
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
轻量化逆可分离残差信息蒸馏网络的图像超分辨率重建
[赵小强1, 2, 3  , 李希尧
, 李希尧1 , 宋昭漾1 ]
, 李希尧, 宋昭漾]
|
|



作者简介:
李希尧,硕士研究生,主要研究方向为图像处理、深度学习等.E-mail:hanlee1999@126.com. 
宋昭漾,博士,讲师,主要研究方向为图像处理、深度学习等.E-mail:szy@lut.edu.cn.
基于深度学习的图像超分辨率重建算法的性能需求导致急剧增加的参数量与高额的计算成本,这限制超分辨率重建在移动设备上的应用.针对此问题,文中提出轻量化逆可分离残差信息蒸馏网络的图像超分辨率重建算法.首先,设计渐进可分离蒸馏重洗模块,进行多重信息蒸馏,在提取多层次特征的同时保持模型轻量化,使用多个特征提取连接,学习更具区别性的特征表示,以便网络能从蒸馏中获得更多有益信息.然后,设计对比感知坐标注意力模块,充分利用通道感知与位置敏感信息,增强特征选择能力.最后,提出逐步补偿残差连接方式,提高浅层特征的利用率,补偿网络的纹理细节特征.实验表明,文中算法在模型复杂性与重建性能之间实现较好的均衡,重建的高分辨率图像主客观质量都很优秀.
About Author:
LI Xiyao, master student. His research interests include image processing and deep learning.SONG Zhaoyang, Ph.D., lecturer. His research interests include image processing and deep learning
The application of the deep learning-based image super-resolution reconstruction algorithm on mobile devices is limited, due to the sharp increase of parameters and high computational cost caused by performance requirement. To solve this problem, a lightweight inverse separable residual information distillation network for image super-resolution reconstruction is proposed in this paper. Firstly, a progressive separable distillation shuffle module is designed to extract multi-level features and in the meantime keep the model lightweight. Multiple feature extraction connections are employed to learn a more distinguishing feature representation, and thus the network acquires more useful information from distillation. Then, a contrast perception coordinate attention module is designed to fully leverage channel-aware and position-sensitive information, enhancing the feature selection capability. Finally, a progressive compensation residual connection is put forward to improve the utilization of shallow features and compensate for the texture detail features of the network. Experiments show that the proposed algorithm achieves a good balance between model complexity and reconstruction performance, yielding excellent subjective and objective quality in the reconstructed high-resolution images.
单图像超分辨率(Single Image Super-Resolu-tion, SISR)技术是从低分辨率(Low-Resolution, LR)图像恢复相应高分辨率(High-Resolution, HR) 图像, 该技术在视频监控[1]、医学诊断[2]、图像检测[3]、遥感成像[4]等领域具有广泛应用.单图像超分辨率过程是一个典型病态逆问题, 即一个输入LR图像映射输出的HR图像有多个, 受重建方式的影响, 往往会出现边缘伪影、细节模糊、像素丢失等问题.为了解决上述问题, 学者们提出许多超分辨率(Super-Resolution, SR)方法, 主要包括基于插值的方法[5, 6]、基于重建模型的方法[7, 8]、基于学习的方法[9](如流行学习、稀疏编码).然而这些方法大多提取图像底层特征以重建高分辨率图像, 大幅限制图像的重建效果.
近年来, 深度学习技术的进步大幅推进计算机视觉领域的发展.相比传统方法, 深度学习方法可以通过训练提取具有表达能力的图像特征, 自适应地调整映射函数, 直接学习LR图像和HR图像之间端到端的映射关系, 表现出解决SISR问题的极大优势.Dong等[10]将卷积神经网络(Convolutional Neural Networks, CNN)应用到超分辨率重建领域, 提出SRCNN(Super-Resolution CNN), 利用3层CNN得到比传统方法更优的重建效果, 但SRCNN引入额外计算成本, 且3层CNN提取的图像信息有限.针对上述问题, Dong等[11]提出FSRCNN(Fast SRCNN), 使用反卷积代替Bicubic进行图像特征上采样, 并构建8个卷积层的神经网络.
随后, 在此基础上, 研究者设计更深的或更宽的网络模型, 提高SR方法的性能.虽然更深的网络会带来更丰富的上下文信息, 但网络的不断加深会带来梯度消失问题, 导致网络难以训练.为此, Kim等[12]采用残差网络, 提出VDSR, 构建一个20层的深度网络, 增强浅层特征与深层特征之间的信息交流.Lim等[13]提出EDSR(Enhanced Deep Super-Re-solution Network), 移除不适应SR方法等低级计算机视觉任务的BN(Batch Norm)层.Li等[14]提出MSRN(Multi-scale Residual Network), 采用多尺度特征融合和局部残差学习, 最大限度地利用LR图像特征.Tai等[15]使用记忆模块和门控单元, 构建MemNet(Very Deep Persistent Memory Network), 使用递归堆叠和密集连接, 增强信息在不同记忆单元间的流动.
尽管上述方法取得较优的重建效果, 但都是通过增大网络深度或连接复杂度为代价实现的, 这往往会导致网络参数量、内存消耗和训练时间的增加, 限制在现实场景的使用.为了减少内存与计算负担, 研究者提出许多更高效的轻量化超分辨率模型.Kim等[16]提出DRCN(Deeply-Recursive Convolutional Network), 引入递归网络, 使用一个卷积层作为递归, 用循环层代替卷积层堆叠, 从而在不引入额外参数的同时实现权值共享.Tai等[17]提出DRRN(Deep Recursive Residual Network), 采用递归学习, 引入局部残差学习与全局残差学习, 组成递归残差块, 提升重建质量.Zhu等[18]提出CBPN(Compact Back-Projection Network), 通过上下采样层级联操作, 提取低分辨率图像与高分辨率图像之间的特征信息.Ahn 等[19]提出CARN(Cascading Residual Network), 构建一个级联的残差网络, 学习多层级的特征, 使信息传递更高效.Hui等[20]为了提高计算速度, 从特征图通道维度考虑, 提出IDN(Information Distillation Network), 引入蒸馏块, 将特征映射分为增强单元和压缩单元, 对增强单元进行局部长路径特征提取后结合压缩单元, 融合局部特征与全局特征, 提高网络表达能力.Hui等[21]又在IDN的基础上, 提出IMDN(Lightweight Information Multi-distillation Network), 在一个网络模块中多次分层使用蒸馏机制, 同时实现性能与实时性, 并提出一种基于对比度感知的通道注意力, 进一步提升SR方法性能.但是IMDN并未充分考虑身份连接对网络性能的影响, 且忽略轻量化网络中卷积自身的轻量化对降低参数的作用.
由于上述蒸馏网络中的蒸馏机制使用标准卷积作为滤波方式, 在轻量化网络中, 为了保持低参数量与高性能, 采用更轻量的卷积方式以及合理高效的全局或局部连接方式尤为重要.针对上述问题, 本文提出轻量化逆可分离残差信息蒸馏网络(Light-weight Inverse Separable Residual Information Distilla-tion Network, LIRDN).首先, 提出一个逆可分离复原浅残差单元(Inverse Separable Recovery Shallow Residual Cell, IRC), 通过交换可分离卷积的前向传递与特征融合方式, 适应通道分离与维度恢复.再提出一个渐进可分离蒸馏重洗模块(Progressive Sepa-rable Distillation Shuffle Module, PDSM), 采用IRC作为多重渐进蒸馏的主要提取单元, 引入通道重洗[22]操作, 并通过设计的连接方式有效减少卷积数量, 降低网络参数量.然后, 提出对比感知坐标注意力模块(Contrast Perception Coordinate Attention Mo-dule, CPCA), 促进对比度通道注意力关注位置信息, 增强网络的特征选择能力.最后, 设计逐步补偿残差连接(Progressive Compensation Residual Connec-tion, PCR), 提高浅层特征的利用率, 平衡模型复杂度与性能, 丰富提取的图像信息.
当前的大多数SR模型在提升性能的同时往往会引入大量的计算成本, 限制SR模型的实际应用.因此, 研究者提出许多高效的轻量模型.大多数轻量化通过模型剪枝、参数量化、知识蒸馏等方法实现.信息蒸馏机制(Information Distillation Mechanism, IDM)是一种基于蒸馏的模型压缩方法, 自提出以来应用于许多轻量化网络.该机制对图像特征采用逐层逐步的方式提取以实现轻量化, 将前路提取的特征分为两部分, 一部分保留, 另一部分进一步提取细化.经过蒸馏后的短路径信息如下所示:
$T_{1}^{P}=S\left( {{G}^{P}}\frac{1}{r} \right)$,
其中, GP表示特征信息输入多卷积层提取的信息, r表示蒸馏率, S(· )表示通道切片操作.长路径保留的特征信息为:
$T_{2}^{P}=S\left( {{G}^{P}}\frac{r-1}{r} \right)$,
其中
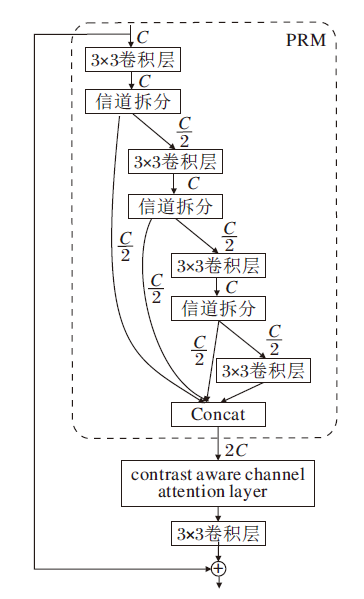
虽然IDM给网络结构带来灵活性, 但设计缺乏有效性, 未能有效利用蒸馏机制优化身份连接.此后Hui等[21]提出IMDN, 实现重建质量和推理速度之间较好地平衡.IMDN设计IMDB模块(Information Multi-distillation Block), 优化身份连接.
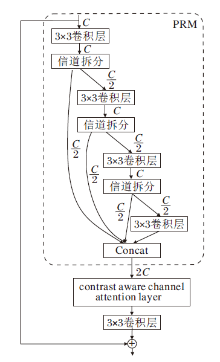
IMDB模块结构如图1所示.核心是一个PRM(Progressive Refinement Module), 包含多个不同层级的信息蒸馏操作, 每个层级的信息蒸馏首先使用3× 3卷积层提取后续多个蒸馏的输入特征.对于层级i(i=1, 2, 3, 4), 对传入的特征采用信道拆分操作, 将输入特征分为2部分:一部分保留特征信息, 另一部分传入下一层计算单元继续蒸馏操作.在最后一层采用1× 1卷积进行通道滤波.虽然IMDB取得较优效果, 但还存在结构冗余, 以及未使用轻量化卷积导致计算量较大的问题.若可以采用更轻量的卷积方式与更合理的身份连接, 仍能进一步提高SR模型性能.
注意力机制是一种高效的特征选择机制, 通过生成注意力权重函数, 使提取图像信息时能够重点关注特征显著区域, 略去冗余特征.该机制由于提升提取特征的准确性且只增加少量参数, 因而被广泛应用于各种视觉任务.Hu等[23]提出SENet(Squeeze-and-Excitation Networks), 调整网络特征信息的通道关注度, 使网络关注有用特征, 提高对计算资源的有效利用.在超分辨率重建领域, Zhang等[24]提出RCAN(Very Deep Residual Channel Attention Networks), 引入通道注意力, 并加入残差提取, 使网络根据每个通道的图像信息学习对应注意力权重.Lu等[25]同时采用空间注意力与通道注意力, 对空间维度和通道维度进行注意力学习.Zhao等[26]提取像素注意力(Pixel Attention, PA), 生成3个维度注意力特征, 并引入较少的附加参数, 提高重建性能.
基于深度学习的图像超分辨率重建算法随着软硬件的提升得到良好的发展, 通过复杂的结构以及深度网络, 能够增加图像的感受野, 从而获得较好的重建效果, 但还存在加深堆叠[13]与复杂的残差跳线连接[27], 会造成计算成本较大、网络参数较多等问题, 无法很好地应用于移动设备.为了在控制运算成本的同时提升网络性能, 近年来学者们提出许多优秀的解决方案, 主要包括设计高效的模型结构、改进CNN架构、模型压缩、使用注意力机制等.这些工作表明, 通过网络改进的方法能够实现模型性能与模型复杂度间的平衡.
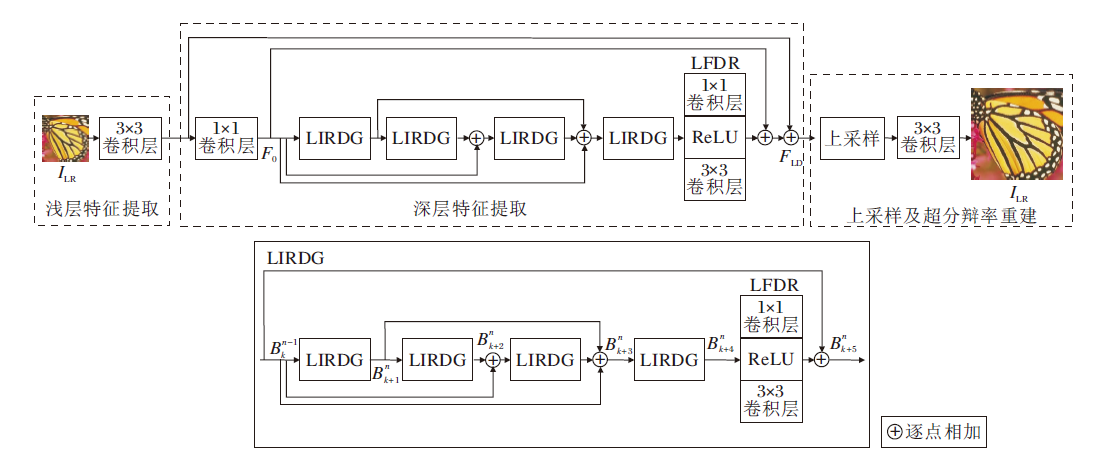
为了构建更强大、轻量以及快速的SR模型, 本文基于信息蒸馏机制, 提出LIRDN的图像超分辨率重建算法.算法由3部分组成:浅层特征提取、深层特征提取和图像超分辨率重建, 具体结构如图2所示, 图中ILR和ISR分别表示网络的输入和输出.
 | 图2 LIRDN的图像超分辨率重建算法结构图Fig.2 Structure of image super-resolution reconstruction algorithm of LIRDN |
给定低分辨率图像被馈入网络时, 首先通过标准3× 3卷积进行浅层特征提取, 得到图像初始特征信息:
F0=f0(ILR),
其中f0(· )表示浅层特征提取操作.
然后, 为了获得深层特征信息, 将浅层特征信息传递到逆可分离残差信息蒸馏模块.在该模块中, 使用4个轻量化逆可分离残差信息蒸馏组(Lightweight Inverse Separable Residual Information Distillation Groups, LIRDG)模块与1个轻量化特征降维(Light-weight Feature Dimension Reduction, LFDR)模块进行特征提取, 采用逐步补偿残差连接(PCR)融合5个模块的特征信息, 用于后续图像重建.由此得到深层特征提取的图像特征:
${{F}_{LD}}={{N}_{PCR}}\left\{ {{F}_{IR{{G}_{1}}}}{{F}_{IR{{G}_{2}}}}{{F}_{IR{{G}_{3}}}}{{F}_{IR{{G}_{4}}}}{{H}_{FC}} \right\}$,
其中,
FUP=HUP(FLD),
其中HUP(· )表示上采样模块.最后, 将FUP传入重建模块, 得到重建获得的精细SR图像:
ISR=HRE(FUP),
其中HRE(· )表示重建映射函数.
2.2.1 逆可分离复原浅残差单元
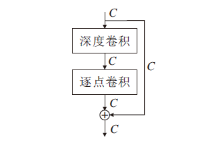
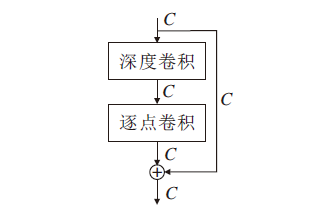
深度可分离卷积是一种非常有效的轻量化卷积, 通过对标准卷积步骤的拆解, 以一个深度卷积和一个逐点卷积组合的方式实现与标准卷积同等的效果.深度可分离卷积结构如图3所示, 相比标准卷积操作, 具有更小的参数量和更低的计算成本, 因此被广泛应用于各类深度卷积网络中.
 | 图3 深度可分离卷积结构图Fig.3 Structure of deep separable convolution |
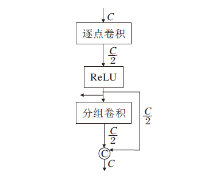
虽然深度可分离卷积对网络轻量化具有一定优势, 但对信息蒸馏网络这类需要信道拆分的网络, 并不能较好地平衡参数量与重建效果, 若采用卷积方式将信道拆分为两部分, 会引入冗余卷积, 增加参数量.通过分解可分离卷积发现, 分组卷积要兼顾组数, 不能随意更改输出特征维度大小, 但逐点卷积却没有维度限制, 因此, 考虑信道拆分对蒸馏机制的必要性, 本文将深度可分离卷积的逐点卷积提到分组卷积之前, 提出逆可分离复原浅残差单元(IRC), 结构如图4所示.
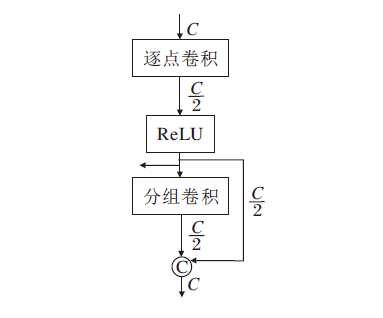 | 图4 IRC结构图Fig.4 Structure of IRC |
相比深度可分离卷积采用分组卷积对每个通道卷积, 再采用逐点卷积对整个通道维度加权聚合, IRC通过逐点卷积压缩通道维度, 在低通道维度下采用分组卷积对每条输入通道进行卷积滤波, 然后采用通道合并操作对滤波后的信息进行补充, 在每个IRC内部实现特征的压缩与扩充, 并且复原的通道维度可以直接参与下层的蒸馏.这种逆向可分离的卷积方式通过逐点卷积将降维特征映射直接传入PDSM的末端, 有效避免引入另一支路卷积带来的计算量.逐点相加操作促进多通道特征信息的融合, 丰富特征图像的细节信息.通道降维下的分组卷积运算保证更小的计算量, 便于更快速地融合特征.
对于输入特征
$F_{distilled(i)}^{n}={{R}_{ac}}(C_{(i)}^{n}(F_{in}^{n}))$,
其中,
$F_{cg(i)}^{n}=C_{g(i)}^{n}(F_{distilled(i)}^{n})$,
其中
$F_{cat(i)}^{n}=T_{con(i)}^{n}(F_{cg(i)}^{n}F_{distilled(i)}^{n})$,
其中
为了不增加额外的卷积进行通道复原, 本文改进深度可分离卷积的特征融合方式, 用通道维度拼接操作(concat)代替逐像素相加聚合操作(add)聚合特征, 这种代替方式保持输入输出通道的一致性.
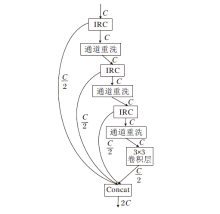
2.2.2 渐进可分离蒸馏重洗模块
直接将标准卷积替换为可分离卷积会带来身份连接不够高效、蒸馏特性发挥不够充分等问题.为了解决上述问题, 本文提出逆可分离卷积方式, 结合蒸馏机制, 设计渐进可分离蒸馏重洗模块(PDSM), 结构如图5所示.PDSM将IRC作为后续多层渐进蒸馏过程的主要提取单元, 对于每一层渐进蒸馏, IRC对输入特征采用信道拆分操作, 将输入特征分为两部分:保留部分保留本层蒸馏获取的特征信息, 渐进蒸馏部分送入下一层继续进行蒸馏操作.第i(i=1, 2, 3, 4)个保留部分特征信息如下:
$F_{distilled(1)}^{n}={{R}_{ac}}(C_{(1)}^{n}(F_{in}^{n}))$,
$F_{distilled(2)}^{n}={{R}_{ac}}(C_{(2)}^{n}(F_{cg(1)}^{n}))$,
$F_{distilled(3)}^{n}={{R}_{ac}}(C_{(3)}^{n}(F_{cg(2)}^{n}))$,
$F_{distilled(4)}^{n}={{R}_{ac}}(C_{4}^{n}(F_{coarse(3)}^{n}))$,
其中,
$F_{coarse(1)}^{n}=shuffl{{e}_{(1)}}(I_{RB(1)}^{n}(F_{in}^{n}))$,
$F_{coarse(2)}^{n}=shuffl{{e}_{(2)}}(I_{RB(2)}^{n}(F_{coarse(1)}^{n}))$,
$F_{coarse(3)}^{n}=shuffl{{e}_{(3)}}(I_{RB(3)}^{n}(F_{coarse(2)}^{n}))$,
其中,
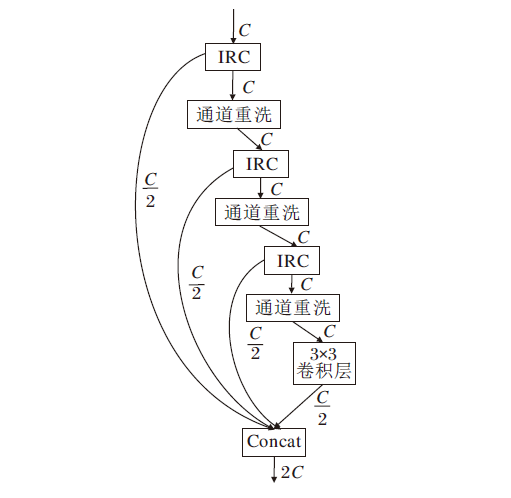 | 图5 PDSM结构图Fig.5 Structure of PDSM |
通道重洗考虑到分组卷积只在组内进行卷积运算, 忽略组与组之间的信息交流.利用通道重洗能够增强特征信息的组间联系, 在一定的计算量下, 允许更多的通道重洗以获取更丰富的信息.通道重洗模块主要通过通道分割、通道重洗和通道合并三种操作提高特征提取能力, 其将通道分割为不同的通道组, 再通过通道重洗将各个通道组打乱, 对打乱后的通道组特征在提取后进行通道合并, 获取更多的组间特征.
分组卷积是通过牺牲通道组之间信息传递降低计算复杂度的, 并不利于深度网络中通道间的信息交流.相比直接使用可分离卷积, PDSM在每层IRC中的分组卷积末端馈入通道重洗, 有效促进通道与通道间的信息流动, 而这种流动正是分组卷积缺乏的, 因此馈入通道重洗可以实现多样化的特征融合, 提高网络的表征能力.
最后, 将所有提取的特征融合作为PDSM的输出:
$F_{distilled}^{n}=concat(F_{distilled(1)}^{n} \ \ \ F_{distilled(2)}^{n} \ \ \ F_{distilled(3)}^{n} \ \ \ F_{distilled(4)}^{n} \ )$,
其中concat(· )表示通道维度的合并操作.
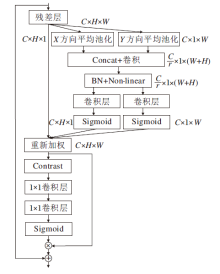
2.2.3 对比度感知坐标注意力模块
近年来, 许多基于CNN的SISR, 通过引入注意力以提升网络的表征能力, 然而, 一种注意力机制只能关注特征图的某一层面, 限制网络性能.CCA(Contrast-Aware Channel Attention)是一种用于低级别视觉任务的注意力结构, 相比使用每个通道维度平均值获得注意力权重的通道注意力, CCA通过平均值和标准偏差总和的对比度信息代替全局平均池化, 能灵活提取有用的纹理边缘信息.输出的第c个元素为:
${{z}_{c}}={{G}_{gc}}({{x}_{c}})=\sqrt{\frac{1}{HW}\sum\limits_{(i, j)\in {{x}_{c}}}{{{\left( x_{c}^{i, j}-\frac{1}{HW}\sum\limits_{(i, j)\in {{x}_{c}}}{x_{c}^{i, j}} \right)}^{2}}}}+\frac{1}{HW}\sum\limits_{(i, j)\in {{x}_{c}}}{x_{c}^{i, j}}$,
其中Ggc(xc)表示全局对比度信息评估函数.
文献[28]和文献[29]证实CCA的有效性, 考虑到位置信息在通道信息提取过程的重要性, 为了获得更广区域信息而避免引入过多开销, 本文设计对比度感知坐标注意力模块(CPCA), 结构如图6所示.坐标注意力[30]将通道注意力沿空间的水平方向和垂直方向分解为两个一维特征编码过程, 沿空间方向分别聚合特征, 其优势在于两个方向编码时, 可以沿一个方向提取长距离依赖关系, 同时沿另一方向保存精确的特征位置信息, 从而得到一对对方向感知和位置敏感的注意力图, 使模型更准确地定位识别感兴趣特征.将坐标注意力捕获的特征传入CCA, 对位置敏感信息进行进一步提取, 获得其通道关注信息, 并通过残差连接, 聚合双注意力提取的特征与输入特征, 得到输出特征.
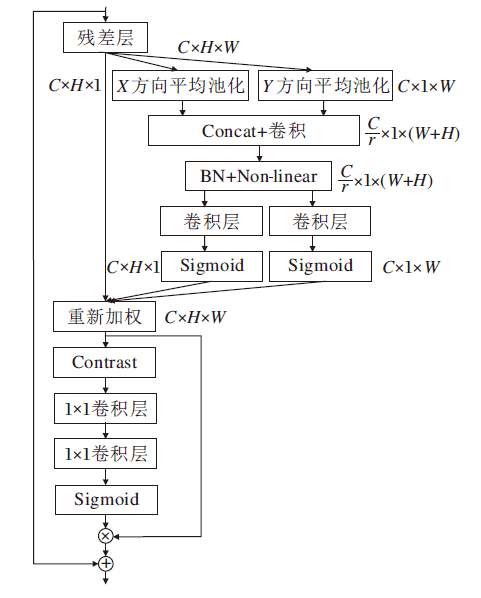 | 图6 CPCA结构图Fig.6 Structure of CPCA |
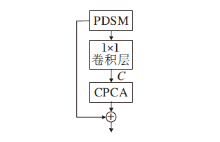
2.2.4 轻量化逆可分离残差信息蒸馏块
轻量化逆可分离残差信息蒸馏块(Lightweight Inverse Separable Residual Information Distillation Blocks, LIRDB)主要包括渐进可分离蒸馏重洗模块(PDSM)、局部特征融合单元与对比度感知坐标注意力模块(CPCA)3部分, 结构如图7所示.
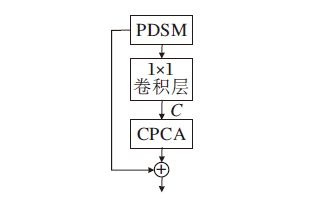 | 图7 LIRDB结构图Fig.7 Structure of LIRDB |
提取上述3部分的特征, 通过端到端连接实现多样化融合.渐进可分离蒸馏重洗模块获得轻量化的特征蒸馏信息后, 局部特征融合单元采用1× 1卷积, 恢复concat扩展的通道维数, 将恢复为初始输入通道维数的特征图传入对比度感知坐标注意力模块进行交互, 以便更精确地对感兴趣特征信息融合.局部特征融合单元恢复维度后的特征为:
$L_{k}^{ij}={{C}_{1\times 1}}({{H}_{PDSM}}(B_{k}^{ij}), {{W}^{ij}})$,
其中,
$B_{k+1}^{ij}={{H}_{CPAM}}(L_{k}^{ij})+B_{k}^{ij}$,
其中HCPAM(· )表示特征通过对比度感知坐标注意力模块.
自残差网络提出以来, 残差连接一直作为一种基础网络结构应用于各种SR网络中, 本文提出LIRDG.LIRDG由4个LIRDB模块与1个LFDR模块使用PCR连接的方式构成, 如图2所示.LFDR模块采用1× 1卷积端到端连接3× 3卷积组成, 1× 1卷积用作LIRDB模块降维, 3× 3卷积细化特征.PCR连接是一种高效的连接方式, 受DenseNet连接的影响, 若对每层的输入特征信息都考虑之前全部层的映射, 则每层都加强对之前层的特征重用, 保证网络最大的信息流通, 但当层结构复杂化时, DenseNet连接带来的计算量和参数量是都陡增的.考虑LIRDB的特性, 本文提出PCR连接, 由于初始传入网络的特征包含更多的前层信息, 将其传入LIRDG的每层, 可以最大程度地保留前层信息, 对于第2、3层输出, 不引入自残差, 而通过跨层跳跃连接将第2层的输入传入第3层尾端聚合, 从而减少残差跳线次数.这一连接方式具体过程如下, 第i(i=1, 2, 3, 4, 5)个LIRDB模块输出特征如下所示:
$B_{k+1}^{n}=H_{LIRDB(1)}^{n}(B_{k}^{n-1})$,
$B_{k+2}^{n}=H_{LIRDB(2)}^{n}(B_{k+1}^{n})+B_{k}^{n-1}$,
$B_{k+3}^{n}=H_{LIRDB(3)}^{n}(B_{k+2}^{n})+B_{k+1}^{n}+B_{k}^{n-1}$,
$B_{k+4}^{n}=H_{LIRDB(4)}^{n}(B_{k+3}^{n})$,
$B_{k}^{n+1}=B_{k+5}^{n}=H_{LFDR}^{n}(B_{k+4}^{n})+B_{k}^{n-1}$,
其中,
本文使用L1损失函数优化提出的LIRDN.L1损失函数具有收敛速度快、鲁棒性强等特点, 给定一个训练集
$L\left( \theta \right)=\frac{1}{N}\sum\limits_{i=1}^{N}{{{\left\| I_{HR}^{i}-{{H}_{LIRDN}}\left( I_{LR}^{i} \right) \right\|}_{1}}}$,
其中, θ 表示LIRDN中需要训练的权值和参数, i表示对应的第i幅图像, HLIRDN(
在训练阶段, 本文使用DIV2K数据集[31]作为训练数据集.DIV2K数据集包含1 000幅2 000分辨率的RGB图像, 其中800幅图像用于训练.LR图像由HR图像的双三次下采样得到, 对训练数据集进行90° 、180° 、270° 旋转和随机水平翻转以增强数据.将LR图像裁剪成尺寸为48× 48的图像块, 将HR图像裁剪成尺寸为48s× 48s的图像块, 其中s表示放大因子.
本文采用Set5[32]、Set14[33]、BSD100[34]、Urban-100[35]这4个常用的标准测试数据集.
本文所有实验基于RGB三通道, 测试时将图像色彩空间从RGB转换到YCbCr, 在Y通道上分别评估峰值信噪比(Peak Signal-to-Noise Ratio, PSNR)[36]和结构相似度(Structural Similarity, SSIM)[37].
LIRDN使用Adam(Adaptive Moment Estimation)优化, 网络权重更新时, 指数衰减率设为β 1=0.9, β 2=0.999, 数值稳定常数ε =10-8.使用L1作为损失函数, 训练迭代轮次为1 000, 批处理大小为16, 学习率为10-4, 每200个迭代轮次学习率减半.LIRDB参数设置如表1所示.
| 表1 LIRDB参数设置 Table 1 LIRDB parameter settings |
实验网络框架搭建、训练和测试都在Ubuntu18.04系统上进行, 编程平台采用Pytorch1.2.实验GPU为NVIDIA GeForce RTX2080Ti, 显存为11 GB, CPU为Inter(R)Core(TM)i9-9900K, 内存为64 GB.
为了验证LIRDN的有效性, 本文设计多组消融实验.
3.2.1 不同模块对重建结果的影响
为了验证LIRDN各部分性能, 将LIRDN按具体功能划分为通道重洗模块、对比度感知坐标注意力模块、逐步补偿残差连接三类.所有实验均保持400个训练批次, 每个实验保持相同的蒸馏率和分组卷积分组数, 放大倍数为4, 在Set5数据集上对比平均PSNR值, 结果如表2所示.在表中, ✓表示使用结构, × 表示不使用结构, 以不包含通道重洗模块、对比度感知坐标注意力模块、逐步补偿残差连接为基准网络.
| 表2 放大倍数为4时各模块的PSNR值对比 Table 2 PSNR value compensation of different modules with a magnification of 4 |
由表2可知, 在基准网络中分别增加三模块之一, 对应的PSNR值均高于基准网络, 表明增加的模块对提升性能具有一定作用.加入任意2个模块, 对应PSNR值高于加入1个模块时的PSNR, 表明模块叠加能提升网络效果.例如, 在对比度感知坐标注意力模块的基础上增加逐步补偿残差连接, PSNR可以提升0.03 dB, 由此可知, 逐步补偿残差连接提升浅层特征的利用率, 减少图像低频信息的损失, 对网络性能提升具有积极作用.最后一行为LIRDN, PSNR进一步提升, 比基准网络增加0.15 dB, 表明同时使用3种模块能提高超分辨率重建的图像质量.
3.2.2 蒸馏方式的影响
为了探索蒸馏方式对模型重建效果的影响, 本文对比IRC与带残差的可分离卷积.训练批次为200, 结果如表3所示.由表可以看出, IRC的平均PSNR值都有所提升, 并且参数量更小, 说明IRC更有利于挖掘图像的浅层特征.
| 表3 蒸馏方式对算法性能的影响 Table 3 Effect of distillation method on performance of different algorithms |
3.2.3 卷积方式的影响
为了分析卷积方式对模型重建效果的影响, 将LIRDN与标准卷积网络、无蒸馏的标准卷积网络进行对比, 训练批次为500, 结果如表4所示, 表中黑体数字表示最优值.
| 表4 卷积方式对算法性能影响 Table 4 Effect of convolution method on performance of different algorithms |
由表4可知, LIRDN与对比网络的平均PSNR值相近, 但所需参数量较少, 说明逆可分离构建的LIRDN既可以实现网络轻量化, 也保持网络性能.
3.2.4 连接方式的影响
为了验证不同连接方式对图像超分辨率重建算法性能的影响, 本文以DenseNet密集连接为基础连接方式, 逐层减少残差连接.由于LIRDB具有残差结构, 本文将跨2个及以上的LIRDB的残差连接作为基础残差结构, 同时考虑低频信息对重建的重要性, 更多地保留初始模块处的残差连接, 将末端模块的残差连接逐层删减, 减少的末端残差连接个数记为Q, Q=0, 1, 2, 3.平均PSNR结果如表5所示, 表中黑体数字表示最优值.
| 表5 连接方式对算法性能的影响 Table 5 Effect of connection on performance of different algorithms |
由表5可以看出, 随着末端残差跳跃连接的减少, 算法性能发生变化, Q=0时表示全部前端LIRDB模块跳跃连接引入末端, 即跨2个LIRDB的密集连接, Q=3时表示末端不引入跳跃连接, 其中Q=3时结果最佳.本文将Q=3时的方式作为LIRDN的连接方式, 并将其记为PCR连接.
为了验证LIRDN的有效性, 在4个标准测试数据集上开展大量实验, 进行客观定量和主观视觉效果的对比.
主要对比方法包括:Bicubic、SRCNN[10]、FSR-CNN[11]、VDSR[12]、MSRN[14]、DRCN[16]、DRRN[17]、CBPN[18]、CARN[19]、IMDN[21]、LapSRN(Laplacian Pyra-mid Super-Resolution Network)[38]、SMSR(Sparse Mask SR Network)[39]、LCRCA(Lightweight Skip Concatenated Residual Channel Attention Network)[40]、FCCSR(Feature Cheap Convolution SR)[41]、LFFN(Lightweight Feature Fusion Network)[42].
3.3.1 客观定量对比
放大倍数为2、3、4时的定量对比结果如表6~表8所示, 表中黑体数字表示最优值, 斜体数字表示次优值.
由表6~表8可知, LIRDN在放大倍数为3、4时都得到最优或次优的结果, 特别地, 在放大倍数为4时, LIRDN在Set5、Set14、Urban100、B100数据集上平均PSNR分别提升0.11 dB, 0.06 dB、0.03 dB, 0.13 dB.相比IMDN, LIRDN在Set5数据集上, 放大倍数为2, 3, 4时, PSNR分别提高0.07 dB, 0.12 dB, 0.12 dB.
| 表6 放大倍数为2时各算法在4个数据集上的定量评估结果 Table 6 Quantitative evaluation results of different algorithms with a magnification of 2 on 4 datasets |
| 表7 放大倍数为3时各算法在4个数据集上的定量评估结果 Table 7 Quantitative evaluation results of different algorithms with a magnification of 3 on 4 datasets |
| 表8 放大倍数为4时各算法在4个数据集上的定量评估结果 Table 8 Quantitative evaluation results of different algorithms with a magnification of 4 on 4 datasets |
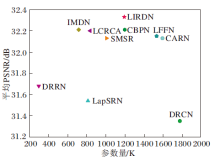
放大倍数为4时各算法在Set5测试集上的平均PSNR值和参数量的对比如图8所示.由图可见, LIRDN的性能和参数量具有更好的平衡.相比MSRN, LIRDN在保证相近甚至略有提高的平均PSNR值和SSIM值的同时, 参数量只有其1/5.
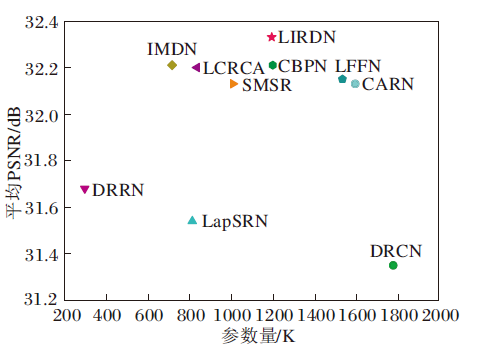 | 图8 放大倍数为4时, 各算法在Set5数据集上的参数量和平均PSNR对比Fig.8 Parameters and average PSNR of different algorithms with a magnification of 4 on Set5 dataset |
对比SMSR、IMDN、LCRCA, 虽然LIRDN的参数量有所增加, 但是在平均PSNR值上具有显著差距, 这表明LIRDN能够在保证参数量较小的同时提升网络的SR性能, 重建出具有更丰富细节纹理的图像.
3.3.2 主观视觉效果对比
在标准测试数据集上的主观视觉效果如图9所示, LIRDN在重建结果方面显著最优.对于具有挑战性的Image005图像, SRCNN、DRRN、IMDN重建的SR图像窗体外框格子模糊不清, 条纹存在明显的伪影, 失真严重, 而LIRDN恢复的图像细节清晰、纹理丰富, 更忠实于真实高分辨率图像.对于Image076图像, DRRN、CARN、LCRCA、IMDN重构的高分辨率图像外轮廓都有不同程度的模糊、畸变产生, 不能准确恢复真实图像的纹理细节, LIRDN恢复的纹理则更接近真实图像.特别对于Image024图像, 其它算法重构的护栏边缘纹理均有不同程度的畸变和扭曲, 部分区域模糊严重, 而LIRDN重构的护栏笔直清晰, 接近真实图像, 没有严重的伪影失真.由此表明LIRDN能够恢复更多的图像信息.
 | 图9 放大倍数为4时各算法在Urban100测试集上的视觉质量对比Fig.9 Visual quality comparison of different algorithms with a magnification of 4 on Urban100 test set |
本节对比算法的计算复杂度, 使用乘加操作和参数量评估7种算法的计算成本和内存消耗, 使用PSNR评价算法的重建性能, 具体如表9所示.LIRDN在可靠地重建高质量SR图像的同时, 消耗的乘加操作位于第二.尽管比MemNet、CBPN引入更多的参数, 但乘加操作运算较少, 说明其计算量更少.因此, 在超分辨率重建过程中, LIRDN更好地平衡模型复杂度与重建性能, 更具有竞争力.
| 表9 各算法在Set5测试集上的复杂度与性能对比 Table 9 Comparison of complexity and performance of different methods on Set5 test set |
本文提出轻量化逆可分离残差信息蒸馏网络(LIRDN)的图像超分辨率重建算法, 不但能够充分发掘低频信息, 还能够快速、准确地提取各种特征, 重建细节丰富的SR图像.具体来说, 轻量高效的渐进可分离重洗信息蒸馏(PDSM)模块通过逆可分离复原浅残差单元(IRC)逐层蒸馏提取特征, 重洗单元增加通道间信息流动, 在确保结构轻量化的同时获得更多样化的特征信息.对比度感知坐标注意力模块(CPCA)可以有效选择包含更多纹理细节的信息, 增强网络的表征能力.逐步补偿残差连接(PCR)可以充分复用浅层特征包含的低频信息, 减少信息损失.实验表明, LIRDN的主客观指标都具有一定竞争力, 并且能平衡模型复杂度与重建性能.由于LIRDN主要针对深层特征进行提取, 因此, 在放大倍数较大时, 效果较优, 但在低倍放大情况下, 仍能进一步提升重建效果.本文虽使用大量的渐进信息蒸馏压缩特征提取的参数量, 但还可以考虑更轻量高效的蒸馏方式.以后将主要针对上述两个问题进行进一步研究.
本文责任编委 徐勇
Recommended by Associate Editor XU Yong
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|