任务中, 相比RS, TMP对下游任务的影响更显著.
根据图2的分析, 这可能是因为RS损失收敛速度较快, 模型在该任务中学习到的信息较有限.相反, 在RS达到收敛的情况下, TMP仍持续学习, 模型在该任务中学习到的信息更丰富.
 | 图2 预训练模块的训练情况Fig.2 Training situation of pre-training module |
综上所述, TMP和RS对下游跨语言检索任务均具有积极影响, 并且这些预训练模块是相互补充的.因为使用两个新的预训练模块进行重新训练, 模型在大多数情况下的性能优于只使用单个预训练模块进行重新训练的模型.
本文通过构建好的事件及时间触发词表, 针对触发词掩盖预测的预训练任务和生成鉴别器纠正对触发词的预测, 不断优化模型对触发词预测的正确率, 提升模型对事件知识的关注度.随着预训练任务损失和对比损失的持续下降, 表明模型逐渐增强对事件知识的关注, 对触发词的预测逐渐准确.
为了评估模型对事件知识的关注造成下游任务性能的影响, 依次采用MLM任务替代TMP和在训练时去除GDC的策略, 每次训练默认引入RS, 重新对模型进行多次预训练, 具体MAP值如图3所示.由图可见, 在汉越跨语言事件检索任务中, 随着训练轮次的深入, 模型对事件的关注提升, 重新训练的模型在下游任务中表现明显优于使用MLM的跨语言模型和不使用GDC的跨语言模型.这表明模型对事件知识的关注, 对汉越跨语言事件检索等的下游任务性能提升具有重要帮助.在零样本任务中, 提升对事件知识的关注对越英、英汉和汉越跨语言事件检索的性能影响不大甚至有所下降, 这可能是对比学习的效果很大程度上取决于学习的特征表示.在零样本学习中, 目标是在未见过的类别上进行分类, 模型可能难以学习到足够有用的特征表示, 从而影响对比学习的性能.
 | 图3 事件知识的关注度对模型性能的影响Fig.3 Influence of attention to event knowledge on model performance |
在检索排序的预训练任务中, 为了建模跨语言事件检索场景, 增强训练模型对相关文档和不相关文档的区分, 在模型输入中对于不相关文档如何进行采样是一个值得探讨的问题.传统的随机采样策略存在难度较低、学习作用有限的缺陷.为了克服这一挑战, 本文使用新的不相关文档采样方法, 计算查询和文档之间的余弦相似度, 选择更具有挑战性的不相关文档.本节将讨论这两种不同的采样方法, 并探讨它们对预训练模型性能的影响.
对于两种采样方法, 分别训练汉越跨语言事件检索模型, 并对比两者在汉越事件检索任务上的性能, 具体MAP值如表4所示.由表可见, 直接的随机采样方法是从不相关文档集合中随机选择文档, 作为对应查询的不相关文档进行拼接, 并作为最终输入.这种方法的优势在于简单直观, 但是由于采样过程随机性较大, 多数匹配到的文档和查询明显不相关, 与实际检索情况相比多有出入, 导致模型对排序的学习作用较有限.本文采用一种使用余弦相似度的不相关文档采样方法, 计算查询和文档之间的余弦相似度, 并选择相似度高于设定阈值的文档作为不相关文档.这种方法能够确保不相关文档具有一定程度语义上的相似性, 为模型提供更具有挑战性的训练样本, 同时更贴近跨语言事件检索的场景, 使模型学到的排序能力更鲁棒, 从而在下游任务中表现更出色.
| 表4 不相关文档采样方法在跨语言事件检索任务上的MAP值对比 Table 4 MAP comparison of unrelated document sampling methods on cross-language event retrieval task |
表征任务作为信息检索和自然语言处理领域的核心任务之一, 旨在将文本或数据映射到高维特征空间, 增强信息的表示和处理能力.本文引入跨语言事件表征任务, 进一步补充验证模型的有效性.
跨语言事件表征任务的主要目标是捕捉不同语言中包含相同事件的查询和文档在高维特征空间中的相似性.本节通过在汉越跨语言事件检索评估数据集上预先进行的事件标注, 对基线模型mBERT和本文模型进行跨语言事件表征实验.在最终的实验结果中随机抽取8个实例, 每个实例由1个查询和4个相关文档构成, 对跨语言事件表征的结果进行综合评估.对表征结果进行降维处理, 使用可视化呈现实验结果.
mBERT和本文模型对汉越查询和文档相似度计算结果的可视化如图4所示, 图中圆形表示汉语查询, 菱形表示越南语相关文档, 相同颜色表示描述同一事件的汉语查询和越南语相关文档实例, 直观展示它们在二维坐标系上的相近程度.由图可见, 经过汉越跨语言事件检索预训练方法训练后, 本文模型的汉越查询-文档表征在高维空间中呈现显著的紧凑性, 即它们在特征空间中的距离较接近.这表明本文的预训练方法对于模型训练的辅助作用, 提升对事件知识的关注和理解, 也提升汉越查询和越南语文档的表征相似性, 从而进一步使模型在汉越跨语言检索任务中更准确匹配相同事件的文档, 提升汉越跨语言事件检索的准确性.
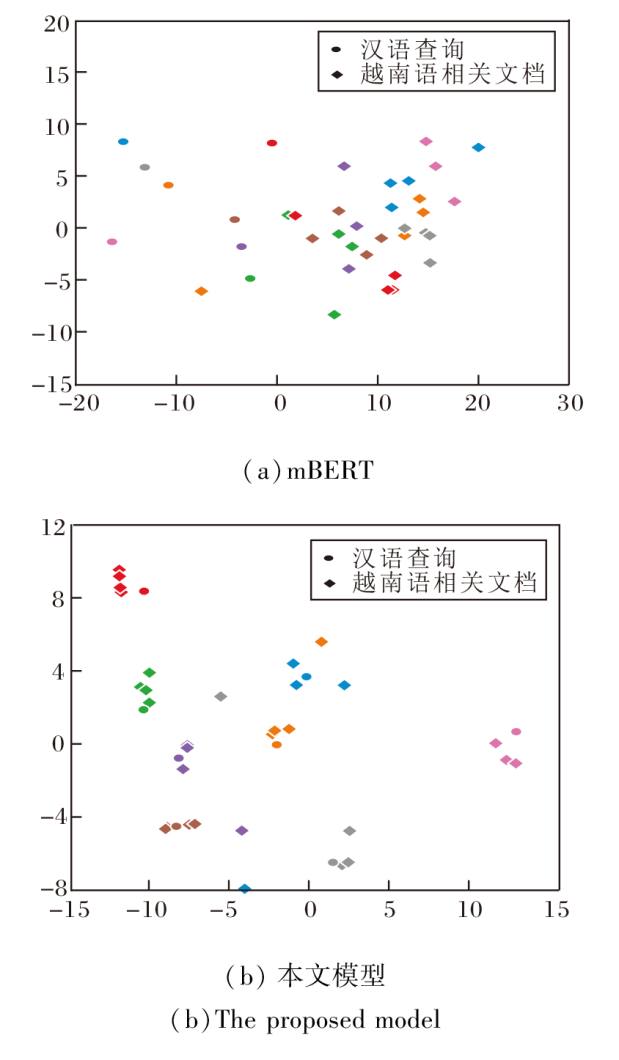 | 图4 各模型在汉越跨语言事件上的二维可视化结果Fig.4 Ttwo-dimensional visualization results of different models on Chinese-Vietnamese cross-language event |
跨语言问答与本文模型没有明确联系, 因此, 本文认为它可以更好地反映本文模型的泛化能力.
本文使用MLQA数据集[14]对模型进行跨语言问答任务的测试.考虑到MLQA数据集本身没有专门的训练数据, 选择使用SQuAD v2.0训练数据[25]进行微调, 利用MLQA数据集上的开发集和测试集评估模型性能.MLQA数据集可提供丰富的跨语言问答资源.
在评估指标方面, 本文采用标准的问答任务评估指标, 即F1分数和精确匹配度分数.为了满足本文的任务需求, 将汉语、越南语和英语进行交叉组合, 得到6种不同的语言组合, 并在这些组合下评估本文模型.
对模型进行10个迭代周期的微调训练, 在开发集上选择具有最佳F1分数的模型, 并在测试集上计算F1分数和精确匹配度分数, 保存最佳结果并输出.最终得到在跨语言问答任务上的最佳F1分数和精确匹配度分数.
选取mBERT和XLM-R作为基准模型, 各模型在跨语言问答任务上的结果如表5和表6所示, 表中黑体数字表示最优值.由表可见, 可能是由于汉语预训练数据资源的缺乏, XLM-R在汉语跨语言表现任务上极其不佳, 但在越英跨语言问答任务上的性能强于mBERT.本文模型在汉越英跨语言问答任务上具有显著改进, 这可能得益于本文预训练过程中使用的双语语言对预训练数据.
| 表5 各模型在跨语言问答任务上的F1分数对比 Table 5 F1 score comparison of different models on cross-language Q& A task |
| 表6 各模型在跨语言问答任务上的精确匹配度分数对比 Table 6 Exact match score comparison of different models on cross-language Q& A task |
2.3节统计基线模型mBERT和本文模型在检索任务上的MAP, 如表2所示.使用TMP+GDC+RS明显提升模型检索的MAP值, 本节将对这一现象进行样例分析.
mBERT按照原有的训练参数, 而非使用额外的汉越数据集进行预训练, 同时也未使用新的预训练模块.mBERT具体样例如下.
查询:近代操作系统发展的趋势是什么?
检索文档:

译文:
操作系统是计算机的核心软件, 负责管理和协调计算机资源, 提供用户和应用程序的接口和服务.它的作用是控制和管理计算机硬件, 使系统运行高效并为用户提供便利.
mBERT召回的文档对“ 操作系统” 的概念和功能做出解释, 并不完全符合查询“ 发展趋势” 的需求, 这可能是在模型检索的过程中由于汉越跨语言对齐效果不佳、对查询语义的理解有误和通过单纯计算语义相似度匹配越南语文档造成的.
本文模型在提升对事件知识关注的同时, 进一步提升跨语言检索的性能和跨语言的能力, 3个模块的结合使本文模型在所有预训练模型中对下游检索任务汉越跨语言事件检索取得最高的MAP值.本文模型具体样例如下.
查询:近代操作系统发展的趋势是什么?
检索文档:

译文:
近代操作系统的发展趋势包括分布式计算、虚拟化、容器化和云计算等创新, 使得操作系统能够更好地满足用户需求并推动计算机系统的发展.研究这些趋势可以为未来操作系统设计提供指导.
对比mBERT召回的文档, 重新预训练后的本文模型召回的文档内容包括操作系统的发展动态和对操作系统未来的分析, 对事件触发词和时间触发词都具有较好响应, 文档内容反映查询的大体需求.这表明模型在使用汉越跨语言事件检索方法中提升汉越跨语言检索性能, 并加强模型对触发词的关注, 从而提升检索结果的质量和相关性.
针对现有模型在汉越跨语言事件检索任务上汉越低资源语言对齐效果不佳以及模型对事件知识的关注不足的问题, 本文提出融入事件知识的汉语-越南语跨语言事件检索模型, 构建汉越跨语言事件预训练模块, 并与对比学习结合, 提升模型在汉越低资源语言上的对齐能力和对事件知识的关注.实验表明, 本文模型在汉越跨语言事件检索和问答等跨语言任务中表现良好, 详细的消融实验表明建模和参数选择上的正确性.此外, 本文模型还可提高跨语言的粗粒度语义对齐能力, 具有可进一步应用于更广泛下游任务的潜力.
本文责任编委 林鸿飞
Recommended by Associate Editor LIN Hongfei
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|