























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于深度学习的RGB-T目标跟踪技术综述
[张天路1  , 张强
, 张强1 ]
, 张强]
|
|



作者简介:

张天路,博士研究生,主要研究方向为深度学习、目标跟踪.E-mail:tianluzhang@stu.xidian.edu.cn.
RGB-热红外(RGB-Thermal, RGB-T)模态目标跟踪旨在利用RGB和热红外数据的互补性实现目标的稳健跟踪.目前基于深度学习的RGB-T目标跟踪前沿成果较多,但缺少系统且全面的综述性文献.因此,文中首先阐述RGB-T目标跟踪面临的挑战,分析总结目前主流的基于深度学习的RGB-T目标跟踪算法.具体来说,根据采用的基线(Baseline)方法不同,将已有方法划分为基于多域网络(Multi-domain Network, MDNet)的目标跟踪算法,基于孪生网络(Siamese Network)的目标跟踪算法和基于判别式相关滤波(Discriminative Correlation Filter, DCF)的目标跟踪算法.然后,介绍RGB-T目标跟踪任务中常用的数据集和评价指标,并在常用数据集上对比已有算法.最后,指出RGB-T目标跟踪领域未来可能的发展方向.
About Author:
ZHANG Tianlu, Ph.D. candidate. His research interests include deep learning and object tracking.
RGB-Thermal(RGB-T) object tracking aims to achieve robust object tracking by utilizing the complementarity of RGB information and thermal infrared data. Currently, there are many cutting-edge achievements in RGB-T object tracking based on deep learning, but there is a lack of systematic and comprehensive review literature. In this paper, the challenges faced by RGB-T object tracking are elaborated, and the current mainstream RGB-T object tracking algorithms based on deep learning are analyzed and summarized. Specifically, the existing RGB-T trackers are divided into object tracking methods based on multi-domain network(MDNet), object tracking methods based on Siamese network and object tracking methods based on discriminative correlation filter(DCF) according to their different baselines. Then, the commonly used datasets and evaluation metrics in RGB-T object tracking tasks are introduced and the existing algorithms are compared on the commonly used datasets. Finally, the possible future development directions are pointed out.
目标跟踪要求已知第一帧目标的位置后, 在视频序列中确定该目标的位置[1], 这是计算机视觉研究领域中一个重要且基础性的研究课题, 具有广泛的应用前景.
近年来, 基于RGB图像的目标跟踪研究已经取得许多突破, 出现大量基于不同理论框架的跟踪算法, 这些算法在运行速度和精度两个方面都显著提升目标跟踪的性能.但是, 现阶段的RGB目标跟踪技术仍然面临许多挑战性问题, 尤其是在各种复杂的环境条件(如低光照、恶劣天气、烟雾、部分遮挡等)下, RGB图像的成像质量受到显著影响, 使仅依靠RGB图像的跟踪算法性能下降, 甚至失效, 极大限制了目标跟踪技术的应用范围[2].
随着传感器技术的发展和制造成本的降低, 各种类型的传感器在军事领域和民用领域都得到广泛的应用.近年来, 随着热红外传感器的普及, RGB-热红外(RGB-Thermal, RGB-T)目标跟踪技术在计算机视觉领域受到越来越多的关注.RGB图像可以捕获丰富的颜色、细节和纹理等信息, 但容易受到环境影响, 这导致基于RGB图像的目标跟踪算法受光照变化、雨雪雾等恶劣天气的影响较大, 难以满足复杂场景下的应用需求.中段波长(3 μ m~8 μ m波段)和长段波长(8 μ m~15 μ m波段)的热红外图像(Thermal Infrared, TIR)利用目标自身发射的热辐射成像, 对光照变化不敏感, 具有较强的穿透雾霾的能力, 在光照昏暗和恶劣天气等条件下也具有较好的成像效果.本文的TIR图像特指波长为3 μ m~15 μ m波段的TIR, 已有的RGB-T目标跟踪算法及数据集也通常针对此波段范围的热红外图像展开研究.
虽然TIR图像能够体现物体的温度信息, 但是通常会缺失物体的边缘、纹理和几何等细节信息, 因此当形态相似且温度相近的物体的运动轨迹发生交叉, 会产生热交叉现象[3], 导致跟踪失败.
在RGB目标跟踪的基础上, RGB-T目标跟踪进一步研究如何恰当合理地使用RGB图像和TIR图像, 克服一些环境条件对单模态目标跟踪的影响.例如, 在光照昏暗、恶劣天气等情况下, 针对RGB图像常无法有效区分目标和背景, 但只要目标和周围环境存在温差, TIR图像就能够区分目标和背景, 从而进行鲁棒的目标跟踪.当目标和温度相似的物体发生热交叉无法区分目标时, RGB图像能够提供目标的细节信息, 进而实现鲁棒的目标跟踪.RGB-T目标跟踪更关注于挖掘两种模态图像的互补信息, 提高跟踪的准确性和鲁棒性.
早期的RGB-T目标跟踪算法利用人工设计视觉特征, 利用匹配或分类算法进行快速有效的目标跟踪.由于在抑制噪声、减少误差方面表现较优, 稀疏表示[4]被用于RGB-T目标跟踪研究中, 并且取得较好的效果, 但稀疏表示模型计算复杂度较高, 难以实时处理.随着相关滤波理论在单模态跟踪中取得较鲁棒的效果, Zhai等[5]在RGB-T目标跟踪中引入跨模态相关滤波器, 有效进行RGB和红外模态的融合.为了改善RGB-T目标跟踪中的模型漂移现象, 研究者在RGB-T目标跟踪中引入图理论, 自适应地使用RGB图像和TIR图像信息学习模态权重[6, 7].
然而, 上述算法使用手工设计的特征, 不能较好地适应具有挑战性的环境, 如剧烈的外观变化、复杂背景、目标快速移动和遮挡等.受深度学习在各类计算机视觉任务的成功应用的启发, 一些RGB-T跟踪器尝试使用深度学习技术改善跟踪性能.Li等[8]首次将卷积神经网络(Convolutional Neural Network, CNN)应用于RGB-T目标跟踪, 提出基于双流网络(Two-Stream Network)和多模态特征自适应融合的RGB-T目标跟踪算法.此后, 基于深度学习的RGB-T目标跟踪逐渐成为一个研究热点, 学者们陆续提出许多不同类型的深度学习算法[9, 10, 11, 12, 13, 14].
目前, 学者们已对部分2018年~2020年间基于深度学习的RGB-T目标跟踪算法进行整理和综述.丁正彤等[15]从融合方式角度对基于手工特征的RGB-T目标跟踪算法和早期基于深度学习的RGB-T目标跟踪算法进行简略介绍.Zhang等[16]从早期融合、中期融合和晚期融合三类融合方式的角度对RGB-T单目标跟踪算法进行归纳总结, 但缺少对最新算法的系统介绍.
因此, 本文对2018年~2022年间基于深度学习的RGB-T目标跟踪算法进行系统描述.与之前的综述不同, 考虑到大多数RGB-T目标跟踪算法是在已有的RGB目标跟踪框架上设计的, 本文根据采用的基线(Baseline)方法不同, 将已有方法划分为基于多域网络(Multi-domain Network, MDNet)的目标跟踪算法, 基于孪生网络(Siamese Network)的目标跟踪算法和基于判别式相关滤波器(Discriminative Correlation Filter, DCF)的目标跟踪算法.2022年之前, 基于MDNet的目标跟踪算法是RGB-T目标跟踪领域的主流, 本文进一步将基于MDNet的RGB-T目标跟踪算法细化分类为基于多模态特征融合的目标跟踪算法、基于多模特征表示的目标跟踪算法、基于多模态特征表示-融合联合的目标跟踪算法和基于属性驱动的目标跟踪算法, 并对各算法的网络结构特点进行总结.
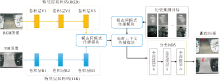
对于RGB-T目标跟踪任务, 主要面临的挑战可分为两类.一类是目标跟踪任务固有的挑战, 包括形状变化、遮挡、尺度变化、背景干扰以及目标移动等情形, 部分挑战如图1所示.上述情况往往导致视频序列中跟踪目标依赖的特征, 如外观、形状或背景等信息, 随时间变化存在较大的不一致性, 使跟踪器在后续视频帧中无法准确识别和跟踪目标.
 | 图1 目标跟踪任务中的通用挑战Fig.1 General challenges in object tracking |
1)形状及尺度变化.在跟踪过程中, 非刚性运动目标(如运动场上的运动员)本身会发生形变.此外, 目标在运动过程中也可能发生较大的尺度变化.
目标的形状及尺度变化会使不同帧之间的目标存在较大的外观差异, 从而导致在跟踪过程中发生漂移[17].在这种场景下, RGB图像和TIR图像的作用通常取决于不同模态图像的成像质量.
2)遮挡.目标在跟踪过程中可能被场景中的物体部分遮挡或者完全遮挡.在发生部分遮挡时, 图像中目标仅有部分区域可视, 跟踪器容易将遮挡物或者背景视为目标的一部分, 从而导致跟踪失败.在发生长时间的完全遮挡时, 往往会造成跟踪器无法有效更新, 从而在目标重新出现时跟踪失败[18].当烟雾造成目标不可见时, 红外图像往往能够提供有效的定位信息用于跟踪.
3)背景杂乱.背景杂乱是指在跟踪的目标周围存在对目标跟踪造成干扰的相似语义目标或背景区域, 需要防止跟踪器无法准确地区分目标和外观相似干扰物体.当存在与目标外观相似的背景区域干扰, 且目标与背景区域温度特性存在较大差异时, TIR图像更有利于定位目标.当存在与目标语义相似的干扰物时, RGB图像由于能够提供丰富的颜色和纹理信息, 更有利于区分语义信息相似的目标和干扰物.
4)目标移动.目标跟踪研究的对象主体往往是运动的目标, 目标移动对目标跟踪造成的困难主要包括目标快速运动和目标运动模糊等情形. 由于目标跟踪通常采取在目标前一帧所处位置周围区域进行搜索的策略, 因此目标快速运动可能造成目标前后帧位置差异较大, 甚至超出搜索区域.另一方面, 目标移动本身造成的运动模糊也会造成目标前景虚化, 从而影响目标特征表达.同样地, 相机移动甚至会造成整幅图像的模糊, 也是影响目标跟踪效果的挑战之一.RGB图像和TIR图像都存在由于运动模糊造成成像质量降低的问题.除了上述目标跟踪任务固有的通用挑战因素以外, 由于RGB-T数据的引入, 还存在另一类联合利用RGB-T图像时面临的特有挑战, 包括热交叉、低光照、极端光照、空间不对齐
等, 部分挑战如图2所示.上述情况往往导致RGB-T数据内某一模态数据或某一区域数据不可靠或存在大量干扰信息, 使跟踪器在跟踪过程中受到干扰而无法准确跟踪.
 | 图2 RGB-T目标跟踪任务中的特有挑战Fig.2 Specific challenges in RGB-T object tracking |
1)热交叉.热交叉是指目标与背景的温度或形态接近时, TIR图像内目标与背景难以区分, 当目标与背景轨迹交叉时, 无法准确定位目标位置.
2)低光照和极端光照.低光照和极端光照现象都是RGB图像受光照条件的影响, 无法在夜晚或强光环境下捕获有效的目标信息, 造成成像质量差或目标不可见.
3)空间不对齐.由于RGB-T数据通常由两个不同的成像平台采集, 因此成像范围及角度有所差异, 已有RGB-T目标跟踪数据集预处理的第一步就是对多模态图像进行空间配准.但多模态图像的空间不对齐问题在已有的公开数据集上广泛存在, 容易影响多模态特征之间的有效交互, 并干扰目标定位.
在实际的跟踪场景中, 固有挑战和特有挑战通常同时出现.RGB图像与TIR图像对这些通用挑战的影响常取决于跟踪场景的特有挑战属性.
为了实现准确鲁棒的RGB-T目标跟踪, 算法在设计过程中不仅需要考虑如何应对目标跟踪任务中的通用挑战, 还需要考虑如何充分利用RGB-T数据的互补信息以应对RGB-T目标跟踪任务中的特有挑战.
相比传统的RGB-T目标跟踪算法, 基于深度学习的RGB-T目标跟踪算法获益于CNN的特征提取和表示能力, 获得比传统算法更优的跟踪结果, 吸引计算机视觉领域研究人员的广泛关注.虽然目前基于深度学习的RGB-T目标跟踪算法发展只有数年, 但已出现大量具有影响力的工作, 跟踪性能也得到大幅提升.
本文对近年来基于深度学习的RGB-T目标跟踪算法的发展历程进行总结, 通过时间线的方式绘制一些具有影响力的工作, 如图3所示.
 | 图3 基于深度学习的RGB-T目标跟踪算法发展历程Fig.3 Development of RGB-T object tracking algorithms based on deep learning |
基于深度学习的RGB-T跟踪器通常是在RGB跟踪器的基础上设计的.因此, 根据基线跟踪方法的不同, 基于深度学习的RGB-T目标跟踪算法可以分为3类:基于多域网络的目标跟踪算法, 基于孪生网络的目标跟踪算法和基于判别式相关滤波的目标跟踪算法.从算法优化角度将基于MDNet的RGB-T目标跟踪算法进一步细化分类为:基于多模态特征融合的目标跟踪算法、基于多模态特征表示的目标跟踪算法、基于多模态特征表示-融合联合的目标跟踪算法和基于属性驱动的目标跟踪算法.
MDNet[19]是一种早期的完全基于CNN的目标跟踪算法, 也是VOT-2015挑战赛的冠军算法.MDNet通过分类的方式确定目标位置, 并使用在线更新的策略训练分类网络和回归网络, 采取的在线学习策略对训练数据集规模要求较低.2022年前, RGB-T目标跟踪数据集规模较小, 缺乏大规模训练数据, 因此, 在2018年~2021年期间大部分RGB-T目标跟踪算法选择MDNet作为其基线跟踪算法.
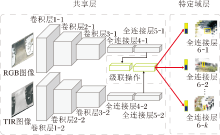
MDNet具体结构如图4所示.MDNet包含共享层(Shared Layers)和特定域层(Domain-Specific La- yers), 这里的域对应训练集上不同的视频序列.在共享层, MDNet在每个域上迭代训练, 获取通用的目标表示.在测试序列上, MDNet固定预训练共享层, 并在线训练特定域层, 获取特定视频序列的目标表示.根据目标上一帧位置随机选取区域候选框, 利用二分类网络判定候选区域是否为目标, 实现目标跟踪任务.此外, MDNet还使用第一帧图像训练回归网络, 对候选框进行回归.
MDNet虽然在当时取得较优的跟踪效果, 然而在GPU上仅有约1帧/秒的运行速度, 无法满足实时运行的需求.这是由于MDNet在跟踪过程中首先生成区域候选框, 再在每帧图像上进行裁剪, 并将多个裁剪后的图像送入特征提取网络, 获取候选区域特征.为此, 受Faster RCNN[20]中使用ROI Align的启发, Jung等[21]提出RT-MDNet(Real-Time MDNet), 在MDNet的基础上, 使用ROI Align操作, 加速候选区域的特征提取过程, 并加入多任务损失函数, 获取更优的目标建模方式.RT-MDNet的运行速度是MDNet的25倍, 但两者却有相似的跟踪精度.
MDNet和RT-MDNet都在RGB-T目标跟踪领域中得到广泛使用, 并在其基础上从多模态特征融合、多模态特征表示等角度进一步优化RGB-T目标跟踪算法的性能.
2.1.1 基于多模态特征融合的方法
一些基于MDNet的RGB-T目标跟踪算法[22, 23, 24]关注于通过多模态特征融合挖掘不同模态特征间的互补信息.这类方法由早期的级联融合、相加融合等操作不断向更有效、更复杂的融合方式发展.
Zhang等[9]将MDNet应用于RGB-T目标跟踪任务, 引入多模态数据, 提高跟踪的鲁棒性, 具体算法结构如图5所示.算法首先使用一个双流网络, 分别提取RGB图像特征和TIR图像特征, 再将两种模态特征以级联的方式融合, 输入特定域层和回归网络, 获得最终的跟踪结果, 在当时取得优于传统RGB-T目标跟踪算法的结果.
为了充分挖掘不同模态图像和层级特征包含的互补信息, Zhu等[10]提出DAPNet(Dense Feature Aggregation and Pruning Network), 具体结构如图6所示.首先, 设计密集聚合模块, 获得两种模态图像的鲁棒特征表示.然后, 设计特征剪枝模块, 选择不同模态特征, 减少冗余特征和干扰信息的影响.在特征剪枝模块中, 首先使用全局平均池化(Global Average Pooling, GAP)操作, 获得每个特征通道的激活状态, 再使用WRS(Weighted Random Samp-ling)[25]进行通道选择.剪枝特征同样被分别用于分类任务和回归任务.
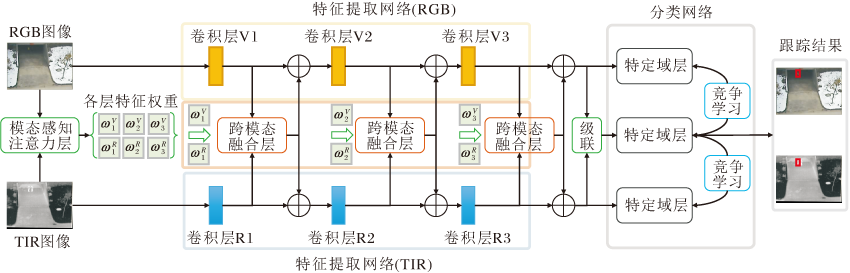
Zhang等[23]基于注意力机制和竞争学习策略, 提出MaCNet(RGB-T Object Tracking Algorithm Based on a Modal-Aware Attention Network and Competitive Learning).不同于上述算法采用双流网络提取多模态特征, MaCNet为三分支结构, 具体如图7所示.首先, 使用双流网络分别提取RGB图像特征和TIR图像特征.然后, 使用模态感知注意力层, 生成不同层级内不同模态特征的权重, 在跨模态特征融合层内采用加权融合的方式获得融合特征, 并将融合特征逐层加入RGB特征提取分支和TIR特征提取分支.最终, 级联双流网络的输出特征用于分类和回归任务.
模态感知注意力层由一层平均池化层、两层全连接层和一层ReLU层组成, 输入级联的多模态图像后预测得到所有特征层的模态权重.此外, 分类网络使用3个并行分类层, 分别用于RGB特征分支、TIR特征分支和融合特征分支, 并通过构建竞争学习损失函数, 引导网络向多模态合作互补的方向优化.具体地, 首先使用交叉熵损失函数分别计算3个分支的损失函数LFUS、LRGB和LTIR, 再融合分支增加惩罚项的损失函数:
LF=LFUS+max(LFUS-LRGB, LFUS-LTIR).
同时, RGB特征分支和TIR特征分支也使用融合分支作为竞争者, RGB分支损失函数或红外分支损失函数为:
其中M∈ (RGB, TIR).通过竞争学习的策略, 网络在训练中向充分利用多模态图像互补信息的方向上优化.Mei等[26]指出两种模态图像特征的充分交互能够进一步挖掘多模态数据内的互补信息, 进而提升跟踪的鲁棒性, 为此提出HDINet(Hierarchical Dual-Sensor Interaction Network), 在不同层级内使用互注意力机制, 将一种模态内的关联特征补充到另一种模态特征内, 实现不同模态特征的信息交互.
上述RGB-T目标跟踪算法采用离线训练的静态卷积操作, 不能以动态滤波的方式处理测试数据, Wang等[27]指出这可能导致次优的跟踪结果.因此, 文献[27]提出MFGNet(Dynamic Modality-Aware Filter Generation Network), 使用在线训练方式预测每个输入数据的特定卷积核, 促进不同模态之间的交流.首先, 使用一个单流网络, 获取每个模态图像的单模态特征.再级联RGB特征和TIR特征, 送入两个独立的模态感知滤波器生成网络, 预测模态特有的卷积核.然后, 进行动态卷积运算, 得到模态特有特征.最后, 两种模态特有特征以级联的方式融合, 获取最终的多模态融合特征, 用于分类和回归任务.
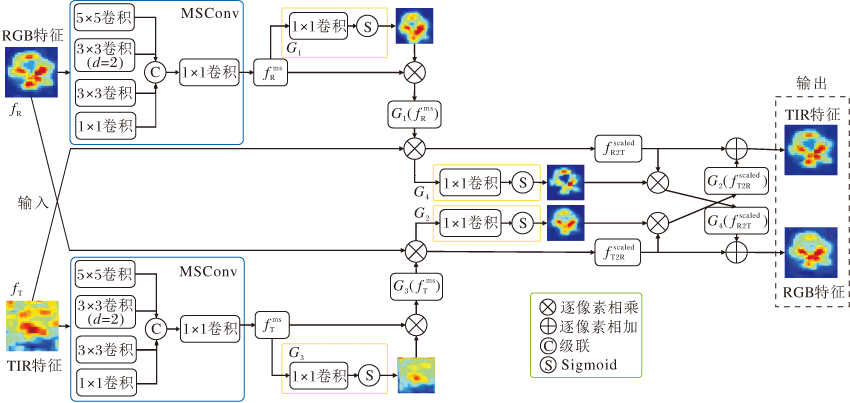
在RGB数据和TIR数据中都包含部分低质量信息, 而这些低质量信息中不仅包含大量的噪声信息, 而且还包含一些具有鉴别力的特征.然而, 低质量信息的潜力并没有在上述算法中得到较好的探索.为了解决该问题, 在MANet(Multi-adapter Con-volutional Network)[28]的基础上, Lu等[24]提出DMC- Net(Duality-Gated Mutual Condition Network), 充分利用所有模态内的鉴别信息, 同时抑制干扰噪声的影响.
DMCNet在融合过程中, 以一个模态特征的目标信息作为参考, 指导另一个模态特征的学习.DMCNet模块包括RGB特征到TIR特征调制和TIR特征到RGB特征调制两个方向, 具体结构如图8所示.
以RGB特征fR到TIR特征fT调制为例, 首先, 考虑到尺度和位移条件的多样性, 设计采用不同卷积核大小的MSConv层, 生成多尺度特征, 得到RGB模态的多尺度条件
G=σ (Conv(f)),
其中, f表示输入特征, σ (· )表示Sigmoid激活函数, Conv(· )表示1× 1卷积层.
RGB特征到TIR特征调制可以表示为
其中, ☉表示逐像素相乘操作, G1和G2表示两个抑制多尺度条件噪声和融合特征的门控模块,
在TIR特征到RGB特征调制中生成.
此外, DMCNet还根据帧间的光流判断是否出现摄像机位移, 从而设置重采样策略, 提高跟踪的鲁棒性.多模态图像内的全局上下文关系在区分目标与干扰物时具有重要作用.为了挖掘多模态数据内的全局上下文关系, Mei等[29]提出AGMINet(Asy-mmetric Global-Local Mutual Integration Network), 在多模态特征融合阶段, 设计全局-局部交互模块, 用于挖掘多模态数据之间的全局上下文关系, 并聚合全局关联信息与局部特征.
与AGMINet相似, Mei等[30]提出DRGCNet(Differential Reinforcement and Global Collabo-ration Network), 旨在同时挖掘模态内和模态间的全局上下文关系, 并使用自适应权重融合模态内和模态间的上下文信息.
2.1.2 基于多模态特征表示的方法
一些基于MDNet的RGB-T目标跟踪算法关注点在特征提取阶段, 重点提高不同模态图像的特征表征能力, 从而提升跟踪性能[28, 31, 32].
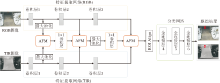
Li等[28]指出, 大部分工作主要通过引入模态权值以实现自适应多模态特征融合.虽然这些方法可以有效利用模态特性, 但忽略模态共享线索和实例感知信息的潜在价值.事实上, RGB模态和TIR模态包含大量共有信息, 包括目标边界和部分细粒度纹理.同时, 也存在一些模态特有信息, 如TIR图像的热辐射信息和RGB图像的颜色信息.为此, Li等[28]提出MANet, 用于RGB-T目标跟踪.MANet包含3种适配器:通用适配器(Generality Adapter, GA)、模态适配器(Modality Adapter, MA)、实例适配器(Instance Adapter, IA).MANet结构如图9所示.
MANet使用VGG-M[33]构建单流网络, GA分别提取RGB模态和TIR模态的共有信息, 网络共有3层, 卷积核大小分别为7× 7× 96、5× 5× 256、3× 3× 512.GA在有效性和效率之间进行良好协调.GA考虑到RGB图像和TIR图像存在的模态差异, MA设计与GA并行的双流网络, 提取模态特有信息.MA使用相对GA卷积核更小的卷积层提取特征, 卷积核大小分别为3× 3× 96、1× 1× 256、1× 1× 512.IA使用MDNet[19]的特定域层建模某个对象的外观属性.
在MANet的基础上, LU等[31]提出MANet++.首先, 设计HD loss(Hierarchical Divergence Loss), 提高GA和MA输出特征的差异, 从而更好地挖掘模态特有信息和模态共有信息.然后, 为了实现不同模态特征的质量感知融合, 在IA中设计动态融合模块, 预测模态权重.最后, 将基线跟踪算法由MDNet[19]替换为运行速度更快的RT-MDNet[21], 大幅提升运行速度.
Xu等[32]指出多层级深度特征在目标定位和分类中起着重要作用.如何有效地聚合来自不同层级的RGB特征和TIR特征是实现鲁棒目标跟踪的关键.然而, 大多数RGB-T目标跟踪算法仅使用特征提取网络最后一层的语义信息, 或使用简单的操作(如求和、级联)从每个模态聚合多层级深度特征, 从而限制多层级特征的有效性.
为此, Xu等[32]提出CBPNet(Quality-Aware Cross-Layer Bilinear Pooling Network), 用于RGB-T目标跟踪.首先, 使用通道注意力机制[34], 在实现分层特征融合之前, 对所有卷积层特征实现特征通道的自适应标定.然后, 通过交叉积对任意两层特征进行双线性池化操作.两层特征相互作用后的双线性特征表示为:
bAB=FA× FB,
其中, FA∈ RH× W× N和FB∈ RH× W× N表示2个经过通道注意力机制以及分辨率调整后的层级特征.
双线性特征矩阵bAB沿列池化的结果为:
ξ AB=
最终的融合特征由对ξ AB执行平方根操作和L2归一化操作得到.这是一种二阶计算, 可有效聚合目标的深层语义信息和浅层纹理信息.
Li等[35]同样研究如何更好地挖掘两种模态内的多层级特征, 提出MBAFNet(Multibranch Adap-tive Fusion Network).该网络在使用一个单流特征提取网络挖掘多模态共有信息的基础上, 设计两个并行的多层级适配器, 分别挖掘两种模态图像的多层级特征.具体地, 在每个多层级适配器内, 使用不同卷积核大小的卷积层获取多尺度特征, 并使用注意力机制聚合多尺度特征.
为了挖掘多尺度的模态共有信息和模态特有信息并抑制目标预测框漂移, Xia等[36]提出CIRNet(Cross-Modality Interaction and Re-identification Network).该网络由多尺度模态共有融合网络和模态互补网络构成, 分别挖掘多尺度模态共有信息和模态特有信息; 同时设计一个目标感知分支评估目标框质量, 从而抑制目标框漂移现象.
2.1.3 基于多模态特征表示-融合联合的方法
多个基于MDNet的RGB-T跟踪算法同时考虑多模态特征融合和特征表示问题[12, 13, 37], 在两个优化方向上同时进行改进以改善跟踪性能.
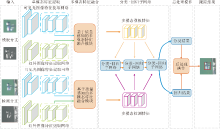
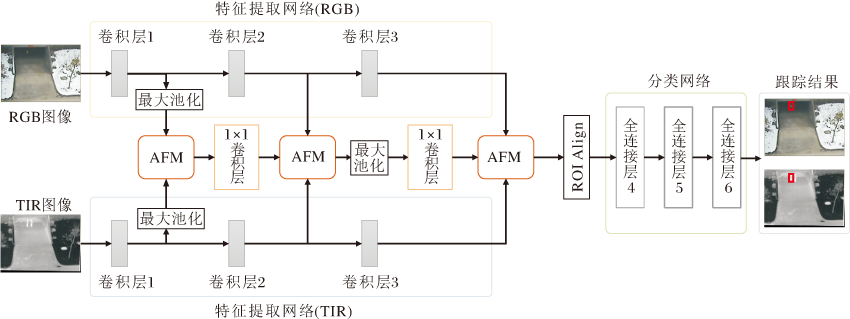
Gao等[13]提出DAFNet(Deep Adaptive Fusion Network), 递归自适应聚合不同层级和不同模态特征, 使用双流网络提取RGB特征和TIR特征, 并设计AFM(Adaptive Fusion Module), 用于每一层级的特征融合, 预测RGB特征、TIR特征和上一层级特征权重, 实现加权相加融合.DAFNet结构如图10所示, 能高效、自适应地聚合来自所有层的RGB特征和TIR特征.
在DAPNet[10]的基础上, Zhu等[37]设计TFNet(Trident Fusion Network), 保留DAPNet的密集聚合网络, 并加入三分支结构, 聚合融合特征、RGB特征及TIR特征.并且每个分支内都加入特征剪枝模块, 剪除冗余特征, 避免网络过拟合问题.
Zhu等[12]提出FANet(Quality-Aware Feature Aggregation Network), 指出挖掘多层级特征的重要性.FANet在每个模态中聚集多层级特征, 处理由低光照、变形、背景杂波和遮挡引发的外观显著变化的挑战.Zhu等[12]还设计自适应聚合子网络, 根据不同模态的可靠性聚合特征, 能够缓解低质量源引入的噪声影响.自适应聚合子网络使用全连接层和Softmax激活层生成不同模态和不同层级特征的权重, 实现特征融合.
2.1.4 基于属性驱动的方法
上述基于MDNet的RGB-T目标跟踪算法未考虑目标在不同场景属性下的外观变化, 可能会限制跟踪性能.在RGB跟踪领域, Qi等[38]设计基于属性表示的CNN模型, 用于目标跟踪.受此启发, 一些基于MDNet的RGB-T目标跟踪算法尝试利用数据集上不同场景的属性标注, 使跟踪器学习不同属性下的鲁棒特征表示.
Li等[39]提出CAT(Challenge-Aware RGBT Tra-cker), 是第一个考虑场景属性的RGB-T目标跟踪算法, 具体结构如图11所示.CAT将已有的RGB-T跟踪数据集上的场景属性划分为如下5类:光照变化(Illumination Variation, IV)、快速移动(Fast Motion, FM)、尺度变化(Scale Variation, SV)、遮挡(Occlusion, OCC)和热交叉(Thermal Crossover, TC).可以发现一些属性是模态无关的, 包括快速移动、尺度变化和遮挡, 而一些属性是模态相关的, 包括热交叉和光照变化.对于热交叉属性的场景, RGB数据较可靠, 而对于光照变化属性的场景, TIR数据较有效.
基于上述观察, 对于模态共有挑战, CAT使用相同的卷积分支提取目标的外观表征.对于模态特有挑战, 设计一个引导模块, 将一个模态具有辨别力的特征补充到另一个模块内, 同时避免噪声信息的传播.具体地, 在热交叉属性中, RGB特征使用门控引导变换层增强TIR模态的识别能力, 在光照变化属性中, TIR特征使用门控引导变换层增强RGB模态的识别能力.并使用自适应聚合层(Adaptive Aggregation Layer, AAL)聚合多种属性特征.
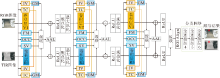
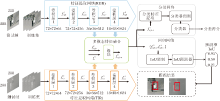
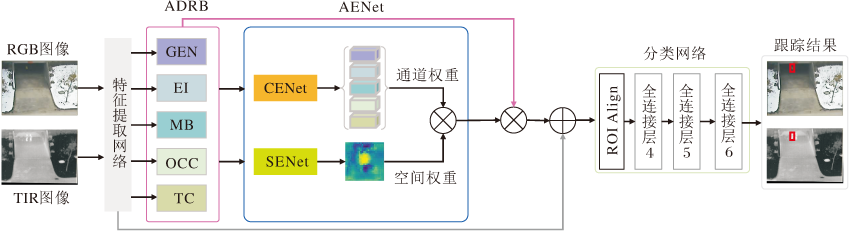
Zhang等[40]指出以往的工作主要是利用有限的属性建立属性特定模型, 无法覆盖所有的跟踪场景.CAT仅使用一个通用的分支处理属性不可知的跟踪场景, 算法实现较冗余, 远不能达到实时的运行速度, 为此Zhang等[40]提出ADRNet(Attribute-Dri-ven Representation Network), 具体结构如图12所示.
首先, 根据RGB-T跟踪场景中的外观变化, 将主要挑战和特殊挑战分为4个典型属性: 极端光照(Extreme Illumination, EI)、遮挡(OCC)、运动模糊(Motion Blur, MB)和热交叉(TC).再为每个属性设计一个ADRB(Attribute Driven Residual Branch), 挖掘属性特定的特征.然后, 利用AENet(Attribute Ensemble Network), 将这些特征表示在通道和像素级别上进行聚合, 适应属性不可知的跟踪过程.属性集成网络内包含一个CENet(Channel Ensemble Network), 预测不同属性特征的通道权重.同时包含一个SENet(Spatial Ensemble Network), 在空间维度上强调目标区域特征并抑制干扰区域响应.通道权重和空间权重将以逐元素相乘的方式生成3D权重, 用于多种属性特征的聚合.
Xiao等[41]通过场景属性分解融合过程, 提出APFNet(Attribute-Based Progressive Fusion Net-work), 以较少的参数提高融合有效性, 同时减少对大规模训练数据的依赖.
APFNet首先为每个属性设计融合分支, 学习属性特有的融合权重.具体地, 将所有跟踪场景归类为光照变化(IV)、快速移动(FM)、尺度变化(SV)、遮挡(OCC)和热交叉(TC)5种属性, 对每种属性特定的融合分支, 使用一个参数较少的模型实现融合, 减少对大规模训练数据的需要.然后, 设计聚合融合网络, 聚合每个属性分支的所有融合特征.最后, 设计基于Transformer的特征增强模块, 增强聚合特征和模态特有特征.
具体地, 使用3个Transformer块中的编码器分别对两种模态特有特征和聚合特征进行自注意力增强, 使用2个Transformer块中的解码器用于聚合特征和模态特有特征的交互增强.
2.1.5 其它方法
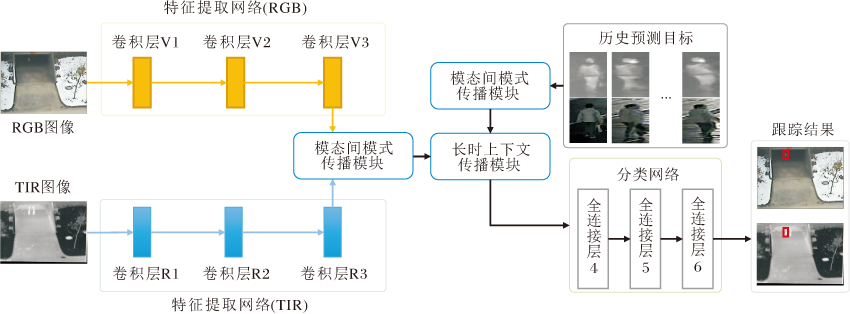
Wang等[42]发现两种模态图像之间的模式相关关系广泛存在, 并且由于视频序列的连续性, 相同的模式会在相邻帧中反复出现.基于上述观察, 设计CMPP(Cross-Modal Pattern-Propagation), 用于模态间和帧间的模式传播, 具体结构如图13所示.设计IMPP(Intermodal Pattern-Propagation)模块, 在两模态间相互传播相关模式, 减少不同模态特征的差异.具体地, 在每个模态内采用自注意力机制[43], 计算每个像素点与其它像素点的关联, 得到模态内亲和性矩阵.再将两模态的亲和性矩阵逐像素相乘, 获得模态间关系矩阵, 实现模态间的模式传播.考虑到目标跟踪任务中历史帧有利于目标定位, CMPP设计LTCP(Longterm Context Propagation), 自适应利用历史帧信息.
Tu等[44]指出, 在跟踪过程中对困难样本进行分类是一个很具有挑战性的问题.现有方法仅仅关注于区分正样本和负样本, 而忽略对困难样本的鲁棒分类.
为此, Tu等[44]提出M5L(Multi-modal Multi-margin Metric Learning Framework), 将所有样本分为普通正样本、普通负样本、困难负样本、困难正样本四类.并设计Multi-modal Multi-margin Structural Loss, 在训练阶段保留不同种类样本的关系, 利于不同种类样本之间的关系, 提高特征嵌入的鲁棒性.同时设计基于注意力机制的多模态特征融合模块, 生成模态权重, 用于加权融合多模态图像特征.
判别式相关滤波算法的原理是两个相关信号的响应大于不相关信号.在目标跟踪中, 滤波器只对感兴趣的目标产生高响应, 对背景产生低响应.所以目标跟踪任务可以近似地视为对搜索图像使用依据目标特征设计的滤波器进行相关滤波, 输出响应图的最大值位置就是目标位置.在近期工作中, 相关滤波算法的建模方式被广泛应用于基于深度学习的目标跟踪框架中.
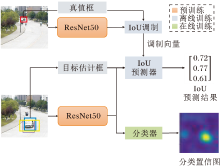
Bhat等[45]提出DiMP, 具体结构如图14所示.DiMP使用离线训练预测真实框与预测框之间的交并比(Intersection over Union, IoU)分数, 并在测试阶段通过梯度上升优化进行目标框确定.同时, 采用共轭梯度策略结合深度学习框架进行快速优化, 对分类器进行参数更新, 提高目标跟踪算法的判别力.
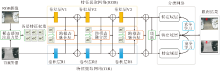
Zhang等[14]提出mfDiMP, 引入DiMP作为基线跟踪算法, 研究不同层次的融合机制, 寻找最优的融合方法, 包括早期融合、中期融合和晚期融合.早期融合将RGB图像和TIR图像沿通道方向进行级联, 再将级联的 RGB-T 图像输入特征提取网络中.中期融合分别对RGB图像和TIR图像进行特征提取, 再对RGB特征和TIR特征进行级联, 并将级联特征输入分类预测网络和回归预测网络中.晚期融合将使用结构相同但参数不同的特征提取网络、分类网络和回归网络分别处理RGB图像和TIR图像, 再对两个模态的响应图进行求和, 获得融合响应图确定目标位置.最终, mfDiMP采用中期融合的方式取得最优的跟踪效果.mfDiMP结构如图15所示.
此外, 针对缺乏大规模训练数据集用于离线训练的问题, mfDiMP使用pix2pix[46]在RGB目标跟踪数据集GOT10K[47]上生成合成的RGB-T数据集, 并用于模型训练.
Zhao等[48]提出CEDiMP(Channel Exchaning DiMP), 基于通道动态交换的融合方式, 增强多模态特征表示.具体来说, 利用批归一化(Batch Norma-lization, BN)[49]的尺度因子衡量每个对应通道的重要性.如果当前模态某一通道对应的比例因子接近于零, 则使用另一模态对应的通道值替换当前通道值.针对缺乏训练数据集的问题, 同样使用图像转换模型[46], 生成一个用于长时跟踪器训练的RGB-T数据集LaSOT-RGBT[50].借助于LaSOT-RGBT数据集, 提高跟踪器应对长时跟踪中典型挑战的能力和泛化能力.
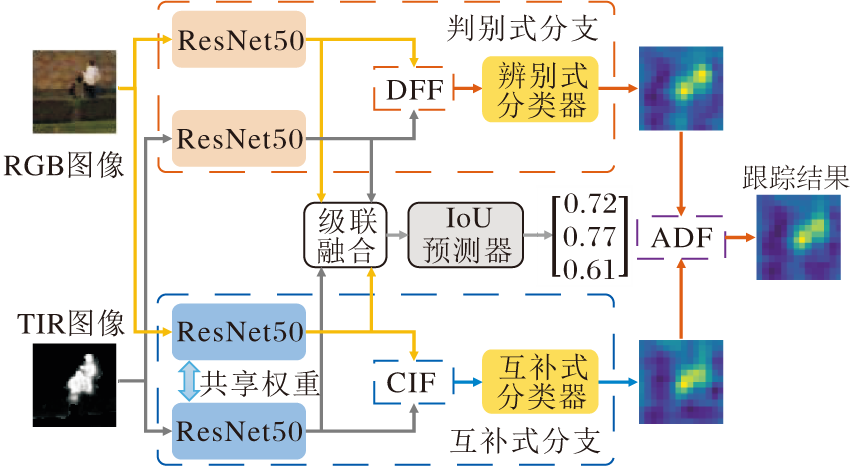
Zhang等[51]提出HMFT(Hierarchical Multi-modal Fusion Tracker), 以便同时挖掘中期融合和晚期融合的潜力.设计CIF(Complementary Image Fusion)模块, 学习两种模态内的共有模式.设计DFF(Discriminative Feature Fusion)模块, 融合多模态图像特征.设计ADF(Adaptive Decision Fu-sion)模块, 从互补分类器和判别式分类器中选择最终的分类结果.HMFT具体结构如图16所示.在CIF模块中, 使用单流网络提取RGB图像和TIR图像的共有特征, 并引入KL散度损失函数约束两种模态的特征分布.在DFF模块中, 使用双流特征网络挖掘RGB图像和TIR图像的特有特征, 预测不同模态特征的通道权重, 并进行加权融合, 获取互补信息.在ADF模块中, 根据两种响应得分的模态置信度进行响应图融合, 获取最终的分类结果.并且, 根据LTMU[52]跟踪框架, 建立长时跟踪版本HMFT_LT, 用于长时RGB-T目标跟踪.
尽管上述算法研究多种融合方式以挖掘多模态数据内的互补信息, 但都忽略多模态特征存在的模态差异, 直接使用RGB特征和TIR特征进行特征融合, 从而丢失多模态数据内部分有效信息.为此, Zhang等[53]提出MFNet, 设计MDC(Modality Diffe-rence Compensation Module)模块, 衡量RGB特征与TIR特征之间的差异信息, 并进行跨模态特征增强, 缩小RGB特征与TIR特征之间的模态差异.此外, 为了避免某一模态数据包含大量噪声信息时降低融合特征的表征能力, 还提出FRS(Feature Re-selection Module)模块, 对多模态融合特征和单模态特征进行自适应选择, 获取辩别力较高的特征, 用于后续跟踪任务.
大多数RGB-T目标跟踪算法主要利用目标的外观信息进行跟踪, 对目标的轨迹信息研究较少.Zhang等[54]指出, 目标的运动信息对于目标准确定位也非常重要, 特别是当目标外观信息不可靠(如目标被遮挡或摄像机移动导致运动模糊等跟踪场景)时, 仅根据目标外观特征难以定位目标, 而目标的运动信息可辅助推断目标位置.据此, Zhang等[54]设计JMMAC(Jointly Modeling Motion and Appea-rance Cues).JMMAC在ECO(Efficient Convolution Operators)[55]的基础上实现, 外观模型采用生成融合权重的晚期融合策略融合响应图, 该外观模型采用离线训练的方式直接用于跟踪, 无需在线微调参数.
目标运动预测网络采用卡尔曼滤波跟踪器, 根据目标运动信息预测目标在当前帧的位置.考虑到外观信息在大多数场景上更可靠, 设计转换模块, 判断采用外观模型还是运动模型.该模块主要根据外观模型的预测可靠性和可变形的DDIS(Deformable Diversity Similarity)[56]计算得到的相似度得分自适应切换使用外观线索和运动线索.在获取目标跟踪框后, 考虑到ECO采用的多尺度搜索策略回归精度有限, 使用YOLOv2[57], 在RGB图像上对目标包围框进行进一步细化回归.
自2016年孪生网络(Siamese Network)首次应用于目标跟踪任务之后[58], 基于孪生网络的目标跟踪算法迅速发展为目标跟踪任务中的主流算法之一.该算法将目标跟踪视为模板匹配任务, 通过寻找和第一帧模板最相似的候选区域进行目标定位.由于孪生跟踪算法的前景、背景判别能力是通过离线阶段大量数据训练得到的, 不需要模型的在线更新, 因此具有极为出色的跟踪效率.考虑到孪生网络在RGB目标跟踪上的成功应用, 一些工作[59, 60, 61, 62]尝试将孪生网络引入RGB-T目标跟踪中, 用于提升计算效率.
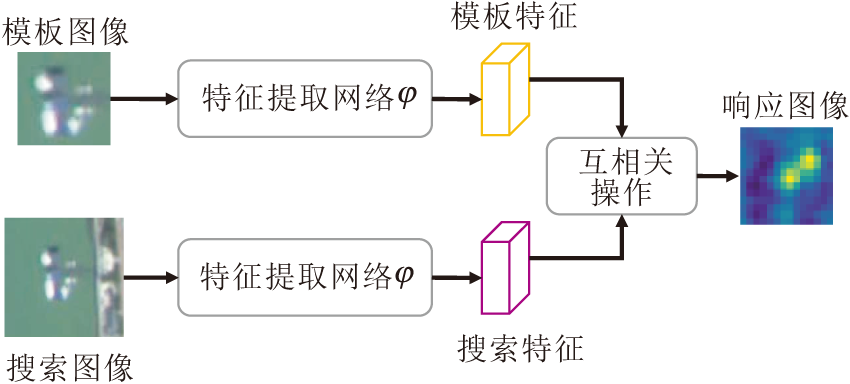
孪生网络定义为包含两个相同网络分支(参数共享)的神经网络结构, 通常用于度量两分支输入的相似性.Bertinetto等[58]提出SiamFC(Siamese Fully-Convolutional Network), 具体结构如图17所示.SiamFC上层分支z表示目标模板图像, 由视频序列第1帧给定的目标区域生成.下层分支的输入是当前帧搜索区域, x表示搜索区域内部不同的目标候选图像.z和x经过相同的特征映射操作φ 将原始图像映射到特征空间, 得到具有相同通道数的特征向量, 最后经过互相关操作得到响应图.其中, 各个位置的值表示不同目标候选图像与目标模板图像的相似度, 通过取最大值选择最相似目标候选区域, 完成目标定位跟踪.图17中特征映射操作φ 由卷积神经网络实现, 并且两个分支中φ 具有相同的网络结构, 因此称为孪生网络.而且在SiamFC中网络结构只包含卷积层和池化层, 因此也是一种典型的全卷积孪生网络(Fully-Convolutional Siamese Network).
Zhang等[63]提出SiamFT(RGB-Infrared Fusion Tracking Method Based on Fully Convolutional Sia- mese Networks), 使用两个并行的孪生网络分别提取RGB图像特征和红外图像特征, 并手工设计生成模态权重的方法, 用于多模态特征融合.具体地, RGB分支和TIR分支分别使用互相关操作, 得到RGB响应得分图RRGB和TIR响应得分图RTIR.基于模态可靠性越高、响应得分越高的假设, 选择每个模态的响应最大值作为模态权重, 同时考虑到目标在帧间的平滑运动假设, 对两帧间目标位移过大的模态加入惩罚系数.随后, 对两种模态权重进行归一化处理, 获取最终的融合响应图.
Zhang等[59]提出DSiamMFT(Dynamic Siamese Networks with Multi-layer Fusion), 设计基于动态孪生网络[60]的RGB-T跟踪器, 在互相关操作前采用级联的融合方式融合多模态特征.尽管基于孪生网络的RGB-T目标跟踪算法达到更快的运行速度, 但其跟踪性能与最优的多模态跟踪算法仍存在很大差距.并且, 由于缺乏大规模的RGB-T目标跟踪数据集, 已有的基于孪生网络的算法只能使用RGB目标跟踪数据集进行训练, 无法充分利用RGB-T数据的互补信息.
针对基于孪生网络的RGB-T目标跟踪算法与目前先进的跟踪算法性能存在巨大差距的问题, Zhang等[61]提出SiamCDA(Complementarity-and Distractor-Aware RGB-T Tracker Based on Siamese Network), 结构如图18所示.具体地, 在融合阶段, 提出基于互补感知的RGB-T多模态特征融合模块, 使模型有选择性地融合有效信息, 增强模型的辨别力.在候选框选择阶段, 提出基于干扰感知的候选框选择模块, 提高跟踪器对干扰物的鲁棒性.最后, 针对目前缺少大规模RGB-T多模态跟踪数据集的问题, 提出语义感知的图像生成方法, 构建大规模的RGB-T合成数据集.
Kang等[64]认为已有的算法从全局角度出发融合多模态特征, 但是当图像中仅包含部分有效信息(如大范围遮挡)时, 算法并未表现出良好的性能.因此, 提出FS-Siamese(Four-Stream Oriented Sia-mese Network), 使用一个四分支孪生结构, 其中两个分支用于嵌入不同模态的模板特征, 另外两个分支用于嵌入不同模态候选区域的特征.算法借鉴基于注意力的图像双线性池化方法, 探索RGB图像和TIR图像部分特征的相互作用, 以此确定正确的目标区域.此外, 还采用元学习更新双线性池化的结果, 通过在线更新的方式更好地区分目标和背景.
Transformer的单模态目标跟踪算法可显著提升跟踪性能.受此启发, Feng等[65]在TransT(Trans-former Tracking)[66]的基础上, 提出RWTransT(Re- liable Modal Weight with Transformer for Robust RGBT Tracking).首先, 在浅层进行多模态特征融合, 再将融合后的特征送入TransT, 获取最终的跟踪结果.借助强有力的基线跟踪算法, 显著提升基于孪生网络的RGB-T目标跟踪算法性能, 并保持实时的运行速度.
Yang等[67]考虑到目前仍缺乏多模态数据集的问题, 提出ProTrack(Multi-modal Prompt Tracker), 将多模态输入数据以提示范式(Prompt Paradigm)的方式生成单模态数据, 将此单模态数据输入基于Transformer的目标跟踪算法中, 获取最终的跟踪结果.值得注意的是, 由于ProTrack在数据输入阶段进行多模态数据融合, 因此不需要使用RGB-T目标跟踪数据集进行模型训练, 而是使用大规模的RGB目标跟踪数据集进行网络训练.
公开的RGB-T目标跟踪基准数据集将为RGB-T目标跟踪算法提供训练数据和性能评估.本文对2016年以来提出的RGB-T目标跟踪数据集进行简要介绍, 主要包括GTOT[68]、RGBT234[2]、LasHeR[69]和VTUAV[51]这4个数据集.其中, RGBT234数据集包含RGBT210[6]和VOT2019-RGBT[70]数据集.各数据集具体信息如表1所示.
| 表1 公开的RGB-T跟踪基准数据集信息 Table 1 Description of public RGB-T tracking benchmark datasets |
2016年, Li等[68]建立第1个标准的RGB-T目标跟踪基准数据集— — GTOT数据集, 由50个RGB-T视频序列组成.场景包括办公区、公共道路、水池等.包括遮挡(OCC)、大尺度变化(Large Scale Vari-ation, LSV)、快速运动(FM)、低光照(Low Illu-mination, LI)、热交叉(TC)、小物体(Small Object, SO)和形变(Deformation, DEF)7个视频级别的场景性标注.数据集上包含较多的小尺寸目标.
2017年, Li等[6]建立RGBT210数据集, 包含210个视频序列, 并引入更多的场景属性用于评估算法性能.2019年, Li等[2]扩充RGBT210数据集, 得到RGBT234数据集, 提供两个模态下的真实框标注.2019年的VOT-RGBT竞赛[70]从RGBT234数据集上选取60 个视频序列, 建立VOT2019-RGBT数据集.
RGBT234数据集标注12个视频级别的场景属性, 包括无遮挡(No Occlusion, NO)、局部遮挡(Partial Occlusion, PO)、严重遮挡(Heavy Occlu- sion, HO)、低光照(LI)、低分辨率(Low Resolution, LR)、热交叉(TC)、变形(DEF)、快速运动(FM)、尺度变化(SV)、运动模糊(MB)、相机移动(Camera Moving, CM)和复杂背景(Background Clutter, BC).最长的视频序列约4 000 帧, 整个数据集包含20万帧以上的RGB-T图像.
GTOT、RGBT234数据集上部分示例及对应场景属性如图19所示.
 | 图19 GTOT[68]、RGBT234数据集[6]上部分示例及其对应场景属性Fig.19 Examples and corresponding attributes on GTOT[68] and RGBT234[6] datasets |
2022年, Li等[69]建立大规模的RGB-T目标跟踪数据集— — LasHeR数据集, 共包含1 224个RGB-T视频序列.在室内外环境拍摄20多个具有不同特征的场景.为了进一步提高目标多样性, 跟踪目标类别共32种.LasHeR数据集在RGBT234数据集12个场景属性的基础上进一步增加7个视频级别的场景属性, 包括透明物体遮挡(Hyaline Occlusion, HO), 高光照(High Illumination, HI), 光照快速变化(Abrupt Illumination Variation, AIV), 相似外观(Similar Appearance, SA), 纵横比变化(Aspect Ratio Change, ARC), 视线外(Out-of-View, OV)和缺失帧(Frame Lost, FL).划分979个视频序列作为训练数据集, 剩余245个视频序列作为测试数据集.透明物体遮挡时TIR图像缺少目标信息, 而热成像仪采用非均匀校正时会停止成像, 从而造成部分TIR帧缺失.这两种属性的示例如图20所示.
2022年, Zhang等[51]构建高分辨率的无人机RGB-T目标跟踪基准数据集— — VTUAV数据集, 是目前规模最大、分辨率最高的RGB-T目标跟踪数据集.VTUAV数据集包括长时跟踪、短时跟踪和视频目标分割3种类型的任务, 由专业无人机(DJI Matrice 300 RTK)搭载Zenmuse H20T相机拍摄.考虑到已有数据集在道路、学校和安全监控等场景下采集, 场景数量和目标类别有限, 该工作在2个城市的15个场景下采集视频, 包括5大类(行人、交通工具、动物、火车、船只)和15个子类的目标类别.数据集采取稀疏标注的方式(每隔10帧标注一次), 并逐帧标注13个挑战因素, 包括目标模糊、摄像机移动、极端光照、变形、部分遮挡、完全遮挡、尺度变化、热交叉、快速移动、背景聚类、视野外、低分辨率和热可见分离.VTUAV数据集共包含500个视频序列, 分辨率为1 920× 1 080.将250个视频序列作为训练数据集, 剩余250个视频序列作为测试数据集.并且提供100个像素级标注的视频序列(其中50个序列作为训练集, 另外50个序列作为测试集), 序列分割掩码标注示例如图21所示.
为了评估算法性能, 本节介绍已有RGB-T目标跟踪算法使用的评估指标.
1)精确率(Precision Rate, PR).精确率表示跟踪算法预测的目标框中心与标注的目标框中心之间的欧氏距离小于选定阈值的视频帧数占该视频总帧数的百分比, 阈值通常根据不同数据集进行手工设置.计算公式如下:
PR(fp, fo)=
其中, fo表示该视频总帧数, fp表示跟踪算法预测的目标框中心与标注的目标框中心之间的欧氏距离小于选定阈值的视频帧数.由于GTOT数据集上目标较小, 因此, GTOT数据集上阈值通常设定为 5, 而在RGBT234、LasHeR数据集上阈值设定为20.
2)成功率(Success Rate, SR).成功率指输出边界框与真值边界框之间的重叠率大于阈值的帧的百分比.改变阈值可以获得SR图.通过计算SR曲线下面积得到成功率.
3)标准化精确率(Normalized Precision Rate, NPR).由于精确率度量容易受到图像分辨率和目标框大小的影响, NPR进一步将精确率标准化, 计算见LaSOT(Large-Scale Single Object Tracking)[50].
根据数据集的默认设置, 在GTOT、RGBT234数据集上使用PR和SR评估算法性能, 在LasHeR数据集上使用PR、SR和NPR评估算法性能.
本文在GTOT[68]、RGBT234[2]和LasHeR[69]数据集上选择25个基于深度学习的RGB-T目标跟踪算法进行性能对比, 结果如表2所示.
| 表2 各算法在3个数据集上的实验结果 Table 2 Experimental results of different algorithms on 3 datasets |
在表2中, 基于多模态特征融合的目标跟踪算法表示为A, 基于多模态特征表示的目标跟踪算法表示为B, 基于多模态特征表示-融合联合的目标跟踪算法表示为C, 基于属性驱动的目标跟踪算法表示为D.
由于2022年前缺少大规模RGB-T目标跟踪数据集, 基于MDNet的目标跟踪算法在RGB-T跟踪领域占据主流, 且通过多模态特征融合、特征表示、属性指导等多种角度提高跟踪性能.早期基于MDNet的目标跟踪算法取得领先的跟踪性能, 但运行速度较慢.后续算法逐渐将基线跟踪器替换为运行效率更高的RT-MDNet[21].其中, DMCNet[24]在MANet[28]增强特征表示的基础上, 提出挖掘低质量模态内的辨别力信息, 在RGBT234数据集上取得最优的精确率和成功率.基于属性指导的APFNet[41]和挖掘模态间模式相关性的CMPP[42]也取得先进的性能.但上述算法均计算效率较低.同时, 基于MDNet的目标跟踪算法在目标定位上优势明显, 但回归精度不足.
基于判别式相关滤波的RGB-T目标跟踪算法同样采用在线更新的策略训练分类器.由于基线跟踪器DiMP[45]的出色设计, HMFT[51]在GTOT[68]、VTUAV[51]数据集上均取得最先进的跟踪性能, 并保持实时的运行速度.
基于孪生网络的RGB-T目标跟踪算法在运行速度上具有明显优势.其中, SiamCDA[61]仅使用RGB目标跟踪数据集合成的RGB-T目标跟踪数据集训练模型, 因此性能受到制约, 虽可达到37帧/秒的运行速度, 但性能仍有明显差距.在引入Transformer后, 基于孪生网络的RGB-T目标跟踪算法性能具有显著提升.其中, RWTransT[65]在GTOT、RGBT234数据集上都取得最优的成功率, 并在LasHeR数据集上获得十分显著的提升.相比最优的基于MDNet的目标跟踪算法APFNet[41], RWTransT在成功率和精确率上分别提升28.0%和26.4%.
为了进一步研究不同算法在不同属性跟踪场景下的性能, 分别选取MANet[28]、MANet++[31]、MaCNet[23]、DAFNet[13]、DMCNet[24]和mfDiMP[14]、JMMAC[54]、SiamCDA[61]等部分先进算法, 在RGB- 234数据集上开展基于属性的性能对比, 结果如表3所示.
| 表3 各算法在RGBT234数据集不同属性上的性能对比 Table 3 Performance comparison of algorithms on different attributes of RGBT234 dataset. % |
从表3可以发现, 对于无遮挡(NO)和局部遮挡(PO)场景, 大部分先进的RGB-T目标跟踪算法都具备良好性能, 而在严重遮挡(HO)场景下, 所有算法性能都明显下降.在低光照(LI)场景下, 基于孪生网络的SiamCDA表现优异; 在存在形变(DEF)、尺度变化(SV)场景下, 基于MDNet的目标跟踪算法回归性能有限, 与采用离线训练的JMMAC、mfDiMP、SiamCDA差距明显.但在热交叉(TC)场景下, 使用合成数据集训练的mfDiMP和SiamCDA表现很差, 这表明目前生成的合成数据集与真实数据还存在一些差异, 影响跟踪器在此类场景下的性能.
同时, 在复杂背景(BC)、运动模糊(MB)和快速运动(FM)场景下, 仅依靠外观模型很难实现准确鲁棒的目标跟踪, 因此目前根据目标外观进行跟踪的大部分算法(如MANet、mfDiMP、SiamCDA等)仍无法取得理想效果.
表2给出不同算法的实验平台和运行速度, 可以发现, 基于MDNet的目标跟踪算法无法达到实时运行速度, 仅可达到2帧/秒左右的运行速度, 基于RT-MDNet的目标跟踪算法速度有所提升.ADRNet可在2080Ti GPU上达到25帧/秒的运行速度.但基于DiMP的mfDiMP和基于孪生网络的SiamFT和SiamCDA在速度上具有明显优势.
部分公布代码的算法的模型尺寸及其在RGBT234数据集上的性能对比如图22所示.
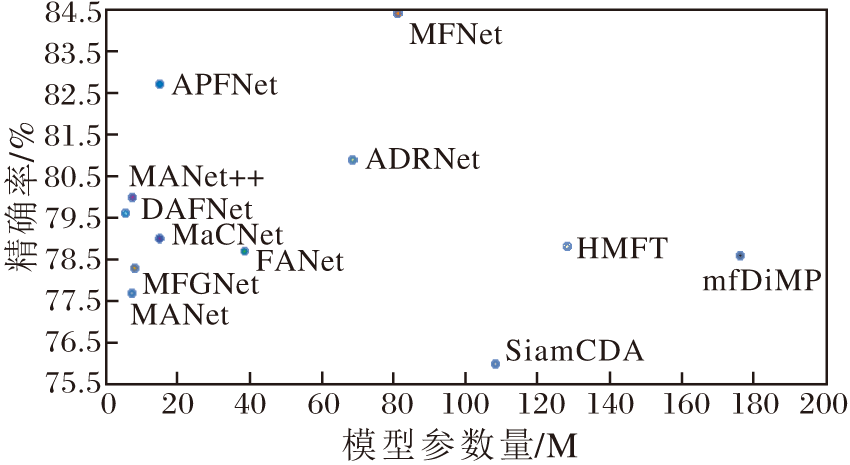 | 图22 不同算法的参数量对比Fig.22 Parameters comparison of different algorithms |
由图22可以发现, 由于使用参数量较少的VGG-M作为特征提取网络, 大部分基于MDNet的RGB-T目标跟踪算法参数量更低.其中, DAFNet的参数量仅为5.50 M.基于属性驱动的方法通常使用多分支的结构, 具有较多的参数量.基于孪生网络的目标跟踪算法和基于判别式相关滤波的目标跟踪算法由于使用更复杂的特征提取网络, 因此参数量显著提高.
考虑到早期算法使用的训练数据集有所差异, 且训练数据集的规模限制算法的性能, 本文选择MANet[28]、DAFNet[13]、FANet[12]和mfDiMP[14]这4个典型算法, 使用LasHeR训练数据集[69]重新训练, 并在规模较大的RGBT234[2]、LasHeR[69]测试数据集上进行测试, 结果如表4和表5所示.
| 表4 重新训练的跟踪算法在RGBT234数据集上的性能对比 Table 4 Performance comparison of retrained tracking algorithms on RGBT234 dataset % |
| 表5 重新训练的跟踪算法在LasHeR数据集上的性能对比 Table 5 Performance comparison of retrained tracking algorithms on LasHeR dataset % |
由表4和表5可以发现, 使用更大规模的真实训练数据集之后, 算法性能都有明显提升.mfDiMP尽管采用简单的级联融合策略, 但获益于DiMP[45]的优异性能和真实的训练数据集, 也可取得最佳的跟踪性能, 在LasHeR数据集上的PR和SR指标分别提升13.6%和11.2%.
而基于MDNet的MANet、DAFNet和FANet性能上升幅度小于mfDiMP, 这是由于采用的基线跟踪算法网络结构简单, 并使用在线训练的回归器, 无法从更大的训练数据集上由离线训练的方式获取更多性能收益.近年来, 出现越来越多的大规模RGB-T目标跟踪数据集, 这意味着未来研究的重点将转向基于孪生网络的目标跟踪算法和基于判别式相关滤波的目标跟踪算法.
从2018年Li等[8]首次提出基于深度学习的RGB-T目标跟踪算法开始, 不足五年的时间内, RGB-T目标跟踪领域的研究工作已经取得巨大的进展, 但仍有很多问题有待研究和解决.下文分别从模型设计、数据集建立和实际应用三个角度讨论RGB-T目标跟踪领域未来的研究方向和可能的解决方案.
1)多模态特征融合方法研究.相比使用单模态数据的目标跟踪任务, RGB-T目标跟踪可以利用多模态数据的互补信息, 提高跟踪的鲁棒性和准确性.由于RGB图像和TIR图像成像机理不同, 多模态图像存在信息差异和特征分布差异, 而大多数已有算法首先使用双流网络或孪生网络进行多模态特征提取, 随后直接进行多模态特征融合, 忽略不同模态特征分布之间的差异, 容易削弱融合特征的辨别力.如何降低模态差异对融合特征的影响, 进而提高多模态目标跟踪的性能是一个需要研究的问题.此外, 现有算法主要研究中期融合策略以自适应从多模态数据内选择具有辨别力的信息, 对其它融合算法(如早期融合和晚期融合)未充分研究.事实上, 早期融合具备降低计算复杂度、减小特征分布差异的优势, 而晚期融合可减少某一模特数据内存在的噪声对融合性能的影响.因此, 进一步充分挖掘不同融合方式以利用多模态数据的互补性也是一个有待解决的问题.
2)更高效的目标跟踪算法框架.大部分RGB-T目标跟踪算法在RGB目标跟踪算法的基础上设计.使用的基线跟踪算法大多是早期的RGB目标跟踪算法, 如MDNet[19]、RT-MDNet[21]和SiamFC[58]等.这些基线算法本身存在一定的局限性, 如基于孪生网络的目标跟踪算法虽然达到实时的运行速度, 但存在辨别力不足问题, 在复杂场景下跟踪性能有限.基于MDNet的目标跟踪算法存在回归精度较差问题, 无法从更大规模的训练数据集上获取显著的性能收益.基于DCF的目标跟踪算法尽管在高性能的硬件设备下可取得优异的跟踪性能和实时的运行速度, 但由于其在线训练的策略, 在性能更弱的移动端设备上难以实现性能和速度的平衡.此外, 已有算法通常依赖目标的外观信息进行跟踪, 对于跟踪场景信息(如目标与背景间的上下文关系)以及跟踪目标的轨迹信息研究较少.这些问题限制RGB-T目标跟踪算法的跟踪鲁棒性和精度.
最近, 基于Transformer的目标跟踪算法[66, 71]在RGB目标跟踪领域取得优异性能, 在性能和速度上达到良好的平衡, 并且挖掘跟踪场景内的上下文信息以提高跟踪的鲁棒性.而RGB-T跟踪领域对Transformer的研究虽然已经取得一定进展, 但研究仍不充分.设计基于Transformer 的RGB-T目标跟踪算法, 并解决上述跟踪框架的固有问题是未来的研究热点之一.
3)轻量化网络设计.RGB-T目标跟踪任务由于需要额外的模态数据, 通常使用双流网络进行特征提取, 增加网络的计算复杂度, 从而导致现有的目标跟踪框架难以满足实时运行的要求.大量算法采用在线更新策略[19, 45]对硬件设备具有更高的要求.已有的跟踪框架通常包括多模态特征提取、多模态特征融合和分类及回归网络三部分.为了减少RGB-T目标跟踪算法的计算复杂度, 需分别减少上述3个部分的计算量.如何使用特征选择[10]、知识蒸馏[72]、网络结构搜索[73]等技术加速网络的前向推理速度将是未来研究的一个重点.
4)视频目标分割.已有RGB-T目标跟踪算法使用矩形包围框表示目标的位置及所在区域.但边界框内通常包含大量的背景信息, 对于旋转、可变形的目标变化描述不够精确, 从而在跟踪过程中造成目标与背景边界的混淆, 甚至导致错误的区分目标与背景干扰物.在这种情况下, 预测精确的目标掩码可以更好地明确目标区域, 获取更准确的跟踪结果.因此, 在RGB目标跟踪领域, 一些跟踪方法结合视频目标分割算法[74], 在视频序列中预测目标掩码以更好地描述目标状态.然而在RGB-T目标跟踪领域, 目标跟踪结合视频目标分割算法还未得到研究.同时, 已有的大部分RGB-T目标跟踪数据集仅提供目标的边界框标注, 缺乏大规模的RGB-T视频目标跟踪数据用于模型训练.对多模态视频进行像素级标注将耗费大量的时间和人力.如何使用已有的边界框级别标注数据, 采用弱监督训练等策略获取RGB-T视频目标分割模型同样是未来研究的重点.
5)长时目标跟踪.已有的大多数RGB-T目标跟踪算法通常在短时序列(帧数小于600幅图像)中跟踪目标.然而, 在实际应用中, 往往需要在长时序列(帧数大于2 000幅图像)中跟踪目标, 并应对可能出现的目标消失、目标遮挡和目标重现等挑战.在基于RGB图像的目标跟踪任务中, 长时目标跟踪已经得到广泛的关注和研究.然而, 在RGB-T目标跟踪算法中, 缺乏对此问题的深入分析和研究.在RGB-T目标跟踪领域, 进一步研究利用多模态数据的互补性提高长时目标跟踪的鲁棒性和目标重检测的准确性将是未来研究的重点.
1)大规模数据集.近年来, 随着RGB-T目标跟踪的发展, 多个RGB-T目标跟踪数据集被提出.其中, LasHeR[69]、VTUAV[51]数据集包括训练数据集和测试数据集, 但目标跟踪任务需要更大规模的训练数据集, 以提高模型的泛化性能.相比RGB目标跟踪数据集的规模, 已有RGB-T目标跟踪数据集的规模通常较小, 例如, 常用的RGB跟踪数据集GOT10K包含9 340个视频用于模型训练.而目前大规模的RGB-T目标跟踪数据集仅包含979个视频用于模型训练, 如表6所示.训练数据集规模上的显著差异导致模型训练过程中容易出现过拟合问题, 且场景多样性的缺乏导致跟踪泛化性能的不足.此外, 仍缺乏大规模的RGB-T目标分割数据集用于训练视频目标分割算法.VTUAV数据集上仅包含50个视频序列用于训练, 相比RGB视频目标分割算法使用的数据集Youtube-VOS[75], 视频序列数量太少, 对于网络的设计和训练造成较大困难.在未来构建更大规模的RGB-T目标跟踪数据集并提供目标的像素级标注, 仍是未来研究的重要工作.
| 表6 各数据集规模对比 Table 6 Comparison of different dataset sizes |
2)模态对齐.已有的RGB-T目标跟踪算法通常假设RGB图像和TIR图像在空间上严格对齐, 这在实际中很难实现.虽然使用配准算法可以改善不对齐现象, 但仍然难以保证所有局部区域的精确对齐.在GTOT[68]、RGBT234[2]、VTUAV[51]数据集上, 不对齐问题仍广泛存在.对此, 本文统计RGBT234、VTUAV数据集上目标在两种模态内的中心像素偏差(即目标在两种模态图像下中心点的像素距离), 如表7所示.空间未对齐问题会导致多模态特征融合过程中信息的无效传播, 从而影响目标回归的精度和目标分类的鲁棒性.一方面, 可以设计更准确的图像配准方法, 实现RGB图像和TIR图像的像素级精确配准; 另一方面, 还可以考虑如何在现有的RGB-T跟踪模型中嵌入相应的多模态图像特征局部对齐模块, 提高模型对输入图像弱配准时的鲁棒性.
| 表7 RGB-TIR模态边界框中心距离对比 Table 7 Comparison of center distance of bounding boxes in RGB-TIR modality |
RGB-T目标跟踪能够在具有挑战性的环境中实现强大的跟踪性能, 具有广泛的应用价值.
1)智能监控系统.监控系统已经广泛应用于各种实际场景中, 而目标跟踪技术是智能监控系统的重要组成部分.RGB-T目标跟踪技术能够全时段、全天候工作.在公安系统方面, 可对监控视频中的嫌疑人进行跟踪和行为分析, 有效提高办案效率.在智能交通方面, RGB-T目标跟踪技术可以监测道路交通状况并实时检测违规车辆, 对肇事逃逸车辆进行追踪以降低人力要求.RGB-T目标跟踪技术也可以部署在无人机上, 实现更加灵活的检测监控.
2)军事领域.在军事领域, RGB-T目标跟踪技术可用于制导和导弹预警, 例如, 通过精确捕获目标位置以确保远程打击的精确性, 或及时预警来袭导弹位置.RGB-T目标跟踪技术也可用于实时监测战场状态, 评估打击效果和敌方军备调动情况.
3)智能导航与定位.在自动驾驶中, 可使用RGB-T目标跟踪技术对周围的行人及物体进行跟踪定位, 实现自动驾驶的最优路线规划并保持最合适的车速.
4)人机交互与虚拟现实.RGB-T目标跟踪可在各种场景下跟踪人的动作, 并结合检测算法识别表情及动作类型, 使计算机发出相应的操作指令, 从而实现机器和用户之间的交互, 也可在未来应用于虚拟现实技术中.
随着传感器技术的不断发展, RGB-T目标跟踪因其全天候、全场景工作特性逐渐成为计算机视觉领域的研究热点.本文首先介绍RGB-T目标跟踪任务目前面临的诸多挑战, 包括目标跟踪任务的通用挑战和RGB-T目标跟踪任务的特有挑战.接着详细介绍目前基于深度学习的RGB-T目标跟踪算法, 并对它们进行分类和对比.然后, 介绍RGB-T目标跟踪任务常用的公开数据集及评估指标, 并对现有方法在各个数据集上的性能进行整理及对比分析.最后, 本文还对RGB-T目标跟踪未来的研究方向进行思考与展望, 以期为广大研究人员的工作提供一些参考和帮助.
本文责任编委 徐 勇
Recommended by Associate Editor XU Yong
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|
| [47] |
|
| [48] |
|
| [49] |
|
| [50] |
|
| [51] |
|
| [52] |
|
| [53] |
|
| [54] |
|
| [55] |
|
| [56] |
|
| [57] |
|
| [58] |
|
| [59] |
|
| [60] |
|
| [61] |
|
| [62] |
|
| [63] |
|
| [64] |
|
| [65] |
|
| [66] |
|
| [67] |
|
| [68] |
|
| [69] |
|
| [70] |
|
| [71] |
|
| [72] |
|
| [73] |
|
| [74] |
|
| [75] |
|