

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
模糊逻辑引导的多粒度深度神经网络
[周天奕1  , 丁卫平
, 丁卫平1 , 黄嘉爽1 , 鞠恒荣1 , 姜舒1 , 王海鹏1 ]
, 丁卫平, 黄嘉爽, 鞠恒荣, 姜舒, 王海鹏]
|
|



作者简介:

周天奕,硕士研究生,主要研究方向为粒计算、模糊集、深度学习.E-mail:choutyear@outlook.com.

黄嘉爽,博士,副教授,主要研究方向为脑网络分析、深度学习.E-mail:hjshdym@163.com.

鞠恒荣,博士,副教授,主要研究方向为粒计算、粗糙集、机器学习、知识发现.E⁃mail:juhengrong@ntu.edu.cn.

姜 舒,博士,讲师,主要研究方向为深度学习、自然语言处理.E⁃mail:jshmjs45@ntu.edu.cn.

王海鹏,硕士研究生,主要研究方向为模糊理论、粒度计算、深度学习.E⁃mail:whpjy79@163.com.
准确识别和分类组织病理图像对于疾病的早期检测和治疗至关重要.病理医生诊断时通常会采用多层次的方式进行判断,即观察各个倍率下细胞的异常区域,然而现有模型通常只能在单一粒度上进行特征提取,忽略细胞的多粒度特性.因此,文中提出模糊逻辑引导的多粒度深度神经网络.首先,针对细胞的构造,在粗粒度、中粒度和细粒度这3个粒度层面上进行多粒度特征提取,充分利用病理组织图像中的信息.同时,针对多粒度特征提取时出现的关键信息冗余问题,引入模糊逻辑理论,设置多个模糊隶属函数,分别描述细胞在不同角度上的特征.然后,通过模糊运算得到模糊通用特征,由此设计模糊逻辑引导的交叉注意力机制模块,实现模糊通用特征对多粒度特征的引导.最后,通过编码器将特征扩散至所有的补丁令牌,获得较好的分类准确性和鲁棒性.实验表明,文中网络在组织病理图像分类上具有较高的准确率.
About Author:
ZHOU Tianyi, master student. His research interests include granular computing, fuzzy sets and deep learning.
HUANG Jiashuang, Ph.D., associate professor. His research interests include brain network analysis and deep learning.
JU Hengrong, Ph.D., associate professor. His research interests include granular computing, rough sets, machine learning and know-ledge discovery.
JIANG Shu, Ph.D., lecturer. Her research interests include deep learning and na-tural language processing.
WANG Haipeng, master student. His research include fuzzy theory, granular computing and deep learning.
The accurate identification and classification of pathological images are crucial for early disease detection and treatment. In the process of diagnosis, pathologists typically employ a multi-level approach, observing abnormal cell regions at various magnifications. However, existing models often extract features at a single granularity, neglecting the multi-granularity nature of cells. Therefore, a fuzzy logic guided deep neural network with multi-granularity is proposed in this paper. Firstly, multi-granularity feature extraction is conducted for cell structures at three levels of granularity-coarse, medium and fine, and thus the information in pathological tissue images is fully utilized. Additionally, to address the issue of key information redundancy during multi-granularity feature extraction, fuzzy logic theory is introduced. Multiple fuzzy membership functions are set to describe cell features from different angles. Subsequently, fuzzy operations are employed to fuse into a fuzzy universal feature. A fuzzy logic guided cross attention mechanism is designed to guide the multi-granularity features by the universal fuzzy feature. Finally, an encoder is utilized to propagate the features to all patch tokens, resulting in improved classification accuracy and robustness. Experiments demonstrate that the proposed network achieves high accuracy in the classification of pathological images.
组织病理图像在医疗诊断中起着至关重要的作用, 在疾病的分期和治疗计划中都不可或缺.近几年, 越来越多的研究者开始将深度学习模型应用于组织病理图像分类任务中.Yang等[1]实现基于阈值的肿瘤优先聚合方法, 用于WSIs(Whole Slide Images)标签推断, 并开发基于深度学习的肺部病变分类器, 用于识别肺癌亚型.Wang等[2]利用全卷积神经网络提取有用的深度特征并进行有效预测, 用于肺癌组织病理学图像分类.因此, 在深度神经网络辅助下, 应用组织病理图像可大幅提升病理诊断的精确性和效率, 也开始支持早期干预和治疗的策略.
组织病理学图像的形态特征通常包括细胞大小、形状、颜色、细胞内核的大小和形状、染色质的分布等.这些特征的变化表明细胞或组织的病理改变, 因此准确提取特征至关重要.目前常见的特征提取方法有卷积神经网络(Convolutional Neural Network, CNN)和注意力机制[3].CNN是深度学习中成功方法之一, 通过卷积核在图像上滑动的同时对覆盖区域进行非线性变换, 提取不同级别的特征.Wahab等[4]集成策略两阶CNN, 提出Hybrid-CNN(HC-NN), 实现有丝分裂和非有丝分裂的分类.另一方面, 注意力机制也广泛应用于病理图像分类任务中.不同于CNN, 注意力机制关注输入序列的所有元素, 捕获全局依赖关系, 并加权聚合这些特征, 形成更高层次的表示.Sadafi等[5]将注意力机制用于遗传性血液疾病的分类任务中, 能更好地关注疾病样本细胞, 提升分类的准确率.Valanarasu等[6]提出MedT(Medical Transformer), 在自注意力模块中引入额外的控制机制, 扩展现有架构.MedT的全局分支建模远程依赖关系, 学习全局上下文特征, 同时局部分支操作补丁, 关注更精细的特征.MebT在医学图像中取得较优结果.
值得注意的是, 上述方法忽略组织病理图像在不同粒度级别上的特征, 仅在单一粒度进行特征提取, 不能完整获取细胞之间蕴含的特征信息.为了解决这一问题, Li等[7]在提取过程中嵌入不同粒度大小的特征, 能有效克服病理图像类间方差小、类内方差大的难题, 降低图像放大的敏感性.Hashimoto等[8]证明, 在不同尺度下, 存在不同类别的特异性特征, 并将此用于肿瘤亚型分类, 识别准确率优于专业病理学专家.因此, 在组织病理图像分类过程中, 采用多粒度方法划分组织病理图像, 提取不同粒度下的医学病理特征, 能有效提升分类的准确率.
与此同时, 融合多粒度特征时还会出现信息冗余的问题.Sinha等[9]在医学图像中使用基于引导的注意力机制, 克服信息冗余, 通过不同模块间的额外损失, 引导注意力机制忽略不相关的信息, 并强调相关特征关联以关注图像中更具辨别力的区域.Xue等[10]提出GG-Net(Global Guidance Network), 利用多层集成特征图作为指导信息学习空间域和通道域的远程非局部依赖关系, 在乳腺超声病变检测方面优于其它医学图像方法.
学者们现也开始使用模糊集理论引导特征.模糊集理论中引入隶属函数, 描述元素对于模糊程度的归属度量.在医学图像中, 这种归属程度可用来表达像素的不确定性与模糊性[11].模糊集理论设置隶属函数, 使每个像素点能灵活表达对不同组织和结构的隶属程度, 较好地捕捉图像中的重叠区域以及模糊边界, 解决通用特征可能受到噪声、伪影和光线变化干扰的问题.Ding等[12]结合区间2型模糊聚类与超像素概念和元启发式方法, 改进传统的模糊c-mean聚类算法的目标函数, 使其融入基于超像素邻近局部窗口的空间信息, 实现对放射图像的有效分割.Murugesan等[13]结合Mamdani模糊模型和自适应神经模糊模型, 构建基于模糊逻辑理论的慢性肾脏疾病诊断系统, 取得优异结果.由此可见, 基于模糊集的医学图像领域已取得一定成果, 为临床诊断和治疗提供有力支持[14].
因此, 本文提出模糊逻辑引导的多粒度深度神经网络(Fuzzy Logic Guided Deep Neural Network with Multi-granularity, FGDNN).在组织病理图像特征提取时考虑细胞的医学构造属性, 分别提取粗粒度(Coarse Granularity)、中粒度(Medium Granularity)和细粒度(Fine Granularity)下的组织医学特征, 提高特征信息空间的丰富程度, 同时引入经典的模糊逻辑, 通过模糊运算提取的通用特征引导模型的学习.为了充分利用这些特征, 本文设计模糊逻辑引导的交叉注意力机制模块(Fuzzy Logic Guided Cross Attention, FGCA), 通过改进的交叉注意力机制, 将模糊通用特征融入补丁令牌中, 达到对不同粒度特征的引导.最终输出分类令牌, 得到分类结果.在多个不同的组织病理图像分类数据集上的大量实验表明, FGDNN表现出较优性能, 充分验证其有效性和实际应用潜力, 为组织病理图像分析领域提供一种解决方案.
CNN和注意力机制已成功应用于图像分类任务中[15].目前, 这些方法大致分为3类:基于多输入特征模型的方法[16, 17]、基于不同注意力机制的方法、基于其它功能模块的方法.
在基于多输入特征的方法中, Wang等[18]提出PVT(Pyramid Vision Transformer), 能像CNN一样产生特征金字塔, 实现对多尺度特征的集成, 性能较优.Zheng等[19]逐渐降低图像的空间分辨率, 利用Transformer框架, 通过串行化图像, 实现纯自注意力的特征表示编码器, 取得有竞争力的结果.Han等[20]提出TNT(Transformer-in-Transformer), 将输入图像拆分为视觉句子和视觉单词, 挖掘较小的特征和细节, 增强特征表示能力.Dai等[21]提出Trans-Med, 结合CNN和Transformer的优势, 捕获低级特征和跨模态高级信息, 将多模态图像串行处理, 并发送到CNN后, 使用Transformer学习串行之间的关系并进行预测.TransMed在参数、速度和准确性方面较优.Tang等[22]提出MATR(Multiscale Adaptive Transformer), 采用多尺度, 设计基于全局互补上下文自适应调制卷积核的自适应卷积, 从不同尺度上充分获取有用的多模态信息.
在基于不同注意力机制的方法中, Wang等[23]证明使用低秩矩阵近似, 可在降低复杂度的同时保持与原始自注意力相当的性能, 并且具有更高的内存和时间效率.Yuan等[24]提出VOLO(Vision Out-looker), 可有效将精细级特征编码为ViT(Vision Transformer)令牌表示, 从而提升分类性能.Chu等[25]提出Twins, 引入空间可分的自注意力机制, 主要采用矩阵乘法运算, 从而优化和加速深度学习模型的计算过程.Chen等[26]提出CrossViT(Cross-Attention Multi-scale Vision Transformer), 改进交叉注意力机制, 在平衡复杂性的同时利用更细粒度的补丁, 获取更丰富的信息.
在基于其它功能模块的方法中, Touvron等[27]提出针对ViT的教师-学生蒸馏训练策略, 并使用基于令牌蒸馏的方法, 仅使用ImageNet且无需使用任何外部数据进行训练, 就能达到SOTA(State of the Art)水平.Chen等[28]利用记忆驱动的Transfor-mer生成医疗报告, 设计相关记忆驱动模块, 用于记录生成的关键信息, 设计记忆驱动条件层归一化, 用于整合相关记忆到Transformer的解码器中.
模糊集理论是一种数学工具, 用于处理不确定性和模糊性的问题[29].它提供一种描述模糊概念的数学框架, 可用于图像特征的建模和表示.与传统的布尔逻辑不同, 模糊逻辑允许一个元素同时属于多个集合, 并为其分配一个介于0和1之间的隶属度值.对于任意元素x, 在模糊集合A中的隶属度可以表示为μ A(x)∈ [0, 1].这种灵活性使模糊逻辑在处理含有模糊性和不确定性的问题时具有出色表现.
针对模糊集与图像结合, 通常有如下方法:1)以机器学习为主的模糊算法; 2)以深度神经网络为主的模糊特征处理.Wan等[30]为了减少图像中变化、重叠(异常值)和稀疏点的影响, 提出SF2DDLPP(Sparse Fuzzy Two-Dimensional Discriminant Local Pre-serving Projection), 通过弹性网络回归降低对数据稀疏点的敏感性, 增强图像特征提取和识别算法的鲁棒性.Bhalla等[31]提出FCNN(Hybrid Fuzzy CNN), 其中模糊集已用于自动消除图像中呈现的各种不确定性, 通过聚焦测量生成决策图, 提供给定输入图像的聚焦区域, 并在融合图像中保留这些关键区域以提升效果.
对于医学图像的处理, 模糊逻辑具有更优的适用性, 这是因为医学图像中的结构和病变通常具有模糊的边界, 模糊集方法可以更好地处理这种模糊性[32].Ding等[33]提出FTransCNN, 基于模糊融合策略, 通过模糊融合模块, 联合利用CNN和Transfor-mer提取特征, 在医学图像分割任务上性能较优.Hu等[34]为了解决脑图像中不同程度的噪声、弱边界和伪影, 设计基于改进模糊聚类和HPU-Net(Hybrid Pyramid U-Net Model for Brain Tumor Segmentation)的脑图像处理和脑疾病诊断预测模型, 仿真实验表明算法具有较高的特征提取精度.
模糊集方法还被用于多模态医学图像的融合, 通过定义多个隶属函数和模糊规则, 融合多个模态的信息, 从而提升分类和诊断的准确性.Wang等[35]提出基于多CNN组合和模糊神经网络Gabor表示方法, 通过一组不同比例和方向的Gabor滤波器组对CT(Computed Tomography)和MR(Magnetic Reso-nance)图像集进行滤波, 得到不同的表示对, 充分表征融合图像中病灶复杂纹理和边缘信息.模糊集方法还应用于医学图像的分类和诊断任务中.通过合适的特征提取和建立模糊集分类器, 可以根据医学图像的特征和属性进行分类和诊断.Das等[36]提出LNF-FE(Linguistic Neuro-Fuzzy with Feature Extrac-tion), 用于医学数据的疾病分类分析, 使用语言模糊化过程生成处理不确定性问题的隶属度值, 同时在模糊神经模型中混合特征提取算法, 提取重要特征.
尽管模糊集理论存在很多优势, 但模糊集合的隶属函数设置较复杂, 需要根据具体的任务进行调整, 参数的合适与否会极大影响模型性能, 且其计算过程会消耗较多的计算资源与时间.在大规模医学图像的深度神经网络分类任务中, 时间复杂度会呈指数级上升.目前, 将模糊集理论应用于医学图像领域还在不断探索中[37, 38].
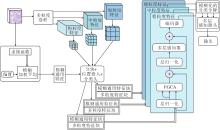
本文提出基于模糊逻辑引导的多粒度深度神经网络(FGDNN), 具体流程图如图1所示.FGDNN主要包含3个模块:多粒度特征提取模块、模糊通用特征模块、模糊逻辑引导的交叉注意力机制模块.
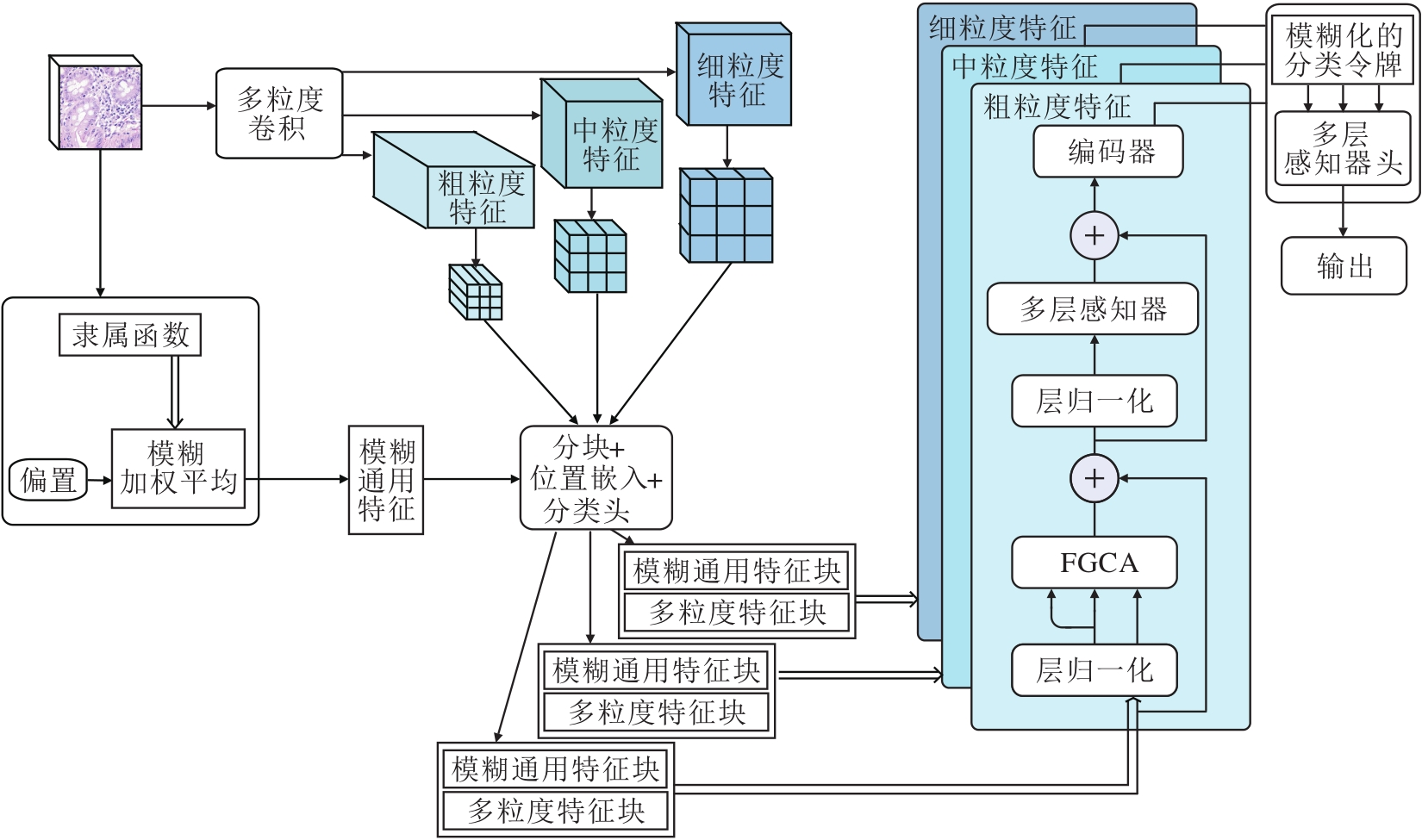 | 图1 FGDNN流程图Fig.1 Flowchart of FGDNN |
在特征提取时, 仅提取单一的特征并不能很好地适用于医学图像, Zhang等[39]将医学图像分解成多个尺度层, 可从不同的尺度层中提取不同的视觉特征.因为医学图像的诊断和分析需要考虑多个方面的信息, 这些信息处于不同的粒度级别中.Lin等[40]提出DS-TransUNet(Dual Swin Transformer U-Net), 提取不同语义尺度的粗粒度特征表示和细粒度特征表示, 用于医学图像分割任务.Kong等[41]使用4幅不同缩放的组织病理学图像, 分别生成4个不同大小的语义特征图, 使模型从组织类型到细胞类型都具有较强的泛化能力.
由于组织病理图像的特殊性, 病理医生在分类组织病理图像时, 通常会采用多粒度的方式进行判断:在低放大倍率观察组织的整体形态, 这有助于确定是否存在明显的异常区域, 如肿瘤或炎症、病变; 在中等放大倍率观察细胞排列、核的形态以及细胞间的关系, 这有助于确定异常区域的性质, 如肿瘤的类型和分级; 在高放大倍率检查细胞的核仁特征、胞浆内的器官以及细胞边界的清晰度.微观层面的观察可以提供更多细节, 帮助确定病变的性质和严重程度[42, 43, 44].
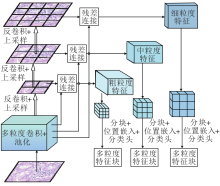
受到病理医生在组织病理图像分类中的多粒度诊断方式的启发, 本文提出多粒度特征提取模块, 结构图如图2所示.该模块使用基于CNN的多粒度特征提取方法, 在细粒度xFine∈
x=(xFine, xMedium, xCoarse),
其中, xFine表示细粒度特征, xMedium表示中粒度特征, xCoarse表示粗粒度特征.
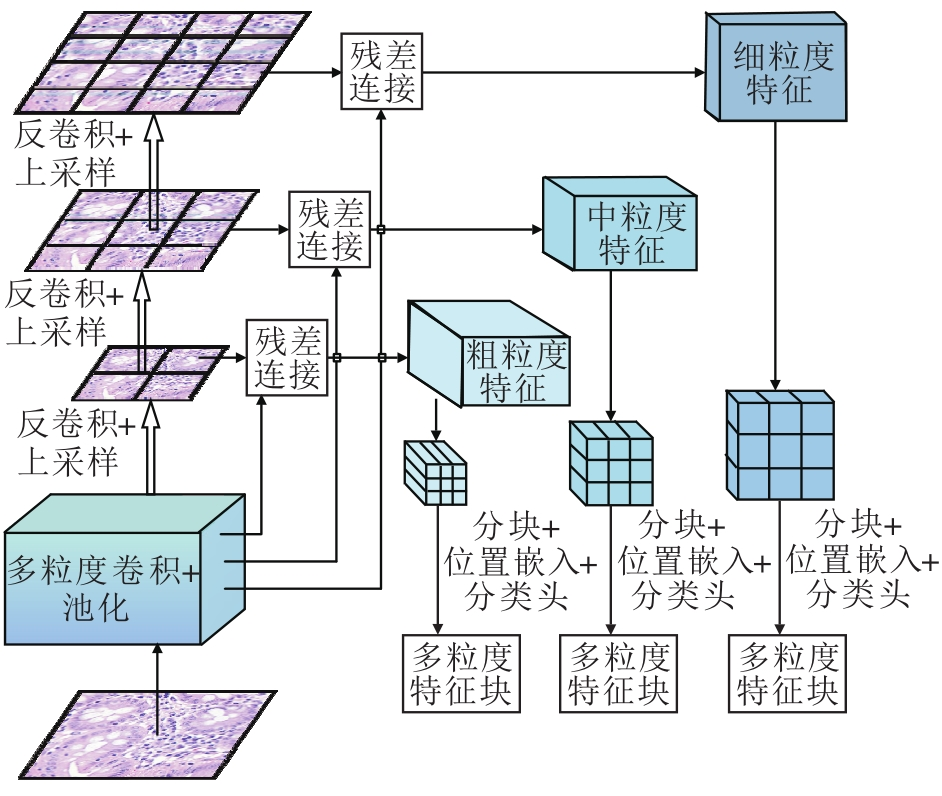 | 图2 多粒度特征提取模块结构图Fig.2 Multi-granularity feature extraction module |
然后, 将多粒度特征xFine、xMedium和xCoarse重新塑形成一系列扁平化的二维特征块:
$\begin{array}{l} \boldsymbol{x}_{\mathrm{FP}} \in \mathbf{R}^{N \times\left(\left(\frac{P}{2 r}\right)^{2} C_{\text {rine }}\right)}, \\ \boldsymbol{x}_{\mathrm{MP}} \in \mathbf{R}^{N \times\left(\left(\frac{P}{r}\right)^{2} C_{\text {mesium }}\right)}, \\ \boldsymbol{x}_{\mathrm{CP}} \in \mathbf{R}^{N \times\left(P^{2} C_{\text {carmer }}\right)}, \end{array}$
其中, (H, W)表示原始特征的分辨率, C表示通道数, (P, P)表示每个特征块的分辨率, N表示生成的特征块数量, 同时也作为与模糊特征融合的有效输入序列长度.通过设计, 使N的维度能匹配在不同粒度, 这在与模糊特征融合时可大幅降低计算复杂度.与ViT的[class]标记类似, 对每个嵌入特征块序列添加可学习的嵌入, 最后的输出为:
$ \begin{array}{l} \boldsymbol{z}_{0}^{\text {Fine }}=\left[\boldsymbol{x}_{\text {class }}^{F} ; \boldsymbol{x}_{P}^{1 F} E_{1} ; x_{P}^{2 F} E_{1} ; \cdots ; x_{P}^{N F} E_{1}\right]+\boldsymbol{E}_{\mathrm{pos}}^{F}, \\ \boldsymbol{E}_{1} \in \mathbf{R}^{\left(\left(\frac{P}{2 r}\right)^{2} C_{F}\right) \times D} ; \\ \boldsymbol{z}_{0}^{\text {Medium }}=\left[\boldsymbol{x}_{\text {class }}^{M} ; \boldsymbol{x}_{P}^{1 M} E_{2} ; \boldsymbol{x}_{P}^{2 M} E_{2} ; \cdots ; \boldsymbol{x}_{P}^{N M} E_{2}\right]+\boldsymbol{E}_{\mathrm{pos}}^{M}, \\ \boldsymbol{E}_{2} \in \mathbf{R}^{\left(\left(\frac{P}{r}\right)^{2} C_{M}\right) \times D} ; \\ \boldsymbol{z}_{0}^{\text {Coarse }}=\left[\boldsymbol{x}_{\text {class }}^{C} ; \boldsymbol{x}_{P}^{1 C} E_{3} ; \boldsymbol{x}_{P}^{2 C} E_{3} ; \cdots ; \boldsymbol{x}_{P}^{N C} E_{3}\right]+\boldsymbol{E}_{\mathrm{pos}}^{C}, \\ \boldsymbol{E}_{3} \in \mathbf{R}^{\left(\left(P^{2} C_{C}\right) \times D\right.} . \end{array}$
其中, 变量
本文选取模糊集理论, 用于解决多粒度特征提取时出现的信息冗余问题, 这是因为模糊集理论在图像处理中是将图像的像素值视为元素, 并通过隶属函数描述元素对模糊概念的隶属程度.这种方法的优势在于:能够捕捉图像中的不确定性和模糊性, 通过设置不同的隶属函数以及临界值, 可以准确提取恶性细胞的通用特征, 提供更准确的信息用于图像分类.
模糊通用特征提取算法如算法1所示.给定一个图像I, 首先, 将I转化为灰度图, 并归一化到[0, 1]范围内, 在提取图像的模糊特征时将每个像素点Ix视为一个模糊集合, 每幅图像分别经过不同的隶属函数.本文提取3个模糊特征Iμ , Iσ 和IT, 得到的模糊通用特征集合表示为{Iμ , Iσ , IT}, 这个模糊集合的定义取决于隶属函数, 描述每个像素点对于某个模糊概念的隶属程度.最后通过模糊运算得到模糊通用特征zFuzzy.
在模型学习过程中, 隶属函数可帮助模型更好地理解每个像素点的含义, 包括它可能的归属类别以及归属程度.这种多角度、多层次的特征表达方式可提供更多的信息, 帮助模型捕捉到更丰富、复杂的特征, 也能提升模型对于噪声和不确定性的鲁棒性.
算法1 模糊通用特征提取算法
输入 待提取模糊通用特征的图像I,
模糊隶属函数μ x(· ), σ x(· ), T(· ),
隶属函数形状位置超参数α , β ,
上升下降斜率a, b, c, d.
输出 模糊通用特征
for each image do
//对每幅图像的像素点计算隶属度
for each pixel in image do
//设置模糊隶属函数参数
μ =
σ =
//定义模糊隶属函数并计算隶属度
Iμ =μ x(I, μ , σ )
Iσ =σ x(I, α , β )
IT=T(I; a, b, c, d)
end
//得到模糊特征矩阵
Set I = (Iμ , Iσ , IT, E)
Set W =
//通过模糊计算得到模糊通用特征
zFuzzy=I· W
end
//对每幅图像的像素点计算隶属度
为了提取图像的多种特征, 本文使用多个隶属函数, 每个隶属函数都对应一种特定的特征描述方法.选取Gaussian函数、Sigmoid函数和Trapezoidal函数作为隶属函数, 分别将组织病理图像模糊化, 使模糊通用特征能够更有效地引导模型学习关键特征.这些特征用于构建模糊集合, 通过模糊集交运算, 提取图像的通用特征.选择Gaussian函数定义第一个隶属函数, 是因为Gaussian函数具有较好的平滑性和对称性, 将每个像素点的灰度值与隶属函数进行运算, 得出每个像素点的隶属度:
$ \mu_{x}=\frac{1}{\sigma \sqrt{2 \pi}} \exp \left(-\frac{(x-\mu)^{2}}{2 \sigma^{2}}\right)$,
其中, μ 表示Gaussian分布均值, σ 表示标准差, x表示像素点的灰度值.
下面定义Sigmoid隶属函数:
σ x=
其中, Ix表示像素点xi的亮度值, α 、β 表示Sigmoid函数的参数, 用于调节函数的形状和位置.
最后, 定义Trapezoidal隶属函数:
T(x; a, b, c, d)=
该函数左右两端分别由上升斜率a和下降斜率b控制, 中间部分为1, 其中, a、d表示函数的左右端点, b表示函数的上升拐点, c表示函数的下降拐点.当像素点灰度数值小于a或大于d时, 隶属度为0, 即完全不属于该模糊属性; 当数值介于a、b之间时, 隶属度逐渐增加, 当数值达到b时, 隶属度达到1, 即完全属于该模糊属性; 当数值介于b、c之间时, 隶属度一直为1, 即完全属于该模糊属性; 当数值介于c、d之间时, 隶属度逐渐减小, 当数值达到d时, 隶属度为0, 即完全不属于该模糊属性.
通过模糊集理论, 将各种隶属函数提取的特征进行有效融合, 形成一个更全面、准确的通用特征.这个通用特征能够反映更多的信息, 也能更好地引导模型的学习.
为了得到图像的模糊通用特征, 本文还引入模糊加权策略, 融合不确定性数据, 以便整合这3个特征并形成一个更全面的特征描述.具体来说, 通过每个模糊特征设置一个权重, 分别为wμ 、wσ 、wT, 这些权重反映每个特征对于总体描述的重要性, 并且满足wμ +wσ +wT=1.此外, 引入一个偏置B, 调整模糊特征融合的基线水平, 提高模型的灵活性.
通过上述的变量和参数得到模糊通用特征:
zFuzzy=wμ Iμ +wσ Iσ +wTIT+B.
在模糊融合中, 数据点的隶属度决定其对平均值的贡献程度, 这种方法能够有效整合多个隶属函数提取的特征, 从而得到一个更全面的图像表示.通过这种方式, 可从图像中提取丰富的模糊特征, 同时可用于后续的深度学习模型.
融合的过程通常采用加权平均, 即将模糊特征矩阵xFuzzy归一化后, 直接加入Transformer编码器中, 或使用其它的一些融合模块[46].然而, 这种方法会给所有模型赋予相同的权重, 未考虑不同模型的贡献度.如果将模型融合后的输出作为输入, 虽然可以增强模型的表达能力和泛化性能, 但同时也可能会丢失一部分粒度上的信息.Zhang等[47]针对医学图像数据集, 使用EGM(Edge Guidance Module)学习边缘注意表示, 并在早期编码层中保留局部边缘特征, 以此指导分割期间的特征提取; 使用WAM(Weighted Aggregation Module)进行特征的融合, 取得较好效果.
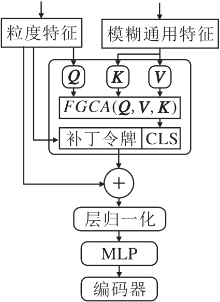
因此, 本文提出模糊逻辑引导的交叉注意力机制模块(FGCA), 结构图如图3所示.在模块中, 作为引导信息的模糊特征不再采用简单的加法进行融合, 而是通过交叉注意力机制与不同粒度的特征进行更深层次的融合, 这个过程的特点是可以不断使用模糊通用特征进行像素级引导, 防止在3个单一粒度上不断学习时出现过拟合的情况.在与模糊补丁令牌交互后, 通过Transformer编码器将分类器中的引导信息散布到其补丁令牌中, 以此不断引导多粒度特征学习.粒度特征和模糊通用特征经过FGCA后的输出结果为:
l=1, 2, …, L,
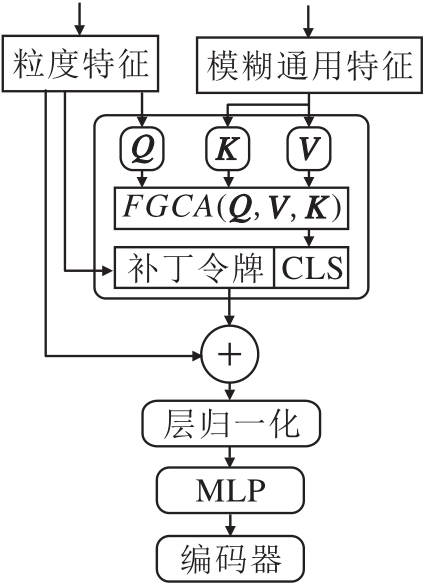 | 图3 FGCA流程图Fig.3 Flowchart of FGCA |
其中LN(· )表示层归一化函数.具体来说, 对于不同的粒度分支
其中, G∈ (F, M, C)分别表示3个不同的粒度, fl(· )表示维度对齐的投影函数.利用引导信息进行融合后, 多粒度的分类令牌会再次进入下一个Transformer编码器, 与自身的补丁令牌进行交互.
这种交互能够促进引导信息的传递, 丰富每个图像块的表示, 提高整体模型的准确性和鲁棒性.最终, 经过多个Transformer编码器处理后, 得到最终的分类结果:
y=LN((
值得注意的是, 本文未采用传统的交叉注意力机制, 即只是简单改变Q、K、V的来源.类似于CrossViT[26], 本文将模糊特征中的补丁令牌作为引导信息与多粒度补丁令牌进行交互, 以此进行深层次的引导.
FGCA的实现细节如下:
FGCA(Q, K, V)=softmax
其中,
Q=zFuzzyWq, K=
Wq∈
Chen等[26]的实验表明, 多粒度分支主要用于提取特征, 而模糊特征分支仅提供附加信息.因此, 仅需要一个轻量级的模糊特征分支就足够引导多粒度分支.本文将交叉注意力机制用于多粒度特征和模糊通用特征融合, 将模糊通用特征作为附加信息, 将3个多粒度特征作为主要信息, 获得较好的准确性.
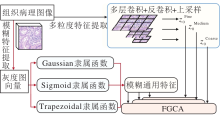
FGDNN总体实现方案如图4所示.首先, 使用多粒度卷积, 从原始图像中提取不同粒度下的特征, 并使用CNN协调各特征之间的维度.与此同时, 使用多个经典模糊隶属函数, 通过各个针对不同特征点的隶属函数的融合, 提取原始图像的通用特征.然后, 分别将提取的多粒度特征和通用模糊特征进行多粒度下的补丁嵌入, 进行维度的统一, 减少后续进程的算法复杂度.
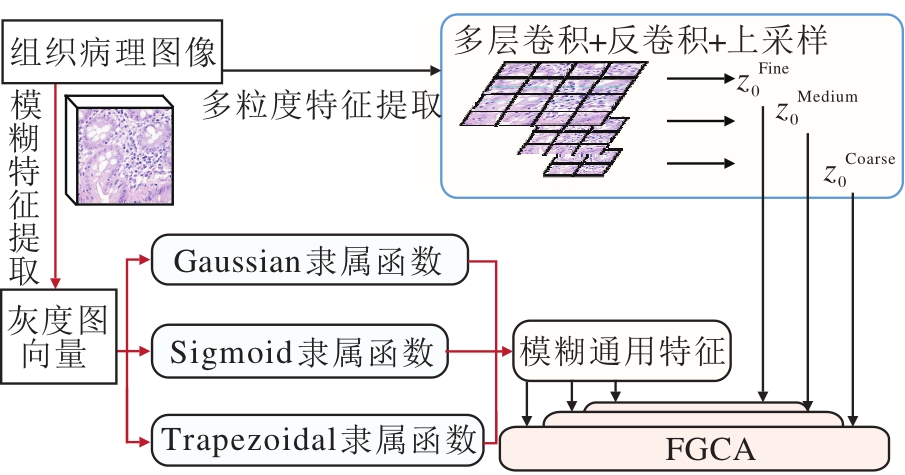 | 图4 FGDNN总体实现方案Fig.4 Overall architecture of FDGNN |
至此, 可以定义模糊逻辑引导的交叉注意力机制模块, 以此将模糊通用特征用于引导不同粒度下的训练.利用多粒度分类器作为代理, 分别将不同粒度下的特征和模糊通用特征融合后学习特征信息, 再将其反向投影到自己的分支中.
具体来说, 每组训练都包含一个粒度特征和一个模糊特征, 在每次训练时, 多粒度分类令牌会与作为引导信息的模糊补丁令牌交互, 与引导信息融合后, 多粒度分类令牌在下一个Transformer编码器中会再次与自己的补丁令牌交互, 将学到的引导信息传递给自己的补丁, 丰富每个图像块的表示.
最后, 通过Wx矩阵将分类令牌特征向量映射到一个新的特征空间中, 拼接用于预测的基于模糊引导的多粒度分类器, 以便更好地捕获和表示输入数据的模式和相关性.
实验中选择如下公开数据集进行性能评估.
1)Lung and Colon Cancer Histopathological Images(LC25000)数据集[48].包含25 000幅肺和结肠癌的组织病理学图像, 分为5类:肺良性组织、肺腺癌、肺鳞状细胞癌、结肠腺癌和结肠良性组织, 每类都有5 000幅768× 768的彩色图像.
2)NCT-CRC-HE-100K(NCT)数据集.包含100 000个非重叠图像块的集合, 图像来自86幅苏木精和伊红染色的人类癌症和正常组织切片, 用于癌症检测和分析的机器学习研究, 包含9个组织类别.
3)APTOS 2019 Blindness Detection(Bl)数据集.包含在印度农村地区收集的5 590幅眼睛图像, 这些图像在各种成像条件下使用眼底摄影技术拍摄, 每幅图像都由临床医生根据糖尿病视网膜病变的严重程度在0~4范围内进行评级, 0表示无糖尿病视网膜病变, 1表示轻度糖尿病视网膜病变, 2表示中度糖尿病视网膜病变, 3表示重度糖尿病视网膜病变, 4表示增殖性糖尿病视网膜病变.
网络中设置不同大小的粒度块, 分别为224× 224× 3, 112× 112× 12, 56× 56× 48.在训练过程中, 将所有的数据集分为训练集、验证集和测试集, 比例为70∶ 15∶ 15, 并使用数据增强技术, 如随机裁剪、水平翻转和旋转, 增加模型的泛化能力.同时使用交叉熵作为损失函数, 通过随机梯度下降优化算法进行训练, 设置批尺寸大小为64, 学习率为0.001, 学习率衰减因子为0.01.
实验平台为PC(13th Gen Intel® CoreTM i9-13900K@3.00 GHz, NVIDIA® GeForce RTXTM 4090, RAM:64 GB), Windows11操作系统, 开发工具为JetBrains PyCharm 2021.2.3专业版, 使用Python语言实现实验中相关算法.
实验采用准确率(Accuracy)、召回率(Re-call)、精确度(Precision)、F1值(F1-score)评价模型.
准确率是常见的分类性能评估指标之一, 衡量模型在所有类别上正确分类样本的百分比, 计算公式如下:
Accuracy=
其中:TP(True Positives)为真阳性, 表示模型正确预测为目标类别的样本数量; TN(True Negatives)为真阴性, 表示模型正确预测非目标类别的样本数量; FP(False Positives)为假阳性, 表示模型错误地将非目标类别预测为目标类别的样本数量; FN(False Negatives)为假阴性, 表示模型错误将目标类别预测为非目标类别的样本数量.
召回率表示模型正确预测为该类别的样本数量占该类别实际总样本数的比例.在医学图像分类中, 表示对于病例的检测准确率, 计算公式如下:
$\begin{array}{l} \text { Recall }=\frac{1}{n} \sum_{i=1}^{n} \text { Recall }_{i}, \\ \text { Recall }_{i}=\frac{T P}{T P+F N} . \end{array}$
在医学图像多分类中, 精确度用于衡量模型在某个特定类别上的预测准确性, 即模型正确预测为该类别的样本数量占所有被模型预测为该类别的样本数量的比例, 计算公式如下:
$\begin{array}{l} \text { Precision }^{=}=\frac{1}{n} \sum_{i=1}^{n} \text { Precision }_{i}, \\ \text { Precision }_{i}=\frac{T P}{T P+F P} . \end{array}$
F1值综合考虑精确度和召回率, 提供一个全面的评估值, 计算公式如下:
$\begin{array}{l} F 1 \text {-score }=\frac{1}{n} \sum_{i=1}^{n} F 1_{i}, \\ F 1_{i}=\frac{2 \times \text { Precision }_{i} \times \text { Recall }_{i}}{\text { Precision }_{i}+\text { Recall }_{i}} . \end{array}$
本文选择如下对比方法:
1)Resnet50_pre.经典的卷积神经网络架构Resnet50, 使用ImageNet数据集上预训练的权重, 使用残差连接构建深层卷积神经网络.
2)ViT_pre.通过自注意力机制学习各图像块之间全局关系的ViT[49], 使用ImageNet-21k数据集上预训练的权重.
3)HiFuse(Three-Branch Hierarchical Multi-scale Feature Fusion Network)[50].通过特征块并行框架, 同时关注全局-局部特征.
4)MLP-Mixer[51].完全基于多层感知器MLP(Multilayer Perceptron)结构, 没有卷积或注意力机制.
各算法在LC25000、NCT、Bl数据集上的指标值对比如表1~表3所示, 表中黑体数字表示最优值.由表1可见, 在LC25000数据集上, MLP-Mixer和ViT_pre的分类性能有限, 分类准确率为93.1%和94.8%, 这是因为MLP-Mixer通过全连接捕获图像的特征, ViT_pre通过注意力机制捕获全局图像的上下文信息, 并未注意图像关键信息分布不均的特点, 容易过多捕获健康细胞的特征, 从而忽视关键特征.FGDNN的分类准确率、召回率、精确度分别为99.2%、98.7%、99.4%, 分别超过次优方法1.6%, 1.7%, 0.9%.
| 表1 各方法在LC25000数据集上的指标值对比 Table 1 Index value comparison of different methods on LC25000 datasets % |
| 表2 各方法在NCT数据集上的指标值对比 Table 2 Index value comparison of different methods on NCT datasets % |
| 表3 各方法在Bl数据集上的指标值对比 Table 3 Index value comparison of different methods on Bl datasets % |
由表2可以看到, 随着数据集类别的增加, ViT_pre面对类别数量较多的多分类任务性能有限, 准确率仅为90.8%, 这说明使用传统的注意力机制在任务量增大时并不能得到较好的结果.而通过模糊逻辑引导的FGDNN的指标值均超过其它方法.
由表3可知, FGDNN取得最高准确率, 为88.2%, 远超其它方法; 在精确度上, FGDNN为80.6%, 同样为最高值.基于细胞图像的医学知识, 相比其它细胞组织, 眼底细胞通常较小、数量较多, 包含较丰富的血管网络, 这对模型的泛化能力提出较高要求.采用多粒度(全局-局部)特征的HiFuse也取得较优结果, 这表明面对复杂任务时, 多粒度属性在医学图像领域尤其是组织病理图像分类领域具有重要作用.但FGDNN还进一步通过模糊通用特征分类关键特征的标记, 避免注意力机制过度学习非相关特征的问题, 这些机制决定FGDNN在眼底图像这类特征不明显的复杂分类任务中表现出较优性能.
由F1值可清晰看出, FGDNN通过模糊引导的交叉注意力机制, 使用模糊通用特征, 不断引导多粒度特征完成引导, 从而提升分类性能.
通过对比注意到, 尽管在LC25000、NCT数据集上, FGDNN达到最优值, 但在Bl数据集上, 分类准确率明显低于预期.这一现象的主要原因在于Bl数据集本身的特点.与其它数据集不同, 视网膜血管分布密集而无规律, 存在大量易与背景混淆、对比度较低的细小血管, 血管边界模糊不清, 同时容易受采集设备和光照以及病变组织的影响.因此Bl数据集的多粒度属性不明显, 这意味着多粒度特征提取方法在这个特定数据集上无法充分发挥作用.
与此同时, 本文还将FGDNN与如下在LC25000、NCT、Bl数据集上SOTA方法进行对比.1)在LC25000数据集上, 选择文献[52]方法、文献[53]方法.2)在NCT数据集上, 选择DiRA[54]、文献[55]方法、文献[56]方法、文献[57]方法、文献[58]方法.3)在Bl数据集上, 选择文献[59]方法、文献[60]方法.
各方法的准确率和F1值对比如表4所示, 表中黑体数字表示最优值.由表可见, FGDNN取得大部分的最优值.
综上所述, 今后可考虑调整特征提取的分辨率, 使算法更好地适应不同类型的数据集, 尤其是那些多粒度属性不明显的数据集.这将有助于提高算法的通用性和适应性, 使其应用于更广泛的实际场景中.
| 表4 FGDNN与3个数据集上的SOTA方法指标值对比 Table 4 Index value comparison of FGDNN and SOTA methods on 3 datasets % |
为了验证FGDNN中各模块的有效性, 进行如下改动.
1)w/o MG.将多粒度特征提取改为仅使用单一粒度的CNN进行特征提取.
2)w/o C.剔除粗粒度.
3)w/o M.剔除中粒度.
4)w/o F.剔除细粒度.
5)w/o Fuzzy.更换作为引导信息的模糊特征, 使用普通的CNN提取的特征用于引导模型的训练.
6)M-ADD.将FGCA替换为普通的加法融合.
7)M-CA.将FGCA替换为普通的交叉注意力机制.
各模块的消融实验结果如表5所示, 表中黑体数字表示最优值.由表可见, 相比w/o MG, 在LC25000、NCT数据集上, FGDNN的准确率分别提高5.0%和5.7%, 召回率分别提高5.1%和5.9%, 精确度分别提高6.7%和5.6%, 由此说明相比单一粒度特征, 多粒度特征提取能使模型学习到更多的特征信息, 提升模型的性能.
| 表5 各模块的消融实验结果 Table 5 Ablation experiment results of different modules % |
在使用两种粒度下特征进行训练时, 指标值普遍高于单一粒度的特征, 尤其是w/o C和w/o M.经过分析认为, 细粒度特征学习到更多的局部信息, 使模型能够更好地捕捉数据中的细微变化, 提升模型性能.
在删除模糊通用特征引导后(即w/o Fuzzy), 在LC25000、NCT数据集上, 准确率下降6.0%和6.0%, 召回率下降4.6%和6.2%, 精确度下降6.4%和6.3%.对此, 本文认为模糊通用特征比多粒度特征更重要, 在组织病理图像中, 通常存在大量正常细胞的干扰以及其它组织的影响, 模糊通用特征能更好地在复杂的组织病理图像中过滤关键特征信息, 抗干扰能力较优.
此外, 本文还对比3种融合方法, M-ADD使用普通的加法融合, 对性能并未起到效果.采用普通交叉注意力机制后, M-CA性能略优.由此可以看出, 直接使用相加的融合方法将取得较差的结果, 而FGCA能有效引导模型学习, 将模糊通用特征融入分类令牌, 再通过编码器散布至所有的补丁令牌中, 以此作为引导, 不断学习图像中的关键信息, 解决多粒度特征提取时出现的信息冗余问题.
为了进一步验证多粒度特征提取的有效性, 本文采用特征可视化方法, 增强模型的可解释性.使用热力图和类激活图CAM(Class Activation Map), 可视化模型学习到的关键特征信息.
通过热力图可以直观观察方法在不同空间位置的关注程度.本文针对细粒度特征、中粒度特征、粗粒度特征分别生成热力图, 并与EfficientNet[61]和AlexNet[62]进行对比, 显示不同特征提取方法提取特征之间的差异.
CAM图能够准确定位模型对于输入图像中不同区域的关注程度, 将CAM图与原始图像叠加, 可有效验证模型在目标检测和定位任务中的有效性与可靠性.本文提取模型末层预测结果中的类别权重, 并与特征图进行逐通道相乘, 得到加权特征图, 最后归一化叠加至原图, 得到CAM图.
本文选取分类标签为colonca和lungaca的病理图像作为分析对象, EfficientNet、AlexNet、FGDNN提取特征热力图和CAM图如图5和图6所示.
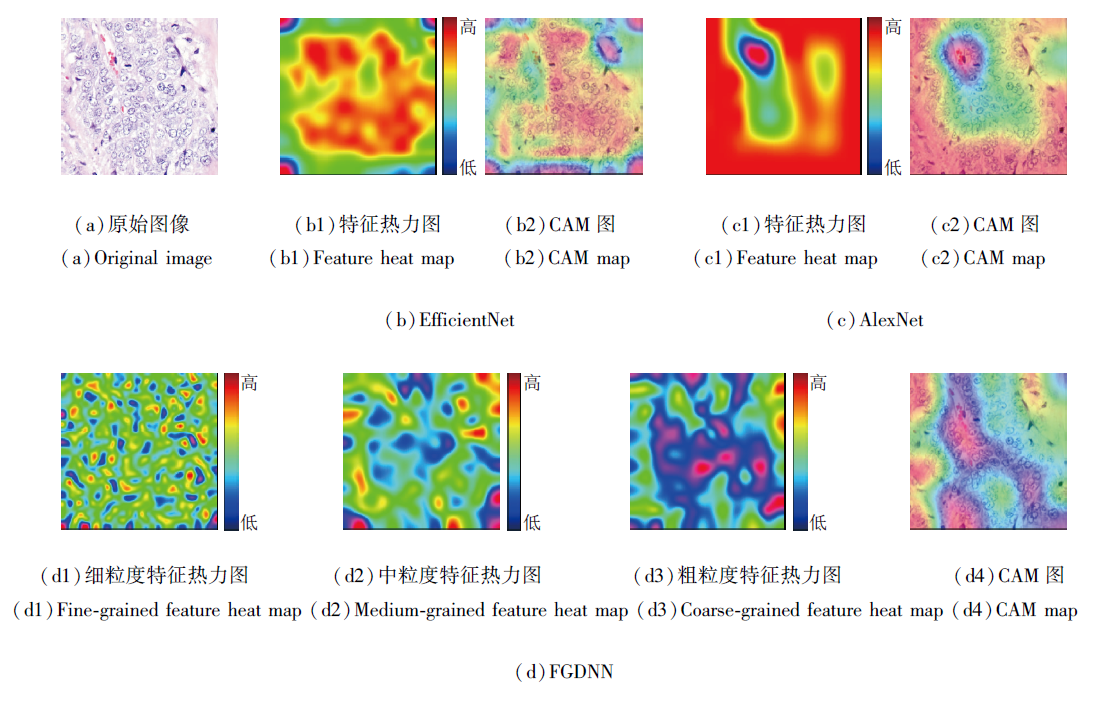 | 图5 分类标签为colonca时3种网络的特征热力图与CAM图Fig. 5 Feature heat map and CAM map of 3 types of networks with colonca as classification label |
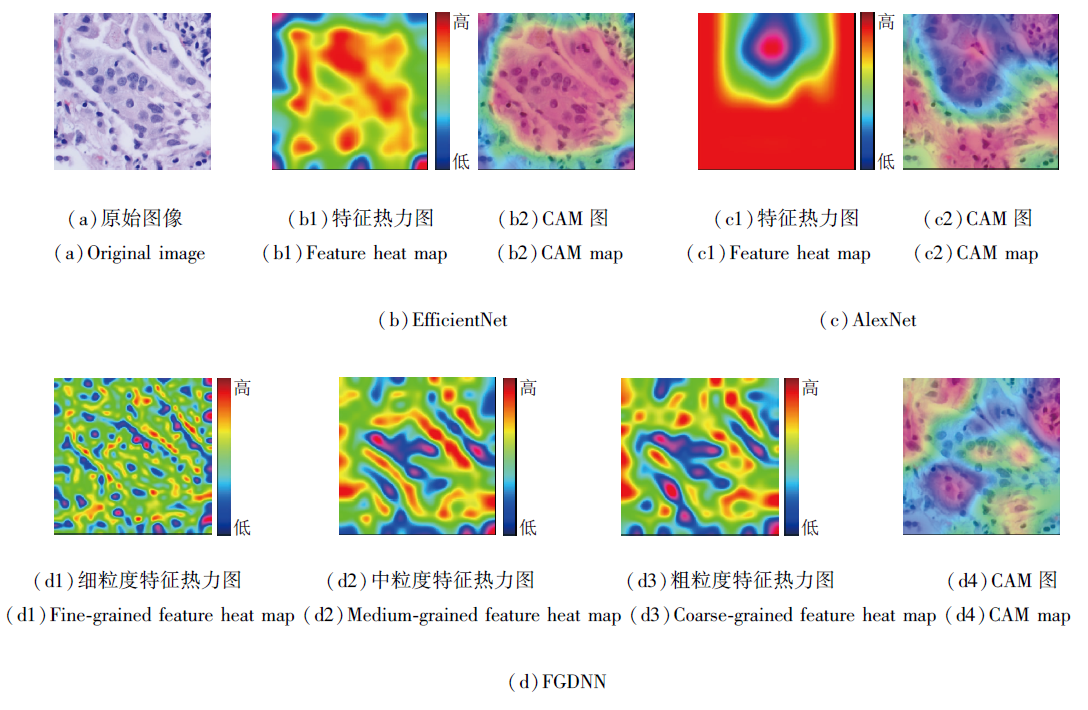 | 图6 分类标签为lungaca时3种网络的特征热力图与CAM图Fig.6 Feature heat map and CAM map of 3 types of networks with lungaca as classification label |
观察EfficientNet生成的热力图可知, Efficient-Net提取的特征细胞之间分界不明显, 由于其复杂的网络设计, 在细粒度和相似类别或较小差异的任务中的可解释性有限.CAM图也显示, Efficient-Net关注的区域呈片状, 并对图像边缘区域特征关注偏少.
观察AlexNet生成的热力图可知, 细胞之间分界不明显, 可分性不强.这是因为AlexNet采用较大的卷积核, 因此在检测分类较小粒度的目标中表现得不敏感, 又因为细胞具有多粒度属性, 导致只能在一个粒度上提取特征, 准确率下降, 可解释性较弱.从CAM图中也可看出, AlexNet对特征图的关注区域较大, 容易受到非关键特征的干扰.
观察不同粒度下FGDNN提取的特征热力图可发现, FGDNN能较好地提取细胞的多粒度特征.这一现象在图5(d)中更明显, 由FGDNN提取的多粒度特征热力图, 对于细胞的多粒度属性具有更强的解释.FGDNN能较好地关注粗粒度、中粒度、细粒度上的特征, 并通过模糊通用特征引导, 全面学习关键特征, 有效提升分类的准确率.同时, 从CAM图中可直观看出FGDNN在图像中的激活区域.因此, FGD-NN能有效、准确地捕获病理图像中的特征, 大幅提升分类的各项评价指标.
本文提出模糊逻辑引导的多粒度深度神经网络(FGDNN), 根据细胞特有的多粒度属性, 提取组织病理图像的多粒度特征, 获得更好的信息表示.同时为了解决多输入时的信息冗余问题, 引入经典的模糊集理论, 通过模糊隶属函数, 提取病理组织图像的通用特征.最后通过模糊逻辑引导的交叉注意力机制, 融合关键特征信息, 通过模糊通用特征不断引导, 使模型具有较强的泛化性和鲁棒性.在3个公开数据集上的实验表明, FGDNN具有较好的分类准确率, 尤其是在大量细胞干扰和不明显特征任务中.
组织病理学图像数据集相对较小, 这与大模型需要大量数据以获得良好性能的需求矛盾.今后可考虑使用对抗学习或迁移学习, 不断提升大模型应用于医学数据集上的性能.同时还可结合多模态数据, 构建具有更强泛化能力的模型.
本文责任编委 桑 农
Recommended by Associate Editor SANG Nong
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|
| [47] |
|
| [48] |
|
| [49] |
|
| [50] |
|
| [51] |
|
| [52] |
|
| [53] |
|
| [54] |
|
| [55] |
|
| [56] |
|
| [57] |
|
| [58] |
|
| [59] |
|
| [60] |
|
| [61] |
|
| [62] |
|