




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于类相似特征扩充与中心三元组损失的哈希图像检索
[潘丽丽1  , 马俊勇
, 马俊勇1 , 熊思宇1 , 邓智茂1 , 胡清华2 ]
, 马俊勇, 熊思宇, 邓智茂, 胡清华]
|
|



作者简介:

马俊勇,硕士,主要研究方向为图像处理、深度学习.E-mail:forest_csuft@163.com

熊思宇,硕士研究生,主要研究方向为图像处理、深度学习.E-mail:1512426188@qq.com.

邓智茂,硕士研究生,主要研究方向为图像处理、深度学习.E-mail:1149120103@qq.com.

胡清华,博士,教授,主要研究方向为大数据的不确定性建模、多模态数据的机器学习、智能无人系统.E-mail:huqinghua@tju.edu.cn.
现有的深度哈希图像检索方法主要采用卷积神经网络,提取的深度特征的相似性表征能力不足.此外,三元组深度哈希主要从小批量数据中构建局部三元组样本,样本数量较少,数据分布缺失全局性,使网络训练不够充分且收敛困难.针对上述问题,文中提出基于类相似特征扩充与中心三元组损失的哈希图像检索模型(Hash Image Retrieval Based on Category Similarity Feature Expansion and Center Triplet Loss, HRFT-Net).设计基于Vision Transformer的哈希特征提取模块(Hash Feature Extraction Module Based on Vision Transformer, HViT),利用Vision Transformer提取表征能力更强的全局特征信息.为了扩充小批量训练样本的数据量,提出基于类约束的相似特征扩充模块(Similar Feature Expansion Based on Category Constraint, SFEC),利用同类样本间的相似性生成新特征,丰富三元组训练样本.为了增强三元组损失的全局性,提出基于Hadamard的中心三元组损失函数(Central Triplet Loss Function Based on Hadamard, CTLH),利用Hadamard为每个类建立全局哈希中心约束,通过增添局部约束与全局中心约束的中心三元组加速网络的学习和收敛,提高图像检索的精度.在CIFAR10、NUS-WIDE数据集上的实验表明,HRFT-Net在不同长度比特位哈希码检索上的平均精度均值较优,由此验证HRFT-Net的有效性.
About Author:
MA Junyong, master. His research interests include image processing and deep learning.
XIONG Siyu, master student. Her research interests include image processing and deep learning.
DENG Zhimao, master student. His research interests include image processing and deep learning.
HU Qinghua, Ph.D., professor. His research interests include uncertainty modeling for big data, machine learning for multi⁃modal data and intelligent unmanned systems.
Convolutional neural networks are commonly employed in the existing deep hashing image retrieval methods. The similarity representation of the deep features extracted by convolutional neural networks is insufficient. In addition, the local triplet samples are mainly constructed for triplet deep hashing from the small batch data, the size of the local triplet samples is small and the data distribution is lack of globality. Consequently, the network training is insufficient and the convergence is difficult. To address these issues, a model of hash image retrieval based on category similarity feature expansion and center triplet loss is proposed. A hash feature extraction module based on vision transformer is designed to extract global feature information with stronger representation ability. To expand the size of mini-batch training samples, a similar feature expansion module based on category constraint is put forward. New feature is generated by the similarity among samples of the same category to enrich the triplet training samples. To enhance the global ability of triplet loss, a center triplet loss function based on Hadamard(CTLH) is constructed. Hadamard is utilized to establish the global hash center constraint for each class. With CLTH, the learning and the convergence of the network are accelerated by adding the center triplet of local constraint and global center constraint, and the accuracy of image retrieval is improved. Experiments on CIFAR10 and NUS-WIDE datasets show that HRFT-Net gains better mean average precision for image retrieval with different bit lengths of hash code, and the effectiveness of HRFT-Net is demonstrated.
近年来, 随着互联网与多媒体技术的飞速发展, 每秒都有庞大的图像数据在互联网上产生和传输.如何从大规模的图像数据中快捷、准确地查询检索用户所需的数据, 成为图像检索技术领域研究的热点之一.
一幅图像蕴含的信息需要高维度特征矢量才能有效表达, 而处理高维度特征矢量需要消耗大量的存储空间和计算资源.哈希技术能将图像的高维特征信息映射到低维汉明空间的二进制编码, 节省存储空间并降低计算复杂度, 同时保证图像检索质量和计算效率[1, 2].图像哈希是将图像编码成紧凑的二进制代码, 同时保留它们彼此的相似性.由于二进制码具有高存储效率和低计算成本, 哈希技术现已成为图像检索中应用最广泛的技术之一.
现有的哈希方法可以分为两类:传统哈希方法和深度哈希方法.
传统哈希方法[3, 4, 5, 6]使用手工特征.例如:SIFT(Scale Invariant Feature Transform)[7]将图像映射为哈希码, 再根据数据的相似性优化哈希码.然而, 传统哈希方法未考虑图像特征的高级语义等信息, 只是简单地对数据进行散列或取模等操作, 导致丢失数据的重要信息, 无法反映数据间的语义相似性, 降低检索精度.
相比传统哈希方法, 基于深度学习的哈希方法取得显著的性能提升[8, 9].现有的深度哈希模型通常由两部分组成.1)通过卷积神经网络(Convolu-tional Neural Networks, CNN)等提取图像判别特征表示, 如AlexNet、ResNet[10]等.2)通过各种非线性函数, 将图像的连续特征压缩成二进制码.
深度哈希方法是一种利用深度神经网络生成哈希码的方法, 通过计算汉明距离以衡量图像之间的相似性.近年来, 学者们已提出许多深度哈希方法, 在几个基准数据集上表现出优秀的检索性能.Zhu等[11]提出DHV(Deep Hashing Network), 用于监督哈希, 同时优化语义相似对的交叉熵损失和紧凑哈希码的量化损失.Cao等[12]提出HashNet, 利用具有收敛保证的连续方法解决深度哈希网络优化中的梯度问题, 可以从不平衡的相似数据中准确学习二进制哈希码.Su等[13]提出Greedy Hash, 采用贪心算法解决离散哈希优化问题.林计文等[14]提出面向图像检索的深度汉明嵌入哈希(Deep Hamming Embe-dding Based Hashing, DHEH), 用于图像检索, 根据哈希编码特征引入汉明嵌入学习, 控制相似性信息的保留.受Fisher LDA(Fisher's Linear Discriminant Analysis)的启发, Li等[15]提出Deep Fisher Hashing, 优化二值空间中的最大类可分性.冯浩等[16]提出深度多尺度注意力哈希(DMAH), 通过多尺度注意力定位和显著性区域提取模块, 捕捉图像判别性区域, 并引入三元组量化损失, 降低量化过程中的信息损失.张志升等[17]提出融合稀疏差分网络和多监督哈希的方法(Sparse Difference Networks and Multi-super-vised Hashing, SDNMSH), 解决基于深度哈希的CNN特征提取效率较低和特征利用不充分的问题.
随着CNN的发展, 基于深度哈希的方法利用CNN将图像编码为保持相似性的哈希码, 显著提升图像检索任务的性能[18].基于成对的方法和基于三元组的方法是两种具有代表性的深度哈希方法.在基于成对的方法中, 成对标签被用作监督信息以指示一对图像相似或不相似.在基于三元组的方法中, 三元组的形式为(A, P, N), 其中, A与P为同一类别, A与N为不同类别, 这表明A更接近P而不是N.相比基于成对的方法, 三元组还捕获相对相似度信息, 即三元组(A, P, N)中(A, P)和(A, N)之间的相对关系.近期工作[19, 20, 21]表明, 基于三元组的方法性能通常优于基于成对的方法.
由于Softmax交叉熵损失无法处理可变数量的类, Schroff等[22]提出三元组损失函数, 构建Face- Net, 并将三元组损失应用于人脸检索任务, 实验表明, 通过三元组损失训练的模型具有优越的识别率和检索精度.为了进一步挖掘三元组之间的潜在关系, Lu等[23]提出平衡三元组损失, 用于全面的特征学习和稳定的模型收敛.平衡三元组损失仅在小批量中挖掘每个类别中最难的负样本.郑大刚等[24]提出基于三元组损失的深度人脸哈希方法, 并用于人脸检索任务.不同于基于余量的三元组损失, Zhao等[25]提出HCTL(Hard Mining Center-Triplet Loss), 降低计算和挖掘困难训练样本的成本, 同时有效优化类内距离和类间距离, 从而增强特征的学习和优化.
基于三元组损失的深度哈希方法通过从三元组数据中捕获相对相似性以学习哈希函数.Liang等[19]使用三元组损失同时进行特征学习和哈希编码.Zhuang等[26]提出将基于三元组的学习任务转换为多标签分类任务, 以此加快训练速度.
还有一些研究工作致力于为成对或三元组分配不同权重.Lai等[27]利用平均精度作为边信息以加权三元组损失.Cao等[28]提出DCH(Deep Cauchy Hashing), 设计基于柯西分布的成对损失, 惩罚汉明距离大于汉明半径阈值的相似图像对.Wang等[29]提出MS Loss(Multi-similarity Loss), 在样本加权过程中涉及多个相似点的损失.
但是, 上述方法在小批量数据集中构建的三元组样本较少, 样本数据分布缺少全局性, 网络在训练时仍然难以收敛.
注意力机制[30]现已大幅推进机器学习的发展, 一种为计算机视觉任务量身定制的视觉转换器(Vision Transformer, ViT)[31]在图像分类、物体检测、语义分割任务中取得优于CNN的性能[32, 33].ViT利用自注意力机制(Self-Attention, SA)及强大的全局建模能力处理计算机视觉任务, 在传统的视觉分类任务中取得较大成功.相比受卷积核大小限制难以捕捉远距离像素关系的CNN, ViT能够通过自注意力机制学习图像的长程空间关系, 在提取图像的全局视觉表征上表现优异.
Transformer首先应用于自然语言处理(Natural Language Processing, NLP)领域中的顺序数据[30].最近, 受NLP领域中Transformer架构成功的启发, 研究人员将Transformer应用于计算机视觉(Com-puter Vision, CV)任务.在视觉应用中通常使用CNN作为特征提取的基础模块[10, 34], 但Transformer展示的性能显示它是CNN的潜在替代品.Chen等[35]训练Sequence Transformer以回归预测图像, 实现与CNN在图像分类任务上相当的结果.Dosovi-tskiy等[31]提出的Vision Transformer在多个图像识别基准任务上实现最优性能.
ViT将一个原始Transformer直接应用于图像补丁序列, 对完整图像进行分类, 各种扩展应用已经取得一定成功.薛峰等[36]提出基于Vision Transformer的端到端中文句子级唇语识别模型.Chen等[37]提出TransHash, 使用ViT作为深度哈希任务的主干, 用于特征提取, 并利用成对损失作为监督任务.Li等[38]提出HashFormer, 同样使用ViT作为主干网络, 并提出一种平均精度损失, 直接优化检索精度.
虽然ViT仍处于萌芽阶段, 但由于其出色的性能, 越来越多的研究人员提出基于Transformer的模型以改善大量的视觉任务[39].
现有的深度哈希图像检索方法主要采用CNN, 提取的深度特征相似性表征能力不足, 检索精度受限.此外, 基于三元组的深度哈希网络在训练过程中从小批量数据中构建局部三元组样本, 这些三元组样本不仅数量较少, 而且不具有数据分布的全局性, 使网络训练不够充分且收敛困难, 影响图像检索的性能.
针对上述问题, 本文提出基于类相似特征扩充与中心三元组损失的哈希图像检索模型(Hash Image Retrieval Based on Category Similarity Feature Expansion and Center Triplet Loss, HRFT-Net).针对CNN提取的深度特征相似性表征能力不足的问题, 使用ViT和哈希层构建基于ViT的哈希特征提取模块(Hash Feature Extraction Module Based on ViT, HViT), 提取相似性表征能力更强的全局性深度哈希特征, 提高图像检索的精度.针对端到端的训练中从小批量数据中构建局部三元组样本数量较少的问题, 提出基于类约束的相似特征扩充模块(Similar Feature Expansion Based on Category Constraint, SFEC), 通过已提取特征合成新的特征, 将每个小批量的训练特征样本扩充为原来的2倍, 从而丰富三元组样本, 有利于网络模型更加充分地训练.针对局部三元组不具有全局性, 导致网络的训练收敛困难、检索性能较低的问题, 提出基于Hadamard的中心三元组损失函数(Center Triplet Loss Function Based on Hadamard, CTLH), 利用Hadamard为每个类别建立全局哈希中心约束, 加速网络的收敛, 同时使优化生成的哈希码更好地分布在汉明空间中, 提高检索性能.
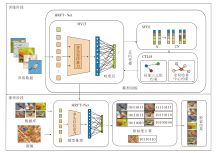
现有的深度哈希图像检索方法主要采用CNN提取深度特征, 相似性表征能力不足, 同时在三元组深度哈希网络训练过程中, 从小批量数据中构建局部三元组样本数量较少, 不具有数据分布的全局性, 使网络训练不够充分且收敛困难等.由此本文提出基于类相似特征扩充与中心三元组损失的哈希图像检索模型(HRFT-Net), 模型结构如图1所示.
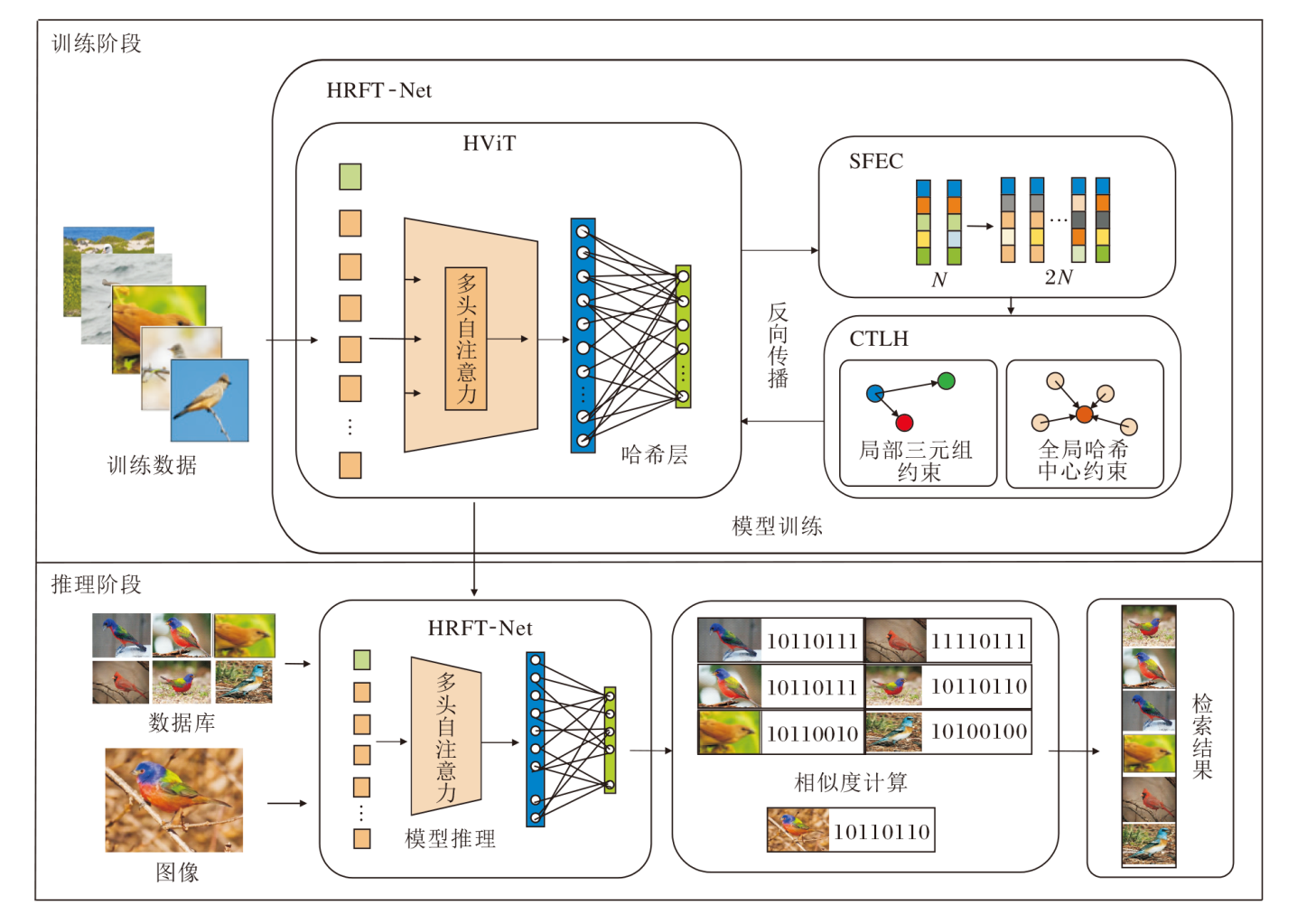 | 图1 HRFT-Net结构图Fig.1 Structure of HRFT-Net |
HRFT-Net主要由基于ViT的哈希特征提取模块(HViT)、基于类约束的相似特征扩充模块(SFEC)和基于Hadamard的中心三元组损失函数(CTLH)组成.
首先对输入图像进行预处理, 包括缩放、剪裁等, 将图像处理至统一尺寸, 在大型数据集ImageNet上预训练的ViT与哈希层构建的HViT中输入图像, 对图像进行特征映射, 生成紧凑的深度哈希特征.然后, 使用SFEC扩充HViT提取的特征, 将扩充后的样本输入CTLH, 进行损失计算, 通过反向传播更新网络参数.本文模型通过上述步骤实现高效率和高精度的图像检索.
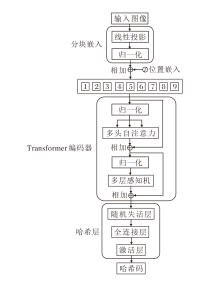
基于ViT的哈希特征提取模块(HViT)用于提取相似性表征能力更强的全局性深度哈希特征, 流程如图2所示.ViT只使用Transformer的编码器部分, 通过自注意力机制捕获图像的局部信息和全局信息.
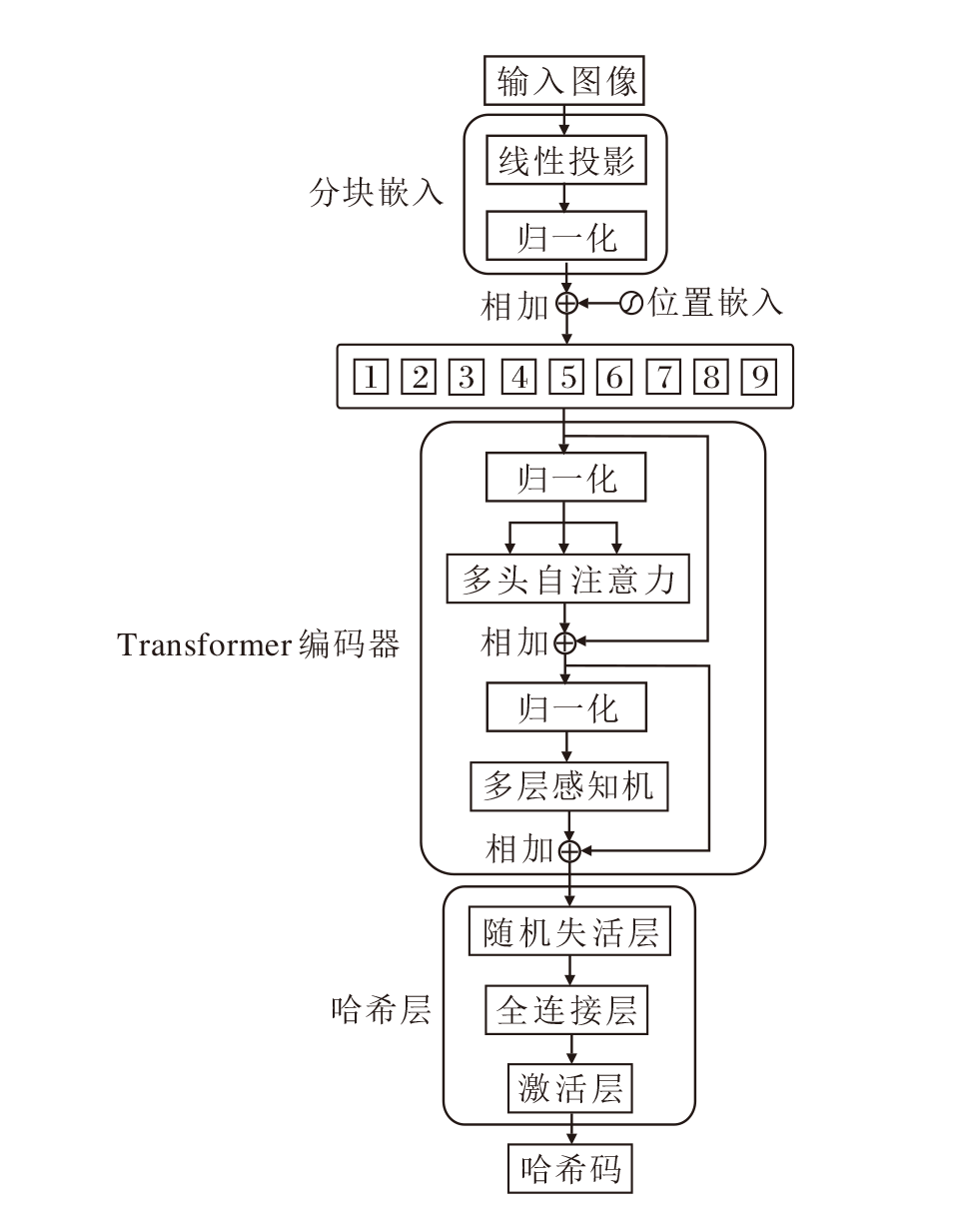 | 图2 HViT流程图Fig.2 Schematic diagram of HViT |
首先, 图像通过线性投影和位置编码, 使后续Transformer编码器可处理一维序列和感知位置信息.然后, 输入Transformer编码器中, 对图像特征进行编码, 每个编码器包含一个多头自注意力(Multi-head Self-Attention, MSA)层和一个多层感知机(Multi-layer Perceptron, MLP)层.MSA能捕捉序列中的全局信息, 增强模型的表达能力.MLP通过非线性变换增强模型的复杂度和拟合能力.每个编码器后面均设置有残差连接和层归一化, 采用ViT的ViT-B_16预训练模型.最后, 将编码后的图像特征输入哈希层, 生成哈希特征.
哈希层包括随机失活层、激活层和全连接层.随机失活层防止特征过拟合; 激活层ReLU对特征激活; 全连接层将特征进行线性映射转换, 生成深度哈希码.
HViT将输入图像分割成固定尺寸的块, 假设输入图像x大小为H× W× C, 先将输入图像x分割为H× W/P2个非重叠分辨率的图像块, P2为每块的大小是16× 16, 将二维图像转化为一维序列, H、W分别为图像的高和宽, C为通道数.分割后得到的序列x'长度为H× W/P2.ViT由于注意力机制无法区分位置差异, 需要将位置信息嵌入序列x', 得到位置增强特征:
F=[x'0, x'1, …, x'L]+EP,
其中, EP表示在截断高斯分布下随机初始化的位置编码信息, +表示加法操作.
位置嵌入表示图像块在图像中的相对位置且是可学习的参数.
Transformer编码器包含12层, 每层包含MSA和MLP.MSA是自注意力的延伸.首先自注意力计算公式如下:
$\begin{array}{l} S A(\boldsymbol{F})=\phi\left(\frac{\boldsymbol{Q} \boldsymbol{K}^{\mathrm{T}}}{\sqrt{d}}\right) \boldsymbol{V}, \\ \boldsymbol{Q}=\boldsymbol{F} \boldsymbol{W}_{q}, \boldsymbol{K}=\boldsymbol{F} \boldsymbol{W}_{k}, \quad \boldsymbol{V}=\boldsymbol{F} \boldsymbol{W}_{V}, \end{array}$
其中, F为自注意力的输入特征, Wq、Wk和WV为具有可训练参数的权重, d为Q、K、V的维数, ϕ (· )为Softmax激活函数.
为了并行应用多个自注意力, MSA具有m个独立的SA, 则
MSA(F)=SA1(F)⊕SA2(F)⊕…SAm(F),
其中⊕表示concat操作.
综上所述, 在第i个Transformer层中, 输出特征
$\begin{array}{l} \boldsymbol{F}_{i}=\operatorname{MLP}\left(L N\left(\overline{\boldsymbol{F}}_{i}\right)\right)+\overline{\boldsymbol{F}}_{i}, \\ \overline{\boldsymbol{F}}_{i}=\operatorname{MSA}\left(L N\left(\boldsymbol{F}_{i-1}\right)\right)+\boldsymbol{F}_{i-1}, \end{array}$
其中LN(· )为层归一化.
通过结合查询结果和特征组合扩充等额外相关信息, 图像检索中的查询扩充和数据库扩充技术可提高图像检索性能[40, 41, 42].
受这些技术的启发, 为了在小批量训练中增加更多的特征样本, 丰富参与训练的三元组样本, 本文提出基于类约束的相似特征扩充模块(SFEC), 结构如图3所示.
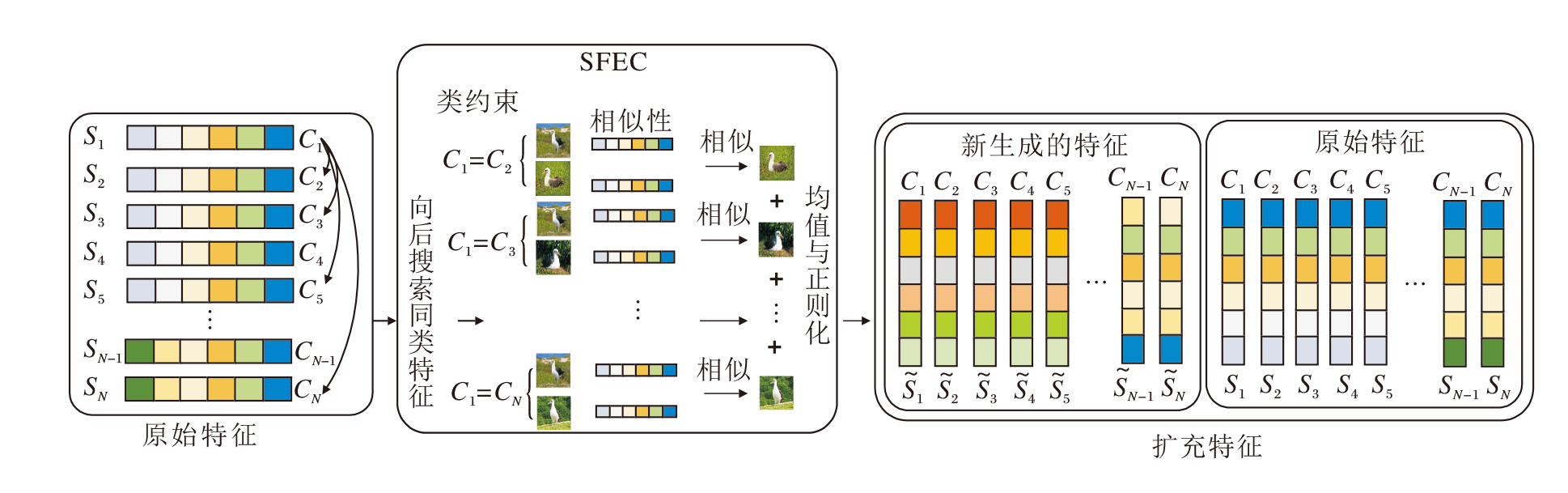 | 图3 SFEC结构图Fig.3 Structure of SFEC |
SFEC的输入为HViT从小批量中提取的原始特征, 数量为N.SFEC的输出为扩充特征, 数量为原始特征的2倍, 即2N.SFEC首先搜索原始特征中同类别特征, 并进行相似性约束判断.然后, 针对类相似性约束特征进行相加融合.最后, 对相加融合的特征进行均值与正则化, 输出基于类约束相似性扩充特征.原始特征和新生成的特征共同参与训练, 为后续基于Hadamard的中心三元组损失函数(CTLH)损失计算增加更多的三元组样本, 使模型可以进行更充分的训练.
假设HViT提取一个小批量训练数据中的N幅图像, 得到原始图像特征集合:
SN={x1, x2, …, xn},
其中, xi为SN中的一个样本图像特征向量,
xi=[xi, 1, xi, 2, …, xi, k].
SFEC对SN中基于类约束的相似特征进行相加运算, 融合同一类别图像之间的特征, 扩充该类别样本的特征表示.
每次在SN寻找与xi同类别的特征, 并且在第i个位置之后, 欧氏距离小于β 的相似样本特征进行相加后取均值, 得
其中,
$\begin{array}{l} \overline{\boldsymbol{x}}_{i}=\left[\frac{1}{T_{i}} \sum_{m \in N} x_{m, 1}, \frac{1}{T_{i}} \sum_{m \in N} x_{m, 2}, \cdots, \frac{1}{T_{i}} \sum_{m \in N} x_{m, k}\right], \\ i \leqslant m, D_{E}\left(\boldsymbol{x}_{i}, \boldsymbol{x}_{m}\right)< \beta, \end{array}$
k为特征维度大小, Ti为第i幅图像后与xi之间的距离小于β 的图像数量, β 为超参数, DE(· , · )为欧氏距离.
为了减少部分噪声特征的干扰和降低特征信息的方差, 增强模型的泛化能力, SFEC采用均值和正则化运算, 对合成特征点
$\begin{array}{l} \tilde{\boldsymbol{S}}_{N}=\left\{\tilde{\boldsymbol{x}}_{1}, \tilde{\boldsymbol{x}}_{2}, \cdots, \tilde{x}_{n}\right\}, \\ \tilde{\boldsymbol{x}}_{i}=\frac{\overline{\boldsymbol{x}}_{i}}{\left\|\overline{\boldsymbol{x}}_{i}\right\|_{2}} . \end{array}$
最终扩充后的特征为
$\boldsymbol{S}=\left\{\boldsymbol{S}_{N}, \widetilde{\boldsymbol{S}}_{N}\right\}$
三元组损失广泛应用于图像检索领域, 由于深度学习方法使用端到端的训练方法, 三元组选取一般从一个批次中构建的相似矩阵选取(A, P, N), 其中, A为锚样本, P为正样本, N为负样本.A与P为同类, A与N为不同类别, 通过不断拉近A与P之间的距离D1的同时拉远A与N之间的距离D2, 造成局部三元组缺失数据分布的全局性, 导致网络学习效率降低、收敛困难.
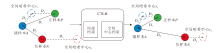
为了增强三元组的全局性, 本文提出基于Hadamard的中心三元组损失(CTLH), 在构建三元组损失时, 利用Hadamard矩阵为每个类别建立一个全局哈希中心, 增强局部三元组的全局性, 加快网络训练的收敛.
CTLH示例如图4所示.在图中, v1为A与P的全局哈希中心, v2为P的哈希中心, 通过CTLH的局部三元组约束和全局哈希中心约束, A与P的距离D1缩小, 同时A与v1的距离D3靠近, P与v1距离靠近.A与N之间的距离D2增大, 同时N与v2的距离D5缩小, 得到类内样本的紧凑性和类间样本的可分离性分布, 提高图像哈希码的表征能力.
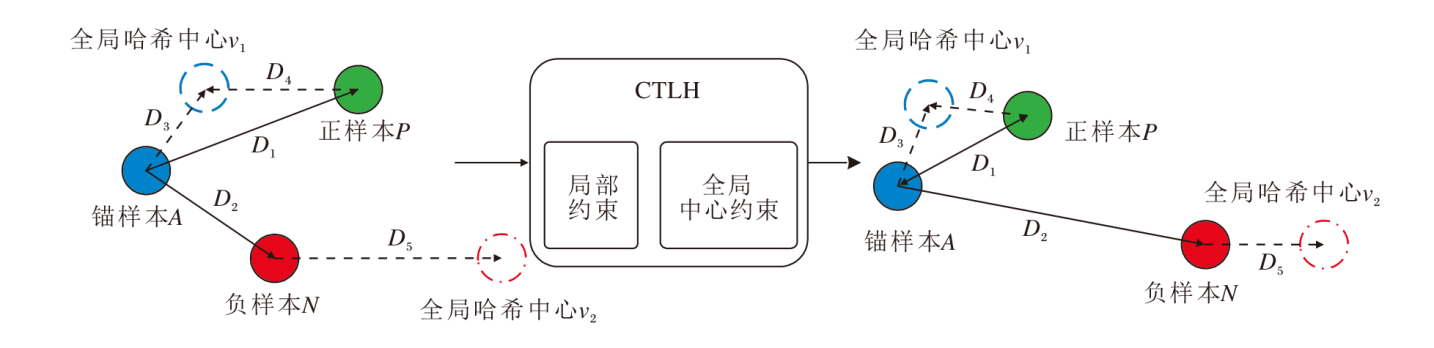 | 图4 CTLH示例Fig.4 Example of CTLH |
相似图像的哈希特征在汉明空间中具有较小的距离, 不相似的图像哈希特征具有较大的距离, 有利于图像间的相似性表达.
为了让哈希特征更好地分布在汉明空间, 每个类别的哈希中心与其它类别中心之间的距离应比与它相关类别的哈希码之间的距离更远, 本文使用Hadamard矩阵构建哈希中心, Hadamard矩阵表示为
HK=[v1, v2, …, vk],
其中, K为矩阵维度, k为特征维度.由于Hadamard矩阵的任意两个行向量v的点乘为0, 任意两个行向量的汉明距离为DH(· , · ), 满足每个类别的哈希中心与其它中心之间的距离分布均匀的要求, 即
DH(vi, vj)=
通过Hadamard矩阵可以得到预定义好的每个类别的全局哈希中心.由于全局哈希中心是二进制向量, 所以本文使用二进制交叉熵度量全局哈希中心损失:
$\begin{aligned} L_{C}= & \frac{1}{K} \sum_{i=1}^{N} \sum_{k \in K}\left[v_{i, k} \log _{2} h_{i, k}+\right. \\ & \left.\left(1-v_{i, k}\right) \log _{2}\left(1-h_{i, k}\right)\right] . \end{aligned}.$
由于每个全局哈希中心都是二进制的, 而现有的优化方法不能保证生成的哈希码完全收敛到哈希中心, 因此加入量化损失LQ以细化网络生成的哈希码, 减少二值哈希码与实数特征之间的误差, 从而提升哈希编码的质量.LQ具体计算公式如下:
$L_{Q}=\sum_{i}^{N} \sum_{k=1}^{K}\left(\log _{2}\left(\cosh \left(\left|2 h_{i, k}-1\right|-1\right)\right)\right) .$
将每个类别样本约束到该类别的全局哈希中心, 同时利用局部三元组学习图像之间的相似性, 从小批量训练数据中选出hA、hP和hN, 分别表示锚样本、正样本和负样本, 将局部三元组损失定义为LT, 则
LT=max(‖ hA-hP‖ 2-‖ hA-hN‖ 2+∂ , 0),
其中∂ 为余量.
最后, 基于Hadamard的中心三元组损失函数为:
LCTLH=LC+LT+λ LQ,
其中λ 为平衡系数.
CLTH训练得到的深度哈希特征既保持同类样本的局部紧凑性, 同时具有不同类样本的全局可分离性, 有利于网络的训练和收敛.
为了验证HRFT-Net的有效性, 在公开的图像检索数据集CIFAR10[43]和NUS-WIDE[44]上进行实验.
CIFAR10数据集是来自10个类别的60 000幅图像的集合, 每个类别有6 000幅图像, 随机抽取5 000幅图像用于训练集, 每个类别有500幅图像.然后, 对查询集中1 000幅图像进行随机采样, 每个类别100幅图像, 其余图像作为查询数据库, 称为CIFAR10@54000.
此外, 按照文献[45]中的设置, 将训练集也划分到查询数据库上, 计算CIFAR10数据集上的检索结果, 即CIFAR10@All.
NUS-WIDE数据集是目前应用最广泛的图像检索数据集之一, 包含从Flick收集的近27万幅图像.按照文献[45]中使用的数据集划分方法, 选用其中21个最常见的类, 训练集由每类随机采样500幅图像组成, 查询集由每个类别随机采样100幅图像组成, 剩余的图像当作数据库进行检索, 称为NUS- WIDE@5000.
实验环境设备采用Windows10操作系统, 配备高性能GPU RTX 2070显卡, 带有8 GB显存, 搭载PyTorch1.7.0深度学习开发环境.
在训练和测试中, 所有图像调整为256× 256, 中心裁剪为224× 224, 每一批次大小设置为32, 学习率初始化为1e-4, 采用权重衰减为1e-5的RMSprop优化器, 训练轮次设置为120.使用ViT[31]提供的预训练权重初始化模型ViT-B_16, 隐藏层大小为768, 多头注意力个数为12, HRFT-Net由12个Transformer块组成.
本文采用图像检索中常用的评价指标— — 平均精度均值(Mean Average Precision, mAP)评估模型的性能.假设在查询数据集中有查询图像xi的yk个相似图像, 可以在查询结果中得到yk幅图像的位置序号分别为
P={p1, p2, …,
则xi的平均准确率为
$A P\left(x_{i}\right)=\frac{1}{y_{k}} \sum_{j=1}^{y_{k}}\left(\frac{j}{p_{j}}\right), $
那么对于整个查询图像数据集, 所有类别的平均检索精度为
mAP=
本文选择如下对比方法.
1)DPN(Deep Polarized Network)[45].基于成对标签的深度哈希检索模型, 通过成对损失保持相似图像之间的汉明距离小、不相似图像之间的汉明距离大.同时通过量化损失, 减少CNN输出和二进制编码之间的误差.
2)DSH(Deep Supervised Hashing)[46].通过类别敏感的哈希目标, 保持同类图像之间的汉明距离小、异类图像之间的汉明距离大, 优化深度哈希网络.
3)IDHN[47].在哈希层使用符号函数, 而不是连续的激活函数, 从而避免量化误差.
4)CSQ(Central Similarity Quantization)[48].鼓励相似的数据对的哈希码趋近于一个共同中心, 可以提高哈希网络学习效率.
5)HashFormer[38].采用基于Transformer的框架解决深度哈希任务, 使用平均精度损失直接优化检索精度.
6)TransHash[37].设计双流多粒度视觉Trans-former模块, 并采用动态构造相似矩阵的方法学习紧凑的哈希码, 提高图像检索性能.
本节在CIFAR10、NUS-WIDE图像检索数据集上进行实验, 采用16 bits、32 bits、64 bits、128 bits这4种不同长度比特位哈希码, 计算平均检索精度, 评估不同模型.为了实现不同方法的公平对比并验证HRFT-Net的泛化性和优越性, 本文设计如下3种不同的深度哈希特征提取模块.
1)HAN(Hash Feature Extraction Based on Alex-Net).表示使用AlexNet与哈希层构建的基于AlexNet的哈希特征提取模块.
2)HRN(Hash Feature Extraction Based on Res-Net50).表示使用ResNet50与哈希层构建的基于ResNet50的哈希特征提取模块.
3)HViT.本文提出的基于Vision Transformer的哈希特征提取模块.
各模块具体信息如表1所示.
| 表1 特征提取模块信息 Table 1 Information of feature extraction modules |
首先, 在不同检索方法均以HAN作为特征提取模块的情况下进行实验, 具体mAP值如表2所示, 表中黑体数字表示最优值.HAN由AlexNet和哈希层构成, 其中AlexNet由5层卷积层和3层全连接层构成, 整体网络深度较浅.从表中结果可知, 在CIFAR10、NUS-WIDE数据集上, HRFT-Net的128 bits哈希码检索mAP值最高, 分别达到78.5%和84.0%.
| 表2 基于HAN的不同检索方法mAP值对比 Table 2 mAP comparison of different retrieval methods based on HAN |
使用基于ResNet50的卷积层数更深的HRN作为特征提取模块, 不同方法的mAP值如表3所示, 表中黑体数字表示最优值.HRN由预训练的ResNet50与哈希层构建而成, ResNet50由50层深度卷积组成, 使用更深的网络, 同时使用残差连接, 可以有效解决深度网络的梯度消失和退化问题.相比HAN, HRN更深, 有更多的参数和计算量.
| 表3 基于HRN的不同检索方法mAP对比 Table 3 mAP comparison of different retrieval methods based on HRN |
由表3结果可看出, 在CIFAR10数据集上, HRFT-Net的16 bits哈希码检索mAP值为84.9%, 对比次优的CSQ, 提高1.8%.
HAN和HRN主要由CNN构成, 而CNN受卷积核大小限制, 提取的特征相似性表征能力不足.因此, 下面使用HViT验证HRFT-Net的检索性能.与HAN和HRN不同, HViT利用Transformer的自注意力机制捕捉图像中的全局依赖关系, 用于提取特征, 能更好地捕获图像的全局相似性.
以HViT作为特征提取模块, 不同检索方法的mAP值如表4所示, 表中黑体数字表示最优值.由表可以看出, 在NUS-WIDE数据集上, HRFT-Net的64 bits哈希码检索mAP值达到87.9%, 比效果次优的CSQ提高2.0%.值得注意的是, 在CIFAR10数据集上, 使用128 bits哈希码时, HRFT-Net的检索精度略有降低, 比最优的IDHN降低0.9%.这是由于网络将连续码转换为二进制码时存在量化误差, 在哈希码较长或较短时, 量化误差对检索精度的影响增大.
| 表4 基于HViT的不同检索方法mAP对比 Table 4 mAP comparison of different retrieval methods based on HViT |
对比表2~表4中的mAP值发现, 在CIFAR10、NUS-WIDE数据集上, 采用相同的特征提取模块时, 使用4种不同长度的哈希码进行图像检索, HRFT-Net的检索精度都取得最优值, 相比次优方法可提高0.2%~2.0%, 这充分说明HRFT-Net图像检索的卓越性能.
综合表2~表4的实验结果还可发现, 相比DPN、DSH、IDHN和CSQ, 在不同比特位长度的哈希码和不同数据集上, HRFT-Net的mAP值波动较小, 且检索精度最高, 这表明HRFT-Net检索的稳定性和优越性.HRFT-Net通过基于类约束的相似特征扩充模块(SFEC)扩充提取的特征, 增加更多的三元组样本进行训练, 有利于网络更充分地学习和优化, 从而提高模型检索的性能和稳定性.同时, HRFT- Net通过基于Hadamard的中心三元组损失函数(CTLH), 利用局部三元组约束和全局哈希中心约束, 加快网络学习的收敛速度, 并优化生成的哈希码特征空间的分布, 使其具有更好的图像深度语义表征能力, 有利于不同类别样本之间在汉明空间中更好地分布, 从而提高图像的检索精度.
为了分析HViT中输入图像的特征提取机制, 随机选取3幅原始图像和其生成的HViT注意力图进行可视化对比, 具体如图5所示.注意力图是对HViT中的自注意力权重进行可视化生成的, 其中较亮区域表示HViT在该位置具有较高的关注度, 而较暗区域表示关注度较低.
 | 图5 HViT注意力图可视化结果Fig.5 Visualization of HViT attention map |
从图5中可以看出, 注意力图中的显著性区域与原始图像中的关键特征区域基本保持一致.HViT通过自注意机制对图像整体计算权重, 可捕获到具有判别性的深度特征, 有助于后续图像检索任务.
本文不仅进行检索性能的实验, 还对比各方法的检索时间.所有检索实验在同一高性能服务器上进行.
服务器配置如下:NVIDIA GeForce RTX 2070、Intel(R) Core(TM) i5-9400F CPU@2.90 GHz、16 GB内存.
不同检索方法的平均计算时间如表5所示, 均采用HViT作为特征提取模块.由表可以看出, HRFT-Net在检索时间上无明显优势, 与其它方法的时间开销是相近的.综合检索精度和检索时间可知, 相比其他方法, HRFT-Net在时间开销相仿的情况下可有效提升检索精度, 由此表明HRFT-Net具有高效的检索性能.
| 表5 基于HViT的不同检索方法的检索时间对比 Table 5 Retrieval time comparison of different retrieval methods based on HviT s |
为了进一步验证HRFT-Net的检索性能, 在CIFAR10、NUS-WIDE数据集上, 采用64 bits哈希码, 分析使用HAN、HRN、HViT这3种特征提取模块的HRFT-Net.在CIFAR10、NUS-WID数据集上提供HRFT-Net的精度-召回率曲线、召回率曲线和精度曲线, 如图6和图7所示.
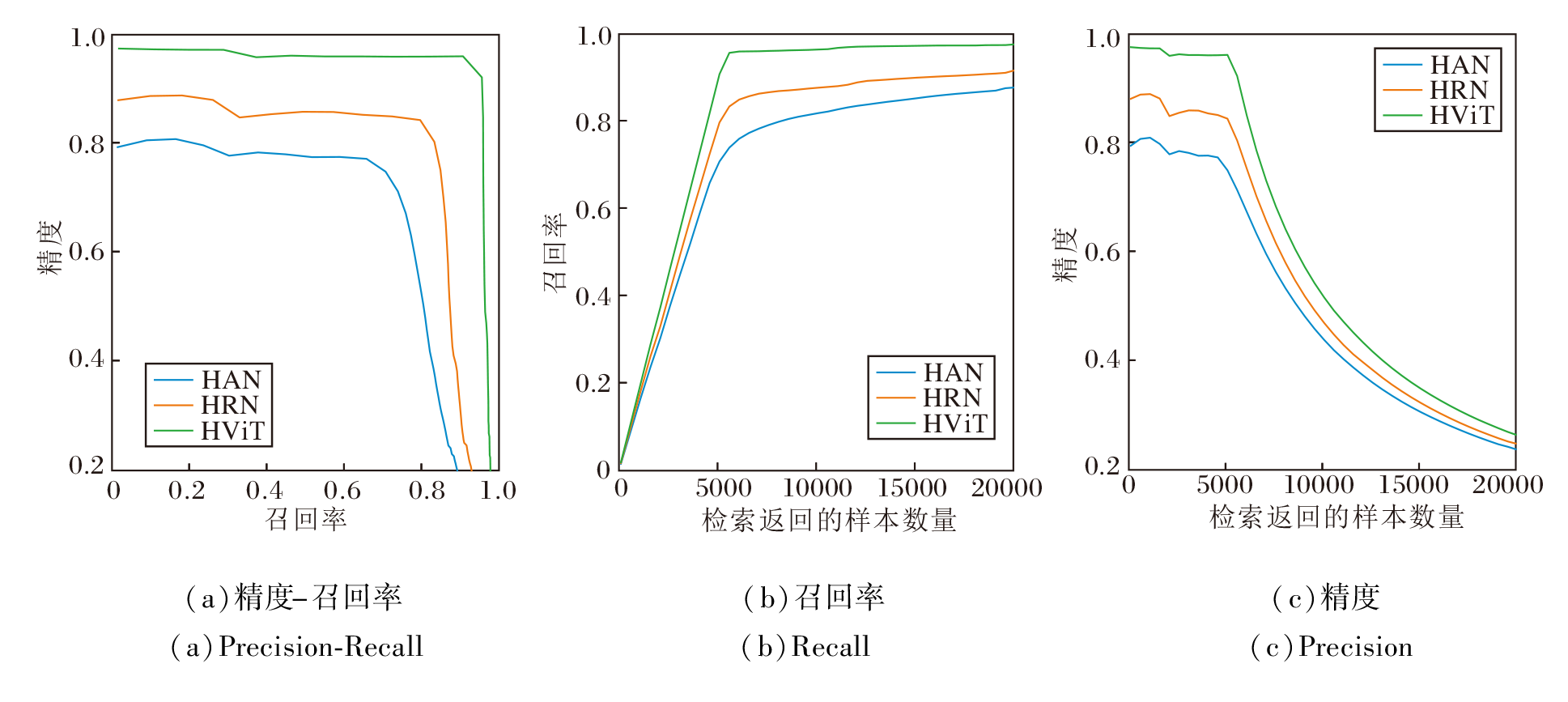 | 图6 HRFT-Net在CIFAR10数据集上64 bits哈希码的检索曲线Fig.6 Retrieval curves of HRFT-Net with 64 bits hash codes on CIFAR10 dataset |
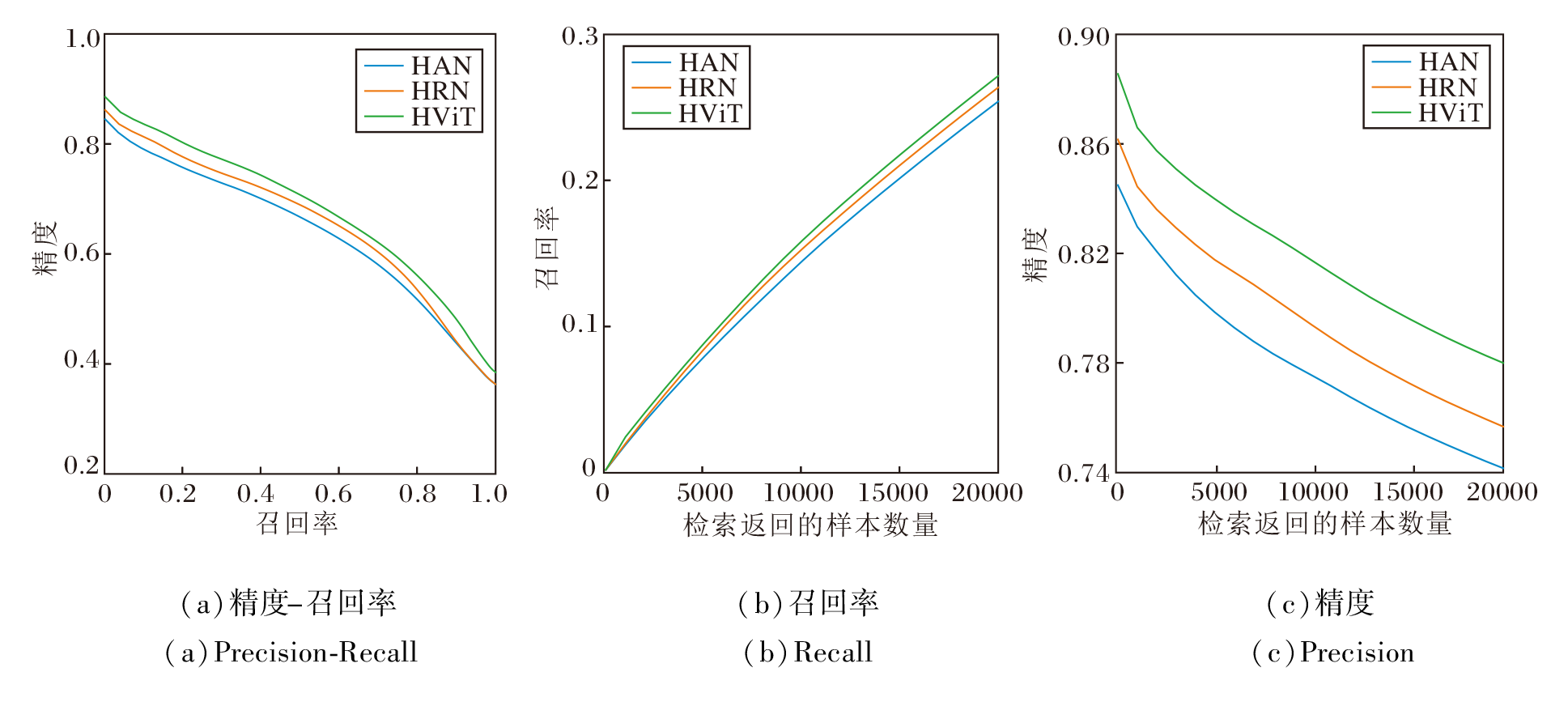 | 图7 HRFT-Net在NUS-WIDE数据集上64 bits哈希码的检索曲线Fig.7 Retrieval curves of HRFT-Net with 64 bits hash codes on NUS-WIDE dataset |
在图6中, 基于HViT的HRFT-Net的精度-召回率曲线在最外围, 接近1.0, 召回率曲线和精度曲线同样处于最顶端, 表示其检索效果最优.
在图7中, 基于HViT的精度-召回率曲线、召回率曲线和精度曲线同样处于其它曲线的上方, 表明HRFT-Net使用HViT的性能优于采用HAN和HRN模块.这是因为HAN与HRN分别由AlexNet和ResNet50构成, 两者均为CNN, 而HViT是由Transformer构成, 相比CNN, Transformer具有更好的全局感受野.因此, 相比HAN和HRN, HViT能更好地捕获图像的整体内容和细节特征信息, 从而提高图像检索的精度.
精度-召回率曲线反映HRFT-Net检索结果的准确性, 曲线和轴围成的面积越大, 检索性能越优.对比图6(a)和图7(a)可以看出, HRFT-Net在CIFAR10数据集上的精度-召回率曲线围成的面积远大于NUS-WIDE数据集, 同时在CIFAR10数据集上整体检索准确率也远高于NUS-WIDE数据集.这是因为相比NUS-WIDE数据集, CIFAR10数据集上图像内容复杂度相对较低, 更容易提取图像判别性特征, 同时CIFAR10数据集在查询集数量上少于NUS-WIDE数据集.
从图6和图7中召回率曲线和精度曲线可以看出, 召回率整体呈上升趋势, 精度整体呈下降趋势.随着检索到的样本图像越来越多, 查询数据库上检索到同类别图像越来越全面, 召回率呈上升趋势.同样, 相似同类别图像检索越全面, 后续检索结果中不相似的非同类别负样本图像也越多, 检索图像越多则检索到同类别的精度越小, 精度整体呈下降趋势.
为了深入探究SFEC扩充训练特征样本对HRFT-Net检索性能的影响, 在HAN、HRN和HViT三种特征提取模块下分别进行SFEC的消融实验, 并通过mAP值验证其有效性.
在CIFAR10、NUS-WIDE数据集上的消融实验结果如表6所示, 表中黑体数字表示最优值.
| 表6 是否加入SFEC的消融实验结果 Table 6 Ablation experiment results with or without SFEC |
由表6可以看出, 在CIFAR10数据集上, HRFT-Net在加入SFEC和不加入SFEC的情况下, 分别使用HAN、HRN和HViT进行不同比特位长度的哈希码检索, mAP值平均提升约0.6%、0.9%和0.5%.在NUS-WIDE数据集上, HRFT-Net在加入SFEC和不加入SFEC的情况下, 分别使用HAN、HRN和HViT进行不同比特位长度的哈希码检索, mAP值平均提升约0.3%和0.4%.这说明HRFT-Net在每个小批量训练中, 通过SFEC对提取的图像特征进行组合, 生成新的合成图像特征, 增加训练特征样本的多样性, 丰富可训练的三元组样本, 有利于网络更充分地学习, 优化网络提取的图像特征, 提高图像检索精度.
为了验证CLTH的有效性, 使用文献[48]的中心量化损失和文献[49]的三元组哈希损失依次替换HRFT-Net中的CLTH, 在CFIFAR10、NUS-WIDE数据集上进行检索精度对比, 结果如表7所示, 表中黑体数字表示最优值.由表7可知, 在CIFAR10、NUS-WIDE数据集上, CLTH在检索精度方面均优于中心量化损失和三元组哈希损失.中心量化损失将相似类别数据对收敛到同一哈希中心, 不同类别数据收敛到不同哈希中心.而三元组哈希损失构建三元组样本, 通过拉近正样本与锚样本之间的距离、推远负样本与锚样本之间的距离, 进行图像的相似性学习.从表7结果可以看出, 中心量化损失和三元组哈希损失在不同长度哈希码上的检索精度相似, 整体上都低于CLTH.本文提出的CLTH不仅构建三元组, 还利用Hadamard矩阵为每个类别构建全局哈希中心, 同时进行局部三元组约束和全局哈希中心约束, 使模型得到的深度哈希特征不仅保持同类样本的局部紧凑性, 而且具有不同类样本的全局可分离性, 从而有效提升图像检索精度.
| 表7 CLTH的消融实验结果 Table 7 Ablation experiment results of CLTH |
本节选择如下一些目前先进的深度哈希图像检索方法进行对比实验.对比方法如下:
DHN[11], Hash-Net[12], Greedy Hash[13], Deep Fisher Hashing[15], DMAH[16], SDNMSH[17], DCH[28], TransHash[37]和Ha-shFormer[38].
各方法在CIFAR10、NUS-WIDE数据集上的mAP值如表8所示, 表中黑体数字表示最优值, -表示该方法未进行实验测试.由表可见, HashFormer、TransHash和HRFT-Net均采用Transformer提取图像特征, 检索性能远高于DHN、HashNet等方法.这是因为DHN、HashNet等深度哈希检索方法主要使用CNN, 提取的特征相似性表征能力不足, 而HashFormer和TransHash均采用Transformer提取图像特征, 能更好地捕获图像的全局特性, 保持图像间的相似性表达能力.
| 表8 各方法在2个数据集上的mAP值对比 Table 8 mAP comparison of different methods on 2 datasets |
此外, 在同样使用Transformer的情况下, 相比HashFormer和TransHash, HRFT-Net仍具有较大优势.在CIFAR10数据集上, HRFT-Net的不同比特位哈希码检索mAP值比HashFormer和TransHash分别提高约4%和5%; 在NUS-WIDE数据集上, HRFT-Net的不同比特位哈希码检索mAP值比HashFormer和TransHash分别提高约9%和10%.这些实验结果都显示HRFT-Net的卓越性能.在16 bits, 32 bits和64 bits长度的哈希码检索的mAP中, HRFT-Net的检索精度均优于其它方法, 再一次表明HRFT-Net的优越性.
在CIFAR10、NUS-WIDE数据集上分别选取1幅查询图像, 使用HRFT-Net和DCH分别返回前10张检索图像, 具体可视化结果如表9所示.由表可见, HRFT-Net可以检索到更多与用户期望相关的检索结果.
| 表9 HRFT-Net和DCH的前10张检索图像 Table 9 Top 10 images retrieved by HRFT-Net and DCH |
为了验证HRFT-Net的鲁棒性和泛化性, 在大型数据集ImageNet[50]和MS COCO[51]上进行模型训练和mAP值对比.
ImageNet数据集是大规模视觉识别挑战赛(ISLVRC 2015)的基准数据集, 实验中遵循与文献[37]相同的设置, 随机选取100类, 将训练集上这些类别的所有图像作为数据库, 并使用验证集上这些类的所有图像作为查询集.MS COCO数据集包含82 783幅训练图像和40 504幅验证图像, 随机选取5 000幅图像作为查询集, 其余图像作为数据库, 并从数据库上随机选取10 000幅图像进行训练.
HRFT-Net和其它8种深度哈希图像检索方法在ImageNet、MS COCO数据集上的mAP值对比如表10所示, 表中黑体数字表示最优值.
| 表10 不同检索方法在2个大型数据集上的mAP值对比 Table 10 mAP comparison of different retrieval methods on 2 large datasets |
由表10可以看出, 在ImageNet数据集上, HRFT-Net比HashFormer的mAP值平均提高约4.2%; 在MS COCO数据集上, HRFT-Net比CSQ的mAP值平均提高约2.1%.HRFT-Net在使用不同长度哈希码时的mAP值均优于其它对比方法, 表明HRFT-Net的有效性.
本文提出基于类相似特征扩充与中心三元组损失的哈希图像检索模型(HRFT-Net), 针对CNN提取的图像特征相似性表征能力不足的问题, HRFT- Net使用预训练的ViT和哈希层, 构建基于ViT的哈希特征提取模块(HViT), 使用ViT提取表征能力更强的全局特征信息.由于从小批量数据中构建有限的局部三元组样本, 导致网络训练不够充分, 因此提出基于类约束的相似特征扩充模块(SFEC), 通过小批量训练中已提取特征, 合成新的训练特征样本, 扩充三元组训练.针对局部三元组约束无法保证全局三元组同时满足约束, 样本数据分布缺失全局性, 网络训练难于收敛的问题, 提出基于Hadamard的中心三元组损失函数(CTLH), 利用Hadamard为每类建立全局哈希中心约束, 通过局部三元组与全局哈希中心约束加速网络的学习和收敛, 提高图像检索精度.大量实验表明, 无论在CIFAR10、NUS-WIDE这种常规数据集上, 还是在ImageNet、MS COCO这种大型数据集上, HRFT-Net在不同长度比特位下的哈希码图像检索中, 整体上具有较强的竞争力和较优的检索效果.
尽管HRFT-Net获得较优的检索精度, 但三元组的选取依赖标签, 现实应用中标签获取昂贵且可能存在错误.今后将深入探索图像类内的相似性和图像类间的关联性, 引入自监督的学习方法, 增强HRFT-Net的特征表达能力, 降低对标签的依赖, 并进一步提升图像检索性能.
本文责任编委 张军平
Recommended by Associate Editor ZHANG Junping
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|
| [47] |
|
| [48] |
|
| [49] |
|
| [50] |
|
| [51] |
|