






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于编码特征学习的3D点云语义分割网络
[佟国峰1  , 刘永旭
, 刘永旭1 , 彭浩1 , 邵瑜渊1 ]
, 刘永旭, 彭浩, 邵瑜渊]
|
|



作者简介:

刘永旭,硕士研究生,主要研究方向为计算机视觉、激光点云处理、深度学习.E-mail:814920755@qq.com.
彭 浩,博士研究生,主要研究方向为计算机视觉、激光点云处理、模式识别.E-mail:apengh@126.com.
邵瑜渊,博士研究生,主要研究方向为计算机视觉、激光点云处理、模式识别.E-mail:ShaoyuyuanNEU@126.com.
目前点云语义分割已广泛应用到自动驾驶、虚拟现实等多个领域,但现阶段点云分割算法无法提取较完整的空间结构信息,难以解释每个点编码信息的问题.针对此缺陷,文中提出基于编码特征学习的3D点云语义分割网络.首先,在引入角度信息和增强特征的基础上构造局部特征编码器(Local Feature Encoder, LFE),学习较完整的局部空间结构,缓解相似物体错分割问题.然后,设计混合池化聚合模块(Mixed Pooling Polymerization, MPP),聚合粗犷特征和精细特征,同时保证点云的排序不变性.最后,采用多尺度特征融合,充分利用编码层不同尺度特征,实现准确的语义分割.在两个大型基准数据集S3DIS和SemanticKITTI上的实验表明文中网络的优越性.
About Author:
LIU Yongxu, master student. His research interests include computer vision, laser point cloud processing and deep learning.
PENG Hao, Ph.D. candidate. His research interests include computer vision, laser point cloud processing and pattern recognition.
SHAO Yuyuan, Ph.D. candidate. His research interests include computer vision, laser point cloud processing and pattern recognition.
Now point cloud semantic segmentation is widely applied in various fields such as autonomous driving and virtual reality. However, the current point cloud semantic segmentation algorithms cannot extract relatively complete spatial structure information, and the information for each point is difficult to explain. To address this deficiency, a 3D point cloud semantic segmentation network based on coding feature learning is proposed. Firstly, the local feature encoder is designed based on the introduction of angle information and the enhanced features to learn more complete local spatial structures and alleviate the problem of misclassification of similar objects. Secondly, mixed pooling polymerization module is designed to aggregate rough features and fine features while ensuring the sorting invariance of point cloud. Finally, the multi-scale feature fusion is adopted to fully utilize the different scale features in the encoding layer and achieve accurate semantic segmentation. The experiment on two large benchmark datasets, S3DIS and SemanticKITTI, demonstrates the superiority of the proposed network.
近年来, 三维点云处理成为计算机视觉和人工智能领域比较重要的任务之一.该任务统筹语义分割、物体分类和实例分割等.其中语义分割最具有挑战性, 这主要得益于深度学习的发展.随着激光雷达传感器的发展, 大规模点云有效语义分割成为实时智能系统中必不可少的能力[1, 2, 3, 4].点云数据通常是不规则、稀疏和无序的, 尽管卷积神经网络(Convo-lutional Neural Network, CNN)在图像视觉中表现良好, 但无法直接应用于不规则的数据, 如何处理点云语义分割仍是一个非常重要的任务.
目前, 具有开创性的工作PointNet[5]已经成为直接对点云进行处理的一种主流方法, 它利用多层感知器逐层提取特征, 并使用最大池化获取全局信息, 但无法获得局部上下文信息.Qi等[6]提出PointNet++, 建议将点云分组采样, 每层都有小型PointNet提取特征, 却忽略局部的细致特征.逐点多层感知机(Multilayer Perceptron, MLP)适合处理大场景点云, 由此Hu等[7]提出RandLA-Net, 使用随机采样的方法, 加快网络进程, 降低计算量, 但丢失部分点云信息.为了弥补上述缺陷, 学者们开始使用局部特征融合方法, 仍无法获取全局依赖性和局部依赖性.Thomas等[8]提出KPConv(Kernel Point Convo-lution), Xu等[9]提出PAConv(Position Adaptive Convolution), 都致力于学习有效的核, 更适合点云几何, 但内存消耗巨大.还有一些基于图的方法[10, 11, 12], 结合卷积算子和图结构, 提取点云特征, 却容易丢失空间结构.
针对大场景点云, 空间结构信息对于点云分割分类非常重要, 尤其是点云处于相似类别时.尽管上述工作[5, 6, 7]尝试捕捉有效的点云空间结构信息, 但仍然处在丢失点云局部特征信息的问题中.这主要有如下3个原因.1)在局部特征提取上缺乏完整性, 难以灵活表征.2)着重考虑局部点云信息的获取, 缺少局部依赖性和全局依赖性.3)缺乏对场景每个点的解释, 导致输出特征图不足以进行细粒度的语义分割, 匮乏不同尺度的信息.
针对点云的不规则性、稀疏性和无序性, 如何学习点云特征是一个具有挑战性的问题.传统方法通常依靠手工制作特征的方法从3D点云中提取特征信息, 目前基于学习的方法主要包括基于体素化的方法、基于点的方法和基于投影的方法.
1)基于体素化的方法[13, 14, 15].由于点云不像图像那样具有固定的特征值, 故不能对点云直接进行三维卷积.一些研究者设计基于体素化的方法, 首先将点云体素化为网格, 再使用3DCNN进行操作.利用体素化的方法会消耗大量的内存, 因此学者们设计基于稀疏卷积的方法, 在体素化的过程中会产生很多空的体素.为了避免卷积层在此消耗的内存, 稀疏卷积的方法会大幅提升网络的速度.例如, Rieger等[16]提出OctNet, 使用具有分层分区的不平衡八叉树.关于稀疏卷积的方法, 卷积核只在有体素的地方进行操作, 大幅减少计算量和消耗内存.但是将点云体素化到网格之上, 仍会丢失点云的空间结构信息.
(2)基于点的方法[17, 18, 19].对于体素化的方法而言, 网络对点云进行体素化时需要耗费大量的时间和内存, 往往会限制网络的训练时间.直接将点云输入网络中, 可减少一定的计算量和时间.PointNet是第一个直接输入点云的网络, 解决点云的无序性问题.针对PointNet没有针对性地学习局部点云空间关系问题, PointNet++设计SA(Set Abstraction)层的结构, 用于提升网络对局部几何结构的敏感性.目前, 针对大场景点云分割效率问题, 直接以点云为输入的RandLA-Net取得较优效果.
(3)基于投影的方法[20, 21, 22].由于点云的结构是不规则的, 一些网络将其表达为规则的表示后送入网络中.基于2DCNN在图像分割中的成功应用, 研究人员将三维点云有规则地进行多视图投影, 利用2DCNN对其进行特征提取, 再采取多视图融合的方法对其提取的特征进行最后的输出表示, 取得一定的成功.基于投影的方法有一个较大的弊端:点云的部分几何信息在投影的过程中被折叠, 而且三维点云也存在遮挡问题, 故投影到二维平面时, 都会影响分割的准确率.
在真实场景下, 大规模的点云通常包含数百万个点, 很难直接进行处理.像RandLA-Net使用有效的随机采样方法, 而不是PointNet++采取的更复杂的最远点采样, 大幅缩减点云数目.由于Transfor-mer[23]的成功使用, 在三维点云方面, 大多数方法类似于二维图像框架.
在网络性能和速度权衡之下, 并且受邻域特征提取取得成功的启发, 本文设计基于编码特征学习的3D点云语义分割网络(3D Point Cloud Semantic Segmentation Network Based on Coding Feature Lear-ning, CFL-Net).网络设计如下4种模块.1)引入角度信息的局部特征编码器(Local Feature Encoder, LFE), 在增强网络旋转鲁棒性的同时对点云原始特征进行注意力增强.2)混合池化聚合模块(Mixed Pooling Polymerization, MPP), 在网络学习中降低点云数目, 保证点云的排序不变性, 高效聚合点云特征.3)扩张感受野模块(Dilated Receptive Field Block, DRFB), 扩大局部区域内点云感受野, 在获取精确特征信息的同时引入全局特征.4)多尺度融合模块(Multi-Scale Fusion Module, MSFM), 融合多层次编码信息, 从不同角度解释点的表征, 获取精细特征地图, 高效完成语义分割.在两个大型基准数据集S3DIS和SemanticKITTI上的实验表明文中网络的优越性.
本文提出基于编码特征学习的3D点云语义分割网络(CFL-Net), 直接以原始点云作为输入, 同时设计局部特征编码器(LFE)、混合池化聚合模块(MPP)、扩张感受野模块(DRFB)和多尺度融合模块(MSFM).
随机采样导致网络丢失一定信息, 为了学习局部点云空间信息特征, 设计局部特征编码器(LFE), 利用位置表示和角度信息, 提升空间角度旋转鲁棒性, 并利用空间距离, 通过注意力增强原始特征, 可以学习到较完整的点云空间结构特征信息, 解释区域内不同物体的区别.
假设给定带有点云坐标和附加特征(RGB、法线等)点云集合P, LFE模块嵌入输入的点云坐标中, 利用极坐标系代替笛卡尔坐标系, 可以保证点云Z轴的旋转不变性.对于一个点pi, 利用欧氏距离的邻域搜索算法(K-Nearest Neighbor, KNN)进行邻域点的搜索.中心点pi和邻域点
$\phi _{i}^{k}=\arctan \left( \frac{y_{i}^{k}}{x_{i}^{k}} \right), $
$\varphi _{i}^{k}=\arctan \left( \frac{z_{i}^{k}}{\sqrt{x{{_{i}^{k}}^{^{2}}}+y{{_{i}^{k}}^{^{2}}}}} \right), $
其中(
寻找邻域范围内的质心, 质心的计算为邻域内点坐标的平均值, 减去质心和中心点之间的水平方向角和垂直方向角, 对上述的角度进行更新, 得到更新后的相对水平方向角和垂直方向角:
$\phi {{_{i}^{k}}^{\prime }}=\phi _{i}^{k}-{{\theta }_{i}}, $
$\varphi {{_{i}^{k}}^{\prime }}=\varphi _{i}^{k}-{{\gamma }_{i}}, $
其中, θ i、γ i表示局部点云内质心和中心点之间的水平方向角和垂直方向角.
更新得到相对水平方向角
其中, pi、
 | 图1 局部点云之间相对角度表示示意图Fig.1 Sketch map of relative angle representation of local point clouds |
对于每个邻域点特征f
f
其中, f(i)表示第i个点的输入特征向量, f(k)表示第k个点的输入特征向量, |· |表示L1范数, mean(· )表示平均值, exp(· )表示负指数函数.
利用共享函数g(· )学习注意力得分, 函数g(· )由一个共享MLP和一个Softmax组成.学习的注意力打分
$s_{i}^{k}=g\left( f_{dis}^{k}, W \right)$,
其中W表示共享MLP中可以学习的权重.
通过学习到的注意力打分, 对邻域点特征f
$\tilde{f}_{i}^{k}=f_{i}^{k}\cdot s_{i}^{k}$.(2)
在由式(1)得到局部位置编码特征和由式(2)得到基于注意力的邻域特征后, 拼接二者, 得到增强后的局部特征:
拼接后的特征信息
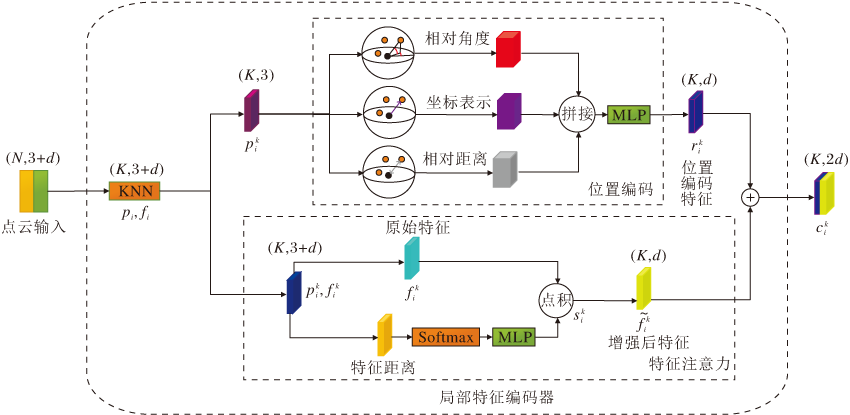 | 图2 局部特征编码器框架Fig.2 Structure of local feature encoder |
原始数据集点云数目较庞大, 需要通过特征学习聚合原始点云, 实现一点代替多点的作用, 网络学习中点云数目的减少可有效降低内存开销和节约时间成本, 因此, 本文设计混合池化聚合模块(MPP), 聚合经过LFE模块后的特征, 降低点云数目.
混合池化主要利用最大池化操作和平均池化操作, 聚合LFE学习到的局部特征信息
$\hat{c}=\max \left( c_{i}^{k} \right)$,
$\bar{c}=avg\left( c_{i}^{k} \right)$,
其中, max(· )表示最大池化操作, avg(· )表示平均池化操作.
得到的特征进行拼接后, 经过一个共享的MLP, 得到一个较丰富的特征向量:
$\hat{f}_{i}^{k}=MLP\left( \hat{c}\oplus \bar{c} \right)$.
MPP模块框架如图3所示.
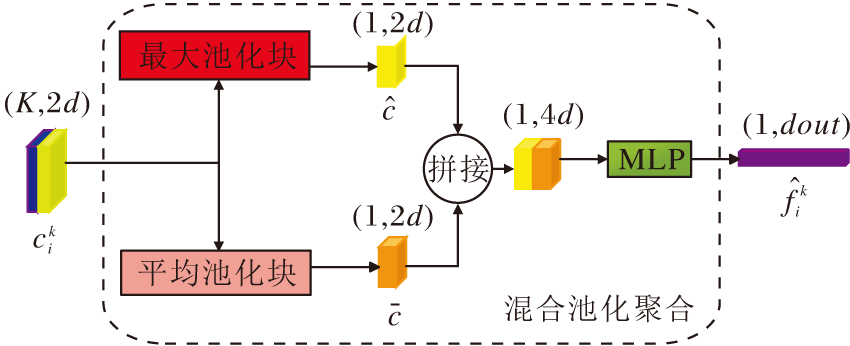 | 图3 混合池化聚合模块框架Fig.3 Structure of mixed pooling polymerization module |
目前在点云分割中使用最多的采样方法为最远点采样(Farthest Point Sampling, FPS)和随机采样(Random Sampling, RS).FPS的采样时间和消耗内存都高于RS, 会导致采样不均匀.RS则会导致局部出现稀疏甚至丢失点云信息的情况, 但时间和消耗内存都远小于其它算法, 因此可以利用局部特征聚合的方法弥补上述缺点.本文在编码层采用RS采样方式.
解码层网络需要将聚合的点云特征还原到初始尺度的点云, 针对点云数据集上点云数量较庞大的问题, 本文采用最近邻插值进行上采样.
大场景点云分割中一些同类别物体往往多是邻近的, 网络在经过一次编码之后, 如果可以尽可能使用一个或多个点信息代替更多点的信息, 对于提升区域内感受野将是非常有效的.
为了实现上述目的, 本文设计扩张感受野模块(DRFB), 扩大点云感受野.在1.1节和1.2节中提取的特征即是点云场景中的局部特征, 为了自动增强邻域有用特征, 本文利用残差块引入全局特征.该方式不仅在三维点云语义分割中使用, 在二维图像分割中也是一个常见的处理操作.
本文采用的采样方式为随机采样, 会导致点云大幅减少.DRFB模块的核心是LFE模块和MPP模块的扩展使用.经多次实验和经验证实, 两次的扩展效果最好.
DRFB模块框架如图4所示.图5为局部区域内点云感受野扩大演示图, 图中彩点表示聚合特征.
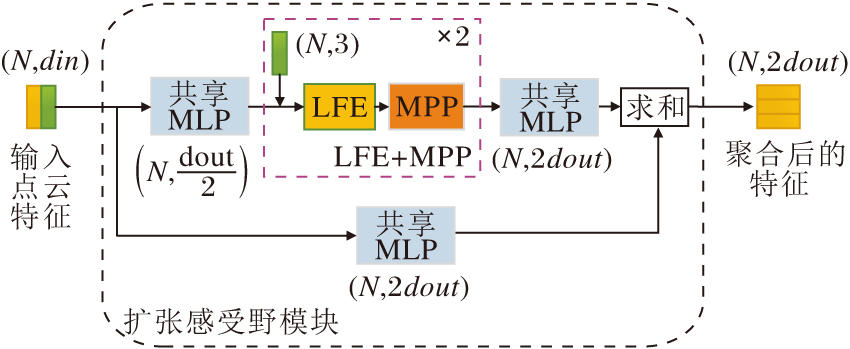 | 图4 扩张感受野模块框架Fig.4 Structure of dilated receptive field block |
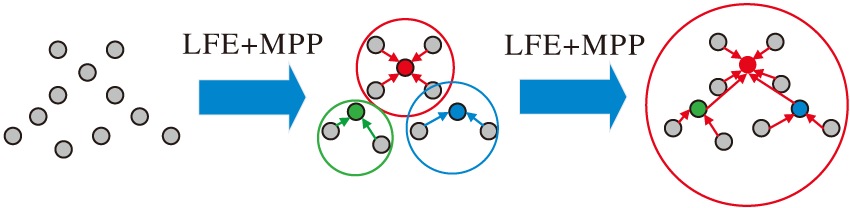 | 图5 点云感受野扩大示意图Fig.5 Expansion of receptive field of point cloud |
大场景点云分割中常用的插值方法是最近邻插值, 还有类似的插值方法(双线性插值、双三次插值等)[24].最近邻插值是较简单的一种插值方法.当利用插值的方法还原原始点云的特征图时, 常会出现标签丢失或分配错误的情况.很多算法利用跳跃拼接的方法将编码层相同尺度的特征信息进行拼接, 同时结合编码层信息, 缺点是忽略不同尺度的点云信息, 导致场景内个别点云错分割的情况.
本文设计多尺度融合模块(MSFM), 采用类似于金字塔的结构进行解码, 与插值方法不同的是, MSFM模块没有采用自适应融合方式, 而是在解码层将不同层次编码层特征利用近邻插值方式进行上采样, 再通过MLP达到相同的维度, 然后融合获取的不同的尺度特征, 保证在基本概括每个点的同时降低网络的计算量.解码层的输出为
${{S}_{\text{out}}}=Concat(\overset{\tilde{\ }}{\mathop{{{S}_{1}}}}\, , \overset{\tilde{\ }}{\mathop{{{S}_{2}}}}\, , ..., \overset{\tilde{\ }}{\mathop{{{S}_{M}}}}\, )$
其中, $(\overset{\tilde{\ }}{\mathop{{{S}_{1}}}}\, , \overset{\tilde{\ }}{\mathop{{{S}_{2}}}}\, , ..., \overset{\tilde{\ }}{\mathop{{{S}_{M}}}}\, )$分别表示解码层不同尺度层次的特征信息.
MSFM模块覆盖解码层和编码层, 融合不同尺度层次信息, 较全面概括场景点云.该模块具体框架如图6所示.
 | 图6 多尺度融合模块框架Fig.6 Structure of multi-scale fusion module |
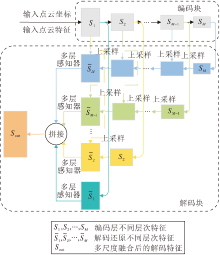
CFL-Net的网络架构如图7所示, 由编码块和解码块组成.
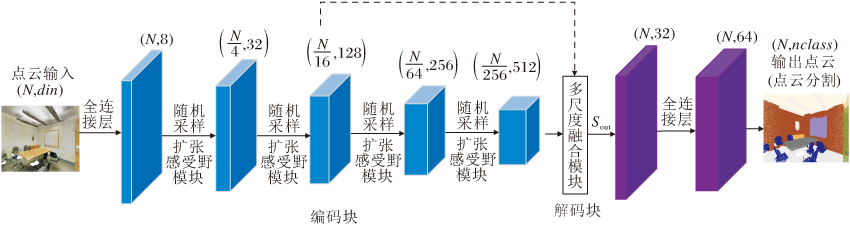 | 图7 CFL-Net架构图Fig.7 Architecture of CFL-Net |
1)编码块.大小为N× din(N表示点数, din表示维度)的点云首先送入一个全连接层中, 用于转换通道维度.接下来编码层通过DRFB模块逐层提取局部上下文特征和全局上下文特征, 编码块分别具有32、128、256、512个输出通道, 输入点云的个数按照下降率为4的随机采样减少.
2)解码块.解码块主要通过MSFM模块进行操作, 本文没有使用像RandLA-Net一样跳跃连接的方式.在编码层将不同尺度的点云特征分别利用最近邻插值完成上采样, 还原到相同原始点云数目后再进行拼接融合, 送入分类器中进行打分, 利用softmax函数预测N× nclass(N表示点数, nclass表示类数量)语义标签.此外, 使用交叉熵损失训练网络, 学习率为0.01.
本节通过实验验证CFL-Net的先进性和有效性, 实验环境如下:Ubuntu18.04, CUDA为9.0, CUDNN为8.0.1.
本文选用S3DIS[25]、SemanticKITTI[26]数据集进行实验.
S3DIS数据集由6个大区域的272个房间组成, 采集方式是使用Matterport相机收集数据, 以数据为基础生成额外的RGB-D数据, 并对网格进行采样制作成点云.为了评估CFL-Net的语义分割性能, 在实验中使用标准的6倍交叉验证.网络设置的批尺寸大小为4, 由于每个场景的点云数目各不相同, 对于不同的场景本文给予不同的点云输入, 输入点数大致为30 000~38 000, 使用学习率为0.01的Adam(Adaptive Moment Estimation)优化器, 每个场景(Area1-Area6)都经历100个迭代周期的训练.
SemanticKITTI数据集由43 552个密集注释的激光雷达扫描组成, 有22个序列.每次扫描都是一个带有105个点的大型点云.正式来说, 序列00~07和09~10(19 130次扫描)用于训练, 序列08(4 071次扫描)用于验证, 序列11~21(20 351次扫描)用于在线测试.原始三维点只有三维坐标, 无颜色信息.
本文采用总体精确度(Overall Accuracy, OA)、平均类别准确度(Mean Accuracy, mAcc)和类别平均交并比(Mean Intersection over Union, mIoU)作为评价指标.假设实验中的类别一共有k类, 定义pii表示类别i的预测标签等于真实标签的个数, pij表示类别i的预测标签为j的个数, 那么mIoU指标可以表示为
mIoU=
mAcc可以表示为
mAcc=
OA可以表示为
OA=
为了验证CFL-Net的先进性和有效性, 选择如下对比网络:PointNet[5]、RandLA-Net[7]、KPConv[8]、SSP+SPG(Supervized SuperPoint+Superpoint Gra- phs)[11]、RSNet(Recurrent Slice Network)[27]、SPG (Superpoint Graph)[28]、PointCNN[29]、Point-Web[30]、ShellNet[31]、PointASNL[32]、SCF-Net[33]、 CBL(Contras- tive Boundary Learning)[34]、RangeNet++[35]、Polar- Net[36]、STPC(Spatial Transformer Point Convolu- tion)[37]、MPF(Multi-projection Fusion)[38].
在S3DIS数据集上使用6折交叉验证的方法.各网络对S3DIS数据集上13个类别物体的性能对比如表1所示, 各网络在S3DIS数据集上的指标值对比如表2所示, 表中黑体数字表示最优值.表1中mIoU表示每个类别在6折交叉验证得到的平均交并比, 表2中mIoU表示13个类别平均后得到的6折交叉验证结果.
| 表1 各网络在S3DIS数据集13个类别上的mIoU对比 Table 1 mIoU comparison of 13 categories of each network on S3DIS dataset % |
| 表2 各网络在S3DIS数据集上的指标值对比 Table 2 Index value comparison of different networks on S3DIS dataset |
由表1和表2可看出, CFL-Net的mIoU值在每个类别上并不都是最高的, 但是对于结构相似复杂和较小的物体(Sofa、Beam和Chair等), CFL-Net表现出较优性能, 这也表明CFL-Net的有效性.
为了验证CFL-Net的可靠性, 在S3DIS数据集内比较具有挑战性的场景5(Area5)上进行单独的对比实验, 各网络指标值对比如表3所示, 表中黑体数字表示最优值.
| 表3 各网络在S3DIS数据集内区域5上的指标值对比 Table 3 Index value comparison of Area 5 of each network on S3DIS dataset % |
由表3可看出, CLF-Net基本领先于其它对比网络, 即使在mIoU值上未超过CBL, 但是在mAcc值上远高于CBL.
由于SemanticKITTI数据集的场景和点云数量都多于S3DIS数据集, 分割类别种类也多, 原始点云还不包含颜色信息, 所以更加具有挑战性.本文在SemanticKITTI数据集上进行相应的分割测试, 各网络具体mIoU值对比如表4所示, 各类别的mIoU值对比如表5和表6所示, 表中黑体数字表示最优值.表4的mIoU表示各网络对19个类别的平均交并比, 表5和表6的mIoU表示19个类别平均后的交并比结果.
| 表4 各网络在SemanticKITTI数据集上的mIoU值对比 Table 4 mIoU comparison of different networks on SemanticKITTI dataset |
| 表5 各网络在SemanticKITTI数据集9个类别上的mIoU值对比 Table 5 mIoU comparison of 9 categories of each network on SemanticKITTI dataset % |
| 表6 各网络在SemanticKITTI数据集另10个类别上的mIoU值对比 Table 6 mIoU comparison of other 10 categories of each network on SemanticKITTI dataset % |
由表4可知, CFL-Net性能较优, 由此说明CFL-Net的有效性.
对于一些复杂较小的物体, CFL-Net表现出较优性能, 这主要得益于CFL-Net局部编码器精炼位置信息和角度信息, 并且对特征进行增强, 对于局部特征提取的鲁棒性较优.
对于一些较稀疏和庞大的物体, 分割性能一般, 主要是由于在全局特征和局部特征关联上提取不充足.虽然CFL-Net的最优表现较少, 但是大多数接近于较优.
实验对比说明, CFL-Net的实验结果优于一些先进的网络, 这也间接验证CFL-Net设计的有效性.
针对模型参数计算量大小问题, 本文选择Point-Net、KPConv、RandLA-Net、SCF-Net、CBL作为对比网络.
各网络参数量和mIoU直观对比如图8所示, 通过对比图也可以看出, CFL-Net在复杂度和精度上基本都是最优的.
 | 图8 不同网络参数精度直观对比图Fig.8 Visual comparison of different network parameter accuracies |
各网络在S3DIS、SemanticKITTI数据集上的复杂性分析如表7和表8所示, 表中黑体数字表示最优值.
| 表7 各网络在S3DIS数据集上的语义复杂性分析 Table 7 Semantic complexity analysis of different networks on S3DIS dataset |
| 表8 各网络在SemanticKITTI数据集上的语义复杂性分析 Table 8 Semantic complexity analysis of different networks on SemanticKITTI dataset |
CFL-Net参数计算量虽然略高于RandLA-Net, 但是相比RandLA-Net, mIoU值在S3DIS数据集上提高3.2%, 在SemanticKITTI数据集上提高1.8%, 而且CFL-Net的计算量小于SCF-Net, 因此效果也更优.
为了验证CFL-Net每个模块设计的必要性及有效性, 本文针对每个模块在S3DIS数据集的Area5上进行单独的训练和测试, 具体消融实验如下.
为了验证加入水平方向角和垂直方向角的有效性, 在位置编码特征信息中选取不同的组合, 具体如下表示.
1)组合1.
2)组合2.
3)组合3.
4)组合4(CFL-Net).
5)组合5.
6)组合6.
各组合在S3DIS数据集上的mIoU值对比如表9所示, 表中黑体数字表示最优值.由表可见, 添加方向角比一些网络使用相对直角坐标位置更有效.
| 表9 不同编码组合对算法的影响 Table 9 Effect of different coding combinations on algorithm % |
RandLA-Net只将编码的局部位置信息和邻域点特征拼接组成局部特征编码模块, CFL-Net利用注意力机制对特征进行加权学习.RandLA-Net和CFL-Net在S3DIS数据集上的mIoU值对比如表10所示.由表可见, 注意力机制可提升网络的有效性.
很多网络在聚合特征模块使用自注意力池化, 而CFL-Net使用最大池化和平均池化组合的方式.各种池化方式的mIoU值对比如表11所示, 表中黑体数字表示最优值.由表可见, 最大池化+平均池化会降低网络的计算量.如果将两种池化单独使用会导致很多信息丢失, 效果不佳.删除平均池化, 网络的mIoU值下降约4%, 删除最大池化, 网络的mIoU值下降约3%, 都大幅降低算法效果.使用平均池化的方法在理论上也聚合局部特征, 提取模块学习的特征, 但是从宏观上看, 没有最大池化概括总体特征, 也会导致分割精度不高.
搜索邻域点常使用搜索方式是邻域搜索(KNN)和球查询(Ball Query).球查询不用针对每个点, 利用欧氏距离搜索的方式进行搜索, 而是划定一个球域且选择其内的点, 在计算量方面略小于KNN搜索.为了保证网络获取点云的均匀性和一致性, 本文采取的方式为KNN搜索.针对K值的选择, 在S3DIS、Seman-ticKITTI数据集上进行对比实验, 具体mIoU值如表12所示, 表中黑体数字表示最优值.由表可见, K=16时CFL-Net性能最优.
点云语义分割过程中遇到相似或者紧密连接的物体, 可能会误判为同种类别.针对此问题, 分别使用下采样和多尺度融合, 具体mIoU值如表13所示.
由表13可看出, 将编码层和解码层同尺度的点云特征信息进行连接, 可提升分割效果.但由于分割过程中点云下采样的跨步较大, 一次随机采样会导致丢失很多点, 故利用多尺度还原特征进行尺度拼接可有效解决大量信息丢失的问题.
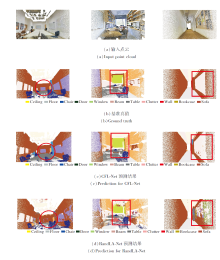
S3DIS数据集覆盖超过6 000 m2, 包含约70 000个RGB图像, 以及相应的深度、表面法线、语义注释等信息, 但其室内空间狭小、形状类似以及环境摆放杂乱程度都会影响语义分割精度, 因此具有挑战性.本文针对比较典型的场景房间进行可视化测试.
CFL-Net在具有挑战性的Area5上的俯瞰语义分割结果如图9所示.由图可看出, CFL-Net在几十个房间的语义分割结果还是较为接近基准真值, 侧面说明CFL-Net的有效性.
 | 图9 S3DIS数据集Area5场景上的俯瞰可视化语义分割结果Fig.9 Visual semantic segmentation results of Area5 scene on S3DIS dataset |
CFL-Net和RandLA-Net在S3DIS数据集上的定性结果如图10所示.由图中红色标注的部分可看出, CFL-Net在语义分割上更优.
 | 图10 S3DIS数据集上典型房间的可视化语义分割结果Fig.10 Visual semantic segmentation results of typical room on S3DIS dataset |
SemanticKITTI数据集是由德国波恩大学开发的基于汽车Lidar大型户外数据集, 使用先进的光探测和测距传感器, 不受照明影响距离的精确测量.由于数据集上点数稠密、类别丰富、几何信息更精确, 因此具有挑战性.
本文经过测试后对其点云帧序列进行可视化, 语义分割可视化结果如图11所示.
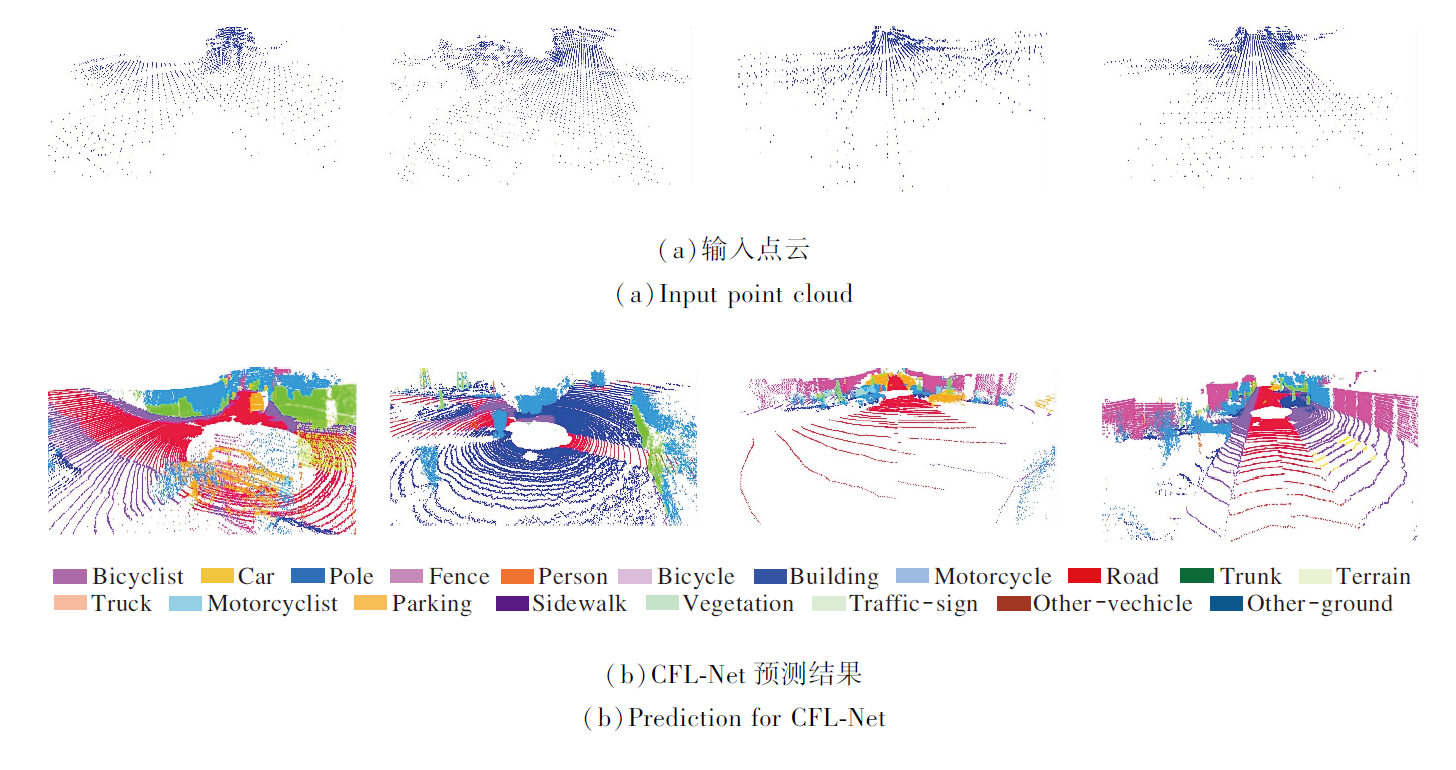 | 图11 CFL-Net在SemanticKITTI数据集上的可视化语义分割结果Fig.11 Visual semantic segmentation results of CFL-Net on SemanticKITTI dataset |
本文主要关注于学习有效局部特征信息, 用于保持大场景点云语义分割的空间结构, 由此提出基于编码特征学习的3D点云语义分割网络(CFL-Net).具体来说, 设计一个学习点云空间结构编码器(LFE)和高效的聚合点云特征模块(MPP), 针对不同尺度点云同步学习, 设计扩张感受野模块(DRFB)和多尺度融合模块(MSFM).在2个公共基准数据集S3DIS和SemanticKITTI上, CFL-Net取得出色表现.本文还通过消融实验分析每个模块的有效性.CFL-Net缺点在于学习邻域特征时着重关注局部特征, 忽略全局特征的依赖性.因此, 今后可进一步探索高效的网络, 提取局部和全局之间的相互关系, 高效应用于大场景点云语义分割.
本文责任编委 兰旭光
Recommended by Associate Editor LAN Xuguang
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|