









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于场景几何信息的显著性目标检测方法综述
[吴岚虎1  , 李智玮
, 李智玮1 , 刘垒烨1 , 朴永日1 , 卢湖川1 ]
, 李智玮, 刘垒烨, 朴永日, 卢湖川]
|
|



作者简介:

吴岚虎,硕士研究生,主要研究方向为深度学习、显著性目标检测、3D计算机视觉与感知.E-mail:sdplwlh@mail.dlut.edu.cn.

李智玮,硕士研究生,主要研究方向为深度学习、显著性目标检测、3D计算机视觉与感知.E-mail:zhiwei@mail.dlut.edu.cn.

刘垒烨,硕士研究生,主要研究方向为深度学习、显著性目标检测、3D计算机视觉与感知.E-mail:flameliu@mail.dlut.edu.cn.

卢湖川,博士,教授,主要研究方向为目标跟踪、显著性目标检测、图像分割.E-mail:lhchuan@dlut.edu.cn.
显著性目标检测在图像和视频压缩、伪装物体检测、医学图像分割等领域具有重要作用.随着深度传感器和光场技术的广泛应用,深度图像和光场数据等场景几何信息开始应用于显著性目标检测,可提升模型在复杂场景下的性能,由此学者们提出一系列基于场景几何信息的显著性目标检测方法.文中旨在分析总结经典的基于场景几何信息的显著性目标检测方法.首先,介绍方法的基本框架及评估标准.然后,围绕多模态特征融合、多模态信息优化、网络模型轻量化三方面,分类概述和分析经典的RGB-D显著性目标检测方法和光场显著性目标检测方法.同时,详细介绍基于场景几何信息的显著性目标检测方法的工作进展.最后,讨论方法目前存在的问题,展望未来的研究方向.
About Author:
WU Lanhu,master student. His research interests include deep learning, salient object detection, and 3D computer vision and sen-sing.
LI Zhiwei, master student. His research interests include deep learning, salient object detection, and 3D computer vision and sen-sing.
LIU Leiye, master student. His research interests include deep learning, salient object detection, and 3D computer vision and sen-sing.
LU Huchuan, Ph.D., professor. His research interests include visual tracking, sa-liency object detection and image segmentation.
Salient object detection is crucial in the fields of image and video compression, camouflaged object detection, medical image segmentation, etc. With the wide application of depth sensor and light field technology, scene geometric information such as depth images and light field images is applied to salient object detection to improve the performance of the model in complex scenes. Therefore, a series of salient object detection methods based on scene geometric information is proposed. The typical algorithms of salient object detection based on scene geometric information are summarized in this paper. Firstly , the basic frameworks of models and evaluation metrics are illustrated. Then, the typical algorithms of RGB-D salient object detection and light field salient object detection are summarized and analyzed from the aspects of multi-modal feature fusion, multi-modal information optimization and network model lightweight. Meanwhile, the recent progress of salient object detection methods based on scene geometry information is introduced. Finally, the problems still faced in the existing salient object detection methods based on scene geometry information are analyzed and the future research is discussed.
显著性目标检测(Salient Object Detection, SOD)是以认知科学、神经生物学及相关计算理论为指导, 模仿人类视觉注意力机制, 通过视觉特征, 从场景提取吸引视觉注意区域或目标的一项计算机视觉任务[1].显著性目标检测可降低场景的复杂程度, 准确捕捉图像中的核心信息, 现已广泛应用于各类计算机视觉任务和相关领域[2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15].SOD具体研究和应用包括:
1)目标跟踪[16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26].目标跟踪是计算机视觉领域的热点研究方向之一, 广泛应用于智能视频监控、交通管理和无人驾驶等领域.然而, 现阶段的目标跟踪算法往往受到背景条件的复杂性和特殊性等方面的制约, 当目标所处的背景环境较复杂时, 如相似目标、遮挡物等, 目标跟踪算法的准确性与高效性都会明显下降.将显著性目标检测方法应用于目标跟踪任务, 可有效抑制背景中的干扰信息, 缩小跟踪目标的搜索区域.因此, 显著性目标检测对目标跟踪任务具有重要意义.
2)图像和视频压缩[27, 28].显著性目标检测的一个重要应用场景为图像和视频压缩, 即通过删减图像和视频在时间维度和空间维度上的冗余信息降低其所需的存储容量.显著性目标检测有助于图像和视频压缩算法检测到图像中包含主要信息的区域, 通过为这些区域分配更多的比特位以表示内容, 可有效降低图像和视频的压缩损失.而对于非显著性区域, 可适当减少比特位, 提升图像和视频压缩算法的压缩率.
3)伪装物体检测[29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40].伪装物体检测作为一个新兴研究方向, 旨在快速准确检测隐藏在背景中的目标对象, 可应用于物种保护、军事监控等领域.伪装物体检测的本质仍为显著性目标检测, 但由于伪装物体在外观与背景上展现极高的相似度, 往往连人眼都难以辨别, 使其难度远高于一般的显著性目标检测.因此, 对显著性目标检测算法的研究有利于进一步解决伪装物体检测这一具有挑战性的任务.
4)医学图像分割[41, 42, 43, 44, 45, 46, 47].随着影像医学在临床医学中的广泛应用, 产生大量的医学图像, 为诊断和预防疾病提供重要依据.然而, 对医学图像的分析和判别依赖于有经验的医生, 这无疑增加医务人员的负担, 容易造成误诊.医学图像分割旨在分割医学图像中某些特殊含义的部分, 并提取相关特征, 为临床诊疗和病理研究提供可靠的依据, 辅助医生做出更准确的判断.目前大部分的医学图像分割仅需要区分病灶和人体组织, 属于显著性目标检测的范畴, 因此, 显著性目标检测相关研究对医学图像分割任务具有重要意义.
5)协同显著性目标检测[48, 49, 50, 51, 52, 53, 54, 55, 56].随着大数据时代的到来, 每天都要面对大量的图像和视频类信息, 此时, 需要在大量图像中快速获取其中的有效信息.协同显著性目标检测致力于找寻多幅图像中公共的显著性物体, 一次性过滤多幅图像中大量的无用信息, 可广泛应用于各种计算机视觉任务, 减小后续处理的计算量.作为显著性目标检测的拓展任务, 协同显著性目标检测无疑在未来具有广阔的应用前景.
此外, 显著性目标检测技术还在立体匹配[57]、动作识别[58]、图像理解[59, 60]等实际应用中起到关键作用[61, 62, 63, 64, 65, 66, 67, 68, 69].
显著性目标检测按输入数据类型及采取的方法可分为基于RGB的显著性目标检测方法、基于RGB-D的显著性目标检测方法和基于光场的显著性目标检测方法, 其中基于RGB-D的显著性目标检测方法和基于光场的显著性目标检测方法可归纳为基于场景几何信息的显著性目标检测方法[70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83].
基于RGB的显著性目标检测方法将2D图像作为卷积神经网络(Convolutional Neural Network, CNN)的输入, 通过学习的多级特征获得全局和局部的显著性预测结果.代表性方法包括:DHSNet(End-to-End Deep Hierarchical Saliency Network)[84]、RFCNs(Recurrent Fully Convolutional Networks)[85]、DSS(Deeply Supervised Salient Object Detection)[86]、Amulet(Generic Aggregating Multi-level Convolutional Feature Framework)[87]、PiCANet(Pixel-Wise Con-textual Attention Network)[88]、R3Net(Recurrent Resi- dual Refinement Network)[89]等.然而, 基于RGB的显著目标检测方法在低对比度、低光照、复杂纹理等复杂场景下, 设计的网络无法提供足够的空间结构信息和全局定位信息, 降低显著性目标检测的精度和鲁棒性.
近年来, 随着深度传感器的广泛应用, 深度信息的获取变得更简单高效.深度信息包含的空间、结构等几何信息, 可弥补RGB图像在复杂场景下的几何信息缺失, 进而帮助模型更好地区分显著性目标或区域.因此, 基于RGB-D的显著性目标检测方法得到广泛关注和快速发展[90, 91, 92, 93].
传统的基于RGB-D的显著性目标检测方法[94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107]通常采用手工设计特征的方法[108, 109].这类方法虽然引入深度特征完善显著性目标检测任务, 但是由于手工特征的设计依赖于有限的先验知识, 导致设计的方法受制于底层特征的表达能力, 在复杂场景下对高层特征的推理存在较大的偏差.
2016年之后, 鉴于CNN出色的多级特征提取能力和表达能力, 相比传统手工特征的方法, 基于深度学习方法性能具有巨大的提升.因此, 学者们提出基于RGB-D的显著性目标检测方法[110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120], 代表性方法包括:DMRANet(Depth-Induced Multi-scale Re- current Attention Network)[121]、SSF(Select, Supple- ment and Focus for RGB-D Saliency Detection)[122]等.基于RGB-D的显著性目标检测方法虽仅增加一维深度信息, 但由于深度测量精度较低和深度非凸(显著性物体非单一深度)等原因, 对显著性目标检测任务提出巨大的挑战.
近期, 基于光场的显著性目标检测方法受到广泛关注.光场数据具有颜色、强度、聚焦、深度及多视角等场景多线索几何信息, 有助于信息间的共享和互补, 可有效解决复杂场景中显著性目标检测的漏检或错检的技术难题.Li等[123]提出LFSD(Light Field Saliency Detection), 使用机器学习的方法验证将光场数据引入显著性目标检测任务当中的有效性.
随后, 基于传统机器学习和手工设计特征的方法[124, 125, 126]受到研究者的广泛关注.随着深度学习技术的快速发展, Wang等[127]提出DLFS(Deep Lear-ning for Light Field Saliency Detection), 并相继出现诸多相关方法, 如Mo-SFM(Memory-Oriented Spa-tial Fusion Module)[128]、文献[129]方法、LFNet(Light Field Fusion Network)[130]、PANet[131]、DLG(Dual Local Graph)[132]、文献[133]方法、MEANet(Multi-modal Edge-Aware Network)[134]等.
本文详细综述近年来基于场景几何信息的显著性目标检测方法, 在分析其难点与挑战性的同时介绍该领域最新的工作进展, 并对后续的研究发展提供预测与建议.
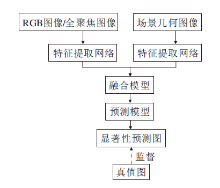
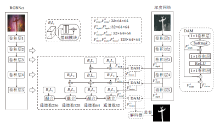
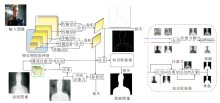
基于场景几何信息的显著性目标检测方法的基本框架如图1所示, 一般包含3个基本部分:特征提取网络、融合模型、预测模型.
 | 图1 基于场景几何信息的显著性目标检测方法的基本框架Fig.1 Basic framework of salient object detection based on scene geometric information |
基于场景几何信息的显著性目标检测方法的首要步骤是从RGB图像和场景几何图像中提取各自的特征.对于基于RGB-D的显著性目标检测方法, 特征提取网络的输入为RGB图像和深度图像.其中, RGB图像包含丰富的内容信息(如外观、颜色、亮度、纹理等), 而深度图像包含丰富的空间结构信息和布局信息.对于基于光场的显著性目标检测方法, 特征提取网络的输入为全焦点RGB图像、焦点堆栈和简略深度图.全焦点RGB图像的每个像素点都是清晰的, 可提供清楚的颜色、纹理特征.焦点堆栈是一组聚焦在不同深度层的RGB图像, 包含丰富的聚焦区域线索.针对不同模态的图像设计适合它的特征提取网络, 准确高效提取多模态特征, 是研究基于场景几何信息的显著性目标检测方法的重要前提.
融合模型的作用是将上游提取的RGB特征和场景几何特征按照最佳方式进行融合, 形成多模态融合特征.在基于场景几何信息的显著性目标检测方法的3个基本部分中, 融合模型处于核心地位.设计一个合理的融合模型, 充分发掘RGB特征和场景多线索特征的差异性和联系, 在融合互补信息的同时有效抑制噪声, 是提高复杂场景下显著性目标检测性能的关键.
预测模型是基于场景几何信息的显著性目标检测方法的最后一步, 旨在对融合模型生成的多模态融合特征进行进一步的特征提取和精炼, 并推理产生显著性预测图.设计一个鲁棒、高效的预测模型, 对来自不同尺度的融合特征进行筛选、融合、推理、预测, 也是基于场景几何信息的显著性目标检测研究的一个重要问题.
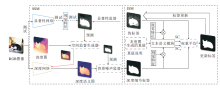
如图2所示, 现有的基于场景几何信息的显著性目标检测方法在进行网络设计时, 面临如下3个主要挑战.1)如何更好地融合RGB特征和场景几何特征; 2)如何避免低质量的场景几何信息对RGB特征的干扰; 3)如何在保证模型性能的同时减少模型的参数和计算量.
 | 图2 基于场景几何信息的显著性目标检测方法的难点Fig.2 Difficulty in salient object detection based on scene geometric information |
基于场景几何信息的显著性目标检测方法常用的RGB-D数据集和光场数据集如下所示.
1)RGB-D数据集.
(1)SIP数据集(Salient Person Dataset)[73].包含929幅RGB图像及其对应的深度图像, 分辨率为992× 744, 深度图像由Huawei Mate10智能手机生成.
(2)文献[91]构建的数据集.包含135幅RGB图像及其对应的深度图像, 分辨率为640× 640.
(3)文献[98]构建的数据集.包含1 985幅立体RGB图像及对应的深度图像, 来源于互联网、3D视频和富士W3立体相机照片.
(4)文献[109]构建的数据集.包含1 000幅RGB图像及对应的深度图像, 分辨率为640× 480, 包括一系列的室内场景和室外场景, 如办公室、超市、校园、街道等.
(5)STEREO数据集(Stereo Saliency Analysis Benchmark Dataset)[135].包含1 000幅RGB图像及对应的深度图像, 来源于Flickr、NVIDIA 3D Vision Live和Stereoscopic Image Gallery.
(6)文献[136]构建的数据集.包含800幅室内场景图像和400幅室外场景图像及对应的深度图像, 分辨率为400× 600, 包括一系列的复杂场景, 如多物体、低照明度、背景复杂、前景与背景相似等场景.
(7)SSD100数据集[137].包含80幅RGB图像及对应的深度图像, 分辨率为960× 1 080, 来源于3个立体视频.
2)光场数据集.
(1)LFSD数据集(Light Field Saliency Detection Dataset)[123].包含100个光场样本, 分辨率为360× 360, 其中60个为室内场景, 40个为室外场景.
(2)HFUT-Lytro数据集[126].包含255个光场样本, 大多数样本包含多个前景物体, 物体位置与尺寸变化较大, 背景较复杂.
(3)文献[127]构建的数据集.包含1 456个光场样本, 其中1 000个训练样本, 465个测试样本, 样本的分辨率为600× 400.该数据集的挑战性在于显著性物体与背景的对比度较低, 样本中存在多个低相关性的物体, 低照明度场景与强照明度场景并存.
(4)文献[138]构建的数据集.包含1 580个光场样本, 其中1 100个训练样本, 480个测试样本, 每个光场样本都包括一个多视角图和与之对应的真值图.
(5)Lytro Illum数据集[139].包含640个光场样本, 照明条件差异较大, 小物体隐藏在高相似度或复杂的背景之中.
1)Precision & Recall.给定一张显著性图S, 设定阈值p, 将S转化为一幅二值图M, 设该样本对应的真值图为G, 则
Precision=
(2)F-measure(Fβ ).为了兼顾precision和recall, 引入F-measure计算二者的加权调和均值:
Fβ =(1+β 2)
(3)MAE(Mean Absolute Error).计算预测图S与真值图G之间像素级的平均错误量:
$MAE=\dfrac{1}{WH}\sum\limits_{i=1}^W\sum\limits_{j=1}^H\bigm|S_{i, j}-G_{i, j}\bigm|, $
其中, W表示图像宽度, H表示图像高度.
(4)S-measure(Sα ).为了描述图像结构信息的重要性, 引入S-measure以获取区域感知(Sr)和物体感知(S0)之间的结构相似性:
Sα =α S0+(1-α )Sr, α =0.5.
(5)E-measure(Eϕ ).基于认知视觉研究提出的用于描述图像级统计数据和局部像素匹配信息的评估指标:
Eϕ =
其中ϕ FM为增强校准矩阵.
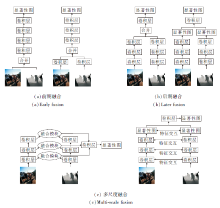
对于RGB-D 显著性目标检测模型, 最重要的一步是RGB特征与深度特征的融合, 通过整合二者的互补信息, 可提高显著性目标检测的性能.常见的融合策略可分为前期融合、后期融合和多尺度融合, 具体结构如图3所示.
 | 图3 RGB-D融合策略Fig.3 RGB-D fusion strategies |
前期融合是指在输入阶段或低级特征提取阶段, 将RGB图像与深度图像在通道方向叠加进行特征融合.后期融合是指将提取的RGB特征和深度特征在高级特征提取阶段或预测阶段进行通道叠加融合.
由于前期融合策略忽略RGB特征和深度特征的内在差异性, 后期融合忽略不同尺度之间RGB特征和深度特征之间的特征交互, 因此, 近年来基于RGB-D的显著性目标检测方法大多采用多尺度融合的方法, 即RGB特征和深度特征在特征提取的不同阶段进行多次融合, 生成RGB-D特征.
按照融合过程中特征流的方向, 本文进一步将基于RGB-D的显著性目标检测方法的特征融合方式分为双流融合、交互融合和注意力机制融合.对于基于光场的显著性目标检测方法, 由于光场多线索数据中可提取的特征包含深度特征、多视角图像特征及焦点堆栈特征, 含有的信息更丰富, 因此选择并融合这些特征成为光场显著性目标检测任务的主要研究内容.按照融合过程中使用的数据类型, 本文进一步将基于光场的显著性目标检测方法的特征融合方式分为多线索特征融合和多任务特征融合.
双流融合方式是指RGB特征与深度特征在不同尺度, 通过一个设计好的融合模块形成多尺度的RGB-D特征, 生成的多尺度RGB-D特征送入解码器进行多级特征融合, 最终生成显著性目标预测图.
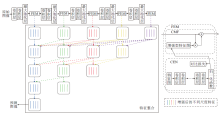
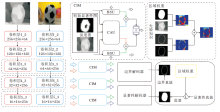
为了提高对不同尺度融合特征的利用能力, Zhao等[71]提出CPFP, 设计5个FEM(Feature En- hanced Module)和1个FPI(Fluid Pyramid Integra- tion).FEM由CEN(Contrast-Enhanced Net)和CMF (Cross-Modal Fusion Strategy)构成.CEN通过对比损失函数, 利用深层网络的对比先验生成增强的深度图, 再与提取的RGB特征在CMF中融合生成多级RGB-D特征.融合生成的RGB-D特征通过FPI进行多次跨尺度融合, 生成最终显著性预测图.CPFP具体结构如图4所示.
Piao等[121]提出DMRANet, 最先将双流融合策略应用于RGB-D SOD任务, 设计DRB(Depth Refinement Block), 在不同尺度上融合RGB特征和深度特征.然后设计DMSW(Depth-Induced Multi-scale Weighting Module), 使用深度信息对融合形成的RGB-D特征进行加权.最后, 借鉴人脑的IGM(Internal Generative Mechanism), 设计RAM(Recu-rrent Attention Module), 综合学习融合特征的内部语义关系, 按照由粗到细的方式迭代生成更准确的显著性预测图.DMRANet具体结构如图5所示.相比传统的前期融合和后期融合模型, DMRANet性能获得大幅提升.但是由于不同尺度的多模态特征采用相同的融合模块, 忽视不同尺度的RGB特征与深度特征的内在差异性, 同时设计的解码器较复杂, 因此增加模型的参数和计算量.
出于对不同尺度的多模态特征之间差异性的考量, Zhang等[140]提出A Top-Down and Adaptive Fusion Network, 使用IFM(Interweave Fusion Mo-dule)和GSFM(Gated Select Fusion Module)分别融合低层和高层的RGB特征和深度特征, 并设计一个高效的融合模块AFM(Adaptive Fusion Module)用于解码, 通过不同层级的RGB-D特征赋予不同权重, 简单有效融合RGB-D特征.Li等[141]提出CMWNet(Cross-Modal Weighting Network), 分别在低、中、高三个尺度对RGB特征和深度特征进行跨模态权重融合, 通过3个不同的跨模态权重模块(CMW-L、CMW-M、CMW-H)分别融合3个对应尺度的RGB特征和深度特征, 进一步探索不同尺度之间的RGB信息与深度信息的内在联系.
为了进一步探索RGB特征与深度特征的互补关系, Chen等[142]提出Disentangled Cross-Modal Fu-sion Network, 将解耦合策略引入RGB-D特征融合领域, 通过多模态解耦合网络, 将RGB特征和深度特征都解耦为结构特征和内容特征, 使用跨模态的结构特征和内容特征进行融合, 从而抑制冗余信息, 提高融合效率.
交互融合是指RGB图像和深度图像在特征提取的过程中, 学习跨模态间特征交互的一种方式.现有大多数RGB-D 显著性目标检测模型通常采用这类跨模态特征融合方式.
Chen等[143]提出MMCI(Multi-scale Multi-path Fusion Network with Cross-Modal Interactions), 最先采用交互融合策略进行RGB特征和深度特征融合, 采用多样化多模态融合路径, 并在多层中引入跨模态交互, 优化传统的两分支结构.作为早期的交互融合模型, MMCI主要存在两点缺陷.
1)深度特征未经任何处理直接加入RGB特征流中, 会引入大量的噪声信息, 对RGB特征造成严重的干扰.
2)仅将深度特征引入RGB支路以提升显著性目标检测的定位能力, 忽视RGB包含的丰富内容信息可增强深度图像的细节的事实.
针对缺陷1), Zhang等[144]提出ATSA(Asy-mmetric Two-Stream Architecture), 具体结构如图6所示.
ATSA考虑深度图像包含的信息量远小于RGB图像, 采用一个轻量化的网络模型用于提取深度特征, 减小整个模型的参数量, 节约计算成本和训练时间.设计FLM(Flow Ladder Module), 递进式地融合局部特征和全局特征, 高效提取局部细节信息和全局上下文信息, 用于显著性目标检测.同时设计DAM(Depth Attention Module), 筛选深度特征中最有效的深度线索, 融入RGB支路, 避免特征冗余, 提高融合的效率.
Fan等[145]提出BBS-Net(Bifurcated Backbone Strategy Network), 使用DEM(Depth-Enhanced Mo-dule)增强不同尺度的深度特征, 使用与同级RGB特征逐点相加的方式, 将深度信息加入RGB支路, 在解码阶段采用BBS, 选取高层的融合特征作为老师特征, 低层融合特征作为学生特征, 通过老师特征对学生特征进行微调, 滤除学生特征中的噪声, 并将调整后的学生特征融合生成显著性目标检测预测图.
针对缺陷2), Zhang等[146]提出CDINet(Cross-Modality Discrepant Interaction Network), 设计RDE(RGB-Induced Detail Enhancement)和DSE(Depth-Induced Semantic Enhancement).RDE利用RGB支路在低级编码器阶段的特征以增强在低级编码器阶段中深度特征的细节信息.DSE利用高层次深度特征的内在一致性和定位精度的优势, 帮助RGB支路捕获更清晰、精细的语义属性.
现有的基于RGB-D的显著性目标检测方法通常平等对待特征图的各个区域, 忽略不同区域对预测结果具有不同贡献的特点, 导致最终预测结果受到背景干扰的影响.此外, 现有的一部分方法过度依赖深度信息, 导致这类方法未充分考虑不同模态(RGB和深度)的特点和重要性.从解决上述问题出发, 引入注意力机制以加权不同区域的方法受到广泛关注.
Chen等[147]提出Three-Stream Attention-Aware Network, 最先在RGB-D显著性目标检测中引入通道注意力机制, 通过Att-CMCL(Attention-Aware Cross-Modal Cross-Level Combination)筛选融合产生的RGB-D特征, 在一定程度上抑制那些不重要甚至对预测结果产生干扰的特征.该模型仅在解码阶段通过注意力机制处理融合的多尺度RGB-D特征, 融合阶段缺少对多模态特征的注意力机制筛选, 使融合产生的RGB-D特征中含有大量的冗余与干扰信息.
为了解决这一问题, Li等[148]提出ICNet(Infor-mation Conversion Network), 在融合阶段通过CDC(Cross-Modal Depth-Weighted Combination Block)处理深度特征, 生成空间注意力图, 并用其对RGB特征进行加权融合, 抑制深度线索中的噪声, 同时设计ICM(Information Conversion Module), 计算RGB特征与深度特征的互相关性, 凸显高层特征中显著性目标.Liu等[149]提出S2MA(Selective Self-Mutual Attention), 设计选择性自交互注意力机制, 融合RGB特征和深度特征, 利用自注意力机制提取每条支路的全局信息, 利用互注意力机制发掘跨模态特征的信息补偿性, 为多模态数据提供补充信息, 提高显著性目标检测性能, 克服仅使用一种模态的自注意力机制的局限性.此外, 为了减小低质量深度图的影响, 提出选择机制, 重新加权交互注意力信息, 不可靠的特征会被赋予较小的权重, 从而实现更准确的显著性预测.Wen等[150]提出DSNet(Dynamic Selective Network), 设计DSM(Dynamic Selective Module), 利用其中CAM(Cross-Modal Attention Mo-dule)、BGPM(Bi-directional Gated Pooling Module)整合来自多模态、多层级、多尺度的特征, 同时提出CGCM(Cross-Modal Attention Modal), 用于挖掘高层RGB特征和深度特征之间的相关性, 帮助定位显著性区域, 抑制背景噪声.
多线索特征融合是指将光场数据中可提取到的全聚焦图像特征、深度特征、焦点堆栈特征及多视角特征中的两种及以上特征送入设计好的融合模块进行特征融合, 并生成光场特征完成显著性目标预测.Wang等[127]提出DLFS, 研究光场数据融合的架构, 设计递归注意力网络, 整合焦点堆栈中的切片, 并将其与全聚焦图像特征融合.Zhang等[128]提出Mo-SFM, 设计面向记忆的新型解码器, 促进焦点堆栈特征和全焦图像特征的融合.Liu等[132]提出DLG, 利用图网络, 在全聚焦特征的指导下完成焦点堆栈的特征提取, 并进行多次焦点堆栈和全聚焦图像的融合.Jiang等[134]提出MEANet, 使用全聚焦图像、深度图像及焦点堆栈进行显著性预测, 设计跨模态补偿模块及多模态边缘监督模块, 完成多模态信息的互补和显著性目标边缘细化的任务.Zhang等[151]提出SA-Net(Synergistic Attention Network), 通过协同注意力机制对全聚焦图像和焦点堆栈的高级特征进行解码, 完成焦点堆栈和全聚焦图像之间互补信息的学习.Zhang等[152]提出CMA-Net(Cas-caded Mutual Attention Network), 设计相关注意力机制, 进行全聚焦图像和深度图像之间的信息融合.
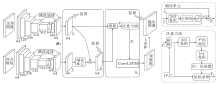
Zhang等[130]提出LFNet, 设计LFRM(Light Field Refinement Module), 使用全聚焦图像特征促进焦点堆栈特征的提取, 迭代消除全聚焦图像特征及焦点堆栈特征之间的相同性, 并精确细化其不同性, 有效挖掘光场数据中独特的显著性线索.同时设计LFIM(Light Field Integration Module), 使用注意力模块及ConvLSTM计算全聚焦图像特征和焦点堆栈特征在显著性目标检测中的相对贡献, 降低不良特征对预测结果的影响.再将二者加权融合, 而不是简单的拼接降维, 较好地融合焦点堆栈特征及全聚焦图像特征, 探索场景的空间结构以预测准确的显著性预测图.LFNet具体结构如图7所示.
多任务融合是指利用光场数据中的多视角图像针对不同任务进行特征提取的操作.将不同的任务特征送入融合模块进行融合, 生成光场特征并完成显著性预测.
Piao等[131]提出PANet, 具体结构如图8所示.在PANet中设计MSLM(Multisource Learning Mo-dule), 有效挖掘焦点堆栈中的显著性区域, 在学习显著性线索的同时进行边缘信息及位置信息的学习, 通过过滤策略区分显著性区域并整合该区域内的
多任务特征, 使用边界预测任务及位置预测任务增强网络显著性检测性能.同时设计SRM(Sharpness Recognition Module), 准确整合显著性区域, 进一步细化和更新过滤策略, 并利用每个区域的锐度突出显著性区域, 抑制焦点切片中模糊区域对预测结果的负面影响.
Zhang等[153]提出Multi-task Collaborative Net- work, 设计多任务协作网络, 利用边缘检测、深度推断、显著性检测协作学习多视角图像特征, 融合不同任务的特征.Jing等[154]提出Occlusion-Aware Bi-di-rectional Guided Network, 结合场景结构, 从遮挡边缘信息中提取显著性边缘信息以指导显著性目标检测, 分别从水平、垂直光场极平面图像中提取特征并完成融合.
在传统的RGB显著性检测任务中, 存在前后景对比度较低、边缘模糊等情况.因此, 学者们引入深度信息, 解决在RGB显著性目标检测任务中遇到的困难.而现有的RGB-D数据集普遍存在深度图的精度较低、数据量较少的问题.因此, 现有的主流多模态信息优化方法主要致力于解决如下两个问题:如何解决深度图像精度较低的问题, 如何解决深度图像数量有限的问题.
在RGB-D显著性目标检测任务中, 深度图来源不一、质量参差不齐, 导致最终的预测结果受到低质量深度图像的干扰.针对这一问题, 诸多学者大多遵循如下两种思路给出相应的解决方案.
学者们首先采用两阶段模型, 即先使用深度估计或深度增强网络提高深度图像的质量, 再将增强后的深度图像用于后续的RGB-D显著性目标检测.Chen等[155]提出一种深度估计的方法, 通过粗略的深度估计及基于显著性先验的深度增强模块, 获取高质量的深度伪标签, 用于后续的多模态特征融合.为了解决深度标签质量参差不齐的问题, Ji等[156]提出DCF(Depth Calibration and Fusion), 设计DCM(Depth Calibration Module), 即使用训练好的网络评估深度图的质量, 挑选质量较高的深度图, 并使用高质量的深度图用于深度估计的训练, 最后使用深度估计图像和原始深度图像中的加权提升深度图的质量.
两阶段模型虽然可有效解决深度图像质量较低的问题, 但是由于训练复杂、模型的推理速度较慢等原因, 学者们开始考虑单阶段模型.相比两阶段模型, 单价段模型具有训练过程简单、参数量较少、推理速度较快等特点.单阶段模型的具体思路是直接利用低层RGB特征中丰富的细节信息完善、增强深度特征.
为了解决深度标签质量较低的问题, Zhang等[122]提出SSF, 具体结构如图9所示.SSF设计CIM(Complimentary Interaction Module), 包括用于提取RGB图像和深度图像中有效信息的CAU(Cro-ss Modal Attention Unit)和用于提取边缘信息的BSU(Boundary Refine Unit).CAU将深度图像分解为若干个二值图, 用于区域级别注意力权重的计算, 而RGB支路和深度支路不同尺度的特征会在依次经过不同类型的注意力计算后得到更新后的特征, 使特征在融合之前能得到初步的增强.对于困难样本, CAU利用初始显著性图再次进行注意力的计算, 从而弥补丢失的有用特征.BSU分别从RGB支路和深度支路提取边缘信息, 最后CIM将每个模态内CAU和BSU的特征依次进行融合, 得到最终的预测结果.
Jin等[157]提出CDNet(Complementary Depth Net-work), 为了获得稳定质量的深度特征, 利用RGB特征得到深度估计图和原始深度图, 以自适应权重的形式直接进行融合, 生成显著性信息深度特征图, 再将RGB特征和显著性信息深度特征图按层次进行融合, 得到最终的显著性预测图.
RGB-D显著性目标检测任务中的深度信息需要专用设备获取, 导致在训练测试过程中存在深度标签数量不足的问题.
为了解决该问题, 近年来基于半监督或自监督学习的方法同样备受学者关注.
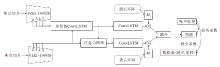
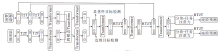
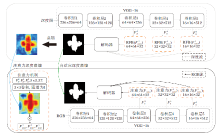
文献[158]模型主要分为两个部分.1)SSM(Spatial Semantic Modeling), 用于捕获特定显著性的深度语义线索, 消除粗显著性预测图中的背景噪声, 产生深度修复后的伪标签.2)JSM(Joint Seman-tic Mining), 利用源数据中的标签或说明性文字, 以与显著性网络中特征融合的方式, 学习图像中的显著性区域.在更新伪标签期间, JSM以双支路的形式输出两个模态下各自的显著性类别概率, 在经过归一化处理后变成伪标签和深度修复后的伪标签对应的权重, 从而用于更新伪标签, 最终实现高精度的显著性目标检测.该模型具体结构如图10所示.
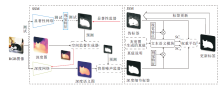 | 图10 文献[158]模型结构图Fig.10 Architecture of model in [158] |
之后, Wang等[159]提出DS-Net(Dual-Semi RGB-D Salient Object Detection Network), 通过半监督学习的方式, 利用未标注的RGB图像提升RGB-D的显著性检测, 并使用RGB图像和深度图像训练深度估计分支, 为无标签的RGB图像生成深度伪标签, 最后利用Labeled Data-Unlabeled Data框架训练整个网络.文献[160]模型首次使用自监督学习的方法解决深度图像数据量少的问题, 利用CDA(Consistency-Difference Aggregation), 依次融合不同级别和模态特征, 得到最终的预测图.
同RGB-D显著性目标检测任务相似, 对于光场显著性目标检测任务, 随着光场数据规模的增大, 获得准确且数量可观的像素级真值标注成为一个需要面对的问题.人工标注耗时且成本高昂, 面对大规模光场数据时代价极大.
为了解决光场数据量有限的问题, 文献[133]设计一个可在像素级噪声标签上完成显著性目标检测的网络, 像素级的噪声标签可由传统无监督显著性检测方法产生.具体地, 将显著性目标检测表述为光场内特征融合和场景相关的联合优化.设计Pixel Forgetting Guided Fusion Module, 探索全焦图像和焦点堆栈之间的相关性, 利用迭代的像素一致性识别噪声像素标签.在这一过程中引导焦点堆栈和全焦图像相互学习, 获得有效特征.然后对于焦点堆栈特征和全焦图像特征的初始噪声估计, 引入像素遗忘事件, 定义一个遗忘矩阵识别噪声像素, 并对有效特征加权以获得显著性预测图.同时提出Cross Scene Noise Penalty Loss, 在整个数据集上随机采样, 捕捉噪声空间的全局相关性, 反映数据的内在结构, 进一步优化模型表现, 使学习过程中模型不受标签噪声的影响.具体模型结构如图11所示.
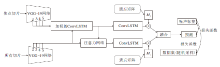 | 图11 文献[133]模型结构图Fig.11 Architecture of model in [133] |
相比传统的RGB显著性目标检测任务, RGB-D显著性目标检测需要额外引入一条支路对深度图像进行特征提取, 并且需要额外的融合模块对跨模态特征进行融合, 从而导致模型参数的增多及推理速度的下降.因此, 近年来基于RGB-D显著性目标检测方法的轻量化方案受到广泛的关注.
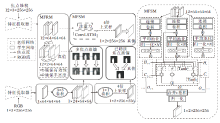
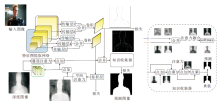
Piao等[161]提出A2dele, 具体结构如图12所示.将知识蒸馏策略引入RGB-D显著性目标检测任务中, 提出深度蒸馏网络, 利用网络之间的预测和网络之间的注意力连接RGB模态和深度模态, 将深度信息转化到RGB支路中, 使训练完成的网络在测试时, 能在不依赖深度图时也能有较好的性能表现, 从而减小低质量的深度图对预测结果的影响, 并大幅减小测试时的模型大小, 加快推理速度.
A2dele的蒸馏策略包括两部分.1)解决局部区域中深度信息流入RGB支路的程度问题, 提出自适应的深度蒸馏策略, 即利用深度支路的预测结果与真值进行对比, 使RGB支路可选择性地从深度支路学习, 从而降低训练期间低质量深度图的负面影响.2)解决RGB支路中的显著性对应定位问题, 即从全局角度, 提出带有注意力的深度蒸馏策略.该策略通过保持深度支路的预测图和RGB支路的注意力图之间的一致性以实现.为了解决深度支路预测的显著性目标不完整的问题, 提出对深度支路预测图进行显著性区域扩张的方法, 降低显著性区域预测缺失的概率, 更好地帮助RGB支路定位显著性目标Fu等[162]提出JL-DCF(Joint Learning and Den-sely-Cooperative Fusion), 采用联合学习的方法减小模型尺寸.由于RGB支路和深度支路共用一个特征提取网络, 所以网络在特征提取阶段的模型参数量远低于其它模型同阶段的参数量, 从而提高推理速度.Zhao等[163]提出DASNet(Joint Depth-Awareness SOD Network), 仅在训练时使用深度图作为监督, 并将学习到的深度特征通过CAF(Generalized Channel-Aware Fusion Model)加入RGB特征中, 因为测试时仅需要输入RGB图像, 所以加快测试期间的推理速度.Zhang等[164]提出DQFM(Depth Qua-lity-Inspired Feature Manipulation), 基于Mobile-V2设计专门的主干深度神经网络, 加快推理速度, 又设计包含一个预融合和全部融合的两阶段解码器, 从降低解码计算量的角度进一步提高效率.Wu等[165]提出MobileSal, 采用轻量级网络MobileNet作为特征提取网络以减少模型参数, 并且为了减轻由模型简化带来的特征提取能力下降问题, 提出IDR(Im-plicit Depth Restoration), 提高MobileNet的特征提取能力, 同时提出CPR(Compact Pyramid Refine-ment), 简单高效地融合不同尺度的跨模态特征.
为了解决模型参数量过大的问题, Ji等[166]提出CoNet(Collaborative Learning Framework), 具体结构如图13所示.CoNet将深度信息的学习和RGB信息的学习整合到高层特征学习过程中, 降低整体学习中所需的参数量.CoNet主要分为4部分:特征提取、边缘检测、粗糙显著性预测及深度估计.为了解决低层特征富含噪声的问题, 模型利用低层特征及注意力机制, 提出边界检测模块, 重点关注目标边界.为了解决高层特征中由于池化和上采样操作导致的边界混乱问题, 提出深度学习模块和显著性学习模块, 以互相帮助的形式增强高层语义的特征处理能力.同时, 为了解决参数量较多的问题, 在这两个模块中创新性地将深度特征学习整合至高层语义处理的过程中, 充当深度估计的监督源, 因此不用单独的深度网络处理深度图像, 减小模型参数量.
对于光场显著性目标检测, 由于光场数据中的焦点堆栈由12幅图像组成, 维度由单幅图像的3维扩展到36维, 造成使用焦点堆栈的算法很大的计算开销及内存开销.因此, 如何减少计算量, 使网络更高效成为一个研究方向.
受知识蒸馏启发, Piao等[129]提出ERNet, 在保证性能的同时减少网络计算量.ERNet提出多焦点蒸馏方案.在教师模型中使用焦点堆栈作为输入, 同时使用MFRM(Multi-focusness Recruiting Module)及MFSM(Multi-focusness Screening Module).MFRM旨在从每个焦点切片中收集丰富的显著性特征, 确保有效性及多样性.MFSM扫描各种位置并强调最相关的特征.这两个模块为学生网络提供双重知识转移.在学生模型中, 通过学习焦点堆栈计算流和RGB计算流之间的多焦点一致性, 以及教师网络提取的焦点知识和RGB中的外观信息之间的相关性, 这样的设计可在学生模型中使用RGB数据代替光场数据, 在减少计算量的同时, 使用教师模型提供的知识优化RGB检测方法.ERNet具体结构如图14所示.
近年来基于场景几何信息的显著性目标检测方法大多采用深度卷积神经网络进行多模态特征的提取与融合, 得益于CNN出色的多级特征提取能力和表达能力, 模型性能显著提升.然而, 由于受卷积核尺寸的限制, CNN感受野较小, 不能较好地建立长径区域之间的联系, 从而导致提取全局特征的能力较差.
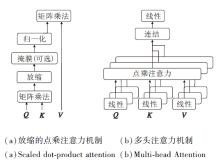
2017年, Vaswani等[167]首次在NLP领域提出Transformer, 其中的注意力机制(Attention)引起研究者们的广泛关注, 注意力机制结构图如图15所示.
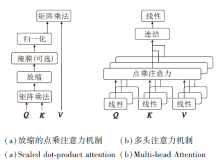 | 图15 注意力机制结构图Fig.15 Architecture of attention |
图15(a)为Attention机制, 首先通过线性映射为每个元素编码形成Q、K、V向量, 再计算不同元素的QKT, 得到它们之间的相似度权重.之后使用Softmax对权重进行归一化, 将归一化权重和对应的V相乘得到最后的Attention值.这一过程可并行化处理, 即得到Multi-head Attention.
2020年, Dosovitskiy等[168]提出ViT(Vision Transformer), 第一次将Transformer应用于计算机视觉领域.具体结构如图16所示.
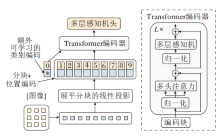 | 图16 ViT结构图[168]Fig.16 Architecture of ViT |
ViT首先将一幅图像分割成若干patch并展平, 再将它们进行编码, 得到对应的token, 同时添加一个类别token 0, 并为每个token加入位置编码.然后将它们送入Transformer编码器, 通过Attention机制计算所有Token之间的相关性.由于所有Token之间都需要两两进行Attention计算, 相当于对原图像的所有区域建立联系, 大幅提升全局特征的提取能力.
鉴于Transformer在视觉领域取得的显著成果, 近期一些基于场景几何信息的显著性目标检测模型[169, 170, 171, 172, 173, 174, 175]也将Transformer应用于该任务.
Liu等[176]提出VST(Visual Saliency Transfor-mer), 是第一个将Transformer应用于RGB和RGB-D显著性目标检测任务的模型, 也是当前唯一一个纯Transformer模型, 即未使用任何的卷积层.VST采用并行的T2T-ViT(Tokens-to-Token ViT)[177]作为网络的编码器, 分别提取RGB特征和深度特征, 同时设计RT2T(Reverse Token-to-Token)代替传统的反卷积或双线性插值进行特征图的上采样.
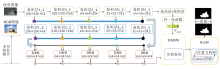
VST分为Encoder、Convertor、Decoder三部分.Encoder由并行的T2T-ViT网络组成, 分别提取RGB特征和深度特征, 然后将二者送入跨模态Trans- former模块, 通过互注意力机制进行跨模态特征融合, 融合后的特征进入一个双支路的Decoder, 分别用于显著性目标检测和边缘检测.设计RT2T模块, 首先通过一个线性层将Token的长度变为原来的4倍, 然后断裂成原Token长度, 从而使Token数量变为原来的4倍, 再将Token重新Reshape回特征图, 使特征图大小变为原来的两倍, 达到上采样的目的.VST具体结构如图17所示.
为了解决RGB-D显著性目标检测网络高层全局特征提取能力不足的问题, Liu等[169]提出Tri-TransNet(Triplet Transformer Embedding Network), 设计共享权重的transformer模块, 对后三层的RGB-D融合特征进行进一步的特征提取, 从而提高模型对显著性目标的定位能力.为了解决CNN无法较好提取RGB图像和深度图像全局特征的缺陷, Pang等[170]提出TransCMD, 设计纯Transformer的Decoder, 用于增强神经网络提取的RGB特征和深度特征, 并将二者融合.TransCMD由4个CMIUs(Cascaded Cross-Modal Integration Units)组成, 每个CMIU包括IMSA(Intra-Modal Self-Attention)、IMCA(Intra-Modal Cross-Attention)、CSSA(Cross-Scale Self-Attention)三部分.IMSA对Encoder提取的各个尺度的RGB特征和深度特征进行进一步的全局信息提取.IMCA融合同一尺度的RGB特征和深度特征, 得到RGB-D特征.CSSA逐步融合不同尺度的RGB-D特征.Tang等[171]提出HRTransNet, 先使用CNN对跨模态图像(深度图、焦点堆栈)进行特征提取并融入RGB特征中, 再使用HRFormer(High-Resolution Transformer)作为backbone, 对不同尺度的融合特征进行全局特征增强, 最后通过一个双向短连接网络进行多尺度特征的融合.
目前基于场景几何信息的显著性目标检测任务已得到研究者的广泛关注和深入研究, 并在模型设计、模型优化等方面取得显著的研究成果.本节进一步总结当前基于场景几何信息的显著性目标检测方法存在的问题, 并围绕特征提取、小样本学习、模型移动端部署三个方向对该领域今后的发展提出相应的预测与建议.
近年来基于场景几何信息的显著性目标检测方法绝大多数采用深度学习的方法, 而影响深度学习效果的一个重要因素就是模型的特征提取能力.目前, 基于场景几何信息的显著性目标检测方法的特征提取网络大多采用CNN, 虽然CNN对于局部特征的提取和表达能力良好, 但对全局特征的提取能力较差.目前, 一些学者将Transformer应用于RGB-D显著性目标检测, 用于提高模型的全局特征提取能力, 但相比Transformer在其它视觉领域取得的成就, 其在基于场景几何信息的显著性目标检测领域依然有较大的发展空间和应用前景.
限制基于场景几何信息的显著性目标检测方法发展的一个主要原因是缺乏高质量的深度图像, 低质量的深度图像往往含有大量的噪声, 边缘处的深度图较模糊, 这样的深度图会对RGB支路的特征流造成干扰, 降低显著性目标检测的精度.同时深度图像的获取较困难, 导致数据集上很多RGB图像没有对应的深度标签, 使可用于场景几何信息的显著性目标检测方法训练的样本数量有限.近年来, 半监督学习方法或无监督学习方法受到学者的广泛关注, 并提出一些基于半监督或无监督的显著性目标检测方法.从长远来看, 使用半监督或弱监督策略不失为解决深度线索有限问题的一种思路.
目前基于场景几何信息的显著性目标检测方法已取得相当高的检测精度, 但在实际场景的应用远不及基于RGB的显著性目标检测方法, 其主要原因分为两方面.1)目前基于场景几何信息的显著性目标检测方法多采用多流网络, 模型较复杂, 参数量较大, 不利于直接应用于实际的移动端平台; 2)场景多线索几何信息的获取需要专用设备, 实际应用中不易获取.在未来的研究中, 使用更轻量级的模型, 减少模型参数, 显然更有利于模型在移动端的实际应用.另外, 一些模型将深度图像作为监督, 仅在训练过程中将深度特征加入RGB特征中, 为此类模型在实际应用时不受几何信息的依赖, 这在未来值得更深入的研究.
本文责任编委 黄 华
Recommended by Associate Editor HUANG Hua
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|
| [47] |
|
| [48] |
|
| [49] |
|
| [50] |
|
| [51] |
|
| [52] |
|
| [53] |
|
| [54] |
|
| [55] |
|
| [56] |
|
| [57] |
|
| [58] |
|
| [59] |
|
| [60] |
|
| [61] |
|
| [62] |
|
| [63] |
|
| [64] |
|
| [65] |
|
| [66] |
|
| [67] |
|
| [68] |
|
| [69] |
|
| [70] |
|
| [71] |
|
| [72] |
|
| [73] |
|
| [74] |
|
| [75] |
|
| [76] |
|
| [77] |
|
| [78] |
|
| [79] |
|
| [80] |
|
| [81] |
|
| [82] |
|
| [83] |
|
| [84] |
|
| [85] |
|
| [86] |
|
| [87] |
|
| [88] |
|
| [89] |
|
| [90] |
|
| [91] |
|
| [92] |
|
| [93] |
|
| [94] |
|
| [95] |
|
| [96] |
|
| [97] |
|
| [98] |
|
| [99] |
|
| [100] |
|
| [101] |
|
| [102] |
|
| [103] |
|
| [104] |
|
| [105] |
|
| [106] |
|
| [107] |
|
| [108] |
|
| [109] |
|
| [110] |
|
| [111] |
|
| [112] |
|
| [113] |
|
| [114] |
|
| [115] |
|
| [116] |
|
| [117] |
|
| [118] |
|
| [119] |
|
| [120] |
|
| [121] |
|
| [122] |
|
| [123] |
|
| [124] |
|
| [125] |
|
| [126] |
|
| [127] |
|
| [128] |
|
| [129] |
|
| [130] |
|
| [131] |
|
| [132] |
|
| [133] |
|
| [134] |
|
| [135] |
|
| [136] |
|
| [137] |
|
| [138] |
|
| [139] |
|
| [140] |
|
| [141] |
|
| [142] |
|
| [143] |
|
| [144] |
|
| [145] |
|
| [146] |
|
| [147] |
|
| [148] |
|
| [149] |
|
| [150] |
|
| [151] |
|
| [152] |
|
| [153] |
|
| [154] |
|
| [155] |
|
| [156] |
|
| [157] |
|
| [158] |
|
| [159] |
|
| [160] |
|
| [161] |
|
| [162] |
|
| [163] |
|
| [164] |
|
| [165] |
|
| [166] |
|
| [167] |
|
| [168] |
|
| [169] |
|
| [170] |
|
| [171] |
|
| [172] |
|
| [173] |
|
| [174] |
|
| [175] |
|
| [176] |
|
| [177] |
|