







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于Transformer的多尺度优化低照度图像增强网络
[牛玉贞1  , 林晓锋
, 林晓锋1 , 许煌标1 , 李悦洲1 , 陈羽中1 ]
, 林晓锋, 许煌标, 李悦洲, 陈羽中]
|
|



作者简介: 
牛玉贞,博士,教授,主要研究方向为计算机视觉、人工智能.E-mail:yuzhenniu@gmail.com. 
林晓锋,硕士研究生,主要研究方向为深度学习、图像增强.E-mail:211020042@fzu.edu.cn. 
许煌标,硕士研究生,主要研究方向为计算机视觉、图像视频理解.E-mail:211027092@fzu.edu.cn. 
李悦洲,博士研究生,主要研究方向为图像视频理解、图像恢复.E-mail:liyuezhou.cm@gmail.com.
低照度图像中亮度、颜色、细节等特征往往存在于不同尺度的信息中,因此实现高质量低照度图像增强极具挑战性.现有基于深度学习的方法无法充分利用多尺度特征,也无法有效结合多个尺度的特征,不能全面提升图像的亮度、颜色和细节质量.针对上述问题,文中提出基于Transformer的多尺度优化低照度图像增强网络(Transformer-Based Multi-scale Optimized Network for Low-Light Image Enhancement, TMO).首先,设计基于Transformer的多任务增强模块,经多任务训练后具有对亮度、颜色、细节的全局建模能力,因此可以初步应对低照度图像存在的亮度不足、颜色偏差、细节模糊、噪声较多等多退化类型挑战.然后,设计结合全局和局部多尺度特征的架构,逐步优化不同尺度的特征.最后,提出多尺度特征融合模块和自适应增强模块,在学习和融合各尺度间信息关联的同时实现在各局部多尺度分支中自适应地增强图像.在6个包含成对图像或不成对图像的公开数据集上的广泛实验表明,文中网络能够有效地综合解决图像中亮度、颜色、细节、噪声等多退化类型问题.
About Author:
NIU Yuzhen, Ph.D., professor. Her research interests include computer vision and artificial intelligence.
LIN Xiaofeng, master student. Her research interests include deep learning and image enhancement.
XU Huangbiao, master student. His research interests include computer vision, and image and video understanding.
LI Yuezhou, Ph.D. candidate. His research interests include image and video understanding, and image restoration.
Enhancing low-light images with high quality is a highly challenging task due to the features of low-light images such as brightness, color, and details in the information of different scales. Existing deep learning-based methods fail to fully utilize multi-scale features and fuse multi-scale features to comprehensively enhance the brightness, color and details of the images. To address these problems, a Transformer-based multi-scale optimization network for low-light image enhancement is proposed. Firstly, the Transformer-based multi-task enhancement module is designed. Through multi-task training, the Transformer-based enhancement module gains the ability to globally model brightness, color, and details. Therefore, it can initially cope with various degradation challenges commonly found in low-light images, such as insufficient brightness, color deviation, blurred details and severe noises. Then, the architecture combining global and local multi-scale features is designed to progressively optimize the features at different scales. Finally, a multi-scale feature fusion module and an adaptive enhancement module are proposed. They learn and fuse the information association among different scales, while adaptively enhancing images in various local multi-scale branches. Extensive experiments on six public datasets, including paired or unpaired images, show that the proposed method can effectively solve the problems of multiple degradation types, such as brightness, color, details and noise in low-light images.
在极弱光、背光等环境下, 拍摄图像往往呈现低质量, 大幅降低如目标检测、图像分割等高层视觉任务的性能[1].因此, 学者们提出低照度图像增强技术, 旨在解决图像存在的亮度不足、图像噪声、颜色偏差、细节模糊等问题[2], 提升低照度图像的可视性与质量, 一方面更符合人类视觉感知特性, 另一方面为下游任务提供更有效的信息.然而, 低照度图像存在不同粒度的各类信息, 而这些粒度往往内嵌于不同尺度中难以获得, 因此低照度图像增强仍极具挑战性.
早期对低照度图像增强的研究主要基于直方图均衡化的方法[3, 4, 5, 6]和基于Retinex理论的方法[7, 8, 9, 10].基于直方图均衡化的方法扩大图像像素的动态范围, 提高图像对比度, 而基于Retinex理论的方法将低照度图像分解成反射图和光照图, 并对它们进行加权合成, 提高图像质量.这两类传统方法主要依赖手工设计的映射函数、光照图操作以及参数调整, 研究往往受限于人工经验, 缺乏数据驱动.
近年来, 学者们提出许多基于深度学习方法.一些方法[11, 12]将Retinex理论与深度学习结合, 通过两个子神经网络增强反射图和光照图.此类方法有效提高图像亮度, 但容易产生细节丢失、颜色不真实等问题.另一些方法[13, 14, 15, 16]注重网络架构设计, 设计生成器和判别器、神经架构搜索、特定曲线估计等各领域主流架构, 实现低照度图像增强, 但缺乏对低照度图像增强任务的特定应用研究.
另外, 学者们提出其它一些应用于低照度图像增强任务的基于Transformer的方法[17, 18].这些方法将Transformer嵌入网络架构中, 与网络其它部分使用相同的针对低照度图像单一任务的数据集进行训练, 却无法利用其它相关图像复原和增强任务, 也无法有效提取多退化类型的失真特征.
相比以往的工作, 本文发现低照度图像中存在复杂的多尺度信息, 如具有不同尺度大小的亮度、颜色、细节等信息块, 若使用单一尺度, 则无法结合多个尺度的特征, 不能全面提升图像的亮度、颜色和细节, 而现有方法缺乏对多尺度信息的有效利用.Guo等[15]提出Zero-DCE(Zero-Reference Deep Curve Estimation), 跳层连接高层特征和低层特征, 这种隐式构建多尺度特征的方式本质上是拼接同一尺度下的多个层次特征.Zhang等[12]提出KinD(Kindling the Darkness), 学习不同尺度的特征, 但缺乏对各尺度的明确约束, 限制高层特征或低层特征的有效利用, 也带来更大的模型训练难度.此外, 低照度问题中往往存在复杂的多退化类型(如噪声明显、细节丢失、颜色退化、光照不足等), 现有基于Transformer的方法仅针对图像亮度和颜色进行提升, 却受限于单一任务特性和数据集规模较小, 导致其网络模型对多退化类型的复原能力较差.
因此, 本文旨在对各尺度信息进行有效提取与融合, 结合低照度图像多尺度中的高层语义信息和低层细节信息, 提高图像增强质量.具体来说, 各层级特征都存在不同尺度大小的信息块, 并且这些多尺度信息块之间往往存在联系, 如图像整体场景由多个局部场景组成, 全局信息可以对其各局部块提供指导.此外, 为了应对低照度图像的多退化类型, 本文设计基于Transformer的多任务综合增强, 旨在利用图像全局信息进行初步整体优化.
根据低照度图像各层次特征对尺度的需求, 本文提出结合全局和局部多尺度特征的低照度图像增强架构, 称为基于Transformer的多尺度优化低照度图像增强网络(Transformer-Based Multi-scale Optimiza-tion Network for Low-Light Image Enhancement, TMO).首先, 对输入的低照度图像引入基于多任务预训练的Transformer, 利用Transformer 的全局信息建模能力进行多任务增强, 初步综合解决低照度图像的多退化类型问题.然后, 通过多尺度卷积神经网络, 在三个不同尺度上提取和增强低照度图像的各层级特征.尺度间设计多尺度特征融合模块(Multi-scale Feature Fusion Module, MFFM), 学习丰富的层级信息, 便于不同尺度特征之间建立联系.每个尺度中均通过自适应增强模块, 自适应地增强亮度和颜色并消除噪声等干扰.
TMO能有效提升图像质量.在6个公共数据集上的实验表明, TMO在客观评价指标上表现较优, 并且在不成对数据集上的实验结果表明TMO具有较优的泛化能力.此外, 可视化增强结果图像显示TMO能够较好地解决低照度图像存在的多退化类型问题.
传统的低照度图像增强方法主要包括基于直方图均衡化的方法和基于Retinex理论的方法.基于直方图均衡化的方法通过扩展图像的动态范围以提高图像对比度和亮度, 达到改善图像质量的目的[19, 20].Xu等[5]综合对比度增强和白平衡, 提出一个广义均衡模型, 性能良好.Lee等[21]利用2D直方图的分层差异表示, 扩大相邻像素之间的灰度差异.基于Retinex理论的方法将图像表示为反映物体本质特征的反射分量R和取决于环境光特性的光照分量I的乘积.经典算法有SSR(Single-Scale Retinex)[22]和MSR(Multiscale Retinex)[23].它们假设光照图像是平滑的, 这种情况下图像在亮度变化大的边缘会形成光晕.
随着深度神经网络的发展, 一些方法[11, 12, 24]将Retinex理论与深度学习结合.欧嘉敏等[24]在估计光照图和反射图中添加去噪损失和颜色损失以进行优化.此类方法假设反射图为增强结果, 可能导致细节丢失、色差严重的不真实的增强.其它一些基于深度学习的方法关注网络架构的设计.江泽涛等[25]采用生成对抗网络学习从低照度图像到正常照度图像的特征映射.尚晓可等[26]使用多重注意力机制分阶段增强图像.这类方法直接将其它领域的主流模型运用到低照度任务, 缺乏对低照度图像特性的关注.
之后, 学者们陆续提出一些针对低照度图像多退化类型问题的解决方法.1)用于颜色增强的方法.该类方法通过神经网络提取图像的颜色特征, 在实现低照度增强的同时重建图像颜色.Kim等[27]提出RCTNet(Representative Color Transform Network), 通过卷积神经网络提取全局和局部的代表颜色并转换.Zhang等[28]提出DCC-Net, 将低照度图像分解成灰度图和颜色直方图分别处理.此类方法对图像颜色重建具有较好效果, 但对图像其余特征缺乏关注, 容易产生伪影和放大噪声.2)用于噪声去除的方法.江泽涛等[29]通过细节重构模块权衡去噪和去模糊.Wang等[30]设计两个逐点式卷积神经网络, 分别模拟环境光和图像噪声的统计规律.这些方法通常加入高斯、泊松等噪声合成数据, 去除噪声时造成细节信息丢失, 在特定数据集上效果良好, 但现实世界中图像噪声各异, 不满足特定分布, 模型泛化性较差.
尽管上述方法都能通过深层和浅层的网络提取到低照度图像的高层语义特征和低层细节特征, 解决低照度图像的常见问题, 但由于单一尺度和感受野的限制, 无法结合全局总览和局部精细, 不能从多角度处理各类问题.为此, 本文提出TMO, 能以多种感受野处理高低层特征, 更全面地解决低照度图像存在的多退化类型问题.
近年来, Transformer在自然语言处理领域的优秀表现也引发学者将其用于计算机视觉任务的研究.Transformer本质是一个编码解码器结构, 用于计算机视觉任务时, 要对原始图像进行切块, 展平成序列, 输入编码器处理后将结果输入解码器部分.Dosovitskiy等[31]提出ViT(Vision Transformer), 展现Transformer在图像处理上有效代替标准卷积的良好效果.随后, Ji等[32]面向图像描述任务, 提出考虑全局信息的GET(Global Enhanced Transformer).Carion等[33]提出DETR(Detection Transformer), 首次使用Transformer处理目标检测问题.Transformer在语义分割[34]和生成模型[35]上的应用也显示Transformer在多任务学习上的表现能力.
本文在使用基于图像恢复和增强任务进行训练得到的预训练模型的基础上, 使用低照度图像数据集进行迁移学习, 将得到的模型用于全局特征增强, 初步解决低照度图像的多场景问题.
注意力机制有助于网络保留有用的信息特征, 抑制价值低的信息特征, 获得更精确的结果.Hu等[36]提出SE(Squeeze-and-Excitation)Block, 显式建模通道之间的相互依赖关系, 自适应地调整对各通道的关注程度.Hou等[37]提出一种轻量级注意力机制, 将通道注意力分解为沿着两个不同方向聚合特征的一维特征编码过程.Woo等[38]设计单路串行的CBAM(Convolutional Block Attention Module), 串行连接通道注意力和空间注意力.陈晓雷等[39]加权融合平均池化和最大池化, 简化注意力模块CBAM.
在图像增强、图像恢复等底层计算机视觉任务上, Hui等[40]针对图像超分任务, 提出对比度感知的注意力算法.Li等[41]提出LPNet(Luminance-Aware Pyramid Network), 在SE Block[2]中加入标准差计算, 恢复低照度图像的对比度.Lü 等计算两个注意力图, 分别指导低照度图像的光照增强和去噪任务.
与以往工作不同, 本文提出双路并行注意力模块, 结合批归一化和空间注意力, 减轻局部位置亮度或颜色的增强的不足或过度增强, 并结合层归一化和通道注意力, 恢复颜色分布.
多尺度信息学习在计算机视觉中已得到广泛应用, 由于能捕捉到细粒度的局部信息和粗粒度的全局信息, 故表现出良好性能.Denton等[42]提出LAP-GAN(Laplacian Generative Adversarial Networks), 将生成过程分为四个尺度逐步细化.Weng等[43]设计CDAN(Cascaded Deep Auto-Encoder Networks), 用于人脸对齐, 可实现较好的实时对齐功能.Li等[41]提出LPNet, 采取从粗到细的策略, 将网络分为两个粗粒度特征提取分支和一个细化分支.江泽涛等[29]使用尺度逐级减小的编码器进行特征概率分别捕获, 应用尺度逐级增大的解码器进行全局重构, 并采用大尺度的多个模块进行细节重构.
相比以往工作, 本文提出的多尺度架构在全局分支和局部多尺度分支中设计不同的网络架构, 实现相应的优化.在全局分支中利用基于Transformer的多任务增强模块, 初步解决低照度图像的多退化类型问题, 在局部多尺度分支中, 利用自适应增强模块, 逐步优化不同尺度的层级特征, 并设计多尺度特征融合模块, 促进不同尺度的信息交换.
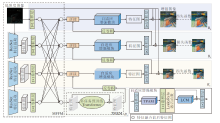
为了增强低照度图像中不同尺度的颜色、光照、细节等高低层特征, 本文根据各层次特征对尺度的需求, 提出基于Transformer的多尺度优化低照度图像增强网络(TMO).网络整体架构如图1所示, 由4个分支组成, 包括全局分支B1和局部多尺度分支B2~B4.
 | 图1 TMO结构图Fig.1 Structure of TMO |
首先, 在全局和局部多尺度分支间设计多尺度特征融合模块(MFFM), 促进不同尺度之间的特征交换和信息交流.然后, 在全局分支B1中设计基于Transformer的多任务增强模块(Transformer-Based Multi-task Enhancement Module, TMEM), 初步解决低照度图像的多退化类型问题.在局部多尺度分支B2~B4中设计自适应增强模块, 由小尺度到大尺度逐层进行增强, 自适应增强模块由双路并行注意力模块(Two-Way Parallel Attention Module, TPAM)和LCCS(Local Color Correction Structure)[44]组成.全局分支处理的信息可以对各局部块进行指导:将全局分支处理后的特征逐层传递到各局部多尺度分支, 具有全局信息的特征与当前局部分支的特征拼接后, 进入自适应增强模块进一步处理, 再将处理后含有全局信息的特征传至下一个分支.
本文设计TPAM, 在每个尺度增强特征的表征能力, 并配合LCCS自适应校正颜色和光照强度, 进一步去除噪声.
具体地, 设Iin为网络输入的低照度图像, Iout为网络输出的增强图像,
其中,
最后,
其中
感受野在神经网络的设计中十分重要.一个大的感受野不仅能提供丰富的语义信息, 而且能学习像素之间的远程关系, 小的感受野则更注重图像的精细特征.为了同时提取低照度图像的不同尺度的层级特征, 本文采用多尺度感受野策略, 兼具大感受野和小感受野的优势.然而, 固定尺度特征的输出与其它尺度特征的输入几乎没有相关性, 这阻碍每个尺度之间的信息流动, 并削弱特征表示.
根据HRNet(High-Resolution Net)[45], 特征间的密集融合对不同尺度特征之间的信息路由尤为关键.为了促进不同尺度之间的特征交换和跨尺度信息交流, 本文设计多尺度特征融合模块(MFFM), 提取不同尺度特征并密集融合各特征信息.首先, 使用预训练的ResNet骨干[46]提取4个尺度的浅层特征
Fi=Conv1(
其中Conv1(· )表示步长为1的1× 1卷积.
然后, 由于融合前后特征的尺度不同, 所以需要通过上采样操作或步长为2的卷积操作t(
t(
其中:
最后, 第i2个分支融合后的特征图
由于
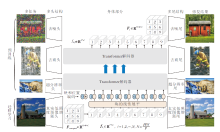
对于低照度图像增强存在的亮度不足、噪声明显、颜色偏差、细节模糊等多种退化问题综合处理的难点在于:现有真实低照度图像训练集的规模和多样性无法令人满意, 并且不存在对特定问题的指向性[1].随着深度学习的不断发展, 在多任务数据集上预训练得到的模型已显示出比传统方法更有效的特点[47].多任务预训练可以使用多领域数据集, 不受真实低照度规模较小、多样性较低的限制, 表现出多方面的优秀性能.近年来, 这一巨大进步主要得益于Transformer及其变体架构的特征表示能力.因此, 本文使用基于Transformer在图像恢复和增强等相关任务中得到的基于多任务学习的预训练模型— — IPT(Image Processing Transformer)[17], 并在其基础上使用真实的低照度图像数据集进行迁移学习, 得到一个特定于低照度图像增强任务的基于Transformer的多任务增强模块(TMEM).该模块可同时具有调整亮度、色差、细节和去除噪声等能力.TMEM结构图如图2所示.
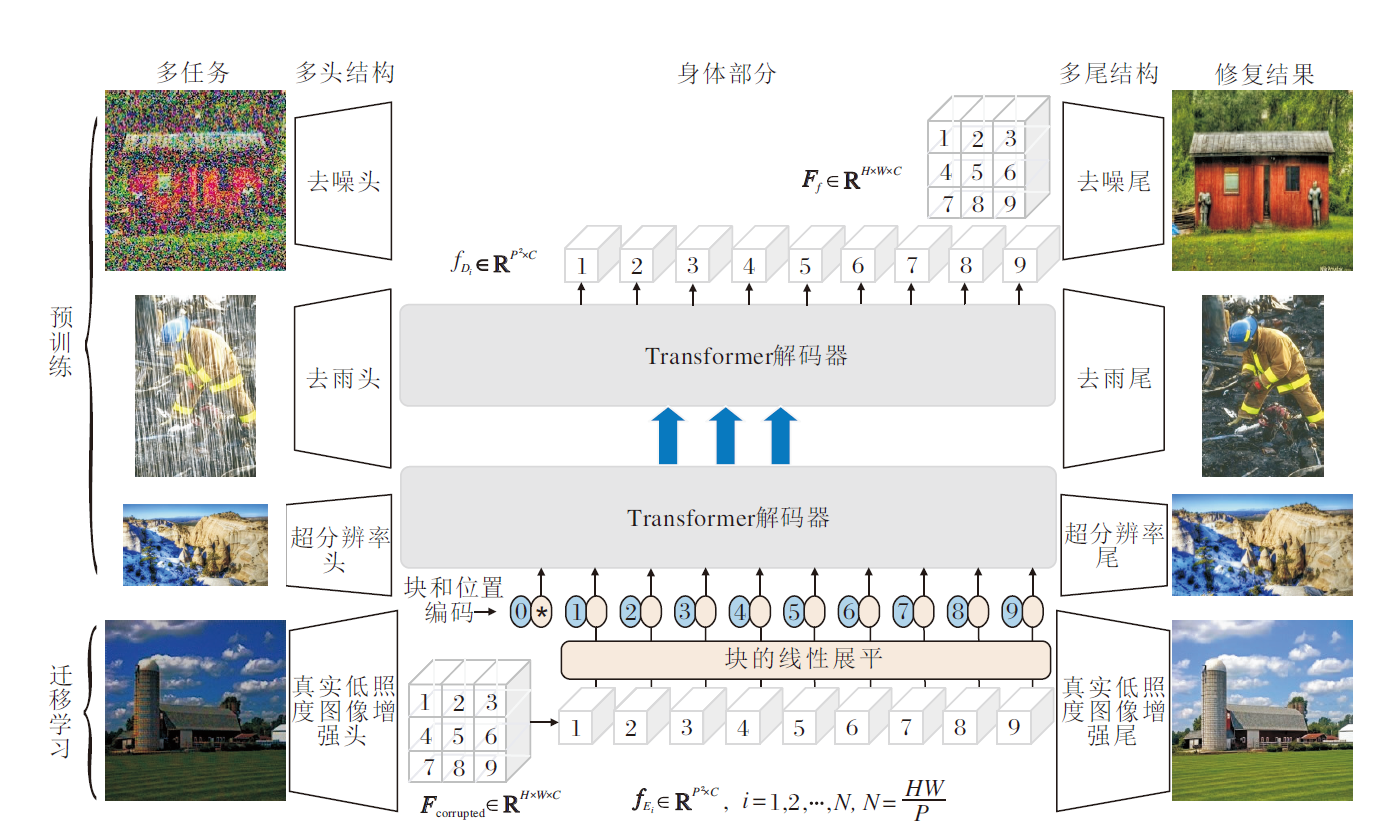 | 图2 TMEM结构图Fig.2 Structure of TMEM |
IPT由多头结构Hi(i=1, 2, …, n)、身体部分B和尾部结构Ei(i=1, 2, …, n)组成, 其中多头结构和多尾结构为了适应不同的任务, 任务和任务之间共享身体部分的参数, 不共享头部和尾部的参数.IPT只能接受特定尺寸的输入图像, 即48× 48, 需将原始图像裁切成若干个尺寸为48× 48的图像块, 依次输入模型增强后进行拼接.IPT处理的任务包括去噪、去雨、超分辨率, 相比这些任务, 本文研究的低照度图像增强模型对不同图像块之间的相互关系的依赖性更强, 不适合分块的处理方式.因此, 本文在最小尺度的特征上应用TMEM, 充分发挥Transformer在全局建模能力上的优势.
在IPT的基础上, 本文使用真实低照度图像数据集对其进行迁移学习, 以便更适合于解决低照度图像存在的多退化类型问题.首先, 增加低照度图像增强头部Hl、低照度图像增强尾部El, 使用原身体部分的参数, 组成完整模型.低照度图像经过头部提取图像特征、身体部分恢复丢失信息、尾部特征映射后, 得到增强图像.由于模型身体部分能够学习到图像恢复和增强任务中普遍存在的图像失真特征, 而结合使用不同的去噪、去雨、超分辨率等多头结构, 能够有效去除对应的图像失真信息, 如在使用去噪对应的头结构得到的结果图像中噪声被有效去除, 因此将IPT的身体部分作为TMEM.
具体地, 输入特征图为B1分支上的全局特征
在全局分支B1上, 经过TMEM处理后, 已初步解决低照度图像的多退化类型问题.接下来, 在局部多尺度分支B2~B4中设计自适应增强模块, 由小尺度到大尺度逐层进行增强.自适应增强模块由双路并行注意力模块(TPAM)和LCCS[44]组成.TPAM在每个尺度增强特征的表征能力, 并配合LCCS自适应校正颜色和光照强度, 进一步去除噪声.
2.4.1 双路并行注意力模块
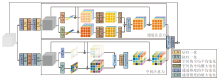
注意力机制和归一化方法被广泛应用于计算机视觉任务中.注意力机制用于加强对不同通道或空间像素点的关注程度, 归一化方法用于减轻内部协变量偏移[48], 增大学习率, 加快收敛速度.由于低照度图像各局部位置往往亮度、颜色、噪声等需要被处理的程度不同, 无法使用统一的增强方式, 因此需要使用空间注意力合理分配局部位置像素点的权重, 实现自适应增强.例如, 对于亮度, 同一幅图像中某些区域的像素需要调亮, 某些区域需要抑制, 而某些区域需要维持.同时, 低照度这种退化类型容易造成颜色分布的改变, 而挖掘通道间的稀疏性和依赖关系对颜色表示学习很重要[49], 因此需要使用通道注意力学习关键通道的信息以帮助颜色恢复.本文提出双路并行注意力模块(TPAM), 结合层归一化和通道注意力, 同时结合批归一化和空间注意力, 用于解决上述问题.TPAM结构如图3所示.输入特征图为当前分支Bi(i=2, 3, 4)与上一分支Bi-1(i=2, 3, 4)的特征图经过式(1)的拼接操作和一个3× 3卷积后得到的特征图, 记为Fatt.
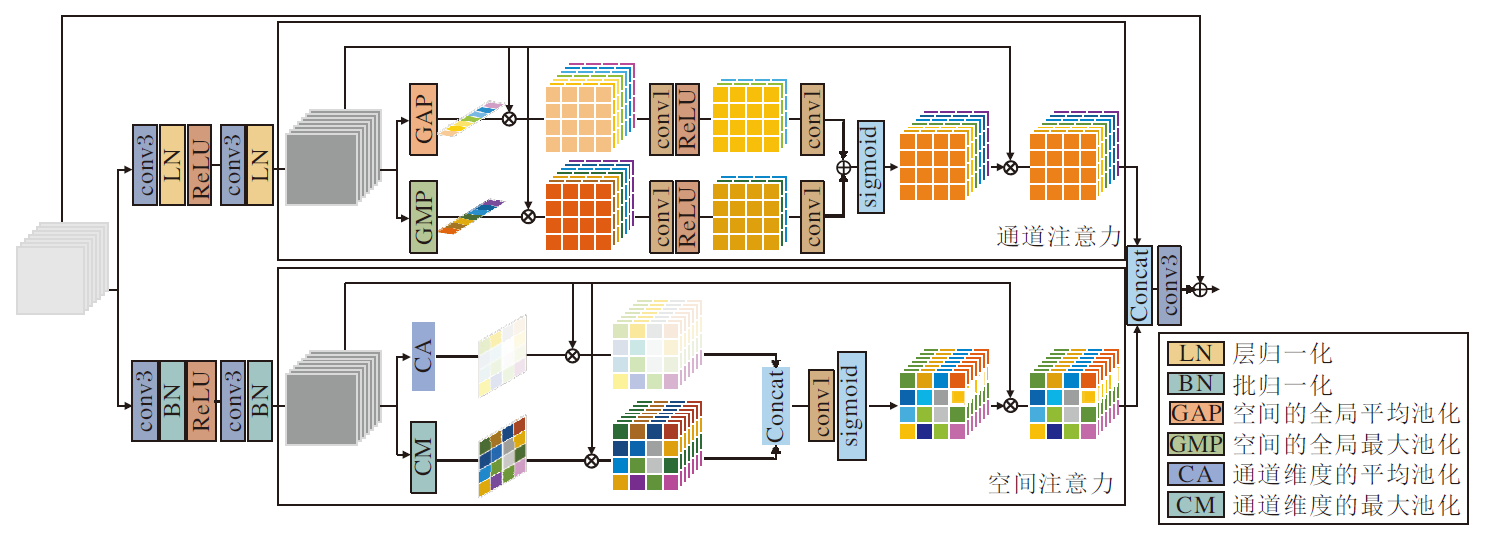 | 图3 TPAM结构图Fig.3 Structure of TPAM |
层归一化是对同一样本内的所有特征进行归一化, 层归一化操作后, 依旧保持样本内所有特征的依赖关系.本文结合层归一化和通道注意力, 一方面通过层归一化保持特征间的依赖关系, 另一方面通过通道注意力增大通道间的稀疏性, 关注通道中的关键信息.具体地, 首先依次经过3× 3卷积、层归一化、ReLU激活函数、3× 3卷积、层归一化, 得到特征图F1.再使用全局平均池化和全局最大池化, 得到具有通道特征平均水平和最高水平的两个向量.由于低照度图像增强是一种低层级计算机视觉任务, 可处理精细信息, 更注重像素级的权重关注, 因此, 将特征图F1分别与两个向量相乘, 将原本的一维向量扩充到三维, 同时保证特征信息的保留和像素级别的关注.然后, 使用1× 1卷积、ReLU激活函数进行通道压缩, 经过1× 1卷积恢复通道维度, 将特征图相加, 得到的特征图具备通道特征的稀疏性和依赖关系.最后, 使用sigmoid函数校准每个通道的权重, 与输入的特征图Fatt相乘, 得到具有通道关注的特征图Fc.
批归一化是对同个批次不同样本的同个通道间进行归一化, 本文结合批归一化和空间注意力, 一方面通过空间注意力对空间中的每个像素点分配不同的学习权重, 对低照度图像不同位置的亮度、颜色、噪声等给予不同的关注, 减轻局部位置的不足或过度增强, 另一方面通过批归一化加速训练.具体地, 首先依次经过3× 3卷积、批归一化、ReLU激活函数、3× 3卷积、批归一化, 得到特征图F2.再使用通道维度的平均池化和最大池化, 分别计算空间像素的平均水平和最高水平, 得到两个二维特征图, 将特征图F2分别与两个二维特征图相乘, 将二维扩充到三维, 得到更适合低照度图像增强这种精细任务的像素级别关注.然后, 把两个特征图沿通道维度拼接, 得到空间位置的像素权重.最后, 使用1× 1卷积恢复通道维度, 使用sigmoid函数校准空间像素的权重, 与输入的特征图Fatt相乘, 得到具有空间关注的特征图Fs.
将由空间注意力和通道注意力得到的特征图沿通道维度拼接后, 经过一个3× 3卷积, 得到具有通道关注和空间关注的权重特征图, 与原始特征图相加, 得到TPAM的输出特征图:
Oatt=Fatt+Conv3(Concat(Fc, Fs)),
其中, Fatt表示TPAM的输入特征图, Fc表示由通道注意力得到的特征图, Fs为由空间注意力得到的特征图.
2.4.2 局部校正模块
本文采用LCCS[44]实现对特征图中特征的调整.LCCS结构如图4所示.输入特征图为TPAM的输出特征图Oatt经过1× 1卷积和LeakyReLU激活函数后得到的特征图.
 | 图4 LCCS结构图Fig.4 Structure of LCCS |
首先, 通过2× 2的平均池化层降低特征图的宽高尺度, 使用2个1× 1卷积、ReLU激活函数提取特征.
然后, 利用1个1× 1卷积进行通道压缩, 通过上采样层达到与输入特征图相同的宽高尺度后, 与输入特征图进行通道维度的拼接.
最后, 使用SE Block[36]调整提取的特征图.在LCCS之后, 经过残差连接和1× 1卷积, 得到自适应增强模块的输出特征图.
低照度图像增强的最终目标是要使网络最终的增强结果Iout和标签图像G尽可能接近.本文使用多个尺度增强结果的加权损失, 对每个分支的增强图像与对应尺度的标签图像G计算L1损失, 同时从高低尺度逼近正常照度图像, 在有效利用特征的同时加速训练.损失函数如下:
其中,
由于对3个分支的约束同等重要, 因此本文没有对λ 1、λ 2、λ 3进行穷举, 默认3个权重均设为1时结果较好.
本文在成对公共数据集LOL[11]、SID[50]、SMID[51]上评估网络的有效性, 在不成对公共数据集MEF[52]、LIME[9]、VV(https://sites.google.com/site/vonikakis/datasets)上验证网络的泛化能力.
LOL数据集为真实场景中拍摄的成对低照度图像数据集, 共500对低照度与对应的正常照度图像, 包括485对训练图像和15对测试图像, 每幅图像大小均为400× 600.SID数据集包含Sony和Fujifilm拍摄的5 094对RAW格式的低照度图像和对应的正常照度图像, 一幅正常照度图像与多幅低照度图像对应.本文使用Sony相机拍摄的子集, 根据文献[50]方法将RAW格式转换为RGB格式, 并划分训练集和测试集.SMID数据集包含35 800对RAW格式的极弱光和其对应的正常照度图像, 包括不同光照条件下的运动车辆和行人, 本文同样把它从RAW格式转换为RGB格式, 并按照文献[53]划分训练集和测试集.其中, SID、SMID数据集上图像由于在极弱光条件下拍摄, 噪声比较严重, 因此可以验证本文网络的去噪能力.
MEF、LIME、VV数据集为低照度图像增强任务中常用的用于检测泛化能力的不成对数据集.为了便于与以往工作对比, 本文按照文献[28]的做法, 将3个数据集的图像均调整为512× 512.
在TMEM的迁移学习中, 本文使用LSRW数据集[54].该数据集包含5 650对真实低照度图像与其对应的正常照度图像.
本文实验基于Pytorch框架, 设置初始学习率为10-4, 在P100 GPU上使用Adam(Adaptive Moment Estimation)优化器训练模型, 设置迭代次数为500.在训练中, 对每幅低照度图像进行3次随机裁剪, 裁剪成384× 384, 批次大小为4, 并对训练数据进行水平翻转、垂直翻转、旋转的数据增强以提高网络的泛化能力.
为了客观评估网络的性能, 在成对数据集LOL、SID、SMID中使用峰值信噪比(Peak Signal-to-Noise Ratio, PSNR)、结构相似度(Structure Similarity Index Measure, SSIM)衡量增强结果和对应的正常照度图像之间内容和结构的相似度.较高的PSNR值表示网络能够抑制低照度图像的噪声并较好地调整光照.较高的SSIM值表示网络较好地保留场景中物体的结构和细节.在MEF、LIME、VV这3个不成对数据集上使用NIQE(Natural Image Quality Evaluator)衡量增强结果的自然度, 越低的NIQE值表示增强结果越真实.
为了评估网络结构各部分的有效性, 在本节中, 以TMO作为基线对多尺度结构、核心模块进行一系列消融实验.
3.3.1 基于Transformer的多任务增强模块有效性评估
基于Transformer的多任务增强模块(TMEM)在TMO中是对全局特征进行初步增强的模块, 综合地对亮度、细节进行增强.表1给出去掉TMEM和没有使用低照度图像数据集进行迁移学习的情况, 可以看到, 相比TMO, 两种情况下PSNR值分别下降0.874 dB, 0.764 dB, SSIM值分别下降0.021, 0.025.
| 表1 有无TMEM的消融实验结果 Table 1 Results of ablation experiment with or without TMEM |
相应地, 图5给出不同网络结构的增强效果对比.由图可以观察到, 去掉TMEM的增强效果中明显出现很多噪声和伪影, 也有较明显的色差, 而使用TMEM后增强结果中亮度、噪声、细节方面明显更优, 这说明TMEM具备综合增强低照度图像的能力.
 | 图5 不同网络结构的增强效果对比Fig.5 Enhancement result comparison of different network structures |
为了进一步验证本文使用TMEM的合理性, 进行对比实验, 结果如表2所示.IPT[17]中的任务包括去噪、去雨和超分辨率重建, 本文研究的低照度图像增强与这些任务相比, 对不同图像块之间相互关系的依赖性更强, 如相同语义的区域通常跨多个48× 48的图像块, 不适合采取分块的处理方式.因此TMO的输入为整幅低照度图像, 先通过ResNet提取多尺度特征, 然后在最小尺度的特征上应用TMEM, 充分发挥Transformer在全局建模能力上的优势.相比仅采用TMEM和图像分块输入, TMO在保留全局分支B1和去除局部多尺度分支B2~B4时, PSNR和SSIM值分别提高4.710 dB和0.073.
| 表2 TMEM的消融实验结果 Table 2 Results of ablation experiments for TMEM |
3.3.2 双路并行注意力模块有效性评估
为了验证双路并行注意力模块(TPAM)的有效性, 分别使用如下网络.
1)网络1.不使用TPAM.
2)网络2.TPAM替换为通道注意力和空间注意力单路串行(保持通道注意力和层归一化、空间注意力和批归一化配合使用).
3)网络3.空间注意力和通道注意力都与层归一化配合使用.
4)网络4.空间注意力和通道注意力都与批归一化配合使用.
4种结构的消融实验结果如表3所示.从表中可以看到, 相比TMO, 4种网络的PSNR和SSIM值都有所下降, 但网络2的效果优于网络3和网络4, 这从客观评估指标上说明通道注意力和层归一化、空间注意力和批归一化配合使用的有效性.因为通道注意力增大通道间的稀疏性, 层归一化保持每个通道内特征间的依赖关系, 而挖掘通道间的稀疏性和特征间的依赖关系对颜色表示学习很重要[48].空间注意力可以根据低照度图像局部位置亮度、颜色、噪声需要被处理的程度合理分配局部像素点的权重, 而批归一化基于同一批次内特征的统计数据进行归一化, 使数据的分布更加稳定.
| 表3 各网络的消融实验结果 Table 3 Results of ablation experiment of different networks |
从图5可以看到, 在不使用TPAM的情况下, 对不同空间位置的光照和颜色采用同样的增强力度, 导致图像中部分区域的伪影和曝光不足或过度曝光, 同时也不能较好地处理噪声, 而TMO能较好地解决上述问题.
B4分支中不同模块的输出特征图如图6所示.
 | 图6 B4分支中不同模块的输出特征图Fig.6 Output feature maps of different modules in branch B4 |
由图6也可以直观地看到, TPAM的输出特征图明显增强特征的表征能力, 对每个像素点采用不同的关注程度, 引入的LCCS可以进一步地对已得到的具有强表征能力的特征图进行不同程度的颜色和亮度增强.这从主观视觉效果中证实TPAM的批归一化与空间注意力结合、层归一化与通道注意力结合成为双路并行注意力的有效性.
3.3.3 多尺度框架有效性评估
为了评估结合全局和局部多尺度架构的有效性, 本节构建不同的多尺度框架, 结果如表4(组合1~组合3、组合5)所示.
| 表4 不同分支数多尺度框架增强效果的客观评价指标对比 Table 4 Comparison of objective evaluation indicators of multi-scale framework enhancement result with different branch numbers |
由表4可见, 组合1网络只保留全局分支B1, 即经过多尺度特征融合模块(MFFM)和基于Transformer的多任务增强模块(TMEM)处理后, 直接经过三次反卷积得到增强图像, 相比TMO, PSNR和SSIM值分别下降1.692 dB和0.095.组合2网络只保留3个局部分支B2、B3、B4, 相比TMO, PSNR和SSIM值分别下降0.699 dB和0.095.组合1网络和组合2网络与TMO的对比实验说明, 全局分支和局部多尺度分支对于低照度图像增强都是必要的, 二者能够取得互补的作用.组合3网络保留一个全局分支B1和一个局部分支B4, 可以看到, 虽然相比TMO, PSNR和SSIM值分别下降0.566 dB和0.007, 但是相比组合1网络和组合2网络这种只保留全局分支或局部分支的结构, 指标值均有所提升, 进一步说明结合全局和局部多尺度架构的有效性.
为了更直观地说明本文提出的全局分支的初步增强效果和三个局部分支的逐步精细增强效果, 给出4个分支的增强图像, 如图7所示.由图可以看到, 全局分支的增强图像已初步恢复光照、颜色、细节等信息, 三个局部分支的细节纹理逐步清晰, 颜色、亮度逐步协调.B4分支增强图像的光照、颜色、细节、纹理都达到最优效果.
 | 图7 四个分支的增强图像Fig.7 Enhanced images of four branches |
为了更好地平衡网络性能和参数, 进一步构建并实验具有全局分支B1和不同局部分支数的多尺度框架, 结果如表4(组合3~组合5)所示.组合4网络保留全局分支B1和两个局部分支B3、B4, 相比组合3网络保留全局分支B1和一个局部分支B4的结构, PSNR和SSIM值分别提升0.353 dB和0.003.组合5网络(TMO)保留全局分支B1和三个局部分支B2、B3、B4, 相比组合4网络, 虽然性能进一步提升, 但提升幅度减小.由于本文使用的主干网络ResNet的特征提取部分包含4个尺度, 这4个尺度在本文架构中已全部使用, 因此本文未尝试继续增加尺度数量.
总之, 综合考虑网络性能、复杂度及主干网络特点, 本文选择采用一个全局分支B1和三个局部分支B2、B3、B4的结构.
为了进一步探究三个局部分支的重要性, 分析损失函数权重参数λ 1、λ 2、λ 3的取值.首先, 由于每个分支使用的损失函数相同, 并且对每个分支的约束都很重要, 因此本文没有进行穷举, 默认λ 1、λ 2和λ 3均设为1时结果较优.其次, 也尝试增大某一分支损失的权重, 如表5所示, 发现实际效果并不理想, 这也验证本文损失函数权重设置的合理性.
| 表5 损失函数权重参数取值不同时指标值对比 Table 5 Indicator values comparison with different weighting parameters of loss function |
本节进行对比实验, 选择如下对比网络:Retinex-Net[11]、KinD[12]、RUAS(Retinex-Inspired Un-rolling with Architecture Search)[13]、EnlightenGAN[14]、Zero-DCE[15]、Zero-DCE++[16]、RCTNet[27]、DCC-Net[28]、文献[30]网络、LPNet[41]、文献[50]网络、MIRNet[55]、DRBN(Deep Recursive Band Network)[56]、KinD++[57]以及两种最近针对低层计算机视觉任务提出的Transformer结构(IPT[17]、Uformer[18]).
所有深度学习算法都使用推荐的参数设置和实现细节进行训练和测试, 以便进行公平对比.
3.4.1 客观评价指标
TMO和常见的低照度增强网络在LOL、SID、SMID数据集上的客观评价指标如表6和表7所示, 表中给出的PSNR、SSIM指标都是在测试集上的平均值, 黑体数字表示最优值, 斜体数字表示次优值.
| 表6 不同网络在LOL数据集上的客观评价指标 Table 6 Objective evaluation indicators of different networks on LOL dataset |
| 表7 不同网络在SID、SMID数据集上的客观评价指标 Table 7 Objective evaluation indicators of different networks on SID and SMID datasets |
从表6和表7可以看到, TMO的PSNR值最高, 说明在对比网络中, TMO得到的增强图像与标签图像最接近.TMO的SSIM值也最高, 说明TMO得到的增强图像能最好地恢复低照度图像的整体结构.具体来说, 相比表6和表7中次优网络, TMO在LOL、SID、SMID测试集上的PSNR值分别获得0.90 dB、0.75 dB、0.68 dB的提升, SSIM值分别获得0.004、0.092、0.018的提升.因此, TMO在LOL、SID、SMID数据集上取得良好性能, 并且优于对比网络.
本节还在MEF、LIME、VV不成对数据集的不成对真实低照度图像上验证网络的泛化能力.各网络在MEF、LIME、VV数据集上的NIQE指标如表8所示, 较低的NIQE值表示较优的感知效果, 表中黑体数字表示最优值, 斜体数字表示次优值.由表可以看到, TMO在MEF、LIME、VV真实数据集上取得最好或具有竞争力的结果, 说明TMO增强的结果具有较优的感知效果.
| 表8 不同网络在MEF, LIME, VV数据集上的NIQE指标 Table 8 NIQE of different networks on MEF, LIME, and VV datasets |
3.4.2 主观视觉效果对比
首先, 在LOL数据集上对比各网络的视觉效果, 具体如图8所示.相比输入图像, 所有网络的增强结果都显著提高对比度与亮度.具体而言, DRBN增强结果整体的自然度较好, 但颜色饱和度整体较低, 不能较好地恢复图像的颜色.Retinex-Net增强结果在全图中有明显噪声, 尤其在玻璃上.KinD++较好地处理噪声, 但对整体的颜色和光照处理一致, 导致部分区域欠曝, 在灯牌处更明显.IPT的增强结果中亮度恢复较好, 但出现许多伪影.Uformer的增强结果中细节恢复较好, 不存在伪影, 但出现过度曝光的问题.
 | 图8 各网络在LOL数据集上的视觉效果对比Fig.8 Visual effect comparison of different networks on LOL dataset |
各网络在SID、SMID数据集上视觉效果对比如图9和图10所示.由图可以看到, Zero-DCE++的增强结果明显放大低照度图像的噪声, KinD++存在明显的色差, 而TMO与标签图像更接近.相比其它网络, TMO综合提升图像质量并校正色差、去除噪声、保留丰富的细节.
 | 图9 各网络在SID数据集上的视觉效果对比Fig.9 Visual effect comparison of different networks on SID dataset |
 | 图10 各网络在SMID数据集上的视觉效果对比Fig.10 Visual effect comparison of different networks on SMID datasets |
各网络在MEF、LIME、VV不成对数据集上的视觉效果如图11所示, 相比输入图像, 所有网络均提高图像的亮度.
 | 图11 各网络在不同数据集上的视觉效果对比Fig.11 Visual effect comparison of different networks on different datasets |
具体而言, Zero-DCE++增强结果较为真实自然, 但带来过度曝光, 从而失去很多细节.Retinex-Net和现实场景存在明显的色差, 导致不真实的增强.KinD++和EnlightenGAN较好地处理噪声, 但在整体上缺乏自然度和协调性.TMO进行真实的增强, 增强结果中具备细节信息, 成功恢复颜色并去除噪声, 由此验证TMO的泛化能力.
本文提出基于Transformer的多尺度优化低照度图像增强网络(TMO), 针对现有方法仅采用单一尺度特征, 无法提取和融合低照度图像中多粒度层级信息的问题, 设计结合全局和局部多尺度的低照度图像增强网络.在全局特征上利用基于Trans-former的多任务增强模块(TMEM)初步解决低照度图像的多退化类型问题, 在局部多尺度架构中利用自适应增强模块在不同尺度中实现逐步优化的高低层特征增强.此外, 设计多尺度特征融合模块(MFFM), 进行尺度间的信息交互, 融合不同尺度分支输入特征的感受野.在成对和非成对数据集上的广泛实验验证TMO的有效性和泛化能力.
本文使用的预训练Transformer在整体优化全局信息的同时, 也带来较多的参数量.今后将考虑轻量化的结合Transformer和多尺度结构的低照度图像增强网络, 在发挥两者优势的同时避免耗费更多的资源.今后也将尝试使用无监督的训练策略, 减少对成对训练数据集的需求, 进一步提升网络的泛化能力.
本文责任编委 桑农
Recommended by Associate Editor SANG Nong
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|
| [47] |
|
| [48] |
|
| [49] |
|
| [50] |
|
| [51] |
|
| [52] |
|
| [53] |
|
| [54] |
|
| [55] |
|
| [56] |
|
| [57] |
|