
{kind=link}
{kind=link}
面向跨数据集指静脉识别的可快速迁移模型
[黄喆1  , 郭成安
, 郭成安1 ]
, 郭成安]
|
|



作者简介:

黄喆,博士研究生,主要研究方向为基于深度学习的生物特征识别技术.E-mail:hzdlmu@mail.dlut.edu.cn.
深度学习技术在手指静脉识别任务中展现出显著的性能优势和潜力.但是,由于其昂贵的训练开销以及不同数据集间存在的类别和分布差异,在某个数据集表现优异的模型可能难以高效应用到新数据或者在新数据上表现不佳.针对识别系统被应用到不同使用群体和设备的实际情景,为了实现模型在不同数据上的高效应用并保持其优良性能,文中提出面向跨数据集指静脉识别的可快速迁移模型,包含两个学习阶段的解决方案.首先,为了得到一个可以较好泛化到未见目标数据的深度模型,在第一阶段提出基于特征对齐和聚类的领域适应算法,引导网络提取有判别力且鲁棒的特征.然后,为了减小图像中由偏差场引起的数据集差异,提出一个偏差场校正网络,消除偏差,并调整潜在分布,使其更相似.最后,为了将模型高效迁移到目标数据并充分利用新数据的模版信息,在执行快速迁移的第二阶段中,设计具有更快学习速度的基于改进极限学习机的分类器,利用它的学习算法,加速模型的迁移训练.在四个公开指静脉数据库上的实验表明,文中模型能够在实现高效迁移的同时,取得与在目标任务上进行充分端到端训练的最佳方法同等的识别性能.对于常见的应用场景,能满足实时部署的需求,从而为深度学习技术在跨数据集指静脉识别应用提供一套可行的解决方案.
About Author:
HUANG Zhe, Ph.D. candidate. His research interests include biometric identification and verification with deep learning.
Deep learning-based methods show excellent recognition performance and potential in finger vein recognition. However, due to the expensive training costs and differences in categories and distributions across different datasets, a model that performs well on one dataset may struggle to efficiently adapt to new data or perform poorly on new data. A fast transferable model for cross-dataset finger vein recognition, including a two-stage solution, is proposed to realize high efficient application of model on different datasets with good performance in practical scenarios where recognition systems are applied to various user groups and devices. Firstly, in the first stage, a domain adaptation algorithm based on feature alignment and clustering is introduced to guide the network in extracting discriminative and robust features, aiming to obtain a deep model that can generalize well on unseen target data. Secondly, a bias field correction network is developed to reduce dataset gaps caused by bias fields in images and further adjust the latent distribution to make the datasets more similar to each other. Then, in the second stage of fast transfer, a modified classifier based on extreme learning machine with a faster learning speed is designed to accelerate model transfer training and make full use of the template information of new data.Experimental results on four public finger vein databases show that the proposed method realizes efficient transfer and achieves recognition performance as good as the best end-to-end training method dose in the target task. For common application scenarios, the proposed method can meet the requirements of real-time deployment and provide a feasible solution for the application of deep learning techniques in cross-dataset finger vein recognition.
指静脉识别[1, 2]采用手指表皮下的静脉结构作为主要判别特征, 是一种新兴的基于生物特征的身份识别技术.相比人脸[3]、指纹[4]等基于外部特征的身份识别模式, 手指静脉识别具有活体检测、安全性高、特征稳定等特点[5].
随着人们对身份安全需求的不断增加, 指静脉识别技术得到广泛的关注和探索, 并已在诸如门禁系统、银行系统(Automated Teller Machine, ATM)、员工考勤系统和汽车安全系统等基础设施上得到广泛应用[2].
近年来, 随着深度学习技术的推广, 指静脉识别得到长足发展, 识别精度大幅提升[5, 6, 7, 8, 9, 10].然而, 这些成果通常是在训练数据和测试数据来自于同一数据集的条件下评估的.实际应用场景难以满足此条件, 因为这些精心训练的识别系统需要被应用到不同的使用群体和采集设备, 这被认为是一个跨数据集识别任务, 即用于训练深度模型的数据(源数据)与目标数据来自于不同的数据集.受采集设备、环境条件和使用群体变更的影响, 在不同场景下采集的数据可能存在明显差异(包括类别差异及潜在数据分布差异[11]), 导致在某些数据集上表现良好的模型可能无法直接应用到新数据(目标数据)或者在新数据上表现不佳.
尽管在目标数据上对深度模型进行重新调整和训练可以缓解上述问题, 但此方案可能并不适用于大部分指静脉识别场景.因为在实际应用中, 目标任务的数据通常是预先不可知的, 需要在应用阶段随着用户的注册不断获取, 这导致微调模型需要在新数据采集后现场执行.然而, 受限于模型巨量的训练开销, 对深度模型进行现场调试需要花费大量时间以及人力计算资源, 这对于许多应用场景而言是难以接受的[12].并且, 对于应用中新增加的数据, 该方案也会大幅增加模型的学习时间, 导致其难以高效适应数据的变化.
此外, 对于指静脉识别问题, 鉴于身份信息安全以及隐私问题, 通常难以收集大量的样本用于训练, 并且现场采集大量数据通常也十分困难.因此, 模型的训练常常面临小样本问题, 这增加模型过拟合的风险.同时, 针对不同的使用群体和场景重新调整模型意味着需要为每个目标任务单独维护一套参数, 增加模型升级和更新的困难.因此, 迫切需要寻求一套切实有效的解决方案, 可以实现深度模型在跨数据集指静脉识别任务中的快速迁移应用, 并能够在小样本训练情况下保持一致的优良性能.在此基础上, 应使模型在不同数据集上保留更多的一致结构和参数, 以便系统的升级和更新.
为了使模型能够在新数据集上取得一致的表现, 一个可行的方案是采用领域适应技术.该技术旨在在预训练数据(源数据)上学习一个可以在许多未见数据上表现良好的模型[13].在这类研究中, 领域不变特征方法[14, 15]取得较大成功.此方法对齐来自不同领域的特征, 提取对数据集差异鲁棒的不变表达.
然而, 尽管已有研究在许多应用中已被证实是有效的, 但通常需要在训练过程中使用目标任务的数据[14, 15, 16].对于指静脉识别任务, 目标数据通常难以提前预知, 这增加方法在跨数据集指静脉识别中的应用困难.此外, 由于难以采集大量的样本, 如何学习鲁棒特征将面临更严峻的考验.尽管不同设备采集的图像存在差异, 但它们通常具有相近的分布, 并且造成不同数据集分布差异的主要因素是由于环境条件和采集设备变更引起的有差异偏差场.因此, 可以通过消除图像偏差场以减小数据集间的差异[8].
尽管应用数据预先并不可知, 但随着系统投入使用, 它的模板图像(即训练样本)也随之可用.此时, 对训练图像进行学习有助于提升模型在新数据上的表现.然而, 受训练效率、数据规模以及模型更新等制约, 现场调试模型以适应新数据通常是困难的.
为了能够利用模板图像的信息并满足使用需求, 一个简单有效的方案是在利用模型提取深度特征后, 设计并训练一个面向目标任务的分类器[17, 18].该方案由于不更新模型参数, 仅调整分类器, 因此, 训练速度较快, 便于维护和更新.鉴于深度模型, 尤其是卷积神经网络(Convolutional Neural Network, CNN)可以分解为基于卷积结构的特征提取器以及基于全连接结构的分类器, 可以调整全连接层结构和参数, 实现模型在新数据上的快速迁移学习.但是, 基于梯度下降法的迭代优化策略调整全连接层依然需要较多的计算和时间, 并且在小样本条件下同样容易发生过拟合问题.
基于上述分析, 本文提出面向跨数据集指静脉识别的可快速迁移模型, 包含两个学习阶段的解决方案.首先, 为了得到一个可以较好泛化到未见目标数据的深度模型, 在第一阶段提出基于特征对齐和聚类的领域适应算法, 引导网络提取有判别力且鲁棒的特征.然后, 为了减小图像中由偏差场引起的数据集差异, 提出一个偏差场校正网络, 消除偏差, 并调整潜在分布, 使其更相似.最后, 为了将模型高效迁移到目标数据并充分利用新数据的模版信息, 在执行快速迁移的第二阶段中, 设计具有更快学习速度的基于改进极限学习机(Extreme Learning Ma-chine, ELM)[19]的分类器, 利用它的学习算法, 加速模型的迁移训练.在四个公开指静脉数据库上的实验表明, 本文模型能够在实现高效迁移的同时, 取得与在目标任务上进行充分端到端训练的最佳方法同等的识别性能.对于常见的应用场景, 能满足实时部署的需求, 从而为深度学习技术在跨数据集指静脉识别应用上提供一套可行的解决方案.
本节旨在探索如何实现深度模型在跨数据集指静脉识别中的应用并满足使用场景对应用效率、识别性能以及升级更新等的需求.为此, 首先简略介绍基于深度学习的指静脉识别方法.然后, 结合已有方法在跨数据集应用的不足, 详细阐述本文的解决方案.
随着人们对身份信息安全需求的不断增长, 指静脉识别技术得到长足发展.特别是近年来, 深度学习的成功推动该领域的显著进展.对于基于深度学习的指静脉识别方法, 可以根据它们实施指静脉识别的方式不同, 将其粗略划分为两类:基于验证的方法[5, 6, 7, 20, 21, 22, 23, 24, 25]和基于分类的方法[8, 9, 10, 26, 27, 28, 29].
基于验证的方法将待检测图像与每个候选类别图像进行逐一对比, 获得识别结果.Tang等[21]使用孪生网络判别输入的两幅图像是否属于同一类别, 并根据与所有候选类别的相似度得分获得最终的判别结果.
基于分类的方法将指静脉识别问题视为图像分类问题, 使用精心设计的分类模型识别它们.Boucherit等[29]提出Merge CNN, 融合多个CNN提取的特征后输出分类得分.
尽管现有基于深度学习的方法在指静脉识别任务中取得优异表现, 但它们通常要求训练数据和测试数据来自同一数据集.目前的研究尚未考虑实际应用中更一般的跨数据集识别场景, 当这些方法应用到跨数据集指静脉识别任务中时, 存在一些不足之处.基于分类的方法通常使用带有全连接结构的输出层输出样本属于每个可能类别的得分, 这要求输出层的每个节点与某个特定的类别对应.在将该模型应用到新任务时, 由于使用群体(类别)发生改变, 基于全连接结构的输出层导致模型无法直接应用到新数据, 仅能在重新调整输出层并重新训练模型后识别它们.鉴于深度模型过高的训练开销, 基于分类的方法不仅难以高效迁移到目标任务, 并且无法快速适应应用中的新用户.基于验证的方法尽管可以直接使用预训练的模型识别目标数据, 但由于不同数据集的分布差异, 难以在新数据上保持一致的性能.此外, 这类方法在训练和识别过程中往往需要将数据两两组合, 导致数据规模增加若干个数量级, 增加识别和训练的计算开销.
现有的指静脉识别方法需要在应用数据上对模型进行微调以适应新数据并保持稳定性能, 而这在实际应用中通常是困难的.
限制深度学习方法在跨数据集指静脉识别应用的原因可以概括为两点.1)由于数据集差异的存在, 精心设计和训练的深度模型难以直接应用到新数据并保持优良的性能.2)由于深度模型昂贵的训练开销, 针对目标任务重新调试模型既需要花费大量的时间, 又增加模型升级和维护困难, 这对于许多场景而言是难以接受的.
为了克服这些问题, 本文从改善模型泛化性能以及提升模型迁移效率两方面入手, 提出面向跨数据集指静脉识别的可快速迁移模型.在改善模型泛化性能方面, 提出基于U-Net[30]的偏差场矫正网络, 旨在消除预训练数据(源数据)和应用数据(目标数据)之间存在的有差异偏差场, 并生成具有更高一致性和分辨率的增强图像, 进而降低由偏差场引起的数据差异对模型性能的影响.这里所指的偏差场, 即图像中亮度的不均匀分布, 通常是由光照条件、相机规格和传感器灵敏度的差异引起的.偏差场的存在可能会对图像质量产生不利影响, 并加大不同数据集之间的差异.在此基础上, 设计用于改善模型泛化性能的学习算法, 引导模型提取对扰动不变的特征表达, 约束特征靠近对应类别中心并远离其它类别中心, 实现基于类别的紧密聚类分布 (即簇分布), 提升模型的判别力和鲁棒性.值得注意的是, 上述对深度模型的训练过程均在源数据上执行, 不会增加模型在目标任务上的学习成本.
在提升模型迁移效率方面, 设计改进ELM分类器以及基于该分类器的迁移学习方法, 在保持CNN参数不变的前提下, 训练针对特定目标任务的分类器, 实现模型向目标数据的高效迁移.在此基础上, 为了进一步提升分类器的训练效率, 采用基于ELM的求解算法, 解析确定分类器参数, 避免迭代求解的优化过程, 学习速度较快.
基于上述设计, 本文模型的整体训练流程如图1所示.训练过程由两个阶段组成, 分别为在预训练数据上进行的用于改善CNN组件泛化能力的第一阶段, 以及针对最终应用数据进行的用于实现CNN在新数据上快速迁移的第二阶段.
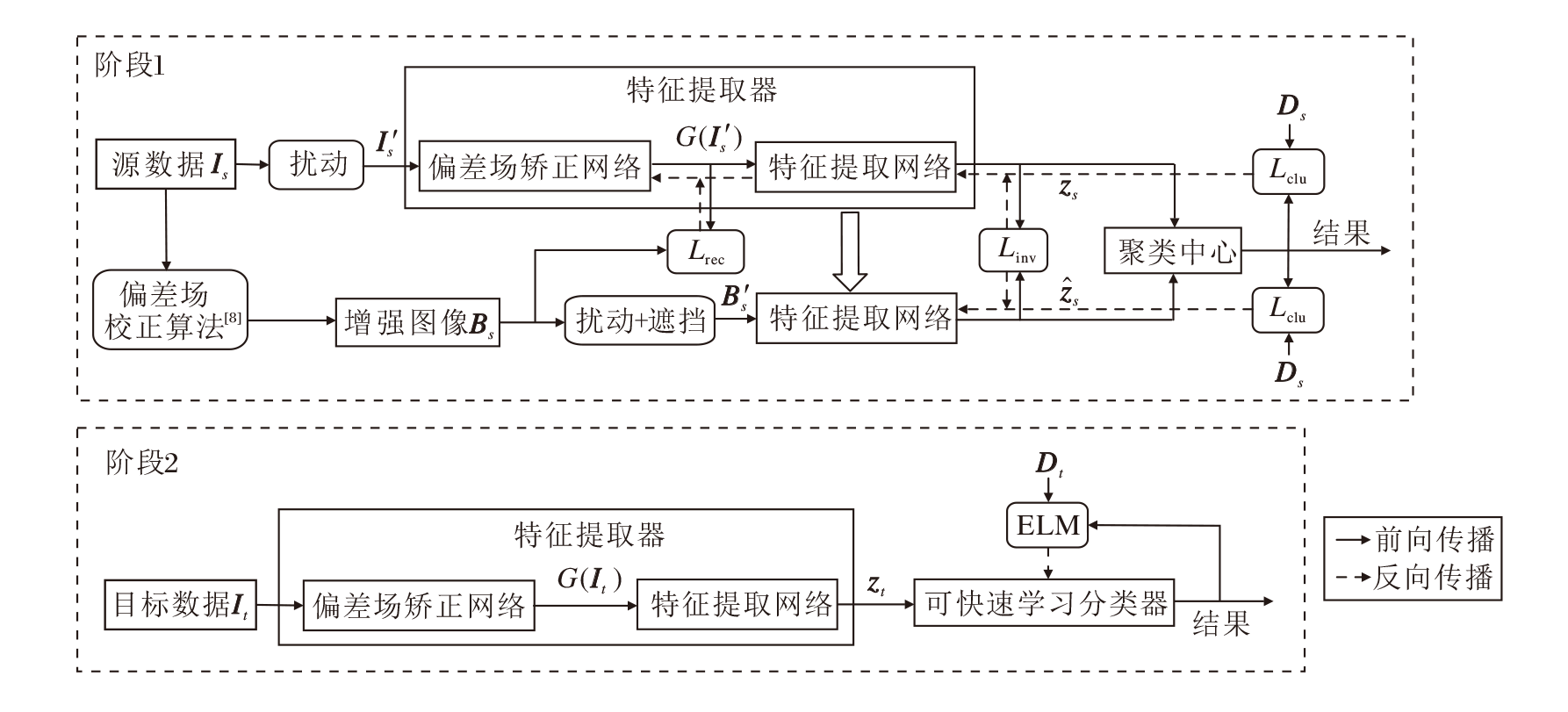 | 图1 本文模型整体流程图Fig.1 Flow chart of the proposed model |
在第一阶段, 给定源数据集Is和对应的标签Ds, 首先使用文献[8]中提出的偏差场矫正算法(Bias Field Correction Algorithm)估计图像中的偏差场, 并在原始图像中移除它们, 改善图像质量.偏差场矫正算法[8]使用一个二维多项式, 估计图像中存在的亮度不均匀分布(即偏差场).使用此算法, 能够较好地估计和移除图像中的偏差场, 从而在改善图像质量的同时, 降低不同数据集间的差异.在此基础上, 还对处理结果进行分布调整, 使其具有更相近的均值和标准差, 使生成的图像具有更高的一致性, 从而得到增强图像Bs.
再以Bs作为像素级标签, 随机扰动后的原始图像I's作为偏差场矫正网络的输入, 使用重构损失函数Lres约束该网络的输出G(I's), 逼近理想标签Bs.由于Bs为Is移除偏差场且经过图像分布调整后的结果, 因此, 使用偏差场矫正网络, 从原始图像I's重构增强图像Bs, 引导模型学习对应的偏差场矫正变换, 进而利用该网络自动消除源数据和未知目标数据的偏差场, 降低由偏差场引起的分布差异.此外, 将同一图像的不同扰动副本映射为相同的增强图像, 也能够提升偏差场矫正网络对扰动的鲁棒性.
然后, 随机扰动Bs并遮挡图像的部分纹理, 更好地模拟实际应用中可能出现的干扰, 获得扰动图像B's.分别将G(I's)和B's送入基于VGG-16[31]的特征提取网络, 得到深度特征对zs 和
最后, 使用特征对齐损失函数Linv最小化特征对之间的距离, 引导特征提取网络提取对扰动鲁棒的不变特征.同时, 使用损失函数Lclu约束特征对到每个类别中心的距离, 使特征呈现紧密的基于类别的聚类分布.
在第二阶段, 为了实现模型在新数据上的高效应用, 不更新特征提取器(包括偏差场矫正网络和特征提取网络)的参数.使用该特征提取器提取目标数据It的深度特征zt.然后, 利用ELM的学习算法以及zt对应的类别标签Dt, 训练改进ELM分类器.最后, 组合特征提取器和分类器, 获得面向应用数据使用的最终模型.
源数据执行第一阶段旨在获得一个可以较好泛化到不同目标任务的特征提取器, 为此, 本文设计用于模型优化的融合损失函数:
Ls=Lrec+Linv+Lclu.
其中:Lrec表示重构损失函数, 用于引导偏差场矫正网络学习偏差场矫正算法[8]; Linv表示特征对齐损失, 用于学习对扰动鲁棒的特征表达; Lclu表示聚类损失, 用于约束特征呈现基于类别的簇分布.
1.3.1 偏差场矫正
对于指静脉识别任务, 数据集之间的潜在分布差异主要由偏差场引起.因此, 为了改善模型的迁移性能, 本文采用偏差场矫正算法[8], 消除不同数据集之间存在的差异性偏差场.然而, 虽然偏差场矫正算法[8]可以估计并消除图像偏差场, 但通常需要预先定义算法参数.对于跨数据集识别任务, 预先定义的参数可能难以适用于新的数据, 并且限制算法进一步调整的潜力.
针对该问题, 本文在偏差场矫正算法[8]处理结果的基础上, 首先进行进一步对齐, 确保增强后的图像具有更加一致的分布.然后, 使用基于U-Net结构[30]的偏差场矫正网络学习该图像变换, 利用该组件实现对未知目标数据偏差场的自动消除, 克服传统方法在跨数据集任务中的限制.并且, 利用深度模型强大的学习能力, 偏差场矫正网络可以在学习传统方法的同时, 根据后端分类器的识别结果, 对生成的图像进行适应调整, 使其在分类器端取得更高得分, 从而改善识别性能.
偏差场矫正网络由两条路径组成:收缩路径和扩展路径.收缩路径采用ResNet-18结构[32], 提取图像特征.扩展路径通过融合收缩路径提供的信息, 重构经过偏差场矫正算法[8]处理后的增强图像Bs, 进而学习对应的图像变换.
对于不同的数据集, 存在的潜在偏差场并不相同.为了使模型能够在仅使用源数据集的情况下适用于不同的应用数据, 采用多种数据增强变换增加样本量, 更好地模拟未知的目标数据.给定源数据集
Is={
其中, Ns表示训练样本数,
接下来, 使用偏差场矫正算法[8]处理Is, 获得处理后的图像Bs.为了能够引导模型对不同的扰动结果均能输出相近的处理结果, 对同幅图像的不同扰动版本采用相同的标签.
最后, 使用重构损失Lrec度量G(I's)与Bs之间的差异, 并最小化该损失, 引导模型学习该图像操作.损失函数Lrec定义为
$\begin{array}{l} L_{\mathrm{rec}}\left(G\left(\boldsymbol{I}_{s}^{\prime}\right), \boldsymbol{B}_{s}\right)=\frac{1}{N_{s} \times W \times H} \cdot \\ \quad \sum_{i=1}^{N_{s}} \sum_{x=1}^{W} \sum_{y=1}^{H}\left\|G\left(I_{s}^{(i)}(x, y)\right)-B_{s}^{(i)}(x, y)\right\|_{2}^{2}, \end{array}$(1)
其中, W和H表示图像的宽和高, G(I'
$\begin{array}{l}B_{s}^{(i)}(x, y) \leftarrow \min \left\{\max \left(0, S_{t}\left(B_{s}^{(i)}(x, y)\right)\right), I_{\max }\right\}, \\S_{t}\left(B_{s}^{(i)}(x, y)\right)=\frac{1}{2}\left(\frac{B_{s}^{(i)}(x, y)-\text { mean }_{i}}{c \cdot s t d_{i}}+1\right) I_{\max } .\end{array}$ (2)
其中:meani和stdi表示
根据式(1)和式(2)可知, 偏差场矫正网络不仅需要学习偏差场矫正算法[8]对应的图像变换, 生成的图像也具备更加相近的均值和标准差, 即更好的一致性.此外, 由于深度模型具有强大的学习能力, 在使用偏差场矫正网络学习该图像变换的同时, 模型可以进行自适应调整, 使生成的图像更容易被正确识别.
1.3.2 特征对齐
尽管在经过偏差场校正后, 来自不同数据集的图像具有更小的数据集差异, 但也很难完全消除这些差异.为了进一步提高模型的泛化能力, 降低它们对迁移性能的影响, 本文将同一图像产生的不同扰动图像映射到特征空间(即样本经过深度网络提取特征后, 将原始数据映射为高维矢量, 这些矢量构成的空间为特征空间)的相同位置, 引导模型提取对图像位移、缩放、旋转以及亮度对比度变化鲁棒的不变特征.为此, 首先使用图像变换T对图像进行调整, 生成具有不同扰动的图像副本.然后, 使用损失函数Linv对齐由它们产生的特征.基于欧氏距离, Linv定义为
$L_{\mathrm{inv}}\left(\boldsymbol{z}_{s}, \hat{\boldsymbol{z}}_{s}\right)=\frac{1}{N_{s}} \sum_{i=1}^{N_{s}}\left\|\boldsymbol{z}_{s}^{(i)}-\hat{\boldsymbol{z}}_{s}^{(i)}\right\|_{2}^{2},$,
其中,
最小化Linv旨在约束由
1.3.3 特征聚类
Linv损失约束网络提取对扰动鲁棒的特征, 但可能会造成模型对所有样本均输出相同结果, 从而使特征失去判别力[33].
为了防止这种“ 崩溃” , 需要在引导模型提取不变特征的同时, 确保不同类别的特征是可区分的, 并应尽可能增大决策边界之间的距离(即裕度)以提升特征的判别力和鲁棒性.
样本在特征空间中的距离通常情况下能够反映它们的相似度关系, 即两个特征的距离越近, 它们属于同一类别的概率越大.基于该簇分布假设, 本文设计如下的损失函数:
$\begin{array}{l}L_{\mathrm{clu}}\left(\boldsymbol{z}_{s}, \hat{\boldsymbol{z}}_{s}, \boldsymbol{\mu}_{s}, \boldsymbol{D}_{s}\right)= \\\quad-\sum_{i=1}^{N_{s}} \sum_{k=1}^{n_{s}} d_{k}^{(i)}\left(\ln \left(\frac{\exp \left(-\gamma\left\|\boldsymbol{z}_{s}^{(i)}-\boldsymbol{\mu}_{s}^{(k)}\right\|_{2}^{2}\right)}{\sum_{j=1}^{n_{s}} \exp \left(-\gamma\left\|\boldsymbol{z}_{s}^{(i)}-\boldsymbol{\mu}_{s}^{(j)}\right\|_{2}^{2}\right)}\right)+\ln \left(\frac{\exp \left(-\gamma\left\|\hat{\boldsymbol{z}}_{s}^{(i)}-\boldsymbol{\mu}_{s}^{(k)}\right\|_{2}^{2}\right)}{\sum_{j=1}^{n_{s}} \exp \left(-\gamma\left\|\hat{\boldsymbol{z}}_{s}^{(i)}-\boldsymbol{\mu}_{s}^{(j)}\right\|_{2}^{2}\right)}\right)\right), \end{array}$
其中, ns表示源数据的类别数,
可以看到, 为使Lclu最小,
由于模型在更新的过程中,
$\boldsymbol{\mu}_{s}=\left\{\boldsymbol{\mu}_{s}^{(k)}\right\}_{k=1}^{n_{s}}$
会随着模型参数的更新不断变化, 为了确保在优化过程中, μ s能够始终较准确地指向每个类别的中心, 采用指数滑动平均的方式更新该参数, 表示为
其中, λ 表示动量系数,
第二阶段旨在利用目标任务提供的模板图像(该图像通常在用户注册时采集, 用于匹配或训练)更好地迁移模型, 并满足应用场景对迁移效率以及升级更新的需求.虽然本阶段提供模板图像, 但受CNN的计算开销、数据规模以及升级更新等制约, 现场调试CNN以适应目标数据是不可行的.为了更好地利用目标数据模板(训练数据)的信息, 并避免现场训练CNN, 本文使用针对目标任务设计和训练的分类器识别特征提取器提取的特征.为了进一步提升分类器的训练效率, 并利用特征的簇分布特点, 设计由基于高斯核函数隐层以及线性输出层构成的改进ELM分类器[19].
给定包含N个样本和n个类别的训练集
$\boldsymbol{I}_{t}=\left\{\boldsymbol{I}_{t}^{(i)}\right\}_{i=1}^{N}$
以及对应的标签
$\boldsymbol{D}_{t}=\left\{\boldsymbol{d}^{(i)}\right\}_{i=1}^{N}, $
其中,
d(i)=[
表示对应的标签.将It送入特征提取器, 得到对应的特征
$\boldsymbol{z}_{t}=\left\{\boldsymbol{z}_{t}^{(i)}\right\}_{i=1}^{N} \text {. }$
接下来, 将
$\varphi_{t}^{(i, k)}=\exp \left(-\frac{\left\|\boldsymbol{z}_{t}^{(i)}-\boldsymbol{\mu}_{t}^{(k)}\right\|_{2}^{2}}{\alpha\left(\sigma_{t}^{(k)}\right)^{2}}\right) $ (3)
其中, k=1, 2, …, n,
其中, N(k)表示It中属于第k类的个数.方差
(
高斯函数具有局部响应的特点, 在式(3)中引入基于类别的方差项, 旨在自适应调整函数的响应范围.
改进ELM的输出层采用线性全连接结构, 表示为
$\boldsymbol{Y}=\boldsymbol{\Phi} \boldsymbol{\beta},$ (6)
其中:
$\begin{array}{l}\boldsymbol{Y}=\left[\boldsymbol{y}_{t}^{(1)}, \boldsymbol{y}_{t}^{(2)}, \cdots, \boldsymbol{y}_{t}^{(N)}\right]^{\mathrm{T}} \in \mathbf{R}^{N \times n}, \\\boldsymbol{y}_{t}^{(i)}=\left[y_{t}^{(i, 1)}, y_{t}^{(i, 2)}, \cdots, y_{t}^{(i, n)}\right]^{\mathrm{T}} \in \mathbf{R}^{n}, \end{array}$
$\begin{array}{l} \boldsymbol{\Phi}=\left[\boldsymbol{\varphi}_{t}^{(1)}, \boldsymbol{\varphi}_{t}^{(2)}, \cdots, \boldsymbol{\varphi}_{t}^{(N)}\right]^{\mathrm{T}} \in \mathbf{R}^{N \times n}, \\ \boldsymbol{\varphi}_{t}^{(i)}=\left[\boldsymbol{\varphi}_{t}^{(i, 1)}, \boldsymbol{\varphi}_{t}^{(i, 2)}, \cdots, \boldsymbol{\varphi}_{t}^{(i, n)}\right]^{\mathrm{T}} \in \mathbf{R}^{n} ; \end{array}$
β ∈ Rn× n表示输出层的权重矩阵.
根据文献[19], 改进ELM分类器的输出层参数为:
其中,
T=[d(1), d(2), …, d(N)]T∈ RN× n,
Φ +表示Φ 的Moore-Penrose广义逆[34].
由式(3)~式(7)可快速计算并获得改进ELM的隐层参数, 解析确定输出层参数.因此, 相比使用梯度下降法训练的分类器, 改进ELM分类器具有更快的学习速度, 赋予模型在待检测类别发生改变时快速调整的能力, 从而更好地适应新增加的类别.此外, 隐层基于高斯核函数的结构可以更好地反映特征的相似度信息.并且基于ELM的求解算法使模型具备优良的识别和泛化性能, 能够更好地适应小样本情况.因为, 根据文献[19], 解析获得的输出层权重
$\|\boldsymbol{\Phi} \widehat{\boldsymbol{\beta}}-\boldsymbol{T}\|_{2}^{2}=\min _{\boldsymbol{B}}\|\boldsymbol{\Phi} \boldsymbol{\beta}-\boldsymbol{T}\|_{2}^{2},$(8)
即
本文模型由于不需要在目标任务上调整特征提取器的参数和结构, 可以在不同目标任务上使用相同参数的CNN组件.当系统需要升级更新时, 仅需要在源数据集上重新优化特征提取器后, 用其替换原模型并重新训练改进ELM分类器, 即可实现对不同目标任务的统一调整.
此外, 由于本文模型并不在应用数据上更新CNN参数, 性能存在进一步改善的空间.在后台维护或允许模型进行长时间训练的情况下, 可以进一步调整CNN组件, 更好地适应目标任务.
根据式(8)可知, 在使用均方误差(Mean Squared Error, MSE)作为损失函数时, 解
为此, 本文设计用于模型端到端训练的基于softmax的Lcla损失:
Lcla=-
其中, τ 表示人工设定的超参数, 避免在实际输出逼近理想输出T时, 损失值过大.根据式(9)可知, 当目标类别对应节点的输出远大于其它节点时, Lcla趋近于0, 从而保障模型能够取得正确的识别结果.
鉴于分类器的优化方式与特征提取器基于反向传播(Back Propagation, BP)算法的迭代优化策略不同, 为了利用分类器的识别结果, 端到端优化模型, 并保持改进ELM解析解算法的优点, 在使用BP算法最小化损失Lcla的过程中, 不调整分类器参数, 待模型收敛后, 重新计算分类器的参数, 进行进一步优化.
本节在如下4个公开指静脉数据库上验证本文模型的有效性.
1)山东大学机器学习与应用同源多模态数据库中指静脉数据库(简称为SDU-MLA)[36].数据库包含从106名志愿者采集的636个指静脉类别.每个手指类别包含6幅图像, 共计3 816幅大小为320× 240的指静脉图像.
2)清华大学指静脉和手指背纹理数据库(简称为THU)[37].数据库由610名志愿者提供的610个指静脉类别组成.每个手指类别包含分2次采集的2幅图像, 共计1 220幅大小为720× 576的图像.在实验中, 使用数据集提供的ROI(Region of Internet)图像作为模型输入.
3)马来西亚理工大学指静脉数据库(简称为FV-USM)[38].数据库由123名志愿者采集的492个指静脉类别组成.每个手指类别包含12幅图像, 这些图像同样分2次采集, 每次每个类别采集6幅图像, 因此共计5 904幅大小为640× 480的图像.在实验中, 同样使用数据集提供的ROI图像作为模型输入.
4)香港理工大学手指图像数据库(简称为PolyU)[39].数据库包括从156名志愿者获得的312个指静脉类别.图像分2次采集, 第1次采集包含312个类别的1 872幅图像, 第2次采集包含210个类别的1 260幅图像.在实验中, 仅使用第1次采集的1 872幅大小为513× 256的图像进行实验.
按照表1所示的划分, 将每个数据集划分为一个训练集和一个测试集, 同时, 在每个数据集内部, 将其划分为两组.在后续实验中, 对于SDU-MLA、PolyU数据集, 均采用6折交叉验证获得实验结果, 即依次选择每个类别6幅图像中的5幅训练图像, 剩余1幅测试图像.对于其余2个数据集, 按照表1中的划分方案重复进行3次训练, 并将平均结果作为最终结果.
| 表1 4个指静脉数据集的划分方案 Table 1 Division scheme of 4 finger vein databases |
实验采用PyTorch在CPU+GPU平台上实现, 该平台配备Intel® CoreTM i7-7700@3.60 GHz 中央处理器和NVIDIA GeForce GTX 1080Ti 图形处理器.在实验中, 设置γ =30, λ =0.5, α =9, τ =10.
使用的图像扰动设置如下.
1)图像遮挡.每个像素值有0.1的概率被遮挡, 被遮挡像素采用其周围3× 3范围内的像素值均值进行填充.
2)图像缩放与裁剪.原始图像随机缩放至高为110≤ H≤ 130, 宽为260≤ W≤ 280, 并随机从缩放的图像中裁剪100× 240的图像块用于训练.
3)亮度对比度变换.对图像的亮度和对比度进行随机调整, 亮度和对比度将在当前图像亮度对比度的0.7倍到1.3倍之间进行随机变化.
图像旋转设置如下:顺时针或逆时针随机旋转0° ~3° , 采用最近邻进行补边.
本节旨在实现CNN在跨数据集条件下的快速迁移应用并取得满足需求的优良性能.
为了评估模型的有效性, 选择如下对比模型:文献[8]模型, MSFBF-Net(Multi-scale Feature Bili-near Fusion Network)[9], 文献[20]模型, 文献[21]模型, FV-GAN(Finger Vein Representation Using Generative Adversarial Networks)[22], LCNN(Light CNN)[23], CNN-CO(CNN Competitive Order)[24], 文献[27]模型, HGAN(Hierarchical Generative Adver-sarial Network)[28], Merge CNN[29], VGG-16[31], 文献[39]模型, 文献[40]算法, 文献[41]算法, 文献[42]算法, SRLRR(Sparse Reconstruction Error Con-strained Low-Rank Representation)[43], 文献[44]模型.
首先, 对比分析本文模型在跨数据集实验设置下的性能(包括识别性能和迁移学习效率), 结果如表2所示, 表中黑体数字表示最优值.实验中根据表1的划分, 选择B0作为源数据集.对于本文模型, 首先在源数据集上执行第一阶段的训练, 获得可泛化到不同任务的CNN组件.然后, 在应用数据集上实施第二阶段迁移, 即使用应用数据的模板图像训练改进ELM分类器并与CNN组件相连, 构成最终模型.
| 表2 各模型在目标数据上的性能评估 Table 2 Performance evaluation of different models on target datasets |
为了公平对比, 部分典型模型(未标记* )同样采用两阶段学习策略进行训练和测试.具体而言, 首先在预训练数据上训练模型, 然后在工作数据上对其所有参数进行微调.
此外, 为了确保结果更加真实可靠, 表2同时对比与本文实验方案一致的最新模型(标记为* ), 它们在表中的结果均来自原文献.表2中所有模型的训练时间均不包括在源数据集上对模型进行充分训练的时间, 仅为在目标任务上微调模型的时间, 并且均为在4个数据集上训练的平均时间.
由表2中结果可以看到, 本文模型在3个数据集上均取得最高的识别精度, 并在SDU-MLA数据集上, 取得与最佳模型基本同等的性能.并且由于本文模型不需要在目标任务上训练CNN组件, 迁移训练速度远优于其它模型.尽管部分基于CNN的对比模型没有给出学习时间, 但由于它们都需要在目标数据上训练CNN组件, 且学习方案十分复杂, 因此它们的训练时间不可避免地远超本文模型.
在不调整CNN参数情况下, 本文模型与典型指静脉识别模型在跨数据集应用条件下的性能对比结果如表3所示, 表中黑体数字表示最优值.
| 表3 各模型跨数据集的性能评估 Table 3 Cross-dataset performance evaluation of different models |
与表2实验不同, 表3中模型均仅在源数据集D0上训练CNN.之所以选择D0作为源数据集进行后续的迁移实验, 是因为PolyU数据集与其它数据集间的差异更大, 图像的姿态更多变, 迁移性能面临的考验更严峻.由于基于全连接结构的分类模型无法直接识别新类别, 为此采用在目标任务上调整分类器(全连接层)的方式进行模型迁移.对于基于验证的方法, 直接使用在源数据集上训练的模型识别目标数据.
为了确保实验的公平性, 采用先提取所有训练样本深度特征, 再使用这些特征优化分类器的方案.因此, 表3中所示的时间由两部分组成, 分别为提取所有样本特征的时间和使用这些特征训练分类器的时间.基于验证的方法可以直接应用到目标任务, 训练时间为0 s.基于分类的方法需要采用基于梯度下降的迭代策略训练分类器.相比本文模型, 在训练时间上有较明显的增加.
在精度上, 由于数据集的潜在分布差异, 对比模型在目标数据集上发生显著的性能下降.本文模型由于采用改进ELM分类器对应用数据进行快速学习, 且CNN组件在预训练阶段对迁移应用进行针对性设计, 因此在不同数据集上均取得最佳结果.此外, 由于单幅图像的特征提取时间很短, 在实际应用中可以在采集的同时进行, 因此本文模型实际所需的训练时间仅为改进ELM分类器的学习时间, 而这部分时间约为2 s.
此外, 在允许后台维护或者进行长时间训练的情况下, 可以在执行第二阶段迁移后, 对模型的所有参数进行微调以更好地适应目标任务.为此, 本文提出结合ELM和CNN的端到端优化算法.
为了考察该优化算法的性能, 进行如下实验.在实验中, 本文模型在表2对应的模型基础上, 采用式(9)中的目标函数进行进一步优化, 并与在每个数据集上取得最佳结果的模型进行对比.具体结果如表4所示, 表中黑体数字表示最优值.由表可以看到, 本文模型在对CNN组件进行调整后, 除了SDU-MLA数据集以外, 均取得最佳的识别结果.值得注意的是, 对比表2的结果可以看到, 本文模型在进行端到端学习后, 在SDU-MLA数据集上取得次高的识别精度, 但本文模型为6折交叉验证的平均结果, 更可靠.
| 表4 在目标数据上调整CNN参数后的跨数据集的性能评估 Table 4 Cross-dataset performance evaluation after fine-tuning CNN parameters on target data % |
此外, 对比表2和表4的结果不难发现, 为了保障模型在应用阶段的迁移效率, 不可避免地降低识别性能, 但对于本文模型, 识别性能损失很小, 在可以接受的范围内.
为了提升模型的泛化性能以及迁移效率, 设计两阶段学习策略, 并针对每个阶段提出相应的优化算法.本节将分别考察这些设计的有效性.
2.4.1 阶段1算法的有效性评估
第一阶段旨在获得一个可以较好泛化到不同目标任务的特征提取器, 为此, 设计偏差场矫正网络以及引导CNN提取鲁棒特征的学习算法.为了评估这些设计的有效性, 设置如下对比实验.
1)Lclu.仅使用Lclu训练VGG-16, 作为基准模型.
2)Lclu+Linv.使用Lclu和Linv训练VGG-16.
3)Lclu+Lrec.使用Lclu训练VGG-16, 并添加偏差场矫正网络.
4)Lclu+Linv+Lrec.使用本文设计的损失函数完成第一阶段的训练.
在实验中, 选择D0作为源数据集, 并在第一阶段分别执行上述实验设置后, 考察模型迁移到应用数据后的表现.所有模型在第二阶段均采用相同的方式, 即在第二阶段训练改进ELM分类器, 并与第一阶段获得的CNN组件组合, 得到迁移后的模型.
第一阶段训练的有效性评估结果如表5所示.对比Lclu和Lclu+Linv的结果可以发现, 在添加Linv损失后, 模型性能得到一定提升, 这说明设计的Linv损失能够提高模型对扰动的鲁棒性, 改善模型迁移后的表现.在基准网络上添加Lrec后, 模型在目标任务上的性能得到大幅提升, 该结果表明偏差场矫正网络能够大幅消除数据集间的差异, 提升模型迁移后的识别性能.在Lclu+Linv+Lrec的设置下, 模型在4个数据集上均取得最优值, 表明各项措施均是有效的.
| 表5 第一阶段训练的有效性评估 Table 5 Effectiveness evaluation of training in stage 1 % |
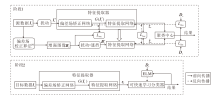
此外, 从表5中结果可以看到, 在使用偏差场矫正网络后, 模型性能得到显著提升, 这表明该网络能够降低不同数据集间的分布差异.为了更好地验证此结论, 给出仅在D0上训练的偏差场矫正网络在不同目标数据集上的表现, 结果如图2所示.
 | 图2 偏差场矫正网络在不同数据集上的性能评估Fig.2 Performance evaluation of bias field correction network on different datasets |
在图2中, 每组结果的第2行为偏差场矫正网络的输出, 第3行为采用偏差场矫正算法[8]处理后的输出结果.从图中结果可以看到, 偏差场矫正能够消除图像偏差场并生成具有更高一致性和分辨力的增强图像.
2.4.2 改进ELM的有效性评估
为了考察改进ELM分类器的有效性, 分别使用ELM分类器[19]、TransM-RKELM(Transfer Learning Mixed and Reduced Kernel Extreme Learning Ma-chine)[45]、SLFN(Single-Hidden Layer Feedforward Network)替换本文的改进ELM分类器(简记为Modified ELM).
在实验中, 首先, 使用D0作为源数据, 并采用第一阶段的学习算法获得特征提取组件.然后, 在第二阶段训练的过程中分别使用不同的分类器以及对应的训练策略进行模型迁移, 并测试它们在目标任务上的迁移学习效率和识别精度.
由于THU数据集仅提供1幅图像用于训练, 不利于分类器参数的求取, 为此, 将1幅原始图像随机裁剪成6幅子图像用于训练.进一步地, 考虑到特征提取通常可以在采集图像的过程中执行, 因此仅计算训练分类器的时间.
各对比模型在SDU-MLA、THU、FV-USM、PolyU数据集上的识别精度和训练时间如表6所示, 表中黑体数字表示最优值.
| 表6 不同分类器用于第二阶段迁移时的性能评估 Table 6 Performance evaluation of different classifiers for second stage of transfer learning |
从表6中结果可以看到, 在识别性能上, ELM和TransM-RKELM凭借其独特的求解算法取得略优于200个迭代周期的SLFN的性能, 且TransM-RKELM由于使用核函数并进行融合, 取得优于ELM的结果.将ELM的隐层替换为基于高斯核函数的Modi- fied ELM, 利用特征基于簇分布的特点, 在实验中取得最佳的识别性能, 这验证改进措施在改善分类器性能的有效性.
在迁移学习效率上, 基于ELM的分类器(ELM、TransM-RKELM、Modified ELM)均远快于SLFN.尽管ELM训练时间快于本文使用的分类器, 但它们均能满足实时应用的需求.综合考虑迁移效率和识别性能, 本文模型具备更优的表现.
在上述实验中, 需要选择一个数据集作为源数据, 并通过在该数据集的训练, 获得一个可以泛化到不同目标任务的模型.由于不同数据集的规模不同、图像的多样性不同, 选择不同的源数据集将对模型的泛化能力造成影响.为了评估影响的程度, 分别选择4个数据集中的一个作为源数据集, 并评估模型在其余3个数据集上的表现, 识别精度如表7所示.根据表中结果不难发现, 选择不同的源数据集, 模型在目标任务上的性能会发生改变.对于本文模型, 由源数据不同而引起的性能波动很小, 这表明本文模型对源数据的规模和多样性具有很低的依赖性.
| 表7 跨数据集交叉验证实验结果 Table 7 Results of cross-validation experiments across datasets % |
受深度模型巨量计算开销以及不同数据集间数据差异的影响, 预训练的CNN难以高效应用到新数据集并取得满足使用需求的优良性能, 限制其在跨数据集指静脉识别中的应用.为了克服该问题, 本文从提升模型泛化性能和迁移学习效率两方面出发, 提出面向跨数据集指静脉识别的可快速迁移模型.在阶段一中, 旨在提升模型的泛化性能, 使用偏差场矫正网络消除图像偏差场, 生成具有更高一致性的增强图像, 降低不同数据集分布差异对识别性能的影响.在此基础上, 在特征空间中对齐同一图像的不同扰动结果, 提取对扰动不变的鲁棒特征.同时, 基于特征的簇分布假设, 将特征按照类别信息进行聚类, 增加不同类别之间的裕度, 提升特征的判别力和鲁棒性.在阶段二中, 旨在利用目标任务的模板图像更好地迁移模型, 并满足应用场景对迁移效率的需求, 对ELM进行适当改进, 同时改进分类器, 完成模型从源数据集向目标数据的快速迁移.在四个公开指静脉数据集上的实验表明, 在不考虑特征提取时间的前提下, 本文模型可以在不到2 s的时间内, 将在源数据集训练的模型迁移应用到新数据集, 并取得与在应用数据上进行充分端到端训练的先进模型同等的识别性能.
在研究中, 仅针对指静脉识别任务对算法的有效性进行评估.考虑到不同的应用领域, 数据分布以及数据漂移产生的机理可能不同, 值得进一步研究算法是否有效.同时, 考虑到特征提取组件使用VGG-16结构, 偏差场矫正网络使用U-Net结构, 模型结构较复杂, 对于边缘设备, 模型部署存在困难, 因此, 设计更通用、轻量级的模型同样值得研究.
本文责任编委 封举富
Recommended by Associate Editor FENG Jufu
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|