


{kind=link}
{kind=link}
{kind=link}
主题增强的多层次图神经网络会话推荐模型
[唐顾1  , 朱小飞
, 朱小飞1 ]
, 朱小飞]
|
|



作者简介:

唐顾,硕士研究生,主要研究方向为推荐系统、自然语言处理.E-mail:Gutang@2020.cqut.edu.cn.
基于会话的推荐旨在基于会话内数据,为匿名或未登录用户做出推荐.现有的研究工作通常仅以会话中单个商品作为最小单位进行建模,忽略商品在不同感受野下的表征.同时,尚未挖掘会话序列中蕴含的商品隐式主题信息.为了缓解上述问题,文中提出主题增强的多层次图神经网络会话推荐模型(Topic-Enhanced Multi-level Graph Neural Network for Session-Based Recommendation, TEMGNN).首先,设计多层次商品嵌入学习模块,拓宽商品的感受野,获取不同粒度下的商品表示.然后,结合文中提出的多层次图神经网络进行同粒度和跨粒度下的商品信息传播,捕获更丰富的商品嵌入表征.此外,提出商品主题学习模块,在不依赖任何商品属性信息的前提下,抽取商品在隐空间下的主题共性,并以显式的向量空间投影方式自动形成商品的主题表示,用于增强模型推荐性能.在3个基准数据集上的实验表明,TEMGNN的表现较优.
About Author:
TANG Gu,master student. His research interests include recommendation systems and natural language processing.
Session-based recommendation(SBR) aims to provide recommendations for anonymous users or users who are not logged in based on data in the session. The existing research models a single item in the session as the smallest unit, ignoring the item representation in different receptive fields. Moreover, the implicit topic information contained in the session sequence is not mined. To alleviate these issues, a topic-enhanced multi-level graph neural network(TEMGNN) for SBR is proposed. Firstly, a multi-level item embedding learning module is designed to broaden the receptive fields of item and obtain the representation of items at different granularities. Then, the proposed multi-level graph neural network is employed to propagate the item information with and cross granularities, capturing richer item embedding representation. Furthermore, a topic learning module is proposed to extract the topic commonalities of items in hidden space and automatically form topic representations of items by explicit vector space projection without relying on any item attribute information. Thus, the recommendation performance of the model is enhanced. Experiments on three benchmark datasets show the superiority of TEMGNN.
基于会话的推荐(Session-Based Recommenda-tion, SBR)旨在根据用户的短期历史行为预测用户最可能点击或购买的目标商品, 在一些视频流平台或电商平台(如Tiktok、YouTube和淘宝等)发挥着重要的作用.基于会话的推荐主要为平台内的匿名用户或未登录用户进行个性化推荐, 这对提升新用户或未登录用户的平台使用体验和提高新用户的留存率起到至关重要的作用.传统的推荐算法(如协同过滤(Collaborative Filtering, CF)[1, 2, 3]、马尔科夫链(Markov Chain, MC)[4, 5])依赖用户的长期行为记录或用户信息, 在用户行为较稀疏的会话推荐场景中性能会受到限制.
近年来, 基于深度学习的方法在基于会话的推荐任务中取得较好的效果[6, 7, 8, 9, 10].这些方法的建模思路可大致分为以下2类.
1)结合循环神经网络(Recurrent Neural Net-work, RNN)捕获会话中商品的顺序转换模式, 并结合注意力机制判断会话中不同商品的重要性.Hidasi等[6]结合门控循环神经网络(Gated Recurrent Unit, GRU)[11], 模拟用户行为的顺序转换模式.在此基础上, Li等[7]提出NARM(Neural Attention Re- commendation Machine), 进一步结合注意力机制, 捕获用户偏好.Liu等[8]提出STAMP(Short-Term Atten-tion/Memory Priority Model), 引入由多层感知机和注意力机制组成的短期记忆网络, 捕获用户的偏好.Ren等[12]注意到用户兴趣漂移的问题, 进而提出RepeatNet, 包含重复模块和探索模块, 重复模块预测用户的重复购买行为, 探索模块预测用户非重复购买行为.Chen等[13]提出DCN-SR(Dynamic Co-attention Network for Session-Based Recommenda-tion), 利用共同注意力机制捕获用户的长期兴趣和短期兴趣.Yuan等[9]提出DSAN(Dual Sparse Atten-tion Network for Session-Based Recommendation), 引入α -entmax函数, 改进注意力机制, 减少噪音商品对用户偏好的影响.
2)应用图神经网络(Graph Neural Network, GNN)捕获会话中商品之间复杂的转换关系.Wu等[10]提出SR-GNN(Session-Based Recommendation with GNN), 将会话序列转换成会话图并结合门控图神经网络(Gated GNN, GGNN)[14], 建模会话中商品之间的转换模式.Qiu等[15]提出FGNN(Fully GNN), 重新考虑会话中商品之间的转换关系, 并将推荐任务转换为图分类任务.此外, Yu等[16]提出TAGNN(Target Attentive GNN), 设计目标感知的注意力模块, 进一步拓展SR-GNN, 使其能够动态捕获用户意图.Wang等[17]提出SHARE(Session-Based Hypergraph Attention Network for Recommendation), 为每个会话构建超图, 并结合超图注意力网络动态聚合商品的上下文表示.Wang等[18]提出GCE-GNN(Global Context Enhanced GNN), 探索商品的全局上下文关系, 构建会话全局图, 并结合会话局部图和全局图, 学习用户的偏好表示.Xia等[19]提出COTREC(Self-Supervised Graph Co-training Framework for Session-Based Recommendation), 从自监督学习角度进一步挖掘会话表示, 结合基于自监督学习的联合训练, 进一步增强模型性能.
上述方法推动SBR的发展, 但上述工作都忽略一些值得挖掘的研究点.首先, 现有方法大多以会话中的单个商品为最小单位进行建模并结合一些池化操作(如平均池化、最大池化、注意力池化等)以获取用户的偏好表示.但是现有方法却忽略对商品不同感受野的建模.以不同大小(不同粒度)的商品块为最小单位能够拓展商品的感受野和丰富商品的表征能力.其次, 聚合同一商品在不同感受野的表征能够进一步增强商品的表征能力.
此外, 由于基于会话推荐的数据中往往缺乏商品的主题和类别信息, 导致现有方法都忽略建模这一信息.直观上, 商品的部分嵌入表示能够在一定程度上反映商品间的相似程度, 这种特征可表征商品间的共性信息(如主题信息或类别信息), 单独分离该类特征以显式的方式进行建模能够更好地捕获用户偏好.所以显式的建模商品的主题信息能够使模型更加准确地捕捉用户偏好.
为了解决上述问题, 本文提出主题增强的多层次图神经网络会话推荐模型(Topic-Enhanced Multi-level GNN for Session-Based Recommendation, TEM-GNN).TEMGNN主要由2个模块构成:多层次商品嵌入学习模块、会话表示学习及推荐模块.受Guo等[20]的启发, 利用多层次会话图结构捕获商品的多粒度表示, 并进行不同层次的图间信息聚合.具体来说, 多层次商品嵌入学习模块包含三个子模块:1)多层次会话图结构; 2)多层次图神经网络(Multi-level GNN, ML-GNN); 3)商品图间信息聚合.多层次商品嵌入学习模块可拓展会话中商品的感受野以捕获不同粒度下的商品信息, 并同时依靠自身的语义信息形成对应的会话拓扑结构.然后结合ML-GNN学习各粒度下会话的拓扑结构信息, 增强各粒度下的商品表示.最后, 不同粒度下的商品表示进行信息交互, 进一步丰富各粒度下的商品表示.另一方面, 会话表示学习及推荐模块包含四个模块:商品主题学习模块、重复预测模块、探索预测模块和概率聚合模块.会话表示学习及推荐模块的目标是学习一个准确的会话表示, 实现较优的推荐效果.本文提出一种主题学习模块, 从商品的语义表示中抽取商品的主题信息, 并以一种显式的建模方式表征商品的主题信息, 最后结合商品主题信息和注意力网络形成更精准的会话表示.在三个广泛使用的基准数据集进行的大量实验表明, TEMGNN在相关评测指标上均较优.
本文提出主题增强的多层次图神经网络会话推荐模型(TEMGNN), 整体架构如图1所示.TEMGNN主要由两部分组成:多层次商品嵌入学习模块、会话表示学习及推荐模块.
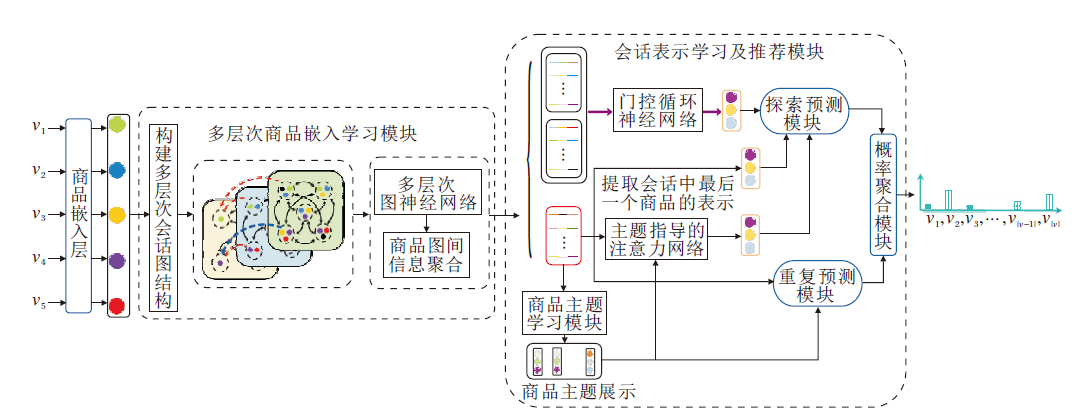 | 图1 TEMGNN的整体架构Fig.1 Framework of TEMGNN |
本节形式化定义基于会话的推荐任务以及文中出现的符号.设
V={v1, v2, …, v|V|}
表示数据中出现的商品集合, 其中|V|为数据中非重复的商品数量,
S=(
表示会话序列, 其中, n为序列长度,
Hs=[
表示会话S在向量空间的嵌入表示, 其中
基于会话的推荐目标是基于会话S为用户推荐用户下一次最可能点击的商品.
受MSGIFSR(Multi-granularity Intent Heteroge-neous Session Graph and Intent Fusion Ranking for Session-Based Recommendation)[20]的启发, 多层次商品嵌入学习模块首先通过拓展会话中商品的感受野捕获不同粒度下的商品信息, 并依靠其语义表示形成对应的会话拓扑结构.然后结合多层次图神经网络, 聚合各粒度下的会话拓扑结构信息, 用于增强各粒度下的商品表示.最后结合注意力机制进行商品的图间信息聚合.
1.2.1 多层次会话图结构
对于会话
S=(
利用滑动窗口拓展商品的感受野, 获得不同粒度下的商品表示.具体来说, 针对会话S中的
$q_i^k=\left[v_{i-\left\lfloor\frac{k-1}{2}\right\rfloor}^{s},\cdots,v_i^s,\cdots,v_{i+\left\lfloor{\frac{k}{2}}\right\rfloor}^s\right],$
其中⌊· 」为向下取整符.
$ p^k_i=\Big[h^s_{i-\left\lfloor\frac{k-1}{2}\right\rfloor}, \cdots, h^s_i, \cdots, h^s_{i+\left\lfloor\tfrac{k}{2}\right\rfloor}\Big].$.
对
值得注意的是, 当k=1时,
接下来, 针对不同粒度下的商品表示构建其对应的会话图.对于粒度为k的会话序列向量表示
对应的会话图为
其中, v
其中
不同粒度(不同k)下的会话序列分别对应各自的图结构
值得注意的是, 会话图的结构是由会话序列中商品的向量空间嵌入决定的, 其结构可以随着图神经网络的层数叠加而动态更新.
1.2.2 多层次图神经网络
多层次图神经网络(ML-GNN)旨在捕获多粒度下会话图的拓扑结构信息以增强商品空间向量的表征能力.受LightGCN(Light Graph Convolution Network)[21]的启发, 移除传统图卷积网络(Graph Convolutional Network, GCN)中的线性转换和非线性激活结构.具体来说, 针对粒度为k的会话序列表示
定义在第l层图神经网络下节点
$\mathbf{A}_s^{k, (l-1)}=BMG(\overline{\mathbf{P}}^{k, (l-1)})~, \\ \tilde{\mathbf{P}}_i^{k, (l)}=\mathbf{A}_{i, s}^{k, (l+1)}(\bar{\mathbf{P}}_1^{k, (l+1)}.\bar{\boldsymbol{p}}_2^{k.(l-1)}~, \cdots, \tilde{\boldsymbol{P}}_n^{k, (i-1)}~), $
其中,
为经过第l层GCN后的第k个粒度下的会话序列表示.
值得注意的是, 当l=1时,
1.2.3 商品图间信息聚合
经过ML-GNN后, 各粒度下的商品表示聚合各自的会话拓扑结构信息.然而以什么样的方式将多粒度下的商品表示进行聚合以形成一个综合的商品表示是一个值得探索的问题.一个简单直接的思路为:将同一商品在不同粒度下的表示构建子图, 并依靠该子图结合GCN进行同一商品在不同粒度下的信息传播.然而该方式适用于子图节点数量较多(即k值较大)的情况, 否则容易出现过度平滑的现象, 从而降低模型性能.由于会话数据较稀疏, 窗口大小k值太大会导致其对应的会话图
为了解决上述问题, 本文对商品在不同粒度下的表示进行区分.具体来说, 将窗口大小k> 2对应的会话序列表示结合注意力机制进行聚合, 形成会话的粗粒度表示.再结合门控机制融合会话的粗粒度表示和细粒度表示(即k=1对应的会话序列表示), 形成会话的综合序列表示.上述过程的公式化定义如下:
$ \begin{aligned}\boldsymbol{\mu}_{i}^{* , c}=\sum_{j=2}^{k}\alpha_{j}\bar{\boldsymbol{\mu}}_{i}^{j, (l)}\in\boldsymbol{\mathbf{R}}^{d}, \\ \alpha_{j}=\frac{\exp(\boldsymbol{\mu}_{p}^{\text{T}}\bar{\boldsymbol{p}}_{i}^{i, (l)})}{\sum_{j=1}^{k}\exp(\boldsymbol{\mathbf{w}}_{p}^{T}\bar{\boldsymbol{\boldsymbol{p}}}_{i}^{j, (i)})}, \\ \end{aligned}$
其中,
聚合窗口大小k> 2后对应的粗粒度会话序列表示为
接下来, 本文结合门控机制, 对粗粒度会话序列表示和细粒度会话序列表示进行特征聚合:
$ \widetilde{\boldsymbol h}^s_i=g_i\odot\boldsymbol h^s_i+(1-g_i)\odot\boldsymbol h^{s, c}, $
其中,
gi=σ (
wg∈ Rd表示可训练参数, σ 表示激活函数Sigmoid.
聚合粗粒度和细粒度会话序列表示后的会话综合表示为:
$ \widetilde{H}_s=\Big(\widehat{h}_1^s, \widehat{h}_2^s, \cdots, \widetilde{h}_n^s\Big).$
通过多层次图神经网络和商品图间信息聚合, 商品的嵌入表示聚合丰富的特征.本节详细介绍如何从商品的嵌入表示中学习用户的偏好表示以进行精确推荐.会话表示学习及推荐模块由4个子模块组成:商品主题学习模块、重复预测模块、探索预测模块和概率聚合模块.
1.3.1 商品主题学习模块
在推荐场景中, 许多商品或短视频都归属于同一主题或同一类别下, 在基于会话的推荐场景中, 由于这类数据往往缺乏对商品主题或类别的显式描述, 现有工作都忽略对该类信息的建模.针对这一问题, 本文提出商品主题模块, 用于建模商品的主题信息.具体来说, 商品主题模块从商品的语义表示中抽取商品的主题信息, 并以一种显式的建模方式表征商品的主题信息.
首先, 对于会话序列表示
$ \widetilde{H}_s=\left(\widehat{h}_1^s, \widehat{h}_2^s, \cdots, \widetilde{h}_n^s\right), $
本文结合双向门控循环神经网络(Bidirectional GRU, Bi-GRU)生成会话中商品
$ \begin{array}{l}c_{i}^{* }=\overrightarrow{h}_{i}^{* }+\overline{\boldsymbol{h}_{i}}^{* }\in\mathbf{R}^{L}, \\ \overrightarrow{\boldsymbol{H}_{i}^{* }}=\overrightarrow{GRU}\left(\widetilde{h}_{i-1}^{* }, \widetilde{\boldsymbol{h}}_{i}^{i}, \boldsymbol{\theta}_{\text{go}}\right).\\ \\ \overline{\boldsymbol{H}}_{i}^{s}=\overline{GRU}\left(\widehat{h}_{i+1}^{i}, \widehat{h}_{i}^{i}, \overline{\boldsymbol{\theta}}_{\text{max}}\right).\\ \end{array}$
其中, θ gru∈ Rd× L表示可训练参数, L为超参数, 表示商品主题的数量.
接下来, 运用归一化函数Softmax将商品的主题待分配状态
其中,
将
其中,
为了解决模型训练和推理过程中由于温度参数τ 带来差异, 本文在模型训练阶段采用式(2)优化模型, 在模型推理过程中采用式(1)进行模型推理.其公式化定义为
获得商品的主题独热向量
$\hat{\boldsymbol{t}}_i^s=W_t\boldsymbol{t}_i^s+\boldsymbol{b}_t,$
$\bar{\bar{t}}_i^s=GRU\left(\hat{t}_{i-1}^s,\hat{t}_i^s,\boldsymbol{\phi}_\text{gru}\right),$
$\bar{\boldsymbol{\bar{t}}}_i^s=\sigma\left(\begin{matrix}\boldsymbol{W}_a\bar{\boldsymbol{t}}_i^s+\boldsymbol{b}_a\end{matrix}\right),$
其中, bt∈ Rd, ba∈ Rd为可训练参数, σ 为激活函数tanh, Wt∈ Rd× L, Wa∈ Rd× d.
会话序列S对应的主题序列表示为
$ T_s=\left(\bar{\boldsymbol{t}}_1^s, \bar{\boldsymbol{\boldsymbol{t}}}_2^s, \cdots, \bar{\boldsymbol{{t}}}_n^s\right), $
其中
1.3.2 重复预测模块
对于一些用户比较感兴趣的商品往往存在一定比例的重复点击或重复购买.受RepeatNet[12]的启发, 结合会话的综合序列表示
$ \widetilde{H}_s=\left(\widehat{h}_1^s, \widetilde{h}_2^s, \cdots, \widehat{h}_n^s\right)$
和会话的主题序列表示
$ T_s=\left(\hat{t}_1^s, \hat{t}_2^s, \cdots, \hat{t}_n^s\right), $
对用户点击或购买过的商品进行打分:
zi=
其中, wr∈ Rd表示可训练参数, yr∈ R|V|表示重复预测概率分布, yr只对在当前会话S中出现过的商品进行打分, 未出现的商品的得分为0.
1.3.3 探索预测模块
在电商平台或视频流平台, 非重复购买和点击行为占据相当一部分的用户习惯.因此, 建模用户的整体偏好并推荐他们未购买或点击过且感兴趣的商品十分重要.
商品的主题或类别信息往往能够反映用户的整体偏好, 所以本文将主题序列表示
$ \boldsymbol{T}_s=\left(\hat{t}_1^s, \hat{t}_2^s, \cdots, \hat{t}_n^s\right)$
以注意力机制的形式指导会话的综合序列表示:
$ \widetilde{H}_s=\Big(\widetilde{h}_1^s, \widehat{h}_2^s, \cdots, \widetilde{h}_n^s\Big).$
聚合形成用户的整体偏好:
$ \begin{aligned}s_i& =\sum_{i=1}^n\beta_i x_i^s, \\ \beta_i& =\frac{\exp(\mathbf{w}_p^T x_i^s)}{\sum_{j=1}^n\exp(\mathbf{w}_{j}^T x_j^s)}, \\ \\ \mathbf{x}_i^i& =\sigma\left(\mathbf{W}_i\widetilde{u}_{i}\widetilde{u}_i^s+\mathbf{W}_{i}\tilde{I}_i^s\right), \end{aligned}$
其中, Wh∈ Rd× d, Wt∈ Rd× d表示可训练参数, wβ ∈ Rd.
用户的粗粒度兴趣对于用户的整体偏好的建模往往能起到一定的补充作用.同时, 会话中的最后一个商品点击往往能反映用户的即时兴趣.因此将粗粒度会话序列表示
结合GRU, 获取用户的粗粒度偏好sc.
同时, 将会话综合序列中的最后一个商品表示
最后, 本文融合sl、sc和st, 获取用户最终的偏好表示sf.该过程定义如下:
$ \widetilde{\boldsymbol{h}}_i^{s, c}=GRU(\begin{matrix}h_{i-1}^{s, c}, h_i^{s, c}, \boldsymbol{\phi}_c)\end{matrix}, $
其中ϕ c∈ Rd× d表示可训练参数.
本文取经过GRU后的粗粒度会话序列表示
$ \widetilde{H}_s^c=\left(\widetilde{h}_1^{s, c}, \widetilde{h}_2^{s, c}, \cdots, \widetilde{h}_{n}^{s, c}\right)$
中最后一个商品表示
sf=sl+δ sc+st,
其中δ 为控制粗粒度用户偏好表示信息量的超参数.
接下来, 结合用户的最终偏好表示sf对用户未点击或购买的商品进行概率分布的预测:
ρ i=
其中, hi∈ Rd为商品集合V中的第i个商品的嵌入表示, ye∈ R|V|为探索预测概率分布, ye仅对未出现在会话S中的商品进行打分.
1.3.4 概率聚合模块
通过重复推荐模块和探索推荐模块分别获取重复预测概率分布yr和探索预测概率分布ye.以用户最终的偏好表示sf生成门控结构, 融合yr和ye, 生成最终的预测概率分布:
$\begin{aligned}&\mathbf{\hat{y}}_i=f_i\odot\mathbf{y}_i^r+(1-f_i)\mathbf{\partial y}_i^e,\\ &f_i=\sigma\left(\mathbf{w}_f^{\mathrm{T}}\mathbf{s}_f\right),\end{aligned}$
其中, wf∈ Rd为可训练参数,
为了提升模型的泛化性, 采用Madry等[24]提出的PGD(Projected Gradient Descent), 对模型参数添加对抗性扰动, 提升模型的泛化性.具体来说, 在商品嵌入上添加对抗性扰动, 扰动量
$ \begin{aligned}\delta_{i+1}& =\prod\limits_{\|\hat{\sigma}\|_i\leq\epsilon}\left(\delta_i+\frac{\alpha g(\delta_i)}{\|g(\delta_i)\|_F}\right), \\ & g(\delta_i) =\nabla_\delta L(f_\theta(X+\delta_i), y), \end{aligned}$
其中, t为PGD的迭代步数, 设置为2, g(δ t)为δ t对应的参数梯度, X为商品嵌入, fθ 为模型参数.为将δ 在以∈ 为半径的球面上进行投影以控制δ 的范围.
最后, 利用交叉熵函数L作为损失函数, 对模型进行优化:
L=-
其中, yi为标签商品的独热向量表示,
为了验证TEMGNN的有效性, 进行相关实验, 回答如下问题:
1)TEMGNN性能是否超越目前最优模型?
2)TEMGNN的每个模块对模型整体性能的影响怎样?
3)TEMGNN在不同长度的会话上表现如何?
4)不同层数的多层次图神经网络对模型性能的影响?
5)TEMGNN训练过程中的时间和空间消耗情况怎样?
与之前的工作一样[9, 16, 25, 26], 本文选择广泛使用的基准数据集Diginetica、Yoochoose、Retailro-cket, 验证TEMGNN和基线模型的性能.
Diginetica数据集来自2016 CIKM Cup.Yoo-choose数据集来自2015 RecSys Challenge, 由于数据量过大, 与之前工作一样, 将Yoochoose进行拆分, 分别取其最后的1/64和1/4部分构造新的数据, 并命名为“ Yoochoose1/64” 和“ Yoochoose1/4” .类似地, 取Retailrocket数据集的最后1/4部分数据作为Retailrocket数据集的训练数据.数据集统计信息如表1所示.
| 表1 数据集统计信息 Table 1 Statistics of dataset |
与文献[9]和文献[15]一样, 滤除会话长度小于2的会话和会话中商品出现次数小于5的商品, 同时进行序列增强以扩增数据, 具体来说, 对于会话
S=(
生成序列和对应的标签:
([
为了验证TEMGNN的整体表现, 选择如下11种基线模型进行性能对比, 基线模型可大致分为如下3类.
1)基于传统方法的模型.
(1)文献[1]模型.依赖协同过滤, 为用户推荐与当前会话中商品最相似的商品.
(2)FPMC(Factorized Personalized Markov Chains)[4].结合矩阵分解和马尔科夫链, 模拟用户行为的顺序转换关系.
2)基于RNN和注意力机制的模型.
(1)文献[6]模型.应用GRU模拟用户的顺序行为, 并利用会话批量训练和排序损失函数优化模型.
(2)NARM[7].使用RNN和注意力机制捕获用户的主要偏好.
(3)STAMP[8].使用注意力机制替换RNN编码器, 并提取会话中最后一个商品的表示作为用户的短期兴趣.
(4)DSAN[9].利用双稀疏注意网络完成会话推荐任务.首先探索会话中每个商品之间的相互作用, 并通过注意力网络学习目标商品的表征.然后, 应用一个普通的注意力网络获取当前会话中商品的重要性, 从而获得会话表示.
3)基于GNN的模型.
(1)SR-GNN[10].将会话序列转换成会话图结构并结合GGNN[14]学习会话表示.
(2)TAGNN[16].在SR-GNN的基础上引入目标注意力模块, 用于揭示给定目标商品与用户的历史点击商品的相关性, 从而改进会话推荐性能.
(3)SHARE[17].为每个会话构建一个超图, 并结合超图注意力网络动态聚合商品的上下文表示.
(4)GCE-GNN[18].从全局角度和局部角度构建商品之间的拓扑关系, 并结合图注意力网络学习会话中商品的表示.
(5)COTREC[19].将自监督学习与基于会话推荐的联合训练相结合.在联合训练中, 利用会话的内/外部关联性, 扩展两种不同的视图, 即商品视图和会话视图.
在TEMGNN中, 设置训练批次大小为512, 商品嵌入大小为256, 多层次图结构中窗口数为3, 窗口大小分别为1, 2和3, 多层次图神经网络的层数为1, 商品主题数量L=512.与之前的工作一样[9, 14, 16], 模型参数按照均值为0、方差为0.1的高斯分布进行初始化.优化器选择为Adam(Adaptive Moment Estimation), 学习率设置为0.001, 本文设置每经过3轮训练, 学习率衰减为原来的0.1倍.值得注意的是, 进行消融实验时, 未被改变或替换的部分保持原始参数不变.
与之前的工作中一样[15, 16, 25, 27, 28], 采用两个广泛使用的评测指标P@20和MRR@20验证模型性能.
1)P@K.准确率(Precision, P)衡量目标商品在召回列表中的样本比例:
P@K=
其中, nhit为目标商品在Top-K召回列表中的样本数量, N为样本总数量.
2)MRR@K.MRR(Mean Reciprocal Rank)衡量目标商品在召回列表中的位置, 位置越靠前, 得分越高, 则
MRR@K=
其中, ranki为第i个目标商品在Top-K召回列表中的位置, N为样本总数量.
TEMGNN与所有基线模型在3个基准数据集上的性能对比如表2所示, 表中* 表示显著性检验, p≤ 0.01, 黑体数字表示最优值, 斜体数字表示次优值.由表可以看出, 在传统推荐模型中, 文献[1]模型的表现优于FPMC, 这表明会话中商品间的共现关系是一种重要的信息.
| 表2 各模型在4个数据集上的指标值 Table 2 Index values of different models on 4 datasets % |
相比基于传统方法的模型, 基于神经网络的模型性往往表现更优.文献[6]模型将RNN应用于会话推荐任务中, 在大多数数据上的表现都优于传统方法, 这显示出RNN建模序列信息的能力.NARM和STAMP的性能均优于文献[6]模型, 这是由于它们引入注意力机制以捕获用户的主要偏好.DSAN在基于RNN和注意力机制的模型中的性能表现最优, 这是由于DSAN设计双重稀疏注意力网络, 缓解会话中噪音商品对建模用户偏好的影响.
在所有基线模型中, 基于GNN的模型性能表现最优.SR-GNN根据会话中商品之间的转换关系将会话转化为图结构, 捕获商品间的隐式连接关系, 且进一步结合GGNN学习会话表示.TAGNN在SR-GNN基础之上添加目标感知注意力模块, 进一步考虑用户的动态偏好.COTREC与SR-GNN的性能表现相当, 通过商品的内/外部连接获得商品在不同视图下的表示, 在一定程度上缓解数据稀疏的问题.在所有基于GNN的基线模型当中, GCE-GNN的表现最优, 这是由于GCE-GNN有效学习商品在局部角度和全局角度下的转换关系, 同时进一步结合反向位置嵌入, 更好地建模商品的位置信息.
TEMGNN在3个基准数据集上的性能优于GCE-GNN.主要原因为TEMGNN提出多层次图神经网络和商品主题学习模块, 用于捕获不同粒度下的商品表示和商品主题表示.
为了验证TEMGNN中商品多粒度表示、多层次图神经网络(ML-GNN)和商品主题模块的有效性, 本文设计如下变种模型.
1)TEMGNN-SG.在多层次会话图结构中仅保留窗口大小为1的会话图结构, 即去除商品的多粒度表示.
2)TEMGNN-MLP.ML-GNN替换为多层感知机(Multi-layer Perception, MLP).
3)TEMGNN-GGNN.ML-GNN替换为SR-GNN中的GGNN.同时, 会话图结构的构造方式与SR-GNN保持一致.
4)TEMGNN-GAT.ML-GNN替换为GCE-GNN中的图注意力网络(Graph Attention Network, GAT).同时, 会话图结构的构造方式与GCE-GNN保持一致.
5)TEMGNN-w/o Topic.移除TEMGNN中的商品主题学习模块, 同时主题指导的注意力网络替换为自注意力网络.
各变种模型的性能对比如表3所示.由表可观察到, 仅保留多层次图结构中窗口大小为1的会话图结构(TEMGNN-SG)会导致模型性能下降, 这验证不同粒度下的商品表示能够优势互补, 使商品表示更加准确.同时, 将ML-GNN替换为MLP、GGNN、GAT均会导致模型性能受到消极影响.具体来说, TEMGNN-GGNN与TEMGNN-MLP表现相当, 这是由于TEMGNN-GGNN未能区分会话图中商品间的连接强度.TEMGNN-GAT的表现更优, 这是由于GAT能够自适应地学习商品间的连接强度, 但是依然根据会话中商品间的转换关系生成会话的拓扑结构, 无法避免会话图中由于用户错点或误点带来的噪音信息.TEMGNN可以根据商品间的语义关系自适应地生成会话对应的图结构, 在一定程度上规避由于用户的错点或误点带来的消极影响.另一方面, 当移除商品主题学习模块(TEMGNN-w/o Topic)时, 模型的表现呈现稳定下降, 这验证商品主题学习模块能够为商品提供有效的主题信息.
| 表3 不同模块的消融实验结果 Table 3 Results of ablation experiment of different modules % |
为了验证TEMGNN在不同长度会话上的性能, 本文将会话分为2组:会话长度小于5的称为短会话, 会话长度大于等于5的称为长会话.将TEMGNN与COTREC和GCE-GNN在上述两种会话上进行实验, 结果如图2所示.
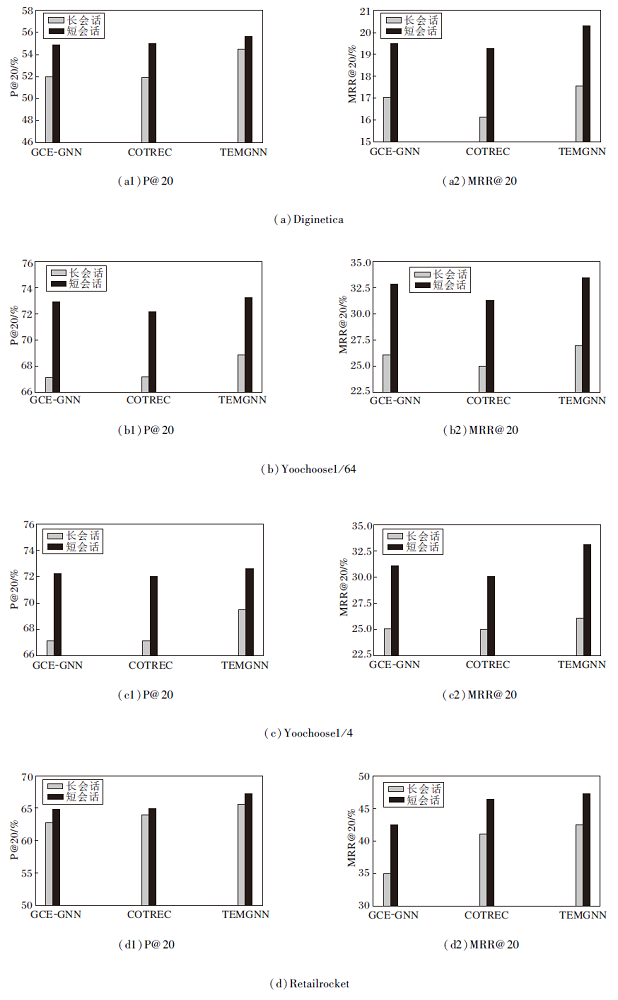 | 图2 不同模型在不同长度会话上的表现Fig.2 Performance of different models on different length sessions |
由图2可以得出如下结论.
1)3种模型在短会话上的性能优于在长会话上的性能.该现象说明长会话包含用户更多的兴趣转换, 导致模型难以捕获用户的主要意图.
2)TEMGNN在各数据集的长会话和短会话上性能均优于GCE-GNN和COTREC, 这说明TEM-GNN不论在长会话和短会话上都具有明显改进.
为了验证多层次图神经网络(ML-GNN)层数对TEMGNN性能的影响, 将ML-GNN的层数设置为1, 2, 3, 4, 分别验证TEMGNN性能的变化, 实验结果如图3所示.
 | 图3 不同ML-GNN层数对TEMGNN性能的影响Fig.3 Effect of different ML-GNN layers on performance of TEMGNN |
由图3可以看出, TEMGNN在Diginetica、Re-tailrocket数据集上性能最优的情况是当ML-GNN层数设置为1时, 同时在Yoochoose数据集上性能最优的情况是当ML-GNN层数为2.这是由于Yoo-choose数据集上的会话平均长度长于Diginetica、Retailrocket数据集上的长度, 会话的拓扑结构更为复杂, 需要更深层的ML-GNN学习拓扑信息.另一方面, 由图可以看出, 随着ML-GNN层数增加到3或4时, TEMGNN的性能出现下降, 这是由于ML-GNN层数过多会导致会话图中节点特征表示出现过度平滑的现象.
为了探索TEMGNN的实用性, 对TEMGNN在训练过程中的耗时、收敛速度及内存消耗进行相关实验, 结果如表4所示.
| 表4 各模型的训练时间和空间复杂度分析 Table 4 Training time and spatial complexity analysis of different models |
由表4可以看出, COTREC耗时最多, TAGNN内存消耗最多, 这是由于COTREC引入自监督学习策略, TAGNN由于需要对每条会话都计算所有候选商品的注意力分数, 导致空间复杂度偏高, 内存消耗最多.TEMGNN的耗时略高于GCE-GNN, 但大幅低于COTREC.
另一方面, 由于TEMGNN引入商品的多粒度表示, 内存消耗略高于GCE-GNN, 但远低于TA-GNN.上述结论表明, TEMGNN的时间复杂度和空间复杂度适中, 具有潜在应用价值.
不同感受野下的商品可能蕴含着不同的表征.同时, 在缺乏显式的商品主题特征的条件下, 商品本身的语义信息能够隐式地反映出该类特征.本文提出主题增强的多层次图神经网络会话推荐模型(TEMGNN), 结合多层次图神经网络进行不同感受野下的商品信息传播, 捕获更丰富的商品嵌入表征.同时, 本文还提出在缺乏显式商品主题特征的情况下能够通过商品的语义表示隐式生成商品主题表示的商品主题学习模块.目前在基于会话的推荐领域, 对于用户的错误点击或误点的识别是一大挑战.为此, 下一步将考虑通过商品的全局上下文关系和局部上下文关系对用户的错误点击或误点进行判别并滤除.
本文责任编委 梁吉业
Recommended by Associate Editor LIANG Jiye
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|