{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于神经架构搜索的非结构化剪枝方法
[王宪保1  , 刘鹏飞
, 刘鹏飞1 , 项圣1 , 王辛刚1 ]
, 刘鹏飞, 项圣, 王辛刚]
|
|



作者简介:
王宪保,博士,副教授,主要研究方向为神经网络、机器学习.E-mail:wxb@zjut.edu.cn. 
刘鹏飞,硕士研究生,主要研究方法为计算机视觉、机器学习.E-mail:16110402051@zjut.edu.cn. 
项 圣,博士,讲师,主要研究方向为机器视觉及其工业应用.E-mail:xiangsheng@zjut.edu.cn.
由于难以使用客观标准删除深度神经网络中的冗余单元,剪枝后的网络表现出性能的急剧退步.针对此问题,文中提出基于神经架构搜索的非结构化剪枝方法.首先,将掩码学习模块定义在搜索空间中,以便删除冗余的权重参数.然后,引入层级相关系数传播,在反向传播过程中为每个网络权重分配一个层级相关系数,以此衡量每个权重对网络输出的贡献度,并帮助二值掩码参数的更新.最后,对网络权重、架构参数和层级相关系数进行统一更新.在CIFAR-10、ImageNet分类数据集上的实验表明,文中方法能够在高剪枝率场景下保持网络的泛化能力,满足模型部署的要求.
About Author:
WANG Xianbao, Ph.D., associate professor. His research interests include neural network and machine learning.
LIU Pengfei, master student. His research interests include computer vision and machine learning.
XIANG Sheng, Ph.D., lecturer. His research interests include machine vision and its industrial applications.
Due to the difficulty of using objective criteria to remove redundant units in deep neural networks, pruned networks often exhibit a sharp decline in performance. To address this issue, an unstructured pruning method based on network architecture search(UPNAS) is proposed. Firstly, a mask learning module is defined in the search space to remove the redundant weight parameters. Then, layer-wise relevance propagation is introduced, and a layer-wise relevance score to each network weight is assigned during the backward propagation process to measure the contribution of each weight to the network output and assist in the update of binary mask parameters. Finally, a unified update is performed on the network weights, architecture parameters and layer-wise relevance scores. Experiment on CIFAR-10 and ImageNet classification datasets shows that UPNAS can maintain the generalization ability of the network in high pruning rate scenarios and meet the requirements for model deployment.
深度神经网络(Deep Neural Network, DNN)已在计算机视觉领域得到众多应用, 表现出较优能力.由于必须满足不同的硬件约束, 如何在不同的硬件平台(如GPU、ASIC或嵌入式设备等)上有效部署这些深度学习模型正逐渐成为业界关注的问题.DNN的高性能往往以高存储和计算成本为代价.例如, VGG-16[1]的模型参数超过138 M, 训练模型需消耗500 MB的存储空间, 对一幅图像进行分类需要155亿次浮点运算次数(Floating-Point Operations, FLO-Ps)[2].
减少模型的存储需求和计算成本对于DNN更广泛的适用性至关重要, 于是学者们提出一些能够解除效率瓶颈同时保持DNN高精度的方法和技术, 如模型压缩(包括网络剪枝[3, 4, 5]、知识蒸馏[6]、网络量化[7, 8]、低秩分解[9])、自动机器学习和高效硬件架构设计[10, 11, 12]等, 以实现高效的深度学习.
网络剪枝已被证明是压缩和加速卷积神经网络(Convolutional Neural Network, CNN)的有用技术, 它使深度网络适应受存储或计算资源限制的硬件设备.根据现有文献, 网络剪枝方法可以分为结构化剪枝[3, 13, 14]和非结构化剪枝[4, 5, 15]两大类.
结构化剪枝方法专注于修剪卷积滤波器、通道甚至网络层, 使修剪后的网络适应不同的环境或设备.Li等[3]提出FCF(Factorized Convolutional Filter), 使用反向传播法更新标准卷积滤波器, 同时使用基于交替方向的乘法优化方法更新二进制标量, 训练一个带有因子化卷积滤波器的CNN.Chin等[13]提出LcP(Layer-Compensated Pruning), 改善资源受限的滤波器的性能, 使其成为一个全局滤波器排名问题.Ye等[14]提出一种通道修剪技术, 将稀疏性约束应用于通道的缩放因子, 确定哪些通道需要被裁剪.虽然结构化剪枝方法更利于硬件加速, 但却牺牲一定的灵活性.
非结构化剪枝试图在不修改网络结构的情况下, 从张量中移除冗余的权重参数, 使一个大的网络变得稀疏.Han等[4]只学习重要的连接, 用三步法修剪多余的连接, 将神经网络所需的存储和计算量减少一个数量级而不影响其准确性.Molchanov等[5]提出减少梯度估计器方差的方法, 使用变分随机失活修剪冗余的权重.Sehwag等[15]提出HYDRA, 将修剪目标表述为一个经验风险最小化问题, 并在剪枝步骤中优化每个连接的重要性得分.相比结构化剪枝, 非结构化剪枝具有优越的灵活性和压缩率.
由于神经网络在不同的抽象层次上提取特征, 因此剪枝过程必须考虑网络超参数的影响, 针对不同层设置不同的剪枝策略.一方面, 剪枝不足即网络中保留过度冗余的连接和参数, 会对模型的计算和推理速度产生影响, 导致模型泛化能力的下降.另一方面, 过度剪枝可能造成网络中剩余的连接和参数变得过于稀疏, 使模型难以捕捉数据中的复杂信息, 同时使准确性和泛化能力下降.
目前人类启发式的剪枝方法难以平衡模型的复杂度和准确性, 在高剪枝率的场景下往往导致网络精度的下降, 无法弥补与其它高效网络设计(如MobileNetV2[16])的巨大差距.除了压缩现有的深度神经网络, 设计新的神经网络架构是另一种提高效率的方法.一些手工高效架构已经显示出出色的性能, 其核心在于高效卷积层的设计.例如, Mobile-NetV2在ImageNet数据集上实现72.0%的准确率, 只用3亿个乘积累加运算(Multiply Accumulate, MAC)和3.4亿个参数.
然而, 网络剪枝和高效架构设计的方法都需要大量的理论思考和测试, 设计者必须满足更严格的标准, 例如拥有既定的知识和大量的经验储备, 否则即使花费大量的人力和时间成本, 也难以保证得到最优的结果.
相比之下, 神经架构搜索(Neural Architecture Search, NAS)自动生成和选择神经网络的超参数, 允许在减少人类参与的情况下自动学习一个有效的神经网络结构, 在很大程度上解决超参数设置的问题.
目前很多NAS无法直接在资源有限的环境中使用.一种日益流行的解决方案是在搜索策略中考虑执行延迟、能源消耗、内存占用等因素, 使用多目标优化算法, 这类NAS统称为硬件感知NAS(Hardware-Aware NAS, HW-NAS).Cai等[17]提出ProxylessNAS, 将模型搜索构建成一个类似于剪枝的过程, 并针对硬件指标进行联合优化, 可以直接学习大规模目标任务和目标硬件平台的架构.
HW-NAS常与网络加速方法结合, 以满足多目标优化的要求.Molchanov等[18]提出LANA(Latency-Aware Network Acceleration), 使用NAS和师生蒸馏结合的方法, 自动使用有效操作替换给定网络中的低效操作.Li等[19]提出DLW-NAS, 重建一个轻量级的搜索空间, 设计一个具有计算复杂度约束的搜索策略, 搜索具有显著性能以及少量参数和浮点运算的CNN.
然而现有的多目标搜索方法总是被较低的搜索效率问题困扰, 为了解决这个问题, Yang等[20]使用自适应数据流映射, 以细粒度的方式描述采样网络结构的推理延迟, 从而扩大可用网络的搜索空间, 满足特定的推理延迟要求.Loni等[21]提出TAS(Ter- narized NAS), 将量化整合到网络设计中, 通过最大梯度传播单元模板和可学习量化器, 大幅减少三元神经网络和全精度对应物之间的精度差距.Peng等[22]提出PRE-NAS(Predictor-Assisted Evolutionary NAS), 利用进化式NAS策略和高保真度的权重继承方法, 避免权重共享带来的评估偏差, 并通过拓扑同构的后代候选提高预测准确性.Li等[23]提出ACGhostNet(Adder-Convolution GhostNet), 设计融合新型加法器算子和传统卷积算子的GhostNet轻量级网络搜索策略, 解决CNN在计算机视觉领域中的能量消耗问题, 平衡加法器和卷积算子的权重.该策略能够使加法器和卷积算子在搜索过程中得到公正的对待, 从而得到更高能效和更优性能的模型.
将NAS应用在网络剪枝上, 可以避免超参数选择和网络结构设计的主观性和复杂性, 并且缓解网络泛化性下降的问题.但NAS与网络剪枝是两个独立的过程, 算法需要制定一个新的搜索目标, 同时更新剪枝参数和搜索架构参数.另外, 剪枝操作需要选择删除的神经单元, 而目前NAS的搜索空间中仅包括卷积、池化和归一化等操作, 无法直接在搜索空间中进行.
针对上述问题, 本文提出基于神经架构搜索的非结构化剪枝方法(Unstructured Pruning Method Based on NAS, UPNAS), 主要工作如下:1)提出一个支持剪枝操作的搜索空间, 并将掩码学习引入搜索空间的卷积和线性操作中.掩码学习模块为每个权重分配一个掩码, 实现对冗余权重的删除.在搜索过程中, 采用同时更新掩码参数与网络结构的方式, 训练具有自适应剪枝能力的模型.2)引入层级相关系数传播(Layer-Wise Relevance Propagation, LRP)[24]作为剪枝标准, 通过反向传播相关性评估网络中每个神经元的重要性.同时, 根据相关系数对二值掩码进行更新.3)提出非结构化剪枝方法, 在预训练阶段同时对网络权重和相关系数进行更新, 实现自适应剪枝, 避免过度剪枝或剪枝不足的问题, 提高方法的泛化性能.
针对深度网络在内存受限的硬件设备上的部署问题, 本文提出基于神经架构搜索的非结构化剪枝方法(UPNAS).方法引入一个掩码学习模块, 并依据学习到的掩码参数删除冗余权重.为了更新二值掩码, 引入层级相关系数传播(LRP)作为剪枝标准, 评估网络单元的重要性, 保持网络的功能完整性.此外, 还提出搜索目标和优化算法, 对网络权重、架构参数和剪枝参数进行统一优化.
本文提出一个具有支持网络剪枝特性的搜索空间, 允许在搜索过程中对网络进行剪枝.
1.1.1 搜索空间与搜索网络
为了从源头上限制神经网络的参数和浮点计算, 考虑将更轻量级的卷积操作引入搜索空间中, 因此提出一个支持网络剪枝的搜索空间, 包含7个操作, 即GhostConv[25]、3× 3 深度可分离卷积、3× 3 扩张卷积、3× 3 最大池化、3× 3 平均池化、恒等映射和零操作.其中GhostConv是一个便捷的卷积操作, 参数和FLOPs约为3× 3深度可分离卷积的一半.
NASNet[26]和DARTS(Differentiable Architecture Search)[27]在预定义的搜索空间中搜索两种类型的单元, 即正常单元和还原单元.正常单元用于返回相同维度的特征图, 而还原单元用于返回高度和宽度减少一半的特征图.本文可借鉴这一思想.
单元的拓扑结构是一个由n个节点组成的有向无环图(Directed Acyclic Graph, DAG), 按照规则有序连接.
具体来说, 每个节点N表示卷积网络的一个特征图.节点Np和Nq连接, 形成单元的一条边E(p, q), 表示从搜索空间中选择的某种操作.每个节点和所有前驱节点连接, 并满足
${{N}_{p}}=\underset{q< p}{\mathop \sum }\, {{o}^{(p, q)}}{{N}_{q}}$,
其中, o(p, q)表示从给定的操作集O中选择一个操作, 并应用于边E(p, q).为了使搜索空间连续化, 对离散操作选择进行连续松弛化:
${{\bar{o}}^{\left( p, q \right)}}\text{=}\underset{o\in O}{\mathop \sum }\, \left( \frac{\text{exp}\left( \alpha _{o} \ ^{\left( p, q \ \right)} \ \ \ \right)}{\mathop{\sum }_{o \ '\in O} \ \ \ \text{exp} \left( \alpha _{o \ '} \ ^{\left( p, q \right)} \ \ \ \right)} \right)o({{N}_{p}})$,
其中, $\alpha _{o \ '}^{\left( p, q \right)}$是$\left| O \right|$维向量α (p, q)的一个元素, 表示Np和Nq之间的操作o'的权重.架构参数α 反映每个操作的重要性, 通过对架构参数进行更新, 得到单元的最终结构.
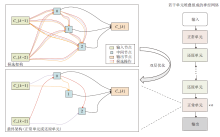
完整的神经网络由若干个正常单元和还原单元堆叠组成, 基本单元的搜索过程如图1所示.在网络总深度的1/3和2/3的位置为还原单元, 其余位置为正常单元, 这样的设置有利于为任何尺寸的输入图像构建可扩展的架构.
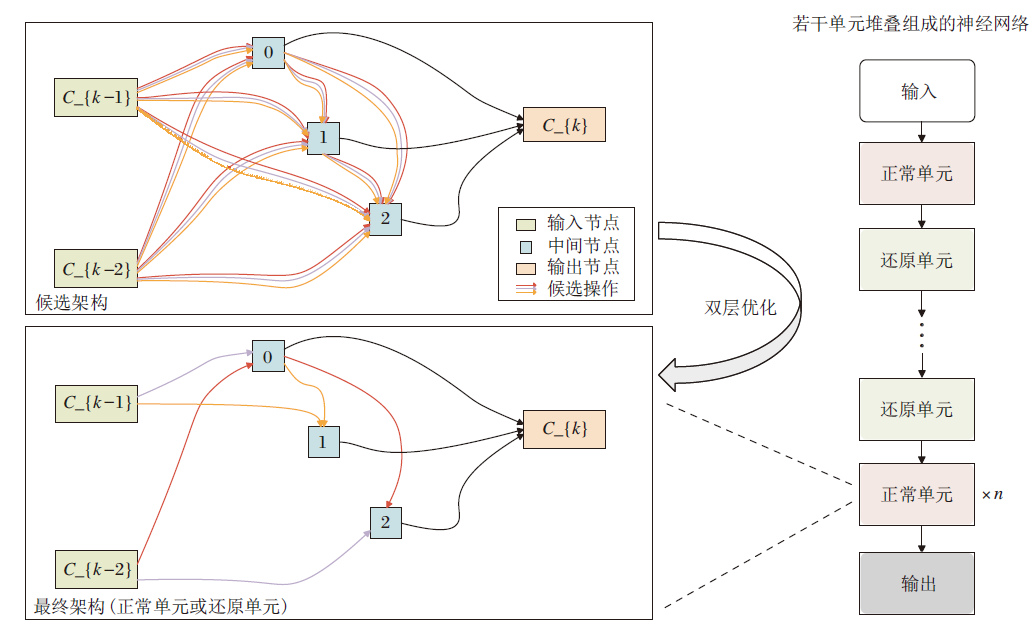 | 图1 基本单元的搜索过程Fig.1 Search process of basic cell |
1.1.2 掩码学习模块
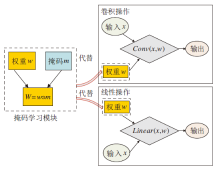
由于NAS的搜索过程中缺乏对网络剪枝的支持, 本文提出一个掩码学习模块, 结构如图2所示.模块包含一组与权重参数维度相同的二值掩码序列, 将其引入搜索空间的卷积和线性操作中, 为每个网络权重分配一个掩码.在搜索过程中, 根据设立的剪枝标准, 对网络性能贡献度低的权重进行掩码, 以便在后续的训练中删除该权重.
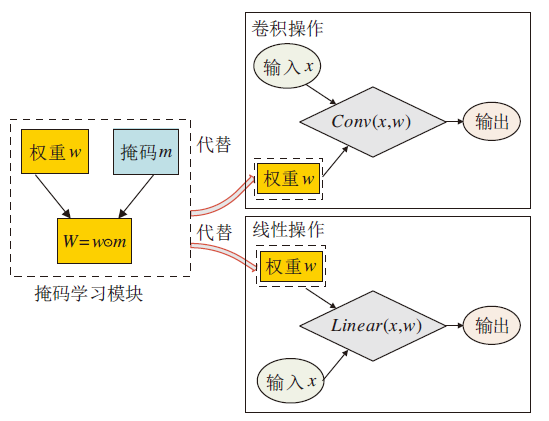 | 图2 掩码学习模块结构图Fig.2 Structure of mask learning module |
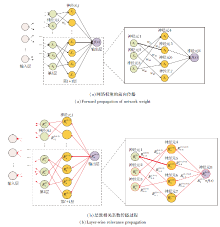
由于掩码是一组二进制参数, 直接更新具有挑战性, 因此引入层级相关系数传播(LRP)[24], 协助掩码参数的更新, 同时作为剪枝标准.LRP最初被用于机器学习的可解释性, 计算每个输入特征对于网络输出的相对重要性, 分析神经网络的决策过程.LRP的计算是通过反向传播实现的, 具体如图3所示.
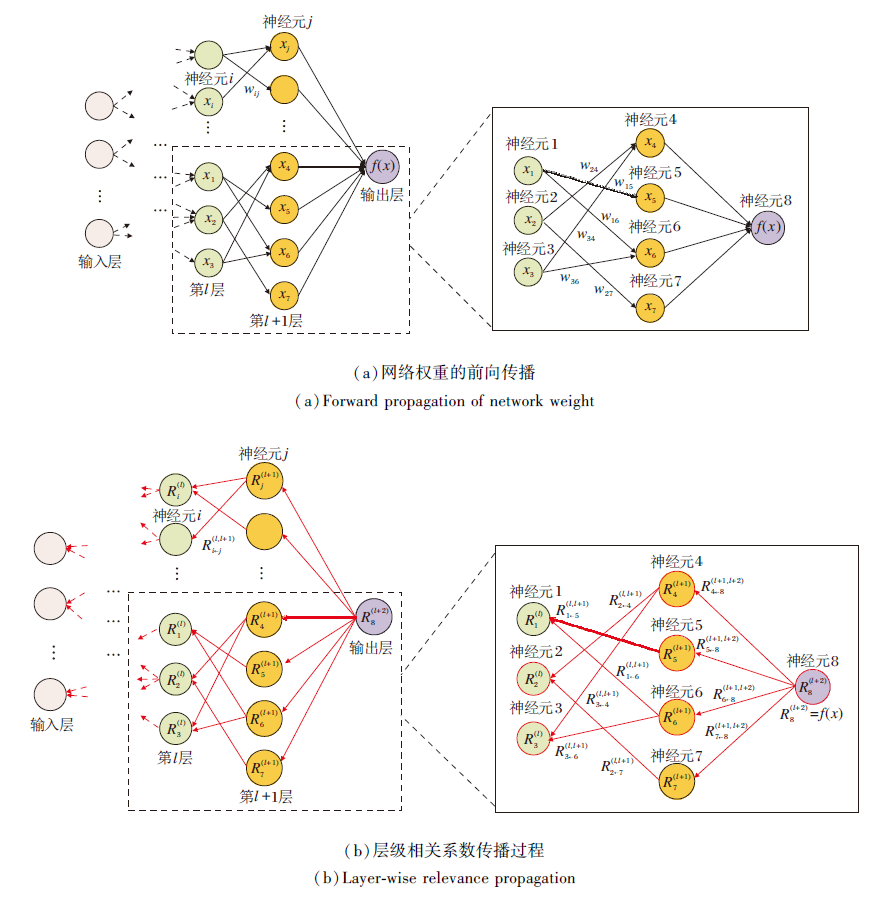 | 图3 网络权重和层级相关性系数的传播过程Fig.3 Propagation process of network weight and layer-wise relevance score |
在反向传播过程中, 通过对神经元激活的正向传播过程进行逆向传播, 计算每个网络单元(神经元或网络权重)对于输出的贡献, 并将这些贡献值分配给相应的网络单元.
传统的剪枝标准通常只考虑每个神经元的权重大小和梯度信息, 无法衡量每个神经元在网络中的作用.例如, 基于权重的剪枝标准可能删除网络中重要的神经元, 导致网络性能的衰退.
相比之下, LRP通过反向传播重要性考虑每个权重在网络中的作用, 从而更好地评估其重要性.此外, 使用LRP作为剪枝标准有助于保持网络的功能完整性.
因为可基于每个权重的贡献度进行剪枝, 所以剪枝后的网络仍然可以保持原有的功能, 而不会失去关键的权重.
为了确保所有重要性得到正确的分配和保存, LRP的重新分配遵守分层守恒原则:
$f(x)=\ldots =\underset{j\in l+1}{\mathop \sum }\, R_{j}^{l+1}=\underset{i\in l}{\mathop \sum }\, R_{i}^{l}=\ldots =\underset{d}{\mathop \sum }\, R_{d}^{1}$,
其中, $R_{j}^{l+1}$表示非线性网络中第l+1层中神经元j的相关系数, $R_{i}^{l}$表示第l层中神经元i的相关系数.
LRP与网络输出f(x)直接建立联系, 并在逐层分配中遵守分层守恒原则.即使在剪枝过程中神经网络隐藏层的大小以及神经元的数量发生变化, 分层守恒原则也能保证LRP的数量固定, 从而保证剪枝程序的平稳运行.
相关系数的分配是根据发送到前一层的神经元的信息获得的, 这种信息为Ri← j.在非线性网络中, 神经元的激活值zj是xj的非线性函数.当激活函数单调递增时, 如双曲切线和整流函数, 相关系数的分配基于局部和全局预激活的比率:
$R_{i\leftarrow j}^{\left( l, l+1 \right)}=\frac{{{z}_{ij}}}{{{z}_{j}}}\cdot R_{j}^{\left( l+1 \right)}$,
其中,
zij=xiwij,
表示第l层的神经元i对第l+1层中神经元j的加权激活值,
$\underset{\text{k}\in \text{l}}{\mathop \sum }\, {{z}_{kj}}+b$,
表示第l层所有与第l+1层神经元j连接的神经元对j的加权激活值, b表示偏置项.
l+1层的某个神经元j的相关系数$R_{j}^{\left( l+1 \right)}$为l+1层的神经元j与l层相连接的神经元的相关系数之和, 即
${{z}_{j}}=\underset{i}{\mathop \sum }\, R_{i\leftarrow j}^{\left( l, l+1 \right)}=R_{j}^{\left( l+1 \right)}$.
当相关性被用作修剪标准时, 无论隐藏层的大小和每层迭代修剪的神经元数量如何变化, 这一特性都有助于保持逐层相关性守恒.根据相关系数R∈ (0, 1)N学习用于剪枝的掩码参数m∈ {0, 1}N, 其中N表示预训练网络权重的数量.根据剪枝的要求, 选择前k个最大的相关系数, 可以表述为第l层的神经元i与第l+1层中神经元j之间的权重wij分配的掩码值:
$m_{\left( i, j \right)}^{\left( l, l+1 \right)}=1(\left| R_{i\leftarrow j}^{\left( l, l+1 \right)} \right|\ge {{\left| {{R}^{\left( l, l+1 \right)}} \right|}_{k}})$,
其中, $R_{i}^{l}$表示第l层中神经元i的相关系数, ${{\left| {{R}^{\left( l, l+1 \right)}} \right|}_{k}}$表示第l层与第l+1层中第k个最大的相关系数值, 1(· )表示判别函数, 如果满足判别条件, 函数值赋为1, 否则赋为0.
将第l层与第l+1层中所有的相关系数按照从大到小的顺序排列, 如果神经元i与神经元j之间的权重对应的相关系数的绝对值
$\left| R_{i\leftarrow j}^{\left( l, l+1 \right)} \right|\ge {{\left| {{R}^{\left( l, l+1 \right)}} \right|}_{k}}$,
则将wij对应的掩码值$m_{\left( i, j \right)}^{\left( l, l+1 \right)}$设置为1, 在后续剪枝中保留该权重.
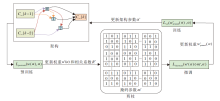
非结构化剪枝通常需要三个阶段:网络预训练、剪枝和微调, 流程如图4所示.为了训练有关剪枝权重的架构参数, 方法将网络权重和掩码参数的更新转化为双层优化中较低层次的优化问题, 使用基于梯度的方式与架构参数交替更新.UPNAS的搜索目标在于获得最优的架构参数α * , 使剪枝后网络的验证损失Lval(wpruned(α ), α )最小, 即
${{\alpha }^{* }}=arg\underset{\alpha }{\mathop{\text{min}}}\, {{L}_{val}}({{w}_{pruned}}(\alpha ), \alpha )$,
$s.t.w{{* }^{(}}\alpha )=arg\underset{\text{w}}{\mathop{\text{min}}}\, {{L}_{p}}{{_{re}}_{-train}}(w(\alpha ), \alpha )$,
$R* =arg\underset{\text{R}}{\mathop{\text{min}}}\, {{L}_{pr}}{{_{e}}_{-train}}(w(\alpha ), \alpha )$,
${{w}_{pruned(}}_{\alpha )}=arg\underset{{{\text{w}}^{\text{* }}}\left( \text{ }\!\!\alpha\!\!\text{ } \right)}{\mathop{\text{min}}}\, {{L}_{\text{fine-tune}}}({{w}^{* }}(\alpha )m* , \alpha )$,
其中, w(α )表示预训练网络的权重参数, wpruned(α )表示微调网络的权重参数.
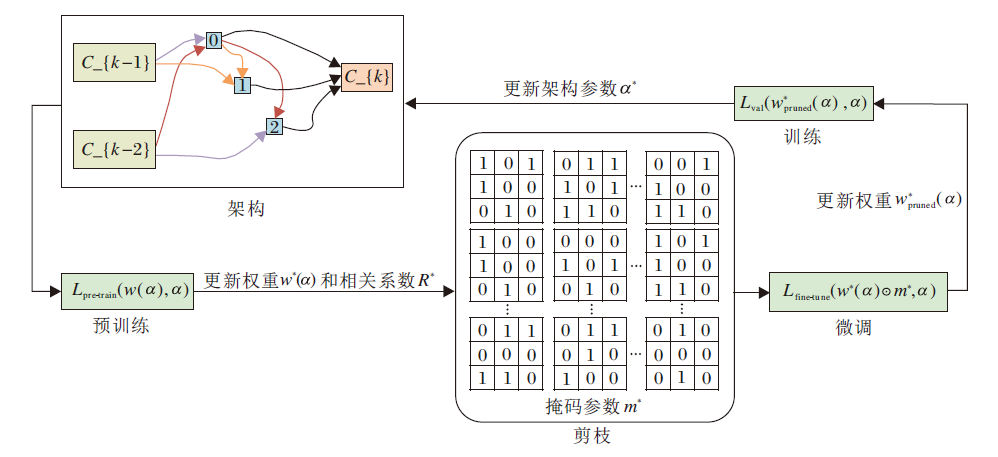 | 图4 非结构化剪枝方法流程图Fig.4 Flowchart of unstructured pruning method |
UPNAS依次实现对w(α )、m、wpruned(α )和α 的学习.首先, 给定一个初始化的搜索架构, 架构参数在预训练阶段保持不变, 而网络权重通过随机梯度下降法(Stochastic Gradient Descent, SGD)进行更新.根据LRP的传播规则, 相关系数采用类似于反向传播的方式进行更新.最小化预训练损失Lpre-train(w(α ), α )以更新权重w* (α )与相关系数R* .然后, 通过更新后的掩码参数m* 删除网络中冗余的权重参数.在微调阶段, 对剪枝后的网络重新训练, 更新非零权重wpruned(α )以达到最佳的网络精度.最后, 最小化验证损失Lval(wpruned(α ), α ), 即可获得最优的架构参数α * .
本文在两个公开的分类数据集CIFAR-10[28]和ImageNet[29]上进行实验, 用于评估UPNAS的有效性.CIFAR-10数据集是一个分类数据集, 由60 000幅彩色图像组成, 平均分为10类, 训练图像50 000幅和测试图像10 000幅.ImageNet数据集共有1 000个类别, 14 197 122幅图像, 是一个用于分类的大型计算机视觉数据集, 每幅图像都经过手工标定.
将CIFAR-10数据集按照1∶ 1的比例划分为训练集和验证集, 便于在搜索过程中交替更新不同的参数.使用Top-1准确率和网络参数量作为评估指标.
本文使用SGD分别对预训练网络和微调网络进行训练, 历时60个迭代周期, 动量设置为0.9, 权重衰减为0.000 3, 每个训练批次由64幅图像组成.预训练和微调阶段的起始学习率分别设置为0.025和0.01, 使用余弦退火在每20个历时后衰减为原来的1/10.搜索网络由不同数量的单元堆叠构成, 网络中1/3和2/3的位置为还原单元, 其它为正常单元.
实验使用PyTorch框架在英伟达Tesla V100上进行训练和推理, 搜索过程累积花费2.1~2.8个GPU-day.
为了权衡网络的分类准确率和参数量, 将剪枝率设置为95%, 在CIFAR-10数据集上展开一组实验, 探究网络层数和初始通道数对剪枝网络的影响.分别取网络层数为14, 16, 18, 20, 初始通道数为36, 48, 64, 实验结果如表1所示, 表中黑体数字表示最优值.由表可以发现, 搜索的剪枝网络的参数量随着网络层数与通道数的增加而增大.而且, 当保持网络层数不变时, 增大网络的初始通道数有益于准确率的提升.但是, UPNAS在CIFAR-10数据集上取得的Top-1准确率与网络层数并未呈现正相关的关系.可以看出, 层数的加深导致网络复杂度的增加, 从而产生过拟合的现象, 阻碍UPNAS取得更佳的表现.
| 表1 网络层数和初始通道数对算法的影响 Table 1 Effect of network layers and initial channels on algorithm performance |
实验数据表明, 当网络层数设置为14, 初始通道数设置为64时, NPF取得最高的分类准确率, 为96.35%, 网络参数仅为0.367Í 106个.PR-DARTS(Pruning-Based DARTS)[30]也测试DARTS网络剪枝后的性能, 在相同的剪枝率下, 在CIFAR-10数据集上取得93.74%的Top-1准确率.相比之下, UPNAS在CIFAR-10数据集上的Top-1准确率提升2.61%.后续实验将在网络层数为14和初始通道数为64下搜索剪枝网络.
为了评估网络在极端剪枝率场景下的准确率衰减情况, 将网络剪枝率设置为99%, 在CIFAR-10数据集上进行实验.HYDRA[15]作为目前先进的非结构化剪枝方法之一, 使用剪枝参数帮助掩码的更新, 能够为网络提供99%的剪枝率.因此, 使用HYDRA对MobileNetV2[16]、DARTS[26]、EfficientNet[31]和ResNet-18[32]进行剪枝, 并与UPNAS进行对比, 实验结果如表2所示, 表中黑体数字表示最优值.压缩比是以DARTS的参数量(3.3× 106)为基准.
| 表2 极端剪枝率下6种方法的结果对比 Table 2 Result comparison of 6 methods with extreme pruning rates |
由表2可看出, 在极端剪枝率下, 不同网络架构的性能均出现退步, 相比在95%剪枝率的场景下, UPNAS在CIFAR-10数据集上的Top-1准确率下降4.72%, 但非剪枝场景设计的网络架构的性能下降得更快.例如, 相比剪枝前, 剪枝后的DARTS在CIFAR-10数据集上的准确率下降15.99%.这一结果也表明, 尽管先进的剪枝技术能够大幅削减网络权重参数量, 但由于人为设计的剪枝策略难以运用最优方式保留或删除网络权重, 因此导致网络在剪枝前后的泛化差距较高.UPNAS将剪枝集成在架构搜索过程中, 通过优化算法自动学习掩码参数m, 可避免此问题.
值得注意的是, 相比DARTS架构, PR-DARTS(Small)在保持89.06%的准确率的同时取得194.12倍的网络压缩率.PR-DARTS与UPNAS类似, 区别在于PR-DARTS在剪枝过程中遵从HYDRA提出的掩码学习方式, 而UPNAS使用层级相关系数[27]作为剪枝标准, 能够衡量每个权重的重要性.相比PR-DARTS(Small), UPNAS取得2.57%的准确率提升, 网络参数量几乎相当.
本文选用如下3种压缩方法:1)神经网络架构搜索方法.TAS[21]、ACGhostNet-B[23]、ACGhostNet-C[23].2)高效架构手工设计方法.ShuffleNet[11]、MobileNetV2[16].3)知识蒸馏方法.文献[33]方法、RKD(Relational Knowledge Distillation)[34]、PU(Po-sitive-Unlabeled) Method[35]、文献[36]方法、DFND(Data-Free Noisy Distillation)[37].
在ImageNet数据集上重新训练UPNAS, 引入指
标A/P, 用于评估神经网络使用参数的效率.A/P结合模型的准确率和参数量, 公式如下:
可以看出, A/P值越大, 说明网络使用参数的效率越高[38].
UPNAS和其它压缩方法在CIFAR-10、ImageNet数据集上的指标值对比如表3所示, 表中黑体数字表示最优值.由表可知, 相比其它方法, UPNAS性能最优.在CIFAR-10、ImageNet数据集上, UPNAS获得96.35%和73.60%的Top-1准确率, 相比MobileNetV2, 分别获得4.30%和1.60%的准确率提升, 网络参数量为0.367× 106和0.480× 106.相比ShuffleNet, UPNAS以10.34倍的A/P值在ImageNet数据集上获得相同的分类精度.相比ACGhostNet-C, UPNAS在CIFAR-10上获得1.25%的准确率提升, 两种方法在ImageNet数据集上获得相等的精度, 但UPNAS取得10.76倍的A/P值提升.此外, 相比文献[36]方法, UPNAS在两个数据集上的准确率分别提升1.69%和1.11%, 并取得262.53和152.33的A/P值.
| 表3 UPNAS与其它压缩方法的指标值对比 Table 3 Index value comparison of UPNAS and other compression methods |
为了进一步探究UPNAS的有效性, 选择如下剪枝方法:WRN(Wide Residual Networks)[7]、HRank(High Rank of Feature Maps)[39]、GAL(Generative Adversarial Learning)-0.5[40]、ABCPruner(A New Chan-nel Pruning Method Based on Artificial Bee Colony Algorithm)[41]、PKP(Progressive Kernel Pruning)[42]、FPGM(Filter Pruning via Geometric Median)[43]、SFP(Soft Filter Pruning)[44]、TAS(Transformable Archi-tecture Search)[45].
各方法在CIFAR-10、ImageNet数据集上的实验结果如表4所示, 表中黑体数字表示最优值, 压缩率是根据使用GAL-0.5修剪后的网络参数量计算的.由表可知, 相比GAL-0.5, UPNAS在CIFAR-10、ImageNet数据集上获得3.80%和1.65%的准确率提升.以GAL-0.5的网络参数量为基准, UPNAS在CIFAR-10、ImageNet数据集上获得2.59倍和44.17倍的网络压缩率, 在CIFAR-10上取得最高的分类精度, 在ImageNet上的分类精度比ABCPruner降低0.26%, 但获得24.54倍的模型压缩率, 参数量大幅减少.可以看出, UPNAS不仅可以删除大量冗余的网络参数, 而且可以保持神经网络的泛化能力, 提高网络效率.
| 表4 UPNAS与剪枝方法的指标值对比 Table 5 Index value comparison of UPNAS and other pruning methods |
为了满足模型部署的需要, 本文提出基于神经架构搜索的非结构化剪枝方法(UPNAS).在预定义的搜索空间中引入掩码学习模块, 为每个权重分配一个掩码, 实现在搜索过程中对冗余权重的删除.此外, 为了解决掩码参数的优化问题, 引入层级相关系数传播(LRP)作为剪枝标准, 评估权重对输出的贡献度, 并根据相关系数更新每个掩码参数值.实验表明, UPNAS可以有效删除相对冗余的参数, 并在最大程度上降低网络性能的衰减程度, 为实际场景下的模型部署问题提供一种有效的解决方案.今后将探索剪枝方法在更多计算机视觉任务上的应用, 解决现实中具体的模型部署问题.
本文责任编委 陈松灿
Recommended by Associate Editor CHEN Songcan
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|