

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于视觉多头注意力与跨层白化的水下图像增强网络
[丛晓峰1  , 桂杰
, 桂杰1, 2 , 贺磊2 , 章军3 ]
, 桂杰, 贺磊, 章军]
|
|



作者简介:
丛晓峰,博士研究生,主要研究方向为水下图像增强、图像去雾.E-mail:cxf_svip@163.com. 
桂 杰,博士,教授,主要研究方向为生成式算法、图像去雾、自监督学习.E-mail:guijie@seu.edu.cn. 
贺 磊,博士,副研究员,主要研究方向为网络空间安全、内生安全.E-mail:helei@pmlabs.com.cn.
由于水下的光吸收现象、散射现象与小粒子的存在,水下图像存在色彩失衡与细节失真问题.为此,文中设计基于视觉多头自注意力与跨层白化的水下图像增强网络.采用层级式的架构,由编码路径进行特征提取并由解码路径进行图像重建,编码与解码路径的核心组件是视觉多头自注意力模块.对浅层特征进行实例白化处理,并将实例白化后的浅层特征通过跨层连接嵌入到深层特征中作为跨层白化路径.内容损失与结构损失用于网络的训练过程.在基准水下图像数据集上进行对比实验,定量与视觉结果表明视觉多头自注意力与实例白化对水下增强任务是有效的.
About Author:
CONG Xiaofeng, Ph.D. candidate. His research interests include underwater image enhancement and image dehazing.
GUI Jie, Ph.D., professor. His research interests include generative algorithm, image dehazing and self-supervised learning.
HE Lei, Ph.D., associate professor. His research interests include cyberspace security and endogenous safety.
Due to the phenomena of light absorption and scattering, as well as the presence of small particles in underwater environment, underwater images suffer from the problems of color imbalance and detail distortion. To address this issue, an underwater image enhancement network based on visual multi-head attention and skip-layer whitening is proposed in this paper. A hierarchical architecture is adopted, feature extraction is performed by the encoding path and image reconstruction is carried out by the decoding path. The main components of the encoding and decoding paths are visual multi-head self-attention blocks. Instance whitening is applied to shallow features. The features of shallow layer after instance whitening are embedded into the features of deep layer by skip-layer connection as skip-layer whitening path. Content loss and structure loss are employed in the training process of the proposed network. The comparative experiment on benchmark underwater image datasets demonstrates the effectiveness of visual multi-head self-attention and instance whitening for underwater enhancement task, both quantitatively and visually.
水下图像的拍摄、分析与处理是水下探索任务的重要组成部分[1], 高质量的水下图像对海洋研究任务具有促进作用[2, 3, 4].水下环境中存在光的吸收与散射现象, 导致水下图像出现色彩偏移等问题, 对水下相关任务造成负面影响, 如失真的水下图像会导致拍摄的水下生物视觉效果降低.在水下环境中不同波长的光被吸收的程度存在差异[5], 海水对红光的吸收作用要高于绿光与蓝光, 因此随着海水深度的增加, 红光成分低于绿光与蓝光, 导致图像颜色更倾向于绿色与蓝色.此外, 水下场景中存在微小粒子引起的光散射[6], 导致图像中存在同质背景噪声.
针对水下图像的失真问题, 当前研究主要分为非基于深度学习的增强算法和基于深度学习的增强算法[7].非基于深度学习的增强算法通常会对水下成像过程进行建模, 并反向求解参数, 对水下图像进行增强[8, 9].Carlevaris-bianco等[10]对水下图像的三个颜色通道的亮度衰减进行差异化分析, 结合图像去雾领域的物理学模型, 提出能够用于深度估计与颜色校正的方法.Peng等[8]分析与对比多种水下深度估计方法, 提出基于图像模糊与亮度吸收的增强模型.Song等[11]对数据集的背景光进行标注, 并采用背景光统计与透射图优化技术, 进行水下图像复原的建模.Song等[9]提出ULAP(Underwater Light Attenuation Prior), 并设计线性深度建模方法.此类非基于深度学习的增强算法不受限于水下图像的数据量, 但是在具体水下数据集上的性能表现略低于基于深度学习的增强算法.
基于深度学习的增强算法主要采用卷积神经网络(Convolutional Neural Network, CNN)技术[5, 12], 一些研究将对抗性训练融入网络训练过程中[13, 14].现有研究同时表明小波分解技术与卷积网络可联合用于构建水下图像增强网络[15, 16].Ma等[15]提出基于频域信息的对偶流网络, 采用离散的小波变换技术, 将原始图像分解为多个频带, 分解所得的频带信息可以作为多颜色空间融合与细节增强网络的输入信息.Uplavikar等[6]设计基于编码与解码结构的对抗网络, 通过对抗性训练学习水类型的相关特征, 用于提升模型对水类型的适用性.Yan等[17]利用计算机视觉领域的注意力模型, 设计ADMNNet(Atten-tion-Guided Dynamic Multibranch Neural Network), 包含动态的特征选择模型与多尺度通道注意力模型, 能够基于输入信息进行自适应调节, 并强化通道间特征的提取过程.Tang等[18]将神经架构搜索(Neural Architecture Search, NAS)应用于水下增强网络的设计过程, 增强网络的特征提取与图像重建能力, 搜索空间包括多种操作符, 如卷积模块和注意力模块等.此方法涉及的架构搜索技术所需的计算资源相对较多.Chen等[19]利用内容与风格分离技术, 提出域适应(Domain Adaptation)增强网络, 增强过程中同时使用交叉域的图像到图像转换方法以及特征编码与解码方法.Islam等[13]提出FUnIE-GAN, 用于增强水下失真图像的质量, 采用U型的对称网络架构方式, 并通过内容损失、对抗损失与感知损失等进行联合训练, 但是存在一定的颜色校正失真问题.Fu等[20]结合空间实例白化与通道归一化, 提出SCNet.Fabbri等[14]使用循环一致性生成对抗网络生成可用于水下增强任务的有监督训练的数据集, 并提出含有对抗损失与图像梯度损失的UGAN(Underwater Generative Adversarial Networks), 用于质量增强过程.Naik等[21]通过堆叠常规的卷积模块, 构建Shallow-UWnet.网络包含特征的降维与升维过程, 并通过跨层连接提升水下图像增强过程的特征复用性, 然而针对结构信息的复原效果不佳.陈学磊等[5]提出融合深度学习与成像模型的水下图像增强算法, 利用深度学习领域的扩张卷积以及带参数的激活方法, 并结合背景散射光和传输映射估计过程, 充分结合数据驱动技术与物理成像技术.Liu等[12]采用残差连接方式, 提出UResnet(Un- derwater Resnet), 采用像素损失与边缘损失对UResnet进行联合优化, 然而UResnet存在结构复原效果不足问题.Li等[22]提出采用3种输入变换进行增强的Water-Net, 包括白平衡变换、直方图均衡变换以及伽马校正变换.
然而, 田永林等[23]指出, 卷积模型受限于基于临近像素具有较大相关性的假设, 因此基于卷积模型的水下图像增强算法存在相对较强的归纳偏置问题.相对于常见的采用小尺寸卷积(如3× 3卷积)的卷积模型, Transformer架构[24, 25]具有相对较弱的归纳偏置, 使其特征学习能力更加灵活.Transformer架构已应用于多个领域, 如目标检测[23]、中文唇语识别[26]、新闻推荐[27]等, Boudiaf等[28]将预训练的Transformer架构[29]直接应用于水下图像增强任务, 该预训练Transformer架构最初应用于去噪与超分辨率等任务.作为网络的核心组件, 设计Pre-trained Image Processing Transformer, 参数量超过400 MB, 较明显地增加水下探索设备的存储开销, 且网络并未考虑水下图像增强任务中水的类型[20]对模型效果的影响.
综上所述, 本文在设计水下图像增强算法时主要考虑如下3个方面.1)利用Transformer模型的数据学习能力设计有效的水下图像增强模型.2)保证基于Transformer的水下图像算法的存储开销相对较小.3)通过对水的类型的处理, 提升水下图像增强模型的效果.因此, 本文提出基于视觉多头注意力与跨层白化的水下图像增强网络(Underwater Image Enhancement Network Based on Visual Multi-head Attention and Skip-Layer Whitening, VMA-SWN).网络采用层级化的编码-解码架构方式, 利用Transformer模型的数据学习能力, 并且每层仅由单个视觉多头自注意力模块构成, 保证模型的存储开销较小.此外, Park等[30]指出Transformer架构中的多头自注意力机制具有低通滤波的效果, 而常规卷积计算具有高通滤波效果, 因此在设计网络的过程中将常规卷积计算与视觉多头自注意力计算联合应用, 兼顾二者优势.进一步地, 实例白化(Instance Whitening, IW)操作[31]嵌入基于视觉注意力的增强网络中作为跨层连接, 用于提升水下图像的增强效果.
总之, 针对水下图像存在的色彩失真与细节模糊问题, 本文采用视觉注意力机制, 设计特征提取与图像重建的整体网络结构, 针对复杂水下退化情况, 对注意力模块提取的特征进行实例白化处理, 降低不同水类型对网络增强效果的影响.在水下图像数据集上的实验验证本文网络的增强效果.
本文提出基于视觉多头注意力与跨层白化的水下图像增强网络(VMA-SWN), 网络结构包括编码路径的降维过程与解码路径的升维过程, 并通过跨层白化进行空间特征的实例白化处理.网络的核心特征提取模块采用多头自注意力机制[24, 25, 32]实现.
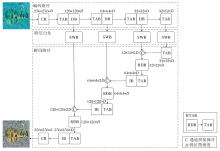
VMA-SWN的整体结构如图1所示, 图中数值表示水下图像与特征图的长宽信息, 网络输入失真的水下图像, 输出增强后的水下图像.记失真水下图像为x, 网络增强后的输出图像为y, 特征图为Ω i, i表示某层的索引, 卷积操作记为Cs(· ), 池化操作记为Ps(· ), 双三次插值操作记为Bs(· ), s表示步长.VMA-SWN主要包含如下5个模块.
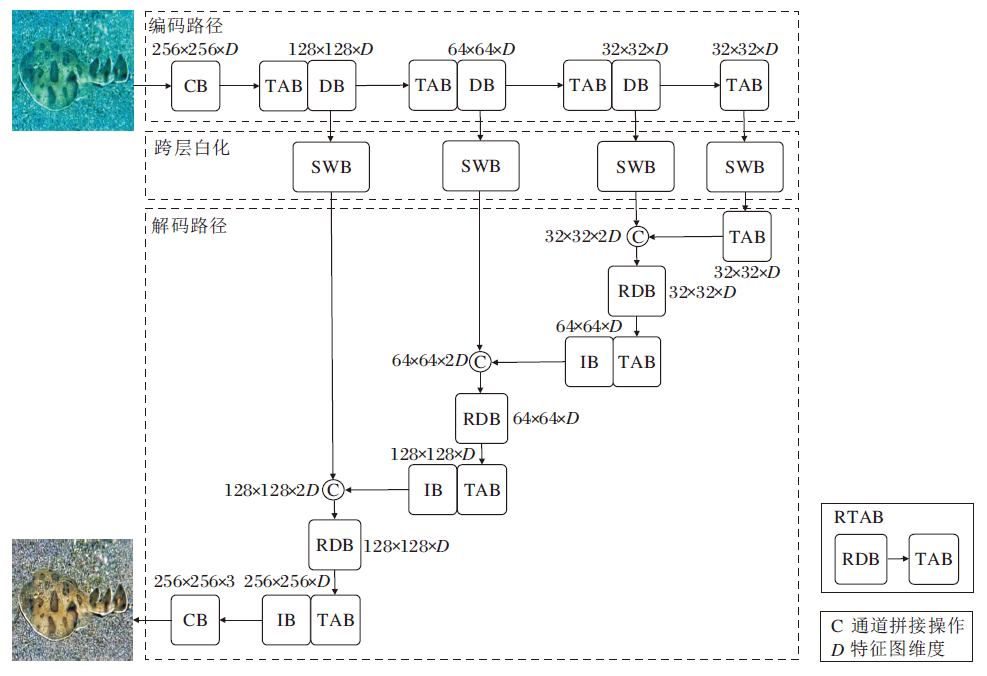 | 图1 VMA-SWN网络结构图Fig.1 Network structure of VMA-SWN |
1)卷积模块(Convolution Block, CB).第1层CB为
Ω 1=ReLU(C1(x)),
最后一层CB为
y=ReLU(C1(Ω i)).
2)下采样模块(Down-Sample Block, DB).采用
Ω i+1=P2(Ω i)
实现, 用于VMA-SWN的特征图降维过程.VMA- SWN共包含3个DB, 特征图尺寸从256× 256降至32× 32.
3)跨层白化模块(Skip-Layer Whitening Block, SWB).采用实例白化[31]实现, 用于空间特征的跨层传递.SWB可以直接嵌入浅层与深层的视觉多头自注意力模块之间, 不需要进行额外的网络修改.以图1左侧第1次跨层路径为例, 该过程为
DB→ SWB→ C→ RDB→ TAB.
DB模块输出特征图尺寸为128× 128× D.首先将该特征图输入SWB进行实例白化.然后将实例白化后的特征与解码特征进行通道拼接操作, 拼接后的特征图尺寸为128× 128× 2D.最后通过降维模块(Reduce Dimension Block, RDB)对尺寸为128× 128× 2D的特征图进行通道降维, 降维后特征图尺寸为128× 128× D, 继续传入下个模块中.
4)基于Transformer的注意力模块(Transformer-Based Attention Block, TAB)与降维的基于Transfor-mer的注意力模块(Reduced Dimensionality TAB, RTAB).TAB采用视觉Transformer中基于窗口的多头自注意力机制实现.RTAB由RDB和TAB构成.RDB通过卷积计算C1(Ω i), 降低跨层白化后特征图的维度, 再将特征图传入TAB.RTAB的实现如下:
Ω i+1=TAB(C1(Ω i)).
此时Ω i的通道数为2D且Ω i+1的通道数为D.
5)插值模块(Interpolation Block, IB).采用
Ω i+1=ReLU(C1(B2(Ω i)))
实现, 用于解码过程的特征图升维过程.VMA-SWN共包含3个IB, 特征图尺寸从32× 32升至256× 256.
上述5个模块可构建VMA-SWN, 编码路径与解码路径均含有4个TAB.为了便于下文分析, 将不含跨层白化模块的增强网络记为VMA-SWN-NoSWB.
采用视觉多头自注意力实现的TAB与RTAB是VMA-SWN的基本模块, 计算原理来自视觉注意力模型[24, 25].首先, 自注意力(Self-Attention, SA)[24]计算方式如下:
$SA\left( Q, K, V \right)= {softmax}\left( \frac{Q{{K}^{T}}}{\sqrt{d}} \right)V$,
其中, 输入矩阵为Q、K、V, 分别表示查询、键和值, d表示维度缩放值.在计算SA时将相对位置偏差B加入上式中, 即
$SA\left( Q, K, V \right)={softmax}\left( \frac{Q{{K}^{T}}}{\sqrt{d}}+B \right)V$.
构建TAB模块时采用多头自注意力机制, 进行n次SA计算, 即
$MSA\left( Q, K, V \right)=\tau \left[ hea{{d}_{1}}, hea{{d}_{2}}, \ldots , hea{{d}_{c}}, \ldots hea{{d}_{n}} \right]{{W}^{O}}$,
其中, τ [· ]表示拼接操作, WO表示投射矩阵,
$hea{{d}_{c}}=SA\left( QW_{c}^{Q}, KW_{c}^{K}, VW_{c}^{V} \right)$,
$\Omega _{i}^{* }=RPMSA\left( \psi \left( {{\text{ }\!\!\Omega\!\!\text{ }}_{i-1}} \right) \right)+{{\text{ }\!\!\Omega\!\!\text{ }}_{i-1}}$. (1)
然后使用多层感知机φ (· )获取第i层的特征:
${{\text{ }\!\!\Omega\!\!\text{ }}_{i}}=\varphi \left( \psi \left( \text{ }\!\!\Omega\!\!\text{ }_{i}^{* } \right) \right)+\text{ }\!\!\Omega\!\!\text{ }_{i}^{* }=\left[ GELU\left( \psi \left( \text{ }\!\!\Omega\!\!\text{ }_{i}^{* } \right){{W}_{1}}+{{b}_{1}} \right){{W}_{2}}+{{b}_{2}} \right]+\text{ }\!\!\Omega\!\!\text{ }_{i}^{* }$, (2)
其中, W1、W2表示权重, b1、b2表示偏差项, GELU(· )表示激活函数.式(1)与式(2)为TAB的计算过程, RTAB中的TAB计算过程与此相同.
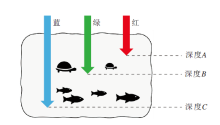
水的类型包括浅海、深海以及浑水等[20], 如图2所示, 海水深度影响光的吸收程度, VMA-SWN- NoSWB的特征主要通过前向计算中堆叠TAB和上下采样模块获得, 未充分考虑水的类型的影响.
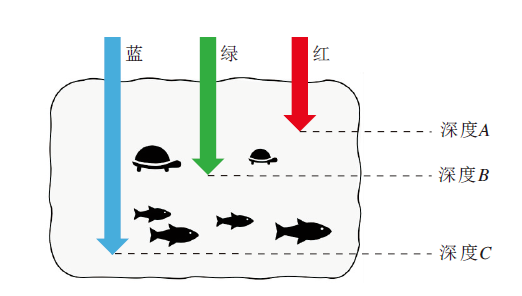 | 图2 水下环境光吸收示意图Fig.2 Sketch map of light absorption in underwater environment |
为了降低水的类型多样性造成的影响[20], 并加强特征信息复用, VMA-SWN通过实例白化(IW)[31]将浅层特征嵌入深层网络.记VMA-SWN第i层的批数量为N且长为M、宽为L的批次特征为Ω i∈ RC× NML.对于第k个特征信息
$\mu =\frac{1}{ML}\text{ }\!\!\Omega\!\!\text{ }_{i}^{k}$.
完成均值向量的计算后, 协方差矩阵为:
$\text{ }\!\!\Lambda\!\!\text{ }=\frac{1}{ML}\left( \text{ }\!\!\Omega\!\!\text{ }_{i}^{k}-\mu \right){{\left( \text{ }\!\!\Omega\!\!\text{ }_{i}^{k}-\mu \right)}^{T}}+\alpha I$.
为了防止Λ 为奇异矩阵, 在Λ 的计算过程中添加α I, I的定义与文献[20]保持一致, α 表示数值较小的正数, 设定为0.000 01.Λ 对角线元素为各个通道的方差, 非对角线元素表示通道间的相关性.实例白化变换的计算如下:
$\text{IW}\left( \text{ }\!\!\Omega\!\!\text{ }_{i}^{k} \right)={{\text{ }\!\!\Lambda\!\!\text{ }}^{-\frac{1}{2}}}\left( \text{ }\!\!\Omega\!\!\text{ }_{i}^{k}-\mu \right)$.
在上述计算中满足的关系是
$\text{IW}\left( \text{ }\!\!\Omega\!\!\text{ }_{i}^{k} \right)\text{IW}{{\left( \text{ }\!\!\Omega\!\!\text{ }_{i}^{k} \right)}^{T}}=I$.
对浅层特征
${{\left( \text{ }\!\!\Omega\!\!\text{ }_{j}^{k} \right)}^{\tau }}=\tau \left( \text{IW}\left( \text{ }\!\!\Omega\!\!\text{ }_{i}^{k} \right), \text{ }\!\!\Omega\!\!\text{ }_{j}^{k} \right)$,
其中, j表示与i对应的深层特征的索引, τ (· )表示通道拼接操作.SWB即为对批次特征Ω i执行实例白化.
由于VMA-SWN架构的有效性, 采用常规的损失函数对VMA-SWN进行训练即可获得较优的水下图像增强效果.将VMA-SWN表示的映射函数记为Ψ (· ), 原始失真水下图像为x(长宽分别为H与W), 标签水下图像为y* .第1部分内容损失为:
${{L}_{mse}}=\frac{1}{H\times W}\underset{a=1}{\overset{H}{\mathop \sum }}\, \underset{b=1}{\overset{W}{\mathop \sum }}\, {{\left\| \text{ }\!\!\Psi\!\!\text{ }\left( x\left( a, b \right) \right)-{{y}^{* }}\left( a, b \right) \right\|}_{2}}$, (3)
其中a、b表示位置索引.
第2部分是结构损失, 采用结构相似性度量(Structural Similarity, SSIM)[33]实现, 对VMA-SWN获得的增强图像Ψ (x)与参考图像y* 计算SSIM值, 得到SSIM(Ψ (x), y* ), 则结构损失定义为
Lss=1-SSIM(Ψ (x), y* ).(4)
VMA-SWN的整体损失为式(3)与式(4)损失之和:
$L={{L}_{\text{mse}}}+\lambda {{L}_{\text{ss}}}$,
其中, λ 为权重因子, 用于控制内容损失与结构损失在VMA-SWN的网络参数更新过程中所占的比重.
水下图像增强算法的效果评估可以从定量结果与视觉效果两方面进行, 本文选用水下图像数据集UIEB[22], 并从水下图像数据库EUVP[13]上选择水下图像集.
UIEB数据集图像包含不同特性的质量退化, 标签图像的构造采用12种增强方法并结合人工视觉筛选过程, 训练数据为800组, 验证数据为90组.在EUVP数据集上选择水下图像集(Underwater ImageNet, UWIN), 该数据集标签的构造主要通过循环一致对抗网络实现, 训练数据为3 300组, 验证数据数为400组.
实验平台为NVIDIA V100 32 GHz GPU, 并采用PyTorch 1.8深度学习框架.
为了公平对比不同算法, 需要使用量化评估指标对比不同算法增强后的水下图像质量, 水下图像增强任务常用的评估指标包含有参考与无参考两类, 本文选取两种常用的有参考评估指标:峰值信噪比(Peak Signal-to-Noise Ratio, PSNR)和SSIM, 二者的计算采用增强后的水下图像与清晰标签[22], 并计算无参考评估指标— — 水下图像质量度量(Underwater Image Quality Measure, UIQM)[34].UIQM主要适用于无清晰标签的情况.无参考评估指标的可靠程度低于有参考评估指标[34].
为了分析VMA-SWN与已有水下增强算法的性能差异, 选择如下11种对比算法.1)4种非基于深度学习的增强算法.文献[8]算法、ULAP[9]、文献[10]算法和文献[11]算法.2)7种基于深度学习的增强算法.文献[5]算法、UResnet[12]、FUnIE-GAN[13]、UGAN[14]、ADMNNet[17]、Shallow-UWnet[21]、 Water- Net[22].4种非基于深度学习的增强算法采用OpenCV 4.7图像处理框架实现, 7种基于深度学习的增强算法与VMA-SWN采用PyTorch 1.8深度学习框架实现.
对比实验中11种算法所用的图像尺寸统一缩放为256× 256× 3.对于7种基于深度学习的增强算法和VMA-SWN, 训练阶段的批大小尺寸统一设定为6, 在UIEB数据集上运行200个迭代周期, 在UWIN数据集上运行100个迭代周期.7种基于深度学习的增强算法的学习率初始值与学习率衰减策略均按照对应文献进行设定.在训练过程中VMA-SWN学习率设定为0.000 2, λ 设定为1, 每隔20个迭代周期学习率衰减0.95倍.
在UIEB数据集上对比VMA-SWN与11种算法, 结果如表1所示, 表中黑体数字表示最优值.由表可见, VMA-SWN获得最高的PSNR与SSIM值, 分别为21.862 dB、0.909, 并且获得相对较高的UIQM值, 为2.997.ADMNNet、UGAN与Water-Net获得的PSNR值与VMA-SWN接近, 但是SSIM值明显低于VMA-SWN.UGAN获得的UIQM值最高, VMA-SWN获得的UIQM值位列第3.总之, 表1结果从定量评估角度表明VMA-SWN在UIEB数据集上的有效性.
| 表1 各算法在UIEB数据集上的定量评估结果 Table 1 Quantitative evaluation results of different algorithms on UIEB dataset |
各算法在UIEB数据集上视觉效果对比如图3所示.将图3中的3个场景分别记为场景1、场景2与场景3.非基于深度学习的增强算法(文献[8]算法、文献[10]算法与ULAP)在场景1和场景2上存在明显的色差现象; 文献[8]算法与ULAP处理后的场景3亮度偏移较大, 导致场景整体呈现暗色; 文献[10]算法处理后的场景3与标签差异较大.基于深度学习的增强算法(ADMNNet、FUnIE-GAN、文献[5]算法、UResnet)处理后的场景1颜色偏移明显, 未能有效对颜色进行校正.UResnet与Water-Net处理后的场景2存在一定的颜色偏移, 且UResnet处理后的场景2对比度偏低.文献[5]算法与UResnet处理后的场景3亮度相对较低.
 | 图3 各算法在UIEB数据集上的视觉效果对比Fig.3 Visual effects comparison of different algorithms on UIEB dataset |
总之, 场景1的处理难度较大, 尽管VMA-SWN在场景1存在轻微的色偏, 但是处理效果最接近标签.相比11种对比算法, VMA-SWN在3个场景的处理效果都相对较优, 能够有效进行颜色校正并提升3个原始水下场景的视觉质量.
VMA-SWN与11种算法在UWIN数据集上的定量评估结果如表2所示, 表中黑体数字表示最优值.
| 表2 各算法在UWIN数据集上的定量评估结果 Table 2 Quantitative evaluation results of different algorithms on UWIN dataset |
由表2可知, ADMNNet与UGAN获得的PSNR值与VMA-SWN相对接近, 其余算法的PSNR值均未超过24 dB.在SSIM指标上只有VMA-SWN超过0.85, 明显高于其余算法.在UIQM指标上, UGAN获得最高值, 为3.053, VMA-SWN的UIQM值为2.931, 但是UGAN获得的PSNR与SSIM值均低于VMA-SWN.
总之, VMA-SWN的定量评估结果相对较优.
各算法在UWIN数据集上视觉效果对比如图4所示.将图4中3个场景由左到右分别记为场景4、场景5与场景6.原始水下图像呈现偏蓝色的状态, 并且与参考图像(标签)的颜色差异明显.非基于深度学习的增强算法(文献[8]算法、文献[10]算法与ULAP)在各场景上增强效果不明显, 图像仍然呈现偏蓝色状态, 文献[11]算法对场景4的处理存在细节丢失与色彩失衡现象, 并且对场景5与场景6的处理效果轻微.基于深度学习的增强算法(ADM- NNet与UGAN)处理后的场景4偏向淡紫色, FUnIE-GAN、文献[5]算法、Shallow-UWnet与URes- net处理后的场景5仍然没有实现较好的颜色复原, Shallow-UWnet与Water-Net处理后的场景6偏向淡蓝色.VMA-SWN处理后的图像最接近相应标签.
 | 图4 各算法在UWIN数据集上的视觉效果对比Fig.4 Visual effects comparison of different algorithms on UWIN dataset |
VMA-SWN含有两个需要进行消融研究的组件, 分别是跨层白化模块SWB与结构损失Lss, 需要对比SWB与Lss使用前后VMA-SWN的增强效果变化情况.消融实验采用每次删除一个模块的方式, 共含有下面3种设置.
1)Lmse+Lss+SWB.使用Lmse与Lss训练VMA-SWN.
2)Lmse+Lss.同时使用Lmse+Lss训练VMA-SWN-NoSWB.
3)Lmse.使用Lmse训练VMA-SWN-NoSWB.
为了保证结果的准确性, 采用PSNR与SSIM作为VMA-SWN量化评估依据, 实验结果如表3所示, 表中黑体数字表示最优值.由表可见, 在UIEB、UWIN数据集上效果最优的是方案1), 方案3)的SSIM值明显低于方案1).该结果表明SWB与Lss对VMA-SWN的增强效果具有促进作用.
| 表3 VMA-SWN的消融实验结果 Table 3 Results of ablation experiment for VMA-SWN |
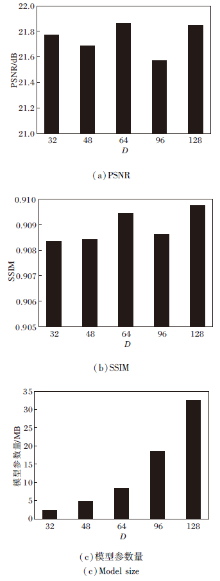
VMA-SWN采用TAB与RTAB作为主要的特征提取模块, TAB与RTAB的特征维度D是一个重要的超参数, 影响VMA-SWN的增强效果与模型大小.D过小可能导致模型的数据学习能力不足, D过大会导致模型的参数量较大.结合已有文献[13]和文献[32]中特征维度的选择方式, 将D的取值设定为16的整数倍数, 分别设定D=32、48、64、96、128, 以此计算相应的评估指标并获取模型参数量.
各算法在UIEB数据集上的结果如图5所示, PSNR与SSIM均取小数点后5位作为有效位.由图可见, D在32、48、64、96与128之间选取(二者维度需要保持一致)时, 定量评估结果存在一定差异, PSNR在21.6 dB左右波动, SSIM在0.909左右波动.根据结果可知, D=64时为较优选择, 此时VMA-SWN获得的PSNR与SSIM值相对较高, 通过计算, 此时模型参数量为8.44 MB.
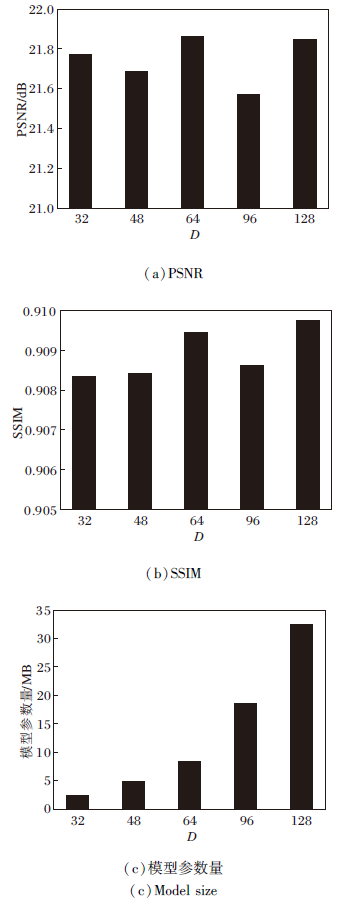 | 图5 D不同时指标值的变化Fig.5 Variation of evaluation metrics with different D |
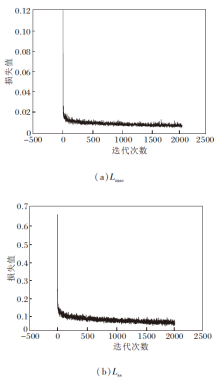
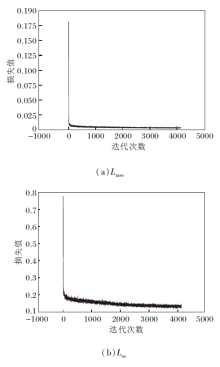
为了验证VMA-SWN训练过程的稳定性, 绘制Lmse与Lss在训练过程中的损失曲线, 每隔10次迭代记录过去10次迭代的损失均值作为一个数据点, 获取VMA-SWN在UIEB、UWIN数据集上损失函数的收敛情况, 具体如图6与图7所示.
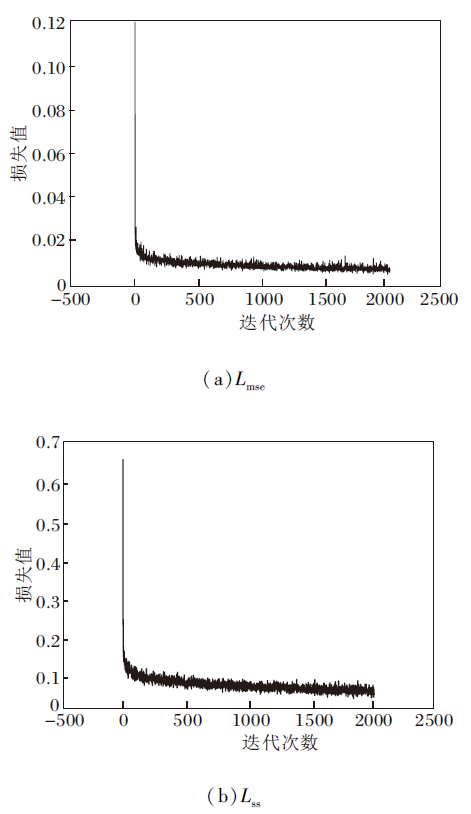 | 图6 VMA-SWN在UIEB数据集上的损失收敛曲线Fig.6 Loss convergence curve of VMA-SWN on UIEB dataset |
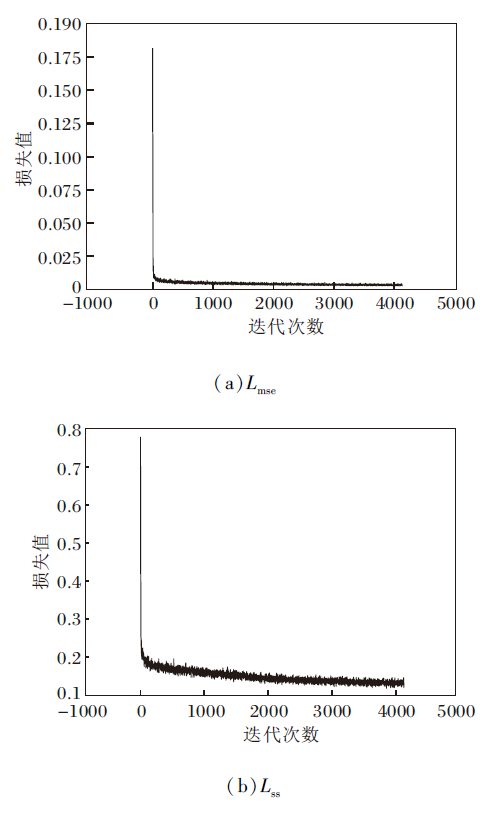 | 图7 VMA-SWN在UWIN数据集上的损失收敛曲线Fig.7 Loss convergence curve of VMA-SWN on UWIN dataset |
由图6和图7可以看出, Lmse与Lss在总体上都呈现稳定的收敛趋势, 表明VMA-SWN训练过程的稳定性.
针对光在水中吸收与散射造成的质量降低问题, 本文提出基于视觉多头自注意力与跨层白化的水下图像增强网络(VMA-SWN), 采用视觉多头自注意力模块构建主体增强网络, 并对VMA-SWN的浅层特征进行实例白化处理, 采用浅层与深层的跨层白化模式增强VMA-SWN对水下图像的处理效果.实验中采用11种水下增强算法, 在水下数据集上对比各算法在量化评估与视觉效果上的差异, 并进行实例白化与结构损失的消融实验, 以及VMA-SWN的收敛性实验, 实验结果验证VMA-SWN在水下图像增强任务上的有效性.本文提出的是有监督方式的水下图像增强方法, 今后会考虑探索针对无监督的训练过程, 缓解水下图像增强模型对成对数据的依赖性.
本文责任编委 桑农
Recommended by Associate Editor SANG Nong
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|