
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
时序动作单元感知的开集动作识别
[杨凯翔1  , 高君宇
, 高君宇2 , 冯洋博1 , 徐常胜2 ]
, 高君宇, 冯洋博, 徐常胜]
|
|



作者简介:

杨凯翔,硕士研究生,主要研究方向为开集动作识别.E-mail:15005379839@139.com.

冯洋博,博士研究生,主要研究方向为计算机视觉、多媒体、动作识别.E-mail:ybfeng6@gmail.com.

徐常胜,博士,研究员,主要研究方向为多媒体分析与检索、模式识别、计算机视觉.E-mail:csxu@nlpr.ia.ac.cn.
开集动作识别任务要求模型不仅能准确识别训练集中的类别,还能拒绝训练集上未出现的未知类动作.目前,大多数方法都将动作视为一个整体,忽略动作本身可被分解为更细粒度的动作单元.为此,文中提出时序动作单元感知的开集动作识别方法.首先,设计动作单元关系模块,学习细粒度的动作单元特征,得到动作和动作单元的关系模式,并通过已知类动作和未知类动作在动作单元上不同的激活程度识别未知类动作.然后,设计动作单元时序模块,建模动作单元的时序信息,研究动作单元的时序性,进一步区分因为外观相似而被混淆的已知类动作和未知类动作.最后,综合考虑关系模式与动作单元时序信息,使模型具备区分已知类动作和未知类动作的能力.在3个动作识别数据集上的实验表明,文中方法性能较优.
About Author:
YANG Kaixiang, master student. His research interests include open set action recognition.
FENG Yangbo, Ph.D. candidate. Her research interests include computer vision, mu-ltimedia and action recognition.
XU Changsheng, Ph.D., professor. His research interests include multimedia analysis and retrieval, pattern recognition and compu-ter vision.
In open set action recognition tasks, a model is requested to identify categories within the training set accurately and reject unknown actions that never appear in the training set. Currently, most of the methods treat the action as a whole, ignoring the fact that the action can be decomposed into finer-grained action units. To address this issue, a method for temporal action unit perception based open set action recognition is proposed in this paper. Firstly, an action unit relationship module is designed to learn fine-grained features of action units, and thus the relational pattern between actions and action units is obtained. The unknown actions are identified according to the different degrees of activation of known and unknown actions on action units. Secondly, an action unit temporal module is designed to model the temporal information of action units. The temporal characteristics of action units are explored to further distinguish between known actions and unknown actions that are visually similar but confusable with each other. Finally, with comprehensive consideration of both relational patterns and temporal information of action units, the model is equipped with the capability of distinguishing known actions from unknown actions. Experimental results on three action recognition datasets demonstrate the superior performance of the proposed method.
动作识别作为计算机视觉领域的重要任务之一, 其目的是识别视频中的人物动作.目前, 大部分的动作识别研究主要基于闭集环境, 训练集和测试集的类别相同且固定, 而真实世界是一个开放的环境, 动作类别不断变化.开集动作识别方法(Open Set Action Recognition, OSAR)旨在开放环境下, 通过有限的训练集类别知识, 使模型不仅能对已知类动作进行准确识别, 还具备拒绝未知类动作的能力.
为了解决上述问题, 一些OSAR直接将基于图像的开集识别方法(Open Set Recognition, OSR)迁移于基于视频的OSAR任务.例如:OpenMax[1]得到已知类动作和未知类动作的分类概率, 通过该概率分布拒绝未知类动作.RPL(Reciprocal Point Lear-ning)[2]对每个已知类都学习一个互斥点, 计算样本和各个互斥点间的距离, 区分已知类动作和未知类动作.尽管上述方法适用于基于图像的OSR任务, 但因其无法处理视频中存在的复杂时序信息, 所以不能较好地迁移到基于视频的OSAR任务.
因此, 学者们逐渐提出一些专门针对OSAR任务的方法.已有OSAR通常将动作视为整体进行研究, 忽略动作内在的复杂性, 同时也未考虑动作单元之间的时序关系, 这导致其对相似的已知类动作和未知类动作缺乏判别力.具体而言, Krishnan等[3]将贝叶斯深度学习框架应用于动作识别任务, 通过不确定性估计区分已知类动作和未知类动作.然而方法仅依赖于三维卷积神经网络提取的视频特征, 没有专门考虑到视频中时序信息的建模, 从而忽略时序信息在开集动作识别中的重要作用, 导致在区分具有相似外观但不同时序特性的已知类动作和未知类动作时性能下降.Bao等[4]提出DEAR(Deep Evi-dential Action Recognition), 在开集动作识别任务中引入证据深度学习, 将学习到的证据分数用于识别已知类动作和未知类动作.但其主要研究对象为动作的整体特征, 未考虑细粒度的动作特征, 导致其未能充分挖掘整体特征与细粒度动作特征之间的潜在联系.而对于OSAR任务来说, 如果能将二者建立关系, 即所有的已知类动作特征与细粒度的动作特征建立关系, 那么未知类动作与已知类动作的差异就表现为该关系的差异, 可据此识别未知类动作.所以不仅需要进行细粒度的动作特征分析, 还要联系动作的整体特征与细粒度的动作特征.具体地, Luo等[5]提出AUMN(Action Unit Memory Network), 通过对视频级动作标签的学习间接更新细粒度的动作单元特征, 构建动作与动作单元间的关系.但对于OSAR任务来说, 这种间接的学习方式无法得到精确的动作单元特征, 不利于模型区分已知类动作和未知类动作.所以需要使用动作单元级别的标签对模型进行监督, 得到准确的细粒度动作单元特征.在此基础上, 再进一步研究动作与动作单元间的关系.
具体而言, 所有动作共享一个动作单元集合, 每个动作都能由该集合中的若干动作单元组成.例如:三步上篮这个动作, 可以划分为跑步、跳跃、投掷三个动作单元.显然, 这些动作单元并不只属于该动作, 也被其它动作共享.不仅如此, 每个动作包含的动作单元间存在时序性.所以针对某个未知类动作, 其动作单元组成一般与已知类动作不同, 即使相同, 由于存在顺序差异, 也可分离未知类动作和已知类动作.
基于上述分析, 本文提出时序动作单元感知的开集动作识别方法.由于缺少动作单元级别的标签, 影响模型的开集识别性能, 所以本文方法分为两个阶段.第一阶段得到动作单元特征表示以及动作单元标签, 用于后续训练.第二阶段包含两个模块, 其中动作单元关系模块用于学习细粒度的动作单元特征, 得到动作和动作单元的关系模式, 并通过已知类动作和未知类动作在动作单元上不同的激活程度以识别未知类动作.动作单元时序模块用于对动作单元的时序信息进行建模, 通过动作单元的时序性区分已知类动作和未知类动作.这样在关系模式和动作单元的时序性这两个角度上使模型具备区分已知类动作和未知类动作的能力.在UCF-101[6]、HMDB-51[7]、MiT-v2[8]数据集上进行的开集动作识别实验表明, 本文方法在准确识别人物动作的同时还能拒绝未知类动作.
动作识别的主要目标是判断一段视频中人物的动作类别.传统的动作识别方法中使用人为设计的特征, 这些特征是根据人类视觉的敏感程度提取的图像中有区分能力的特征, 包括全局特征和局部特征.全局特征描述视频的整体颜色、纹理、形状[9, 10], 而局部特征则是从图像局部区域中抽取的特征, 包括边缘、角点、线、曲线等.然而, 这种人为选取特征的方法费时费力且依赖人类的专业知识.随着深度学习的发展, 深度神经网络可自动从数据和标注中学习相关特征, 因此逐渐摒弃传统的特征提取方法.Wang等[11]利用光流场获得视频序列中的一些轨迹, 再沿轨迹分别提取HOF(Histograms of Optical Flow)、HOG(Histograms of Oriented Gradients)、MBH(Motion Boundary Histograms)、trajectory四种特征进行分类.Simonyan等[12]提出Two-Stream Convolu-tional Networks, 通过光流捕捉视频帧之间的运动信息.
此外, 一些研究人员将循环神经网络用于视频中的时序信息建模.Ng等[13]连接长短时记忆网络(Long Short-Term Memory, LSTM)与卷积神经网络(Convolutional Neural Network, CNN)的输出, 通过CNN获取视频级的全局特征.考虑到视频是由一系列图像帧组成的, 一些工作提取视频每帧的特征, 再对这些特征进行耦合[14], 得到视频级别特征并进行分类预测, 但是这种方法忽略帧间的时序关系.因此, 为了对视频时序信息进行建模, Tran等[15]提出C3D(Convolutional 3D), 将二维CNN扩展为三维, 实验表明其在视频时空特征提取方面的有效性.
此外, 特征融合[16, 17]以及注意力机制[18]也广泛应用于动作识别任务中.为了提高网络性能, 一些工作[19, 20, 21]已开始研究具有双流或多流设计的三维CNN模型.最近, 随着基于Transformer[22]的预训练模型在许多自然语言处理任务中实现较优结果, 一些工作将 Transformer[23, 24, 25, 26]引入动作识别任务.
虽然上述方法在动作识别任务中已经取得较优效果, 但研究均基于闭集环境.在开放环境下, 未知类动作的出现会导致上述方法的性能明显下降.
Li等[27]提出开集识别问题, 用于人脸识别系统.其后, 随着深度学习的成功, 深度神经网络广泛应用于开集识别.Bendale等[1]提出OpenMax, 通过已知类动作和未知类动作的分类概率的分布[28]识别未知类动作.随后, Ge等[29]提出G-OpenMax(Generative OpenMax), 结合OpenMax与生成式对抗网络(Generative Adversarial Network, GAN), 将GAN生成的未知类动作样本用于开集识别模型的训练.Krishnan等[3]将贝叶斯深度学习框架应用于动作识别, 通过不确定性估计区分已知类动作和未知类动作.Busto等[30]提出ATI(Assign-and-Trans-form-Iteratively), 其中目标域包含源域中不存在的类别实例.Bao等[4]在开集动作识别任务中引入证据深度学习, 将学习到的证据分数用于识别已知类动作和未知类动作.Feng等[31]提出STE-CapsNet(Spatial-Temporal Exclusive Capsule Network), 通过时空路由机制联合捕获视频的时空信息, 使用点积路由机制限制闭集和开集的数据分布, 降低OSAR的开集风险.Cen等[32]从信息瓶颈理论分析OSAR任务, 提出PSL(Prototypical Similarity Learning), 扩大特征中包含的实例级信息和类级信息, 获得较好的开集识别性能.Zhao等[33]提出MULE(Multi-label Evidential Learning), 解决场景中存在多个动作的问题.Du等[34]提出Humpty Dumpty, 通过重建误差判断视频样本是否为未知样本.
与上述方法不同, 本文方法研究细粒度的动作单元特征, 通过动作和动作单元的关系模式以及动作单元的时序性区分已知类动作和未知类动作.
时间序列分类是指将时间序列数据分为不同类别.例如:对于不同的运动项目, 采集它们的运动轨迹数据集, 那么给定一个未知运动轨迹, 判断其相关的运动项目就是一个典型的时间序列分类问题.一般而言, 可以计算两个序列间的欧氏距离进行分类, 但是这种基于欧氏距离的经典分类算法在这类问题中表现不佳, 因为时间序列通常会按照某种模式变化, 不同时刻间存在很强的关联性.于是使用动态时间归整(Dynamic Time Warping, DTW)对比两个时间序列的相似性, 但是计算的时间复杂度较高.为此, Rakthanmanon[35]等优化DTW, 成功将其应用于大型数据集上.其后, Hadji等[36]扩展DTW, 不仅能通过时间嵌入进行细粒度动作识别, 还能够缓解不同拍摄角度对动作识别的影响.
本文提出时序动作单元感知的开集动作识别方法.其中, 动作单元关系模块用于学习细粒度的动作单元特征, 进而得到动作和动作单元的关系模式, 并通过已知类动作和未知类动作在动作单元上不同的激活程度以识别未知类动作.动作单元时序模块用于对动作单元的时序信息进行建模, 通过动作单元的时序性区分已知类动作和未知类动作.这样在关系模式和动作单元的时序性这两个角度上使模型具备区分已知类动作和未知类动作的能力.
具体来说, 本文方法分为两个阶段.
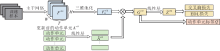
1)第一阶段流程图如图1所示, 先通过训练得到动作单元的特征表示及动作单元的标签信息.
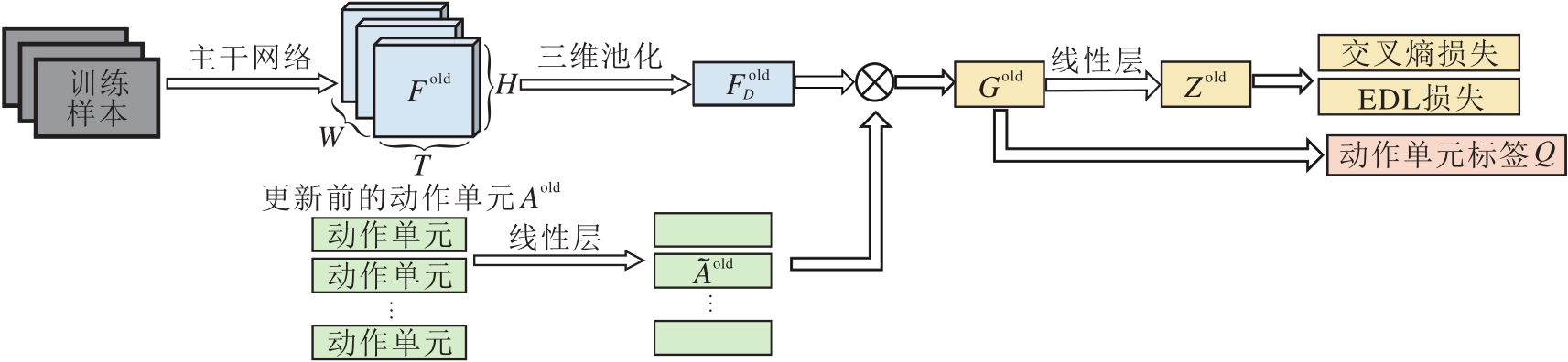 | 图1 动作单元特征及动作单元标签提取模块流程图Fig.1 Flow chart of action unit features and action unit label extraction module |
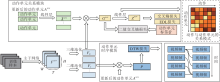
2)第二阶段流程图如图2所示, 使用动作单元标签和更新后的动作单元特征, 重新进行动作单元学习, 得到细粒度的动作单元特征以及动作和动作单元的关系模式, 并完成对动作单元时序信息的建模.
 | 图2 动作单元学习模块流程图Fig.2 Flow chart of action unit learning module |
集合
为训练集, 包含N个视频样本, 其中, $x_i$ 为第i个视频样本, $y_i∈ {1, 2, …, M}$为第i个视频样本对应的标签, M为动作的类别数.集合$D_{test}$ 为测试集, 数据标签为
其中U为开集数据集中动作类别的数量.
OSAR任务不仅要将已知类动作划分至正确类别, 还需要通过计算得到的阈值θ 区分已知类动作和未知类动作, 选取的阈值θ 要确保95%的训练集D被识别为已知类动作.对于测试数据, 如果其区分已知类动作和未知类动作的置信度大于阈值θ , 认为是已知类动作, 否则为未知类动作.
本节为本文方法的第一阶段, 本阶段得到动作单元的特征表示以及动作单元的标签, 用于后续训练, 通过动作单元级别的标签对模型进行监督, 得到细粒度动作单元特征, 在此基础上, 再进一步研究动作与动作单元间的关系.为了与后续章节中的特征进行区分, 为特征添加上标old.
首先, 进行视频特征的提取, 如图1所示, 给定训练样本$x_i$, 通过主干网络(TSM (Temporal Shift Module)[37]等)获得视频时空特征:
其中, T为时间维度, H、W为空间维度, D为通道维度.在以后章节中, 省略下标i以精简公式.
定义一组可学习动作单元$A^{old}∈ R^(K× D) $, K表示动作单元的个数, 所有动作都能由$A^{old}$ 中的若干动作单元组成, 即$A^{old}$ 为所有的动作共享.然后, 定义变换后的动作单元:
其中, $W^a∈ R^(D× D) $ 为线性变换参数, $b^a∈ R^(1× D) $ 为偏置.再定义三维池化后的视频特征:
其中AvgPool3d(• )为三维平均池化.将
为了得到有效的动作单元预测得分$G^{old}$, 关联K个动作单元与M个动作, 即
其中, $z_m$ 为第m类动作的预测得分, $W^o∈ R^(M× K) $ 为线性变换参数, $b^o∈ R^(1× M) $ 为偏置.这样可以通过已有的视频级别的动作标签进行监督, 促进对动作单元的预测.对于第m类动作, 使用交叉熵损失进行学习:
此外, 还使用EDL(Evidential Deep Learning)损失[4] 优化模型.EDL损失统筹考虑动作分类和不确定性建模, 即
最终, 本节的损失函数表示为
其中α 、 β 为超参数.
在训练后, 动作单元$A^{old}$ 更新为$A^{new}∈ R^(K× D) $, 并且动作类别和动作单元之间具备语义相关性, 因此可以统计其相互的关系作为标签.具体地, 对于每个样本x, 都有其在动作单元上的预测得分$G^{old}$, 将第m类动作样本的$G^{old}$ 均值化, 得到该动作类对应的动作单元标签$Q_m∈ R^{(1× K)} $, 将M个动作类别分别求取其对应的动作单元标签, 得
动作单元$A^{new}$ 和动作单元标签Q将用于后续章节的训练.
如图2所示, 本节共包含两个模块, 第1个模块为动作单元关系模块, 旨在学习动作与动作单元间的关系模式, 通过已知类动作和未知类动作在动作单元上激活的差异识别未知类动作.第2个模块为动作单元时序模块, 旨在学习动作单元间的时序关系, 通过动作单元的时序性差异识别未知类动作.
特别地, 本节将对模型重新进行训练, 所以使用上标new与上述章节中的特征进行区分.图2中$A^{new}$ 为更新后的动作单元, 动作单元标签Q用于模型训练.
2.3.1 动作单元关系模块
为了使模型具备拒绝未知类动作的能力, 必须能捕捉已知类动作和未知类动作的差异, 如果能够获得所有已知类动作与动作单元间的关系模式, 当一个未知类动作进入模型时, 该动作与动作单元间的关系模式一般和已知类动作与动作单元间的关系模式不同, 据此可以拒绝未知类动作.
首先训练样本通过式(1)得到特征$F^{new}$, 通过式(2)~式(4)得到样本在动作单元上的预测得分$G^{new}$, 此时公式中的$A^{old}$ 已替换为更新后的$A^{new}$.然后, 训练过程与式(5)~式(7)一致.不同的是, 为了进一步建立动作和动作单元的关联, 对动作单元进行更细粒度的学习.对于第m类动作, 使用二值交叉熵损失, 对动作单元上的预测得分$G^{new}$ 进行多标签学习, 即
其中,
为第m类动作对应的动作单元标签,
从图2中动作与动作单元的关系模式可以看出, 不同动作单元和动作之间的激活程度不同.
2.3.2 动作单元时序模块
考虑到未知类动作的动作单元组成若与已知类动作的动作单元组成相同, 就会将未知类动作误认为已知类动作, 所以研究动作单元的时序性可以使模型进一步拒绝未知类动作.
首先, 对视频数据进行采样, 并通过主干网络和池化操作, 提取高维的时序特征.这样, 建立底层视频帧和高维时序特征的联系.再去除空间维度, 保留时间信息, 得到特征
其中AvgPool2d(• )为二维平均池化.然后, 将更新后的动作单元$A^{new}$ 与时序特征$F_T$ 建立联系, 通过动作单元与不同时刻的不同关联程度识别由于关系模式相同而无法拒绝的未知类动作, 各动作单元与不同时刻的关联程度如下:
通过这种方式, 从底层的视频帧到高维的时序特征, 再到与动作单元的关联, 模型经过训练后能够学习动作单元与视频帧之间的关系.
考虑到对于同种类别动作, 其动作单元与不同时刻的关联较相似, 而不同种类动作则相反.所以, 聚集一个批量的视频数据的特征P, 记为$P^* $, 对于其中每个视频样本, 与其类别相同的样本为正样本, 类别不同的样本为负样本, 在DTW损失的约束下, 同种类别动作样本间的DTW距离更近, 而不同类别动作样本间的DTW距离更远, 这样得到更具有判别力的特征$P^* $ 的损失:
最终, 整体损失函数为
其中α 、β 、γ 、δ 为超参数.
综上所述, 通过动作单元关系模块, 获得动作与动作单元的关系模式, 通过动作时序模块, 对动作单元时序信息进行建模, 使模型不仅能对已知类动作进行分类, 还能在遇到未知类动作时, 根据关系模式的差异以及动作单元的时序性拒绝未知类动作.
本文使用UCF-101[6]、HMDB-51[7]、MiT-v2[8]这3个动作识别数据集验证方法的有效性.UCF-101数据集是由YouTube上收集的真实动作视频组成的动作识别数据集, 提供来自101个动作类别的13 320个视频.HMDB-51数据集包含51个类别, 6 766个短视频数据.MiT-v2数据集由100万个标记为3 s的视频组成, 视频内容包括人物、动物和物体, 数据集的类内差异和类间差异均很大.本文将UCF-101数据集作为闭集数据集, HMDB-51、MiT-v2数据集作为开集数据集.
实验使用3种评价指标:闭集精度(Closed-Set Accuracy)、Open Set AUC分数和Open maF1分数.闭集精度衡量闭集动作分类的准确率.Open Set AUC分数表示区分已知类动作和未知类动作的能力.Open maF1分数表示将未知类视频与M个已知类数据一起评判模型的M+1类macro-F1分数, 即同时考虑各类的准确率和召回率.
本文方法在DEAR[4]代码框架下实现.使用在Kinetics-400数据集[19]上训练的ResNet-50预训练模型的参数对本文方法进行初始化, 并在UCF-101数据集上进行微调.动作单元的数量设置为20, 基础学习率设置为0.001, 学习的回合数为50, 批量大小为8.在方法的第一阶段中, α 设置为0.3, β 设置为1.在方法的第二阶段中, α 设置为0.3, β 设置为1, γ 设置为0.1, δ 设置为0.1.其余超参数保持与DEAR的默认参数相同.
本文选择如下7种对比方法:OpenMax[1]、RPL[2]、文献[3]方法、DEAR[4]、STE-CapsNet[31]、MC Dropout[38]、文献[39]方法.分别在主干网络I3D(Two-Stream Inflated 3D ConvNet)[19]、TSM[37], SlowFast[40]、TPN(Temporal Pyramid Network)[41]上进行对比实验.
各方法具体指标值对比如表1所示, 表中黑体数字表示最优值.由表可见, 当TSM作为主干网络, HMDB-51数据集作为开集数据集时, 相比STE-CapsNet, 本文方法的Open maF1和Open Set AUC分数分别提升1.18%和1.55%.MiT-v2数据集作为开集数据集时, 本文方法的这两项评价分数得到更明显的提升, 分别提高10.43%和1.71%.所以, 通过对动作与动作单元关系模式的学习和对动作单元时序信息的建模, 大幅提高模型的开集识别性能.
| 表1 各方法在两个开集数据集上的测试结果 Table 1 Test results of different methods on two open datasets % |
虽然本文方法提高模型的开集识别性能, 但是在闭集数据集上识别性能有少许下降, 这是因为闭集精度的提升主要依赖于在Kinetics-400数据集上的预训练ResNet-50.然而, 本文方法更关注开集性能的提高而忽略对闭集识别性能的优化, 可能导致一些相似的类别无法正确分类.尽管如此, 本文方法仍然能得到较高的闭集精度, 在SlowFast作为主干网络时, 闭集精度为96.78%, 相比STE-CapsNet得到的最高精度97.01%, 仅降低0.23%.与开集识别性能的大幅提升来说, 少量闭集精度的降低对模型整体性能的影响很小.
在今后的研究中, 为了尽可能平衡在开集和闭集上的性能表现, 首先, 可以考虑设计更轻量级的模块, 通过使用更简单的网络结构或减少模块的复杂度, 保留预训练模型在闭集识别上的能力.其次, 可以尝试使用适当的特征融合方法, 如注意力机制等, 使开集识别模块的引入更平衡, 减轻对闭集性能的影响.
此外, 当TPN作为主干网络, HMDB-51数据集作为开集数据集时, 本文方法的Open Set AUC分数略低于STE-CapsNet, 这可能是因为TPN对视频中动作在不同的时间尺度上进行建模, 而本文方法也对动作进行细粒度的动作单元学习, 所以在HMDB-51开集数据集上表现不佳.而当MiT-v2数据集作为开集数据集时, 本文方法的Open Set AUC分数比STE-CapsNet提高1.19%.这是因为MiT-v2数据集视频更多样, 与闭集数据集UCF-101存在明显差异, 所以模型更容易区分UCF-101数据集上的已知类动作和MiT-v2数据集上的未知类动作.
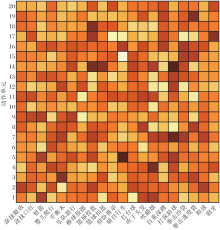
下面对动作与动作单元的关系模式进行可视化.动作单元数量设置为20, 消融实验中讨论不同动作单元数量对模型性能的影响.因为UCF-101数据集上动作类别过多, 选取前20个动作类别, 动作与动作单元的可视化结果如图3所示, 图中方格颜色越深表示对应动作与动作单元关联性越强.由图可见, 动作单元14与投篮、扣篮、打保龄球等动作关联性较强, 所以该动作单元可能为持有物品(球状).动作单元17与篮球投篮和刷牙关联性较强, 所以该动作单元可能与手腕活动有关.动作单元5与射箭、骑自行车、打保龄球有关, 所以该动作单元可能表示长距离的位移.由于人类动作的复杂性, 视频样本间存在巨大差异, 通过自适应的学习可得到各个动作与动作单元间的复杂关联.
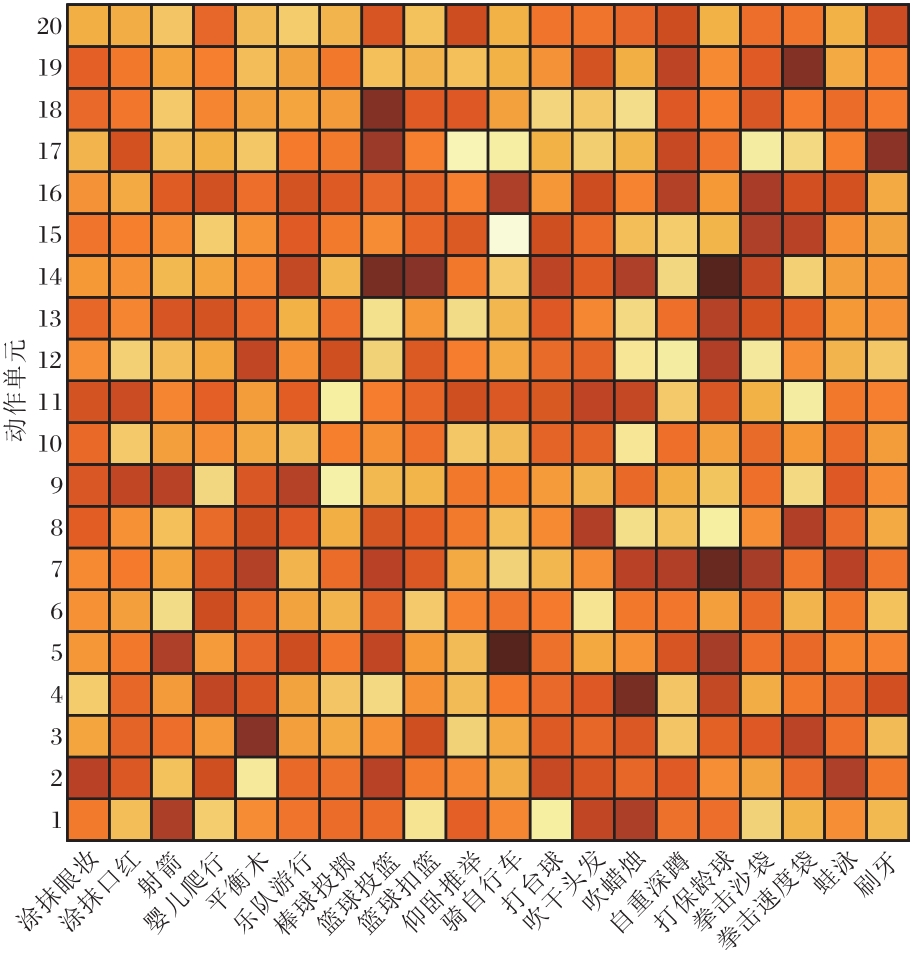 | 图3 动作与动作单元的关系模式Fig.3 Relationship patterns between actions and action units |
本节实验均使用TSM作为主干网络, UCF-101数据集作为闭集数据集, HMDB-51数据集作为开集数据集.
有无动作单元关系模块和动作单元时序模块对模型性能的影响如表2所示, 表中黑体数字表示最优值.由表可见, 当加入动作单元关系模块(简称为关系模块)时, Open maF1和Open Set AUC分数分别提高4.21%和2.39%, 这说明关系模块通过对动作与动作单元间关系模式的学习, 捕捉到已知类动作和未知类动作在动作单元上不同的激活程度, 提升模型的开集识别性能.当只加入动作单元时序模块(简称为时序模块)时, Open maF1和Open Set AUC分数分别提高0.51%和0.53%.时序模块通过将动作单元与时序特征建立联系, 并计算动作单元与不同时刻的关联程度以识别未知类动作, 提高模型的准确性和可靠性.当同时加入两个模块时, 相比未加入两个模块的模型, Open maF1和Open Set AUC分数分别提高4.06%和2.79%, 这说明两个模块能够协同工作, 利用关系模块和时序模块的优势, 可进一步提高模型在开集动作识别任务中的性能.
| 表2 不同模块对模型性能的影响 Table 2 Effect of different modules on model performance % |
为了分析动作单元的数量对模型开集识别性能的影响, 设置10个、20个、30个、40个、50个这5种不同的动作单元数量进行实验, 结果如表3所示, 表中黑体数字表示最优值.由表可见, 当动作单元数量设置为10时, Open maF1分数最高, 为89.94%, 当动作单元数量为20时, Open Set AUC分数最高, 为81.44%.可以看出, 较少数量的动作单元能够更好地捕捉不同动作之间的共性特征, 提高模型的开集识别性能.而随着动作单元数量变大, 动作被划分为更细粒度的动作单元, 反而不利于拒绝未知类动作.
| 表3 动作单元数量对开集识别性能的影响 Table 3 Effect of number of action units on open set recognition performance |
有无动作单元标签对开集识别性能的影响如表4所示, 表中黑体数字表示最优值.由表可见, 当在动作单元关系模块中使用动作单元标签对动作单元进行细粒度学习时, Open maF1和Open Set AUC分数分别提高5.22%和1.27%.通过细粒度动作单元学习, 模型能够更准确地学习不同动作之间的细微差异和动作单元之间的关联.对于未知类动作的识别也会受益于动作单元的细粒度学习, 因为未知类动作的动作单元组成通常与已知类动作不同, 模型可以通过学习到的动作单元关系模式进行拒绝判断.
| 表4 有无动作单元标签对开集识别性能的影响 Table 4 Open set recognition performance with and without action unit labels % |
因此, 动作单元的细粒度学习在提高模型的开集识别性能方面起到积极作用, 增强模型对动作和动作单元之间关系的建模能力, 从而提高模型在开集动作识别任务中的表现.
3.4.1 混淆矩阵
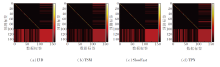
HMDB-51、MiT-v2数据集作为未知数据集时的混淆矩阵如图4和图5所示, 图中, 前101行和列来自UCF-101数据集上的已知类, 而其余类别来自未知数据集, 图中, 颜色越浅表示值越大, 左下角区域表示模型将已知类动作错误分类为未知类动作, 右上角区域表示模型将未知类动作错误分类为已知类动作.
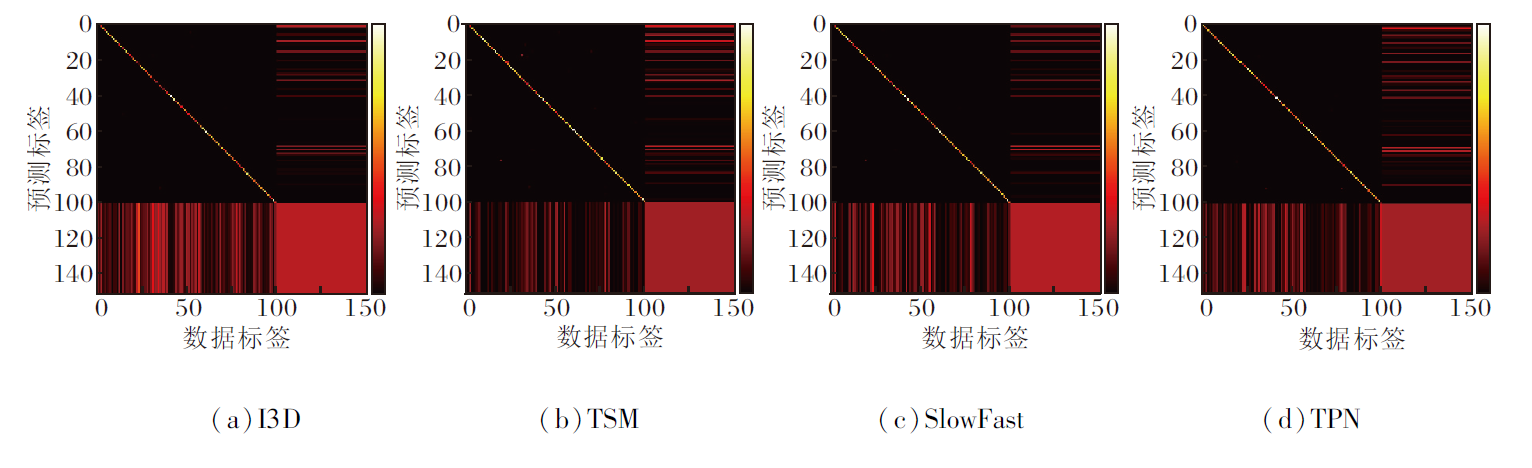 | 图4 HMDB-51数据集作为未知数据集时的混淆矩阵Fig.4 Confusion matrix using HMDB-51 dataset as unknown dataset |
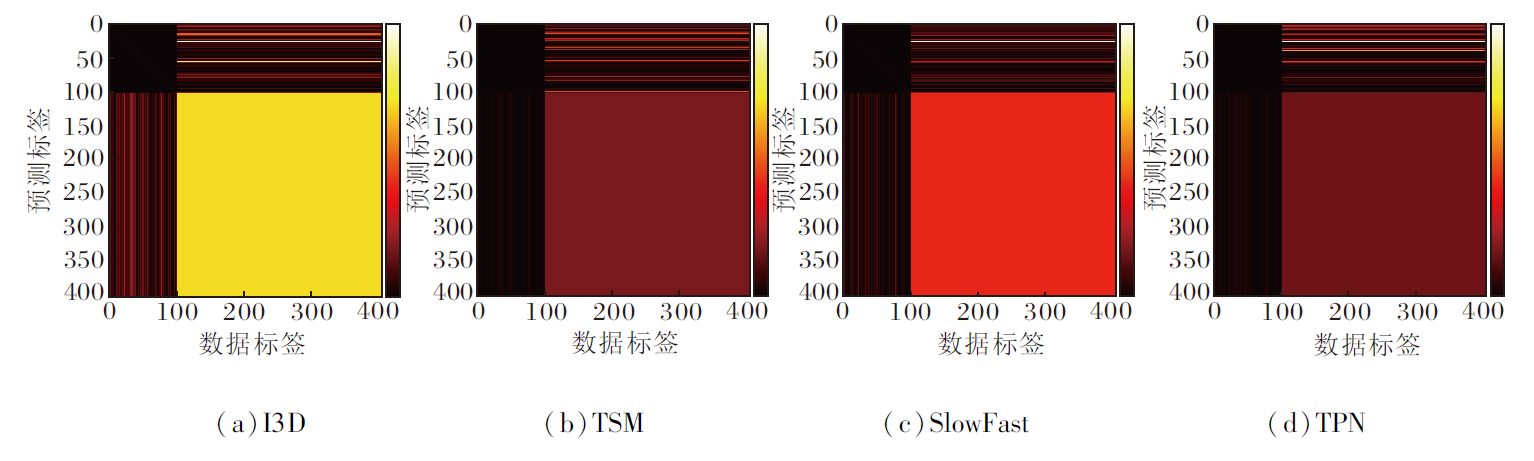 | 图5 MiT-v2数据集作为未知数据集时的混淆矩阵Fig.5 Confusion matrix using MiT-v2 dataset as unknown dataset |
由图4和图5可见, 当使用HMDB-51数据集作为未知数据集时, 相比其它模型, TSM将已知类动作错误分类为未知类动作的情况较少.相反, TSM更倾向于将未知类动作错误分类为已知类动作.然而, 当使用MiT-v2数据集作为未知数据集时, I3D和SlowFast显示出明显优势, 相比TSM和TPN, 能更准确地识别未知类动作.这表明在面对较大规模的未知数据集时, I3D和SlowFast能够更好地识别未知类动作.
此外, 由于MiT-v2数据集比UCF-101数据集更庞大, 存在大量未知类动作被错误归类为已知类动作的情况.这一结果进一步凸显开集动作识别领域面临的挑战以及不同模型之间的性能差异.
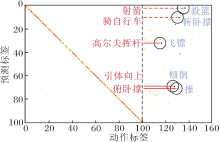
此外, 还分析最容易被误分类的未知类动作, 具体结果如图6所示, 图中, x轴表示UCF-101、HMDB-51数据集上的动作标签, y轴表示UCF-101数据集上动作类别的预测标签, 选取最容易被错误分类为已知类动作(红色)的前5个未知类动作(蓝色).
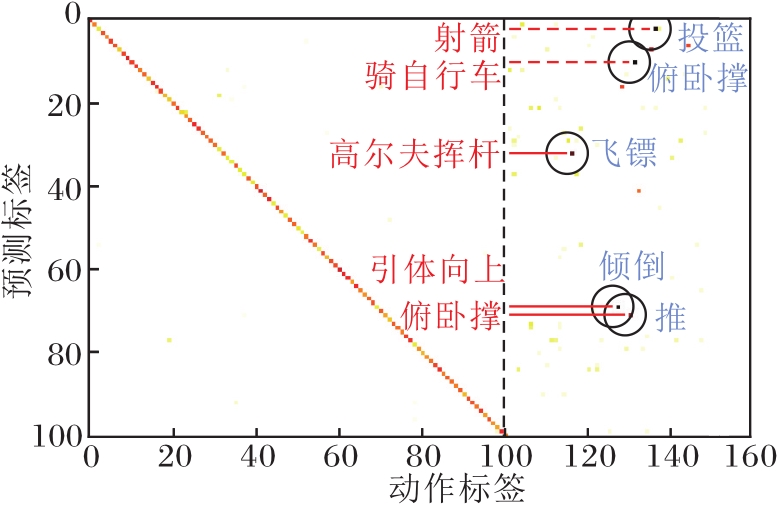 | 图6 最容易被错误分类的前5个未知类动作Fig.6 Top 5 unknown actions most likely to be misclassified |
由图6可以看出, 在闭集设置中, 尽管模型的准确率(对角线上的元素)相对较高, 但仍存在未知类动作被错误分类为已知类动作的情况.
具体而言, 在HMDB-51数据集上, 未知类动作“ 推” 经常被错误归类为已知类动作“ 俯卧撑” .这种错误分类主要是因为这两个动作在动作特征上具有相似性.该结果进一步验证本文方法的必要性, 因为仅依靠整体动作特征无法准确区分这些相似的动作, 需要考虑动作的时序信息以更好地进行分类和识别.通过对动作单元的感知和建模, 能更好地捕捉动作的细粒度信息和时序性, 提升未知类动作的识别性能, 降低已知类动作被错误归类的风险.
3.4.2 特定动作类别的性能分析及其相关性
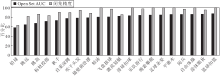
本文使用UCF-101数据集作为开集数据集, HMDB-51数据集作为闭集数据集, TSM作为主干网络, 随机选取20个动作类别的Open Set AUC分数及它们对应的闭集精度进行分析, 具体如图7所示.
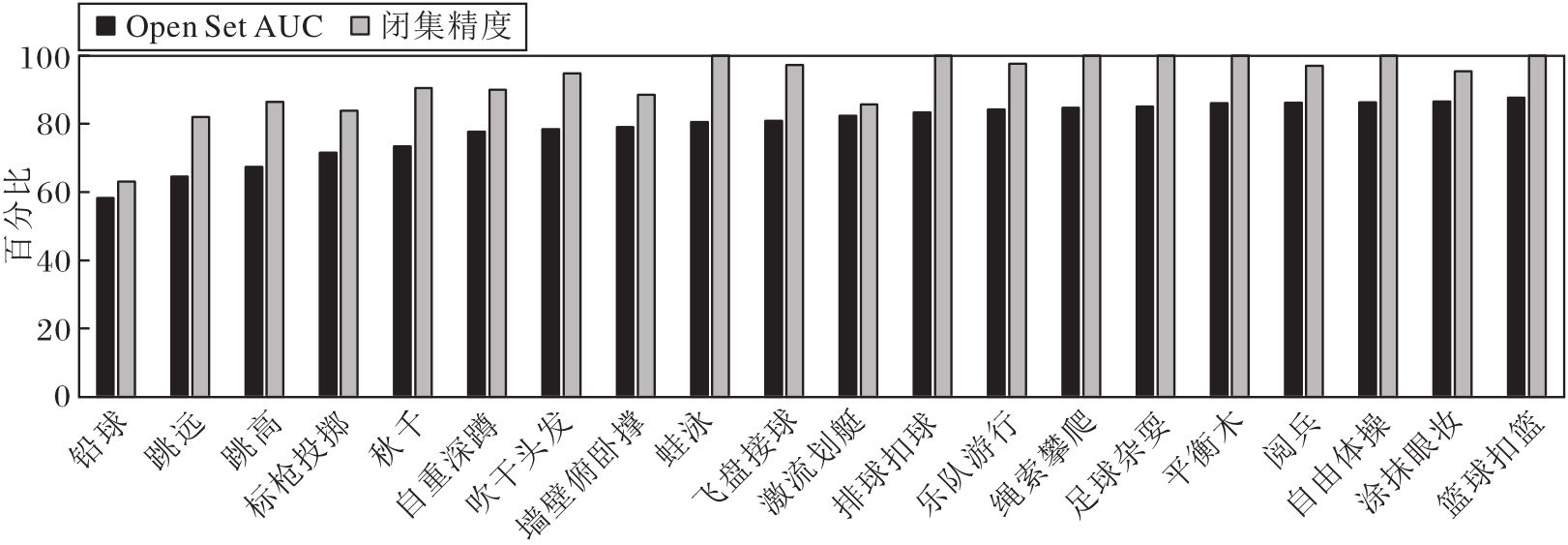 | 图7 TSM作为主干网络时20个动作类别的指标值对比Fig.7 Comparison of indicator values of 20 action categories with TSM used as backbone network |
由图7可观察到, 动作类别的Open Set AUC分数在58.34%~87.69%之间变化, 闭集精度在63.04%~100%之间变化.有一些动作类别在Open Set AUC和闭集精度上都表现出色, 如足球杂耍、平衡木和自由体操, 指标值接近或达到100%.这表明模型在识别和区分这些动作类别方面非常准确.然而, 也有一些动作类别在Open Set AUC上得分相对较低, 如铅球、跳远和跳高, 同样地, 它们的闭集精度也相对较低.这可能是因为这些动作类别的特征表示与其它类别较相似, 导致模型难以准确分类.这种分类错误进一步导致模型在区分已知类动作和未知类动作时发生混淆.
尽管Open Set AUC分数和闭集精度之间存在一定的相关性, 较低的闭集精度往往伴随着较低的Open Set AUC分数, 但它们并不是完全一致的.如图7所示, 尽管“ 激流划艇” 动作的闭集精度较低, 但相对于具有类似闭集精度的动作类别, 如“ 跳高” 和“ 标枪投掷” 来说, “ 激流划艇” 的Open Set AUC分数相对较高.
本文提出时序动作单元感知的开集动作识别方法, 包括动作单元关系模块和动作单元时序模块.首先, 动作单元关系模块用于学习细粒度的动作单元特征并捕捉动作与动作单元之间的关系模式.通过这种方式, 模型能够了解不同动作与动作单元的关联程度, 因为未知类动作的动作单元组成一般与已知类动作不同.因此, 当遇到未知类动作时, 模型可以通过关系模式的不匹配拒绝未知类动作.然后, 动作单元时序模块用于建模动作单元的时序信息, 能够捕捉动作单元在时间上的变化, 更好地理解动作的演变过程.通过对动作单元的时序性进行建模, 模型可以进一步提升对已知类动作和未知类动作的区分能力.实验表明, 本文方法在开集动作识别任务上表现较优.今后可考虑采用更简单的网络结构或减少模块的复杂度, 加快训练速度, 在保持一定性能水平的前提下提升模型效率.
本文责任编委 张军平
Recommended by Associate Editor ZHANG Junping
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|