{kind=link}
{kind=link}
{kind=link}
基于过滤机制的链式实体关系抽取模型
[夏鸿斌1, 2  , 沈健
, 沈健1 , 刘渊1, 2 ]
, 沈健, 刘渊]
|
|



作者简介:

沈 健,硕士研究生,主要研究方向为自然语言处理.E-mail:1452112297@qq.com.

刘 渊,硕士,教授,主要研究方向为网络安全、社交网络.E-mail:lyuan1800@sina.com.
当前实体关系抽取任务中普遍采用堆叠标注层的方式处理关系重叠问题.这种处理方式中很多关系对应标注层的计算是冗余的,会导致标注矩阵的稀疏化,影响模型的抽取效果.针对上述问题,文中提出基于过滤机制的链式实体关系抽取模型,先通过编码层获得文本的向量特征,再通过五阶段的链式解码结构顺序抽取关系三元组的主体、客体和关系.链式解码结构在避免标注矩阵稀疏化的同时,能够通过过滤机制完成实体和关系的自动对齐.在解码过程中:条件层规范化用于提高阶段间特征的融合程度,减少误差累积的影响;门控单元用于优化模型的拟合性能;首尾分离和关系修正模块用于关系集的多重校验.在公开数据集上的对比实验表明,文中模型取得较优性能.
About Author:
SHEN Jian, master student. His research interests include natural language proce-ssing.
LIU Yuan, master, professor. His research interests include cyber security and social network.
Stacking labeling layer is commonly adopted to deal with relation overlap in current entity relation extraction task. In this method, the calculation of the labeling layers corresponding to many relations is redundant, resulting in sparse labeling matrix and weak extraction performance of the model. To solve these problems, a chain entity relation extraction model with filtering mechanism is proposed. Firstly, the vector feature of the text is obtained through the encoding layer, then the subject, object and relation of the relation triple are sequentially extracted through the five-stage chain decoding structure. The chain decoding structure avoids the sparse labeling matrix, and the automatic alignment of entities and relations is completed through the filtering mechanism. In the decoding process, conditional layer normalization is employed to improve the fusion degree of features between stages and reduce the impact of error accumulation. Gated unit is utilized to optimize the fitting performance of the model. Head-to-tail separation and relation correction module are applied to multiple verification of relation sets. Comparative experiments on public datasets show that the proposed model achieves better performance.
实体关系抽取任务目的是从文本数据中抽取出由主体(Subject)、客体(Object)和谓语(Pre-dicate, 即主体和客体之间的关系)组成的关系三元组[1].实体关系抽取是知识图谱构建的关键步骤[2, 3], 在医学知识发现[4]、情感分析[5]等领域都具有广泛应用.
关系重叠问题是实体关系抽取中的一个关键问题, 包括Normal、SEO(Single Entity Overlap)和EPO(Entity Pair Overlap)三种情况.Normal表示一对实体之间关系唯一, SEO表示多个实体与同一个实体间存在关联, EPO表示一对实体之间拥有多个不同的关系.
实体关系抽取任务可以分为实体抽取和关系抽取两个子任务.常用的实体抽取方式有基于序列标注的方式和基于跨度(Span)的方式.Zheng等[6]将关系类别与序列标注中的BIEO标签结合, 为每个分词片段进行分类, 再按照标签类型进行组合, 得到三元组.这种处理方式将实体限定在某种关系上, 无法处理关系重叠问题.
常用的基于跨度的方式有片段排列和指针网络两种.Dixit等[7]提出的Span-Level Model for Relation Extraction和Eberts等[8]提出的SpERT(Span-Based Entity and Relation Transformer)都采用片段排列的方式抽取实体Span.这种方式会先列举出本文序列中所有可能的实体Span, 再使用过滤器进行筛选, 实际抽取过程中会对很多冗余的实体Span进行判断, 导致计算开销变大.指针网络通过两个标注层分别标注实体的首部和尾部, 最后组合成实体Span, 这种抽取方式更简单高效.Wei等[9]提出的CASREL和王泽儒等[10]提出的指针级联标注策略(Novel Pointer Cascade Tagging Strategy, NPCTS)都采用指针网络处理实体抽取任务.
在关系抽取任务方面, 早期模型在抽取得到实体对后, 会采取基于特征的方式[11]和基于核函数的方式[12]抽取关系, 当前模型更倾向于实体与关系的联合抽取.例如:CASREL和TPLinker[13]都会按照关系类别数堆叠标注层, 即在每个关系下预测对应的实体, 从而实现实体和关系的自动对齐.
实体关系抽取模型可以分为管道模型(Pipeline)和联合模型(Joint).管道模型的任务按照顺序执行, 任务之间的关联性较低, 存在误差累积、曝光偏差等问题.联合模型通过参数共享或联合解码的方式, 提高子任务之间的关联性.参数共享的联合模型(如CASREL)在本质上仍是多阶段模型, 同样存在误差累积、曝光偏差等问题.而类似TPLinker的联合解码模型, 虽然能够在单阶段内抽取三元组的全部内容, 避免曝光偏差和误差累积的产生, 但解码结构会相对变得更复杂, 导致模型的计算性能不佳.
CASREL的堆叠指针网络和TPLinker的握手标注机制(Handshaking Tagging Scheme)都采用按照关系种类数堆叠标注层的策略, 即在每个关系类别下抽取对应的实体对.在实际情况中, 多数文本包含的关系三元组不会很多, 能够覆盖到的关系种类很少, 因此大量关系对应的标注层计算是冗余的, 导致模型标注矩阵的稀疏化, 最终影响抽取性能.为了处理这种由关系类别失衡而产生的矩阵稀疏问题, Zheng等[14]提出PRGC(Potential Relation and Global Correspondence), 采用关系和实体分开抽取的策略, 并使用全局对应矩阵(Global Correspondence Matrix, GCM)对齐实体.全局对应矩阵的大小为文本序列长度的平方, 其中只有实体首部对应位置会进行标注, 同样是一个较稀疏的矩阵.
CASREL和PRGC均为两阶段的解码模型, CASREL利用主体信息抽取对应的客体和关系, PRGC利用关系信息抽取对应的实体对, 这两个模型在第二阶段都利用第一阶段的输出结果, 成功过滤不必要的信息, 完成三元组的部分元素之间的对齐.本文将这种利用前一阶段输出排除无用信息, 并自动对齐三元组内元素的机制称为过滤机制.
针对上述模型的一些问题, 本文提出基于过滤机制的链式实体关系抽取模型(Chain Entity Rela-tion Extraction Model with Filtering Mechanism, Chain-Rel).首先, 通过BERT(Bidirectional Encoder Repre-sentations from Transformers)[15]获取文本的编码输出, 使用门控注意力单元(Gated Attention Unit, GA-U)[12]对输出特征进一步编码.然后, 将特征输入关系修正模块和链式解码模块中分别进行抽取, 得到文本的全局关系集和关系三元组集.最后, 使用全局关系集对关系三元组集进行校验, 得到输出结果.链式解码结构分为五个阶段, 前四个阶段用于抽取主体和客体, 最后一个阶段用于获取实体对间的关系.从第二阶段开始, 每个阶段都会使用前驱阶段的输出进行数据过滤, 使主体、客体、关系能够在链式的抽取过程中自动对齐.为了提升过滤机制的作用, 减少误差累积的影响, ChainRel使用条件层规范化(Conditional Layer Normalization, CLN)[16]进行阶段间的特征融合.在进入最后一阶段前, 模型会通过门控线性单元(Gated Linear Unit, GLU)[17]以及首尾分离操作进一步丰富输入特征包含的信息, 提升关系抽取效果.
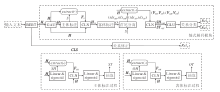
ChainRel分为3部分:BERT编码层、链式解码模块和关系修正模块.
ChainRel的具体结构如图1所示:H0为BERT的输出编码; H为H0经过GAU处理过后的文本编码; CLS为BERT输出中用作分类的一个向量; SH、OH、ST、OT为主体首部、主体尾部、客体首部和客体尾部对应的索引下标候选集; S和O为对齐后的实体Span集, 包括4个对齐后的索引集idxSH、idxST、idxOH、idxOT; FSH、FOH、VSH、VST、VOH、VOT为SH、OH、idxSH、idxST、idxOH和idxOT中的下标信息, 通过extra-ct(·)从H中截取得到的特征向量; H*S为H和FS的融合向量, SH*OH为VSH和VOH的融合向量, ST*OT为VST和VOT的融合向量; RelH和RelT为关系抽取部分得到的两个关系集, RelG为通过关系修正模块得到的全局关系集.
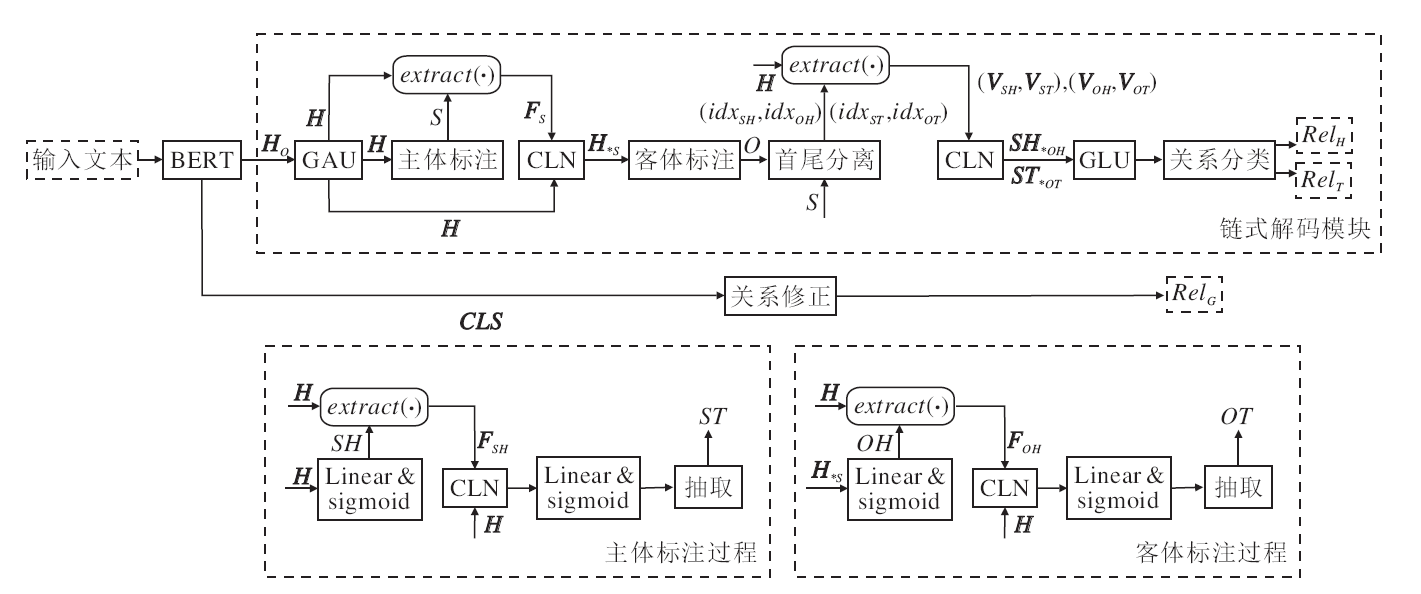 | 图1 ChainRel结构图Fig.1 Structure of ChainRel |
BERT是由Transformer[18]的Encoder Block堆叠而成.模型结合上下文进行训练, 生成深度的语义表征.ChainRel使用BERT的分词器对输入文本进行处理, 得到文本序列, 并将该序列输入预训练的BERT中, 用于计算对应的编码向量.本文取BERT最后一个Block的输出H0以及对应的CLS向量供后续模块使用.
GLU源于门控卷积网络(Gated Convolutional Network, GCN)[17], 其本质是通过两个相同的卷积层对输入向量进行强化输出.两个卷积层对应两个通道, 未加激活函数的通道保证运算过程中梯度的不易消失, 加激活函数的部分实现特征的非线性转换.两个通道相加后的输出能够有效强化输入特征.ChainRel中的GLU结构, 在网络层上使用简单高效的线性层, 具体计算公式如下:
glu(X)=(W1X+b1)$\otimes$σ(W2X+b2),
其中, W1、b1和W2、b2为两个结构一致的线性层的可训练参数, $\otimes$为元素级乘法, 即两个矩阵的对应元素相乘.
Hua等[12]在FLASH(Fast Linear Attention with a Single Head)中提出GAU的结构, 并结合GLU、Attention及FFN(Feed Forward Network).其中Dense层包含线性层和激活函数, 激活函数使用SiLU函数.SiLU函数的计算公式如下:
SiLU(x)=x*σ(x),
其中, σ(·)为sigmoid激活函数, *为矩阵间元素级的乘法, 并支持广播机制.
与原生GLU不同, GAU参考的GLU结构使用两个Dense层, 即两个通道都使用SiLU函数进行激活.GAU在GLU的基础之上加入注意力机制, 计算过程如下:
U=SiLU(WUX+bU),
V=SiLU(WVX+bV),
Z=SiLU(WzX+bz),
$\mathbf{A}=\frac{1}{n}{{\operatorname{relu}}^{2}}(\frac{Q(\mathbf{Z})K{{(\mathbf{Z})}^{T}}}{\sqrt{s}})$
$\operatorname{gau}(\mathbf{U, V})=(\mathbf{U}\odot \mathbf{AV}){{\mathbf{W}}_{gau}}$
其中:U、V、Z为输入X通过Dense层后得到的输出, A为注意力计算公式; n为文本长度, s为注意力头的个数, ☉为哈达玛积; Q(·)和K(·)对应两个仿射变换; Wgau为最后输出时Dense层的可训练权重.
需要注意地是, Hua等[12]在基础GAU的注意力计算过程中会计算RoPE(Rotary Position Embed-ding)[19], 由于RoPE的计算过程较耗时, 并且对抽取结果的影响不大, 因此本文使用的GAU中不包含RoPE的计算过程.
将1.2节中得到的文本编码H0输入GAU中, 进行二次编码, 得到共享编码H, 即
U0=SiLU(WUH0+bU),
V0=SiLU(WVH0+bV),
H=gau(U0, V0).
链式解码模块分为五个阶段的抽取任务, 前四个阶段用于抽取主、客体的首部和尾部, 最后一个阶段为关系抽取, 阶段之间采用CLN进行特征融合.
1.4.1 条件层规范化
为了减少误差累积的影响, ChainRel在链式解码结构中使用CLN强化阶段间的特征融合.CLN计算公式如下:
cln(y, e)=
其中, y为输入序列, E[·]为求输入的均值, Var[·]为求输入的方差, ε 为保持分母不为0的一个极小常量, Wγ为可训练的缩放矩阵, Wβ为可训练的平移矩阵, e为限制条件, *为矩阵间元素级的乘法, 并支持广播机制.
CLN的整体流程就是将限制条件e分别通过缩放矩阵和平移矩阵映射成缩放变量和平移变量并加入y的层规范化过程中.由于融合时, 主变量和额外变量的位置一旦交换, 会产生不同的输出, 因此CLN在能够融合特征的同时, 也能够有效体现各输入向量间的方向性特征.
1.4.2 实体抽取部分
指针网络在未进行拆分前, 会在两个标注层中分别标注实体的首部和尾部, 然后按照一定的规则进行首部和尾部的对齐.例如:CASREL使用就近原则, 每个首部片段与其距离最近的尾部片段构成一个实体Span.
实体抽取部分使用拆分后的指针网络, 即先抽取实体首部, 再利用首部的信息抽取尾部.实体抽取部分包括两个拆分后的指针网络, 分别对应主体首部抽取、主体尾部抽取、客体首部抽取和客体尾部抽取四个阶段.抽取主体时的计算过程如下:
FSH=extract(H, SH),
H*SH=cln(H, FSH),
$\mathbf{p}_{ST}^{i}=\sigma ({{\mathbf{W}}_{ST}}\mathbf{H}_{*SH}^{i}+{{\mathbf{b}}_{ST}})$
在获得主体首部的概率序列
抽取客体时的操作与抽取主体相同, 只需把最初的输入换成H*S.H*S为H与主体特征融合后的特征, 具体计算过程如下:
FSH=extract(H, idxSH),
FST=extract(H, idxST),
FS=avg(FSH, FST),
H*S=cln(H, FS),
其中avg(·)为求输入的平均值.由于抽取客体时使用主体的信息进行过滤, 因此主体和客体完成自动对齐.
1.4.3 关系抽取部分
链式解码的最后一个阶段会对前四个阶段抽取得到的实体对进行关系预测.ChainRel使用主体和客体的融合向量进行实体间关系的预测, 融合过程采用CLN和GLU组合的特征融合结构, CLN用于特征融合及体现实体对间的方向性特征(主客体逆序可能会对应另一个关系, 因此必须保留方向性特征), GLU用于强化特征输出.
TPLinker 的握手标注机制进行三次对齐:实体首部对齐实体尾部(EH to ET), 主体首部对齐客体首部(SH to OH), 主体尾部对齐客体尾部(ST to OT).ChainRel根据这种对齐思想将主体和客体特征拆分成(主体首部, 客体首部)和(主体尾部, 客体尾部)两个组合, 进行特征融合后得到两个融合特征, 然后输入同一个分类器进行关系抽取, 最终得到两组关系集.本文将这种操作称为首尾分离操作.
首尾分离阶段首先从H中截取实体对对应的4个特征向量VSH、VST、VOH、VOT, 将VOH和VOT作为额外条件, 通过同一个CLN分别融入VSH和VST中.具体计算公式如下:
SH*OH=cln(VSH, VOH),
ST*OT=cln(VST, VOT).
然后将SH*OH和ST*OT输入一个带残差结构的GLU中, 进一步处理融合后的特征:
PH=glu(SH*OH)+SH*OH,
PT=glu(ST*OT)+ST*OT.
最后使用PH和PT对所有关系进行二分类预测:
rphj=σ(WrpPH+brp),
rptj=σ(WrpPT+brp),
其中, rphj和rptj为实体对间包含关系j的概率, Wrp和brp为可训练的权重和偏置.
在得到实体的关系预测概率序列后, 给定一个阈值θ2, 对序列进行二值化处理, 可抽取得到两个候选关系集RelH和RelT, 分别对应实体对的首部融合特征和尾部融合特征.
关系修正模块使用BERT输出中的CLS向量对文本中所有潜在关系进行一次预测, 则文本包含关系j的概率如下所示:
global_rpj=σ(WgCLS+bg).
根据阈值θ2可以抽取文本中所有可能包含的关系集合RelG.在输出三元组之前, 采用取RelH、RelT及RelG交集的方式确定实体对之间的关系.
关系修正本质上是一个简单二分类任务, 在数据量不足或关系种类表庞大时, 可能由于拟合效果较差导致RelG中的关系可靠性下降, 进而对模型性能产生负面影响.
ChainRel的总体损失由预测主体、客体和关系时的二分类标注层产生的损失构成, 如果使用关系修正模块, 需要加上该部分的损失.二分类标注层的损失使用二元交叉熵计算:
bce(p, q)=-[q ln p+(1-q)ln(1-p)],
其中, p为预测值, q为真实值.
预测实体时的四个二分类层的损失计算流程一致, 以实体首部的损失计算lossSH为例.关系预测的两个部分的损失计算过程一致, 以关系预测中实体首部融合特征部分的损失计算lossRP-H为例.lossGRP为关系修正模块的损失.lossSH、lossRP-H和lossGRP的计算公式如下:
$los{{s}_{SH}}=-\frac{1}{n}\sum\limits_{i}^{n}{\operatorname{bce}(\mathbf{p}_{SH}^{i}, \mathbf{q}_{SH}^{i})}$,
$los{{s}_{RP-H}}=-\frac{1}{N}\sum\limits_{j}^{N}{\operatorname{bce}(\mathbf{rp}{{\mathbf{h}}^{j}}, \mathbf{r}{{\mathbf{q}}^{j}})}$,
$los{{s}_{GRP}}=-\frac{1}{N}\sum\limits_{j}^{N}{\operatorname{bce}(\mathbf{global\_r}{{\mathbf{p}}^{j}}, \mathbf{global\_r}{{\mathbf{q}}^{j}})}$,
其中, n为经过分词后的文本序列长度, N为关系种类总数, rqj为关系预测时的真实标签值, global_rqj为全局关系的真实标签值.
模型的整体损失即为各部分损失的总和.
本文使用NYT[20]、WebNLG[21]这两个通用数据集对ChainRel进行性能综合评估.NYT数据集上样本量较大, 关系种类数较少.WebNLG数据集上实体类型多样, 样本量较小, 但关系种类数约为NYT数据集的7倍.NYT、WebNLG数据集上都包含有关系重叠情况的文本.2个数据集具体构成如表1~表3所示, 表3中N为单个文本包含三元组的个数.
| 表1 实验数据集统计信息 Table 1 Statistical information of experimental datasets |
| 表2 按照关系重叠问题划分测试集 Table 2 Test sets divided by relation overlap |
| 表3 按照N划分测试集 Table 3 Test sets divided by N |
在评价指标上, 实验采用实体关系抽取任务中常用的精确率(Precision, P)、召回率(Recall, R)和F1值(F1-Score)作为性能的衡量标准.
本文实验环境中使用的CPU为Intel(R) Core(TM) i9-10900K, GPU为GeForce RTX 1080 Ti, 内存为DDR4 16 GB.
ChainRel使用bert-base-uncased预训练模型进行编码.学习率为0.000 01, 输入文本最大长度(max_text_len)为100, 批量(batch_size)大小为8, 在NYT、WebNLG数据集上的迭代次数分别为150次和300次, 在链式抽取模块中出现的实体抽取阈值θ1设为0.6, 关系阈值θ2设为0.6.
本文选择如下对比模型.
1)GraphRel[22].利用GCN构建的两阶段实体关系抽取模型.
2)文献[23]模型.在End2end Model Based on Sequence-to-Sequence Learning with Copy Mechanism中加入强化学习机制.
3)ETL-span[24].利用指针网络的抽取式模型, 将实体关系抽取分为HE(Head-Entity)和TER(Tail-Entity and Relation)两部分, 利用指针网络替代传统的BIES方案进行实体标注.
4)CASREL[9].在第二阶段使用级联的指针网络联合解码客体和关系信息.
5)TPLinker[13].利用握手标注机制一次解码关系三元组, 避免曝光偏差、误差累积等问题的产生.
6)SPN(Set Prediction Networks)[25].使用非自回归并行解码方式的生成式模型, 能够一次性输出三元组集合.
7)PRGC[14].两阶段抽取式模型, 先预测关系, 再在对应关系下预测实体对的解码策略, 避免堆叠标注层方式中的一些问题, 同时使用GCM进行实体间的对齐.
8)EmRel(Embedded Representations of Rela-tions)[26].将关系作为嵌入信息, 通过三个注意力模块对实体、关系和上下文信息进行建模, 最后通过对齐函数判断有效三元组.
9)OneRel[27].在TPLinker的基础上, 重新设计填表策略, 优化整个三元组的抽取过程.
本文将ChainRel与基线模型在NYT、WebNLG数据集上进行整体抽取性能对比, 具体结果如表4所示, 表中ChainRel+为在ChainRel中添加关系修正模块, 黑体数字表示最优值.
由表4可见, 由于稀疏标注矩阵的影响, TP-Linker虽然在NYT数据集上的F1值会比CASREL提高2.3%, 但在关系种类数较大的WebNLG数据集上, F1值只提升0.1%.PRGC在改变抽取的策略之后, 相比TPLinker, 在两个数据集上的整体F1值也具有明显提升, 由此表明实体和关系分开抽取也能获得较优效果.在NYT数据集上, ChainRel+除了在召回率上不及OneRel以外, 在精确率和F1值上取得最高值, 相比SPN、PRGC和OneRel, 精确率分别提升0.5%、0.4%、1.0%, F1值分别提升0.5%、0.3%、0.1%.在WebNLG数据集上, ChainRel+取得最高的精确率.相比SPN和PRGC, ChainRel虽然在整体性能上具有明显提升, 但与OneRel仍有一定的差距.从两个数据集上的结果也可以发现, 在加入关系修正模块以后, ChainRel+在精确率上都会有相应提升, 而召回率则对应下降, 在WebNLG数据集上的召回率下降0.8%, 推测为关系修正模块未得到充分拟合, 因为WebNLG数据集上样本量较小而关系种类数较多.
| 表4 各模型在2个数据集上整体性能对比 Table 4 Overall performance comparison of different models on 2 datasets % |
综合表4中的各项数据来看, ChainRel和ChainRel+在两个数据集上的综合性能优于SPN、PRGC等模型.对比当前较先进的单阶段解码模型OneRel, ChainRel和ChainRel+虽然在WebNLG数据集上效果稍弱, 但在NYT数据集上取得的结果与其相当, 且抽取时的精确率更高.表4中实验结果表明多阶段链式解码结构的可行性, 也暴露出关系修正模块的局限性, 并不适用于WebNLG数据集.
各对比模型在处理不同复杂程度文本时的性能如表5所示, 表中黑体数字表示最优值.由表可见, 在NYT数据集上, GraphRel、文献[23]模型、ETL-span、CASREL、TPLinker、SPN在N≥ 5时F1值都较低, ChainRel、ChainRel+、PRGC、OneRel则改善这种情况, 同时ChainRel+在处理N=1或N=2的简单文本时, 都取得最高的F1值.在WebNLG数据集上, 相比对比模型, ChainRel在N=2时的F1值具有明显提升, 分别比SPN、PRGC、OneRel提高2.4%、2.1%、0.7%, 同时其在处理N> 2的文本时性能优于PRGC.
| 表5 N不同时各模型的F1值对比 Table 5 F1 value comparison of different models with different N |
各模型在处理不同关系重叠问题时的性能对比如表6所示, 表中黑体数字表示最优值.
| 表6 关系重叠问题不同时各模型的F1值对比 Table 6 F1 value comparison of different models with different relation overlaps % |
由表6可见, 在NYT数据集上, 加入关系修正模块的ChainRel+在处理各种问题时的能力都有正向提升, 在Normal上取得最高的F1值, 对比OneRel, F1值提升0.7%.在WebNLG数据集上, PRGC、TPLinker、CASREL在应对EPO问题时的F1值都比应对SEO问题时提高近2%到3%, ChainRel和OneRel在这两个问题上的处理性能则较平衡.相比GraphRel、文献[23]模型、ETL-span、CASREL、TPLinker、SPN和PRGC, ChainRel在处理SEO问题上具有明显性能提升.
综合表5和表6的数据来看, ChainRel和ChainRel+在保证处理复杂文本(含三元组数较多)的性能的同时, 提升处理简单文本的性能, 在WebNLG数据集上处理SEO问题的能力具有一定提升.
为了验证链式解码结构以及各模块的有效性, 本节从四个方面进行消融实验, 分别验证链式解码结构、门控单元、首尾分离操作及关系修正模块的有效性.参与消融实验的模型如下.
1)CASREL.利用主体信息预测客体.
2)CASREL-CLN.将CASREL原本使用特征相加的融合方式替换为CLN.
3)S2O2R-base.将CASREL的客体和关系联合预测进行拆分, 建立由主体到客体, 再到主体和客体的特征一起预测关系的解码链, 解码结构扩展至三阶, 并使用CLN处理阶段间的特征融合.
4)ChainRel-base.在S2O2R-base基础上, 进一步拆分指针网络, 用实体首部信息解码实体尾部, 整体解码阶段扩展至五阶.
5)ChainRel-base-v1.在ChainRel-base基础上, 在关系抽取层加入GLU.
6)ChainRel-base-v2.在ChainRel-base-v1基础上, 加入GAU处理共享编码层.
7)ChainRel-base-v2-rope.在ChainRel-base-v2的GAU中加入PoPE.
8)ChainRel-base-v3.在ChainRel-base-v1基础上, 加入GLU处理共享编码层.
9)ChainRel.在ChainRel-base-v2基础上, 加入首尾分离操作.
10)ChainRel+.在ChainRel基础上, 加入关系修正模块.
2.6.1 链式解码结构有效性实验
链式解码结构的有效性实验结果如表7所示, 表中黑体数字表示最优值.由表可见, CASREL在使用CLN处理特征融合过程以后, 在两个数据集上的F1值都有较明显的提升, 表明CLN确实能够强化特征的融合输出, 使后续步骤可过滤更多无用的信息, 减少误差累积的影响.S2O2R-base以此为基础, 单独分离关系抽取, 构成三阶段的解码结构, 并使用CLN提高过滤机制的作用.相比CASREL-CLN, S2O2R-base避免堆叠标注层带来的问题, 表现更优, 在NYT、WebNLG数据集上的整体F1值分别提升0.4%和0.7%.ChainRel-base则进一步拓宽S2O2R-base的解码结构, 构成五阶段的过滤链.相比S2O2R-base, ChainRel-base在NYT数据集上的F1值提升0.3%, 在WebNLG数据集上的F1值提升0.2%.上述实验结果表明多段链式解码结构的可行性和有效性.
| 表7 链式解码结构有效性实验结果 Table 7 Validity experiment results of chained decoding structure % |
2.6.2 门控单元有效性实验
门控单元的有效性实验结果如表8所示, 表中黑体数字表示最优值.由表可见, 在门控结构方面, ChainRel-base-v1使用GLU优化ChainRel-base原本较简单的关系预测层, 相比ChainRel-base, 在NYT、WebNLG数据集上的F1值分别提升0.1%和0.2%, 表明GLU对模型性能提升具有正向作用.ChainRel-base-v2、ChainRel-base-v2-rope和ChainRel-base-v3通过GAU或GLU对BERT的输出进行二次处理, 从结果上来看, 加入GAU的模型会有更优的抽取效果.
| 表8 门控单元有效性实验结果 Table 8 Validity experiment results of gated unit % |
ChainRel各变体模型在2个数据集上的性能对比如表9所示, 表中黑体数字表示最优值.从表中可以看到, ChainRel-base拥有最快的训练时间和推理时间, 在其基础上添加GAU和GLU都会带来一些时间的增加.ChainRel-base-v2和ChainRel-base-v2-rope在两个数据集上分别取得最优的F1值, 且两者的整体效果差距不大, 但ChainRel-base-v2-rope需要更多的计算时间.
| 表9 ChainRel各变体模型在2个数据集上的性能对比 Table 9 Performance comparison of ChainRel variant models on 2 datasets |
综合表8和表9的数据来看, RoPE的加入并没有使ChainRel-base-v2-rope在性能上优于ChainRel-base-v2, 且ChainRel-base-v2-rope在计算时间和推理时间上都会有较明显的增加.综合考虑后, 本文在使用GAU时, 去除RoPE的计算过程.
2.6.3 首尾分离操作有效性实验
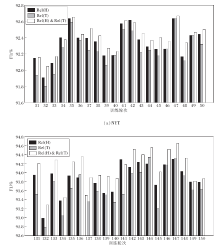
对于关系抽取层的首尾分离操作, 以ChainRel为例, 在NYT、WebNLG数据集的验证集上的性能如图2和图3所示.对于NYT数据集, 选择第31轮至第50轮的抽取结果; 对于WebNLG数据集, 选择第131轮至第150轮的结果.由于WebNLG数据集上样本量较少, 模型在前100轮中拟合程度较低.
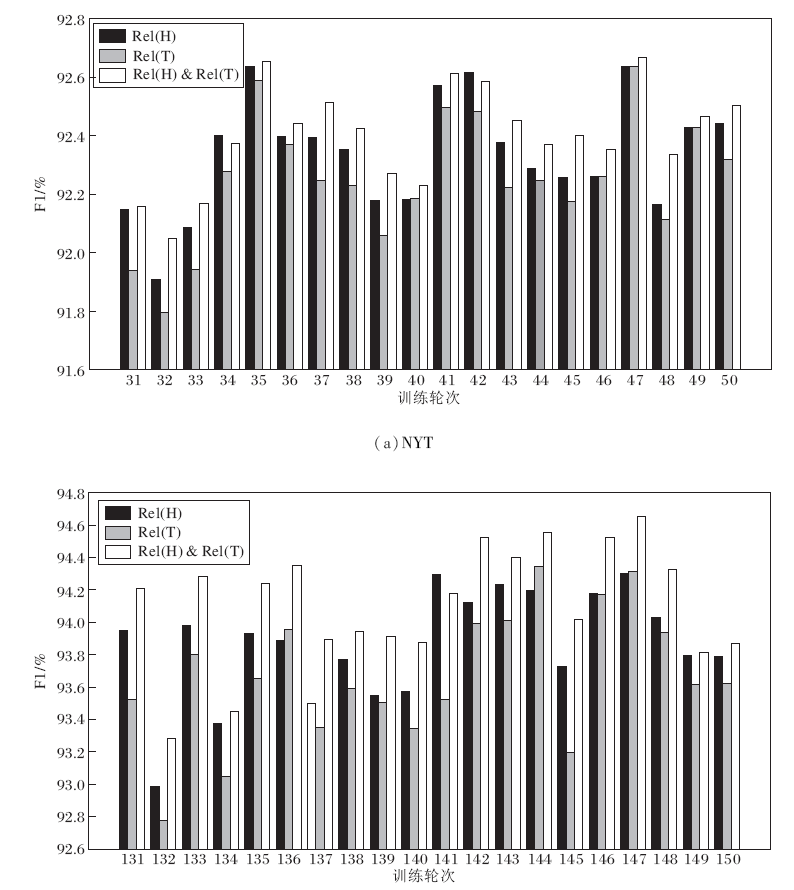 | 图2 ChainRel在验证集上的F1值Fig.2 F1 values of ChainRel on validity set |
图2为ChainRel在两个验证集上的三种方式对应的F1值柱状图.在图中, Rel(H)对应只使用关系集RelH中的关系作为实体对最后的关系, Rel(T)对应只使用关系集RelT中的关系作为实体对最后的关系, Rel(H)& Rel(T)对应求取RelH和RelT的交集中的关系作为实体对最后的关系.
从图2中可以看出, 3种方式得到的F1值差距不大, Rel(H)的F1值基本在Rel (T)之上, 表明首部融合特征中包含的有效信息略多于尾部融合特征.Rel(H)& Rel(T)的F1值大部分都在Rel (H)之上, 因此ChainRel最后选择求取RelH和RelT交集的方式.
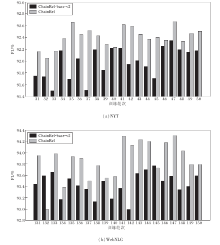
图3是未进行首尾分离的ChainRel-base-v2和ChainRel在验证集上的性能对比.由图可以清晰看出, 相比ChainRel-base-v2, ChainRel具有较明显的性能提升, 表明首尾分离操作的有效性.
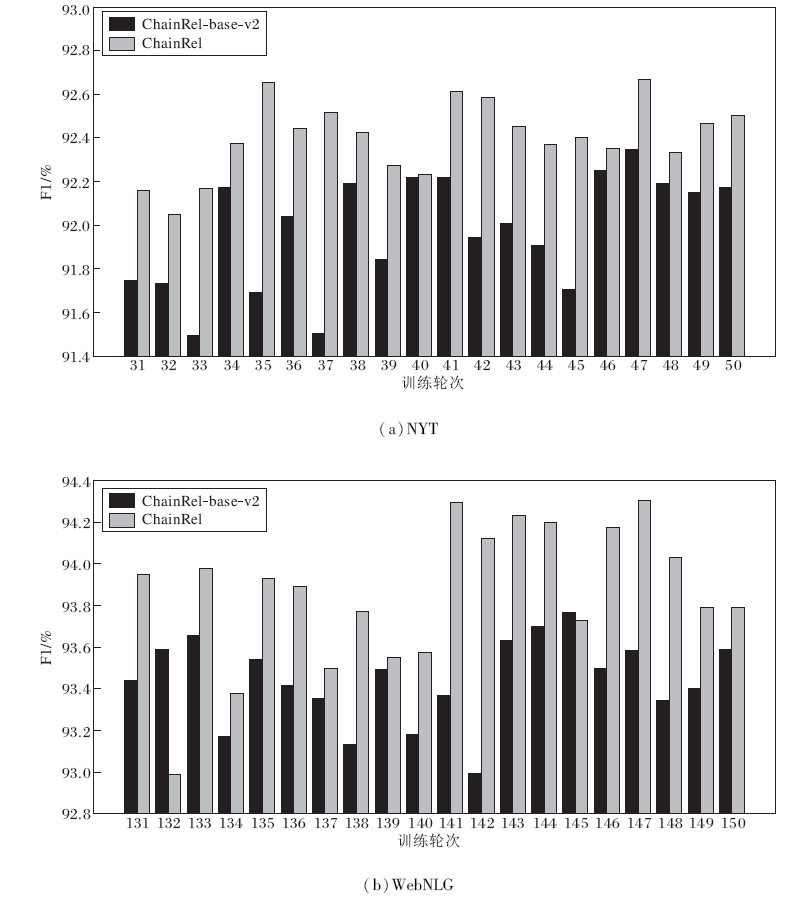 | 图3 ChainRel-base-v2和ChainRel在验证集上的F1值Fig.3 F1 values of ChainRel-base-v2 and ChainRel on validity set |
ChainRel-base-v2和ChainRel的有效性实验结果如表10所示, 表中黑体数字表示最优值.由表可见, 相比ChainRel-base-v2, ChainRel在NYT、WebNLG数据集上的F1值分别提升0.2%、0.1%, 在测试集上的提升幅度小于验证集, 这从侧面验证测试集和验证集的样本分布存在一定的差距, 但都对模型的抽取效果带来正向提升.
| 表10 首尾分离操作有效性实验结果 Table 10 Validity experiment results of head-to-tail separation operation % |
2.6.4 关系修正模块有效性实验
关系修正模块的有效性实验结果如表11所示, 表中黑体数字表示最优值.由表可以明显看到, 在进行关系修正之后, ChainRel+在两个数据集上都出现精确率上升和召回率下降的特点, 表明关系修正的过程中存在误删正确三元组的情况.在NYT数据集上, 由于训练集本身样本量充足以及关系种类数较少, 关系修正模块的分类器拟合效果相对较优, 误删的情况较少, 因此模型整体性能得到正向的提升.由于WebNLG数据集上样本较少且关系种类数较多, 关系修正模块的拟合情况相对较差, 关系集RelG的可靠性随之下降, 进而导致很多正确的三元组被误删, 召回率大幅下降.综合表中实验结果来看, 关系修正模块并不适用于WebNLG这种体量较小且关系类别繁多的数据集.
| 表11 关系修正模块有效性实验结果 Table 11 Validity experiment results of relationship modification module % |
本文提出基于过滤机制的链式实体关系抽取模型(ChainRel), 是实体关系抽取多阶段解码的一种尝试.ChainRel构建五阶段的链式解码结构, 顺序抽取实体和关系, 避免由关系类别失衡带来的稀疏矩阵问题, 并且通过过滤机制实现实体和关系的自动对齐.CLN以及门控结构的使用有效提升模型的抽取性能.受握手标注机制的启发, ChainRel在关系预测层采用首尾分离的操作, 优化特征融合结构和分类器的训练输入, 使关系预测层的解码效果获得一定提升.关系修正模块没有适用于所有的数据集, 实验结果表明其存在一定的局限性.
ChainRel在NYT、WebNLG数据集上已获得与当前先进基线模型相近的抽取性能.在未来的工作中, 将进一步优化整个链式解码过程的结构, 并探索解决关系修正模块局限性的方法.
本文责任编委 陈恩红
Recommended by Associate Editor CHEN Enhong
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|