

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于自引导注意力的双模态校准融合目标检测算法
[张惊雷1, 2, 3  , 宫文浩
, 宫文浩1, 2 , 贾鑫3 ]
, 宫文浩, 贾鑫]
|
|



作者简介:

宫文浩,硕士研究生,主要研究方向为图像处理、目标检测.E-mail:gwh@stud.tjut.edu.cn.

贾 鑫,博士,讲师,主要研究方向为机器学习、图像处理、三维重建.E-mail:tjut_jiaxin@email.tjut.edu.cn.
为了解决传统双模态目标检测方法难以在复杂场景(如大雾、眩光、黑夜)中克服低对比度噪声以及无法有效识别小尺寸目标的问题,文中提出基于自引导注意力的双模态校准融合目标检测算法.首先,设计双模态融合网络,利用通道特征和空间特征校准纠正输入图像(可见光图像与红外图像)中的低对比度噪声,从纠正后的特征中获取互补信息,并准确实现特征融合,提高算法在眩光、黑夜和大雾等场景下的检测精度.然后,构建自引导注意力机制,捕捉图像像素之间的依赖关系,增强不同尺度特征的融合能力,提高算法对于小尺寸目标的检测精度.最后,在行人、行人车辆、航拍车辆三类六种数据集上进行的大量实验表明,文中算法检测精度较高.
About Author:
GONG Wenhao, master student. His research interests include image processing and object detection.
JIA Xin, Ph.D., lecturer. His research interests include machine learning, image processing and 3D reconstruction.
The traditional dual-modal object detection algorithms struggle to overcome low-contrast noise in complex scenes, such as fog, glare and dark night, and they cannot recognize small-size objects effectively. To solve these problems, an object detection algorithm with dual-modal rectification fusion based on self-guided attention is proposed. Firstly, a dual-modal fusion network is designed to rectify the low-contrast noise in the input images(visible and infrared images) by channel and spatial feature rectification. Consequently, the complementary information is acquired from the rectified features to accurately achieve feature fusion and the detection accuracy of the algorithm in the complex scenes is improved. Secondly, a self-guided attention mechanism is established to learn the dependency among pixels in the images. Thus, the fusion capability of features at different scales and the detection accuracy of the algorithm for small-scale objects are improved. Extensive experiments on six datasets, including pedestrian datasets, pedestrian-vehicle datasets and aerial vehicle datasets, demonstrate the superiority of the proposed approach.
目标检测是计算机视觉领域的基本任务之一, 在自动驾驶和无人机航拍领域等都有重要的应用, 因此其精确性和鲁棒性至关重要.基于深度学习的目标检测是目前目标检测领域的主流方法之一, 根据检测步骤的不同, 算法可以分两阶段检测算法和单阶段检测算法.
两阶段检测算法首先使用区域提取器生成一组候选框, 再对每个候选框进行分类和定位.代表性算法包括区域卷积神经网络(Region-Based Convolu-tional Neural Network, RCNN)、Fast-RCNN和Faster-RCNN等.
单阶段检测算法直接将检测任务和分类任务集成到一个神经网络中, 如FCOS(Fully Convolutional One-Stage Object Detector)[1]和YOLO(You Only Look Once)[2]系列等.其中, YOLOv5在检测精度上具有明显优势.
上述算法在普通环境下能获得较令人满意的检测结果, 而在复杂场景(大雾、眩光、黑夜)以及小尺寸目标时, 单一图像传感器受到低对比度噪声的影响, 难以提取图像的丰富信息.由于不同传感器的成像特性不同, 采集的图像存在互补性和一致性, 因此学者们提出融合可见光与红外检测的双模态传感器融合类目标检测算法.相比可见光图像, 红外图像在光照不足时可以捕捉更清晰的行人和车辆轮廓.小目标尺寸的车辆在红外图像中不易区分, 而可见光图像会提供更多的细节信息, 如边缘、纹理和颜色等.因此, 学者们尝试利用双传感器的模态互补优势克服复杂场景对于算法的影响.
双模态方法常见策略是融合可见光与红外两个模态图像的特征以实现信息互补, 此类方法的核心— — 跨模态特征融合技术在复杂场景目标检测中具有重要作用.Zhou等[3]提出MBNet(Modality Ba-lance Network), 使用DMAF(Differential Modality Ba-lance Aware Fusion)实现两种模态相互补充.Kieu等[4]提出TC Det, 采用域自适应方法解决夜间和恶劣天气下的行人检测问题.Zhang等[5]提出CFR(Cyclic Fuse-and-Refine), 利用多光谱特征的互补平衡, 循环融合和细化每个光谱特征, 后又提出引导注意力特征的多光谱特征融合[6], 同时将主动学习策略[7]应用于跨模态行人检测领域.An等[8]提出ECISNet(Effectiveness Guided Cross-Modal Informa-tion Sharing Network), 设计CIS(Cross-Modal Infor-mation Sharing), 增强特征提取能力.Sun等[9]提出UA-CMDet(Uncertainty-Aware Cross-Modality Vehicle Detection), 提高复杂环境中车辆目标的检测性能.Yuan等[10]提出TSFADet(Two-Stream Feature Align-ment Detector), 对齐两个模态特征之间的偏差, 降低跨模态错位的影响.孙颖等[11]提出基于双模态融合网络的目标检测算法, 通过门控融合网络调整两路特征的权重分配, 实现跨模态特征融合.Zhang等[12]提出SuperYOLO, 利用跨模态融合模块, 在数据中提取互补信息.Fang等[13]提出CFT(Cross-Mo-dality Fusion Transformer), 提高多光谱目标检测性能.Zhao等[14]提出CDDFuse(Correlation-Driven Fea-ture Decomposition Fusion), 用于多模态图像融合.Zhu等[15]提出MFPT(Multi-modal Feature Pyramid Transformer), 通过模态内和模态间的transformer特征金字塔学习语义和模态互补信息.Shao等[16]提出MOD-YOLO(Multispectral Object Detection Based on Transformer Dual-Stream ), 使用CSP(Cross Stage Par-tial)融合不同层中的学习特征信息.Bao等[17]提出Dual-YOLO, 设计D-Fusion(Dual-Fusion), 用于减少冗余融合特征信息.Fu等[18]提出LRAF-Net(Feature-Enhanced Long-Range Attention Fusion Network), 融合增强的可见光特征和红外特征的远程依赖性, 提高检测性能.
尽管现有方法通过双模态特征融合的方式提供互补信息, 实现较好的目标检测, 但仍面临一些挑战:1)光照和天气等复杂环境因素会对传感器产生干扰, 这些干扰信息导致图像对比度降低, 产生低对比度噪声.由于大雾、眩光、黑夜等复杂场景图像具有低对比度的特点, 目标大量边缘混杂在复杂背景中, 目标提取结果中会出现大量背景噪声, 称为低对比度噪声.在太阳眩光和大灯眩光下, 图像受到过度曝光的影响, 导致图像中的亮部区域丧失细节, 对比度降低, 造成细节无法分辨; 在天气阴沉或黑夜大雾时光线变暗, 缺乏明显的颜色和纹理, 物体之间的差异变得不够明显; 大雨天气会导致光线散射, 使图像中的物体变得模糊, 背景消失.因此, 对于干扰信息的纠正与校准应有助于实现更准确的特征融合.然而, 现有方法通常未充分考虑这一思想, 导致在此类场景下的检测性能不佳.2)当同一对象处于不同的视角和位置时, 尺寸往往存在较大差异.因此, 在对象尺寸较小时, 这种差异引起的图像对比度降低将更明显, 仅通过互补信息和纠正低对比度噪声无法缓解对象尺寸差异对检测性能的影响, 造成小尺寸目标的误检或漏检.
为了克服上述挑战, 本文提出基于自引导注意力的双模态校准融合目标检测算法(Object Detec-tion Algorithm with Dual-Modal Rectification Fusion Based on Self-Guided Attention, DRF-SGA).考虑到YOLOv5在检测精度上的明显优势, DRF-SGA选择YOLOv5作为基准网络.以双模态图像作为输入, 用于实现输入图像的特征提取与目标定位和分类.为了解决眩光、黑夜和大雾等复杂场景中的低对比度噪声问题, 设计双模态校准融合网络(Dual-Modal Rectification Fusion, DRF), 利用通道特征和空间特征校准建模输入图像(可见光图像与红外图像)目标位置和结构间的一致性, 从而纠正输入图像特征中的低对比度噪声.然后, 从纠正后的特征中获取互补信息, 并实现准确的特征融合.为了有效识别小尺寸目标, 构建自引导注意力机制(Self-Guided Atten-tion, SGA), 捕捉图像像素之间的依赖关系, 根据该依赖关系, 融合具有不同尺度目标的特征, 实现小尺寸目标检测.
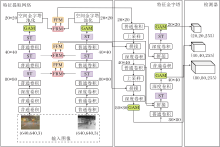
本文提出基于自引导注意力的双模态校准融合目标检测算法(DRF-SGA), 算法结构如图1所示.DRF-SGA主要分为两部分.一部分将双模态融合网络(DRF)加入YOLOv5的特征提取网络(Feature Extraction Network)中.其中, DRF由特征校准模块(Feature Rectification Module, FRM)与特征融合模块(Feature Fusion Module, FFM)组成.为了纠正可见光特征和红外特征中的低对比度噪声并实现充分的特征融合, 考虑到检测器在80× 80、40× 40、20× 20三层进行定位和分类, 将FRM和FFM组装在特征提取网络的80× 80、40× 40、20× 20三层之间.
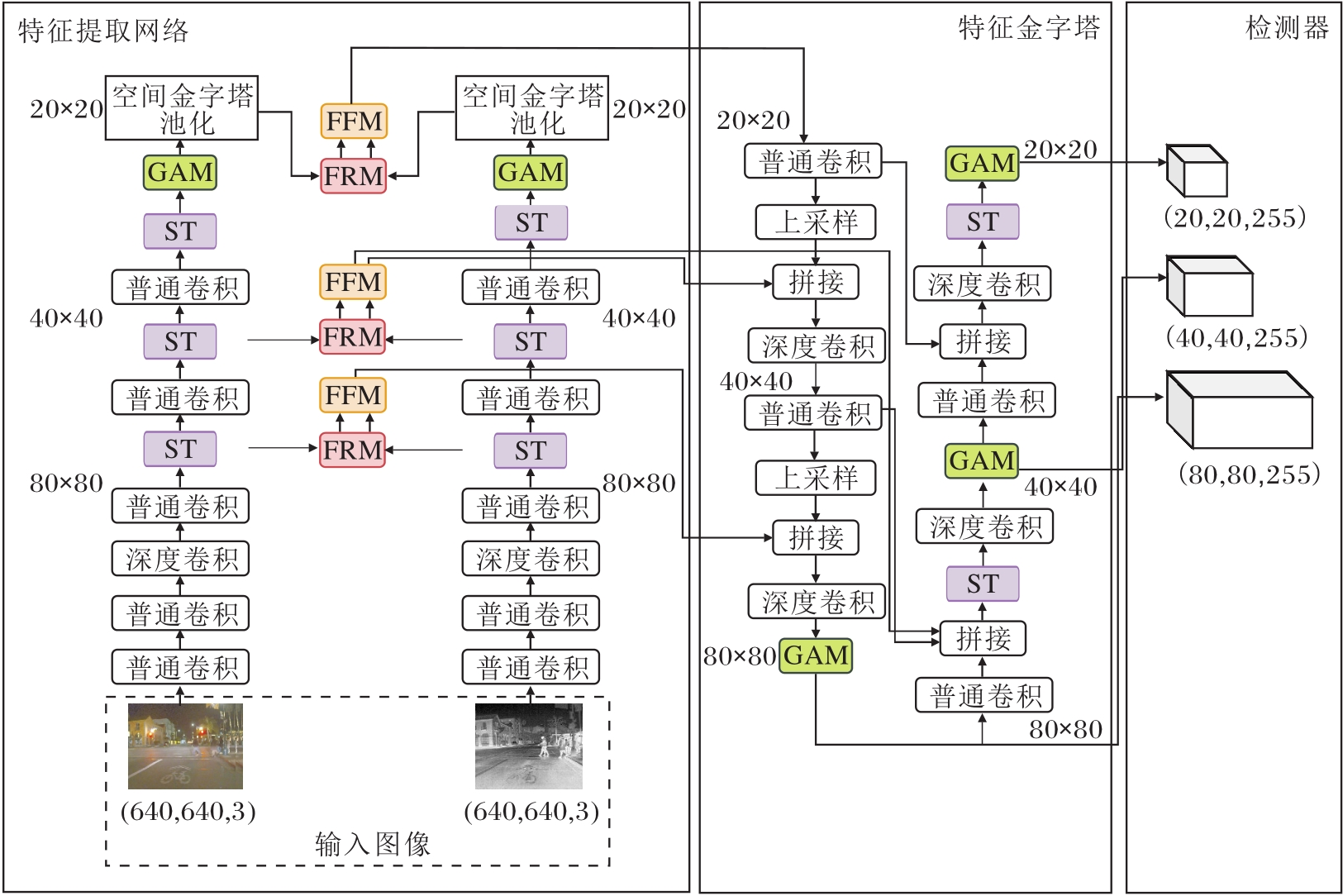 | 图1 DRF-SGA结构图Fig.1 Structure of DRF-SGA |
另一部分将自引导注意力机制(SGA)组装在YOLOv5的特征提取网络和特征金字塔(Feature Pyramid Network, FPN)之间.该机制由Swin Trans-former模块(ST)[19]、全局注意力模块(Global Attention Mechanism, GAM)与BiFPN(Bi-directional FPN)[20]构成.为了增强小目标特征的分辨率, 考虑到特征提取网络和FPN末端的特征图像分辨率较低, 将ST分别替换特征提取网络80× 80、40× 40、20× 20三层以及特征金字塔40× 40、20× 20两层中YOLOv5原有的C3模块.为了避免小目标特征缩减, 考虑在特征提取网络和FPN末端集成GAM, 使模型保留更多的小目标特征, 将GAM添加到特征提取网络的20× 20层以及特征金字塔的80× 80、40× 40、20× 20三层中.为了增强FPN对小目标的检测能力, 考虑到BiFPN基本不增加成本并对模型参数量影响不大的同时使小目标特征提取更充分, 使用16倍下采样后形成的40× 40特征与后面的特征进行跨层连接.最后由YOLOv5的检测器实现目标分类和定位.
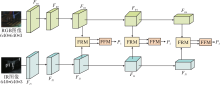
双模态融合网络(DRF)的关键在于其能够从不同模态的信息中提取有用特征[21], 并进行有效融合和增强, 从而改善图像质量, 帮助纠正低对比度噪声问题, 提高图像的可用性和可读性.DRF结构如图2所示.
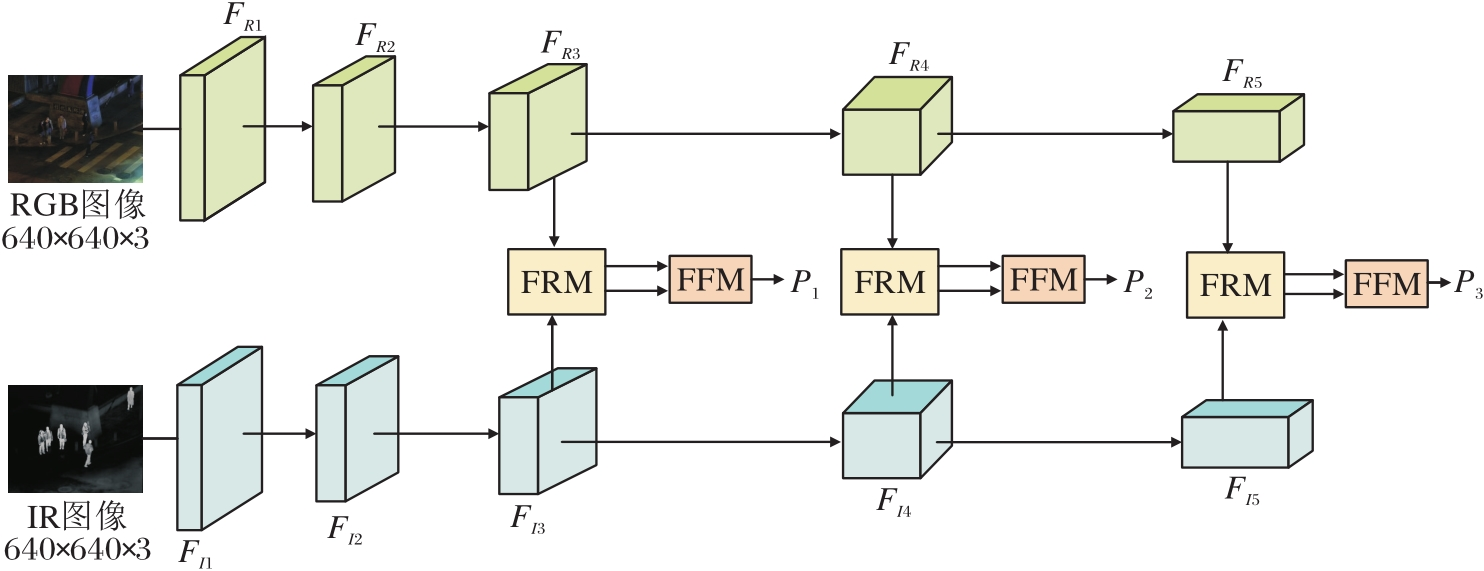 | 图2 DRF结构图Fig.2 Structure of DRF |
FRM校准可见光特征和红外特征中的低对比度噪声, 纠正输入图像存在的低对比度噪声, 由可见光特征FRi和红外特征FIi作为输入.FFM在FRM之后, 能够实现可见光特征和红外特征之间互补信息的交换并进行特征融合, FRM的输出Pi作为特征金字塔的输入.
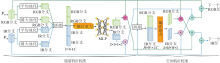
FRM结构如图3所示.FRM经过通道特征校准和空间特征校准两阶段, 纠正双模态图像中的低对比度噪声, 实现更准确的特征融合.
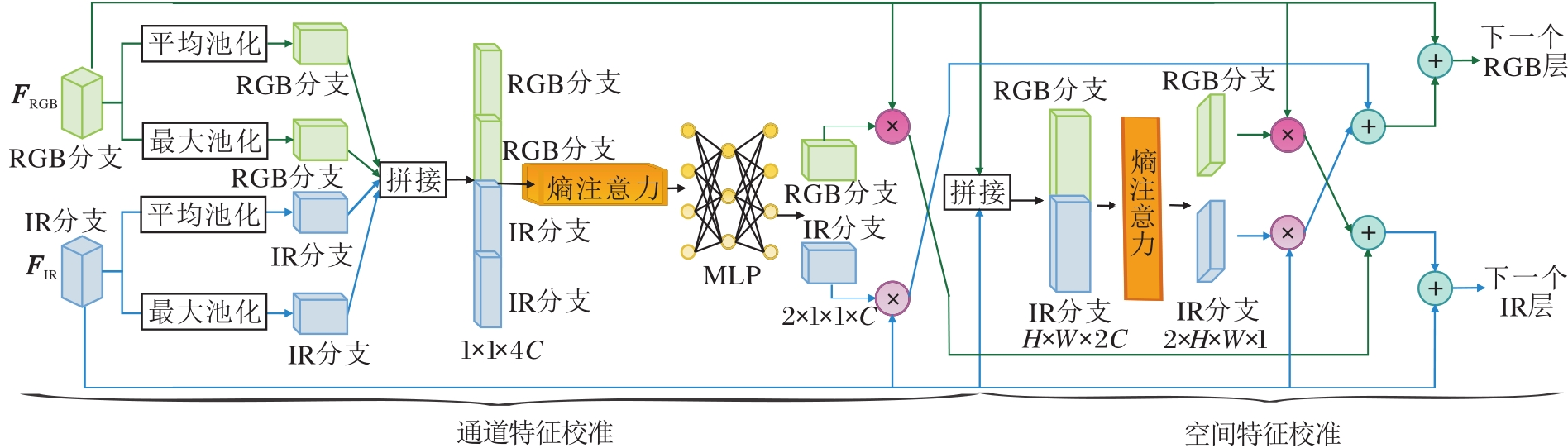 | 图3 FRM结构图Fig.3 Structure of FRM |
具体地, 针对成对的双模态图像, 在通道特征校准中, 对于可见光图像, 从RGB通道中提取颜色特征信息.对于红外图像, 从红外波段中提取波段特征信息.并对通道特征信息进行匹配和校准, 以确保它们在颜色、对比度和亮度方面一致.将校准后的可见光图像和红外图像合并为一幅图像, 生成校准后的双模态图像.
在空间特征校准中, 使用第一阶段生成的校准双模态图像作为输入, 从校准后的双模态图像中提取空间特征, 这些特征包括纹理、边缘、结构等.对提取的空间特征进行增强, 提高图像的对比度和细节.将增强后的空间特征与校准后的双模态图像融合, 生成最终的纠正低对比度噪声的图像.
通过两阶段的处理, 通道特征校准确保颜色和亮度的一致性, 而空间特征校准增强图像的结构和对比度.从而FRM有效纠正双模态图像中的低对比噪声, 实现准确特征融合.
在通道特征校准阶段, 通过调整和校正双模态图像中不同通道之间的特征, 消除低对比度噪声并提高特征的一致性.
将两个模态的特征RGBin∈ RH× W× C和IRin∈ RH× W× C沿着空间轴线嵌入两个注意力向量
其中σ 表示sigmoid函数.
通道特征校准结果:
其中· 表示通道级别的乘法.
在空间特征校准阶段, 通过调整和校正双模态图像中的空间特征, 解决由于视角、尺度、旋转等因素引起的不一致性.在双模态图像中, 可能存在空间对齐不准确的问题, 从而影响特征的一致性.通过空间特征校准可以对图像进行几何变换、配准和对齐操作, 使双模态图像中的目标位置和结构实现一致, 从而更好地实现特征融合和目标检测.
两个模态的输入RGBin和IRin连接后并嵌入
$ \begin{array}{l} \boldsymbol{F}=E\left(\operatorname{Conv}_{1 \times 1}\left(\operatorname{RELU}\left(\operatorname{Conv}_{1 \times 1}\left(\boldsymbol{R} \boldsymbol{G} \boldsymbol{B}_{\text {in }} \| \boldsymbol{I R}_{\text {in }}\right)\right)\right)\right), \\ \boldsymbol{W}_{\mathrm{RGB}}^{S}, \boldsymbol{W}_{\mathrm{IR}}^{S}=F_{\text {split }}(\sigma(\boldsymbol{F})), \end{array}$
与通道校准类似, 空间特征校准结果为:
其中* 表示空间级别上的乘法.
RGBout和IRout两种模态的综合校准特征为:
其中, λ C和λ S表示两个超参数, 都设为0.5.RGBout和IRout后面将进入FFM进行特征融合.
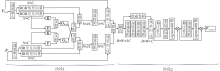
FFM结构图如图4所示.FFM能够从FRM纠正后的特征图中获取互补信息, 并融合特征图.因此, FFM分为互补信息交换阶段和融合阶段.
 | 图4 FFM结构图Fig.4 Structure of FFM |
在互补信息交换阶段, 两个模态的特征通过对称结构交换信息, 利用双模态图像中的互补信息弥补各自模态的局限性, 从而得到更全面和准确的特征.此处选择可见光通道RGB进行说明.
首先将维度为H× W× C的输入特征经过通道嵌入展平维度为N× C的特征, N=H× W.使用线性嵌入生成残差向量Xrec和交互向量Xinter, 维度为N× Ci.然后, 由于自注意力输入向量编码为Query Q, Key K和Value V, 为了节省内存占用, 使用全局上下文向量G=KTV进行计算, 维度为Chead× Chead.
最后, Xinter嵌入每个头的K和V中, 维度为N× Chead.另一模态的输出由交互向量和全局上下文向量相乘获得.全局上下文向量为:
信息交换后的结果为:
其中Softmax(· )表示归一化函数.将结果向量U和残差向量Xrec连接后并应用线性嵌入将特征维度调整成维度为H× W× C的特征.最后将信息交换后的特征与输入特征加权规范化, 为融合阶段做准备.
在融合阶段, 通过1× 1卷积层实现合并两种模态的特征.采用深度卷积层DWConv3× 3实现跳接结构, 将维度为H× W× 2C的合并特征融入维度为H× W× C的输出中进行特征解码.融合后的特征使用EBAM(Entropy-Block Attention Module) [22]增强鲁棒性.EBAM依次由1D通道注意力AC∈ RC× 1× 1和2D空间注意力AS∈ R1× W× H组成.输入特征F后中间状态为:
F'=AC(F)$\otimes$F,
其中$\otimes$表示张量积.最终输出特征为:
F″=AS(F')$\otimes$F'.
通道注意力强调赋予更多权重给不确定的特征, 在反向传播中优先考虑梯度方向, 以提取更多信息.计算通道注意力如下:
Ac(F)=σ (MLP(E(F))),
其中, σ (· )表示sigmoid函数, E(· )表示熵矩阵, MLP(· )表示多层感知机.
在空间注意力中, 赋予更多的权重给熵值较小的网络有助于提高网络性能.基于熵的空间注意力为:
AS(F')=σ (Conv7× 7(1-
其中Eij表示位于第i行和第j列网格的熵矩阵.
为了进一步解决小尺寸的目标检测问题, 采用SGA机制, 具体情况如下.
ST利用移动窗口进行跨窗口连接和跨窗口的特征交互, 提取具有较强表征能力的特征以有效提高小尺寸目标特征提取能力.其关键是指在特征图内每个像素需要与所有像素进行关联计算, 所有像素都需要通过变换矩阵Wq, Wk, Wv生成对应的qi, ki, vi, 将qi和所有ki进行相关性计算后通过归一化处理, 权重系数和vi进行加权求和, 得到最终的注意力机制:
Attention(Q, K, V)=SoftMax(
其中, Q、K、V表示注意力机制中所需的三个向量, 分别为Query, Key和Value.
GAM能关注图像中的关键特征点, 捕捉图像像素之间的依赖关系, 从而更好地结合不同尺度下的小目标特征.其过程如下:在通道注意力中, 维度为C× W× H的输入特征F1先采用三维通道置换的方式保存信息维度为W× H× C, 再通过一个MLP, 经过sigmoid函数, 得到权重MC.在空间注意力中, 输入特征F2使用两个7× 7卷积层, 同样经由sigmoid函数得到权重MS.过程如下:
其中, $\otimes$表示张量积, F1表示输入特征, F2表示中间状态, F3表示输出特征, MC(· )表示通道注意力模块, MS(· )表示空间注意力模块.
当融合不同分辨率特征图时, 通常是先调整它们的大小以达到相同的分辨率, 再求和.然而不同分辨率的输入特征对输出端的影响并不相同.因此, 需要为不同的输入特征设置可调节的权重系数.BiFPN能根据每个输入特征的影响程度设置不同的权重.采用加权特征融合的方法为每个特征引入额外权重, 增强不同尺度间上下文信息的融合能力, 同时保留更多小目标的特征信息.使用归一化融合公式约束每个权重的大小, 最终输出特征为:
O=
其中, ω i、ω j表示可以学习的权重大小, ε =0.000 1, 是避免数值不稳定的小数值, Ii表示输入特征.
实验平台为一台装有 NVIDIA Tesla V100 的 Linux 服务器, 运行 Ubuntu20.04 操作系统.实验环境配置包括 CUDA 11.7、PyThon 3.8 和 Pytorch 1.10.1.
采用KAIST[23]、LLVIP[24]行人数据集, FLIR、FLIR_v2行人车辆数据集和VEDAI[25]、Drone-Vehicle[9]航拍车辆数据集进行算法评测实验.
在KAIST数据集上, 为了消除原始数据集上不准确注释对实验结果的影响, 使用经过处理的多光谱行人检测数据集[26].该数据集包含7 601对用于训练的RGB-Thermal图像和2 252对用于测试的图像.经过净化的数据集消除原始训练中的注释错误, 确保测试集注释的准确性, 以便进行公平对比.
LLVIP数据集为低光视觉可见光红外配对行人数据集, 包括12 025个配对训练图像和3 463个配对测试图像, 其中大部分图像是在非常黑暗的场景下拍摄的.此外, 所有图像都是严格时空对齐的, 确保实验结果的准确性.
FLIR数据集(https://www.flir.com/oem/adas/adas-dataset-form)为多光谱目标检测数据集, 包括白天场景和夜晚场景.原始数据集中存在大量未对齐的图像对, 使网络训练变得困难.最近发布的“ 对齐” 版本[5], 手动删除未对齐的可见热图像对.新的数据集包含5 142个对齐良好的多光谱图像对, 涵盖3个对象类别(人、汽车、自行车), 其中4 129对图像用于训练, 1 013对图像用于测试.为了提高边界框的准确性和从原始数据集上恢复更多的数据, 采用交叉标签算法[22]执行预处理步骤.进一步对齐的数据集分别有6 924对和1 982对图像用于训练和验证.
Teledyne FLIR红外热传感器可以在具有挑战性的条件下进行检测和分类, 包括完全黑暗、大多数雾、烟雾、恶劣天气和眩光.FLIR_v2数据集(https://www.flir.com/oem/adas/adas-dataset-form)的标签已经扩展到15类, 注释帧总数扩展到26 442个.其中训练集上可见图像为9 233幅, 红外图像为9 711幅, 验证集上可见光图像为3 749幅, 红外图像为3 749幅, 比v1版本增加83%.由于数据集上存在大量未对齐的可见光图像和红外图像对, 因此选定标签为人和车, 并从中选择7 044对红外可见光匹配对作为训练集, 3 749对视频帧匹配对作为验证集.调整红外和可见光数据对, 最终得到10 793对配准良好的匹配对.
VEDAI数据集为航空图像车辆检测数据集, 其特点是表现出多种不同的变化, 如多方向、灯光/阴影变化、反射或闭塞等.数据集共包含1 246个图像对, 其中997对图像用于训练, 249对图像用于验证.数据集的小体积可以提高训练和验证的效率, 而数据集上的各种变化可以帮助提高算法的鲁棒性和泛化性能.这些特点使得该数据集成为一个有价值的测试平台, 可以评估车辆检测算法在各种复杂场景下的性能表现.
DroneVehicle数据集为天津大学推出的一个大型无人机航拍车辆数据集, 特点包括:拍摄环境覆盖从白天到晚上的时间段; 提供可见光图像和红外图像; 数据集上包含15 532对(共31 064幅)图像, 其中包含441 642个标注实例; 数据集上存在真实环境下的遮挡和尺度变化.该数据集上有17 990对图像用作训练集, 1 469对图像用作验证集.
算法评价指标为平均检测精度(Mean Average Precision, mAP), 包括交并比(Intersection over Union, IoU) 为0.5 的mAP(记为mAP@0.5)和 0.5∶ 0.95的 mAP(记为mAP@[0.5∶ 0.95]).
将本文算法与近几年具有代表性的单模态目标检测算法和多模态目标检测算法进行对比, 验证本文算法的有效性.
在KAIST、LLVIP行人检测数据集上, 选择如下算法.1)单模态目标检测算法:FCOS[1]、YOLOv5、YOLOv7.2)双模态目标检测算法:MBNet[3]、TC Det[4]、CFR[5]、 ECISNet[8] 、UA-CMDet[9]、文献[11]算法、Dual-YOLO[17]、LRAF-Net[18].
各算法的指标值结果如表1所示, 表中黑体数字表示最优值.由表可见, 相比双模态算法, 在KAIST数据集上, DRF-SGA在mAP@0.5指标上分别比MBNet、TC Det、CFR、 ECISNet、文献[11]算法和Dual-YOLO提升4.2%、5.2%、4.0%、3.8%、 2.0%和3.3%.在LLVIP数据集上, DRF-SGA在mAP@0.5指标上分别比MBNet、TC Det、CFR、ECISNet 和UA-CMDet提升3.2%、2.4%、3.6%、0.7%和0.1%.对比算法由于忽略纠正输入图像的低对比噪声, 无法实现良好的特征融合.与上述方法不同的是, DRF-SGA能够建模输入可见光图像与红外图像目标位置和结构间的一致性, 从而准确实现特征融合.
| 表1 各算法在KAIST、LLVIP数据集上的指标值对比 Table 1 Index value comparison of different algorithms on KAIST and LLVIP datasets |
在FLIR、FLIR_v2行人车辆检测数据集上, 选择如下双模态目标检测算法:CFR[5]、GAFF(Guided Attentive Feature Fusion)[6]、文献[7]算法、 UA-CMDet[9]、SuperYOLO[12]、CFT[13]、MFPT[15]、MOD-YOLO[16]、Dual-YOLO[17]、LRAF-Net[18].
各算法的指标值对比如表2所示, 表中黑体数字表示最优值.由表可得, 在FLIR数据集上, DRF-SGA在mAP@0.5指标上分别比CFR、GAFF、文献[7]算法、UA-CMDet、SuperYOLO、CFT、MFPT、Dual-YOLO和LRAF-Net提升12.6%、11.2%、12.9%、6.4%、0.9%、7.3%、8.2%、0.5%、4.5%.在FLIR_v2数据集上, DRF-SGA在mAP@0.5指标上比UA-CMDet、SuperYOLO和CFT提升3.6%、2.0%、3.3%.对比算法由于忽略对象尺寸差异, 检测效果略差.DRF-SGA能更好地关注不同视角和位置下相同目标不同尺寸的差异, 有效提高检测精度.
| 表2 各算法在FLIR、FLIR_v2数据集上的指标值对比 Table 2 Index value comparison of different algorithms on FLIR and FLIR_v2 datasets |
对于VEDAI、DroneVehicle航拍车辆数据集, 选择如下对比算法.1)单模态目标检测算法:FCOS[1]、YOLOv5、YOLOv7.2)多模态目标检测算法:TC Det[4]、CFR[5]、ECISNet[8]、TSFADet[10]、SuperYOLO[12]、CFT[13].
各算法的指标值对比如表3所示, 表中黑体数字表示最优值.由表可观察到, 在VEDAI数据集上, DRF-SGA在mAP@0.5指标上比TC Det和CFT分别提升14.9%和0.3%.在DroneVehicle数据集上, DRF-SGA在mAP@0.5指标上比TC Det、CFR、ECISNet、TSFADet、SuperYOLO和CFT分别提升15.7%、9.9%、7.8%、10.74%、1.8%和0.6%.由于现有双模态目标检测算法更倾向于输入图像特征之间的充分融合, 因此通常忽略探索不同像素之间的依赖关系, 导致尺寸较小的目标不能得到有效检测.DRF-SGA却能捕捉图像像素之间的依赖关系, 根据该依赖关系, 融合具有不同尺度目标的特征, 提高小尺寸目标检测的效果.
| 表3 各算法在VEDAI、DroneVehicle数据集上的指标值对比 Table 3 Index value comparison of different algorithms on VEDAI and DroneVehicle datasets |
为了更直观地对比, SuperYOLO、CFT、DRF-SGA的可视化结果如图5所示.由图可知, SuperYOLO存在错检情况, 如第二幅图像和第四幅图像中将van误检为car.CFT会有部分漏检情况, 例如第一幅图像未检测到bus, 第三幅图像未检测到freight.值得注意的是, DRF-SGA可以有效检测复杂场景中尺寸较小的目标, 这种优异的检测效果得益于DRF-SGA在纠正双模态特征中低对比噪声的同时有效缓解目标尺寸变换较大带来的影响.
 | 图5 各算法在DroneVehicle数据集上的检测效果对比Fig.5 Detection result comparison of different algorithms on DroneVehicle dataset |
本节在行人、行人车辆以及航拍车辆这6个数据集上分别进行消融实验.为了验证不同组件的有效性, 设计基线为简单相加可见光特征和红外特征提取网络的算法, 记为YOLOv5-Add.在YOLOv5-Add上加入FFM和FRM以验证DRF的有效性, 记为YOLOv5-Add-DRF.在此基础上加入ST、GAM和BiFPN以验证SGA的有效性, 记为YOLOv5-Add-DRF-SGA.
各算法在6个数据集上的指标值对比如表4所示, 表中黑体数字表示最优值.由表可见, 针对含有目标尺度变换不大的行人和行人车辆检测数据集, 通过DRF纠正大雾、黑夜以及眩光引起的对比度降低产生的噪声, 可以有效改善行人及车辆的检测精度.在KAIST数据集上, YOLOv5-Add在mAP@0.5和mAP@[0.5∶ 0.95]指标上分别为72.5%和33.2%; 添加DRF纠正低对比度噪声后, 算法在检测精度上提升3.1%和1.9%.在LLVIP数据集上, YOLOv5-Add在mAP@0.5和mAP@[0.5∶ 0.95]指标上分别为95.5%和60.7%; 加入DRF后检测精度分别提升0.4%和2.1%.在FLIR_v2数据集上, 相比YOLOv5-Add, YOLOv5-Add-DRF的mAP@0.5和mAP@[0.5∶ 0.95]指标分别提升2.5%和1.1%.在小目标较多的行人车辆和航拍车辆数据集上, 纠正低对比度噪声可以提升部分目标的检测精度, 但一些尺寸差异较大的目标仍存在误检测或漏检的情况.添加SGA可以有效缓解尺度较小目标引起的对比度降低带来的影响.为了验证SGA中ST和GAM的有效性, 在DRF中分别加入ST和GAM, 分别记为DRF-ST和DRF-ST-GAM.
| 表4 各算法在5个数据集上的消融实验结果 Table 4 Ablation experiment results of different algorithms on 6 datasets |
DRF添加不同组件后的指标值对比如表5所示, 由表可见, 在FLIR 数据集上, 相比DRF, DRF-ST在mAP@0.5和mAP@[0.5∶ 0.95]指标上分别提升0.6%和0.5%, 添加GAM后再次提升0.6%和0.9%, 这得益于GAM关注图像中的关键特征点并捕捉图像像素之间的依赖关系, 使小尺寸目标自行车的检测效果变优.在全部都是小尺寸目标的航拍车辆数据集上增添SGA后检测精度的提升效果更为明显.在VEDAI数据集上, DRF的mAP@0.5和mAP@[0.5∶ 0.95]指标分别为71.2%和42.1%.加入ST后, 可提取具有较强表征能力的特征, 提高小尺寸目标特征提取能力, 使检测精度分别提升0.5%和0.4%; 加入GAM结合不同尺度下目标特征后, 检测精度再次提升0.8%和0.4%.在DroneVehicle数据集上, DRF的mAP@0.5和mAP@[0.5∶ 0.95]指标分别为82.4%和55.6%; 添加ST后, 检测精度提升0.5%和0.6%; 而加入GAM后, 检测精度再次提升0.6%和0.5%.
| 表5 SGA上不同组件在6个数据集上的消融实验结果 Table 5 Ablation experiment results of different components of SGA on 6 datasets |
为了更直观地对比检测结果, DRF-SGA部分可视化结果如图6所示.
 | 图6 DRF-SGA在FLIR_v2数据集上的检测效果Fig.6 Detection result comparison of DRF-SGA on FLIR_v2 dataset |
由图6可见, 在大雾天气能见度极低时, DRF-SGA可以检测到行人和车辆.在太阳眩光和大灯眩光下, DRF-SGA能够检测到对面的车辆.在具有冷热物体的繁忙城市环境中, DRF-SGA可以检测到所有冷热物体.在雨滴的积聚导致难以识别物体的光条纹情况下, DRF-SGA可以有效检测到车辆.值得注意的是, 这种优异的检测效果得益于DRF和SGA对于双模态网络模型带来的有效改善.
本文提出基于自引导注意力的双模态校准融合目标检测算法(DRF-SGA).算法充分利用不同模态之间的内在互补性, 降低光照和环境等因素带来的图像低对比度噪声, 增强算法在眩光、黑夜、大雾等复杂场景下的检测精度.另外, 算法可以缓解复杂场景下对象的尺度差异, 有效减少小尺寸目标误检和漏检的情况.在经典的双模态行人、行人车辆、航拍车辆数据集上进行的大量实验表明, DRF-SGA具有较优的检测性能.本文使用的校准融合模块和自引导注意力在优化特征信息的同时, 也带来较多的参数量.今后将尝试设计更通用、轻量级的模型, 在发挥两者优势的同时避免耗费更多的资源, 并且计划将轻量化的模型部署在边缘计算平台以实现实时双模态目标检测.
本文责任编委 叶东毅
Recommended by Associate Editor YE Dongyi
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|