
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
纹理和深度特征增强的双流人脸呈现攻击检测方法
[孙锐1, 2  , 冯惠东
, 冯惠东1, 2 , 孙琦景1, 2 , 单晓全1, 2 , 张旭东1 ]
, 冯惠东|
|



作者简介:
冯惠东,硕士研究生,主要研究方向为图像信息处理、计算机视觉.E-mail:2021171123@mail.hfut.edu.cn.

孙琦景,硕士研究生,主要研究方向为图像信息处理、计算机视觉.E-mail:861242257@qq.com.

单晓全,硕士研究生,主要研究方向为图像信息处理、计算机视觉.E-mail:2334321350@qq.com.

张旭东,博士,教授,主要研究方向为智能信息处理、机器视觉.E-mail:xudong@hfut.edu.cn.
人脸呈现攻击是一种利用照片、视频等将人脸通过媒介呈现在摄像头前欺骗人脸识别系统的技术.现有的人脸呈现攻击检测方法大多采用深度特征辅助监督分类,忽略有效的细粒度信息以及深度信息与纹理信息的相互联系.因此,文中提出纹理和深度特征增强的双流人脸呈现攻击检测方法.一端网络通过中心差分卷积网络提取比原始卷积网络更鲁棒的欺骗人脸纹理模式.另一端网络通过生成对抗网络生成深度图的深度线索,提高对外观变化和图像质量差异的稳定性.在特征增强模块中,设计中心边缘损失,对两类互补特征进行融合和增强.在4个数据集上的实验表明,文中方法在数据集内以及跨数据集的测试中都取得较优性能.
About Author:
FENG Huidong, master student. His research interests include image information processing and computer vision.
SUN Qijing, master student. His research interests include image information processing and computer vision.
SHAN Xiaoquan, master student. His research interests include image information processing and computer vision.
ZHANG Xudong, Ph.D., professor. His research interests include intelligent information processing and machine vision.
Face presentation attack is a technology using photos, videos and other media to present faces in front of cameras to spoof face recognition systems. Most of the existing face presentation attack detection methods apply depth feature for supervised classification, while ignoring the effective fine-grained information and the correlation between depth information and texture information. Therefore, a texture and depth feature enhancement based two-stream face presentation attack detection method is proposed. One end of the network extracts the facial texture features with a more robust deception texture pattern than the original convolution network through the central differential convolution network. The other end of the network generates the depth information of the depth map through generative adversarial network to improve the robustness to the appearance changes and image quality differences. In the feature enhancement module, a central edge loss is designed to fuse and enhance two types of complementary features. The experimental results on 4 datasets show that the proposed method achieves superior performance in both intra-data set and cross-data set tests.
目前生物识别技术日趋成熟, 人脸识别系统得到广泛应用, 随之而来的是系统的安全性问题.现阶段人脸识别技术能够识别人脸图像的身份, 但无法准确辨别输入人脸的真伪[1, 2].面对人脸识别应用系统的防攻击需求, 研究者们提出多种呈现攻击检测算法(Presentation Attack Detection, PAD), 旨在检验传感器获取的人脸特征是否来自真实的人脸, 提高生物特征识别系统的安全性和鲁棒性.目前常见的呈现攻击方式主要包括两种:1)利用打印机打印拍摄的人脸照片, 即照片攻击; 2)将拍摄的视频借助于电子设备手机、平板电脑等媒介呈现, 即重放视频攻击.
传统的PAD通常采用手工制作的特征, 如局部二值化模式(Local Binary Patterns, LBP)[3], SUFR(Speeded-up Robust Features)[4], 图像质量评估(Image Quality Assessment, IQA)[5]和尺度不变特征变换(Scale-Invariant Feature Transform, SIFT)[6]等, 取得较好效果.
由于照片攻击和重放视频攻击的欺骗人脸都经历多次获取过程, Wen等[7]和Mä ä ttä 等[8]将欺骗人脸产生的模糊、摩尔纹、印刷噪声等纹理差异作为区分依据.甘俊英等[9]融合时空纹理特征, 区分真实人脸和攻击人脸.
近年来, 深度卷积神经网络在计算机视觉和模式识别中呈现较好结果, 也逐渐扩展到人脸呈现攻击检测领域.Yang等[10]使用深度卷积神经网络作为分类器, 直接分类真实人脸和欺骗人脸.类似地, Patel等[11]使用预训练的VGG(Visual Geometry Group)网络人脸模型作为分类的特征提取器.一些文献通过卷积神经网络(Convolutional Neural Network, CNN)和传统方法混合提取人脸的细节特征, 进行人脸分类.Li等[12]从卷积特征图中提取颜色LBP描述符, 然后使用支持向量机进行真伪人脸分类.Asim等[13]利用CNN和手工特征进行特征提取和分类器训练.
然而, 现实中存在的不同攻击类型和环境变化限制了人脸呈现攻击检测系统的泛化能力, 现有的研究常使用深度辅助信息增强模型的区分性和泛化性.Atoum等[14]利用深度信息作为监督以检测攻击, 提出Face Anti-Spoofing Using Patch and Depth-Based CNNs.Liu等[15]用来自人脸视频的rPPG(Remote Photoplethysmography)信号联合深度信息进行检测.在此基础上, Yu[16]等提出CDCN(Central Difference Convolutional Network), 使用中心差分卷积的结构替代文献[15]原始的卷积, 构成中心差分卷积网络, 取得state-of-the-art的性能.Zheng等[17]设计Two-Stream Spatial-Temporal Network, 分别发掘潜在的深度信息和多尺度信息.Wang等[18]提出Deep Spatial Gradient and Temporal Depth Learning for Face Anti-Spoofing, 堆叠剩余空间梯度模块, 捕获细粒度信息和传统卷积特征.Yu等[19]提出BCN(Bilateral Convolutional Networks), 学习不同材料之间的深度信息、反光信息和纹理信息差异, 达到基于材质区分真假人脸的目的.
目前深度辅助信息的PAD研究主要存在如下问题.1)深度学习网络往往提取高阶的语义信息[20], 忽略伪造人脸在纹理细节(打印噪声、眼睛、鼻子、反射光线等)上的特性.2)深度信息提供额外的区分特征, 但需要进一步研究深度信息与纹理信息的相关性[17].攻击人脸采用打印照片、电子设备重播视频呈现的2D平面人脸, 缺少真实人脸存在的3D深度信息.3)呈现媒介的欺骗模式存在不变的特征响应, 图像的纹理细节和深度信息分别描述真实人脸和攻击人脸分别在二维空间和三维空间的区别.
因此, 本文提出纹理和深度特征增强的双流网络人脸呈现攻击检测方法, 使用更适合呈现攻击任务的中心差分卷积算子获取多种欺骗模式的摩尔纹、打印噪声等细节纹理信息, 使用多层卷积和生成对抗网络(Generative Adversarial Network, GAN)[21]联合生成深度图, 提取包含深度信息的人脸特征, 设计双流网络, 同时融合两种特征信息, 在中心边缘损失的监督下优化提取的两部分特征, 学习类内区分性更强的特征信息.在大量数据集内与数据集间的实验表明, 本文方法在OULU-NPU、Replay-Attack、CASIA-FASD、MSU-MFSD数据集上的检测结果较优.同时, 在不同数据集上的跨集实验也验证网络泛化性能的优越性.
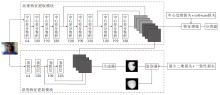
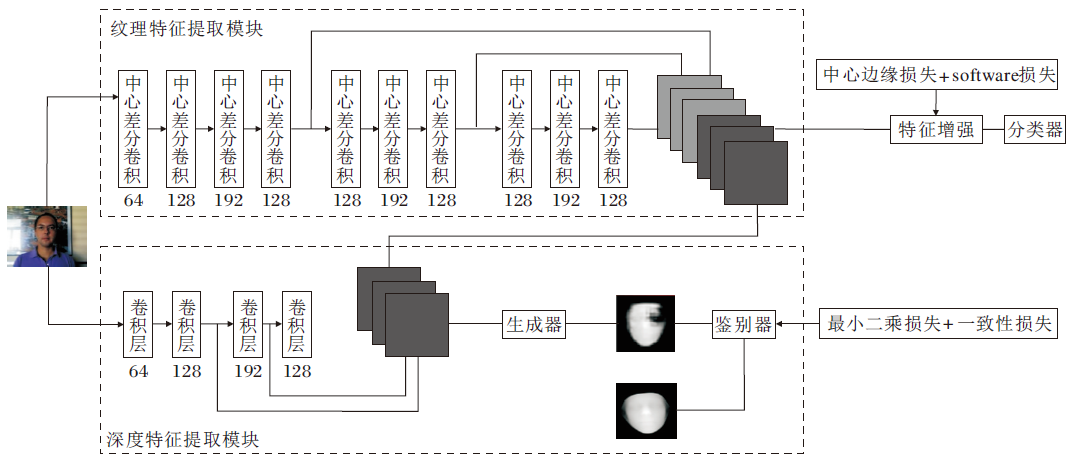
本文提出纹理和深度特征增强的双流人脸呈现攻击检测方法, 结构如图1所示.纹理特征提取模块通过中心差分卷积网络提取连续的人脸纹理; 深度特征提取模块通过GAN生成人脸深度图像, 得到深度隐特征; 中心边缘损失在纹理特征增强模块指导两端特征融合增强.
 | 图1 本文方法结构图Fig.1 Structure of the proposed method |
由于印刷设备的技术限制, 打印的照片通常包含印刷质量缺陷造成的微小纹理图案, 如细节的模糊、丢失.真实人脸是一个复杂的非刚性3D物体, 而照片和屏幕可以视作平面刚性物体, 摄像机采集的攻击人脸具有特殊阴影和光线结构.
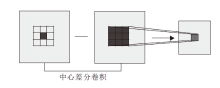
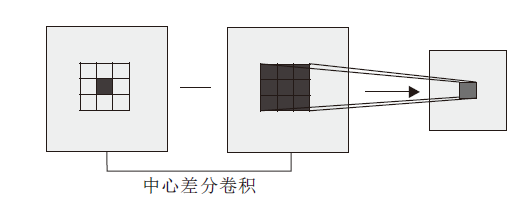
CNN可以提取高阶的语义信息, 但是在提取一些不变的细粒度信息方面, 传统的手工特征更有效, 因此本文使用中心差分卷积(Central Difference Convolution, CDC)[16]提取纹理信息.CDC计算图像像素邻域的梯度, 提供细粒度信息, 更适用攻击人脸的欺骗模式特征.
原始的卷积通过卷积核W覆盖区域P采样特征图, 通过卷积操作进行加权求和, 获得区域特征值, 中心差分卷积算子在原始卷积的基础上进行梯度计算, 原理与LBP相似, 具体如图2所示.计算卷积核覆盖区域P的各点特征值与中心点X0的差值, 获取梯度变化量, 再将计算的特征差值聚合到下层卷积中, 即
Y=
人脸的语义信息对于人脸呈现攻击任务同样是有效的, 因此在利用梯度变化量进行卷积, 得到图像的细节信息的同时融入原始卷积, 作为人脸在嵌入空间的表示, 以此增强模型的泛化性和鲁棒性.最终的中心差分卷积操作可以表示为
Y=
 | 图2 CDC示意图Fig.2 Sketch map of CDC |
纹理特征提取模块如图1上半部分所示, 原始的256× 256 可见光人脸图像通过3个CDC输出不同层级的表征F1、F2和F3.为了充分结合不同细粒度的纹理信息, 3个卷积块的纹理信息的跨连接
FT=cat(F1, F2, F3)
作为最终攻击人脸的欺骗模式特征响应.
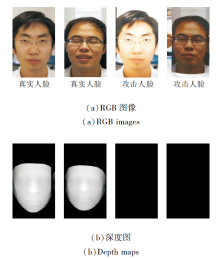
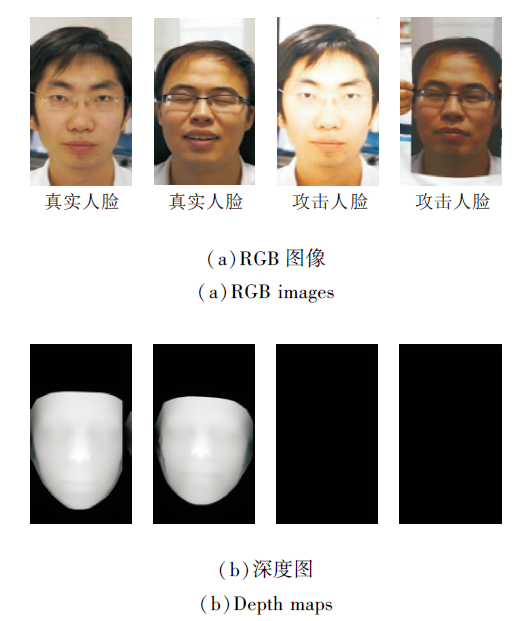
深度图包含从视觉对象表面到视点的距离信息, 可以观察到真假人脸表面与相机之间的距离差异.如图3所示, 真实人脸应具有明确的深度特征, 而攻击人脸实际上缺少这种信息.
 | 图3 RGB图像及其对应的深度图Fig.3 RGB images and their corresponding depth maps |
本文针对PAD任务使用广泛的GAN生成深度图, 提取潜在的深度信息.
GAN是一种生成网络, 由生成器和判别器组成, 生成器的目标是产生尽可能真实的图像欺骗判别器, 而判别器的目的是将生成器生成的样本与真实样本进行分类.本文使用DCGANs(Deep Convo-lutional GANs)[22]结构, 生成器由多层反卷积层连接, 使用ReLU激活函数, 判别器由多层卷积层构成, 使用LeakyReLU激活函数.
深度特征提取模块具体结构如图1下半部分所示, 包含两个子模块:特征提取子模块和深度图像生成子模块.可见光图像I输入特征提取子模块, 通过4层的卷积网络提取人脸的浅层特征, 特征提取子网络Net1的输出将后三层卷积层的特征(F4, F5, F6)连接作为GAN生成器G的输入, 提高生成的准确性.深度图像生成子模块Net2的生成器由输入特征FD生成虚拟的深度图Depthf, 实现从可见光图像到深度图像不同域的转换, 即RGB→ Depth.此后, 真实的深度图Depthr输入判别器D中.需要注意的是, 由于数据集中深度模态的缺失, 此处输入的真实深度图实际上是由深度人脸生成网络生成图像.判别器在对抗性损失及一致性损失的指导下, 区分Depthf和Depthr, 当生成器生成的深度图使判别器无法分辨真假时, 网络训练完成.网络流程可以表示为
FD=cat(Net1(I))=cat(F4, F5, F6),
Depthf=Net2(FD).
对抗性损失使用LSGANs(Least Square GANs)[23]改进的最小二乘损失, 最小二乘损失使GAN的训练过程更加稳定, 生成更高质量的结果.生成对抗性损失的主要目的是判别器通过计算生成图像和实际图像的差距以指导生成器进行修正和完善生成的图像, 可以表示为
LLSGAN(G, D, FD, Df)=
为了提高生成图像的质量以及网络训练时的稳定性, 现有方法常常使用额外的图像一致性损失, 如L1损失或L2损失, 这种损失约束生成图像和实际图像的距离, 使生成图像和实际图像相似度更接近.本文也使用L1重建损失:
$\begin{aligned} & L_{L 1}\left(D_r, D_f\right)=E_{D_r, D_f}\left[\left\|D_r-D_f\right\|_1\right] .\end{aligned}$
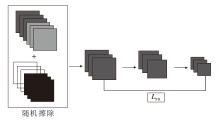
目前基于深度学习的人脸呈现攻击检测方法通常使用softmax损失函数监督网络分类训练.然而, 交叉熵损失的分类决策是找到一个决策边界以分离不同的类, 并未明确考虑类内紧密性和类间可区分性.为了解决这个问题, 本文设计由中心边缘损失监督的特征增强模块, 结构如图4所示.
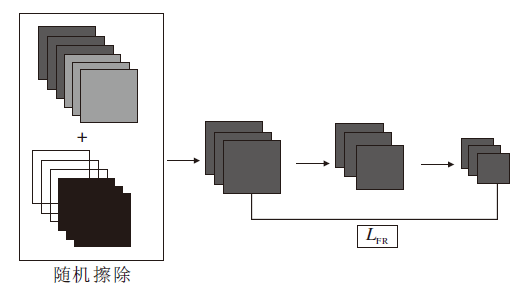 | 图4 特征增强模块结构图Fig.4 Structure of feature enhancement module |
从纹理特征提取的特征FT和从深度信息提取的特征FD作为特征增强模块的双流输入cat(F1, F2, …, F6), 两端输入特征大小都为32× 32× 384.为了提高网络的鲁棒性及融合深度纹理特征, 使用随机擦除模块, 双流网络的特征输出随机选取纹理特征或深度特征进行擦除, 将擦除区域设为0, 在交叉熵损失和中心边缘损失的监督下, 通过3层卷积提取更具鉴别性的特征, 作为最终分类器的一个输入.
度量学习通过学习数据之间的相似性程度, 获得一个更具可分性的特征空间, 但大多数度量学习方法在使用时不加区分地分离嵌入空间中的多类特征, 如三重损失[24]和中心损失[25].由于不同攻击类型产生的样本特征不同, 在嵌入空间中不加区分地约束攻击人脸的类内紧密性, 往往会因为优化困难而导致次优解, 甚至会因为过拟合而损害性能.因此, 本文设计改进的中心边缘损失函数.由于欺骗模式的多样性, 设定真实人脸作为距离计算的中心点C, 文中所用数据以数据对的形式(Xi, Li)表示, 其中, Xi(i∈ N)为数据集上的数据, Li∈ {0, 1}为数据对应的标签, 0表示真实人脸, 1表示欺骗人脸.
本文的中心边缘损失(Center Edge Loss, CEL)定义为
LCE=Ertc+max(αErtc-(1-α)Eatc+M, 0), (1)
其中, Ertc表示真实人脸到中心点的平均欧氏距离, Eatc表示攻击人脸到中心点的平均欧氏距离, α表示调节真实人脸和攻击人脸之间距离的参数.
Ertc和Eatc的具体表达式为
Ertc=
Eatc=
其中, Nr表示数据中真实人脸的数量, Na表示攻击人脸的数量.
如式(1)所示, 中心边缘损失使真实人脸尽量环绕在中心点的周围, 同时抑制欺骗人脸和中心点的距离.对于中心点的更新问题, 采用和中心损失相似的更新规则.每输入一批图像数据后, 更新一次中心点, 更新公式如下:
其中, Nr表示真实人脸的数据, β表示控制中心更新幅度的参数, 是可学习的参数.
CEL基于小批量的数据更新类中心, 导致训练的不稳定, 因此, 额外引入带有全局信息的交叉熵损失, 指导中心点的更新.
综上所述, 总损失包含生成对抗损失、一致性损失、中心边缘损失和softmax损失, 即
Ltotal(G, D, FD, Dr, Df)=LGAN(G, D, FD, Df)+λ LL1(Dr, Df)+μLCE+Lsoftmax,
其中, λ表示调节一致性损失权重的超参数, μ表示调节中心边缘损失权重的超参数.
本文在Replay-Attack[3]、MSU-MFSD[7]、CASIA-FASD[26]、OULU-NPU[27]这4个公开的基准数据集上进行测试.
Replay-Attack数据集由1 200段视频组成, 包括50名实验对象.数据集上有2种不同的光照条件和2种不同的相机支撑条件(手持和固定), 主要存在2种欺骗攻击:打印攻击和屏幕重放攻击.
MSU-MFSD数据集由280个视频剪辑的图像和35个实验者的攻击视频组成, 数据采集使用2种类型的摄像机, 利用3种不同的呈现媒介:使用iPad Air屏幕的高分辨率回放视频攻击、使用iPhone 5S屏幕的手机回放视频攻击和使用A3纸张的打印照片攻击.
CASIA-FASD数据集包含50名实验者的600个真实视频和攻击人脸的视频.视频由3种不同成像质量的相机拍摄, 包括3种欺骗攻击, 即照片打印攻击、照片剪切攻击和视频重放攻击.有7个测试场景、3种假脸类型、3种成像质量和整个数据.
OULU-NPU数据集包含55名实验对象(15名女性, 40名男性)的5 940个真实视频和攻击视频, 在3次不同的照明条件下收集, 使用6种不同智能手机的前置摄像头录制.设计4种攻击模式:2种打印攻击(打印机1和打印机2)、2种显示设备(显示器1和显示器2).
实验PC平台包括Ubuntu 18.04.5 LTS 系统, Intel Core i7-8700 CPU, Nvidia GeForce GTX 1070Ti GPU, 基于Pytorch框架, 版本为1.6, 使用python编程语言.
为了与现有的工作保持一致, 对图像进行帧采样和人脸对齐的数据预处理.视频间隔10帧抽取的图像合集作为该视频的实验所用数据, 以此获得人脸的不同姿态.实验所用数据集均为单模态数据集, 缺少实际的深度图.使用PRN(Position Map Regre-ssion Network)[28]重建深度人脸.提取的每帧图像的大小为256× 256× 3, 同时进行随机水平翻转、随机擦除等数据增强操作.对于网络训练过程, 批量处理大小设置为16, 学习率设置为3e-5.超参数设置如下:a=0.6, λ=100, μ=0.5.网络使用自适应矩估计(Adaptive Moment Estimation, Adam)优化器[29]进行网络训练.所有实验中不同数据集的设置都是固定的.
实验中使用的评价指标都遵循每个数据集规定的原始评估指标.CASIA-FASD数据集上使用等错误率(Equal Error Rate, EER).Replay-Attack数据集上采用半总错误率(Half Total Error Rate, HTER)作为指标,
HTER =
其中, FRR为错误拒绝率(False Rejection Rate), FAR为错误接受率(False Acceptance Rate).OULU-NPU数据集上使用攻击演示分类错误率(Attack Pre-sentation Classification Error Rate, APCER)、真实呈现分类错误率(Bona Fide Presentation Classification Error Rate, BPCER)和平均分类错误率(Average Classification Error Rate, ACER), 而
ACER=
本节在4个数据集上分别进行数据集内部的测试和跨数据集上的测试, 验证方法的有效性.
选择如下对比方法:文献[3]方法、文献[10]方法、文献[11]方法、文献[12]方法、文献[15]方法、CDCN[16]、文献[17]方法、文献[18]方法、FARCNN(Face Anti-Spoofing Region-Based Convolutional Neural Network)[30]、文献[31]方法、文献[32]方法、TSCNN(Two-Stream Convolutional Neural Network)[33]、DTN(Domain Transfer Network)[34]、文献[35]方法、STASN(Spatio-Temporal Anti-Spoof Network)[36]、CPqD[37]、文献[38]方法、STDN(Spoof Trace Disentanglement Network)[39]、MADDG(Multi-adversarial Discriminative Deep Domain Generalization)[40].
首先在CASIA-FASD、Replay-Attack数据集上分别进行模型的测试.使用EER和HTER作为评价标准, 结果如表1所示.由表可知, 相比使用部分手工特征和深度学习方法(文献[3]方法和文献[10]方法):在CASIA-FASD数据集上, 本文方法的ERR值为1.30%; 在Replay-Attack数据集上, 本文方法的ERR值为0.08%, HTER值为0.05%, 实现较优性能.
| 表1 各方法在2个数据集上的指标值 Table 1 Index values of different methods on 2 datasets % |
目前呈现攻击检测任务存在的一大问题是模型跨数据集的泛化能力不足, 为此, 使用同样的数据集进行开集测试, 两个数据集分别作为测试集和训练集, 实验结果如表2所示, 表中A→ B表示A为训练集, B为测试集, 后文相同.本文方法在跨数据集上的检测能力有所下降, 但相比其它方法, 仍有更好表现.
| 表2 各方法跨库测试的HTER值 Table 2 HTER values of different methods for cross-dataset test % |
OULU-NPU数据集上包括4个协议:协议1设置不同的照明亮度, 测试不同光照条件下的检测效果; 协议2使用不同的打印机打印照片的同时使用多种屏幕显示设备, 测试在不同呈现人脸的媒介上的检测结果; 协议3使用多部拍摄设备拍摄人脸的视频, 测试不同采集设备对于攻击检测的影响; 协议4将上述3个协议合并为一个新的测试协议.各方法在OULU-NPU数据集的4种协议上的指标值如表3所示, 表中黑体数字表示最优值.由表可见, 本文方法在4个协议上的ACER值分别为0.9%、2.4%、(2.1± 1.8)%、(2.7± 2.8)%, 除了在协议2上欠佳以外, 在其余的3个协议上都取得最好结果.由此表明, 本文方法在环境照明、拍摄设备、呈现媒介等发生变化时具有较强的鲁棒性.
| 表3 各方法在OULU-NPU数据集的4种协议上的指标值 Table 3 Index values of different methods on 4 protocols of OULU-NPU dataset % |
为了进一步检测本文方法在更加复杂的条件下的跨数据集性能, 进行多种数据集混合的实验, 实验中将CASIA-FASD数据集简记为C、Replay-Attack数据集表示简记为R、OULU-NPU数据集简记为O、MSU-MFSD数据集简记为M.混合3个数据集作为训练集, 剩余数据集作为测试集, 测试在4种情况下的HTER和AUC(Area Under Curve)值, 结果如表4所示, 表中黑体数字表示最优值.由表可以看到, 本文方法在多种数据集混合的条件下实现最佳的泛化性.
| 表4 各方法在多种数据集跨库测试的指标值 Table 4 Index values of different methods for cross-dataset test % |
实验中损失函数使用的超参数包含控制类内紧密性和类间区分性的α、一致性损失权重λ和中心边缘损失权重μ, 其中λ参考以往工作[34], 实验中取值为100.
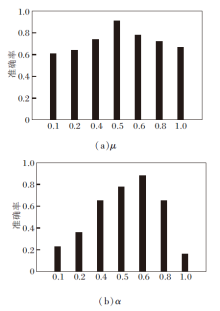
为了研究其余两个超参数的影响, 在OULU-NPU数据集的协议4上分析使用的超参数, 结果如图5所示.由图可见, 参数α=0.6时取得最优效果, μ=0.5时得到最高准确率.
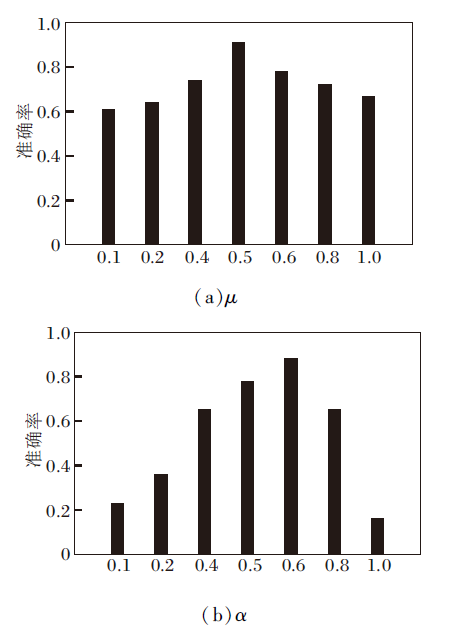 | 图5 μ和α对本文方法性能影响Fig.5 Effect of parameter μ and α on performance of the proposed method |
本文使用深度信息辅助监督网络, 同时引入区分真假人脸的纹理信息, 在特征增强模块中设计中心边缘损失, 增强提取特征的区分性.为了验证引入的纹理信息以及损失函数的有效性, 进行相关的消融实验, 在OULU-NPU数据集的协议4上进行实验.各模块结果如表5所示.由表可见, 深度信息模块和深度信息+纹理信息模块结果表明中心差分卷积网络可以提供图像的细粒度特征, 提高检测对光照、攻击设备等的鲁棒性.Lsoftmax、LCE、Lsoftmax+LCE结果显示特征增强模块中使用常规的分类损失函数后效果提升有限, 使用中心边缘损失后提升明显, 综合使用两种损失函数可以取得最优效果.实验表明中心边缘损失的有效性.
| 表5 在OULU-NPU数据集的协议4上的消融实验结果 Table 5 Results of ablation experiment on protocol 4 of OULU-NPU dataset % |
在4个数据集上进行数据集内和跨数据集的测试, 结果表明本文方法具有一定的竞争力.同时, 消融实验显示深度信息和纹理信息的有效性, 以及特征增强模块有助于网络检测性能的提升.
为了进一步探究中心边缘损失函数在网络中发挥的作用, 使用t-SNE[41]对实验过程中使用的OULU-NPU数据集上的提取人脸特征进行平面的可视化, 如图6所示.本文分别进行只使用Lsoftmax和同时使用Lsoftmax+LCE作为监督学习损失函数的可视化.从可视化图可看到, Lsoftmax将真实人脸和攻击人脸分为两个相邻的簇, 但是存在一定的相交区域, Lsoftmax+LCE是以真实人脸为中心, 将其余同类聚集在一起的同时分离攻击人脸, 两者之间存在明显的空白分界区域.中心边缘损失对于攻击人脸的检测可提高提取特征的鉴别能力和网络在不同数据集上的鲁棒性, 实现更好的泛化性能.
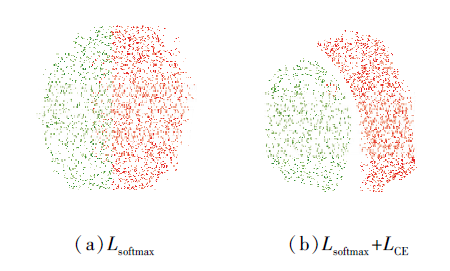 | 图6 不同损失函数监督得到的特征可视化结果Fig.6 Feature visualization results based on different loss function supervision |
本文提出纹理和深度特征增强的双流人脸呈现攻击检测方法, 一端网络通过中心差分卷积网络提取欺骗人脸纹理特征, 另一端网络通过生成对抗网络生成深度图, 获得深度差异线索.在特征增强模块设计中心边缘损失, 监督网络学习, 提高特征的鉴别性以及模型的跨数据集的泛化能力, 缓解由于光照、环境等变化引起的性能下降问题, 提升不同层次的人脸区分特性.在CASIA-FASD、Replay-Attack、OULU-NPU、MSU-MFSD数据集上的实验表明, 本文方法能有效提高性能和泛化能力.目前的研究只针对图像的静态信息, 缺少时序信息, 在今后的工作中将会进行进一步探索.
本文责任编委 封举富
Recommended by Associate Editor FENG Jufu
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|