
{kind=link}
{kind=link}
{kind=link}
多智能体强化学习理论及其应用综述
[陈卓然1  , 刘泽阳
, 刘泽阳1 , 万里鹏1 , 陈星宇1 , 朱雅萌2 , 王成泽2 , 程翔3 , 张亚4 , 张森林5 , 王晓辉6 , 兰旭光1 ]
, 刘泽阳, 万里鹏, 陈星宇, 朱雅萌, 王成泽, 程翔, 张亚, 张森林, 王晓辉, 兰旭光]
|
|



作者简介:

陈卓然,博士研究生,主要研究方向为深度强化学习.E-mail:zhuoran.chen@stu.xjtu.edu.cn.

刘泽阳,博士,助教,主要研究方向为深度强化学习.E-mail:zeyang.liu@stu.xjtu.edu.cn.

万里鹏,博士,助教,主要研究方向为深度强化学习、共融机器人.E-mail:xjtuwanlip@126.com.

陈星宇,博士,助教,主要研究方向为主要研究方向为计算机视觉、机器学习.E-mail:xingyuchen1990@gmail.com.

朱雅萌,硕士,工程师,主要研究方向为智能体博弈、自动控制.E-mail:yameng_zhu@126.com.

王成泽,硕士研究生,主要研究方向为智能体博弈、自动控制.E-mail:19906362381@163.com.

程 翔,博士,教授,主要研究方向为基于数据驱动的智慧网络和网联智能.E-mail:xiangcheng@pku.edu.cn.

张 亚,博士,教授,主要研究方向为群体博弈对抗、强化学习.E-mail:yazhang@seu.edu.cn.

张森林,硕士,教授,主要研究方向为控制理论及应用.E-mail:slzhang@zju.edu.cn.

王晓辉,博士,高级工程师,主要研究方向为电力人工智能、电力系统及其自动化.E-mail:wangxiaohui@epri.sgcc.com.cn.
强化学习是一种用于解决序列决策问题的常用机器学习方法,核心思想是让智能体与环境交互获得反馈,从而逐步学会最佳策略.随着实际应用对计算能力和数据规模的要求不断提高,单体智能转向群体智能逐渐成为人工智能未来发展的必然趋势,这为强化学习带来诸多新的机遇和挑战.文中首先从深度多智能体强化学习概念着手,针对目前的理论困境,如可拓展性较差、效用分配较难、探索-利用困境、环境非稳态、信息部分可观测等问题,进行提炼和分析.然后,详细阐述目前学者对于这些问题提出的多种解决方法及其优缺点.最后,介绍当前多智能体强化学习的典型训练学习环境和智慧城市建设、游戏、机器人控制、自动驾驶等复杂决策领域的实际应用,并总结协作多智能体强化学习面临的挑战和未来发展方向.
, LIU Zeyang, WAN Lipeng, CHEN Xingyu, ZHU Yameng, WANG Chengze, CHENG Xiang, ZHANG Ya, ZHANG Senlin, WANG Xiaohui, LAN Xuguang
About Author:
CHEN Zhuoran, Ph.D. candidate. His research interests include deep reinforcement learning.
LIU Zeyang, Ph.D., assistant professor. His research interests include deep reinforcement learning.
WAN Lipeng, Ph.D., assistant professor. His research interests include deep reinforcement learning and coexisting-cooperative-cognitive robots.
CHEN Xingyu, Ph.D., assistant profe-ssor. His research interests include computer vision and machine learning.
ZHU Yameng, Master, engineer. Her research interests include game theory and autonomous control of agents.
WANG Chengze, Master student. His research interests include game theory and autonomous control of agents.
CHENG Xiang, Ph.D., professor. His research interests include data-driven intelligence network and networked intelligence.
ZHANG Ya, Ph.D., professor. Her research interests include multi-agent game theory and reinforcement learning.
Zhang Senlin, Master, professor. His research interests include control theory and its applications.
WANG Xiaohui, Ph.D., senior engineer. His research interests include electric power artificial intelligence, electric power systems and automation.
Reinforcement learning(RL) is a widely utilized machine learning paradigm for addressing sequential decision-making problems. Its core principle involves enabling agents to learn optimal policies iteratively through feedback derived from interactions between an agent and the environment. As the demands for computational power and data scale of practical applications continue to escalate, the transition from single-agent intelligence to collective intelligence becomes an inevitable trend in the future development of artificial intelligence. Therefore, challenges and opportunities are abundant for RL. In this paper, grounded on the concept of deep multi-agent reinforcement learning(MARL), the current theoretical dilemmas are refined and analyzed, including limited scalability, credit assignment, exploration-exploitation dilemma, non-stationarity and partial observability of information. Various solutions and their advantages and disadvantages proposed by researchers are elaborated. Typical training and learning environment of MARL and its practical applications in complex decision-making fields, such as smart city construction, gaming, robotics control and autonomous driving, are introduced. The challenges and future development direction of collaborative multi-agent reinforcement learning are summarized.
近年来, 强化学习(Reinforcement Learning, RL)[1]和多智能体强化学习(Multi-agent Reinforce-ment Learning, MARL)[2]在人工智能领域取得显著进展.随着计算能力和数据规模的提升, RL和MARL已成为解决复杂决策问题的重要途径之一.
强化学习是一种以试错(Trial-and-Error)为基础的机器学习方法, 旨在通过与环境的反复交互, 根据环境反馈的奖励信号进行自主优化, 从而学到具有最大化累积奖励的最佳策略.
随着深度学习技术的崛起, 深度强化学习(Deep Reinforcement Learning, DRL)结合深度神经网络和强化学习的优势, 提升其在高维状态空间和连续动作空间中的决策能力[3].这一结合显著提升RL的应用效果, 使其在许多复杂任务中取得突破性进展.深度神经网络能从原始输入数据中自动提取特征, 大幅减少人工设计特征的需求, 这为RL在复杂环境中的应用提供极大的便利.DRL的一个重要进展是2016年AlphaGo[4]的成功.AlphaGo结合深度神经网络和蒙特卡罗树搜索(Monte Carlo Tree Search, MCTS), 在围棋比赛中击败多位顶尖人类棋手.这一成就标志着DRL在游戏领域的突破, 并激发更广泛的研究和应用.
然而, 很多应用场景涉及多个智能体之间的交互与协作, 如多机器人导航、多人游戏等, 因此学界和业界逐渐将视野转向多智能体场景下的强化学习应用.多智能体强化学习的核心思想是通过强化学习让多个智能体在复杂环境中高效协作或对抗, 以获取全局最优或博弈均衡的联合策略.近年来, MARL在许多领域都取得一定成就.AlphaStar[5]是DeepMind在Nature上发表的一项重要成果, 展示MARL在复杂策略游戏中的应用.通过在星际争霸II环境下进行训练, AlphaStar达到人类对战天梯的宗师(Grandmaster)段位, 体现MARL在处理高维度、多智能体互动问题上的强大能力.在群体无人机任务中, Lowe等[6]提出MADDPG(Multi-agent Deep Deterministic Policy Gradient), 优化无人机的协作策略, 提升无人机在复杂环境中的协作能力, 减少碰撞风险, 提高任务完成效率[6].此外, 深度多智能体强化学习在资源调度[7]、交通控制[8]、军事战争[9]等领域也具有广泛应用.
深度多智能体强化学习一般被建模为Dec-POMDP(Decentralized Partially Observable Markov Decision Process)[10], 应用通常需要面对探索-利用困境、部分可观测等传统强化学习存在的问题.同时, 深度多智能体强化学习还需要解决多智能体系统特有的问题, 如可扩展性较差、环境非稳态、效用分配较难、演化效率较低等.为了解决这些问题, 研究人员使用涌现行为法[11, 12]分析单智能体强化学习算法在多智能体环境下应用的收敛性, 并提出基于值分解的多智能体效用分配算法[13, 14]、基于反事实估计的多智能体效用分配算法[15, 16]、学习通信协议的多智能体通信算法[17, 18, 19].此外, 针对探索-利用困境、样本利用率较低等问题, 基于单智能体强化学习探索算法[20, 21, 22], 研究人员也提出基于多智能体间相互影响算法[23]、基于内在好奇心的探索算法[24], 提升样本收集和算法学习的效率.
深度多智能体强化学习任务按照奖励函数设计的不同, 一般可分为3类:完全协作型(Fully Coope-rative)、完全竞争型(Fully Competitive)和混合型(Mixed)[25].在完全协作型任务中, 智能体目标均为最大化团队奖励.在完全竞争型任务中, 两个智能体进行零和博弈, 即智能体的奖励函数互为相反数.在混合型任务中, 智能体目标为最大化各自独立的奖励函数.例如:智能体可能需要合作完成某项任务, 但也需要从中最大化自己的利益.本文将主要针对完全协作型任务中的多智能体强化学习算法进行深入讨论.
总之, 深度多智能体强化学习目前仍处于发展阶段, 属于人工智能的新兴研究领域, 拥有广阔的发展空间和美好的应用前景, 但也在实际应用中面临诸多挑战.本文将从深度多智能体强化学习原理入手, 介绍多智能体强化学习的基本要素及策略优化方法, 引出多智能体强化学习的理论困境, 包括可扩展性较差、奖励函数设计较难、环境非稳态、效用分配较难、探索-利用困境及部分可观测等问题, 进而探讨当前文献中提出的解决方法, 包括面向效用分配的多智能体强化学习方法、基于通信的多智能体强化学习方法、涌现行为及多智能体的探索与利用等, 并介绍当前业内流行的多智能体训练环境.最后, 简要说明深度多智能体强化学习的当下研究进展和未来的应用前景, 并总结当前存在的问题.
多智能体强化学习任务一般被建模为一个分布式部分可观测马尔科夫决策过程, 可表征为六元组{A, S, O, U, P, R, Ω }, 其中, A表示决策主体, S表示状态空间, O表示观测空间, U表示动作空间, P∶ S× U× S→ [0, 1]表示状态转移概率, R∶ S× U→ R表示回报函数, Ω ∶ S× U× O→ [0, 1]表示观测函数.决策主体A为所有参与决策的多智能体集合; 状态空间S为所有可能的环境状态集合; 观测空间O为多智能体所有可能获得的观测集合; 动作空间U为多智能体所有可选的联合动作集合; 状态转移概率P(s'|s, u)为给出状态s下执行联合动作u, 环境转移到状态s'的概率; 回报函数R(s, u)为给出多智能体在状态s下执行联合动作u后, 从环境立即获得的回报值; 观测函数Ω (o|s)为给出多智能体在状态s下观测到联合观测o的概率.多智能体强化学习过程如图1所示.
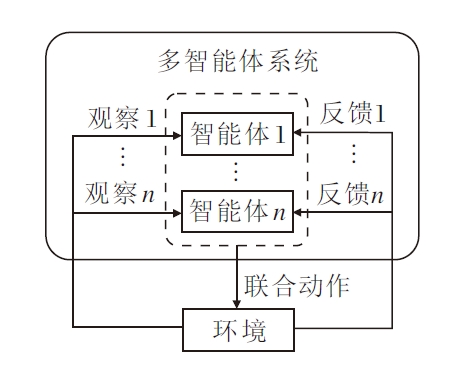 | 图1 多智能体强化学习过程Fig.1 Process of multi-agent reinforcement learning |
对于离散时间的部分可观马尔科夫决策过程, 在每个决策时间步t, 每个智能体i根据观测函数Ω (o|s)对状态st∈ S进行观测, 根据自己的观测
$G_{t}=R_{t}+\gamma R_{t+1}+\gamma^{2} R_{t+2}+\cdots=\sum_{k=0}^{T} \gamma^{k} R_{t+k}, $
其中, T为轨迹长度, γ ∈ [0, 1)为折扣因子, 用于平衡决策对应的短期奖励与长期奖励.
多智能体进行决策时依据的策略一般表征为随机策略π ∶ O→ U, 学习目标即为优化该策略, 使累积回报最大化:
$J=E_{\pi, s_{0}}\left[\sum_{k=0}^{T} \gamma^{k} R_{t+k} \mid \boldsymbol{u}_{t}=\boldsymbol{\pi}\left(\cdot \mid \boldsymbol{o}_{t}\right)\right] .$
强化学习方法引入智能体和环境的概念, 智能体能自主地与环境交互, 获取训练样本, 进一步根据优化对象的不同, 使用值函数法或策略搜索法更新策略, 还原生物体的学习过程.深度强化学习使从数据到决策的端到端训练成为可能, 大幅节省数据处理的耗时.一方面, 深度网络的非凸函数拟合能力扩展策略的表征能力和强化学习方法的应用范围; 另一方面, 深度网络强大的特征提取能力可使强化学习能处理视觉信息、声音信息等复杂输入.
基于深度多智能体强化学习原理, 在解决多智能体的交互问题时, 需要借助特定方法评估不同策略的优劣, 引导策略优化.下面分别介绍MARL中常用的值函数法和策略搜索法.
1.2.1 值函数法
类似于单智能体强化学习, 值函数法是MARL中一种经典的策略优化方法, 旨在通过评估状态或状态-行为对的价值指导智能体的决策.值函数法的核心思想是学习值函数, 找到联合状态-动作值函数的良好估计(即最优Q函数Qπ * ), 随后通过采取Q函数估计的贪婪联合动作提取(近似)最优策略.值函数分为联合价值函数Vπ (s)和联合状态-动作值函数Qπ (s, u).其中联合价值函数
$V_{\pi}(s)=E\left[G_{t} \mid s_{t}=s\right], $
为从当前状态到终止状态能获得的累积团队共享回报的期望.联合状态-动作值函数
$Q_{\pi}(s, \boldsymbol{u})=E\left[G_{t} \mid s_{t}=s, \boldsymbol{u}_{t}=\boldsymbol{u}\right], $
为在状态s下的联合动作u能获得的累积回报期望值.联合价值函数和联合状态-动作值函数之间存在如下关系:
$\begin{array}{l} Q_{\pi}(s, \boldsymbol{u})=R_{t+1}+\gamma \sum_{s^{\prime} \in S} P_{s s^{\prime}} V_{\pi}\left(s^{\prime}\right), \\ V_{\pi}(s)=\sum_{\boldsymbol{u} \in U} \pi(\boldsymbol{u} \mid s) Q_{\pi}(s, \boldsymbol{u}) \end{array}$
RL中通用的基于价值的算法之一是Q-Lear-ning[26], 智能体关系到Q值函数Q'(s, u)的估计.当从状态-动作对(s, u)转到下一个状态s'时, 多智能体获得团队共享收益r, 并更新Q函数:
$\begin{aligned} Q^{\prime}(s, \boldsymbol{u}) \leftarrow & (1-\alpha) Q^{\prime}(s, \boldsymbol{u})+ \\ & \alpha\left[r+\gamma \max _{\boldsymbol{u}^{\prime}} Q^{\prime}\left(s^{\prime}, \boldsymbol{u}^{\prime}\right)\right], \end{aligned}$
其中α > 0为步长或学习率.在α 的相应约束条件下, 可证明Q-Learning能收敛到具有有限状态和动作空间的最优Q值函数.此外, 结合神经网络之后, 深度Q网络[27]更是在人类级别的控制中效果显著, 广泛应用于多智能体领域的拓展算法.
除此之外, 主流的基于值函数的深度强化学习方法还有深度双Q网络[28]、对偶深度Q网络[29]、循环深度Q网络[30]等, 都能拓展到多智能体领域应用.
值函数法是一种直观的学习方法, 需要在特定状态对具体联合动作进行评价, 不适用于高维连续的动作空间.
1.2.2 策略搜索法
与值函数法不同, 策略搜索法[31, 32, 33]直接在联合策略空间中搜索最优联合策略, 而不是评估具体联合状态-动作对的价值, 通常通过神经网络等参数化函数逼近器进行估计, 即使
$\pi(\cdot \mid s) \approx \pi_{\theta}(\cdot \mid s) .$
策略搜索法通过参数化策略, 并使用优化技术使策略能最大化累积共享回报:
$J(\theta)=E\left[\sum_{k=1}^{T} \gamma^{k} R_{t+k+1} \mid \pi_{\theta}\right] .$
在强化学习中, 一般使用梯度下降法对该优化问题进行求解:
$\begin{array}{l} \nabla_{\theta} J(\theta)=\nabla_{\theta} E\left[\sum_{k=0}^{T} \gamma^{k} R_{t+k} \mid \pi_{\theta}\right]= \\ \quad \int_{s} P_{s s^{\prime}}^{\pi} \mathrm{d} s \int_{\boldsymbol{u}} \nabla_{\theta} \pi_{\theta}(\boldsymbol{u} \mid s) Q_{\pi}(s, \boldsymbol{u}) \mathrm{d} \boldsymbol{u}= \\ \quad \int_{s} P_{s s^{\prime}}^{\pi} \mathrm{d} s \int_{\boldsymbol{u}} \pi_{\theta}(\boldsymbol{u} \mid s) \frac{\nabla_{\theta} \pi_{\theta}(\boldsymbol{u} \mid s)}{\pi_{\theta}(\boldsymbol{u} \mid s)} Q_{\pi}(s, \boldsymbol{u}) \mathrm{d} \boldsymbol{u}= \\ \quad \int_{s} P_{s s^{\prime}}^{\pi} \mathrm{d} s \int_{\boldsymbol{u}} \pi_{\theta}(\boldsymbol{u} \mid s) \nabla_{\theta} \ln \pi_{\theta}(\boldsymbol{u} \mid s) Q_{\pi}(s, \boldsymbol{u}) \mathrm{d} \boldsymbol{u}= \\ \quad E_{s \sim P_{s s^{\prime}}^{\pi}, \boldsymbol{u} \sim \pi_{\theta}}\left[\nabla_{\theta} \ln \pi_{\theta}(\boldsymbol{u} \mid s) Q_{\pi}(s, \boldsymbol{u})\right] . \end{array}$
该方法考虑当前策略所有可能出现的轨迹, 并对所有轨迹对应的累积共享回报依照其出现概率求平均, 即求累积共享回报在所有状态s和联合动作u上关于状态转移
$\nabla_{\theta} J(\theta)=\frac{1}{m} \sum_{t=0}^{T-1} \sum_{i=1}^{m} \nabla_{\theta} \ln \pi_{\theta}\left(\boldsymbol{u}_{t}^{i} \mid s_{t}^{i}\right) Q\left(\boldsymbol{u}_{t}^{i}, s_{t}^{i}\right), $
其中m为采样的轨迹数量.当采样轨迹中的策略
$\begin{array}{l} \nabla_{\theta} J(\theta)= \\ E_{s \sim P_{s s^{\prime}}^{\pi_{\theta}}, \boldsymbol{u} \sim \pi_{\theta_{\text {demo }}}}\left[\frac{\nabla_{\theta} \ln \boldsymbol{\pi}_{\theta}(\boldsymbol{u} \mid s)}{\ln \pi_{\theta_{\text {old }}}(\boldsymbol{u} \mid s) m} Q^{\pi_{\theta}}{ }_{\text {old }}(s, \boldsymbol{u})\right] . \end{array}$
主流的基于策略搜索的强化学习方法包括信赖域策略优化[31]、近端策略优化[32]等.相比基于价值的强化学习方法, 基于策略的强化学习方法具有更好的收敛保证, 尤其是与神经网络结合后, 可轻松处理连续的状态动作空间.但是, 策略搜索法主要基于蒙特卡洛采样法和重要性采样进行更新, 导致策略梯度的方差较大, 容易收敛到局部极小值.
为了同时解决值函数法无法应用至高维状态-动作空间以及策略搜索法方差较大的问题, 行动器-评判器模型[33, 34, 35]结合策略搜索与值函数的优势, 通过值函数的方法训练评判器, 使其为行动器的策略进行评价, 有效减小策略评估的方差.行动器根据评判器的评价, 更新策略.该模型的优化目标分为两部分:一方面需要优化值函数, 使其能为策略做出准确评估; 另一方面需要优化策略, 最大化值函数.
主流的基于行动器-评判器的强化学习方法包括Q-Prop[34]、A3C(Asynchronous Advantage Actor-Critic)[35]等.在上述模型中, 行动器和评判器的表现互相影响, 因此常需要对参数进行细致微调, 提升训练过程的稳定性.
在一个具体的决策问题中, 无论是采用基于模型的强化学习方法还是免模型的强化学习方法, 无论是以值函数或策略作为优化对象, 还是采用二者结合的行动器-评判器结构, 都离不开强化学习的基本过程.一个基本的强化学习迭代过程可分解为策略执行、策略评估、策略优化三个子过程, 每个子过程中都存在一些固有难题, 成为限制强化学习理论和应用发展的巨大障碍.本节将针对这些问题进行简要说明和分析.
1.3.1 可扩展性问题
可扩展性(Scalability)问题也称为多智能体强化学习的组合特性(Combinational Nature), 是多智能体强化学习中面临的核心问题之一[36].在多智能体强化学习任务中, 将整个多智能体系统视为一个决策主体, 直接优化联合动作的状态-行为价值或联合策略是直接将强化学习应用在多智能体决策的方式.然而, 由于状态空间和多智能体联合动作空间会随着智能体数目的增多而呈指数增加, 这种方法会导致系统探索及学习效率极低, 甚至无法收敛到最优的联合策略.
1.3.2 效用分配问题
效用分配(Credit Assignment)问题的研究目标是在多智能体系统中, 公平有效地分配奖励, 引导智能体协同工作, 实现整体系统的最优性能.这一问题的核心在于设计和实现能平衡个体智能体和全局系统目标的奖励机制.由于每个智能体的行动不仅影响自身的奖励, 还影响其它智能体的奖励, 导致在分配奖励时必须考虑复杂的交互关系.在传统的单智能体强化学习中, 奖励函数相对简单, 只需要反映单个智能体的表现, 而在MARL中, 奖励函数需要同时考虑多个智能体的表现及其相互影响, 这使得设计一个有效的奖励机制变得异常复杂.若奖励机制设计不当, 可能会导致智能体之间的合作不足, 从而无法达到全局最优的效果.效用分配问题还涉及如何在个体不均衡的贡献下进行公平的奖励分配, 即在一个合作的多智能体系统中, 不同智能体对任务的完成可能贡献不同.如何在这种情况下设计一个奖励机制, 既能鼓励高贡献的智能体, 又能避免低贡献的智能体失去积极性, 这是一个重要的挑战.
为了应对效用分配问题, 研究者提出一些方法和策略.例如:值分解方法通过将全局奖励分解为每个智能体的局部奖励, 使每个智能体能独立优化策略, 同时确保整体系统的目标得以实现.还有一些研究采用基于对手建模的方法, 预测和评估其它智能体的贡献, 更精确地分配奖励.然而, 这种方式的实际计算成本较大, 难以应对部分多智能体场景下的效用分配问题.
1.3.3 探索-利用困境
探索-利用(Exploration-Exploitation) 困境是强化学习的一个经典难题, 是指在多智能体系统中, 智能体需要在探索未知环境和利用已有知识之间进行权衡[37].在单智能体系统中, 智能体需要在尝试新策略以发现潜在的高奖励区域(探索)和利用已知最优策略最大化奖励(利用)之间找到平衡.然而, 在多智能体系统中, 随着每个智能体不断探索和调整策略, 环境状态不断变化, 增加探索和利用的难度.此外, 多智能体系统中的探索-利用困境还受到智能体之间相互依赖关系的影响.过度探索可能导致系统不稳定, 无法快速收敛到最优策略; 过度利用可能导致智能体陷入次优解, 无法发现更优的协作策略.为了有效解决这一困境, 研究者们提出多种方法, 如使用经验回放、递减的探索率、多智能体协作探索策略等, 增强智能体在动态环境中的适应能力和平衡探索与利用的需求.通过这些方法, 可提高多智能体系统的学习效率和整体性能, 实现更优的协作和决策效果.
1.3.4 环境非稳态问题
环境非稳态(Non-stationarity)问题是指系统中多个智能体同时学习和调整策略, 导致环境状态不断变化, 使单个智能体在学习过程中面临一个动态且不稳定的环境[38].传统的强化学习算法假设环境是静态的, 即智能体的策略变化不会显著影响环境.然而, 在多智能体系统中, 每个智能体的行为都会影响其它智能体的决策和学习过程, 导致环境状态频繁变化.这种非稳态环境为策略优化和学习过程带来极大的挑战.首先, 环境非稳态问题增加收敛的难度.在一个动态变化的环境中, 智能体难以通过试错过程找到稳定的最优策略, 因为其它智能体的策略也在不断变化.这种相互依赖的关系使智能体很难判断其行为的长期效果, 从而影响策略的有效性.因此, 智能体在一个非稳态环境中可能会陷入不断变化的循环中, 无法找到一个稳定的最优解.其次, 环境非稳态问题导致学习过程中的噪声增加.在一个多智能体系统中, 每个智能体的行为都会引入额外的变数和不确定性.这种不确定性增加学习过程中的噪声, 使智能体在进行策略评估和更新时更困难.智能体需要分辨哪些反馈是由于自身行为引起的, 哪些是由于其它智能体的行为引起的, 而这种分辨过程增加策略学习的复杂性和时间成本.
环境非稳态问题进一步导致很多多智能体学习困境, 如相对过泛化(Relative Overgeneralization), 即在协作多智能体任务中, 由于非协作智能体带来的惩罚超过协作智能体带来的奖励, 协作智能体会认为其选择的协作动作为错误动作, 导致多智能体最终收敛在次优联合策略.
1.3.5 部分可观测问题
部分可观测(Partial Observability)问题是强化学习在实际应用中需要应对的重要问题之一, 是指在许多实际场景中, 智能体无法获得完整的环境状态信息, 只能通过不完全的局部观测数据进行决策.这种信息的不完备性导致智能体在策略学习和优化过程中面临更大的挑战, 因为它们必须在有限的信息条件下进行推理和决策.在一个部分可观测环境中, 每个智能体只能看到环境的一部分状态, 而无法直接获取其它智能体的意图、行动和全局环境状态.在这种情况下, 智能体需要依赖历史观测和动作序列, 通过推测和预测填补信息空缺.然而, 这种推测往往是不准确的, 策略优化过程会因此变得更加复杂和不稳定.另外, 部分可观测问题还增加智能体之间的协作难度.由于每个智能体的视角有限, 它们必须通过通信等其它共享信息方式改善决策质量, 但这样又可能受到带宽、时延和安全问题的限制.有效的通信策略需要平衡信息共享的开销和收益, 同时确保智能体之间的信息交换足够准确和及时.
目前, 循环神经网络(Recurrent Neural Network, RNN)等深度学习技术已广泛应用于处理历史观测序列, 帮助智能体从不完全信息中提取有用特征, 可从一定程度上提高决策质量[41].部分可观测问题是MARL中的一个关键挑战, 解决这一问题对于提高多智能体在复杂动态环境中的决策能力和系统整体性能具有重要意义.
1.3.6 奖励函数设计问题
奖励函数(Reward Function)的设计是有效评估决策优劣的重要环节[3].奖励函数的设计一般依赖于人类专家的设计, 能引导智能体有效学习的奖励函数在复杂的决策环境下设计起来十分困难.进一步, 在多智能体系统中, 假设每个智能体的奖励函数能依靠智能体动作之间的依赖关系进行分解, 将每个智能体均视为独立的决策主体并单独优化其策略.虽然这样的方式能提升多智能体的可扩展性, 但无法在理论上保证算法整体的最优性和收敛性.同时, 在实际应用中, 由于智能体之间决策的相关性, 分解奖励函数可能无法实现.因此, 研究人员提出两种解决方案.1)直接为联合动作提供反馈信号, 即为智能体团队提供一个全局奖励, 并结合效用分配的方式进行策略评估与更新.2)直接学习奖励函数, 利用逆强化学习(Inverse Reinforcement Lear-ning, IRL), 使用专家样本拟合任务目标, 并利用该奖励函数训练多智能体策略[39].由于训练难度较大、泛化能力较差等限制, 这些方法只能在一定程度上解决奖励函数设计困难的问题.
多智能体强化学习的这些理论困境给学界和业界带来巨大挑战.针对这些问题, 研究者们提出多种具有启发意义的解决方案.尽管这些方案还不足以解决上述所有问题, 但为部分问题提供可行的思路.
针对深度多智能体强化学习存在的理论困境, 研究人员们提出许多解决方案, 部分如表1所示.本节将对深度多智能体强化学习的研究现状进行简要的分析与总结.
| 表1 多智能体强化学习算法理论困境和解决方案 Table 1 Theoretical challenges and solutions in multi-agent reinforcement learning algorithms |
涌现行为是一类较为早期的工作, 它的核心思想是将单智能体中的强化学习方法(如深度学习Q网络、近端策略优化等)直接拓展到多智能体系统中.这些算法最初是为单智能体环境设计的, 但通过调整奖励函数和策略框架, 可应用于多智能体系统.Tampuu等[40]提出DQN(Deep Q-Network), 在Atari环境的Pong游戏中展示智能体如何通过奖励函数学习合作行为或竞争行为.Leibo等[11]进一步研究DQN在连续社会困境中的表现, 揭示智能体如何在合作与竞争间找到平衡.Lerer等[41]将Tit-for-Tat策略扩展到深度强化学习中, 证明其在多智能体环境中能实现协作.Bansal等[42]在MuJoCo(Multi-joint Dynamics with Contact)环境下使用PPO(Proximal Policy Optimization), 引入内在奖励和对手采样方法, 促进对抗策略学习, 展现PPO在多智能体系统中的强大适应性.Gupta等[43]结合DQN与RNN, 并应用到多智能体环境中, 在简单的部分可观测环境中取得较优效果.受到集中式训练-分散式执行框架的启发, 研究人员结合该框架与PPO对智能体进行训练, 并显示此方法在部分多智能体环境中也能取得较优性能[44, 45].
然而, 当单智能体场景拓展到多智能体场景时, 由于状态空间和多智能体联合动作空间会随着智能体数目的增多而呈指数增加, 算法的实际性能会有不同程度的下降, 可拓展性面临严重挑战.学者发现, 共享策略参数能帮助强化学习算法扩展到大量多智能体, 并加速合作学习.实际上, 通过该方式学习的智能体会倾向于获得同质化行为, 这可能会阻碍多样化的探索和合作智能体间的协调性.
为此, 文献[46]~文献[48]都试图通过区分每个智能体与其它智能体, 促进个体化行为, 但往往通过隐式任务分配忽视高效的团队组合.早期相关工作将角色概念引入多智能体系统, 表征一组具有相似执行效果的动作.通过角色的分组, 缩减联合动作空间的维度.然而, 通常需要先验领域知识预先定义角色, 这不仅需要大量先验知识, 还在实践中获取难度较高, 并且可能会影响算法学习的泛化性.因此, 通过学习的方式获得一组合适的角色至关重要.实际上, 从头开始学习角色可能并不比预先定义角色更容易, 因为直接寻找最佳分解会遇到与其它集中式训练-分散式执行框架学习方法相同的问题, 同样需要在巨大联合空间中进行大量探索.
为了解决这个问题, Wang等[49]提出RODE(Lear-ning Roles to Decompose), 学习角色以分解多智能体任务, 根据动作功能分解联合动作空间, 而非从头开始学习角色, 以便更容易地发现角色.具体地, RO- DE通过角色分解多智能体任务, 将智能体的动作空间分解成若干个与角色对应的受限动作空间, 智能体根据自身子任务类别选取对应的角色, 确定决策时的动作空间, 并在受限动作子空间中进行探索与决策, 降解联合动作空间的复杂度, 提高探索和策略学习效率.但RODE对角色出现的复杂行为描述不足, 也忽视不断变化的多智能体团队动态, 这妨碍智能体的有效学习探索和多智能体间的协调合作.对此, Liu等[50]提出COPA(Coach-and-Player), 在执行期间向每个智能体分发团队构建的全局视图以允许动态角色分配.
为了进一步促进智能体之间的行为异质性、知识转移和有效协调, Hu等[51]设计ACORM(Atten-tion-Guided Contrastive Role Representation Learning for MARL), 利用互信息最大化以形式化角色表征学习, 借助注意力机制促使全局状态关注价值分解中学到的角色表征, 隐式指导智能体在熟练的角色空间中进行协调合作, 在缓解多智能体算法可拓展性问题的同时获得具有更强表征能力的效用分配.
在多智能体系统中, 团队奖励通常难以分配到各个智能体.这不仅影响策略评估, 还会对策略更新带来困难.传统方法往往无法准确地衡量每个智能体的贡献, 从而导致效率低下[52].为了解决这个问题, 研究者们提出CTDE(Centralized Training with Decentralized Execution).在这种框架下, 训练过程中使用全局信息进行策略评估, 而在执行时, 智能体仅依赖自身的观测进行决策.2种CTDE框架如图2所示.
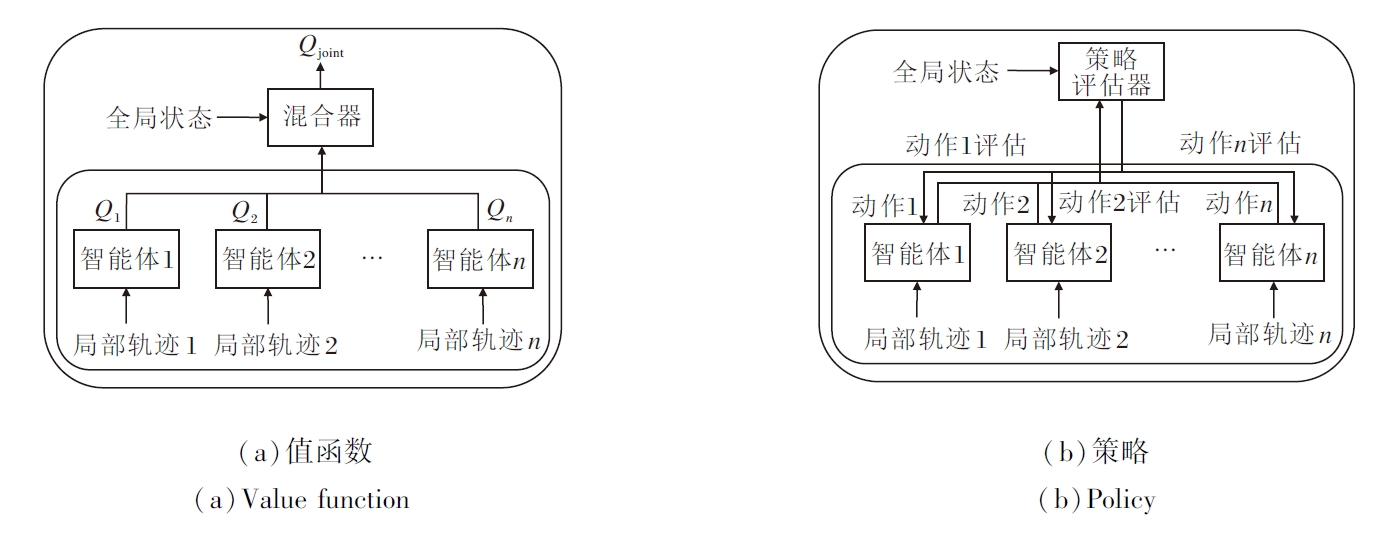 | 图2 基于值函数和策略的CTDE框架图Fig.2 CTDE framework based on value function and policy |
CTDE有效平衡全局信息的利用和实际执行中的智能体信息局限性, 显著提升系统的整体性能.在集中式训练-分散式执行的框架下, 面向效用分配的多智能体强化学习方法主要可以分为如下两类.
第一类方法是利用反事实估计(Counterfactual Estimation)的方法实现效用分配, 核心思想是通过对比实际发生的情况与假设某个智能体采取不同行动时的可能结果, 评估该智能体的贡献.反事实估计的主要实现方法有差分奖励(Difference Reward)和反事实基准(Counterfactual Baseline).COIN(Collec-tive Intelligence)通过差分奖励机制激励多智能体系统中的个体合作, 提高整体性能, 其核心思想是计算全局奖励与假设个体未参与时的反事实奖励之差, 从而评估每个智能体的贡献[53].
虽然COIN能有效增强合作性, 但在大型多智能体系统中计算开销较大, 并且反事实场景构建可能不够准确.为此, Foerster等[15]提出Counterfactual Multi-agent(COMA) Policy Gradient, 利用集中式评判器计算的反事实基准优化多智能体系统中的效用分配, 获得每个智能体对全局奖励的实际贡献.COMA构建基准模型, 预测每个智能体采取不同动作时的全局奖励, 再计算实际奖励与基准奖励之间的差异, 形成反事实优势函数, 用于调整多智能体策略.COMA可有效减少策略梯度中的方差, 提高多智能体系统的学习效率和稳定性.然而, 该方法需要同步评估和更新智能体策略, 在大规模系统中仍面临挑战.
第二类方法是使用值分解机制隐式完成效用分配.Lowe等[6]提出MADDPG, 在每个智能体的策略中引入其它智能体的观测信息和动作信息, 减少环境的非平稳性.使用集中式评判器评估所有智能体的联合策略, MADDPG提高策略优化的稳定性, 但其计算复杂度会随着智能体数量的增加而显著上升.
Sunehag等[14]假设可由局部状态-动作值简单加和得出整体状态-动作值, 将全局值函数分解为各个智能体的局部值函数, 简化多智能体系统的策略评估过程.然而, 这种加性假设限制模型的表征能力, 其联合状态-动作值的表征能力大为受限.为了增强联合状态-动作值的表征能力, Rashid等[13]提出QMIX, 假设整体状态-动作值随着局部状态-动作值的增加而单调不减.QMIX设计一个混合网络, 将局部值函数组合成全局值函数, 同时保证其单调性, 从而提高模型的表征能力和策略优化效果.Yang等[54]提出Qatten(Multi-head Attention Based Q-Value Mixing Network), 使用注意力网络进行效用分配, 动态调整智能体间的权重, 提高模型的灵活性和准确性.
注意力机制使模型能关注重要状态和行为, 提高策略评估的效率.Yao等[55]提出SMIX(λ ), 将QMIX里的单步Q-学习目标改为SARSA(λ )目标, 通过平衡采样的方差与偏差提升多智能体的学习性能.Yang等[56]提出QPD(Q-Value Path Decomposi-tion), 利用集成梯度归因技术分解联合Q值函数, 直接沿轨迹路径分解联合Q值, 为智能体分配效用.积分梯度方法使模型能更准确地估计智能体间的协作效果, 改进策略评估的精度.
虽然上述方法在一定程度上提升QMIX的学习能力, 但本质上仍然都是使用单调值分解的模式, 表征联合状态-动作值的能力并没有改变.Son等[57]提出QTRAN, 学习具有完整表征能力的联合Q值函数, 并引入两个软正则化以近似个体全局最大化原理.虽然QTRAN在理论上能解决表征能力不足导致的学习困境, 但由于在实现过程中使用的软约束并不能保证个体-全局最优准则, 在较复杂的多智能体任务中性能很差.Wang等[58]提出QPLEX(Du-plex Dueling Multi-agent Q-Learning), 通过对抗混合网络实现个体在全局最大化原理下的完整表征, 其中完整的表征能力是通过个体优势函数的混合引入的.然而, 随着智能体数量的增加, 状态空间和联合动作空间呈指数级增长, 在复杂的MARL任务中学习完整的表征是不切实际的, 这可能会导致收敛困难和性能下降.Rashid等[59]提出WQMIX(Weighted QMIX), 学习有偏差的联合Q值函数以防止收敛到次优, 引入辅助网络, 区分具有低表征值的样本.通过在这些样本上放置预定义的低权重, WQMIX学习一个有偏差的联合Q值函数, 该函数能专注于表征具有良好性能的动作.Wan等[60]提出GVR(Greedy-Based Value Representation), 完全抛弃完整的联合状态-行为值表征能力, 认为对于非最优联合动作而言, 算法仅需要表征其非最优性, 而不需要精确拟合该值.因此, GVR重塑学习目标, 将非最优动作的学习目标改变为当前贪婪动作值的α 倍, 从而简化学习过程, 有效提升算法效用分配的能力.
基于联合探索的多智能体强化学习算法主要解决多智能体探索-利用困境.探索-利用困境最早见于多臂赌博机问题[61], 决策者需要尽可能多地试探各个摇臂, 大致了解每个摇臂对应的回报期望, 同时, 决策者还需要充分利用已知信息, 尽可能地去试探回报期望较大的摇臂, 以准确估计其回报并选择期望回报最大的摇臂.在单智能体强化学习中, 研究人员们提出UCB(Upper Confidence Bound)[20]、ε -greedy[21]、策略添加噪声[22]等探索方式, 其基本思想都是在训练前期以高探索度寻找不同特征的样本, 在训练后期更倾向于利用当前策略完成深度探索, 即对当前策略进行微调以降低探索度.
在多智能体强化学习中, 探索-利用困境变得更加棘手.对于每个智能体而言, 其它智能体均可以视为环境的一部分, 任意一个智能体的无效探索行为均会影响联合动作的表现, 进而导致收集样本的效率和质量大幅降低.Mahajan等[62]在QMIX的基础上, 引入一个分层控制的隐变量空间, 利用该隐变量控制智能体在每条轨迹上的探索策略, 使智能体的探索更加多样化, 进而避免多智能体由于探索不充分而收敛至次优联合策略.事实上, 多智能体环境之所以难以探索, 是因为存在许多智能体之间互相影响的状态.这些状态也被称为相互作用点, 往往位于过渡到潜在重要的未探索区域的临界连接处.因此, Wang等[23]提出EITI(Exploration via Information-Theoretic Influence)和EDTI(Exploration via Deci-sion-Theoretic Influence), 分别利用差分奖励和互信息量化和表征一个智能体对其它智能体的影响, 将其作为内在奖励(Intrinsic Reward), 通过最大化此内在奖励, 鼓励智能体更频繁地访问相互作用点, 使多智能体能到达分布式探索中很少访问的潜在最优状态.
Zheng等[24]根据VDN的更新方式, 推导值分解网络中每个智能体的局部状态-行为值在收敛时是具备差分奖励的形式的, 并据此提出EMC(Episodic Multi-agent Reinforcement Learning with Curiosity-Driven Exploration), 使用基于内在好奇心的多智能体探索模块, 预测智能体局部状态-行为值和真实状态-行为值的差异, 引导智能体探索未充分探索的区域.同时, EMC还引入情景回放池(Episodic Memory), 记录每个状态-动作对的最高累计奖励, 并以此辅助联合状态-行为值的训练, 提升多智能体的训练效率.然而, 这种基于内在奖励的方法是比较直觉的探索方法, 缺乏理论保证, 同时平衡内在奖励和外在奖励的权重系数也较敏感, 难以调节.
Liu等[63]提出CMAE(Cooperative Multi-agent Exploration), 认为多智能体环境中的高维状态中存在许多冗余信息, 可将其投影至低维的受限状态树中, 再从受限状态树中抽取关键信息, 通过计数的方法选择到访次数少且具备探索价值的状态作为多智能体的共享目标.Gupta等[64]提出UneVEn(Univer-sal Value Exploration), 认为等值分解方法无法解决相对过泛化等问题的主要原因是奖励函数设计的问题, 因此, 使用后继特征(Successor Feature), 将奖励函数分解为环境信息和权重特征, 并提出基于目标任务采样的动作选择方法, 在采样到的、更容易学习的奖励函数下, 学到能同时使得原奖励函数最大化的联合策略.类似的方法也在奖励随机化(Reward Randomization)中得到应用[65].然而, 通过随机采样得到的奖励函数所学到的策略并不能保证是在原奖励函数中的最优策略, 因此这类方法往往需要大量的采样和训练, 难以在大规模复杂任务中得到应用.
Go-Explore 系列算法[66, 67]将探索分解为两个阶段:返回到之前的状态, 从之前的状态开始探索.这些方法存储高回报轨迹, 并通过运行目标条件策略(Goal-Conditioned Policy)从该存档处返回采样状态.然而, 在多智能体领域, 智能体应被鼓励传送至发生交互的状态, 原因是这些状态可能通向关键的未充分探索区域.该系列算法仅考虑单智能体环境中的稀疏和欺骗性奖励, 因此不适用于具有复杂奖励和较强依赖关系的协作型多智能体强化学习场景.
对此, Liu等[68]提出IIE(Imagine, Initialize, and Explore), 利用GPT(Generative Pre-training Transfor-mer)架构想象从初始状态到交互状态的轨迹, 生成不同的智能体行为, 解决复杂协调任务中的有效探索问题.IIE通过提供高影响力的起点作为自动课程(Auto-Curricula), 显著提高多智能体在复杂场景中发现重要但未充分探索区域的可能性.
学习通信协议是解决协作任务的关键问题之一, 并且已成为多智能体强化学习的一个活跃领域.近年来的多智能体基于通信的强化学习算法主要可分为三类:高效融合与传递观测信息、抽取智能体关系建模进行稀疏通信、分享意图信息减小环境非稳态.
第一类多智能体基于通信的强化学习算法侧重于有效共享观测信息以解决部分可观测问题.CommNet(Communication Neural Net)[19]和DIAL(Di-fferentiable Inter-Agent Learning)[69]分别使用离散及连续的可微通信信道, 实现对通信信息及联合策略的端对端训练, 但模型无法差异化地处理不同智能体的信息, 在多智能体环境下训练稳定性较差.因此, ATOC(Attentional Communication Model)[70]和TarMAC(Targeted Multi-agent Communication)[17]提出基于签名的软注意力机制, 学习智能体间关系, 使智能体能自主选择通信时间及对象, 实现对其它智能体信息的差异化融合, 并对智能体数量动态变化环境提供泛化能力.与ATOC等类似, Singh等[71]提出IC3Net(Individualized Controlled Continuous Communication Model), 同样通过门机制选择智能体的通信对象和时机.然而, 此类方法仍需进行全局通信, 计算智能体融合信息, 因此稀疏通信成为进一步降低通信代价和提升融合效率的关键问题.为了解决这一问题, Zhang等[72]提出VBC(Variance Based Control), 通过智能体的状态-动作价值函数选取接收信息的智能体与发送信息的智能体, 通过将其它智能体的消息转换为自身状态-动作值函数的增量, 提升智能体的决策能力, 大幅减少通信频率.Wang等[73]提出NDQ(Nearly Decomposable Q-Func-tions), 将信息视为基于观测的随机变量, 通过信息瓶颈理论建模带宽约束与信息熵之间的关系, 提出基于互信息的多智能体通信方法, 使用带权重的信息调度器, 减小多智能体通信过程中的带宽要求.此类方法仅聚焦于如何优化消息编码和通信频率, 未考虑智能体间的策略协商过程, 无法对多智能体协同决策提供有效信息.
第二类多智能体基于通信的强化学习算法通过图方法对智能体间的关系进行建模, 并通过图中的边进行消息传播.Battaglia等[74]将图神经方法应用至多智能体系统中, 利用基于互信息的熵优化方法直接获得通信信息.然而, 由于基于熵的关系优化方法的计算开销较大、 更新不稳定, 无法应用于大规模智能体环境中.因此, Bö hmer等[75]提出DCG(Deep Coordination Graph), 使用深度协调图表征多智能体的交互过程, 通过预设的协调图分解多智能体的联合状态-动作价值函数, 提升多智能体通信及训练的稳定性.然而, 由于多智能体决策环境的动态性, 预设的协调图结构很难与真实最优的关系图保持一致, 进而引入额外的交互和学习复杂度.为了解决这一问题, Li等[76]使用软性注意机制学习图的边权重, 实现动态的协调图结构, 增强协调图的灵活性.由于软性注意力机制无法完全消除冗余信息的权重, 此方法仍然具有较高的通信代价, 且难以平衡联合状态-动作价值函数的表征能力及交互复杂度.因此, Yang等[77]提出自组织的协调图, 使用可训练的动态结构图拟合真实的最优交互关系, 同时保证联合状态-动作价值函数的表征能力, 提升在不同状态下的协同策略选择的准确性和计算效率.
类似地, 基于共享图建模的多智能体强化学习通信方法[78, 79, 80]同样全局显式地建立通信图, 以此提升通信效率.此类方法将智能体间关系构建为无向图模型, 未考虑智能体节点的策略和消息边的最优一致性, 无法保证交互信息与联合策略在非平稳多智能体环境中的收敛性.为了解决这个问题, Liu等[81]提出DHCG(Deep Hierarchical Communication Graph), 根据智能体的消息学习其间的依赖关系.这些关系被表述为DAG(Directed Acyclic Graph), 其中正确拓扑的选择被视为一个动作并以端到端的方式进行训练.为了消除图中的循环, DHCG应用非循环约束作为内在奖励, 再将图投影到可接受的 DAG 解集中, 消除冗余通信边缘并保证联合策略收敛.
第三类多智能体基于通信的强化学习算法将智能体的意图信息编码在通信消息中, 使智能体能在通信过程中进行协商.针对多智能体非稳态环境问题, 基于意图分享的智能体策略协商方法将智能体的意图信息编码在通信消息中, 通过策略协商提升智能体的决策质量.Chu等[82]提出NeurComm, 设计一种可微分通信协议, 将策略指纹引入通信过程中, 降低信息损失和非平稳性.Qu等[83]提出IP(Inten-tion Propagation), 允许智能体将初始决策传播至邻居智能体, 并根据其接受的信息进行策略修正, 最终实现联合策略的平均场近似收敛.然而, 此类方法假设智能体的通信及决策仅跟其邻居智能体相关, 无法适用于更普遍的异构多智能体决策过程中.与之相对的是, Kim等[84]提出IS(Intention Sharing), 对环境的状态转移函数进行建模, 实现对智能体未来路径的预测, 并基于软注意力机制实现智能体间的自主意图分享.然而, 由于所有智能体均相互传播意图信息并修改决策, 无法保证传播的意图信息与决策的相关性, 进而无法保障策略的单调提升[85].Kuba等[86]提出HATPRO(Heterogeneous-Agent Trust Region Policy Optimisation)和HAPPO(Heterogeneous-Agent Proximal Policy Optimisation), 引入多智能体优势函数分解与序列策略更新方法, 使用线型交互方法降低交互复杂度, 从理论上保证多智能体算法能收敛在纳什均衡点.然而, 在复杂多智能体的协同任务中, 线型交互与更新的方式导致严重的通信延迟与更新消耗, 不能保证收敛至全局最优点.
近年来, 随着ChatGPT的问世, 生成式模型强大的逻辑推理和知识储存能力受到广泛关注, 其与人工智能各类算法的联系也开始逐渐紧密.RL也开始与生成式模型和人类反馈结合, 进行更智能化的演变.
早些年, RL在解决游戏、自动驾驶、机器人控制以及其它具有明确奖励结构设置的不同领域取得显著成功.然而, 在以复杂交互为特征的多智能体协作场景中, 明确定义奖励结构可能会出现问题.例如:智能体可能在策略学习和优化阶段陷入奖励操纵, 涉及利用奖励结构中的漏洞最大化累积奖励, 而非真正解决预期任务.因此, 为MARL设计准确的奖励函数难点落在如何有效建模考虑智能体交互的奖励函数, 并理清多智能体任务中人类偏好之间复杂的全局依赖关系.事实上, 人类对多智能体轨迹的偏好主要源于评估联合行动的合作效果, 而不是对个体行动的单独评估.为每个智能体创建单独的奖励模型会忽视捕捉智能体合作的能力, 从而导致次优结果[87].另一方面, 在所有智能体之间建立集中、共享的奖励模型会给效用分配带来挑战, 通常会阻碍多智能体系统集体性能的提高.
为了解决这个问题, Zhu等[88]提出MAPT(Multi-agent Preference Transformer), 扩展传统基于偏好的强化学习(Preference-Based RL, PbRL)处理多智能体场景, 并准确表征人类偏好和智能体组合奖励之间的联系.具体来说, MAPT捕获每个智能体的全局依赖关系(包括时间和合作两个方面), 创建一个解耦的奖励模型, 反映每个智能体独特的贡献.面对稀疏奖励场景, PbRL类算法利用人类偏好, 将稀疏奖励转变为稠密奖励, 提供一种有前景的解决方案.Kang等[89]提出DPM(Dual Preferences-Based Multi-agent Reinforcement Learning), 同时对比多智能体轨迹和个体智能体贡献的偏好, 进一步增强PbRL 扩展到 MARL上时的适配性, 优化个体奖励函数, 有效提高稀疏奖励场景中的表现.
此外, 生成式大模型也开始与多智能体强化学习算法产生较好的相互作用.一方面, IIE[68]利用GPT架构生成多样的智能体行为轨迹, 为多智能体强化学习结合大模型应用提供良好的先例.进一步地, 为了解决复杂多智能体决策问题, Liu等[90]研究结合生成式模型与MARL的新范式, 结合语言模型与世界模型, 使其能通过仿真生成合理的答案.通过在仿真环境中生成的试错经验训练多智能体策略, 生成的策略不仅在已知任务上表现出色, 还能在未知任务上实现零样本迁移.另一方面, 强化学习作为针对特定任务模型微调的关键技术, 也对大型语言模型的实际能力起着至关重要的作用.Ma等[91]提出CORY, 使用多个大语言模型构成一个多智能体系统, 由此将大语言模型的微调转化为一个MARL问题, 能帮助大语言模型进行能力的协同演化.
由于多智能体强化学习中问题错综复杂, 研究人员提出许多多智能体强化学习的训练环境, 包括小球世界(Particle World)[6]、星际争霸II(StarCraft II)[5, 92]、谷歌足球(Google Football)[93]、捕食者-掠食者(Predator-Prey)[75]、交通调度(Traffic Junc-tion)[8]、捉迷藏(Hide-and-Seek)[94]、守卫遗迹II(Defence of the Ancients II, DOTA II)[95]等, 用于考察算法在不同问题、不同场景下的收敛性及性能.部分多智能体强化学习环境示意图如图3所示.
 | 图5 多智能体强化学习环境示例Fig.5 Examples of multi-agent reinforcement learning environments |
本文选取4个最受欢迎的多智能体训练环境, 即小球世界、星际争霸II、谷歌足球和MAMuJoCo(Multi-agent MuJoCo), 进行简要介绍.在实际算法训练过程中, 研究人员可根据自身需求选取或设计相应的训练环境.
2.6.1 小球世界
小球世界为一个由OpenAI发布的多智能体强化学习训练环境, 支持连续及离散的动作空间、协同及对抗的多智能体任务.针对不同场景, 研发人员可自定义状态空间、观测空间、障碍物种类与个数、智能体种类及个数、游戏规则与难度、环境接口等.例如:在围捕任务中, 智能算法控制多个拦截人员, 在躲避移动障碍物的同时, 对速度及加速度均高于己方的敌方目标进行围堵拦截; 在弹力绳任务中, 两个智能体之间使用弹性绳连接, 目标物体在不确定时间内从上至下高速掉落, 智能体需要协同运动, 接住并将其反弹至指定位置.小球世界的环境支持高度自定义, 并提供良好的环境及算法接口, 研发人员可容易地训练并测试各类多智能体算法, 受到业内的广泛认可[96, 97, 98].
2.6.2 谷歌足球
谷歌足球是由谷歌公司研发的多智能体强化学习环境, 支持许多可高度自定义的简单场景及复杂的全场人机对抗、多智能体对抗任务.该环境使用物理三维引擎, 提供状态向量、小地图图像和摄影机图像等不同的观测空间, 设计稀疏奖励和基于足球状态的稠密奖励, 并内置角球、边球、红黄牌、手球、越位等足球规则.智能体需要根据实时变化的场内形式, 学会长传、短传、射门等基础行为, 并学习与其它智能体进行协调配合, 如补位、围抢、造越位等高阶战术.在简单场景中, 研究人员可自定义场内人员数量及场景, 如三过二配合、快速反击、边路进攻、定位球等, 考察算法在细粒度控制上的学习效果.在全场对抗场景中, 算法控制11个智能体与对手对抗, 综合考察算法在随机对手策略下的攻防战术设计与微观操控能力.谷歌足球的开源环境提供简易的环境接口, 所需计算资源较小, 因此成为业内欢迎的多智能体训练环境之一[99, 100, 101].
2.6.3 多智能体物理引擎
MAMuJoCo是一个用于多智能体强化学习的环境, 基于MuJoCo物理引擎构建.该环境旨在提供一个标准化的平台, 供研究人员和开发者进行多智能体学习和策略研究[102].环境支持多个智能体在同一环境中互动.每个智能体可以拥有独立的观测和动作空间, 进行合作或竞争.基于MuJoCo引擎, MAMuJoCo能模拟复杂的物理交互, 包括碰撞、摩擦和重力等, 使智能体在学习过程中获得更真实的反馈.同时, MAMuJoCo设计时考虑到扩展性, 用户可轻松添加新的智能体、任务或环境元素.这对于研究不同的多智能体算法和策略非常重要.另外, 环境中包含多种不同的任务和挑战, 从简单的协作任务到复杂的竞争场景, 研究人员可根据需求选择适合的任务进行实验.
总之, MAMuJoCo是当下多智能体强化学习领域中一个广受欢迎的仿真环境, 适合进行多智能体强化学习研究, 尤其是在需要复杂物理交互的场景时.它为研究人员提供一个灵活的平台, 促进多智能体系统的探索与创新.
2.6.4 星际争霸II
星际争霸II是暴雪(Blizzard)公司开发的一款即时策略游戏, 玩家可在人族、神族或虫族中选择种族, 观测和指挥部队, 争夺战场的控制权, 并最终击败对手, 是一个非常接近现实世界的虚拟环境.在此基础上, Vinyals等[5]提出基于宏观战略控制的多智能体强化学习环境, 用于训练在完整的即时策略游戏中与职业选手抗衡的人工智能.为了更好地验证多智能体间的协作能力, 并为研究者提供简易轻便的环境, Samvelyan等[92]提出微观单元控制多智能体强化学习环境, 用于在局部战役里显示智能体学到的复杂战术.宏观战略控制主要面向高层次的战略协作问题, 考察算法应对组合动作空间、延迟奖励、非完美信息等问题的能力.宏观战略控制主要考虑如何在成百上千的控制单位间使高水平经济决策达到平衡, 同时建立与作战单元相关的微观战术, 学到能与顶级玩家抗衡的博弈策略.由于标志性的高维状态、游戏难度、多智能体的协调复杂度及庞大的训练资源, 宏观战略控制成为难度极大但又很受欢迎的多智能体强化学习训练环境之一.微观单元控制主要面向少量作战单元的细粒度操作的学习, 支持多种同构及异构兵种、对称场景及非对称场景、不同的训练难度, 考察算法在不同场景下的协同能力.在微观单元控制中, 由算法控制的智能体需要根据敌我兵种及数量差异, 学到集火敌方、风筝、交替火力等高难度战术动作.星际争霸II的环境较好地模拟作战场景下多智能体的协作和对抗关系, 为协同多智能体强化学习算法的训练提供一个良好的实验平台.
近年来, 也有不少学者认为现有星际争霸II环境的随机性不足[103], 特征存在冗余和可推断性及相关性.因此, 改良后的第二版星际争霸II加入兵种随机生成、智能体初始位置随机、视野攻击范围限制, 使该环境可以更全面地评估多智能体强化学习算法.
基于理论研究, 不少MARL开始逐渐迁移到具有一定现实意义的场景中并发挥作用.本节简要介绍深度多智能体强化学习在智慧城市、游戏、机器人等领域的应用.
近年来, 随着城市化进程的加快和城市系统复杂性的增加, 对更智能和高效的管理解决方案的需求也在不断增长.MARL作为一种强大的人工智能算法, 在智慧城市建设的多个方面展现其独特的应用价值.在智能电网中, MARL能实现动态需求响应、能量高效分配和实时故障检测, 提升电网的可靠性和稳定性.Chung等[104]提出基于分布式深度确定性策略梯度的多智能体系统, 用于智能电网中的动态负载平衡, 通过智能体协作优化能量分配, 显著提高电网的稳定性和能效.
Cao等[105]设计用于高光伏渗透率配电系统的分布式电压控制方法, 基于深度多智能体强化学习, 通过分布式智能体协同工作, 实现系统电压的动态调整和优化控制, 能在不同负载和光伏发电条件下有效维持系统的电压稳定.类似地, Zhao等[106]提出电网系统频率控制方法, 结合多智能体强化学习和数据驱动的预测控制, 利用历史数据引导策略搜索, 提升频率控制的准确性和效率, 在电力系统频率波动管理中表现出优异性能.
Liu等[107]使用一种协作多智能体强化学习算法协调智能电网, 利用分布式Q-Learning和合作机制优化电网中的能源管理, 实现高效的电力资源分配.Gao等[108]使用分布式多智能体系统, 结合深度强化学习进行实时电力优化控制.智能体通过共享环境信息, 协同决策, 实现电力流的优化控制, 有效提高电网的响应速度和整体效率, 减少能量损失.
进一步地, Radhakrishnan等[109]采用分布式多智能体强化学习算法, 结合能源管理系统, 实现智能电网中的能源管理, 通过智能体间的通信和协作, 实现高效的能源分配和动态调整, 减少峰值负载, 显著提高电网的稳定性和能源利用效率.Chniter等[110]提出自适应多智能体系统, 用于智能电网的实时分布式控制, 能有效提高电力系统的灵活性和鲁棒性, 优化电力分配, 增强系统应对突发情况的能力.另外, Wang等[111]使用多智能体强化学习算法, 进行智能电网中的协作电压控制.智能体通过局部信息和全局目标的综合考虑, 通过动态电压调节提高电网的电压稳定性, 优化电力质量, 减少电压波动带来的风险.
在智能物流领域, MARL能通过优化路径规划和资源分配, 提高物流运输的效率和准确性, 降低运营成本.
Zhang等[112]开发基于多智能体近端策略优化算法的模型, 在仿真环境中成功优化物流运输路径和车辆调度, 大幅降低运营成本.Zhang等[113]提出结合区块链和物联网的质量管理平台, 应用于易腐物品供应链物流, 利用多智能体独立Q-Learning方法, 优化资源调度和物流路径, 确保在整个供应链中实现高效和安全的物流管理.Krnjaic等[114]提出一种多智能体强化学习方法, 用于优化仓储环境中机器人和人工拣货员的协作, 开发一个高性能的仓库模拟器, 并通过部分可观测随机游戏模型训练多智能体策略, 在提高拣货效率方面具有显著效果.Jo等[115]提出利用多智能体强化学习优化无人机在物流环境中路径规划和任务协调的方法, 应用深度Q网络和策略梯度算法, 使多个无人机能够在部分可观测的马尔可夫决策过程中自主学习和协作, 从而提高物流配送的效率和准确性.Khayyat等[116]开发城市区域的协同物流多智能体系统, 结合强化学习算法, 实现物流环节的协同优化, 提高物流系统的协调和响应能力.Li等[117]为了实现动态物流管理, 结合多智能体强化学习方法, 通过智能体的协作, 实时优化物流流程, 动态调整运输策略, 有效提高物流系统的灵活性和效率, 减少延误和资源浪费.文献[118]~文献[122]也通过多智能体强化学习对大量数据进行非线性拟合, 据此进行高效推理, 从而完成对整个物流过程的规划和调整.
目前, 德国汉堡港的智能物流系统[123]也结合多智能体强化学习, 实现港口资源的高效调度和货物运输的优化, 提高港口运营效率.
现实交通系统具有多样性与动态性, 其中的个体(如车辆、行人、交通信号灯等)具有不同的目标和行为方式.多智能体强化学习能帮助交通系统实现动态、自适应的分布式决策和高效协作, 优化交通流量、减少拥堵、提升系统鲁棒性, 最终提高交通管理的整体效率和安全水平.
Mao等[124]提出基于软行动器-评判器算法的多智能体系统, 用于智能交通信号控制, 通过智能体间的协作, 有效减少交通拥堵.为了解决自动驾驶车辆的高速公路入口合并问题, Chen等[125]提出一种多智能体强化学习方法, 通过多智能体合作学习策略, 使自动驾驶车辆能适应人类驾驶车辆, 提高交通流的效率和安全性.
Wang等[126]引入基于多智能体强化学习的时空超图, 用于改进交通信号控制系统, 利用超图捕捉多模态数据中的高阶关系, 并通过多头注意力机制实现动态时空交互, 从而有效控制交通流量.Vidhate等[127]应用多智能体集中式学习分布式执行框架管理智能交通, 实现交通调度的全局优化.类似地, Louati等[128]也设计一个多智能体车辆协调系统, 每个智能体通过协作学习, 优化车辆之间的互动和路径选择.
Wu等[129]结合分布式深度Q网络方法, 使经过训练的控制器可通过与动态交通环境交互不断在线学习, 提高其在交通拥堵且传感器具有噪声观测时的性能.Zeynivand等[130]将文献[129]方法应用于协同自动驾驶, 通过智能体之间的协作和深度学习, 优化自动驾驶车辆的路径规划和决策.然而, 现有算法通常采用细粒度信息(即当前步态)获取交通网络特征嵌入, 却忽略大粒度信息(如之前的多个步态).Yang[131]在智能交通灯控制场景中, 通过多智能体分层图强化学习, 实现复杂交通场景下的信号优化, 有效解决该问题.Wu等[132]进一步拓展应用多智能体深度确定性策略梯度算法, 在城市交通中优化信号控制, 减少等待时间.
目前中国香港特别行政区已在智能交通系统中采用多智能体强化学习技术, 通过实时数据和多智能体协作优化交通信号, 显著改善高峰时段的交通流量和减少拥堵[133].
这些应用充分展示MARL应对复杂实际情况调度和多方策略联合优化的高效学习能力, 表现出在未来智慧城市建设中不可或缺的作用.
在游戏任务中, 各种深度多智能体强化学习的研究成果得到广泛应用, 并取得出色性能.自2016年Deepmind公司的AlphaGo[4]战胜世界顶级棋手李世石后, 深度强化学习在人工智能领域引发新一次的热潮, 并在Atari和Nintendo中的多个小游戏中全面超越人类顶尖玩家.随后, 研究人员将深度强化学习应用至更复杂的多智能体游戏环境中, 如DOTA II、星际争霸、雷神之锤III等状态及联合动作空间庞大的游戏中, 并研发能与职业游戏选手抗衡的人工智能.
2017年, OpenAI发布其在DOTA II游戏环境下使用深度多智能体强化学习训练的智能体, 在1V1的比赛中击败世界顶尖选手Denti.此后, 该项目一直在迭代推进, 并最终在2019年, OpenAI发布名为OpenAI Five的游戏智能体[98].OpenAI Five每局的决策步长高达20 000余次, 同时在部分可观测的设定下每步观测到16 000个不同变量.OpenAI Five使用长短期记忆网络、近端策略优化算法和自博弈的训练方式, 并利用迁移学习的思想, 使旧模型可在游戏版本更新后快速恢复其原先的性能.OpenAI Five在正式的5V5地图中击败DOTA II的世界冠军战队OG, 并在线上开放体验环节中的7 000场对局里击败99.4%的人类对手.
2019年, DeepMind在Nature上发表其在主流电子竞技游戏星际争霸II环境下的多智能体强化学习算法AlphaStar[5].基于AlphaStar的多智能体能在没有任何游戏先验知识的情况下进行训练, 达到人类对战天梯的宗师段位, 在游戏服务器上的排名超越99.8%的活跃玩家, 并在与全球顶级玩家的90场比赛中取得61场胜利.为了保证与人类玩家竞技的公平性, AlphaStar具有和人类玩家一样的视野限制, 并且限制动作频率和网络延迟.研究人员设计联盟训练模式, 使用加权虚拟自博弈, 使用历史战绩作为加权因子, 使智能体更倾向于与困难的对手进行博弈, 并帮助智能体寻找当前策略的弱点, 提升其性能和鲁棒性.此外, AlphaStar还使用残差网络、注意力机制、循环网络、自模仿学习等结构, 构建更深的网络模型, 提升算法性能.
在DOTA II、星际争霸等复杂游戏中, 智能体不仅需要精细的微观操作和短期策略, 同时也需要根据不同的对手策略做出长期的局势判断和战术设计.由于受到人类先验知识匮乏、状态动作空间庞大等限制, 传统的基于规则的人工智能很难实现这些功能, 而深度多智能体强化学习帮助智能体自主获得这些能力, 显示此类算法在游戏场景中的优越性.
在机器人领域, 深度多智能体强化学习在多机器人的应用场景中得到一定应用, 主要是通过提升多个机器人之间的协作能力, 进而改进系统的性能和效率.近年来, 深度强化学习方法在单机器人导航、抓取等任务中取得一定成果.Wang等[134]搭建一套包括机械手、移动基座和视觉系统的移动机器人抓取系统, 利用深度目标姿态估计算法[135]进行目标信息感知, 使用近端策略优化算法帮助机器人学到自主移动及物体抓取策略.
自主避障和路径规划是移动机器人底层应用的关键技术, 而在多机器人的应用场景中, 需要进一步考虑机器人之间的协调问题, 实现多机器人之间的避免碰撞和高效通行.Pham等[136]在多无人机目标选取和路径规划任务中, 使用多智能体深度确定梯度下降算法, 优化无人机策略, 使无人机能学到较强的协作能力, 可避免与其它无人机和障碍物的碰撞, 同时最小化其飞行时间.Sartoretti等[137]利用独立Q-Learning单智能体的路径规划, 并使用模仿学习, 学习如何与其它智能体协作以获取更高的团队利益, 并应用在工厂环境中的小型无人驾驶车辆上.
多智能体强化学习的训练过程需要从真实物理场景中获取样本数据, 而采集这些数据往往是十分困难且繁琐的.强化学习解决的序贯决策问题需要消耗大量的时间, 而准确估计策略价值又需要大量的样本, 导致样本采集过程十分缓慢.同时, 采集数据的过程需要大量试错, 会大幅损耗机器人的寿命, 甚至产生不可预知的危险, 使强化学习应用的经济成本较高.因此, 在机器人控制领域, 多智能体强化学习的研究重点在于如何提高样本的利用效率, 即使用少量样本训练可用的模型.另一种思路是如何弥补物理世界和虚拟世界之间的差异, 利用虚拟到现实的迁移技术, 在虚拟平台中训练得到的智能体应用在真实场景中.如何提升多智能体强化学习算法的稳定性和泛化性是另一个十分现实而艰巨的挑战.一种解决思路是对状态空间进行表征学习, 从中选取与决策相关的数据, 进而提升机器人在具有相近策略的不同场景下的泛化能力.
本文主要针对深度多智能体强化学习理论、存在的问题、解决方案及其应用进行深入分析.与目前学界其它综述不同, 本文不仅聚焦于传统MARL领域, 同时将视野转向热门新兴技术与MARL的交叉领域, 也对当前的热门应用方向与成果进行较全面的概括和评述.
现阶段, 深度多智能体强化学习凭借其高度自主的决策能力受到研究人员和社会各界的广泛关注.尽管如此, 当前的深度多智能体强化学习理论还存在许多问题.首先是无法避免的环境非稳态问题, 即如何解决智能体在其它智能体策略变化时完成正确的更新.当前的研究工作大部分还是停留在通过在训练过程引入其它智能体动作缓解该问题, 而这种方法不得不再次应对随智能体数目呈指数增长的组合动作空间.目前有少部分工作开始聚焦于对多智能体组合动作空间进行降维, 按照当前状态对多智能体进行区域化分组, 将组合动作空间分解为多个较小的联合动作空间, 或是按照智能体特性及协作模式为每个智能体提供角色和不同的动作空间, 并以此降低组合动作空间的维度.然而, 这些方法的效果高度依赖分组或是角色的预训练情况, 在实际场景中应用有限.
其次是深度多智能体强化学习中的效用分配问题, 即如何解决在团队奖励时推断每个智能体的贡献度, 进而避免采取正确动作的智能体不受采取错误动作的智能体的影响.当前的研究工作大部分使用值分解的方法实现隐式的效用分配, 而这样的方法并不能真正判断是哪些智能体导致好或坏的结果, 进而在相对过泛化等学习困境下无法收敛到最优策略.虽然已有研究人员提出一些方法以缓解该问题, 如目标重塑, 但这种方法导致算法在很多场景下无法实现效用分配, 降低样本的利用率.能否使用因果推断的方式, 对多智能体的行为和结果建立联系, 并以此推断采取错误动作的智能体, 在值分解方法的基础上实现正确的效用分配, 是一个有前景的研究方向.
尽管深度多智能体强化学习算法在许多虚拟智能决策问题中表现出色, 但其在很多真实场景中仍面临许多挑战, 因此应用具有较大的拓展空间.例如:多智能体场景数据采集困难便是一个重要问题.真实物理场景中的样本数据采集过程繁琐且成本较高, 训练过程缓慢.此外, 现实环境的复杂性和不确定性使RL模型的训练和部署变得更困难.为了解决这些问题, 研究者们提出少量样本训练和虚拟到现实的迁移技术(Sim-to-Real Transfer)[139], 这些技术通过在虚拟环境中进行初步训练, 再将模型迁移到现实环境中进行微调, 从而降低数据采集成本和训练时间.然而对于多智能体场景, 此类多智能体离线强化学习的研究和应用还有待继续发掘.
深度多智能体强化学习还包括单智能体深度强化学习中面临的所有难题, 如探索-利用困境与样本采集难题等.在探索-利用困境中, 当前的研究工作大部分还是停留在启发式的探索模型, 而此类模型的超参数很难调节, 却对收敛结果具有较大影响.为了打破这一瓶颈, 可为采取正确动作的智能体分配较低的探索度, 提升多智能体联合探索到最优策略的可能性.在样本采集难题中, 由于在真实物理环境中的试错成本较高, 无法体现数据驱动的深度多智能体强化学习算法的优势.要突破这一问题, 可研究如何填补真实场景与虚拟环境的鸿沟, 使得在虚拟平台中训练得到的多智能体系统, 能依靠少量的真实样本实现在现实场景中的广泛应用.
另外, 随着大模型的兴起, 多智能体决策大模型的构建也是业内热门的研究方向之一.如何帮助多智能体进行有效训练, 使其具有少样本的泛化能力, 最大化通用决策大模型对新场景的适应能力是一个关键问题.同时, 随着具身智能理论的推进, 结合个人技能学习、策略转移和多人协调合作的多智能体机器人控制也是一个十分具有前景的方向.然而, 如何帮助机器人学到更类人化的灵巧操作而非简单物理建模下的模糊执行是一个难点.再者, 目前该方向的研究也是仅基于简单的仿真环境, 距离现实世界的部署仍有一定距离.
本文责任编委 吴 飞
Recommended by Associate Editor WU Fei
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|
| [47] |
|
| [48] |
|
| [49] |
|
| [50] |
|
| [51] |
|
| [52] |
|
| [53] |
|
| [54] |
|
| [55] |
|
| [56] |
|
| [57] |
|
| [58] |
|
| [59] |
|
| [60] |
|
| [61] |
|
| [62] |
|
| [63] |
|
| [64] |
|
| [65] |
|
| [66] |
|
| [67] |
|
| [68] |
|
| [69] |
|
| [70] |
|
| [71] |
|
| [72] |
|
| [73] |
|
| [74] |
|
| [75] |
|
| [76] |
|
| [77] |
|
| [78] |
|
| [79] |
|
| [80] |
|
| [81] |
|
| [82] |
|
| [83] |
|
| [84] |
|
| [85] |
|
| [86] |
|
| [87] |
|
| [88] |
|
| [89] |
|
| [90] |
|
| [91] |
|
| [92] |
|
| [93] |
|
| [94] |
|
| [95] |
|
| [96] |
|
| [97] |
|
| [98] |
|
| [99] |
|
| [100] |
|
| [101] |
|
| [102] |
|
| [103] |
|
| [104] |
|
| [105] |
|
| [106] |
|
| [107] |
|
| [108] |
|
| [109] |
|
| [110] |
|
| [111] |
|
| [112] |
|
| [113] |
|
| [114] |
|
| [115] |
|
| [116] |
|
| [117] |
|
| [118] |
|
| [119] |
|
| [120] |
|
| [121] |
|
| [122] |
|
| [123] |
|
| [124] |
|
| [125] |
|
| [126] |
|
| [127] |
|
| [128] |
|
| [129] |
|
| [130] |
|
| [131] |
|
| [132] |
|
| [133] |
|
| [134] |
|
| [135] |
|
| [136] |
|
| [137] |
|
| [138] |
|
| [139] |
|