


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
面向道路目标检测的多模态融合语义传输
[朱增乐1  , 魏智伟
, 魏智伟2 , 张荣庆3 , 杨柳青1 ]
, 魏智伟, 张荣庆, 杨柳青]
|
|



作者简介: 
朱增乐,博士研究生,主要研究方向为语义通信、人工智能.E-mail:zzhu622@connect.hkust-gz.edu.cn. 
魏智伟,博士研究生,主要研究方向为车载雾计算、计算资源分配.E-mail:2311769@tongji.edu.cn. 
杨柳青,博士,教授,主要研究方向为无线通信网络、多智能体系统、通讯感知一体化等.E-mail:lqyang@ust.hk.
在长尾效应的极端场景下,多车多传感器协作感知可为车辆提供有效的感知信息,但异构数据的差异化带宽限制和不同的数据格式使车辆在处理信息时难以进行统一高效的调度.为了在有限通信带宽下实现不同车辆间多传感器信息的有机融合,文中从语义通信的角度出发,提出基于Transformer的多模态融合目标检测语义通信模型.不同于传统的数据传输方案,文中模型利用自注意力机制融合不同模态的数据,着重探究各模态数据之间的语义相关性与依赖性.在有限的通信资源下帮助车辆进行信息传递和相互协作,提高车辆对复杂路况的理解能力.在Teledyne FLIR Free ADAS Thermal数据集上的实验表明,文中模型在多模态目标检测语义通信任务中表现出色,不仅大幅提升目标检测的准确性,同时也减少一半传输代价.
About Author:
ZHU Zengle, Ph.D. candidate. His research interests include semantic communication and artificial intelligence.
WEI Zhiwei, Ph.D. candidate. His research interests include vehicular fog computing and computational resource allocation.
YANG Liuqing, Ph.D., professor. Her research interests include wireless communication networks, multi-agent systems and integrated communication and sensing.
In extreme scenarios with long-tail effects, collaborative perception involving multiple vehicles and sensors can provide effective sensory information for vehicles. However, the differentiation in heterogeneous data, coupled with bandwidth constraints and diverse data formats, makes it challenging for vehicles to achieve unified and efficient scheduling in processing. To organically integrate multi-sensor information among different vehicles under limited communication bandwidth, a semantic communication framework for multimodal fusion object detection based on Transformer is proposed in this paper. Unlike traditional data transmission solutions, self-attention mechanisms are utilized in the proposed framework to fuse data from different modalities, focusing on exploring the semantic correlation and dependencies among modal data. It helps vehicles transmit information and collaborate under limited communication resources, thereby enhancing their understanding of complex road conditions. The experimental results on Teledyne FLIR Free ADAS Thermal dataset show that the proposed model performs well in multimodal object detection semantic communication tasks with accuracy of object detection significantly improved and transmission costs reduced by half.
在新时代的智慧城市生活中, 为了满足人们日益增长的智能驾驶需求, 出现各种车联网应用[1, 2].这些车联网应用, 如智能辅助驾驶、自动泊车等, 需要能够实时准确识别周围的车辆、行人等道路目标, 做出符合道路场景的智能决策.不难发现, 在“ 识别-决策” 过程中, 车辆对外部环境的感知能力决定车载智能“ 看见” 什么, 而在高度动态且风险敏感的驾驶场景下, 只有准确无误的感知才能引导智能高效的决策.因此, 为了保障实时车联网应用的安全性, 大量研究致力于提升车辆对环境的准确感知能力[3, 4].
在现有研究中, 基于单一传感器数据的处理与决策技术已经可以保证在绝大部分场景下的高效可用[5, 6, 7].以视觉处理为例, 在正常光照条件下, 车载摄像头采集的RGB图像通常包含丰富的语义信息, 如物体颜色、纹理和形状等细节信息, 这在目标识别、自动驾驶等高级视觉任务中至关重要.但是, 在光线较弱、背光等情况下, RGB图像常常质量较差[8].此外, 在极端恶劣天气条件下, 能见度急剧降低, 单一RGB摄像头无法准确反映环境变化.不仅是视觉传感器, 任何基于单一传感器的方案都面临着适用场景有限、无法保证极端场景下高可靠性的问题.这种情况被称为感知任务的“ 长尾问题” .在实际应用中, 也正是这些极端场景下的应用限制[9, 10, 11]阻碍相关技术方案的应用与发展.
对于如何保证车辆在各种场景, 尤其是难以预料的极端场景中, 都能具备准确感知识别目标物体的能力, 一种可行的思路是采用多传感器融合感知技术, 这一方法也叫多模态融合感知.通过多种传感器的融合构建车辆的全局感知环境, 不仅要处理大量复杂和动态的信息, 还必须在实时条件下为车辆提供准确可靠的环境理解.此外, 考虑到单一车辆在复杂和密集的交通环境中可能存在的感知局限性, 基于车联网的多车协作感知也是一个关键的解决思路.在车联网[12]中, 车辆不再是孤立的个体, 而是通过无线网络相互连接, 形成一个智能化的交通生态系统[13].这种互联互通使车辆能实时获取周围车辆、行人和道路设施的信息, 为道路目标检测提供丰富的多模态数据源.通过车联网中车辆间的协作, 可帮助车辆共同应对复杂多变的道路条件.
因此, 构建多车多模态协作感知框架, 能为车辆提供更广泛、更准确的感知范围, 提升整个系统的可靠性和适应性.然而, 在车联网场景下, 这种协作感知框架的应用面临如下挑战.
1)通信时延和带宽压力.在动态拓扑结构的车联网环境下, 额外增加其它模态数据的传输需要较大的带宽, 这导致直接传输原始感知数据可能会引发较高的通信时延, 传输带来的时延会大幅影响检测任务的实时性和性能[14].
2)信道噪声.在开放信道的车联网场景中, 多模态传感器通信常会受到各种信道噪声和干扰的影响.传统方法难以应对这些干扰, 这使准确数据传输和解析变得极具挑战性.
3)异构数据间的语义融合.多模态感知涉及多种传感器, 如摄像头、激光雷达和热成像仪等, 这些传感器产生的数据类型各异.如何有效融合这些不同类型的数据, 挖掘它们之间的语义相关性和依赖性, 是一个复杂的挑战.
为了解决传统方式下直接传输原始感知数据引发的高通信时延问题, 本文引入语义通信[15]的概念.语义通信的核心在于通过特征提取, 抽取并压缩原始数据的语义信息, 使其能在降低传输代价的同时增强噪声抗干扰能力, 从而提高下游智能任务的性能.但是, 由于其它模态语义信息的引入, 也面临一个关键的挑战:如何高效融合这些异构信息, 确保系统能够在全面准确理解道路环境的同时减少传输代价.一种可行的策略是利用深度学习和人工智能技术, 在语义通信中融合不同传感器提取的语义信息.语义信息融合能有效挖掘各种数据之间的语义相关性和互补性, 获得更全面的信息.融合后的数据在语义通信的框架下进行传输, 可进一步降低通信代价.
综上所述, 针对实时车联网中多车协作的道路目标检测问题, 本文着眼于多模态融合感知技术, 提出基于Transformer的多模态融合目标语义通信模型.与传统孤立处理语义信息的模型不同, 本文模型通过语义编码器对不同模态的感知数据进行语义提取, 并且着重探究各模态数据之间的语义相关性和依赖性.在语义通信的基础上, 提出基于Transformer的多模态融合框架, 有效融合提取的语义信息.实验表明, 在协同目标检测任务中, 本文模型不仅将传输数据量降低50%, 同时也取得2%~3%的性能提升.这说明本文模型在维持卓越性能的同时, 大幅提升数据传输的效率, 降低传输代价, 这对于实现多模态多车协作具有重要意义.
在车联网应用领域中, 道路目标检测技术起到至关重要的作用[16].传统的道路目标检测算法主要包括基于特征工程的方法和传统机器学习方法[17, 18], 这些算法通过手工设计的特征和经典的机器学习模型进行目标检测.然而, 手工设计的特征通常难以捕捉到复杂目标的信息, 多样化的道路场景会导致这些检测算法性能的下降[19].近年来, 随着人工智能的迅猛发展, 基于深度学习的道路目标检测算法已成为主流[20, 21, 22].这些模型通常依赖单一传感器(如RGB相机)的数据进行目标检测, 在绝大多数场景下表现高效可靠[5, 6, 7].算法能够自动学习特征, 显著提高道路目标检测的准确性.但是, 道路上的光照和天气条件的变化会对这些目标检测系统的性能产生重大影响[23], 形成感知任务的“ 长尾问题” .
由于单一传感器存在场景限制问题, 因此多传感器方案应运而生.一种有效的方法是将RGB相机和热成像仪结合使用, 增强模型性能.传统的RGB相机会受到光照变化的影响, 导致拍摄后目标外观发生变化, 而热成像仪不受光照影响, 能在各种光照和天气条件下保持稳定的性能.相比仅依赖单一RGB传感器的传统方法, 采用多模态数据更有利于弥补光照变化对目标检测性能的影响, 提高系统的鲁棒性和可靠性.
使用多传感器方案也带来一个关键问题:如何融合不同的输入模态数据[24].在这个领域中, 通常有早期融合(Early Fusion)、中期融合(Intermediate Fusion)和后期融合(Late Fusion)等不同的融合策略[25].早期融合是一种将不同模态的原始数据集成到一个单一多模态表示中的策略[26], 能捕捉底层特征.中期融合发生在模态信息经过独立处理但尚未进行高级特征提取之前[27], 平衡模态间信息处理和抽象特征提取.后期融合发生在模态信息已经过独立处理并提取高级特征之后[28], 侧重于高级特征的整合.
传统方法在多模态融合时使用诸如多层感知机(Multilayer Perceptron, MLP)和卷积等经典架构[25, 26, 27, 28], 取得一定进展.但在处理多模态数据时, 结构固定, 难以适应不同数据之间的变化关系[29].这种固定结构的限制使模型在处理复杂多模态数据时, 难以实现灵活的特征学习.随着研究的深入, Transfor-mer[30]逐渐引起学者的关注.
Transformer最初引入自然语言处理(Natural Language Processing, NLP)领域, 现已成为多领域中的一个重要工具.它独特的架构基于自注意力机制, 关联输入序列的各部分, 有效捕获序列数据中的依赖关系.在各领域中, Transformer都表现出优异效果.BERT(Bidirectional Encoder Representations from Transformers)[31]改进文本理解的能力, 进一步提高各种自然语言处理任务的性能.ViT(Vision Transfor-mer)[32]、MaskFormer[33]、DETR(Detection Transfor-mer)[34]等将自注意力机制引入图像处理, 实现图像分类、语义分割、目标检测等任务显著的性能提升.
Transformer不仅可在文本模态发挥巨大的作用, 在图像、语音等模态同样可发挥强大的作用, 这说明将Transformer应用在多模态语义融合的可行性.本文将不同模态语义信息的组合视为一个输入序列, 使用Transformer架构对其进行语义融合, 充分发挥模型自注意力机制的优势, 使模型能够自动学习和捕捉多模态数据中的复杂语义关系.这种探索不仅提高模型性能, 也为多模态任务提供新的范式.
在车联网的背景下, 车辆可通过无线网络相互连接[13], 为道路目标检测提供丰富的数据源.使用传统通信直接传输原始信息, 会造成较大时延.据测算, 仅通过图像识别方式获取的单车数据速率[35]将超过40 Gbit/s.而5G移动通信系统的上行空口时延最低为4 ms, 无法满足面向L4级别自动驾驶的需求, 即数据端到端传输和处理时延[36]需要小于1 ms.
为了车辆能更好地实时理解周围环境并做出智能决策, 更需要传递数据背后的语义信息.在这种背景下, 引入语义通信[15]的概念.相比传统通信方法追求的无损传输, 语义通信是以任务为主体, 对原始信号进行有选择的特征提取、压缩和传输, 满足接收端的智能任务.这种通信方式可显著降低数据流量, 提高通信效率, 更好地支持车辆间的智能协同.
一个语义通信模型主要可分为3部分:发射网络、物理信道和接收网络.发射网络包括语义编码器和信道编码器, 接收网络包括语义解码器和信道解码器.语义通信模型的基本原理是通过发射网络对原始数据提取语义信息, 再通过物理信道传输到接收端, 最终由接收网络使用传输的语义信息执行智能任务.其中, 语义编码器(Semantic Encoder)负责提取原始数据的语义信息, 信道编码器(Channel Encoder)对语义信息进行压缩, 降低传输代价.信道解码器(Channel Decoder)在接收端负责恢复压缩的语义信息.语义解码器(Semantic Decoder)使用恢复后的语义信息执行各种智能任务.
现有的语义通信工作通常在特定的模态数据[37, 38, 39, 40]上进行设计和训练, 如文本、语音或图像.这些模型在处理多模态数据融合时, 难以适应不同模态之间相互作用的语义关系.由于车联网场景涉及到多源异构数据, 现有模型的单一模态设计方法限制其在复杂多模态场景下的表现.此外, 少数多模态语义通信工作[41]也只是将多模态数据拼接后传输, 增加通信代价.
因此, 本文深入探讨在车联网环境下, 道路目标检测任务中的两个关键问题:多模态融合和车辆间通信.面对道路上复杂多变的光照和天气条件, 通过Transformer有效融合多模态数据, 提高目标检测的鲁棒性和可靠性.同时, 为了降低传输代价, 采用语义通信框架, 实现不同模态数据间的融合和传输, 为今后多模态通信研究提供有价值的参考.
本文提出基于Transformer多模态融合目标语义通信模型.模型结构分为4部分:语义编码层、信道编码层、信道解码层、语义解码层, 具体架构如图1和图2所示.
 | 图1 本文模型总体架构Fig.1 Overall architecture of the proposed model |
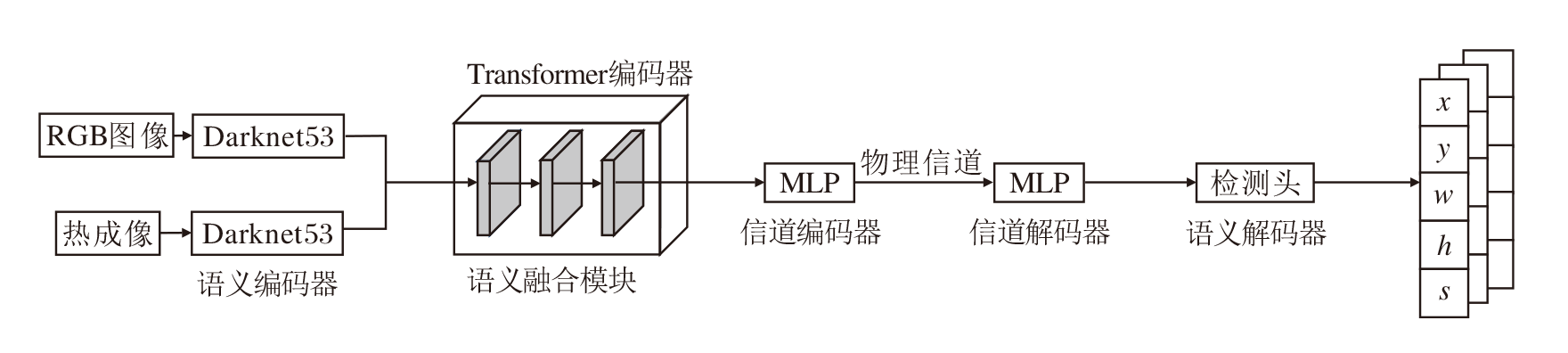 | 图2 本文模型详细架构Fig.2 Detailed architecture of the proposed model |
语义编码层由2个骨干网络构成.给定热成像
其中,
这个融合模块是一个基于Transformer的融合架构, 通过自注意力机制进行不同模态语义特征间的交互. 融合后的语义特征既具有各模态独特的属性, 也具有不同模态的交互属性, 表示热成像和RGB图像共同提供的信息.
这些特征随后送入信道编码层, 该层的作用是进一步压缩融合后的语义信息, 从而降低传输代价. 压缩后的语义信息通过物理信道传输, 接收到的信号:
其中, H表示信道矩阵,
2.2.1 语义特征提取层
在本文模型中, 语义特征提取层是一个关键的组成部分, 负责从不同的数据源中提取语义特征.本文使用Darknet53[21]作为模型的语义特征提取层, 对RGB图像数据和热成像数据进行特征提取.
Darknet53[21]是一个经典的深度神经网络, 通常用于目标检测任务.将RGB图像数据传递给Dark-net53网络, 提取RGB图像的语义特征.这些特征包括图像中的物体、纹理和结构信息, 这对于理解视觉信息非常关键.同时, 也将热成像模态数据输入另一个Darknet53网络, 获取热成像数据的语义特征.热成像数据通常包含物体的温度分布和热量信息, 这对于一些特定场景(如光照不足、可见度不高等场景)非常重要.
Darknet53网络架构如表1所示.主要包括如下两个关键部分.
| 表1 Darknet53网络架构 Table 1 Darknet53 network architecture |
1)卷积层(Convolutional Layers).Darknet53网络以一系列卷积层开始, 这些层负责在图像数据中捕捉低级别的特征, 如边缘和纹理.这些卷积层使用不同大小的卷积核检测不同尺度的特征.
2)残差块(Residual Blocks).Darknet53引入残差连接的思想, 使用残差块构建深度网络.残差块允许网络更深, 同时减轻梯度消失问题, 使训练更稳定.
使用Darknet53对这两种不同的数据源进行特征提取, 能获得RGB模态和热成像模态数据的语义表示.
2.2.2 语义特征融合层
当涉及到道路目标检测这一具体的场景时, 多模态信息的融合变得尤为重要.在这个场景中, 模型需要同时理解道路上的视觉信息(如车辆、行人等)和温度信息.RGB图像提供道路上车辆和行人的视觉信息, 热成像图像能显示热源的温度分布.因此, 在可见度不高、RGB图像分辨率较低的情况下, 使用热成像弥补RGB信息缺失是一个较好的方法.这两种信息相互补充, 但如何有效融合它们则成为一个挑战.
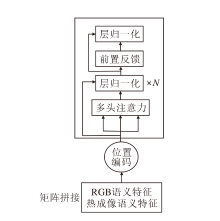
为了克服这一挑战, 本文引入Transformer, 实现这两种模态信息的融合.将这两种模态的语义信息视为两段不同的序列拼接在一起, 送入Transformer中.Transformer的自注意力机制使模型能在不同模态的语义信息之间建立关联, 在道路目标检测中, 这意味着模型可将车辆和行人的视觉信息与其在热成像中的热分布关联.这种关联有助于更全面理解道路上的情况, 提升目标检测的性能.具体融合架构如图3所示.
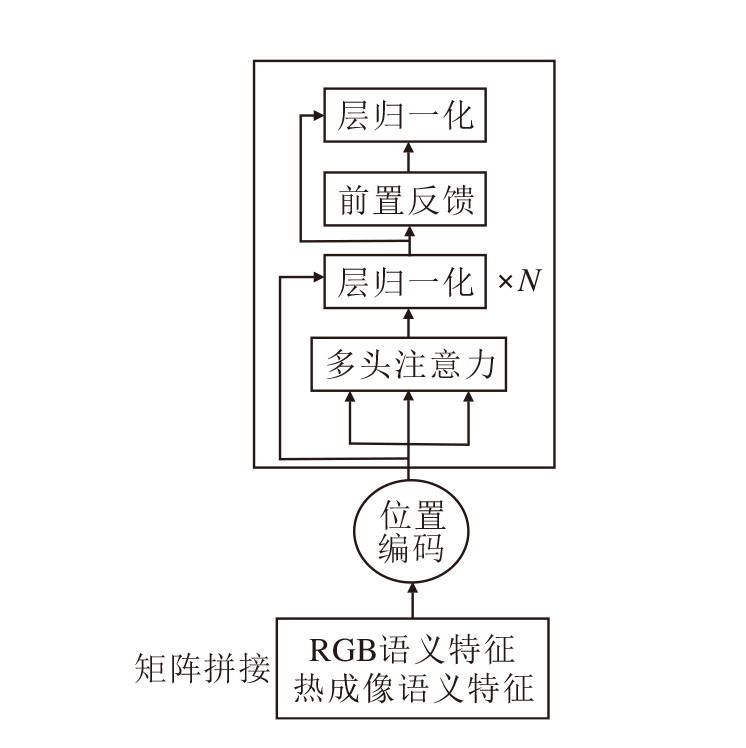 | 图3 基于Transformer的融合架构Fig.3 Transformer-based fusion architecture |
在信道编码层中, 使用两层MLP.第1层MLP用于接收原始的语义特征.这些原始特征是RGB图像和热成像图像融合后的语义特征.这一过程有助于对原始语义特征进行初步的压缩.
第2层MLP用于进一步压缩第1层的输出.这一层包含更少的神经元, 因此输出维度低于第一层.通过这种方式, 网络能学习到更抽象的特征表示.第2层MLP的输出可视为对原始语义特征的紧凑表示, 具有更高的信息密度, 同时可进一步降低语义通信的传输代价.
压缩后的语义特征包含原始特征的核心信息, 但维度较低.为了恢复原始特征的信息, 同样使用两层MLP进行解码.
第1层MLP将对压缩后的特征进行线性组合和非线性变换, 重建部分原始特征的信息.
第2层MLP用于进一步改进解码过程.这一层包含更多的神经元, 能学习到更复杂的特征重建模式.通过多层的非线性变换, 网络可以更好地捕捉原始特征之间的相互关系和模式.
在语义解码层中, 使用检测头对目标信息进行检测, 检测头的输出包括如下关键部分.
1)目标位置信息(x, y, w, h).这些值表示检测目标的边界框信息.x和y表示目标边界框的左上角坐标, w和h表示宽度和高度.通过这些值可确定目标在图像中的位置大小.
2)目标置信度s.s表示模型对检测目标的信心程度.目标置信度是在0到1之间的值, 越接近1表示模型越确信检测到目标.
为了验证本文模型的有效性, 选择在Teledyne FLIR Free ADAS Thermal 数据集(https://www.flir.in/oem/adas/adas-dataset-form)上进行实验.使用官方标准划分训练集和测试集.在该数据集上, 训练集和测试集的比例分别为90%和10%.
数据集总计包含14 452幅标注的热图像, 其中10 228幅来自短视频, 4 224幅来自长视频.所有视频均是在美国加利福尼亚州圣巴巴拉的街道和高速公路上拍摄, 涵盖白天和夜晚的拍摄场景.数据集包含4种类别:人、自行车(包括自行车与摩托车)、汽车和狗.鉴于狗这一类别的数量极少, 而本文研究关注道路上的常见目标, 因此在检测过程中, 选择忽略狗这一类别的数据.
基于PyTorch进行一系列实验.初始学习率设置为10-2, 采用SGD(Stochastic Gradient Descent)优化器训练模型, 共进行300次迭代.在训练过程中对每幅RGB图像以及其对应的热成像进行多种图像增强操作, 包括随机缩放、翻转、裁剪及色域变换等, 通过这些数据增强手段增加训练数据的多样性和模型的鲁棒性.
为了客观评估模型性能, 选择AP(Average Precision)作为主要的评价指标.阈值设定为0.5, 即当预测框与真实目标框的IoU(Intersection over Union)大于0.5时, 才视为正确的检测结果.
为了验证本文模型的效果, 在不同的信噪比(Signal-to-Noise Ratio, SNR)(-6 dB~15 dB)下进行实验.此外, 在仿真实验中, 重点关注 AWGN 信道, 传统通信方法选择分离信源信道编码.对于图像数据, 采用联合图像专家组(Joint Photographic Ex-perts Group, JPEG)和低密度奇偶校验码(Low Den-sity Parity Check Code, LDPC)作为图像源编码和图像通道编码.基线模型采用直接拼接两组语义特征的策略.
不同方法在3种类别下的AP值对比如图4所示.由图可得出, 当SNR较低时, 相比传统通信方法, 本文模型性能更优.特别是在低信噪比环境下, 本文模型呈现出更可靠的性能, 这种鲁棒性可能归因于其更好地处理噪声干扰和信号丢失的能力.
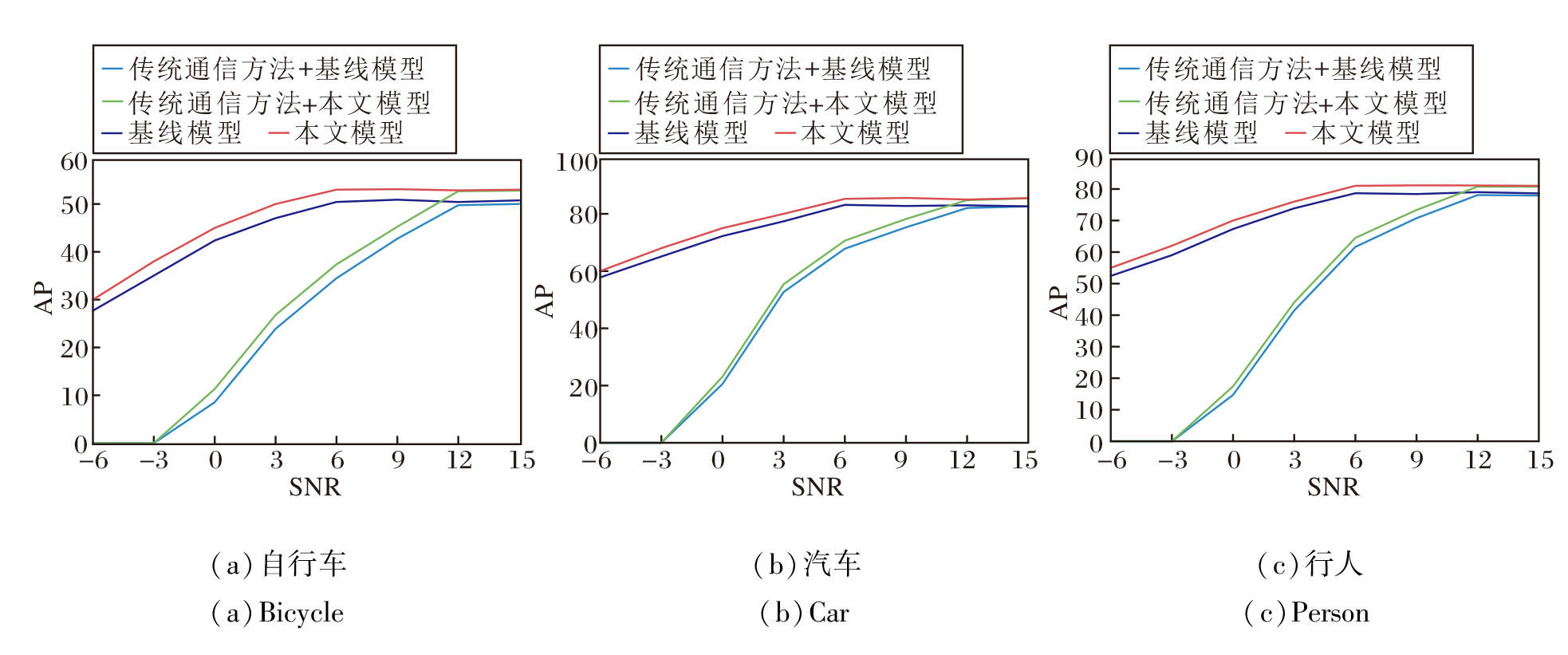 | 图4 不同方法在3类图像下的AP值Fig.4 AP values of different methods under 3 categories of images |
为了更明显地呈现本文模型在性能上的优势, 抽取4幅图像进行检测, 可视化结果如图5所示.在图中, 场景1和场景2为正常光条件, 场景3和场景4为弱光条件.
 | 图5 两种模型检测结果可视化Fig.5 Visualization comparison of model detection results |
从图5检测结果可看出, 在正常光条件下, 基线模型与本文模型检测的位置和置信度差异不大, 这说明这两种模型在光照充足时, 都可较好地发挥作用.
然而, 如图5(c)和(d)所示, 在弱光条件下, 基线模型容易出现漏检的情况, 而本文模型可以避免这一情况.这是因为本文模型能更好地融合不同模态间的互补性语义, 提高模型检测性能, 而基线模型的直接拼接特征可能导致信息的冗余和模糊性, 在弱光环境下难以准确捕捉目标的关键特征.
相比基线模型, 本文模型在性能上实现2%~3%的提升, 并且显著降低传输代价.相比基线模型, 可减少50%的传输代价, 这意味着在实际通信过程中, 可以以更低的代价获得更优性能, 这对于资源受限的通信系统而言具有重要意义.这种降低传输代价的优势将使本文模型在实际应用中更具竞争力.
为了在实时车联网应用中使车辆能快速应对各种复杂多变的路况, 立足于多车多传感器协同感知技术, 车与车之间通过传感器提供的多源异构感知数据相互协同.
相比传统单车单传感器或单车多传感器面临的信息不足和遮挡问题, 多车多传感器协同感知能帮助车辆更好地构建全局感知环境, 提升车辆对目标精准识别的能力.鉴于多源异构数据传输和处理的挑战, 本文提出基于Transformer的多模态融合目标检测语义通信模型.首先, 通过语义编码器对传感器提供的多模态感知数据进行语义抽取.再借助Transformer的自注意力机制, 深度融合不同模态之间的语义信息, 充分发挥各模态数据的互补性.最后, 通过协同传递多模态融合后的数据, 有效完成多模态感知目标检测语义通信任务.相比传统基线模型, 本文模型将数据传输量降低50%.此外, 即使在通信代价较低时, 本文模型仍保持卓越的性能, 实现2%~3%的目标检测性能提升.
总之, 本文模型不仅能在实际应用中获得更优性能, 而且在资源受限的通信系统中更具竞争力, 能显著降低通信代价和数据传输消耗, 使车辆在多模态感知环境下更高效地交换信息以合作应对复杂的路况.
尽管本文模型取得不错性能, 但仍有一些方面可以进一步探索和改进.目前, 本文模型采用Trans-former融合各传感器的数据, 今后可探索更优的融合架构, 实现更灵活智能的协同感知.同时, 需要在真实道路环境中对本文模型进行更广泛、深入的验证, 从而更全面地评估模型的适用性和鲁棒性.
本文责任编委 程翔
Recommended by Associate Editor CHENG Xiang
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|