
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于融合池化和注意力增强的细粒度视觉分类网络
[肖斌1  , 郭经伟
, 郭经伟1 , 张兴鹏1 , 汪敏2 ]
, 郭经伟, 张兴鹏, 汪敏]
|
|



作者简介:

肖 斌,硕士,教授,主要研究方向为模式识别.E-mail:xiaobin@swpu.edu.cn.

郭经伟,硕士研究生,主要研究方向为细粒度视觉分类.E-mail:guojingwei459@163.com.

汪 敏,硕士,教授,主要研究方向为人工智能、信号分析与处理.E-mail:wangmin80616@163.com.
细粒度视觉分类核心是提取图像判别式特征.目前大多数方法引入注意力机制,使网络聚焦于目标物体的重要区域.然而,这种方法只定位到目标物体的显著特征,无法囊括全部判别式特征,容易混淆具有相似特征的不同类别.因此,文中提出基于融合池化和注意力增强的细粒度视觉分类网络,旨在获得全面判别式特征.在网络末端,设计融合池化模块,包括全局平均池化、全局top- k池化和两者融合的三分支结构,获得多尺度判别式特征.此外,提出注意力增强模块,在注意力图的引导下通过注意力网格混合模块和注意力裁剪模块,获得2幅更具判别性的图像参与网络训练.在细粒度图像数据集CUB-200-2011、Stanford Cars、FGVC-Aircraft上的实验表明文中网络准确率较高,具有较强的竞争力.
About Author:
XIAO Bin, master, professor. His research interests include pattern recognition.
GUO Jingwei, master student. His research interests include fine-grained visual classification.
WANG Min, master, professor. Her research interests include artificial intelligence and signal analysis and processing.
The core of fine-grained visual classification is to extract image discriminative features.In most of the existing methods, attention mechanisms are introduced to focus the network on important regions of the object.However, this kind of approaches can only locate the salient feature and cannot cover all discriminative features. Consequently, different categories with similar features are easily confusing. Therefore, a fine-grained visual classification network based on fusion pooling and attention enhancement is proposed to obtain comprehensive discriminative features. At the end of the network, a fusion pooling module is designed with a three-branch structure to obtain multi-scale discriminative features. The three-branch structure includes global average pooling, global top- k pooling and the fusion of the previous two. In addition, an attention enhancement module is proposed to gain two more discriminative images through attention grid mixing module and attention cropping module under the guidance of attention maps. Experiments on fine-grained image datasets, CUB-200-2011, Stanford Cars and FGVC-Aircraft, verify the high accuracy rate and strong competitiveness of the proposed network.
细粒度视觉分类(Fine-Grained Visual Classifi-cation, FGVC)是图像分类中的一个分支, 旨在识别特定类别的子类, 如不同种类的鸟、汽车等.然而, 由于姿势、背景、光照等因素, 该任务存在类内方差大、类间方差小等难题, 所以现阶段FGVC是一项极具挑战的任务[1].
卷积神经网络(Convolutional Neural Network, CNN)提取物体之间的显著性差异, 在图像分类领域表现优异.但是, FGVC通常需要多个判别式特征, 而CNN却只能提取最显著的图像特征, 所以这种现象可能会导致其在FGVC领域的效果不佳.因此, 对于FGVC任务, 需要针对性地设计网络结构和相应的特征提取方法, 达到较优的分类效果.
在FGVC研究中, 通常将方法分为强监督方法和弱监督方法两类, 具体取决于是否使用额外标注的判别式特征.
强监督方法通过手工标注判别式特征, 让CNN更关注类别之间的微小差异, 从而提高模型的识别性能.Zhang等[2]结合全局特征检测器和局部特征检测器, 引导网络更多地关注类别之间的细节差异.Branson等[3]采用姿势归一化的方法以减少类内方差、提高分类准确率.Zhang等[4]提出SPDA-CNN, 通过检测器获取局部语义特征, 并用于分类.Huang等[5]提出PS-CNN(Part-Stacked CNN), 通过对局部块的堆叠建模图像局部之间的细微差异, 明确细粒度识别的过程.然而, 手动标注局部特征需要大量的时间和人力成本, 限制方法的广泛应用.
与强监督方法不同, 弱监督方法仅依靠类别标签进行分类, 核心是通过注意力机制使模型更关注图像的细粒度特征.Fu等[6]提出RA-CNN(Recu-rrent Attention CNN), 是一种多阶段网络, 每个阶段都利用注意力机制裁剪最显著的区域, 并输入到下一个阶段中进行学习.为了解决RA-CNN只关注目标物体最显著区域的问题, Zhang等[7]提出MA-CNN(Multi-attention CNN), 使用多注意力卷积神经网络学习局部特征, 增强局部特征和精细特征之间的相互关系.Hu等[8]提出WS-DAN(Weakly Su-pervised Data Augmentation Network), 通过1× 1卷积生成32幅注意力图, 并从中随机选择两幅, 一幅用于放大图像中最显著的部分, 另一幅用于遮盖最显著的部分, 再将数据增强生成的两幅图像输入网络中, 增强模型的泛化能力.这种数据增强方式可以让网络既关注图像的最显著部分, 同时也关注除最显著部分之外的其它判别式特征, 是对RA-CNN的一种改进.
上述方法表明, FGVC的核心在于捕获目标物体的多尺度特征, 除了最显著特征之外, 还需要提取目标物体的额外细节信息.
除强监督方法和弱监督方法这种借助于辅助信息的细粒度视觉分类方法以外, 近期学者们提出很多基于Vision Transformer(ViT)[9]的方法[10, 11].比较具有代表性的就是TransFG[1], 主要工作是提出PSM(Part Selection Module), 选择与物体目标区域相关度较大的图像块, 这种方式还能一定程度地避免背景噪声的干扰.大量研究表明, 基于ViT的方法在细粒度图像数据集上取得优异结果, 但是此类方法整体实现的复杂度很高.
由于FGVC需要多个判别式特征, 所以特征融合方法也能在一定程度上提高其性能.在很多工作[12, 13, 14, 15]中, 融合不同尺度的特征是提高分类性能的一个重要手段.低层特征感受野较小, 包含更多位置、细节信息, 但是由于经过的卷积更少, 语义性更低、噪声更多.高层特征感受野较大, 具有更强的语义信息, 但是对细节感知能力更差.
在FGVC中, 往往需要图像的很多细节信息, 所以特征融合方法也适用于FGVC.ResNet[12]使用跳跃连接(Skip Connection)实现深层特征和浅层特征融合.Huang等[13]在DenseNet中使用拼接(Concat)的方式融合不同层的特征, 拼接两个特征向量, 拼接后的特征向量维数是两个特征向量的维数和.特征金字塔(Feature Pyramid Network, FPN)[14]将浅层特征、中层特征、高层特征进行金字塔融合, 分别分类.Lin等[15]提出B-CNN(Bilinear CNN), 将特征表示为两个CNN的外积, 并以平移不变的方式获取局部特征交互.这种方式能够显著提高分类性能, 却会带来很多计算和内存消耗.
对比上述特征融合方式, 发现跳跃连接和拼接这两种方式比较轻量级, 而特征金字塔和双线性池化则需要更多的计算力和显存.
此外, 在FGVC领域中存在图像数据集少的问题, 然而深度学习方法需要大规模的数据集以训练模型, 因此出现大量的数据增强方法[16, 17, 18, 19]以实现数据集的扩充.
数据增强主要包括有监督的数据增强和无监督的数据增强.有监督的数据增强又分为单样本数据增强和多样本数据增强.
单样本数据增强是在增强一个样本时, 对样本本身进行操作, 主要包括几何变换和颜色变换.几何变换包括旋转、裁剪、缩放、翻转等操作.通过对样本进行几何变换, 能够利用CNN的平移不变性增强模型的鲁棒性.颜色变换则是向原始样本中加入一些噪声数据或对其进行擦除和填充, 扩充数据集和增强模型的泛化能力.
相比单样本数据增强, 多样本数据增强是利用多个样本产生新的样本.De Vries等[16]提出Cutout, 随机删除样本的某个区域, 并将删除的区域使用0进行填充.Zhong等[17]改进Cutout, 提出Random Erasing, 在数据填充部分使用均值进行填充.Zhang等[18]提出Mixup, 将两个样本每个位置的像素按照一定的比例进行叠加, 对应的标签按照像素叠加的比例进行分配.Yun等[19]提出CutMix, 随机删除一个矩形区域, 再将另一张样本上对应位置的像素值进行填充, 对应标签按照混合后不同类别的面积比例进行分配.由于CutMix会引入背景噪声数据, 因此在训练过程中迭代速度较慢.
在无监督的数据增强领域中, 主要是利用模型学习样本数据的分布, 再随机生成与训练分布一致的图像, 代表方法为GAN(Generative Adversarial Net-works)[20]、Conditional GANs[21].另一种是利用模型学习适合当前任务的数据增强方式, 代表方法为AutoAugment[22].
因此, 为了解决FGVC需要多个判别式特征和数据集数量少的问题, 本文提出基于融合池化和注意力增强的细粒度视觉分类网络, 主要包含轻量且高效的特征融合模块(称为融合池化模块(Fusion Pooling Module, FPM))和注意力增强模块(Atten-tion Enhancement Module, AEM).FPM在不引入大量参数和计算的方式下, 提高模型的细粒度识别能力.主要操作如下:首先, 将CNN中最具语义信息的特征分别进行全局平均池化和全局top-k池化, 让模型关注最显著特征和细粒度特征, 同时将两个池化特征进行拼接, 生成融合特征, 再将三个特征送入分类器中输出预测结果.AEM是针对于细粒度数据集图片少的特点提出的.核心操作为:将CNN最深层特征按照通道维度取平均, 得到一幅注意力图.对上述操作生成的注意力图, 首先按照阈值裁剪目标物体最显著的部分并放大到原图大小.然后根据注意力图筛选图像中最显著的N个部位, 将N个部位的图像混合到另一幅图像上.最后将上述两种方式得到的图像再输入网络中参与模型训练.结果表明, 本文网络在细粒度视觉分类任务上取得较令人满意的效果, 由此验证网络的有效性.
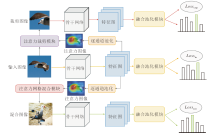
本文提出基于融合池化和注意力增强的细粒度视觉分类网络.网络结构是一个多分支网络, 包括原始输入分支、裁剪分支、混合分支, 具体结构如图1所示.此网络结构由融合池化模块(FPM)和注意力增强模块(AEM)组成.注意力增强模块由注意力网格混合(Attention Grid Mixing, AGM)子模块和注意力裁剪(Attention Cropping, AC)子模块组成.
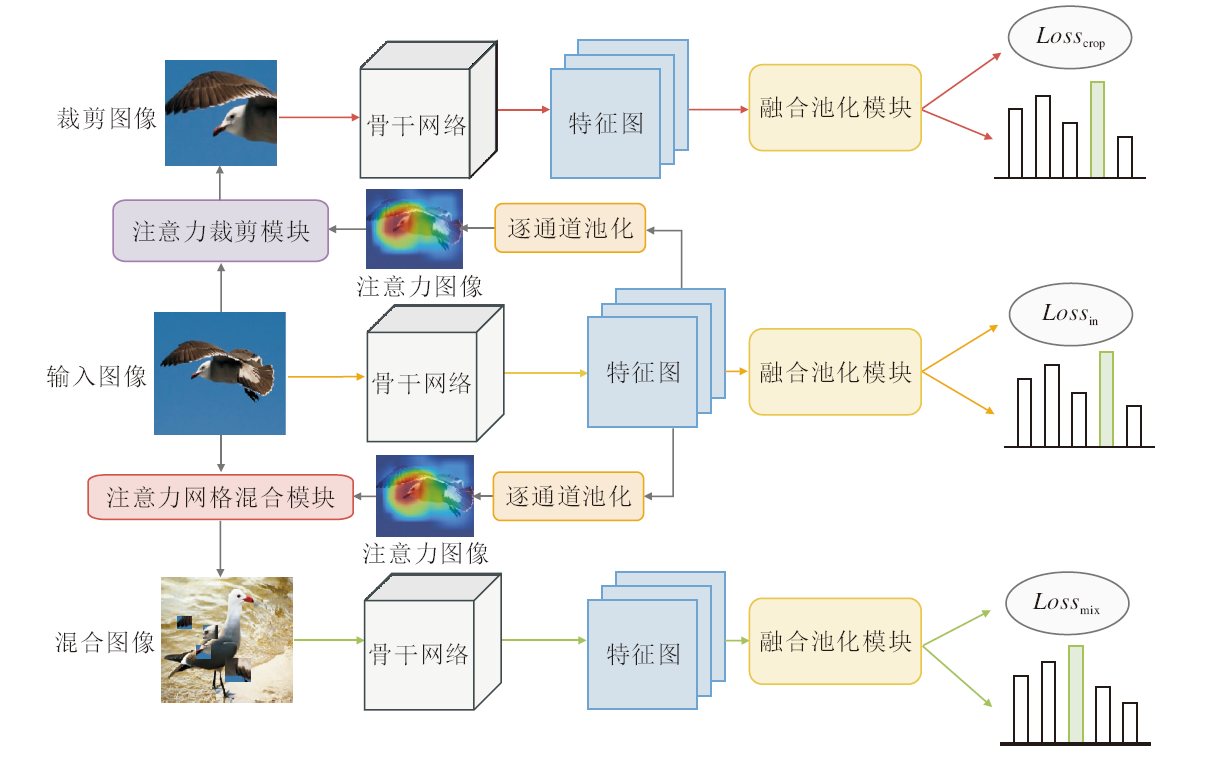 | 图1 本文网络结构图Fig.1 Structure of the proposed network |
网络整体流程如下.在原始输入分支中, 首先给定一幅输入图像Xin∈ RC× H× W, C表示输入图像的通道数, H、W分别表示输入图像的高和宽.经过骨干网络(Backbone)进行特征提取, 输出特征图Fin∈ Rc× h× w, c表示特征图Fin的通道数, h、w分别表示Fin的高和宽.再将得到的特征图Fin进行逐通道池化, 得到一幅注意力图A∈ R1× h× w.然后, 将注意力图A分别输入AGM和AC, 得到两幅形状和Xin一致的图像Xmix和Xcrop.将Xmix和Xcrop输入到混合分支和裁剪分支的Backbone中, 得到特征图Fmix和Fcrop, 不更新Backbone参数, 三个分支的Backbone互相分享权重.最后, 分别将特征图Fin、Fmix、Fcrop输入FPM中, 并相加3个分支的损失Lossin、Lossmix、Losscrop.不断进行迭代收敛, 得到最优网络.
在训练阶段, 使用所有分支共同训练网络.在测试阶段时, 仅使用原始输入分支获得最终分类的结果.
1.2.1 注意力网格混合模块
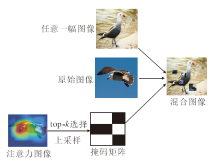
针对数据集样本少的问题, 目前大部分的解决方法是通过数据增强的方式提高模型的泛化能力, 常见的数据增强方式有Cutout、Random Erasing、Mixup、CutMix.上述方法都是随机处理图像, 这种方式会带来很多噪声数据, 并且存在收敛较慢的问题.为了解决上述问题, 本文提出注意力网格混合模块(AGM), 主要在注意力的引导下将图像的指定部分混合到同一批次的图像上, 从而能够避免裁剪到大量的背景噪声数据.
AGM的中心思想如下.通过两个不同的训练样本(xraw, yraw)和(xrandom, yrandom), 创建一个新的训练样本(xmix, ymix), 其中, xraw∈ RC× H× W表示当前输入的训练图像, yraw表示当前输入图像的标签, xrandom∈ RC× H× W表示除当前图像外同一批次的随机一幅图像, yrandom表示当前图像的标签.和CutMix相似, 本文训练图像和标签的组合操作如下:
xmix=Mask☉xraw+(1-Mask)☉xrandom, ymix=λ yraw+(1-λ )yrandom. (1)
其中:Mask∈ {0, 1}W× H表示一个掩码矩阵, 这个掩码矩阵中值为1的部分需要被保留, 值为0的部分需要被舍弃; ☉表示掩码矩阵Mask和训练图像x逐元素相乘; λ 表示混合后的图像xmix中xraw所占比例.
AGM结构如图2所示.首先将原始图像输入分支生成的注意力图A∈ R1× h× w按照像素值进行排序, 选择最大的N个值并将其设置为1, 其余值设置为0, 再上采样到原图大小, 最终得到一个掩码Mask, 其中
λ =
然后根据式(1)以及上述流程得到的Mask和λ , 生成新的训练样本(xmix, ymix).
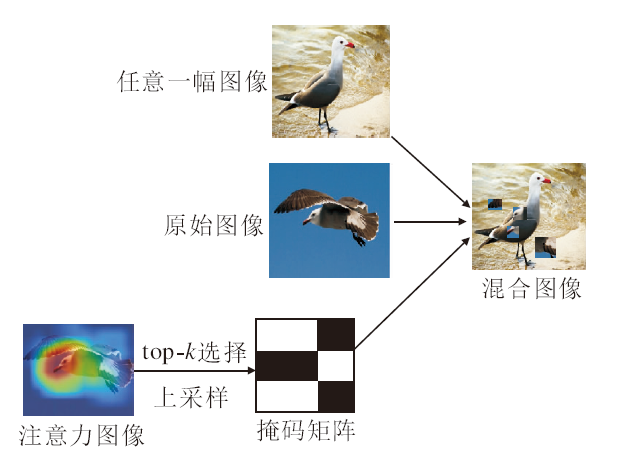 | 图2 AGM结构图Fig.2 Structure of AGM |
相比CutMix随机生成的掩码矩阵Mask, AGM通过注意力图的方式生成掩码矩阵Mask, 能够防止引入大量的背景噪声数据.
1.2.2 注意力裁剪模块
在细粒度视觉分类的弱监督方法中, 图像显著部位裁剪处于重要位置, 于是本文提出注意力裁剪模块(AC), 提升分类准确率.
AC模块具体流程如下.首先为了后续能够更好地裁剪出目标物体中最显著的部分, 将原始输入分支得到的注意图A∈ R1× h× w中的值归一化到0和1之间, 具体操作如下:
A*=
然后按照设置的阈值θ筛选注意力图A*中的像素点, 将大于此阈值的像素点设置为1, 反之设置为0, 最终得到一个裁剪掩码C:
C(i, j)=
其中(i, j)表示注意力图的行和列的像素索引.
AC结构如图3所示, 将上述操作得到的掩码C上采样到原图大小, 并将掩码中值为1的部分裁剪后放大到原图大小, 最终获得注意力裁剪后的图像Xcrop.
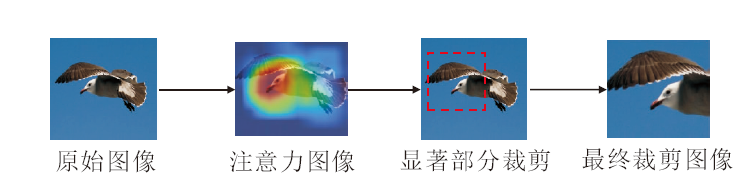 | 图3 AC结构图Fig.3 Structure of AC |
细粒度视觉分类需要提取多个判别式特征, 并且各个特征存在大小不同的问题, 所以常见的解决方式是通过融合不同层输出特征的方式捕捉多个尺度的特征, 但是这种方法会提升模型的整体复杂度, 带来大量的模型参数.较常见的特征融合方法有特征金字塔和双线性池化.受MGE-CNN[23]的启发, 本文提出一种高效且轻量级的特征融合模块, 称为融合池化方法模块(FPM).FPM结构如图4所示, 通过融合不同池化方法以获取更具判别力的特征.
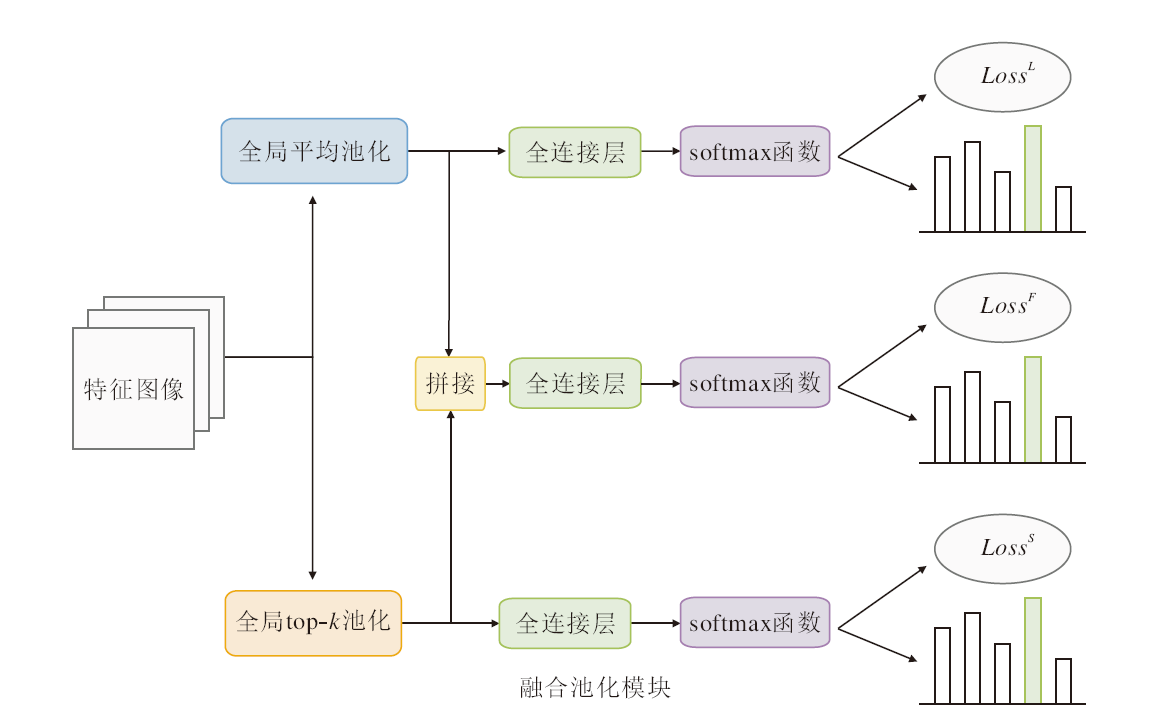 | 图4 FPM结构图Fig.4 Structure of FPM |
FPM模块主要是对全局平均池化和全局top-k池化的融合.全局平均池化在CNN中常用于代替全连接层, 主要是对每个通道特征图的值取平均, 表示较大感受野的综合特征.全局top-k池化则是对全局最大池化的一种改进, 对每个通道特征图中最大的k个值取平均.相比全局平均池化, 全局top-k池化更关注是否有特定的空间位置被卷积核激活, 所以学习到的是多个局部点的特征.总之, 全局平均池化关注大区域, 全局top-k池化关注小区域, 所以融合两种池化方式能够提取到多个尺度下的图像特征.
本文网络共分为原始输入分支、裁剪分支、混合分支, 三个分支得到的特征图分别为Fin、Fmix、Fcrop.以原始输入分支的特征图Fin为例, 阐述FPM的运行原理.
分别对特征图Fin∈ Rc× h× w进行全局平均池化和全局top-k池化并拉平, 最后得到两个特征向量:
$\begin{aligned} & \boldsymbol{F}_{\text {in }}^1=\text { Flatten }\left(\operatorname{GAP}\left(\boldsymbol{F}_{\text {in }}\right)\right) \in \mathbf{R}^{c \times h_1 \times w_1}, \\ & \boldsymbol{F}_{\text {in }}^2=\text { Flatten }\left(\operatorname{GTKP}\left(\boldsymbol{F}_{\text {in }}\right)\right) \in \mathbf{R}^{c \times h_1 \times w_1}, \end{aligned}$ (2)
其中, GAP(·)表示全局平均池化, GTKP(·)表示全局top-k池化.
由于两种池化方式关注不同的区域, 所以对两个特征向量进行融合能够得到更具判别力的特征.于是使用拼接的方式进行特征融合, 拼接后的特征为
FPM的3个输出使得最终的收敛模型能够基于物体的显著特征、融合特征、细粒度特征进行分类预测, 则相应损失为:
$\begin{aligned} & \operatorname{Loss}_{\mathrm{in}}^L\left(\boldsymbol{y}_{\mathrm{in}}^L, \boldsymbol{y}_{\mathrm{in}}^T\right)=C E\left(\boldsymbol{y}_{\mathrm{in}}^L-\boldsymbol{y}_{\mathrm{in}}^T\right), \\ & \operatorname{Loss}_{\mathrm{in}}^F\left(\boldsymbol{y}_{\mathrm{in}}^F, \boldsymbol{y}_{\mathrm{in}}^T\right)=C E\left(\boldsymbol{y}_{\mathrm{in}}^F-\boldsymbol{y}_{\mathrm{in}}^T\right), \\ & \operatorname{Loss}_{\mathrm{in}}^S\left(\boldsymbol{y}_{\mathrm{in}}^S, \boldsymbol{y}_{\mathrm{in}}^T\right)=C E\left(\boldsymbol{y}_{\mathrm{in}}^S-\boldsymbol{y}_{\mathrm{in}}^T\right), \end{aligned}$ (3)
其中
则原始输入分支的总损失为:
Lossin=
对于注意力网格混合模块和注意力增强模块的特征图分支Fmix、Fcrop, 同样可以使用式(2)~式(4)得到分支的总损失, 即
Lossmix=
Losscrop=
网络的总损失为3个分支的损失之和:
Losstotal=Lossin+Lossmix+Losscrop.
这三个分支在反向传播过程中共同优化网络性能.
为了验证本文网络的有效性, 在CUB-200-2011[24]、Stanford Cars[25]、FGVC-Aircraft[26]这3个细粒度视觉分类数据集上进行实验, 使用官方标准划分的训练集和测试集.CUB-200-2011数据集在细粒度视觉分类任务中最具代表性, 各类别之间极易混淆.数据集包含属于鸟类的200个子类别的11 788幅图像, 其中, 5 994幅图像用于训练, 5 794幅图像用于测试.Stanford Cars数据集由196 类汽车组成, 共有16 185幅从车尾拍摄的图像.数据被分成几乎1∶1的训练/测试分割, 包含8 144幅训练图像和8 041幅测试图像.FGVC-Aircraft数据集包含10 200幅飞机图像, 102种不同的飞机模型变体各有100幅图像, 其中大部分是飞机.
本文实验选择PyTorch 1.8.0作为深度学习环境, 训练机器使用NVIDIA GTX 3090.本文选用在ImageNet[27]上预训练的ResNet50作为骨干网络.在训练阶段, 采用随机裁剪和水平翻转的方式进行数据集扩充, 再将图像尺寸设置为448× 448.测试阶段先进行中心裁剪, 再进行尺寸设置.
超参数设置如下:FPM中全局top-k池化中k=4, AGM中N=32, AC中阈值θ=0.5.在训练过程中, 迭代次数设置为100, 采用随机梯度下降(Stochastic Gradient Descent, SGD)优化器, 具体参数如下:动量为 0.9, 权重衰减为5e-4, 学习率为0.001, 批次大小设置为12.
本节选择如下细粒度视觉分类中的弱监督网络进行对比实验:RA-CNN[6]、MA-CNN[7]、WS-DAN[8]、B-CNN[15]、NTS-Net(Navigator-Teacher-Scrutinizer Net-work)[28]、MAMC(Multi-attention Multi-class Cons-traint)[29]、DCL(Destruction and Construction Lear-ning)[30]、ACNet(Attention Convolutional Binary Neu-ral Tree Architecture)[31].
分别选择VGG-19[32]和ResNet50作为骨干网络, 各网络在3个数据集上的分类准确率如表1所示, 表中-表示当前方法在对应的数据集上未进行实验, 表中对比结果严格引自原论文.
| 表1 各方法在3个数据集上的分类准确率对比 Table 1 Classification accuracy comparison of different networks on 3 datasets % |
如表1所示, 本文网络以ResNet50作为骨干网络, 在CUB-200-2011、Stanford Cars、FGVC-Aircraft数据集上的分类准确率分别为88.6%、93.1%、94.2%, 几乎为最优, 只在Stanford Cars数据集上, 比WS-DAN降低0.4%, 比ACNet降低0.2%.综上所述, 本文网络能够在细粒度数据集上达到优异的分类性能.
为了验证本文网络各模块的有效性, 设置如下消融实验:分别将网络的FPM、AGM、AC加入骨干网络(ResNet50), 求得的实验结果如表2所示.
| 表2 本文网络在3个数据集上的消融实验结果 Table 2 Ablation experiment results of the proposed network on 3 datasets % |
由表2可以得出, 在ResNet50加上FPM, 在CUB-200-2011、FGVC-Aircraft、Stanford Cars数据集上分类准确率分别上升2.4%、2.6%、1.3%.再加上AGM, 准确率又分别上升1.3%、1.1%、1.3%.最后加上AC, 准确率再次上升0.9%、1.3%、0.9%.综上所述, 通过对网络的三个模块分别进行消融实验, 证实三个模块都具有一定的有效性.
为了验证FPM的有效性, 分别在CUB-200-2011数据集上对全局平均池化、全局最大池化、全局top-k池化、FPM进行消融实验, 最终的分类准确率如下:全局平均池化为83.8%, 全局最大池化为84.4%, 全局top-k池化为84.5%, FPM为86.2%.由实验结果可以看出, FPM性能最优, 是有效的.
本文的AGM在细粒度视觉分类方法中是通用的, 只要通过特征提取, 再生成一幅注意力图, 就可以进行网格注意力混合数据增强.为了验证AGM的通用性, 将其应用于WS-DAN上, 最终分类准确率如表3所示.由表可见, 添加AGM后, WS-DAN在3个细粒度数据集上分类准确率分别提升0.9%、0.8%、0.7%.
| 表3 有无AGM的消融实验结果 Table 3 Ablation experiment results with and without AGM % |
为了验证FPM中超参数K、AGM中超参数N及AC中超参数θ的有效性, 分别在CUB-200-2011数据集上进行实验.
首先设置超参数K=1, 4, 8, 16, 32, 最终发现K=4时, 网络分类准确率最高, 再增加K后, 分类准确率逐渐降低, 故本文网络中K=4时FPM的效果最优.
然后设置超参数N=16, 32, 64, 并和CutMix进行对比, 最终发现AGM的性能都优于CutMix, 并且在N=32时性能相对最优.
最后为了验证AC中超参数θ的有效性, 设置θ=0.25, 0.5, 0.75, 最终发现θ=0.5时, 分类性能最优.对比ResNet50在CUB-200-2011数据集上83.8%的分类准确率, 发现加入AC后, 均能够增强分类性能.
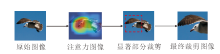
在CUB-200-2011数据集上, AGM和AC的可视化结果如图5所示.
 | 图5 两个模块的数据增强结果Fig.5 Data augmentation results of 2 modules |
由图5可见, AGM主要是将目标物体的显著部位混合到另一幅图像上.从图5(a)可以看出, AGM能够一定程度地遮盖目标物体上的最显著特征, 从而让网络学习除显著特征以外的其余特征.AC主要是裁剪物体最显著部分, 从(b)可以看出, 网络主要是关注物体的头、腹部、脚等身体部位, 将AC得到的结果再次输入网络中, 能够学习到显著部位更细节的特征.
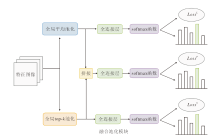
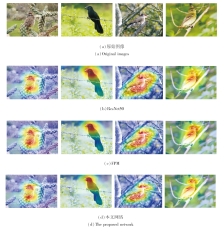
为了细致观察本文网络学习到的细粒度特征, 采用梯度加权类激活映射(Gradient-Weighted Class Activation Mapping, Grad-CAM)[33], 实现特征可视化.
为了突出本文网络的有效性, 对比ResNet50、FPM和本文网络的热力图, 结果如图6所示.由图可以看出, 三者都能定位到目标物体.但是与普通图像识别不同, 细粒度视觉识别需要更多的细粒度特征, ResNet50更关注最显著的特征, 无法得到更细节的特征.相比ResNet50, FPM的热力图关注更多的部位.在FPM基础上加入AGM和AC后, 网络能够学习到更细微的特征.上述分析表明本文的FPM和AEM能够学习多尺度的细粒度特征.
 | 图6 三个网络的热力图对比Fig.6 Heat map comparison of 3 networks |
本文提出基于融合池化和注意力增强的细粒度视觉分类网络.由于不同的池化方法具有不同的感受野, 本文设计基于全局平均池化和全局top-k池化的特征融合模块(即融合池化模块), 能够关注多尺度的物体信息.同时考虑到细粒度数据集数量较少的问题, 设计注意力增强模块, 最终通过上述两个模块有效提升细粒度图像的识别准确率.但是本文网络有如下两个缺陷.1)超参数K、N和θ很难调到最优.2)本文网络为多阶段网络, 在不添加注意力增强模块的情况下, 识别性能一般, 并且迭代速度慢于单阶段网络.
未来的研究工作包括以下两个部分:1)将融合池化模块中的超参数K变为可学习的参数.2)将网络优化为单阶段网络, 使用特征增强或特征抑制等方式增强单阶段网络的性能.
本文责任编委 何 清
Recommended by Associate Editor HE Qing
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|