









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
融合多感受野与注意力的太阳能电池缺陷生成算法
[周颖1, 2  , 裴盛虎
, 裴盛虎1 , 陈海永1, 2 , 颜毓泽1 ]
, 裴盛虎, 陈海永, 颜毓泽]
|
|



作者简介:

裴盛虎,硕士研究生,主要研究方向为图像处理.E-mail:1650954141@qq.com.
陈海永,博士,教授,主要研究方向为机器视觉、图像处理.E-mail:haiyong.chen@hebut.edu.cn.
颜毓泽,硕士研究生,主要研究方向为目标检测.E-mail:1969232540@qq.com.
针对太阳能电池某些缺陷图像样本较少的问题,提出融合多感受野与注意力的太阳能电池缺陷生成算法,并将生成图像用于缺陷检测模型的训练.首先,构造双判别器的生成对抗网络,全局判别器与局部判别器分别关注图像中的全局信息与局部细节.然后,设计多感受野特征提取,与改进的注意力模块融合为多感受野注意力模块,用于设计生成器和判别器的网络结构.最后,在损失函数中加入结构相似性损失与峰值信噪比损失,用于训练生成器,并对生成图像进行均值滤波处理.在太阳能电池电致发光数据集上对3种不同尺度的缺陷图像进行生成实验,结果表明,3种缺陷生成图像的结构相似性指标与峰值信噪比指标都较高.此外,在利用生成的缺陷图像进行YOLOv7检测模型的训练后,3种缺陷的平均精度均值较高.
About Author:
PEI Shenghu, master student. His research interests include image processing.
CHEN Haiyong, Ph.D., professor. His research interests include machine vision and image processing.
YAN Yuze, master student. His research interests include target detection.
Aiming at the problem of insufficient image samples for some certain defects in solar cells, a solar cell defect generation algorithm combining multiple perception fields and attention is proposed. The generated images are utilized to train the defect detection model. Firstly, a generative adversarial network with dual discriminators is constructed, and a global discriminator and a local discriminator focuse on global information and local details, respectively. Secondly, the multiple perception field feature extraction is designed and fused with the improved attention module to form a multiple perception field attention module. The module is utilized in the network structure of both the generator and the discriminator. Finally, structural similarity loss and peak signal-to-noise ratio loss are added to the loss function for generator training, and the generated images are mean filtered. The generation experiments for 3 different scales of defect images on the solar electroluminescence dataset show that the structural similarity and peak signal-to-noise ratio are high. Additionally, after training the YOLOv7 detection model with the generated defect images, the average precision values for all three defects are high.
太阳能作为一种可再生能源, 已得到广泛应用, 从而推动新能源产业的发展.太阳能电池在生产制造过程中, 难免会产生实心黑、阴影和隐裂等不同尺度的缺陷, 这些缺陷的存在不仅影响太阳能电池的发电效率和使用寿命, 还会引起用电危险.缺陷检测是避免有缺陷的太阳能电池进入下一个生产阶段的关键, 但现有缺陷数据集上某些种类缺陷的数据量过小, 这样的数据用于缺陷检测模型的训练时会出现模型的过拟合现象[1].
避免因缺陷数据集过少而导致的检测模型过拟合的方法之一是对缺陷图像进行数据扩充处理.传统的图像处理方法有几何变换、色彩空间变换和多图像混合等[2], 但这些方法不能获得新的内容, 增广数据的频谱有限.基于博弈思想的生成对抗网络(Generative Adversarial Network, GAN)[3]自提出以来, 研究者们将基于GAN的方法应用于数据扩充的各个领域, 促进了无监督学习技术的发展.张一平等[4]提出全连接辅助分类器GAN, 对太阳能电池电致发光(Electroluminescence, EL)图像进行数据扩充.刘坤等[5]在GAN中引入大量负样本, 提高模型的特征表达能力, 解决太阳能电池正负样本不均衡的问题.
传统的GAN只有一个生成器和一个判别器, 单判别器仅局限于提取生成图像的全局特征, 不能关注生成图像的细节特征.为了解决这一问题, Ma等[6]提出DDCGAN(Dual-Discriminator Conditional GAN), 关注不同分辨率图像中的纹理细节.Yang等[7]使用双判别器, 实现重构人脸的全局连贯性和局部连贯性.注意力机制因其在抑制复杂背景和突出目标特征方面表现的良好效果, 已成为GAN中不可缺少的一部分.Tan等[8]将通道注意力应用于图像隐写, 提高隐写图像的生成质量和提取信息的准确性.Cao等[9]在GAN中融入自注意力机制, 提高模型的大规模特征学习能力.
不同感受野下获取的特征信息是不同的, 为了获得更丰富的特征信息, 文献[10]~文献[12]将Inception模型与GAN结合, 利用Inception中不同卷积提取不同尺度特征的特点, 大幅提高GAN的生成能力.为了充分结合注意力机制突出目标特征信息与多感受野提取不同尺度特征信息的能力, 文献[13]~文献[15]将注意力机制融入多感受野特征提取中, 进一步提高GAN的生成质量, 但其注意力对多级感受野提取特征的表示强度不高, 并且增加模型的参数量与计算复杂度.
在上述研究的基础上, 本文提出融合多感受野与注意力的太阳能电池缺陷生成算法(Solar Cell Defect Generation Algorithm Combining Multiple Per- ception Fields and Attention, Solar-MFA).为了提高生成图像的质量, 构建双判别器的生成对抗网络, 全局判别器与局部判别器分别关注图像中的全局信息与局部细节.根据不同类型缺陷尺度变化范围的不同, 并为了在复杂背景的干扰下准确关注缺陷信息, 在生成器与判别器中设计多感受野特征提取模块, 并与改进的注意力模块(Improved Attention Module, IAM)融合为多感受野注意力模块(Multiple Percep-tion Fields Attention, MFA).为了提高生成图像的纹理细节, 将结构相似性(Structural Similarity Index Measure, SSIM)损失与峰值信噪比(Peak Signal-to-Noise Ratio, PSNR)损失加入生成器损失函数中进行网络训练.为了提高生成图像的清晰度, 将生成的缺陷图像进行均值滤波(Mean Filter, MF)处理.在太阳能电池电致发光数据集上对3种不同尺度的缺陷图像进行的生成实验, 结果表明, 3种缺陷生成图像的结构相似性指标与峰值信噪比指标都较高.此外, 在利用生成的缺陷图像进行YOLOv7检测模型的训练后, 3种缺陷的平均精度均值较高.
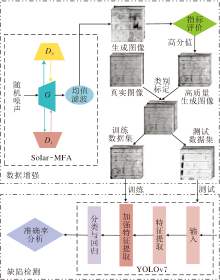
本文研究包括数据增强和缺陷检测2部分, 具体如图1所示.数据增强部分由融合多感受野与注意力的太阳能电池缺陷生成算法(Solar-MFA)、指标筛选和数据混合标定组成, Solar-MFA输入随机噪声向量获得大量的生成图像, 将生成图像经过评价指标筛选指标阈值大于设定值的高质量生成图像.为了避免仅使用真实图像或生成图像作为检测网络的测试集造成较大偏差, 将生成的高质量图像与现有全部真实图像混合为缺陷检测模型YOLOv7使用的数据集.在进行YOLOv7模型训练前, 将混合数据集进行类别标定, 并按比例将混合数据集划分为训练数据集与测试数据集.缺陷检测部分利用来自数据增强部分的训练数据集训练YOLOv7检测模型, 训练完成后, 保存相应的模型权重, 输入测试数据集, 输出对于各类缺陷的检测指标并分析.
 | 图1 数据增强与缺陷检测总体结构Fig.1 Overall structure of data augmentation and defect detection |
Solar-MFA框架如图2所示, 由1个生成器和2个判别器组成.生成器G通过输入随机噪声生成缺陷图像.全局判别器D1关注整幅图像的全局信息, 将整幅图像分割为16幅局部图像后输入局部判别器D2中.D2负责判别16幅局部图像的真假.最后将生成图像经过MF处理, 得到最终清晰的生成图像.
 | 图2 Solar-MFA总体框架Fig.2 Framework of Solar-MFA |
本文使用改进的注意力模块(IAM)分别改进卷积注意力机制模块(Convolutional Block Atten-tion Module, CBAM)[16]中的通道注意力模块和空间注意力模块.IAM结构如图3所示.
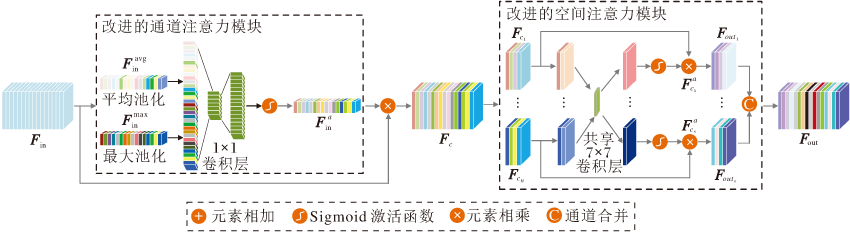 | 图3 IAM结构图Fig.3 Structure of IAM |
改进的通道注意力模块将平均池化与最大池化的特征融合通过特征拼接和卷积操作实现.特征拼接不仅能够整合更多的信息特征, 而且保留更强的鉴别特征.卷积操作进一步整合拼接特征, 形成每个通道的适当权重.
首先, 应用平均池化与最大池化, 减少输入特征Fin∈ RH× W× C的空间维度信息, 得到2个特征向量
其中, c[· ]表示在通道维度上进行拼接操作, C1× 1(· )表示2个卷积核为1× 1的卷积操作, σ (· )表示sigmoid激活函数处理.
Fc=Fin$\otimes$
其中$\otimes$表示对应元素相乘操作.
CBAM中的空间注意力模块直接对通道细化特征Fc在通道维度上进行最大值与平均值的操作, 得到2个特征图后拼接, 作为后续卷积运算的输入, 但获得的空间位置信息有限.
如图3所示, 改进的空间注意力模块首先将Fc在通道维度上均分为n组, 每个子特征图的通道数设置为N, 即
Fc→ [
其中n=C/N, C表示Fc的通道数.
然后, 分别对每个子特征图
其中C7× 7(· )表示卷积核为7× 7的卷积操作.
最后, 将
将每个
Fout=c[
在生成器G中, 输入维度为1× 100的随机正态分布噪声, 依次经过1个全连接层、2个生成器多感受野注意力模块(MFA of Generator, G_MFA)和2个卷积模块后, 得到320× 320× 1的特征图.
单一感受野在提取不同尺度的缺陷特征时, 不能同时获取缺陷的局部信息和全局信息, 而现有的多感受野在不改变输入特征图的空间大小与通道数的情况下, 增加模型复杂度, 减缓特征的提取速度.同时现有方法往往忽略原特征的传递, 导致模型的收敛速度较慢.
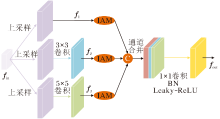
为了解决上述问题, 本文设计G_MFA.G_MFA的输入特征经过多感受野特征提取后, 降低特征图维度, 减少计算复杂度, 传递原输入特征通过IAM突出后的关键信息, 加快模型的收敛速度.G_MFA结构如图4所示.
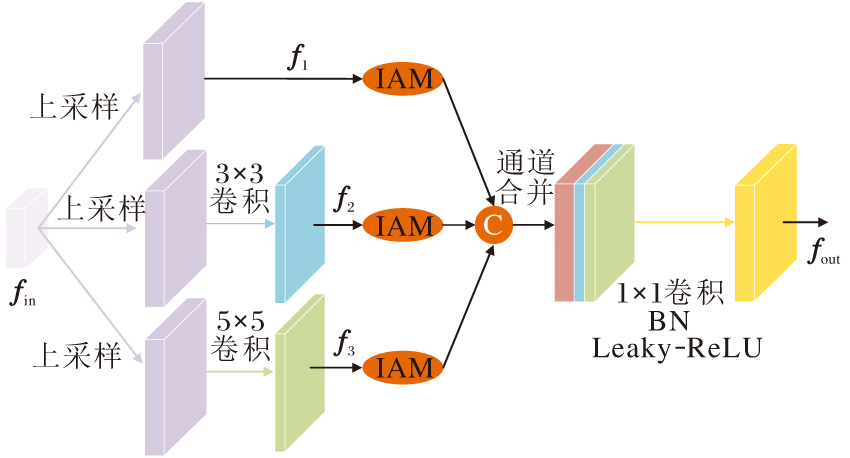 | 图4 G_MFA结构图Fig.4 Structure of G_MFA |
输入特征图fin∈ RH× W× C, 上采样后, 得到特征图:
f1=U(fin)∈ R2H× 2W× C,
其中U(· )表示上采样层.
f1首先进行卷积核分别为3× 3与5× 5的卷积操作, 得到特征图:
f2=C3× 3(f1)∈ R2H× 2W× C/2, f3=C5× 5(f1)∈ R2H× 2W× C/2,
其中, C3× 3(· )表示核为3× 3的卷积层, C5× 5(· )表示核为5× 5的卷积层.
然后, f1、 f2和f3分别输入IAM中, 输出相应的注意力特征图.为了最大化保留缺陷信息, 将f1、 f2和f3的注意力细化特征在通道维度上进行拼接.最后, 经过1× 1卷积、BN(Batch Normalization)和Leaky-ReLU后, 进一步整合拼接特征, 得到输出
fout=L(B(C1× 1(c[A(f1), A(f2), A(f3)])))∈ R2H× 2W× C,
其中, C1× 1表示核为1× 1的卷积层, A(· )表示注意力细化操作, B(· )表示BN处理, L(· )表示Leaky-ReLU激活函数.
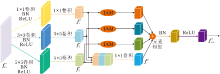
判别器D1关注输入图像的全局信息, 输入维度为320× 320× 1的整幅图像, 依次经过2个判别器多感受野注意力模块(MFA of Discriminator, D_MFA)和1个全连接层后, 输出整幅图像的判别结果.D_MFA同样降低模型的复杂度, 加快模型训练时的收敛速度.与G_MFA不同的是, D_MFA不仅聚合相应的注意力细化特征, 而且融入原输入特征与不同感受野下的特征.为了降低模型的复杂度与特征信息的冗余, 输入特征在进行特征聚合与注意力细化前进行1次特征提取.D_MFA结构如图5所示.
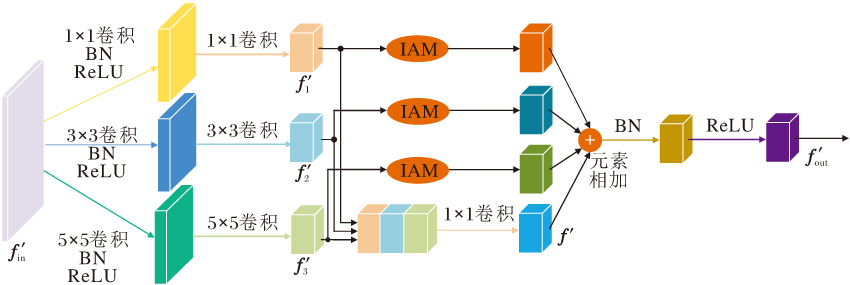 | 图5 D_MFA结构图Fig.5 Structure of D_MFA |
输入特征f'in∈ R4H× 4W× C, 进行两次卷积核分别为1× 1、3× 3和5× 5的卷积后, 得到不同感受野下的特征:
f'1=C1× 1(R(B(C1× 1(f'in))))∈ RH× W× 4C,
f'2=C3× 3(R(B(C3× 3(f'in))))∈ RH× W× 4C,
f'3=C5× 5(R(B(C5× 5(f'in))))∈ RH× W× 4C,
其中R(· )表示ReLU激活函数.为了避免缺陷特征细节纹理的丢失, f'1, f'2与f'3在通道维度上拼接, 并经过1× 1卷积, 将拼接特征整合为
f'=C1× 1(c[f'1, f'2, f'3])∈ RH× W× 4C.
为了突出缺陷特征的内容信息, f'1, f'2与f'3分别经过IAM, 得到相应的注意力细化特征图.最后将f'与各注意力细化特征聚合, 并经过BN、ReLU激活函数后输出特征:
f'out= R(B(f'+A(f'1)+A(f'2)+A(f'3)))∈ RH× W× 4C.
为了提高生成图像局部区域的细节特征与真实图像相应区域的相似性, 本文设计局部判别器D2, 关注整幅图像的不同局部区域.D2的输入为一幅图像分割的16幅局部图像, 因此局部图像的分辨率只有80× 80× 1, 为了避免不同多感受野的特征过分重叠, D2在使用1个D_MFA模块后, 采用2个卷积核为3× 3的卷积层进行后续的特征提取, 最后输出16幅局部图像的判别向量.此外为了加快网络的收敛速度, 每个卷积后均添加BN层与ReLU激活函数.为了减少计算量, 在2个卷积层的最后均添加失活率为0.5的失活层.
判断判别器D1是否达到收敛的条件是其能否准确判别输入是真实图像还是生成图像, 即
其中, xr表示真实图像, xu表示生成图像, E[· ]表示数学期望, 1表示D1对整幅生成图像的输出目标值.
D2关注图像的局部信息, 损失包括对局部真实图像和局部生成图像的判别结果的反馈, 即
其中, xr'表示局部真实图像, xu'表示局部生成图像, I表示D2对局部生成图像的输出目标向量, 向量各元素值均为1.
G的损失函数为对抗性损失Ladv、PSNR损失LPSNR和SSIM损失LSSIM的加权和:
LG=λ 1Ladv+λ 2LPSNR+LSSIM,
其中, λ 1=0.5, λ 2=0.01.
对抗性损失Ladv包括D1对整幅生成图像判别结果的反馈和D2对各局部生成图像判别结果的反馈, 则
Ladv=
PSNR损失与SSIM损失分别用于评估生成图像与真实图像之间的颜色差异与结构相似程度:
LPSNR=10lg[
其中,
MSE=
表示生成图像与真实图像之间的均方误差, H、W表示图像的高度和宽度, n表示图像的亮度范围.
LSSIM=[
其中,
本文的所有实验都是基于Torch框架的Python编写实现, 计算机系统配置为:Windows10 64-bit系统, Intel core i7-11th CPU, NVIDIA 3060 GPU.
太阳能电池电致发光(EL)数据集均来自天津英利集团采集拍摄的太阳能电池外观图像, 数据采集过程和数据集均已公开[17].生成实验所用数据为EL数据集上3种数量较少的缺陷数据, 共有90幅图像, 分辨率均为320× 320, 包含隐裂、实心黑和阴影缺陷各30幅.3种缺陷图像如图6所示.
 | 图6 3种缺陷图像示例Fig.6 Examples for 3 types of defect images |
训练过程中G与D1、D2交替优化.通过实验对比将IAM中每个子特征图通道数N设置为16; 总迭代次数为3 000, 批尺寸大小设置为6; 生成器和2个判别器的反向传播优化器均为Adam(Adaptive Moment Estimation)优化器, 初始学习率为0.000 2, 一阶动量项为0.5, 二阶动量项为0.999.
2.1.1 IAM消融实验
为了验证IAM在生成器和判别器中均起到作用, 进行IAM的消融实验, 结果如表1所示, 表中黑体数字表示最优值, G_MF、D_MF分别表示G_MFA、D_MFA中未融入IAM, 只有多感受野特征提取.
| 表1 IAM的消融实验结果 Table 1 Ablation experiment results of IAM |
由表1可看出, G_MF+D_MF时各类缺陷的PSNR与SSIM值均最低, G_MFA+D_MF的指标值略低于G_MF+D_MFA, G_MFA+ D_MFA时各类缺陷的PSNR与SSIM值均为最优值, 表明IAM提高生成器与判别器的特征提取能力, 并且在判别器中发挥的作用高于在生成器中.
G_MF+D_MF与G_MFA+D_MFA(即本文算法中有无IAM)对3种缺陷的生成图像对比如图7所示.由图可知, IAM加在生成器与判别器中, 在生成缺陷图像时可以从复杂背景中准确提取缺陷特征, 获得更多的缺陷信息, 提高缺陷的完整性.
 | 图7 有无IAM时生成图像对比Fig.7 Comparison of generated images with and without IAM |
当本文算法中有无IAM时, 全局判别器在训练收敛时对于实心黑和阴影2种缺陷图像的关注点的可视化分析如图8所示, 图中真实图像中的蓝色框内为缺陷信息.由图中可以看出, IAM减轻背景对全局判别器的干扰, 关注更完整的缺陷信息, 同时对于缺陷边缘细节信息的捕捉更充分.
 | 图8 有无IAM时全局判别器的可视化分析Fig.8 Visualization analysis of global discriminator with and without IAM |
2.1.2 模型结构消融实验
下面进行模型结构的消融实验, 分别删除Solar-MFA中的D2、D_MFA、G_MFA、MF模块, 测试不同结构对于3种缺陷的生成效果, 具体生成图像对比如图9所示.由图可看出, 相比Solar-MFA的生成图像, 删除判别器D2可以生成较完整的缺陷, 但背景噪声干扰严重, 缺陷缺少局部细节, 这表明D2起到关注局部细节的作用.删除D_MFA模块与G_MFA模块后, 该模型在缺陷完整性和抑制背景噪声干扰2方面都较差.删除D_MFA模块或G_MFA模块后, 生成的实心黑和阴影缺陷较完整, 背景噪声干扰较轻, 但对于隐裂缺陷生成效果较差, 这表明G_MFA模块与D_MFA模块起到提取不同尺度缺陷特征并抑制背景噪声关注缺陷信息的作用.删除MF模块后, 生成效果仅在背景噪声上略差, 这表明MF模块起到提高图像清晰度的作用.
 | 图9 6种结构的生成图像对比Fig.9 Comparison of images generated by 6 structures |
图9中6种结构在3种缺陷生成图像上的测试结果如表2所示, 表中黑体数字表示最优值.从表中可以看出, Solar-MFA的PSNR和SSIM值都达到最大值, 进一步验证D2、G_MFA、D_MFA和MF模块均发挥各自的作用.
| 表2 6种结构的指标值对比 Table 2 Index value comparison of 6 structures |
2.1.3 生成器G的损失函数消融实验
G的损失函数中包含LPSNR、LSSIM、Ladv, 选择不同的损失函数后, 具体消融实验结果如表3所示, 表中$\surd$表示G在训练时包含相应的损失函数, 黑体数字表示最优值.
| 表3 G中损失函数的指标值对比 Table 3 Index value comparison of G with different loss functions |
从表3中可以看出, G损失函数同时包含3种损失时整体效果最佳.与之对比, 如果G损失函数中只有Ladv, 生成的3种缺陷的PSNR与SSIM值均达到最低, 说明生成图像与真实图像的颜色差异最大、结构相似性最低.如果仅移除G损失函数中的LPSNR, 3种生成缺陷的SSIM值无明显变化, 但3种缺陷的PSNR值分别降低1.11、2.27、1.94.同样仅移除G损失函数中的LSSIM, 3种生成缺陷的PSNR值无明显变化, 但SSIM值分别降低0.11、0.13、0.11.
2.2.1 注意力对比实验
为了证实IAM的有效性, 将Solar-MFA中的IAM分别替换为如下4种注意力模块:CBAM[16]、ECA(Efficient Channel Attention)[18]、SimAM(Sim-ple, Parameter-Free Attention Module)[19]、CA(Co-ordinate Attention)[20], 进行对比实验.Solar-MFA使用5种注意力模型的指标值如表4所示, 表中黑体数字表示最优值.由表可以看出, CBAM的效果优于ECA, 与SimAM的效果接近, 相比其它注意力, CA的效果均有较大提高, 但IAM的2项指标均为最优值, 这表明IAM的有效性.
| 表4 Solar-MFA使用5种注意力模块的指标值对比 Table 4 Index value comparison of Solar-MFA with 5 attention modules |
为了证实IAM的通用性, 将DCGAN(Deep Convolutional GAN)[21]作为基础算法, 在DCGAN中同样分别使用ECA、CBAM、SimAM、CA和IAM这5种注意力模块, 结果如表5所示, 表中黑体数字表示最优值.由表可以看出, 将不同注意力模块加入DCGAN后, IAM同样表现出最优性能, 表明IAM的通用性.
| 表5 DCGAN使用5种注意力模块的指标值对比 Table 5 Index value comparison of DCGAN with 5 attention modules |
2.2.2 不同算法对比实验
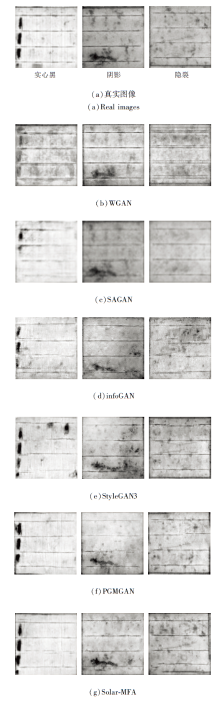
本节选择如下算法进行对比实验:WGAN(Wasserstein GAN)[22]、SAGAN(Self-Atten-tion GAN)[23]、infoGAN(Information Maximizing GAN)[24]、PGMGAN(Partition-Guided Mixture of GAN)[25]和StyleGAN3[26].
6种算法在3种缺陷上的指标值对比如表6所示, 表中黑体数字表示最优值.由表可以看出, WGAN、SAGAN和infoGAN的指标值在3种缺陷上均很低, 相比之下, StyleGAN3和PGMGAN的指标值均有大幅提升, PGMGAN表现最优.对于实心黑缺陷, 相比PGMGAN, Solar-MFA的PSNR值和SSIM值分别提高1.91和0.15; 对于阴影缺陷, Solar-MFA的PSNR值和SSIM值分别提高2.87和0.12; 对于隐裂缺陷, Solar-MFA的PSNR值和SSIM值分别提高2.76和0.12.
| 表6 6种算法的指标值对比 Table 6 Index value comparison of 6 algorithms |
6种算法在3种缺陷上的生成图像如图10所示.由图可看出, WGAN和SAGAN在缺陷完整度与抑制背景干扰上均很差.infoGAN生成图像的背景噪声干扰较轻, 但缺陷完整度较低.StyleGAN3生成的各类缺陷完整度较高, 但生成的图像背景噪声干扰严重.相比StyleGAN3, PGMGAN生成的缺陷完整度略低, 生成的背景细节有大幅提升, 但存在背景亮度较高的问题.Solar-MFA在生成缺陷特征的完整性和抑制背景噪声干扰的能力上均优于其它算法.
 | 图10 6种算法的生成图像对比Fig.10 Comparison of images generated by 6 algorithms |
在对比算法中, StyleGAN3和PGMGAN对3种缺陷的生成质量最优, 因此选取这2种算法与Solar-MFA进行对比, 对比模型参数量和模型训练时达到收敛状态的时间如表7所示, 表中黑体数字表示最优值.由表可看出, Solar-MFA在不增加参数量的情况下可提高算法的训练速度.
| 表7 3种算法的参数与训练时间 Table 7 Parameters and training time of 3 algorithms |
本文采用使用传统数据增强方式(翻转、缩放和添加噪声等)、WGAN、PGMGAN和Solar-MFA扩充后的数据集进行模型检测实验.
针对3类缺陷生成情况的不同, Solar-MFA将生成的3类缺陷图像的PSNR和SSIM指标的筛选阈值设置为不同值.PSNR筛选阈值分别为21.00, 23.00, 25.00; SSIM筛选阈值分别为0.60, 0.60, 0.65.在设定的指标筛选阈值下, 3种缺陷的生成图像与全部真实图像混合至4 500幅, 每类缺陷图像的数量均为1 500幅.其余3种算法均对训练数据进行相同方式的扩充.
在使用4种算法扩充后的数据集进行YOLOv7缺陷检测网络训练时, 所有参数均一致.模型均采用VOC数据集训练权重的预训练模型, 训练集与测试集比例为9∶ 1; 优化器为随机梯度下降(Stochastic Gradient Descent, SGD), 初始学习率为0.01, 动量参数为0.937, 权值衰减率为0.000 5; 训练总迭代次数为150, 前50代采用冻结训练以加快模型的收敛速度, 前50代与后100代的批尺寸大小分别为8和4.
YOLOv7训练完成后, 使用测试集进行测试, 在交并比(Intersection over Union, IoU)设置为0.5时3种缺陷检测的平均精度(Average Precision, AP)如表8所示, 表中黑体数字表示最优值.由表可以看出, 传统数据增强方式下各类缺陷的AP值均很低, 存在类间AP值差距较大的问题.相比传统数据增强方式, WGAN的AP值虽有大幅提升, 但仍存在类间差距较大的问题, 如实心黑的AP值为88.91%, 而阴影的AP值只有78.64%.在现有算法中, PGM- GAN各类缺陷的AP值均为最优值.相比PGMGAN, Solar-MFA进一步提升各类缺陷的AP值, 平均精度均值(Mean AP, mAP)上升2.26%, 并在一定程度上缓解类间差距大的问题, 这表明Solar-MFA生成图像的有效性.
| 表8 4种算法的检测精度对比 Table 8 AP comparison of 4 methods % |
4种算法对3种缺陷的预测结果对比如图11所示.由图可看出, 相比对比算法, Solar-MFA生成的缺陷图像在检测过程中对各类缺陷的预测置信度有大幅提升, 预测框对于缺陷的定位更准确.
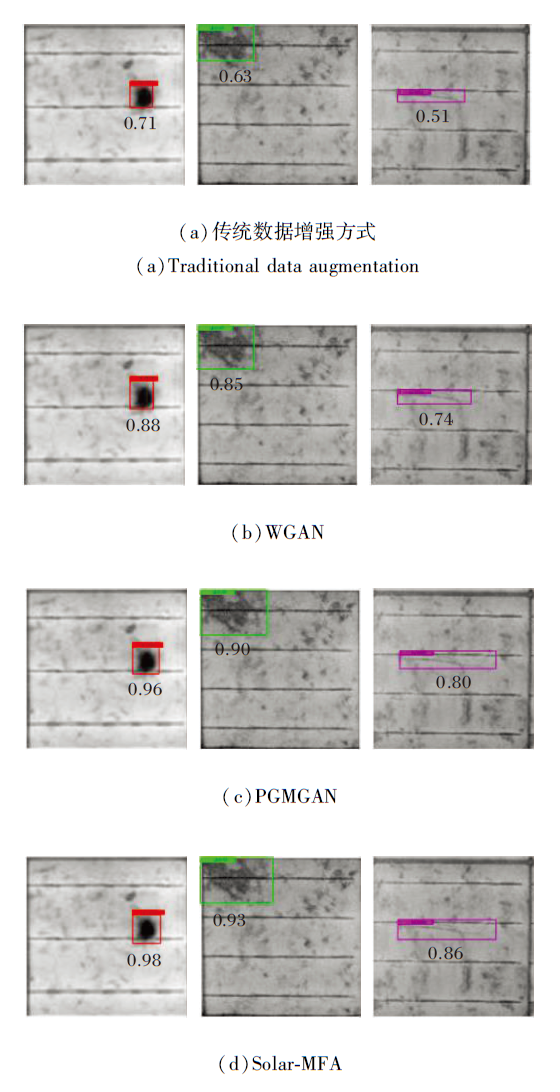 | 图11 4种算法的预测结果对比Fig.11 Prediction result comparison of 4 methods |
为了证实Solar-MFA的通用性, 将对比算法中对于太阳能电池EL数据生成质量最优的PGMGAN和Solar-MFA应用于东北大学热轧带钢表面缺陷开源数据集.该数据集包含常见型、油污干扰型和微小型3种类型的缺陷数据.
常见型缺陷包含夹杂、压入氧化皮、麻点、裂纹、划痕和斑块6种缺陷, 6种常见型缺陷的真实图像与2种算法的生成图像如图12所示, 图中绿色框内为缺陷(氧化皮、麻点和裂纹只标注图像中的部分).由图可看出, 相比PGMGAN, Solar-MFA生成的缺陷完整性与真实性更高, 对背景噪声的抑制更强, 具备生成各类缺陷纹理细节的能力.
 | 图12 各算法在6种常见型缺陷上的生成图像Fig.12 Images of 6 common types of defects generated by different algorithms |
微小型包含点状和钢坑2种缺陷, 2类缺陷的真实图像与2种算法的生成图像如图13所示, 图中绿色框内为缺陷.由图可以看出, PGMGAN几乎不能生成微小型的缺陷, 但Solar-MFA可以从复杂的环境中捕捉微小缺陷信息, 适用于微小微弱缺陷的生成.
 | 图13 各算法在2种微小型缺陷上的生成图像Fig.13 Images of 2 types of small defects generated by different algorithms |
油污干扰型包含划痕、小缺陷和擦纹3种缺陷, 各类缺陷的真实图像与2种算法的生成图像如图14所示, 图中蓝色框内为油污干扰, 绿色框为缺陷.
 | 图14 各算法在3种油污干扰型缺陷上的生成图像Fig.14 Images of 3 types of oil interference defects generated by different algorithms |
由图14可看出, PGMGAN在缺陷的完整性和油污形状还原两方面均较差, 但Solar-MFA在生成完整缺陷的情况下准确还原油污形状, 适用于有外界物质干扰缺陷的生成.
PGMGAN与Solar-MFA对3种数据集上各类缺陷的指标值对比如表9所示, 表中黑体数字表示最优值.由表可知, 对于背景噪声较小的缺陷图像, PGMGAN的生成效果与Solar-MFA相近, 如常见型缺陷中的夹杂.在3种数据集上, PGMGAN对微小型缺陷的生成指标值与Solar-MFA差距最小, 结合图13可以看出, PGMGAN可以生成较好的背景, 导致指标值较高, 但难以生成其中的微小缺陷.
| 表9 各算法在不同类型缺陷上的指标值对比 Table 9 Index value comparison of 2 algorithms for different types of defects |
本文针对太阳能电池EL数据集某些种类缺陷数据较少的问题, 提出融合多感受野与注意力的太阳能电池缺陷生成算法(Solar-MFA), 生成高质量的缺陷图像用于数据增强.设计的双判别器结构提高生成图像的局部细节; 多感受野特征提取提高网络模型的特征提取能力, 可以适应不同类型缺陷在尺度上的变化.IAM进一步提升多感受野模块, 抑制背景噪声干扰, 增强提取关键缺陷特征的能力.在生成器损失函数加入PSNR与SSIM损失训练生成器, 提高生成图像的纹理细节.最后将生成的缺陷图像进行均值滤波处理, 提高生成图像的清晰度.实验表明, Solar-MFA对不同尺度缺陷图像的生成质量明显较高, 使用生成的缺陷图像训练YOLOv7检测模型, 提高检测模型对各类缺陷的检测精度.Solar-MFA也适用于其它应用领域, 但生成的隐裂缺陷在检测模型中的精度不如其它缺陷, 今后将进一步研究微弱缺陷, 提高检测模型对微弱缺陷的检测精度.
本文责任编委 高 隽
Recommended by Associate Editor GAO Jun
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|