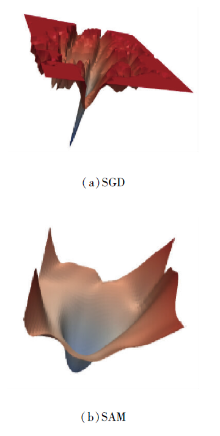

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
双分支多注意力机制的锐度感知分类网络
[姜文涛1  , 赵琳琳
, 赵琳琳1 , 涂潮2 ]
, 赵琳琳, 涂潮]
|
|



作者简介:

赵琳琳,硕士研究生,主要研究方向为图像处理、模式识别、人工智能.E-mail:1846788394@qq.com.

涂 潮,博士研究生,主要研究方向为图像处理、模式识别、人工智能.E-mail:745700558@qq.com.
基于卷积神经网络的图像分类方法的关键是提取有区分性的重点特征.为了提高重点特征的关注度,增强网络泛化能力,文中提出双分支多注意力机制的锐度感知分类网络(Double-Branch Multi-attention Mechanism Based Sharpness-Aware Classification Network, DAMSNet).该网络以ResNet-34残差网络为基础,首先,修改ResNet-34残差网络输入层卷积核尺寸,删除最大池化层,减小原始图像特征的损失.再者,提出双分支多注意力机制模块,嵌入残差分支中,从全局特征和局部特征上提取图像在通道域和空间域的上下文信息.然后,引入锐度感知最小化算法,结合随机梯度下降优化器,同时最小化损失值和损失锐度,寻找具有一致低损失的邻域参数,提高网络泛化能力.在CIFAR-10、CIFAR-100、SVHN数据集上的实验表明,文中网络不仅具有较高的分类精度,而且有效提升泛化能力.
About Author:
ZHAO Linlin, master student. Her research interests include image processing, pattern recognition and artificial intelligence.
TU Chao, Ph.D. candidate. His research interests include image processing, pattern recognition and artificial intelligence.
The key to image classification methods based on convolutional neural networks is to extract distinctive important features. To focus on crucial features and enhance the generalization ability of the model, double-branch multi-attention mechanism based sharpness-aware classification network(DAMSNet) is proposed. Based on the ResNet-34 residual network, the size of the convolutional kernel in the input layer of the network is modified and the max pooling layer is removed to reduce the loss of original image features. Then, the double-branch multi-attention mechanism module is designed and embedded into the residual branch to extract the global and local contextual information in both channel and spatial domains. Additionally, sharpness-aware minimization(SAM) algorithm is introduced and combined with stochastic gradient descent optimizer to simultaneously minimize both loss value and loss sharpness, seeking for neighboring parameters with consistently low loss to enhance the generalization ability of the network. Experiments on CIFAR-10, CIFAR-100 and SVHN datasets demonstrate that DAMSNet achieves high classification accuracy and effectively enhances the generalization ability of the network.
图像分类是计算机视觉领域的研究热点, 是学术界和工业界共同关注的问题, 广泛应用于农业、医学、交通等诸多领域.常见的图像分类方法主要可分为两类:传统的图像分类方法和基于深度学习的图像分类方法.
传统的图像分类方法主要采用手工提取特征, 代表性方法有朴素贝叶斯分类器、K-均值(K-means)、K最近邻(K-Nearest Neighbor, KNN)、决策树、支持向量机等.传统图像分类方法主要依赖研究者的主观经验, 只对简单任务有效, 通用性较差, 存在局限性, 泛化能力较弱.
基于深度学习的图像分类方法采用卷积神经网络(Convolutional Neural Network, CNN), 依靠CNN强大的非线性映射能力, 逐渐取代传统的图像分类方法.Lecun等[1]提出LeNet, 使用卷积层和池化层构成局部连接, 并实现权值共享.Krizhevsky等[2]提出AlexNet, 在LeNet的基础上加深网络层数, 增大卷积核尺寸, 并证实CNN在复杂模型上的有效性.Simonyan等[3]提出VGGNet, 连续采用多个小卷积核替代一个大卷积核, 并验证增加网络深度可以有效提升模型的分类效果.Szegedy等[4]提出GoogLe-Net, 利用不同尺寸卷积核提取不同程度的信息.He等[5]提出ResNet(Residual Network), 深度网络中使用残差块, 在加深神经网络深度的同时大幅提升分类准确率.
基于DenseNet[6], Zhang等[7]提出CAPR-Dense-Net(Channel-Wise and Feature-Point Reweights Dense-Net), 添加特征点重标定模块, 建模卷积特征点之间的相互依赖关系.基于ResNet, Abdi等[8]提出Multi-ResNet(Multi-residual Networks), 在保持深度不变的同时, 增加每个残差块中残差函数的数量, 用于拓宽网络的宽度, 提高分类网络的性能.郭玉荣等[9]提出双通道特征重标定密集连接卷积神经网络(Dual Feature Reweight-DenseNet, DFR-DenseNet), 实现DenseNet通道特征和层间特征的重标定, 从而实现网络端到端的学习.陈超凡等[10]提出基于三支决策的二阶段图像分类方法, 从三支决策的角度结合阴影集理论, 划分论域, 提高分类性能.姚潇等[11]提出循环退火的神经网络结构搜索(Cycle Annealing Neural Architecture Search, CANAS), 将不同分组的卷积单元作为搜索空间, 使用神经网络结构搜索, 得到网络的分组结构和整体架构.付晓等[12]提出半监督编码生成对抗网络(Semi-Supervised Encoder Ge-nerative Adversarial Network, SSE-GAN), 在原生成对抗网络(Generative Adversarial Networks, GANs)中添加一个编码器结构, 作为生成结构的逆运算, 获得原始数据的本质特征, 并将此特征用于图像分类.
但是, 上述分类方法处理图像分类问题时均存在提取特征不充分以及不能高效利用关键特征的问题.针对该问题, Wang等[13]提出Non-local Block, 融合自注意力机制与全局信息, 帮助深度网络更好地融合非局部信息, 但是该方法考虑使用所有的特征点进行加权计算, 并不能为重要特征分配较高权重.对此, Hu等[14]提出SENet(Squeeze-and-Excitation Network), 通过学习的方式自动获取关键特征, 再依照特征重要程度提升有用特征, 并抑制无用特征.受SENet的启发, Wang等[15]提出ECA-Net(Efficient Channel Attention for Deep CNN), 使用不降维的局部跨通道交互策略, 有效避免降维对通道注意力学习效果的影响.Qin等[16]提出FcaNet(Frequency Channel Attention Networks), 在频率域上计算通道之间的权重, 提高对重要通道的关注程度.Hou等[17]提出Coordinate Attention, 使用专门坐标编码器, 将通道特征分解为两个一维特征编码, 并沿着这两个空间方向对特征进行聚合, 聚合后的坐标信息与特征图中的每个像素一起传递到注意力模块中, 用于计算每个像素的权重.Hu等[18]提出SPAN(Spatial Pyramid Attention Network), 将不同尺度的图像信息进行层次化处理, 引入空间注意力机制, 在不同尺度的特征图上学习并加权特征图中每个位置的表示, 用于强调特征图中更关键的信息.
由于Transformer[19]在自然语言处理领域取得的显著成绩, Dosovitskiy等[20]将Transformer引入图像处理领域, 在图像分类中取得较优性能.在此基础上, Lan等[21]提出Couplformer, 引入一种耦合注意力映射的机制, 耦合位置信息与通道信息, 从而更好地捕捉图像中不同位置和通道之间的关系.受Transformer的启发, Konstantinidis等[22]提出Multi-manifold Attention, 计算自注意力矩阵, 得到特征表示和特征之间的距离, 通过相似特征彼此更靠近、不同特征进一步分开的方式, 更好地建模输入序列, 从而可以更好地增强给定计算机视觉任务的输入序列的重要特征, 产生具有高区分性能力的输出特征表示.
但是, 上述网络均不能从全局和局部出发考虑特征信息和保证模型泛化能力, 针对此问题, 本文提出双分支多注意力机制的锐度感知分类网络(Double-Branch Multi-attention Mechanism Based Sharp-ness-Aware Classification Network, DAMSNet).首先, 修改ResNet-34的第1层卷积核尺寸, 删除最大池化层, 防止丢失原始图像的特征信息, 提取浅层特征, 使后续网络能够更加充分地提取关键特征.然后, 设计即插即用的双分支多注意力机制(Double-Branch Multi-Attention Mechanism, DAM)模块, 插入残差分支中, 提高网络对关键特征的关注度, 为重点特征分配高权重, 非重点特征分配低权重.最后, 引入锐度感知最小化算法(Sharpness-Aware Minimiza-tion, SAM)[23], 优化分类方法, 同时寻找具有最小损失值和最小损失锐度的邻域参数, 提高网络的泛化能力.在CIFAR-10、CIFAR-100、SVHN数据集上进行实验, 确定最优网络参数, 并通过对比实验验证本文网络的合理性.
为了提高重点特征关注度, 增强网络泛化能力, 本文提出双分支多注意力机制的锐度感知分类网络(DAMSNet).以ResNet-34残差网络为基础, 首先, 修改ResNet-34残差网络输入层卷积核尺寸, 删除最大池化层, 减小对原始图像特征的损失.再提出双分支多注意力机制模块, 嵌入残差分支中, 从全局特征和局部特征上提取图像在通道域和空间域的上下文信息.然后引入锐度感知最小化算法, 结合随机梯度下降优化器, 同时最小化损失值和损失锐度, 寻找具有一致低损失的邻域参数, 提高网络泛化能力.
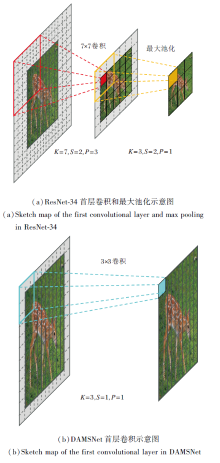
在ResNet-34残差网络中, 首先使用7× 7的卷积层和最大池化层提取图像的浅层特征, 池化层的目的是对特征图进行下采样, 减小特征图的尺寸, 理论上间接增大后续卷积层的感受野, 保证获取更多的特征信息, 但是随着卷积核的增大和引入, 池化层会丢失大量的原始图像信息.因此, 需要提取更加细微的特征.
本文利用一个3× 3小卷积核替换首层7× 7卷积核并删除池化层, 同时减小卷积层的步长和填充大小, 平衡网络参数和特征表达, 在有效提取底层特征的同时尽可能保留原始图像的信息.
首层卷积核尺寸前后卷积操作对比如图1所示, 以尺寸为10× 10的图像为例, 分别进行7× 7卷积操作、最大池化操作和3× 3卷积操作, 提取浅层特征, 卷积后的尺寸可表示为
N=
其中, N表示输出特征图像尺寸, W表示输入图像尺寸, K表示卷积核尺寸, S表示卷积步长, P表示填充大小.
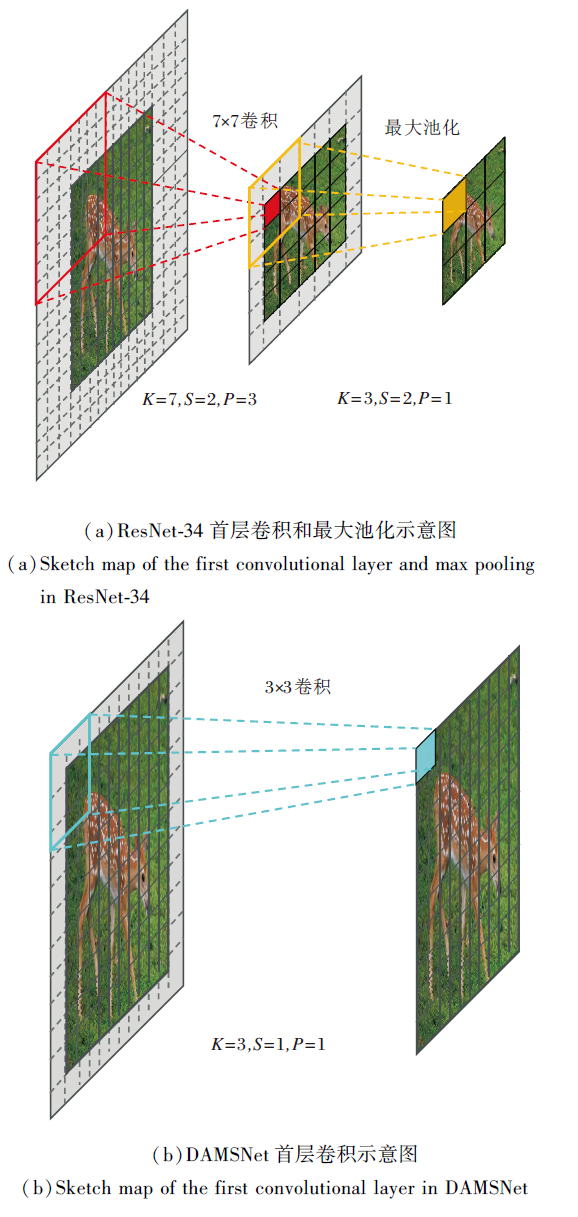 | 图1 修改首层卷积核尺寸前后卷积操作对比Fig.1 Comparison of convolutional operations before and after modifying the size of the first layer convolutional kernel |
根据式(1)可以计算出, 10× 10的图像经过ResNet-34的首层7× 7卷积层和最大池化层后, 输出特征图尺寸为3× 3, 不利于后续深层网络的特征表达.经过减小步长和填充的3× 3卷积层后, 输出特征图像仍为10× 10.经过卷积层和池化层的图像尺寸特征损失可表示为
其中, W表示输入图像尺寸, N表示输出特征图像尺寸.
由式(2)可以计算出, 在经过7× 7卷积后, 图像尺寸特征损失为75%, 输出后的特征图像经过最大池化层后特征损失为64%.由此可知, 对于小尺寸的原始图像, 减小卷积核尺寸、步长和填充大小会提取到更细微的特征, 有效减少图像原始信息的丢失.
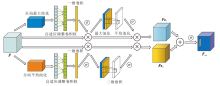
CNN虽然能够自动提取图像特征, 但是特征仅由网络提取的各类特征叠加而成, 缺少高级认知的指导.受人类视觉系统的启发, CNN在特征提取时对于不同特征的倚重应有所不同.对此, 本文提出双分支多注意力机制(DAM)模块, 综合考虑通道和空间提取的特征对于关键区域的贡献度并赋予权重, 通过特征与权重的乘积和, 确定关键特征区域, 降低由单一特征不充分引起的歧义, 增强全局特征和局部关键特征的表达能力.
DAM结构如图2所示, 每个分支由通道注意力机制和空间注意力机制组成.通道注意力机制提取通道显著特征纹理, 可以减少图像复杂背景对分类方法训练的影响.空间注意力机制在空间的尺度上进一步筛选显著特征.本文将ECA(Efficient Channel Attention)通道注意力机制和Spatial Attention[24]空间注意力机制中的sigmoid函数替换为ReLU函数.
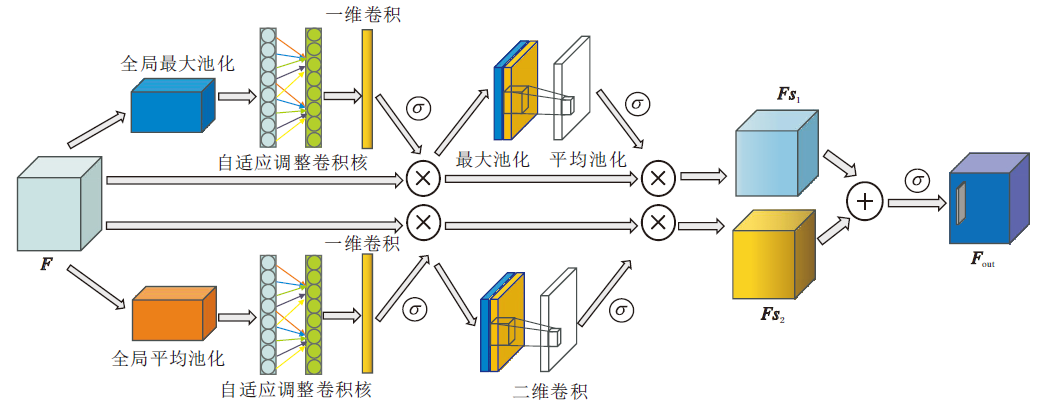 | 图2 DAM模块结构图Fig.2 Structure of DAM module |
在第1个分支中, 将ECA注意力机制的全局平均池化替换为全局最大池化, 可更加关注局部特征.输入特征F∈ RC× H× W, 其中, (H, W)为特征图的空间维度, C为通道数.DAM同时推导2个分支的2个一维通道注意力特征矩阵Mc1∈ RC× 1× 1、Mc2∈ RC× 1× 1和2个二维空间注意力特征矩阵Ms1∈ R1× H× W、Ms2∈ R1× H× W, 总体注意力最终输出为:
$F_{out}=\sigma(Fs_{1}\oplus Fs_{2}), $
其中,
Fs1=Ms1ⓧFc1,
表示第1分支输出特征,
Fs2=Ms2ⓧFc2,
表示第2分支输出特征, Fc1表示第1分支输出的通道特征, Fc2表示第2分支输出的通道特征, σ(· )表示ReLU激活函数.
第1个分支首先经过全局最大池化, 获取局部通道信息, 得到1个一维矢量.然后经过自适应调整卷积核尺寸的一维卷积和ReLU激活函数, 进行通道特征提取, 得到通道特征权重矩阵:
Mc1=σ(Conv1d(Gmaxpool(F))),
其中Gmaxpool(· )表示全局最大池化.最后, 将F与Mc1相乘, 得到通道特征:
Fc1=FⓧMc1.
将通道特征Fc1通过最大池化和平均池化, 得到2个特征图
经过Concat操作, 拼接2个特征图, 采用卷积核尺寸7× 7和激活函数ReLU的卷积层进行特征提取, 得到空间特征权重矩阵:
Ms1=σ(Conv2d(Concat[Maxpool(Fc1); Avgpool(Fc1)]))=σ(Conv2d[Concat(
其中, Concat(· )表示通道方向上的级联操作, Maxpool(· )表示空间方向上的最大池化, Avgpool(· )表示平均池化.
将通道输出的特征Fc1与经过空间注意力机制得到的特征矩阵Ms1相乘, 得到第1条分支的特征:
Fs1=Ms1ⓧFc1.
第2个分支首先经过全局平均池化, 获取全局通道信息.然后经过自适应调整卷积核尺寸的一维卷积和ReLU激活函数进行特征提取, 得到权重矩阵:
Mc2=σ(Conv1d(Gavpool(F))),
其中Gavpool(· )表示全局平均池化.最后, 将F与Mc2相乘, 得到通道特征:
Fc2=Mc2ⓧF.
将通道特征Fc2通过最大池化和平均池化, 得到2个特征图
经过Concat操作, 拼接2个特征图, 采用卷积核尺寸7× 7和ReLU激活函数的卷积层进行特征提取, 得到空间特征权重矩阵:
Ms2=σ(Conv2d(Concat[Maxpool(Fc2); Avgpool(Fc2)]))=σ(Conv2d[Concat(
将通道输出的特征Fc2与经过空间注意力得到的特征矩阵Ms2相乘, 得到第2条分支的特征:
Fs2=Ms2ⓧFc2.
由于sigmoid激活函数两端饱和, 在接近饱和区时, 变换过于缓慢, 导数趋于0, 在反向传播时, 权重几乎不更新, 导致无法完成深层网络的训练.本文的注意力机制使用ReLU激活函数, 可表示为
R(x)=max(x, 0)=
由式(3)可知, ReLU激活函数在反向传播不断更新参数的过程中都是分段线性进行的, 并且为非饱和激活函数, 能够加快训练收敛速度, 防止梯度消失.
随着网络层数的加深, 浅层参数的微弱变化经过多层线性变换与激活函数后会被放大, 导致反向传播梯度较小, 参数更新速度较慢, 最终使网络训练难以收敛.针对该问题, 本文在DAM模块后采用批量归一化方法(Batch Normalization, BN), 缓解梯度消失, 加快收敛.
对于超参数化的深度神经网络模型, 通常使用随机梯度下降(Stochastic Gradient Descent, SGD)或Adam(Adaptive Moment Estimation)优化器优化模型, 但是此类优化器只优化训练损失值, 容易导致模型质量次优, 从而无法保证模型的泛化能力.训练损失Ls(w)在模型参数w处通常是非凸的, 具有多个局部最小值甚至全局最小值, 这些最小值可能会产生相似的Ls(w)值, 使模型具有明显不同的泛化性能.
受损失图片的锐度和泛化之间联系的启发, Foret等[23]提出SAM, 在领域内寻找均匀的低损失值参数, 而不是寻找只具有低损失值的某个参数.由于计算邻域参数而非计算单个参数, 损失平面比其它优化方法更平坦, 反而增强模型的泛化能力.
SGD和SAM这2种优化器的超平面图如图3所示.由图可见, SGD优化器训练的ResNet收敛到的一个尖锐的最小值, 而SAM训练相同的ResNet时, 收敛到一个平坦的最小值.
 | 图3 两种损失的超平面图Fig.3 Hyperplanes of 2 types of loss |
给定一个训练数据集
$\begin{aligned} & \mathrm{S} \triangleq \bigcup_{\mathrm{i}=1}^{\mathrm{n}}\left\{\left(\boldsymbol{x}_i, y_i\right)\right\}, \end{aligned}$
模型参数w∈ W⊂Rd, 每个数据点损失函数为
l∶ w× x× y→ R+,
训练集损失定义为
LS(w)≜
总体损失定义为
Lγ (w)≜E(x, y)~D[l(w, x, y)].
模型训练的目标是寻找使总体损失Lγ (w)最小的参数w.使用训练损失Ls(w)估计总体损失Lγ (w)以寻求学习一个较好的泛化模型.对于∀ ρ> 0, 从分布γ生成的训练集s上, 损失函数可表示为
$\begin{aligned} & L_\gamma(\boldsymbol{w}) \leqslant \max _{\|\boldsymbol{\epsilon}\|_2 \leqslant \rho} L_S(\boldsymbol{w}+\boldsymbol{\epsilon})+h\left(\frac{\|\boldsymbol{w}\|_2^2}{\rho^2}\right), \end{aligned}$
其中函数h(· )∶ R+→ R+表示严格递增函数.
为了得到损失函数Lγ (w)的极小解, 将上面不等式的右侧重写, 得到的损失函数可表示为
$\begin{aligned} & L_\gamma(\boldsymbol{w}) \leqslant\left[\max _{\|\boldsymbol{\epsilon}\|_2 \leqslant \rho} L_S(\boldsymbol{w}+\boldsymbol{\epsilon})-L_S(\boldsymbol{w})\right]+ L_S(\boldsymbol{w})+h\left(\frac{\|\boldsymbol{w}\|_2^2}{\rho^2}\right), \end{aligned}$
其中,
$\begin{aligned} & \max _{\|\boldsymbol{\epsilon}\|_2 \leqslant \rho} L_S(\boldsymbol{w}+\boldsymbol{\epsilon})-L_S(\boldsymbol{w})\end{aligned}$
可通过测量训练损失从w移动到相邻近的参数值增加的速度, 获得Ls在w处的锐度, 然后将此锐度值与训练损失本身和w大小的正则化相加.鉴于特定函数h(· )受细节的影响较大, 使用
$\begin{aligned} & \min _{\boldsymbol{w}} L_S^{\mathrm{SAM}}(\boldsymbol{w})+\lambda{\|\boldsymbol{w}\|_2^2, } \\ & \text { where } L_S^{\mathrm{SAM}}(\boldsymbol{w}) \max _{\|\epsilon\|_p \leqslant \rho} L_S(\boldsymbol{w}+\boldsymbol{\epsilon}), \end{aligned}$ (4)
其中, p∈ [1, +∞ ], 表示一个超参数.
SAM会阻止模型收敛到最小值, 为了最小化
$\begin{aligned} & \boldsymbol{\epsilon}^* (\boldsymbol{w}) \triangleq \arg \max _{\|\boldsymbol{\epsilon}\|_p \leqslant \rho} L_S(\boldsymbol{w}+\boldsymbol{\epsilon}) \approx \\ & \arg \max _{\|\boldsymbol{\epsilon}\|_p \leqslant \rho} L_S(\boldsymbol{w})+\boldsymbol{\epsilon}^{T} \nabla_{\boldsymbol{w}} L_S(\boldsymbol{w})= \\ & \arg \max _{\|\boldsymbol{\epsilon}\|_p \leqslant \rho} \boldsymbol{\epsilon}^{\mathrm{T}} \nabla_{\boldsymbol{w}} L_S(\boldsymbol{w}), \end{aligned}$
其中$\epsilon$近似于0.反之, 求解该近似值的值$\hat{\epsilon}(w)$, $\hat{\epsilon}(w)$可表示为
$\begin{aligned} & \hat{\boldsymbol{\epsilon}}(\boldsymbol{w})=\rho \operatorname{sign}\left(\nabla_w L_S(\boldsymbol{w})\right) \frac{\left|\nabla_w L_S(\boldsymbol{w})\right|^{q-1}}{\left(\left\|\nabla_w L_S(\boldsymbol{w})\right\|_q^q\right)^{\frac{1}{p}}}, \end{aligned}$ (5)
其中,
|· |q-1表示元素绝对值和的幂.
将式(5)代入式(4), 并微分, 得
$\begin{aligned} & \nabla_w L_S^{\mathrm{SAM}}(\boldsymbol{w}) \approx \\ & \nabla_w L_S(\boldsymbol{w}+\hat{\boldsymbol{\epsilon}}(\boldsymbol{w}))= \\ & \left.\frac{\mathrm{d}(\boldsymbol{w}+\hat{\boldsymbol{\epsilon}}(\boldsymbol{w}))}{\mathrm{d} \boldsymbol{w}} \nabla_w L_S(\boldsymbol{w})\right|_{w+\hat{\boldsymbol{\epsilon}}(\boldsymbol{w})}= \\ & \left.\nabla_w L_S(\boldsymbol{w})\right|_{w+\hat{\boldsymbol{\epsilon}}(\boldsymbol{w})}+\left.\frac{\mathrm{d} \hat{\boldsymbol{\epsilon}}(\boldsymbol{w})}{\mathrm{d} \boldsymbol{w}} \nabla_w L_S(\boldsymbol{w})\right|_{w+\hat{\boldsymbol{\epsilon}}(\boldsymbol{w})} . \end{aligned}$
可以通过自动微分直接计算近似值
$\begin{aligned} & \left.\nabla_w L_S^{\mathrm{SAM}}(\boldsymbol{w}) \approx \nabla_w L_S(\boldsymbol{w})\right|_{w+\hat{\boldsymbol{\epsilon}}(\boldsymbol{w})} .\end{aligned}$ (6)
使用SGD优化器实现SAM目标
本文将SGD优化器和SAM一起使用, 寻找具有一致低损失值的邻域参数, 通过同时最小化损失值和最小化损失锐度, 改善模型泛化能力.
近年来, CNN一直向着更深更宽的网络结构发展, 分类精度也得到不断提升.然而当CNN层数不断加深时, 容易出现梯度消失或梯度爆炸的问题, 从而导致性能下降.
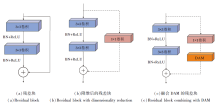
He等[5]提出ResNet, 原始输入通过跳跃连接与经过卷积层的输出直接连接的残差块, 残差块结构如图4(a)、(b)所示.
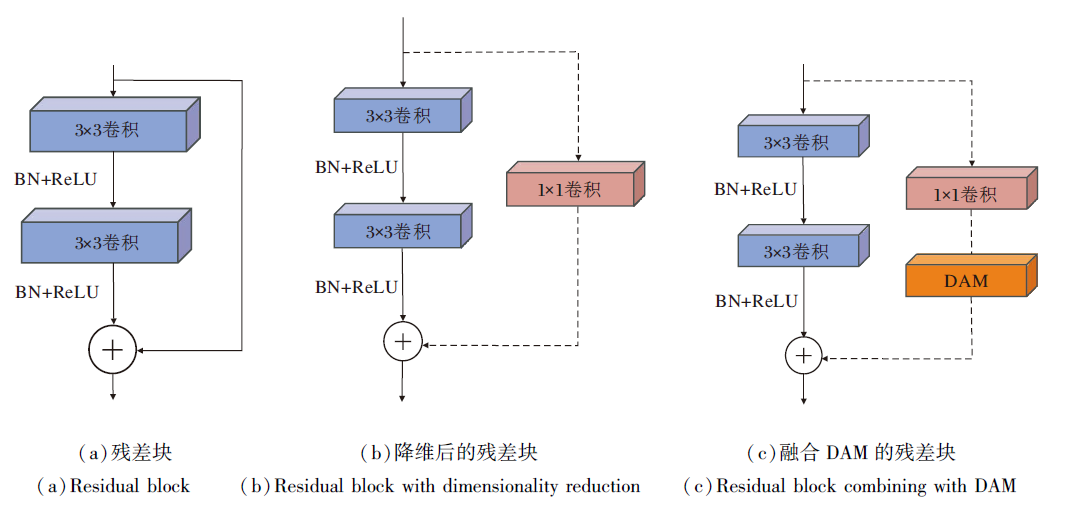 | 图4 三种残差块Fig.4 Three types of residual block |
图4(c)为本文融合DAM的残差块(简记为D-Block).常规残差块(简记为Block)由2个卷积核尺寸为3× 3的卷积组成, 使用残差分支跳跃连接.常规的降维残差块(简记为R-Block)由2个3× 3卷积和残差分支组成, 残差分支中采用1× 1卷积降维.D-Block由2个3× 3卷积和残差分支组成, 残差分支包含1× 1卷积降维和DAM模块, 对特征权重进行重新分配, 进而区分特征的贡献度.在每次卷积后, 输出的特征图像经过BN层和ReLU层, 防止梯度消失, 加快收敛, 增强网络层间的特征关系.
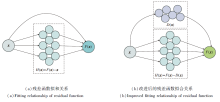
常规的残差网络虽然性能较优, 但是无法为图像的关键特征分配较高的权重.本文在残差分支中融合DAM模块, 设计具有注意力机制的残差块, 提高对关键特征的表达能力.改进前后的残差函数拟合关系如图5所示.
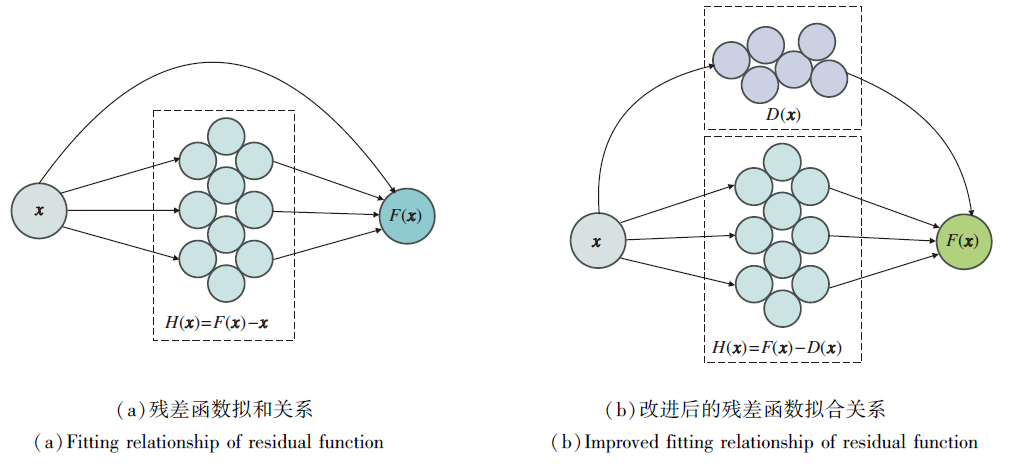 | 图5 改进前后的残差函数拟合关系Fig.5 Fitting relationship of residual function before and after improvement |
融合注意力机制的拟合函数可表示为
F(x)=H(x)+D(x),
其中, F(x)表示待拟合对象, x表示学习输入, H(x)表示残差函数, D(x)表示DAM注意力机制函数.
通过CNN的反向传播机制, 学习H(x)的参数以拟合F(x)-D(x), 达到进一步拟合F(x)的效果.
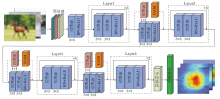
本文网络(DAMSNet)由多个残差块(Block)和融合DAM的残差块(D-Block)串联而成, 网络结构如图6所示.
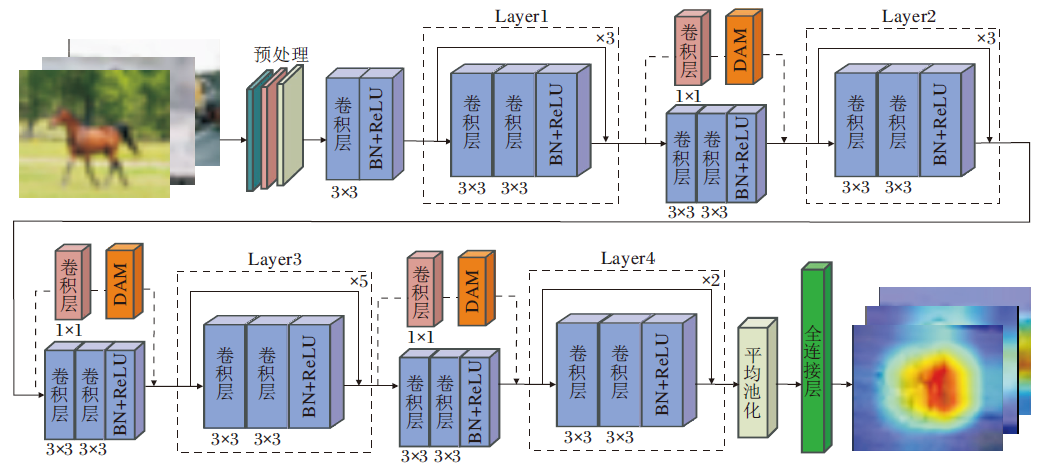 | 图6 DAMSNet总体结构图Fig.6 Overall architecture of DAMSNet |
主干网络部分包括如下7个阶段.
1)阶段1.输入图像尺寸为32× 32, 对输入图像进行图像增强预处理操作, 即随机翻转、填充后随机剪切和cutout操作, 提高分类方法对图像微小畸变的适应能力, 提高分类方法的鲁棒性.
2)阶段2.将增强后的图像输入网络的第1层3× 3卷积, 对特征映射降维, 进行浅层特征提取.
3)阶段3.将输出的特征图经过3组Block(称为Layer1)进行深层特征提取和1组D-Block进行特征映射降维.
4)阶段4.将输出的特征图经过3组Block(称为Layer2)进行深层特征提取和1组D-Block进行特征映射降维.
5)阶段5.将输出特征图经过5组Block(称为Layer3)进行更深层特征提取和1组D-Block进行特征映射降维.
6)阶段6.将输出特征图经过2组Block(称为Layer4)提取图像高层抽象特征.
7)阶段7.输出结果结构, 利用平均池化层提取残差块输出特征映射信息, 经过全连接层输出图像分类结果.
总之, DAMSNet针对ResNet-34的改进如下.
1)为了减少ResNet的第1层7× 7卷积和池化操作丢失图像的一部分特征信息, 采用3× 3卷积替换7× 7卷积, 删除池化层, 同时减小该卷积层的步长和填充大小, 以此避免图像原始特征的流失.
2)为了合理分配不同特征的比重, 在残差分支中加入DAM模块, 提高关键特征权重, 加强有效特征的流动.
3)为了防止只优化训练损失值导致模型次优的问题, 引入SAM, 结合SGD优化器优化网络, 寻找最优的邻域参数值, 增强模型泛化能力.
本文实验采用的操作系统为Ubuntu18.04.硬件环境为:NVIDIA Tesla P100显卡、60 GB内存.软件环境为:Pytorch1.9.1、CUDA11.1、CUDNN8.05.编程语言为Python3.8.
选择CIFAR-10、CIFAR-100、SVHN数据集作为实验数据集.自然图像数据集CIFAR-10包含10种类别图像, CIFAR-100数据集包含100种类别图像.街牌号数据集SVHN包含10种类别图像.具体数据集信息如表1所示.
| 表1 实验数据集 Table 1 Experimental datasets |
实验采用图像分类常用指标— — 分类准确率作为评价指标.
影响DAMSNet的参数有融合注意力机制的残差块嵌入的位置与数量、网络层数、残差网络的第1层卷积核尺寸k、学习率lr、网络训练迭代次数.
本文首先使用ResNet-34, 在k=3, lr=0.001, 迭代次数为200时, 分析残差块插入的位置与数量对分类准确率的影响.确定最优的嵌入位置和数量后, 分析不同网络层数、k、lr及迭代次数对分类准确率的影响, 从而选择最佳网络参数.
本文实验均在数据增强后的数据集上进行.
以ResNet-34为基础, 划分为4个Layer, 如图6所示.ResNet-34共有3个降维残差块(R-Block), 由于降维前使用注意力机制会在降维时损失更多的有用特征, 为了防止重复多次使用注意力机制造成特征冗余, 本文在特征映射降维处嵌入融合DAM的残差块(D-Block).
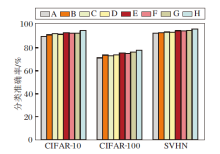
为了深入研究嵌入D-Block位置和数量对分类准确率的影响, 本文设计嵌入D-Block的8种排列组合方式, 如图7所示.
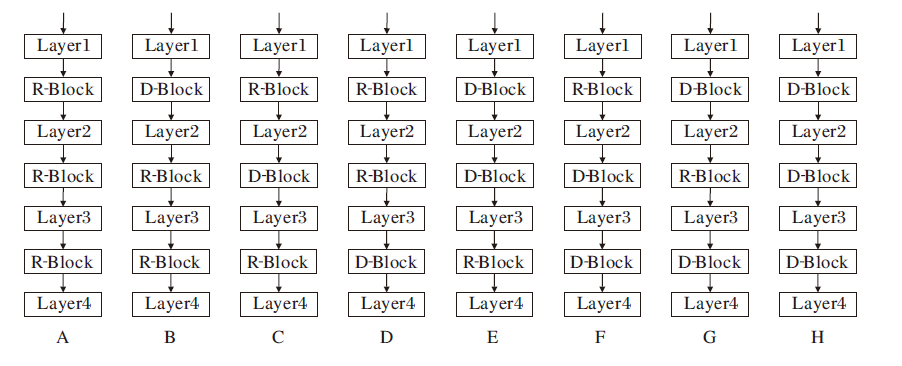 | 图7 D-Block位置和数量的8种排列方式Fig.7 Eight position and quantity arrangements of D-Block |
嵌入不同位置及不同数量的D-Block在3个数据集上对分类准确率的影响如图8所示.由图可以看出, 排列方式H在CIFAR-10、CIFAR-100、SVHN数据集上分别取得94.91%、77.95%、96.29%的分类准确率, 均为最高值.因此, 在3个特征降维处嵌入3个D-Block拟合效果最佳.
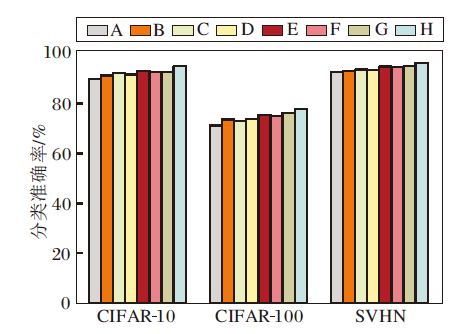 | 图8 不同位置和数量D-Block对分类准确率的影响Fig.8 Influence of different positions and numbers of D-Block on classification accuracy |
网络层数能够影响分类方法表示特征的能力, 当层数过少时, 可能导致特征表达能力不足.反之, 网络层数过多可能会出现过拟合以及神经网络特征层之间的特征冗余等问题.本文选用现在主流的残差网络ResNet-18、ResNet-34、ResNet-50、ResNet-101以及ResNet-152, 将本文在1.5节总结的改进之处分别嵌入上述残差网络中, 得到DAMSNet-18、DAMS-Net-34、DAMSNet-50、DAMSNet-101以及DAMSNet-152, 在CIFAR-10、CIFAR10、SVHN数据集上进行训练, 网络层数对分类准确率的影响如表2所示.由表可见, DAMSNet-34在3个数据集上的分类准确率均最优.
| 表2 不同网络层数对分类准确率的影响 Table 2 Influence of different numbers of network layers on classification accuracy % |
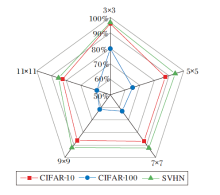
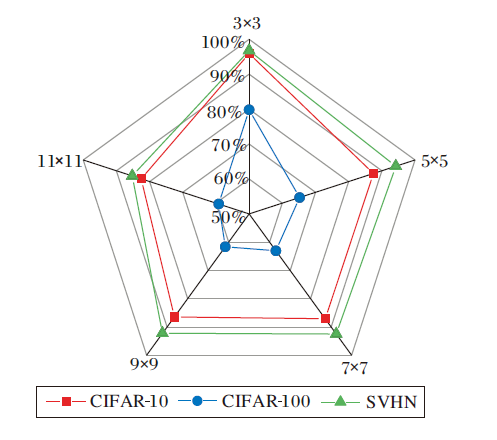
网络第1层的特征表达能力决定其对原始图像的特征提取能力, 因此网络第1层卷积核尺寸的选择至关重要.在DAMSNet-34的基础上, 分别使用大小为3× 3、5× 5、7× 7、9× 9、11× 11的卷积核, 在其它参数均相同的情况下进行实验, 不同尺寸卷积核对分类准确率的影响如图9所示.
 | 图9 不同卷积核尺寸对分类准确率的影响Fig.9 Influence of different convolutional kernel sizes on classification accuracy |
由图9可见, 随着卷积核尺寸的增大, 分类准确率并没有上升, 却在尺寸为3× 3的卷积核上得到最优值, 继续增大卷积核尺寸可能会出现特征提取能力退化的现象, 从而导致分类准确率下降.
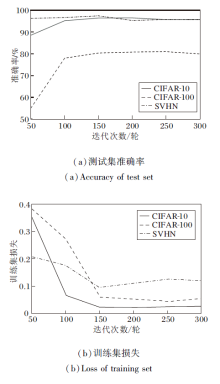
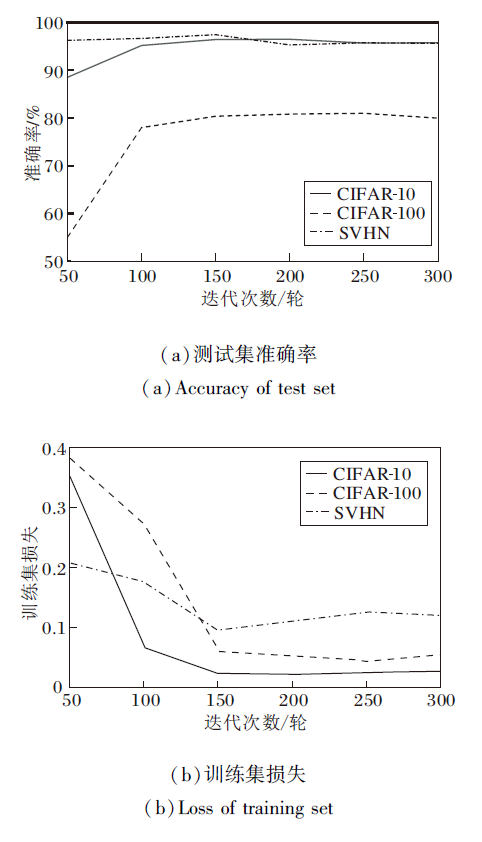
迭代次数能够直接影响模型的泛化能力.在CIFAR-10、CIFAR-100、SVHN数据集上, 网络在不同迭代次数下的测试集准确率和训练集损失变化曲线如图10所示.由图可见:对于CIFAR-10数据集, 在迭代次数为200轮时, 测试集准确率达到96.21%; 对于CIFAR-100数据集, 在迭代次数为250轮时, 测试集准确率达到79.51%; 对于SVHN数据集, 在迭代次数为150轮时, 测试集准确率达到96.90%.因此, 本文在CIFAR-10、CIAFR-100和SVHN数据集上, 迭代次数分别采用200轮、250轮和150轮.
 | 图10 不同迭代次数下的损失和准确率对比Fig.10 Comparison of loss and accuracy with different iteration times |
DAMSNet采用SGD进行优化, SGD可表示为
wt+1=wt-η
其中, n表示批尺寸, η表示学习率.
由上式可知, 在批尺寸相同时, 学习率能够直接影响模型的权重更新, 进而影响模型收敛.在批尺寸为64, 其它参数相同的情况下, 分别取
lr1=0.001, lr2=0.005, lr3=0.01.
设置动态调整学习率, 动态调整策略为初始学习率0.1, 当验证集损失在10轮内没有下降时, 分别取lr4、lr5、lr6、lr7学习率降至原来的0.4、0.5、0.6、0.7倍.
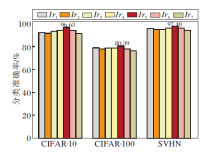
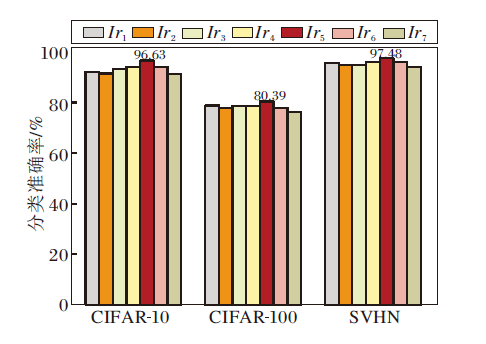
不同学习率对分类准确率的影响如图11所示, 由图可见, 学习率lr5在CIFAR-10、CIFAR-100、SVHN数据集上分类准确率分别为96.63%, 80.39%, 97.48%, 均为最优值.
 | 图11 不同学习率对分类准确率的影响Fig.11 Influence of different learning rates on classification accuracy |
为了验证DAMSNet的先进性, 在CIFAR-10、CIFAR-100、SVHN数据集上进行对比实验.
对比分类方法如下:ResNet-34[5], Efficient-Nets[25], GhostNet[26], CAPR-DenseNet[6], Multi-Res-Net[8], DFR-DenseNet[9], 文献[10]网络, CANAS[11], SSE-GAN[12], Couplformer[21], MMA-CCT-7/3× 2[22], FAVOR+(Fast Attention via Positive Orthogonal Random Features Approach)[27].
本文的分类准确率对比实验数据来源如下:1)未开源的代码优先采用对比网络对应论文提供的实验结果; 2)通过论文提供的开源代码复现.
各网络在3个数据集上的分类准确率对比如表3所示, 表中黑体数字表示最优值.由表可得出, DAMSNet在3个数据集上的分类准确率最高.
| 表3 各网络在3个数据集上的分类准确率 Table 3 Classification accuracy comparison of different networks on 3 datasets % |
使用GANs的SSE-GAN分类准确率最低, 虽然加入半监督学习, 在SVHN数据集上的分类准确率达到92.92%, 但是在CIFAR-10数据集上的分类准确率为85.14%.这是由于半监督学习难以控制生成的结果, 生成的样本可能会出现不合理的情况, 如图像中出现奇怪的颜色或形状, 所以分类效果不稳定.
残差-密集类网络的分类准确率有所提升, 如Multi-ResNet和DFR-DenseNet在CIFAR-10数据集上分别为94.65%和94.51%, 这是因为残差-密集类传递信息的方式与常规卷积网络不同, 该类采用跳跃连接的方式, 可提高特征的重利用率, 有效缓解网络深度的增加带来的梯度弥散和网络退化等问题.对于常规卷积网络, 如CANAS, 采用线性堆叠卷积层的方式增加网络深度, 间接增大网络的感受野, 有效提取更多的全局特征, 在分类难度较大的CIFAR-100数据集上, 分类准确率为72.72%, 但特征重利用率较低.
使用注意力机制的网络, 如加入通道注意力机制的EfficientNets, 在3个数据集上的分类准确率分别达到94.01%、75.96%、93.32%, 效果明显优于CANAS和SSE-GAN, 这是因为加入的通道注意力机制可以为重要通道特征分配较高权重, 但是单一的注意力机制无法充分考虑通道特征和空间特征, 效果差于DAMSNet.
基于Transformer的自注意力机制的网络, 如Couplformer、MMA-CCT-7/3× 2等, 分类准确率在CIFAR-100数据集上有所提升, 但是Transformer是一种全局注意力机制, 不能有效捕捉图像中的局部信息, 泛化能力较差.
对比后发现, 对于从局部特征和全局特征出发、充分提取通道域特征和空间域特征、提高模型泛化能力的问题, DAMSNet效果最优, 这表明DAMSNet的有效性和优越性.
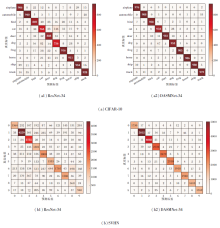
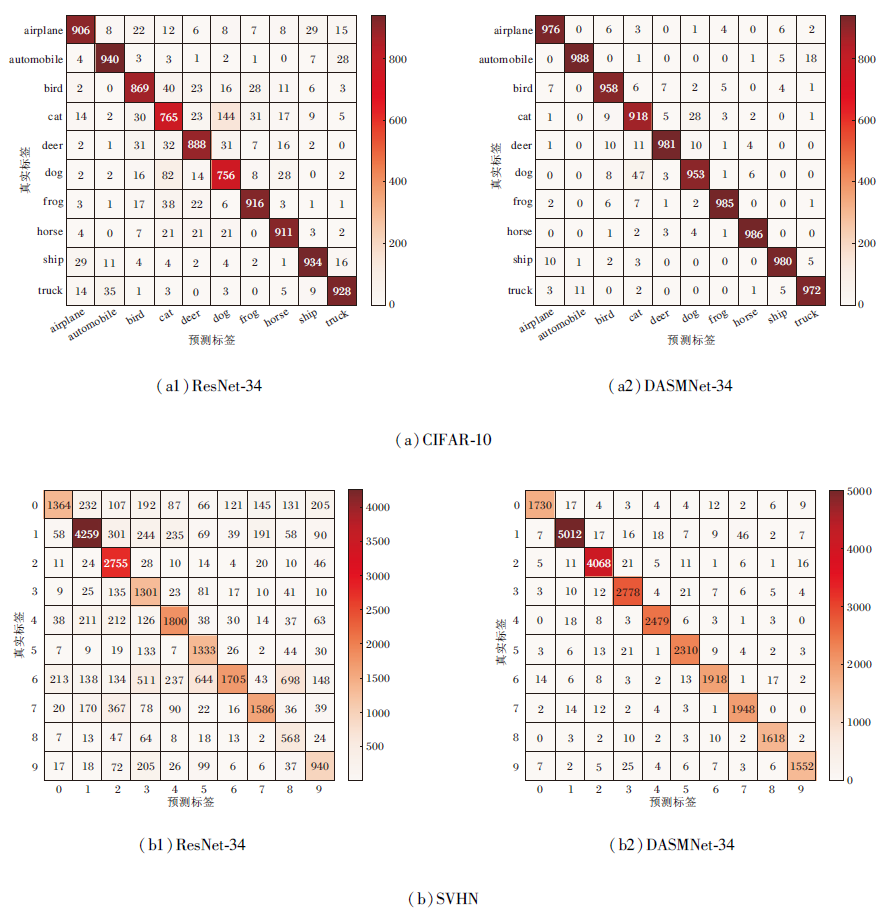
为了进一步验证DAMSNet的有效性, ResNet-34和DAMSNet-34在CIFAR-10、SVHN数据集上的分类混淆矩阵如图12所示, 图中列出预测正确、预测错误的各类样本的数量.DAMSNet-34在CIFAR-10、SVHN数据集上正确分类的样本数量远多于ResNet-34, 预测错误的样本数量远少于ResNet-34, 说明DAMSNet-34能够有效区分各种类别, 具有较强的分类性能.
 | 图12 ResNet-34和DAMSNet-34在2个数据集上的混淆矩阵Fig.12 Confusion matricies of ResNet-34 and DAMSNet-34 on 2 datasets |
为了进一步观察提出的DAM本文注意力机制的效果, 选择如下注意力机制进行对比:Frequency Channel Attention)[16]、Coordinate Attention[17]、Spatial Attention Pyramid[18]、Couplformer[21]、Performer[27].
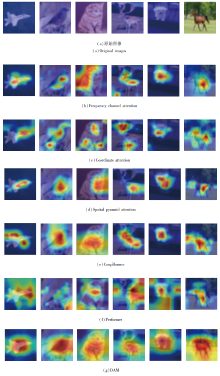
各注意力机制在CIFAR-10数据集上的可视化图像如图13所示.
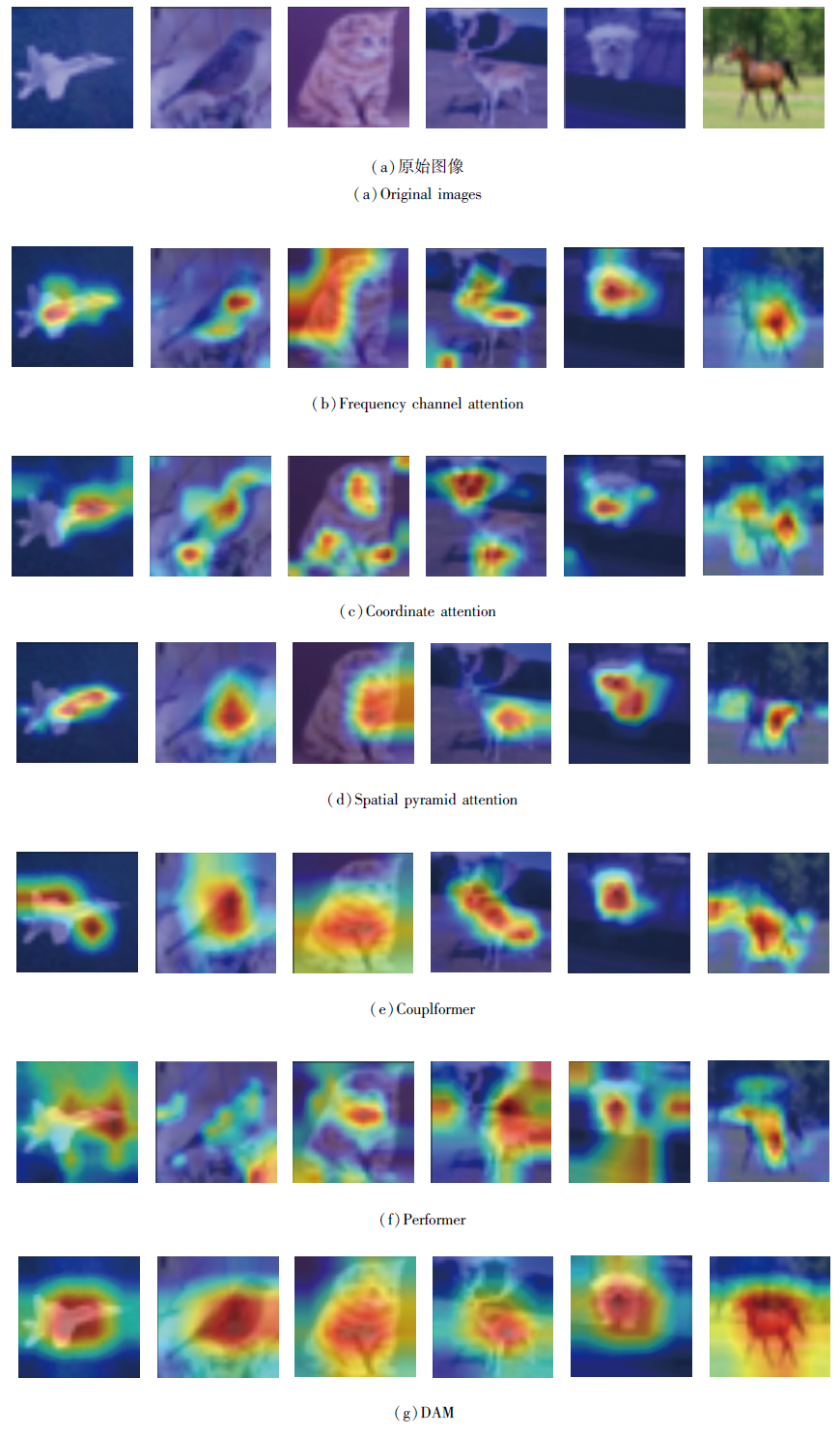 | 图13 加入不同注意力机制后的可视化图像Fig.13 Visualized images after employing different attention mechanisms |
由图13可以清晰地观察到, Spatial Attention Pyramid、Frequency Channel Attention采用单一的注意力机制, 分类效果明显不佳, 易受外界因素的干扰.Coordinate Attention未能综合考虑局部特征和全局特征, 效果不稳定.Couplformer、Performer基于全局上下文信息计算每个位置的权重, 而在图像分类中, 像素之间的上下文关系不是全局的, 故泛化能力较差.DAM从局部特征和全局特征出发分配权重, 能够更加高效利用关键特征, 例如, DAM能够注意到鹿的鹿角和腿、飞机的机翼等细节特征.相比其它注意力机制, DAM更全面提取关键特征, 更关注细节, 从而增加网络分类结果的可信度.
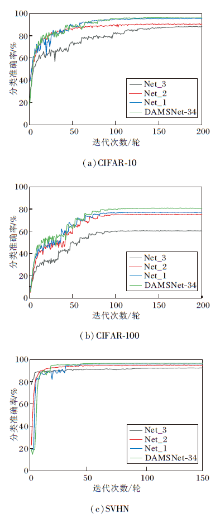
为了验证修改第1层卷积核尺寸、删除池化层, 在残差分支中使用DAM模块以及引入SAM的有效性, 在CIFAR-10、CIFAR-100、SVHN数据集上进行消融实验.
定义如下网络:Net_1表示在DAMSNet-34中去掉SAM, Net_2表示在DAMSNet-34中去掉残差分支中使用的DAM模块, Net_3表示在DAMSNet-34中不修改第1层卷积核尺寸并删除池化层.
各网络具体消融实验结果如表3所示.表中黑体数字表示最优值.由表可见, DAMSNet-34中各模块对网络性能都有一定影响.
| 表4 各网络的消融实验结果 Table 4 Ablation experiment results of different networks % |
各网络在3个数据集上不同迭代次数下的分类准确率对比如图14所示.
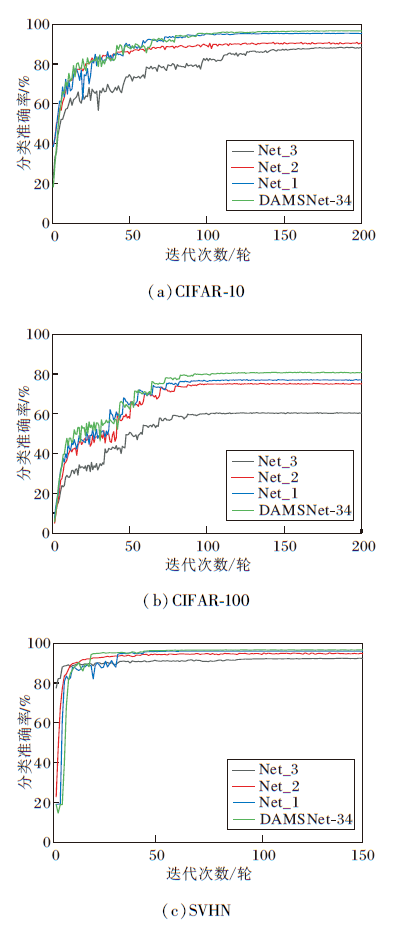 | 图14 迭代次数不同时各网络的分类准确率Fig.14 Classification accuracies of different networks with different iteration times |
由图14可知, 分类准确率由高到低依次为DAMSNet-34, Net_1, Net_2, Net_3, 从而验证引入SAM可以有效寻找均匀最小值的邻域参数, 提高模型泛化能力.修改第1层卷积核尺寸、删除池化层, 能够有效减少原始图像特征损失, 缓解特征提取能力退化的问题.在残差分支中使用DAM, 能够有效提高对关键特征的关注度.
实验表明, 同时改进第1层卷积核尺寸、删除最大池化层, 使用DAM以及引入SAM时, 网络性能得到一定的提升.
针对图像分类时无法高效利用关键特征, 在过度参数化的模型中存在只优化训练损失值, 导致模型泛化能力较差等问题, 本文提出双分支多注意力机制的锐度感知分类网络(DAMSNet).模仿人脑视觉认知, 提出双分支多注意力机制(DAM)模块, 使网络快速定位到目标区域, 减少非关键特征造成的计算耗时和分类干扰.使用SGD优化器结合锐度感知最小化算法(SAM)优化网络, 寻找具有均匀低损失值的邻域参数, 使网络更有效地执行梯度下降, 提高模型的泛化能力.修改网络第1层卷积核尺寸, 减少特征流失, 丰富图像的特征表达.在CIFAR-10、CIFAR-100、SVHN数据集上的实验表明, DAMSNet能够提高分类准确率和模型泛化能力.下一步工作重点在于结合神经网络轻量化, 进一步减少网络参数量, 优化模块结构, 降低时间复杂度, 提高网络的运行效率.
本文责任编委 黄华
Recommended by Associate Editor HUANG Hua
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|