{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于自监督图掩码神经网络的社交推荐模型
[臧秀波1  , 夏鸿斌
, 夏鸿斌1, 2 , 刘渊1, 2 ]
, 夏鸿斌, 刘渊]
|
|



作者简介:
臧秀波,硕士研究生,主要研究方向为推荐系统、深度学习.E-mail:1372489070@qq.com.
刘 渊,博士,教授,主要研究方向为网络安全、社交网络.E-mail:lyuan1800@sina.com.
现有自监督社交推荐模型大多通过人工启发式图增强和单一关系视图间对比的策略构建自监督信号,性能受到增强自监督信号质量的影响,难以自适应地抑制噪声.由此,文中提出基于自监督图掩码神经网络的社交推荐模型.首先,分别构建用户社交和物品分类的单一关系视图及高阶连通异构图,采用图掩码学习范式指导用户社交图进行自适应和可学习的数据增强.然后,设计异构图编码器,学习视图中的潜在语义,跨视图对用户、物品嵌入进行对比学习,完成自监督任务,分别对用户、物品嵌入进行加权融合,完成推荐任务.最后,利用多任务训练策略联合优化自监督学习任务、推荐任务和图掩码任务.在3个真实数据集上的实验表明文中模型性能具有一定提升.
About Author:
ZANG Xiubo, master student. His research interests include recommendation system and deep learning.
LIU Yuan, Ph.D., professor. His research interests include network security and social network.
The existing self-supervised social recommendation models mostly construct self-supervised signals through the strategies of manual heuristic graph enhancement and contrasts between single-relational views. Thus, the performance of the model is easily affected by the quality of enhanced self-supervised signals, making it challenging to adaptively suppress noise. To solve these problems, a social recommendation model based on self-supervised graph masked neural networks(SGMN) is proposed. Firstly, single-relational views for user-social interaction and item classification are constructed respectively, as well as high-order connected heterogeneous graphs. Specifically, the graph masked learning paradigm is adopted to guide adaptive and learnable data augmentation for the user-social graph. Secondly, a heterogeneous graph encoder is designed to learn the latent semantics of the views, and cross-view contrastive learning is performed on user and item embeddings to complete self-supervised tasks. Then, weighted fusion is conducted on the user and item embeddings separately for recommendation task. Finally, a multi-task training strategy is employed to jointly optimize self-supervised learning, recommendation and graph masked tasks. Experiments on three real datasets demonstrate a certain performance improvement of SGMN.
推荐系统通过学习用户的个性化兴趣提供服务, 缓解信息过载问题, 是信息传递不可或缺的工具之一[1, 2, 3].传统的协同过滤推荐算法[4]受到稀疏数据、冷启动等问题的限制, 随着在线社交社区的发展, 用户之间可通过信息分享与关注等操作产生社交关系, 由此产生社交推荐.社交推荐模型利用这些社交信息增强用户-物品交互信息, 向用户推荐物品, 从而缓解数据稀疏性等因素的影响[5].
目前社交推荐方向已有大量的研究工作.早期研究工作集中在矩阵分解(Matrix Factorization, MF)[6]上.MF具有良好的高斯先验解释性, 是早期社交推荐模型中常用技术之一[7].受图神经网络(Graph Neural Network, GNN)[8]的启发, 近年来的社交推荐模型开始利用图神经编码器, 将包含社交关系的异构关系中的丰富语义嵌入隐性表征中.一些研究利用图卷积, 将社交协同过滤信息嵌入用户表征中.Huang等[9]提出KCGN(Knowledge-Aware Coupled GNN), Yu等[7]提出MHCN(Multi-channel Hypergraph Convolutional Network), 都侧重于应用图卷积网络对用户物品交互关系和用户社交关系进行建模.还有一些研究利用图注意力机制区分异构关系[10], 例如:Chen等[11]提出SAMN(Social Atten-tional Memory Network), Fan等[12]提出GraphRec.Xia等[10]提出DGNN(Disentangled GNN), 针对异构关系开发一个内存增强网络, 保存不同类型关系的专用特征表示, 分离异构语义.
但是大多数图神经网络社交推荐模型的性能会受到稀疏训练标签的影响, 无法生成高质量的用户、物品嵌入[13].自监督学习能够从未标记数据中进行数据增强, 可有效解决数据稀疏性问题, 其与图神经网络的结合已成为应对数据标签缺乏情况的有效解决方案之一[14].在推荐系统领域, 学者们主要构建各种嵌入对比的图增强方案, 完成自监督学习任务, 解决数据稀疏性问题.Wu等[15]提出SGL(Self-Supervised Graph Learning), 通过随机节点或边的丢弃操作生成对比视图.Yang等[16]提出KGCL(Know-ledge Graph Contrastive Learning Framework), 结合自监督学习与知识图谱.在社交推荐方向, Yu等[17]提出SEPT(Self-Supervised Tri-training Framework), 对用户社交图进行不同的增强, 得到社交图的两种对比方案.Long等[18]提出SMIN(Self-Supervised Meta-graph Informax Network), 使用多种元关系维护用户和物品嵌入表征, 进行数据增强.Chen等[13]提出HGCL(Heterogeneous Graph Contrastive Learning), 使用异构图对比学习范式, 利用元网络对不同视图进行知识迁移, 从而实现异构图增强.
尽管上述模型可有效缓解数据稀疏性的问题, 但是模型性能仍然受到如下两点限制.1)当前对比学习自监督的成功很大程度上依赖于人工启发式创建的高质量的增强和对比视图, 这种策略容易受到自监督信号质量的影响, 难以自适应应对噪声的干扰.2)仅构建用户社交、物品依赖与用户物品交互的单一关系间的对比视图, 但未充分考虑它们之间高阶连通异构图下的依赖偏好关系, 忽略高阶连通异构图的自监督信号, 导致自监督学习不够充分.
近年来, 受语言表示下生成式自监督学习的启发, Ye等[19]提出MAERec(Graph Masked Autoen-coder-Enhanced Sequential Recommender System), 现已引入图表示学习中.Hou等[20]提出GraphMAE, Tan等[21]提出S2GAE(Self-Supervised Graph Auto- encoder), 都采用随机掩码的方式重构特征.在推荐系统方向, MAERec通过图掩码自适应动态提取全局项目过滤信息, 进行自监督增强.Xia等[22]提出AutoCF(Automated Collaborative Filtering), 设计掩码自动编码器, 重构掩码子图结构, 在数据增强过程中聚合全局信息.
受MAE在推荐模型上成功应用的启发, 本文提出基于自监督图掩码神经网络的社交推荐模型(Self-Supervised Graph Masked Neural Networks, SGMN).首先, 将物品依赖关系具体化为物品分类关系, 构建包含用户社交关系、物品分类关系和用户物品交互关系的高阶连通异构图, 同时构建用户社交图和物品分类图.再利用图掩码学习范式动态学习高语义用户集合, 这种高语义用户在其邻域中具有较高的结构一致性和较低的噪声百分比.以此为基础, 采用随机游走策略重建用户社交图, 实现自适应和可学习的数据增强.然后, 设计异构图编码器, 分别对视图进行特征提取, 得到用户特征、物品特征嵌入后, 跨视图对嵌入进行对比学习, 完成自监督学习任务, 并分别对不同视图下的用户、物品嵌入进行加权融合, 完成推荐任务.最后, 利用多任务训练策略联合优化自监督学习任务、推荐任务和图掩码任务.
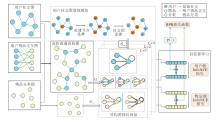
本文提出基于自监督图掩码神经网络的社交推荐模型(SGMN), 整体框架如图1所示.
 | 图1 SGMN框架图Fig.1 Structure of SGMN |
SGMN由如下3部分组成.1)用户社交图增强模块.负责对原始社交图进行自适应和可学习的数据增强.2)异构图特征学习模块.利用异构图神经网络学习重建后的异构社交图、高阶连通异构图和物品分类图中的特征.3)跨视图的自监督学习模块.对来自3幅图的特征进行对比学习, 完成自监督任务.
本文中, 使用U={u1, u2, …, uI}表示I个用户的集合, V={v1, v2, …, vJ}表示J个物品的集合.定义用户物品交互矩阵
Y∈ RI× J={yi, j|u∈ U, v∈ V}.
如果用户ui与物品vj之间存在交互(如点击、购买), yi, j=1; 否则, yi, j=0.
定义Guu={U, Euu}为用户社交图, 其中
${{E}_{uu}}=\{{{e}_{{{u}_{i}}, {{u}_{i'}}}}|{{u}_{i}}\in U, {{u}_{i'}}\in U\}$,
为了更好地定义物品分类关系, 定义
$\mathcal{R}=\{r_1, r_2, · · · , r_K\}$
表示K个物品类别的集合, 在此基础上定义
$G_{vr}=\{V, \mathcal{R}, E_{vr}\}$
为物品分类图, 其中
$E_{v r}=\left\{e_{v_j, r_k} \mid v_j \in V, r_k \in \mathcal{R}\right\}$,
最后定义高阶连通异构图G=\{\mathcal{V}, \mathcal{E}\}, 其中$\mathcal{V}$, $\mathcal{E}$分别与节点映射函数关联, $\mathcal{V}$→ $\mathcal{A}$, $\mathcal{E}$→ $\mathcal{B}$, $\mathcal{A}$表示节点类型集合, $\mathcal{B}$表示边类型集合, $|\mathcal{A}|+|\mathcal{B}|> 2$.
定义
${{E}_{uv}}=\{{{e}_{{{u}_{i}}, {{v}_{j}}}}|{{u}_{i}}\in U, {{v}_{j}}\in V\}$
为用户物品交互边的集合, 其中
$\mathcal{V}=U\cup V \cup \mathcal{R}, \mathcal{E}=E_{uu} \cup E_{vr} \cup E_{uv}$.
本文的社交推荐任务为输入高阶连通异构图G、用户社交图Guu和物品分类图Gvr, 得到可针对特定用户ui与物品vj之间交互概率的预测函数.
受MAERec[19]启发, 本文提出自适应和可学习的用户社交图增强模块.整个模块包含图掩码学习范式模块和社交图重建模块.
1.2.1 图掩码学习范式模块
图掩码学习范式模块的目标是学习用于可学习数据增强的高语义用户集合Ua的范式, 指导后续社交图的重建.具体地, 对社交图Guu中社交节点u的k阶邻居进行采样, 生成社交子图级表征, 并表示其在社交子图内的上下文信息与语义相关性.
受InfoMax(Information Maximization)编码的影响[23, 24, 25, 26], 利用互信息计算节点嵌入和社交子图之间的语义相关性.为了形式化上述方法, 为社交图分配与ID对应的嵌入矩阵Huu∈ RI× d并初始化, 定义社交节点u和其k阶社交子图的相关语义度:
$\gamma (u, k)=sigmoid\left( \underset{u'\in \text{N }_{u}^{k}}{\mathop \sum }\, \frac{{{H}_{uu}}{{\left[ u \right]}^{\text{T}}}{{H}_{uu}}\left[ u' \right]}{\left\| {{H}_{uu}}\left[ u \right] \right\|\left\| {{H}_{uu}}\left[ u' \right] \right\|} \right)$,
其中, $\mathcal{N}_{u}^{k}$表示社交节点u在社交图Guu上的k阶邻居集合, Huu[u]∈ Rd, Huu[u']∈ Rd表示随机初始化的用户嵌入.
通过求和的方式, 聚合k阶子图中除中心节点以外的所有社交节点嵌入表征, 生成节点的社交子图级表征.在其邻域中具有较高的结构一致性, 同时在其社交子图中具有较低噪声百分比的社交节点具有较高的语义相关性分数.而具有噪声交互影响的社交节点在嵌入表示上可能具有不同的信息分布, 导致其语义相关性分数被抑制.
为了提高图掩码学习范式的鲁棒性, 注入Gumbel分布噪声[27] :
γ '(u, k)=γ (u, k)-ln(-ln μ ),
μ ~Uniform(0, 1).
计算所有社交节点的语义相关性γ '(u, k), 通过排名选择其中语义相关性得分较高的用户组成高语义用户集合Ua.
最后使用基于InfoMax的优化目标, 引入自监督学习信号的语义相关性, 提高数据增强过程的自适应性和可学习性, 即
$\mathcal{L}_{\text{mask}}=-\underset{u\in U}{\mathop \sum }\gamma '(u, k)$.
1.2.2 社交图重建模块
社交图重建模块是在图掩码学习范式模块生成高语义用户集合Ua的基础上, 基于自监督学习重建信号重建社交图Guu.重建后的社交图为异构社交图, 从不同角度描述用户社交关系.
高语义用户具有更高的结构一致性和更低的噪声百分比, 所以对以高语义用户为中心的社交子图进行重建可得到更高质量的自监督信号, 帮助模型对用户偏好进行充分建模.具体地, 通过以高语义用户为中心起点进行递归随机游走的策略选择参与重建的社交点集合:
$U_{b}^{k}=\left\{ \begin{array}{* {35}{l}} {{U}_{a}}, & k=1 \\ U_{b}^{k-1}\cup \zeta \left( {{\mathcal{N}}_{U_{b}^{k-1}}}, {{p}^{k}} \right), & k> 1 \\ \end{array} \right.$
其中: $\mathcal{N}_{U_{b}^{k-1}}$表示直接与
递归进行随机游走后, 得到重建社交点集合$U_{b}^{k}$, 然后对选择的社交点${{u}_{src}}\in U_{b}^{k}$周围的社交关系进行转换, 定义转换后的社交关系为
${{\bar{E}}_{uu}}=\{{{\bar{e}}_{{{u}_{\text{dst}}}\ \ ,\ \ {{u}_{\text{src}}}}}\ \ |{{u}_{dst}}\in U, {{u}_{src}}\in U\}$,
其中${{\bar{e}}_{{{u}_{\text{dst}}}\ \ ,\ \ {{u}_{\text{src}}}}}\ \ \ $表示用户udst、usrc之间存在转换的社交关系.保留其余社交关系$({{E}_{uu}}\backslash U_{b}^{k})$, 从不同角度描述社交关系, 帮助模型进行用户偏好建模, 反映各重建社交子图间的依赖关系, 注入高质量自监督信号.
通过节点采样操作, 保证各个不同规模的重建社交子图中社交路径长度不大于2k.进一步为社交图注入动态的社交自监督信号, 完成数据增强过程.最后形成异构社交图:
${{\bar{G}}_{uu}}=\left\{ U, {\mathcal{E}_{uu}}|{\mathcal{E}_{uu}}=({{E}_{uu}}\backslash U_{b}^{k})\cup {{{\bar{E}}}_{uu}} \right\}$.
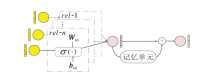
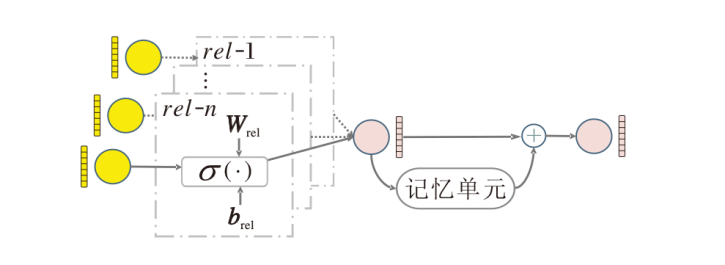
异构图特征学习模块负责提取3幅视图中的特征, 受DGNN[10]的启发, 设计能学习异构关系类型并提取异构语义的异构图编码器.具体的异构图编码器结构如图2所示.
 | 图2 异构图编码器结构图Fig.2 Heterogeneous graph encoder |
1.3.1 异构关系信息传播
在信息传递过程中, 首先执行局部特征转换和非线性激活, 再聚合具有异构关系感知的上下文表征.形式上, 目标节点t在l+1层时的表征如下:
${{H}^{(l+1)}}[t]=func\left( \underset{s\in {{\mathcal{N}}_{t}}}{\mathop \sum }\, \varphi ({{H}^{(l)}}[s], {{e}_{s}}_{, t}) \right)$,
其中, $\mathcal{N}_{t}$表示节点t的邻居节点集合, 边es, t表示连接节点s、t, func(· )表示聚合函数, φ (· )表示异构关系编码操作.为了提取异构图中异构关系下的异构因子并参数化到嵌入中, 使用rel-1, rel-2, …, rel-n表示具体的异构关系类型, 并对异构关系进行不共享的特征转换和非线性激活操作, 形式化为
φ (H[t], es, t)=σ (H[t]· Wrel+brel),
其中, Wrel∈ Rd× d表示可训练的转换矩阵, brel∈ Rd表示偏置, σ (· )表示LeakyReLU激活函数, 即
σ (x)=max(x, α x).
该异构编码器针对特定的节点连接关系使用特定的不共享超参数空间进行处理, 以维护特定关系节点的专用表示.通过这种方式将异构语义融入嵌入特征中.
1.3.2 异构关系信息聚合
在对异构图中节点与其邻居的异构关系进行编码之后, 对来自异构关系节点信息源下的信息进行聚合.节点嵌入信息聚合过程形式化表示为
$H[t]={{\left( \overset{N}{\mathop{\underset{n=1}{\mathop \sum }\, }}\, |\mathcal{N}_{t}^{re{{l}_{n}}}| \right)}^{-1}}\left( \overset{N}{\mathop{\underset{n=1}{\mathop \sum }\, }}\, \left( \underset{s\in \mathcal{N }_{t}^{re{{l}_{n}}}}{\mathop \sum }\, \right)\varphi (H[s], {{e}_{s, t}}) \right)$,
其中, $\mathcal{N}_{t}^{re{{l}_{n}}}$表示节点t在特定关系reln下的邻居节点集合, N表示与节点t相连关系的数量.
为了进一步挖掘潜在异构因子, 使用DGNN[10]中的记忆单元处理节点自循环并加入嵌入中, 即
${{\tilde{H}}^{\left( l+1 \right)}}[t]={{H}^{(l+1)}}[t]+\phi ({{H}^{(l+1)}}[t]){{H}^{(l+1)}}[t]$,
$\phi ({{H}^{(l)}}[t])=\overset{\left| \mathcal{M} \right|}{\mathop{\underset{m=1}{\mathop \sum }\, }}\, \sigma ({{H}^{(l)}}[t]\cdot W_{m}^{2}+{{b}_{m}})W_{m}^{1}$.
其中:ϕ (· )表示具体的编码器, 通过外部存储单元将自循环边中节点的异质性参数化到嵌入中; M表示记忆单元的集合; $W_{m}^{1}\in {{R}^{d}}^{\times d}$, $W_{m}^{2}\in {{R}^{d}}$表示可训练的转换矩阵, bm∈ R表示偏置项.
最后, 对各层嵌入进行平均池化, 并结合层归一化(Layer Normalization)[28], 进一步对嵌入进行聚合, 得到节点t的嵌入:
${{H}^{* }}[t]=LayerNorm\left( \frac{1}{L}\overset{L}{\mathop{\underset{l=0}{\mathop \sum }\, }}\, {{\widetilde{H}}^{(l)}}[t] \right)$,
$LayerNorm(x)={{\lambda }_{1}}\left( \frac{x-\mu }{\sigma } \right)+{{\lambda }_{2}}$,
其中, L表示神经网络层数, LayerNorm(· )表示层归一化函数, μ 、σ 表示x的均值和方差, λ 1、λ 2表示可训练的参数.
对3幅视图进行异构关系学习后, 得到异构社交图中的用户嵌入$H_{uu}^{\text{* }}\in {{R}^{I}}^{\times d}$、物品分类图的物品嵌入
$\mathcal{L}_{cl}^{u}=\underset{u\in U}{\mathop \sum }\,-\ln \left( \frac{\text{exp}\left( \frac{s\left( H_{uu}^{\text{*}}\ \ \left[ u \right],H_{u}^{\text{*}}\ \ \left[ u \right] \ \ \right)}{\ \ \ \ \ \tau } \ \right)\ \ \ \ }{\underset{u'\in U}{\mathop \sum }\,\text{exp}\left( \frac{s\left( H_{uu}^{\text{*}}\ \ \left[ u \right],H_{u}^{\text{*}}\ \left[ u' \right] \ \ \right)}{\ \ \ \ \tau } \ \right)\ \ \ } \right)$
其中:$H_{uu}^{\text{*}}[u]\in {{R}^{d}}$表示属于Huu的嵌入向量, $H_{u}^{\text{* }}[u]\in {{R}^{d}}$表示属于Hu的嵌入向量; s(· )定义为相似函数, 具体使用余弦相似度作为s(· ); 由于不同数据集上数据分布差异较大, 引入一个超参数τ 作为影响因子以适应不同场景; u'表示负样本.类似地, 可获得物品侧的InfoNCE损失$\mathcal{L}_{cl}^{v}$.
最后使用两个超参数权值α 1、α 2, 得到最终的对比损失函数:
$\mathcal{L}_{cl}=\alpha_{1}\mathcal{L}_{cl}^{u}+\alpha_{2}\mathcal{L}_{cl}^{v}$.
不同视图下建模的嵌入内部包含丰富的信息, 为了将这些信息充分利用到模型的预测阶段, 首先将不同视图下的用户、物品嵌入进行加权融合.以用户嵌入为例:
$\overset{}{\mathop{H}}\, _{u}^{\text{* }}={{\beta }_{1}}H_{uu}^{\text{* }}+{{\beta }_{2}}H_{u}^{\text{* }}$,
其中β 1、 β 2表示两个超参数权值.
然后, 使用校准函数τ (· )细化用户嵌入.具体地, 根据原始社交图Guu平均池化社交节点和其邻居节点嵌入, 注入原始社交图Guu的影响因子, 丰富用户信息, 用于下一步预测阶段, 即
${{\hat{y}}_{u, v}}\text{=}{{\left( \widehat{H}_{u}^{* }[u]+\tau (\widehat{H}_{u}^{* }[u]) \right)}^{T}}\cdot \widehat{H}_{v}^{* }[v]$.
采用BPR(Bayesian Personalized Ranking)[29]损失函数完成推荐任务.具体地, 为每个训练样本配置一个用户u、用户交互过的正样本v+和用户未交互过的负样本v-.对于每个训练样本, 最大化预测得分:
$\mathcal{L}_{\text{bpr}}=\underset{\left( u, {{v}^{+}}, {{v}^{-}} \right)\in O}{\mathop \sum }\, ~(-ln(\delta ({{\hat{y}}_{u, {{v}^{+}}}}-{{\hat{y}}_{u, {{v}^{-}}}})))+\lambda {{\left\| \Theta \right\|}^{2}}$,
其中, δ (· )表示sigmoid激活函数, λ 表示正则化项权重超参数, Θ 表示可学习的超参数.将BPR损失函数与对比学习损失、图掩码损失结合, 最终得到模型损失函数:
$\mathcal{L}=\mathcal{L}_{\text{bpr}}+\gamma \mathcal{L}_{\text{cl}}+\mathcal{L}_{\text{mask}}$.
本节对SGMN的各模块进行时间复杂度分析.
1)用户社交图增强模块的计算成本主要集中在图掩码学习范式模块, 计算社交节点u和其k阶社交子图相关语义度的时间复杂度为O(k|Euu|d), 其中, d表示隐含层维度, |Euu|表示社交图中边的数量.
2)异构图编码器主要时间复杂度为
$O((|\mathcal{E}|+|{\mathcal{E}_{uu}}|+|{{E}_{vr}}|){{d}^{2}})$,
其中, $|\mathcal{E}|$表示高阶连通异构图中边的数量, $|{\mathcal{E}_{uu}}|$表示异构社交图中边的数量, |Evr|表示物品分类图中边的数量.
3)在跨视图自监督学习模块中, 对比学习部分的时间复杂度为O(b(I+J)d), b表示每个批次样本数量, I表示用户数量, J表示物品数量.
综上所述, SGMN中的用户社交图增强模块和跨视图的自监督学习模块与现有技术的自监督图神经网络推荐模型(如SGL[15])时间复杂度相同, 而异构图特征学习模块的时间复杂度也与目前一些先进推荐模型(如DGNN[10]、HGCL[13]、AutoCF[22])相近.
本文在Ciao、Epinions、Yelp这3个真实世界的社交推荐基准数据集上进行实验.Ciao、Epinions数据集都收集自在线产品评论网站, 包含用户对不同物品的评分行为, 同时具有用户信任关系与物品分类关系.Yelp数据集包含用户对商家的评分行为和用户社交关系信息, 还包含场所评分、位置等信息.3个数据集的统计数据如表1所示.
| 表1 实验数据集信息 Table 1 Description of experimental dataset |
实验使用2个广泛的top-N推荐指标评估模型: HR@N(Hits Ratio, HR)和NDCG@N(Normalized Discounted Cumulative Gain).在设置中, 为每位用户选择1个交互物品作为正样本和100个非交互物品作为负样本.评价指标计算公式如下:
$HRN=\frac{1}{M}\overset{M}{\mathop{\underset{i=1}{\mathop \sum }\, }}\, \overset{N}{\mathop{\underset{j=1}{\mathop \sum }\, }}\, {{r}_{i}}_{, j}$,
$NDCGN=\overset{M}{\mathop{\underset{i=1}{\mathop \sum }\, }}\, \left( \frac{1}{M\cdot IDC{{G}_{i}}}\overset{N}{\mathop{\underset{j=1}{\mathop \sum }\, }}\, \left( \frac{{{r}_{i, j}}}{\text{lo}{{\text{g}}_{2}}\left( j+1 \right)} \right) \right)$.
其中:M表示测试用户数量; 如果第i个用户的推荐物品排序列表中的第j个项目是正确样本, ri, j=1, 否则ri, j=0; NDCG的分子为DCG@N(Discounted Cumulative Gain); IDCGi表示对第i位测试用户的最大可能DCG@N值.
基于Pytorch实现SGMN, 并使用学习率为0.01的Adam(Adaptive Moment Estimation)优化模型.SGMN的嵌入维度范围设置为{8, 16, 32, 64}.批次选择范围为{512, 1 024, 2 048, 4 096}.正则化项系数λ 调整范围为{10-3, 10-4, 10-5}.在异构图神经网络中对自循环节点使用的记忆网络单元的数量设置为8.在所有实验中, 保持上述参数设置在所有模型中均一致.
为了验证SGMN的有效性, 本文选用如下8个基线模型进行对比实验.
1)MHCN[7].设计多通道的超图神经网络捕获用户关系, 并加入辅助的自监督学习任务.
2)DGNN[10].设计隐式记忆单元以分解用户、物品之间异构关系的社交推荐网络.
3)SAMN[11].设计基于注意力的记忆网络, 引入用户侧的社交影响力以构建用户偏好.
4)HGCL[13].使用元网络完成知识迁移, 构建自适应对比增强的个性化知识, 增强异构图对比学习.
5)SMIN[18].设计多条元关系维护用户和物品嵌入, 将辅助图学习任务纳入主任务的自监督社交推荐模型.
6)NGCF(Neural Graph Collaborative Filte-ring)[30].将用户之间的社会信息纳入基于图卷积的协同过滤模型.
7)KGAT(Knowledge Graph Attention Net-work)[31].引入物品侧知识, 采用注意力机制, 处理用户物品交互信息和物品的知识图信息.
8)HAN(Heterogeneous Graph Attention Net-work)[32].以元路径引导的层次注意模型对异构图进行编码, 通过这种方法进行编码的节点能保持用户社交关系之间的社会意识和物品的知识意识.
各对比模型在3个数据集上的指标值如表2所示, 表中黑体数字表示最优值, 斜体数字表示次优值, * 表示本文训练得到的结果, 其它结果引用自文献[10].
| 表2 各模型在3个数据集上的指标值对比 Table 2 Index value comparison of different models on 3 datasets |
从表2中可见.相比其它基线模型, SGMN在3个数据集上性能均有所提升, 由此表明模型的有效性.具体而言:1)SGMN对社交图进行可学习和自适应的数据增强, 采用图掩码学习范式模块, 选择具有邻域内结构一致性较高的高语义用户所在的社交子图进行重建, 从不同角度对用户社交偏好进行建模, 注入高质量和自适应的自监督信号, 有效抑制噪声影响, 提高对比学习精度.2)将用户社交关系、用户物品交互关系和物品分类关系构成高阶连通异构图, 与社交图、分类图形成对比视图.相比单交互视图, 对比视图包含更多的协作因子, 可有效完成自监督任务.3)设计异构图神经网络, 挖掘异构图中异构关系的隐形因子, 同时通过记忆网络处理节点自循环, 加强对异构关系的处理, 提高推荐性能.
相比SAMN和KGAT, NGCF表现更优, 这表明使用图结构进行嵌入传播的合理性.同时, DGNN和HGCL在基于图神经网络模型的基础上进一步提升性能, 表明异构神经网络对高阶信息建模的有效性.
MHCN、SMIN和HGCL性能表现较优, 表明自监督学习技术增强用户物品交互编码的合理性, 而SGMN与MHCN、SMIN、HGCL之间的性能差距表明使用可学习和自适应的数据增强以及综合考虑高阶连通异构图与社交图、分类图之间协作关系的重要性.
为了研究SGMN中各模块的贡献, 设计如下变体, 在Ciao、Epinions、Yelp数据集上进行消融实验.
1)-AM.使用相同比例随机挑选社交节点的策略替换本文中的自适应图掩码策略.
2)-SP.为了研究社交图重建的重要性, 将社交子图的社交路径最大长度设置为1.
3)-ML.去除图掩码损失.
4)-HG.将SGMN中的异构图编码器替换为DGNN中的分离异构编码器.
5)-SSL.去除自监督学习任务.
不同变体在3个数据集上的指标值如表3所示, 表中黑体数字表示最优值.由表可以明显看到:1)相比自适应策略, 使用非自适应的随机掩码策略的模型性能有所下降, 这说明非自适应策略无法选择与周围用户节点嵌入高度语义一致的高语义用户节点, 无法有效应对噪声影响, 降低模型性能.2)-SP的表现说明本文的社交图重建策略的有效性, 可有效注入动态的社交自监督信号进行数据增强.3)去除图掩码损失的-ML的结果说明注入的自监督信号能够在自适应任务的约束下有效防止增强与任务无关的信息, 有效引导社交图向更好的方向增强.4)-HG在3个数据集上的综合性能表现都不及SGMN, 表明本文使用的异构图编码器能在异构图中有效提取用户物品特征, 挖掘异构因子.5)-SSL的结果表明跨视图进行对比学习构建自监督任务的有效性.
| 表3 各模块在3个数据集上的消融实验结果 Table 3 Ablation experiment results of different modules on 3 datasets |
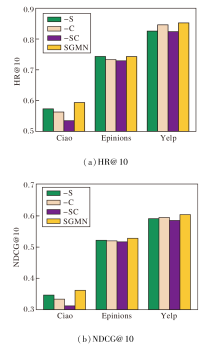
为了分析高阶连通异构图G={V, E}中用户社交关系、物品分类关系对推荐性能的影响, 设计3种模型变体.
1)-S.去除高阶连通异构图中的原始社交关系部分.
2)-C.去除高阶连通异构图中的物品分类关系部分.
3)-SC.去除高阶连通异构图中的原始社交关系和物品分类关系.
在3个数据集上进行top-10实验, 各模块的指标值如图3所示.由图可看出, SGMN的性能始终最优, 说明构建高阶异构关系、挖掘潜在的异构语义可对模型性能产生积极影响.-S和-C的性能说明模型分别融入社交关系、物品分类关系都能有效帮助模型建模.-SC在所有实验中都表现出最差的性能, 说明社交关系和物品分类关系都能有效提高模型的准确性.
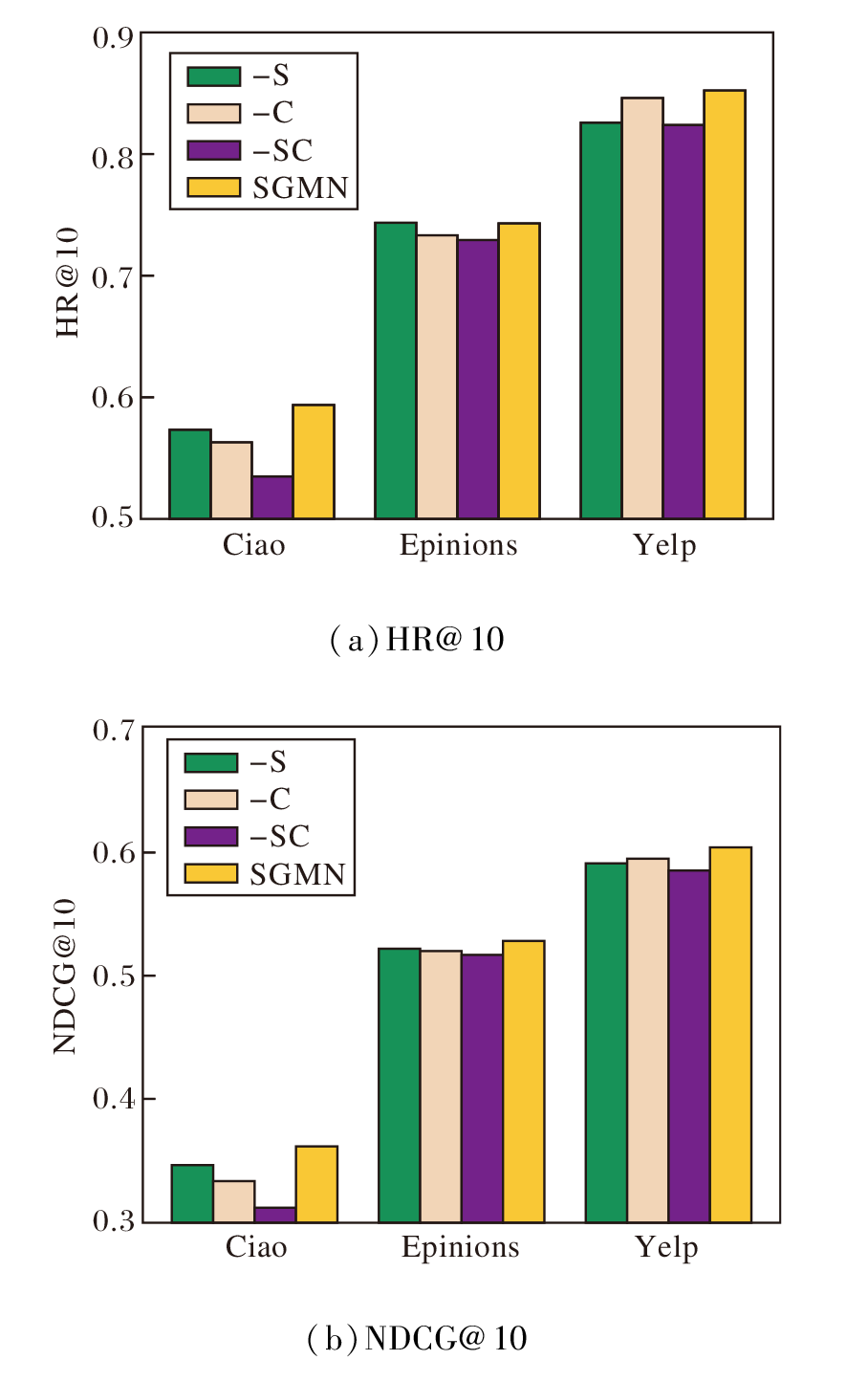 | 图3 异构关系对推荐性能的影响Fig.3 Influence of heterogeneous relationship on model performance |
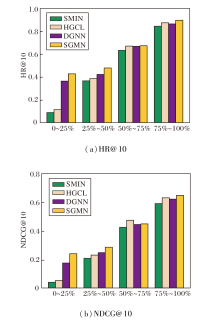
本节将验证模型缓解数据稀疏性的能力, 在Yelp数据集上, 给出SGMN在用户交互行为稀疏数据上的表现.首先根据用户与物品的交互密度对所有用户进行排名, 并平均划分为4组.交互密度排名位于0~25%的用户分组的平均交互数量为1; 排名位于25%~50%的用户分组的平均交互数量为2; 排名位于50%~75%的用户分组的平均交互数量为5; 排名位于75%~100%的用户分组的平均交互数量为23.
SMIN、HGCL、DGMN和SGMN缓解不同数据稀疏度的性能对比如图4所示.由图可知, 在用户交互数据稀疏的情况下, SGMN整体表现最优, 尤其在数据极度稀疏的情况下, SGMN性能远超其余模型, 表明SGMN在处理用户物品交互行为数据稀疏度上的鲁棒性, 也表明引入自适应可学习数据增强和高阶连通异构图对提高模型性能的重要作用.总之, SGMN能有效缓解现实推荐场景下数据稀疏的问题.
 | 图4 各模型在不同数据稀疏度下的性能对比Fig.4 Performance comparison of various models with different data sparsity degrees |
本节进一步进行超参数分析, 具体研究图传播层数L、隐含层维度d以及社交路径比例k对SGMN性能的影响.
设置图神经网络的传播层数L=1, 2, 3, 4, L对SGMN性能的影响如表4所示, 表中黑体数字表示最优值.由表可观察到, 使用3层神经网络能得到最优性能, 而更高的层数会导致模型学习噪声, 反而降低性能.
| 表4 图传播层数对模型性能的影响 Table 4 Influence of graph propagation layers on model performance |
本文设置d=8, 16, 32, 64, d对SGMN性能的影响如表5所示, 表中黑体数字表示最优值.由表可以观察到, 适当增强嵌入维度能有效提高推荐性能, 但是过高的嵌入维度会由于模型过拟合导致性能有所下降, 嵌入维度为32时SGMN性能最优.
| 表5 隐含层维度对模型性能的影响 Table 5 Influence of hidden layer dimensionality on model performance |
重建社交子图的社交路径最大值为2k, 设置路径比例k=1, 2, 3, 4, k对SGMN性能的影响如表6所示, 表中黑体数字表示最优值.由表可观察到, 长度在中间范围时效果最好, 较低的长度无法对重建社交关系进行充分学习, 而过长的社交长度会导致社交子图中的节点结构差距过大, 从而影响用户偏好建模.
| 表6 社交路径比例对模型性能的影响 Table 6 Influence of social path scale on model performance |
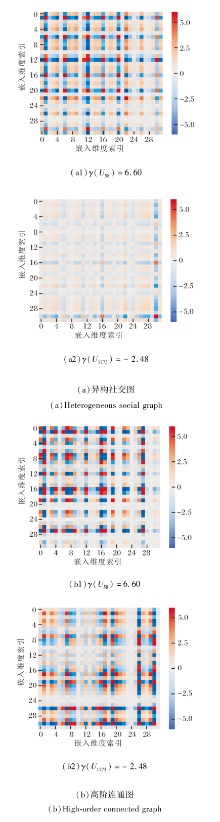
在Ciao数据集上对SGMN进行实例分析.具体地, 选择图掩码过程中计算得到的高语义用户和低语义用户, 对在异构社交图和高阶连通异构图上学习到嵌入变换后进行可视化, 在异构社交图和高阶连通异构图中学习到的嵌入结果如图5所示, 图中u58表示高语义用户, u1773表示低语义用户.
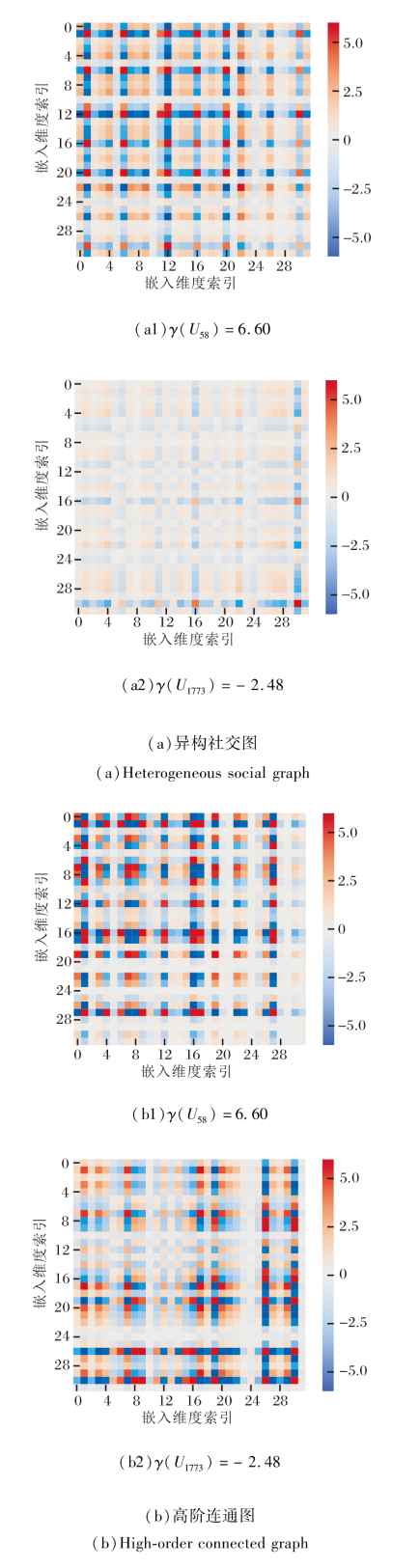 | 图5 在Ciao数据集上的实例分析Fig.5 Example analysis on Ciao dataset |
由图5可观察到, 从异构社交图中学习到的高语义用户嵌入具有比低语义用户更多的信息, 表明图掩码学习范式指导社交图重建进行可学习和自适应数据增强的有效性, 其与高阶连通异构图中学习的用户嵌入之间的信息差距也有利于自监督任务的完成.异构社交图视图下的用户嵌入可有效帮助高阶连通异构图抑制噪声影响, 提高推荐性能.
本文提出基于自监督图掩码神经网络的社交推荐模型(SGMN), 能进行自适应和可学习的社交图数据增强, 关注高阶连通异构关系下的自监督信号, 有效抑制噪声影响, 提高自监督学习精度, 增强推荐性能.在3个数据集上的实验表明SGMN性能具有一定提升.同时, 消融实验和数据稀疏性实验验证模型各模块的有效性和缓解数据稀疏问题的能力, 表明自适应图增强策略的可行性.而异构关系对模型性能影响的实验验证构建高阶连通异构图的必要性, 其蕴含的自监督信号和协作因子可帮助模型更好对偏好关系进行建模.今后, 将继续探索可学习的社交图重建方法, 进一步提高复杂社交场景下图增强策略的自适应性.
本文责任编委 陈恩红
Recommended by Associate Editor CHEN Enhong
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|