
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于图注意力和表指针网络的中文事件抽取方法
[刘炜1, 2  , 马亚威
, 马亚威1 , 彭艳3 , 李卫民1 ]
, 马亚威, 彭艳, 李卫民]
|
|



作者简介:
马亚威,硕士研究生,主要研究方向为事件抽取、自然语言处理.E-mail:mayawei@shu.edu.cn. 
彭 艳,博士,教授,主要研究方向为海洋无人艇的建模和控制、现场机器人、运动系统.E-mail:pengyan@shu.edu.cn. 
李卫民,博士,教授,主要研究方向为数据智能、生物信息、智慧医疗、社交网络.E-mail:wmli@shu.edu.cn.
现有的中文事件抽取方法存在触发词和论元依赖建模不足的问题,削弱事件内的信息交互,导致论元抽取性能低下,特别是论元角色存在重叠的情况下.对此,文中提出基于图注意力和表指针网络的中文事件抽取方法(Chinese Event Extraction Method Based on Graph Attention and Table Pointer Network, ATCEE).首先,融合预训练字符向量和词性标注向量作为特征输入,并利用双向长短期记忆网络,得到事件文本的强化语义特征.再将字符级建模的依存句法图引入图注意力网络,捕获文本中各组成成分的长距离依赖关系.然后,使用表填充的方法进行特征融合,进一步增强触发词和其对应的所有论元之间的依赖性.最后,将学习得到的表特征输入全连接层和表指针网络层,进行触发词和论元的联合抽取,使用表指针网络对论元边界进行解码,更好地识别长论元实体.实验表明:ATCEE在ACE2005和DuEE1.0这两个中文基准数据集上都有明显的性能提升,并且字符级依存特征和表填充策略在一定程度上可以解决论元角色重叠问题.ATCEE源代码地址如下:https://github.com/event6/ATCEE.
About Author:
MA Yawei, master student. His research interests include event extraction and natural language processing.
PENG Yan, Ph.D., professor. Her research interests include modeling and control of unmanned surface vehicles, field robotics, and locomotion systems.
LI Weimin, Ph.D., professor. His research interests include data intelligence, bioinformation, smart medical and social network.
The existing Chinese event extraction methods suffer from inadequate modeling of dependencies between an event trigger word and all its corresponding arguments, which results in weakened information interaction within an event and poor performance in argument extraction, especially when there is argument role overlap. To address this issue, a Chinese event extraction method based on graph attention and table pointer network(ATCEE) is proposed in this paper. Firstly,pre-trained character vectors and part-of-speech tagging vectors are fused as feature inputs. Then, the enhanced feature of the event text is obtained by a bidirectional long short-term memory network. Next, a character-level dependency syntax graph is constructed and introduced into multi-layer graph attention network to capture long-range dependencies among constituents of the event text. Subsequently, dependencies between an event trigger word and all its corresponding arguments are further enhanced via a table filling strategy. Finally, the learned table feature is input into a fully connected layer and table pointer network layer for joint extraction of trigger words and arguments. Consequently, long argument entities can be identified better by decoding argument boundaries with a table pointer network. Experimental results indicate that ATCEE method significantly outperforms previous event extraction methods on Chinese benchmark datasets, ACE2005 and DuEE1.0. In addition, the overlap problem of the event argument role is solved by introducing character-level dependency feature and table filling strategy to some extent. The source code of ATCEE can be found at the following website: https://github.com/event6/ATCEE.
事件抽取(Event Extraction, EE)是信息抽取领域最具挑战性的任务之一, 是指从非结构化的文本中自动识别事件类型及其参与者的技术, 广泛应用于事理图谱构建[1]、舆情分析[2]、信息检索[3]等方面, 是自然语言处理(Natural Language Processing, NLP)在工程应用领域强有力的技术支撑之一.根据自动内容提取(Automatic Content Extraction, ACE)[4]评测会议给出的定义, 事件抽取分为事件检测和论元抽取两个子任务, 其中, 事件检测是从一段文本中识别触发词并判断它所属的事件类型, 论元抽取是识别事件的参与者并分析它们在事件中充当的角色.
近年来, 得益于神经网络强大的特征提取能力, 基于深度学习的方法是事件抽取领域研究的主流[5].针对最大池化机制可能会丢失有助于事件抽取任务的语义信息的问题, Chen等[6]提出DMCNN(Dynamic Multi-pooling Convolutional Neural Network), 捕捉句子中局部的重要语义信息.Nguyen等[7]提出JRNN(Joint Event Extraction via Recurrent Neural Network), 在编码阶段使用双向循环神经网络(Bidirectional Recurrent Neural Network, Bi-RNN)学习句子级特征, 在预测阶段, 引入记忆矩阵和记忆向量, 建模事件类型和论元角色之间的依赖关系.Yang等[8]提出PLMEE(Pre-trained Language Model Based Event Extractor), 利用预训练模型生成部分训练数据, 并通过角色预测分离的方法处理论元抽取中存在的角色重叠问题.
然而, 由于中文会出现分词结果和触发词或论元边界不匹配的情况, 上述方法在中文事件抽取任务中并未取得理想效果.针对这一问题, Zeng等[9]将事件检测任务转化为序列标注任务, 将中文字符和分词结果分别输入模型中, 然后使用卷积神经网络(Convolutional Neural Network, CNN)[10]捕捉局部词汇特征, 使用双向长短期记忆网络(Bidirectional Long Short-Term Memory, BiLSTM)[11]捕捉句子级特征, 用于检测BIO(B-begin, I-inside, O-outside)[12]标注模式标注的触发词标签.针对中文事件抽取中存在的触发词歧义问题, Ding等[13]引入外部知识库HowNet, 增强字符和词汇的语义特征表示, 并使用树状长短期记忆网络(Long Short-Term Memory, LSTM)融合多种特征, 用于事件检测.Wu等[14]考虑到字符特征和词语特征融合的过程中, 各个字符的语义信息不同, 以及字符信息与其在词汇中的位置也有关系, 提出一种字符级别的注意力机制, 学习各个字符和词语之间的权重, 以便更好地融合字符和词汇的语义信息.Xu等[15]提出JMCEE(Joint Multiple Chinese Event Extractor), 针对论元角色重叠问题, 使用预训练模型学习事件三元组< 触发词, 论元角色, 论元> 之间的相互依赖关系, 并设计多个二分类器, 判别触发词和论元的起止位置.Sheng等[16]提出CasEE(Cascade Decoding for Overlapping Event Extrac-tion), 针对触发词和论元重叠问题, 提出具有级联解码的联合学习框架, 分阶段完成事件类型、事件触发词和事件论元的抽取, 并采用多任务学习的方式捕获子任务之间的依赖关系.但是, 上述方法大都将句子表示为顺序结构进行建模, 导致模型在捕捉文本中各组成成分的长距离依赖关系时, 效果并不理想.
相比顺序建模, 通过依存句法弧可以强化触发词和关键论元之间依赖关系, 缩短触发词间的距离, 进而促进事件内和事件间的信息交互.为此, 近年来一些学者陆续利用图神经网络结合依存句法分析(Dependency Parsing, DP)进行建模.Liu等[17]使用图卷积网络(Graph Convolutional Network, GCN)[18]和依存句法图, 增强多个事件之间的信息交互.Yan等[19]在GCN和句法依存图的基础上, 引入注意力机制, 聚合多阶句法关系, 进行触发词的识别.You等[20]将事件编码为语义图, 事件触发词和论元作为图中节点, 进而把事件抽取转化为一个图解析问题, 用于捕获事件内的复杂交互.
同样, 相比英文文本, 中文句法结构复杂, 存在主语或宾语常常省略、在复杂句子中难以找到清晰的从句分割词(如英文中的that, where, when等)[21]以及分词错误引发的误差传递等问题, 导致句法特征未较好地融入中文事件抽取任务.
针对上述差异和挑战, Wu等[21]提出CAEE(Chinese Event Extraction Framework via Graph Atten-tion Network), 设计依存句法分析和中文字符结合的方式, 并引入图注意力网络(Graph Attention Net-work, GAT)[22], 捕捉句法树中各组成成分的长距离依赖关系, 然而未单独处理触发词和论元依赖建模不足的问题, 也未考虑论元角色重叠的情况, 因此论元抽取没有显著的性能提升.
此外, 基于表填充(Table Filling, TF)的方法也广泛应用于信息抽取任务中.基于表填充, Gupta等[23]提出实体关系联合抽取方法, 捕捉二者的相关性, 有效解决实体重叠的问题.Wu等[24]提出网格标注方案, 将面向方面的观点抽取(Aspect-oriented Fine-grained Opinion Extraction, AFOE)转化为词对标注任务, 效果良好.Zeng等[25]将论元抽取建模为表填充问题, 提升英文语料上多事件抽取的性能.
综上所述, 尽管当前事件抽取方面已有较多的研究工作, 但是还尚未很好地解决中文事件抽取中存在的触发词和论元依赖建模不足、论元角色重叠难以抽取等问题.触发词和论元依赖建模不足会削弱事件内的信息交互, 导致论元抽取性能低下, 特别是论元角色存在重叠的情况下.此时, 触发词和论元之间的依赖关系建模不足会导致模型只能成功分类论元对应的多个事件角色中的一个, 进而导致论元抽取性能低下.
针对上述问题, 本文提出基于图注意力和表指针网络的中文事件抽取方法(Chinese Event Extraction Method Based on Graph Attention and Table Pointer Network, ATCEE).首先, 使用知识增强语义表示模型(Enhanced Representation through Knowledge Inte-gration, ERNIE)[26]和Bi-LSTM获取文本中各组成成分的深层语义特征.然后, 将语言技术平台(Language Technology Platform, LTP)[27]依存句法分析模块处理事件文本得到的依存句法树扩充为依存句法图, 并引入图注意力网络层, 捕获各组成成分间的长距离依赖关系.最后, 在解码阶段引入表填充策略[23, 24, 25], 进一步增强论元和其对应的所有触发词之间的依赖性, 并将学习得到的表特征用于触发词和论元的联合抽取.
本文将事件抽取建模为基于表格标注的多分类任务, 提出基于图注意力和表指针网络的中文事件抽取模型(ATCEE), 框架如图1所示.
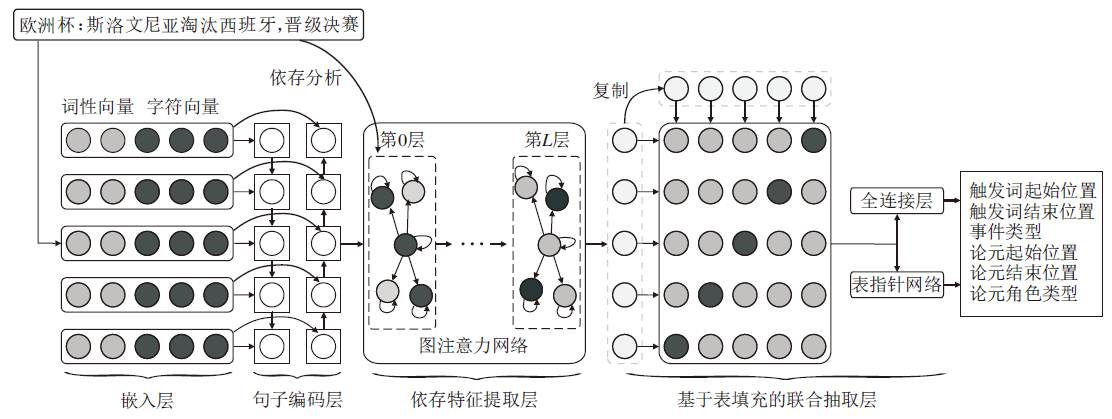 | 图1 ATCEE框架图Fig.1 Framework of ATCEE |
考虑到任务的最终目标是识别一些文本块作为事件触发词和论元, 中文文本的分词结果会出现和这些文本块不匹配的情况, 故基于序列标注的思想, 本文将中文字符作为模型的基本处理单元.对于输入模型的事件文本, 首先, 使用ERNIE对其切分编码, 获取动态变化的字向量, 并拼接词性标注向量作为句子编码层的特征输入.再利用BiLSTM获取句子的强化语义特征.然后, 将依存分析得到的依存句法图引入GAT层, 捕获文本中各组成成分的长距离依赖关系.使用表填充的方法进行特征融合, 增强触发词和论元隐层向量之间的关联性.最后, 将学习得到的表特征输入全连接层和表指针网络层, 并结合softmax分类器进行触发词和论元的联合抽取.
表特征对应的表格标签标注示例如图2所示.在表中:触发词标签采用BIO标注模式, 15、16表示“ B-胜负” 和“ I-胜负” 等触发词标签标识, 对应的触发词是“ 淘汰” ; 论元角色采用表指针标注模式, 7表示“ 胜负” 这一事件关联的论元角色“ 赛事名称” 的标识, 对应的论元为“ 欧洲杯” , 使用两个表格分别标注论元的首尾位置.
 | 图2 事件表格标注示例图Fig.2 Illustration of event-table annotation |
表格标注的方法可以标注句子中所有触发词-论元对的关系, 进一步增强触发词和论元之间的依赖性.同时, 相比选用条件随机场(Conditional Random Fields, CRF)[28]作为解码器, 使用表指针网络识别论元的首尾位置进行抽取, 可有效解决长论元实体抽取断裂的问题.
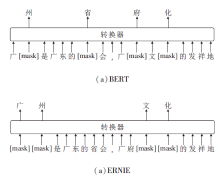
ATCEE首先使用ERNIE对输入文本进行切分并编码, 获取输入的字符向量.ERNIE主要对BERT(Bidirectional Encoder Representations from Transformers)[29]的掩码机制进行改进, 二者不同的掩码策略如图3所示, 在训练中文文本时, BERT只是随机掩码一些字, 学到的更多是字与字之间的关系, 如图3(a)中的“ 府” 与“ 广” 、“ 文” 之间的局部关系.而ERNIE通过对词、实体等语义单元的掩码, 使模型除了能学到字与字之间的局部关系, 还能学到如(b)中所示的“ 广州” 与“ 省会” 之间的知识信息, 进一步提升预训练模型的语义表示能力.
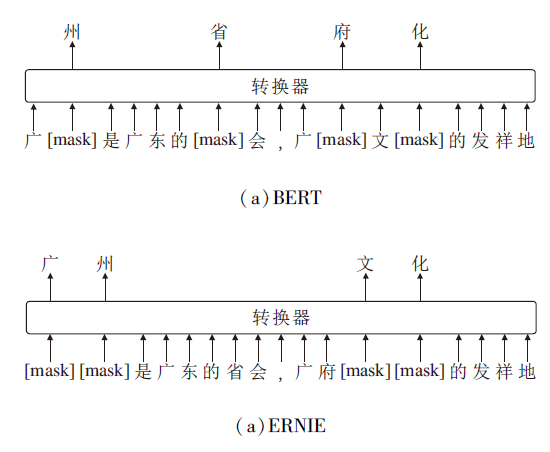 | 图3 BERT和ERNIE的掩码策略Fig.3 Masking strategies of BERT and ERNIE |
对于给定的句子
S=[s1, s2, …, sn],
其中, si表示事件文本中的第i个字符, n表示句子的长度, ERNIE可将其编码为定长的向量表示:
$E=[{{e}_{0}}, {{e}_{1}}, \ldots , {{e}_{n}}]\in {{R}^{\left( n+1 \right)\times {{d}_{e}}}}$,
其中, de表示字符嵌入向量的维度, e0表示ERNIE在文本前插入的[CLS]符号对应的输出向量, 可作为句子的语义表示.
此外, 在事件文本中, 不同的组成部分常对应不同的词性.例如, 触发词的文本通常为动词, 而论元的文本常对应名词或数词, 不同类别的论元在词性上也呈现一定的分布规律, 同时词性标注特征还能提供词汇的边界信息.本文使用LTP的词性标注模块对句子分词, 并识别每个词的词性标签, 使用BIO标注模式进行标注, 然后随机初始化为dpos维词性标注向量:
P=[p0, p1, …, pn].
最后, 将ERNIE嵌入向量E和词性标注向量P进行拼接, 得到输入句子W对应的嵌入向量序列:
X=[x0, x1, …, xn]∈ R(n+1)× d,
其中,
xi=[ei‖ pi],
‖ 表示向量拼接操作, d=de+dpos表示隐藏层维度.
为了更好地融合句子中上下文语义信息, 本文使用BiLSTM编码得到的嵌入向量序列X, 这一过程可被形式化为
${{\vec{h}}_{i}}=\overrightarrow{LSTM}\left( {{x}_{i}}, {{{\vec{h}}}_{i-1}} \right), {{\overset{\scriptscriptstyle\leftarrow}{h}}_{i}}=\overleftarrow{LSTM}\left( {{x}_{i}}, {{{\overset{\scriptscriptstyle\leftarrow}{h}}}_{i-1}} \right), {{h}_{i}}=[{{\vec{h}}_{i}}||{{\overset{\scriptscriptstyle\leftarrow}{h}}_{i}}]$,
其中,
H=[h1, h2, …, hn]∈ Rn× d.
句子编码层之后是依存特征提取层, 使用GAT对依存句法图进行编码, 可以更好地捕捉文本中各组成成分的长距离依赖关系, 进而学习到蕴含丰富语义信息和句法结构信息的特征向量.
GAT是将图卷积和注意力机制结合的模型, 当聚合邻域节点信息时, 可为相邻节点分配不同的权重.同时本文将GAT中的自注意力层扩展为Vaswani等[30]提出的多头注意力机制, 把输入转换到多个子空间, 使模型关注邻域节点不同方面的特征信息, 进而使训练后的模型结构更稳定.
本文使用的依存句法图的构造策略如下。
1)使用LTP的依存句法分析模块处理事件文本, 得到依存句法树.
2)参考文献[31]的做法, 忽略依存句法树中“ Root” 指向根节点的弧和所有弧的标签.
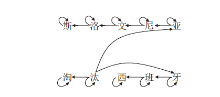
3)将依存句法图定义为G={V, E}, 其中, V表示节点集合, E表示边集合, 每条边eij表示节点(vi, vj)之间的有向弧.由于ERNIE和BiLSTM可以较好地学习文本各组成成分的上下文语义特征, 故这里将节点(vi, vj)内部最后一个字符(cin, cjn)之间的连接表示边eij.
4)针对每个节点vi, 将其对应词语wi内部字符“ ci1, ci2, …, cin” 进行连接, 完成对节点集V的扩充, 通过在每个节点上添加自循环弧eii, 完成对边集E的扩充.字符级依存句法实例如图4所示.
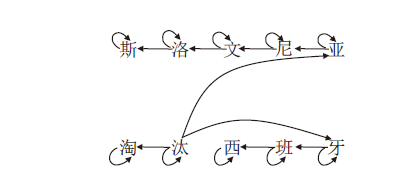 | 图4 字符级依存句法图示例图Fig.4 Illustration of character-level dependency syntax graph |
本文首先使用BiLSTM层输出的特征H初始化依存句法图的节点嵌入:
${{U}^{0}}=[u_{1}^{0}, u_{2}^{0}, ..., u_{n}^{0}]$,
其中$u_{i}^{0}={{h}_{i}}$.
再计算节点对之间的关联度:
$e_{ij}^{(k)}=\sigma \left( {{a}^{(k)}}\cdot \left( {{\mathbf{W}}^{(k)}}u_{i}^{l}\|{{\mathbf{W}}^{(k)}}u_{j}^{l} \right) \right)$,
其中, k表示多头机制中第k个注意力, $u_{i}^{l}\in {{R}^{d}}$和$u_{j}^{l}\in {{R}^{d}}$表示第l层节点i和j的特征, ${{W}^{(k)}}\in {{R}^{{{d}_{h}}\times d}}$表示线性投影矩阵, ${{a}^{(k)}}\in {{R}^{2{{d}_{h}}}}$表示可学习的注意力权重向量, σ (· )表示一个非线性激活函数.
然后对关联度进行归一化, 得到节点i和邻域节点j(j∈ Ni)之间的注意力系数:
$\alpha _{ij}^{\left( k \right)}=\frac{exp\left( e_{ij}^{\left( k \right)} \right)}{\mathop{\sum }_{m\in {{N}_{i}}}exp\left( e_{im}^{\left( k \right)} \right)}$,
其中Ni表示节点i的所有邻域节点.
对所有邻域节点的特征进行基于注意力系数的加权求和, 得到第k个注意力下第i个节点更新后的特征向量:
$u_{i}^{\left( k \right)}=\underset{j\in {{N}_{i}}}{\mathop \sum }\, \alpha _{ij}^{\left( k \right)}{{W}^{(k)}}u_{j}^{l}$,
其中
最后将K组相互独立的注意力机制得到的输出结果进行拼接, 得到$u_{i}^{l}\in {{R}^{d}}$更新后第l+1层节点i的节点特征向量:
$u_{i}^{l+1}=\overset{K}{\mathop{\underset{k=1}{\mathop{\|}}\, }}\, ~(\sigma (u)_{i}^{\left( k \right)})\in {{\text{R}}^{{{d}_{h}}\times K}}$.
为了便于实现, 设置每层GAT的输入特征维度等于输出特征维度, 即d=dhK.
通过L层GAT网络后, 每个节点都可以聚集它的L跳之内邻居节点信息.最终得到GAT最后一层的输出UL, 用于触发词和论元的联合抽取.
首先, 将从图注意力模块得到向量序列:
U=[u1, u2, …, un].
输入表填充模块, 得到表特征:
${{T}_{ij}}=\sigma ({{W}^{table}}[{{u}_{i}}\|{{u}_{j}}]+{{b}^{table}})$,
其中, T∈ Rn× n× d, σ (· )表示一个非线性激活函数, Wtable∈ Rd× 2d表示权值向量, btable表示偏置项.
再将表特征的主对角线元素Tii输入全连接层和softmax分类器中, 用于识别和预测采用BIO模式标注的触发词标签, 第i个字符为不同事件类别的概率分布:
$p_{ii}^{t}=softmax({{W}^{t}}{{T}_{ii}}+{{b}^{t}})$,
其中, Wt∈
然后, 选取预测概率最大值对应的索引作为预测的触发词标签标识:
$y_{ii}^{t}=arg\text{ }max(p_{ii}^{t})$.
最后, 将非主对角线元素Tij(i≠ j)输入2个多分类器中, 使用表指针网络预测论元的首尾位置及类别以实现抽取, 具体形式如下:
$p_{ij}^{as}=\text{softmax}({{W}^{as}}{{T}_{ij}}+{{b}^{as}})$,
$y_{ij}^{as}=\text{argmax}(p_{ij}^{as})$,
$p_{ij}^{ae}=\text{softmax(}{{W}^{ae}}{{T}_{ij}}\text{+}{{b}^{ae}})$,
$y_{ij}^{ae}=\text{argmax}(p_{ij}^{ae})$.
其中:
最终, 模型可以输出形式如图2所示的两个表格, 作为某一事件文本输入模型后的预测结果.在解码阶段, 首先根据对角线上预测的BIO标注模式标注的触发词标签
< 触发词起始位置(i'), 触发词结束位置(i″), 事件类型> .
如图1中所示的文本, 事件检测结果为
[< 9, 10, “ 胜负” > , < 15, 16, “ 晋级” > ].
然后针对检测的每个事件, 遍历两个表格中触发词所在的行(如事件“ 胜负” 的触发词“ 淘汰” 对应表格中的第9, 10行), 如果
< 触发词起始位置(i'), 触发词结束位置(i″), 事件类型, 论元起始位置(j'), 论元结束位置(j″), 论元角色类型> .
最终可以得到事件“ 胜负” 的论元抽取结果为
[< 9, 10, 胜负, 0, 2, 赛事名称> , < 9, 10, 胜负, 4, 8, 胜者> , < 9, 10, 胜负, 11, 13, 败者> ].
在设计损失函数时, 为了增强模型的泛化性, 引入标签平滑正则化(Label Smoothing Regularization, LSR)策略[32].LSR能在采用one-hot标签计算交叉熵损失时, 考虑到错误标签位置(one-hot值为0的位置)的损失, 降低真实标签类别在计算损失时的权重, 从而避免过拟合.平滑后的one-hot标签值为:
$y{{'}_{c}}={{y}_{c}}(1-\alpha )+\frac{\alpha }{C}, c=1, 2, \ldots , C$.
其中:yc表示one-hot标签值, 当样本真实类别等于c时yc=1, 否则yc=0; C表示样本类别总数; α 表示需要调节的超参数, 取值范围为0~1, 描述标签平滑的程度, α 值越大, 标签越平滑[33, 34].
引入标签平滑策略后, 主对角线上触发词分类的平均交叉熵损失函数为:
$los{{s}^{t}}=-\frac{1}{n}\overset{n}{\mathop{\underset{i=1}{\mathop \sum }\, }}\, \overset{{{n}^{t}}}{\mathop{\underset{c=1}{\mathop \sum }\, }}\, ({{y}_{i}}{{_{ic}}^{t}})'\text{ln}({{p}_{i}}{{_{ic}}^{t}})$,
其中,
非主对角线(i≠ j)上论元首尾位置分类的平均交叉熵损失函数为:
$los{{s}^{as}}=-\frac{1}{{{n}^{2}}-n}\sum\limits_{i=1}^{n}{\sum\limits_{j=1}^{n}{\sum\limits_{c=1}^{{{n}^{a}}}{{{\left( y_{ijc}^{as} \right)}^{\prime }}\log }}}\left( p_{ijc}^{as} \right)\text{ }\left( i\ne j \right)$,
$los{{s}^{ae}}=-\frac{1}{{{n}^{2}}-n}\sum\limits_{i=1}^{n}{\sum\limits_{j=1}^{n}{\sum\limits_{c=1}^{{{n}^{a}}}{{{\left( y_{ijc}^{ae} \right)}^{\prime }}\log }}}\left( p_{ijc}^{ae} \right)\text{ }\left( i\ne j \right)$,
其中,
基于表填充的联合抽取层分为触发词抽取和论元抽取两个模块, 由于两个模块无明显的主、辅任务之分, ATCEE采取较朴素的联合学习思想, 将二者的损失函数直接相加, 形成联合损失函数:
loss=losst+(lossas+lossae).
然后使用带权重衰减的自适应性矩估计(Adaptive Moment Estimation with Decoupled Weight Decay, AdamW)[35]作为优化器训练优化网络参数, 从而最大程度地最小化联合损失函数, 提升模型的抽取性能.
综上所述, ATCEE包括嵌入层、句子编码层、基于图注意力网络的依存特征提取层和基于表填充的联合抽取层四个模块, 整体执行流程如算法1所示.
算法1 ATCEE
# n为句子长度, d为隐层维度, de为字符嵌入向量的维度, dpos为词性嵌入向量维度, d= de+dpos.
# pos_embedding:随机初始化的词性嵌入模型, 词典的大小为词性的种类, 嵌入向量维度为dpos.
# init_graph:构造字符级依存句法图, 并初始化节点嵌入.
# broadcast_tensors:将多个张量根据广播规则转换成相同的维度.
# table_fc, trigger_fc, arg_start_fc, arg_end_fc:全连接层, 对应的权值向量形状分别为[2d, d], [d, nt], [d, na], [d, na], 其中, nt为事件类型的数目, na为论元类型的数目.
# trigger_mask, arg_mask:形状为[n, n]的矩阵, 标志触发词和论元在表格中的位置, 前者主对角线为1、其余为0, 后者主对角线为0、其余为1.
输入 描述事件的文本S=[s0, s1, …, sn], BIO标注模式标注的词性标签W=[w0, w1, …, wn], 依存句法树DPTree, 图2所示的2个真实的表格标签yas、yae, s0为ERNIE中的 [CLS], w0为[PAD]
输出 事件检测结果三元组< event_start, event_end, event_type> , 每个事件对应的论元抽取结果六元组< event_start, event_end, event_type, argument_start, argument_end, argument_type>
step 1 E← ernie(S)
# E为字符向量, 形状为[n+1, de]
step 2 P← pos_embedding(W)
# P为词性向量, 形状为[n+1, dpos]
step 3 X← concatenate(E, P, dim=-1)
# 在最后一个维度上拼接E和P, 得到X, 形状为[n+1, d]
step 4 H← bilstm(X)[1, ∶ , ∶ ]
# H为隐层向量, 形状为[n, d]
step 5 G← init_graph(DPTree, H)
#G = {V, E}, 节点vi对应的特征向量为hi
step 6 U← gat(G, L)
# U为聚合L跳内邻居节点信息后的节点特征, 形状为[n, d]
step 7
U1, U2← broadcast_tensors(U[∶ , None], U[None])
# U1, U2形状为[n, n, d]
T← table_fc(concatenate(U1, U2, dim=-1))
# T为表特征, 形状为[n, n, d]
step 8 Pt← trigger_fc(T)
# Pt为触发词预测概率分布, 形状为[n, n, nt]
losst← loss_function(Pt* trigger_mask, yas* trigger_mask)
# 计算触发词分类损失
Pas← arg_start_fc(T)
# Pas为论元开始位置预测概率分布, 形状为[n, n, na]
lossas← loss_function(Pas* arg_mask, yas* arg_mask)
# 计算论元开始位置分类损失
Pae← arg_end_fc(T)
#
lossae← loss_function(Pae* arg_mask, yae* arg_mask)
# 计算论元结束位置分类损失
loss =losst + (lossas + lossae)
# 联合损失函数
step 9 将Pt, Pas, Pae输入arg max函数中, 获取预测的触发词标签类别和论元角色类别
step 10 根据
为了评估模型效果, 在ACE2005[4]和DuEE1.0[36]这两个中文事件抽取数据集上开展实验.ACE2005数据集是事件抽取领域最广泛使用的数据集之一, 共计649篇文章, 事件类型分为8个大类和33个小类.为了保证实验的严谨性, 本文语料划分的方式和对比模型一致.随机抽取521篇作为训练集、64篇作为验证集、64篇作为测试集.DuEE1.0数据集是百度发布的中文事件抽取数据集, 包含8个事件大类和65个事件小类, 本文在打乱数据排列顺序获得特征分布近似均匀的数据后, 按照8∶ 1∶ 1的比例将数据划分为训练集、验证集和测试集.
同之前的中文事件抽取任务一样, 本文使用精确率(Precision, P)、召回率(Recall, R)和F1值作为子任务评价指标.具体公式如下:
$P=\frac{TP}{TP+FP}$,
$R=\frac{TP}{TP+FN}$,
$F1=\frac{2\times P\times R}{P+R}$,
其中, TP(True Positive)表示模型预测为正的正样本, FP(False Positive)表示模型预测为正的负样本, FN(False Negative)表示模型预测为负的正样本.
对于事件检测子任务, 若触发词相对于文本的位置、所属事件类型都和标注结果一样, 视为检测成功.
对于论元抽取子任务, 一个论元被正确抽取当且仅当论元在文本中的位置、论元的类型、关联的事件类型和触发词在文本中的位置都和标注结果完全匹配.
本文实验中的操作系统为Ubuntu 20.04.4 LTS, CPU为Intel(R) Core(TM) i5-11400F @2.60 GHz, 显卡为GTX 3060, 使用Python3.7实现实验中的相关算法, PyTorch1.8搭建深度学习框架.
训练过程中使用ReLU作为模型的非线性激活函数, AdamW作为优化器训练优化网络参数, 对ERNIE预训练模型进行微调并设置较低的学习率, 而下游任务设置较大的学习率, 使模型快速达到收敛.
为了使模型更加稳定, 训练过程中采用学习率预热策略[37], 同时为了防止模型过拟合, 本文还使用权重衰减(Weight Decay, WD)[38]技术.具体使用的超参数如表1所示.
| 表1 事件抽取实验超参数设置 Table 1 Experimental hyper-parameter settings of event extraction |
为了验证ATCEE的有效性, 选择如下6种性能较优的模型进行对比实验.
1)ERNIE-BiLSTM.本文参考Liu等[17]提出的联合解码策略, 把官方测评基于预训练模型的Baseline改成基于ERNIE-BiLSTM的联合抽取模型.
2)PLMEE[8].通过角色预测分离的方法处理论元抽取中存在的角色重叠问题.
3)MTL-CRF(Multi-task Learning with CRF Enhan-ced Chinese Event Extraction)[39].针对论元角色重叠问题, 采用分类训练策略为每类事件都训练一个基于CRF的事件抽取联合模型.为了缓解分类后带来的语料稀疏问题, 还采用多任务学习方法对各事件子类进行相互增强的联合学习.
4)JMCEE[15].针对论元角色重叠问题, 设计多个二分类器以抽取事件三元组< 触发词, 论元角色, 论元> .
5)EE-DGCNN(Event Extraction Approach Based on Multi-layer Dilate Gated CNN)[40].提出一种具有参数数量优势的多层膨胀门卷积神经网络, 并引入一些局部特征以提升论元抽取的精度.
6)CasEE[16].针对触发词和论元重叠问题, 提出一种具有级联解码的联合学习框架, 并采用多任务学习的方式捕获子任务之间的依赖关系.
7)CAEE[21].在字特征的基础上通过Word-Character-Based Graph引入词汇的语义信息和边界信息, 并使用图注意力网络捕捉长距离依赖.
为了在相同实验环境下进行实验, 复现的模型中使用的词向量以及触发词和论元是否被正确抽取的标准都和ATCEE保持一致.
各模型在ACE2005、DuEE1.0数据集上的指标值对比结果如表2和表3所示, 表中黑体数字表示最优值.
| 表2 各模型在ACE2005数据集上的指标值对比 Table 2 Index value comparison of different models on ACE2005 dataset |
| 表3 各模型在DuEE1.0数据集上的指标值对比 Table 3 Index value comparison of different models on DuEE1.0 dataset |
由表2和表3可见, ATCEE在ACE2005、DuEE- 1.0数据集上触发词分类F1值分别提高2.2%和0.3%, 论元分类F1值分别提高2.4%和2.6%.这主要得益于编码阶段词性和依存特征的引入以及解码阶段采用表填充策略和表指针网络模块强化触发词和论元之间的依赖关系.
此外, 从表2和表3中还可以看出, 在ACE2005数据集上, ATCEE触发词分类的P值明显低于CAEE、MTL-CRF、JMCEE, 论元分类的P值明显低于CAEE、MTL-CRF, 触发词和论元分类的R值明显高于对比模型.在DuEE1.0数据集上, ATCEE触发词分类的R值明显低于CasEE, 论元分类的R值明显低于CasEE、EE-DGCNN.主要原因分析如下.
1)CAEE引入BME(B-begin, M-middle, E-end)结构的词典嵌入, 相比ATCEE使用的词性标签嵌入, 更能提供丰富的词语语义信息.MTL-CRF将ACE2005数据集语料中提供的实体、值和时间信息当作已知特征使用, 相比ATCEE使用LTP获取的词性标注特征, 这些人工标注的特征能提供更准确的实体边界信息和深层语义特征.JMCEE设计多个二分类器判别触发词的起止位置, 相比ATCEE使用的基于BIO标注模式的多分类方式, 能实现更准确的预测效果.进而CAEE、MTL-CRF和JMCEE能够预测更少的FP, 分类的P值会有所提高, 但是CAEE、MTL-CRF和JMCEE对应的R值较低, 说明有较多的触发词和论元没有被抽取到.
2)当一个句子中存在多个事件时, CasEE和EE-DGCNN针对每个事件构造一个样本, 这相当于扩充训练集, 使模型更好地学到语义特征, 进而能够预测更多的TP, 分类的R值会有所提高.但重复训练集上的样本也会使模型预测更多的FP, 因此CasEE和EE-DGCNN对应的P值都相对较低, 导致在F1指标上, 明显低于ATCEE.
3)ACE2005数据集上存在严重的数据不平衡性, 据统计, 33个事件类别中标注样本数少于100个、50个、25个的占比分别为78%、42%、27%.ATCEE在R值上具有较大的提升, 说明依存特征和表填充策略的引入能较好地促进事件内和事件间的信息交互, 提升模型在标注样本较少的事件类别上的抽取效果.
本文提出基于图注意力网络的依存特征提取和表指针网络两个模块, 用于解决中文事件抽取中存在的触发词和论元依赖建模不足、论元角色发生重叠难以抽取的问题, 并使用ERNIE嵌入向量和LTP词性标注向量作为模型的初始输入.
为了验证上述模块的有效性, 在测试集角色重叠数据(ACE数据集上为7.31%, DuEE1.0数据集上为6.91%)上进行消融实验.
实验的基准模型是BERT-BiLSTM, 然后依次将预训练模型BERT替换为ERNIE(简记为ERNIE-BiLSTM)、将解码模块替换为表指针网络(Table Pointer Network, TPN)、加入词语级依存句法图(Word-Level Dependency Syntax Graph, WDSG)、将WDSG替换为字符级依存句法图模块(Character-Level Dependency Syntax Graph, CD-SG)和去除词性标注特征(Part-of-Speech, POS).
基准模型中的解码模块参考Liu等[17]提出的联合解码策略, 词语级依存句法图的构造采用Lyu等[41]提出的方法.在角色重叠情况下, 论元识别和论元分类的F1值如表4所示, 表中黑体数字表示最优值.
| 表4 不同模块下的消融实验结果 Table 4 Result of ablation experiment with different modules |
表4结果表明:1)ERNIE预训练模型对词、实体等语义单元进行建模, 可增强模型的语义表示能力, 实验结果优于使用BERT预训练模型.2)词性标注特征的融入能够使模型学习到更丰富的语义信息和词汇边界信息, 进而在一定程度上提高模型的抽取性能.3)本文提出的两个模块可有效提升角色重叠情况下论元的识别与分类性能, 说明字符级依存句法图和表填充策略的引入可在一定程度上解决触发词和论元依赖关系建模不足的问题.
为了探究GAT的层数对模型抽取性能的影响, 本次实验中保持其它超参数不变, 将GAT层数从0层(即不引入依存特征)增加到6层, 再在ACE2005、DuEE1.0数据集上记录不同GAT层数对应的触发词和论元分类的F1值, 结果如表5所示, 表中黑体数字表示最优值.
| 表5 GAT层数不同时ATCEE的性能对比 Table 5 Performance comparison of ATCEE with different GAT layers |
从表5可以看出:1)GAT层数不超过4时, 模型抽取性能随着层数的增加而上升.这是由于触发词和触发词、触发词和论元间可能存在多跳的句法依赖关系, 此时GAT层数的增加使节点能够获取更多跳的邻居节点特征信息, 进而增强事件内和事件间的信息交互, 提升模型性能.2)GAT层数为4~6时, 模型性能总体呈现下降趋势, 主要是因为不断堆叠的GAT模块使联合抽取模型的参数量不断增加, 从而导致网络训练时不能很好地优化模型参数, 出现过拟合问题.因此, 在本文的其它实验中, 将模型的GAT层数设置为4.
本文针对中文事件抽取, 提出基于图注意力和表指针网络的中文事件抽取方法(ATCEE).将依存句法树扩充为依存句法图, 并引入图注意力网络层, 捕获文本中各组成成分的长距离依赖关系.同时使用表格标注的方法标注句子中的触发词-论元对关系, 进一步增强触发词和论元之间的依赖性.实验表明, ATCEE在中文事件抽取任务上取得显著的性能提升, 基于依存特征的图注意力网络模块和表填充模块可有效提升角色重叠下论元识别和分类的性能.消融实验结果表明词性标注特征的引入有助于提升模型的抽取性能, 但是目前的研究只是把字符向量和词性向量进行直接拼接, 再输入后续模块进一步编码, 这会导致字符特征和词性标注特征的融合程度无法被准确地评估和控制, 也可能会给模型带来一定的噪声.因此, 在未来的工作中, 考虑使用深度对抗域适应模型学习事件抽取和词性标注任务的共享特征, 进而达到字符特征和词性标注特征深度融合的目的, 进一步提升模型的抽取性能.
本文责任编委 林鸿飞
Recommended by Associate Editor LIN Hongfei
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|