
{kind=link}
{kind=link}
{kind=link}
{kind=link}
属性知识引导的自适应视觉感知与结构理解研究进展
[张知诚1  , 杨巨峰
, 杨巨峰1 1 , 林巍峣2 , 汤进3 , 李成龙3 , 刘成林4 ]
, 杨巨峰, 程明明, 林巍峣, 汤进, 李成龙, 刘成林]
|
|



作者简介:






机器通过自适应感知从环境中提取人类可理解的信息,从而在开放场景中构建类人智能.因属性知识具有类别无关的特性,以其为基础构建的感知模型与算法引起广泛关注.文中首先介绍属性知识引导的自适应视觉感知与结构理解的相关任务,分析其适用场景.然后,总结四个关键方面的代表性工作.1)视觉基元属性知识提取方法,涵盖底层几何属性和高层认知属性;2)属性知识引导的弱监督视觉感知,包括数据标签受限情况下的弱监督学习与无监督学习;3)图像无监督自主学习,包括自监督对比学习和无监督共性学习;4)场景图像结构化表示和理解及其应用.最后,讨论目前研究存在的不足,分析有价值的潜在研究方向,如大规模多属性基准数据集构建、多模态属性知识提取、属性知识感知模型场景泛化、轻量级属性知识引导的模型开发、场景图像表示的实际应用等.
, YANG Jufeng, CHENG Mingming, LIN Weiyao, TANG Jin, LI Chenglong, LIU Chenglin
Corresponding author:
YANG Jufeng, Ph.D., professor. His research interests include computer vision.
About Author:
ZHANG Zhicheng, Ph.D. candidate. His research interests include computer vision.
CHENG Mingming, Ph.D., professor. His research interests include computer vision.
LIN Weiyao, Ph.D., professor. His research interests include computer vision.
Machines extract human-understandable information from the environment via adaptive perception to build intelligent system in open-world scenarios. Derived from the class-agnostic characteristics of attribute knowledge, attribution-guided perception methods and models are established and widely studied. In this paper, the tasks involved in attribution-guided adaptive visual perception and structure understanding are firstly introduced, and their applicable scenarios are analyzed. The representative research on four key aspects is summarized. Basic visual attribute knowledge extraction methods cover low-level geometric attributes and high-level cognitive attributes. Attribute knowledge-guided weakly-supervised visual perception includes weakly supervised learning and unsupervised learning under data label restrictions. Image self-supervised learning covers self-supervise contrastive learning and unsupervised commonality learning. Structured representation and understanding of scene images and their applications are introduced as well. Finally, challenges and potential research directions are discussed, such as the construction of large-scale benchmark datasets with multiple attributes, multi-modal attribute knowledge extraction, scene generalization of attribute knowledge perception models, the development of lightweight attribute knowledge-guided models and the practical applications of scene image representation.
机器感知的本质是从传感器捕获的数据中提取智能系统可理解的信息, 包括场景[1]、物体[2]、行为[3]、关系[4]、时间[5]等, 为智能系统做出决策提供判据, 是智能化的重要技术支撑[6, 7].深度学习的发展推动模式识别和智能感知算法取得长足进步[8].然而, 开放环境下的自适应感知仍面临新的挑战, 包括感知对象类别集变化、数据分布变化与数据噪声、模态异质性的干扰等, 因而需要感知模型和算法具有对领域变化的自适应性、对噪声与异常数据的鲁棒性、对感知结果的可解释性[9, 10, 11, 12].
构建鲁棒、可解释、自适应的感知模型面临如下困难.
1)开放场景中的某些类别样本量较少, 依赖大量数据的训练框架难以获得小样本泛化能力[13].不同类别数据的样本量差距可达百倍以上, 且开放环境中不仅有数据集所含的常见类别, 还有面向特定应用场景的少见类别, 如工业车间中的元器件、教学场景中的工具等.
2)数据质量不一, 存在噪声和异常, 造成现有模型的稳定性与鲁棒性较差[14].开放环境中获取的图像视频数据通常包含大量噪声, 既有视觉内容因低质、干扰等因素自己携带的噪声, 也有因数据来源繁杂或搜集过程困难造成的很多标签噪声.
3)数据分布不受限制, 模型难以适配数据分布与标注类别变化的情况[15].数据集上的训练样本难以覆盖所有属性的样本, 当同一类别的数据样本存在较大的分布差异时, 算法难以准确感知.同时, 当类别分布发生变化, 如新增类别时, 算法无法进行相应的迁移调整.
4)现有深度模型大部分属于黑盒模型, 难以解释开放场景下的感知过程和结果[16].深度神经网络由数千个神经元组成, 这些神经元以一种分散的方式共同工作以解决问题.每个神经元可能对提取的某些特征进行编码, 但这些编码往往缺乏物理含义, 因此难以被人类理解.
针对上述挑战, 学者们分别从感知模型结构设计、特征提取、学习算法、知识表示和推理等不同角度提出解决办法.相关的研究工作包括可解释深度神经网络[17]、小样本学习[13]、场景图生成[18]等.神经科学研究表明, 采用对不同场景和目标具有通用性且符合人类视觉机理的基元属性作为特征, 有利于提升感知模型的泛化性、可解释性、自适应性和鲁棒性[19, 20, 21, 22].场景结构理解也依赖具有通用性和鲁棒性的基元属性知识.因此, 本文聚焦基元属性知识引导的自适应感知和结构理解, 汇聚相关的研究问题, 评述最新研究进展.
属性知识引导的自适应感知与结构理解任务主要包括如下方面.
1)任务类别无关的视觉基元属性感知.通过模拟人类感知机制, 算法从图像中提取任务类别无关的视觉基元属性, 包括视觉结构的几何基元(如角点、线段、边缘、平面、显著区域等)和视觉图像的认知属性(如情感、复杂度、记忆性、图像质量、图像美学等).这些基元属性可作为后续步骤的输入, 用于场景理解和识别.
2)属性知识引导的弱监督视觉感知.基于提取的属性知识, 指导模型从弱标注数据中学习模型结构和参数, 完成视觉对象的识别、检测、分割和定位.例如:可以使用语义标签、场景描述等信息辅助图像分类、目标检测和分割模型的学习.
3)图像无监督自主学习.利用海量的无标签数据, 挖掘数据中的潜在结构和规律, 让模型借助提取的知识完成自主学习.然而开放环境中的数据通常包含大量噪声且数据质量不同, 由此引入新的挑战.
4)场景图像的结构化表示和理解.基于从图像中提取的基元属性, 得以训练并辅助模型提取更高级别的结构化表示, 如场景图、语义网格等.这些表示帮助算法更好地理解图像中的语义信息和空间关系, 从而实现更准确和全面的场景理解.
本文回顾属性知识引导的自适应感知与结构理解的研究进展, 总结4个关键任务的发展历程及其在开放场景自适应感知领域的代表性工作, 分析不同方法的特点和适用条件.最后, 总结全文并展望未来值得探索的方向.
目前针对视觉感知与结构理解中的各个感知任务已有充分的综述工作, 这些综述在弱监督感知、无监督学习与自监督学习等领域中进行大量的调研整理工作.尽管研究任务相同, 但本文基于属性引导的研究工作与它们具有显著差异, 尤其是本文提供一种新的视角(属性知识)实现自适应的感知方法, 涵盖从底层到高层属性知识的提取、标签不足与缺失时的模型、算法与学习范式的设计以及面向开放环境场景图像的算法应用.并且现有综述多针对单一自适应视觉感知与结构理解任务, 而本文回顾属性知识应用的多个感知任务, 提供更全面的视角.
视觉基元属性感知可追溯到20世纪80年代初, Fukushima[23]提出神经认知机(Neocognitron), 模拟人类视觉感知系统的一些基本特性.
视觉基元属性感知领域早期的研究主要集中在边缘、角点等基本图像特征的检测和描述上.随着计算机技术和算法的发展, 人们开始研究更复杂的几何基元, 如线段、曲线、平面等, 进而关注图像的高层属性, 如物体类别、场景类型、情感等.这些属性通常是由多个基本特征组合而成, 因此需要进行更高级别的特征提取和分析.
基元属性广泛存在于视觉数据中, 有助于完成很多不同的图像分析和理解任务.
现有各种基元属性的定义如表1所示.各种基元属性的示例样本如图1所示.
| 表1 视觉基元属性的定义 Table 1 Definition of visual primitive attribution |
 | 图1 视觉基元属性示例Fig.1 Examples of visual primitive attribution |
关键点作为视觉基元属性, 在计算机视觉和图像处理领域得到广泛应用, 包括图像拼接、目标跟踪、三维重建等.Lowe等[24, 25]提出SIFT(Scale Inva-riant Feature Transform), 可在不同尺度下检测到图像中的特征点, 这些特征点具有旋转、尺度和光照不变性.
随着深度学习的发展, 大量工作采用数据驱动的方式提取关键点, 大幅提升关键点提取的精确性.DeTone等[26]提出SuperPoint(Self-Supervised Interest Point Detection), 在合成图像数据集与真实图像数据集上进行联合自监督训练, 具有跨域检测上的泛化性.Liu等[27]提出GIFT(Group Invariant Feature Transform), 考虑特征点在多个视角上的一致性, 设计组卷积神经网络提取特征, 并进一步通过群线性池化融合这些特征.
在现实场景中, 关键点涉及的任务类别广泛, 如人的身体部件、物体的角点等.近年来, 一些工作利用提取得到的关键点, 指导完成特定任务.基于提取到的特征点, Lin等[28]提出用于无损关键点视频序列压缩的方法, 消除视频中关键点的时空冗余以实现压缩, 关键点序列的范围涵盖2D边界框、人体骨架、3D边界框和面部特征点.该无损压缩方法可保持数据的完整性, 确保在后续的视频分析任务中准确可靠.
在图像中, 直线线段是一种有用的中间层表示, 在人类视觉由底层到高层进行语义信息转换时发挥重要作用.Hough变换[29]是具有代表性的方法之一.根据截距和斜率进行参数化, 图像中的直线被转化为Hough空间中横坐标为截距、纵坐标为斜率的参数点, 此时直线检测等价变换为点检测的问题.
近年来, 一些方法通过训练卷积神经网络以检测图像中的直线.PPGNet[30]提取直线的关键点信息, 采用图结构描述连接点、直线段以及它们的关联关系.不同于参数空间变换, PPGNet利用CNN(Convolutional Neural Network)直接从图像推理得到图结构, 从而获得直线和端点的结构化信息.Xue等[31]进一步利用图像的区域划分图指导直线的检测和提取, 首先将每个像素分配给对应的一个线段, 构建区域划分图, 再通过其相对于线段的二维投影向量对区域中的每个像素进行编码.最终, 压缩编码后的区域, 得到预测的线段图.
不同于物体中存在的线结构, 自然图像中的“ 语义线” 是指能勾勒图像内容结构的直线, 如不同区域的分割线、建筑物的中轴线等.语义线检测在摄影构图、图像处理等下游任务中具有广泛应用.例如:将图像中的语义线置于照片的黄金分割位置, 有助于拍出视觉效果更好的图像.
Lee等[32]首次使用CNN提取线条的候选集合, 将语义线识别视作目标检测问题的特例, 沿整条直线对特征进行双线性插值.然后类似于Faster-R-CNN(Faster Region-CNN), 通过分类器和回归器验证线条表示.Han等[33]从Hough变换的角度将语义线提取视作线条提取问题, 遍历图像中所有可能的直线, 沿直线将特征聚合到参数空间中对应的点上, 语义线估计因此转换为参数域中的点检测问题, 获得更高的检测效率.Zhao等[34]进一步提出边缘信息指导的修正模块, 将空间域与参数域的直线进行对齐, 获取精确的直线估计.
边缘提取算法的基本思想是通过对图像进行滤波、梯度计算等操作, 找到像素值变化较大的区域, 从而得到物体的边缘轮廓.最具代表性的Sobel类离散差分算子[35]计算图像亮度函数的梯度近似值.在图像的任何一点使用此算子, 将会产生对应的梯度向量或是其范数.
Soria等[36]提出DexiNed(Dense Extreme Inception Network for Edge Detection), 基于视觉特征解耦的假说, 即边缘、轮廓与边界是三个不同的视觉特征, 分开进行基准数据集的评估.为此, 该工作提出一个新的边缘数据集, 并展示DexiNed在该数据集上的表现.DexiNed不需要预先训练的权重, 也无需基于目标识别的预训练.
场景中的平面区域为基于视觉的很多应用提供重要信息, 包括立体视觉与机器人视觉等.平面区域检测旨在使机器可以像人类一样具有理解高层场景结构的感知能力.在从单个图像中提取所有平面后, 人们可选择他们感兴趣的平面, 并基于这些平面区域设计有效且有吸引力的应用程序.例如:可使用喜爱的纹理装饰墙壁; 广告商可在宣传视频中充分利用信息稀疏的区域(如桌子、墙壁和木板), 更有效地营销他们的产品.此外, 平面特征也是自主机器人感知周围环境和通过相机视图构建地图的关键线索.
随着深度神经网络的兴起, 平面区域分析逐渐演化为平面分割、平面重建、平面跟踪等若干子任务.Liu等[37]提出PlaneNet, 基于CNN的端到端架构检测平面区域.作者将这项任务考虑为像素分割问题, 因此只能检测固定数量的平面.
为了解决平面数量受限的问题, Liu等[38]利用Mask R-CNN生成任意数量的平面, 设计精炼模块, 同时集成所有平面的特征, 进一步对预测结果进行细化处理.
为了提升图像对间的平面搜索能力, Wang等[39]提出Gracker(Graph-Based Tracker), 将问题建模为图像对之间的图匹配问题, 在参考帧与搜索帧之间分别构建平面区域特征图, 并进行跨图匹配的搜索优化, 在室内场景和室外场景均获得良好的跟踪性能.
尽管大多数工作关注于跟踪视频中的单个平面, 事实上, 真实世界中通常同时存在多个平面.Zhang等[40]提出PRTrack(Tracking Framework Com-prised of Procedures for Appearance Perception and Occ-lusion Reasoning).为了应对引入多个平面后的相互遮挡问题, PRTrack统一外观感知和遮挡推理, 使用双分支网络跟踪平面对象的可见部分, 包括顶点和掩码.他们还开发一个遮挡区域定位策略, 用于推断不可见部分, 即被遮挡的区域, 最终通过双流注意力网络实现精细化预测.
近来, 为了整合平面分析任务, Zhang等[41]提出PlaneSeg, 利用物体的边缘信息, 给模型提供具有判别性的平面特征, 以即插即用的形式嵌入到下游任意的平面区域分析深度网络中.该框架分别提取边缘特征与上下文特征, 并对这两种特征在多个层级进行成对融合.之后提供给神经网络, 完成众多平面分析任务, 包括平面分割、平面重建与深度估计等.
显著性是指图像中引起人眼注意的区域或物体.这些区域可能与周围环境不同, 或者在图像中有特殊的位置、颜色、纹理或形状.显著性对于计算机视觉和图像处理非常重要, 因为它可以帮助计算机自动识别和理解图像中的重要信息.常见的应用包括图像检索、自动驾驶、视频监控等.
为了从多种角度综合考虑显著性, 大量工作都选择设计深度神经网络架构.Liu等[42]提出重新设计的U形结构, 用于显著目标检测中的多尺度特征提取, 该结构集中底部向上和顶部向下的通路, 实现跨尺度信息交互, 并提取语义上更强、位置更精确的特征.Wu等[43]提出EDN(Extremely Downsampled Network), 通过极端下采样技术有效学习整个图像的全局视图, 提高高级特征的表现, 从而实现精确的显著目标定位.同时, 作者构建SCPC(Scale-Corre- lated Pyramid Convolution), 用于从上述极端下采样中恢复目标细节.Wu等[44]提出用于SIS(Salient Instance Segmentation)的网络架构, 网络预测每个显著实例的类别无关掩码.经过正则化的密集连接, 从所有特征金字塔中注意到促进信息性特征并抑制非信息性特征.
为了联合提取多种知识基元, 近年来, 研究者设计通用网络框架, 同时整合多种基元属性的提取.Liu等[45]提出PoolNet+, 应用于边缘检测、RGB-D显著性对象检测和伪装对象检测任务.PoolNet+可逐步提炼高层语义特征, 获得细节丰富的显著性地图, 适合于移动应用.现有显著物体检测模型存在的问题主要是针对理想条件下的数据集进行的训练难以应对真实场景中的复杂情况.
为了更好地反映真实场景中的复杂性, Fan等[2]分析现有显著物体检测(Salient Object Detection, SOD)数据集的设计偏差问题, 并提出一个高质量数据集— — SOC, 该数据集包含多个常见物体类别的显著图像和非显著图像.基于真实场景的SOC数据集, 作者提出的数据增强策略包括标签平滑、随机图像增强和自监督学习, 可提高现有SOD模型的性能.SOC数据集对SOD领域的研究意义在于提供一个更综合和平衡的基准, 可从不同角度客观评估模型性能.
为了解决显著性主观定义的问题, Fan等[46]提出评估前景映射的结构度量指标S-measure, 同时评估前景映射和基准映射之间的区域感知和对象感知结构相似性.该指标能有效区分模型的优点和缺点, 是之前评估方法的有益补充.
在显著性检测的实际应用中, 深度图由于其便捷性广泛应用于移动边端设备[47].为了有效整合RGB和深度信息以提高检测性能, Fan等[48]提出BBS-Net(Bifurcated Backbone Strategy Network), 采用分叉的骨干策略, 将多级特征分成教师特征和学生特征, 并使用深度增强模块, 从通道和空间视图中挖掘深度线索的信息.BBS-Net+[49]更进一步使用深度适配器模块以压缩模型参数量.
此外, 受应用场景驱动, 轻量化的显著性检测成为重要研究方向之一.HVPNet[6]模拟灵长类的视觉皮层进行分层感知学习, 设计HVP(Hierarchical Visual Perception)模块.MobileSal[50]采用移动网络进行深度特征提取, 实现高效RGB-D显著目标检测.Gao等[51]提出CSNet, 利用灵活的广义卷积模块Oct-Conv提取多尺度特征, 同时通过动态权重衰减方案减少特征冗余.该模型仅需100 K的参数量, 并在常用的显著性目标检测基准测试中取得与大型模型相当的性能.Cheng等[52]进一步研究显著性目标检测模型的语义信息编码方式, 以及它们是否是类别不可知的.
研究表明, 显著性检测和分类方法基于不同的机制, 因此SOD对类别不敏感且不必要使用ImageNet预训练对SOD进行训练, 同时, SOD所需的参数量少于分类模型.
情感是重要的认知属性.Minsky指出, “ 问题不在于智能机器是否会有情感, 而是没有情感的机器能否智能” [53].基于图像载体, 情感计算技术可帮助智能机器更好地理解人类的观点和意图, 从而更好地与人类进行交互.例如:在人机对话中, 情感识别帮助机器更好地理解用户的情感状态, 从而更好地回应用户的需求.随着视觉情感领域的快速发展, 其广泛的应用场景受到更多关注, 如社交助手[54, 55]、商务智能[56]、意见挖掘[57, 58]等.
与图像感知层面的研究不同, 情感图像内容分析的目标是理解认知层次的语义信息.为了建模情感的刺激诱因, 一些工作研究如何定位图像中传递情感的物体[59, 60].She等[61]提出WSCNet(Weakly Supervised Coupled Network), 考虑非受限于事物性的更普遍的情感区域, 采用弱监督学习的方式在图像级情感标签的帮助下进行定位.最近, Feng等[7]将情感产生的诱因归结为三个阶段:刺激获取、整体组织以及高层感知.为每个阶段设计专门的情感预训练任务以发掘具有区分性的特征表示.
情感的另一个特点来自于人的认知差异, 现有工作通过刻画这种差异以获取更准确的情感预测.Yang等[62]探讨社交媒体中用户情绪的表达方式, 揭示朋友互动的作用.Yang等[63]提出SAMNet(Sub- jectivity Appraise-and-Match Network), 为了描述群众投票过程中的多样性, 进行多支路的主观评估, 其中每条支路模拟一个特定个体的情感唤醒过程.考虑到情感的特性, 研究者们发现标签共现存在规律性, 特定情感标签往往成对出现[64, 65].针对标签距离情感相关性, Yang等[66]设计隐含和排斥两种生成策略, 构建标签分布.
由于心理学专家定义的情感模型没有确定的统一形式, 现实世界对不同情感类别的需求也多种多样.Yang等[67]提出三元对比损失, 统一情感模型与极性模型的关系.Yao等[68]提出APSE(Attention-Aware Polarity Sensitive Embedding), 进一步提出来自极性-情感两个尺度的有监督注意力模块, 增强特征表示能力.
此外, 标签稀缺是情感识别长久以来的问题, 大量工作[69, 70, 71]探索是否可只使用少量标签或获取便捷的情感线索训练模型.最近, 视频因其包含多种情感刺激物而备受关注[72], 其中, 情感主要由视频的某些关键帧和相应的判别区域引起.Zhao等[73]提出VAANet(Visual-Audio Attention Network), 在帧间实施空间维度、通道维度与时间维度上的注意力检测, 提取到具有关键信息的关键帧.Zhang等[74]提出视频情感定位任务, 同时定位情感段落并识别相应的情感类别, 提出弱监督视频情感定位框架, 基于对比一致性的多模态特征融合模块, 利用反向映射策略融合多模态特征, 并利用情感分布建模定位所需的伪标签.Zhang等[75]设计跨模态时域擦除网络, 捕获关键帧和非关键帧的互补信息.除了分类以外, 情感的时域定位在实际应用中也具有重要意义, 尤其是长视频中传达情感的片段位置与时长不定.
视觉复杂度即图像中包含的信息量和视觉元素的数量.对于人类来说, 图像复杂度是理解图像的基本视觉线索之一, 因此评估图像复杂度可更好地模拟人类感知并提高计算机视觉任务的性能.其应用场景包括图像分割、图像隐写、网页设计、文本检测和图像增强等.早期的复杂度研究关注于复杂度的表示方式, 如图像熵[76]、边缘信息[77]或颜色[78].此外, 数据驱动的深度学习在复杂度评估领域展现令人印象深刻的性能.Chen等[79]研究基于纹理、边缘和区域的神经网络, 评估图像的复杂度, Saraee等[80]使用深度网络中间层特征进行视觉复杂度分析.
为了进一步促进图像复杂度领域的发展, Feng等[81]设计由9 600幅图像组成的、实例级的、经过精心注释的图像复杂度基准数据集IC9600, 涵盖抽象、广告、建筑、物体、绘画、人物、场景和交通等多种类别.每幅图像都经过17个人的精细标注, 目的是降低主观性.作者还提出ICNet, 可在弱监督的情况下预测图像的复杂度得分, 生成复杂度密度图.此外, ICNet可协助提升计算机视觉任务的性能, 如图像美学评估、人群计数和显著性目标检测等.
相比非记忆性图像, 记忆性图像往往具有更明显、更容易识别的模式, 这是因为具有强烈模式的图像更容易在人的脑海中留下深刻印象.因此, 模式识别在决定图像可记忆性方面起着重要作用.Khosla等[82]构建大型数据集LaMem, 包含60 000幅带注释的图像.通过使用CNN, 他们发现经过微调的深度特征是预测可记性的最佳指标.此外, 他们还发现哪些物体和区域与可记性呈正相关和负相关关系, 能为每幅图像创建可记性的分布图.从文献[83]开始, 已有多项研究证明, 训练神经网络的输出可用于成功执行成员推理攻击, 即高精度地推断给定数据点是否属于训练集的一部分.该领域的一个重要问题是找到更能抵御此类隐私攻击的学习算法.Arpit等[84]研究随机标签的记忆与网络在真实标签上的性能之间的关系.研究表明, 使用各种正则化技术可降低算法拟合随机标签的能力, 而不会显著影响其在真实标签上的测试准确性.
图像质量描述从物理世界拍摄的数据的失真程度.感知技术深受图像失真的影响, 一幅具有清晰边界的高质量图像可容易地被感知算法识别.为了评估图像质量, 早期工作聚焦在对比理想场景下收集的图像与拍摄图像之间的差异, 出现大量指标, 如SSIM(Structure Similarity Index Measure)[85]、PSNR(Peak Signal-to-Noise Ratio)[86].这些指标根据图像的内容差异和边缘的结构信息进行估计.而考虑到人类对于局部结构信息的认知, LPIPS(Learned Perceptual Image Patch Similarity)[87]利用深度卷积神经网络分别提取参考图像和拍摄图像的局部特征, 再计算两种深度特征之间的余弦距离.更进一步, Ding等[88]基于深度特征的空间相似性和结构相似性评估图像质量, 以研究影响人类感知的关键因素.研究表明人类视觉系统不同于现有的逐像素比较图像差异的指标, 能从视觉纹理中进行度量, 如空间上同质的区域.与此同时, 研究者提出盲图像质量评估, 直接估计输入图像的质量分数[89, 90, 91, 92].Kang等[93]提出首个端到端的基于卷积神经网络的盲图像质量评估方法, 直接优化回归损失以预测图像的质量得分.更进一步, Pan等[94]利用全卷积神经网络以及池化网络, 同时预测图像质量的得分以及对应的逐像素质量图.根据FCNN(Fully Connected Neural Network)生成的中间质量图, 池化网络通过压缩空间维度以预测位置无关的图像质量得分.Su等[91]提出自适应的超网架构, 适应于通用场景下的图像质量评估.作者设计内容理解超网和质量得分预测网络.内容理解超网根据提取的语义特征自适应预测质量得分网络的权重, 再将骨架网络提取的多层特征输入质量得分预测网络, 完成最终的预测.更进一步, Roy等[89]提出基于批次和样本层级的测试阶段增强方法, 在批次级别的多个样本中进行分组对比学习以及在样本的不同退化实例之间进行排序学习, 完成测试阶段的自适应质量评估.
图像美学是一种描述视觉吸引力的图像属性, 是一个与图像质量、图像复杂度类似的主观概念.图像美学的评估受主客观因素影响:客观因素有图像的色调、纹理、色彩丰富度等因素; 主观因素包括观察者的情感反应、个人偏好、文化背景等因素.图像美学的评估可模拟人类的视觉感知和情感反应, 进而提高计算机视觉系统的性能.
图像美学的应用非常广泛, 包括摄影和图像设计、网页和用户界面设计、市场营销和商业广告等.Murray等[95]建立AVA(Aesthetic Visual Analysis)数据集, 是目前最大的图像美学数据集, 包括大约250 000幅图像, 涵盖66个语义类别, 每幅图像都标注美学分数和摄影风格类别.该数据集已广泛应用于图像美学评估之中.对于图像美学评估的模型, Zhang等[96]提出一个门控视网膜卷积神经网络, 用于模仿人类的审美感知机制, 还可以同时编码整体信息和细粒度特征.
受下游感知任务的需求引导, 研究者从数据中提取视觉结构的几何属性和图像对应的认知属性作为先验知识.现有工作通过数据驱动的方式, 从开放场景中收集数据并构建大规模数据集.基于构建好的数据集, 知识提取算法可在使用大量标注情况下, 基于监督信号学习到图像的属性, 提取数据中蕴含的知识.一些研究基于此探索如何在多个属性之间进行关系建模, 并将其应用于目标检测和图像分割任务中.此外, 由于属性知识与感知任务的类别无关, 通常可覆盖多个感知任务, 如关键点、边缘可用于目标检测、图像分割、视频理解等多个感知任务, 因此受到广泛的关注.
本节回顾现有的几何基元属性感知与认知基元属性感知的代表性工作.作为计算机视觉的经典问题, 基元属性感知具有悠久的研究历史.基元属性感知可分为视觉结构的几何属性和视觉图像的认知属性.视觉结构的几何属性包括角点、线段、边缘、平面和显著区域等, 研究的感知任务覆盖检测、分割、重建、关联、描述及跟踪.而视觉图像的认知属性包括情感、复杂度、记忆性、图像质量和图像美学等, 研究的感知任务覆盖分类、检测、回归、分割、排序.这些属性可作为自适应视觉感知与结构理解后续步骤的输入, 辅助感知模型的训练和学习过程.
总之, 从视觉数据中提取几何属性和认知属性作为先验知识是一种有效方法, 可提高下游感知任务的准确性.然而, 这种方法仍然存在一些挑战.如何准确提取多模态的属性信息、如何处理开放环境下数据场景变化等都是值得探索的问题.
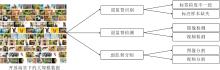
属性知识引导的弱监督视觉感知旨在利用大规模未标记或粗糙标记的图像配合少量良好标记数据以训练深度神经网络.其中, 属性知识可来自领域专家、从其它相关任务中获得、从视觉对象中自动提取.通过使用属性作为先验知识引导弱监督学习, 可在不需要大量标记数据的情况下有效训练深度神经网络, 从而提高计算机视觉任务性能.如图2所示, 本节围绕弱监督识别、弱监督检测与弱监督分割展开, 介绍针对不同场景的现有解决方案.
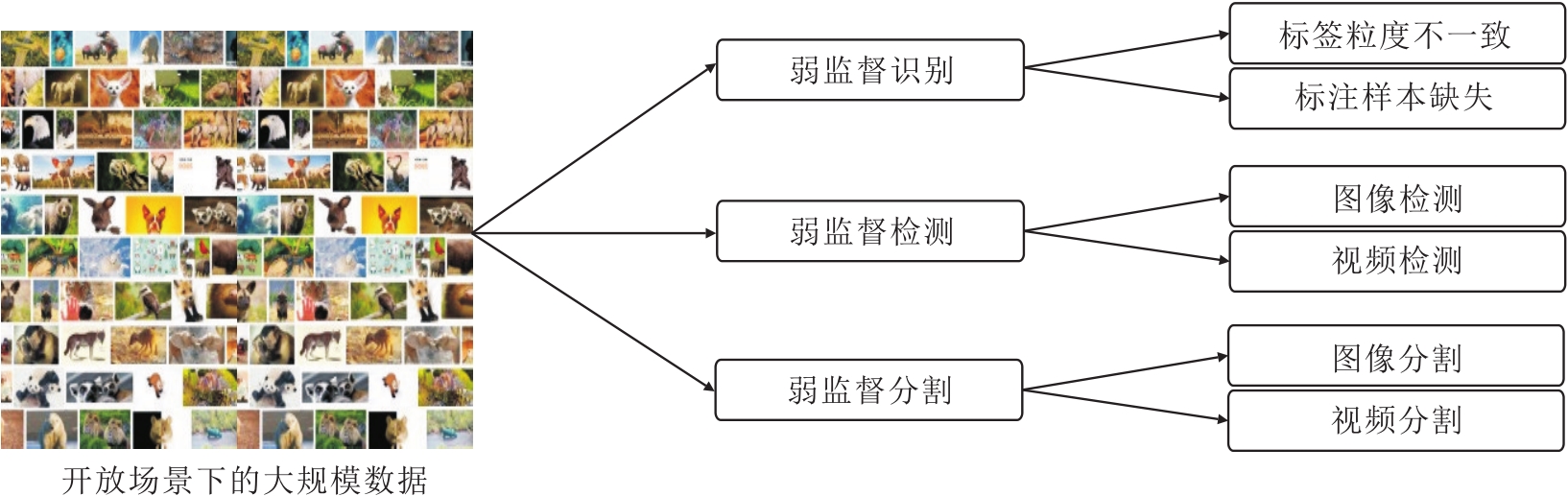 | 图2 属性知识引导的弱监督视觉感知Fig.2 Attribution knowledge-guided weakly-supervised visual perception |
模型训练作为模式识别的关键技术, 研究者关注如何有效利用数据的标签.然而在开放场景中, 某些数据集因其规模较大而面临难以标注的挑战, 无法获得足量完全的数据标签.为此, 弱监督识别使用不完全准确的标签数据训练模型, 涉及到两个关键问题:1)如何使用不正确的数据标签; 2)如何使用不完全的数据标签.
在通常情况下, 互联网图像数据集是通过爬虫软件从多个不同的社交平台等网络站点获取的.这些爬取的图像数据受限于用户提供的关键词, 标签信息往往具有不完备和不准确的特点, 导致数据集上存在不理想标注, 如仅有粗粒度的标注或仅有部分数据被标注.
当数据标注粒度不足[97]时, 通常只有原始的网络tag标签可用.Nayak等[98]提出一种弱监督识别方法, 使用组级别的二进制标签作为弱监督信号, 训练实例级别的二进制分类模型.他们将组级别标签建模为适用于单个实例的类条件噪声(Class-Condi-tional Noisy, CCN)标签, 并使用噪声标签规范在强标记实例上训练模型的预测.
更进一步针对细粒度识别, Xu等[99]讨论当只有粗略分类标签时, 学习目标任务的细粒度模式的挑战, 利用粗略类别的信息, 减弱该挑战带来的负面影响, 学习适当的表示并用于目标任务.
当仅有部分数据被标注时, 半监督学习利用数据标签的密度作为指导, 引导模型构建伪标签进行训练.Jiang等[100]提出GPENs(Graph Propagation-Embedding Networks), 将特征传播和低维嵌入同时集成到一个网络中, 实现图结构数据的紧凑表示.Jia等[69]设计S2-VER(Semi-Supervised Visual Emotion Recognition), 算法包含可信情感标签学习和模糊感知自适应阈值策略.可信情感标签学习策略计算维护的情感原型与样本嵌入之间的相似度, 生成平滑标签, 提高伪标签的准确性; 模糊感知自适应使用信息熵衡量平滑标签的模糊程度, 然后自适应调整阈值, 选择高置信度的未标记样本.
传统检测任务[101, 102, 103]需要训练数据标注每个目标的位置和类别, 与之不同, 弱监督检测[104, 105]只需使用不完全的标注, 如图像的标签或图像中是否存在目标, 就可训练模型.属性引导的弱监督检测采用不同属性知识作为先验, 以此指出或矫正物体可能出现的位置, 补全给定的不完全标注, 指导模型的学习和训练.
图像中的弱监督检测通过图像级别的标注(如图像中存在的物体类别)训练模型.在弱监督检测的早期工作中[106], 研究者将显著性作为属性知识[107, 108], 协助估计物体可能出现的位置, 并进一步训练检测模型.
Shi等[109]提出基于几何与外观知识的贝叶斯联合主题建模框架, 联合编码多个目标的共现特征, 并通过弱标记和未标记的互联网图像数据实现混合学习.不同于直接指定物体位置, Cinbis等[110]通过多实例学习, 将图像划分成多个区域, 根据每个区域中的特征点迭代检测, 矫正物体可能出现的位置并完成训练.Deselaers等[111]借助类间的语义信息挖掘目标位置, 并通过网络训练循环更新可能的候选区域.
近年来, 越来越多的工作[112, 113]开始利用其它领域的预训练模型作为知识的提取器, 辅助检测模型的学习.Shi等[114]利用物体的先验知识, 辅助弱监督学习过程, 其思想是基于源域数据集训练一个语义分割模型, 在目标域数据集进行弱监督的学习和推理.Zhang等[115]基于预训练深度特征的协作式课程学习网络, 定位感兴趣的对象.
在视频弱监督检测任务中, 一段几秒钟的短视频就可包含上百幅图像.因其增加额外的时间维度, 使获取视频数据的完整标注信息变得更困难.因此, 近期的研究工作开始关注利用视频级别的标签, 提取时间一致性作为先验知识, 引导模型在学习过程中更好地理解视频数据.这种方法可帮助模型更准确地定位和检测对象, 提高检测性能.
Zhang等[74]提出TSL-Net, 每个片段只需标记一帧, 使用贪婪搜索策略为未标记帧生成伪标签, 再融合视觉和音频模态的特征, 预测时间标签分布.Sang等[116]提出从单帧图像中估计物体6D姿态的网络框架INVNet, 结合不可见信息与可见的2D-3D对应关系, 建模物体的几何特征.INVNet通过跟踪生成密集的可见对应关系以及几何的路径图, 以此构建在视频所有帧中的物体姿态伪标签并用于训练.
分割的目的是在像素级别进行精细分类, 因此需要更细节的标注信息.现有的弱监督分割工作除了使用图像级别的标签以外, 还利用大量属性知识, 如物体类别、关键前景点、线条, 提供有效且容易标注的弱标签, 辅助模型训练.
由于弱监督分割[117]需要在像素层级定位和区分物体, 因此带来新的挑战.Liu等[118]提出弱监督实例分割的方法, 将所有训练数据的粗糙标注信息汇集成一个大型知识图谱, 再从该图谱中利用语义关系辅助后续处理.作者提出多实例学习框架, 同时计算每个候选区域的概率分布和类别感知的语义特征, 并使用这些特征构建一个大型无向图.该图的最优多路切割可为每个候选分配可靠的类别标签.KnifeCut[119]通过用户在误分割的细小部分上绘制一条线条, 作为分割边界, 从而有效实现细小部分的分割.相比传统的交互式图像分割方法, KnifeCut更直观易懂, 用户只需进行低强度的交互操作即可完成任务, 不再需要进行复杂的点击、涂鸦或多边形绘制等操作.
针对类别噪声问题, 侯淇彬等[120]设计一种噪声擦除模型, 以跨样本的方式, 从小批次样本的置信区域学习语义信息, 实现对图像中与类别无关的区域的擦除.
在下游应用中, 医疗图像分割由于其数据的私密性, 难以获得准确的标注.SANet(Slice-Aware Network)[121]是一种肺结节区域分割的切片感知网络.作者建立大规模的PN9数据集, 包含8 798幅CT扫描图像和40 439个标注结节.SANet利用切片分组非局部模块, 捕获特征图中任意位置和任意通道之间的长程依赖性.引入3D区域提议网络, 生成具有高灵敏度的肺结节候选项, 而检测阶段通常伴随着许多假阳性.为此, 作者使用多尺度特征图生成一个假阳性消除模块.
相比图像, 在视频中分割物体更难, 这是因为视频的语义信息很难被直接用于指导分割过程.大量弱监督视频分割研究工作关注于仅使用第一帧图像标注的情况下如何有效训练模型[122, 123, 124].Wang等[125]提出一种时间环一致性框架, 将第一帧的标注传播到后续帧, 并回传到第一帧, 以此计算时间一致性损失.Li等[126]进一步利用视频内的重要区域和关键点, 分别从目标和像素级别构建区域跟踪和像素传播的自监督任务, 并构建渐进式训练策略, 耦合两个自监督任务, 完成弱监督学习.
相比使用掩码, 坐标框因其更容易标注而在检测领域被广泛使用, 但其只能提供有限的目标位置信息, 并且引入额外的背景像素.为了解决背景混淆, Yan等[127]设计STC-Seg(Spatio-Temporal Colla-boration for Instance Segmentation in Videos), 利用深度和光流信息, 从目标框中去除背景像素并构建伪标签.在弱监督训练过程中, STC-Seg考虑伪标签的置信度, 将掩码切分为多个区域, 分块计算拼图损失.
Lin等[128]讨论跨帧的目标框表征一致性, 将两帧的目标框表征通过双边聚合模块进行特征对齐.为了获取更精确的物体位置信息, Liu等[129]利用关键点作为弱标签, 设计记忆蒸馏策略对齐跨帧的关键点表征.
本节回顾属性知识引导的弱监督视觉感知的代表性工作.弱监督学习是开放场景下数据标签缺失的代表性学习方法, 通常受制于标签质量, 模型难以取得令人满意的准确率.属性知识指导的弱监督学习通过提取任务无关的先验, 指导模型学习.基于提取的基元属性, 一些研究通过属性知识将弱监督标签转换为具有全监督标签形式的伪标签, 以此指导模型学习, 如通过显著性图将分类标签转换为分割任务所需的掩码标签.另一些研究则聚焦在学习范式上, 以属性知识为评价指标, 设计损失函数、学习策略, 提高模型性能.因此, 通过属性知识引导的弱监督学习可在不需要大量标注数据的情况下, 学习到图像中物体的属性信息, 进而提高模型的准确性.
然而, 在现有的弱监督视觉感知研究工作中, 常用的模型架构与弱监督学习范式由于引入额外的结构以提取属性知识, 虽然可以提高模型性能, 但属性知识的提取产生额外的计算开销, 延长训练所需的
时长.
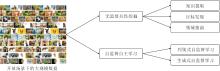
开放场景平台作为一个巨大的图像数据源, 为各种复杂任务, 如动作分析、场景图生成等, 提供丰富的数据支持.然而, 传统的图像数据标注和监督学习方法却伴随着昂贵的时间成本以及庞大的人力资源投入, 这成为训练模型的制约因素之一.为了应对这些挑战, 无需标签的无监督/自监督学习引起学者的高度关注.
本节聚焦于图像无监督自主学习方法, 旨在克服传统方法面临的种种限制.如图3所示, 深入探讨图像无监督自主学习中自监督对比学习及无监督共性学习这两个关键子领域, 它们在推动图像自主学习方面具有重要作用.
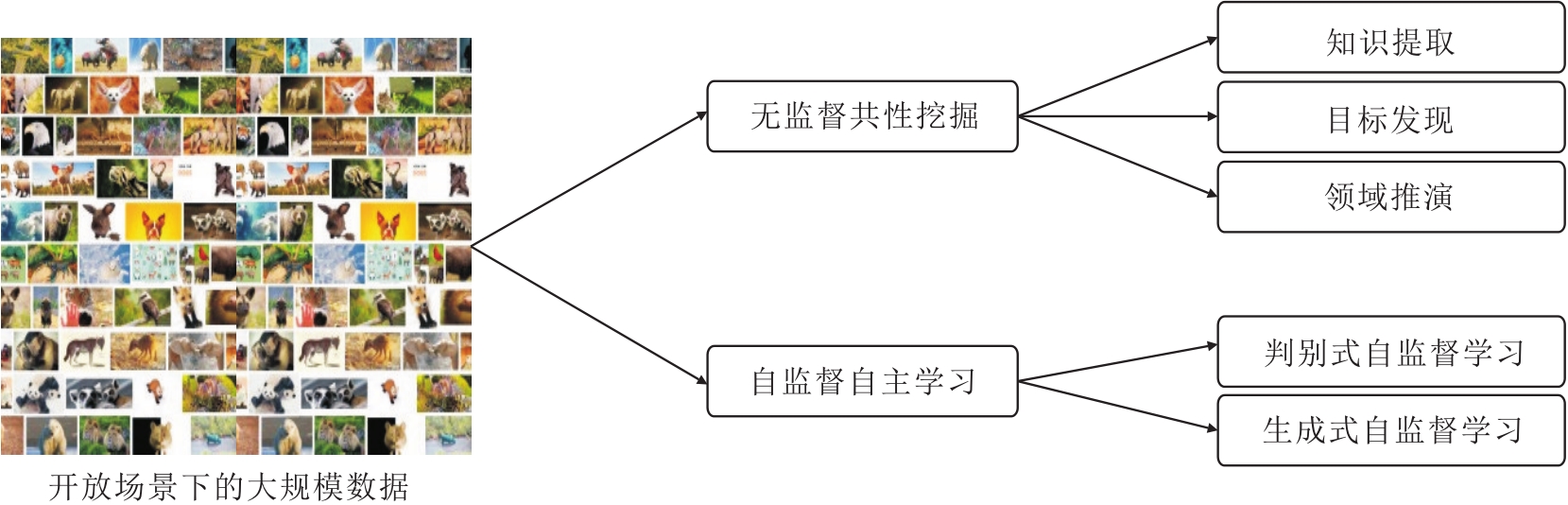 | 图3 图像无监督自主学习Fig.3 Image unsupervised autonomous learning |
共性学习强调在大规模图像数据集上挖掘共同特征的重要性.通过发现图像集合中的普适模式, 建立跨样本的联系, 为跨任务的学习提供更丰富的信息支持.这种共性体现在物体形状、轨迹等语义特征上的共性、不同数据域的共性等方面.
通常使用聚类或相似度等方法挖掘数据之中共现的属性知识, 如关键点、显著区域.自监督关键点提取以多视角图像数据之间的关键点共现规律为线索, 提取图像中不变的关键点.
SuperPoint[26]构建单应变换引导的多视角图像对, 在图像对之间提取关键点匹配关系作为伪标签, 预训练关键点检测网络和关键点表征网络以提取关键点.协同显著性检测利用图像中显著物体的共性特征, 在相关图像组中分割共同显著的前景物体.Zhang等[130]借鉴人类行为, 提出基于梯度诱导的共同显著性检测方法, 将单个图像和一组图像的一致表示进行对比, 利用反馈的梯度信息, 将更多注意力放在引起协同显著性的区域.Li等[131]结合多目标跟踪方法与基于轨迹的聚类方法, 构建视频摘要系统, 提升对监控视频分析的速度和准确性.
在没有标签的情况下, 研究者试图从图像或视频中自动发现物体, 对其进行分类和定位.Slot Attention Module[132]作为一种与感知表示对应的架构组件, 可产生一组任务相关的抽象表示, 称为slot.这些slot是可交换的, 并且可通过多轮注意力竞争过程专门绑定到输入中的任何对象.研究结果表明, Slot Attention Module可提取以对象为中心的表示, 在无监督对象发现和监督属性预测任务上进行训练, 并实现对未见组合的泛化.
在大规模的开放数据上, 以往无监督的聚类方法或概率模型的尺度泛化性有限.为了解决这一问题, Vo等[133]提出无监督目标发现的方法, 将目标发现转化为排序问题, 并使用自监督特征进行处理.该方法在单个物体和多个物体的发现设置中都表现出色, 并适用于大型数据集.
为了更精确地理解图像中的语义, 无监督语义分割也获得更多关注.Gao等[134]不仅提出大规模语义分割的数据集, 还构建PASS作为基准模型.模型自动学习形状和类别表示, 应用基于像素注意力的聚类方案, 获得伪类别, 并将生成的类别分配给每个图像像素.
利用无标记数据减少数据跨域影响, 可提高模型的泛化性能.Yao等[135]提出包含多个源域网络和一个伪目标域网络的架构.在这种架构中, 不同源域网络的参数以加权的方式搜索目标子集的最优参数, 并提出候选区域网络的一致性正则化, 促使不同域的子网学习更多抽象的域共性.
自监督学习旨在从无标注的数据中构造伪标签以训练有效网络, 以此完成网络的自主学习.通过引入额外的数据结构知识, 如对不同图像样本之间的关系、数据增强对的相似和不同情感极性数据的差异进行建模, 从而学习更具有判别性的特征表示.
通过对比正负样本, 可挖掘图像数据中用于感知任务的模式, 进而提升学习算法的性能, 在缺乏标签信息的情况下, 能有效捕捉数据的内在结构.这种对比体现在语义的差异、情感的两极性等方面.Qian等[136]在视频表示学习中, 利用朴素对比学习和原型对比学习构建分布图, 指导低中级特征的学习过程.Chen等[137]提出SSL++, 利用下游任务学习的低级通用特性与生成语义伪标签的高级语义特性之间的互补性, 缓解学习表征在不同下游代理任务中产生的特异性和局限性.Yao等[138]构建一个极性敏感的嵌入网络, 使用强推力、弱推力、拉力三种损失类型, 充分考虑标签的极性内关系和极性间关系.Huang等[9]提出类特定语义重建策略, 集成自编码器和原型学习的能力.
生成式自监督学习旨在重建数据本身的特征和信息, 引入数据的底层结构知识, 使用数据集本身的信息构造伪标签.早期的自回归式模型可视作贝叶斯网络结构, 通过最大化前向自回归分解的似然函数, 逐像素建模图像的概率分布[139, 140].考虑到直接优化似然函数(即概率密度)是一件困难的事情, Flow类的模型通过一系列的几何变换函数描述不同的数据点[141, 142].
不同于上述方法, 自编码器类模型[143]通过训练前向传播网络, 在输出层预测其输入, 目标由最大化似然函数转变为最小化输入与编解码的结果, 最近, 掩码自编码器(Masked Autoencoders, MAE)通过恢复被隐去的部分数据结构, 如图像的关键区域、视频的部分关键帧等, 有效完成自监督学习[144].掩码学习在自然语言中早有应用, 经典的BERT(Bidirectional Encoder Representations from Transformers)通过预测下一句文本建模语句之间的顺序关系[145].受其启发, MAE将图像切分成块并随机进行掩码, 使模型学习不同区域之间的视觉底层结构.更进一步, MaskFea(Masked Feature Prediction)[146]研究中层的视觉知识表征, 要求模型恢复具备语义信息的结构, 包括像素、边缘HoG(Histogram of Oriented Gradients)、网络提取的特征等.不同于视觉可见的特征, A2MIM(Architecture-Agnostic Masked Image Modeling)[147]引入频率域约束, 对齐Transformer自监督学习与CNN自监督学习的性能, 缓解MAE难以拓展到CNN架构的局限.除了视觉知识以外, MI- LAN(Masked Image Pretraining on Language Assisted Representation)[148]更进一步设计视觉-语言跨模态模型CLIP(Contrastive Language-Image Pre-training)引入语言知识, 要求模型恢复CLIP输出的语言特征, 并在特征层次进行对齐.
本节回顾图像无监督自主学习的代表性工作.计算机视觉的自主学习方法主要包括无监督共性学习和自监督自主学习两个关键子领域.其中, 无监督共性学习方法基于大规模的开放场景数据, 挖掘无监督数据中的属性知识、共现规律, 并进一步泛化到多个场景.自监督自主学习根据从数据中提取的属性知识, 构造伪标签以训练模型.两者均在无可用标签的情况下, 利用数据的属性知识进行特征学习和模型训练.现有无监督自主学习方法仍然依赖长耗时的训练过程, 比监督式学习方法更难以收敛, 因此有待后续工作研究解决.
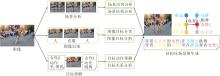
场景图像的结构化表示和理解一直是计算机视觉领域的重要研究方向.如图4所示, 本节重点关注场景分析、图像识别和目标理解等关键问题, 通过更完备的结构化表示, 提高模型对场景图像的理解能力.
 | 图4 场景图像的结构化表示和理解Fig.4 Structured representation and understanding of scene images |
场景内容分析旨在理解当前图像的上下文信息, 提取图像拍摄的地点等属性.根据图像所处的环境、图像中包含的对象类别以及各对象的布局关系, 将场景图像分类为预定义的场景类别之一(如图书馆、海滩、商场等)[149].作为场景分析的重要环节, 场景分类引导智能系统对视觉场景中出现的物体、动作或事件等要素进行重新思考, 构建物体与物体以及物体与环境之间的联系.通过掌握不同物体的语义类别以及物体间的组织关系, 智能系统构建对场景的全面理解, 能服务于自动驾驶[150]、智能机器人[151]、智慧城市[152]等下游应用.
场景内容分析任务根据数据来源及分类目标不同被分为室内/外场景分类[153, 154]、遥感场景分类[155, 156]、声学场景分类[151, 157]、地点分类[158, 159]等子任务.这些任务各自面临着领域内特有的挑战.例如:室内场景受物体摆放位置和拍摄角度影响较大、遥感场景的图像空间分辨率较低、声学场景分类需要考虑声音的时变性和时序性等, 但仍在存在如下共性问题.
1)类内变化较大.同一类别的场景可能呈现出完全不一致的特征.
2)语义模糊.即使包含相同的视觉特征, 但姿态、布局的差异可能造成不同场景下的同一物体语义上的差异, 影响对场景类别的判断.此外, 类别标签本身依赖于主观注释, 不同的场景标签并非完全互斥, 同一场景可能与多个标签相关.
3)计算效率.下游应用一般服务于移动场景, 对计算资源限制较大.
传统场景分类方法常被分为特征检测、特征描述和特征分类三个阶段, 在特征检测阶段, 学者们提出大量的特征检测器, 包括:SIFT[160]、FAST(Features from Accelerated Segment Test)[161]、SURF(Speeded-Up Robust Features)[162]等.考虑到手工特征在面对复杂场景时的性能退化, 传统方法已逐渐被具有强大特征提取和学习能力的CNN取代.即使在深度学习方法中, 研究人员对特征提取的关注也远大于分类阶段, 最新的工作[163, 164]通过构建更强大的特征提取网络, 得到视觉特征的更优表示, 服务于场景理解的下游任务.未来的工作将更关注于场景理解领域的共有特性, 构建更通用和可扩展的网络框架, 统一各个子任务.
场景结构感知对场景中的物体和结构进行感知, 以获取丰富和准确的场景信息.然而直接从图像中理解场景结构需要大量的先验知识, 如物体的类别、形状、尺寸以及场景类型、朝向等.现有方法利用深度信息, 也就是图像中物体到相机的距离, 作为辅助信息感知场景的结构.在传统的计算机视觉中, 深度信息通常通过使用双目或多目相机等硬件设备获取.
最近, 深度估计方法可通过识别物体的轮廓和特征点自动确定物体的位置和方向, 从而估计图像的深度信息, 这在计算机视觉领域、机器人、增强现实等领域具有广泛的应用前景.张羽丰等[165]提出基于双目视差回归的目标距离估计方法, 基于区域卷积神经网络, 同时进行目标检测和目标距离估计.通过双目图像输入网络, 提取区域特征, 利用双目视差回归算法计算目标距离, 并将结果通过双目包围框进行输出.该方法可有效解决传统双目目标距离估计方法精度较低或数据准备困难等问题.Zhang等[166]提出基于R-CNN结构的区域回归网络, 用于实现单目物体距离估计.网络通过添加浅层网络处理相机外参参数, 并优化特征处理结构, 改善估计结果.
图像识别是计算机视觉的基础任务, 旨在确定图像中物体的类别和位置.在场景图像中, 准确识别不同物体的存在对于进一步理解和分析图像至关重要.
判别区域定位和特征学习对细粒度视觉识别至关重要.Liu等[167]集成网格门注意力单元、尺度一致的注意力部件选择策略和部件关系建模模块, 充分利用注意力机制与局部部件之间的一致性以及部件之间丰富的关系信息, 实现细粒度识别.开放环境下的图像种类多样, 高分辨率的图像类型也在监控等领域发挥重要作用.以往针对高分辨率图像识别任务是简单地将图像切割成小块, Fan等[168]提出小块排列网络, 通过确定哪些小块可以打包成一个紧凑的画布以加速检测.随后, 从剩余的小块中, 决定如何将这些小块打包成更小数量的画布.这些画布被分别送入检测器, 得到最终结果.
目标分割是将图像中的每个像素分配给特定的物体类别, 从而获得物体的精确边界.这对于场景理解和图像编辑等任务具有重要意义.传统的图像分割方法通常考虑分割结果在像素级上的覆盖率或交并比等.Guo等[169]证明卷积注意是比自注意机制更有效的编码上下文信息的方法, 并据此提出SegNe-Xt.Wu等[1]将金字塔池应用于视觉转换器的多头自注意中, 同时减少序列长度并捕获强大的上下文特征, 构建一个通用的视觉变压器骨干, 称为金字塔池变压器.它在图像分类、语义分割、目标检测和实例分割等各种视觉任务中表现出实质性的优势.在下游应用中, 语义分割面临更多的挑战, 如避免遥感图像中碎片化的分割结果[170]或是针对细胞完成精细的分割[171].为了提升道路抽取的拓扑正确性, Mei等[170]从道路形状角度出发, 提出条带卷积模块, 并从连通性角度出发, 考虑到建筑物和树木的遮挡, 提出连通性注意模块, 探索相邻像素之间的关系.
视频动作分类可直接理解物体动作, 将视频中目标发生的动作按照类别进行分类.由于目标动作的复杂性, 通常需要使用深度学习等技术, 对视频进行特征提取和分类.Li等[172]将事件边界作为指导时间对齐的先验, 设计基于时间边界的帧采样策略, 减小类内方差, 此外, 引入一种边界选择模块, 将视频特征与其动作持续时间进行对齐.Li等[3]还构建两阶段动作识别模型, 先定位动作的时间起始范围, 降低动作持续时间估计偏差, 再学习运动变化特征, 降低动作演化偏差.对于动作识别问题, Liu等[173]注重帧选择策略, 通过时间选择器选择更重要的视频帧, 通过空间放大器寻找关键帧中最显著的部分.
更进一步, 视频定位沿时间轴定位动作发生的起止时间, 可提供更丰富的信息.Li等[174]提出用于有效的时空动作定位的检测器, 首先从视频流中估计粗略的时空动作变换体积, 再根据抽取的关键时间戳进一步精细化该体积.Li等[175]提出LSTC(Long-Short Term Context), 为了更准确地进行原子动作检测, 将动作识别线索独立分解为信息丰富的短期依赖和用于交互推理的长期依赖.
除了仅通过视觉模态进行定位以外, 多模态视觉理解与定位提供丰富的判别信息以提高动作理解的准确性, 通过使用包括文本、音频、温度在内的额外模态作为辅助信息进行动作理解和定位.
Qian等[176]利用视觉和音频模态解决在非受限场景下一次性定位多个声源位置的问题, 从复杂场景中分离不同类别的视听表示, 在不同粗细粒度的尺度上进行模态间特征对齐.Guo等[4]根据视觉问答中可能包含对图像的描述, 提出一种重新注意机制框架, 对答案提供的信息进行注意力修正, 将视觉注意力图重新定位到正确的位置.Li等[177]利用RGB视觉和温度模态, 解决热成像下的目标跟踪问题, 提出的挑战感知神经网络通过参数共享分支解决模态共享的问题, 通过参数独立分支处理各模态的特定问题.
场景图是一种用于描述场景中的对象、属性和对象关系的结构化表示方法.作为图像的一种语义化表示, 图像中的目标对应场景图中的节点, 目标间的关系对应场景图中的边[178].为了尽可能涵盖图像更多的细节, 有时图中还会表示目标的属性, 如颜色、状态、大小等.尽管场景图将图像语义化表示, 在形式上与知识图谱十分相似, 但场景图强调对象主体, 而知识图谱强调语义标签[179].
场景图自从被提出后, 得益于其直观、高效、模态无关的特性, 广泛应用于推理、检索和推荐等领域, 在多模态信息融合领域表现出巨大的潜力.深度学习领域的飞速进展造成对大规模数据集的迫切需求, 基于目标检测数据集人工标注场景图的方式逐渐被抛弃, 如何自动生成高质量的场景图成为热门的研究任务.
场景图生成旨在对图像或视频进行解析, 生成一个结构化表示, 弥合视觉特征和人类感知之间的差距, 帮助智能系统理解现实视觉场景.场景图的生成需要检测到视觉特征中的所有实体并挖掘实体间的视觉关系, 这是一个自下而上的过程, 从图像的基本元素出发, 逐渐建立对其的感知[180].
现有场景图的生成有两种主流方案[181].
1)将场景图生成进行拆分, 视作一个两阶段任务.首先检测图像中的对象, 得到场景图的节点及每个对象的属性, 再推断对象之间的关系.
2)先定位目标, 再构建一个未标记的图结构, 从图的角度分别对节点和边进行类别预测.
进一步, 根据采用的技术手段, 场景图生成又被分为4类:基于CRF(Conditional Random Field)[182]的方法、基于TransE(Translating Embeddings)[183]的方法、基于深度学习的方案、引入外部先验的场景图生成方法.
CRF是一种将统计关系纳入判别任务的工具.研究人员基于场景图中的关系谓词和对象之间存在的统计相关性推理对象间相关性并给出有效性证明.受此启发, DRNet(Deep Relational Network)[184]、SG-CRF(Scene Graph Generation via CRF)[185]等模型都借用这种基于频率的方式进行关系预测.基于CRF的方法虽然有效, 但忽略图像的上下文信息, 无法准确区分同一类别的多个实例.
基于TransE的方法是从场景图和知识图谱的相似性层面考虑的.TransE已经被证明在将知识图谱中的三元组嵌入到低维向量空间中的有效性, 场景图拥有与知识图谱类似的定义和属性, 在视觉关系嵌入层面应共享有效性.因此, 研究人员尝试使用TransE将场景图的相关元素进行低维嵌入, 并建模不同元素间的视觉关系, 相关的研究结果表明这种方案的有效性[186, 187].
深度学习的快速发展为场景图生成提供更有效和可靠的方案.一个通用的框架是先使用常规的目标检测器, 分别获得图像中的不同物体, 再对不同物体进行特征提取, 包括视觉特征、空间关系、语义信息等, 得到多个中间表示.然后考虑多个特征表示之间的差异与关联, 应用注意力机制调整权重, 最终对关系进行预测.
除了常规架构以外, 一些特殊架构也被认为对于建模物体间关系具有优势.例如:RNN(Recurrent Neural Network)的多次迭代能融合全局信息, 这种考虑上下文的方案可减少关系预测的模糊性[188]; 基于GNN的方法借助图论改进关系图的生成[181].更进一步, 纳入更多人为先验或自然常识被认为有助于减轻模型推理物体间关系时的负担, 并能有效提高结果的准确性.语言先验[189]、统计信息先验[183]都被证实能指导模型进行更准确的关系推理.
场景图像的结构化表示和理解是计算机视觉领域的一个重要研究方向, 它将图像中的物体、关系和属性呈现为结构化的形式.传统的场景图像表示方法主要基于手工设计的特征和规则, 在复杂场景下往往难以扩展和适应.近年来, 随着深度学习技术的发展, 基于深度神经网络的场景图像表示方法逐渐成为主流.
虽然场景图生成已被广泛研究并构建一系列解决方案, 但仍面临一些挑战.从场景图本身来说, 有限的关系种类、浅层语义的关系表示、难以对节点进行实例级别的区分等问题, 都限制场景图的实用性.另外, 视觉图像中包含的信息难以支撑复杂的关系推理, 这促使研究者进一步探索更多种类的额外先验以协助模型生成场景图.最后, 和大多数任务一样, 数据规模和细粒度都限制深度学习方法性能的进一步提高, 探索更高效的数据标注方案或有限数据的深度学习方法值得进一步探索.
1)大规模多属性知识数据集.在开放场景中, 同幅图像涵盖的属性知识多样, 而现有基准数据集均针对单一属性知识构建, 难以研究属性之间的相关性.因此大规模的多属性知识数据集具有巨大的研究价值.在构建大规模属性知识数据集时, 需要考虑如何获取包含丰富属性信息的数据, 并对数据进行标注和质量控制.同时, 还需要考虑如何将这些数据转化为结构化的形式, 以便指导后续感知任务的分析和应用.与普通单一属性知识数据集不同, 多属性数据集在构建过程中需要把多种属性知识之间的影响考虑在内, 避免多种属性捆绑出现的偏置情况.
2)多模态属性知识提取.现有工作的属性知识提取聚焦在单一模态(主要是视觉模态), 然而开放世界中可大量获取的数据通常涵盖多种模态, 包括图像、文本、语音等.针对这种场景, 需要从实际应用, 如模态对齐、图文匹配中, 总结所需的模态知识, 如视频多模态数据的时间一致性、图文数据的语义性.常见的提取方法涵盖跨模态关联学习、多模态生成模型及强化学习等.因此, 多模态属性知识提取是一个复杂而又具有实际意义的研究问题, 需要结合不同领域的技术和方法进行研究和实践.
3)属性知识感知模型的场景泛化性.在开放场景的图像中, 属性知识的提取和表示需要考虑到不同场景和环境的变化, 以保证模型具有良好的泛化性能.设计和优化属性知识感知模型, 提高其在不同场景下的泛化性能成为当务之急.这个问题涉及3个方面:基准数据集的数据多样性、评估指标的设计合理性以及感知算法的鲁棒性.此外, 对于开放场景下的感知问题, 还可从感知模型结构设计、特征提取、学习算法、知识表示和推理等不同角度提出解决办法.相关研究工作包括可解释性深度神经网络、小样本学习等.
4)轻量级属性知识引导的视觉感知模型.在设计视觉感知模型的过程中, 由于引入属性知识, 模型通过中间结果取得更好的可解释性和预测表现, 也同时引入额外的结构进行属性知识的提取, 因而需要进行轻量化模型的设计, 并考虑如何保证模型具有足够的感知能力.此外, 属性知识的学习与物体语义的理解不同, 其类别无关且更具有一般性, 通常所需的模型参数量大幅小于常规的感知模型, 如显著区域提取可仅用100 K参数的模型完成.
本文从属性知识的角度切入, 综述开放场景自适应感知领域的研究进展.本文并未囊括领域内的所有方法, 而是关注一些有代表性的方法.总结和对比广泛使用的属性知识提取方法、弱监督与无监督视觉感知模型、图像结构化表示和理解方法.最后, 讨论属性知识引导的自适应感知与结构理解的一些开放性问题和潜在的研究方向.
尽管近年来属性知识的应用取得快速发展, 但是仍未出现一个完全解决开放场景下有效、高效、鲁棒的多模态多属性知识引导的算法框架.随着领域专家知识的不断扩充、深度感知模型的快速发展, 属性知识引导的自适应感知会在之后很长时间内保持活跃, 作为计算机视觉与人工智能领域的前沿方向与研究热点之一.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|
| [47] |
|
| [48] |
|
| [49] |
|
| [50] |
|
| [51] |
|
| [52] |
|
| [53] |
|
| [54] |
|
| [55] |
|
| [56] |
|
| [57] |
|
| [58] |
|
| [59] |
|
| [60] |
|
| [61] |
|
| [62] |
|
| [63] |
|
| [64] |
|
| [65] |
|
| [66] |
|
| [67] |
|
| [68] |
|
| [69] |
|
| [70] |
|
| [71] |
|
| [72] |
|
| [73] |
|
| [74] |
|
| [75] |
|
| [76] |
|
| [77] |
|
| [78] |
|
| [79] |
|
| [80] |
|
| [81] |
|
| [82] |
|
| [83] |
|
| [84] |
|
| [85] |
|
| [86] |
|
| [87] |
|
| [88] |
|
| [89] |
|
| [90] |
|
| [91] |
|
| [92] |
|
| [93] |
|
| [94] |
|
| [95] |
|
| [96] |
|
| [97] |
|
| [98] |
|
| [99] |
|
| [100] |
|
| [101] |
|
| [102] |
|
| [103] |
|
| [104] |
|
| [105] |
|
| [106] |
|
| [107] |
|
| [108] |
|
| [109] |
|
| [110] |
|
| [111] |
|
| [112] |
|
| [113] |
|
| [114] |
|
| [115] |
|
| [116] |
|
| [117] |
|
| [118] |
|
| [119] |
|
| [120] |
|
| [121] |
|
| [122] |
|
| [123] |
|
| [124] |
|
| [125] |
|
| [126] |
|
| [127] |
|
| [128] |
|
| [129] |
|
| [130] |
|
| [131] |
|
| [132] |
|
| [133] |
|
| [134] |
|
| [135] |
|
| [136] |
|
| [137] |
|
| [138] |
|
| [139] |
|
| [140] |
|
| [141] |
|
| [142] |
|
| [143] |
|
| [144] |
|
| [145] |
|
| [146] |
|
| [147] |
|
| [148] |
|
| [149] |
|
| [150] |
|
| [151] |
|
| [152] |
|
| [153] |
|
| [154] |
|
| [155] |
|
| [156] |
|
| [157] |
|
| [158] |
|
| [159] |
|
| [160] |
|
| [161] |
|
| [162] |
|
| [163] |
|
| [164] |
|
| [165] |
|
| [166] |
|
| [167] |
|
| [168] |
|
| [169] |
|
| [170] |
|
| [171] |
|
| [172] |
|
| [173] |
|
| [174] |
|
| [175] |
|
| [176] |
|
| [177] |
|
| [178] |
|
| [179] |
|
| [180] |
|
| [181] |
|
| [182] |
|
| [183] |
|
| [184] |
|
| [185] |
|
| [186] |
|
| [187] |
|
| [188] |
|
| [189] |
|