



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于知识引导的自适应序列强化学习模型
[李迎港1  , 童向荣
, 童向荣1 ]
, 童向荣]
|
|



作者简介:
李迎港,硕士研究生,主要研究方向为深度强化学习、推荐系统.E-mail:lyg565795678@163.com.
序列推荐可形式化为马尔科夫决策过程,进而转化为深度强化学习问题,其关键是从用户序列中挖掘关键信息,如偏好漂移、序列之间的依赖关系等,但当前大多数基于深度强化学习的推荐系统都是以固定序列长度作为模型输入.受知识图谱的启发,文中设计基于知识引导的自适应序列强化学习模型.首先,利用知识图谱的实体关系,从完整的用户反馈序列中截取部分序列作为漂移序列,其中漂移序列中的项目集合表示用户的当前偏好,序列长度表示用户的偏好变化速度.然后,通过门控循环单元提取漂移序列中用户的偏好变化和项目之间的依赖关系,同时利用自注意力机制对关键的项目信息进行选择性关注.最后,设计复合奖励函数,包括折扣序列奖励和知识图谱奖励,用于缓解奖励稀疏的问题.在4个真实世界数据集上的实验表明,文中模型的推荐准确率较优.
AboutAuthor:
LI Yinggang, master student. His research interests include deep reinforcement learning and recommender system
The sequence recommendation can be formalized as a Markov decision process and then transformed into a deep reinforcement learning problem. Mining critical information from user sequences is a key step, such as preference drift and dependencies between sequences. In most current deep reinforcement learning recommendation systems, a fixed sequence length is taken as the input. Inspired by knowledge graphs, a knowledge-guided adaptive sequence reinforcement learning model is proposed. Firstly, using the entity relationship of the knowledge graph, a partial sequence is intercepted from the complete user feedback sequence as a drift sequence. The item set in the drift sequence represents the user's current preference, and the sequence length represents the user's preference change speed. Then, a gated recurrent unit is utilized to extract the user's preference changes and dependencies between items, while the self-attention mechanism selectively focuses on key item information. Finally, a compound reward function is designed, including discount sequence rewards and knowledge graph rewards, to alleviate the problem of sparse reward.Experiments on four real-world datasets demonstrate that the proposed model achieves superior recommendation accuracy.
随着互联网的高速发展, 以及抖音、新浪微博等多元化互联网产品的兴起, 互联网信息更新的速度越来越快, 用户可选择的信息也越来越丰富, 用户的偏好也可能在短时间内急剧变化.这就给推荐系统带来新的挑战:序列推荐系统[1]必须及时捕获用户的当前偏好和序列模式.如果仅利用协同过滤[2, 3]和矩阵分解[4, 5]等传统方法为用户推荐项目, 那么将无法应对用户-项反馈数据的自适应性问题以及长期推荐性能问题.
近来, 深度强化学习(Deep Reinforcement Lear-ning, DRL)的兴起为顺序推荐系统带来新的解决方案[6, 7, 8, 9]:构建一个与用户交互的智能体, 挖掘潜在有趣的项目.基于DRL的推荐系统[10, 11, 12, 13, 14, 15]通过最大化累计奖励值优化长期性能, 受到研究者的广泛关注, 但目前仍存在一些问题亟待解决.
1)基于DRL的顺序推荐系统大多采用固定的序列长度作为状态表示.当用户偏好发生急剧变化时, 无法对过往偏好的交互数据进行有效分割.此外, 用户需要购买某个产品, 可能仅仅由序列中个别关键的交互数据决定, 但是当前的推荐系统无法识别这些关键的交互信息.
2)奖励值的稀疏性.在用户-项反馈数据出现数据稀疏和冷启动问题时, 一般采用随机策略探索用户的动态偏好, 使推荐系统得到用户的正反馈较少.传统方法仅使用正反馈作为奖励值, 由于推荐智能体无法获得足够且有效的奖励值, 不仅导致模型的训练时间增加, 甚至可能导致推荐智能体无法收敛到一个合适的策略.
近年来, 知识图谱(Knowledge Graph, KG)[16]已在许多领域中表现出强大的适用性和可行性, 也已广泛应用到序列推荐任务中[17, 18].KG中两个不相关的商品在特征表示上存在本质的不同, 通过商品的特征表示就能找到商品之间的关联性, 从而向用户推荐关联性强的商品.
基于KG的推荐系统可以分为两类:1)基于KG生成实体和商品特征, 进而提高推荐系统的准确性; 2)基于显式路径推理的可解释推荐系统, 利用KG结构化信息生成推荐路径.
Zhang等[19]将KG中实体和关系的结构化信息通过TransR得到实体的特征向量, 扩充项目的结构化信息, 与协同过滤结合, 解决推荐结果多样性问题.Huang等[20]采用TransE生成KG的实体和关系特征, 设计内嵌键值对的循环神经网络模型, 捕捉用户的序列偏好和用户属性偏好.此外, 一些研究人员将用户-项二部图和KG结合, 生成协同知识图谱用于推荐系统.Zhang等[21]定义用户物品知识图的概念, 并采用TransE生成图中关系和节点的特征, 提高推荐性能.Wang等[22]提出KGAT(Knowledge Graph Attention Network), 采用图卷积和注意力机制的形式挖掘用户和项目之间的高阶连通性.宁泽飞等[23]借助两种知识图谱强化用户的标签信息和项目的语义信息, 同时利用图卷积神经网络捕捉知识图谱中的低、高阶连通性.李想等[24]利用知识图谱中实体之间的关系学习用户和项目的向量表示, 缓解数据稀疏和冷启动的问题, 提高推荐准确率.
上述基于KG的推荐系统仅将推荐系统作为一个静态模型, 不考虑项目带来的长短期收益.
序列推荐系统与用户交互得到的交互轨迹本身就是序列, 因此序列推荐系统的问题可以由马尔科夫决策过程(Markov Decision Process, MDP)描述, 并利用深度强化学习优化解决.基于DRL的推荐系统主要改进用户状态表示、设计奖励函数及添加额外的神经网络辅助深度强化学习网络训练.Lei等[25]设计图卷积神经网络的变体, 由结构化的特征表示DQN(Deep Q-Network)中用户状态和动作, 加强不同用户之间的潜在联系.Liu等[26]在基于深度确定性策略梯度的推荐系统基础上, 设计四种状态表示方法, 提高推荐系统对商品序列的感知能力.Xin等[27]结合自监督学习和强化学习, 提高监督端和强化学习端在缺乏负奖励环境下的推荐性能.He等[28]采用多智能体强化学习方法, 在不同推荐模块协助下训练全局最优的推荐模型.Xian等[17]借助KG中的结构化信息, 设计路径搜索的状态表示和奖励函数, 使推荐系统具有显式的可解释性.Lei等[29]利用社交网络强调用户之间的信任关系, 构建具有社交网络的用户状态表示, 解决数据稀疏和冷启动问题.王潇等[30]从实时、静态、动态三方面建模深度强化学习状态表示模型, 并用于排序直播推荐.亓法欣等[31]采用强化学习的方法提高用户对推荐系统的信任, 设计关于信任的奖励函数, 提高推荐系统的推荐准确度.
上述工作虽然利用KG信息和强化学习优化推荐效果, 但是通过固定的用户反馈序列长度作为模型输入, 因此限制推荐的准确率.
本文提出基于知识引导的自适应序列强化学习模型(Knowledge-Guided Adaptive Sequence Reinfor-cement Learning Model, KASRL), 将序列推荐任务转化MDP, 通过KG信息引导状态表示和设置奖励函数.当引导状态表示都使用KG的特征信息时, 容易产生对KG信息过度依赖.当KG信息出现偏差时, 推荐智能体不仅误判用户的偏好漂移而且生成错误的状态表示, 扰乱推荐智能体的决策.因此KASRL将引导和表示分离, 仅在引导阶段利用KG信息, 再使用传统特征向量进行状态表示, 避免KG信息偏差对状态表示的影响.另外, 在奖励函数的设置上, 传统方法通常以单步推荐为指标, 而单步推荐的奖励值无法提供后续推荐的反馈信息.因此KASRL以多步推荐和KG信息为指标, 设置折扣参数, 权衡当前推荐序列的奖励值, 以此使推荐智能体快速得到用户的正反馈.
具体过程如下.首先, 利用KG将完整用户-项交互序列转化为自适应的漂移序列, 再通过门控循环单元(Gated Recurrent Unit, GRU)从漂移序列中提取漂移状态, 用于探索用户的偏好漂移.同时, 利用自注意力机制(Self-Attention Mechanism)为完整用户-项交互序列中的项目调整相应权重, 输出注意力状态, 辅助模型区分数据中有益于推荐的信息.漂移状态和注意力状态的结合能增强状态表示.最后, 借助KG特征信息设计复合奖励函数.该奖励函数分为折扣序列奖励和KG奖励.折扣序列奖励在当前推荐商品的基础上分析后续推荐效果, 并将后续推荐效果作为奖励值.KG奖励将推荐项目与目标项目的相似度作为奖励值.二者分别通过深度和广度的探索方式为推荐智能体提供有效奖励, 增加奖励的密度, 加快训练收敛的速度.
定义1 用户集和项目集 U为用户集, 任意用户ui∈ U; I为项目集, 用户在第j步选中的项目xj∈ I.
定义2 用户交互序列 x1∶ t={x1, x2, …, xt}定义为用户-项交互序列.xm∶ n={xm, xm+1, …, xn}定义为x1∶ t的子序列, 1≤ m≤ n≤ t.
定义3 特征向量 将用户集和项目集映射到低维的向量空间, et∈ Rd表示项目xt的特征向量, em∶ n∈ R(n-m+1)× d表示序列xm∶ n的特征向量矩阵.此外, 利用TransE将项目集和用户集映射到低维的知识向量空间, 生成KG的结构化信息, kt∈ Rd表示项目xt的KG特征向量, km∶ n∈ R(n-m+1)× d表示序列xm∶ n的KG特征向量矩阵.
在序列推荐任务中, 对于每个用户ui, 考虑用户-项交互序列x1∶ t和KG信息, 在项目集I中找出ui最喜欢的项目xt+1, 借此提高用户对于推荐系统的满意值.
序列推荐任务可转化为MDP, 并采用DRL解决.MDP可以由(S, A, R, P, γ )五元组表述, 其中:S定义为状态集合, s∈ S用于描述用户和项目历史交互信息和KG信息; A表示智能体(推荐系统)动作集合, 包含离散候选项目, a∈ A表示智能体能够向用户推荐的项目; R定义为奖励函数, r=R(s, a)表示智能体在状态s时, 执行动作a获得的立即奖励; P表示状态转移概率函数, 其中下一个时间步状态P(st+1 |st, at)表示智能体在状态st时, 执行动作at到达下个时间步状态st+1的概率; γ ∈ [0, 1]表示折扣因子, 权衡当前和未来奖励的重要程度.
KASRL按照MDP构建任务模型.在每一幕中, 推荐智能体将在离散时间步长t=1, 2, …, T中与目标用户顺序交互.在每个时间步t下, 智能体会观测到一个状态st.st不仅包含用户-项反馈序列信息, 还添加KG信息作为辅助信息.
用户根据相应策略
其中,
通过历史反馈数据以及KG信息, 推荐智能体的目标是学习一个最优策略
G(π * )=
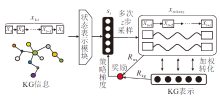
KASRL采用DRL, 在构建基于强化学习的模型时, 关键的两点是设计状态表示和奖励函数.状态表示用于建模目标用户的所有历史交互特征, 但是现有方法大多都关注如何从历史交互特征中构建综合偏好表示, 而不是利用外部信息探索用户是否发生偏好漂移.此外, 奖励函数的本质是向推荐智能体传递训练目标, 奖励函数设计的好坏直接影响到算法能否收敛, 甚至会影响算法性能.因此KASRL通过KG信息建模用户偏好漂移表示, 并基于KG信息设计复合奖励函数, 减少历史交互数据中的噪声, 进而提高推荐的准确率.KASRL基本框架如图1所示.
 | 图1 KASRL的基本框架Fig.1 Basic framework of KASRL model |
在真实序列推荐任务中, 往往具有如下特点:1)每个用户偏好漂移速度是不相同的, 因此选定固定序列长度学习用户偏好表示是不实际的.2)用户购买某个商品, 并不完全依赖整个序列, 而是归因于序列中某个或几个商品.
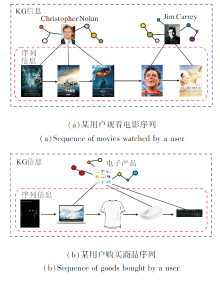
KG和用户-项交互序列如图2所示.(a)表示某用户观看电影的序列, 随着时间的推移, 该用户的偏好由Christopher Nolan导演的喜剧片 (第一阶段)转变为Jim Carrey主演的科幻片(第二阶段).在本例中, 如果状态表示时采取的固定序列长度大于4, 基于DRL的推荐系统将无法脱离第一阶段, 只能在第一阶段上继续探索.(b)表示某用户购买商品的序列, 该用户在购买电子产品期间也购买书籍和衣物等商品, 基于DRL的推荐系统可能会受到这些信息的误导, 导致推荐效果不佳.状态表示时采用交互序列越大, 状态中的噪音就会越多, 导致推荐智能体无法关注有益于决策的关键项目.
 | 图2 知识图谱和用户-项交互序列Fig.2 Knowledge graph and user-item interaction sequence |
因此, KASRL聚合漂移状态表示和注意力状态表示, 具体流程如图3所示.首先利用KG信息针对完整的用户-项交互序列截取部分序列作为漂移序列, 再将漂移序列和完整的用户-项交互序列分别通过GRU和自注意力网络生成漂移状态和注意力状态表示, 最后聚合两者, 生成最终状态表示.漂移序列能自适应调整序列的长度, 解决用户之间偏好漂移速度不同的问题.自注意力网络能捕捉序列中关键的项目信息, 赋予关键的项目信息更高的权重.
 | 图3 KASRL中完整的状态表示模块Fig.3 Complete state representation module in KASRL |
2.2.1 漂移状态表示
对于漂移状态表示, 首先借助KG信息从完整的历史交互序列x1∶ t中截取部分序列xm∶ t作为自适应漂移序列.采取标准的余弦相似度方法, 设计两种截取方式确定m的位置.
第一种截取方式单独选取最近固定长度的序列项目, 无法发现完整的用户偏好漂移, 因此借助KG信息中的项目特征向量作为相似度度量, 选取x1∶ t中的不同子序列的项目特征向量均值
$m=\arg\max_{m\in[0, t-b)}\bigg(\dfrac{\bar{k}_{t-b+1:\bar{k}}\bar{k}_{m:t}}{|\bar{\boldsymbol{k}}_{t-b+1:t}||\bar{\boldsymbol{\boldsymbol{k}}}_{m:t}|}\bigg)$,
其中,
第二种截取方式与第一种方式唯一不同之处在于x1∶ t中的不同子序列选取第一个历史项目xm与xt-b+1∶ t进行对比, 这样能够避免子序列中部分过时数据影响漂移的选择, 减少序列之间的相关性, 具体公式如下:
$m=\arg\max_{m\in[0, t-b)}\bigg(\dfrac{\bar{k}_{i-b+1:t}\bar{k}_m}{|\bar{k}_{t-b+1:t}||\bar{k}_m|}\bigg)$.
基于上述原因, 为了权衡两种方式在模型中的优劣之处, 采用加权的方式, 利用β ∈ [0, 1]控制两者的权衡, 即
$\begin{aligned}m=\arg\max_{m\in[1, i-i]}\bigg((1-\beta)\bigg(\frac{\bar{k}_{i-k+1, i}\cdot\bar{k}_{n-i}}{|\bar{k}_{i-i+1, i}||\bar{k}_{m-i}|}\bigg)+\\ \beta\bigg(\frac{\bar{\bar{k}}_{i-k+i\cdot i}\bar{k}_m}{|\bar{\bar{k}}_{i-k+1\cdot i}||\bar{k}_m|}\bigg)\bigg).\end{aligned}$
为了提取漂移序列中的序列性偏好, 如图3所示, 采用循环神经网络中的GRU进行编码:
ht=GRU(ht-1, et; wgru), (2)
其中, et表示项目xt的内嵌向量, wgru表示GRU的可训练参数.这里没有使用KG信息中的内嵌向量, 为了减少对KG信息的过度依赖, 从而构建用户的序列偏好.
2.2.2 注意力状态表示
注意力机制已成功应用在计算机视觉、自然语言处理等多个领域.在推荐任务中, 注意力机制能有效地对历史反馈序列中重要的项目赋予更大的权重, 使不同用户历史反馈序列中的相同项目拥有不同的权重.注意力机制中存在一种特殊方法— — 自注意力机制[32].自注意力机制对不同项目选择性关注的同时, 能适用长序列捕捉历史反馈序列之间的依赖关系.
因此, 如图3所示, KASRL将自注意力机制应用到完整的历史反馈序列, 结合KG信息, 捕捉有益于个性化推荐的项目信息.
具体地, 计算自注意力机制对不同项目信息的选择性关注:
Q'=ReLU(k1∶ twq), K'=ReLU(k1∶ twk),
其中, wq∈ Rd× d, wk∈ Rd× d分别表示Query和Key中可训练参数, k1∶ t∈ Rt× d, ReLU(· )表示激活函数.
通过Q和K非线性转换得到的Q'和K'作为输入, 输出注意力矩阵:
$\boldsymbol{\alpha}=softmax\left(\dfrac{\boldsymbol{Q}'\boldsymbol{K}^{\text{T}}}{\sqrt{d}}\right)\in\boldsymbol{R}^{t\times t}$,
其中d表示特征向量的维度.
注意力矩阵α 和KG序列特征向量矩阵k1∶ t相乘得到注意力加权矩阵:
k'1∶ t=α k1∶ t∈ Rt× d.
最后, 采用均值的方式聚合k'1∶ t, 得到最终的注意力状态表示:
$\bar{\boldsymbol{k}}_{1:t}'=\dfrac{1}{t}\sum_{j=1}^t\boldsymbol{k}_j'\in\textbf{R}^d$.(3)
2.2.3 最终状态表示
由KG信息截取得到漂移序列, 经过GRU生成漂移状态表示, 同时利用完整的历史反馈序列通过自注意力机制生成注意力状态表示.最终状态表示st由漂移状态表示和注意力状态表示拼接而成:
$s_t=\boldsymbol{h}_t\oplus\bar{\boldsymbol{k}}_{1:t'}$,
其中, ⊕表示拼接算子, ht中以自适应子序列的方式个性化地为每位用户寻找各自的偏好漂移程度, 并通过GRU捕捉序列之间的相关性,
奖励R(s, a)用于估计智能体的推荐质量, 如果仅仅以是否命中目标项目作为奖励, 可能在数据稀疏和冷启动时会受到奖励稀疏的影响.为了缓解此问题, 将KG信息作为评价推荐性能的指标.具体来说, 将奖励定义为
Rt=Rws(xt+1∶ t+z,
其中, xt+1∶ t+z表示用户真实交互的子序列,
2.3.1 折扣序列奖励
在序列推荐任务中, 奖励函数不仅仅以单步推荐为指标, 还需要多步序列的匹配程度作为衡量指标.在这里借用BLEU[33] 评价指标, BLEU能够准确评估预测序列的准确率.但是在机器翻译中, 序列中的信息都是等价的, BLEU并未考虑强化学习中折扣因子对于现在和未来的权衡.基于此改进BLEU, 即
$R_{\mathrm{ws}}(x_{t+1i+z}, \hat{x}_{t+1i+z})=\exp\bigg(\dfrac{1}{Y}\sum\limits_{y=1}^y\ln(prec_y)~~\bigg), $
其中
$pree_y=\frac{\sum_{c\in[t+1, z-y]}p^{c+t-1}\min(\#(x_{c+y+y-1}, x_{t+1, z+z}), \#(x_{c+z)-1}, \hat{x}_{t+1+z+z}))}{\sum_{c\in[(t+1, z)]}p^{r-1-1}\#(x_{c+t+z)-1}, x_{t+1+z})}.$
xc ∶ c+y-1表示xt+1∶ t+z的子序列; #(xc ∶ c+y-1, xt+1∶ t+z)表示xc ∶ c+y-1在xt+1∶ t+z中出现的次数; pc-t-1∈ [0, 1]表示以真实交互序列xt+1∶ t+z为根据, 为先后次序分配权重, xc ∶ c+y-1在xt+1∶ t+z中越靠前, 分配的权重越大; Y表示子序列xc ∶ c+y-1的长度上限.
该方法不仅能增加奖励的密度, 而且添加参数p, 考虑到推荐项目的重要程度和先后次序.
2.3.2 KG奖励
在KG奖励中, 借助KG信息关注推荐智能体推荐的项目与真实推荐项目的相似度.当推荐的项目并不匹配真实推荐项目时, 也能采用此方式估计推荐的质量.具体定义如下.给定kt+1∶ t+z和
Rkg(kt+1∶ t+z,
Rkg(kt+1∶ t+z,
为了充分训练KASRL, 在相同状态下多次进行z步采样, 采用蒙特卡洛强化学习算法建模KASRL.推荐智能体的目标是训练一个最优策略, 采用截断策略梯度方法训练模型参数, 在每个时间步st下多次采样z步子序列, 使推荐智能体得到充分训练, 即
$\nabla_{\phi}J(\pi_{\Phi})\approx\sum\limits_{j=l+1}^T\bigg(\gamma^{j-l-1}I_j\bigg(\dfrac{\nabla\pi_\Phi(\hat{x}_{l+1}^l\mid s_l)}{\pi_{\Phi}(\hat{x}_l^l\mid s_t)}\bigg)\bigg), $(5)
其中
KASRL步骤如下所示.
算法 KASRL
初始化 π 中参数Φ , 超参数p, β , b
利用TransE获得KG信息
for episode=1, 2, …, N do
for t=1, 2, …, T do
根据式(2)生成漂移状态表示ht, 根据式(3)生成注意力状态表示
生成当前状态表示st=ht⊕
for l=1, 2, …, L do
根据式(1)采样一条z步子序列
通过式(4)生成奖励rt
通过式(5)更新KASRL中的网络参数Φ ,
Φ ← Φ +μ
end for
end for
end for
在算法中, 每一幕的时间步下会生成当前的状态表示st, 推荐智能体通过st逐步交互生成L段序列
为了验证KASRL的推荐性能、状态表示和复合奖励函数的有效性, 采用3个亚马逊电子商务数据集(CDs、Books、Beauty数据集)和一个音乐数据集LastFM作为验证对象.数据集具体的统计信息如表1所示.
| 表1 实验数据集的统计信息 Table 1 Statistics of experimental datasets |
为了保证训练的可行性, 删除历史反馈序列小于5的用户和出现次数少于5的项目.此外KASRL需要通过KG信息引导, 因此在Books、LastFM数据集上通过KB4Rec[34]将项目和用户与实体连接, 生成KG特征.在CDs、Beauty数据集上按照PGPR中KG信息生成KG特征.
在序列推荐任务中, 需要根据时间戳对用户的历史记录进行排序, 生成历史反馈序列, 将历史反馈序列最后一项作为测试项目, 其余数据和KG信息作为输入信息.从项目集上随机抽取100个目标用户未购买或未点击的负反馈项目, 这些负反馈项目和测试项目组成候选项目集, 推荐智能体需要对候选项目集中的项目进行排序.
本文采用命中率(Hit Ratio, HR)和归一化折损累计增益(Normalized Discounted Cumulative Gain, NDCG)作为评价指标, 对比序列推荐性能.HR@K表示测试项目是否在推荐智能体推荐的前K个项目之中.NDCG@K着重考虑测试项目在前K个项目的具体位置, 测试项目越靠前, NDCG@K值越大, 推荐准确率越高.
为了评价KASRL的推荐性能, 分别采用如下3种模型进行对比实验.1)基于KG的模型.KGAT[22], RippleNet[35].2)序列推荐模型.DREAM(Dynamic Relation Aware Model)[36], GRU4Rec[37], FPMC(Fac-torized Personalized Markov Chains)[38].3)混合模型.KSR(Knowledge-Enhanced Sequential Reco-mmender)[20].
KGAT借助KG信息挖掘项目和用户的高阶连通信息, 以端到端的方式实现关系建模.RippleNet同时采用基于路径推理和特征学习的方式建模KG推荐模型.DREAM建模用户的自适应表示和购物篮中项目之间的顺序特征.GRU4Rec基于循环神经网络, 利用历史反馈序列构建用户的序列偏好.FPMC为用户构建马尔科夫转移矩阵, 结合个性化和序列信息.KSR基于GRU和KG信息建模用户序列偏好和用户属性偏好.
在每个数据集上, 将训练集、验证集、测试集的比例设为8∶ 1∶ 1, 采用5个随机种子进行分割, 并将测试平均值作为实验结果.
所有模型计算梯度的批数量设置为2 048, 统一采用Adam(Adaptive Moment Estimation)优化器进行优化.对比模型采用验证集进行参数优化.KASRL中神经网络节点数设置为64, 用户和项目的特征向量设置为50, β 设置为0.2, Y设置为3, HR@K和NDCG@K中 K设置为10.
本节将KASRL与基线模型进行对比, 在4个数据集上的对比结果如图4所示.
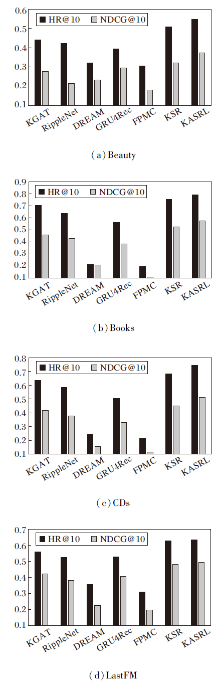 | 图4 各模型在4个数据集上的性能对比Fig.4 Performance comparison of different models on 4 datasets |
由图4可观察到, 无论在哪个数据集上, KASRL一直保持着最优的性能.KASRL和KSR都是基于序列和KG信息的混合模型, 但是KSR没有利用KG信息探索考虑用户偏好漂移, 也没有利用自注意力机制着重开发有助于决策的重要信息.总体来说, 相比KSR, 在Beauty数据集上, KASRL的HR@10和NDCG@10分别提高3.8%和5%; 在Books数据集上, HR@10和NDCG@10分别提高4.1%和4.6%; 在CDs数据集上, HR@10和NDCG@10分别提高6.1%和6.3%; 在LastFM数据集上, HR@10和NDCG@10分别提高0.7%和1.2%.除了在LastFM数据集上RippleNet性能低于GRU4Rec, 基于KG的模型KGAT和RippleNet都优于序列推荐模型, 这也间接验证引入KG中实体之间的关系能够提高推荐的准确率.在基于序列推荐模型中, GRU4Rec性能均优于其它模型, GRU4Rec由于借助GRU单元捕捉到用户反馈序列中序列之间的依赖关系和综合偏好, 从而得到更优的推荐性能.
在KASRL中借助KG信息将状态表示分为两部分, 包括用于探索的漂移状态和基于开发的注意力状态.此外为了缓解奖励稀疏, 设计复合函数, 增加与用户交互过程中的奖励密度.KASRL在状态表示和奖励函数的设计中进行扩展.为了验证扩展的有效性, 本文开展多个消融实验, 设计如下多个KASRL的变体.RL-S仅移除漂移序列, 将完整用户反馈序列输入GRU单元内.RL-ATT仅移除自注意力机制, 将KG信息通过平均求和的方式获得状态信息.RL-R把推荐序列
| 表2 KASRL变体的结构信息 Table 2 Structural information of KASRL variants |
KASRL及三个变体在四个数据集上的HR@10和NDCG@10值如表3所示.由表可看出, KASRL在4个数据集上取得最优表现.移除漂移状态的RL-S和移除注意力状态的RL-ATT取得较差结果.在状态表示中没有变动的RL-R和KASRL均取得不错结果, 表明合理利用KG信息构建状态表示能够提高推荐性能.RL-ATT中移除自注意力机制, 在各数据集上都表现最差, 其主要原因是注意力单元的缺失降低序列信息中关键信息的选择性关注, 也缺乏对长期序列项目之间的依赖性表达, 自注意机制能够更好地捕获反馈序列中重要的项目信息, 从而得到更好的推荐性能.RL-R取消复合奖励函数的设计, 性能却仅低于KASRL, 虽然复合奖励函数并没有使模型推荐效果得到巨大提升, 但是在收敛速度上快于RL-R.总之, KASRL中基于KG信息的扩展均有利于提高推荐性能, 由此验证模型中注意力机制和漂移序列的构建均发挥重要作用.
| 表3 KASRL及其变体在4个数据集上的性能差异 Table 3 Performance difference between KASRL and its variants on 4 datasets |
在奖励函数中设计复合奖励函数, 包含折扣序列奖励和KG奖励两部分.下面验证折扣序列奖励和KG奖励能否加快KASRL的收敛速度及能否提高模型的推荐性能.
为此, 设计两个额外的变体:RL-DS, 仅在奖励函数中移除折扣序列奖励; RL-KG, 仅在奖励函数中移除KG奖励.KASRL、RL-DS和RL-KG在Beauty数据集上不同训练批次下的性能对比如图5所示.由图可见, 以HR@10为评价指标, RL-KG的收敛速度和性能低于KASRL和RL-DS, 这是因为KG奖励为KASRL和RL-DS提供更多的奖励密度, 使推荐智能体不会盲目地随机探索, 从而加快收敛速度和推荐效果.以NDCG@10为评价指标, 前期RL-DS推荐效果优于RL-KG, 但在训练后期, RL-DS已经不再依靠盲目探索, 并且带有折扣的序列奖励会着重关注推荐的排名序列, 使RL-KG的NDCG@10值超过移除折扣序列奖励的RL-DS.
 | 图5 KASRL及其变体在Beauty数据集上的性能对比Fig.5 Performance comparison of KASRL and its variants on Beauty dataset |
3.5.1 漂移序列度量长度
超参数b表示选取历史反馈序列最近交互的b个项目作为漂移序列的相似度度量, 本节对比b=1, 2, 3以及移除漂移序列b=0对KASRL性能的影响, 实验结果如表4所示.
| 表4 b对KASRL性能的影响 Table 4 Effect of parameter b on KASRL performance |
在表4中, b=0时移除漂移序列, 不以任何项目序列作为相似度指标, 可看出相比b=0, 当b=1, 2, 3时, KASRL性能都具有较大提升, 并且b=2时表现最优, 仅在Books数据集上低于b=3时.这是因为太小的b值可能使漂移序列中噪声的影响变大, 然而b值越大会使噪声的影响越小, 偏好漂移的特征也会变得平缓.
3.5.2 漂移序列的权衡参数
2.2.1节中采用β 加权的方式权衡两种子序列选取的策略, 为了确定β 的选取对于推荐效果的影响, 选取β =0, 0.2, 0.4, 0.6, 0.8, 1, 在Beauty数据集上进行实验, 结果如图6所示.
 | 图6 β 对KASRL性能的影响Fig.6 Effect of parameter β on KASRL performance |
由图6可观察到, 当β =0.2时, KASRL的HR@10和NDCG@10值均最优, 这是因为2.2.1节中第一种截取方式虽然能够扩大长度, 但是过于大的长度使得漂移序列并不能准确表示用户的偏好变化, 反而从完整的用户-项反馈序列中带来更多的噪声, 影响智能体推荐的效果.
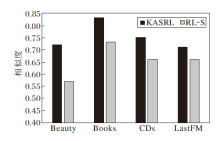
将移除漂移序列的RL-S与KASRL在4个数据集上进行实验, 对比漂移序列和完整序列与下一个推荐成功项目的相似度, 结果如图7所示.
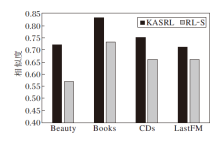 | 图7 漂移序列和完整序列与下一个推荐成功的项目相似度对比Fig.7 Similarity comparison between drift sequence and next successfully recommended item as well as between full sequence and next successfully recommended item |
由图7可知, 在Beauty数据集上, 相比RL-S中完整序列, 漂移序列的相似度提高15%, 在Books数据集上, 漂移序列的相似度提高10%, 在CDs数据集上, 漂移序列的相似度提高9%, 在LastFM数据集上, 漂移序列的相似度提高5%.实验结果表明漂移序列能够提高序列与下一个推荐成功项目的相似度, 进一步验证相比完整序列, 漂移序列能更好地捕捉用户的当前偏好, 提高推荐的准确率.
本文提出基于知识引导的自适应序列强化学习模型(KASRL).借助KG信息, 从完整的用户-项反馈序列中截取自适应的序列长度作为漂移序列, 该序列反映用户的偏好变化及变化速度.基于此, 对推荐智能体做出如下扩展:首先利用GRU捕获漂移序列中当前偏好及项目之间的依赖关系, 同时利用自注意力机制为完整用户-项反馈序列中的关键项目分配更高的权重.此外, 为了加快模型的收敛速度, 增加训练时奖励的覆盖范围, 设计复合奖励函数, 缓解奖励值稀疏的问题.最后在4个数据集上进行实验评估, 结果表明KASRL性能较优, 推荐准确率相对稳定.今后可关注如何利用神经网络学习不同用户的偏好变化趋势, 并将漂移序列应用到其它推荐领域, 使漂移序列拥有更强的适用性.
本文责任编委 吴 飞
Recommended by Associate Editor WU Fei
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|