



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
应用于毫米波车车通信的多模态感知辅助波束预测
[文韦博1  , 张浩天
, 张浩天1 , 高诗简2 , 程翔1 , 杨柳青3, 4, 5 ]
, 张浩天, 高诗简, 程翔, 杨柳青]
|
|



作者简介: 
文韦博,博士研究生,主要研究方向为多模态感知辅助的通信系统传输方案设计.E-mail:iweber.wen@gmail.com. 
张浩天,博士研究生,主要研究方向为多模态感知辅助的通信系统传输方案设计.E-mail:haotianzhang@stu.pku.edu.cn. 
程 翔,博士,教授,主要研究方向为基于数据驱动的智慧网络、网联智能.E-mail:xiangcheng@pku.edu.cn. 
杨柳青,博士,教授,主要研究方向为无线通信网络、多智能体系统、通讯感知一体化等.E-mail:lqyang@ust.hk.
为了确保车联网通信的传输可靠性,大规模多天线技术的毫米波通信亟需精确的波束赋形.在高动态的车辆通信环境下,传统的波束对准方式会造成巨大的资源开销,难以在相干时间内建立可靠链路.因此,文中提出基于多模态感知信息辅助的波束预测方案.该方案融合视觉和激光雷达点云两种非射频感知信息,利用深度神经网络进行多模态信息的特征提取,通过透视投影实现图像空间语义信息和物理空间位置信息的精准匹配和深度融合.通过协同感知坐标校正和车辆位置预测,将物理环境的特征精确映射到角域信道,从而实现实时准确的波束预测.在多模态感知仿真数据集(M3SC)上的测试结果表明,文中方案能实现较高的角度追踪精度和可达通信速率.
About Author:
WEN Weibo, Ph.D. candidate. His research interests include multi-modal sensing-assisted transceiver design in communication systems.
ZHANG Haotian, Ph.D. candidate. His research interests include multi-modal sen-sing-assisted transceiver design in communication systems.
CHENG Xiang, Ph.D., professor. His research interests include data-driven intelligent network and networked intelligence.
YANG Liuqing, Ph.D., professor. Her research interests include wireless communication networks, multi-agent systems and integrated communication and sensing.
To ensure the transmission reliability of vehicular communication network, precisely aligned beamforming of millimeter-wave communication using massive multi-input multi-output(mMIMO) technology is urgently required. In highly dynamic vehicular communication scenarios, traditional beam alignment schemes incur significant resource overhead and struggle to establish reliable links within the coherence time. To address this critical challenge, a scheme of multi-modality sensing aided beam prediction for mmWave V2V communications is proposed. Two non-RF sensing modalities, vision and ranging(LiDAR) point cloud, are integrated, and deep neural networks are employed for feature extraction and integration of multi-modal information. Accurate matching and deep fusion of image space semantic information and physical space location information are achieved through perspective projection. By collaborative sensing coordinate calibration and vehicle position prediction, the features of physical environment are accurately mapped to the angular-domain channel, enabling real-time and precise beam prediction. The experimental results on the mixed multi-modal sensing-communication dataset(M3SC)show that the proposed scheme achieves high angle tracking accuracy and achievable communication rate.
面对智能交通系统下应用的多样化, 如4K高清视频传输、高分辨率实时地图下载、360° 全景感知等, 车辆通信网络(Vehicular Communication Net-work, VCN)面临前所未有的挑战, 具体包括但不限于高达10 Gbps的峰值速率和低至毫秒级的传输时延[1, 2].毫米波(Millimeter Wave, mmWave)作为5G时代下通信频段的重要补充, 被蜂窝车联网(Cellular Vehicle-to-Everything, C-V2X)标准认定为满足未来智能车联网的海量数据需求的重要媒介之一.
相比目前广泛使用的Sub-6 GHz频段, 毫米波频段的电磁波在自由空间中衰减严重, 导致毫米波频段的高路径损耗.发射机通常会配备大规模多天线, 引入更多的空间自由度.波束成形能利用这些自由度, 将能量集中在目标用户方向, 增加对目标用户的增益、减少对非目标用户的干扰.由于大规模天线阵的波束宽度较窄, 发射机和接收机的波束必须严格对准, 以获得较高的接收信噪比(Signal-to-Noise Ratio, SNR), 建立可靠的车联网通信.
传统的波束对准方法通常基于波束训练(Beam Training)获得预编码矩阵.一种常见的方案是周期性扫描预定义码本中的波束[3, 4], 获得最佳性能的波束.其它改进方案, 如基于线下特征学习[5, 6]和稀疏特征重构[7, 8]的波束训练方案, 在准静态场景中的训练开销和计算复杂度上表现优异.但是在车联网应用场景中, 信道状态快速时变, 频繁的波束训练带来的信令反馈仍会导致高时延和频谱资源开销, 因此在整个通信过程中一直使用波束训练是不实际的.
为了解决这一问题, 研究者利用信道状态或车辆运动状态等参数的时间相关性, 开发一系列波束追踪(Beam Tracking)方案.Va等[9]利用EKF(Ex-tended Kalman Filter)追踪信道状态.Liu等[10]利用DFRC(Dual-Functional Radar-Communication)追踪车辆运动状态.由于EKF的状态演化模型无法良好匹配实际非平稳的运动轨迹, Larew等[11]尝试使用UKF(Unscented Kalman Filter)追踪信道状态的演化过程, 减少EKF的线性近似误差.Zhang等[12]提出VBC-PF(Vehicle Behavior Cognition-Based Particle-Filter), 预测车辆间的运动学特征, 估计信道状态, 计算最佳波束成形矢量.Zhu等[13]考虑在通信波束旁形成ABP(Auxiliary Beam Pair), 实现高精度的波束角度追踪.然而室外相对丰富的非直射径(None-Line-of-Sight Path, NLoS Path)分量降低ABP对直射径(Line-of-Sight Path, LoS Path)的追踪效果.
虽然毫米波通信信道丰富的几何特性与物理空间的通信目标具有较强的关联性, 基于信道的波束追踪精度仍容易受到电磁传播环境的干扰[14].受到人类联觉机制的启发[15], 研究者发现多种感知设备(如相机、激光雷达、毫米波雷达等)可潜在反映电磁空间的部分特性, 因此探索利用单模态感知辅助通信的方案.同时, 传统的线性近似建模在高动态车联网场景中精度不佳, 研究者开始利用深度学习(Deep Learning, DL)技术解决车辆运动固有的非线性问题.Alrabeiah等[16]利用RGB图像辅助车联网中的波束预测和阻塞预测任务.Demirhan等[17]开发基于雷达原始波形数据和Range-Doppler-Angle(RDA)谱的波束预测方案.Klautau等[18]和Wu等[19]利用LiDAR(Light Detection and Ranging)辅助波束选择和链路阻塞预测任务.Charan等[20]结合RGB图像和毫米波波束信息, 主动预测阻塞情况.
目前, 感知辅助波束追踪机制的相关研究集中在V2I场景中[21, 22, 23].考虑到V2V通信同样作为3GPP[24]关键的通信标准之一, 也是C-V2X中侧链通信的重要组成部分[21, 25], 在支持车辆的实时数据交换和保证道路安全性上至关重要, 相比V2I, V2V的通信双方均处于高速移动状态, 需要更频繁获取环境测量信息.感知设备中的车辆语义信息和背景语义信息均快速变化, 需要设计更有效的神经网络, 用于分离和提取这些语义特征.Luo等[26]提出利用卷积神经网络(Convolutional Neural Network, CNN)提取毫米波雷达RDA谱的特征, 联合历史时刻的最佳波束, 预测未来时刻的最佳波束.然而该方法中通信设备的波束追踪范围取决于雷达设备的视场角(Field of View, FoV), 因此波束追踪范围受到单个雷达水平FoV的限制.为了解决FoV受限问题, Osman等[27]融合多个视角的RGB图像信息和射频信息, 估计目标车辆的位置信息, 实现360° FoV的波束追踪.然而该方法使用的单目相机难以准确估计目标的深度信息, 导致坐标估计的误差.值得注意的是, 上述V2V波束追踪方案均未考虑实际情况中智能车配备的多个感知设备和天线设备的部署位置差异, 以及车辆距离非常近的情况, 因此通过感知设备获得的波束角度会出现较大偏差.
如同人类感官的感知原理各异, 不同感知模态的工作原理和产生的感知数据性质也有所不同[14], 单一感知设备均有不同的应用限制.例如:RGB相机可以获取语义信息丰富的2D环境图像, 但是难以精确估计目标和相机的相对距离; 激光雷达通过发射激光束对环境进行距离和反射强度的测量, 获得高精度、稀疏的三维点云, 但是缺少车辆的语义信息.上述仅依靠单模态感知数据辅助的方案会受到这些应用限制的制约.同时, 感知辅助V2V通信的相关研究并未考虑到智能车部署的感知设备和通信设备之间的位置差异, 而是将车辆质点化(Point Object)处理, 在实际部署波束追踪方案时会引入位置或角度处理的系统误差.
综上所述, 本文提出视觉和激光雷达信息多模态感知辅助的车对车通信波束预测方案(Multi-modality Sensing Aided Beam Prediction with Vision and LiDAR Information, MMSA-VL), 包括多模态的特征提取模块、多模态特征融合模块和预测性波束成形, 实现V2V场景下实时、精准的波束预测.MMSA-VL采用RGB图像和激光雷达点云的多模态感知获取目标车辆的运动特征, 使不同模态的感知能力优势互补, 精确捕获环境中目标车辆的视觉和运动状态特征.设计的专用长短期记忆(Long Short-Term Memory, LSTM)网络用于预测未来时刻的车辆运动状态, 指导波束预测.MMSA-VL将车辆作为一个拓展物体处理, 考虑车辆在非理想远场下的体积和形状.在多个感知设备协同感知阶段, 利用各设备部署位置的先验信息, 校正从感知设备获得的目标车辆坐标, 消除系统误差, 精确对准波束.
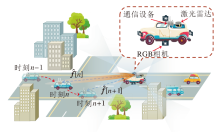
如图1所示, 本文考虑一个车联网V2V通信场景.在一个智能交通系统中, 配备通信设备的多个智能车之间互相提供通信服务.车辆的通信设备工作在毫米波频段, 并配备一个多入多出(Multiple-Input Multiple-Output, MIMO)均匀线性阵列(Uniform Linear Array, ULA).发射端车辆的ULA具有Nt个天线单元, 接收端车辆的ULA具有Nr个天线单元.此外, 每个智能车配备激光雷达和相机, 用于获取实时的多模态感知数据.
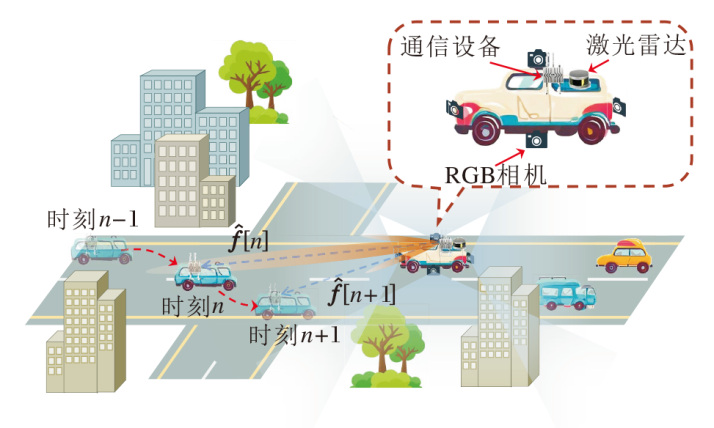 | 图1 基于多模态感知的车联网V2V通信场景示意图Fig.1 Multi-modality sensing based V2V communications in VCN |
发射端需要实时准确获取与接收端的相对角度, 形成指向目标用户的窄发射波束.为了降低这一过程的延迟和信令开销, MMSA-VL在下一次波束更新之前, 提前预测波束成形的角度, 减少信令交互和数据处理产生的延迟.
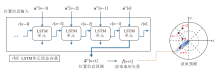
MMSA-VL充分利用多模态感知数据协助发射端的波束预测.具体而言, 发射端以固定频率感知交通环境并与目标车辆保持持续的通信.在时刻n, 发射端车辆使用激光雷达和RGB相机获得感知信息, 并在时刻n+1到来前, 利用时刻n以及历史时刻的感知信息预测时刻n+1的波束角度$\hat{\theta}[n+1]$.为了实现这个目标, MMSA-VL需要开发专用的多模态感知信息提取和融合方法, 具体流程图如图2所示.
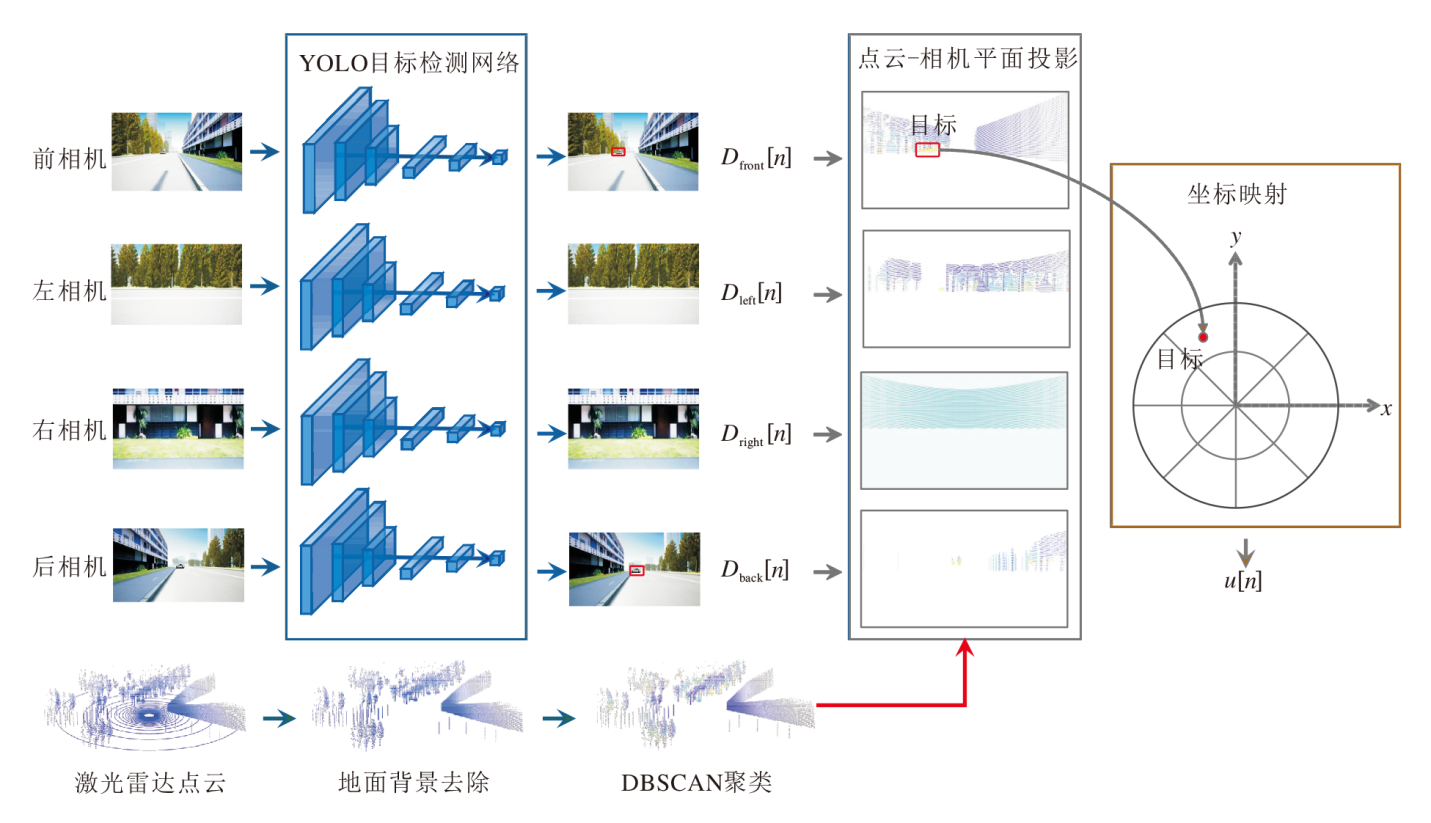 | 图2 多模态感知信息提取和融合方法流程图Fig.2 Flowchart of multi-modality sensing information extraction and fusion |
假设发射端有充足的计算能力进行波束角度预测, 并通过当前的通信链路将结果发给接收端.根据预测结果, 发射端和接收端的MIMO ULA在时刻n+1制定发射波束成形矢量
$\boldsymbol{f}[n+1]=\boldsymbol{a}_{t}(\hat{\boldsymbol{\theta}}[n+1])$
和接收波束成形矢量
$\boldsymbol{w}[n+1]=\boldsymbol{a}_{r}(\hat{\phi}[n+1]), $
形成相互对准的波束对, 具体计算方法如下:
$\begin{array}{l} \boldsymbol{f}[n]=\boldsymbol{a}_{t}(\hat{\theta}[n])=\frac{1}{\sqrt{M}_{t}}\left[1, \exp \left(j \frac{2 \pi}{\lambda} d_{t} \cos \hat{\theta}[n]\right), \cdots, \exp \left(j\left(M_{t}-1\right) \frac{2 \pi}{\lambda} d_{t} \cos \hat{\theta}[n]\right)\right]^{\mathrm{T}}, \\ \boldsymbol{w}[n]=\boldsymbol{a}_{r}(\hat{\phi}[n])=\frac{1}{\sqrt{M}_{r}}\left[1, \exp \left(j \frac{2 \pi}{\lambda} d_{r} \cos \hat{\phi}[n]\right), \cdots, \exp \left(j\left(M_{r}-1\right) \frac{2 \pi}{\lambda} d_{r} \cos \hat{\phi}[n]\right)\right]^{\mathrm{T}}, \end{array}$
其中,
在MMSA-VL中, RGB相机持续采集智能车周围的2D环境图像.RGB图像中包括丰富的语义信息, MMSA-VL利用目标检测神经网络识别环境中的智能车, 这一过程称为车辆语义信息提取.
用于V2V波束预测任务的目标检测器需要精准快速地检测图像中的智能车.在计算机视觉研究领域中有许多成熟的目标检测网络模型, 一个典型的例子是YOLOv5(You Only Look Once)[28].
基于预训练的YOLOv5框架, MMSA-VL通过微调参数, 使模型在更快收敛的同时, 更适应本文的研究任务.
对于每个输入的图像样本, YOLO模型输出若干个智能车的二维边界框信息:
D[n]={
每个边界框信息由
dobj[n]=[xcenter, ycenter, w, h]
确定, 包括中心坐标(xcenter, ycenter)和长宽w、h.
车载激光雷达采集的点云包含物理空间中物体的精确位置信息, 为了后续提取车辆的位置信息, MMSA-VL需要对采集的原始点云进行预处理.
首先剔除激光点云的地面背景, 减少计算复杂度.一种简单直观的方法是去除所有z坐标值在0附近的点.对于复杂高动态城镇十字路口车联网场景, 基于高度的地面背景去除方案已能满足要求.实际情况中可能会出现更复杂的地面情况, 因此可针对不同地面情况设计各种专用的地面背景去除方案.
为了更精确地从点云中提取车辆的位置信息, 考虑使用聚类将每辆车和背景噪声形成单独的点云簇.鉴于物理环境中存在的车辆数量对于算法是未知的, 各种车的形状各异但是尺寸相似, 因此MMSA-VL选择DBSCAN(Density-Based Spatial Clu-stering of Applications with Noise)聚类已去除地面背景的点云.
RGB图像和激光雷达点云具有不同的数据格式和不同的感知能力, 本文希望构建一种融合机制, 使两种模态的优势互补.RGB相机使用透镜聚焦物理空间中反射的光线, 将景物投影到感光材料上, 形成二维图像, 这个过程即透视投影.
如图3所示, MMSA-VL使用透视投影, 将3D物理空间中采集的点云投影至2D图像空间(2D平面), 与YOLO模型输出的检测框匹配, 筛选车辆对应的点云簇, 实现图像空间语义信息和物理空间位置信息的精准匹配.
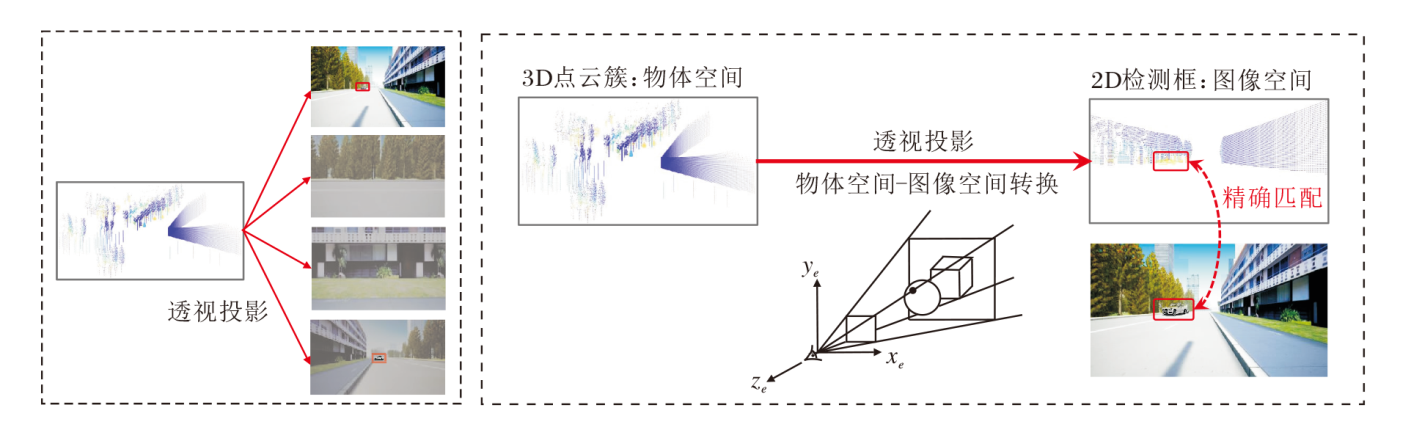 | 图3 透视投影原理图Fig.3 Perspective projection |
具体而言, MMSA-VL对每个相机进行透视投影, 整个过程分为如下步骤.
1)求出投影相机相对于激光雷达设备的相对坐标:
$\begin{array}{l} {\left[x_{0}, y_{0}, z_{0}\right]=} \\ \quad\left[x_{\text {camera }}, y_{\text {camera }}, z_{\text {camera }}\right]-\left[x_{\text {LidAR }}, y_{\text {LidAR }}, z_{\text {LidAR }}\right] . \end{array}$
2)根据相机以X轴、Y轴、Z轴为中心的旋转角β x、 β y、 β z, 计算旋转矩阵Rx、Ry、Rz和平移矩阵T:
$\boldsymbol{R}_{x}=\left[\begin{array}{cccc} 1 & 0 & 0 & 0 \\ 0 & \cos \beta_{x} & -\sin \beta_{x} & 0 \\ 0 & \sin \beta_{x} & \cos \beta_{x} & 0 \\ 0 & 0 & 0 & 1 \end{array}\right], $
$\boldsymbol{R}_{y}=\left[\begin{array}{cccc} \cos \beta_{y} & 0 & \sin \beta_{y} & 0 \\ 0 & 1 & 0 & 0 \\ -\sin \beta_{y} & 0 & \cos \beta_{y} & 0 \\ 0 & 0 & 0 & 1 \end{array}\right], $
$\boldsymbol{R}_{z}=\left[\begin{array}{cccc} \cos \beta_{z} & -\sin \beta_{z} & 0 & 0 \\ \sin \beta_{z} & \cos \beta_{z} & 0 & 0 \\ 0 & 0 & 1 & 0 \\ 0 & 0 & 0 & 1 \end{array}\right]$
$\boldsymbol{T}=\left[\begin{array}{cccc} 1 & 0 & 0 & x_{0} \\ 0 & 1 & 0 & y_{0} \\ 0 & 0 & 1 & z_{0} \\ 0 & 0 & 0 & 1 \end{array}\right] \text {. }$
3)计算刚体变换矩阵
$\boldsymbol{R}=\boldsymbol{R}_{y} \boldsymbol{R}_{x} \boldsymbol{R}_{z} \boldsymbol{T} .$
4)计算3D物体空间每个点$\boldsymbol{p}_{i}=\left[x_{i}, y_{i}, z_{i}\right]$的旋转后坐标:
$\left[\begin{array}{c} x_{i}^{r t} \\ y_{i}^{r t} \\ z_{i}^{r t} \end{array}\right]=\boldsymbol{R}\left[\begin{array}{l} x_{i} \\ y_{i} \\ z_{i} \end{array}\right], $
其中i表示第i个点.
5)计算每个点投影至2D图像空间(2D平面)的坐标:
$\left[x_{i}^{p j}, y_{i}^{p j}\right]^{\mathrm{T}}=\left[\frac{f_{0} x_{i}^{r t}}{z_{i}^{r t}}, \frac{f_{0} y_{i}^{r t}}{z_{i}^{r t}}\right]^{\mathrm{T}}, $
其中f0表示相机焦距.
6)剔除投影相机的检测框之外的2D图像空间的点, 将距离相机平面最近的剩下点云簇作为目标车辆对应的点云簇.
7)计算目标车辆对应点云簇的质心坐标, 作为该时刻目标车辆与相机的相对坐标.
在2.3节中, 智能车已获得目标车辆相对于相机的坐标, 考虑到相机与天线之间具有位置差异, 并且该差异可被预先测量.因此平移变换 T可将所有相对于相机的坐标转换成相对于天线的坐标, 具体如图4所示.坐标校正后消除系统误差, 实现波束角度的精确估计.
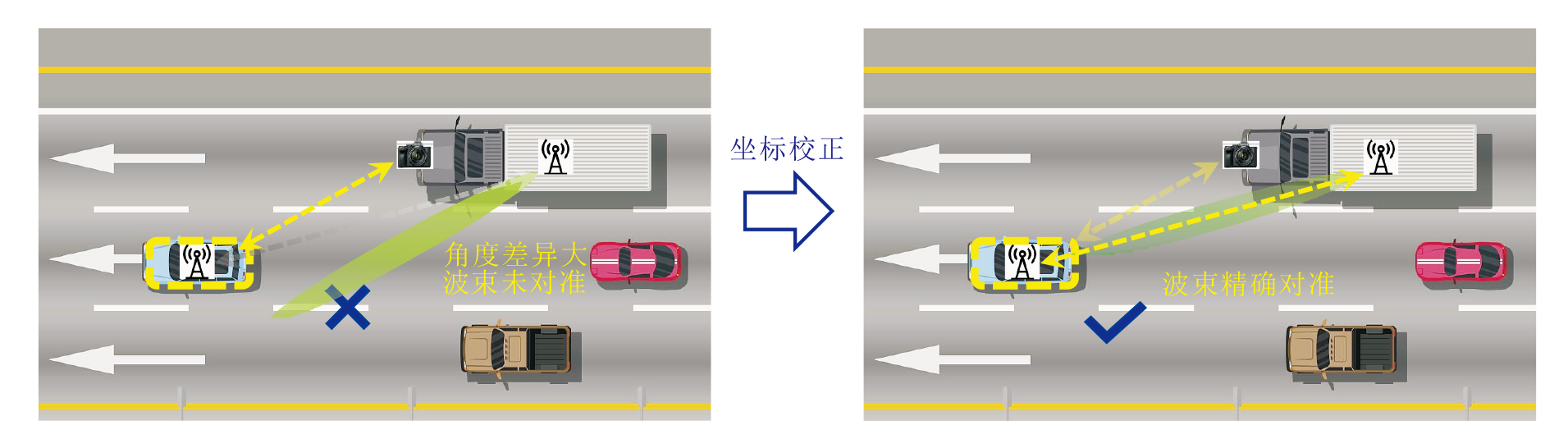 | 图4 坐标校正示意图Fig.4 Coordinate calibration |
智能车在每个时刻都有能力获得周围环境中所有车辆的运动状态.假定在初始接入时, 发射端通过波束训练或卫星定位等先验信息获得目标车辆的大致位置, 与多模态感知检测的所有车辆匹配, 筛选目标车辆的位置信息$\boldsymbol{u}^{(t)}[n] \in \boldsymbol{U}[n]$, 其中
$\boldsymbol{U}[n]=\left\{\boldsymbol{u}^{(1)}[n], \boldsymbol{u}^{(2)}[n], \cdots\right\}$
为车辆位置信息集合,
$\boldsymbol{u}^{(m)}[n]=\left[x^{(m)}, y^{(m)}\right] \text {. }$
在后续过程中依据目标车辆的历史轨迹点, 筛选目前时刻目标车辆的运动状态.由于整个系统从多模态感知数据的采集、处理到信号的发射存在延时, 导致波束追踪精度下降.MMSA-VL考虑使用LSTM预测这一过程, 具体如图5所示.
 | 图5 运动状态预测和波束预测示意图Fig.5 Motion state prediction and beam prediction |
具体而言, MMSA-VL将目标车辆历史时刻的坐标
$\left[\boldsymbol{u}^{(t)}[n], \boldsymbol{u}^{(t)}[n-1], \cdots, \boldsymbol{u}^{(t)}[n-k]\right]$
作为LSTM的输入, 输出下一个时刻的运动状态估计值$\hat{\boldsymbol{u}}^{(t)}[n+1]$, 估计AoD, 产生下一时刻的发射波束成形矢量:
$\boldsymbol{f}[n+1]=\boldsymbol{a}_{t}(\hat{\theta}[n+1])$
本文选择M3SC(Mixed Multi-Modal Sensing-Co-mmunication)仿真数据集[29]的复杂高动态城镇十字路口车联网场景(如图6所示), 网联智能车配备通信设备和多模态感知设备.
 | 图6 十字路口场景车辆轨迹示意图Fig.6 Vehicle trajectories in urban crossroad scenario |
M3SC数据集涵盖各种天气条件、不同频段和一天中的不同时间, 场景中的智能车在连续帧下同步采集RGB图像、激光雷达点云、毫米波雷达点云、信道状态信息(Channel State Information, CSI)等.具体数据样例如图7所示.
 | 图7 一辆智能车在不同时刻收集的感知数据Fig.7 Sensing data collected by an intelligent vehicle at different times |
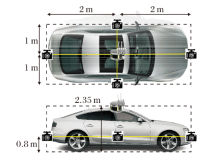
车载设备的部署情况如图8所示.发射端车辆配备前后左右共四个视角的相机, 距离地面0.8 m, 捕获360° FoV的环境信息.车的顶部中心距离地面2.35 m处配备激光雷达和毫米波通信设备.
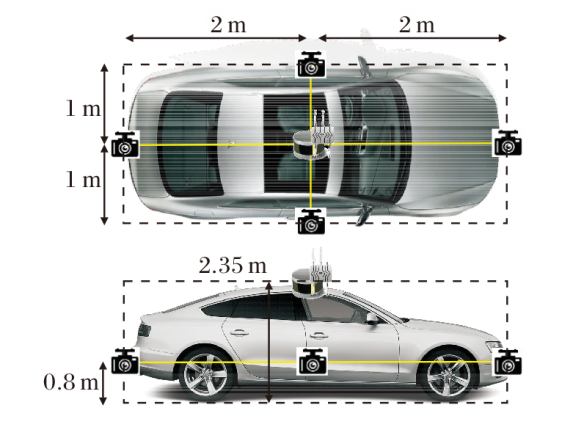 | 图8 车载设备部署示意图Fig.8 Onboard equipment deployment |
为了突出多模态感知辅助的重要性, 选择如下3种方案作为基准方案.
1)文献[10]方案(简记为EKF-DFRC).利用DFRC(Dual-Functional Radar-Communication)信号同时进行雷达感知和通信, 并使用EKF追踪车辆的角度、距离、速度和反射系数的演化, 从而避免专用的下行导频.在车联网动态场景中, 雷达感知性能和通信性能均会下降.EKF将运动状态线性化处理也会导致难以在复杂的车辆轨迹中获得良好的波束追踪性能.此方案可作为单模态射频感知辅助波束追踪的基准方案.
2)文献[13]方案(简记为ABP).利用额外的两条射频链形成一对辅助波束, 发送正交的两组Zadoff-Chu (ZC)序列.接收端通过序列的互相关性估计AoD, 并反馈给接收端, 用于波束追踪.然而方法假定直射径增益远大于非直射径增益, 在散射体丰富的车联网场景中追踪精度不佳, 只作为仅利用通信进行波束追踪的基准方案.
3)UMSA-V(Uni-Modal Sensing Assisted Beam Tracking with Vision Information).是MMSA-VL在失去LiDAR情况下的特例, 仅利用车辆前后左右的RGB相机获取 360° FoV的单模态视觉信息, 获取目标车辆与发射端之间的相对角度.由于失去LiDAR点云的位置信息, UMSA-V将发射端质点化处理, 这意味着相机与天线之间的位置差异会引入角度估计的系统误差.此方案可作为单模态非射频感知辅助波束追踪的基准方案.
M3SC数据集上使用的通信系统和信道参数如下.载波频率设为38 GHz, 带宽为380 MHz.接收噪声功率谱密度的设置参考文献[30].发射端功率为30 dBm, 接收端噪声功率谱密度为-174 dBm/Hz, 100 m自由空间路径损耗为100 dB.
EKF-DFRC引入的状态演化噪声方差均在10-3数量级, 测量噪声方差均在 10-6数量级.ABP利用收发端的16个天线的ULA, 每个辅助波束角度与中轴线间隔为π /16.
3.4.1 角度误差
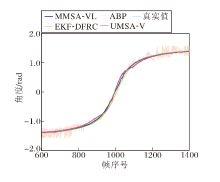
对比4种方案的角度追踪效果, 角度追踪的绝对值和真实值如图9所示.由图可发现, 4种方案在连续角度追踪过程中均表现出接近真实值的追踪性能.
 | 图9 角度追踪绝对值Fig.9 Absolute values of angle tracking |
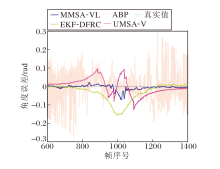
为了更清晰观察各种方案的追踪效果差异, 4种方案角度追踪结果与真实值的误差如图10所示.由图可见, ABP在整个追踪过程中的误差值表现出明显的不稳定性, 尤其是整个过程的起始和结束时.原因是用于仿真的场景环境中存在丰富的散射体, 非直射径弱化两组ZC序列的正交性, 导致接收端估计的AoD含有严重的噪声.这种不稳定性会导致通信系统出现异常中断.EKF-DFRC在整个过程的中间部分出现偏移现象, 这是由于中间部分两车相距较近, EKF对状态演化的线性化与实际运动行为差异过大.UMSA-V同样出现类似的问题:在车辆相近时, 相机与天线之间的位置差异导致角度估计不准确.MMSA-VL虽然在中间部分出现略微的偏移, 但是在整个追踪过程中角度估计一直保持相对稳定的水平.
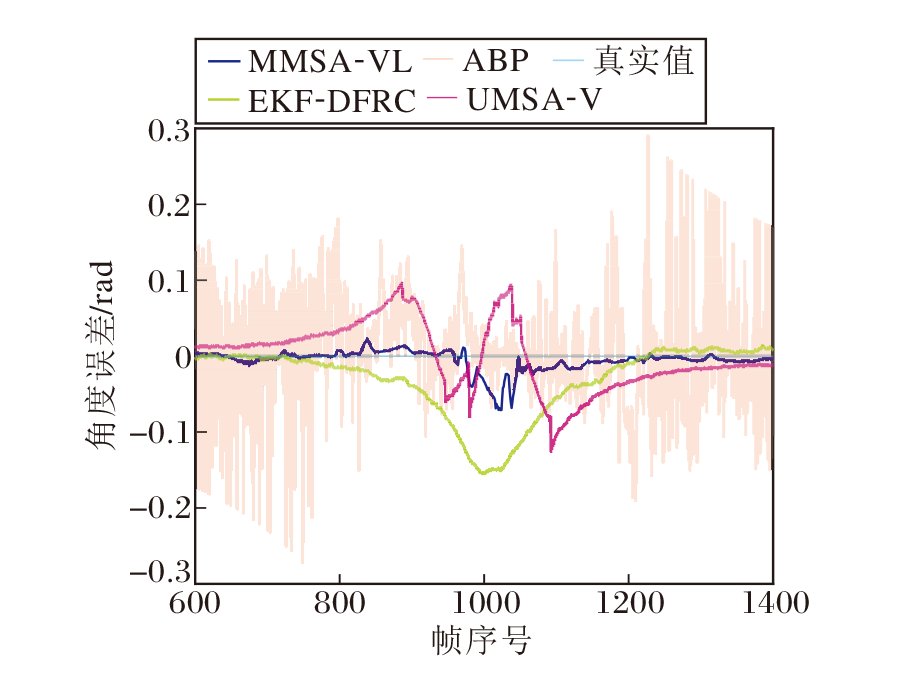 | 图10 角度追踪误差值Fig.10 Error values of angle tracking |
此外, 选择平均绝对误差(Mean Absolute Error, MAE)和平均平方误差(Mean Square Error, MSE)量化评估4种方案的性能, 结果如表1所示.
| 表1 各方案角度追踪的MAE和MSE对比 Table 1 MAE and MSE comparison of different angle tracking schemes |
由表1可见, MMSA-VL的角度追踪指标最佳.MMSA-VL追踪的 MAE值分别是ABP、EKF-DFRC、UMSA-V 的12.86%、26.69%、25.45%.MMSA-VL的MSE值更优, 分别是ABP、EKF-DFRC、UMSA-V的4.62%、19.90%、18.10%.由此可见, MMSA-VL能获取更优的角度追踪性能.
3.4.2 可达传输速率
为了更直接评估各种波束追踪方案的性能, 计算
$S N R_{n}=\frac{p_{n}\left|\kappa \alpha_{n} \boldsymbol{w}^{H}[n] \boldsymbol{a}_{r}(\phi[n]) \boldsymbol{a}_{t}^{H}(\theta[n]) \boldsymbol{f}[n]\right|^{2}}{\sigma^{2}}, $
进一步代入
$\text { Rate }_{n}=\log _{2}\left(1+S N R_{n}\right), $
计算可达速率, 其中, 天线阵列增益
$\kappa=\sqrt{N_{t} N_{r}} \text {, }$
α n表示直射径系数, ar(ϕ [n])表示直射径的接收导向矢量, at(θ [n])表示直射径的发射导向矢量, pn表示发射端功率, σ 2表示接收端零均值高斯噪声的功率.假定收发端的波束理想对准, 该结果作为可达速率的上界(以下简称上界).
实验设定100 m自由空间路径损耗为100 dB, 发射端功率为30 dBm, 接收端噪声功率谱密度为-174 dBm/Hz, 系统带宽为380 MHz.在整个追踪过程中, 目标车辆和发射端相向行驶, 发射端和接收端的相对距离先减小后增加, 最远为209.5 m, 最近为14.5 m.
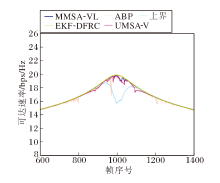
在收发端的ULA均配备8个天线的情况下, 各方案可达速率对比如图11所示.
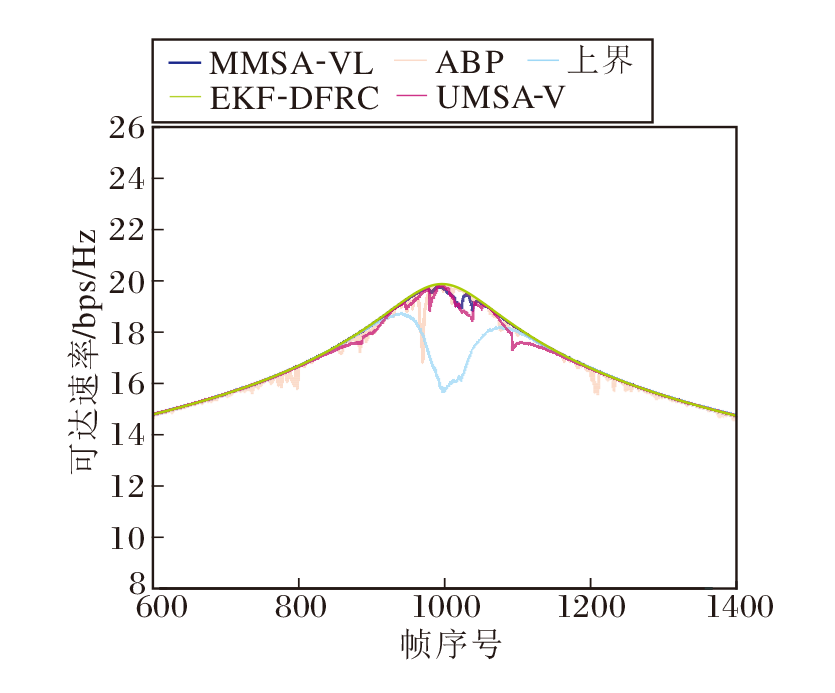 | 图11 各方案的可达传输速率对比Fig.11 Performance comparison of achievable transmission rates |
由图11可见, EKF-DFRC在车辆距离较近时表现出明显的速率下降, 仅能达到上界的97.89 %.而MMSA-VL、ABP和UMSA-V的平均可达速率分别能达到上界的99.86%、99.37%和99.41%.具体数值结果见表2和表3.
| 表2 各方案的平均可达速率 Table 2 Average achievable transmission rates |
| 表3 各方案平均可达速率与平均上界速率之比 Table 3 Ratio of average achievable rate to average upper bound rate |
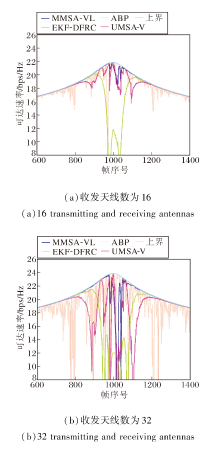
尽管增加天线可提高波束增益, 但更高的天线维度对波束追踪方案的追踪精度要求更高, 细小的偏差可能会降低可达速率.在收发端ULA分别配备16个和32个天线的情况下, 各方案的可达速率对比如图12所示.
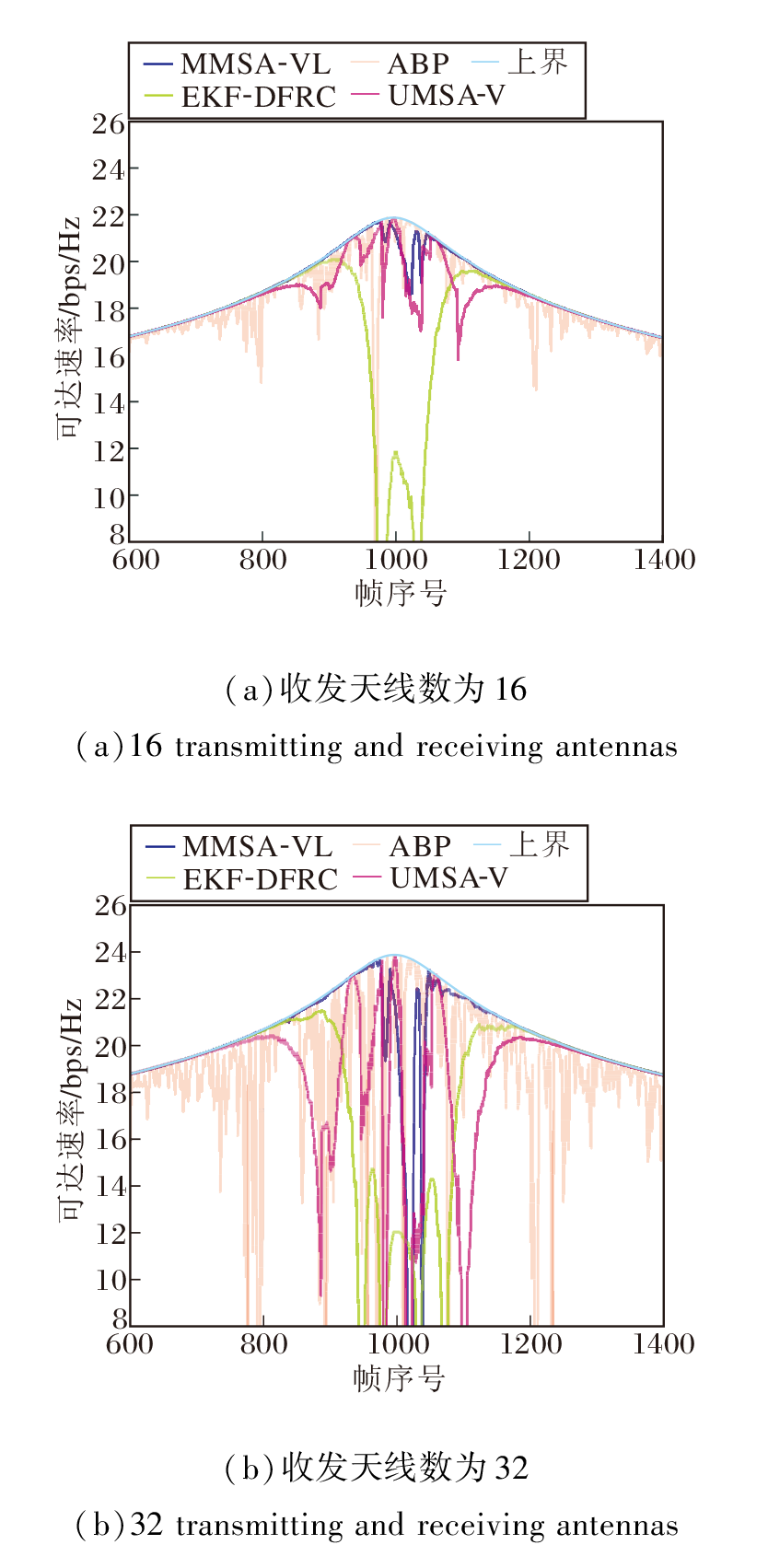 | 图12 收发天线数不同时的可达传输速率Fig.12 Comparison of achievable transmission of different number of transmitting and receiving antennas |
由图12可见, 在16个天线的情况下, 虽然每种方案的平均可达速率都有所增加, 但是更容易由于波束不对准而出现通信速率下降的情况.在32个天线的情况下, 几乎所有的方案都难以保持稳定的通信速率, MMSA-VL的平均可达速率仍能维持在上界的97.56%.
为了保证公平性, 在实验中假定EKF-DFRC、ABP、UMSA-V没有信号处理延迟, ABP没有反馈延迟, 即第n帧的感知信息和信号反馈信息直接用于辅助第n帧的波束追踪, 而不需要预测这一过程.同时, VBC-PF额外形成的辅助波束对需要额外的两条射频链开销, 难以在实际情况中应用.此外, EKF-DFRC中10-6数量级的测量噪声功率等参数接近于理想情况, 在现实情况中也是难以达到的.因此, MMSA-VL对比其它方案的优越性能并不是参数设置导致的, 而是方案设计的固有差异.
本文提出应用于毫米波V2V通信的多模态感知辅助的波束预测方案(MMSA-VL).利用RGB图像提取环境中目标通信车辆的语义特征, 同时利用激光雷达点云获得高精度的位置信息, 并将两种模态的感知能力优势互补.与此同时, MMSA-VL考虑实际情况下感知设备和通信设备在通信传输车辆上的部署位置情况, 将车辆建模为拓展物体, 校正多感知设备协同时坐标估计的系统误差.在M3SC仿真数据集上的测试表明, MMSA-VL表现出较优的角度追踪性能和较高的可达速率.今后会继续基于SoM框架, 设计可灵活调整部署细节的通信传输方案, 以适应不同的环境和通信系统, 推动B5G/6G时代通信感知一体化技术的发展.
本文责任编委 陈仕韬
Recommended by Associate Editor CHEN Shitao
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|