










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
路端多源数据空间一致性数据集构建及评估方法研究
[陈志伟1  , 张皓霖
, 张皓霖1 , 严宇宸1 , 陈仕韬1 ]
, 张皓霖, 严宇宸, 陈仕韬]
|
|



作者简介: 
陈志伟,硕士研究生,主要研究方向为智能交通.E-mail:3121155023@stu.xjtu.edu.cn. 
张皓霖,博士研究生,主要研究方向为无人驾驶、车路协同.E-mail:zhanghaolin@xjtu.edu.cn. 
严宇宸,博士研究生,主要研究方向为多传感器的标定与感知.E-mail:yanyuchen@stu.xjtu.edu.cn.
构建多源传感数据空间一致性是路端多模态数据融合的基础,在车路协同及路端智能中发挥重要作用.然而,现有的路端多模态数据集主要侧重于目标检测等识别类任务的研究,缺少多源传感器之间的多种空间变换信息,不足以支撑路端多源数据空间一致性问题的研究.因此,文中构建一个专门用于路端多源数据空间一致性问题研究的数据集——InfraCalib(
About Author:
CHEN Zhiwei, master student.His research interests include intelligent transportation.
ZHANG Haolin, Ph.D. candidate. His research interests include autonomous driving and vehicle-to-infrastructure.
YAN Yuchen, Ph.D. candidate. His research interests include multi-sensors calibration and perception.
The spatial consistency of multi-source sensing data is established as the foundation for the fusion of roadside multi-modal data, playing a crucial role in vehicle-to-infrastructure and roadside intelligence. However, existing roadside multi-modal datasets predominantly focus on recognition tasks such as object detection, lacking various spatial transformation information between multi-source sensors. This deficiency hinders the research into the spatial consistency problem of multi-source data at the roadside. Therefore, a dataset specifically designed for the study of the spatial consistency problem in roadside multi-source data is constructed in this paper-InfraCalib(
随着人工智能与深度学习技术的发展, 智能车的自主驾驶能力已取得重大突破[1, 2, 3, 4].然而, 由于交通场景的不确定性与复杂性, 单车智能无法应对一些极端驾驶环境, 如极端天气、物体遮挡[5]等.随着网联协同智能驾驶与智慧交通[6]相关概念的提出, 研究者开始逐步探索如何利用车路协同技术实现更安全高效的自动驾驶.
车路协同技术的发展与应用离不开路端智能感知的研究发展.路端智能可帮助车辆提前感知视野盲区, 做出更合理的驾驶决策, 大幅减少自动驾驶车辆的事故发生率.另外, 自动驾驶汽车硬件成本较高, 如果将部分算力资源转移到路端, 不仅可弥补单车智能的短板, 还可降低自动驾驶的应用成本.
路端智能的关键技术发展离不开多模态数据的有效融合[7].例如:在相机视野中, 一个正在过马路的行人被车辆遮挡, 此时利用激光雷达就有可能捕获到被遮挡的行人.另外, 激光雷达在不同距离下分辨率不同, 受极端天气影响较大.例如:在暴雨中, 雨滴吸收激光束, 使激光雷达无法探测远处物体, 还可能引入噪声, 此时相机能弥补激光雷达的缺陷, 通过捕捉自然反射光避免雨滴干扰.
多模态数据融合意味着信息互补、稳定和安全.相比单模态数据, 多模态数据融合往往能获得更全面、准确、及时的信息, 从而辅助自动驾驶车辆实现更安全、性能更高的感知任务.
为了实现路端多模态数据融合, 首先必须构建多源传感器数据的空间一致性, 这里的“ 空间一致性” 是指在空间坐标系上关联和对齐多个传感设备采集的数据.只有实现多模态数据的空间一致性, 才能保障数据在之后的融合过程中没有空间对齐误差.一般来说, 特征的匹配与关联是实现多模态数据空间一致性的关键步骤, 常见的匹配关系有图像特征与图像特征的匹配、图像特征与点云特征的匹配、点云与点云的配准.
图像特征与图像特征的匹配旨在从两个或多个图像中识别相同或相似的结构或内容, 包含基于关键点的特征匹配、基于区域的特征匹配、基于深度学习的特征匹配等.基于关键点的特征匹配算法较常见, 通常是从源图像和目标图像中各提取一组特征点, 再通过特征描述符建立特征点对应关系的一类算法, 如经典的SIFT(Scale-Invariant Feature Trans-form)[8]、ORB(Oriented Features from Accelerated Seg-ment Test and Rotated Binary Robust Independent Ele-mentary Features)[9]、SURF(Speed Up Robust Fea-tures)[10]等.
图像特征与点云特征的匹配是跨模态数据间的匹配, 因此存在固有困难.Feng等[11]提出2D3D-MatchNet, 使用深度度量学习匹配基于图像的SIFT关键点[12]与基于点云的ISS(Intrinsic Shape Signa-tures)关键点[13], 实现跨模态配准.然而, 由于两种模态的SIFT特征和ISS特征的巨大差异, 效果不佳.Li等[14]提出DeepI2P, 绕过困难的跨模态描述子学习, 将配准问题转化为一个分类问题与一个“ 逆投影” 问题, 取得相对较优的性能.
点云与点云的配准无需建立直接的特征对应关系, 如ICP(Iterative Closest Point)[15]、NDT(Normal Distributions Transform)[16].但是这类算法都在一定程度上依赖相对准确的初始估计.Go-ICP(Globally Optimal Iterative Closest Point)[17]等全局优化方法弥补这一缺陷, 使算法在没有初始化要求的情况下也能较好运行.DeepVCP(Deep Virtual Corresponding Points)[18]、RPM-Net[19]等数据驱动方法尽管不需要特征对应, 但仍严重依赖同一模态中点结构的几何细节.还有一类常见的方法, 采用经典的点云特征检测器和描述符实现点云配准, 但是通常会受到噪声和杂波环境的影响.
近年来基于深度学习的特征检测器(如USIP(Unsupervised Stable Interest Point Deep Learning-Based Detector)[20]、3DFeat-Net(Weakly Supervised Deep Learning Framework)[21])和描述符(如3D-Match[22]、Perfect Match[23])在点云配准任务中表现出更优性能.
通过特征匹配可找到不同数据间的对应关系, 构建约束方程, 求解传感器之间的外参.获得外参的过程通常称为外参标定, 通过多源传感器标定, 可校正和调整不同设备和传感器的参数, 确保它们产生的数据在地理空间上是一致的.
标定一般有内参标定和外参标定两类.内参标定常用于估计摄像头的内部参数, 如焦距、主点坐标和畸变系数, 而外参标定可大致分为手动标定、半自动化标定[24, 25]和自动化标定[26], 各有优缺点, 适用于不同场景.手动标定较灵活, 允许操作员根据具体需求, 手动调整传感器的位置和朝向, 还可使用不同的参照物, 如棋盘格标定板[27]、二维码标定板[28]等, 获得更精确的标定结果.同时, 手动标定适用于不同类型的传感器, 成本较低, 不需要昂贵的设备或大量计算资源.但是手动标定往往依赖于丰富的工程经验, 另外, 手动标定需要花费较长时间, 尤其是在一些较复杂的标定任务中.而自动化标定通常更快速, 可重复执行, 不受人为操作技能的影响, 甚至在有些具体场景中有望实现比手动标定更高的精度.
随着技术的不断进步, 自动化标定算法的准确性不断提升, 因此在很多情况下, 自动化标定可能是更可靠的选择, 逐渐成为未来构建多源传感器空间一致性的趋势.当前的自动化标定算法研究大多在公开的车端多模态数据集上展开.对于车端来说, 传感器系统中不同传感器的空间分布距离与姿态相近, 标定难度较小.然而, 由于路端交通场景的多样性、特殊性与复杂性, 在路端传感器系统部署与标定时, 存在宽视角、大尺度、低共视范围、复杂姿态变化等难点, 缺乏相关的研究工作.
目前可供路端多源数据空间一致性问题研究的数据集较少, 难以支撑路端智能感知相关的多模态数据配准、自动化标定、多源数据融合等研究的进一步发展.现有的路端公开数据集有Rope3D[29]、DAIR-V2X-I[30]、V2X-Seq[31]、A9[32]数据集等.
Rope3D数据集是纯视觉数据集, 主要针对路侧视角下的3D感知任务的研究, 只包含图像数据, 不具备多模态属性.
DAIR-V2X-I数据集是首个同时具备图像和点云3D联合标注的大规模路侧多模态数据集, 可进行路侧3D目标检测等任务的研究.虽然该数据集具备激光雷达点云与相机图像数据, 也提供标定真值, 但在每个交通场景中, 数据的采集只使用单个智能设备.在实际情况下, 尤其是复杂的交通环境中, 往往需要路端多智能设备之间的协同感知(Infras-tructure-to-Infrastructure, I2I).另外, DAIR-V2X-I数据集上数据较离散, 缺少时间连续性, 难以研究与时序相关的任务.
V2X-Seq数据集是基于真实道路场景的时序车路协同数据集, 弥补DAIR-V2X-I数据集上数据离散的不足, 同时增加时序信息.但是该数据集依然只涉及单路端智能设备与单车端智能设备, 无法兼容关于I2I的研究.
A9数据集是多模态大规模路端数据集, 富含高速公路和路口的大量数据, 拥有两个以上的智能设备, 但缺少传感器之间位姿与位置的变化, 这也是上述数据集共有的不足之处, 因此更适合于后续目标检测等视觉任务的研究, 而不足以支撑复杂的空间一致性问题研究.
相比路端, 车端在多模态数据集上已有很丰富的开源成果, 如KITTI[33]、nuScenes[34]、Waymo[35]、Argoverse[36]、ONCE[37]数据集等, 拥有百万级的数据量.
综上所述, 相比车端数据集, 现有的路端多模态数据集数据量较少, 存在传感器空间对齐测试复杂度不够、传感器外参变化较少、时间同步不精准、时序信号离散等不足.
为了弥补路端多模态数据集的空白, 本文构建专门用于路端多源数据空间一致性问题研究的数据集— — InfraCalib(Infrastructure Calibration Dataset).InfraCalib数据集具有如下3个特色.
1)多模态数据来自多样化姿态、角度、高度变化的传感源(激光雷达与相机), 数据采集覆盖不同的光照变化, 便于相关研究者对不同的多源数据空间一致性相关算法进行鲁棒性测试, 如点云配准、图像匹配、图像和点云联合标定等.
2)数据集使用两个路端移动采集设备, 保持相对更连续的时间进行数据采集, 并保证严格的时间同步校准, 方便研究者研究I2I的空间对齐, 并且探索使用时序信号解决空间一致性问题.
3)详细介绍数据采集方式与内外参真值标定方法, 为后续研究人员构建路侧数据采集与标定系统提供方案实例, 并且针对多源路端传感系统的空间对齐效果提供量化评估的准则与指标参考.
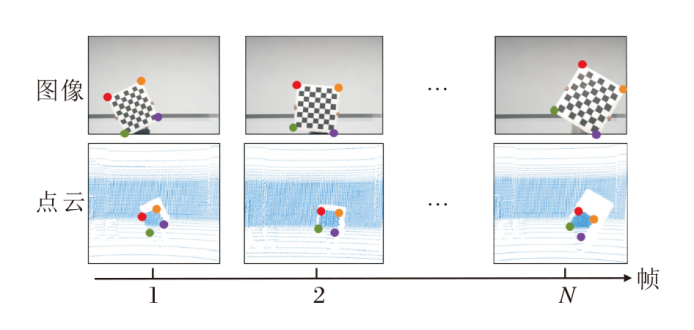
InfraCalib数据集是一个专门用于路端传感器系统空间一致性问题研究的多模态数据集, 依托路端移动采集设备(RS-V2X-ST)完成数据采集, 图1为设备的实物图.设备包含工业相机(SG2-AR0231C-0202-GMSL)和80线激光雷达(RS-Ruby-80V).数据集包含场景变化、模态变化、光照变化、路端设备空间位置及传感器姿态变化, 弥补现有路端公开数据集传感器空间对齐测试复杂度不够、传感器外参变化较少、时间同步不精准、时序信号离散等缺点, 适用于路侧多源传感器空间一致性问题的研究, 如异构传感器外参标定的算法设计与精度验证.
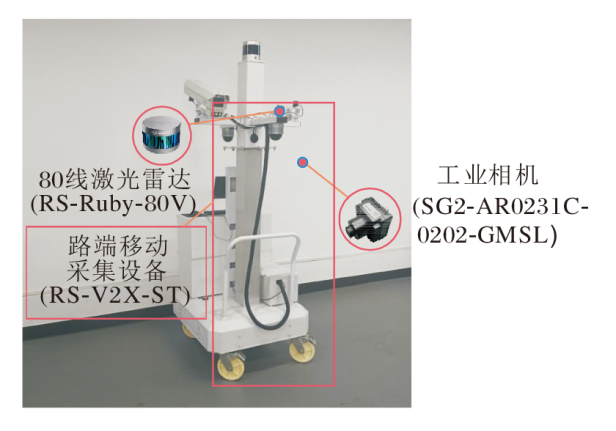 | 图1 智能交通路端设备展示图Fig.1 Display of intelligent transportation roadside equipment |
为了保障路端传感器系统的时间同步精确性与数据采集的高效连续性, 在数据采集前执行精准的时间同步步骤, 并设计数据自动化采集程序, 数据采集现场示例如图2所示.
 | 图2 实际路口数据采集示意图Fig.2 Illustration of actual intersection data collection |
路端智能设备内部模块连接图如图3所示, 使用交换机搭建不同模块之间的局域网通信.将工控机、时间同步盒、激光雷达、采集卡与交换机进行网络连接, 实现工控机对整个系统的集中控制和管理.采集卡连接工业相机, 可将相机捕获的模拟信号转化为计算机可处理的数字化图像数据.时间同步盒的作用是实现网络时间同步, 确保系统中各模块的时钟一致.另外, 设备还可根据实际应用需求扩展其它传感器模块, 如毫米波雷达等, 用于特定任务的研究.
 | 图3 路端智能设备内部模块连接图Fig.3 Internal module connection of roadside intelligent equipment |
时间同步盒具体采用便携式多功能同步盒(XQ-500V3), 外接GPS模块, 利用精准的卫星时间对同步盒授时.同个路端智能设备内部传感器想要实现时钟同步, 无需GPS模块进行外部授时, 启动同步盒内部时钟即可实现传感器之间的时间同步.然而, 实际数据采集同时需要两个路端智能设备之间实现时间对齐, 仅启动同步盒内部时钟无法实现多路端智能设备之间的时间同步.因此, 引入GPS模块进行卫星授时, 实现多路端智能设备所有传感器的精准时间同步.
同步盒支持PTP(Precision Time Protocol)和NTP(Network Time Protocol)两种同步方式.PTP是一种高精度的时间同步方案, 能实现亚微秒级别的时间同步, 适用于对时间精度要求非常高的应用场景.而NTP是一种精度相对较低的时间同步方案, 通常只能达到毫秒级别的时间同步精度, 更适用于一般的网络应用场景, 如计算机网络、云计算、工业自动化等, 可提供稳定的时间同步, 保证网络设备的一致性和可靠性, 同时满足大多数应用的时间精度需求.实际采用PTP协议进行时间同步, 因为PTP协议更能满足数据采集高时间同步精度的需求.
完成时间同步后, 设计自动化数据采集程序并部署在基于Ubuntu18.04系统的工控机上.使用图像采集卡(GMSL CCG3-4H)驱动相机, 此相机具有高帧率、高速、低延时等优点.选择与操作系统对应的驱动包进行相关的配置, 并测试相机能否顺利采集图像数据.
激光雷达的数据采集基于ROS1 Melodic, 通过配置雷达驱动包, 在ROS1环境中进行编译, 实时可视化点云数据, 验证激光雷达是否顺利获取点云数据.
最后, 同步并自动化相机与激光雷达的数据采集和存储, 在实际数据采集时能同时触发相机和激光雷达的采集程序, 实现相机和激光雷达数据的时间戳同步和起始采集时刻的同步.至此, 完成时间同步和自动化数据采集程序的部署和测试.
为了保证数据的多样性, 满足不同任务或算法测试的需求, 选取西安交通大学(创新港校区)校内外4个交通路口场景, 每个场景又划分为白天场景与黑夜场景.在每个子场景中, 调节路端移动采集设备的设备高度、相隔距离、姿态角度, 形成12组不同的传感器系统相对空间位置关系, 每小组数据采集时长持续约30 s到1 min, 最终共收集96组数据子集.
路口场景的多样性有利于保证数据集用于机器学习类方法的泛化性研究与模型训练的有效性.覆盖昼夜变化可用于模型的光照鲁棒性测试, 避免测试与验证时的偏差和局限.传感器系统的复杂空间变化使数据集包含多源传感器空间一致性对齐的不同难易程度, 可层次性地评估不同方法的精度差异与普适性能.
InfraCalib数据集上的子集划分与层次关系如图4所示.图中设备的姿态角度变化分为平行视角(平行)和斜向视角(斜视)两种情形.平行视角表示两个路端移动采集设备上传感器系统的视角近乎平行, 斜向视角表示两个路端移动采集设备上传感器系统的视角呈向内30° ~60° .每个视角下划分的短距离和长距离决定传感器系统间不同的共视范围.距离指两个路端移动采集设备间的直线距离, 短距离在8~15 m之间, 长距离在23~30 m之间.每种距离下划分设备高低对比模拟传感器系统间不同的共视尺度, 由于移动设备可调节高度升降, 因此共设计两个路端移动采集设备间低-低、低-高、高-高三种组合, 其中, “ 低” 大约为1.8 m, “ 高” 大约为2.7 m.部分数据采集实例如图5所示, 包括相机图像与激光雷达点云.
 | 图4 InfraCalib数据集上子集划分与层次关系Fig.4 Subset division and hierarchical relationship on InfraCalib dataset |
 | 图5 数据采集实例Fig.5 Data collection examples |
为了便于相关工程人员充分利用数据, 对数据集上的多源传感器进行内外参标定.同时也为了保证标定结果尽可能准确(无限接近真值), 选择成熟通用的工具或精细的手工优化方法.标注的内外参可用于半自动化标定方法或自动化标定方法的模型训练或结果验证, 为后续多模态融合研究提供空间一致性先验基础.
内外参标定的过程如图6所示.首先, 对于相机内参的标定, 选择采用经典的张氏标定法[27]分别标定两个智能设备上相机的内参和畸变系数.
 | 图6 内外参标定过程示意图Fig.6 Illustration of internal and external parameter calibration process |
相机标定是使用大量观测值进行参数模型拟合的过程, 在此拟合的参数模型是已知的, 所以尽可能寻找可获取大量观察值的方案, 如果观测值之间还满足一些其它的几何约束, 更有助于求解具体单个参数值.
张氏标定法是一种提供观察值的方案, 同时观察值之间还满足一定的几何约束(平面约束).假设某图像上坐标
m=[u v]T,
齐次表达式
$\widetilde{\boldsymbol{m}}=\left[\begin{array}{lll} u & v & 1 \end{array}\right]^{\mathrm{T}}, $
世界坐标系一点坐标
M=[X Y Z]T,
齐次表达式
$\widetilde{\boldsymbol{M}}=\left[\begin{array}{llll} X & Y & Z & 1 \end{array}\right]^{\mathrm{T}}, $
则相机模型可表示为
$s \widetilde{\boldsymbol{m}}=\boldsymbol{K}\left[\begin{array}{ll} \boldsymbol{R} & t \end{array}\right] \widetilde{\boldsymbol{M}}, $
其中, s为尺度因子, [R t]为外参矩阵, K为相机内参矩阵,
$\boldsymbol{K}=\left[\begin{array}{lll} \alpha & \gamma & u_{0} \\ 0 & \beta & \nu_{0} \\ 0 & 0 & 1 \end{array}\right] \text {, }$
α 、 β 为焦距值(单位为像素), (u0, ν 0)为像主点坐标(像素单位), γ 为倾斜因子.
使用张氏标定法时, 世界坐标系固定在标定板上, 且Z=0, 使用ri表示旋转矩阵R的第i列, 因此
$s\left[\begin{array}{l} u \\ v \\ 1 \end{array}\right]=\boldsymbol{K}\left[\begin{array}{llll} r_{1} & r_{2} & r_{3} & t \end{array}\right]\left[\begin{array}{l} X \\ Y \\ 0 \\ 1 \end{array}\right]=\boldsymbol{K}\left[\begin{array}{lll} r_{1} & r_{2} & t \end{array}\right]\left[\begin{array}{l} X \\ Y \\ 1 \end{array}\right], $
又由于$\widetilde{\boldsymbol{m}}$和$\widetilde{\boldsymbol{M}}$可通过单应性矩阵H关联, 即
$\tilde{s \boldsymbol{m}}=\boldsymbol{H} \widetilde{\boldsymbol{M}}, $
因此
$\boldsymbol{H}=\lambda \boldsymbol{K}\left[\begin{array}{lll} r_{1} & r_{2} & t \end{array}\right], $ (1)
其中λ 为尺度因子.
张氏标定法通过观察置于一个平面的标定图像, 获取$\widetilde{\boldsymbol{m}}$与$\widetilde{\boldsymbol{M}}$的映射关系单应性矩阵
$\boldsymbol{H}=\left[\begin{array}{lll} h_{1} & h_{2} & h_{3} \end{array}\right], $
再计算内参, 则式(1)可改写为
$\left[\begin{array}{lll} h_{1} & h_{2} & h_{3} \end{array}\right]=\lambda \boldsymbol{K}\left[\begin{array}{lll} r_{1} & r_{2} & t \end{array}\right], $
进而推导出
$\begin{array}{l} \boldsymbol{r}_{1}=\frac{1}{\lambda} \boldsymbol{K}^{-1} h_{1}, \\ \boldsymbol{r}_{2}=\frac{1}{\lambda} \boldsymbol{K}^{-1} h_{2}, \\ t=\frac{1}{\lambda} \boldsymbol{K}^{-1} h_{3} . \end{array}$ (2)
由于r1、r2为正交矩阵的列向量, 两两正交且为单位向量, 则具有如下两个约束:
$\begin{array}{l} \left\|\boldsymbol{r}_{1}\right\|=\left\|\boldsymbol{r}_{2}\right\|=1, \\ \boldsymbol{r}_{1}^{\mathrm{T}} \boldsymbol{r}_{2}=\mathbf{0}, \end{array}$
结合式(2)可得
$\begin{array}{l} \boldsymbol{h}_{1}^{\mathrm{T}} \boldsymbol{K}^{-\mathrm{T}} \boldsymbol{K}^{-1} \boldsymbol{h}_{2}=\mathbf{0}, \\ \boldsymbol{h}_{1}^{\mathrm{T}} \boldsymbol{K}^{-\mathrm{T}} \boldsymbol{K}^{-1} \boldsymbol{h}_{1}=\boldsymbol{h}_{2}^{\mathrm{T}} \boldsymbol{K}^{-\mathrm{T}} \boldsymbol{K}^{-1} \boldsymbol{h}_{2} . \end{array}$ (3)
令
$\boldsymbol{B}=\boldsymbol{K}^{-\mathrm{T}} \boldsymbol{K}^{-1}=\left[\begin{array}{llc} B_{11} & B_{12} & B_{13} \\ B_{21} & B_{22} & B_{23} \\ B_{31} & B_{32} & B_{33} \end{array}\right]=\left[\begin{array}{ccc} \frac{1}{\alpha^{2}} & -\frac{\gamma}{\alpha^{2} \beta} & \frac{\nu_{0} \gamma-u_{0} \beta}{\alpha^{2} \beta} \\ -\frac{\gamma}{\alpha^{2} \beta} & \frac{\gamma^{2}}{\alpha^{2} \beta^{2}}+\frac{1}{\beta^{2}} & -\frac{\gamma\left(\nu_{0} \gamma-u_{0} \beta\right)}{\alpha^{2} \beta^{2}}-\frac{\nu_{0}}{\beta^{2}} \\ \frac{\nu_{0} \gamma-u_{0} \beta}{\alpha^{2} \beta} & -\frac{\gamma\left(\nu_{0} \gamma-u_{0} \beta\right)}{\alpha^{2} \beta^{2}}-\frac{\nu_{0}}{\beta^{2}} & \frac{\left(u_{0} \gamma-u_{0} \beta\right)}{\alpha^{2} \beta^{2}}+\frac{\nu_{0}^{2}}{\beta^{2}}+1 \end{array}\right], $
注意到B为对称矩阵, 可用6维向量表示:
$\boldsymbol{b}=\left[\begin{array}{llllll} B_{11} & B_{12} & B_{22} & B_{13} & B_{23} & B_{33} \end{array}\right]^{\mathrm{T}} .$
令H矩阵的列
$\boldsymbol{h}_{i}=\left[\begin{array}{lll} h_{i 1} & h_{i 2} & h_{i 3} \end{array}\right]^{\mathrm{T}}, $
则
$\boldsymbol{h}_{i}^{\mathrm{T}} \boldsymbol{B} \boldsymbol{h}_{j}^{\mathrm{T}}=\boldsymbol{v}_{i j}^{\mathrm{T}} \boldsymbol{b}, $
因此, 式(3)可改写为
$\left[\begin{array}{c} v_{12}^{\mathrm{T}} \\ \left(v_{11}-v_{22}\right)^{\mathrm{T}} \end{array}\right] \boldsymbol{b}=\mathbf{0} .$
求解内参b转换为求解关于b的线性方程组:
Vb=0.
已知1个单应性矩阵可提供2个约束, 线性方程组有6个未知数, n≥ 3个单应性矩阵可求取全部未知数, 即可求得b和B.
由矩阵B=λ K-TK, 内参矩阵可通过B矩阵进行求解, 即
$\begin{aligned} v_{0} & =\frac{B_{12} B_{13}-B_{11} B_{23}}{B_{11} B_{22}-B_{12}^{2}}, \\ \lambda & =B_{33}-\frac{B_{13}^{2}+v_{0}\left(B_{12} B_{13}-B_{11} B_{23}\right)}{B_{11}}, \\ \alpha & =\sqrt{\frac{\lambda}{B_{11}}}, \\ \beta & =\sqrt{\frac{\lambda B_{11}}{B_{11} B_{22}-B_{12}^{2}}}, \end{aligned}$
$\begin{array}{l} \gamma=\frac{-B_{12} \alpha^{2} \beta}{\lambda}, \\ u_{0}=\frac{\gamma v_{0}}{\beta}-\frac{B_{13} \alpha^{2}}{\lambda} . \end{array}$
到目前为止, 所有推导都是相机无畸变的理想状态, 但在实际情况中, 相机畸变往往是不可忽略的.相机畸变是指由于透镜和光学系统的设计和制造不完美, 导致图像中物体形状、大小或位置的扭曲或偏移现象, 而畸变系数是一个用于描述光学系统中畸变程度的物理量.
为了纠正这些畸变, 通常都会进行相机标定, 即确定畸变系数, 然后使用这些系数校正图像, 从而提高图像质量.一般来说, 只需要考虑径向畸变和切向畸变.
由透镜形状引起的畸变称为径向畸变, 在针孔模型中, 直线投影至像素平面仍为直线, 而在实际照片中, 直线在图像中将变为曲线, 越靠近边缘, 该现象越明显.径向畸变主要分为两类:桶形畸变和枕形畸变.桶形畸变图像放大率随着与光轴之间的距离增加而减小, 而枕型畸变恰恰相反.在这两种畸变中, 穿过图像中心和光轴有交点的直线还能保持形状不变.
除了透镜的形状会引入径向畸变, 由于相机的组装过程中不能使透镜和成像面严格平行而造成的畸变称为切向畸变.
下面用严格的数学形式描述径向畸变与切向畸变.考虑到归一化平面上的任意一点p(归一化平面指相机坐标系中z=1平面), 坐标为[x y]T, 也可以写成极坐标形式[r θ ]T, 其中, r表示点p与坐标系原点之间的距离, θ 表示与水平轴的夹角.径向畸变可看成坐标点沿长度方向变化, 即距离原点的长度变化.切向畸变可看成坐标点沿切线方向变化, 即水平夹角θ 变化.通常假设这些畸变呈多项式关系, 即
$\left\{\begin{array}{l} x_{\text {distorted }}=x\left(1+k_{1} r^{2}+k_{2} r^{4}+k_{3} r^{6}\right) \\ y_{\text {distorted }}=y\left(1+k_{1} r^{2}+k_{2} r^{4}+k_{3} r^{6}\right) \end{array}\right.$ (4)
其中,
$\left\{\begin{array}{l} x_{\text {distorted }}=x+2 p_{1} x y+p_{2}\left(r^{2}+2 x^{2}\right) \\ y_{\text {distorted }}=y+p_{1}\left(r^{2}+2 y^{2}\right)+2 p_{2} x y \end{array}\right.$ (5)
因此, 联合式(4)和式(5), 对于相机坐标系中的一点p, 能通过5个畸变系数找到这个点在像素平面上的位置, 具体步骤如下.
首先, 将三维空间点投影到归一化图像平面, 记归一化坐标为[x y]T.再对归一化平面的点进行径向畸变和切向畸变:
$\left\{\begin{aligned} x_{\text {distorted }}= & x\left(1+k_{1} r^{2}+k_{2} r^{4}+k_{3} r^{6}\right)+2 p_{1} x y+ \\ & p_{2}\left(r^{2}+2 x^{2}\right) \\ y_{\text {distorted }}= & y\left(1+k_{1} r^{2}+k_{2} r^{4}+k_{3} r^{6}\right)+p_{1}\left(r^{2}+2 y^{2}\right)+ \\ & 2 p_{2} x y \end{aligned}\right.$
最后, 将畸变后的点通过内参矩阵投影到像素平面, 得到该点在图像上的正确位置:
$\left\{\begin{array}{l} u=\alpha x_{\text {distorted }}+u_{0} \\ v=\beta y_{\text {distorted }}+v_{0} \end{array}\right.$
张氏标定法是一种通用的相机标定方法, 使用针孔相机模型和畸变模型描述相机的成像过程, 通过最小化重投影误差求解相机的内参和畸变系数.在实际应用中, 往往采用棋盘格等标定板进行辅助标定.棋盘格标定板角点明显、标定精度较高、容易制作, 是常用的相机内参标定标靶之一.具体来说, 先使用角点检测算法检测图像中棋盘格标定板上的角点, 至此角点的像素坐标和世界坐标系中的位置已知.再通过直接线性变换(Direct Linear Transfor-mation, DLT)[38]对内参进行初步估计.然后, 使用非线性优化技术(如Levenberg-Marquardt Algori-thm[39])最小化所有角点的重投影误差, 对相机的内参和畸变系数进行精细调整.最后, 输出优化后的相机内参和畸变系数.
基于上述原理, 实际采用基于张氏标定法的ROS1相机内参标定工具估计相机内参矩阵和畸变系数, 具体示意图如图7所示.ROS1的相机内参标定工具优势在于会根据一定的标准(如特征点的分布、图像质量等)对采集的图像数据有一定的择优筛选功能, 通过不断调整位置、距离、角度, 保证采集数据的多样化, 提高参数估计的鲁棒性.另外, 更多的信息和约束也有助于避免优化过程陷入局部最优解, 更有可能找到全局最优解.
 | 图7 ROS1相机内参标定过程示意图Fig.7 ROS1 camera internal parameter calibration process |
ROS1的相机内参标定工具还能自动过滤一些棋盘格角点检测不准或不全的图像, 使标定结果更准确可靠.如图8所示, 使用估计的畸变系数对图像进行去畸变操作.由图可见, 柱子的棱边线在原图上是有些弯曲的, 经过去畸变操作后变成一条直线.相机内参在后面的点云和图像的投影验证环节中进行测试.
 | 图8 去畸变效果图示例Fig.8 Examples for de-distortion |
标定完相机内参和畸变系数后, 在室内分别标定两个路端智能设备内部的相机和激光雷达之间的外参, 因为传感器在设备上安装的位置是固定的, 因此同设备内部的相机和激光雷达的外参也是固定的, 只需要标定一次即可.具体方式是采用角点明显的目标物分别放在相机视野范围内的不同位置, 使用相机和雷达分别采集多组图像和点云, 采用手动提取关键点的方式得到多组图像和点云的对应点.具体外参标定过程如图9所示.再用这些对应点构造PnP(Perspective-n-Point)问题进行解算, 输出最终的外参.
 | 图9 室内同设备上激光雷达与相机外参标定过程Fig.9 External parameter calibration process of lidar and camera on same equipment indoors |
采用手动提取关键点的方式提取特征点对有如下优势.
1)通过手动提取关键点, 用户可选择图像和点云中最具代表性和精确度较高的特征点, 提高计算外参的精度.
2)手动提取关键点可避免自动化关键点检测算法中的误检和漏检问题, 增加计算结果的鲁棒性.
3)在一些复杂的场景, 如遮挡、光照变化中, 自动关键点检测算法可能无法准确识别关键特征, 而手动提取关键点可更好地应对这种情况.
4)手动提取关键点可自由控制提取点的位置及数量, 便于调试和分析外参计算过程中发生的问题.
因此, 相比自动化方法, 手动提取关键点的方式虽然稍显繁琐, 但是往往能够提供更准确的外参真值.
PnP是求解3D点到2D点对运动的方法, 已知n个3D空间点及其投影位置时, 能估计传感器之间的位姿.PnP问题的求解方法有很多.例如:使用3对点估计位姿的P3P(Perspective-Three-Point)[40]、直接线性变换(Direct Linear Transformation)、EPnP(Efficient PnP)[41]、UPnP(Uncalibrated PnP)[42]等, 还能使用非线性优化的方式构建最小二乘问题并迭代求解, 也就是光束法平差(Bundle Adjustment).
采用最小化重投影误差求解PnP问题, 具有如下优势.
1)精确性较高.采用非线性优化的方法最小化重投影误差可取得全局最优解.
2)鲁棒性较强.在实际应用中, 最小化重投影误差法对于噪声具有一定的鲁棒性, 能在一定程度上抑制噪声影响, 提供更稳健的位姿估计.
3)灵活性较高.最小化重投影误差法不要求图像点与三维点之间存在严格的对应关系, 即使存在一些匹配错误, 仍可通过最小化误差求解相机位姿.
下面用严格的数学推导描述最小化重投影误差法的求解过程.已知n个三维空间点P及其图像投影点p, 计算激光雷达与相机之间的旋转矩阵R和平移向量t, 李群表示为转移矩阵T.假设空间点的坐标
$\boldsymbol{P}_{i}=\left[\begin{array}{lll} X_{i} & Y_{i} & Z_{i} \end{array}\right]^{\mathrm{T}}, $
投影的像素坐标
$\boldsymbol{u}_{i}=\left[\begin{array}{ll} u_{i} & v_{i} \end{array}\right]^{\mathrm{T}} .$
三维空间点和二维空间点之间的关系如下:
$\begin{aligned} s_{i}\left[\begin{array}{c} u_{i} \\ v_{i} \\ 1 \end{array}\right] & =\boldsymbol{K} \boldsymbol{T}\left[\begin{array}{c} X_{i} \\ Y_{i} \\ Z_{i} \\ 1 \end{array}\right], \\ s_{i} \boldsymbol{u}_{i} & =\boldsymbol{K} \boldsymbol{T} \boldsymbol{P}_{i}, \end{aligned}$
其中K为相机的内参矩阵.由于相机与激光雷达的位姿关系未知及观测点有噪声, 该等式存在一个误差.因此, 将所有点的投影误差求和, 构建最小二乘问题, 再寻找最优的位姿关系, 即令其最小化,
$\boldsymbol{T}^{* }=\arg \min _{\boldsymbol{T}} \frac{1}{2} \sum_{i=1}^{n}\left\|\boldsymbol{u}_{i}-\frac{1}{s_{i}} \boldsymbol{K} \boldsymbol{T} \boldsymbol{P}_{i}\right\|_{2}^{2} .$
在使用优化算法求解前, 需要知道每个误差项关于优化变量的导数, 也就是线性化
$e(\boldsymbol{x}+\Delta \boldsymbol{x}) \approx e(\boldsymbol{x})+J^{\mathrm{T}} \Delta \boldsymbol{x} .$
讨论JT的形式是解决问题的关键.下面使用扰动模型求解李代数的导数.首先, 记变换到相机坐标系下的空间坐标为P', 并将前3维取出:
$\boldsymbol{P}^{\prime}=(\boldsymbol{T P})_{1: 3}=\left[\begin{array}{lll} X^{\prime} & Y^{\prime} & Z^{\prime} \end{array}\right]^{\mathrm{T}}, $
那么, 投影模型可写为
su=KP',
展开上式:
$\left[\begin{array}{c} s u \\ s v \\ s \end{array}\right]=\left[\begin{array}{ccc} \alpha & 0 & \mu_{0} \\ 0 & \beta & \nu_{0} \\ 0 & 0 & 1 \end{array}\right]\left[\begin{array}{l} X^{\prime} \\ Y^{\prime} \\ Z^{\prime} \end{array}\right], $
其中s表示P'的距离, 消去第3行s, 得
$\begin{array}{l} u=\alpha \frac{X^{\prime}}{Z^{\prime}}+\mu_{0}, \\ v=\beta \frac{Y^{\prime}}{Z^{\prime}}+\nu_{0} . \end{array}$ (6)
在定义中间变量后, 对转移矩阵T左乘扰动量δ ε , 再求e关于扰动量的导数.利用求导的链式法则:
$\frac{\partial e}{\partial \delta \boldsymbol{\varepsilon}}=\lim _{\delta \boldsymbol{\varepsilon} \rightarrow 0}\left(\frac{e(\delta \boldsymbol{\varepsilon} \oplus \boldsymbol{\varepsilon})-e(\boldsymbol{\varepsilon})}{\delta \boldsymbol{\varepsilon}}\right)=\frac{\partial e}{\partial \boldsymbol{P}^{\prime}} \frac{\partial \boldsymbol{P}^{\prime}}{\partial \delta \boldsymbol{\varepsilon}}$
其中⊕表示李代数上的左乘扰动.上式中第1项是误差关于变换到相机坐标系下空间点的导数, 在式(6)中已获得变量之间的等式关系, 易得
$\frac{\partial e}{\partial \boldsymbol{P}^{\prime}}=-\left[\begin{array}{ccc} \frac{\partial u}{\partial X^{\prime}} & \frac{\partial u}{\partial Y^{\prime}} & \frac{\partial u}{\partial Z^{\prime}} \\ \frac{\partial v}{\partial X^{\prime}} & \frac{\partial v}{\partial Y^{\prime}} & \frac{\partial v}{\partial Z^{\prime}} \end{array}\right]=-\left[\begin{array}{ccc} \frac{\alpha}{Z^{\prime}} & 0 & -\frac{\alpha X^{\prime}}{Z^{\prime 2}} \\ 0 & \frac{\beta}{Z^{\prime}} & -\frac{\beta Y^{\prime}}{Z^{\prime 2}} \end{array}\right] .$
而第2项为变换到相机坐标系下的空间点关于李代数的导数, 得
$\frac{\partial(\boldsymbol{T P})}{\partial \delta \boldsymbol{\varepsilon}}=(\boldsymbol{T P})^{\odot}=\left[\begin{array}{cc} \boldsymbol{I} & -\boldsymbol{P}^{\prime \wedge} \\ \mathbf{0}^{\mathrm{T}} & \mathbf{0}^{\mathrm{T}} \end{array}\right], $
其中, ∧ 定义为反对称符号, 用于将向量转化为与之唯一对应的反对称矩阵,
$\boldsymbol{P}^{\prime \wedge}=\left[\begin{array}{ccc} 0 & -Z^{\prime} & Y^{\prime} \\ Z^{\prime} & 0 & -X^{\prime} \\ -Y^{\prime} & X^{\prime} & 0 \end{array}\right] .$
因为在之前P'的定义中, 只取前三维, 于是可得
$\frac{\partial \boldsymbol{P}^{\prime}}{\partial \boldsymbol{\delta}}=\left[\begin{array}{ll} \boldsymbol{I} & -\boldsymbol{P}^{\prime \wedge} \end{array}\right] .$
将上面两项相乘, 得到2× 6的雅可比矩阵:
$\begin{array}{l} \frac{\partial e}{\partial \delta \varepsilon}= \\ {\left[\begin{array}{cccccc} \frac{\alpha}{Z^{\prime}} & 0 & -\frac{\alpha X^{\prime}}{Z^{\prime 2}} & -\frac{\alpha X^{\prime} Y^{\prime}}{Z^{\prime 2}} & \alpha+\frac{\alpha X^{\prime 2}}{Z^{\prime 2}} & -\frac{\alpha Y^{\prime}}{Z^{\prime}} \\ 0 & \frac{\beta}{Z^{\prime}} & -\frac{\beta Y^{\prime}}{Z^{\prime 2}} & -\beta-\frac{\beta Y^{\prime 2}}{Z^{\prime 2}} & \frac{\beta X^{\prime} Y^{\prime}}{Z^{\prime 2}} & \frac{\beta X^{\prime}}{Z^{\prime}} \end{array}\right] .} \end{array}$
上述雅克比矩阵描述重投影误差关于激光雷达与相机之间位姿李代数的一阶变化关系, 因此能在优化过程中提供重要的梯度方向, 对于指导优化的迭代十分重要, 最终输出激光雷达与相机之间的外参.之后, 再使用得到的外参以及相机的内参和畸变系数将点云投影到图像中进行可视化效果的验证(如图6中的可视化效果).
数据采集完毕后, 需要将1号设备的激光雷达和2号设备的相机进行外参标定, 同样采用手动提取关键点对并构造PnP问题求解的方法.室外手动提取关键点的示意图如图10所示, 同种颜色指明匹配的关键点对.手动提取关键点分为单帧和多帧两种提取方式, 当场景特征点较丰富时, 只需一幅图像和一帧点云就可获得足够的关键点对, 但是单帧图像和点云往往不能提取到足够多的点对, 因此采用多帧提取关键点的方式能弥补单帧特征点对不足的问题.
 | 图10 室外提取图像和点云的关键点对Fig.10 Extraction of key point pairs from images and point clouds outdoors |
两个路端智能设备能对齐到一个统一的坐标系中, 并只需通过计算就能得到任意两个传感器之间的外参.因为采集的数据分校内校外和白天黑夜等不同场景, 富含不同的高度、角度、距离等变化, 因此有96组不同的外参关系需要标定.具体标定方法也是采用角点明显的目标物放在相机视野范围内的不同位置, 用1号设备的激光雷达和2号设备的相机分别采集多组点云和图像数据, 采取手动打点的方式捕获一些对应点, 再将这些对应点用PnP进行解算, 输出最终外参.同样, 再使用雷达到相机的可视化投影验证结果.
InfraCalib数据集包含143 304帧图像, 95 467帧点云数据, 96组内外参标注信息.具体信息如下:
1)图像和点云的命名格式为数据采集时刻的时间戳;
2)图像分辨率为1 080× 1 920; 3)图像格式为png, 点云格式为pcd; 4)标注信息包含相机内参、单设备传感器系统内部激光雷达和相机外参, 以及多设备传感器系统之间激光雷达和相机外参.
相比现有的公开数据集, InfraCalib数据集在多源数据空间一致性问题上更具有研究意义, 以一些典型的车端数据集、车路协同数据集、路端数据集为例, 与本文构建的InfraCalib数据集进行多方面的对比, 结果如表1所示, 表中V表示Vehicle, I表示Infrastructure.由表可见:首先, InfraCalib数据集是唯一一个I2I的数据集, 其它路端数据集传感器之间位姿较近, 空间对齐测试复杂度不够, 对多源数据空间一致性的研究价值不大.其次, InfraCalib数据集的数据规模可观, 虽无法与ONCE等数据集相比, 却比KITTI、DAIR-V2X-I、A9(R0)等多个数据集要大, 为后续研究者提供足够的数据支撑.最后, InfraCalib数据集最大的特点之一便是拥有丰富的外参信息, 包含高度、角度、距离等多种变化, 便于研究者进行各种鲁棒性测试.
| 表1 各数据集信息对比 Table 1 Information comparison of different datasets |
在采集完数据后, 给每组数据标注外参真值.首先, 分别在图像和点云上手动提取对应的关键点, 根据实际场景特征点是否丰富选择单帧或多帧提取法.提取到足够多的特征点后, 使用最小化重投影误差的优化方法求解PnP问题, 输出外参对应的转移矩阵.最后, 再用这个转移矩阵, 将点云的3维坐标投影到图像的2维坐标上, 验证可视化效果.
为了推动多源数据空间一致性相关算法研究, 基于本文构建的InfraCalib数据集进行一些特征匹配的经典算法实验, 如SIFT[8]图像特征匹配, ORB[9]图像特征匹配, 以及基于RANSAC(Random Sample Consensus)[43]和ICP[15]的自适应点云配准.一方面验证经典算法在真实数据集上的有效性, 并揭示其局限性和适用范围.另一方面, 根据InfraCalib数据集的特性分析任务难点以及相关算法未来的研究和改进方向.同时, 讨论用于量化外参标定结果的评估指标, 作为其它算法在InfraCalib数据集上进行性能测试的衡量标准.
2.1.1 图像特征匹配
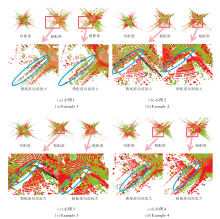
SIFT是一种图像局部特征提取算法, 通过在不同的尺度空间中寻找极值点的精确定位和主方向, 构建关键点描述符以提取特征.在InfraCalib数据集上测试多组基于SIFT的图像特征匹配实验, 部分可视化效果如图11所示, 图中蓝点为提取的特征点, 绿线为特征点匹配线.
 | 图11 SIFT的图像特征匹配示例Fig.11 Examples of SIFT feature matching |
由图11可知, SIFT在InfraCalib数据集上的特征匹配效果较优, 这得益于SIFT如下3个重要特性.
1)通过生成高斯差分(Difference of Gaussian, DOG)尺度空间, 寻找不同尺度下共同存在的关键点, 在目标物体尺度变化较大时仍能准确匹配特征点.
2)计算以特征点为中心的邻域内各像素点的梯度幅角和幅值, 再通过直方图统计梯度幅角, 确定特征点的方向, 使SIFT对图像视角的旋转相对稳健, 可在一定范围内处理物体的旋转变化。
3)特征描述子采用直方图统计图像局部梯度幅值和方向, 这种独特的描述子有助于在不同的特征点之间提供明显的差异, 增加匹配的准确性.
尽管SIFT在InfraCalib数据集上的特征匹配效果良好, 但也存在如下少数匹配不准确的情况.
1)由于InfraCalib数据集上数据是由两个路端智能设备采集而来, 包含不同的设备距离变化, 当设备之间距离较远时, 可能会出现目标物体离其中一个设备较近, 而离另一个设备较远的情况, 此时目标物体在两个不同的相机视野中会呈现较大的尺度差异, 进而SIFT的尺度不变性可能会受到挑战, 导致匹配不准确.
2)InfraCalib数据集上包含不同的视角变化, 较大的视角变化可能超出SIFT对物体旋转变化的处理能力.
3)InfraCalib数据集包含光照变化, 有白天和夜晚两种情形, 而SIFT对于光照变化较敏感, 在场景中存在较大光照变化的情况下, SIFT的特征匹配可能会受到影响, 因为光照变化可能导致关键点的描述子变化较大.
4)当图像中存在重叠或相似结构的区域时, SIFT特征可能不足以区分这些区域, 导致匹配不准确, 如图11中的草丛区域或石墩区域.
ORB也是一种常用的图像特征提取算法, 基于改进的FAST(Features from Accelerated Segment Test)[44]提取特征点, 并利用BRIEF(Binary Robust Independent Elementary Features)[45]构建特征点的描述子, 实现特征点的尺度不变性与旋转不变性, 即经过缩放与旋转后的特征点仍能产生与原来相近的描述符.在InfraCalib数据集上测试多组基于ORB的图像特征匹配实验, 部分可视化效果如图12所示, 图中蓝点为提取的特征点, 绿线为特征点匹配线.
 | 图12 ORB的图像特征匹配示例Fig.12 Examples of ORB feature matching |
由图12可明显看出, ORB提取的特征点数量相对小于SIFT, 因为ORB使用改进的FAST角点检测器, 通常对具有强纹理的区域感兴趣, 但对于一些弱纹理区域兴趣较少.实验表明, ORB在InfraCalib数据集上的表现差于SIFT, 存在不少匹配错误的点对.原因是ORB的尺度不变性和旋转不变性的实现方式相对简单, 无法对InfraCalib数据集上视角跨度或尺度差异较大的两幅图像进行有效特征匹配.另外, ORB使用二进制字符串作为特征描述子, 而SIFT使用更连续的浮点数向量, 这意味着ORB描述子对于局部纹理和结构的表达能力相对较弱.
通过上述算法的特征匹配实验可看出, 特征匹配的效果可能与InfraCalib数据集上场景的复杂程度有关.InfraCalib数据集上数据由两个智能设备通过调整不同间距采集而来, 会导致较大的尺度变化, 从而对特征提取算法的尺度不变性带来更大的挑战.构建更多层数的高斯金字塔可在一定程度上提高尺度不变性, 但无疑会增加高斯模糊和降采样的计算量, 从而使算法复杂度升高.因此, 如何根据图像内容自适应地选择尺度, 而不是依赖固定的尺度空间, 这是未来值得研究的方向之一.InfraCalib数据集上包含不同的光照变化, 有白天和夜晚两种情形, 虽然大部分特征提取算法对光照变化有一定的鲁棒性, 但是在一些光照变化较剧烈时还是容易受到影响, 未来的研究可设计专门用于表征光照不变性的特征描述子或改进传统特征描述子, 更好地适应光照变化.另外, InfraCalib数据集上较大的视角变化可能会对特征提取算法的旋转不变性带来巨大挑战.对此, 在生成特征描述子时, 可考虑不仅仅使用关键点的主导方向, 而是计算多个方向的描述子.这样, 即使图像在某个方向上发生旋转, 仍然可匹配到相似的特征.虽然这样做提高算法的旋转不变性, 但额外的计算开销也是一个需要思考的问题.因此, 研究自适应的多方向描述子是一个具有实际意义的方向之一, 使算法能根据场景视角变化程度自适应选择方向描述子的数量, 在旋转不变性和计算复杂度之间有一个较好的取舍.
综上所述, InfraCalib数据集上存在较大的尺度变化、光照变化、视角变化等难点, 针对这些难点, 研究者可在InfraCalib数据集上进一步测试和研究特征提取算法, 获得更优表现.
2.1.2 点云配准
采用基于RANSAC和ICP的自适应点云配准方法在InfraCalib数据集上进行点云配准实验, 每组用于配准的点云数据来自同一时刻不同路端智能设备上部署的激光雷达传感器.ICP尽管在点云配准任务中表现出色, 但性能在很大程度上依赖于初始变换的好坏, 如果初始变换存在较大偏差, 算法可能会陷入局部最优解, 导致配准失败.因此, 在进行ICP外参变换估计之前需要先提供一个相对准确的初始变换, 而RANSAC由于其对噪声数据和异常值有很强的鲁棒性等优势, 往往可以较好地满足此需求.
采用RANSAC-ICP点云配准算法分为粗配准和精配准两个步骤.
粗配准使用RANSAC估计初始变换矩阵.1)在对应点集中随机选取3个对应点对, 求解变换矩阵.2)计算对应点中剩余点对在1)中求得的变换矩阵的作用下形成的距离误差, 若其中一个点对的距离误差小于设定的阈值误差, 该点为样本内点, 否则为样本外点, 统计样本内点数目.重复1)、2), 直至抵达迭代次数的上限.统计不同变换模型下的样本内点数量, 样本内点数量最多的作为最佳数学模型输入, 再进行点云配准操作, 最终返回重合度最高的变换, 作为ICP精配准的初始变换.
精配准采用ICP, 不断迭代最小化两个点云之间的距离以优化它们的相对位置.在使用RANSAC获得一个相对准确的初始变换后, 对于源点云中的每个点, 找到目标点云中最近的点, 这样便创建一个初始的点对应关系.利用点对应关系计算刚性变换, 通常采用最小二乘法优化变换矩阵, 使两个点云之间的距离最小化.将计算得到的变换应用到源点云上, 得到新的变换后的点云.重复上述步骤, 直到收敛或达到预定的迭代次数.在每次迭代中, 都会不断优化变换矩阵, 从而逐渐使两个点云更拟合.在每次迭代中, 检查相邻两次迭代的变换矩阵之间的差异, 当差异小到一定阈值时, 认为配准已收敛, 算法结束.
点云配准可视化效果示例如图13所示, 从图中的RANSAC粗配准效果可看出, 两帧点云大致重合, 但一些边缘并未完全对齐, 而ICP精配准效果显示两帧点云几乎完全对齐.
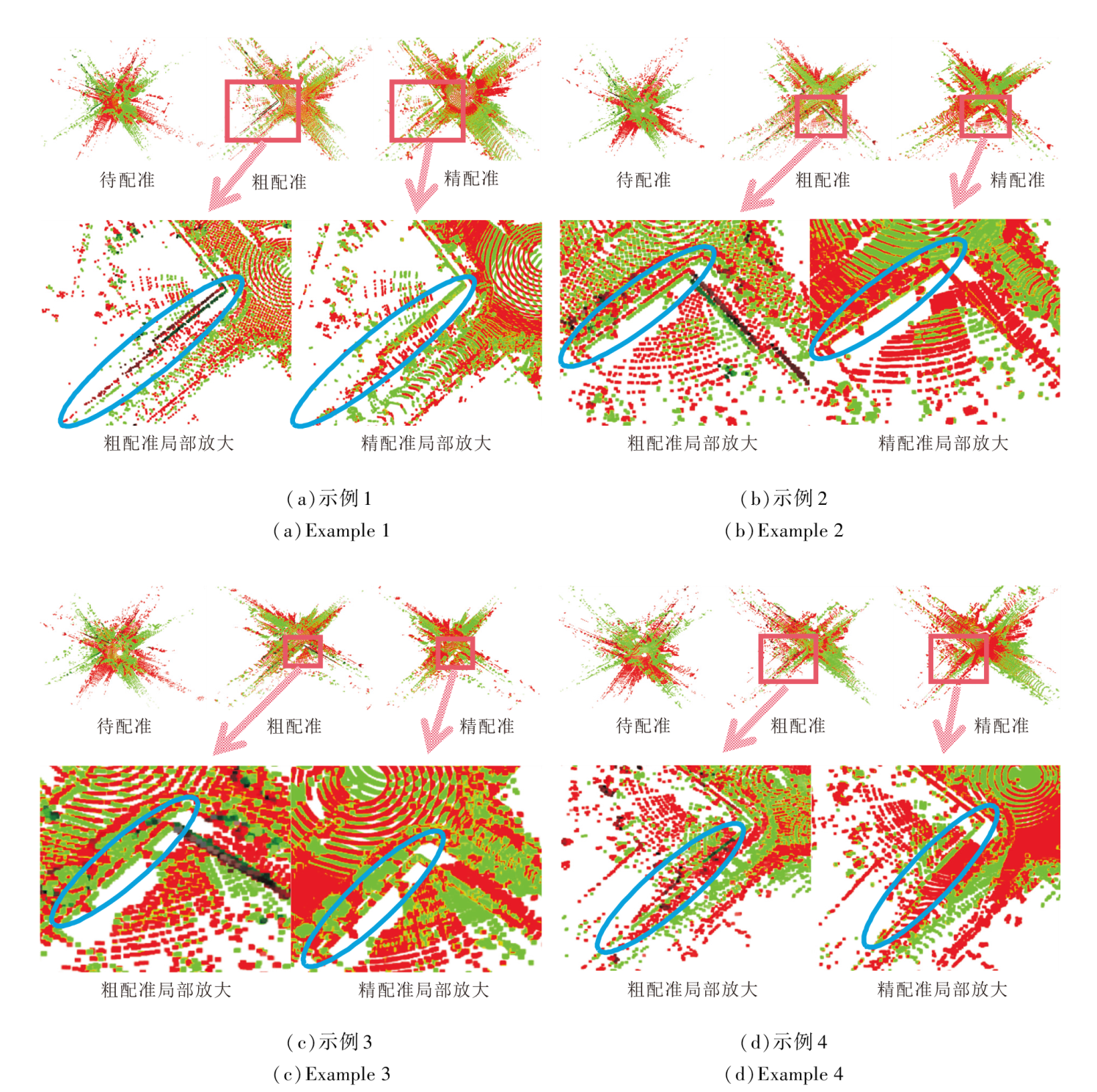 | 图13 点云配准可视化效果示例Fig.13 Examples for visualization of point cloud registration |
在实验过程中偶尔也会出现点云配准完全失效的情况, 如图14所示. 通常是由于RANSAC粗配准阶段未获得较准确的初始变换, 使ICP最终陷入局部最优解, 进而导致配准失败.实验中发现RANSAC-ICP点云配准算法对旋转矩阵的估计相对准确, 平移向量稍有偏差.算法平均运行时间在十几秒左右, 这是由于RANSAC需要更多的迭代次数才能给ICP提供相对准确的初始变换, 而ICP为了达到理想的点云配准精度也需要增加迭代次数, 总体迭代次数的增加导致更长的运行时间.另外, RANSAC的效率也受到采样策略的影响.如果采样数量太小, 可能需要更多的迭代次数找到稳定的模型, 从而增加算法运行时间.
 | 图14 点云配准失效示例Fig.14 Example for point cloud registration failure |
InfraCalib数据集上存在一些具有重复结构或对称性的场景数据, 配准算法难以确定正确的特征对应关系, 因此更容易陷入局部最优解, 这是导致实验结果存在偏差的一个重要原因.研究更先进的全局优化方法是解决此类难题的一个有效方案, 这些方法可考虑整体的点云结构, 避免过度依赖局部信息.另外, 遮挡问题也会造成点云配准出现偏差, 例如:InfraCalib数据集上可能存在一些大型车辆, 会造成雷达视野局部盲区, 使某些地方在其中一个雷达点云数据中可见, 在另一个雷达点云数据中不可见, 从而导致特征对应关系的缺失, 影响配准效果.InfraCalib数据集上还包含视角、高度、距离等变化, 都可能会造成雷达点云之间的共视区域大小发生变化, 或者导致两个雷达点云数据观察到同一物体的不同视角, 这同样使点云配准更困难.因此, InfraCa-lib数据集上含有丰富的传感器位置关系, 给匹配算法带来更多样的挑战, 方便研究者对相关算法进行深入研究, 针对InfraCalib数据集的难点进行测试和改进算法性能.
多源传感器的空间一致性对齐效果的评估与分析一般可分为量化评估分析与可视化评估分析.量化评估分析主要用于评估外参标定结果的精度与稳定性, 可视化评估分析通过观察多模态数据的重投影误差, 验证相关方法的有效性.
精度是外参标定最直接、重要的评估指标, 是指标定结果与实际外参之间的差异.这个差异可使用绝对误差、相对误差或其它形式表示.通常标定精度越高, 说明标定结果越接近于实际值.稳定性是指在多次重复外参标定后, 这些标定结果几乎一致, 波动足够小.如果多次标定的结果都很相近, 说明标定稳定性较高, 否则, 稳定性较差.这两个指标之间也有一些关联性, 并不是完全独立的.通常情况下, 标定精度越高, 稳定性能也会越优.
此外, 还有其它评测外参标定的指标, 如重投影误差, 可将物体的三维坐标投影到图像二维平面, 观察投影位置有没有与图像中的原物体对应.如果对应较好, 表明标定结果较准确, 否则不太准确.
然而, 对于可视化结果的评估分析存在一定的主观性.相对而言, 量化评估分析更客观、精细.
上述评估分析思路可用来衡量标定算法优劣, 尤其是量化评估分析.为了便于相关研究人员快速使用InfraCalib数据集完成对标定算法的量化评估分析, 总结标定算法的误差量化形式, 并形成Infra-Calib数据集的评估基准.
InfraCalib数据集的评估基准主要以标定精度为评估目标.针对外参转移矩阵, 采用平移向量误差和旋转向量误差描述标定精度.
平移向量误差度量估计平移向量和真实平移向量之间的差异.假设T为真实的转移矩阵, 对应的平移向量是t, $ \hat{\boldsymbol{T}}$为估计的转移矩阵, 对应的平移向量为$\hat{\boldsymbol{t}}$, 则平移向量的误差定义为
$E_{t}=\|\boldsymbol{t}-\hat{\boldsymbol{t}}\|, $
其中‖ · ‖ 表示欧氏范数.上式表示真实的平移向量与估计的平移向量之间的距离, 距离越小, 标定结果越准确.
旋转矩阵误差度量估计旋转矩阵和真实旋转矩阵之间的差异.本文采用基于Frobenius范数的误差, 定义为
$E_{r}=\|\boldsymbol{r}-\hat{\boldsymbol{r}}\|_{\mathrm{F}}, $
其中, r表示真实的旋转矩阵, $ \hat{\boldsymbol{r}}$表示估计的旋转矩阵, ‖ · ‖ F表示Frobenius范数.上式表示真实旋转矩阵和估计旋转矩阵之间的距离, 距离越小, 标定精度越高.
当实际使用InfraCalib数据集评估标定算法时, 可利用数据集上提供的多样性外参标注值作为近似真实值, 对算法在数据集上生成或预测的平移向量及旋转矩阵进行误差计算, 获得待评估算法在InfraCalib数据集上的一个量化评估分析结果, 并在此基础上指导研究人员有针对性地优化相关算法, 并给予后续研究的基线.
平移向量误差和旋转矩阵误差通常是独立衡量的, 因为它们表示不同的几何性质, 分别是空间位置的变化和角度方向上的变化.这两者的数值单位和量纲不同, 直接合并为一个指标是不合理的.但是, 在某些具体的实际应用中, 有时可能需要一个综合指标衡量整体精度.在这种情况下, 考虑引入一个加权因子, 这个加权因子通常需要根据具体应用和需求确定.例如, 定义一个加权综合误差:
$E=w_{t} E_{t}+w_{r} E_{r}, $
其中, wt表示平移向量误差权重, wr表示旋转矩阵误差权重, Et表示平移向量误差, Er表示旋转矩阵误差.上式表示一个综合指标, 考虑平移和旋转的误差, 并通过加权因子平衡两者的贡献.这个指标可用于衡量整体的标定精度.权重的选择依赖于具体的应用需求, 也可用作优化函数有侧重性地影响模型的迭代训练或在线校准过程.
多源数据空间一致性作为路端数据融合的基础, 迫切需要更优的解决方案, 但是已知可供研究路端多源数据空间一致性问题的数据集很少, 因此, 本文构建一个专门用于研究和评测的多源数据空间一致性数据集, 采用基于张氏标定法的ROS1 Melodic(Ubuntu18.04)相机内参标定工具获得内参真值, 通过手动方式提取点云和图像上的关键点对, 最小化重投影误差法求解PnP问题获得外参真值.数据包含不同模态、场景、光照强度等多达96组外参变化, 适合于研究一些多模态特征匹配等任务.在In-fraCalib数据集上对一些经典的特征匹配算法进行有效性实验, 揭示现有算法的不足和未来可能的改进方向, 并分析InfraCalib数据集的难点与研究价值.另外, 讨论在InfraCalib数据集上测试多源传感器外参标定算法的量化评估指标, 为后续算法研究提供性能上的衡量标准.
今后可致力于构建更真实和多样性的数据集, 以更好地呈现实际场景.例如:可在路端智能移动设备上部署事件相机, 捕捉普通工业相机难以捕捉的亮度变化, 从而能在实际任务中追踪高速运动的物体; 部署低时延相机, 获取更高实时性的数据, 用于研究需要快速响应和高精度同步的实际应用任务.除了部署多源的传感器以外, 还可采集含有更多动态元素、复杂光照条件及不同天气甚至不同季节的场景数据, 为相关算法的鲁棒性与通用性测试提供更多的可能性.
本文责任编委 郑心湖
Recommended by Associate Editor ZHENG Xinhu
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|