
{kind=link}
{kind=link}
知识驱动的多模态语义理解研究综述
[郑祎豪1  , 郭奕君
, 郭奕君2 , 毋立芳1 , 黄岩3
, 郭奕君, 毋立芳, 黄岩]
|
|



作者简介:



基于深度学习模型的多模态学习方法已在静态、可控等简单场景下取得较优的语义理解性能,但在动态、开放等复杂场景下的泛化性仍然较低.近期已有不少研究工作尝试将类人知识引入多模态语义理解方法中,并取得不错效果.为了更深入了解当前知识驱动的多模态语义理解研究进展,文中在对相关方法进行系统调研与分析的基础上,归纳总结关系型和对齐型这两类主要的多模态知识表示框架.然后选择多个代表性应用进行具体介绍,包括图文匹配、目标检测、语义分割、视觉-语言导航等.此外,文中总结当前相关方法的优缺点并展望未来可能的发展趋势.
HUANG Yan, Ph.D., associate professor. His research interests include computer vision.
About Author:
ZHENG Yihao, Ph.D. candidate. His research interests include artificial intelligence.
GUO Yijun, master, engineer. Her research interests include computer vision.
WU Lifang, Ph.D., professor. Her research interests include artificial intelligence.
Multimodal learning methods based on deep learning model achieve excellent semantic understanding performance in static, controllable and simple scenarios. However, their generalization ability in dynamic, open and other complex scenarios is still unsatisfactory. Human-like knowledge is introduced into multimodal semantic understanding methods in recent research, yielding impressive results. To gain deeper understanding of the current research progress in knowledge-driven multimodal semantic understanding, two main types of multimodal knowledge representation frameworks are summarized based on systematic investigation and analysis of relevant methods in this paper. The two main types of multimodal knowledge representation frameworks are relational and aligned, respectively. Several representative applications are discussed, including image-text matching, object detection, semantic segmentation, and vision-and-language navigation. In addition, the advantages and disadvan-tages of the current methods and the possible development trend in the future are concluded.
深度学习技术的兴起直接推动计算机视觉、自然语言处理等领域技术的飞速发展.例如:在计算机视觉领域中, 目标检测与识别、语义分割、三维重建等任务的性能获得显著提升, 并已进入实际应用阶段.总体来讲, 现有深度学习方法在静态、可控等简单场景下能取得较好的准确度和鲁棒性, 有时甚至超过人类.但是, 当把它们应用到服务机器人、无人车等开放、不可控的复杂多模态场景时, 语义理解性能显著下降, 远达不到实用水平.因此, 如何实现开放环境下的自适应多模态语义理解是一个亟待解决的问题.
近期, 学者们提出多种多模态预训练模型[1, 2], 并且在多个任务上大幅提升多模态语义理解的性能.但是, 它们本质上还是数据驱动的学习范式, 即在大规模有标注数据的帮助下, 拟合基于Trans-former[3]的复杂网络结构.虽然训练后的模型能从大量数据中学习丰富的多模态知识(包括语义概念、关系、结构等), 但是这些知识与模型是高度耦合、内置的, 无法灵活地进行修改和独立使用.因此, 在进行跨场景迁移时, 仍需要在新场景下收集大量有标注的多模态数据, 再通过模型微调提升新场景下的泛化性.
与数据驱动的方法不同, 人类能在不依赖海量有标注数据的情况下, 鲁棒且自适应地理解复杂场景下的多模态语义信息, 其中一个主要原因就是人类对于知识的学习和运用[4].根据认知神经科学领域的最新研究成果[5], 人脑中包含知觉(视觉、听觉、触觉等)-语义双系统知识加工和存储模块, 可将语义类别知识与来自不同感知通道的多模态信息关联, 进而实现复杂场景下多模态语义信息的选择性提取、长时分布式存储、动态交互式推理等重要认知功能.显然, 这些功能都是目前数据驱动的方法不具备的.
人类学习和运用知识实现多模态语义理解需要依靠双重知识表征、情景知识学习、演绎知识推理等关键认知过程.其中, 双重知识表征是语言驱动的表征和感官驱动的表征这两种不同来源的知识表征的统称.语言驱动的表征主要来自自然语言, 而感官驱动的表征主要来自触觉、视觉、嗅觉和听觉等感知觉.因此人脑中不同模态的知识是语义关联、分布式存储的, 不需要复杂模型就能关联多模态信息.情景知识学习是指人脑在一个场景内学习的新知识, 可与记忆进行交互, 通过更新记忆中的旧知识实现知识学习.因此在人脑中, 知识学习主要与记忆机制密切相关.人脑利用情景记忆对动态事件进行时空记忆, 有效处理高动态内容, 因此不需要标注大量成对数据进行模型学习.演绎知识推理是结合已有知识进行推理, 推导具有逻辑必然性的结论的这一过程.人脑基于已有知识, 结合不同场景信息进行自适应决策, 这是一种归纳演绎的过程, 并且是一种跨场景泛化性很强的符号化推理过程, 认知机制和过程是低功耗的.
近年来, 已有部分学者尝试把类人知识进行建模, 并且引入深度学习方法中[6, 7].Wu等[6]引入知识库并生成查询, 向模型提供图像本身以外的信息, 能回答广泛的基于图像的问题.他们通过大量实验证实, 引入知识确实有助于提升复杂场景下的多模态语义理解性能.因此, 为了更深入地了解当前知识驱动的多模态语义理解方法的研究进展, 本文首先对现有多模态学习方法进行简要回顾, 再介绍两类多模态知识表示框架并进行对比分析.然后, 以图文匹配、视觉-语言导航等作为典型任务, 介绍知识驱动的方法, 并通过实验展示引入知识带来的性能增益.最后总结相关方法, 展望未来可能的发展趋势.
多模态语义理解经过几十年的发展, 涌现出种类繁多、功能各异的方法.由于篇幅受限, 本文仅选取其中最具代表性的多模态融合、多模态对齐、多模态生成这3类方法进行简要回顾, 更加详细的方法分类和介绍请参考文献[8].
多模态融合主要研究如何有效整合来自两个或多个模态的语义信息以执行预测, 它是多模态学习中提出最早、研究最多、应用最广的方向之一.早期的多模态融合方法大多与使用的具体模型无关, 更多关注不同模态数据在不同阶段的整合.按照整合阶段划分, 大致可以分为特征层融合和决策层融合.其中, 特征层融合方法[9, 10, 11]通常在提取特征后串联不同模态的特征, 而决策层融合[12, 13, 14]在利用每种模态做出预测后再融合相应的结果.当然, 这两种融合方法也可结合进行, 通常也会获得更优结果.
与模型无关的方法不同, 还有很多模型相关的多模态融合方法, 针对不同模型各自的特点设计相应更好的特征或决策融合方式.具有代表性的方法包括:基于多核学习的融合方法[15, 16]、基于图模型的融合方法[17, 18]、基于深度神经网络的融合方法[19, 20].多模态融合能有效整合来自不同模态的信息, 提高预测的准确性.融合的层面、网络结构多种多样, 但如何处理不同模态数据整合的复杂性, 以及在特定应用中选择最合适融合方法, 仍是待解决的难点之一.
多模态对齐主要研究如何确定来自不同模态数据包含内容之间的语义关系.例如:给定一幅图像和一个文本, 希望找到与文本单词对应的图像区域.早期的多模态对齐方法大多是显式地对不同模态之间对应关系进行建模, 通常利用成对标注的多模态数据进行有监督学习.这方面具有代表性的方法包括:典型关联分析[21, 22, 23]、动态时间规整[24, 25]和卷积神经网络[26, 27].
在有监督学习之外, 还有一部分方法探索无监督学习和半监督学习方式, 但是性能通常低于有监督学习方法.
与此同时, 一些方法不再显式对齐多模态数据, 而是隐式在模型训练中实现隐式对齐.这些方法通常是把多模态对齐作为其它相关任务的中间步骤.例如:在语言驱动的视频事件检索任务中隐式对齐语言单词和视频片段[28]、在机器翻译任务中隐式对齐不同语言的单词[29]、在图像描述任务中隐式对齐图像区域和描述单词[30].多模态对齐有助于确定不同模态间的语义关系, 增强数据的解释性.然而, 显式对齐依赖于成对标注的数据, 这可能限制其在未标注数据中的应用.
多模态生成主要研究如何基于一种模态数据生成另一种模态数据, 并且保持两者的语义一致性.早期的多模态生成方法通常是基于数据检索的方式, 即直接使用检索的目标模态数据作为生成结果.按照检索方式划分, 又可进一步分为单模态检索方法和跨模态检索方法.
单模态检索方法[31, 32]通常是以给定的一种模态数据作为查询, 在候选集上检索语义相关的相同模态数据, 再将对应的其它模态数据作为查询模态数据的生成结果.跨模态检索方法[33, 34]是将不同模态数据映射到同个特征空间, 直接对比不同模态数据之间的相似性并进行检索.除了基于数据检索的多模态生成方法之外, 近期更多的方法是直接采用跨模态数据生成的方式.这些方法主要基于编码器-解码器的框架, 即使用编码器对给定模态数据进行模态无关的特征编码, 再使用解码器从编码后的特征中生成目标模态的数据.其中, 编码器和解码器通常是各种深度学习模型, 如深度神经网络[35, 36]、卷积神经网络[37, 38]、长短时记忆网络[39, 40]等.
多模态生成能在捕获跨模态的复杂关系方面显示出巨大的潜力, 并据此学习到更好的特征表示, 提高模型性能.然而, 可能难以保证生成模态间的语义一致性, 特别是在复杂或抽象的数据生成中, 如何生成质量较高的其它模态数据仍是一个挑战性的问题.
Huang等[11]提出ML-CRBM(Multi-label Conditional Restricted Boltzmann Machine), 可处理多模态(如图像和文本)的融合, 并预测多个标签.该方法在某种程度上类似于关系知识表示框架, 其中不同的多模态语义概念(如图像中的对象、属性、动作, 以及文本中的名词、动词、形容词)被表示为图网络中的节点.ML-CRBM虽未显式形成一个图网络, 但在类标签的监督下隐式对齐和融合这些多通道概念.Plummer等[21]将特定的图像区域(包括目标、属性、行为的视觉语义)与文本提示(包括名词、形容词、动词的语言语义)联系起来, 在视觉和语言语义概念之间建立对应关系, 从而为视觉内容中的语言提供丰富、结构化的基础.
与上述多模态语义理解方法不同, 知识驱动的方法需要额外对类人知识进行建模.依据使用的知识表示方式, 可划分为两类方法, 分别使用两种知识表示框架, 即关系型知识表示框架和概念型知识表示框架.
关系型知识表示框架的主要特点是将不同的多模态语义概念知识, 如图像中的目标、属性和行为, 文本中的名词、动词和形容词, 都表示为同个图网络中的不同节点, 不同节点之间的连接边表示不同知识之间的语义关系.其中的语义关系可能包含多种类型, 如从属、方位等.关系型知识表示框架方面的代表性工作是维基图像百科(IMGpedia)[41]和多模态知识图谱(Multi-Modal Knowledge Graph, MMKG)[42].它们都是通过补充视觉信息将传统单模态文本知识图谱扩展成图文多模态知识图谱.
为了构建关系型知识表示框架, 首先需要确定将要使用的单模态语言知识图谱, 其中语言知识图谱的数量可以不止一个.它们包含图结构化的单词, 单词总体数量可达到万级.然后, 在语言知识图谱的基础上, 对于其中重要的单词, 从公开图像数据库上检索获得语义相关的图像, 再与单词关联.关联方式主要有两种:1)图像作为单词节点的属性节点, 仅与当前的单词节点建立联系; 2)图像作为与单词节点地位对等的图像节点, 可与其它图像节点和单词节点同时建立联系.最后, 当给定一个复杂场景下的多模态语义理解任务, 可把观测到的数据作为查询, 在多模态知识图谱中检索得到相关的文本、图像作为相关知识, 以“ 数据+知识” 融合的推理方式预测结果.
图1给出关系型多模态知识表示框架, 在图中, 建筑物图像与建筑物名称均为多模态知识图谱上的节点, 节点与节点之间以有向边进行连接, 这些边描述由谓词标记的两个实体之间的关系.在图中, 有向边表达节点之间“ 位于” 、“ 包含” 、“ 邻近” 和“ 类似” 等方位或从属关系.
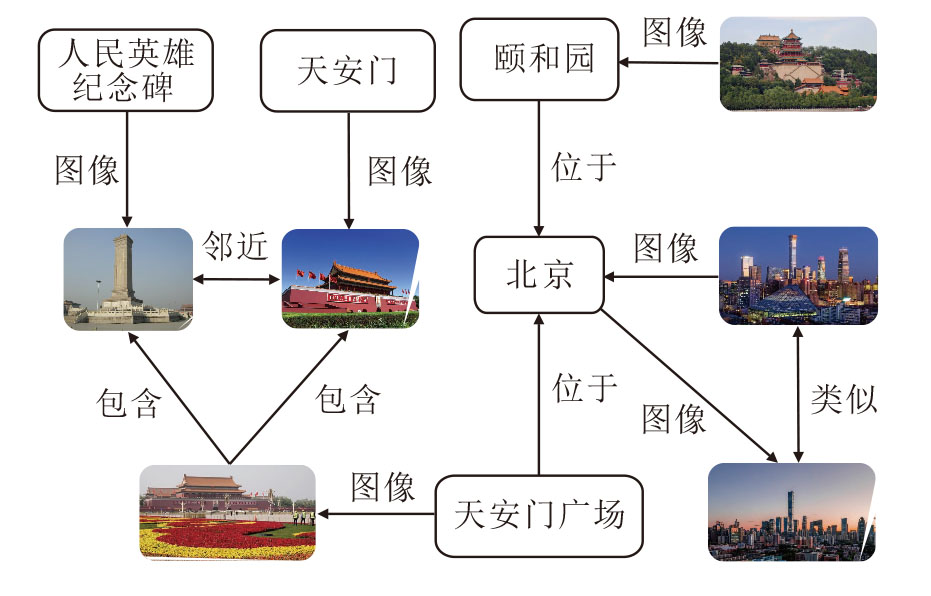 | 图1 关系型多模态知识表示框架Fig.1 Framework for relational multimodal knowledge representations |
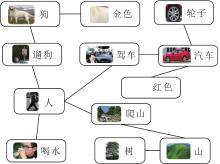
对齐型知识表示框架的主要特点是建立不同模态语义概念知识之间的一一对应关系, 如将视觉语义概念(包括目标、属性、行为)与语言语义概念(包括名词、形容词、动词)分别配对.这里的一一对应关系没有多种类型, 仅仅只是表示不同模态的概念知识在语义上是一致的.对齐型知识表示框架方面的代表性工作是MACK(Multimodal Aligned Concep-tual Knowledge)[43]和ACMM(Aligned Cross-Modal Memory)[44].它们都是受到人脑记忆双系统等机制的启发, 构建多模态一一对应的概念知识.
为了构建对齐型知识表示框架, 首先需要从公开的图像或多模态数据集上收集成对的图像区域与相应类别标签, 其中, 图像区域包含视觉语义概念, 类别标签包含语言语义概念.对于每个类别标签, 对应的图像区域可能包含成千上万个, 这主要是由于视觉语义概念在不同场景下存在明显的表观差异.为了实现一一对应, 需要对属于同个类别的图像区域进行统一表示, 如视觉原型表示.然后, 类别标签总体是隐含层级结构的, 如“ 动物” 类别包含“ 猫” 、“ 狗” 、“ 水獭” 等类别, 因此以树结构的知识组织方式可提升知识的可解释性.在知识使用方面, 通常采用“ 数据→ 知识” 层次化的推理方式预测结果.首先, 采用数据驱动的方式对结果进行大致预测, 在此基础之上, 采用知识驱动的方式对结果进行精细优化.
图2给出对齐型多模态知识表示框架, 图中每个节点都包含一对图像及其语义概念上一致的文本, 如“ 汽车” 的图像及类别标签.这些节点以无向边进行连接, 构成一个树结构, 根节点是“ 人” 的图像及类别标签.
 | 图2 对齐型多模态知识表示框架Fig.2 Framework for aligned multimodal knowledge representations |
本文从数据来源、知识种类、知识数量、知识组织方式等方面, 对比两种知识表示框架的代表性方法MMKG和MACK, 具体如表1所示.
| 表1 MMKG和MACK的对比 Table 1 Comparison between MMKG and MACK |
1)由于更多侧重于实体类型的知识, MMKG的数据来源分为两个方面.
(1)语言实体等直接来自已有的语言知识图谱, 如Freebase[45]和DBpedia[46].
(2)与实体相关的图像数据来自Google Image等搜索引擎.而MACK更关注概念知识, 数据来源通常是公开的视觉或多模态数据集上的标注信息, 如Visual Genome数据集[47]等.
2)在数量上, MMKG的知识数量比MACK的数量大约少一半, 因此有可能无法有效识别少样本的多模态类别.当然, 两者的知识数量都具有进一步扩充的能力, 通过添加新的语言实体(或概念)及其相应的图像(或视觉原型表示)即可.
3)MMKG和MACK在组织方式上也有很大区别.MMKG采用知识图谱常用的三元组方式, 表征侧重不同模态知识之间的关联性, MACK采用树结构方式组织知识, 在每个树节点上都明确建立不同模态知识之间的一一对应关系.
4)MMKG提供的关联知识更多的是辅助已有模型进行有监督学习, 而MACK提供的对齐知识能独立于已有模型之外进行无监督学习.相应地, 两者的知识推理方式不同, MMKG是“ 数据+知识” 融合的方式, 而MACK是“ 数据→ 知识” 层次化方式.
5)当给定新场景, MMKG主要是为场景中的多模态内容提供关联的知识, 这些知识无法针对这个场景进行自适应更新.而MACK设计无监督的知识自适应更新方式, 能对关联的知识表示进行二次优化, 使其更适应该场景.
在多模态语义理解方法与多模态知识表示框架的基础上, 选取图文匹配、目标检测、语义分割、视觉-语言导航等作为代表性应用场景, 简要介绍与分析知识驱动的新型多模态语义理解方法.
图文匹配是指在给定多个图像和文本的情况下, 通过计算图像和文本之间的跨模态相似度以判断任意一对图像和文本是否匹配.例如:未配对的图文匹配场景、遥感影像检索、少镜头图像和句子匹配等.在关联型知识表示框架下, Shi等[48]提出SCG(Scene Concept Graph), 首先预测图像的语义概念, 再在知识图谱中进行概念拓展, 提供更多的视觉信息用于关联文本.Mi等[49]从外部知识图谱中依据文本信息找到语义相关的知识三元组, 允许基于句子中提到的目标作为起点, 挖掘知识图谱中的扩展节点和边, 并作为特征嵌入, 丰富仅从文本内容中提取的特征, 进而提升文本表示能力.该方法成功应用于遥感图文匹配任务中.作者提出的基于知识的跨模态检索方法, 可挖掘外部知识图谱中的相关信息, 丰富搜索查询中可用的文本范围, 减轻文本和图像之间的信息差距, 从而实现更好的匹配.
传统的图像-文本匹配方法侧重于全局对应(整个图像和文本)或局部区域-单词对应, 然而, 这些方法往往无法捕捉结构化目标关系和属性之间的细粒度对应关系.Liu等[50]虽然未利用外部知识, 但是通过将图像和文本数据表示为类似知识图谱的形式, 其中节点表示目标、关系或属性, 边基于语义或空间依赖而存在, 可学习更详细的对应关系, 克服学习图像和文本之间的细粒度对应的挑战, 包括在传统方法中经常被忽视的关系和属性, 也能有效提升图文匹配的精度.
在对齐型知识表示框架下, Huang等[43]提出多模态对齐概念知识方法, 通过显式存储成对的单词-视觉原型表示, 能将关于目标、动作和属性的语义知识关联视觉和语言信息, 克服训练需要成对的图文数据集的限制, 稳定提升多个主流多模态预训练模型在零样本图文匹配上的泛化性.作者使用自动化技术建模多模态对齐的概念知识, 减少对详细标注的依赖, 同时提高图文匹配模型的性能.Huang等[44]提出ACMM, 知识的图结构允许对多模态少样本内容进行连续表示、对齐和记忆, 便于在匹配任务中使用这些表示作为参考, 有助于自适应平衡匹配过程中少镜头和常见内容的相对重要性, 有效改善少样本对模型性能的影响.
表2对比多种图文匹配方法在Flickr30k数据集[51]上的性能, 表中文献[52]方法为基准方法, R@N表示检索结果排序前N的召回率.由表可看出, 相比SCG, ACMM能更明显提升图检索文和文检索图两个子任务的精度.
| 表2 各图文匹配方法在Flickr 30k数据集上的性能对比 Table 2 Performance comparison of different image-text matching methods on Flickr 30k dataset % |
综上所述, 虽然现有的图文匹配方法能提取全局视觉信息, 但通常无法有效捕捉图像中的高级语义信息, 特别是当这些概念是长尾或被遮挡时, 导致图像和语言之间存在语义鸿沟.
通过构建知识图谱, 可扩展图像中的语义概念, 为模型提供常识性知识, 使其能推断图像中未直接检测的相关概念, 提高模型在现实世界中应用的适应能力.
引入知识图谱还有助于减少文本和图像之间的信息差距, 实现更好的匹配.然而, 在少数样本内容与常见内容之间的取舍、被遮挡或长尾数据的处理上, 或由于信息不对称、复杂的句子结构干扰图结构的节点生成时, 现有方法性能下降.
目标检测是在给定的图像或视频中, 识别一组区域或边界框, 并使用预定义的目标标签之一进一步对每个边界框进行分类.
现有目标检测算法主要依赖图像中的特征, 往往忽略关于现实世界的大量背景知识.人类使用常识或关于世界的隐含知识, 这通常不会被标准的物体检测算法利用.知识图谱可提供这种缺失的背景知识, 使用节点表示真实世界的概念, 边表示这些概念之间的关系, 对语义知识进行建模.例如:某些目标组合的可能性高于其它目标.
在关联型知识表示框架下, Fang等[53]提出KG-CNet, 采用语义一致性量化目标之间的关联关系, 将知识图谱集成到目标检测流程中.Wang等[54]将知识图谱用于描述视觉目标之间的语义关系, 再将语义关系用于提升模型对于新目标的检测能力.作者使用知识图谱, 并根据检测的目标及其属性构建知识子图, 以此增强场景的语义表达, 从而辅助检测新对象, 最终提高在标注数据有限的复杂场景中的目标检测性能.此外, 作者还对知识图谱中的知识进行量化和泛化, 允许模型推断图像中未明确出现在训练数据中的关系和上下文.KG-CNet可在不影响平均精度的情况下显著提高召回率, 提升模型理解复杂场景的能力.
传统方法通常使用跨模态数据(如语言和统计数据)获得上下文先验, 但性能不佳.Yang等[55]将视觉信息表征为知识图谱的形式, 用于模型知识蒸馏, 有效提升目标检测模型的效率.知识图谱通过基于几何或语义相似性建立的边编码节点间的上下文, 提供一种更直观有效的上下文表示方式.
在对齐型知识表示框架下, Rambhatla等[56]提出双记忆模型, 利用工作记忆和语义记忆模块分别发现未知类别和已知类别的目标.Xiong等[57]建立目标类别与视觉原型表示之间的联系, 提升开放场景下目标检测的性能.
KG-CNet[53]、POD[57]、SSD(Single Shot Multibox Detector)[58]、文献[59]方法在VOC2007[60]、Thu-mos14[61]数据集上的平均精度均值(Mean Average Precision, mAP)对比如表3所示.
| 表3 各目标检测方法在2个数据集上的mAP对比 Table 3 mAP comparison of different object detection methods on 2 datasets % |
VOC2007数据集是自然场景下的通用目标检测数据集, 而Thumos14数据集是视频场景下的行为检测数据集.
除了目标检测之外, Huang等[59]提出双流关系原型网络, 建立成对的行为类别-视觉原型表示集合, 较好地解决场景标注数据缺失的问题, 取得当时弱监督行为检测的最佳性能.
综上所述, 融合知识图谱的少镜头目标检测方法提供一种结构化的方式, 结合新目标类型的关系推理和常识知识, 如目标、属性及相互关系, 增强在数据有限和目标间关系复杂场景下的检测能力, 以及理解真实世界场景中上下文关系的能力.然而, 目前的方法仍需要构建专门为视觉任务量身定做的知识图谱, 限制方法的泛化能力.
为搜索到的网络结构样本建立一个快速的性能预测和推理开销估计方法体系是一项挑战性工作.主要困难在于, 对于每个采样结构, 在给定的图像或视频中语义分割, 分割不同语义类别对应的目标轮廓, 包括通过仅使用几个带注释的支持图像, 分割查询图像中未见类别的前景目标.
传统方法在处理每个像素区域时, 往往只关注局部的信息, 却忽略区域之间的关键语义依赖性.而融入外部知识后, 可以引导模型同时学习全局语义特征.
在关联型知识表示框架下, Chen等[62]提出KRNet(Knowledge Reasoning Net), 包含一个先验知识映射模块, 能把外部知识图谱通过图卷积网络进行整合, 进而为语义分割提供更多辅助信息.Liang等[63]提出SGR(Symbolic Graph Reasoning), 能使深度学习模型在进行局部特征学习的同时, 与外部知识图谱进行有机结合.通过结合本地特征和符号节点的表示, 并在知识图谱中进行信息传播, SGR实现全局语义一致性和推理, 不仅增强局部特征表示, 也使网络能在更广泛的概念词汇中进行有效识别.
Xie等[64]提出SAGNN(End-to-End Scale-Aware Graph Neural Network), 将不同图像组织为图结构中的不同节点, 通过关系推理的方式提升少样本语义分割任务的性能.
在对齐型知识表示框架下, Fan等[65]提出基于记忆的跨图像上下文方法, 其中的记忆模块包含成对的语义类别和相应的跨图像共享的上下文特征, 能有效提升弱监督语义分割的性能.Mao等[66]提出DPNet(Dual Prototype Network), 能同时提取查询图像和候选图像的原型特征, 成功应用于少样本语义分割任务.
Yang等[67]提出AAMN(Actor and Action Modular Network), 模拟多模态对齐记忆机制, 较好地处理语言驱动的视频分割任务.
多种语义分割方法在PASCAL-
| 表4 各语义分割方法在3个数据集上的性能对比 Table 4 Performance comparison of different semantic segmentation methods on 3 datasets |
综上所述, 通过图卷积网络融入外部知识, 能指导语义表示的学习, 增强网络的全局语义推理能力.然而, 在利用知识获得额外信息时, 应当更具有选择性, 只使用有用的补充信息, 避免丢失重要的上下文或特定于功能的细节.
视觉-语言导航是在让机器人在三维室内环境中, 在用户给定语言指令的情况下, 结合动态采集的环境视觉信息, 多次采取导航行为到达指定位置.例如:基于视觉的语言辅助导航(Vision-Based Naviga-tion with Language-Based Assistance, VNLA)是为机器人在现实环境中执行高级语言指令而设计的.
在关联型知识表示框架下, Li等[72]提出KERM(Knowledge Enhanced Reasoning Model), 利用外部知识图谱中关联导航场景的事实信息与环境的当前上下文相匹配, 增强模型对复杂的导航场景的理解和决策能力, 同时增强机器人的视觉特征表示能力, 减少对大量带注释的数据集的依赖.
Li等[73]把外部知识图谱中的常识引入视觉-语言导航任务中, 允许机器人进行多步骤目标实体动态推理, 更全面的理解房间和物体关系.
在对齐型知识表示框架下, Lin等[74]提出基于多模态Transformer的记忆模型, 整合视觉和语言信息到一个可变长度的记忆模块中, 为机器人长时间跨度决策提供支撑.Lin等[75]提出ADAPT(Modality-Aligned Action Prompts), 建立机器人的语言指令-视觉行为集合, 在机器人导航过程中进行自适应选择.An等[76]提出BEVBert, 让机器人具备自适应建立语义-空间地图记忆的能力, 提升在新场景下的导航泛化性.
多种视觉-语言导航方法在R2R[77]、REVE-RIE[78]数据集上的性能对比如表5所示, 表中包括一个基准方法HAMT(History Aware Multimodal Trans-former)[79].从表中可以发现, 融入知识能普遍降低机器人的导航误差, 并取得与基准方法可比或更高的成功率.其中, 基于对齐型知识表示框架的方法(BEVBert)相比同期基于关联型知识表示框架的方法(KERM)具有可比或更优的性能, 这体现对齐型知识表示框架在视觉-语言导航任务上的发展潜力.
| 表5 各视觉-语言导航方法在2个数据集上的性能对比 Table 5 Performance comparison of different vision-and-language navigation methods on 2 datasets |
综上所示, 知识增强智能体的泛化能力.通过融入知识, 模型可较好地解释和遵循复杂的指令, 从而实现更准确的导航.目标属性和关系的知识有助于更好的解释说明, 并将其与可视内容对齐.此外, 引入知识还可提供物体和房间之间、从直接的视觉和语言输入中不容易获得的额外背景和关系, 加深机器人对环境的理解.然而, 模型应进一步探索如何在引入知识图谱的情况下, 提高处理更动态的输入环境的能力, 并减少框架设计的复杂程度.
通过回顾传统的多模态语义理解方法, 对比两种主要的知识表示框架, 分析不同任务的最新研究进展, 能得出如下结论.
1)传统的以数据驱动为主的多模态语义理解方法高度依赖与场景相关的有标注数据, 无法适应复杂场景下的多模态语义理解的新需求.在处理复杂场景时, 可能无法准确识别和对应图像中的细节信息与文本中的描述.
2)引入知识确实可有效提升多模态语义理解的性能, 但是目前的知识表示、推理与组织的方式还较单一, 还有很大的提升空间.
3)目前已有的知识驱动的方法更关注静态的语义概念和实体, 很难适应以事件为中心、快速动态发展的复杂场景.
因此, 本文展望未来可能的发展趋势.
1)建议探索更细粒度的对象级别连接, 以及在句子中单词与知识图谱节点之间的关系, 扩展到更多模态任务中.考虑从动态知识更新和高级知识推理等方面挖掘更多的有用信息.此外, 应当学习结构化对象关系和属性的细粒度对应.
2)将知识推理应用于新的多模态场景下游任务, 模拟人类知识推理, 提高鲁棒性和泛化能力.可尝试使用Transformer进行知识图谱的提取和学习, 有助于捕获图像中的结构信息和序列级别的依赖关系.探索面向开集(Open Set)的方法, 从图像中检测看不见的目标.
3)提高模型的可解释性, 有助于较好理解和改进决策过程.
总之, 知识驱动的多模态语义理解方法具有广阔的应用场景, 但目前面临知识来源单一、推理模型简单、难以适应动态事件等挑战性难题.未来有望从这些问题出发, 分析现有方法存在的局限性, 结合复杂场景下多模态数据和知识自身的特点, 构建大规模系统化的知识建模理论和方法, 探索知识与数据有机结合的新框架.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|
| [47] |
|
| [48] |
|
| [49] |
|
| [50] |
|
| [51] |
|
| [52] |
|
| [53] |
|
| [54] |
|
| [55] |
|
| [56] |
|
| [57] |
|
| [58] |
|
| [59] |
|
| [60] |
|
| [61] |
|
| [62] |
|
| [63] |
|
| [64] |
|
| [65] |
|
| [66] |
|
| [67] |
|
| [68] |
|
| [69] |
|
| [70] |
|
| [71] |
|
| [72] |
|
| [73] |
|
| [74] |
|
| [75] |
|
| [76] |
|
| [77] |
|
| [78] |
|
| [79] |
|