{kind=link}
{kind=link}
{kind=link}
{kind=link}
用于多跳阅读理解的双视图对比学习网络
[陈谨雯1, 2  , 陈羽中
, 陈羽中1, 2 ]
, 陈羽中]
|
|



作者简介:
陈谨雯,硕士研究生,主要研究方向为自然语言处理、机器阅读理解.E-mail:1272668035@qq.com.
多跳阅读理解是机器阅读理解的重要任务,旨在从多段文档中构造一条多跳推理链,以此结合多文档中证据回答问题.近年来,图神经网络广泛应用于多跳阅读理解任务,但仍存在多文档推理链的上下文互信息获取不充分、部分答案仅因为与题目相似就被误判为候选答案而引入噪声的缺陷.针对上述问题,文中提出用于多跳阅读理解的双视图对比学习网络(Dual View Contrastive Learning Networks, DVCGN).首先,提出基于异构图的节点级正负样本对比学习方法,对异构图进行节点级损坏和特征级损坏,构造双视图.被损坏的两个视图经图注意力网络迭代后生成两个更新后的视图,DVCGN通过最大化双视图节点表示相似性学习节点表示,获取丰富的上下文语义信息,精确建模当前节点表示及其与推理链其余节点关系,有效辨别多粒度上下文信息及干扰信息,为推理链构造更丰富的互信息.然后,提出问题引导的图节点剪枝方法,充分利用问题信息筛选答案实体节点,缩小候选答案范围,减弱证据句子中相似性表述带来的噪声.在HOTPOTQA数据集上的实验表明,DVCGN的性能较优.
About Author:
CHEN Jinwen, master student. Her research interests include natural language processing and machine reading comprehension.
Multi-hop reading comprehension is an important task in machine reading comprehension, aiming at constructing a multi-hop reasoning chain from multiple documents to answer questions with requirement of combining evidence from multiple documents. Graph neural networks are widely applied to multi-hop reading comprehension tasks. However, there are still shortcomings in terms of insufficient acquisition of context mutual information for the multiple document reasoning chain and the introduction of noise due to some candidate answers being mistakenly judged as correct answers solely based on their similarity to the question. To address these issues, dual view contrastive learning networks(DVCGN) for multi-hop reading comprehension are proposed. Firstly, a heterogeneous graph-based node-level contrastive learning method is employed. Positive and negative sample pairs are generated at the node level, and both node-level and feature-level corruptions are introduced to the heterogeneous graph to construct dual views. The two corrupted views are updated iteratively through a graph attention network. DVCGN maximizes the similarity of node representations in dual views to learn node representations , obtain rich contextual semantic information and accurately model the current node representation and its relationship with the remaining nodes in the reasoning chain. Consequently, multi-granularity contextual information is effectively distinguished from interference information and richer mutual information is constructed for the reasoning chain. Furthermore, a question-guided graph node pruning method is proposed. It leverages question information to filter answer entity nodes, narrowing down the range of candidate answers and mitigating noise caused by similarity expressions in evidence sentences. Finally, experimental results on HOTPOTQA dataset demonstrate the superior performance of DVCGN.
随着智能技术的发展, 建立一个良好的人机问答系统越来越受到研究人员的关注.机器阅读理解是人机问答系统的重要组成部分, 其目标是让计算机拥有与人类相媲美的文章理解能力.与信息检索任务不同, 机器阅读理解不是简单地让机器根据问题匹配文本数据库中相似度最高的字符串, 而是让机器能够理解用户描述的自然语言问题, 这些问题的答案可能存在于文本段落中, 可能是“ 是或否” , 也有可能是无法回答的, 甚至需要机器根据自己的理解生成或计算正确的答案[1].
多跳阅读理解是指给出的问题无法在单个段落或单个文档中回答, 需要经过至少两次文档跳转的推理链才能得到答案.相比传统的阅读理解问题, 多跳阅读理解更需要提高模型的推理能力, 要求模型具有更好的解释性和拓展性.对文本语义理解的准确性会影响人机问答系统下游的各种学习任务的性能, 而仅使用简单匹配文章文本和问题词的方式无法获取具体的文章语义信息.因此获得真实的文本语义信息至关重要.
近年来, 随着预训练模型BERT(Bidirectional Encoder Representation from Transformers)的兴起, 单跳阅读理解的简单阅读理解任务, 如SQuAD(Stanford Question Answering Dataset)[2]、TriviaQA[3]、NewsQA[4]等已取得重大突破, 研究者们逐渐将目光转到更能检验模型理解程度的“ 多跳” 、“ 推理” 情形上.Welbl等[5]设计的WIKIHOP数据集和Yang等[6]设计的HOTPOTQA数据集是新近发布的较有挑战性的多跳阅读理解数据集.HOTPOTQA数据集提供各种推理策略, 包含多种问题类型, 每个问题对应多段文档, 模型应根据不同问题类型在多段文档中构造一条多跳推理链, 整合推理链上的信息, 得出最终答案.
由于单跳任务已取得较大突破, 许多单跳模型使用的方法可跨任务借鉴.例如:QFE(Query Focu-sed Extractor)[7]和基于标签增强的机器阅读理解模型(Label-Enhanced Reader, LE-Reader)[8]使用多任务方法辅助主任务预测答案.然而, 大多数研究依旧使用检索方式查找可能包含正确答案的段落, 再使用单文档答案预测方法.Min等[9]使用跨度预测的方法将多跳阅读理解问题分解为单跳问题, 大幅降低训练样本数量, 并使用打分制, 从每个子问题的答案中选择最优答案.一些研究工作则尝试避免推理, 采用分模块、单跳方法或动态寻找研究模型多跳推理的可解释性.姜文超等[10]分别匹配问题与文本内容后, 对多个文本中可能出现的答案进行再排序和组合.
但是, 多跳推理需要同时应用不同粒度的信息, 单一的检索方式不能有效地将收集到的推理证据进行整合.由于图神经网络能够有效整理节点之间的依赖关系, 学者们提出实体词构图、使用关系构图或使用段落和实体词混合构图, 在图网络层后的实体词中选择答案, 更好地整合细粒度信息.Song等[11]使用段落作为节点构图, 希望使用图结构获得全局意义上的证据信息并实现多跳推理.De Cao等[12]使用实体词作为节点构图, 图上的边是不同实体之间的关系, 利用图神经网络进行消息传递并构建推理链, 实现段落跨越推理, 整合实体信息, 并从中预测正确答案.Dhingra等[13]利用循环层从外部系统获取实体词的共指消解, 从而将实体词划分为不同集群进行连接构图.Ding等[14]模仿人类对关键信息的提取记忆过程, 先提取与问题相关的实体词和候选答案, 与此同时构造一个认知图, 整合当前线索并预测下一跳可能的跨度信息, 直至不能时再给出新的候选答案时, 将认知图中当前的推导结果作为最终答案.但是, 此类方法构造的图难以支持事实信息, 许多情况下只是实体词匹配成功, 构造的推理链无法实现真正的推理效果.
鉴于此种情况, 学者们使用段落、句子、实体词构造多粒度异构图.Tu等[15]使用候选答案、文章、实体词作为构图节点, 边是节点之间的交互关系, 使用互注意力机制及自注意力机制学习问题感知的初始节点表示, 并使用图神经网络传递结点消息.Qiu等[16]提出DFGN(Dynamically Fused Graph Network), 构造一个动态实体图, 每次推理时使用模块融合相关实体构造的实体图和文档, 从给定的与问题相关的实体开始, 沿着文章动态探索相关实体词以进行推理.Fang等[17]提出HGN(Hierarchical Graph Net-work), 使用匹配和打分查找推理链, 构建多粒度层次图, 图中包含的节点类型有问题、段落、句子、实体词, 初始结点表示通过图传播进行更新和多跳推理, 遍历不同类型的边以完成后续的子任务, 并使用多任务学习完成不同种类问题的回答.但是, 多层次细粒度图将所有线索合并成一个图, 难以解释模型的决策.文献[17]还发现, 模型在证据句子中容易被相似性噪声影响, 关键信息的获取受到挑战, 训练时容易引入错误的实体进行答案推理.图神经网络方法过于依赖邻接矩阵, 缺乏扩展性.
综上所述, 图注意力网络在融合文本和问题之间语义表示上取得一定成就, 但在语义理解方面依旧存在不足, 在证据句子中容易被相似性噪声影响.分析人类阅读理解过程可知, 在阅读文章回答问题时, 人们通常需要再结合问题内容以明确答案应具有的关键信息, 列出候选答案, 再通过候选答案得出正确答案.在阅读时人类通常会通过辨别文章和问题中的关键信息和干扰信息以得到正确答案, 由此本文提出用于多跳阅读理解的双视图对比学习网络(Dual View Contrastive Learning Graph Networks, DV-CGN).主要贡献如下.
1)DVCGN基于异构图的节点级正负样本对比学习任务获取更加丰富的上下文互信息.该任务首先通过随机破坏异构图中的多粒度节点表示和拓扑边生成双视图, 而不是仅仅对文本表示进行扰动.使用两个视图之间的结点对比损失训练模型, 目标是最大限度计算节点之间的相似性.经对比学习后的网络拥有更丰富的上下文语义信息, 能够有效辨别多粒度上下文信息以及干扰信息, 更能关注到与问题有关的正确答案的范围, 使推理链拥有更加丰富的互信息.
2)DVCGN通过问题引导筛选答案节点以缩小候选答案范围, 该方法使用问题表示对答案实体节点构造注意力权重矩阵, 再利用关系筛选算法保留关联性最强的部分关系, 减弱相似性表述对网络预测候选答案造成的噪声, 为网络提供更加精确的答案预测范围, 解决模型证据句子确定但无法得出正确答案的问题.
给定问题文本
$Q=\left\{ {{q}_{1}}, {{q}_{2}}, \ldots , {{q}_{m}} \right\}$
和文章文本
$P=\left\{ {{p}_{1}}, {{p}_{2}}, \ldots , {{p}_{n}} \right\}$,
其中, qi为问题文本Q中的第i个词, i=1, 2, …, m, m为问题Q中的词语数量, pj为文章P中的第j个段落, j=1, 2, …, n, n为文章段落群中的段落数量.
多跳阅读理解任务的目标为:根据给定的问题Q和多段落文章P, 经多跳推理预测问题的答案
A∈ {span, entity, Yes/No}.
答案A不仅仅来源于单一文章且形式不固定, 包括跨度、实体与是非类型.
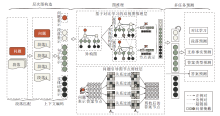
本文提出用于多跳阅读理解的双视图对比学习网络(DVCGN), 总体架构如图1所示.网络包括5个模块:上下文编码层、层次图构造层、基于对比学习的双视图推理层、问题引导图节点剪枝层、多任务预测层.图1中左边的段落匹配模块为层次图段落节点筛选步骤, 是层次图构造的一部分.
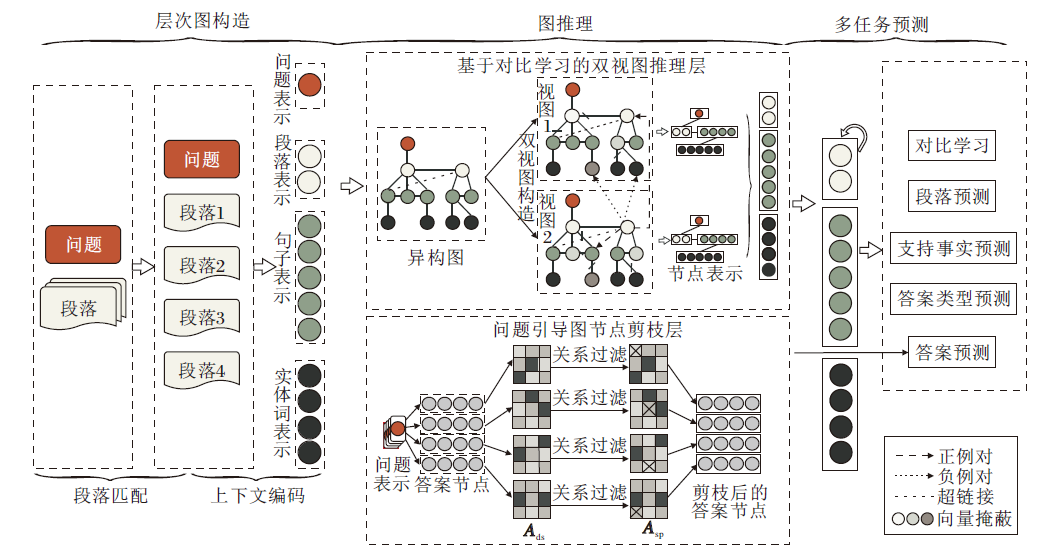 | 图1 DVCGN整体架构Fig.1 Overall architecture of DVCGN |
上下文编码层通过文本多跳匹配算法构建推理链, 进一步采用RoBERTa(Robustly Optimized BERT Pre-training Approach)语言模型编码问题、段落、句子、实体词, 获得图节点的初始特征表示.层次图构造层基于问题、段落、句子、实体词之间的边关系构建一个层次图, 连接不同来源的线索.段落匹配模块为数据预处理阶段, 通过标题匹配、实体词匹配和RoBERTa打分器评分等方式筛选层次图中与问题匹配的段落.基于对比学习的双视图推理层将上述层次图以及节点特征进行扰动处理, 生成两个视图, 采用对比学习的方法将双视图分别送入GAT(Graph Attention Networks)联合更新, 学习节点表示.问题引导图节点剪枝层将上一步更新的节点表示进行进一步的筛选, 再与上下文编码的初始节点特征表示经门控注意力模块进行问题引导的答案预测.多任务预测层将答案预测、段落预测、支持事实预测、实体预测以及双视图对比学习子任务的特征信息分别传入分类器进行打分预测, 并预测最终答案输出.
数据集上的问题与文章经过数据预处理, 得到每条样本对应的初步层次图, 在上下文编码层中使用预训练模型RoBERTa, 获得所有图节点的初始表示.首先将该问题对应选定的段落与上下文合并, 并与问题一起送入RoBERTa中, 获得初始表征.经互注意力层获得问题表示
Q={q0, q1, …, qm-1}∈ Rm× d
和段落上下文表示
P={p0, p1, …, pn-1}∈ Rn× d,
其中, m表示问题数量, n表示段落数量, d表示表征向量维度.
第二步将问题和上下文表示分开处理, 上下文表示经Bi-LSTM(Bidirectional Long Short-Term Me-mory)网络提取段落、句子、实体三种类型的节点表示(
${{f}_{{{p}_{i}}}}=ML{{P}_{1}}[LSTM(p_{i}^{\text{start}}); LSTM(p_{i}^{\text{end}})], $
${{f}_{{{s}_{i}}}}\text{=}ML{{P}_{2}}[LSTM(s_{i}^{\text{start}}); LSTM(s_{i}^{\text{end}})], $
${{f}_{{{e}_{i}}}}=ML{{P}_{3}}[LSTM(e_{i}^{\text{start}}); LSTM(e_{i}^{\text{end}}))], $
其中,
具体地, 对于不同类型的节点, 均以跨度形式表示加入计算, Bi-LSTM网络的两个方向正对应跨度的开始与结束, 而问题节点经过最大池化层获得节点表示:
fq=maxpooling(Q).
RoBERTa为RoBERTa-large, 是BERT更精细的调优版本, 能够适应更大的模型参数量以及更多的训练数据, 适合本文的大型数据集.
综上所述, 经过上下文编码层得到第i项段落、句子、实体3种类型的节点表示(
层次图的构建主要分为两步:段落匹配和图的构建.段落匹配基于每条样本中的问题, 匹配文章中符合该问题的段落.图的构建是基于段落匹配中得出的关系对、段落中句子关系和实体词关系在邻接矩阵中构建节点、添加边.将图的构建放在数据预处理阶段, 形成数据文件, 在训练时载入并进行计算.
1.4.1 段落匹配模块
HOTPOTQA数据集样本中的每个段落都有对应的标题, 记标题和段落的关系对为(ti, pi), 标题涉及段落大意的关键词, 所以先考虑使用标题进行文本和问题的匹配依旧是DVCGN的首选.当标题匹配失败时, 选择使用问题中出现的实体词在段落中进行匹配.
为了辅助段落匹配结果的选择, 还使用预训练模型RoBERTa对段落pi包含黄金证据事实的概率进行打分.计算过程的具体描述如下.
第一跳匹配.首先, 训练一个基于预训练RoBE-RTa的编码器作为打分器对段落进行排序, 得到排序后的段落集合:
Pranking=RoBERTaranking(P),
其中RoBERTaranking()表示基于预训练RoBERTa打分器, 排序的依据是段落中包含数据集中黄金支持事实的概率, 依据此分数决定匹配的选择.打分器工作原理是在训练好的基于预训练RoBERTa的编码器后接一个二进制分类层, 以对输入段落包含支持事实的概率进行排序.接下来, 将问题跨度(qstart, qend)与标题跨度(
${{P}_{sel}}=\left\{ \begin{array}{* {35}{l}} P_{1, 2}^{ranking}, & {{p}_{\text{sel}}}> 0 \\ {{P}_{{{e}_{esl}}}}, & {{e}_{\text{sel}}}> 0 \\ P_{1}^{ranking}, & 其他 \\ \end{array} \right.$
其中, psel表示段落标题与问题匹配成功的段落数量, $P_{1, 2}^{ranking}$表示此种可能所选择的Pranking前二的段落, esel表示实体词与段落匹配是否成功,
第二跳匹配.为了模拟人类进行多跳阅读, 第二跳节点应与第一跳节点直接相关以回答问题, 但直接使用第一跳节点进行段落间的实体词匹配, 会引入大量噪声.这里直接引用数据集上第一跳节点段落中的超链接(Hyperlink_Titles), 搜索可能存在的第二跳段落, 该段落需是在第一跳没有被选中的段落.寻找到第二跳段落后随即构建两段落节点之间的边(pi, pj).
两跳的段落选择构建的边均为双向边, 计算结束后会得到n个候选段落
pcandi={p1, p2, …, pn}.
为了减少图推理中的噪声, 进一步使用打分器选择排名前N的段落.
1.4.2 层次图构建
由于段落和句子之间、句子和实体词之间自然有包含关系, 利用此包含关系能够丰富多粒度图结构中的语义关系, 于是定义为层次图.层次图中还包含段落之间的关系(如第二跳得到的超链接匹配关系), 同一段落中的句子之间的兄弟关系, 句子和段落之间的超链接匹配所得的边关系.
综上可知, 构建的层次图中存在4种节点:问题节点q、段落节点
$p=\left\{ {{p}_{1}}, {{p}_{2}}, .., {{p}_{{{n}_{p}}}} \right\}$、
句子节点
$s=\left\{ {{s}_{1}}, {{s}_{2}}, ..., {{s}_{{{n}_{s}}}} \right\}$、
实体词节点
$e=\left\{ {{e}_{1}}, {{e}_{2}}, ..., {{e}_{{{n}_{e}}}} \right\}$,
其中, np、ns、ne分别表示图中限定的段落、句子、实体词节点的个数.存在如下边关系:
1)第一跳匹配的问题节点和段落节点的连边(q, pi);
2)句子节点和通过超链接相连的段落节点的连边(si, pi);
3)第二跳的段落节点之间的连边(pi, pj);
4)同一段落中的相邻句子节点之间的连边(si, sj);
5)段落节点及其包含的句子节点之间的连边(pi, si);
6)句子节点及其包含的实体词节点之间的连边(si, ei);
7)问题节点及其包含的实体词节点之间的连边(q, ei)(图1中未展示).
1.5.1 双视图构造
负样本的生成是对比学习的关键.机器阅读理解领域工作的负样本策略主要集中在文本表示的负样本生成, 本文考虑采用基于异构图结构的负样本生成.由于本文的层次图涵盖多粒度的文本信息, 在图结构上进行负样本生成有助于对比学习作用于全局, 同时也有助于网络在多粒度节点上学习到更丰富的语义信息.
DVCGN考虑使用随机删除边关系和随机掩蔽节点特征的方法对视图进行破坏, 从图结构和节点特征级别对图进行损坏, 从而构建多粒度节点对比.定义图G=(V, E), 其中, V为图节点集, E为图中的边关系集合.图的邻接矩阵Aadj∈
删除边.首先将邻接矩阵Aadj转换为稀疏矩阵Acoo, 根据节点个数随机构造一个矩阵Amask∈
其中, β (· )为伯努利分布, pv为自定义的掩蔽概率.
当Aadj中存在边关系时为掩蔽矩阵分配相应数值, 其值是根据伯努利分布计算得到.再将掩蔽矩阵与原邻接矩阵进行哈达玛乘积, 得到被损坏的邻接矩阵:
${{\tilde{A}}^{adj}}=~{{A}^{adj}}\circ {{A}^{mask}}\in {{\text{R}}^{{{\text{n}}_{\text{V}}}\times {{\text{n}}_{\text{V}}}}}$
其中$\circ$为哈达玛积,
向量掩蔽.首先采样随机向量 fmask作为d维掩蔽向量, 向量中的值采用伯努利分布提取, 即
$f_{i}^{mask}=\beta \left( 1-{{p}_{f}} \right)$.
再将节点特征与掩蔽向量进行哈达玛乘积, 生成被损坏的节点特征:
$\tilde{F}={{\left[ {{f}_{1}}\circ {{f}^{mask}}; {{f}_{2}}\circ {{f}^{mask}}; \ldots ; {{f}_{{{n}_{V}}}}\circ {{f}^{mask}} \right]}^{T}}\in {{\text{R}}^{{{\text{n}}_{\text{V}}}\times d}}$.
1.5.2 图推理
图推理模块聚合的特征来自不同粒度邻居节点, 用于更新节点自身表示.由于在多粒度图中, 不同的邻居节点可能对节点本身具有不同的作用, 节点本身需要学习不同粒度相应的节点表示.
为了更好地进行层次图的推理, DVCGN采用GAT进行图推理模块的计算.GAT通过自注意力机制对不同的邻居节点分配不同权值, 有助于网络更好地学习不同邻居结点之间的信息.具体来说, 定义相邻节点为Ni, 邻接矩阵为${{\tilde{A}}^{adj}}$, 图中节点特征为$\tilde{F}$.首先计算节点i与邻居节点之间的相关性系数:
eij=([Wehi; Wehj]), j∈ Ni,
其中, hi为当前计算的节点i表示, hj为节点i的邻居节点j的表示, We∈ Rd为共享参数矩阵.
再经过归一化后得到注意力系数
${{\alpha }_{ij}}=\frac{\text{exp}\left( {LeakyReLU}\left( {{e}_{ik}} \right) \right)}{\mathop{\sum }_{k\in {{N}_{i}}}\text{exp}\left( LeakyReLU\left( {{e}_{ik}} \right) \right)}$,
则当前节点i更新后的表示为:
$h{{'}_{i}}=LeakyReLU\left( \underset{j\in {{{N}}_{i}}}{\mathop \sum }\, {{\alpha }_{ij}}{{W}_{1}}{{h}_{j}} \right)$,
其中W1∈ Rd× d为共享参数矩阵.
接着将注意力系数与邻居节点进行加权计算, 得到更新后的节点特征$\tilde{F}\in {{\text{R}}^{{{\text{n}}_{\text{V}}}\times d}}$.
在GAT运算后添加一个门控注意力模块, 用于答案跨度预测任务.使用图网络学习后的节点特征与上下文表示输出融合, 能够有指导性地找到用于跨度提取的上下文门控表示集合.
具体来说, 定义E={Q, P}为上下文编码层经RoBERTa编码后的初始嵌入表示, 以类似注意力机制的计算方式计算上下文嵌入和更新图节点的相关性系数:
$\bar{G}=Softmax{{\left( Relu\left( E{{W}_{2}} \right)\cdot Relu\left( \tilde{F}{{W}_{3}} \right) \right)}^{T}}\cdot \tilde{F}$,
其中, W2∈ R2d× 2d, W3∈ R2d× 2d, 均为可学习参数矩阵.再结合门控机制获得门控上下文表征:
${{E}_{G}}=\sigma \left( \left[ E; \bar{G} \right]{{W}_{4}} \right)\cdot Tanh\left( \left[ E; \bar{G} \right]{{W}_{5}} \right)$,
其中, W4∈ R4d× 4d, W4∈ R4d× 4d, 均为可学习参数矩阵.EG用于答案跨度预测.
1.5.3 双视图对比学习
在进行图推理的同时, 在节点级别上进行双视图对比学习.被损坏的2个视图经GAT迭代后生成2个更新的视图G1、G2, 通过学习两个视图之间的节点表示进行对比学习.具体来说, 定义G1、G2的邻接矩阵A1∈
${{e}_{pv}}=\exp \left( \frac{1}{\tau }\text{cos(}A_{ij}^{1}, A_{ij}^{2}\text{)} \right)$,
其中τ 为温度系数.当前图中负例对的训练目标为:
$e_{\text{nv}}^{1}=\overset{{{n}_{V}}}{\mathop{\underset{k=1}{\mathop \sum }\, }}\, \text{exp}\left( \frac{1}{\tau }\text{cos}\left( A_{ij}^{1}, \bar{A}_{k}^{1} \right) \right)$,
其中,
$e_{\text{nv}}^{2}=\overset{{{n}_{V}}}{\mathop{\underset{k=1}{\mathop \sum }\, }}\, \text{exp}\left( \frac{1}{\tau }\text{cos}\left( A_{ij}^{1}, \bar{A}_{k}^{2} \right) \right)$,
其中,
${{L}_{gra}}=\underset{i=1}{\overset{{{n}_{V}}}{\mathop \sum }}\, \left( L_{gra}^{1}+L_{gra}^{2} \right)$,
$L_{gra}^{1}=\log \left( \frac{{{e}_{pv}}}{{{e}_{pv}}+e_{nv}^{1}+e_{nv}^{2}} \right), \text{ }i=1, 2$.
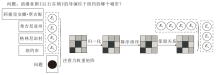
图2展示一个用于关系过滤方法示例的主要筛选步骤, 给定问题“ 浪漫喜剧《巨石谷镇》的导演位于纽约的哪个城市?” .经过图推理后的候选答案节点分别为E1、E2、E3、E4, 其中, E1为人名, 与题目要求的地名答案导向不一致, 故经过算法筛选后删除E1节点.
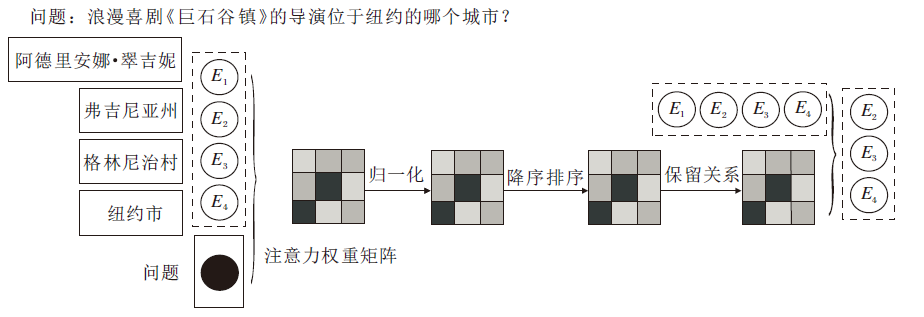 | 图2 关系过滤方法示例Fig.2 Example of relationship filtering method |
具体地, 将上下文编码后的问题表示q∈ R1× d与更新后的候选答案节点$\tilde{F}_{e}^{'}\in {{\text{R}}^{{{\text{n}}_{e}}\times d}}$采用注意力机制得到注意力权重矩阵${{A}_{sp}}\in {{\text{R}}^{1\times {{n}_{e}}}}$.Ads使用softmax函数按最后一维进行归一化, 并使用排序函数按最后一维进行降序排序, 得到矩阵
${{\bar{A}}_{ds}}=sort\left( {{A}_{ds}} \right)$,
其中sort(· )为降序排序函数.再按上述排序顺序对
注意力权重矩阵保留Nrelation个维度, 获得较精准的注意力权重稀疏矩阵:
${{A}_{sp}}={{f}_{Pruning}}\left( {{{\bar{A}}}_{ds}} \right)\in {{\text{R}}^{1\times {{n}_{e}}}}$,
其中, fPruning(· )为剪枝函数, 具体操作为保留排序后的矩阵中联系最为紧密的Nrelation个关系, 从而对候选答案节点$\tilde{F}{{'}_{e}}$进行筛选.保留的Nrelation个维度即为问题与候选答案节点联系最紧密的Nrelation个关系.增强后的稀疏矩阵用于筛选当前候选答案节点, 以在当前证据句子中生成更加符合题目要求的候选答案节点.最后, 采用注意力权重稀疏矩阵Asp与原候选答案矩阵的乘积作为筛选后的候选答案节点, 并送入答案预测任务参与计算.由此得出的候选答案用于最终答案预测, 同时引导图神经网络传播更加符合题意的特征.
1.7.1 子任务预测
根据图网络层更新后的不同类型节点进行不同的子任务预测, 主要有段落预测、支持事实预测、实体词预测.定义总损失为Lall, 使用交叉熵损失计算, 总损失
Lall=Lstart+Lend+μ 1Lpara+μ 2(Lsent+μ graLgra)+μ 3Lent+μ 4Ltype,
其中, μ 1、 μ 2、 μ 3、 μ 4、 μ gra为超参数, Lstart、Lend为跨度预测, Lpara为段落预测, Lsent为句子预测, Lent为实体词预测, Ltype为答案类型预测.
段落预测具体是预测一个段落中是否包含正确标注数据的支持事实, 句子预测具体是预测一个句子是否被选择为支持事实, 实体词预测是预测来自于问题和上下文中匹配的实体节点之间是否存在黄金答案.由于句子的语义学习对于答案预测以及段落预测都十分重要, 本文将双视图对比学习的损失与句子预测损失放在一起进行计算.段落中包含支持事实的概率
${{p}^{para}}=ML{{P}_{4}}\left( \tilde{F}{{'}_{p}} \right)$,
句子被选择为支持事实的概率
${{p}^{sent}}=ML{{P}_{5}}\left( \tilde{F}{{'}_{s}} \right)$,
实体节点中存在正确答案的概率
${{p}^{ent}}=ML{{P}_{6}}\left( \tilde{F}{{'}_{e}} \right)$.
段落预测和句子预测是一个二分类预测任务, 实体词预测是一个多分类任务.
1.7.2 答案预测
然而, 在多答案阅读中直接使用实体预测最终答案是不合理的, 本文使用实体词预测作为一个依据, 与答案类型预测以及跨度预测一起进行答案预测.具体地, 由于答案具有多种类型, 主要有跨度、实体、是非类型.首先进行答案类型预测以判断答案类型, 定义答案类型预测任务为ptype.使用多层感知机(Multi-layer Perception, MLP), 基于门控注意力层的隐藏状态进行计算, 编码方式如下:
${{p}^{type}}=ML{{P}_{7}}\left( {{E}_{G}}\left[ 0 \right] \right)$.
若答案为是非类型, 直接返回答案.若答案为实体类型, 返回实体词预测结果.若答案为跨度预测类型, 使用上述门控注意力层的隐藏状态进行跨度预测计算.答案开始位置的概率为:
${{p}^{start}}=ML{{P}_{8}}\left( {{E}_{G}} \right)\in {{\text{R}}^{{{n}_{p}}}}$,
其中EG为候选答案表示.答案结束位置的概率为:
${{p}^{end}}=ML{{P}_{9}}\left( {{E}_{G}} \right)\in {{\text{R}}^{{{n}_{p}}}}$.
为了验证DVCGN的有效性, 本文使用HOTPO-TQA数据集进行实验评估.HOTPOTQA数据集是2018年提出的新型多跳数据集, 由113 000个Wikipedia问答对组成, 其中的答案是通过在多个文档上建立的证据链推理生成.HOTPOTQA数据集的问题形式多样, 对推理模型的泛化性要求较高.DVCGN在HOTPOTQA数据集上带有干扰性设置类型的数据集上评估网络性能, 此类设置主要由2个Gold段落和8个来自Wikipedia的干扰句段落组成.
HOTPOTQA数据集提供句子级支持事实以实现强监督推理, 因此, 除了答案预测任务, 数据集还包含支持事实预测任务和联合度量任务, 用于评估模型性能.每个任务都采用完全匹配指标(Exact Match, EM)和部分一致的F1指标(简称F1)作为评价指标.表1列出HOTPOTQA数据集的统计数据.
| 表1 HOTPOTQA数据集的统计信息 Table 1 Statistics information of HOTPOTQA dataset |
为了验证DVCGN的有效性, 选取如下基准模型.
1)文献[6]模型.主要由循环神经网络、双向注意力、自注意力模块构成, 同时, 加入判断支持事实、判断是非、判断跨度答案的模块.
2)QFE[7].由于不同证据句子之间存在相关性, 受抽取式总结模型的启发, 使用循环神经网络结合注意力的方式抽取证据句子, 使其能覆盖问题句子中的重要信息, 以此缩小模型预测答案的范围.
3)DFGN[16].首个在此类阅读理解方法中使用图神经网络的模型, 将问题的实体词与文档中的实体词结合构建动态的实体词图网络, 在每个时间步上对问题赋予不同权重、更新问题表示.经过不断的迭代形成推理链.
4)文献[18]模型.利用基于命名实体识别和共指消解的启发式算法, 得到离散推理链, 减少对支持事实的依赖.
5)文献[19]模型.提出除BERT的两个预训练任务以外的跨度选择预训练任务, 该任务类似于完形填空任务, 在有限的训练数据内提升预测性能.
6)LQR-Net(Latent Question Reformulation Net-work)[20].提出新的问答系统, 将问题表示简化为向量, 在阅读模块使用自注意力方法、读取阅读块堆栈, 以及使用弱监督帮助答案生成.
7)SAE-large(Select, Answer and Explain)[21].仅使用BERT完成整个模型的构建, 根据问题与输入文档的相关性对句子进行评分, 从而得到分数最高的句子集并以此预测答案, 再利用生成的答案识别支持事实句子.
8)文献[22]模型.提出图结构及其邻接矩阵都是任务相关的先验知识, 而图注意可以看作是自注意的特例, 并用实验证实图结构效果不如直接使用子注意力或Transformers.
9)Longformer(Long-Document Transformer)[23].采用新的融合机制, 结合滑动窗口的自注意力表示和全局自注意力机制, 并且可通过多个注意力层构建全文理解, 以此方式解决长文本问答.
10)IRC(Interpretable Reading Comprehension)[24].将段落建模为序列数据, 并将多跳信息检索视为一种序列标记任务, 捕获段落间的依赖关系, 并利用门控机制消除段落间的噪声, 以此增强模型信息性能.
11)LOUVRE(Learning from Multi-hop Variation of Document Relations)[25].提出新的预训练检索器, 采用问题和子问题嵌套结构的可扩展数据生成方法, 作为预训练的弱监督, 预训练还使用复杂问题向量表示以及密集编码器, 以此提升模型的鲁棒性.
12)文献[26]模型.从问题生成角度提出一个捕获上下文语义的方法, 通过询问固有的逻辑子问题帮助模型理解上下文, 以便提供清晰的推理链完成答案预测.
13)LittleBird[27].基于BigBird, 采用基于线性偏差注意的位置表示方法拆分表示全局信息的方法, 模型也适用于长文本, 既提高运行速度又降低内存占用, 实现性能的提升.
实验所用的处理器为NVIDIA A100, 基于Pytorch开源库设计, 采用Stanford CoreNLP工具包处理输入, 使用spacy3提取实体词.为了更好地获取多文档上下文表示, 采用RoBERTa-large编码, 最大输入维度为1 024, 隐藏层设置为600.RoBERTa-large能够容纳更多的训练数据和参数量.段落匹配中打分器在段落排序后选择前4个分数最高的段落构造异构图, 异构图中的段落、句子、实体词节点个数分别限制在4、40、60以内.
在双视图对比学习中, 为了得到更好的节点级语义学习效果, 构造负样本图像的掩蔽概率, 分别设置为0.1、0.3, 构造负样本特征掩蔽概率, 分别设置为0.25、0.3.在答案剪枝模块中, 为了细化答案范围, 保留Nrelation(Nrelation=52)个关系.训练使用Adam优化器(Adaptive Moment Estimation), 在20个阶段进行微调, 每个阶段数据批次大小为24, 初始学习率设置为1× 10-5, 设置多任务预测的 μ 1=1, μ 2=1, μ 3=5, μ 4=1.
各模型在HOTPOTQA数据集上的性能如表2所示, 表中黑体数字表示最优值.在distractor设置上, 相比使用传统启发式算法的文献[18]模型, DVCGN具有较大的性能提升, 其原因主要是传统的启发式算法具有较大的不稳定性, 深度学习模型通过高精度的计算获得更加细致的语义表示, 有助于模型理解问题.
| 表2 各模型在HOTPOTQA数据集上的性能对比 Table 2 Performance comparison of different models on HOTPOTQA dataset |
DVCGN在答案预测任务和联合度量任务上均取得最佳性能, 在答案预测任务上, 相比基准模型中最佳的Longformer, DVCGN的EM和F1值分别提升1.99%和1.3%, 在联合度量任务上, 相比基准模型中最佳的Longformer, DVCGN的EM和F1值分别提升1.23%和1.73%.这可以归因于DVCGN提出的双视图对比学习方法能够捕获更多的节点级语义信息, 使网络更好地理解推理链上关键信息, 问题引导节点剪枝算法能够有效缩小候选答案范围, 引导网络在图网络传播时着重传播关键信息, 精确预测正确答案.
由表2可知, DVCGN在答案预测任务和联合度量任务上的EM和F1值最优, 并在支持事实预测任务的EM和F1指标上取得次优的结果, 表明DVCGN在答案跨度预测及所有类型联合预测方面表现优秀.相比DVCGN, 构建新的自注意力网络模式并进行长文档建模的Longformer在证据句子预测方面的表现略优, EM和F1分别提高0.82%和0.40%, 这可以归因于Longformer的长文档建模的编码器, 使编码后的节点信息携带丰富的上下文信息.然而, DVCGN在答案跨度预测及所有类型联合预测指标上都明显优于Longformer, 在答案跨度预测任务上分别提高1.99%和1.30%, 在联合预测任务上EM和F1值分别提高1.23%和1.73%.这是因为DVCGN的贡献主要在于丰富模型在编码后的语义信息学习, 在答案预测方面再一次使用问题进行关键引导, 故DVCGN的答案预测性能与联合预测性能均优于Longformer.同时, 与Longformer的对比分析也启发本文后续对于数据预处理和编码方向的改进.
综上所述, DVCGN具有更强的竞争力和更好的领域适应性.DVCGN相对基准模型的性能优势也表明:DVCGN在学习推理链上节点信息和预测正确答案方面更有效.
本节通过不同模块的消融实验分析其对网络整体的性能贡献.
定义消融网络如下:1)DVCGN w/o DVC.表示从DVCGN中去除双视图对比学习模块.2)DVCGN w/o Pruning.表示从DVCGN中去除问题引导图节点剪枝模块.各网络消融实验结果如表3所示.
| 表3 各模块消融实验结果 Table 3 Results of ablation experiment for each module |
由表3可知, DVCGN w/o DVC性能较差, 这说明本文提出的双视图对比学习方法可有效丰富节点级语义信息, 引导模型正确理解推理链中不同节点的相关性.DVCGN w/o Pruning表现次于DVCGN w/o DVC, 这说明本文提出的问题引导图剪枝方法可正确引入问题信息筛选答案节点, 缩小候选答案范围, 从而降低网络对于候选答案的预判, 减弱相似信息带来的噪声影响.DVCGN w/o Pruning的性能差于DVCGN w/o DVC, 这说明构造双视图进行节点级别的样本对比学习能够提升网络理解答案节点的准确度, 从而引导网络预测正确答案, 对提升网络性能起到关键性作用.
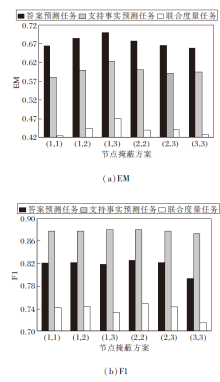
双视图构造方法中选取的损坏两个图节点的掩蔽概率
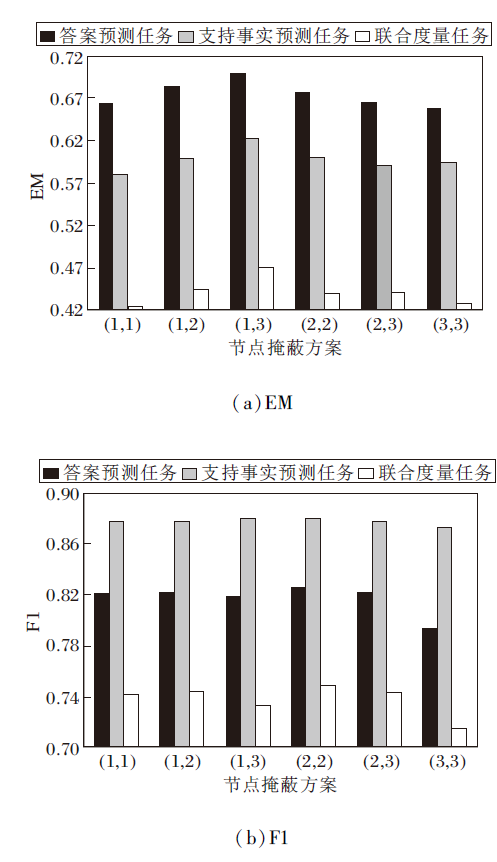 | 图3 不同的节点掩蔽方案对DVCGN的性能影响Fig.3 Influence of different node masking schemes on performance of DVCGN |
由图3可以观察到, 当
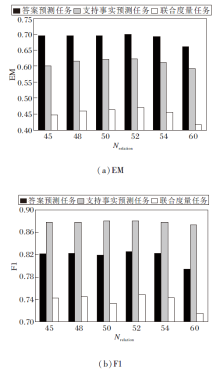
在问题引导图节点剪枝层中, 为了细化答案范围, 在过滤方法的最后保留Nrelation(Nrelation=52)个关系以确定参与最终答案预测计算的候选答案数量, 去除相似性的冗余噪声.为了确定Nrelation取何值对DVCGN性能改善最为合适, 本节将Nrelation分别设置为45, 48, 50, 52, 55, 60, 进行参数实验, 分析最适合DVCGN的Nrelation取值.
在3个预测任务中设置不同的Nrelation, 其对DVCGN的性能影响如图4所示.由图可观察出, 其余参数不变的情况下, 在Nrelation=52时, DVCGN的支持事实预测任务中F1值接近最优, 其余指标达到最优, 故在Nrelation=52时, DVCGN的综合性能达到最优.Nrelation过小, 容易过滤真正可参考的候选答案; Nrelation过大, 图节点剪枝层便起不到筛选答案的作用, 反而使过滤方法成为冗余操作, 影响网络预测答案的准确性.
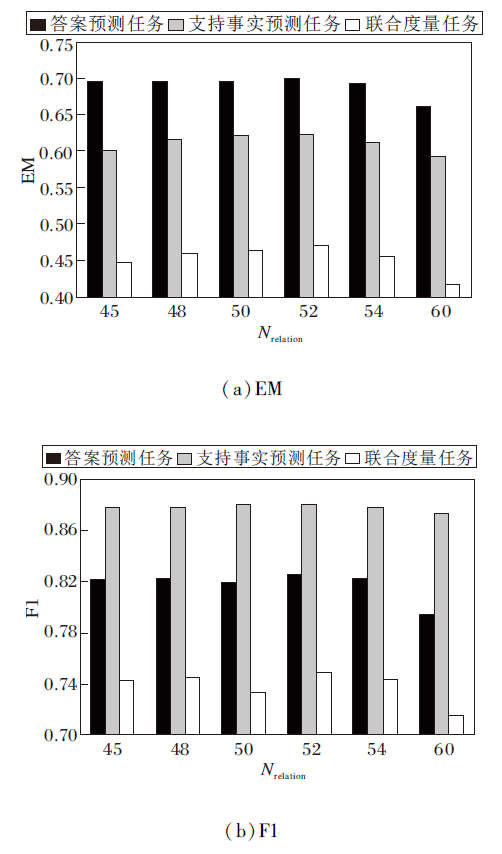 | 图4 Nrelation取值对DVCGN的性能影响Fig.4 Influence of Nrelationvalue on performance of DVCGN |
针对现有的多跳阅读理解模型对跨文档阅读中语义信息理解不充分以及相似性表述再预测答案时引入的噪声影响问题, 本文提出用于多跳阅读理解的双视图对比学习网络(DVCGN), 以此丰富多文档推理链上的语义信息、减弱噪声.DVCGN主要使用正负样本对比学习、图注意力网络以及注意力机制.首先, 使用RoBERTa预训练模型, 得到文档以及问题的上下文表示, 通过语义匹配和打分器构造推理链, 使用推理链的上下文特征向量构造异构图网络.再对该异构图进行节点级和特征级的损坏, 以此构造双视图, 让两视图中损坏后的节点和其余节点作为负样本, 两视图中对应的节点作为正样本, 以此构造对比学习子任务.在答案预测层, 首先使用经编码后的问题初始表示与答案实体节点进行注意力计算, 得到注意力权重矩阵, 对此注意力矩阵进行相关性筛选, 去除关联性较弱的部分权重, 以此过滤答案节点中与问题关联性不强的部分节点, 让图网络传播更加符合问题要求的信息, 缩小候选答案范围, 避免相似性表述造成的误判问题.最后, 筛选后的候选节点经门控注意力层预测不同问题种类的答案.实验验证DVCGN在多跳阅读理解方面的性能, 消融实验验证双视图对比学习和图节点剪枝方法的有效性, 参数实验验证双视图构造中掩蔽节点概率的选择对性能的影响.
在研究负样本构造时发现, 负样本的质量对学习过程至关重要.如果负样本与正样本相似度过高, 模型会过度拟合; 如果负样本与正样本相似度过低, 模型就无法很好地学习数据特征, 导致欠拟合.因此, 今后将考虑更高效的负样本设计方法.
本文责任编委 梁吉业
Recommended by Associate Editor LIANG Jiye
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|