
{kind=link}
{kind=link}
{kind=link}
神经网络结构自适应研究综述
引用本文
李淑, 覃娴萍, 翟晓童, 张龙, 仲国强, 向世明. 神经网络结构自适应研究综述. 模式识别与人工智能, 2023,36(12): 1087-1103
LI Shu, QIN Xianping, ZHAI Xiaotong, ZHANG Long, ZHONG Guoqiang, XIANG Shiming. A Review on Architecture Adaptation of Neural Networks. PATTERN RECOGNITION AND ARTIFICIAL INTELLIGENCE, 2023,36(12): 1087-1103.
Doi: 10.16451/j.cnki.issn1003-6059.202312003
LI Shu, QIN Xianping, ZHAI Xiaotong, ZHANG Long, ZHONG Guoqiang, XIANG Shiming. A Review on Architecture Adaptation of Neural Networks. PATTERN RECOGNITION AND ARTIFICIAL INTELLIGENCE, 2023,36(12): 1087-1103.
Permissions
Copyright©2023, 《模式识别与人工智能》编辑部
《模式识别与人工智能》编辑部 所有
神经网络结构自适应研究综述

作者简介:





摘要
网络结构自适应旨在根据特定学习任务和数据对神经网络结构进行自动设计和模型优化,以适应开放环境智能感知学习任务的综合需求.文中旨在全面综述网络结构自适应方法.首先,阐述并分析神经架构搜索的主要方法.然后,分别从轻量化神经架构搜索、智能感知任务、连续学习三个方面呈现网络结构自适应的研究进展.在此基础上,建立一套面向开放环境应用的深度神经网络组件与结构的自适应评价指标体系,提出一种网络结构自适应方法,通过注意力引导的微观架构自适应机制和渐进式离散策略,在优化过程中实现网络结构的自适应调整优化和逐步离散化,并与现有方法进行对比分析.最后,探讨当前方法存在的问题与挑战,展望未来的研究方向.
关键词:
网络结构自适应; 神经架构搜索; 自适应评价; 深度学习
中图分类号:TP 183
A Review on Architecture Adaptation of Neural Networks
Corresponding author:
ZHONG Guoqiang, Ph.D., professor. His research inte-rests include artificial intelligence and deep learning.
About Author:
LI Shu, master student. Her research interests include deep learning and neural architecture search.
QIN Xianping, master student. Her research interests include deep learning and neural architecture search.
ZHAI Xiaotong, master student. Her research interests include deep learning and neural architecture search.
ZHANG Long, master student. His research interests include marine chemistry and neural architecture search.
XIANG Shiming, Ph.D., professor. His research interests include pattern recognition, machine learning and computer vision.
Abstract
Network architecture adaptation aims to automatically design and optimize the neural network architectures based on specific learning tasks and data to meet the comprehensive needs of intelligent perception learning tasks in open environment. This paper is intended to provide a comprehensive review of network architecture adaptation methods. Firstly, the main methods of neural architecture search are elucidated and analyzed. Then, the research progress of network architecture adaptation is presented from three aspects: lightweight neural architecture search, intelligent perception tasks and continuous learning. On this basis, an adaptive evaluation index system of deep neural network components and architectures for open environment applications is established, and a network architecture adaptive method is proposed. Through the attention-guided micro-architecture adaptive mechanism and progressive discretization strategy, adaptive adjustment, optimization and gradual discretization of network structures are realized in the optimization process. The proposed method is compared with the existing methods. Finally, problems and challenges of current methods are discussed, and the future research directions are prospected.
Key words:
Network Architecture Adaptation; Neural Architecture Search; Adaption Evaluation; Deep Learning
近年来, 以卷积神经网络为代表的深度学习方法在众多应用领域取得巨大成功.计算能力的提升和大数据的涌现导致神经网络结构变得越来越深, 在全球人工智能领域形成“ 深度学习” 这一热点研究方向, 并迅速推动智能感知技术的进步和相关人工智能产业的全面发展.
深层神经网络架构是实现深度学习的计算基础设施.当前, 面向日趋复杂的数据和任务, 深度神经网络呈现连接方式多样、结构组件复杂、模块层层堆叠等特点.人工设计核心组件和搭建网络模型耗时费力, 并且严重依赖对领域先验知识的掌握程度和设计者的经验.此外, 网络拓扑结构一旦被固化, 网络一旦被训练, 将以“ 无法修改” 的方式被应用.依据经验设计深度神经网络需要专家知识, 在开放环境下其泛化性能和可迁移性较差.为此, 研究神经网络结构自主设计与自适应方法, 建立深度神经网络组件与结构的评价指标和高效搜索算法, 突破传统的“ 积木式静态堆积” 的结构设计藩篱, 成为神经网络结构设计中一种新的实践范式.
自神经架构搜索(Neural Architecture Search, NAS)[1]这一新的研究方向被提出之后, 针对网络结构自适应方法的研究取得大幅进展.网络结构自适应是指通过自动化和智能化的方式, 减少人工介入, 根据不同的数据和任务对网络结构及其组件进行动态调整和优化, 从而更好地适应多变的数据分布和环境需求.该方法的自适应能力可使神经网络更灵活和智能, 在变化的环境中持续学习和调整网络结构, 可帮助提高模型泛化性能, 探知性能上限, 简化模型结构, 并适应动态环境.
实际上, 在面向开放环境自适应感知任务中, 输入数据的特性、分布和条件可能会受到环境影响, 随时发生变化.为此, 深度学习模型应具备更强的适应性, 能在不同环境中有效感知、识别、跟踪、分类或处理目标对象.此类任务的关键挑战在于应对开放环境的多样性和不确定性.网络结构自适应方法通过与特征学习的紧密结合, 可根据当前环境的特点自动调整特征提取器结构, 更有效捕捉目标信息, 使模型在不同环境下能进行准确感知.
此外, 面向开放环境自适应感知任务通常需要进行领域自适应, 将模型从一个已知领域迁移到目标领域.网络结构自适应方法可通过动态调整网络结构以适应不同领域任务的特点, 应对不同环境中的噪声、变化和异常情况, 帮助模型更好地适应目标领域的数据分布和特性, 提高模型领域适应的性能和鲁棒性.
NAS是一种基础的网络结构自适应方法, 根据搜索策略, 在预定义的搜索空间中选择神经网络结构, 并利用性能评估方法评估该网络结构性能, 基于评估结果的反馈不断优化网络结构的选择, 为网络结构自动生成和环境感知自适应提供技术支撑, 旨在成为网络结构自动设计的通用方法.NAS不仅在简单的图像识别任务[1]、目标检测[2, 3]、语义分割[4, 5]等密集型任务上取得卓越成果, 还在三维人体姿态估计[6]、三维点云数据处理[7]等复杂的开放环境智能感知和现实场景复杂数据处理等任务中取得出色的表现.
网络结构自适应是指神经网络可根据不同任务和数据集的需要自动调整、优化网络结构, 无需手动设计和改进, 并试图通过基于学习的自适应方式对搜索空间进行自动化探索, 以实现网络结构搭建, 力图最大化减少人工干预, 解决深度学习领域复杂度最高、灵活度最大、设计难度最高的深度神经网络自动化搭建问题.搜索空间、搜索策略和性能评估是实现这一目标的三个主要技术要素.
具体而言, 搜索空间决定可发现的神经网络模式范围, 搜索空间定义所有可能的网络组件和参数集合.对搜索空间的定义, 需要综合考虑平衡模型性能和计算资源消耗.搜索策略决定有效探索搜索空间的算法, 以获取最优的网络结构.搜索策略的选择会直接影响搜索效率和结果, 不同的搜索策略具有各自优缺点, 需要根据具体情况选择合适的策略.性能评估是指通过预先设定的规则对采样到的网络结构进行指标评估, 其目标是为候选网络结构提供一个公正和可靠的评价方法.在这一过程中, 其核心任务是根据网络模型性能的相对排序以指导网络结构的搜索、发现、训练和优化.
本文总结NAS的研究框架, 从搜索空间和搜索算法两方面对现有NAS研究工作进行系统梳理.在此基础上深入讨论网络结构自适应方法, 介绍基于轻量化NAS的网络结构自适应方法、面向学习任务的网络结构自适应方法、连续学习条件下的网络结构自适应方法.基于现有神经网络组件与结构的评价指标, 建立一套面向开放环境应用任务的深度神经网络组件与结构的评价指标体系.最后, 讨论目前网络结构自适应方法存在的挑战和问题, 并探讨未来的研究方向.
1 神经架构搜索方法
作为网络结构自适应的一种具体实现方法, 神经架构搜索是一种包含离散结构和连续参数的混合变量优化问题.本节将从搜索空间和搜索算法两个维度对现有神经架构搜索方法进行系统阐述.
1.1 搜索空间
搜索空间定义用于构建网络模型的所有可选择操作, 在一定程度上决定NAS的性能上限.Liu等[8]指出, 得益于一个合适的搜索空间, 基于简单的随机搜索方法也能得到极具竞争力的网络结构.
1.1.1 全局搜索空间
全局搜索空间是指直接从搜索空间中探寻一个完整的神经网络结构, 主要包括链式结构和多分支结构.
基于链式结构的搜索空间A可表示为一个n层序列, 其中第i层Li只接收来自第i-1层Li-1的输入, 输出只作为第i+1层Li+1的输入, 即
A=Lnº Ln-1º …º L1º L0.
然后通过如下三方面参数化搜索空间.
1)网络模型的层数.
2)每层可供选择的操作, 如卷积、池化等[9, 10, 11].
3)与操作相关的超参数, 如卷积层的滤波器数量、卷积核大小及步长等.LeNet-5[12]、AlexNet[13]等网络结构即为典型的链式结构.
随着研究的不断深入, 网络层数持续加深, 导致链式结构容易出现梯度消失和梯度爆炸等问题.为了缓解这些问题, 研究者们致力于设计多分支结构, 与链式结构不同, 多分支结构搜索空间中的体系结构不再是顺序的, 网络中每层都可与前面任一层连接.例如:GoogLeNet[14]利用不同的Inception模块增加网络深度和宽度.此外, He等[15]提出的ResNet引入跳跃连接的思想, 将浅层网络的特征通过跳跃连接直接传递给更深的网络层, 一定程度上克服梯度消失对深度网络的影响.
1.1.2 基于Cell的搜索空间
观察一些手工设计的优秀网络结构, 研究者们发现这些神经结构通常会重复使用某些相同操作或结构块[14, 15, 16, 17, 18].因此, 学者们开始探索模块化搜索空间, 即将多种操作组合为一个Cell, 并作为构建神经网络结构的基本单元.构建一个基于Cell的网络结构, 首先需要选择某些操作以构建最优的Cell结构, 再通过预定义的规则对Cell进行堆叠, 从而设计最终的网络结构.基于Cell的搜索空间通常只需要搜索几个小的Cell结构并反复堆叠就可形成最终的网络结构.此外, Cell堆叠的数量可根据不同的数据集或任务进行灵活调整.相比全局搜索空间, 基于Cell的搜索空间不仅更紧凑、灵活和容易泛化, 并且可有效降低网络搜索的复杂性, 在各类NAS任务中都得到广泛应用.
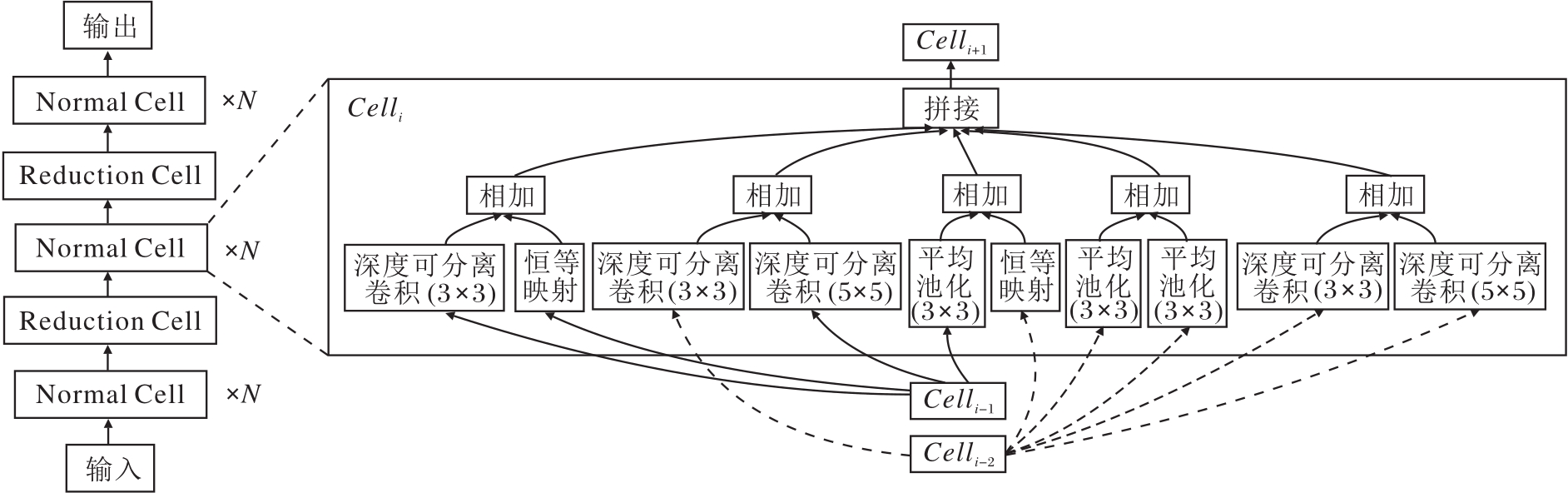
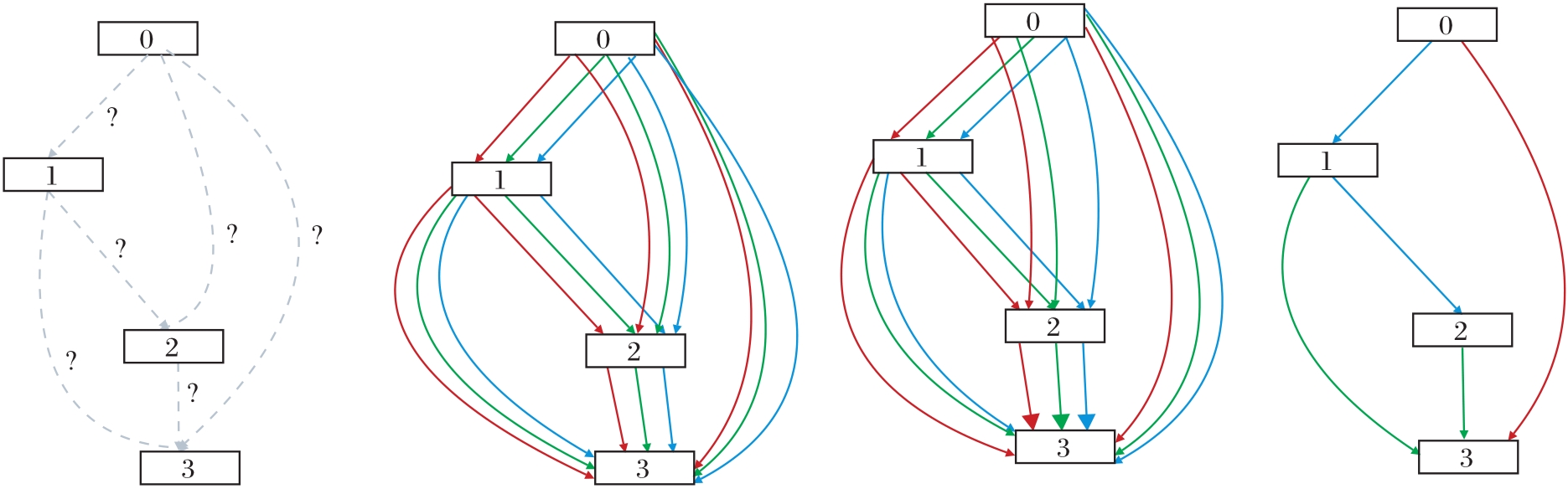
NASNet[1]是最早提出这类搜索空间的工作之一, 搜索两种Cell结构:Normal Cell和Reduction Cell.Normal Cell在保持空间分辨率不变的情况下提取高级特征, 而Reduction Cell主要降低空间分辨率.通过多次堆叠这两种Cell结构, 形成最终的网络结构.图1给出基于这两种Cell的神经网络结构及NASNet中最优Normal Cell的内部结构.
目前基于Cell的模块化搜索思想被广泛应用于NAS研究中.Liu等[19]提出DARTS(Differentiable Architecture Search), 以基于Cell结构的搜索空间为基础, 首次以可微分的方式定义NAS问题.此后, 涌现出许多DARTS的改进工作[20, 21, 22, 23, 24, 25, 26], 基于Cell的结构也成为NAS中搜索空间的主流设计之一.
总体上, 全局搜索空间中的链式结构直观简单, 可通过加深网络结构以提升网络性能, 多分支结构则通过拓宽网络宽度以探索多维度特征.基于Cell的结构融合链式结构和多分支结构的优点, 既可以通过堆叠更多数量的Cell结构以增加网络深度, 又可以通过增多Cell内部连接数量以扩大网络宽度.此外, 基于Cell的搜索空间只需要关注Cell的内部结构, 在缩小搜索空间的同时加快搜索速度.从可扩展性方面来说, 链式结构和多分支结构受限于卷积神经网络, 而基于Cell的结构不仅可扩展到循环神经网络中, 并且在搜索最优Cell结构后, 通过调整堆叠Cell的数量, 灵活控制神经网络的深度和复杂度, 适应不同的任务.
1.2 搜索策略
搜索策略旨在以搜索空间为基础探索其中可能的神经结构组合, 并试图找到最优网络模型.当前通用的搜索策略包括:基于强化学习(Reinforcement Learning, RL)的搜索策略、基于进化算法的搜索策略和基于梯度的搜索策略.
1.2.1 基于离散空间的搜索策略
在基于强化学习的NAS搜索策略中, 状态、动作、奖励分别表示当前搜索过程中已确定的网络结构、新的操作、新操作带来的增益.其中, 动作空间等同于搜索空间, 而奖励基于对未知数据的结构性能评估, 每个动作的奖励会决定是否在当前状态选择该动作.
Zoph等[27]结合强化学习方法与神经架构搜索, 利用循环神经网络作为控制器, 从搜索空间中进行采样, 并在搜索过程中利用RL方法优化各种参数.常用的强化学习算法主要有基于策略的算法和Q-Learning算法.
基于策略的算法的典型代表是Zoph等[1]提出的NASNet, 采用近端策略优化(Proximal Policy Optimization, PPO)代替强化学习方法进行神经结构学习, 提高搜索效率.使用Q-learning算法的典型代表是MetaQNN[10], 通过带有经验回放的Q-learning和ε -greedy贪婪搜索策略进行网络结构搜索.
总体上, 基于强化学习的NAS方法在自动化网络设计方面具有巨大潜力, 但仍然面临诸多挑战.由于搜索空间巨大, 执行搜索需要大量的计算成本, 在计算资源有限的环境应用上受到限制.此外, 强化学习代理在搜索过程中可能会陷入局部最优解, 需要一些启发式方法或改进的搜索策略解决此问题.
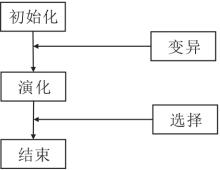
基于进化算法的NAS搜索策略的核心思想是基于进化算法演化网络结构中的权重、激活函数及超参数等组件.搜索策略框架如图2所示.每个网络结构作为进化算法中的种群个体.演化过程会选择每代产生的个体, 对优异个体进行突变、重组等操作, 从而产生下一代种群.不断重复这个过程直至产生性能最优的个体或达到最大演化数.目前, 进化算法中包括的遗传算法、进化策略、遗传编程和进化规划等均被研究人员扩展到神经架构搜索领域.
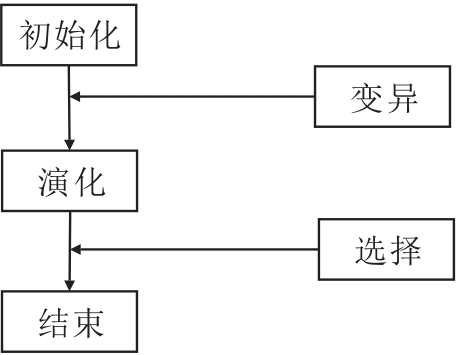 | 图2 基于进化算法的搜索策略框图Fig.2 Schematic diagram of search strategy based on evolutionary algorithm |
21世纪初, 研究人员的重点在于如何借助进化算法优化选定的网络结构中的权重.Stanley等[28]基于遗传算法设计出增强拓扑的神经进化网络, 从最基本的单元结构对网络结构进行演化, 同时优化网络权重[29].随着搜索空间的不断扩大, 基于进化算法的NAS搜索策略逐渐流行起来.Salimans等[30]验证进化算法可取代强化学习进行结构搜索.Real等[31]提出适用于大规模图像分类任务的进化算法, 在CIFAR-10、CIFAR-100数据集上达到与手工设计的网络模型相当的效果.此后, Real等[32]又对文献[31]算法进行改进, 提出适用于图像分类任务的AmoebaNet, 并在进化过程中引入Aging的概念, 使NAS搜索的网络结构性能首次超过手工设计的模型.
总之, 基于进化计算的NAS搜索策略通常维护一个多样性的网络种群, 采用多种策略, 实现种群变异, 有助于在搜索过程中充分探索网络结构, 防止陷入局部最优解.然而, 该策略搜索时仍需耗费大量的计算资源和时间, 尤其是在大规模数据和复杂任务上, 并且进化算法有时会陷入早熟收敛, 导致搜索停滞或过早收敛到次优解.如何保持网络结构的多样性和有效性、避免早熟收敛仍是一个挑战.
1.2.2 基于连续空间的搜索策略
基于强化学习和进化计算的神经架构搜索本质上是一类结构采样方法, 需要花费大量的计算资源和时间, 因此, 实用性和普及性在一定程度上受到影响.为此, 学者们开发基于可微分梯度的NAS方法.
Liu等[19]提出DARTS, 将离散、不可微分的搜索空间松弛为连续可微的, 并通过反向传播算法实现对网络结构参数和权重参数的同时优化.DARTS通过求解一个双层优化问题, 将混合操作的概率和网络权重进行联合优化, 以搜索到最优网络结构, 具体表示为
其中, Ltrain表示训练损失, Lval表示验证损失, α 表示架构参数, ω 表示网络权重参数.
DARTS搜索过程如图3所示, 搜索空间包含8种候选操作, 并使用Softmax对每条边上的候选操作进行加权.自DARTS问世后, 基于梯度优化的NAS成为主流算法, 但同时也有研究者们发现DARTS中存在一些需要改进优化的问题[22, 33, 34, 35, 36, 37, 38, 39, 40, 41].
针对DARTS中跳跃连接富集现象引起的性能不稳定问题, Chu等[20]提出在Cell中的每两个节点之间添加一个额外的跳跃连接操作, 打破跳跃连接在搜索过程中占据的主导地位, 大幅提升算法的鲁棒性.Li等[25]提出DLW-NAS(Differentiable Light-Weight NAS), 构建一个轻量级搜索空间, 并设计具有计算复杂度约束的可微NAS策略及基于最小生成树的神经结构优化方法.
为了减轻DARTS的计算负担, Wang等[42]提出FP-DARTS(Fast Parallel Differential Neural Archi- tecture Search), 基于两个缩减搜索空间构建一个两路并行的超网, 在大幅减少计算成本的情况下取得相当好的性能表现.为了加强搜索和评估之间的关联交互, Yu等[43]提出CDARTS(Cyclic DARTS), 将搜索和评估网络集成到一个统一的网络结构中, 并提出以周期循环的方式同时优化搜索网络和评估网络, 进一步提升可微分NAS的性能.Zhang等[44] 提出DATA(Differentiable Architecture Approximation), 利用模块化的网络组件搭建包含所有搜索空间的超网络, 并使用网络结构概率参数对各网络模块的概率进行建模, 从而对超网中的子网结构进行离散化采样与集成.
此外, 在可微分搜索的框架下, 研究者们提出多种优化策略, 如离散化采样、扩展搜索空间、双层搜索空间、架构高斯建模、硬件约束关联搜索、感受野搜索、循环可微结构搜索、架构增长与复用、面向三维点云的结构搜索、面向图神经网络的结构搜索等.相比传统NAS, 可微分神经架构搜索方法不需要在高维的离散结构空间中搜索, 而是在连续的参数空间中寻找最优结构, 减少搜索的计算开销, 能自动搜索目标任务的网络结构, 可适应不同数据分布和环境.
2 网络结构自适应方法
网络结构自适应方法是实现网络结构在开放环境感知任务及面对不同数据分布时进行网络结构自适应调整的关键所在, 通过搜索算法和指标函数的配合, 实现对网络结构的自动调整优化, 以适应不断变化的环境和需求.
2.1 基于轻量化NAS的网络结构自适应方法
轻量化网络结构设计的本质是在保持网络模型性能的同时减少参数量、降低计算复杂度和存储空间, 推动深度学习技术应用在计算资源受限的移动设备上.传统的手工轻量化网络结构设计方法存在严重依赖专家先验知识、设计空间受限、信息损失、优化难度和成本较高、迁移困难等无法避免的缺点, 并且缺乏通用性和可扩展性, 无法自动适应开放环境下不同的数据和任务.现有轻量化NAS工作主要从模型压缩和硬件感知两方面开展.
2.1.1 基于模型压缩的网络结构自适应方法
将神经架构搜索方法和模型压缩技术进行显式或隐式的集成, 可充分发挥各自优势, 实现自适应构建轻量化网络结构.基于模型压缩的轻量化神经架构搜索方法主要通过模型剪枝、知识蒸馏和参数量化实现在搜索过程中性能、效率和计算代价的平衡, 找到最佳的参数配置和网络组件, 从而完成网络结构自适应过程, 更好地适应各种应用场景和硬件设备.
在模型剪枝方面, Li等[45]提出PaS(Pruning-as-Search), 添加深度二进制卷积, 利用梯度下降直接学习剪枝策略, 结合结构重参数化, 成功搜索一组性能更优的轻量级网络.Zhang等[46]提出DSO-NAS(Direct Sparse Optimization NAS), 将模块化的网络结构连续化成超网络, 并在稀疏优化的框架下进行参数训练, 通过剪枝网络结构参数为零的分支生成网络结构.在知识蒸馏方面, Li等[47]使用分块搜索技术, 将原本端到端的网络搜索空间在深度上分块, 利用来自教师模型不同深度的监督信息, 实现对搜索空间独立分块的权重共享训练, 最后将所有块中的学生网络组合成一个完整的轻量级网络.在参数量化方面, Wang等[48]提出APQ, 使用量化感知的精度预测器加快搜索过程, 以较低的成本实现对模型结构、修剪和量化策略的端到端搜索, 显著提高通过量化策略搜索最佳网络结构的速度, 可在各种部署方案中自动调整结构.
基于模型压缩的网络结构自适应通过强大的自学习能力, 在较大的设计空间中联合优化所有模型参数, 允许网络在训练过程中动态调整结构, 适应不同的任务、硬件或资源约束.学习到的压缩策略明显优于人工设计的启发式策略和传统基于规则的策略, 能获得具有更快运行速度和更短延时的轻量级网络模型, 实时处理开放场景下的数据和任务, 对于在线学习、增量学习和分布式学习具有重大意义.
2.1.2 基于硬件感知的网络结构自适应方法
基于硬件感知的轻量化神经架构搜索方法可根据硬件设备的特性和要求, 自动搜索特定资源约束下性能最优、适应性更强的轻量化网络结构, 同时感知硬件环境的变化并进行动态调整, 实现基于硬件感知的网络结构自适应目标.
此类方法通常共同优化网络结构精度和硬件性能相关指标, 将网络结构自适应问题建模为多目标优化问题.FBNet (Facebook-Berkeley-Nets)系列算法[49, 50, 51]将网络结构的实际时延明确纳入优化目标内, 构建分层的轻量级搜索空间, 使用可微神经架构搜索策略快速、端到端地生成特定条件下的高性能轻量化网络.Tan等[52]提出MnasNet, 直接在移动设备上运行模型以衡量真实延迟, 并提出分解式层次搜索空间, 搜索到的网络在多个视觉任务上取得较优的性能和实时性.Yang等[53]提出NetAdapt, 在优化循环中包含直接度量, 以自动的方式渐进地简化预训练网络, 直到满足计算资源预算.Yü zü gü ler等[54]提出U-Boost NAS, 不仅提升任务的准确性、缩短推理延迟, 还提高资源利用率.
此外, 还有很多应用于现实资源有限场景的网络结构自适应方法, 可解决固定模型结构无法对网络进行自动优化和调整的问题.Yuan等[55]提出AGCNs(Adaptive Gabor Convolutional Networks), 使用Gabor滤波器自适应地调整卷积核, 其参数可自适应地更新以增强深度卷积神经网络的表达能力, 同时减少参数量.
总体上, 基于硬件感知的网络结构自适应能感知硬件环境变化, 自动执行网络结构自适应搜索优化.但现有大多数方法仍依赖硬件无关的度量或将操作延迟视为可微正则化损失, 简单地将硬件感知建模为多目标优化问题.然而, 多目标损失并不总是最佳选择.开发更智能准确的硬件感知算法, 可更好地理解和预测不同硬件平台的性能特性, 从而实现跨硬件平台的通用自动硬件感知搜索方法设计将是这一领域未来的研究重点.
2.2 面向学习任务的网络结构自适应方法
2.2.1 基于分类任务的自适应
当前, 图像分类任务是计算机视觉中基础的任务之一.相比目标检测和图像分割任务, 图像分类任务所需网络结构相对简单.因此, 绝大部分网络结构自适应方法均是针对分类任务而设计的.
特别地, 基于DARTS, Ye等[26]提出β -DARTS(DARTS with Beta-Decay Regularization), 使搜索到的网络结构参数值和方差不至于过大, 可稳定搜索过程, 在提高准确率的同时, 减少对训练时间和数据分布的依赖性.Wang等[42]将操作集分解为两个互不重叠的子集, 构建一个两路并行的超网络, 并引入二进制门, 控制超网络训练路径选择, 最终在ImageNet数据集上仅用2.44个GPU-days就实现23.7%的Top-1错误率.Zheng等[56]提出RMI-NAS, 使用表示互信息对网络结构进行排序, 从理论上保证搜索到网络结构的全局最优性, 在图像分类数据集上取得出色表现的同时显著提高搜索过程的速度.
总之, 针对分类任务的网络结构自适应方法相对较成熟, 并且在不断演进.未来研究将聚焦于搜索空间设计、硬件感知和轻量化、多模态任务学习等方面, 以应对深度学习在各应用领域中的挑战.
2.2.2 基于检测任务的自适应
近年来, 面向检测任务的网络结构自适应方法得到一定程度的发展.Chen等[57]在训练好的超网络中利用进化算法搜索网络结构路径, 并应用于目标检测任务之中.针对移动设备的目标检测模型设计中的不足, Xiong等[58]提出MobileDets, 使用全卷积层优化模型的性能, 通过自适应网络结构搜索得到一系列针对不同移动设备的目标检测模型.针对目标检测模型难以在移动芯片组上运行的问题, Yan等[59]提出LightTrack, 设计一个轻量级的搜索空间, 包含深度可分离卷积和移动反向瓶颈等低延迟的基本单元, 允许构建高效的跟踪检测架构, 平衡特征提取和目标定位两部分.针对无人机场景目标检测任务, Yao等[60]利用GhostShuffle单元构建轻量化的搜索空间, 借助自适应网络结构搜索得到最优的GSmodel-L作为骨干网络, 结合Ghost-PAN(Ghost-Path Aggregation Network)和检测头, 最终提出GSNet(GhostShuffleNet), 并将其部署在无人机嵌入式设备上, 实现对遥感图像的动态分析.
早期针对检测任务的网络结构自适应主要采用基于图像分类任务而设计的骨干网络, 检测与分类任务之间的差异导致模型特征提取能力有限, 因此性能较差.此后, 大量的研究工作开始尝试不使用代理直接搜索目标检测骨干网络, 然而仍需花费大量的计算资源及时间.如何在保证性能的前提下加速搜索仍是一个需要深入研究的难题.
2.2.3 基于分割任务的自适应
研究人员在近期的研究中提出多种有关基于分割任务的网络结构自适应的方法.Shaw等[61]提出针对密集语义分割任务进行的无代理硬件感知搜索, 设计由顺序倒置残差块构成的语义分割网络编码器的搜索空间, 将结构搜索视为在随机超网络中进行路径选择的问题, 通过自适应网络结构搜索替代结构迁移, 针对特定任务和特定计算平台, 动态设计网络结构.Zhang等[4]提出DCNAS(Densely Connected NAS), 使用可学习的权重将Cell之间连接起来, 引入一个密集连接的搜索空间.此外, 通过结合路径级和通道级采样策略, 设计一个融合模块和混合层, 提升图像分割的性能.在医学图像分割任务上, Peng等[62]提出HyperSegNAS, 利用输入图像和采样架构的元信息, 动态调整超网权重, 提高子网的学习效果.
针对分割任务中的感受野组合制定, Gao等[63]提出RF-Next(Next Generation Receptive Field Models), 在不同层设计不同膨胀率组合, 用于制定感受野, 将搜索过程分解为全局搜索和局部搜索, 并采用一种由粗到细的方式搜索最优感受野组合, 最终搜索得到的RF-Next能将感受野搜索插入各种模型中, 提高许多任务的性能, 如时间动作分割、目标检测、实例分割和语音合成.
分割任务对处理高分辨率图像有较高要求, 需要收集像素级别的信息, 因此大多数针对分割任务的网络结构自适应方法采用两级分层设计, 即只在内层的Cell级别进行自动搜索, 直接设计外层网络.这种方法在处理密集图像信息时需耗费大量计算资源, 性能表现不佳.如何为分割任务量身定制网络结构自适应搜索算法, 同时平衡计算资源与搜索效率将是未来的重点研究内容.
2.2.4 其它场景任务的自适应
除上述任务外, 针对其它场景任务, 研究人员也提出许多有效的网络结构自适应方法, 面对不同任务场景下的挑战.针对三维点云分析任务, Nie等[7]提出一种在点云上操作的可微卷积搜索范式Point-SeaConv, 建立一个联合可微优化框架, 搜索核心卷积和外部结构, 将网络结构自适应的工作从规则化的图像数据扩充到不规则的点云数据.针对三维人体姿态估计任务, 传统方法通常使用网络结构估计人体所有关键点的三维坐标, 忽略人体不同部位形状以及运动模式的差异性.为了缓解该问题, Chen等[6]提出基于神经网络结构搜索的单视角三维人体姿态估计方法, 将所有人体部位分为几组, 并为每组分配特定部位的神经网络结构.Thomas等[64]利用经典可微分神经架构搜索方法, 以较少的搜索时间代价自动生成最优的Transformer结构, 能检测和定位不同的电力系统故障和不确定条件, 如对称并联故障、不对称并联故障、高阻抗故障等问题.
2.3 连续学习条件下的网络结构自适应方法
连续学习是机器学习领域一个复杂且具有挑战性的问题, 要求模型或系统能够在连续的时间序列中不断接收和适应新的知识和任务, 同时保持已有知识的完整性.
与传统的离散学习不同, 连续学习强调模型的持续演化和适应能力, 能在接收到新数据时进行增量学习.模型需要不断积累新的知识, 同时保持之前学到的知识, 并避免忘记或丧失旧任务的能力.连续学习条件下的结构自适应研究着眼于开发强大的自适应算法, 使网络结构能应对连续学习条件下的非静态数据分布、遗忘问题、计算存储资源有限等特点, 从而适应不断变化的数据分布和任务, 实现更灵活、可持续的学习.
连续学习条件下的网络结构自适应方法提供一种在连续域中动态调整网络结构以适应新任务的机制, 而如何设计更强大的算法使自适应模型能够不断学习新场景和避免所谓的“ 遗忘问题” 是两大关键要素.为了应对上述挑战, Li等[65]提出Learn-to-Grow Framework, 分离模型结构的学习和模型参数的估计, 使用结构搜索为每个顺序任务找到最优结构, 解决灾难性遗忘问题.Tonioni等[66]对深度立体网络进行无监督和连续的在线自适应, 提出MADNet(Modularly Adaptive Network), 并开发一种模块化自适应算法, 在无监督的情况下能够自适应不可见的未知环境.Zhang等[67]提出RAG(Reusable Ar-chitecture Growth) Framework, 由特定任务的神经单元搜索和结构增长组成, 可在避免灾难性遗忘问题的情况下持续学习新场景, 同时表现出良好的神经单元可重用性.
连续学习条件下的网络结构自适应为现实场景持续变化的数据流和任务流提供强大的解决方案.这些方法的核心特性在于其能在网络结构层面上实现动态调整, 以适应新任务的出现, 同时保持对旧任务的性能, 更高效地找到适应性更强的结构及研究更有效的知识传输机制.
此类方法代表深度学习技术不断演进中的重要部分, 为多任务学习、在线学习及不断变化的开放环境应用提供有力工具.此外, 连续学习条件下的网络结构自适应是一个尚未得到充分研究的新兴领域, 有望为构建更灵活、更持久、更智能的机器学习系统提供重要支持, 能在不断变化的任务环境中取得出色表现.随着进一步的深入研究, 可期待看到更多实际应用, 从而更好应对不断变化的开放环境任务.
3 深度神经网络组件与结构的自适应评价指标
目前网络结构自适应主要聚焦于借助NAS实现网络结构的自动构建.神经架构搜索本质是高维空间的优化问题, 对搜索过程中的网络结构样本进行采样和有效性能评估是决定NAS搜索效率的关键因素.
3.1 现有网络组件与结构自主设计的性能评价指标
为了搜索到的网络结构样本, 建立一个快速的性能预测和推理开销估计方法体系是一项挑战性工作.其主要困难在于, 对每个采样到的结构, 需要通过充分的训练才能预知其性能, 并在此基础上为后续搜索提供指导.在NAS框架下, 这将消耗极大的算力和计算时间.因此, 为了提升NAS效率, 在模型性能评估过程中, 对采样结构的性能进行相对排序是一个避免大量计算的替代方法.
综合分析现有网络结构自适应相关文献, 将现有优化评价度量分为3类, 建立起现有神经网络组件与结构的评价指标体系.
1)基于验证集表现驱动.特点是:1)评估采样结构在验证集上的表现, 以准确率(Accuracy, Acc)、mAP(Mean Average Precision)、IoU(Intersection over Union)等通用指标排名作为选择依据.2)考虑目标终端软硬件平台的资源约束, 设计问题建模为多目标搜索优化.代表性工作有:FBNets[49]、FB-NetV2[50]、FBNetV3[51]、 MnasNet[52]、 NetAdapt[53]、U-Boost NAS[54]、EfficientNet[68]、Single-Path NAS[69]、SNAS(Stochastic Neural Architecture Search)[70]、DPP-Net(Device-Aware Progressive Search for Pa-reto-Optimal Neural Architectures)[71].
无论是早期将结构选择视为一个顺序决策或遗传进化过程的黑盒离散优化方法[1, 27, 31, 32], 还是使用更高效的性能评估策略预测自适应网络结构性能表现的现代NAS[19, 21, 24, 72, 73, 74, 75, 76, 77, 78, 79, 80], 这类方法的优化目标本质上始终为验证集性能驱动的网络结构优化问题.
此外, 轻量化NAS往往需要考虑开放环境和现实场景中的应用.因此, 轻量化NAS通常将目标终端软硬件平台的资源约束信息纳入评价指标内, 将网络结构自适应设计问题建模为多目标规划问题[49, 50, 51, 53, 54].
2)基于实际泛化性能驱动.特点是:基于收敛速度或损失曲线的平坦度, 提出新的代理指标以准确评估结构样本的泛化性能, 找到在异构数据和跨任务泛化最好的结构, 可与传统结构评分测量集成.代表性工作有, R-DARTS(RobustDARTS)[35]、RLNAS(Random Label NAS)[81]、ABS(Angle-Based Search Space Shrinking)[82]、GeNAS(Generalization-Aware NAS)[83]、SDARTS(Perturbation-Based Regulariza-tion-Smooth DARTS)[84]、Generalization Guarantees for NAS[85].
现有NAS大多直接使用验证数据集上的精度或负损失值为度量函数, 作为可泛化性的代理度量[19, 73].此类方法仅能发现在验证集上表现最佳的结构, 在异构数据集和新任务上均表现出较差的泛化性, 即会产生“ 验证集上的过拟合” 现象.此外, 该类评估方法在NAS基准数据集上的验证精度与真实测试精度之间存在较大差异[35, 82, 83].其核心是:在结构搜索过程中, 重新探索能实际反映候选结构泛化性能的评估方法, 希望在偏移数据分布上找到具有低泛化误差的鲁棒网络结构.
另外一些工作基于收敛速度与泛化性能之间的经验联系, 使用指示收敛速度的指标作为搜索过程中的代理性能度量[81, 82]; 或基于损失曲线的平坦度, 在搜索过程中准确区分结构样本的泛化性能[35, 83, 84].
3)基于Zero-Cost代理指标驱动.不同于传统性能评估方法, 基于Zero-Cost NAS是一个用于NAS的快速性能评估器, 从各自不同的角度出发, 提出各种通用评估指标直接对未训练或仅部分的训练网络进行评分, 并与它们的最终性能建立高度相关性, 实现快速筛选.Zero-Cost NAS引入指标往往没有显式的训练或反复的调参过程, 而是从深层理论挖掘神经网络的结构信息, 仅使用小批量数据即可在初始化时评估网络结构样本的性能.
众多现有Zero-Cost代理评估指标的分析可归纳成3类.
(1)基于深度学习理论的Zero-Cost代理评估指标.依靠深度学习理论的最新进展, 对未训练或仅部分训练的网络结构进行评分并与它们的最终性能建立相关性.目前最具代表性的是依据神经切线核和线性区域分析提出的各种度量指标, 它们互相解耦并能有效地表征复杂NAS搜索空间中网络结构样本的可训练性和表达能力.代表性工作有:LGA(La-bel-Gradient Alignment)[86]、TE-NAS(Training-Free NAS)[87]、NASWOT(NAS without Training)[88].
(2)基于梯度信息的Zero-Cost代理评估指标.通过在初始化时利用网络的梯度信息预测推断网络结构样本的性能表现.通常将小批量样本梯度作为输入, 在随机初始化点评估, 输出网络结构的相关统计信息, 并与其在整个数据集上的真实预测性能高度相关.代表性工作有:SNIP(Single-Shot Network Pruning)[89]、GraSP(Gradient Signal Preservation)[90]、SynFlow(Iterative Synaptic Flow Pruning)[91]、Grad-Sign[92].
(3)基于性能表征的Zero-Cost代理评估指标[90].研究者通过强大的先验知识和深入的知识迁移, 提出各种反映网络结构性能表现的通用评估指标, 直接评估网络模型, 实现快速筛选.指标的巧妙设计使评分排名与最终性能表现极具相关性, 并且可直接集成到各种NAS中, 形成新的框架, 指导网络结构搜索过程, 实现对搜索空间的探索.代表性工作有:RMI-NAS[56]、EPE-NAS[93].
3.2 面向开放环境应用的深度神经网络组件与结构的评价指标体系
在3.1节中, 本文将传统NAS性能评价指标和最新NAS性能评价指标按照其优化目标进行归类.尽管先前众多工作促进各种任务的实质性改进, 但仍难于进行不同评估方法之间的对比.本节进一步在分别具象化的基础上对其进行抽象性统一, 将各类评价指标统一为同级比较层次, 从而表明来自不同类别的评价度量是互补的, 可结合后进一步提高网络结构搜索的精度和效率, 即结合这些不同角度的评价指标方法, 从而获得对结构样本的评估和筛选更好的预测能力.为此, 本文建立一套面向开放环境应用的深度神经网络组件与结构的评价指标体系.
对于以验证集精度驱动且具有计算资源约束的结构样本评估.给定结构样本α , P(α )表示候选结构在目标任务上的验证性能, 因具体任务而异.在分类任务中, P(α )可为Acc或Cross-Entropy Loss, 表示模型在验证集上正确分类的样本比例或度量模型预测概率分布与实际概率分布之间的差异.在回归任务中, P(α )可为Mean-Square Error, 衡量模型预测与实际值之间的平均平方差.而针对目标检测、目标分割或语音识别任务, P(α )对应特定的性能指标, 如mAP、IoU、F1-score、Word Error Rate等.T(α )表示结构在目标终端平台上的资源占用及耗费, 具体可为推理时延、内存占用、计算量、参数量、功率能耗、实际利用率等.T表示目标资源约束信息, 即允许的最大资源占用上限.该类NAS优化问题以T为实际环境感知, 以探知模型性能上限为优化目标, 显式建模为Multi-objective搜索问题:
因此, 将该类以验证集性能驱动的评估指标进行抽象化, 统称为性能上限平衡得分:
F(score)=P(α )β [lg(
在具体应用中, F(score)可为任何反映网络结构最终性能的表示度量, β 和γ 为控制幅值超参, 可灵活调整.在具体操作中, 通常采用交叉验证方法, 减小随机性带来的误差, 并提供更可靠的性能估计.
现代NAS从各种不同角度改进原始评估策略, 但其优化目标本质仍为最大化设计空间结构样本的F(score), 旨在发现验证集表现性能最优且具有最低资源消耗成本的网络结构, 实现搜索过程中多方面的最佳平衡.值得指出的是, 当在训练结束或用户能承担起一定的训练成本以充分训练模型时, 验证集精度始终是评估深度神经网络自适应组件与结构真实测试性能的“ 金标准” .
对于以泛化性能驱动的结构样本评估, 此类方法基于收敛速度或损失图的平坦度与泛化性能之间的密切联系, 通过找到最佳代理测量以量化网络结构样本的泛化性能, 筛选搜索过程中更具泛化性的结构.
因此, 将该类以泛化性能驱动的评估指标进行抽象化统称为泛化区分性得分G(score).该类指标的度量通常与结构的泛化性能之间具有明确的实证研究或理论证明, 从而挖掘在偏移数据分布和下游任务上具有低泛化误差的鲁棒网络结构.G(score)还可与其它先进的搜索方法集成, 用于搜索泛化性能更高的网络体系结构, 提高模型的性能和通用性.以G(score)作为评价指标的搜索算法目标为最大化搜索空间中网络结构样本的
G(score)=Θ -1,
其中Θ -1为衡量网络结构泛化能力的可靠代理.最具代表性的即为基于损失函数平坦度的搜索方法.损失函数的平坦度可通过对网络参数的Hessian矩阵进行分析或直接对参数组添加随机扰动噪声进行验证等相关方法估计.平坦的损失函数表示在某一结构点附近微小的结构变化不会引起显著的损失值变化.此外, 为了进一步保证最终结果的验证准确性, 此类评估方法通常与基于验证集表现驱动的第1类指标进行组合度量.
对于结构样本快速评估的通用Zero-Cost代理, 该类方法为了减少对超网训练的资源消耗, 在超网初始化后, 无需多次重复的训练过程, 即可对子网进行性能评估度量.引入各种反映性能表现的评估指标, 直接对没有训练过或仅少量训练的结构进行评分, 并且相应的评估得分与结构样本的真实性能排序之间具有很强的正相关性.
因此, 将所有Zero-Cost代理度量指标进行抽象化, 统称为网络结构样本表达的显著区分性得分M(score), 目标为最大化网络结构样本的
M(score)=lg|D|,
其中D即为具体的相关性度量指标.
具有代表性的度量指标如下:
1)SNIP,
Sp(θ )= |
2)GraSP,
Sp(θ )=-(H
3)SynFlow,
Sp(θ )=
其中, L表示参数为θ 的神经网络损失函数, H表示Hessian矩阵, Sp(· )表示每个参数的显著度, ☉表示Hadamard乘积.
SNIP指标基于使用单个小批量数据在初始化时计算的显著性度量执行参数修剪, 近似于移除特定参数损失函数的变化.GraSP指标将SNIP指标中损失变化近似为梯度范数的变化.SynFlow指标使用SynFlow计算损失, 该损失仅仅是网络中所有参数的乘积, 能在执行参数修剪时避免层崩溃.在实际操作中, 通过对模型所有参数N求和, 扩展这些显著性度量指标作为模型性能预测器, 则整个神经网络评分
$S_{n}=\sum_{i=1}^{N} S_{p}(\theta)_{i} .$
一个精心设计的优秀评估指标有助于预测网络结构之间的相对性能排名, 并且可对各种搜索空间和数据集均有效.此外, Zero-Cost NAS往往正交于各种NAS, 可直接与现有搜索算法集成, 形成新的框架, 指导搜索算法对庞大搜索空间的有效探索.当然, 显著区分性得分D也可作为损失函数与通用损失一起联合优化.
上述分析表明来自不同类别的性能评价指标之间是互补的, 可结合后实现对网络结构更全面的评估, 并进一步使搜索的结构获得预测增益.为此, 本文提出一套面向开放环境应用的深度神经网络组件与结构的评价指标:
Z=λ F(score)+μ G(score)+ν M(score),
其中, 每个单独的评价度量指标无法准确且综合评价潜在网络结构样本的实际表现能力.该指标体系可根据开放环境场景中不同的任务和数据集自适应调整网络结构.F(score) 根据具体任务选择特定的性能指标作为算法优化目标, 保证网络结构样本的验证表现性能和所需计算资源成本.G(score)基于理论实证的可靠代理评估, 保证网络结构样本在实际异构数据和跨任务的实际泛化性能.M(score)通过可高度表征模型性能的性能预测器, 进一步保证网络结构样本的相对性能排序的公平性, 实现快速筛选.λ 、 μ 、 ν 为平衡因子, 需要根据开放环境中实际评估的侧重与需要合理规划选择, 既可将其视为超参的手动定义, 也可纳入搜索过程进行自动化搜索.例如:将这些平衡因子相应绘制为表达树, 利用自适应进化算法搜索最好的平衡选择.λ 、 μ 、 ν 的取值范围为[0, 1], 在实际应用中当无需考虑某一表现度量时, 三者可任意为0, 但三者不可同时为0.
4 注意力引导的渐进式可微神经架构搜索方法
针对开放环境下的自适应感知任务, 本文提出注意力引导的渐进式可微神经架构搜索方法(Pro-gressively Attentional Architecture Search, PAAS), 采用注意力引导的渐进式可微神经架构搜索策略, 能在进行高效网络搜索的同时, 根据不同任务场景动态调整、优化网络结构.
4.1 方法介绍
针对大多数可微分架构搜索方法中网络结构在搜索和评估过程中存在极大的不一致性问题, 本文提出PAAS, 通过注意力引导的微观架构自适应机制, 在优化过程中实现网络结构的自适应调整优化, 从而更好地拟合评估网络.在此基础上, 提出一种渐进式离散策略, 通过嵌入的注意力引导模块和结构参数的联合作用共同决定离散化结果, 这种根据优化进程逐步执行离散化的方式有效弥合搜索和评估阶段的结构差距, 在减少计算资源的同时搜索到高性能的网络结构.
在PAAS中, 构建一种包含多种高性能候选操作的基于Cell的搜索空间, 并从性能、参数量、唯一性等因素综合考虑, 对候选操作的选取进行充分研究和探索.
首先, 限制卷积和池化操作的感受野大小为3× 3, 通过堆叠3× 3的卷积核能以较小的参数量实现与大卷积核类似的效果.同时, 针对一些输出特征图高度线性相关的操作进行筛选, 仅保留存在多重共线性操作中的一个操作.最后, 引入新颖高效的候选操作, 从神经架构搜索的源头为自动构建高性能神经网络提供保障.
其次, 本文提出注意力引导的结构自适应搜索范式.当前大多数可微分神经架构搜索方法在计算Cell中节点的输出时, 仅将该节点各条输入边的信息流直接相加求和, 整个搜索过程并未区分节点之间信息流的贡献度.因此, 本文提出一种注意力引导的微观架构自适应机制, 与人脑如何选择性地关注输入的某些部分类似, 注意力机制可用于强调网络中的有用部分, 同时忽略不太重要的部分.PAAS通过嵌入注意力模块以显式建模所有输入信息流的贡献, 从而指导搜索过程中边的动态选择, 实现Cell结构的自适应进化.
在此基础上, 进一步引入一种渐进式离散策略, 在搜索过程中以循序渐进的方式逐步离散化Cell结构, 基于不断积累的经验和评估结果指导后续轮次的搜索.在优化过程中, 通过注意力权重指导的输入信息流的贡献度和结构参数指示的候选操作的重要性共同决定离散化结果.
总之, PAAS在进行网络结构确定时, 不仅采用基于注意力机制引导的自适应搜索范式以区分Cell结构中每条边对当前节点的贡献度大小, 而且引入一种渐进式离散网络结构的方法, 大幅提升网络结构自适应的精度和效率.
4.2 性能表现
为了验证PAAS的有效性, 在图像识别、目标检测、图像分割这3种视觉感知任务上进行实验.选择NASNet[1]、Inception-v1[14]、PC-DARTS(Partially-Connected DARTS)[22]、SSD(Single Shot MultiBox Detector)[94]、RefineNet(Multi-path Refinement Net-work)[95]作为基准模型.
遵循实验设置, 将主干网络替换为PAAS搜索到的网络结构, 从而得到PAAS在图像识别、目标检测及语义分割任务上的性能表现.
针对目标图像识别任务, 在ImageNet数据集上进行对比实验, 评价指标为Top-1准确率.针对目标检测识别和目标语义分割任务, 在COCO数据集上进行对比实验, 评价指标分别为mAP和IoU, 具体结果如表1~表3所示.由表可见, PAAS在大幅降低参数量和计算量的同时, 能针对不同任务场景的需求, 实现高效的网络结构自适应.
| 表1 各方法在目标图像识别任务上的性能对比 Table 1 Performance comparison of different methods on target image recognition task |
| 表2 各方法在目标检测识别任务上的性能对比 Table 2 Performance comparison of different methods on target detection and recognition task |
| 表3 各方法在目标语义分割任务上的性能对比 Table 3 Performance comparison of different methods on target semantic segmentation task |
5 结束语
5.1 网络结构自适应挑战性问题
网络结构自适应是深度学习领域中备受关注的研究内容, 旨在通过自动调整网络结构提高网络模型在不同任务场景下的性能表现和泛化能力.然而, 网络结构自适应领域的研究仍面临一些问题和挑战.
1)计算资源需求.网络结构自适应方法通常需要在庞大的高维搜索空间中进行搜索, 找出最佳的网络结构或参数配置.这种搜索过程会导致昂贵的计算资源和内存需求, 包括高性能GPU、大规模内存和大量的训练时间, 限制相关方法的可扩展性.
2)评价标准不一致.目前, 网络结构自适应仍然缺乏一种通用的准则或评价标准以指导网络结构的搜索、评估和优化等过程.每个任务可能需要不同的指标和评价方法, 使方法的对比和选择变得十分复杂.
3)泛化性能不佳.网络结构自适应方法需要确保找到的网络结构不仅在训练集上表现良好, 还能在未见过的数据上泛化良好.这涉及到一个重要的平衡问题:如何在任务自适应过程中平衡模型的性能和复杂度.如果模型过于复杂, 容易过拟合数据; 如果模型过于简单, 无法捕获任务的复杂特征.因此, 需要研究如何有效控制模型复杂度, 避免资源的浪费和过拟合问题.
4)迁移学习挑战.网络结构自适应在迁移学习领域中也面临挑战.将在一个任务上学到的结构迁移到另一个任务上可能会涉及域适应和知识传递等问题.如何在不同领域或任务之间有效共享和迁移结构知识, 仍是一个具有挑战性的研究方向.
5.2 未来研究方向
尽管神经架构搜索研究取得极大进展, 但仍存在大量亟待解决的问题.
1)自适应搜索空间.目前的搜索空间基于人类先验知识且大多使用同构的Cell进行堆叠, 能实现不同深度Cell异构的搜索空间很少, 未实现真正意义上的“ 自动化设计” , 搜索空间上的局限性限制搜索策略充分发挥其搜索能力, 使NAS的性能无法获得本质性的进步.因此, 如何设计更通用、灵活和以任务需求为导向的自适应搜索空间是值得考虑的一个研究重点.
2)可解释性.神经架构搜索通常涉及大量的参数和计算, 因此很难对为什么最终选择的结构会产生特定结果加以解释.搜索过程和结果是无法解释的, 导致哪些参数对结果产生影响, 哪些结构更适合任务同样是无法解释的.因此, 未来的研究需要关注NAS的可解释性, 开发能揭示搜索过程和结果背后原因的方法, 从而更好地理解神经架构搜索的工作机制.
3)寻找合适基线.尽管随机搜索已被证明在NAS领域是一个强有力的基线, 但是对基线的研究仍然不够充分.为了更好地评估NAS的性能, 需要进行更多的消融实验, 深入研究哪些参数设置或网络组件可带来模型性能的提升.研究人员应对神经架构搜索导致性能提升的部分投入更多的精力研究, 而不仅仅依赖通过堆叠更多层以提高性能, 因此相关的理论分析也是神经架构搜索未来一个重要的研究方向.
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|
| [47] |
|
| [48] |
|
| [49] |
|
| [50] |
|
| [51] |
|
| [52] |
|
| [53] |
|
| [54] |
|
| [55] |
|
| [56] |
|
| [57] |
|
| [58] |
|
| [59] |
|
| [60] |
|
| [61] |
|
| [62] |
|
| [63] |
|
| [64] |
|
| [65] |
|
| [66] |
|
| [67] |
|
| [68] |
|
| [69] |
|
| [70] |
|
| [71] |
|
| [72] |
|
| [73] |
|
| [74] |
|
| [75] |
|
| [76] |
|
| [77] |
|
| [78] |
|
| [79] |
|
| [80] |
|
| [81] |
|
| [82] |
|
| [83] |
|
| [84] |
|
| [85] |
|
| [86] |
|
| [87] |
|
| [88] |
|
| [89] |
|
| [90] |
|
| [91] |
|
| [92] |
|
| [93] |
|
| [94] |
|
| [95] |
|