
{kind=link}
{kind=link}
基于门控双层异构图注意力网络的半监督短文本分类
[蒋云良1, 2, 3  , 王青朋
, 王青朋1, 2 , 张雄涛1, 2 , 黄旭2, 4 , 申情1, 2 , 饶佳峰1, 2 ]
, 王青朋, 张雄涛, 黄旭, 申情, 饶佳峰]
|
|



作者简介:

蒋云良,博士,教授,主要研究方向为智能信息处理、地理信息系统等.E-mail:jyl@zjhu.edu.cn.

王青朋,硕士,主要研究方向于自然语言处理、机器学习等.E-mail:18751976668@163.com.

黄 旭,博士,副教授,主要研究方向为人工智能、模式识别、机器学习等.E-mail:hx@zjhu.edu.cn.

申 情,硕士,教授,主要研究方向为智能信息处理等.E-mail:sq@zjhu.edu.cn.

饶佳峰,硕士,主要研究方向为智能信息处理、机器学习等.E-mail:rjf2345@163.com.
针对现有的基于异构图神经网络的短文本分类方法未充分利用节点之间的有效信息,以及存在的过拟合问题,文中提出基于门控双层异构图注意力网络的半监督短文本分类方法(Semi-Supervised Short Text Classification with Gated Double-Layer Heterogeneous Graph Attention Network, GDHG).GDHG包含节点注意力机制和门控异构图注意力网络两层.首先,使用节点注意力机制,训练不同类型的节点注意力系数,再将系数输入门控异构图注意力网络,训练得到门控双层注意力.然后,将门控双层注意力与节点的不同状态相乘,得到聚合的节点特征.最后,使用softmax函数对文本进行分类.GDHG利用节点注意力机制和门控异构图注意力网络的信息遗忘机制对节点信息进行聚集,得到有效的相邻节点信息,进而挖掘不同邻居节点的隐藏信息,提高聚合远程节点信息的能力.在Twitter、MR、Snippets、AGNews四个短文本数据集上的实验验证GDHG性能较优.
About Author:
JIANG Yunliang, Ph.D., professor. His research interests include intelligent information processing and geographic information system.
WANG Qingpeng, master. His research interests include natural language processing and machine learning.
HUANG Xu, Ph.D., associate professor. His research interests include artificial inte-lligence, pattern recognition and machine learning.
SHEN Qing, master, professor. Her research interests include intelligent information processing.
RAO Jiafeng, master. His research inte-rests include intelligent information processing and machine learning.
To address the issues of insufficient utilization of information between nodes and overfitting in short text classification based on heterogeneous graph neural network, a method for semi-supervised short text classification based on gated double-layer heterogeneous graph attention network(GDHG) is proposed. GDHG consists of two layers: node attention and gated heterogeneous graph attention network. Firstly, different types of node attention coefficients are trained by node attention, and then the node attention coefficient is input into the gated heterogeneous graph attention network to obtain the gated double-layer attention. Secondly, the gated double-layer attention is multiplied by different states of the nodes to acquire the aggregated node features. Finally, the short texts are classified with the softmax function. In the proposed GDHG, the information forgetting mechanism of node attention and gated heterogeneous graph attention network is utilized to aggregate node information. Consequently, the information of neighboring nodes is effectively obtained. And then the hidden information of different neighboring nodes is mined to improve the ability to aggregate information from remote nodes. Experiment on four short text datasets , Twitter, MR, Snippets and AGNews, illustrate the superiority of GDHG.
短文本分类是自然语言处理中的一项基本任务.随着互联网技术的发展, 大量的短文本不断出现, 如何利用自然语言处理技术对短文本进行分类成为目前研究热点之一.
短文本分类应用于垃圾邮件检测、新闻标题分类等诸多领域[1].相比长文本分类, 短文本大部分是由一个句子组成, 缺少上下文信息, 导致性能不够理想.因此, 研究人员提取短文本中的语义和语法, 丰富短文本的信息, 进而提升分类的准确性.Wang等[2]使用分类学知识库, 将短文本概念化, 把词和相关概念合并到预训练好的词向量上, 达到丰富短文本信息的目的.Wang等[3]使用Wikipedia概念表示文本分类, 再进行分类.
上述方法虽然在短文本分类上都取得不错效果, 却需要大量标记的样本训练, 而在许多真实场景下手工标记样本非常耗时, 所以对半监督短文本分类的研究显得尤为迫切.Li等[4]从标注数据集上抽取类别词构建强类别特征集, 并结合余弦定理设计SCFSC(Semi-Supervised Classification Algorithm for Short Text Based on Fusion Similarity and Class Cen-ter).Lee等[5]提出SALNet(Semi-Supervised with Atten-tion-Based Lexicon Construction Network), 使用注意力机制给标记的数据集训练一个基于长短期记忆网络(Long Short-Term Memory, LSTM)的文本分类器.之后给每类文本收集一组词汇并利用构造的词汇与标记的新数据引导分类器, 进而提高短文本分类的准确性.Johnson等[6]提出半监督卷积神经网络, 从未标记的数据中学习小文本区域的嵌入, 集成到有监督的卷积神经网络中.Chen等[7]提出FLiText(Faster and Lighter Semi-Supervised Text Classifica-tion), 引入启发网络和一致性正则化框架.该框架利用轻量级模型上的广义正则约束, 实现高效的半监督学习.但是, 由于短文本的长度较短、特征稀疏, 上述方法都不能充分学习短文本中的信息.
有研究表明图神经网络可以通过构建短文本图解决上述特征稀疏问题.Wang等[8]提出SHINE(Hierarchical Heterogeneous Graph Representation Lear-ning Method for Short Text Classification), 利用词级组件图将短文本数据集建模成分层异构图, 并对异构图引入更多的语义和语法信息, 动态学习短文本图, 促进相似短文本之间的有效标签传播.Liu等[9]提出DADGNN(Deep Attention Diffusion Graph Neural Network), 基于注意力扩散与解耦技术学习短文本表征, 解决词与其远邻之间交互困难的问题.Yao等[10]提出Text GCN(Text Graph Convolutional Net-work), 将整个文本语料库建模成具有单词关系的文档-单词图, 使用GCN(Graph Convolutional Net-works)[11]进行分类.Liu等[12]提出TensorGCN.首先, 构造张量文本图描述语义、句法和顺序上下文信息.然后, 对张量文本图进行两种传播学习:1)图内传播, 从单个图中的邻域节点聚合信息; 2)图间传播, 协调图之间的异构信息.宋泽宇等[13]提出融合标签关系的法律文本多标签分类方法, 重新构建标签共现矩阵, 利用图卷积网络获得标签之间的信息并与标签注意力结合, 计算法律文本和标签的相关程度, 得到法律文本表示, 最后融合依赖关系和特定法律文本语义表示, 实现文本分类.
然而, 上述方法无法捕捉节点之间的高阶互动, 导致容易遗漏节点的重要信息.因此, Ding等[14]提出HyperGAT(Hypergraph Attention Networks), 通过注意力机制, 可以在文本表示学习中以更少的计算量获得更多的表达能力.Yang等[15]提出HGAT(Heterogeneous Graph Attention Networks), 充分利用有限标记数据和大量未标记数据对短文本进行分类.上述方法虽然可以有效解决短文本数据的稀疏性等问题, 但是在训练少量的标记数据时会出现过拟合.
针对以上问题, 受 HGAT和 GRU(Gated Recu-rrent Unit)[16]启发, 本文提出基于门控双层异构图注意力网络的半监督短文本分类方法(Semi-Super-vised Short Text Classification Based on Gated Double-Layer Heterogeneous Graph Attention Network, GDHG).为了充分学习短文本的信息特征, 使用异构信息网络(Heterogeneous Information Network, HIN)[15]提取短文本的实体和主题, 用于构建短文本异构图, 丰富短文本之间的关系.为了处理短文本异构图, 提出门控双层异构图注意力网络, 该网络由节点注意力机制和门控异构图注意力网络两层组成.首先使用节点注意力机制对节点类型进行注意力训练, 得到节点注意力系数.再将节点注意力系数放入门控异构图注意力网络, 训练门控双层注意力.然后将门控双层注意力与不同状态的节点特征相乘, 得到聚合节点信息, 最后输入GCN, 并使用softmax函数对文本进行分类.与HGAT不同的是, GDHG采用门控双层注意力机制, 形成门控双层节点特征通道, 从不同角度聚集邻居节点信息, 并从网络深层寻找有效的节点信息, 能够减少无用节点信息的影响.因此, GDHG可以充分学习节点之间的权重系数, 重点关注节点之间有效的信息聚集, 使模型充分挖掘节点隐藏的特征信息, 提升短文本分类性能.在Twitter、MR、Snippets、AGNews这4个短文本数据集上的大量实验表明, GDHG总体上性能较优, 因此是有效的.
本文提出基于门控双层异构图注意力网络的半监督短文本分类方法(GDHG), 结构如图1所示.首先把短文本作为一个整体, 使用HIN[15]提取其中的主题C和实体N, 构建短文本异构图G=(V, E).然后将短文本异构图G作为输入, 使用由节点注意力机制和门控异构图注意力网络组成的门控双层异构图注意力网络进行训练, 目的是为了让异构图节点更好地聚集邻居节点的信息, 充分挖掘短文本异构图节点中的隐藏信息.
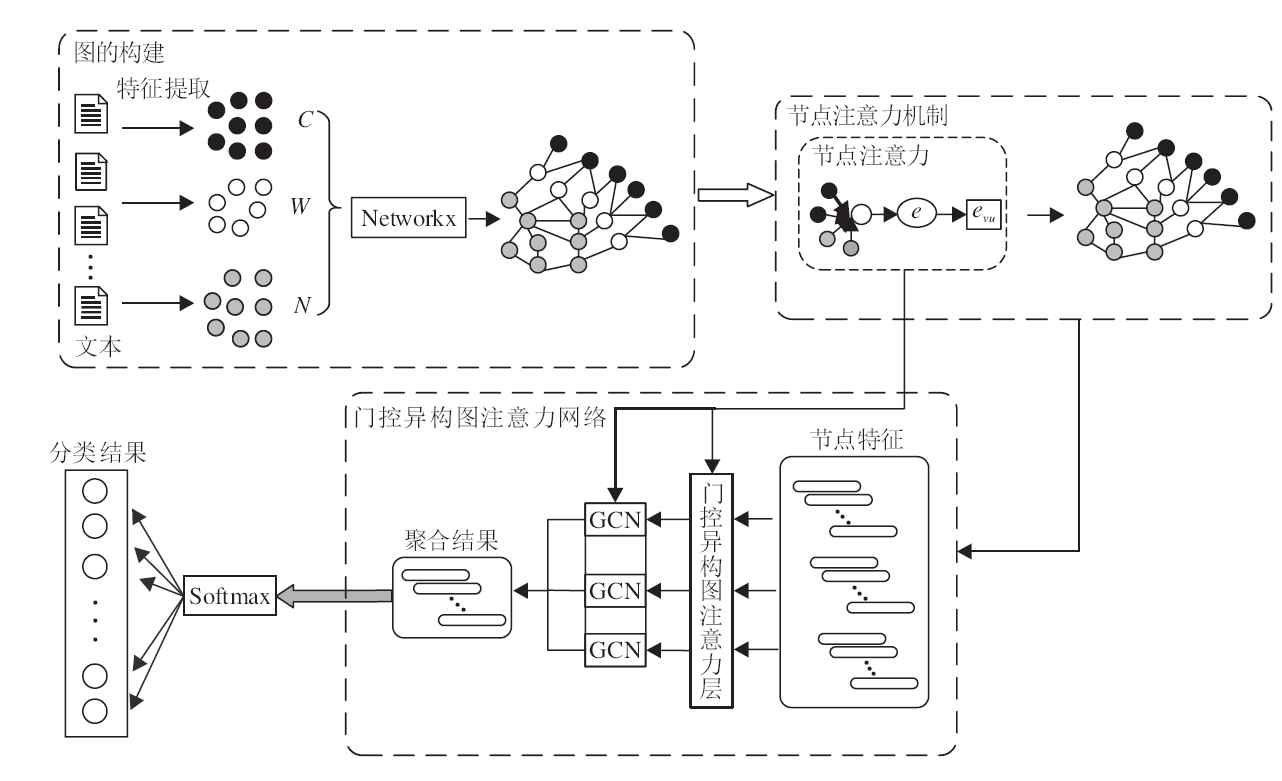 | 图1 GDHG结构图Fig.1 Architecture of GDHG |
与同构图不同的是, 异构图[17]由不同类型的节点和边组成.异构图G=(V, E)由节点集V和边集E组成.异构图节点类型的映射函数∈∶V→A, 边类型映射功能函数ψ∶E→R, A表示特定节点类型集合, R表示边类型集合.
本文使用HIN构建短文本异构图, HIN可以提取短文本之间的附加信息.对短文本建立异构图, 能够有效缓解短文本特征的稀疏性.相比以往的构图方式, HIN可以灵活整合短文本中的附加信息.
HIN主要考虑两种类型的附加消息:主题和实体(短文本中名词性单词).HIN将短文本异构图G=(V, E)的节点类型分为如下3种.
1)短文本W={w1, w2, …, wm}, 其中m表示文本量,
2)主题C ={c1, c2, …, co}, 其中o表示主题量,
3)实体N={n1, n2, …, nt}, 其中t表示实体量.节点
V=W∪C∪N,
E表示节点之间的关系.
HIN构图过程描述如下.
1)对短文本使用潜在狄利克雷分布(Latent Dirichlet Allocation, LDA)[18], 找出短文本的主题C.为了减少其它主题对短文本的影响, 设置一个变量i, 给短文本分配前i个主题.如果短文本包含主题, 就会建立主题节点和短文本节点的边.
2)识别短文本中的实体.使用TAGME工具将实体与Wikipedia相连, 如果短文本包含实体, 就会建立实体与短文本之间的边.之后, 使用Wikipedia和Word2Vec对实体进行学习嵌入.为了进一步丰富短文本的语义, 促进信息传播, 考虑每个实体之间的关系.对于每个实体, 计算它们之间的余弦相似度.如果两个实体的相似度得分大于设置阈值a, 就会建立实体与实体之间的边.最后形成短文本异构图G=(V, E).
在利用HIN和构图工具NetworkX对短文本构建异构图后, 使用本文提出的门控双层异构图注意力网络对短文本异构图进行分类.门控双层异构图注意力网络能够有效聚集图节点信息, 解决异构图神经网络存在的过拟合等问题.
门控双层异构图注意力网络分为两层: 第一层是节点注意力机制, 第二层是门控异构图注意力网络.首先节点注意力机制能够根据异构图具有不同类型的节点以及不同类型的邻居节点对节点影响不同的特点, 对不同类型的邻居节点训练不同的注意力系数.然后将注意力系数输入门控异构图注意力网络, 训练门控双层注意力, 把门控双层注意力与不同状态的节点特征相乘, 得到聚合的节点特征, 并输入GCN, 得到节点嵌入.最后使用Softmax函数进行分类.
1.2.1 节点注意力机制
短文本异构图是由3种类型的节点组成, 不同类型的邻居节点对目标节点的影响是不同的.给定一个节点对(v, u), 节点注意力机制是学习不同类型邻居节点u对节点v的注意力系数, 使节点v能够更好地捕捉邻居节点u的信息, 即
其中, attτ(·)表示对于不同类型节点的注意力, τ表示节点类型, hu表示节点v的邻居节点, u∈ Nv, Nv表示邻居节点集.
节点对(v, u)的权重是由它们的类型决定的, 节点v对节点u的注意力和节点u对节点v的注意力是不同的.由式(1)得到节点v的邻居节点的类型注意力系数之后, 使用Softmax函数, 对所有类型注意力系数进行归一化处理, 获得节点的类型注意力, 权重系数为:
${{e}_{\tau }}=Softmax(e_{vu}^{\tau })=\frac{exp(\sigma (\beta _{\tau }^{T}\bullet [{{h}_{v}}||{{h}_{u}}]))}{\sum\limits_{{\tau }'\in \Gamma }{exp(\sigma (\beta _{\tau }^{T}\bullet [{{h}_{v}}||{{h}_{{{\tau }'}}}]))}}$ ,(2)
其中,
1.2.2 门控异构图注意力网络
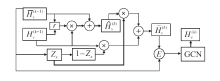
在基于异构图神经网络的短文本分类任务中, 随着异构图神经网络层数的增加, 会出现过拟合, 影响短文本分类结果.本文结合门控机制和注意力机制, 提出门控异构图注意力网络, 目的是挖掘节点之间的特征信息, 充分学习节点之间的关系, 并且重点加强捕捉邻居节点信息的能力, 从而解决异构图神经网络过拟合问题.
为了改善异构图注意力网络反向传播的能力, 本文使用GRU[16]函数.门控异构图注意力网络结构如图2所示.
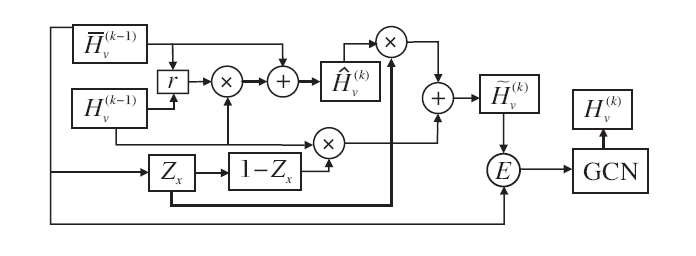 | 图2 门控异构图注意力网络结构图Fig.2 Structure of gated heterogeneous graph attention network |
首先, 基于节点注意力机制计算不同类型的节点注意力, 获得门控双层节点注意力系数:
$E_{1}^{(k)}=\sigma ({{\alpha }^{T}}\bullet {{e}_{1{\tau }'}}[{{h}_{v}}||{{h}_{u}}])$,
$E_{2}^{(k)}=\sigma ({{\alpha }^{T}}\bullet {{e}_{2{\tau }'}}[{{h}_{v}}||{{h}_{u}}])$ ,(3)
其中, α T表示节点注意力系数, e1τ'[·‖·]、e2τ'[·‖·]由式(2)得到, σ(·)表示激活函数, 本文采用LeakyReLU函数, ‖表示拼接操作.
通过Softmax函数对门控双层节点注意力系数进行归一化处理, 获得门控双层注意力权重系数:
$\hat{E}_{1}^{(k)}=Softmax(E_{1}^{(k)})$
$\hat{E}_{2}^{(k)}=Softmax(E_{2}^{(k)})$ (4)
为了使目标节点充分挖掘邻居节点的信息, 避免被无用特征信息干扰, 训练重置门和更新门, 用于对目标节点的信息进行选择, 具体公式如下:
$r_{\text{h}}^{\text{(k)}}\text{= }\!\!\sigma\!\!\text{ (}{{W}_{\text{rh}}}\bar{H}_{\text{v}}^{\text{(k-1)}}\text{+}{{U}_{\text{rh}}}H_{\text{v}}^{\text{(k-1)}}\text{)}$,
$z_{\text{x}}^{\text{(k)}}\text{= }\!\!\sigma\!\!\text{ (}{{W}_{\text{r}}}\bar{H}_{\text{v}}^{\text{(k-1)}}\text{+}{{U}_{\text{r}}}H_{\text{v}}^{\text{(k-1)}}\text{)}$,
$\hat{H}_{v}^{(k)}=tanh({{W}_{h}}\bar{H}_{v}^{(k-1)}+U(H_{v}^{(k-1)}\odot r_{h}^{(k)}))$, (5)
其中, r表示重置门, z表示更新门,
考虑到图节点的特征对节点分类影响较大和不同的层对节点特征影响的不同, 以及为了有效保留每层节点的有用特征, 本文将节点的
$H_{v}^{(k)}=GCN(({{E}_{\tau }}\hat{E}_{1}^{(k)}\odot \bar{H}_{v}^{(k-1)}+\hat{E}_{2}^{(k)}\odot \tilde{H}_{v}^{(k)}))$,(8)
其中, GCN(·)表示图卷积神经网络, Eτ(·)由式(2)得到, 表示注意力系数,
短文本异构图经过节点注意力机制和门控异构图注意力网络, 得到节点信息聚合的结果.根据短文本分类的任务, 将节点生成的
X=Softmax(
在训练过程中, 利用训练数据的交叉熵损失和L2-norm对短文本进行分类, 边缘损失允许对每个类别进行独立训练, 并确保训练不会过多地集中在已经高置信度正确预测的样本上, 从而减轻过度拟合, 即
L=-
其中, Dtrain表示用于训练的短文本集合, T表示短文本种类数量, Y表示标签, θ表示模型参数, p表示正则化因子.
GDHG具体步骤如下所示.
算法 GDHG
输入 输入文本W, 初始学习率L,
最大迭代次数epoch
输出 文本嵌入X
数据预处理 将文本W输入HIN, 得到短文本异构图G=(V, E), 其中V=W∪C∪N
FOR h< epoch:
输入训练样本G=(V, E), 根据式(1)将图的节点特征和邻接矩阵放入节点注意力机制, 得出节点类型注意力权重
将
将eτ输入式(3)和式(4), 得到节点注意力
将节点集V输入式(6), 得到节点特征;
将处理好的特征
将
将
将节点信息聚合的结果
利用式(10)计算模型损失;
END
本文选择如下4个短文本数据集进行实验.
1)Twitter数据集[15].二元情感分类数据集, 由5 000条正面推特和5 000条负面推特组成.
2)MR数据集[19].电影评论数据集, 每个评论只包含一个句子, 每个句子都注明积极或消极的二元情绪分类, 包含5 331条正面评论和5 331条负面评论.
3)Snippets数据集[20].Phan等发布, 由网络搜索引擎返回的片段组成.
4)AGNews数据集[21].新闻分类数据集.本文从AGNews数据集上随机挑选6 000条新闻, 平均分成4类.
各数据集的详细信息如表1所示.大约有80%的文本包含实体.根据Yang等[15]对数据集预处理的建议, 本文删除出现次数少于5次的非英语字符、停止词和低频词.
| 表1 实验数据集 Table 1 Experimental datasets |
本文选择正确率(Accuracy)和F1值(F1-score)作为评价指标.
Accuracy表示正确分类的测试样本与全部测试样本的比率:
Accuracy=
F1-score表示查准率和查全率的调和平均值:
Precision(Pτ)=
Recall(Rτ)=
F1-score=
其中, TPτ表示类别τ的真正例, FPτ表示类别τ的假正例, FNτ表示类别τ的假反例, Γ表示类别集.
为了全面评估GDHG的性能, 选择如下对比方法.
1)传统机器学习方法.
(1)SVM+TF-IDF、SVM+LDA[22].基于经典手动特征TF-IDF(Term Frequency-Inverse Document Fre-quency)和LDA对短文本进行特征处理, 再将短文本的特征放入SVM(Support Vector Machines)进行短文本分类.
(2)KNN+TF-IDF[23].基于经典手动特征TF-IDF对短文本进行特征处理, 再将短文本的特征输入KNN(K Nearest Neighbor)进行短文本分类.
2)深度学习方法.
(1)LSTM-pre[24] .将预处理好的文本放进LSTM进行分类.
(2)FastText[25].高效文本分类技巧, 将word/n-gram嵌入的平均值视为文档嵌入, 再将文档嵌入输入线性分类器.
(3)CNN-rand, CNN-pre[26].将短文本进行词向量嵌入, 输入CNN进行短文本分类, 使用Wikipedia库预训练而成.
(4)BERT(Bidirectional Encoder Representations from Transformers)[27].由Transformers的双向编码器组成, 本文选取的方法是BERT_base和BERT-large, 先对BERT进行预训练, 再针对不同的任务对BERT进行微调.
(5)STCKA(Deep Short Text Classification with Knowledge Powered Attention)[28].基于知识驱动注意力的深度短文本分类方法, 从外部知识源中检索知识, 加强短文本的语义表示, 将概念信息引入深度神经网络, 并引入注意力机制, 对短文本进行分类.
3)图神经网络模型.
(1)Text GCN[10].根据单词和文档之间的关系, 对短文本建立单个短文本图, 再输入GCN, 对短文本图进行单词和文档的嵌入并分类.
(2)HyperGAT[14].超图注意力网络, 使用文档级别的超图对文本进行建模, 之后使用GAT(Graph Attention Networks)[29]对短文本进行分类.
(3)SHINE[8].利用词级组件图将短文本数据集建模成分层异构图, 并对异构图引入更多的语义和语法信息, 动态学习短文本图, 从而促进相似短文本之间的有效标签传播.
(4)HGAT[15].使用实体和主题对短文本进行建图, 即异构图信息网络, 使用注意力网络进行短文本分类.
(5)HIN+GCN.使用HIN对短文本进行构图, 再使用GCN[11]对短文本异构图进行分类.
(6)HIN+GAT.使用HIN对短文本进行构图, 对GAT[29]进行调整以适应HIN, 并进行短文本分类.
参数设置分为如下两部分.
1)HIN部分.参考文献[15]中的参数设置, 在LDA中, 在AGNews、MR、Twitter数据集上设置主题数o=15, 在Snippets数据集上设置主题数o=20, 每个文档分给概率最大的前i=2的主题, 实体之间的相似阈值a=0.5.
2)门控异构图注意力网络部分.学习率在集合{0.1, 0.01, 0.001, 0.0001, 0.5, 0.05, 0.005, 0.0005}中通过网格搜索得到最优值, 最终在Twitter、MR、AGNews数据集上设置学习率为0.005, Snippets数据集上设置学习率为0.01.迭代次数设置为100, 隐节点数设置为512, 正则化系数p设置为5e-8, 隐节点数和正则化系数均参考HGAT的设置.
在对比实验中, SVM采用RBF(Radial Basis Function)核函数, KNN设置近邻数为5.其余对比实验均参考对应文献, 通过网格搜索可以找到最优超参数.
训练的实验环境如下:操作系统采用Windows10, 处理器采用AMD Ryzen 5 3400G with Radeon Vega Graphics 3.70 GHz, Python模块主要使用自然语言处理库Gensim 3.6.0, 数学运算库NumPy 1.19.2, 复杂图结构库NetworkX 2.5.1.对于深度学习, 主要使用深度学习框架PyTorch 1.8.0.
对比实验环境和本文方法训练环境保持一致.
各方法在Twitter、MR、Snippets、AGNews数据集上的测试结果如表2所示, 表中黑体数字表示最优值.
| 表2 各方法在4个数据集上的指标值对比 Table 2 Indicator value comparison of different methods on 4 datasets % |
由表2可以看出GDHG总体上取得最优结果.从表中可得如下结论.
1)深度学习方法(LSTM-pre、CNN-pre、BERT_base和BERT_large)在两个指标上均优于传统机器学习方法(SVM+TF-IDF、SVM+LDA、KNN+TF-IDF), 这是由于传统机器学习方法不能准确捕捉短文本之间的信息, 也不能有效提取短文本的特征.
2)CNN-pre在两个指标上的表现优于CNN-rand, 说明加入预训练的词嵌入可以提高分类准确性.相比其它深度学习方法, 使用预训练的BERT_base和BERT_large的Accuracy和F1-score值更高.Bert-large 仅在 Twitter、Snippets 数据集上的Accuracy值优于GDHG, 在AGNews数据集上的F1-score值优于GDHG.因此, 综合考虑后GDHG略优于BERT_large, 这是由于短文本的稀疏性使深度学习方法不能准确学习到短文本之间的关系, 进而影响短文本分类的结果.
3)HGAT加入附加信息, 充分学习短文本之间的关系, 但是异构图神经网络在分类过程中出现过拟合, 效果不佳.
4个数据集上结果显示本文的门控双层异构图注意力网络可以有效缓解HGAT存在的过拟合等问题, 从而证实GDHG从不同角度学习节点注意力的有效性.SHINE在AGNews数据集上表现较差, 主要是因为在小样本中SHINE未能充分学习语义和句法信息, 导致效果不佳.
综上所述, GDHG在两个指标上的表现总体上优于所有对比方法, 说明GDHG使用门控双层注意力网络, 能够充分利用有限的节点特征信息, 并对重要的节点信息进行重点关注, 聚集远程节点有用信息, 提高短文本分类的性能.
为了说明在相同构图方式下, GDHG可以有效缓解异构图神经网络存在的过拟合问题, 实验中使用相同的HIN构图方式, 将GDHG分别与HIN+GCN、HIN+GAT、HGAT进行对比, 结果如表3所示.由表可见, 在4个数据集上, GDHG的Accuracy和F1-score值均优于其它三种方法, 说明本文提出的门控双层异构图注意力网络充分学习每个节点的特征, 可更好地捕捉邻居节点之间的信息, 有效缓解异构图神经网络中出现的过拟合问题, 提高短文本分类效果.
| 表3 相同构图方式下4种方法的指标值对比 Table 3 Indicator value comparison of different methods with same composition on 4 datasets % |
下面选取3种具有不同构图方式的方法进行对比, 分别是Text GCN、HyperGAT、GDHG.Text GCN使用TF-IDF和点互信息进行构图, HyperGAT使用序列超边和语义超边的方式进行构图, GDHG使用HIN构图.3种方法均采用GDHG进行分类.
各方法在4个数据集上的指标值对比如表4所示.
| 表4 不同构图方式下3种方法的指标值对比 Table 4 Indicator value comparison of 3 methods with different compositions on 4 datasets % |
从表4可明显看出, 采用HIN构图的GDHG均明显优于Text GCN和HyperGAT, 由此说明HIN构图方式可以有效解决短文本特征的稀疏和短文本分类任务中信息不足的问题, 这从另一个角度也说明GDHG选择HIN构图方式的有效性.
本文提出的门控双层异构图注意力网络分为两部分, 为了探究不同部分的作用以及门控异构图注意力网络和节点注意力机制对异构图节点信息聚合的影响, 在实验中将门控双层异构图注意力网络拆成两个模型:节点注意力模型(GDHG-node)和门控异构图注意力模型(GDHG-gated).将这2个模型与GDHG分别在4个数据集上进行性能对比, 结果如表5所示.
| 表5 各模型在4个数据集上的消融实验结果 Table 5 Results of ablation experiment of different models on 4 datasets % |
由表5可以观察出, GDHG在4个数据集上的Accuracy和F1-score值均最优.具体地:在 Twitter数据集上, GDHG-node的Accuracy和F1-score值均大于GDHG-gated; 在MR数据集上, GDHG-node的Accuracy和F1-score值均小于GDHG-gated; 在AG-News、Snippets数据集上, GDHG-node的Accuracy值大于GDHG-gated, 而F1-score值小于GDHG-gated.由此可以看出, GDHG-node和GDHG-gated不能充分学习节点的特征和节点之间的关系, 造成分类效果不稳定, 而融合两种注意力模型的GDHG能够挖掘节点之间的隐藏信息, 充分利用节点之间的信息, 使短文本分类更精准.
在GDHG中, 最终节点嵌入经过Softmax输出每个类型的概率.借鉴文献[15], 在实验中引入孤立类型实验, 孤立类型可以得到文本的“背景”信息, 如停顿词和特定类型单词无关的停止词, 这样可以增加分类的正确性.本文加入不同数量的孤立类型进行实验, 定义no_orphan表示未加入孤立类型, orphan_1表示加入一个孤立类型, 以此类推, orphan_4表示加入四个孤立类型, 最后得到指标值结果如表6所示, 表中黑体数字表示最优值.由表可以看出, 在Twitter、MR、Snippets、AGNews数据集上, 当孤立类型是orphan_2时, Accuracy和F1-score值达到最高.当进一步增加孤立点时, 两个指标会同时下降, 原因在于当孤立点大于orphan_2时, 文本学习到更多噪声信息, 而方法只能提取有限的信息, 导致与短文本潜在的关键信息丢失.因此, 只添加2个孤立类型可以使GDHG更好地嵌入短文本异构图, 有效捕捉文本的背景信息, 提高短文本分类性能.
| 表6 加入不同孤立类型后GDHG的指标值对比 Table 6 Indicator values of GDHG after adding different isolation types % |
GDHG在构图过程中添加两种附加信息:实体和主题.为了探究附加信息对方法性能的影响, 定义如下两种方法:1)去掉主题, 表示为GDHG-T; 2)去掉实体, 表示为GDHG-E.
各方法实验结果如表7所示.从表可以观察到, 在Twitter、MR、Snippets、AGNews数据集上, GDHG的Accuracy和F1-score值均优于GDHG-T和GDHG-E.因此, 只有使用两种附加信息 (主题、实体)共同构图, 才能使模型充分学习到节点的信息, 提升短文本分类的性能.
| 表7 有无附加信息对GDHG指标值的影响 Table 7 Indicator values of GDHG with and without additional information % |
本文提出基于门控双层异构图注意力网络的半监督短文本分类方法(GDHG).首先利用HIN框架构建短文本异构图, 集成附加信息, 解决短文本的语义稀疏性问题.然后, 针对HIN框架, 使用门控双层异构图注意力网络嵌入HIN.该网络通过节点注意力机制与门控异构图注意力网络获得节点聚集的信息.门控双层异构图注意力网络可以将各种信息类型投影到一个隐含的公共空间以考虑它们的异构性, 进而捕获节点关键信息, 有效缓解异构图神经网络中的过拟合等问题.最后, 在4个短文本数据集上的大量实验表明, GDHG总体上性能较优.未来工作的重点会尝试新的构建文本异构图的方式, 使短文本的信息更丰富, 并探索新的异构图神经网络模型, 更好地解决异构图神经网络的过拟合等问题.
本文责任编委 林鸿飞
Recommended by Associate Editor LIN Hongfei
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|