

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
用于流式语音识别的轻量化端到端声学架构
[杨淑莹1  , 李欣
, 李欣1 ]
, 李欣]
|
|



作者简介:

李 欣,硕士研究生,主要研究方向为深度学习、语音识别、自然语言处理等.E-mail:lixin9595@outlook.com.
在流式识别方法中,分块识别破坏并行性且消耗资源较大,而限制自注意力机制的上下文识别很难获得所有信息.由此,文中提出轻量化端到端声学架构(CFLASH-Transducer).为了获取细腻的局部特征,采用轻量化的FLASH(Fast Linear Attention with a Single Head)与卷积神经网络块结合.卷积块中采用Inception V2网络,提取语音信号多尺度的局部特征.再通过Coordinate Attention机制捕获特征的位置信息和多通道之间的相互关联.此外,采用深度可分离卷积,用于特征增强和层间平滑过渡.为了使其可流式化处理音频,采用RNN-T(Recurrent Neural Network Transducer)架构进行训练与解码.将当前块已经计算的全局注意力作为隐变量,传入后续块中,串联各块信息,保留训练的并行性和相关性,并且不会随着序列的增长而消耗计算资源.在开源数据集THCHS30上进行训练与测试,CFLASH-Transducer取得较高的识别率.并且相比离线识别,流式识别精度损失不超过1%.
About Author:
LI Xin, master student. His research interests include deep learning, speech recognition and natural language processing.
In streaming recognition methods, chunked recognition destroys parallelism and consumes more resources, while contextual recognition with restricted self-attention mechanism is difficult to obtain all information.Therefore, a lightweight end-to-end acoustic recognition method based on Chunk, CFLASH-Transducer, is proposed by combining the fast linear attention with a single head(FLASH) and convolutional neural networks(CNNs) to obtain delicate local features. Inception V2 network is introduced into the convolutional block to extract multi-scale local features of the speech signal.The coordinate attention mechanism is adopted to capture the location information of the features and interconnections among multiple channels. The depthwise separable convolution is utilized for feature enhancement and smooth transition between layers. The recurrent neural network transducer(RNN-T) architecture is employed for training and decoding to process audio. Global attention computed in the current block is passed into subsequent blocks as a hidden variable, connecting the information of each block, retaining the training parallelism and correlation, and avoiding the consumption of computing resources as the sequence grows.CFLASH-Transducer achieves high recognition accuracy on the open source dataset THCHS30 with the loss of streaming recognition accuracy less than 1% compared to offline recognition.
自动语音识别(Automatic Speech Recognition, ASR)是一种通过机器将语音信号转变为文本的人工智能技术.近年来, 端到端E2E(End-to-End)的ASR取得巨大进步, E2E ASR技术包括CTC(Connec-tionist Temporal Classification)[1]、AED(Attention Based Encoder Decoder)[2, 3]和RNN-T(Recurrent Neural Network Transducer)[4].其中, RNN-T提供具有较高识别精度的流式ASR的解决方案[5].
最近, 基于Self-Attention的Transformer模型[6]在许多任务中取得较优成果, 如机器翻译[7]、语言建模和语言理解[8].该模型同样也成功应用于E2E ASR.相比RNN(Recurrent Neural Network), 基于Self-Attention的Transformer模型训练更快, 效果更优.Transformer模型擅长对全局信息编码, 高效的长距离交互能力和并行训练能力使其广泛应用于ASR领域, 取得不错的识别效果[9, 10].
然而, Transformer模型并没有较好的局部建模能力, 计算复杂度较高, 在编码时需要获取整个输入的特征序列再进行Self-Attention运算, 很难运用于流式识别.针对局部建模能力问题, 有研究者提出将卷积神经网络(Convolutional Neural Network, CNN)与Self-Attention结合的思路[11, 12], 这样既能学习位置上的局部特征, 又能进行基于内容的全局交互.这种结合的方式识别效果优于单纯基于Transformer声学模型.Gulati等[13]提出Conformer模型, 将轻量化的卷积结构与Self-Attention结合, 目前已取得较优的识别效果.然而, 虽然这种结合的方式取得较好的识别效果, 但计算复杂度依然是二次的, 并且参数量庞大, 从而导致训练不稳定、模型收敛困难等问题.
为了解决Transformer模型计算复杂度较高的问题, Child等[14]和Kaiser等[15]中提出自注意力矩阵稀疏化的方法, 降低模型的计算复杂度.虽然这种将输入序列某个位置与有限个位置进行关联可有效降低模型的计算复杂度, 但实际上计算复杂度还是二次的, 并且降低Transformer模型长距离交互的能力.Lu等[16]和Katharopoulos等[17]将Self-Attention运算线性化, 降低模型的计算复杂度.此方法处理较长序列时具有一定优势, 但是在处理短序列时效果甚至不如标准的Self-Attention.
针对全局Self-Attention机制无法应用于流式识别的问题, Zhang等[10]和Moritz等[18]提出使用基于look-ahead的方法, 限制当前帧与历史帧和未来帧的交互, 获取有限的上下文关联, 从而实现流式识别.但是这种方法会随着层数的累加产生延迟的线性增长, 并且获取的历史信息与未来信息也很局限.Tsunoo等[19]和Dong等[20]提出使用基于块的方法, 将音频序列切分成固定长度的块, 并逐块编码与识别.但是传统的这种基于块的方法破坏Self-Attention机制并行训练的平行性, 导致训练效率低下, 且不同大小的块识别效果差异过大, 不够稳定, 还会随着块个数的增多而消耗更多的计算资源.Wang等[5]提出SN(Scout Network), 能够检测到单词的边界信息, 自主判断一个词是否已结束, 并让编码器和解码器能够有一个自适应的正确的上下文窗口, 从而实现流式识别.虽然这种方式很大程度上提高流式识别的准确率并且平衡延迟, 但还存在随着序列长度增长而消耗大量计算资源和上下文交互局限的问题.
FLASH(Fast Linear Attention with a Single Head)[21]是一种优化后的Transformer模型, 摒弃Transformer模型的多头注意力机制, 采用单头注意力机制, 并且优化计算方法, 大幅降低参数量, 使模型更加轻量化.然而它与Transformer模型一样, 在提取细腻度的局部特征时表现一般.为此, 本文采用FLASH替换Transformer模型, 并受到Conformer模型的启发, 结合CNN模块与FLASH, 提出CFLASH(CNN Com-bined with FLASH), 应用到语音识别任务中.CFLASH在FLASH的基础上添加2个卷积块, 第1个卷积块主要使用多尺度卷积和Coordinate Attention[22], 用于提取更精细的局部特征, 强化模型的局部建模能力.在第2个卷积块中将一种轻量化的深度可分离卷积结构[13]添加在门控机制运算之后, 目的是为了进一步增强特征, 使层间平滑过渡.由于FLASH是基于块结构的模型, 通过固定块的长度, 逐块进行识别, 因此每块都会计算一个全局注意力和局部注意力, 并且每块的注意力值都是由历史块(包括当前块)的全局注意力的累加与当前局部注意力相加得到.该方式不仅通过线性计算复杂度获取所有历史块的信息, 而且块内的每帧通过局部注意力都能与未来帧进行交互, 从而获取未来信息.但是, 在进行流式语音识别时, 无法串联各个单独音频之间的联系.为了使其能够流式化处理音频, 提出基于线性块的流式识别方法, 引入隐变量, 将当前块已经计算的全局注意力作为隐变量, 传入后续块中, 串联各块的信息.这种方法在实现流式结构时并不影响并行训练, 也不会随着序列长度的增加而消耗大量的计算资源, 并采用RNN-T损失函数进行训练.本文将这种轻量化端到端声学架构命名为CFLASH-Transducer.在开源数据集THCHS30上进行训练与测试, CFLASH-Transducer取得较高的识别率.同时, 延迟在1 s内流式识别的精度损失可小于1%, 而延迟大于1 s时, 流式识别的效果近似于非流式识别.
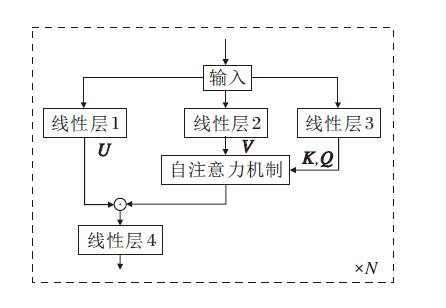
FLASH[21]由GAU(Gate Attention Unit)和MCA(Mixed Chunk Attention)机制联合而成.其中, GAU将Transformer模型中的FFN(Feed Forward Network)模块和Self-Attention模块进行改进与优化, 使用GLU(Gate Linear Unit)模块[23]替换FFN.GAU结构如图1所示.
 | 图1 GAU结构图Fig.1 Structure of GAU |
GAU中将Self-Attention机制改为
Attention=Vrelu2(
可以看出, GAU的Q、K、V计算方式与Transformer模型不同, 即输入矩阵通过两次线性变换得到V、Z, 而Q、K则是Z通过两次简单的仿射变换得到, 变换过程如下所示:
$Q=γ_{1}Z+\beta_{1}, \\ K=γ_{2}Z+\beta_{2},$ (2)
其中γ1、γ2是可训练的.式(2)相当于一种LayerNorm的操作.GAU的整个计算过程如下:
O=(U☉Attention)Wo.
其中:U为图1中线性层1的输出, 即输入矩阵通过一次线性变换而来, 参数量为e; Wo为权重矩阵; ☉表示哈达玛积.
由于GAU中的自注意力机制只采用单头, 相比Transformer模型的编码器部分, 在结构上更轻量化, 模型参数量更低.Transformer编码器部分的参数量为12d2(d表示模型大小, Transformer模型中的d是指d_model参数, 默认大小为512), GAU的参数量为3de(GAU中的d是指图1中线性层2与线性层3的参数, 默认为512, 而e为线性层1的参数, 默认为128)[21].当e=2d时, 两层GAU的参数量等于一层Transformer编码器的参数量.
为将GAU的计算复杂度由二次型优化到线性, 在FLASH中提出MCA机制, 结合局部注意力与全局注意力.对于一个音频输入序列S, 首先需要将其切分成G个大小为C的不重叠块.每个块g类似于一个输入矩阵, 通过GAU可以得到
Ug∈ RC× e, Vg∈ RC× e, Zg∈ RC× s.
再将Zg利用式(2)所示的仿射变换得到
式(3)的复杂度为O(GC2d), 即O(TCd), 如果固定C的长度, 它的计算复杂度就是线性的.
因此整个FLASH的实现过程如下:
Og=(Ug☉(
RNN-T[4]架构是一种利用RNN-T损失函数进行端到端训练的神经网络架构, 天然的语言模型使其在效果上优于CTC架构, 因此更适合流式语音识别.给定一个长度为T, 输入序列为(x1, x2, …, xT)的实值向量, RNN-T架构会预测一个长度为U, 目标序列为(y1, y2, …, yU)的标签输出序列.RNN-T架构在每个时间步给出标签的概率分布, 输出标签包含一个额外的空标签, 表示当前帧的输出为空.
RNN-T架构模拟所有可能的对齐关系条件概率P(z|x), 其中
z=[(z1, t1), (z2, t2), …, (
表示
P(y|x)=
其中Z(y, T)为标签长度为T的有效对齐集.对齐关系的条件概率P(z|x)可以分解为
P(z|x)=
其中Labels(z1∶ (i-1))表示z1∶ (i-1)中去除空白符的序列.
RNN-T架构通过两个编码器和一个联合网络将P(z|x)参数化.编码器是两个独立的神经网络模型, 一般采用RNN模型或LSTM(Long Short Term Memory), 分别对输入序列和标签序列进行编码.
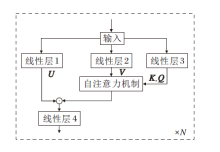
为了提高音频局部细腻度特征的提取能力, 本文提出结合全局建模与局部建模优势的轻量化CFLASH, 并将其与RNN-T架构结合, 形成一种轻量化端到端声学架构— — CFLASH-Transducer.该架构是一种基于块的神经网络模型, 结构如图2所示.一段语音被切分成3块进行编码与识别.每块都会计算局部注意力和全局注意力, 局部注意力用于获取当前块的信息, 全局注意力通过串联各块获取历史块的信息.块1需要计算局部注意力
Attention=
改进为
Attention=
从而串联各块, 实现历史信息的获取.
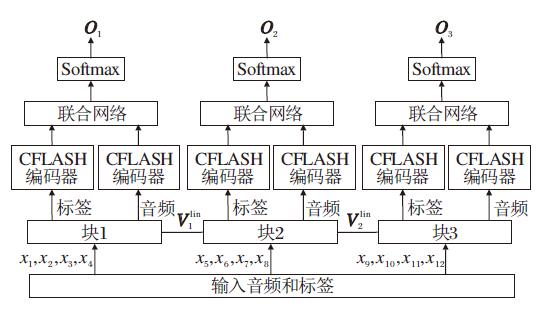 | 图2 CFLASH-Transducer结构图Fig.2 Architecture of CFLASH-Transducer |
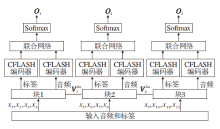
本文分别将两种卷积块添加在序列输入和门控机制计算之后.卷积块的添加可以提高模型对音频局部细腻度特征的提取能力, 从而使模型不仅可以维持高效的全局建模能力, 还能提高模型局部建模的能力.CFLASH结构如图3所示.
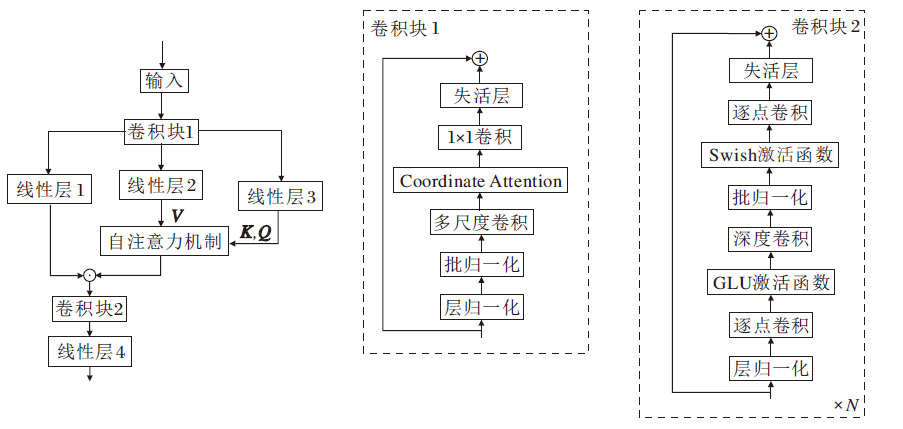 | 图3 CFLASH结构图Fig.3 Structure of CFLASH |
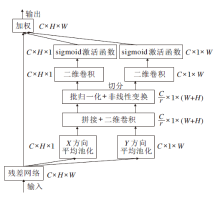
卷积块1(Conv1)的实现过程如图3所示.输入序列首先进行层归一化处理(LayerNormalization, LN)和一次多尺度卷积运算(Multi-scale Convolu-tion, MSVConv).再进行一次批归一化处理(Batch Normalization, BN)和Coordinate Attention.最后采用1× 1卷积进行降维, 并将该输出序列与输入序列进行残差连接.MSVConv模块受到Inception V2网络[24]的启发, 采用3种不同尺寸的卷积核和池化层, 获取不同视野下的局部特征.经过多尺度卷积运算后输入矩阵会从单通道变为多通道, 然而, 卷积运算只能捕获局部的关系, 无法精准捕捉特征的位置信息, 且卷积通道之间也没有相互关联, 因此经过多尺度运算后再进行一次Coordinate Attention运算, 可沿一个空间方向捕获远程依赖关系, 同时可沿另一个空间方向保留精确的位置信息.Coordinate Attention通过精确的位置信息对通道关系和长期依赖性进行编码, 具体操作分为Coordinate信息嵌入和Coordinate Attention生成两步, 实现过程如图4所示.
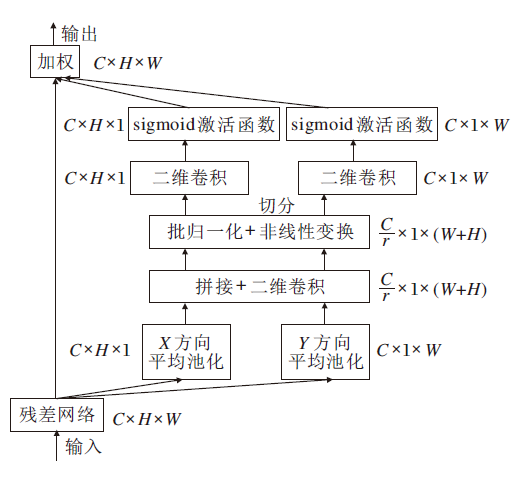 | 图4 Coordinate Attention结构图Fig.4 Structure of coordinate attention |
为了促使Coordinate Attention模块能够捕捉具有精确位置信息的远程空间交互和通道间的相互关系, 首先将输入序列沿水平方向和垂直方向进行一维平均池化, 计算过程如下:
再对
f=δ(F1([zh, zw])).
对f分别进行卷积和激活,
最后输出
yc(i, j)=xc(i, j)
Coordinate Attention模块的输出是一个通道数为C的矩阵, 此后还需要采用1× 1卷积进行降维, 得到一个与输入矩阵相同的单通道矩阵, 并进行残差连接.Conv1的引入使输入矩阵具备更精细、细腻的局部特征.
卷积模块2(Conv2)的实现过程如图3所示.输入矩阵首先进行层归一化运算, 采用1× 1× M卷积核和GLU激活函数进行逐点卷积运算.再使用3× 3的卷积核和Swish激活函数进行逐通道卷积(深度卷积)运算, 并进行批归一化.然后使用1× 1× 1的卷积核进行逐点卷积运算并降维.最后将得到的输出矩阵与输入矩阵进行残差连接.
Conv2添加在门控单元运算之后并且采用深度可分离卷积, 它的引入可以提高特征的辨识度, 起到数据增强的作用.
通过图3的模型结构, CFLASH的整体运算过程如下:
$\begin{aligned} & \boldsymbol{X}_1=\operatorname{Conv1}(\boldsymbol{X}), \\ & \boldsymbol{X}_2=\boldsymbol{U}_g \odot\left(\boldsymbol{V}_g^{\text {quad }}+\boldsymbol{V}_g^{\text {lin }}\right), \\ & \boldsymbol{X}_3=\operatorname{Conv} 2\left(\boldsymbol{X}_2\right) \boldsymbol{W} .\end{aligned}$ (5)
X3为CFLASH的输出.由于CFLASH是一个多层的编码器模型, 因此X3还将作为输入继续下一层的编码运算.
为了更好地模拟音频序列与标签序列的时序性, CFLASH中采用相对位置编码[7], 可以重复利用之前计算过的状态值, 并且可以为新的序列添加新的位置.相对位置编码不仅降低计算的复杂度, 还能更好地适配序列逐步增长的流式结构.
受文献[10]的启发, 本文将RNN-T原生的2个编码器替换成CFLASH, 命名为CFLASH-Transducer, 并将P(zi|x, ti, Labels(z1∶ (i-1)))的参数化过程重新定义为
$\begin{aligned} & P\left(z_i \mid x, t_i, \text { Labels }\left(z_{1:(i-1)}\right)\right)= \\ & \text { Sofimax (Linear ( tanh( Joint }))) \text {, } \end{aligned}$ (6)
其中,
$\begin{aligned} & \text { Linear }_1=\text { Linear }\left(\text { AudioEncoder }_{t_i}(x)\right) \text {, } \\ & \left.\text { Linear }_2=\text { Linear (LabelEncoder }(L)\right) \text {, } \\ & \text { Joint }=\text { Linear }_1+\text { Linear }_2 \text {, } \\ & L=\operatorname{Label}\left(z_{1:(i-1)}\right) \text {, } \\ & \end{aligned}$ (7)
Linear(· )函数表示一个单层的前馈神经网络层, AudioEncode
然而对所有有效对齐z进行求和以计算式(7)是非常困难的, 本文沿用Transformer-Transducer中提出的前向算法[4, 25]计算概率分布.前向算法中将前向变量α(t, u)定义为序列结束时的时间帧t和标签位置u的所有路径概率之和, 再计算最后一个α变量α(T, U), 对应式(4)中的P(y|x).相比求和算法, 前向算法更加高效, 因为在计算P(y|x)时, 任何一个时间帧和标签位置的局部概率估计(即式(6))不依赖于对齐.模型训练的损失函数[10]如下:
loss=-
其中, Ti表示第i个训练样本的输入特征序列, Ui表示第i个训练样本的输出标签序列的长度.
CFLASH与RNN-T架构的结合契合流式语音识别.本文在此基础上提出基于线性块的流式识别方法, 使用分块的方法进行流式识别.在进行流式识别时, 无法一次性获取完整的语音信号, 需要分块获取音频数据并提取特征.然而此时块与块之间是无关联的, 每块都相当于一个单独的音频.
为了使当前块能够获取历史块的信息, 引入隐变量
则当前块的Attention可改进为
Attention=
因此式(5)中X2可改写为
X2=Ug☉(
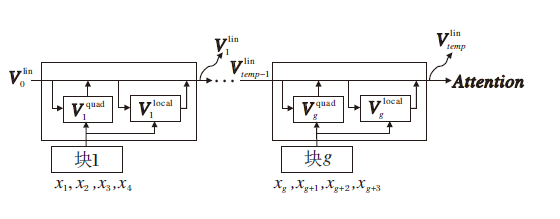 | 图5 改进的MCA机制示意图Fig.5 Sketch map of improved MCA mechanism |
本文实验使用公开的开源数据集THCHS30进行测试与评估.THCHS30数据集包含40多个小时的音频数据(约10 000多条音频数据)以及相应的文本标签(拼音标签和汉字标签), 并且自动划分训练集train、测试集test和验证集div.实验中提取80个通道的梅尔滤波器特征, 音频通过分帧后的帧长为25 ms, 帧移为10 ms.为了防止训练过程中出现过拟合现象, 实验中采用SpecAugment[26]的特征增强的方法进行训练, 频域掩码参数为F=10, mF=1, 时间掩码参数为T=6, mT=3.
本文提出的CFLASH-Transducer中有20层音频编码器和3层标签编码器.音频编码器与标签编码器的每层都是相同的, 详细信息如图3所示, 超参数如表1所示, 其中, 卷积核都默认采用3× 3卷积.
实验设备为i7-12700k CPU和4张RTX3070 GPU, 批尺寸大小设置为16, 模型均在 Ubuntu18.04系统下进行实验与论证.本文使用Adam(Adaptive Moment Estimation)优化器(β1=0.9, β2=0.9, $\epsilon$=10-9)对模型进行训练, 学习率的变化采用文献[13]中的设定, 并且模型在训练到大约10 000步时向模型权重中添加高斯噪声(μ=0, σ=0.01).
本文实验采用2种识别方式:1)直接从音频到汉字的不附加语言模型的方式, 2)从音频到拼音再经过语言模型转换为汉字的方式.
本文定义如下解码类型+声学架构:Hybird+Transformer[27]、Hybird+Conformer+Transformer[28]、CTC+DeepCNN[29]、CTC+QuarzNet[30]、CTC+Transfor-mer[31]、LAS(Listen, Attend and Spell)+Transformer[32]、LAS+LAS+SpecAugment[26]、RNN-T+LSTM[33]、RNN-T+ContextNet[34]、RNN-T+ Transformer[10]、RNN-T+ Conformer[13].在非流式模式下, 各声学架构在THCHS-30数据集上的词错率(Word Error Rate, WER)对比如表2所示.
| 表2 各声学架构的词错率与模型参数对比 Table 2 Comparison of WER and model parameters of different acoustic architectures |
实验中语言模型都采用Transformer模型, 参数设置与文献[6]一致, 但是Transformer块设置为5层, 通过THCHS30数据集上的文本标签(从拼音到汉字)训练得到.实验中的WER精确到小数点后一位数.
由表2可以看出, 基于Hybird、LAS或RNN-T架构的声学模型通过复现后都能在THCHS30数据集上取得不错的识别效果.然而, Hybird架构在训练时不够稳定, LAS架构的参数量庞大, 需要消耗大量的计算资源, CTC架构在相同条件下效果差于RNN-T架构, RNN-T架构的综合效果最佳.此外, 单纯的基于CNN、LSTM或Transformer的声学模型都很难达到最优效果.基于CNN的声学模型虽然可以提取语音信号更细腻的局部特征, 起到较好的局部建模效果, 但是却无法获取基于内容的全局交互.LSTM虽然可以更好地模拟音频时序性, 但随着音频长度的增加会出现梯度消失与爆炸的现象.基于Transformer的声学架构具备较好的全局建模能力, 如果能将它与CNN结合, 还能取得更好效果, 如Conformer模型.ContextNet模型结合CNN和SE(Squeeze-and-Excitation)模块, 有效实现模型全局建模能力, 因此也取得较好的效果.
由此可见, 结合模型的局部建模能力与全局建模能力是提升模型效果的关键.然而, 基于Trans-former模型或Conformer模型的声学架构由于采用多头Self-Attention和较深层的编码器块(大约18层的Transformer编码块或Conformer编码块), 导致模型的参数量庞大、训练难度较大和收敛时间较长.本文将采用单头Self-Attention的FLASH(包含20层的FLASH编码块)引入声学架构中, 效果优于Transformer模型.模型参数量只有72 M, 更加轻量化.与此同时, 本文中将卷积块与FLASH模型结合的CFLASH也取得很高的识别率, 参数量也低于对比模型, 当与FLASH的参数设置相同时, 降低近1%的WER.
CFLASH-Transducer是一个端到端流式语音识别模型, 表2中的数据已经展示它在非流式条件下的优越性, 实际上由于它的计算复杂度是线性的, 所以在进行流式识别时也具有较低的延时.CFLASH-Transducer在实现流式语音识别时是基于块的, 因此块的大小决定识别效果和延时高低.在流式识别条件下, 不同音频块长度和标签块长度的延时大小和词错率对比如表3所示.音频块长度是指一次性输入的音频帧长, 而标签块长度是指对音频序列逐帧预测后取若干帧历史记录中已识别的非空数据作为标签编码器的输入继续下一轮的标签编码.由表可看出, 随着音频块长度的增加, WER也会降低, 但是延时会变高, 而随着历史预测序列长度的增加, WER并未发生变化.
| 表3 不同音频块长度和标签块长度的延时和词错率对比 Table 3 Comparison of Latency and WER of different audio chunk lengths and label chunk lengths |
3.4.1 FLASH vs. CFLASH
CFLASH在FLASH的基础上引入2个卷积块, 充分挖掘音频细腻度的局部特征.下面将CFLASH逐步降为FLASH, 研究卷积块对模型的影响.在非流式条件下CFLASH每次改动后的消融结果如表4所示.由表可以看出, 删除两个卷积块都会提高模型的WER, 说明卷积块的引入使模型不仅维持全局建模的优势, 还提高局部建模能力, 因此提升综合建模能力.
| 表4 卷积块对CFLASH的影响 Table 4 Effect of convolution blocks on CFLASH |
为了进一步研究卷积块内部组件对模型的影响, 本文又分别进行Conv1与Conv2内部组件的消融实验, 通过替换和删除内部组件, 观察模型的识别效果变化.
Conv1模块主要是由一个多尺度卷积 (MSC)模块、Coordinate Attention模块、残差连接和1× 1卷积组成.删除Coordinate Attention模块和残差连接两个组件对CFLASH识别效果的影响如表5所示.
| 表5 Conv1模块中各组件对CFLASH的影响 Table 5 Effect of components in Conv1 module on CFLASH |
由表5可看出, Conv1模块的两个组件Coordi-nate Attention模块和残差连接都提升模型识别效果, 其中Coordinate Attention模块的贡献最大, 不仅可以模拟特征的位置信息, 还能促进通道之间的交互, Conv1模块为整个模型提供更精细的局部特征.
Conv2模块主要是由一个深度可分离卷积(Depthwise Separable Convolution, DepConv)和Resi-dual Connection模块组成.采用普通轻量化卷积(Lightweight Convolution, LighConv)替代深度卷积和删除Residual Connection模块后对CFLASH的影响如表6所示.
| 表6 Conv2模块中各组件对CFLASH的影响 Table 6 Effect of components in Conv2 module on CFLASH |
由表6可以看出, 采用DepConv的效果略优于普通的LighConv, 消耗的计算资源更少, 参数量更低.
下面研究Conv2模块中不同卷积核个数对CFLASH的影响, 具体如表7所示.
| 表7 Conv2模块中卷积核个数对CFLASH的影响 Table 7 Effect of number of convolution kernels in Conv2 on CFLASH |
由表7可以看到, 当卷积核个数为32时, WER最小.
从上述实验可以看出, 卷积块的引入提升模型的识别效果.然而, 卷积块的引入并未能直接体现对细腻度局部特征的提取作用.为了进一步研究卷积块在细腻度特征提取能力上的明显作用, 将CFLASH的两个卷积块中默认采用的小卷积核3× 3分别替换成中卷积核5× 5和大卷积核7× 7, 观察不同卷积核下模型性能, 具体如表8所示.由表可见, 当卷积核大小为3× 3时, WER最小, 说明卷积核为3× 3时能够提取更精细的局部特征, 而当卷积核大小为5× 5或7× 7时, 具有范围更大的特征提取视野, 也就导致提取的局部特征无法像卷积核为3× 3时那么细腻, 从而引起模型识别效果的差异.结合表2中未引入卷积块的FLASH的识别效果, 综合来看, 卷积块的添加使模型不仅维持全局交互能力, 还有效发挥模型提取细腻度的局部特征能力.
| 表8 卷积核大小对CFLASH的影响 Table 8 Effect of convolution kernel size on CFLASH |
3.4.2 标签块长度的消融效果
3.3节实验证实在进行流式识别时, 音频块长度越长, 识别效果越优, 但随着标签块长度的增长, 识别效果却并未发生变化.为了进一步研究标签块长度是否会对流式识别效果产生影响, 在音频块长度为10时, 标签块长度对模型的流式识别效果的影响如表9所示.表中黑体数字表示对识别效果有影响的最长序列长度.由表可以看出, 如果标签块长度不附加任何历史信息(即长度为0), 模型的识别效果大幅降低, 同时, 当标签块长度大于3时, 模型的识别效果就不会受到其长度的影响.
| 表9 标签块长度对CFLASH的影响 Table 9 Effect of label chunk length on CFLASH |
3.4.3 块内未来信息的消融效果
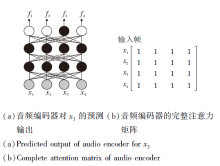
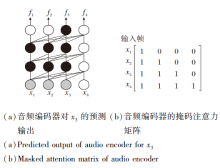
如图6所示, CFLASH中音频编码器的局部注意力
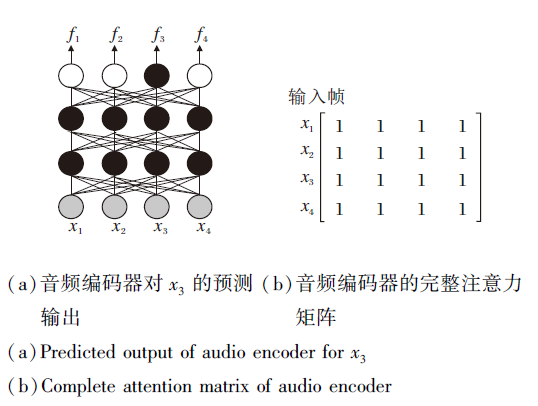 | 图6 采用基于全局的自注意力交互机制的音频编码器的预测输出和注意力矩阵Fig.6 Global self-attention interaction mechanism based predicted output and attention matrix |
为了验证块内的未来信息对于流式识别的影响程度, 本文重新设计模型结构, 采用如图7所示的基于历史的自注意力交互以获取当前块的局部注意力
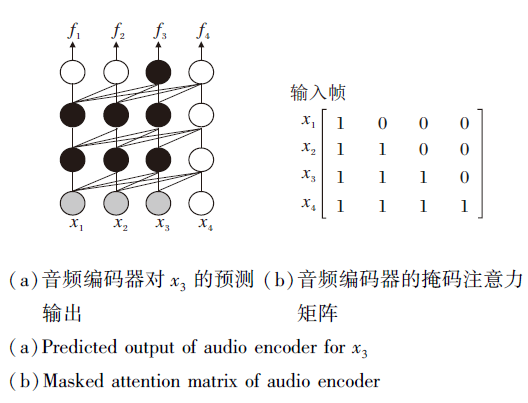 | 图7 采用基于历史的自注意力交互机制的音频编码器的预测输出和注意力矩阵Fig.7 Historical self-attention interaction mechanism based predicted output and attention matrix |
具体地, 每块都会计算基于历史自注意力交互的
当历史预测序列长度为4, 音频编码器采用基于历史的自注意力交互机制(简记为Historical)和基于全局的自注意力交互机制(简记为Global), 在不同长度的音频块下, 流式识别效果对比如表10所示.由表中实验数据可以看出, 未来信息对于模型的识别影响是巨大的, 如果当前块内所有帧只与历史帧进行交互, 会导致模型有一个很大的精度损失, 然而, 如果与未来帧进行交互, 会有一个质的提升.同时, 从结果还可看出, 随着块长度的增加, 识别效果也逐步提升, 这说明历史信息对于模型的识别效果也有较大的影响, 历史信息越长, 模型的识别效果越优.
| 表10 采用不同注意力机制时音频编码器对CFLASH的影响 Table 10 Effect of AudioEncoder with different attention mechanisms on CFLASH |
3.4.4 块外未来信息的消融效果
CFLASH-Transducer在进行流式识别时会有一个精度上的损失, 无法达到非流式识别时的效果.表10已经证实音频块内未来帧对于当前块的识别具有一定影响, 本节进一步研究未来音频块对于当前块识别效果的影响.在之前实验中, 流式识别使用的是采集一个音频块进行一次识别, 即逐块识别, 这种实现方式的每个待识别块都是最后一个块, 即无法使得当前块与未来块进行交互, 而在离线识别中, 每块都可以与后面的块进行交互, 因此流式识别的精度损失在很大程度上与获取不到更全面的未来信息有关.
为了验证这个猜想, 本文设计如下实验:流式识别初始阶段, 首先采集N个音频块, 然后将这N个块一起送入音频编码器中进行编码并识别, 但是只输出块1的识别结果, 接着每采集一块就进行一次识别.第2次识别是将块2到块N+1送入音频编码器中进行编码与识别, 并输出块2的识别结果, 以此内推逐个输出块3及以后的音频块的识别结果.
当历史预测序列长度为4, 音频块长度为10时, 不同个数的未来音频块对于模型的流式识别效果影响如表11所示.由表可看出, 未来音频块的个数越多, 模型的识别效果越优, 同时, 流式识别的延迟也越高.流式结构之所以无法达到非流式结构的识别效果, 主要原因就是未来信息获取的局限性, 流式结构由于延时性的因素很难获取较充足的未来信息, 从而导致识别效果低于非流式结构.如果不考虑延迟的高低(大于1 s), CFLASH-Transducer在流式结构上的识别效果不差于非流式结构.
本文提出CFLASH-Transducer, 这是一种在RNN-T架构中嵌入基于CFLASH的音频编码器和标签编码器的轻量化端到端声学架构.使用RNN-T损失函数进行训练, 有效地对所有可能的排列进行边缘化处理, 适用于时间同步的解码.实验中研究每个CNN块及其组件的重要性, 并验证CNN块有助于CFLASH的性能提升.在开源数据集THCHS30上的训练与测试表明, CFLASH-Transducer取得较高的识别率, 参数量较少, 结构较轻量化.另外, 本文还提出基于线性块的流式识别方法, 以线性的计算复杂度获得与历史音频的交互信息, 在进行流式识别时, 模型不会随着音频个数的增加而消耗更多的计算资源.实验中研究各种影响流式识别效果的因素, 并证实延迟在1 s内, 流式识别的词错率仅比非流式识别提高不到1%, 而延迟大于1 s时, 流式识别的识别效果不逊于非流式识别.今后将考虑进一步扩大数据集, 优化模型参数, 使模型的鲁棒性更强.此外, 进一步研究如何在保证识别效果的同时, 削减冗余的历史信息.
本文责任编委 周水庚
Recommended by Associate Editor ZHOU Shuigeng
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|