
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于伪全局Swin Transformer的遥感图像识别算法
[王科平1, 2  , 左鑫浩
, 左鑫浩1, 2 , 杨艺1, 2 , 费树岷1, 3 ]
, 左鑫浩, 杨艺, 费树岷]
|
|



作者简介:

左鑫浩,硕士研究生,主要研究方向为图像识别、目标检测跟踪.E-mail:919582785@qq.com.

杨 艺,博士,副教授,主要研究方向为人工智能、机器视觉.E-mail:yangyi@hpu.edu.cn.

费树岷,博士,教授,主要研究方向为非线性控制系统设计和综合、神经网络控制、时滞系统控制.E-mail:smfei@seu.edu.cn.
如何在多目标并列的情况下,确定符合人类思维习惯的核心目标是遥感图像识别的关键之一.因此,在全局视野下,为各目标分配符合人类视觉习惯的注意力,是甄选核心目标的有效途径之一.文中结合Transformer提取全局特征的思想和Swin Transformer对图像栅格化处理可降低计算量的优点,提出基于伪全局Swin Transformer的遥感图像识别算法.构建伪全局Swin Transformer模块,将遥感图像栅格化后的各局部信息聚合为一个特征值,替代以像素为基础的全局信息,以较小计算量为代价,获取全局特征,有效提升模型对所有目标的感知能力.同时,通过以可变形卷积为基础的感受野自适应缩放模块,使感受野向核心目标偏移,提高网络对核心目标信息的关注,从而实现对遥感图像的精确识别.在RSSCN7、AID和OPTIMAL-31遥感图像数据集上的实验表明,文中算法取得较高的识别精度和参数识别效率.
About Author:
ZUO Xinhao, master student. His research interests include image recognition, target detection and tracking.
YANG Yi, Ph.D., associate professor. His research interests include artificial intelligence and machine vision.
FEI Shumin, Ph.D., professor. His research interests include nonlinear control system design and synthesis, neural network control and delay system control.
Determining the core target aligning with human thinking habits in the context of multiple concurrent targets is one of the key factors in remote sensing image recognition. Therefore,the effective allocation of attention in accordance with human visual habits in a global perspective is one of the ways to select core targets. In this paper, combining the concept of extracting features using the Transformer and the advantages of the Swin Transformer in reducing computational complexity through image gridding, a remote sensing image recognition algorithm based on pseudo global Swin Transformer is proposed.The pseudo global Swin Transformer module is built to aggregate the local information of rasterized remote sensing images into a single feature value, replacing the pixel-based global information to obtain global features with smaller computational cost, and thus the perceptual ability of the model for all targets is effectively improved. Meanwhile, by introducing a receptive field adaptive scaling module based on deformable convolutions, the receptive field is shifted towards core targets to enhance the network attention to core target information and then achieve precise recognition of remote sensing images. Experiments on RSSCN7, AID, and OPTIMAL-31 remote sensing image datasets show that the proposed algorithm achieves high recognition accuracy and parameter identification efficiency.
高分辨率卫星遥感可大范围对地实施观测, 其成像结果是重要的地理信息源之一.遥感图像识别可快速完成地表物检测和地形地貌分类, 为土地利用与规划[1]、自然资源勘探[2]、环境监测[3]等重大活动提供重要的基础信息.
高分辨率遥感图像识别的本质是基于核心目标特性信息的分类问题.因此, 如何让神经网络具备核心目标提取能力是提高遥感图像识别精度的关键问题之一.然而, 在将遥感成像结果裁剪为单个图像时, 若裁剪尺度过大, 容易弱化关键目标的特征; 裁剪尺度过小时, 又不可避免地割裂森林、河流、海洋等大尺寸目标, 在同一图像中, 容易形成多目标并列的情况.因此, 难以通过简单的目标分类实现遥感图像的识别.
人类在观察同一遥感图像中的不同目标时, 通常具备不同的观察注意力.注意力最高的目标即可认定为核心目标和分类结果.因此, 如何提取各目标的特征, 并在全局视角下为各目标赋予合理的注意力, 是提升遥感图像识别精度的有效途径之一.
自2012年起, 以卷积神经网络(Convolutional Neural Network, CNN)[4, 5]为代表的深度学习引发新一轮人工智能研究热潮.CNN通过堆叠卷积层获取具备全局视野的目标特征, 使遥感图像识别精度达到新的高度.在此基础上, 循环神经网络[6]、图卷积网络[7]和生成对抗网络[8]等相继与CNN结合[9, 10, 11], 在遥感图像识别领域取得一定进展.
由于CNN通过有限的感受野表征上下文关系, 特征图中并不具备明显的差异化特征, 而人在处理视觉信息时, 目标和背景具备明显的注意力差别.为此, Vaswani等[12]提出Transformer, 在自然语言处理中取得较大成功.Wu等[13]提出ViT(Vision Transfor-mer)架构, 并用于图像识别.ViT具备全局建模能力, 有助于提高图像识别精度.Bazi等[14]在ViT的基础上, 添加裁剪、混合等数据增强策略, 使遥感图像识别的精度领先于大部分CNN.Scheibenreif等[15]提出ViT与自监督学习结合的网络, 提高潜在表征不明显的遥感图像目标特征.
ViT可以捕获远距离像素之间的上下文关系, 从而具备提取全局特征信息的能力.然而, 自注意力机制是通过轮询方式计算像素点间的注意力, 这导致ViT的计算量剧增.此外, ViT在提取目标特征时采用单一尺度, 不利于识别目标尺度变化范围较大的情况.为此, Liu等[16]提出Swin Transformer, 将图像进行栅格化处理, 而自注意力计算仅限于各个划分的窗口中, 从而大幅降低计算量.Jannat等[17]将Swin Transformer应用于遥感图像识别.
在遥感图像中通常存在并列的多个目标.如何将注意力聚焦在核心目标上, 是实现遥感图像精确识别的关键之一.然而, Swin Transformer的注意力重点考虑窗口内部像素的影响, 一定程度上会损失全局特征提取能力.当遥感图像的目标分布于不同的窗口时, Swin Transformer在各目标之间的信息交互较弱, 从而无法使注意力聚焦在核心目标上.为此, Hao等[18]提出TSTNet(Two-Stream Swin Transformer Network), 添加目标边缘特征, 提升核心目标特征提取能力.Zheng等[19]提出LDBST(Lightweight Dual-Branch Swin Transformer), 在网络中增加CNN分支和最大池化分支, 增强核心目标的特征.
上述方法从不同角度对Swin Transformer增加的局部特征、边缘特征加以改进, 并在各自领域取得较优效果.在遥感图像识别中, 获取更完善的全局特征, 有利于为各个目标赋予合理的注意力.同时, 丰富的全局特征能从全局视野的高度出发, 指导网络捕获遥感图像中的核心目标, 从而有效提高对遥感图像识别的精度.为此, 本文结合Transformer提取全局特征的思想和Swin Transformer栅格化处理降低计算量的优点, 提出基于伪全局Swin Transformer(Pseudo Global Swin Transformer, PG-ST)的遥感图像识别算法, 主要包括伪全局Swin Transformer模块和感受野自适应缩放模块.伪全局Swin Transformer模块将遥感图像栅格化后的各局部信息聚合为一个特征值, 替代以像素为基础的全局信息, 以较小计算量为代价, 有效提升模型对所有目标的感知能力.感受野自适应缩放模块以可变形卷积为核心, 使感受野向核心目标偏移, 提高网络对核心目标信息的关注, 实现对遥感图像的精确识别.
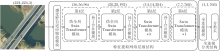
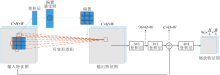
本文提出基于伪全局Swin Transformer(PG-ST)的遥感图像识别算法, 整体结构如图1所示.PG-ST由4个特征提取网络层级结构和全连接分类结构组成.特征提取网络层级结构主要包含感受野自适应缩放模块、伪全局Swin Transformer模块、补丁合并模块和Swin Transformer模块这4类功能模块.感受野自适应缩放模块用于改变输入图像的尺寸和通道, 同时提高网络对核心目标信息的关注, 降低背景信息的冗余.伪全局Swin Transformer模块实现核心目标特征的增强和全局信息的交互, 便于网络在全局视野下, 捕获核心目标及其完整性.Swin Trans-former模块主要用于提取信息的深度特征, 在降低计算量的同时, 便于局部信息的交互.补丁合并模块作为各层级的连接器, 改变特征维度, 便于后续层级调用.
 | 图1 PG-ST结构图Fig.1 Structure of PG-ST |
PG-ST增强核心目标特征和全局特征, 同时弥补图像因栅格化丢失的部分特征, 进而使网络具备完善的全局视野, 便于捕获遥感图像中的核心目标及其完整性信息.此外, 感受野自适应模块的应用能有效提高网络对核心目标信息的关注, 降低背景信息的冗余.
1.2.1 Swin Transformer模块
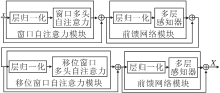
Swin Transformer模块是Transformer模块在视觉领域的又一次提升.该模型采用类似卷积结构的层级下采样方式进行特征提取, 并将不同尺度的特征图栅格化为多个均匀、不重叠窗口, 再在窗口内进行自注意力计算.相比ViT, Swin Transformer窗口区域式注意力机制可以有效减少运算量.另外, 为了增加窗口自注意力各窗口间的信息交互, 设计移位窗口自注意力模块.
Swin Transformer模块具体结构如图2所示.模块主要由如下3个功能模块组成:窗口自注意力模块、前馈网络模块、移位窗口自注意力模块.为了提高网络泛化能力和避免梯度消失问题, 每个模块中都使用归一化和残差结构.
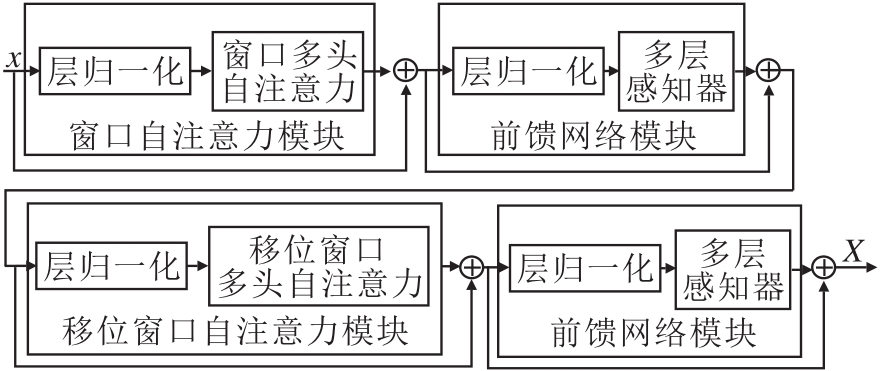 | 图2 Swin Transformer模块结构图Fig.2 Structure of Swin Transformer module |
在Swin Transformer模块中, 窗口自注意力采用并行计算自注意力的方法, 计算过程如下:
Attention(Q, K, V)=SoftMax(
其中:Q表示查询向量、K表示键向量、V表示值向量, 用于特征之间的相似度计算; d表示查询或键的维度; B表示相对位置编码矩阵.
纵观Swin Transformer模块整个阶段, 发现其图像内部虽实现信息交互, 但窗口自注意力模块在提取特征时, 不具备全局视野, 会弱化依靠全局信息的核心目标.在移位窗口自注意力模块提取特征时, 最外圈移位重组窗口并未参与信息交互, 而是特征信息进行降维或其它处理后, 在下一层参与信息交互, 这容易丢失部分边角信息, 导致核心目标缺乏整体性.特别是对于核心目标在图像边角处, 或图像目标占据整幅图的遥感图像等, 都会产生较大影响.
1.2.2 融合伪全局信息的Swin Transformer模块
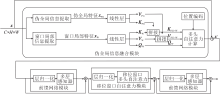
Swin Transformer模块全局视野不足, 一方面会减弱对核心目标的特征提取, 另一方面, 容易引起位于边角区域的目标信息丢失, 使目标缺乏整体性, 这两方面都影响对核心目标的有效提取.因此, 本文提出伪全局Swin Transformer模块.该模块在窗口自注意力阶段通过空间信息聚合提取伪全局特征, 替代以像素为基础的全局信息, 并将其融于多头自注意力计算, 弥补Swin Transformer全局视野不足引起的部分核心目标关注度较低、目标整体性信息不完善的问题.由于在局部特征中加入全局相关特征, 保证窗口自注意力计算可以实现全局信息交互, 同时, 后续参与移位窗口自注意力计算的特征, 包含全局性信息, 这样有利于网络在全局视野下, 捕获具有整体性的核心目标特征.
伪全局Swin Transformer模块具体结构如图3所示.模块主要由如下3个功能模块组成:伪全局信息融合模块、前馈网络模块、移位窗口自注意力模块.前馈网络模块、移位窗口自注意力模块的功能和Swin Transformer模块中一致.伪全局信息融合模块由伪全局信息提取分支和窗口局部信息提取分支并联组成, 分别负责提取伪全局特征xPG和窗口局部特征xW.再将线性层生成的键向量K和值向量V对应进行拼接, 得到包含全局信息的KPG-W、VPG-W, 最后与查询向量QW进行多头自注意力计算, 获得具有全局信息的特征.
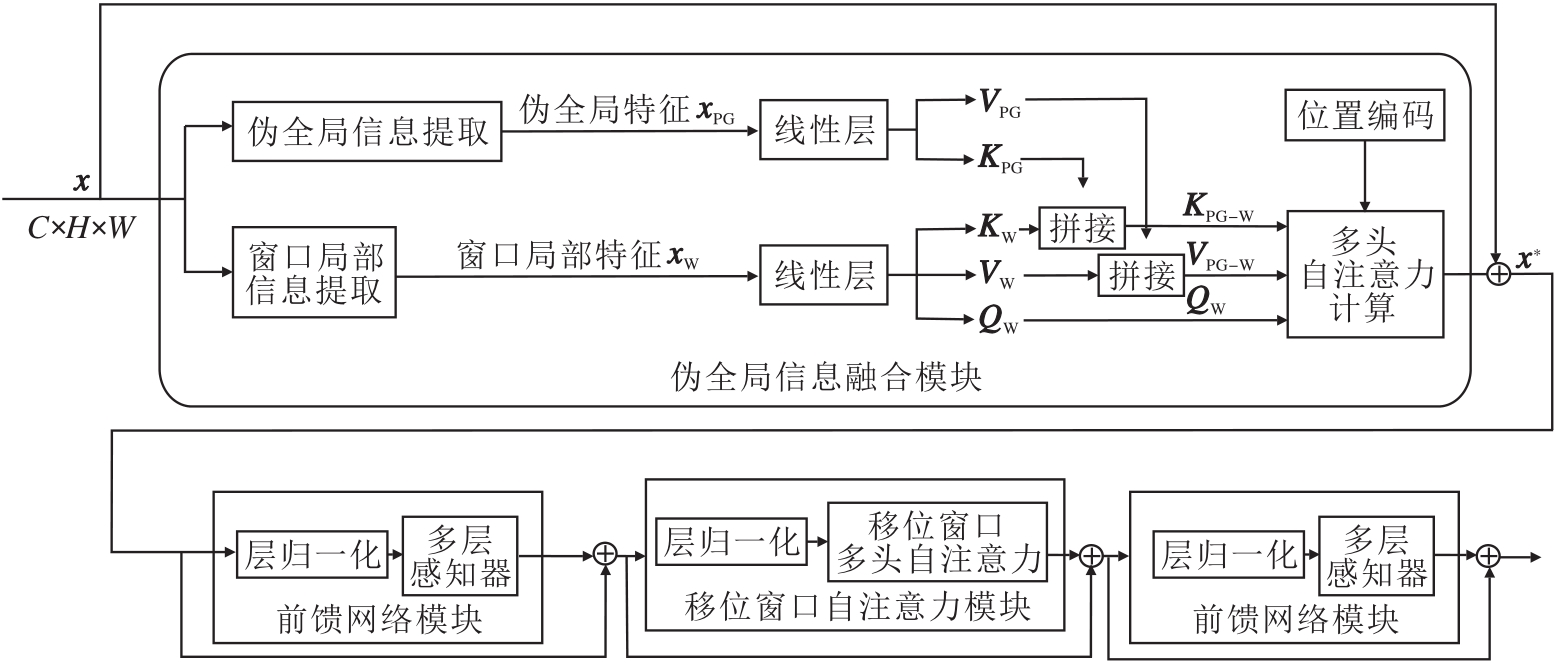 | 图3 伪全局Swin Transformer模块结构图Fig.3 Structure of pseudo global Swin Transformer module |
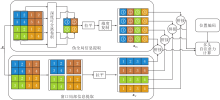
伪全局信息融合模块详细结构如图4所示.模块由伪全局信息提取分支和窗口局部信息提取分支并联组成.
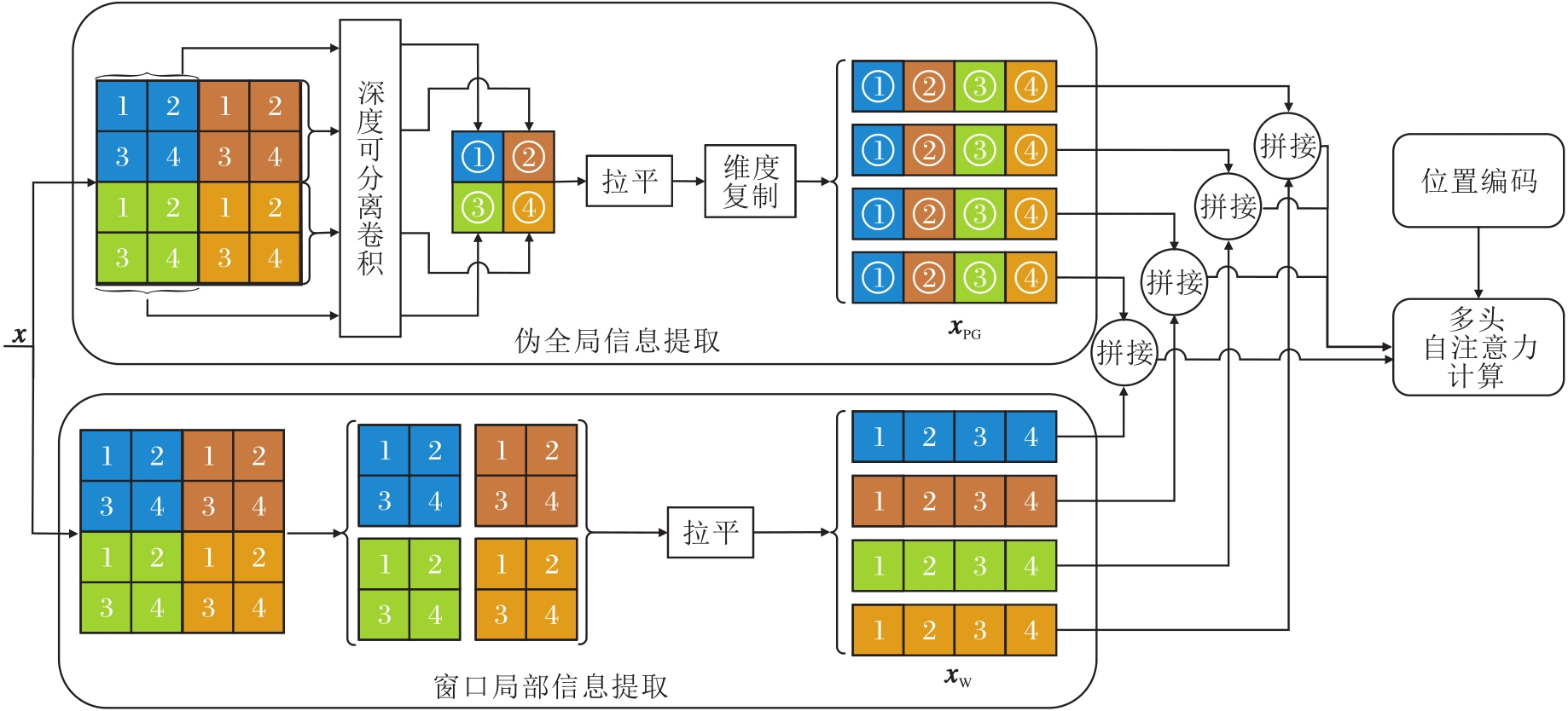 | 图4 伪全局信息融合模块结构图Fig.4 Structure of pseudo global information fusion module |
伪全局信息提取分支主要用于提取包含全局信息的特征.普通Swin Transformer模块将特征图进行栅格化处理后, 直接计算各窗口的自注意力.本文为了使获取的特征包含全局性, 首先通过卷积映射对各窗口实现特征空间上的高度聚合, 并按照原图像位置进行排列, 组成包含目标或边角的特征.然后, 将其特征进行拉平和第二维度上复制, 得到具有所有窗口视野的伪全局特征xPG.最后, 与局部特征融合, 计算各个包含全局信息的窗口对应的自注意力, 获取具有全局信息的特征.
窗口局部信息提取分支主要用于对图像进行栅格化处理, 形成并列的局部特征, 便于进行自注意力计算.主要流程为:将栅格化后的窗口信息进行分割, 每个窗口并联排列, 拉平, 得到窗口局部特征xW, 将其与伪全局特征xPG在每个维度上保持一致.
将两个分支得到的伪全局特征xPG和窗口局部特征xW, 对应的键向量K和值向量V, 在第二维度上进行拼接, 得到包含窗口信息和全局信息的KPG-W、VPG-W, 最后与查询向量QW进行多头自注意力计算, 获得具有全局信息的特征.这使每个窗口信息都能与全局信息直接交互, 弥补全局视野不足, 有利于后续特征提取阶段, 增强核心目标的特征表达和完整性.
伪全局信息融合模块中多头自注意力计算获得的具有全局信息的特征如下所示:
$\begin{array}{c} \boldsymbol{x}^{* }=\text { Attention }_{\mathrm{PG}-\mathrm{WT}}(\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V})= \\ \operatorname{SoftMax}\left(\frac{\boldsymbol{Q}_{\mathrm{W}} \boldsymbol{K}_{P G-W}^{\mathrm{T}}}{\sqrt{d}}+\widehat{\boldsymbol{B}}\right) \boldsymbol{V}_{\mathrm{PG}-\mathrm{W}}, \end{array}$
其中,
$\begin{array}{c} \boldsymbol{K}_{\mathrm{PG}-\mathrm{W}}=\operatorname{Concat}\left(\boldsymbol{K}_{\mathrm{W}}, \boldsymbol{K}_{\mathrm{PG}}\right), \end{array}$
$\begin{array}{c} \boldsymbol{V}_{\mathrm{PG}-\mathrm{W}}=\operatorname{Concat}\left(\boldsymbol{V}_{\mathrm{W}}, \boldsymbol{V}_{\mathrm{PG}}\right), \end{array}$
d表示查询或键的维度, 位置编码
伪全局信息融合模块的推理细节如下所示.
算法1 伪全局信息融合模块推理细节
输入 待提取特征图像I=(x)
输出 融合全局信息的特征图O=(x* )
step 1 通过伪全局信息提取分支, 提取伪全局特征xPG.
step 2 通过窗口局部信息提取分支, 提取窗口局部特征xW.
step 3 通过线性层, 生成xPG和xW对应的Q、K、V.
step 4 将全局信息和窗口局部信息对应的K、V进行拼接, 获得KPG-W和VPG-W.
step 5 将拼接后的KPG-W, VPG-W与QW进行多头自注意力计算, 获取具有全局信息的特征x* .
伪全局Swin Transformer模块确保网络在单层级阶段提取特征时, 得到融合全局信息的特征, 便于网络在全局视野下捕获核心目标特征, 提高目标特征的整体性.
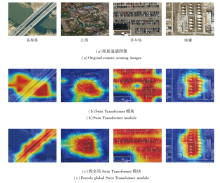
为了更直观地说明伪全局Swin Transformer模块有利于网络捕获核心目标特征, 并且可以提高目标特征的整体性.将输出特征图进行可视化, 转化为热力图, 具体如图5所示.
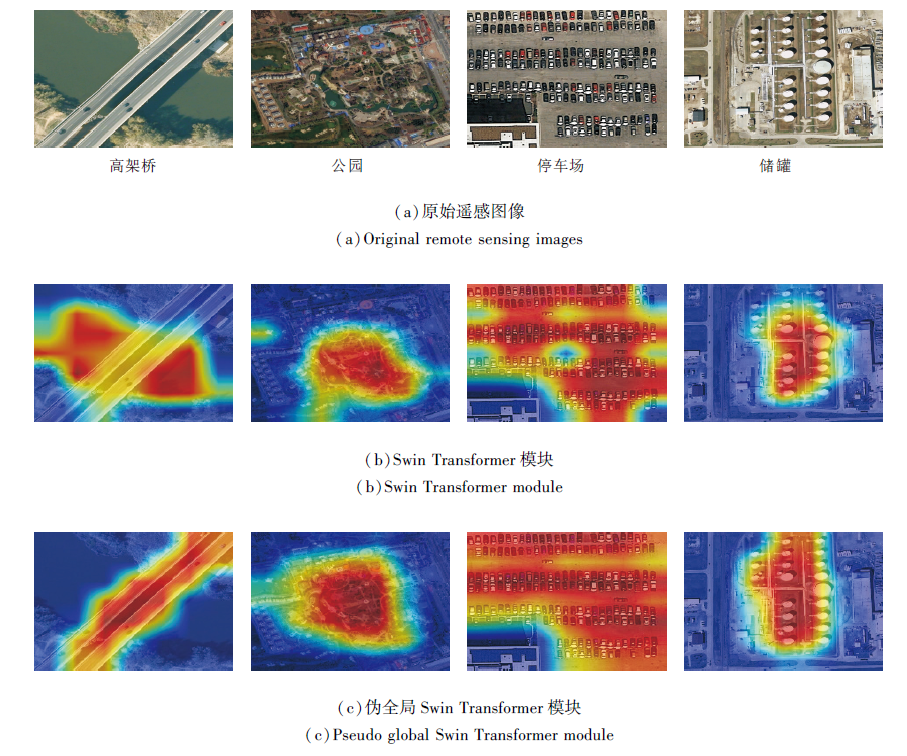 | 图5 2个模块对应的热力图实例Fig.5 Examples of heat maps for 2 modules |
由图5可以看出, 加入伪全局Swin Transformer模块, 可以帮助网络在全局视野下, 将关注重点放在核心目标上, 并提高目标特征的整体性.
在高架桥对应的热力图上, 相比Swin Trans- former模块, 伪全局Swin Transformer模块一方面将关注重点放在核心目标高架桥上, 减少背景河水的捕获, 降低背景信息冗余, 另一方面补偿Swin Transformer模块中高架桥关注的不完整区域.在公园对应的热力图上, 相比Swin Transformer模块, 伪全局Swin Transformer模块将注意力重心放在核心公园上, 提高公园特征的连贯性, 并完善公园整体范围的特征.在停车场对应的热力图上, 相比SwinTransformer模块, 伪全局Swin Transformer模块弥补因图像栅格化造成边角丢失的目标, 增强停车场的整体性.在储罐对应的热力图上, 相比Swin Transformer模块, 伪全局Swin Transformer模块对目标储罐的关注更完整, 提高对Swin Transformer模块储罐上方的关注.
1.2.3 伪全局Swin Transformer模块的计算量分析
以尺寸C× H× W的图像为例, 假设每个窗口包含M× M个图像块, 全局多头自注意力(Multi-head Self Attention, MSA)的图像块数为HW, 窗口多头自注意力(Window MSA, W-MSA)的图像块数为M2, 窗口数为「
Ω MSA=4HWC2+2(HW)2C,
Ω W-MSA=4HWC2+2M2HWC.
W-MSA比MSA节省的计算量为:
Ω W-MSA-Ω MSA=2HWC(HW-M2),
可减少计算量为4.160 GFLOPs.因为基于伪全局Swin Transformer模块在设计中不生成伪全局特征的查询向量QPG, 所以, 考虑舍弃QPG节省的计算复杂度:
Ω Q=(C+
舍弃QPG减少计算量为1.054 GFLOPs.
相比全局多头自注意力, 伪全局Swin Transformer模块在运算量方面共减少计算量为:
4.160+1.054= 5.214 GFLOPs.
在对图像进行特征提取时, 为了减少网络计算量, 通常会在输入特征提取网络主干前, 对图像进行尺寸缩小和通道数的改变.遥感图像内容复杂, 采用普通卷积的方式进行图像缩放容易引入较多的背景信息冗余, 降低对核心目标信息的捕获效果.
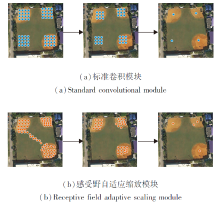
如图6所示的棒球场, 在图像的左上、右上、右下都存在目标信息, 而左下角只存在背景信息.若采用普通卷积的方式进行尺度变化, 固定的感受野也会对左下角背景区域位置进行特征提取, 造成较多背景信息冗余.(a)为标准卷积模块的采样过程及感受野范围, 蓝色圆点表示普通卷积的感受野采样点.随着网络层数的加深, 标准卷积的感受野只关注特定局部位置信息, 不能有效避免对背景信息的关注.
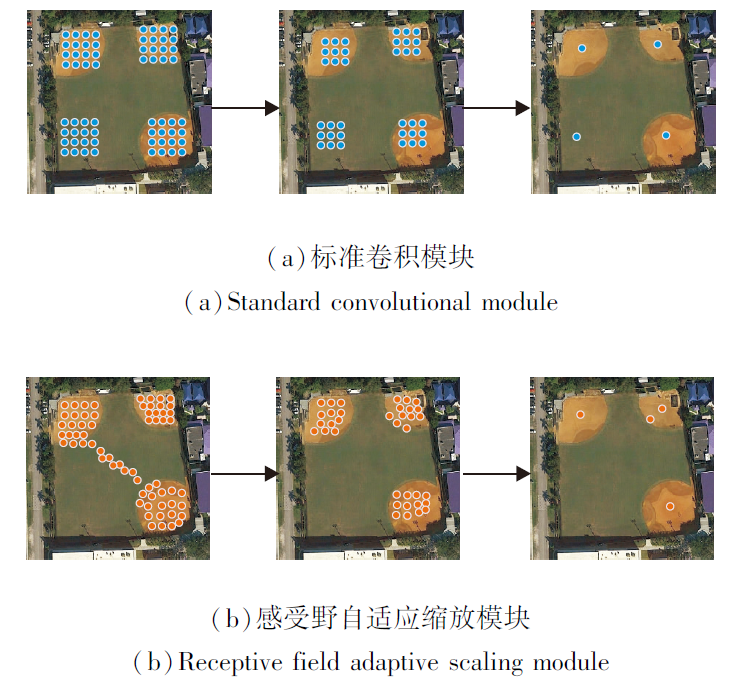 | 图6 标准卷积模块与感受野自适应缩放模块采样过程实例Fig.6 Examples of sampling process of standard convolution module and receptive field adaptive scaling module |
因此, 为了能够在网络浅层充分提取图像目标特征并减少背景冗余信息, 本文设计可变形卷积与普通卷积融合组成的感受野自适应缩放模块, 实现图像尺度和通道的变化, 模块结构图如图7所示.模块主要包含两个功能:1)通过可变形卷积使感受野根据目标结构和区域发生自适应的偏移, 并与后续特征以残差结构相连; 2)通过核为4的卷积将特征图进行缩放.具体地, 由于可变形卷积能够根据目标位置自动学习感受野的偏置, 对于给定输入特征图C× H× W, 采用可变形卷积, 使感受野自适应地向目标区域偏移, 获取重点关注目标的特征图.之后应用3× 3卷积增强通道级别局部上下文特征、1× 1逐点卷积聚合空间级别跨通道上下文特征, 最后与输入特征图以残差结构进行融合, 送入4× 4卷积进行尺寸缩小和通道数的改变.
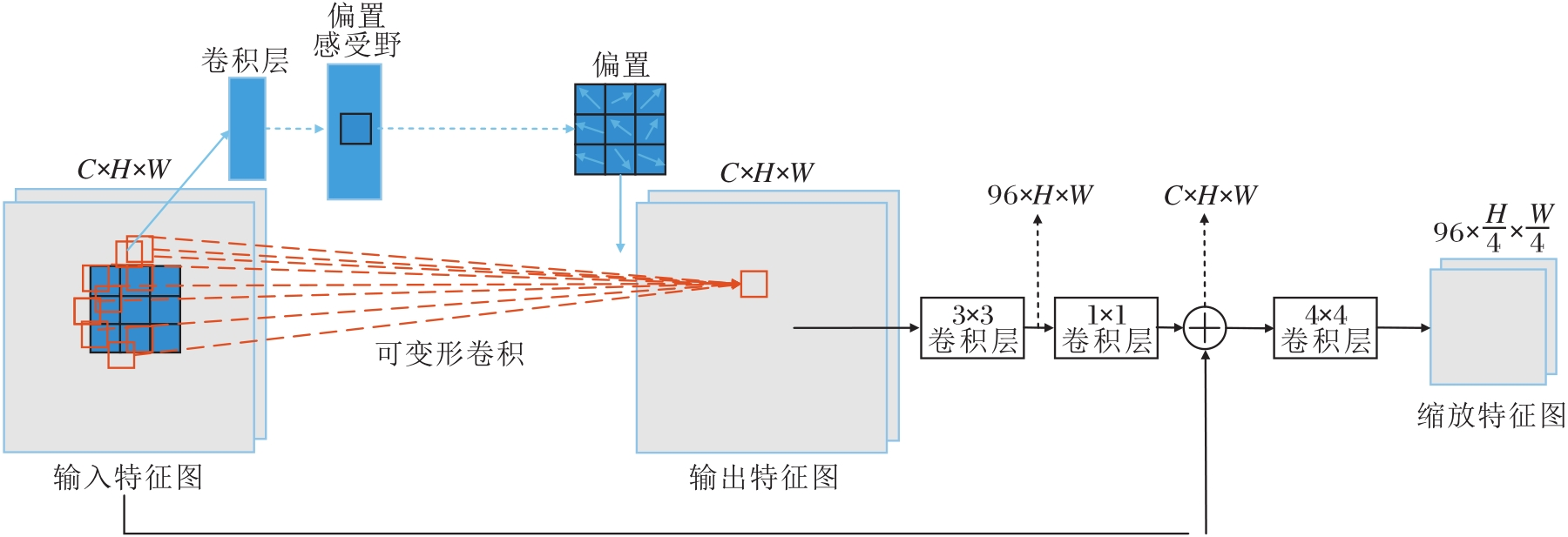 | 图7 感受野自适应缩放模块结构图Fig.7 Structure of receptive field adaptive scaling module |
感受野自适应缩放模块的采样过程及感受野范围变化如图6(b)所示.感受野向目标实际位置偏移, 从而将关注点放在目标特征上, 一定程度上避免对背景信息的关注, 提高对目标特征的提取能力.
感受野自适应缩放模块保证将尺寸缩减后的图像特征在送入特征提取网络主干之前, 尽可能将特征提取重点放在目标特征上, 减少背景信息的冗余, 同时, 加快后续模型的收敛速度, 降低运算成本.如图6所示, 图像左下角不存在待识别目标, 标准卷积会提取背景的冗余信息, 而感受野自适应缩放模块可以将采样点向待识别目标位置偏移, 进行有效的目标特征提取.
为了更直观地说明感受野自适应缩放模块可以减少背景信息的冗余, 提高对目标信息的关注, 将输出特征图进行可视化, 转化为热力图, 具体如图8所示.对比(b)、(c)可以清楚看出, 加入感受野自适应缩放模块, 可帮助网络将关注重点放在目标棒球场和铁路线上, 减少对背景信息的关注.对比(d)、(e)可以看出, 在伪全局Swin Transformer模块的基础上, 加入感受野自适应缩放模块后, 也能帮助网络减少对背景信息的关注, 将关注重点聚焦在目标场景上, 如减少棒球场左下背景和铁路线四周背景的特征提取.感受野自适应缩放模块可自适应地将注意力重心放在目标特征区域, 减少对背景区域的注意力度.
 | 图8 各模块的热力图实例Fig.8 Heat map examples of different modules |
另外, 对比(c)、(e)可以发现, 在感受野自适应缩放模块的基础上, 采用伪全局Swin Transformer模块比Swin Transformer模块更能捕获全局信息, 如右下角较窄的铁路线, 伪全局Swin Transformer模块能够从全局视野对其分配注意力.
综上所述, 当采用伪全局Swin Transformer模块+感受野自适应缩放模块时, 网络在具备全局视野有效分配注意力的同时, 能有效减少背景信息的冗余.
本文选用RSSCN7[20]、AID[21]、OPTIMAL-31[22]这3个遥感图像数据集进行实验.
RSSCN7数据集包含2 800 幅遥感图像, 共7个典型的场景类别, 每类包含400幅图像, 每幅图像的像素大小为400× 400.每类基于1∶ 700, 1∶ 1300, 1∶ 2600, 1∶ 5200这4种不同的尺度进行采样, 4个尺度各100幅.
AID数据集包含10 000幅遥感图像, 共30个场景类别, 每类约220~420幅图像, 每幅图像像素大小约为600× 600.
OPTIMAL-31数据集包含1 860幅遥感图像, 共31个场景类别, 每类包含60幅图像, 每幅图像的像素大小为256× 256.
这3个遥感数据集的图像场景类别不尽相同, 分别进行网络训练和准确率测试.3个数据集按照7∶ 3的比例进行划分, 即70%的数据作为训练集, 30%的数据作为验证集.
本文使用2个评价指标:识别准确率和参数识别效率.参数识别效率θ 可验证算法在遥感图像识别中参数量的优势, 值越大, 反映模型在相同参数量下取得的识别精度越高.具体地,
θ =
其中, mAP表示识别准确率, P表示模型参数量.
实验使用的配置如下:Inter i7-8700K处理器, 6核12线程, 32 GB大小内存, NVIDIA 4090显卡, 24 GB大小显存.
实验使用PyTorch深度学习框架, 训练过程中使用AdamW(Adam with Decoupled Weight Decay)优化器进行优化, 对模型中每个参数使用相同的学习率, 迭代次数为100, 初始学习率为0.000 1, 学习率衰减方法为余弦退火, 训练时批处理大小设置为32, 图像预处理分辨率设为224× 224.
本文选择如下对比算法:VGG16(Base16)、ResNet101、ViT[13]、Swin Transformer[16]、LDBST[19]、ConvNeXt(Small)[23].
在相同的实验环境和图像预处理条件下, 实验结果如表1~表3所示, 表中黑体数字表示最优值.由表1和表2可知, PG-ST取得较好的识别效果, 在3个遥感图像数据集上获得最高的识别准确率, 比次优算法分别提升1.07%、1.20%和1.25%, 参数量和计算量较优, 在同等参数量的情况下, 识别效率最高.此外, 为了与LDBST进行公平对比, 在表3中提供训练集与验证集比例为5∶ 5的AID、UC-Merced[24]数据集上的识别准确率.由表3可以发现, 在相同实验条件以及同等训练验证比下, PG-ST仍取得较优的识别效果.
| 表1 各算法的参数量和计算量对比 Table 1 Comparison of parameter count and computational cost of different algorithms |
| 表2 各算法在3个数据集上的指标值对比 Table 2 Index value comparison of different algorithms on 3 datasets |
| 表3 各算法在AID、UC-Merced数据集上的识别准确率对比 Table 3 Recognition accuracy comparison of different algorithms on AID and UC-Merced datasets % |
VGG16、ResNet101、ConvNeXt、ViT在3个遥感图像数据集上的识别准确率相对较低, 这是因为ConvNeXt、ResNet101、VGG16通过CNN提取特征且降低局部冗余, 但由于CNN不具备注意力机制, 且有限的感受野不能有效表征上下文关系, 因此遥感图像识别效果不理想.ViT因自注意力机制, 具备全局建模能力, 但送入Transformer前的降采样幅度过大且ViT需要大数据集学习单点特征, 因此在小数据集上的识别效果不明显.Swin Transformer减少降采样幅度, 运用并行窗口计算注意力的方式提取局部特征, 并且移位窗口可以进行局部特征交互, 但对于全局依赖较高的目标, 容易降低目标的关注度和整体性.LDBST在网络中增加CNN分支和最大池化分支, 增强核心目标的特征, 一定程度上提高遥感图像识别精度, 但缺少一定的全局建模能力.
在图像送入特征提取网络之前, PG-ST进行降采样操作, 采用感受野自适应缩放模块提高对目标的关注, 并且引入伪全局Swin Transformer模块, 使网络具备完善的全局视野, 便于捕获遥感图像中的核心目标及其完整性信息, 所以具有更高的识别准确率.
为了验证本文设计的感受野自适应缩放模块和伪全局Swin Transformer模块的有效性, 进行消融实验, 测试两个模块对于识别准确率的提升效果.在相同的实验环境、图像预处理和网络超参数设置条件下进行实验, 识别准确率如表4所示.
| 表4 感受野自适应缩放模块和伪全局Swin Transformer模块的消融实验结果 Table 4 Ablation experiment results of receptive field adaptive scaling module and pseudo global Swin Transformer module % |
由表4可知, 相比Swin Transformer, 仅使用感受野自适应缩放模块或仅使用伪全局Swin Trans-former模块, 在两个数据集上的总体识别准确率都有较大提升, 若同时使用感受野自适应缩放模块和伪全局Swin Transformer模块, 可以使识别准确率进一步提升.这是因为本文提出的感受野自适应缩放模块能提高网络对核心目标信息的关注; 伪全局Swin Transformer模块可增强目标的全局信息, 使目标整体语义信息表达更完善, 显著提高网络的识别准确率.
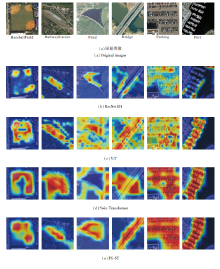
为了更直观地表现PG-ST的优势, 使用类激活图(Class Activation Mapping, CAM)[25]可视化模型.选取Baseball-Field, Railway-Station, Pond, Bridge, Parking, Port这6类图像.
ResNet101、ViT、Swin Transformer、PG-ST的热力图对比如图9所示.
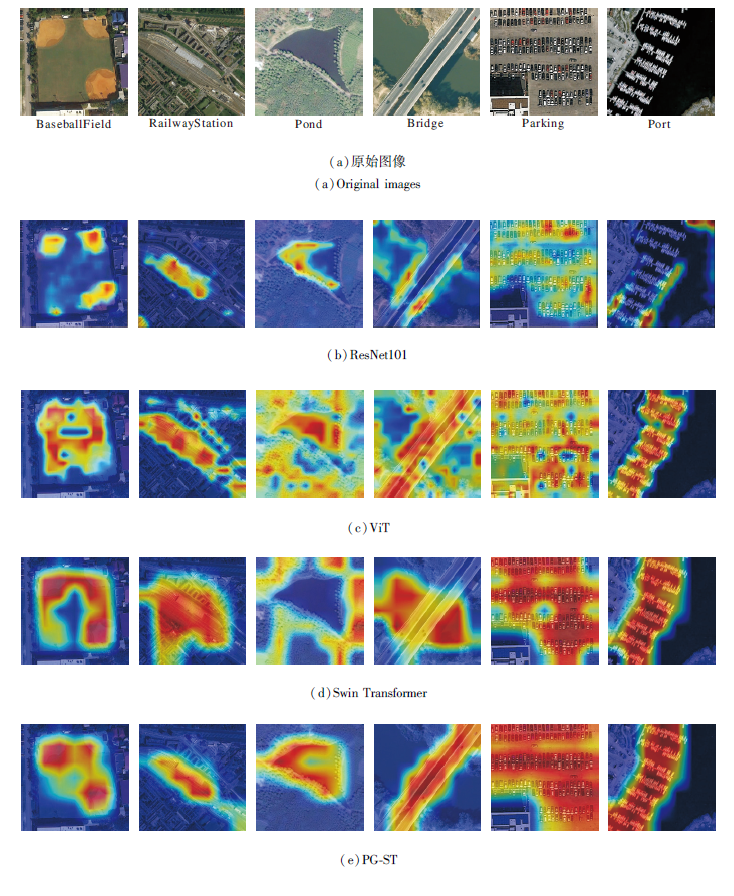 | 图9 各算法的热力图对比Fig.9 Heat map comparison of different algorithms |
由图9可知, ResNet101对特征的提取较局部, 有限的感受野限制网络对远程信息的交互能力, 对全局信息丰富的遥感图像具有一定的局限性.由ViT得到的RailwayStation、Pond、Bridge、Parking热力图发现, ViT因其全局自注意力机制的优点, 尽管能捕获全局信息, 但提取的特征存在较多的背景信息, 造成大量信息冗余, 并会干扰对核心目标的识别.由Swin Transformer得到的Bridge、Parking、Port热力图可发现, Swin Transformer因其窗口自注意力机制, 存在全局特征交互不足的问题, 导致提取的目标特征缺乏整体性.
通过对比可以发现, 在BaseballField、Railway-Station热力图上, PG-ST明显减少对背景信息的关注, 将关注重点大都放在目标上, 降低信息冗余.由此可以直观说明, 本文的感受野自适应缩放模块能重点关注目标特征, 减少背景信息冗余.
在Pond、Bridge图像上, PG-ST帮助网络在全局视野下捕获最核心的目标— — 池塘和桥梁, 在Parking、Port热力图上, PG-ST明显增强目标特征的整体性.
对比Swin Transformer与PG-ST发现, 在Pond、Bridge的热力图上, PG-ST将关注重点放在Pond和Bridge核心目标上, Swin Transformer将重点放在非核心的森林和河水上.PG-ST因具备全局视野的优势, 有利于将关注重点放在核心目标上, 降低其它目标的干扰.在Bridge、Parking、Port热力图上, PG-ST有效提取目标整体性特征, 而Swin Transformer在Bridge图像右上角、左下角特征提取的不足在PG-ST中获得完善, Swin Transformer在Parking图像整体特征中存在的缺口在PG-ST中获得完善, Swin Transformer在Port图像左下角特征中存在的整体性不足在PG-ST上获得完善.
热力图进一步证实PG-ST增强核心目标特征和全局特征, 使网络具备完善的全局视野, 便于捕获遥感图像中的核心目标及完整性信息.此外, PG-ST还能提高网络对核心目标信息的关注, 降低背景信息的冗余.
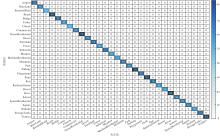
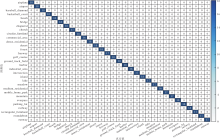
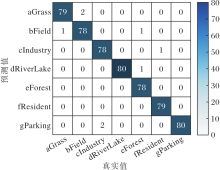
本节使用混淆矩阵对算法进行误差分析, PG-ST在AID、OPTIMAL-31、RSSCN7验证集上对应的混淆矩阵如图10~图12所示.
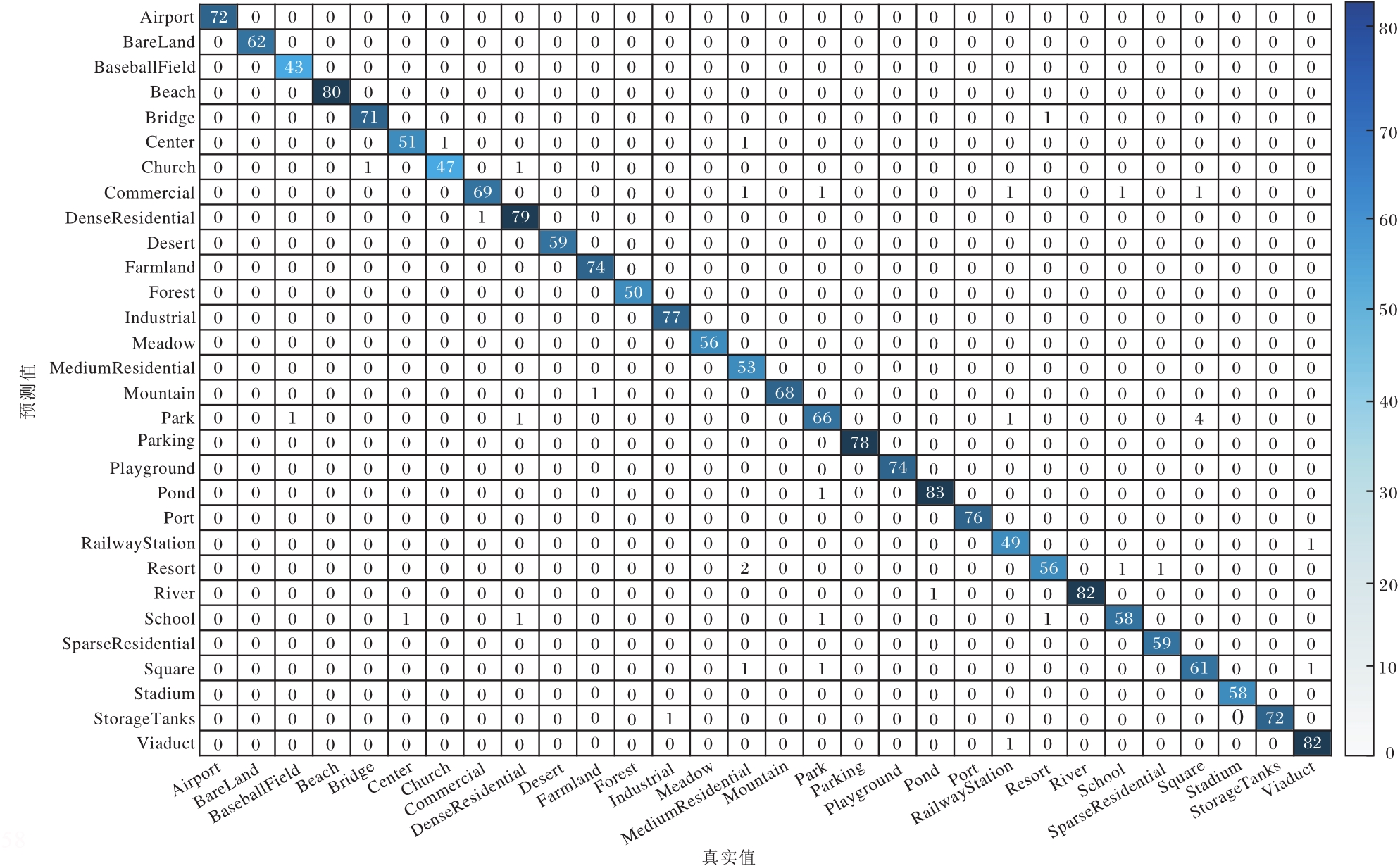 | 图10 PG-ST在AID验证集上的混淆矩阵Fig.10 Confusion matrix of PG-ST on AID validation set |
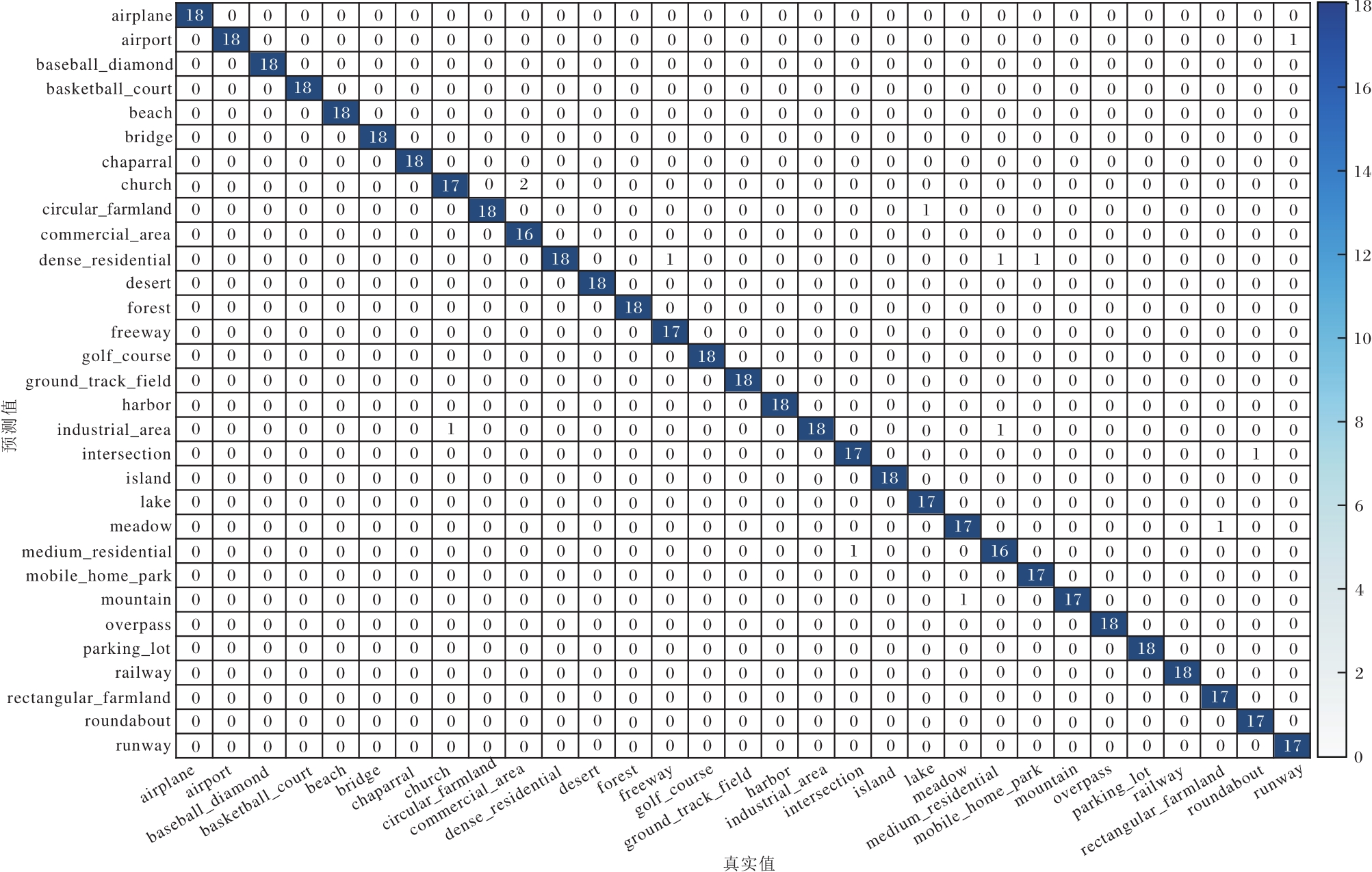 | 图11 PG-ST在OPTIMAL-31验证集上的混淆矩阵Fig.11 Confusion matrix of PG-ST on OPTIMAL-31 validation set |
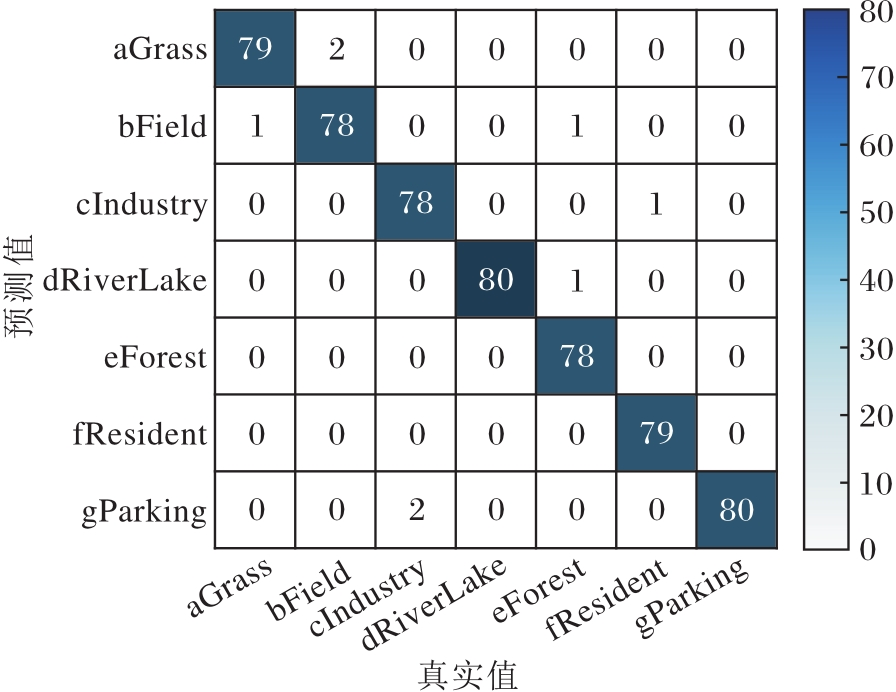 | 图12 PG-ST在RSSCN7验证集上的混淆矩阵Fig.12 Confusion matrix of PG-ST on RSSCN7 validation set |
通过图10~图12可直观看出最终的识别结果, 验证集中的图像基本上都集中在对角线上, 表明这些图像均被正确识别成相应类别.PG-ST对RSSCN7验证集的整体识别误差率仅为1.43%; 对AID验证集的整体识别误差率仅为1.75%, 其中对Airport、Bareland、BaseballField、Beach、Desert等15类的识别准确率为100%.对OPTIMAL-31验证集的整体识别误差率为2.51%, 对bridge、freeway、harbor、island、overpass等21类的识别准确率为100%.此外, 对于Pond和River、Resort和Residential这类目标形状相似、核心特征区分不明显的遥感图像, 容易识别错误.
由混淆矩阵进一步证实PG-ST增强核心目标特征和全局特征, 使网络具备完善的全局视野, 便于捕获遥感图像中的核心目标及其完整性信息, 因此, 可有效对遥感图像进行识别.
本文针对遥感图像中如何有效确定核心目标问题, 以Swin Transformer为基础网络, 并结合Trans-former提取全局特征的思想, 提出基于伪全局Swin Transformer(PG-ST)的遥感图像识别算法.算法通过可变形卷积机制, 提高捕获核心目标信息能力.构建空间高度聚合伪全局Swin Transformer模块, 提升模型对所有目标的感知能力, 有助于网络重点捕获核心目标特征.
在RSSCN7、AID、OPTIMAL-31数据集上的实验表明, 对于多目标共存的遥感图像, 如桥梁处于河流之上、池塘处于草地之中, PG-ST能根据人类习惯将注意力更多的分配给桥梁、池塘等核心目标.此外, 针对停车场、港口等大尺度核心目标, 因图像栅格化引起的信息缺失问题, PG-ST提取特征的感受野能更好地覆盖核心目标的全部范围, 从而提升识别精度.
然而, PG-ST尚未较好解决如下问题:1)当根据人类认知习惯无法确定遥感图像的核心时, 可能出现识别上的偏差; 2)当目标形状相似、核心特征区分不明显时, 很难提升方法的识别精度.为此, 今后将提取同一类别的不变特征作为关键信息, 解决上述问题.
本文责任编委 兰旭光
Recommended by Associate Editor LAN Xuguang
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|