{kind=link}
{kind=link}
{kind=link}
多特征融合短会话推荐模型
[夏鸿斌1, 2  , 黄凯
, 黄凯1 , 刘渊1, 2 ]
, 黄凯, 刘渊]
|
|



作者简介:

黄 凯,硕士研究生.主要研究方向为个性化推荐、机器学习.E-mail:1205549613@qq.com.
刘 渊,硕士,教授,主要研究方向为网络安全、社交网络.E-mail:lyuan1800@sina.com.
多数会话推荐系统研究都聚焦于长会话推荐而忽略短会话.但是在实际情况下,短会话信息却占据大多数.由于短会话包含的信息有限,如何从短会话中学习更丰富的用户偏好和更精确地找到相似上下文会话成为一个急需解决的问题.为此,文中提出多特征融合短会话推荐模型.首先,通过邻域聚合和循环神经网络分别学习会话的节点特征和序列特征.再使用自定义的相似度计算公式检索当前用户历史会话和其他用户会话作为上下文,缓解短会话信息稀少的问题.然后,利用位置感知多头自注意力网络充分发掘会话的隐藏特征.最后,模型以多特征融合的当前会话为依据推荐下一个项目.在两个真实数据集上的实验表明文中模型在指标值上都较优.本文模型代码地址为http://github.com/ScarletHK/MFF-SRR.
About Author:
HUANG Kai, master student. His research interests include personalized recommendation and machine learning.
LIU Yuan, master, professor. His research interests include network security and social network.
Most research on session recommendation systems focuses on long session recommendation and neglects short sessions. However, in practice short session information account for majority of the information. Due to the limited information contained in short sessions, it is crucial to learn more diverse user preferences and find similar context sessions accurately from short sessions. Therefore, a multi-feature fusion based short session recommendation model(MFFSSR) is proposed. Firstly, the node features and sequence features of sessions are learned respectively via neighborhood aggregation and recurrent neural networks. Secondly, the custom similarity calculation formula is utilized to retrieve the current user history session and other user sessions as context information, which alleviate the lack of information in short sessions. Next, the location-aware multi-head self-attention network is applied to fully explore the hidden features of sessions. Finally, the model recommends the next item based on the current session of multi-feature fusion. Experiments on two real datasets show that the proposed model is superior in terms of metrics. The code for the proposed model can be found at http://github.com/ScarletHK/MFF-SRR.
随着Internet上数据量的迅速增长, 在搜索、电子商务、流媒体网站等许多Web应用程序中, 推荐系统成为帮助用户缓解信息过载、选择感兴趣信息的工具.其中, 基于内容的推荐[1]和协同过滤推荐[2]是两种具有代表性的方法.这些推荐系统需要根据明确的用户标识信息进行推荐.然而, 在许多应用场景中, 用户标识可能是未知的并且无法使用.
因此, 研究者们提出会话推荐[3], 根据用户的行为序列预测用户下一个点击目标.会话序列可以是匿名的而不需要依赖任何用户的标识信息.目前, 会话推荐任务已广泛应用于多个领域, 如网页推荐、音乐推荐、商品推荐等.然而大多数现有的推荐系统依据长会话建模预测, 从而过滤短会话信息.长短对话的定义主要依据一个会话序列中包含的项目数量(本文选择项目数小于20的会话).具体而言, 现有研究大部分在数据预处理时就过滤短会话, 以期降低预测的挑战性和解决短会话学习不到位造成的干扰问题.短对话只包含稀少的项目, 其中包含的信息有限, 如果不能有效学习其特征, 反而会降低预测的准确性.
但是, 忽略短会话不是一个很好的选择.实际上, 在真实世界中, 短会话所占的比例远远超过长会话.用户通常会在碎片时间查看一些他们感兴趣的事物, 由于时间很短, 造成用户的交互行为很少.如果无法从短暂的行为中有效学习用户的偏好, 可能会造成预测的误差.所以, 在具有短会话的情况下预测用户的下一次行为是一个重要的研究方向.
为了缓解短会话信息稀疏的问题, 上下文信息成为重要的参考资料.按是否学习会话的上下文信息, 可以将会话推荐简单分为单会话模型和多会话模型.基于循环神经网络(Recurrent Neural Network, RNN)[4]的模型便是经典的方法之一.它们建模当前会话所有项目之间的相关性, 对其中的下一个项目进行推荐.但是在真实情况下, 会话中的项目之间可能相关性不强[5], 这种严格依赖顺序相关性的模型存在一定的问题.所以, Liu等[6]将注意力机制引入推荐之中, 提出STAMP(Short-Term Attention/Memory Priority Model), 为会话中与下一个项目预测更相关的项目分配更高的权重以解耦严格顺序假设要求.但是, 由于注意力机制会在学习过程中越来越偏向于多次出现的项目, 即流行的项目, 因此很可能会引起用户厌烦的心理.Wu等[7]提出SR-GNN(Session-Based Recommendation with Graph Neural Networks), 将会话建模到图神经网络(Graph Neural Network, GNN)中, 学习项目之间的复杂转换, 从而获得更准确的推荐.Lai等[8]提出MGS(Mirror Graph Enhanced Neural Model for Session-Based Recommendation), 集成项目的属性信息, 为每个会话项目选择最具属性代表性的信息, 从而将项目属性作为会话的上下文补充信息, 用于预测推荐.
对于长会话而言, 由于会话中的信息充足, 所以能够取得相对准确的结果.但是对于短对话而言, 由于信息稀少, 单会话模型很难充分学习用户的偏好信息, 从而造成推荐的误差.所以, 学者们提出多会话模型, 考虑当前会话的上下文信息, 充分学习用户的偏好.Quadrana等[9]提出HRNN(Hierarchical RNN), Ruocco等[10]提出II-RNN(Inter-Intra RNN), 使用会话级RNN和项目级RNN分别编码当前用户的历史会话和目标会话序列, 再组合两个RNN的输出, 预测用户感兴趣的下一个项目.然而, HRNN和II-RNN忽略其他用户可能也有与当前用户相似的会话信息.为此, 荣辉桂等[11]提出基于用户相似度的协同过滤推荐算法, 寻找与当前用户相似的用户作为参考依据.
相比当前用户的历史会话, 其他用户的会话数量繁多, 能否有效检索相似会话序列是关键问题之一.Ludewig等[12]提出SKNN(Session-Based K-Nearest Neighbor), Garg等[13]提出STAN(Sequence and Time Aware Neighborhood), 使用K近邻(K-Nearest Neighbor, KNN)[14]从整个数据集中找出与当前会话相似的会话作为上下文信息, 用于预测下一个项目推荐.
然而, 上述方法使用的相似计算方法过于简单, 很难精确找出真正相似的会话.Wang等[15]提出CSRM(Collaborative Session-Based Recommendation Machine), Pan等[16]提出ICM-SR(Intent-Guided Collaborative Machine for Session-Based Recommenda-tion), 使用自定义的会话检索网络, 从其他用户中检索和当前会话相似的会话.但是在当前会话很短并且上下文信息有限的情况下, 引入其他用户的协作信息会增加找到具有不同用户偏好和上下文会话的风险.
上述多会话模型虽然将上下文会话作为当前短会话的补充信息, 缓解短会话信息稀疏的问题, 但其仅仅使用会话嵌入之间的平均值或最小距离计算相似度, 获得的会话相似性可能不准确.因为会话编码器很难保存会话中的所有信息, 并且也忽略项目的位置和顺序.Song等[17]提出INSERT(Inter-Session Collaborative Recommender Network), 使用改进的会话检索网络, 从相似用户的会话中检索较优的相似会话.INSERT主要通过直接测量两个会话的相似性以筛选相似会话.然而该模型选择随机初始化的上下文会话信息作为输入, 未能充分考虑会话本身内部的结构信息, 性能受到一定限制.另外, INSERT公平看待会话中的所有项目, 但依据现实情况, 项目之间通常会存在位置重要性的区别, 因此在提取会话信息上也存在一定的局限性.
针对上述问题, 本文基于上下文信息补充和图神经网络的思想, 提出多特征融合短会话推荐模型(Multi-feature Fusion Based Short Session Recommen-dation Model, MFF-SSR), 充分学习短会话中的用户偏好, 有效检索当前会话的相似会话信息, 并纳入下一个项目推荐中.具体来说, 首先将用户和项目节点建模到图神经网络当中, 并进行邻域聚合操作.项目聚合节点作为会话序列的补充, 与门控网络的输出(序列特征)一起作为相似会话检索网络的输入节点.用户聚合节点作为相似度权重计算的重要依据.然后, 使用目标会话与其它会话计算相似度, 筛选相似短会话, 并与用户相似度权重相乘, 获得丰富的上下文信息.最后, 利用加入位置向量信息的多头自注意力机制, 提取当前会话和上下文会话的特征信息, 并结合两者, 获得最终会话表示, 从而预测用户的下一次行为.
本文提出多特征融合短会话推荐模型(MFF-SSR), 框架如图1所示.模型包含3个部分:特征学习层、上下文会话检索网络和位置感知网络.
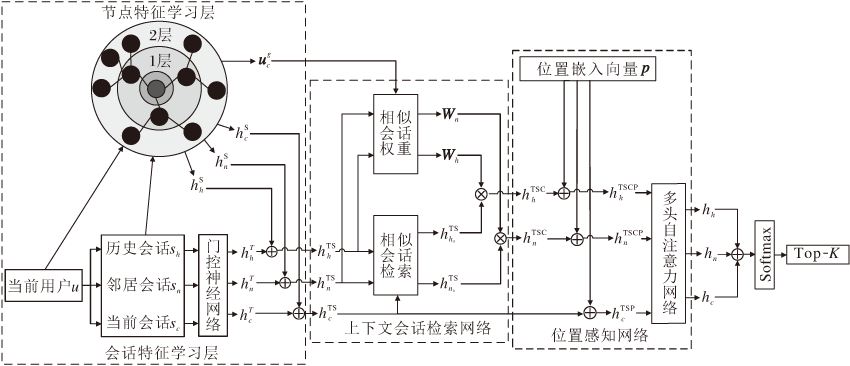 | 图1 MFF-SSR框架图Fig.1 Architecture of MFF-SSR |
特征学习层包括两个部分:节点特征学习层和会话特征学习层, 分别关注会话内部节点和整个会话的特征信息.特征学习层的目的是预处理输入数据, 再将两部分学习层的输出融合, 作为下一模块的输入.
1.1.1 节点特征学习层
本文将节点特征学习层和会话特征学习层定义为数据预处理阶段, 两层同步训练互不干扰.节点特征学习层根据用户与项目交互信息建立交互矩阵, 每行表示一位用户, 每列表示一个项目(交互为1, 未交互为0), 即邻接矩阵.此时模型需要进行信息构造, 将用户和项目根据ID建立嵌入向量.本文使用ui∈ U表示用户, U表示用户集; 使用ii∈ I表示项目, I表示项目集.另外, 使用eu表示用户嵌入, 使用ei表示项目嵌入.然后根据用户-项目交互矩阵, 建立交互图, 若用户与项目之间有交互, 则存在连边.
对于当前用户节点或目标会话内每个项目节点, 都存在高阶邻域信息.短会话的内部节点较少, 更需要聚合高阶邻域信息以丰富特征.本文依据邻域聚合[18]的思想, 将相邻节点的特征聚合到目标节点当中, 丰富目标节点的特征, 并在后续作为短会话的信息补充及相似会话权重的重要依据.本文选择He等[19]提出的LightGCN学习邻域高阶特征.LightGCN根据推荐任务节点信息稀疏并且特征维度较低的特点, 去除特征变换和非线性激活函数, 在图卷积模型[20]中性能优秀.
首先, 节点特征学习层根据用户和项目邻接矩阵建立邻接图(如图1所示), 根据连边从高阶邻域向目标节点聚合.主要通过迭代和加权求和的方式求取目标用户和物品的邻域聚合特征编码, 抽象公式
其中,
迭代公式
其中,
通过高阶邻域聚合, 节点特征学习层将节点信息从高阶向低阶传播, 获得每层的嵌入节点信息ek, 本文选择使用加权求和的方式获得最终节点表示:
其中, K表示邻接层数量, ak表示第k层聚合向量的权重, 本文使用简单的1/(K+1)表示, 已被证明足够有效[19].
该阶段模型获取所有包含邻居节点特征信息的目标节点嵌入向量, 为了与会话特征学习层输出结果融合, 需要将其转化为会话形式, 即{e1, e2, …, en}.项目和长度取决于目标短会话序列.本文将节点特征学习层输出的会话表示为hS, 将当前用户的聚合嵌入向量表示为
1.1.2 会话特征学习层
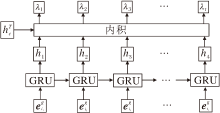
MFF-SSR使用会话特征学习层学习会话序列本身隐藏的信息, 主要利用门控循环单元(Gated Recurrent Unit, GRU)[21]学习顺序信息.当前会话的信息最为重要, 它是筛选相似会话的重要依据.上下文会话即用户的历史会话和其他用户的会话则是用来与当前会话进行相似度计算, 筛选相似会话并作为当前会话的信息补充, 从而预测下一个项目.
具体来说, 首先需要将项目i表示为一维空间的嵌入向量ei, 再根据会话的项目顺序表示为序列S, 即{
ht=GRU(
其中, 1≤ t≤ N, N表示每条会话的长度,
当前会话使用最后一刻的状态ht, 可表示当前用户的当前偏好, 本文使用
为了缓解短会话信息稀少的问题, 模型需要从当前用户的历史会话和其他用户的会话中筛选出相似会话, 从而学习相似特征, 丰富当前会话的信息.
首先, 将特征学习层的结果作为本模块的输入, 也就是两个相似会话候选集.第一个是当前用户的历史会话集{
1.2.1 相似会话检索网络
面对数量庞大的当前用户历史会话和其他用户的会话信息, 如果无法筛选真正相似的会话, 会导致用户偏好的误差和造成计算的高负担.所以, 为了使模型更加精确和高效, 需要从庞杂的会话中选取与当前用户最相似的会话.
当前用户的历史会话集H(uc)数量稀少并且最符合当前用户的偏好, 模型无需对其进行先验筛选, 直接将其输入相似会话检索网络中进行计算.而对于其他用户的会话集H(un), 由于用户数量众多, 每位用户又会产生大量历史会话集, 如果将所有会话都纳入计算当中, 将会对模型造成非常高的负担, 花费大量的时间.
所以模型需要预先选取一定数量的相似用户, 再将他们的历史会话作为相似检索网络的输入.这里本文选取10个与当前用户最相似的用户.MFF-SSR选取与当前用户具有相似偏好的用户, 相似度
si
其中, uc表示当前用户, uo表示其他用户,
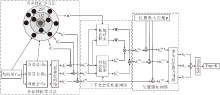
不管是当前用户的历史会话集还是其他用户的会话集, 当引入其它会话作为补充信息时都会在一定程度上造成模型学习到错误偏好的风险, 尤其是短会话信息本身所含信息量有限, 更容易受到补充信息的影响.所以, 如何更有效地找到与当前会话相似的会话成为至关重要的问题.当前研究大多使用基于注意力机制的向量加权和或嵌入向量加权平均, 计算当前会话和其他会话的相似度, 但是这样会忽略会话中每个项目的位置信息.所以, Song等[17]选择使用自定义的相似度测量方法筛选相似会话, 计算网络如图2所示.
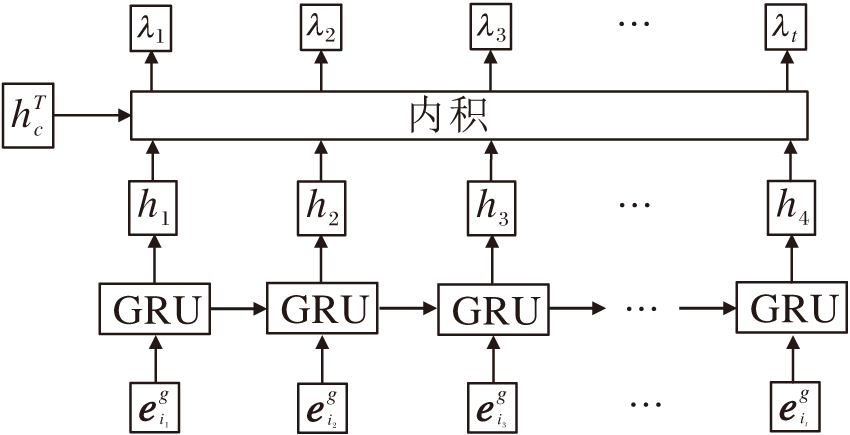 | 图2 相似度计算网络Fig.2 Similarity computing network |
对于当前给定的会话候选序列, 自定义的相似度测量方法将其内部每个项目输入GRU中, 这一步在时间信息学习模块上已经完成, 最终得到包含每一时刻状态的状态集hT.然后选择将当前会话
sim(hT,
其中
λ i=hi
相比于Song等[17]直接使用相似度作为候选会话的特征信息, 本文选择将候选会话与其相似度进行相乘, 得到最终会话表示:
其中,
1.2.2 相似会话权重网络
在为相似会话检索网络找到与当前会话相似的会话之后, 因为每个会话所含项目的种类和数量都不同, 也就是说每个会话与当前用户的相似度也有差异, 此时并不能统一将它们直接作为补充信息.所以, 需要一个权重矩阵, 用于体现不同会话与当前用户的差异性.
本文通过注意力机制(Attention Mechanism)[22]表征每个候选会话与当前用户的相似度权重.首先, 将通过空间信息学习模块得到的
最终进行加权和操作, 得到当前用户对于整个候选集的偏好权重矩阵:
1.2.3 上下文会话检索结果
当前用户的历史会话集和其他用户的会话集通过相似会话检索网络筛选的结果分别表示为
相比Song等[17]的工作, 此时并不直接通过MLP(Multilayer Perceptron)[23]对候选会话集进行聚合表征.因为1.1.2节中会话特征学习层为简化模型, 仅使用GRU学习会话的前向传播特征.后续为了学习会话中更深层次的用户偏好信息, 仍需要上下文候选会话集作为输入.
1.1.2节中会话特征学习层中的门控循环神经网络在计算会话时, 只是将前一个状态纳入当前状态计算当中, 即前向特征学习.为了有效体现会话中每个项目所在位置的重要性, 本文利用位置感知多头自注意力网络学习不同节点之间的位置权重.注意力网络本身无法捕捉会话顺序, 对于相同项目处于会话不同位置的情况, 注意力网络计算得出的结果是一样的.所以为了使注意力网络能够学习相对位置信息, 需要在注意力网络之前, 对每个序列嵌入一个位置向量.Wang等[24]关注会话的反向位置信息, 使用一个自定义的反向位置向量学习会话中更深层次的位置信息.相比前向位置信息, 当前会话中的项目到预测项目的距离包含更有效的信息, 也就是说, 越靠近末尾的物品应该越重要.
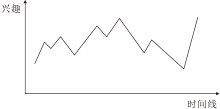
但是, 主观地认为末尾的物品更重要是不合理的.每位用户在一段时间内的兴趣曲线都不一样.若将单位用户的所有交互项目按照时间线拼接成一整条会话, 假设相邻交互项目特征相似用户兴趣提升, 特征不相似兴趣下降, 可以发现用户的兴趣曲线呈上下波动趋势, 如图3所示.如果此时将整段会话按照时间段拆分成无数段短会话, 将无法预测每段短会话处于何种曲线类型(上升、下降、波动).所以, 主观认为每段会话越靠后的物品更重要是不合理的.用户可能在一段会话的最后刚好误点击一个项目, 那么此项目反而会成为噪点项目, 影响模型的预测.
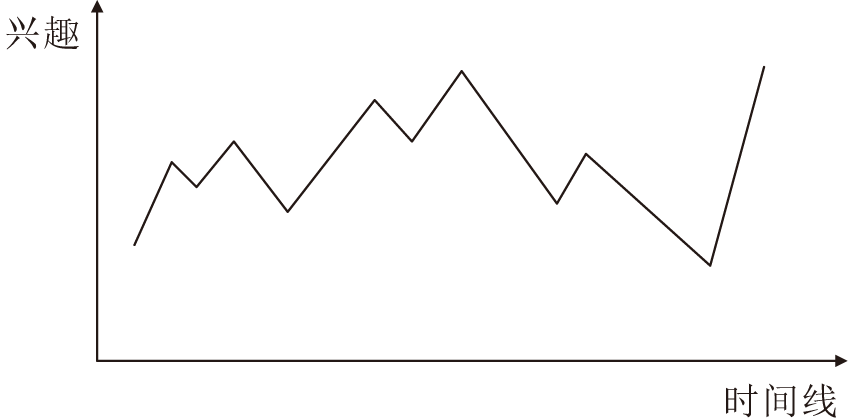 | 图3 用户兴趣曲线Fig.3 User interest curve |
观察图3可以发现, 用户兴趣曲线与正余弦曲线较相似.所以本文利用正余弦函数的思想建模位置向量, 捕捉不同短会话的兴趣偏好.此外, 本文使用多头自注意力网络代替普通注意力网络.相比普通注意力网络, 多头自注意力网络能通过多重注意力机制学习会话中更准确的用户兴趣偏好.
首先, 本文选择正弦函数为每个会话设定一个位置嵌入向量psin, 再与会话向量相加, 得到包含位置信息的特征向量:
hTSCP=hTSC$\oplus$psin.
然后将hTSCP输入多头自注意力网络[25]中, 学习会话的用户兴趣偏好, 这里使用符号τ 表示.相比传统自注意力网络, 多头自注意力网络利用多个注意力网络得出不同结果再拼接的方式获得会话更深层次的特征, 公式如下:
h=
其中
对于输出结果, 本文分别将当前用户的当前会话、历史会话和其他用户的会话表示为hc、hh和hn.
得出最终会话表征后, 模型需要将它们拼接后计算, 得到最终输出结果:
最后本文将预测视为多分类任务, 使用交叉熵损失函数训练模型, 损失函数如下所示:
loss(i+)=-[log
其中,
为了验证MFF-SSR的性能, 使用如下环境进行实验:PyTorch框架、Windows10 64位操作系统、python3.7、Intel(R) Core(TM) i7-10700F CPU、DDR4 16 GB内存、GeForce RTX 2060 6 GB显卡.
本文选择在Delicious和Reddit这两个真实数据集上进行实验.Delicious数据集包含用户在一个图书评分社交系统中对图书的标记行为.Reddit数据集包含用户对reddit论坛中帖子的评论行为.
首先, 删除整个数据集上出现频率小于10次的用户和项目.再将用户相邻交互小于阈值(本文设定为3 600 s)的交互分配到同个会话当中.然后, 为了专注于短会话的研究, 删除项目数量大于20的会话.最后, 按照8∶ 1∶ 1的比例将数据集划分为训练集、验证集和测试集.
表1列出实验数据集的信息.由表可以看到, 2个数据集的会话平均长度分别为5.6和2.6.
| 表1 数据集的基本信息 Table 1 Basic information of datasets |
为了验证MFF-SSR在短会话推荐领域的优越性, 选取如下12个对比模型, 主要分为3类.
1)单会话模型.
(1)RNN[5].基于门控循环神经网络的RNN模型, 使用GRU提取当前会话中包含的用户偏好信息, 用于推荐下一个项目.
(2)STAMP[6].利用注意力机制同时关注用户的短期兴趣和长期兴趣, 从而进行联合推荐.
(3)SR-GNN[7].基于GNN的单会话推荐模型, 将会话建模为图结构, 并使用GNN获得物品之间的转移信息, 同时单独提取会话中最后一个项目, 作为补充信息.
(4)MGS[8].利用双图学习项目表示.一个是从用户交互动作序列生成的会话图.另一个是由属性感知模块构建的镜像图, 通过集成项目的属性信息为每个会话项目选择最具属性代表性的信息.
2)多会话模型.
(1)SKNN[12].基于KNN的模型, 从整个会话数据集上检索与当前会话相似的会话作为当前会话的补充信息.
(2)STAN[13].改进版的SKNN, 在检索相似会话的同时, 考虑会话中更多的信息, 获得更准确的推荐.
(3)CSRM[15].多会话模型, 利用两个存储网络高效学习当前会话信息和相似会话信息, 获得更精确的推荐.
(4)HRNN[9].建模当前用户的当前会话和历史会话, 用于推荐当前会话的下一个项目.
(5)II-RNN[10].基于RNN的模型, 使用第2个RNN, 从最近的会话中学习并预测用户对当前会话的兴趣, 并通知原始RNN以改进推荐.
(6)INSERT[17].将用户的历史会话和其他用户的会话建模为全局模块, 补充作为本地模块的当前会话的上下文特征信息, 获取在短会话中更准确的推荐.
3)传统顺序推荐模型.
(1)SASRec(Self-Attention Based Sequential Model)[26].基于自注意力机制的序列推荐模型, 在每个时间步, 都从用户的行为历史中找出相关项目以预测下一个项目.
(2)BERT4Rec(Bidirectional Encoder Represen-tations from Transformer for Sequential Recommen-dation)[27].基于双向自注意力机制的序列推荐模型, 融合用户历史行为中的每个项目左右的上下文以预测项目.
本文选择广泛使用的排名指标Recall@K和MRR@K, 评估所有模型的推荐性能.
1)Recall@K.通常验证在正样本中有多少被预测为真, 推荐系统中理解为有多少项目被模型正确推荐, 公式如下:
Recall=
其中, u表示用户, Ru表示模型预测的需要被推荐的项目集合, Tu表示真实测试集上被推荐的集合.
2)MRR@K.反映推荐的项目是否处在序列的前列, 强调位置关系, 公式如下:
MRR=
其中, N表示推荐次数, 1/pi表示用户真实访问项目在结果序列中的位置, 若该项目不在序列中, 此时pi为无穷大.
本文在两个真实数据集上对比各模型, 结果如表3所示.在表中, 黑体数字表示最优值, 斜体数字表示次优值.为了公平起见, 除MFF-SSR结果以外, 对比模型结果均引用自参考文献.
| 表3 各模型在2个数据集上的实验结果 Table 3 Experimental results of different models on 2 datasets |
由表3可见, 相比次优模型:在Delicious数据集上, MFF-SSR分别在评分标准Recall@5、Recall@20、MRR@5、MRR@20上提升20.96%、9.71%、27.93%、24.46%; 在Reddit数据集上, MFF-SSR分别提升16.50%、1.73%、28.09%、26.00%.从结果可以看到, 本文模型性能提升比较明显.
从表3可以看到, 基于单会话的对比模型(RNN、STAMP、SR-GNN、MGS)表现最差.这是因为当专注于短会话推荐时, 由于当前会话中包含的信息有限, 模型无法做出更精确的推荐.同时在这4种模型当中, RNN的性能最低, 这是因为会话中的项目使用严格的顺序假设, 而由于短会话项目稀少, 无法有效学习会话中的顺序信息.STAMP在Delicious数据集上表现优于RNN, 但是在Reddit数据集上性能最差.这是因为STAMP使用的注意力机制擅长于从长会话中学习有效信息, 但是从表1可以看出, 由于Reddit数据集上平均每条会话长度(2.6)远小于Delicious数据集上平均每条会话长度(5.6), 所以无法从Reddit数据集上学习到足够的有效信息.得益于GNN在表示学习方面的优势, SR-GNN将单个会话建模到GNN之中, 从而获取会话中更多的信息, 但其仍然局限于项目嵌入向量, 所以效果不佳.MGS关注项目的属性信息, 通过集成项目的属性信息为每个会话项目选择最具属性代表性的信息.该模型将项目的属性信息(如标签)作为会话内项目的上下文补充信息, 在一定程度上丰富会话的特征性息, 因此在4种单会话模型中效果最优, 也优于一些多会话模型.由于MGS上下文信息取决于会话内部项目, 若内部项目数量过少, 可获得的项目属性也相应较少, 所以其在会话平均长度为5.6的Delicious数据集上效果好于在会话平均长度为2.6的Reddit数据集上的效果.
在多会话模型(SKNN、STAN、CSRM、HRNN、II-RNN、STAGE、INSERT)中, SKNN和STAN结构相似, 两者的主要区别在于是否考虑到会话中更多的信息.但是由于两者都只使用简单的方法衡量会话之间的相似度, 因此很难保证检索的会话是否真的对当前会话的下一项推荐有效.CSRM针对这一点进行改进, 通过存储网络相对精确地检索与当前会话相似的会话, 提供更精确的推荐.HRNN和II-RNN的思想比较相似, 都是直接使用当前用户的历史会话信息以补充当前会话的特征, 不需要考虑相似度问题, 所以两者的性能优于KNN、STAN和CSRN.但是HRNN和II-RNN假设用户的历史会话与当前会话强相关, 然而用户在不同时间段内可能会产生不同的偏好兴趣, 因此两者的性能并不是最优.INSERT区分当前用户的历史会话和其他用户的会话, 并将两者纳入考虑之中, 通过自定义的会话检索网络比较精确地检索与当前会话真正相似的会话序列, 再将这些会话作为当前短会话的补充信息.所以, 除了Reddit数据集上的Recall指标, INSERT的其它指标结果都优于对比模型.
传统顺序推荐模型(SASRec、BERT4Rec)使用用户的项目序列补充当前会话的信息, 该项目序列由用户的所有会话按照时间顺序拼接而成.BERT4Rec在Reddit数据集上的召回率是所有模型中最高的, 适用于词向量的BERT语言模型[28]运用于会话推荐.BERT4Rec在Reddit数据集上表现最优的原因是因为Reddit数据集是一个论坛评论数据集, 用户可能对于同一话题重复访问并评论多次, 从而造成该话题在用户的相互序列中重复出现, 使模型能够较准确地推荐该主题.除了召回率之外, SASRec和BERT4Rec在2个数据集上的其它指标都低于多会话模型.这可能是在处理数据集时过滤长会话导致用户只剩下短会话信息, 从而造成有些用户没有足够的历史会话以充分学习其偏好信息.另外, 将用户所有历史会话拼接到一个序列中, 可能会破坏会话的内在事务结构[3].在真实数据集上, 用户的不同会话之间有时会存在较大的差异性, 将它们拼接在一起反而会干扰推荐模型.
相比之下, MFF-SSR针对上述问题进行优化, 同时考虑当前用户的历史会话和其他用户的会话作为当前会话的上下文信息, 并使用更精确的相似会话检索网络筛选上下文会话.为了缓解短会话自身项目稀少的问题, 引入图神经网络, 充分学习每个项目的特征.另外, 模型也使用位置感知多头自注意力网络, 补充学习每个会话项目之间的位置信息.由表3可以看到, MFF-SSR在2个真实数据集上的指标值最高.
由2.5节可以看到, 相比其它对比模型, MFF-SSR性能具有明显提升.为了验证MFF-SSR中不同模块对于整个模型的作用以及一些超参数的设置对于本文模型的影响, 设置3组不同的消融实验.
2.6.1 模型中不同模块的影响
为了验证MFF-SSR各个模块的有效性, 使用依次屏蔽各个模块结果的方式进行消融实验, 各对比模型如下所示.
1)Version-1.在该模型中, 删除空间信息学习模块, 不再对用户和项目节点进行预处理的领域聚合操作, 即只使用随机初始化的用户和项目特征向量.
2)Version-2.在该模型中, 删除时间信息学习模块, 不再通过GRU学习会话中项目之间的顺序信息, 而是直接将会话输入到后续模块之中.
3)Version-3.在该模型中, 删除上下文信息学习模块, 即模型变成基于单会话的模型.
4)Version-4.在该模型中, 删除位置感知多头自注意力网络, 不再学习会话中各项目之间的反响位置信息.
5)Version-5.在该模型中, 选择忽略当前用户的历史会话, 只将其他用户的会话作为当前会话的上下文信息.
6)Version-6.在该模块中, 选择忽略其他用户的会话, 只将当前用户的历史会话作为当前会话的上下文信息.
7)Version-7.在该模块中, 只使用随机初始化而不是空间信息学习模块预处理的用户特征向量作为相似会话权重网络的参考依据.
各模型消融实验结果如表4所示, 表中黑体数字表示最优值.
由表4可以看出, 删除上下文信息学习模块的模型(Version-3)性能最差, 这是因为对于项目稀少的短对话来说, 上下文信息是最重要的补充信息.这一点在忽略当前用户历史会话的模型(Version-5)和忽略其他用户会话的模型(Version-6)的结果中也能体现.但是值得注意的是, Version-5和Version-6在两个数据集上的性能完全相反.在Delicious数据集上, 其他用户的会话对于当前会话的重要性大于当前用户的历史会话.这是因为Delicious数据集上的用户各会话之间的差异性较大, 即用户不同时间段的兴趣偏好差异较大, 所以其他用户的会话的参考意义相对更高.而在Reddit数据集上, 当前用户的历史会话对当前会话的重要性大于其他用户的会话.这是因为Reddit数据集是一个社交论坛评论数据集, 用户对于感兴趣的话题会重复评论, 所以用户的历史会话之间的相关性较强, 参考意义也更强.这也是SASRec和BERT4Rec能在召回率指标上超过多会话模型的原因之一.删除空间信息模块的模型(Version-1)和删除用户聚合特征向量的模型(Version-7)可以看成一类, 只是相比Version-1, Version-7通过邻域聚合操作预处理项目节点.这两者的实验结果也表明预处理用户和项目节点的重要性.去除时间信息学习模块的模型(Version-2)和删除位置信息学习模块的模型(Version-4)都是删减一部分针对单个会话的操作, 也不能放弃会话自身的特征学习.综上所述, 模型的各个模块都对本文模型做出一定的贡献, 删除任何一个都会在一定程度上降低MFF-SSR的精确性.
| 表4 不同模块在2个数据集上的消融实验结果 Table 4 Results of ablation experiment of different modules on 2 datasets |
2.6.2 图神经网络层数的影响
本文检测图神经网络邻域层数对模型的影响, 分别测试采用1层, 2层, 3层, 4层邻域下模型的性能, 结果如表5所示, 表中黑体数字表示最优值.
| 表5 图神经网络层数对模型性能的影响 Table 5 Influence of GNN layers on model performance |
从表5中可以看到, 模型在邻域层数为3时总体效果最优, 这与文献[19]中的结果一致.这是因为邻域层数较少会导致聚合的邻域节点不足, 不能够充分学习用户特征和项目节点特征.从另一方面讲, 过多的邻域层数也会导致过拟合问题, 反而降低模型效果.对比权衡之下, 邻域层数设置为3.
2.6.3 相似用户数量对推荐效果的影响
选取合适数量的相似用户也是本文研究的重要问题之一.过多的相似用户会导致过拟合和增大模型的负担, 过少则会导致模型学习到的上下文会话信息不够.所以, 本文选择数量为5、10、15的相似用户, 测试模型性能, 结果如表6所示.
| 表6 相似用户数量对模型性能的影响 Table 6 Influence of number of similar users on model performance |
从表6可以看到, 选择相似用户数量为10时效果最优.这点与文献[17]中的结论一致.过多的相似用户并不能有效提升模型性能, 反而会增加模型的训练时间.这是因为前N位用户与当前用户足够相似, 而超过阈值的相似用户反而可能产生负面信息.所以, 本文选择与当前用户相似度排名前10的其他用户的会话作为上下文信息.
为了从短会话中学习更丰富的用户偏好和更精确地找到相似上下文会话, 本文提出多特征融合短会话推荐模型(MFF-SSR), 同时关注短会话自身项目隐藏信息和上下文信息.对于会话自身信息, 模型首先将项目节点建模到图神经网络中, 学习邻域特征, 然后利用门控循环神经网络和位置感知多头自注意力网络充分发掘会话时序和位置上的隐藏特征.对于会话的上下文信息, 通过相似会话检索网络, 寻找与当前会话最相似的会话, 缓解短会话信息稀少的问题, 并通过相似会话权重网络, 为每个上下文会话根据当前用户的偏好分配差异性的权重.最终通过学习的短会话特征为用户推荐下一个项目.在两个真实数据集上的实验结果均体现MFF-SSR的优越性.今后将考虑引入更多辅助信息, 如用户和项目的标签信息, 进一步强化模型短会话特征学习能力.另外, 也将考虑模型在复杂会话环境下的适应能力, 进行更深一步的研究.
本文责任编委 林鸿飞
Recommended by Associate Editor LIN Hongfei
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|