
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
图像分布外检测研究综述
[郭凌云1, 2, 3  , 李国和
, 李国和1, 2 , 龚匡丰1, 2 , 薛占熬3 ]
, 李国和, 龚匡丰, 薛占熬]
|
|



作者简介:

李国和,博士,教授,主要研究方向为人工智能、机器学习等.E-mail:lgh102200@163.com.

龚匡丰,博士研究生,主要研究方向为机器学习、数据挖掘.E-mail:fjgongkf@126.com.

薛占熬,博士,教授,主要研究方向为人工智能、数据挖掘等.E-mail:xuezhanao@163.com.
分类器学习一般假设训练样本和预测样本具有独立同分布.由于该条件过强,实践中当分类器面向分布外(Out-of-Distribution, OOD)样本时容易导致预测错误.因此,对OOD检测进行深入研究就显得尤为重要.文中首先介绍OOD检测的概念及其相关研究领域,根据网络训练方式的差异性对有监督的检测方法、半监督的检测方法、无监督的检测方法和异常值暴露的检测方法进行系统概述.然后按照关键技术从神经网络分类器、度量学习和深度生成模型三方面总结现有OOD检测方法.最后讨论OOD检测未来的研究方向.
About Author:
LI Guohe, Ph.D., professor. His research interests include artificial intelligence and machine learning.
GONG Kuangfeng, Ph.D. candidate. His research interests include machine learning and data mining.
XUE Zhan'ao, Ph.D., professor. His research interests include artificial intelligence and data mining.
Classifier learning assumes that the training data and the testing data are independent and identically distributed. Due to the overly stringent assumption, erroneous sample recognition of classifiers for out-of-distribution examples is often caused. Therefore, thorough research on out-of-distribution(OOD) detection becomes paramount. Firstly, the definition of OOD detection and the relevant research are introduced. A comprehensive overview of supervised detection methods, semi-supervised detection methods, unsupervised detection methods and outlier exposure detection methods is provided according to the difference of network training methods. Then, the existing OOD detection methods are summarized from the aspect of three key technologies: neural network classifiers, metric learning and deep generative models. Finally, research trends of OOD detection are discussed.
分布外(Out-of-Distribution, OOD)检测是深度学习的重要研究内容之一. 传统深度学习任务通常假设训练样本和测试样本具有独立同分布, 并在训练集上训练模型用于预测测试集样本.当训练集和测试集的独立同分布假设不成立时, 机器学习建立的模型(如分类器)精确度急剧下降, 甚至对错误的预测结果给出高置信度[1].随着深度学习的发展, 图像识别和自然语言处理获得广泛应用, 需要识别的对象不断增加, 甚至随时产生未知类型.深度学习分类模型面临开放环境时, 对未知类别(即不具有同分布)的待检测样本表现出过度自信, 将其预测为训练集上的某个类别(即已知类别).在安全性要求较高的场景中, 这种错误预测将造成严重后果.
2017年, Hendrycks等[2]首次提出OOD检测概念, 在保证原始任务的前提下检测未知类别的对象.近年来, OOD检测受到学者们的广泛关注, 在计算机视觉和自然语言处理领域都有深入的研究, 以期在原始深度学习任务的基础上提高模型对未知样本的鲁棒性.具体地:OOD检测在计算机视觉方面主要应用在人脸识别[3]、人体动作识别[4]、医疗诊断[5, 6, 7, 8, 9]和自动驾驶[10, 11]等; 在半导体晶圆识别[12]和天文学[13]领域也有少量应用; 在自然语言处理领域, OOD检测在对话系统域外话题识别[14, 15]、情感分类[2]、文本分类[2]和自动语音识别[2, 16]等方面都有相关研究.
现已有大量OOD检测研究, 但只有少量综述性文献.2019年, Roady等[17]从推理和特征表征两方面分析相关研究.2020年, Bulusu等[18]从意外异常和故意异常分析深度学习异常检测, 其中意外异常检测即OOD检测, 主要从有监督、半监督和无监督方面总结相关研究工作, 对其它角度的研究路线缺乏梳理.2021年, Yang等[19]定义广义OOD检测统一框架, 重点分析OOD检测及其相关研究领域之间的区别和关联.
本文以图像识别为应用背景, 系统分析并梳理OOD检测的最新研究成果.首先介绍OOD检测的概念及其相关研究领域, 根据网络训练方式的差异性对有监督的检测方法、半监督的检测方法、无监督的检测方法和异常值暴露的检测方法进行系统概述.然后, 按照关键技术从神经网络分类器、度量学习和深度生成模型三方面总结现有OOD检测方法.最后讨论OOD检测未来的研究方向.
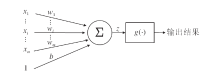
深度神经网络(Deep Neural Network, DNN)是深度学习的基础, 由基本处理单元神经元按照一定的层次结构构成.神经元的基本结构如图1所示.在图中, wi(i=1, 2, …, m)表示权重, b表示偏置项.神经元接受多个输入信号xi(i=1, 2, …, m)后, 首先利用加权求和函数计算
z=x1w1+x2w2+…+xmwm+b,
再经过非线性激活函数g(·)得到该神经元的最终输出结果.常用激活函数有sigmoid、tanh、ReLU等.
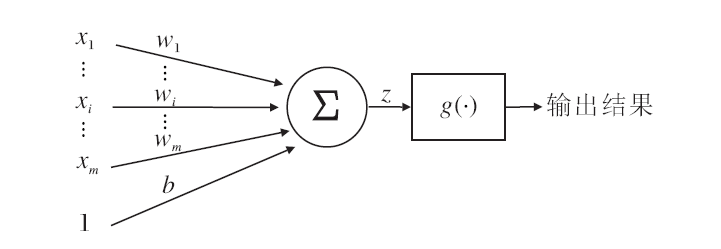 | 图1 神经元模型结构图Fig.1 Structure of neuron model |
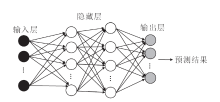
经典的DNN结构[20]如图2所示, 神经网络层主要分为输入层、隐藏层和输出层.DNN训练的过程大致分为五步:变量初始化、前向传播、损失计算、反向传播、参数更新, 其中前向传播和反向传播是两个关键步骤.前向传播主要是利用各层神经元计算预测结果y, 通过损失函数L(y, yt)衡量真实结果yt和预测结果y之间的差异.类似地, 反向传播主要基于梯度下降和链式求导法则求解网络权重, 优化模型参数.经过迭代训练使损失函数值最小, 最终得到理想的模型.
 | 图2 DNN基本结构Fig.2 Basic structure of DNN |
构建图像分类器一般首先提取训练集样本的特征, 获得从训练样本到标签的映射关系f∶xtr→ytr, 然后利用f将测试集样本xte映射到对应的类标签
在实际应用中, 模型面临的测试集可能包含未知类别的样本, 属于训练集已知类别的样本称为分布内(In-Distribution, ID)样本, 而不属于训练集类别(即未知类别)样本称为OOD样本.
定义1 OOD检测 训练集和测试集由样本-标签对构成, 训练集Dtr和测试集Dte分别表示为
Dtr=
Dte=
其中:Xtr和Ytr分别表示训练集Dtr的样本空间和标签空间; 样本xi∈ Xtr对应的标签yi∈ Ytr, yi的值为
{(xj∈ Xte, yj∈ Ytr={
分类, 并将其它样本预测为OOD样本.
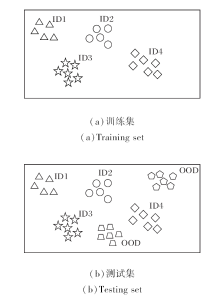
OOD检测的目标是训练模型对测试集中的已知类别样本分类, 并检测出与训练集类别不相交的样本, 将其预测为OOD[19].OOD检测的训练集和测试集样本分布不一致, 即
Ptr(X, Y)≠ Pte(X, Y),
测试集样本与训练集样本存在语义偏移, 即
Ptr(Y)≠ Pte(Y).
具体样本分布如图3所示.
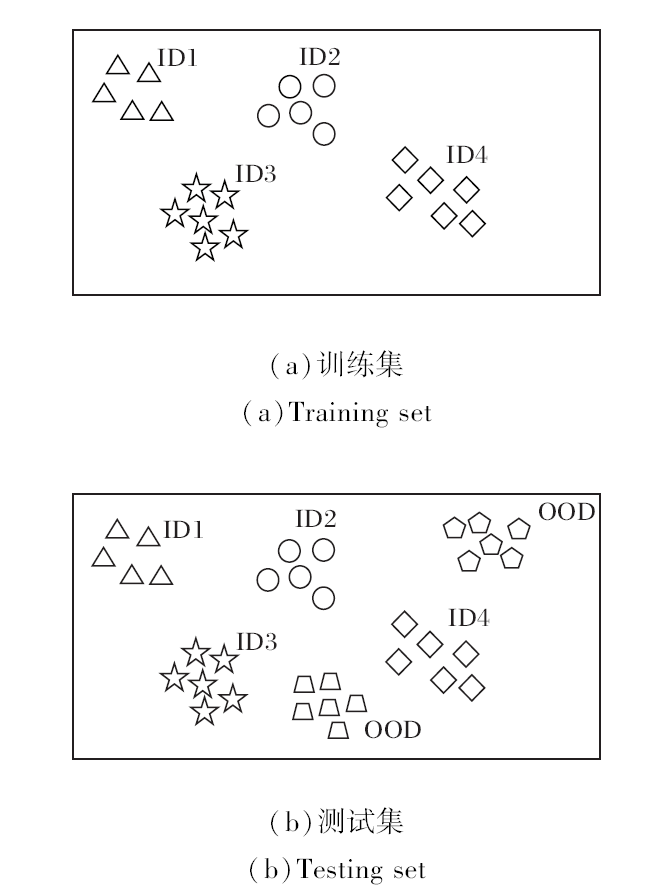 | 图3 OOD检测的训练集与测试集样本分布对比Fig.3 Comparison of sample distribution of training and testing datasets in out-of-distribution detection |
OOD检测与不确定性估计和模型校正有关, 其实质是拒绝神经网络的不当输入.OOD检测器gτ表示为
gτ(x; f)=
基于神经网络模型f的输出设计OOD样本评估函数s, 并依据验证集设定阈值τ, 通过计算输入样本x的s函数评估值与阈值τ对比判定样本为ID样本或OOD样本.
根据训练集ID样本的类别数目, 将OOD检测分为多分类OOD检测(Multi-class OOD Detection)和单分类OOD检测(One-Class OOD Detection).训练集ID样本包含多个类别, 即为多分类OOD检测.在测试阶段, 需要预测输入样本属于k个类中某一类, 并检测出OOD样本, OOD样本不识别其具体类别, 均归为同一类.训练集ID样本为单类时, 即单分类OOD检测, 此类OOD检测简化为传统深度学习异常检测问题, 利用单一类别的正常样本训练模型区分正常样本和异常样本.
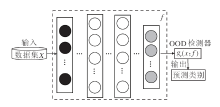
OOD检测的整体框架如图4所示.输入训练数据集X训练模型f, 获得ID样本的表征, 在测试阶段, 输入待测样本x, 利用f输出预测类别, 并计算OOD样本评估函数s的值.提高OOD检测精度的关键是获取ID样本的精确表征, 增加ID样本和OOD样本的差异.
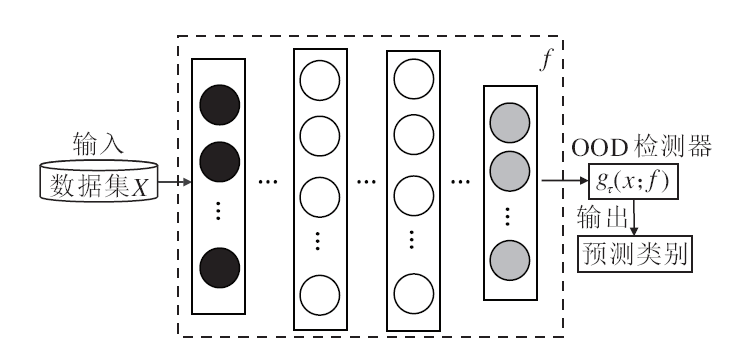 | 图4 OOD检测的整体框架图Fig.4 Overall framework of OOD detection |
按照不同阶段, 可在数据预处理、神经网络模型和样本评估指标三方面进行设计和优化.在数据输入阶段, 对数据预处理, 扩大ID样本和OOD样本的差异.在模型设计阶段, 优化神经网络模型, 获得更精准的ID样本表征, 增大ID样本和OOD样本的表征差异.在结果输出阶段, 设计有效的评估指标, 区分ID样本和OOD样本.
OOD检测的目的是在保证原始任务精度下检测未知类别样本.针对图像识别问题, 根据原始任务的不同, 将OOD检测分为图像级OOD检测、区域级OOD检测和像素级OOD检测, 具体概述如下.
1)图像级OOD检测.图像分类是对整个图像的语义信息分类, 在计算机视觉领域获得广泛应用.图像级OOD检测目标是实现图像分类并判断整个图像语义标签是否在训练集的类别空间内.在开放环境中, 训练集和测试集之间存在数据偏移, 数据偏移分为语义偏移和特征偏移两种方式[19, 21].语义偏移是测试集上包含与训练集语义类别不同的样本, OOD检测主要针对这一类型的样本偏移.特征偏移包括样本含噪声、对抗干扰、样本损坏或风格迁移等, 主要采用领域自适应[22]、领域泛化[23, 24]等方法.
2)区域级OOD检测.目标检测在图像中通过矩形框定位目标区域, 并识别该区域的对象, 目标区域的数量、位置和大小均可不固定.区域级OOD检测在目标检测基础上检测未知类别对象.深度学习在目标检测的准确性方面拥有相对成熟的研究成果, 但大部分研究不考虑对未知类别对象的错误检测问题.Park等[25]利用异常值暴露方法对目标检测模型神经网络YOLOv3进行微调, 将特定类的不确定性估计应用于目标检测的置信度评估.
3)像素级OOD检测.语义分割对图像的每个像素分类, 从而区分图像中各种语义对象, 如人、动物、背景等.像素级OOD检测在语义分割的基础上检测未知类别对象.面向开放环境时语义分割模型应能及时指出识别到的未知类别对象.针对此问题, 2019年, Blum等[26]提出Fishyscapes.同年, Hendrycks等[27]提出CAOS(Combined Anomalous Object Segmen-tation), 在自动驾驶模拟环境中检测未遇到过的新对象.2021年, Yang等[28]研究医学图像分割的不确定性估计, 对放射图像的模糊区域和焦点边界做出更准确的预测和不确定性量化.
目前对图像级OOD检测的研究相对较多, 像素级OOD检测和区域级OOD检测主要集中在自动驾驶环境检测[27, 29]和医学图像[28, 30]领域.本文主要关注图像分类中样本存在语义偏移的OOD检测.
1)异常检测(Anomaly Detection).异常样本是与其它观测样本存在较大偏差的样本, 异常检测是识别与给定观测样本明显不一致的样本的过程.不同的应用领域对异常检测定义不同, Yang等[19]在广义OOD检测框架中较详细地区分离群值检测(Outlier Detection)、新颖性检测(Novelty Detection)等几种定义.离群值检测使用观测到的所有样本, 采用直推的方法找出离群点.图像异常检测使用单一类别的正常样本构建模型, 可分为定性异常的分类和定量异常的定位.定性异常的分类判断整体图像是否异常, 定量异常的定位类似于目标检测或图像分割, 需要定位异常区域[31].单分类OOD检测与定性异常检测的任务基本一致.新颖性检测的正常样本可以是单类或多类, 重点是检测未知类别的样本, 无需对正常样本分类.OOD检测需对正常ID样本分类, 并检测未知类别样本.
2)主动学习(Active Learning).主动学习根据样本评估策略选择部分无标签样本交由专家标注, 将人工标注的数据重新放至训练集中优化分类模型, 使用较少的带标签样本训练准确性较高的模型, 降低获取数据的成本.标签样本获取代价较高, 主动学习基本思想是使用更少的人工成本构建更高质量的数据集.评估无标签样本是主动学习的核心, 评估方式主要有不确定性准则和代表性准则[32], 主动学习的样本评估策略对OOD检测有一定启发作用.
3)带拒绝分类(Classification with a Reject Op-tion).带拒绝分类也称弃权学习或选择分类(Selec-tive Classification), 在尽量保证预测精度的同时, 对无法保证预测准确性的对象根据某种度量采取拒绝操作[33].带拒绝分类应用在诸如智能驾驶、智能医疗等领域, 在不能保证精确预测时放弃预测并给出提示, 避免错误操作引起严重后果.拒绝分类以拒绝代价小于错分代价为标准, 不关注放弃预测的样本是否属于已知类别或未知类别, 保证预测精度.
4)开放集识别.分类模型基于训练集和测试集样本满足独立同分布的假设, 训练集和测试集的类别空间一致, 因此分类器可以预测测试集样本类别.但在实际应用中, 模型面对的环境是开放的, 待测试样本中包含新出现的类别, 需要识别已知类和新类别的对象, 即开放集识别(Open Set Recognition), 甚至开放世界学习(Open World Learning), 除了能够识别新类别的样本, 还以增量方式将识别到的新类增加到已知类中, 实现持续学习.Dhamija等[34]从增量学习、OOD检测和开放世界学习三个维度, 提出统一的开放世界识别框架.开放集识别目前处于发展阶段, 现有的开放集识别模型通常将新类别对象作为同一类别[35], 这类方法与OOD检测的问题设置基本一致, 二者可以相互借鉴.
根据数据可用性和模型训练方式的不同, OOD检测可分为无监督OOD检测、有监督OOD检测、半监督OOD检测和异常值暴露(Outlier Exposure, OE).
为了直观阐述, 表1总结OOD检测四种方法的设计思路和特点.
| 表1 OOD检测的四类方法 Table 1 Four kinds of out-of-distribution detection methods |
无监督OOD检测仅利用ID样本训练模型, 设计评估方式, 使ID样本和OOD样本的差异尽可能大, 无需任何额外的辅助样本.常见方法是利用神经网络的输出设计样本评估指标、基于重构和概率密度估计检测OOD.
2017年, Hendrycks等[2]首次提出OOD检测概念, 设计简单易行的基线方法MSP(Maximum Soft-max Probability).相比错误分类的样本和OOD样本, 正确分类的样本往往具有更大的MSP值.利用MSP与阈值比较检测错误分类和OOD样本, 并在计算机视觉和自然语言处理数据集上评估方法的有效性.上述方法是典型的利用分类网络的输出设计样本评估指标的无监督OOD检测方法.
2018年, Liang等[36]在MSP[2]的基础上提出ODIN(Out-of-Distribution Detector for Neural Networks), 对输入样本加入扰动, 并增加温度参数T, 加大ID样本和OOD样本的softmax概率分布的差异, 提升检测的精确度.此方法在OOD检测研究中作为样本预处理方法被广泛应用.
基于重构的方法使用ID样本训练生成模型.相比ID样本, OOD样本重构误差较大, 可使用重构误差检测OOD样本.基于概率密度估计的方法使用ID样本训练模型, 拟合样本的概率密度分布, 在该分布下, 相比ID样本, OOD样本似然值较低.
有监督OOD检测利用带标签的ID样本和OOD样本, 将OOD检测建模转为有监督分类问题, 利用OOD辅助样本或生成OOD样本加入训练集, 参与模型训练.由于真实OOD样本难以获取, 生成OOD参与训练是一种直观方法, 有研究者采用不同方法生成OOD样本参与模型训练.
2019年, Vernekar等[37]利用条件变分自动编码器CVAE(Conditional Variational Autoencoder)生成在样本流形外的和在样本流形上的两类OOD样本, 有效覆盖整个分布边界, 然后利用训练集中的ID样本和生成的OOD样本训练分类器.
2021年, Gao等[38]利用生成对抗网络GAN (Generative Adversarial Network)[39]生成OOD样本, 针对现有基于图像分类的方法对整个图像进行检测的问题, 提出UEAOD(Uncertainty Enhanced Atten-tion for OOD Detection), 利用注意力机制对图像的不同区域进行不确定性估计, 提高检测能力.同年, Amit等[40]设计FOOD(Fast Out-of-Distribution Dete-ctor), 采用对抗性方式生成OOD样本参与训练, 利用扩展的DNN分类器快速检测OOD样本.
2021年, Thulasidasan等[41]把OOD检测作为K+1类分类任务, 辅助样本作为一个额外的弃权类.利用包含K类ID样本的数据集Din与一个已知的OOD辅助数据集训练一个带弃权类的分类器DAC(Deep Abstaining Classifier), 优化交叉熵损失训练网络.检测器g(x)根据softmax预测概率和阈值确定待测样本是否为OOD样本.
2022年, Ran等[42]设计INCPVAE(Improved Noise Contrastive Priors Variational Auto-encoder), 在正常样本中增加不同程度的高斯噪声, 生成OOD样本参与训练, 优化反向KL(Kullback-Leibler)散度训练模型, 训练完成后使用INCP-KL Ratio(Improved Noise Contrastive Prior-KL Ratio)作为评判指标.
有监督OOD检测利用已知的或生成的OOD样本参与训练, 可增加OOD样本的数量和种类, 直接扩大训练集, 但实际应用中待测试样本的分布是无法控制的, OOD样本可能无限多, 并不断变化, 不断更新数据集并重新训练模型需要高昂的计算代价.
半监督OOD检测的训练集包括带标签的ID样本和无标签辅助样本, 无标签辅助样本无需知道是ID样本或OOD样本, 或利用少量带标签的异常样本辅助训练[3].
2019年, Ren等[8]利用辅助OOD样本, 设计基于深度生成模型的似然率Likelihood Ratios检测OOD.该方法假设样本由相互独立的语义主体和背景两部分组成, 即样本x={xB, xS}.利用背景相同但语义主体不同的OOD样本辅助训练, 在输入样本中添加适当的扰动以破坏样本中的语义结构.根据加入扰动的输入样本训练的模型只捕获样本总体的背景统计特征, 以此构建背景模型, 去掉背景成分, 仅保留语义成分, 增强ID样本的特定特征.pθ(·)表示基于ID样本训练的模型,
LLR(x)≈ log pθ(xs)-log
根据似然率与阈值比较判断待测样本是否为OOD样本.
2020年, Ruff等[43]提出Deep SAD(Deep Semi-supervised Anomaly Detection), 同时利用有标签样本和无标签样本, 同时有标签样本中可以包含少量异常样本, 基于度量学习训练神经网络, 将正常样本映射到超球中心附近, 同时将异常样本映射到远离中心的区域, 根据测试样本与超球中心的距离判断异常样本.
半监督OOD检测更符合实际需求, ID样本容易获得, 而带标签的OOD样本难以获得, 如果存在少量带标签的OOD样本或无标签的辅助样本应对其加以利用.半监督OOD检测研究目前较少, 因此是值得研究的问题之一.
异常值暴露是在训练时引入与测试数据集不相交的异常样本, 增强神经网络的泛化能力, 从已知的异常样本中获得启发, 识别未知异常样本.
2019年, Hendrycks等[44]提出利用辅助的异常数据集检测OOD的异常值暴露方法OE.训练集中ID样本的分布Din已知, 现实环境中OOD样本的分布Dout未知.OOD检测的任务是确定测试样本来自Din或Dout.异常值暴露方法利用ID数据集和与测试集上OOD样本不相交的辅助异常数据集, 训练模型判断测试样本来自Din还是
2021年, Papadopoulos等[45]在OE[44]基础上提OECC(Outlier Exposure with Confidence Control), 其优化目标在标准交叉熵损失基础上增加两个正则化项, 在优化交叉熵损失的同时, 使异常值暴露辅助数据集的softmax类别预测概率分布接近均匀分布, ID样本的训练准确率和平均置信度的欧氏距离尽可能小.
2023年, Wang等[46]在OE[44]的基础上设计DOE(Distributional-Agnostic Outlier Exposure), 针对OE中训练所用的OOD样本可能偏离测试集OOD样本的问题, 采用对模型扰动进而产生隐式数据变换的方式, 生成与分布无关的OOD样本, 对各种未知的OOD样本检测均表现良好.
在利用异常值暴露辅助训练时, 大多数的辅助OOD样本可能对算法性能改进没有实际推动意义, 甚至损害检测器的决策边界.Chen等[47]针对这一问题, 提出ATOM (Adversarial Training with Informative Outlier Mining), 在训练时使用干净的OOD样本和加入扰动的OOD样本, 有选择地利用OOD样本加入训练, 避免随机选择辅助异常值参与训练会产生大量无信息样本的问题, 通过挖掘富含信息的OOD样本, 提高检测精度, 并推广到未知的对抗性攻击.随后, Chen等[48]又针对输入样本加入微小扰动时OOD检测器容易误判的问题, 提出ALOE(Adver-sarial Learning with Inliner and Outlier Exposure)[48], 分别讨论在ID样本添加扰动和同时在ID样本和异常值暴露样本上添加扰动两种情况对检测精度的影响.2022年, Du等[49]提出VOS(Virtual Outlier Syn-thesis), 对比不同的异常样本合成方法, 在特征空间低似然区域中采样生成虚拟异常值, 解决真实异常样本难以获取和高维空间合成图像难以利用的难题, 同时使ID样本和OOD样本之间决策边界更紧凑.
异常值暴露方法在训练过程中使用已知的OOD样本, 试图在检测过程中泛化到未知的OOD.目前研究表明利用异常值暴露方法使用真实图像和类别多样性高的辅助样本可以有效提高OOD检测精度, 同时, 发现富含信息的异常值、利用少量辅助样本参与训练也提供全新的思路.
本节梳理OOD检测的关键技术, 根据不同的学习模式, 将现有OOD检测关键技术分为基于神经网络分类器的OOD检测方法、基于度量学习的OOD检测方法和基于深度生成模型的OOD检测方法.表2从神经网络分类器、度量学习和深度生成模型三个方面总结OOD检测的关键技术.
| 表2 图像OOD检测方法的特点对比 Table 2 Characteristics comparison of different out-of-distribution detection methods |
使用神经网络分类器的OOD检测方法主要包括基于设计样本评估函数的OOD检测方法、基于设计神经网络模型的OOD检测方法、基于深度学习结合传统方法的OOD检测方法和基于不确定性估计的OOD检测方法.
3.1.1 基于设计样本评估函数的OOD检测方法
基于样本评估的OOD检测方法不改变神经网络分类器的训练过程和目标, 利用神经网络的输出设计评估函数s, 对比样本评估值与阈值τ, 检测OOD样本.
2017年, Hendrycks等[2]利用神经网络输出的最大softmax预测概率即MSP作为置信度评估待测样本, Liang等[36]在其基础上对输入样本添加扰动, 提出ODIN, 增大ID和OOD的预测概率分布差异.神经网络输出的预测概率, 也是模型自身隐含的置信度, 直觉上是合理的, 但不是判断结果可信度的最佳方法.随后出现一些更有效的样本评估方法.Hsu等[50]基于概率统计解释ODIN的MSP作为置信度导致的DNN对预测结果过于自信的原因, 并提出Generalized ODIN, 设计分解置信度, 提升OOD检测精度.Begon等[51]从基于优化和基于批归一化的角度设计多种OOD评估指标.
仅利用分类器网络最末端的输出信息不足以精确区分OOD样本和ID样本, 而充分利用网络中间各层特征可以提升检测效果.
2018年, Lee等[52]利用分类网络提取的各层特征拟合多元高斯分布, 设计马氏距离置信度(Ma- halanobis Distance), 以各层特征所得马氏距离的加权值作为最终的置信度, 并以增量学习的方式更新已知类和置信度.马氏距离对检测与ID样本语义和风格差别较大的远-OOD有效, 但对与ID样本语义差别不大的近-OOD失效.2020年, Kamoi等[53]在其基础上提出Partial Mahalanobis Distance和Marginal Mahalanobis Distance, 并与ODIN[36]结合, 进一步提高检测精度, 但需要调优超参.2021年, Ren等[54]分析马氏距离对近-OOD失效的原因, 提出RMD(Relative Mahalanobis Distance)置信度, 无需调优超参.
2019年, Abdelzad等[55]假设网络深层的特征更有利于分类, 而浅层特征更有利于区分ID样本和OOD样本, 因此利用神经网络各层特征训练OSVM(One-Class Support Vector Machine)分类器, 寻找OODL(Optimal OOD Discernment Layer), OSVM针对给定的输入样本输出评估值检测OOD.2020年, Sastry等[56]利用神经网络提取的各层特征, 基于Gram矩阵计算特征的相关性, 设计基于Gram矩阵的OOD评估指标.2021年, Erdil等[57]采用边缘核密度估计模型, 代替高维核密度估计, 对神经网络各层各通道特征进行KDE(Kernel Density Estima-tion), 将概率密度加权平均值作为样本的总体置信度.同年, Nimi等[58]提出EARLIN(Early OOD Detec-tion for Collaborative Inference), 从网络的浅层挖掘重要特征, 在潜在特征空间中定义距离函数, 利用待测样本到ID样本空间质心的距离检测OOD样本.
2006年, LeCun等[59]提出EBM(Energy-Based Mo-dels), 构建能量函数, 将输入空间的每个样本映射到一个非概率能量标量上, 可以作为概率估计的替代方法, 能量值无需归一化, 避免概率模型中归一化的相关问题.2020年, Liu等[60]提出Energy-Based OOD, 在分类网络上使用能量函数代替softmax函数, 通过计算能量值检测OOD样本.
基于能量的样本评估方法可以灵活地应用于基于预训练网络的分类器.2021年, Lin等[61]提出MOOD(Multi-level Out-of-Distribution Detection), 在网络不同深度的多个特征层上设置分类器, 利用中间分类器的输出动态检测OOD样本, 并设计校正能量分数Eadjusted作为样本评估值.
2020年, Hendrycks等[62]最早将Transformer引入OOD检测, 在7个NLP数据集上对比多种网络模型对异常样本和OOD样本的检测效果, 验证预训练Transformer对OOD检测的有效性.2021年, Koner等[63]设计OODformer, 将Transformer作为特征提取器, 基于隐空间距离度量和MSP置信度的联合检测OOD样本.2023年, Li等[64]以MIM(Masked Image Modeling)为原始任务训练ViT (Vision Trans- former)模型, 设计MOOD, 利用训练好的ViT提取测试样本的特征, 计算出的欧氏距离作为OOD样本评估指标.该方法以图像重构模型代替分类模型, 获取ID样本表征, 扩大ID样本和OOD样本的表征差异, 取得良好效果.
此外, 一些研究者通过数据增强方式提升检测效果.2018年, Golan等[65]对正常样本几何变换生成增广样本, 通过几何变换生成的样本将单分类转换为多分类, 优化交叉熵损失训练分类器, 测试时对测试样本也进行同样的几何转换, 以softmax概率向量的加权平均值作为最终的样本评估值.2019年, Hendrycks等[66]改进文献[65]方法, 通过几何旋转增广样本进行自监督学习, 将多分类任务转换为多任务模型, 设计旋转预测辅助的交叉熵损失, 并在检测阶段将KL散度和旋转分数结合作为样本评估值.同年, Yun等[67]设计CutMix, 在训练图像中随机剪切一部分区域, 随机填充训练集上其它样本的区域像素值, 结合预训练模型, 通过阈值判断样本是否为OOD样本, 采用数据增强策略提升模型的鲁棒性.
目前绝大多数的OOD检测主要考虑数据语义偏移问题.2022年, Yang等[68]提出FS-OOD(Full-Spectrum OOD), 将数据分布细分为训练集ID、特征偏移ID、近-OOD和远-OOD四类, 从不同的分布差异研究OOD检测, 考虑数据同时存在语义偏移和特征偏移的情况.模型假设CNN(Convolutional Neural Network)输出的样本特征x包含语义特征xs和非语义特征xn, 且二者是独立生成的, 浅层特征包含非语义特征, 高层特征包含语义特征, 据此设计SEM(Simple Feature-Based Semantics Score Function), 能够检测语义偏移OOD数据, 并识别特征偏移ID数据.
基于样本评估的OOD检测方法可以直接利用预训练模型, 根据神经网络的输出计算样本评估值.这类方法直观、高效, 但是预训练模型的设计初衷是图像分类, 提取的特征未必有利于OOD检测, 同时, 在自然图像集上预训练的神经网络可能不适用于其它行业样本, 如医学样本和工业样本, 因此需要设计神经网络模型和优化训练策略提取更具有区分度的特征.
基于设计样本评估函数的OOD检测方法发展过程如图5所示.
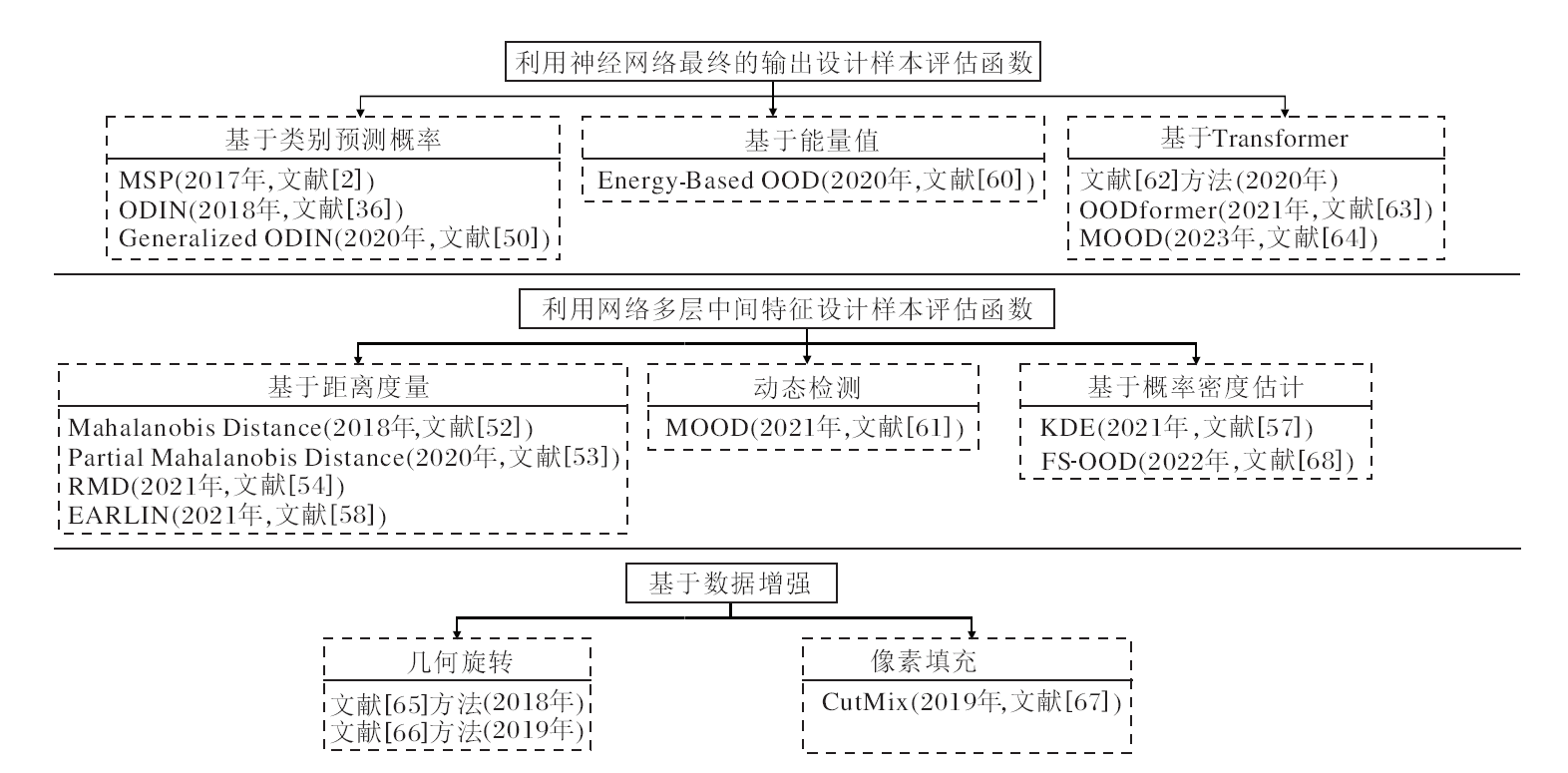 | 图5 基于设计样本评估函数的OOD检测方法Fig.5 OOD detection methods based on designing sample score function |
3.1.2 基于设计神经网络模型的OOD检测方法
基于设计神经网络模型的OOD检测方法通过设计神经网络结构、损失函数和调整训练方式等, 使网络能够提取到有利于区分ID和OOD的特征, 提高预测精度.同时, 多标签样本、大语义空间、ID样本不平衡、图数据等特殊数据的OOD检测及集成方法也有相关的研究.
2018年, DeVries等[69]设计一种神经网络结构, 在网络最末的输出层增加一个置信度分支, 损失函数包括分类任务的交叉熵损失和置信损失两部分, 输出包括类别概率和置信度, 以置信度估计预测类别概率的可信程度.同年, Lee等[70]提出一种置信损失, 使分类器对ID样本正确分类, 对OOD样本的预测概率分布接近均匀分布.由于OOD样本多样性强且难以收集, 引入GAN联合训练, 采用约束生成的方法训练GAN, 生成ID样本边界低密度区域均匀分布的OOD样本, 从而使分类器获得更好的决策边界, 最终通过置信度检测OOD样本.
2018年, Shalev等[71]使用多头网络结构训练k个分类器, 利用多个语义标签训练模型, 损失函数是k个分支的预测表征和目标标签词嵌入向量之间的余弦距离的和, 并使用L2范数作为样本评估值检测OOD, 在图像识别和语音命令检测中评估模型.
当ID样本类别不平衡时, 检测算法会更偏向于训练集上样本数量较多的类别, 从而产生不公平的预测结果.2019年, Hendrycks等[72]利用预训练模型和过采样方法解决ID样本类别不平衡问题.2021年, Mohseni等[9]在医学图像诊断中研究ID样本类别不平衡的OOD检测方法, 提出BH(Binary Heads), 网络由一个共享的特征提取器和多个分类器组成, 每个分类器对应训练集上一个已知类别, 将训练多个分类器转换为多任务学习问题.
2021年, Huang等[73]研究大语义空间的OOD检测, 提出MOS(Minimum Others Score), 将大的语义空间分解为小组, 简化决策边界, 并减少ID样本和OOD样本之间的不确定性空间.
在集成学习方面, 2018年, Vyas等[74]设计K Leave-Out Classifiers, 将训练样本的随机子集作为OOD, 其余样本作为ID, 以自监督的方式训练多个分类器, 设计基于熵的边际损失, 以集成方式融合各分类器的输出并作为预测结果.2021年, Yang等[75]设计Ensemble-Based OOD, 融合两个网络的样本特征, 对融合特征计算马氏距离置信度, 检测OOD样本.
近年来, 图神经网络(Graph Neural Networks, GNN)[76]在图数据的各个领域都取得重大进展, 基于GNN的OOD检测也引起研究人员的极大关注.图数据OOD检测与常规图像分类OOD检测的重要区别是图节点之间存在相互依赖关系.
2022年, Song等[77]沿用计算机视觉和自然语言处理的概念, 将不包含在训练集类别空间的节点作为OOD节点, 定义含有OOD节点的图学习问题, 识别已知类节点, 并检测未知类节点, 由此提出OODGAT(Out-of-Distribution Graph Attention Network), 利用注意力机制, 显式建模ID节点和OOD节点的交互, 在特征传播过程中识别ID节点和OOD节点, 并设计一致性损失、熵损失和差异损失三种正则化方式, 共同引导OODGAT的学习过程.在图数据集上的广泛实验表明OODGAT的有效性.
2023年, Li等[78]假设图节点的表征包含相关部分和不相关部分, 相关部分能够预测节点类别的真正判别信息, 在分布偏移情况下是不变的, 不相关部分是随着域偏移而发生变化的非信息特征, 二者难以区分.针对这一问题, 提出OOD-GNN(Out-of-Distribution Generalized Graph Neural Network), 在复杂的分布偏移条件下学习OOD广义图表征.设计基于随机傅里叶特征和样本重加权的非线性图表征去相关方法, 消除相关性表征和不相关表征之间的统计依赖性, 提高模型的OOD泛化能力.其次, 针对大规模数据集整体进行优化训练时计算成本过高、分批次训练不共享信息、不能保证权重一致性的问题, 利用可扩展的全局-局部权重评估方法学习整个数据集的一致性权重.
2023年, Wu等[79]设计GNNSAFE, 同时采用异常值暴露方法设计GNN
基于设计神经网络模型的OOD检测方法能够较好地获取ID样本的表征, 区分ID样本和OOD样本, 提高检测精度, 但模型缺乏通用性.事实上, 2022年, Fang等[80]从可学习性角度研究OOD检测的PAC(Probably Approximately Correct).首先找到OOD检测可学习性的一个必要条件, 再利用此条件证明OOD检测可学习性的不可能定理(Impossibility Theorems).然后, 给出实际条件下OOD检测可学习性的充要条件, 其结论表明无法使用一种通用的方法处理所有场景中的OOD检测.因此, 针对不同任务场景设计OOD检测方法是合理且必要的.
目前, 针对大语义空间、多标签样本、ID类别不均衡、集成学习和图结构数据等, 已经有研究者提供基线方法, 有待开展更深入的研究.
基于设计神经网络模型的OOD检测方法发展过程如图6所示.
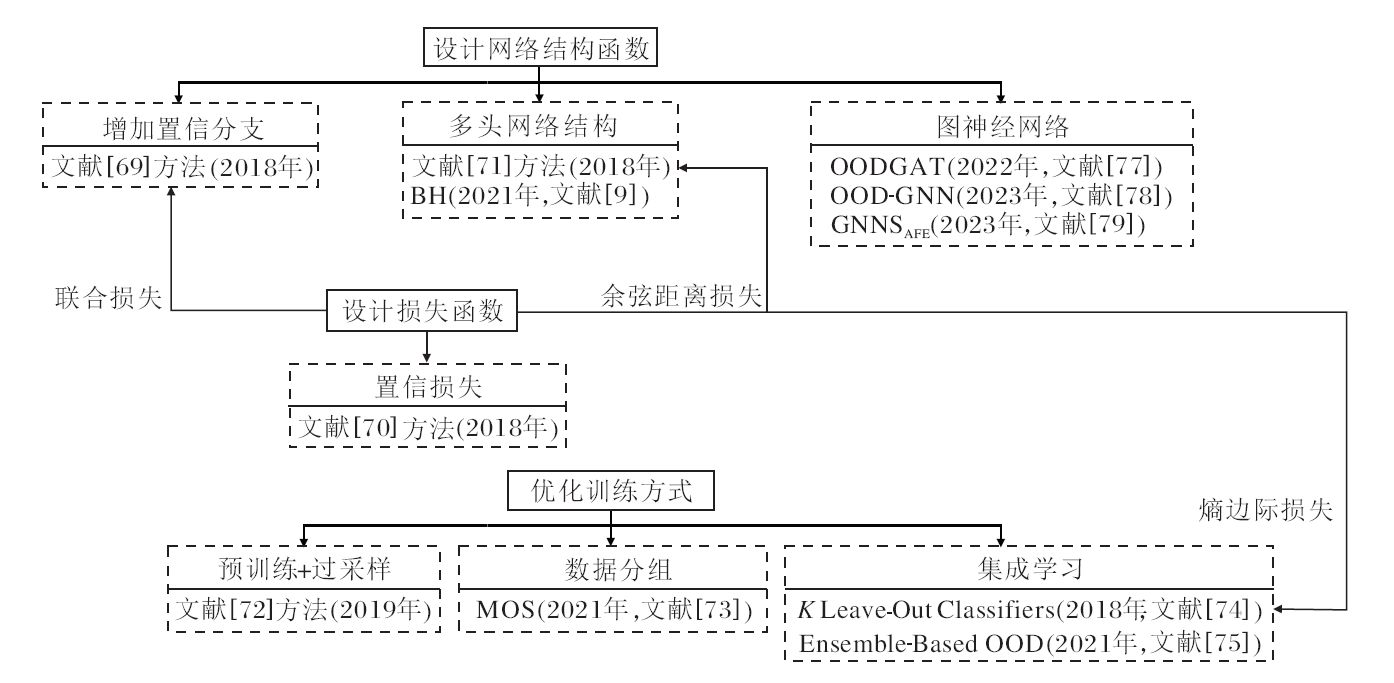 | 图6 基于设计神经网络模型的OOD检测方法Fig.6 OOD detection methods based on designing neural network model |
3.1.3 基于深度学习结合传统方法的OOD检测方法
传统机器学习有相对成熟的异常检测方法, 可利用深度神经网络提取特征, 结合传统异常检测方法检测OOD样本.
2018年, Papernot等[81]提出DKNN(Deep K-Nearest Neighbors), 使用神经网络提取的各层特征计算输入样本与其相邻的样本点之间的距离, 检测对抗性输入样本.DKNN采用基于局部敏感哈希的近似KNN(K Nearest Neighbor)提高搜索速度, 但仍需存储整个训练集用于推理.针对这一问题, 2021年, Lehmann等[82]对神经网络多个隐藏层特征进行聚类分析, 并根据每层特征聚类结果的交集判断测试样本是否为OOD, 相比DKNN, 层次聚类的方法推理速度更快, 仅保存每层的聚类信息.2022年, Sun等[83]设计KNN+, 利用预训练编码器获得训练集和测试集样本的特征嵌入, 计算测试样本与训练集特征嵌入之间的KNN距离, 基于阈值准则检测OOD样本.该方法采用非参数估计的方法, 样本特征空间不再受限于混合高斯分布, 适用于各种模型架构.
2022年, Hendrycks等[84]在自动驾驶模拟环境中研究多类别、多标签的图像OOD检测和异常分割问题, 采用数据增强技术, 结合隔离森林(Isolation Forest)[85]和局部离群因子(Local Outlier Factor)[86], 为多标签OOD检测提供基线和评估准则.
结合传统方法进行OOD检测主要应用神经网络的输出结合现有异常检测算法, 利用深度神经网络良好的特征提取能力.现有的预训练网络和异常检测算法都可以直接使用, 但特征提取和检测阶段相互独立, 检测精度很大程度上取决于网络提取的特征, 容易产生次优的样本评估值.
3.1.4 基于不确定性估计的OOD检测方法
OOD检测与不确定性估计密切相关, 在分类模型中输入一个OOD图像, 基于softmax分类的模型必然将该样本分到训练集类别中的某一类, 并且可能给出较高的预测概率, 因此模型不仅应给出预测结果, 还应判断结果的“不确定性”程度.深度学习中的不确定性有两种:1)由于观测样本中的固有噪声导致的偶然不确定性(Aleatoric Uncertainty), 该不确定性是无法被消除的; 2)由于模型训练不足导致的模型预测结果不确定性, 即认知不确定性(Epistemic Uncertainty), 也称模型不确定性.后者可通过利用更多的训练样本弥补现有模型知识上的不足进行消除.
2019年, Ovadia等[21]在数据偏移的前提下, 评估各种不确定性估计方法和指标, 研究数据偏移背景下不确定性估计方法的有效性.在独立同分布条件下不确定性校正随着数据偏移而减弱, 而独立同分布条件下的校正也不会直接转化为数据偏移下的校正.
2020年, Sedlmeier等[87]将OOD检测作为单分类问题, 在深度强化学习框架下提出基于不确定性估计的检测框架, 设计动态阈值进行OOD检测.
2020年, Yong等[88]认为自动编码器(Auto- Encoder, AE)[89]检测OOD失败的原因是使用伯努利似然法, 因此设计BAE(Bayesian Autoencoders), 采用高斯似然估计, 结合似然估计和不确定性估计, 使用集成方式提高检测精度.
2021年, Gao等[38]设计UEAOD, 基于注意力机制估计图像不同区域的不确定性, 利用特征加权, 提高模型的OOD检测能力.
针对OOD检测的不确定性估计存在计算复杂度较高的问题, 应进一步探索在数据偏移下保证预测精度, 同时降低计算和存储代价的方法.
基于度量学习的OOD检测方法训练神经网络拟合样本与特征之间的映射, 在该映射下ID样本的特征分布尽量紧凑, 通过计算样本距离和相似性检测OOD样本.
对比损失是深度度量学习的经典方法.2018年, Masana等[90]提出基于度量学习的检测方法, 将对比损失引入OOD检测, 使同类图像之间的距离更近, 不同类图像的距离更远.2020年, Winkens等[91]采用对比训练的方式检测OOD样本, 对原始图像进行几何变换, 获得增广样本, 设计对比损失, 使两个来自同一图像的样本对余弦相似性最大, 同时使两个来自不同图像的样本对的余弦相似性最小.
2018年, Ruff等[92]提出Deep SVDD(Deep Su- pport Vector Data Description), 训练神经网络将正常样本映射到超球中心点c附近, 基于距离判定异常样本.2020年, Ruff等[43]将Deep SVDD扩展到Deep SAD(Deep Semi-Supervised Anomaly Detection), 同时利用正常样本和辅助异常样本, 训练模型将正常样本映射到超球中心附近, 并将异常样本映射到远离中心的区域.测试阶段根据测试样本与超球中心的距离判断异常样本.2021年, Ruff等[93]又在Deep SAD基础上, 提出HSC(Hypersphere Classification)[93], 在标准交叉熵损失基础上, 将概率输出函数修改为径向基函数, 进一步提升检测精度.
2020年, Huang等[94]假设OOD样本在潜在特征空间集中分布, 将OOD特征空间的中心称为FSS(Feature Space Singularity), 样本特征到FFS的距离表示为FSSD(FSS Distance), 设置距离阈值检测OOD.
基于度量学习的OOD检测方法简单高效, 但设定一个全局中心点的方法在一定程度上约束图像背景, 容易受到训练集上OOD样本的干扰, 在训练中利用异常值暴露或辅助OOD样本可以增强模型鲁棒性, 学习到更紧凑和更具区别性的表征.
深度生成模型利用训练集显式或隐式地估计样本的概率密度分布, 通过随机采样生成不包含在训练集上的样本.应用深度生成模型的OOD检测方法主要有两类:基于概率密度估计的OOD检测方法和基于重构的OOD检测方法.
3.3.1 基于概率密度估计的OOD检测方法
深度生成模型利用概率密度估计检测OOD样本的基本假设是使用ID样本直接对样本分布p(x)建模, 在该模型下评估输入样本属于该分布的似然值, ID样本似然值较高, OOD样本似然值较低.
常用的深度概率生成模型有ARM(Autoregressive Model)、流模型Flow、VAE(Variational Autoencoder)[95]和GAN[39], 以下逐一梳理它们在OOD检测中的应用.
1)ARM.ARM利用链式准则以条件概率乘积表示联合概率分布, 其中最有影响力的是神经自回归网络模型.在图像处理领域, 经典的自回归网络模型有PixelRNN(Pixel Recurrent Neural Network)和Pixel-CNN(Pixel Convolutional Neural Network).PixelRNN将图像像素作为循环神经网络的输入, PixelCNN则利用卷积神经网络处理像素, 以似然函数为优化目标.
2019年, Nalisnick等[96]对比PixelCNN、VAE和流模型Glow, 发现PixelCNN几乎无法检测出与训练样本分布不同的输入样本, 并发现对给定的生成模型, 对抗性样本和未训练过的样本可能比训练集ID样本具有更高的似然值, 表明深度生成模型应该对OOD输入具有更高的敏感性.
针对深度生成模型利用似然值在OOD检测中失效, 2019年, Ren等[8]提出Likelihood Ratios度量.假设样本有语义主体和背景两部分组成, 分别训练语义模型和背景模型, 使用语义和背景模型构成的似然率检测OOD样本.
2020年, Serrà 等[97]认为不同数据集的图像复杂度具有很大差异, 当输入样本和测试样本显著不同时, 输入样本的复杂性对生成模型的似然值有一定影响, 据此设计Input Complexity, 包括负对数似然和输入复杂性的相反数两部分, 训练PixelCNN++和Glow, 估计输入样本的复杂性和似然值以获得有效的样本评估值.
2)流模型[98].流模型是一种基于可逆变换的概率生成模型, 将真实样本分布由转换函数映射到给定的简单分布, 简单分布与转换函数的逆函数构成一个生成模型.流模型可以显式估计样本的概率分布, 是一个精确模型.标准化流(Normalizing Flow)是最主要的流模型, 包括NICE(Nonlinear Indepen-dent Components Estimation)、Real NVP(Real-Valued Non-volume Preserving)和Glow三个模型.
2020年, Zisselman等[99]利用Normalizing Flows进行概率密度估计, 并设计适用于样本符合高斯分布的通用模型— — Residual Flow, 进行OOD检测.
同年, Kirichenko等[100]通过实验证实基于流学习的生成模型主要关注图像局部像素的相关性, 而不是语义信息, 这使语义异常的样本难以检测.通过修改流耦合层的结构优化流模型, 使其偏向于学习目标样本的语义, 提高OOD检测精度.
3)VAE.VAE以自编码器结构为基础, 假设隐变量服从正态分布, 使解码过程具有生成能力.优化的目标是使输入样本的概率分布与重构样本的概率分布差异尽量小, 采用近似方法优化似然函数变分下界.
2020年, Ramakrishna等[101]提出β-VAE, 利用生成的隐空间, 基于KL散度度量输入图像分布与训练集分布的相似性检测OOD.Sundar等[102]使用一个三阶段的方法, 将多标签数据集分成小的分区, 为每个分区训练一个β-VAE, 生成隐空间用于OOD检测.这项工作目前采用单一阈值的方法检测OOD, 未来会研究结合时间窗技术检测OOD.
2021年, Havtorn等[103]认为OOD检测错误的主要原因是低层特征可以跨数据集泛化, 在似然估计中起主导作用, 而区分ID样本和OOD样本的关键是高级语义特征, 据此设计Hierarchical VAEs, 并提出Likelihood-Ratio Score, 对每层特征计算似然率以检测OOD, 避免低层特征占主导.
同年, Choi等[104]提出ROSE(Robust Out-of-Dis-tribution Detection Score), 并应用于VAE和Glow, 在不同数据集上验证OOD检测性能, 采用加速算法提升检测效率, 降低内存消耗.该方法不需要异常值暴露、辅助模型和额外训练, 适用于单一深度生成模型.
4)GAN.GAN由生成器和判别器两部分构成, 通过博弈的形式训练神经网络, 分别优化判别器和生成器, 生成器生成逼真的伪样本, 判别器判断样本来自真实样本还是伪样本, 直至二者达到纳什均衡, 判别器无法正确判断样本来源, 生成器隐式地学习到真实样本的分布.
2018年, Choi等[105]提出一种生成模型集成式OOD检测方法(Generative Ensembles), 训练多个GAN, 并结合概率密度估计和不确定性估计, 检测OOD样本.
基于概率密度估计的OOD检测方法发展过程如图7所示.
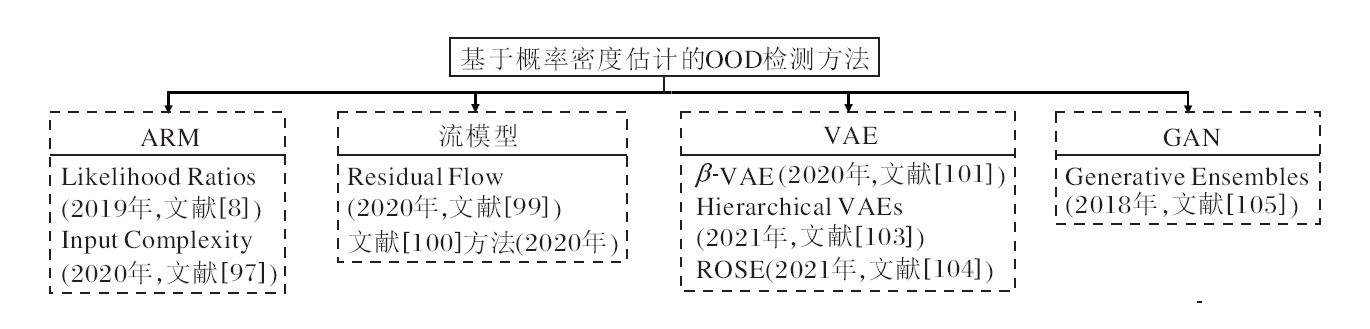 | 图7 基于概率密度估计的OOD检测方法Fig.7 OOD detection methods based on propability density estimation |
3.3.2 基于重构的OOD检测方法
基于重构的OOD检测方法假设利用ID样本训练的深度生成模型在重构样本时, ID样本产生的重构误差更小, 利用重构图像与原始图像的差异评估测试样本, 并能够定位异常区域.该类方法的要点是精确重构原始图像.常用于重构图像的两类模型有AE和GAN.
1)AE.AE包括编码器和解码器两部分, 训练完成后, 编码器可用作特征提取器, 解码器使用提取的特征重构输入原始图像, 利用重构图像和原始图像的差异衡量测试样本的异常程度[106].
2018年, Sabokrou等[107]在新颖性检测研究中发现新类样本难以压缩和重构, 开始以重构误差作为样本新颖性的度量, 在AE的基础上增加一个判别器, 通过对抗训练提升重构图像的质量.同年, Denouden等[108]认为基于重构的方法难以捕获与隐空间已知类别样本距离较远但与模型参数定义的流形(Manifold)距离较近的特定异常样本, 并将马氏距离和VAE的重构误差结合作为评估指标, 提升OOD检测精度.
2019年, Gong等[109]提出MemAE(Memory-Augmented Autoencoder), 增加记忆模块, 存储代表性特征向量, 提升重构的稳定性.2021年, Ma[110]提出ODDObjects, 在MemAE基础上提出MemCAE(Memory-Augmented Convolutional Autoencoders), 记忆模块能够帮助编码器和解码器创建更清晰、 准确的重构图像.同年, Zhang等[111]提出两个检测器LAMAE(Label-Assisted Memory Autoencoder)和LA-MAE+, 通过分类器和标签辅助的记忆增强单元调整自编码器的结构, 限制OOD样本的重构, 同时保留重构ID的能力, 结合考虑输入样本的复杂性改进重构误差.2022年, Zhang等[112]设计OOD-Aware AE, 并应用于化学流体动力学模拟.
2)GAN.第一个基于GAN的异常检测模型是AnoGAN[113], 使用重构图像与原始图像的残差定位缺陷, 效果良好, 但需要不断更新参数, 耗时较长, 不适用于实时检测任务.2018年, Zenati等[114]改进AnoGAN, 提出ALAD(Adversarially Learned Anomaly Detection), 避免更新参数的过程.在以上两项工作的基础上, Akcay等[115]提出GANomaly, 不再比较图像分布, 转而比较图像编码得到的隐空间, 根据两次编码得到的隐空间差异判定异常.
2021年, Han等[116]采用GAN集成的方法检测异常, 训练一组生成器和一组鉴别器, 每个生成器从多个鉴别器中得到反馈, 异常分数为所有编码器-解码器对计算出异常分数的平均值.相比单个GAN, GAN集成能更好地拟合正常样本的分布, 从而提升检测性能.
基于重构的OOD检测方法计算成本较高, 并且神经网络的瓶颈结构可能导致图像的正常区域重构误差较大, 正常样本较少则会导致过拟合.基于重构的OOD检测方法发展过程如图8所示.
 | 图8 基于重构的OOD检测方法Fig.8 OOD detection methods based on reconstruction |
大部分OOD检测是在图像分类的基础上进行, 图像数据集是OOD检测的主题, 目前常用于OOD检测的ID图像基准数据集有MNIST[117]、CIFAR-10[118]、CIFAR-100[118], 常用作OOD的样本包括场景数据集Fashion-MNIST[119]、Tiny-ImageNet[120]、Omniglot[121]、SVHN(Street View House Number)[122]、SUN(Scene Understanding Dataset)[123]、LSUN(Large-Scale Scene Understanding Dataset)[124]和合成噪声样本.具体数据集信息如表3所示.
| 表3 图像OOD检测常用数据集信息 Table 3 Commonly used datasets for out-of-distribution detection |
MNIST数据集是手写数字图像数据集, 包含10类手写数字图像.Fashion-MNIST数据集是替代MNIST的商品图像数据集, 图像数目、大小、格式、训练集与测试集划分都与MNIST数据集完全一致.CIFAR-10、CIFAR-100数据集是RGB三通道彩色图像数据集.CIFAR-10数据集包含10个类别, 共60 000幅图像.CIFAR-100数据集按层次划分, 共分为细粒度和粗粒度两个层次, 20个粗粒度大类被分成100个细粒度小类, 每幅图像有两个标签, 标志所属的小类和大类.ImageNet数据集是大规模带标签图像数据集, 约1 500万幅图像, 总计2.2万类.Tiny-ImageNet数据集是ImageNet数据集的子集, 包含200个不同类别的图像.Omniglot数据集是手写字母数据集, 包含50个不同语言的字母表, 共1 623种字符, 具有类别多、样本少的特点, 每个类别仅包含20个样本, 部分类别仅有10个样本, 是小样本学习常用的数据集.SVHN数据集来源于google街景房屋门牌号, 包含10个类别, 对应0~9的数字, 训练集包含73 257幅图像, 测试集包含26 032幅图像.SUN数据集是场景识别数据集, 共包含899个类别的130 519幅图像, 其中采样良好的常用图像有397类.LSUN数据集是大型场景分类图像数据集, 包含厨房、客厅、卧室、教室等10个场景类别和20个对象类别.
混淆矩阵是衡量分类模型最直观的方法, 在混淆矩阵中有4个基础指标:TP(True Positive)、FN(False Negative)、FP(False Positive)、TN(True Nega-tive).二分类混淆矩阵如表4所示.
| 表4 二分类混淆矩阵 Table 4 Confusion matrix for binary classification |
OOD检测中ID样本和OOD样本数量极不平衡, 在评价指标中需考虑样本数量的影响.常用衡量OOD检测指标如下.
1)TNR@95%TPR[52].真正例率(True Positive Rate, TPR)表示模型预测正样本数占全部真实正样本数的比例,
TPR=
真负例率(True Negative Rate, TNR)表示预测正确的负样本占全体负样本的比例,
TNR=
TNR@95%TPR表示真正例率TPR高达95%时的真负例率.
2)FPR@95%TPR[36].假正例率(False Positive Rate, FPR)指负样本被预测为正样本占总的负样本的比例, 也叫误检率、虚警率,
FPR=
FPR@95%TPR表示真正例率TPR高达95%时的假正例率.
3)Erro
Error=
考虑到测试集上OOD样本和ID样本数量比例悬殊, OOD检测的错误率为:
Erro
其中, λ 表示权重系数, 根据实验经验设置λ =0.5.
4)AUROC(Area Under the Receiver Operating Characteristic Curve)[2].直接评估分类器性能的常用指标之一, 也是评估OOD检测模型的重要指标, 表示由FPR为横坐标, TPR为纵坐标构成的ROC(Receiver Operating Characteristic)曲线下方的面积.AUROC是介于0到1之间的数值, 数值接近1时表示模型具有较好的分类能力.
5)AUPR(Area Under the Precision-Recall Cur-ve)[2].由正确率(Precision)和召回率(Recall)构成的PR曲线下的面积, 其中,
Precision=
Recall=
AUPR是与阈值无关的独立度量标准, 也常常用作衡量OOD检测模型的指标.AUPR值受正样本数量影响, 通常ID作为正样本, OOD作为负样本时记AUPR-In, OOD作为正样本, ID作为负样本时记为AUPR-Out.
目前OOD检测普遍使用一个数据集作为ID样本, 将其它数据集的部分样本作为OOD样本.表5统计典型的OOD检测方法的实验结果, 数据来自相关文献.各方法使用的数据集不尽相同, 主要选取在CIFAR-10、SVHN数据集上的实验结果.
| 表5 典型OOD检测方法的实验结果 Table 5 Experimental results of typical out-of-distribution detection algorithms |
各算法使用的主干网络结构、数据集和数据预处理的方式不尽相同, 并且OOD样本与ID样本越相似检测难度越大, 实验结果没有绝对的可比性.从总体实验结果上看, 目前OOD检测性能提升主要集中在以下方面.
1)更加精细的样本评估指标.MSP置信度[2]和Generalized ODIN的分解置信度[50]等基于分类模型的输出设计样本评估指标.Mahalanobis Distance[52]和RMD[54]等从基于距离的度量设计样本评估指标.KDE[57]和Likelihood Ratios[8]等基于概率密度估计设计样本评估指标.Energy-Based OOD[60]、MOOD[61]和GNN
2)增强特征利用效率.各层特征对分类和OOD检测的作用不同, 充分利用不同层次的特征有助于检测OOD样本[40, 52, 53, 54, 55, 56, 57, 58, 61], 利用各层和各通道的特征检测OOD样本, 取得良好效果.不同含义的特征对OOD检测的重要性不同, OOD检测源于数据存在语义偏移, 因此语义特征是关键特征.Likelihood Ratios[8]区分背景和主体特征, FS-OOD[68]区分语义特征和非语义特征, 其核心均为提取语义特征检测OOD样本.UEAOD[38]利用注意力机制对图像的不同区域进行不确定性估计, 充分利用全局特征和局部特征.增强特征的利用效率能够提高分类和OOD检测精度.
3)良好的样本预处理方法.ODIN[36]对输入数据加入扰动, 增大神经网络分类器模型softmax预测概率的分布差异, 有效提高OOD检测的精度, 成为广泛使用的OOD检测预处理方法之一.CutMix[67]采用像素填充的方式进行数据增强, 提升OOD检测精度.文献[97]从输入图像数据的复杂性考虑, 利用Input Complexity结合似然值检测OOD样本, 获得良好效果.对输入数据进行恰当的预处理能够提升OOD检测精度.
4)更复杂的网络结构和损失函数.最早的OOD检测方法MSP[2]采用分类模型常用的交叉熵损失, 提供OOD检测基线.文献[69]方法在网络中增加置信度分支, 并在损失函数中增加置信损失.Masana等[90]首次将对比损失引入OOD检测, Ensemble-Based OOD检测方法[75]结合两种网络模块提取和融合特征.UEAOD[38]结合注意力图, 基于不确定性估计检测OOD.OODGAT等[77]设计基于GNN的网络模型, 检测图结构数据中的OOD节点.随着损失函数和网络结构越来越复杂, 可增强深度神经网络的特征提取能力, 也进一步提升OOD检测精度.但是, 模型复杂需占用更多的计算资源, 如能解决模型轻量化问题, 实现快速检测, 将大幅提升模型的实用性.
近年来, OOD检测发展迅速, 在图像识别、自然语言处理等领域成就瞩目.OOD检测是对传统封闭场景下识别问题的突破, 能够通过OOD检测算法识别已知类样本并检测未知类样本, 提升机器学习算法对未知类样本的鲁棒性.
OOD检测是一个新的领域, 现有算法还存在一些不足, 本节根据现有算法的不足, 讨论OOD检测的未来研究方向.
1)真实场景的OOD数据集.真实世界的样本类别丰富, OOD样本未知性强, 目前各种方法的实验通常将一个数据集(如CIFAR10数据集)作为ID样本, 选取其它数据集(SVHN、Tiny-ImageNet、LSUN数据集等)的部分样本作为OOD样本, 而不同工作场景需要分类的图像千差万别, 构建适用于OOD检测的真实场景数据集是十分必要的.首先, 目前主要在CIFAR等数据集上进行研究和评估, 样本分辨率低、类别少, 不能有效转换到大规模语义空间, 而在高分辨率图像、大规模场景中进行OOD样本检测更符合实际需求.其次, 现有OOD检测方法主要针对数据存在语义偏移的情况, 在真实世界中, 模型面临的数据很可能同时存在语义偏移和特征偏移, 研究两种偏移并存的OOD检测极其重要.最后, 现有OOD检测在计算机视觉方面的研究主要集中在图像分类, 在语义分割和目标检测中仍有待研究.
2)增量学习.OOD检测本质上是解决开放环境检测问题, 但现有的检测方法大多还是基于封闭假设的, 在封闭的训练集上训练模型, 根据得到的模型预测样本标签和样本评估值, 并将评估值较低的样本认定为OOD样本.当ID样本类别增加时, 需重新训练模型.目前增量学习已经引起学者们的关注, 在检测的初期面临标注样本缺乏的问题, 随着越来越多样本进入系统, 识别到的新类别应该更新到分类器, 逐步扩大类别空间, 提高识别精度.增量学习OOD检测在许多场景更符合实际需求, 将增量学习和OOD检测结合有利于OOD检测技术的落地应用.
3)轻量化网络设计.图像样本是典型的高维样本, 现有的检测方法得益于神经网络强大的学习能力, 但需要较长的计算时间和较大的计算量, 因此需要降低计算和存储代价, 设计更轻量化的网络结构, 减少计算量和运行时间, 同时也能降低对硬件设备的要求, 为实际生产现场部署节约设备成本.这一问题的解决方法主要有轻量模型设计和模型压缩, 有待后续研究针对OOD检测设计轻量化网络.
4)相关领域交叉研究.OOD检测相关领域有带拒绝的分类、主动学习、新颖性检测、开放集识别和对抗样本防御等, 各领域的任务不尽相同, 但有相似之处, 共同目标是提高深度模型的鲁棒性.各研究路线之间相互交叉, 可互相借鉴, 梳理各路线之间的关联, 寻找鲁棒性深度模型的一般目标.另外, 目前研究大部分基于实验分析, 缺乏统一框架, 在理论分析方面存在空白, 亟待研究.
OOD检测是近年来深度学习领域新兴的研究热点, 它针对开放性应用, 摆脱训练集样本和测试集样本独立同分布的封闭假设.在深度学习分类任务的基础上能够检测出训练集上未知类别的样本, 对提高深度模型的可靠性具有重要意义.本文首先梳理OOD检测的形成和应用、OOD检测的类型、定义以及相关研究领域, 然后总结无监督OOD检测、有监督OOD检测、半监督OOD检测、异常值暴露OOD检测, 重点从神经网络分类器、度量学习和深度生成模型方面分析相关研究工作.OOD检测是新兴的研究领域, 有许多问题亟待解决, 并且可以与相关领域相互交叉借鉴.随着研究的深入进行, OOD检测算法将更加成熟, 深度学习模型将更加安全可靠.
本文责任编委 兰旭光
Recommended by Associate Editor LAN Xuguang
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|
| [47] |
|
| [48] |
|
| [49] |
|
| [50] |
|
| [51] |
|
| [52] |
|
| [53] |
|
| [54] |
|
| [55] |
|
| [56] |
|
| [57] |
|
| [58] |
|
| [59] |
|
| [60] |
|
| [61] |
|
| [62] |
|
| [63] |
|
| [64] |
|
| [65] |
|
| [66] |
|
| [67] |
|
| [68] |
|
| [69] |
|
| [70] |
|
| [71] |
|
| [72] |
|
| [73] |
|
| [74] |
|
| [75] |
|
| [76] |
|
| [77] |
|
| [78] |
|
| [79] |
|
| [80] |
|
| [81] |
|
| [82] |
|
| [83] |
|
| [84] |
|
| [85] |
|
| [86] |
|
| [87] |
|
| [88] |
|
| [89] |
|
| [90] |
|
| [91] |
|
| [92] |
|
| [93] |
|
| [94] |
|
| [95] |
|
| [96] |
|
| [97] |
|
| [98] |
|
| [99] |
|
| [100] |
|
| [101] |
|
| [102] |
|
| [103] |
|
| [104] |
|
| [105] |
|
| [106] |
|
| [107] |
|
| [108] |
|
| [109] |
|
| [110] |
|
| [111] |
|
| [112] |
|
| [113] |
|
| [114] |
|
| [115] |
|
| [116] |
|
| [117] |
|
| [118] |
|
| [119] |
|
| [120] |
|
| [121] |
|
| [122] |
|
| [123] |
|
| [124] |
|