{kind=link}
{kind=link}
基于熵的多尺度多重集值信息系统的最优尺度选择与属性约简
[王蕾晰1, 2  , 吴伟志
, 吴伟志1, 2 , 谢祯晃1, 2 ]
, 吴伟志, 谢祯晃]
|
|



作者简介: 
王蕾晰,硕士研究生,主要研究方向为粗糙集、粒计算.E-mail:wangleixi22@163.com. 
谢祯晃,硕士研究生,主要研究方向为粗糙集、粒计算.E-mail:xiezh1120@163.com.
针对现有的信息系统难以体现和处理数据融合时出现的数据重复问题,文中提出多尺度多重集值信息系统的概念,并讨论该系统的最优尺度选择和属性约简问题.首先,在多尺度多重集值信息系统的每个属性中,基于属性值域中多重集之间的海林格距离定义论域上的相似关系,获得由每个属性子集导出的论域中所有对象的相似类构成的信息粒.然后,引入多尺度多重集值信息系统中知识粗糙熵的概念,进一步给出多尺度多重集值信息系统中的最优尺度与熵最优尺度的概念,证明基于相似关系定义的最优尺度和基于知识粗糙熵定义的最优尺度是等价的.最后,在熵最优尺度的基础上提出系统中基于相似关系的约简和基于知识粗糙熵的约简的概念,并分别给出筛选熵最优尺度和熵约简的算法.
About Author:
WANG Leixi, master student. Her research interests include rough set and granular computing.
XIE Zhenhuang, master student. His research interests include rough set and granular computing.
Existing information systems are difficult to reflect and deal with the data duplication in the process of data fusion. In this paper, the concept of multi-scale multiset-valued information systems is introduced and the optimal scale selection and attribute reduction in these systems are discussed. Firstly, a similarity relation on the universe of discourse from any attribute subset in a multi-scale multiset-valued information system is defined by employing the Hellinger distance on multi-sets of the domain of any attribute. Then, information granules in the form of similarity classes are constructed. Knowledge rough entropy is further introduced in the context of multi-scale multiset-valued information systems. Optimal scales based on the similarity relation and the knowledge rough entropy are defined in a multi-scale multiset-valued information system, respectively. It is examined that the optimal scale based on the similarity relation and entropy optimal scale are equivalent. Finally, reducts and entropy reducts based on the optimal scale are discussed in the multi-scale multiset-valued information system, and algorithms for calculating the entropy optimal scale and an entropy reduct are also designed in a multi-scale multiset-valued information system.
大数据时代下, 各行各业产生的数据具有不确定性和复杂性.高效处理数据, 挖掘数据背后的规律, 并运用于实际问题是数据挖掘的主要任务.粒计算[1, 2, 3]是模拟人脑思维以处理数据不确定性和复杂性的一种方法, 源于Zadeh[4]提出的“ 信息粒度” 概念.粒计算的核心思想是通过合适的粒化提取信息粒, 对信息粒进行处理和计算, 进而分析数据规律和解决实际问题[5, 6, 7].
在粒计算的研究和发展过程中, 粗糙集数据分析发挥重要的作用.粗糙集最早由Pawlak[8]于1982年提出.粗糙集最初讨论的对象-属性取值多为数值或符号.随着数据挖掘的不断深入和实际应用的需要, 学者们研究数据类型日趋多样化, 如集值、区间值、区间集、模糊数、混合数据类型等.
多重集[9, 10, 11]是一种元素可重复出现的集合, 元素在多重集中出现的次数称为该元素在多重集中的重数并且元素的顺序可以互换.多重集在组合数学[12]、关系数据库理论[13]、图论[14]等领域都有重要应用.可以使用多重集描述决策分析中很多问题的数据.例如, 在专家评审系统中, 有4位专家参与评审, 专家评审结果可能存在重复, 如多重集{well, well, well, bad}中的元素分别为4位专家的评审结果.如果用经典集合{well, bad}则无法体现专家对评审对象的具体评价.此外, 多重集在模式识别[15, 16]、多准则决策[17]、医疗诊断[18]等领域也有重要应用.
当信息系统的对象-属性取值为多重集时, 该系统称为多重集值信息系统, 多重集值信息系统是集值信息系统的推广.多重集值信息系统在决策分析[19, 20, 21]、多源信息融合[22, 23]等领域具有重要的研究价值.Zhao等[19]在多重集值信息系统中建立决策理论粗糙集模型.王虹等[20]结合多粒度粗糙集和模糊决策论, 研究在多重集值信息系统中乐观与悲观粗糙集的上、下近似的性质, 并讨论粗糙集精度与粗度等问题.Zhang等[22]探索多重集值信息系统在多源信息融合领域的重要应用.Huang等[23]利用多重集值信息系统, 解决在多源信息融合时产生的信息缺省问题, 从粒计算的角度给出多重集值信息系统中的信息结构, 并研究其在不确定度量中的应用.
众所周知, 经典粗糙集数据分析处理系统为单尺度信息系统, 即系统中每个对象在每个属性下只能取唯一的值.但在实际应用中, 对象属性的取值可以具有多种尺度的值, 如成绩的评定, 有百分制、五级记分制或二级记分制.生活中存在许多类似的多尺度属性的例子, 尺度过细会导致数据的存储代价过大, 而尺度过粗又会导致决策的准确性降低.因此, 在不同决策问题中可能会采用不同的属性尺度.针对类似问题, Wu等[24]首次提出多尺度粗糙集数据分析模型, 处理的数据称为多尺度信息系统, 这种系统中每个属性对于同个对象具有不同尺度的取值, 并且在不同的尺度之间存在粒度变换的关系.
近年来, 多尺度粗糙集数据分析已成为粒计算领域的一个重要方向[25, 26, 27, 28, 29].陈应生等[25]建立多尺度覆盖决策系统模型, 并使用布尔矩阵研究系统的粒描述.Zhan等[26]利用多尺度信息系统与多专家群体决策系统的关系, 研究排序决策问题.陈艳等[27]提出多尺度集值信息系统的概念, 给出系统在不同尺度下的粗糙近似.但多尺度集值信息系统无法处理属性的取值为多重集的情形.
信息熵是刻画信息系统不确定性的重要指标之一, 熵的概念最早来源于热力学理论, 由Shannon[30]引入信息论中.信息熵越大, 系统的不确定程度越高.在保持信息熵不变的情况下, 即在保持系统不确定性不变的情况下找到原系统的最优尺度和属性约简, 是多尺度数据分析研究的一个重要问题[31, 32].张嘉宇[31]研究条件熵和互补熵在多尺度信息系统中的最优尺度选择问题, 并类比两种方法的效果.郑嘉文等[32]利用香农熵, 研究多尺度信息系统中的最优尺度选择问题, 并证明最优尺度与熵最优尺度的等价性, 但香农熵建立在由等价关系产生的划分上.Liang等[33, 34]引入在相似关系下知识粗糙熵的概念, 并运用于不完备系统的知识表示与知识约简中.之后, Liang等[35]讨论不完备信息系统中的信息熵、粗糙熵和知识粒化之间的关系.Sun等[36]基于粗糙熵构造低计算复杂度的启发式算法.Ma等[37]研究双论域上概率粗糙集的知识粒度和粗糙熵的不确定度量.邓切等[38]讨论双论域覆盖空间中的粗糙熵与知识粒度等问题.
针对现有的信息系统难以体现和处理数据融合时出现的数据重复问题, 本文提出多尺度多重集值信息系统的概念, 并讨论该系统的最优尺度选择和属性约简问题.首先, 在多尺度多重集值信息系统的每个属性中, 基于属性值域中多重集之间的海林格距离(Hellinger Distance)定义论域上的相似关系, 并获得由每个属性子集导出的论域中所有对象的相似类构成的信息粒.然后, 引入多尺度多重集值信息系统中知识粗糙熵的概念, 并进一步给出多尺度多重集值信息系统中的最优尺度与熵最优尺度的概念, 证明基于相似关系定义的最优尺度和基于知识粗糙熵定义的最优尺度是等价的.最后, 在熵最优尺度的基础上提出系统中基于相似关系的约简和基于知识粗糙熵的约简的概念, 并分别给出筛选熵最优尺度和熵约简的算法.
本节介绍相关的基础知识, 包括多重集、信息系统、多重集值信息系统、多尺度信息系统和熵的概念与基本性质.
定义1[9] 设Z={z1, z2, …, zo}为一个非空有限集合, N为自然数集合, 称M为集合Z上的一个多重集, 若Z中的元素zi(zi∈ Z)在M中重复出现ki次, 即
则M称为Z上的一个多重集.
由定义1可见, 一个多重集M可由函数CM:Z→ N表示, 即
M={
其中
CM(zi)=ki, zi∈ Z.
由多重集的定义可知, 多重集中元素的顺序无关紧要.集合Z上所有多重集的集合记为M(Z), 若集合Z的幂集记为P(Z), 则
P(Z)⊆M(Z),
故多重集是经典集的推广.
一个多重集M的基数记为|M|, 定义如下:
|M|=
例1 在专家评审系统中, 每篇论文的评审结果由3位专家共同给出.假设每位专家的意见只可能有2种情况— — 接受(a)和拒绝(r).那么所有评审结果M都是多重集, 且M∈ M(Z), 其中Z={a, r}.若3位专家中有2位专家给出接受的意见, 1位专家给出拒绝的意见, 则评审结果为
M={a, a, r},
也可以表示为
M={
文献[23]引入概率论中的海林格距离以定义多重集之间的距离.
定义2[23] 对于Z={z1, z2, …, zo}上的两个多重集M1∈ M(Z), M2∈ M(Z), M1和M2之间的海林格距离定义为
其中
pi=
有时, 一个多重集M也可以表示为
M={
其中
pi=
例2 多重集
M1={a, a, r, r}, M2={a, r, r, r}
可以写成
M1={
而M1和M2之间的海林格距离
HD(M1, M2)=
定义3[8] 称S=(U, A)为一个信息系统, 其中
U={x1, x2, …, xn}
为非空有限对象集, 称为论域,
A={a1, a2, …, am}
为非空有限属性集, 对于
∀ aj∈ A, aj:U→ Vj,
其中Vj为属性aj的值域.
若信息系统中存在对象有未知的或缺省的属性值, 则称该信息系统为不完备信息系统, 此时, 用符号* 表示不完备信息系统中的缺省值.
定义4[19] 称S=(U, A)为一个多重集值信息系统, 其中
U={x1, x2, …, xn}
为非空有限对象集, 称为论域,
A={a1, a2, …, am}
为非空有限属性集, 每个对象的属性取值都为多重集, 即
∀ aj∈ A, aj:U→ M(Vj),
其中Vj为属性aj的值域.
针对对象的属性可能存在多种尺度的情况, Wu等[24]首次提出多尺度信息系统的概念.
定义5[24] 称S=(U, A)为一个多尺度信息系统, 其中
U={x1, x2, …, xn}
为论域,
A={a1, a2, …, am}
为非空有限属性集, 每个属性都具有多尺度.假设所有属性的尺度个数都是I, 则一个多尺度信息系统可以表示为
(U, {
其中
∀
V
使得
即
称
对于k=1, 2, …, I, 记
Ak={
则一个多尺度信息系统S=(U, A)可以分解为I个子信息系统
Sk=(U, Ak), k=1, 2, …, I.
定义6[39] 称S=(U, A)为一个多尺度集值信息系统, 其中
U={x1, x2, …, xn}
为论域,
A={a1, a2, …, am}
为非空有限属性集, 每个属性都具有多尺度, 且尺度个数都是I, 每个对象的属性取值都为集值.
非空有限集合U的幂集记为P(U), 设
C={C1, C2, …, Ce}⊆P(U),
若Ø ∉C, 且
则称C为U的一个覆盖.进一步, 若
则称C为U的一个划分.
定义7[40] 设U是非空有限集合,
X={X1, X2, …, Xt}, Y={Y1, Y2, …, Ys}
为U上的两个覆盖, 若对于∀ Xi∈ X, 都存在Yj∈ Y, 使得Xi⊆Yj, 则称X细于Y, 或称Y粗于X, 记作X⪯Y.另外, 若进一步存在
定义8[28] 设U为非空有限集合, 若
X={X1, X2, …, Xt}
为U上的一个划分, 则X的信息(香农)熵H(X)定义为
H(X)=-
其中
P(Xi)=
|· |表示集合的基数.
命题1[41] 设U为非空有限集合, 对于U上两个划分X和Y, 若满足X⪯Y, 则H(X)≥ H(Y).
对于一个不完备信息系统(U, A), 由任一属性子集B产生的相似关系定义为
相似关系RB将论域U粒化为若干相似类
U/RB={[x]B|x∈ U},
其中
[x]B={y∈ U|(x, y)∈ RB}.
显然, 相似类全体U/RB构成论域U的一个覆盖.
香农熵是定义在等价关系上的, 但在相似关系上并不适用.为此, Liang等[33, 34]在不完备信息系统中提出在相似关系下的知识粗糙熵的概念.
定义9[33] 设(U, A)为一个不完备信息系统, B⊆A, 属性集B的知识粗糙熵定义为
E(B)=-
性质1[33] 设(U, A)为一个不完备信息系统, B⊆A, C⊆A.若
U/RB≺U/RC,
则
E(B)< E(C).
性质2[33] 设(U, A)为一个不完备信息系统, B⊆A, 则
U/RB=U/RA
当且仅当
E(B)=E(A).
定义10 称S=(U, A)为一个多尺度多重集值信息系统, 其中
U={x1, x2, …, xn}
为非空有限对象集, 称为论域,
A={a1, a2, …, am}
为非空有限属性集, 每个属性都具有多尺度且每个对象的属性取值都为多重集.假设所有属性的尺度个数都是I, 则一个多尺度多重集值信息系统可以表示为
(U, {
其中
∀
V
使得
即
称
需要说明的是, 这里通过
对于k=1, 2, …, I, 记
Ak={
则一个多尺度多重集值信息系统S=(U, A)可以分解为I个多重集值信息系统
Sk=(U, Ak), k=1, 2, …, I.
在多源信息融合问题中, 数据来自于多个信息源, 其等级尺度和属性总量影响数据融合过程的效率和数据融合后信息系统的数据量, 因此筛选合适的属性尺度和属性在实际应用中具有研究意义.同时, 多重集值信息系统能够有效应对信息融合时容易出现的数据重复情况.
例3是一个手机质检问题, 也是多源信息融合问题.不同检测员表示不同信息源, 将对不同品牌手机的检测结果融合到一个信息系统中.
例3 设
U={x1, x2, …, x8}
为论域, 分别表示8个手机品牌,
A={a1, a2, a3}
为属性集, 多尺度多重集值信息系统如表1所示.
| 表1 一个多尺度多重集值信息系统 Table 1 A multi-scale multiset-valued information system |
表1中, 属性a1为4名检测员对抽检手机的处理器性能评分, 属性a2为4名检测员对抽检手机的使用流畅度评分, 属性a3为4名检测员使用抽检手机相同时间后所剩的电池容量, 每个属性的尺度个数都是2.
表1是一个多尺度多重集值信息系统
S=(U, {
其属性在不同尺度标记之间的粒度变换为
根据定义2中的多重集之间的海林格距离, 定义多尺度多重集值信息系统上对象的属性值之间的相似度.
定义11 设
为一个多尺度多重集值信息系统, 对于∀ x∈ U, y∈ U, 在属性aj的第k个尺度标记下的相似度为
SIM(
命题2 定义11的相似性度量SIM满足如下性质, 对于∀ M∈ M(Z), M1∈ M(Z), M2∈ M(Z), 其中Z={z1, z2, …, zo},
1)SIM(M, M)=1,
2)SIM(M1, M2)=SIM(M2, M1),
3)SIM(M1, M2)=1⇔ M1=M2.
证明 1)和2)显然成立, 只需证明3).充分性的证明是显然的, 下面证明必要性.
若
SIM(M1, M2)=1,
设
M1={
则
于是
由Hö lder不等式可知
又
故
由Hö lder不等式等号成立条件可得
pi=qi, i=1, 2, …, o,
即M1=M2. 证毕
命题3 设
为一个多尺度多重集值信息系统, 对于∀ x∈ U, y∈ U, 在属性aj下的相似度关于尺度具有单调性, 即对于k∈ {1, 2, …, I-1}, 有
SIM(
证明 对于∀ x∈ U, y∈ U, k∈ {1, 2, …, I-1}, 设属性
V
其中
Zk={
设
由
$\begin{array}{l}\tau_{1} \in\{1, 2, \cdots, o+1\}, \\ \tau_{2} \in\{1, 2, \cdots, o+1\}, \\ \vdots \\ \tau_{l+1} \in\{1, 2, \cdots, o+1\}, \end{array}$
其中
1=τ 1< τ 2< …< τ l< τ l+1=o+1,
使得
其中
τ γ ≤ λ < τ γ +1, γ =1, 2, …, l.
由此可得
由Hö lder不等式进一步可得
$\sum_{i=1}^{o} \sqrt{p_{i} q_{i}} \leqslant\left(\sum_{i=1}^{o} p_{i}\right)^{\frac{1}{2}}\left(\sum_{i=1}^{o} q_{i}\right)^{\frac{1}{2}}$
可知
故
HD(
得证
SIM(
证毕
例4 (续例3) 对于例3中的多尺度多重集值信息系统中的数据, 通过定义11给出的相似度, 可以计算每个属性在各个尺度标记下的相似度矩阵, 如表2~表7所示.
| 表2 属性a1在第1个尺度标记下的相似度矩阵 Table 2 Similarity matrix of attribute a1 under the first scale |
| 表3 属性a1在第2个尺度标记下的相似度矩阵 Table 3 Similarity matrix of attribute a1 under the second scale |
| 表4 属性a2在第1个尺度标记下的相似度矩阵 Table 4 Similarity matrix of attribute a2 under the first scale |
| 表5 属性a2在第2个尺度标记下的相似度矩阵 Table 5 Similarity matrix of attribute a2 under the second scale |
| 表6 属性a3在第1个尺度标记下的相似度矩阵 Table 6 Similarity matrix of attribute a3 under the first scale |
| 表7 属性a3在第2个尺度标记下的相似度矩阵 Table 7 Similarity matrix of attribute a3 under the second scale |
在一个多尺度多重集值信息系统S=(U, A)中, 当阈值α ∈ (0, 1]时, 属性aj在第k个尺度标记下的相似关系定义为
例5 (续例4) 当阈值α =0.95时, 属性a1在第1个尺度标记下的相似关系:
属性a1在第2个尺度标记下的相似关系:
属性a2在第1个尺度标记下的相似关系:
属性a2在第2个尺度标记下的相似关系:
属性a3在第1个尺度标记下的相似关系:
属性a3在第2个尺度标记下的相似关系:
命题4 设
为一个多尺度多重集值信息系统, 当阈值α ∈ (0, 1]时, 对于∀ aj∈ A, k∈ {1, 2, …, I-1},
成立.
证明 对于∀ aj∈ A, k∈ {1, 2, …, I-1}, 若(x, y)∈
SIM(
成立.由命题3可知, 有
SIM(
因此得
SIM(
即
(x, y)∈
从而
相似关系
U/
其中
[x
且
即相似类全体U/
在一个多尺度多重集值信息系统S=(U, A)中, 当阈值α ∈ (0, 1]时, 属性子集B⊆A在第k个尺度标记下的相似关系定义为
显然
同样相似关系
U/
其中,
[x
且
即相似类全体U/
命题5 设
为一个多尺度多重集值信息系统, B⊆A, 当阈值α ∈ (0, 1]时,
证明 只需要证明
从而对
∀ (x, y)∈
有
(x, y)∈
又因为
则
(x, y)∈
所以
(x, y)∈
因此
又由于
故得证
类比定义9中定义在不完备信息系统的相似关系下的知识粗糙熵, 本文在多尺度多重集值信息系统的相似关系下给出知识粗糙熵的定义.
定义12 设
为一个多尺度多重集值信息系统, B⊆A.当阈值α ∈ (0, 1]时, 对于k∈ {1, 2, …, I}, 属性集B在第k个尺度标记下的知识粗糙熵定义为
性质3 设
为一个多尺度多重集值信息系统, B⊆A, C⊆A.当阈值α ∈ (0, 1]时, 对于k∈ {1, 2, …, I}, 若
U/
则
Eα (Ck)≤ Eα (Bk).
证明 对于阈值α ∈ (0, 1], k∈ {1, 2, …, I}, 若
U/
则由定义7可知, 对于∀ x∈ U, 有
[x
于是
1≤ |[x
成立.由x log2x在
$\begin{array}{l}\sum_{i=1}^{|U|}\left(\frac{\left|\left[x_{i}\right]_{C^{k}}^{\alpha}\right|}{|U|} \log _{2}\left(\left|\left[x_{i}\right]_{C^{k}}^{\alpha}\right|\right)\right) \leqslant \\ \sum_{i=1}^{|U|}\left(\frac{\left|\left[x_{i}\right]_{B^{k}}^{\alpha}\right|}{|U|} \log _{2}\left(\left|\left[x_{i}\right]_{B^{k}}^{\alpha}\right|\right)\right), \\\end{array}$
即
$\begin{aligned}-\sum_{i=1}^{|U|}( & \left.\frac{\left|\left[x_{i}\right]_{C^{k}}^{\alpha}\right|}{|U|} \log _{2}\left(\frac{1}{\left|\left[x_{i}\right]_{C^{k}}^{\alpha}\right|}\right)\right) \leqslant \\ & -\sum_{i=1}^{|U|}\left(\frac{\left|\left[x_{i}\right]_{B^{k}}^{\alpha}\right|}{|U|} \log _{2}\left(\frac{1}{\left|\left[x_{i}\right]_{B^{k}}^{\alpha}\right|}\right)\right) .\end{aligned}$
因此
Eα (Ck)≤ Eα (Bk).证毕
性质3说明在阈值α ∈ (0, 1]的情况下, 对于每个尺度标记, 若两个属性集生成的覆盖具有粗细关系, 则两个属性集对应的知识粗糙熵满足对应的大小关系.对应于覆盖越粗的属性集, 其知识粗糙熵越大.
推论1 设
为一个多尺度多重集值信息系统, B⊆A.当阈值α ∈ (0, 1]时, 对于k∈ {1, 2, …, I}, 则
Eα (Ak)≤ Eα (Bk).
性质4 设
为一个多尺度多重集值信息系统, B⊆A.当阈值α ∈ (0, 1]时, 对于k∈ {1, 2, …, I}, 则
U/
当且仅当
Eα (Ak)=Eα (Bk).
证明 先证必要性, 对于阈值α ∈ (0, 1]和k∈ {1, 2, …, I}, 若
U/
则
[x
由知识粗糙熵的定义可知
Eα (Ak)=Eα (Bk).
再证充分性.只需证明对于阈值α ∈ (0, 1]和k∈ {1, 2, …, I},
若
Eα (Ak)=Eα (Bk),
则
U/
对于阈值α ∈ (0, 1]和k∈ {1, 2, …, I}, 由
Eα (Ak)=Eα (Bk)
和知识粗糙熵的定义可知
可化简为
因为
即对于∀ x∈ U, 有
[x
从而相似类的基数满足
$1 \leqslant\left|[x]_{A^{k}}^{\alpha}\right| \leqslant\left|[x]_{B^{k}}^{\alpha}\right|$.
由函数x log2x在[1, +¥ )上的单调性, 可得
$\left|[x]_{A^{k}}^{\alpha}\right| \log _{2}\left(\left|[x]_{A^{k}}^{\alpha}\right|\right) \leqslant\left|[x]_{B^{k}}^{\alpha}\right| \log _{2}\left(\left|[x]_{B^{k}}^{\alpha}\right|\right)$.
进而有
$\left|[x]_{A^{k}}^{\alpha}\right|=\left|[x]_{B^{k}}^{\alpha}\right|, \forall x \in U$,
否则
$\begin{array}{l} \sum_{x \in U}\left(\left|[x]_{A^{k}}^{\alpha}\right| \log _{2}\left(\left|[x]_{A^{k}}^{\alpha}\right|\right)\right)< \\ \sum_{x \in U}\left(\left|[x]_{B^{k}}^{\alpha}\right| \log _{2}\left(\left|[x]_{B^{k}}^{\alpha}\right|\right)\right), \end{array}$
矛盾.又因为
[x
故
[x
得证
U/
性质5 设
为一个多尺度多重集值信息系统, B⊆A.当阈值α ∈ (0, 1]时, 则对于1≤ k≤ l≤ I, 有
Eα (Bk)≤ Eα (Bl).
证明 由命题5可知, 对于阈值α ∈ (0, 1]和1≤ k≤ l≤ I, 有
即
U/
则由定义7可知, 对于∀ x∈ U, 有
[x
于是
成立.由x log2x在[1, +∞]有单调性, 故
$\begin{array}{l}\sum_{i=1}^{|U|}\left(\frac{\left|\left[x_{i}\right]_{B^{k}}^{\alpha}\right|}{|U|} \log _{2}\left(\left|\left[x_{i}\right]_{B^{k}}^{\alpha}\right|\right)\right) \leqslant \\ \sum_{i=1}^{|U|}\left(\frac{\left|\left[x_{i}\right]_{B^{l}}^{\alpha}\right|}{|U|} \log _{2}\left(\left|\left[x_{i}\right]_{B^{l}}^{\alpha}\right|\right)\right) \\\end{array}$
即
$\begin{aligned}-\sum_{i=1}^{|U|}( & \left.\frac{\left|\left[x_{i}\right]_{B^{k}}^{\alpha}\right|}{|U|} \log _{2}\left(\frac{1}{\left|\left[x_{i}\right]_{B^{k}}^{\alpha}\right|}\right)\right) \leqslant \\ & -\sum_{i=1}^{|U|}\left(\frac{\left|\left[x_{i}\right]_{B^{l}}^{\alpha}\right|}{|U|} \log _{2}\left(\frac{1}{\left|\left[x_{i}\right]_{B^{l}}^{\alpha}\right|}\right)\right) .\end{aligned}$
因此
Eα (Bk)≤ Eα (Bl)
成立. 证毕
性质6 设
$\begin{aligned} S= & (U, A)= \\ & \left(U, \left\{a_{j}^{k} \mid k=1, 2, \cdots, I, j=1, 2, \cdots, m\right\}\right)\end{aligned}$
为一个多尺度多重集值信息系统, B⊆A.当阈值α ∈ (0, 1]时, 对于1≤ k≤ l≤ I,
U/
当且仅当
Eα (Bk)=Eα (Bl).
证明 先证必要性.对于阈值α ∈ (0, 1]和1≤ k≤ l≤ I, 若
U/
则
[x
由知识粗糙熵的定义可知
Eα (Bk)=Eα (Bl).
再证充分性.只需证明对于阈值α ∈ (0, 1]和1≤ k≤ l≤ I, 若
Eα (Bk)=Eα (Bl),
则
U/
对于阈值α ∈ (0, 1]和1≤ k≤ l≤ I, 由
Eα (Bk)=Eα (Bl)
和知识粗糙熵的定义可知
$\begin{aligned}-\sum_{i=1}^{|U|} & \left(\frac{\left|\left[x_{i}\right]_{B^{k}}^{\alpha}\right|}{|U|} \log _{2}\left(\frac{1}{\left|\left[x_{i}\right]_{B^{k}}^{\alpha}\right|}\right)\right)= \\ & -\sum_{i=1}^{|U|}\left(\frac{\left|\left[x_{i}\right]_{B^{l}}^{\alpha}\right|}{|U|} \log _{2}\left(\frac{1}{\left|\left[x_{i}\right]_{B^{l}}^{\alpha}\right|}\right)\right) .\end{aligned}$
可化简为
$\begin{array}{l}\sum_{i=1}^{|U|}\left(\left|\left[x_{i}\right]_{B^{k}}^{\alpha}\right| \log _{2}\left(\left|\left[x_{i}\right]_{B^{k}}^{\alpha}\right|\right)\right)= \\ \sum_{i=1}^{|U|}\left(\left|\left[x_{i}\right]_{B^{l}}^{\alpha}\right| \log _{2}\left(\left|\left[x_{i}\right]_{B^{l}}^{\alpha}\right|\right)\right) .\end{array}$
由命题5可知, 对于1≤ k≤ l≤ I, 有
即对于∀ x∈ U, 有
[x
从而
$1 \leqslant\left|[x]_{B^{k}}^{\alpha}\right| \leqslant\left|[x]_{B^{l}}^{\alpha}\right|$.
又由函数x log2x在[1, +∞]上的单调性, 可得
$\left|[x]_{B^{k}}^{\alpha}\right| \log _{2}\left(\left|[x]_{B^{k}}^{\alpha}\right|\right) \leqslant\left|[x]_{B^{l}}^{\alpha}\right| \log _{2}\left(\left|[x]_{B^{l}}^{\alpha}\right|\right)$.
进而有
$\left|[x]_{B^{k}}^{\alpha}\right|=\left|[x]_{B^{l}}^{\alpha}\right|, x \in U, $
否则
$\begin{array}{l}\sum_{x \in U}\left(\left|[x]_{B^{k}}^{\alpha}\right| \log _{2}\left(\left|[x]_{B^{k}}^{\alpha}\right|\right)\right)< \\ \sum_{x \in U}\left(\left|[x]_{B^{l}}^{\alpha}\right| \log _{2}\left(\left|[x]_{B^{l}}^{\alpha}\right|\right)\right), \end{array}$
矛盾.又因为
[x
故
[x
得证
U/
本节主要讨论多尺度多重集值信息系统基于知识粗糙熵的熵最优尺度选择和熵约简的问题, 首先给出多尺度多重集值信息系统中最优尺度和熵最优尺度的概念, 再给出约简和熵约简的概念.
定义13 设
$\begin{aligned} S= & (U, A)= \\ & \left(U, \left\{a_{j}^{k} \mid k=1, 2, \cdots, I, j=1, 2, \cdots, m\right\}\right)\end{aligned}$
为一个多尺度多重集值信息系统, 对于阈值α ∈ (0, 1]和第k个尺度标记(k∈ {1, 2, …, I}), 若
则称Sk关于S是α -协调的.若进一步有
则称k为S的α -最优尺度.
定义14 设
$\begin{aligned} S= & (U, A)= \\ & \left(U, \left\{a_{j}^{k} \mid k=1, 2, \cdots, I, j=1, 2, \cdots, m\right\}\right)\end{aligned}$
为一个多尺度多重集值信息系统, 对于阈值α ∈ (0, 1]和第k个尺度标记(k∈ {1, 2, …, I}), 若
Eα (Ak)=Eα (A1),
则称Sk关于S是α -熵协调的.若进一步有
Eα (Ak+1)≠ Eα (A1), k+1≤ I,
则称k为S的α -熵最优尺度.
例6 (续例5) 当阈值α =0.95时,
$\begin{aligned} R_{A^{1}}^{\alpha}= & \left\{\left(x_{1}, x_{1}\right), \left(x_{2}, x_{2}\right), \left(x_{3}, x_{3}\right), \left(x_{4}, x_{4}\right), \right. \\ & \left.\left(x_{5}, x_{5}\right), \left(x_{6}, x_{6}\right), \left(x_{7}, x_{7}\right), \left(x_{8}, x_{8}\right)\right\}, \\ R_{A^{2}}^{\alpha}= & \left\{\left(x_{1}, x_{1}\right), \left(x_{2}, x_{2}\right), \left(x_{3}, x_{3}\right), \left(x_{4}, x_{4}\right), \right. \\ & \left.\left(x_{5}, x_{5}\right), \left(x_{6}, x_{6}\right), \left(x_{7}, x_{7}\right), \left(x_{8}, x_{8}\right)\right\}, \end{aligned}$
故
从而S2关于S是α -协调的.又由于
Eα (A1)=0, Eα (A2)=0,
即
Eα (A2)=Eα (A1),
因此S2关于S也是α -熵协调的.
当阈值α '=0.8时,
$\begin{aligned} R_{A^{1}}^{\alpha^{\prime}}= & \left\{\left(x_{1}, x_{1}\right), \left(x_{2}, x_{2}\right), \left(x_{3}, x_{3}\right), \left(x_{4}, x_{4}\right), \right. \\ & \left.\left(x_{5}, x_{5}\right), \left(x_{6}, x_{6}\right), \left(x_{7}, x_{7}\right), \left(x_{8}, x_{8}\right)\right\}, \\ R_{A^{2}}^{\alpha^{\prime}}= & \left\{\left(x_{1}, x_{1}\right), \left(x_{2}, x_{2}\right), \left(x_{3}, x_{3}\right), \left(x_{4}, x_{4}\right), \right. \\ & \left(x_{5}, x_{5}\right), \left(x_{5}, x_{6}\right), \left(x_{6}, x_{6}\right), \left(x_{6}, x_{5}\right), \\ & \left.\left(x_{7}, x_{7}\right), \left(x_{8}, x_{8}\right)\right\}, \end{aligned}$
故
从而S2关于S不是α '-协调的.又由于
Eα '(A1)=0, Eα '(A2)=
即
Eα '(A2)≠ Eα '(A1),
因此S2关于S也不是α '-熵协调的.
综上所述, 当阈值α =0.95时, 系统S的α -最优尺度和α -熵最优尺度都为2, 但当阈值α '=0.8时, 系统S的α '-最优尺度和α '-熵最优尺度都为1.
定理1 设
$\begin{aligned} S= & (U, A)= \\ & \left(U, \left\{a_{j}^{k} \mid k=1, 2, \cdots, I, j=1, 2, \cdots, m\right\}\right)\end{aligned}$
为一个多尺度多重集值信息系统, 对于阈值α ∈ (0, 1]和k∈ {1, 2, …, I}, 则Sk关于S是α -协调的当且仅当Sk关于S是α -熵协调的.
证明 根据定义13, 若Sk关于S是α -协调的, 则
成立, 从而
U/
而由定义14和Sk关于S是α -熵协调的, 可知
Eα (Ak)=Eα (A1).
因此, 只需证明
U/
是等价的.由性质6可得两者的等价性成立, 即Sk关于S是α -协调的当且仅当Sk关于S是α -熵协调的.
证毕
定理1说明多尺度多重集值信息系统的α -协调和α -熵协调是等价的, 由定理1可直接得到定理2.
定理2 设
$\begin{aligned} S= & (U, A)= \\ & \left(U, \left\{a_{j}^{k} \mid k=1, 2, \cdots, I, j=1, 2, \cdots, m\right\}\right)\end{aligned}$
为一个多尺度多重集值信息系统, 对于阈值α ∈ (0, 1]和k∈ {1, 2, …, I}, 则k是S的α -最优尺度当且仅当k是S的α -熵最优尺度.
定义15 设
$\begin{aligned} S= & (U, A)= \\ & \left(U, \left\{a_{j}^{k} \mid k=1, 2, \cdots, I, j=1, 2, \cdots, m\right\}\right)\end{aligned}$
为一个多尺度多重集值信息系统, 对于阈值α ∈ (0, 1]和S的α -最优尺度k, 当B⊆A时, 若
则称B是S在α -最优尺度k下的一个α -约简.
定义16 设
$\begin{aligned} S= & (U, A)= \\ & \left(U, \left\{a_{j}^{k} \mid k=1, 2, \cdots, I, j=1, 2, \cdots, m\right\}\right)\end{aligned}$
为一个多尺度多重集值信息系统, 对于阈值α ∈ (0, 1]和S的α -熵最优尺度k, 当B⊆A时, 若
Eα (Bk)=Eα (A1),
则称B是S在α -熵最优尺度k下的一个α -熵协调集.若进一步对于∀ b∈ B, 都有
Eα (Bk-{bk})≠ Eα (A1),
则称B是S在α -熵最优尺度k下的一个α -熵约简.
例7(续例6) 当阈值α =0.95时, 在α -最优尺度2的情况下,
$\begin{aligned} R_{A^{2}-\left\{a_{1}^{2}\right\}}^{\alpha}= & \left\{\left(x_{1}, x_{1}\right), \left(x_{2}, x_{2}\right), \left(x_{3}, x_{3}\right), \left(x_{4}, x_{4}\right), \right. \\ & \left.\left(x_{5}, x_{5}\right), \left(x_{6}, x_{6}\right), \left(x_{7}, x_{7}\right), \left(x_{8}, x_{8}\right)\right\}, \end{aligned}$
$\begin{aligned} R_{A^{2}-\left\{a_{2}^{2}\right\}}^{\alpha}= & \left\{\left(x_{1}, x_{1}\right), \left(x_{2}, x_{2}\right), \left(x_{3}, x_{3}\right), \left(x_{4}, x_{4}\right), \right. \\ & \left.\left(x_{5}, x_{5}\right), \left(x_{6}, x_{6}\right), \left(x_{7}, x_{7}\right), \left(x_{8}, x_{8}\right)\right\}, \end{aligned}$
$\begin{aligned} R_{A^{2}-\left\{a_{3}^{2}\right\}}^{\alpha}= & \left\{\left(x_{1}, x_{1}\right), \left(x_{2}, x_{2}\right), \left(x_{3}, x_{3}\right), \left(x_{3}, x_{8}\right), \right. \\ & \left(x_{4}, x_{4}\right), \left(x_{5}, x_{5}\right), \left(x_{5}, x_{6}\right), \left(x_{6}, x_{6}\right), \\ & \left.\left(x_{6}, x_{5}\right), \left(x_{7}, x_{7}\right), \left(x_{8}, x_{3}\right), \left(x_{8}, x_{8}\right)\right\} .\end{aligned}$
显然有
同时
成立.因此在α -最优尺度2下多尺度多重集值信息系统的α -约简为{a2, a3}和{a1, a3}.又因为
$\begin{array}{l}E^{\alpha}\left(A^{2}\right)=0, \\ E^{\alpha}\left(A^{2}-\left\{a_{1}^{2}\right\}\right)=0, \\ E^{\alpha}\left(A^{2}-\left\{a_{2}^{2}\right\}\right)=0, \\ E^{\alpha}\left(A^{2}-\left\{a_{3}^{2}\right\}\right)=1, \\ E^{\alpha}\left(a_{1}^{2}\right)=\frac{9}{4} \log _{2} 3+\frac{1}{2}, \\ E^{\alpha}\left(a_{2}^{2}\right)=\frac{9}{8} \log _{2} 3+1, \\ E^{\alpha}\left(a_{3}^{2}\right)=\frac{1}{2}, \end{array}$
因此, 在α -熵最优尺度2下多尺度多重集值信息系统的α -熵约简为{a2, a3}和{a1, a3}.
定理3 设
$\begin{aligned} S= & (U, A)= \\ & \left(U, \left\{a_{j}^{k} \mid k=1, 2, \cdots, I, j=1, 2, \cdots, m\right\}\right)\end{aligned}$
为一个多尺度多重集值信息系统, 对于阈值α , 当B⊆A时, 则B是S在α -最优尺度k下的一个α -约简当且仅当B是S在α -熵最优尺度k下的一个α -熵约简.
证明 先证必要性.由于B是S在α -最优尺度k下的一个α -约简, 因此
且∀ b∈ B, 都有
对于阈值α 和S的α -最优尺度k, 由α -最优尺度的定义可知
从而
又由性质4的证明可知, 有
Eα (Bk)=Eα (Ak).
同时由定理2得k也是α -熵最优尺度, 从而
Eα (Ak)=Eα (A1),
因此
Eα (Bk)=Eα (A1).
若对于∀ b∈ B, 都有
则
U/
由于k是α -最优尺度, 因此
U/
即
U/
由性质4的逆否命题可知
Eα (Bk-{bk})≠ Eα (Ak).
同时由k也是α -熵最优尺度可知
Eα (Ak)=Eα (A1),
从而
Eα (Bk-{bk})≠ Eα (A1).
故B是S在α -熵最优尺度k下的一个α -熵约简.
再证充分性.由于B是S在α -熵最优尺度k下的一个α -熵约简, 因此
Eα (Bk)=Eα (A1),
且∀ b∈ B, 都有
Eα (Bk-{bk})≠ Eα (A1).
对于阈值α 和S的α -熵最优尺度k, 由α -熵最优尺度的定义可知
Eα (Ak)=Eα (A1),
从而
Eα (Bk)=Eα (Ak).
又由性质4的证明可知, 有
同时由定理2得k也是α -最优尺度, 从而
因此
若对于∀ b∈ B, 都有
Eα (Bk-{bk})≠ Eα (A1)
成立, 由于k是α -熵最优尺度, 因此
Eα (Ak)=Eα (A1),
即
Eα (Bk-{bk})≠ Eα (Ak).
又由性质4的逆否命题可知
U/
同时由k也是α -最优尺度可知
U/
从而
U/
即
故B是S在α -最优尺度k下的一个α -约简. 证毕
定理3说明多尺度多重集值信息系统的α -约简和α -熵约简是等价的.
接下来, 基于知识粗糙熵给出计算α -熵最优尺度和α -熵约简的算法, 算法1是基于知识粗糙熵计算α -熵最优尺度的算法, 算法2是基于知识粗糙熵计算α -熵约简的算法.两种算法流程图如图1和图2所示.
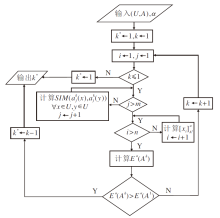
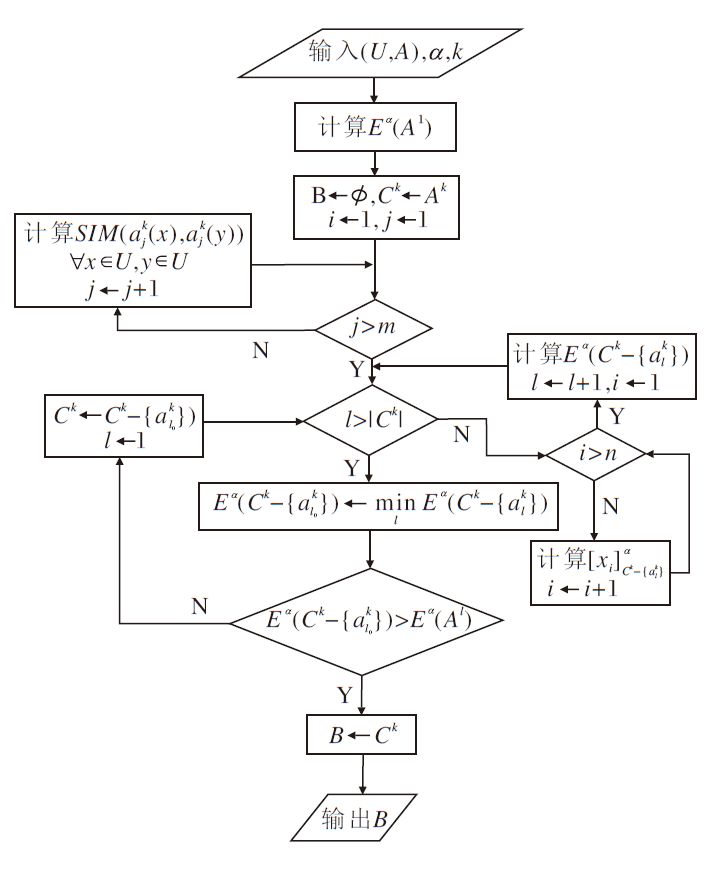
 | 图1 算法1流程图Fig.1 Flow chart of Algorithm 1 |
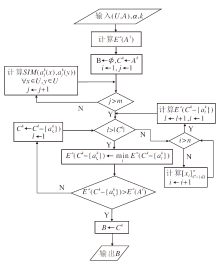
 | 图2 算法2流程图Fig.2 Flow chart of Algorithm 2 |
算法1 基于知识粗糙熵的最优尺度算法
输入I个尺度的多尺度多重集值信息系统(U, A), 阈值α ∈ (0, 1]
输出α -熵最优尺度k*
1.初始化k* ← 1, k← 1
2.while k≠ I do
3. for each
4. 计算对象两两之间的相似性
SIM(
5. end for
6. for each x∈ U do
7. 计算对象x的相似类[x
8. end for
9. 求第k个尺度标记下的知识粗糙熵Eα (Ak)
10. if Eα (Ak)> Eα (A1) then
11. k* ← k-1
12. break
13. end if
14. k← k+1
15.end while
在算法1中, 步骤3~5用于计算对象间的相似度, 时间复杂度为O(mn2), 其中m表示属性个数, n表示对象个数.步骤6~8用于计算每个对象的相似类, 时间复杂度为O(n).因为算法1最多需要考虑I个尺度, 因此算法1的时间复杂度为O(Imn2), 其中I表示系统的尺度标记个数.
算法2 基于知识粗糙熵的属性约简算法
输入I个尺度的多尺度多重集值信息系统(U, A), 阈值α ∈ (0, 1], α -熵最优尺度k
输出α -熵约简B
1.求最细尺度标记下知识粗糙熵Eα (A1)
2.初始化B← Ø , Ck← Ak
3.for each
4. 计算对象两两之间的相似性
SIM(
5.end for
6.for each
7. for each x∈ U do
8. 计算对象x的相似类[x
9. end for
10. 求属性集Ck-{
Eα (Ck-{
11.end for
12.Eα (Ck-{
13.if Eα (Ck-{
14. B← Ck
15.else
16. Ck← Ck-{
17. return 6
18.end if
在算法2中, 步骤3~5同样也用于计算对象间的相似度, 时间复杂度为O(mn2).步骤6~11用于计算属性集Ck-{
$O\left(\frac{(1+m) m}{2} n\right)$
即为O(m2n).所以算法2的时间复杂度为
O(mn2+m2n).
多尺度信息系统中的最优尺度的选择和基于最优尺度的属性约简是多尺度数据分析研究的关键问题, 迄今尚未见到属性取值为多重集且具有多个尺度的信息系统的数据分析研究.本文将多重集引入多尺度信息系统, 提出多尺度多重集值信息系统的概念, 基于海林格距离的相似度在论域上构造对应于任一属性子集的相似类, 定义基于相似关系和基于知识粗糙熵的最优尺度概念, 并证明两者是等价的, 在最优尺度的基础上提出α -约简和α -熵约简的概念, 并给出计算α -熵最优尺度和α -熵约简算法.由于文中定义的相似度在处理尺度较细的属性时, 相似度变化不均匀, 影响模型的稳定性和鲁棒性, 因此所能应用的问题存在一定的局限性, 在后续的研究中需进一步改进.另外, 多尺度多重集值决策系统的最优尺度选择和知识获取是有待继续探讨的课题, 包括广义多尺度多重集值决策系统和不完备多尺度多重集值决策系统的知识获取问题.
本文责任编委 苗夺谦
Recommended by Associate Editor MIAO Duoqian
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|