

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于对比学习的多视角特征融合方面级情感分析模型
[伍星1  , 夏鸿斌
, 夏鸿斌1, 2 , 刘渊1, 2 ]
, 夏鸿斌, 刘渊]
|
|



作者简介:

伍 星,硕士研究生,主要研究方向为自然语言处理、深度学习.E-mail:1522327129@qq.com.

刘 渊,博士,教授,主要研究方向为网络安全、社交网络.E-mail:lyuan1800@sina.com.
当前方面级情感分析方法大多通过依赖树和注意力机制提取情感特征,容易受上下文无关信息的噪声干扰,往往忽略对句子全局情感特征的建模,难以处理隐含表达情感的句子.为了解决该问题,文中提出基于对比学习的多视角特征融合方面级情感分析模型(Contrastive Learning Based Multi-view Feature Fusion Model for Aspect-Based Sentiment Analysis, CLMVFF).首先,使用图卷积网络编码依赖图、成分图和语义图中的信息,并在每个图中构建全局情感节点,学习全局情感特征,同时引入外部知识嵌入,丰富情感特征.然后,通过对比学习减少噪声的负面影响,并结合相似度分离增强情感特征.最后,融合依赖图表示、成分图表示、语义图表示和外部知识嵌入,得到多视角特征增强表示.在3个数据集上的实验表明,CLMVFF的性能取得一定提升.
About Author:
WU Xing, Master student. His research interests include natural language processing and deep learning.
LIU Yuan, Ph.D., professor. His research interests include network security and social network.
Current aspect-based sentiment analysis methods typically extract sentiment features through dependency tree and attention mechanism. These methods are susceptible to noise from irrelevant contextual information and often neglect to model the global sentiment features of sentences, making it difficult to process sentences that implicitly express sentiment. To address these problems, a contrastive learning based multi-view feature fusion model for aspect-based sentiment analysis(CLMVFF) is proposed. First, graph convolutional networks are utilized to encode information in dependency graph, constituent graph and semantic graph. The global sentiment node is constructed in each graph to learn global sentiment features while introducing external knowledge embedding to enrich sentiment features. Second, contrastive learning is exploited to mitigate the negative influence of noise. Combined with the similarity separation, the sentiment features are enhanced. Finally, the dependency graph representation, constituent graph representation, semantic graph representation and external knowledge embeddings are fused. Experimental results on three datasets demonstrate that CLMVFF achieves the improvement of performance.
方面级情感分析(Aspect-Based Sentiment Ana-lysis, ABSA)的目标是识别文本中特定方面项的情感极性, 它是一种细粒度的情感分类任务[1].因此, 不同于传统的句子级情感分析, 方面级情感分析可精准识别句子中每个方面项的情感极性, 而不是只给整个句子仅分配一个笼统的情感标签.得益于这一特性, 当前方面级情感分析在学术界和工业界都受到广泛关注[2].
方面级情感分析的关键在于准确捕捉方面项与对应观点项之间的关系.最近的研究提出多种注意力机制, 对方面项和上下文之间的语义关系进行建模以获得相关情感信息[3, 4, 5, 6].此外, 也有研究者使用依存分析构建依赖树, 再利用方面项与观点项之间的句法依赖关系进行情感分析[7, 8, 9].尽管这些方法取得一定进展, 但无关的上下文会有一定干扰.一方面, 基于注意力机制的方法可能会错误地让与方面项无关的单词获得较高的注意力分数.另一方面, 在基于句法的方法中, 依赖树也可能由于多个方面项之间的相互干扰而存在噪声.因此, 现有方法难以有效对抗无关上下文的干扰, 这会阻碍情感分析.
此外, 现有方法主要聚焦于对句子中单词之间的关系进行编码, 往往忽略句子的全局情感特征.当方面项的情感被隐含表达时, 仅依靠注意力机制或基于句法的方法难以准确捕捉相应观点项的上下文.因此, 在情感分析过程中, 增加对句子全局情感特征的建模尤为重要.
Chai等[10]提出A2SMvCL(Aspect-to-Scope Multi-view Contrastive Learning), 缓解无关上下文的干扰.A2SMvCL让依赖图句法表示和语义表示进行对比学习, 在一定程度上减少无关上下文带来的负面影响.但是句法表示和语义表示之间应存在显著差异[3], 而在对比学习的作用下, 句法表示和语义表示会变得靠近, 这可能会降低情感特征丰富性, 不利于两种表示之间的信息互补.同时A2SMvCL也未考虑对句子全局情感特征的建模.
针对上述问题, 本文改进A2SMvCL, 提出基于对比学习的多视角特征融合方面级情感分析模型(Contrastive Learning Based Multi-view Feature Fusion Model for Aspect-Based Sentiment Analysis, CLMVFF).受到EMGF(Extensible Multi-granularity Fusion)[11]的启发, 引入成分树, 得到另一种视角下的句法表示.同时, 使用Zhong等[12]提出的外部知识嵌入, 进一步丰富情感特征.具体来说, CLMVFF首先通过图卷积网络(Graph Convolutional Networks, GCN)编码依赖图、成分图和语义图中的句法和语义信息, 并在每个图中构建一个全局情感节点, 学习句子的全局情感特征.再让依赖图句法表示和成分图句法表示进行对比学习, 同时将语义表示和这两种句法表示进行相似度分离, 在减少无关上下文干扰的同时, 确保语义信息和句法信息互补.然后, 融合依赖图表示、成分图表示、语义图表示和外部知识嵌入这四种视角下的特征, 得到多视角特征增强表示.最后, 将多视角特征增强表示中方面项范围内的表示进行均值池化, 得到局部情感表示, 并与全局情感表示拼接, 结果输入softmax层中进行情感预测.
最初, 方面级情感分析主要通过支持向量机、词袋等传统的机器学习技术完成对情感的预测[13, 14].之后, 随着深度学习的不断发展, 研究者开始探索使用长短期记忆网络(Long Short-Term Memory, LSTM)和注意力机制挖掘文本中更深层次的语义信息.近年来, 使用图神经网络对文本句法信息进行建模也成为一种主流方法.此外, 还有研究者尝试结合不同的图处理ABSA任务.因此, 当前对ABSA的研究大致可分为三类:基于注意力机制的方法、基于句法的方法和多图结合的方法.
学者们提出各种注意力机制, 用于捕捉方面项与其上下文之间的语义关系.Tan等[4]利用具有双注意机制的多标签分类模型, 对具有多种情感极性的句子进行情感分析.Hu等[15]提出CAN(Con-strained Attention Networks), 对多个方面项进行正交正则化, 对单个方面项进行稀疏正则化, 从而减少注意力机制可能带来的噪声.Fan等[16]提出MGAN(Multi-grained Attention Network), 通过一种多粒度的注意力机制, 捕捉方面项和上下文之间的交互关系.Song等[17]提出AEN(Attentional Encoder Net-work), 使用一种注意力编码器网络, 在上下文和方面项之间进行建模, 同时引入标签平滑正则化.Liu等[18]提出AOAN(Aspect-Oriented Opinion Alignment Network), 结合相邻跨度增强模块和多视角注意力机制, 对齐方面项与相应观点项.
当前还有研究者通过学习句法关系构建方面项和观点项之间的联系.Sun等[19]提出CDT(Convolu-tion over a Dependency Tree), 将依赖树与图神经网络集成, 进行方面项的情感表示学习.Liang等[20]提出InterGCN(Interactive Graph Convolutional Net-works), 利用方面项和上下文之间的依赖关系, 为每个样本构建异构图, 能有效学习方面项的情感特征.Zhao等[21]提出SDGCN(Sentiment Dependencies with Graph Convolutional Networks), 结合位置编码和GCN, 捕获句子中不同方面项之间的情感依赖关系.Tian等[22]提出T-GCN(Type-Aware Graph Convolu-tional Networks), 同时使用通过依存分析获得的依赖关系和依赖类型信息, 为上下文和方面项之间关系的分析提供较好的句法信息指导.Jiang等[23]提出WGAT(Relation-Weighted Graph Attention Network Model), 根据不同依赖关系的重要程度构造依赖加权邻接矩阵, 解决对句法依赖类型利用不足的问题.
随着对图神经网络研究的不断加深, 一些研究者探索将不同的图结合后用于ABSA任务.Feng等[24]提出AG-VSR(Attention-Assisted Graph and Va-riational Sentence Representation), 将单词间的自注意力分数作为边, 单词表示作为节点, 构建注意力机制图, 然后使用注意力机制图调整依赖树构建的图, 从而提升模型的鲁棒性.Chai等[10]提出A2SM-VCL, 通过依赖树和注意力机制获得的两种表示进行对比学习, 减少无关上下文的干扰.Wang等[25]提出DAGCN(Distance-Based and Aspect-Oriented Graph Convolutional Network), 利用基于距离的句法权重图和通过方面融合注意力机制构建的图, 对方面项对应的观点项进行精确识别.Chen等[26]提出S2GSL(Segment to Syntactic Enhanced Graph Structure Lear-ning for ABSA), 同时利用段落感知的语义图和基于句法的潜在图建模方面项与其上下文之间的情感关系.
本文提出基于对比学习的多视角特征融合方面级情感分析模型(CLMVFF), 结构如图1所示.
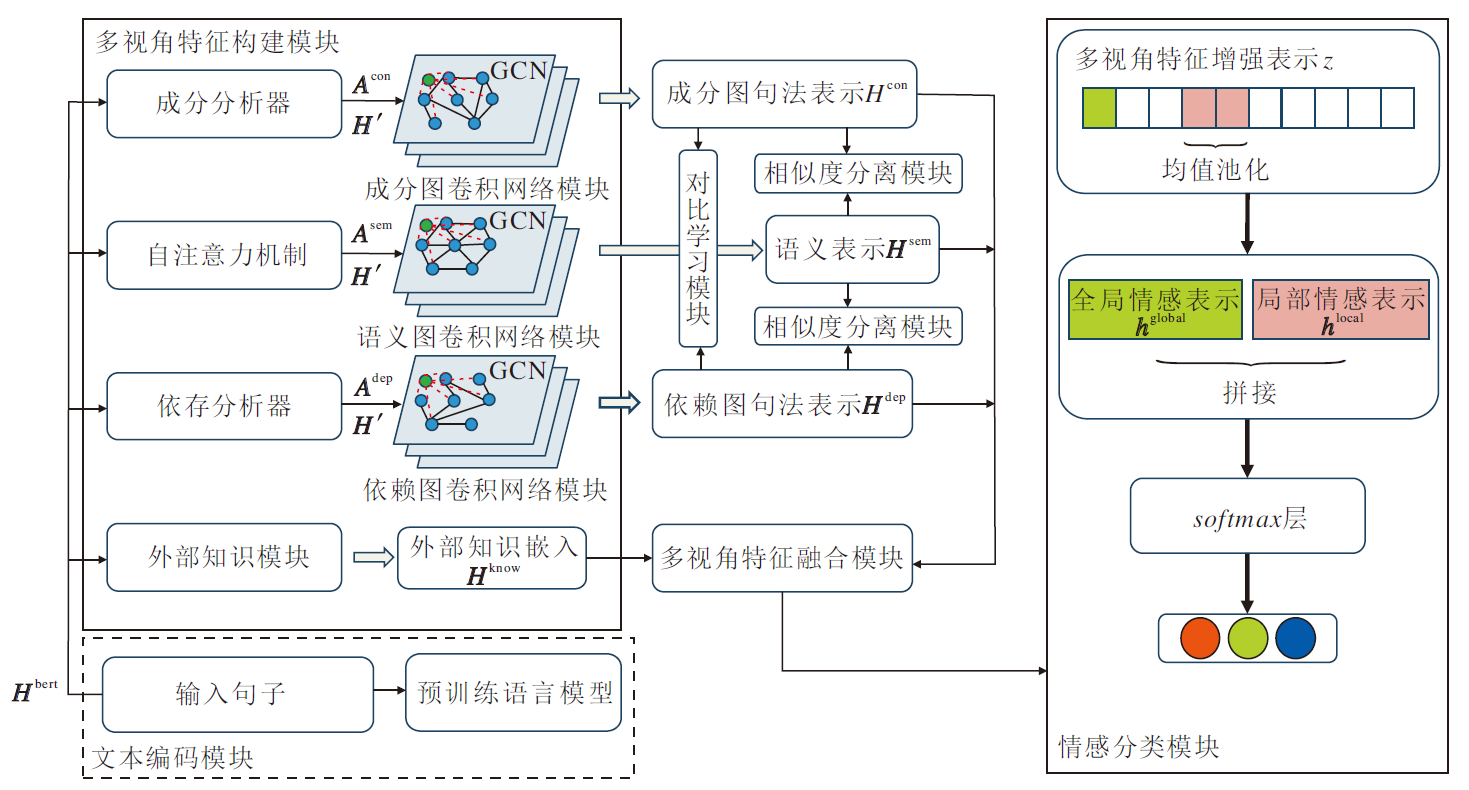 | 图1 CLMVFF结构图Fig.1 Structure of CLMVFF |
CLMVFF由6部分组成:文本编码模块、多视角特征构建模块、对比学习模块、相似度分离模块、多视角特征融合模块、情感分类模块.
给定一个由n个单词组成的句子
$s=\left\{w_{1}, w_{2}, \cdots, w_{n}\right\}$
以及句子中由m个单词构成的方面项
a={wj+1, wj+2, …, wj+m},
其中wi表示句子s中的第i个单词.方面项a是句子s的一个子序列.方面级情感分析旨在识别方面项a的情感极性pa,
pa∈ {Positive, Neutral, Negative}.
文本编码模块用于将输入序列转化为上下文表示.为了获得高质量的上下文表示, 本文采用预训练语言模型BERT(Bidirectional Encoder Representations from Transformers)[27]作为文本编码器.
遵循Song等[17]提出的BERT-SPC(BERT for Sentence Pair Classification), 本文将一个句子-方面项序列输入BERT编码器中.句子-方面项序列表示为
[CLS]s[SEP]a[SEP],
其中, [CLS]表示BERT的分类标记符号, 最终隐藏状态可作为下游分类任务的序列整体表示, [SEP]表示BERT的分隔标记符号, 用于分隔不同序列[27].将BERT输出的上下文表示记作
$\boldsymbol{H}^{\text {bert }}=\left[\boldsymbol{h}_{1}^{\text {bert }}, \boldsymbol{h}_{2}^{\text {bert }}, \cdots, \boldsymbol{h}_{n}^{\text {bert }}\right] \in \mathbf{R}^{n \times d_{m}} .$
其中,
多视角特征构建模块由依赖图卷积网络模块、成分图卷积网络模块、语义图卷积网络模块和外部知识模块构成, 得到4种视角下的情感特征.
2.3.1 依赖图卷积网络模块
首先, 对输入句子s进行依存分析, 得到依赖树.将句子s中的每个单词作为节点, 并根据依赖树获得每个节点之间的连接关系, 从而构建依赖图.此外, 在依赖图中还构建一个全局情感节点hglobal, 并将BERT的[CLS]标记符号向量作为这个全局情感节点的初始表示, 因为[CLS]标记符号向量可代表序列整体表示[27].然后, 让全局情感节点hglobal和其它所有节点相连, 利用图卷积网络学习句子的全局情感特征.图1中GCN里的绿色节点表示全局情感节点, 红色虚线表示全局情感节点和其它节点相连.
依赖图卷积网络的邻接矩阵
$\boldsymbol{A}^{\mathrm{dep}} \in \mathbf{R}^{L_{\operatorname{dep}} \times(n+1) \times(n+1)}, $
其中Ldep表示依赖图卷积网络的层数,
$A_{i j}^{\operatorname{dep}(l)}=\left\{\begin{array}{ll} 1, & \operatorname{link}(i, j)=1 \text { or } i=0 \text { or } j=0 \\ 0, & \text { 其它 } \end{array}\right.$
link(i, j)=1为在第l层中句子s的第i个单词和第j个单词之间存在句法依赖关系.i=0 or j=0时,
拼接[CLS]标记符号向量与上下文表示Hbert, 结果表示为
$\boldsymbol{H}^{\prime}=\boldsymbol{h}^{\text {global }} \oplus \boldsymbol{H}^{\text {bert }}$
然后, 输入H'到依赖图卷积网络中, 对句法信息进行编码, 得到依赖图句法表示:
$\boldsymbol{H}^{\mathrm{dep}}=\left\{\boldsymbol{h}_{0}^{\mathrm{dep}}, \boldsymbol{h}_{1}^{\mathrm{dep}}, \cdots, \boldsymbol{h}_{n}^{\mathrm{dep}}\right\}, $
其中,
图卷积网络第l层第i个节点的隐藏状态表示为
$\boldsymbol{h}_{i}^{l}=\sigma\left(\sum_{j=0}^{n} A_{i j}^{l} \boldsymbol{W}^{l} \boldsymbol{h}_{j}^{l-1}+\boldsymbol{b}^{l}\right), $ (1)
其中, $ \boldsymbol{W}^{l} \in \mathbf{R}^{d_{m} \times d_{m}} 、 \boldsymbol{b}^{l} \in \mathbf{R}^{d_{m}}$分别为图卷积网络第l层的权重矩阵和偏置, σ 为激活函数ReLU.
2.3.2 成分图卷积网络模块
在EMGF[11]的启发下, 本文使用成分树获得另一种视角下的句法表示.使用成分分析器解析输入句子s, 得到成分树.成分树分割输入句子, 得到若干个短语, 根据这些短语构建相应的成分图.与依赖图一样, 在成分图中也额外构建一个与其它节点相连并用[CLS]标记符号向量初始化的全局情感节点hglobal.
成分图卷积网络的邻接矩阵
$\boldsymbol{A}^{\mathrm{con}} \in \mathbf{R}^{L_{\mathrm{con}} \times(n+1) \times(n+1)}, $
其中, Lcon为成分图卷积网络的层数,
$A_{i j}^{\operatorname{con}(l)}=\left\{\begin{array}{ll} 1, & \operatorname{samePh}\left(w_{i}, w_{j}\right)=1 \text { or } i=0 \text { or } j=0 \\ 0, & \text { 其它 } \end{array}\right.$
samePh(wi, wj)=1为在第l层中第i个单词和第j个单词在同一个短语中.i=0 or j=0时,
按照式(1)的方式进行图卷积, 输出成分图句法表示:
$\boldsymbol{H}^{\text {con }}=\left\{\boldsymbol{h}_{0}^{\text {con }}, \boldsymbol{h}_{1}^{\text {con }}, \cdots, \boldsymbol{h}_{n}^{\text {con }}\right\}, $
其中,
2.3.3 语义图卷积网络模块
为了得到句子中的语义信息, 将H'输入自注意力机制, 得到注意力分数矩阵.此处的全局情感节点hglobal也由[CLS]标记符号向量初始化.然后, 将H'中的每个向量作为节点, 节点间的注意力分数作为边, 构建语义图.
语义图卷积网络的邻接矩阵
Asem∈
其中, Lsem为语义图卷积网络的层数,
$\boldsymbol{A}^{\operatorname{sen}(l)}=\operatorname{softmax}\left(\frac{\left(\boldsymbol{Q} \boldsymbol{W}_{q}\right)\left(\boldsymbol{K} \boldsymbol{W}_{k}\right)^{\mathrm{T}}}{\sqrt{d_{m}}}\right), $
Q和K都赋值为H', Wq∈
然后, 按照式(1)对语义图进行图卷积, 输出语义表示:
Hsem={
其中,
2.3.4 外部知识模块
为了提高情感特征的丰富程度, 本文将Zhong等[12]提出的外部知识嵌入Hek与上下文表示Hbert以及全局情感节点hglobal结合, 得到更全面的情感特征:
Hknow=hglobal(Wknow([Hek; Hbert])+bknow),
其中, hglobal由[CLS]标记符号向量进行初始化, 为在数量维度上进行拼接, Wknow∈
Hknow={
其中,
在Chai等[10]的启发下, 本文对成分图和依赖图使用对比学习, 减少无关上下文的噪声干扰.对比学习模块的结构如图2所示.模块由两个部分构成:图内对比学习和图间对比学习.将成分图中节点表示为{ui}i∈ [0, n], 依赖图中的节点表示为{vi}i∈ [0, n], ui和vi分别对应Hcon和Hdep中的
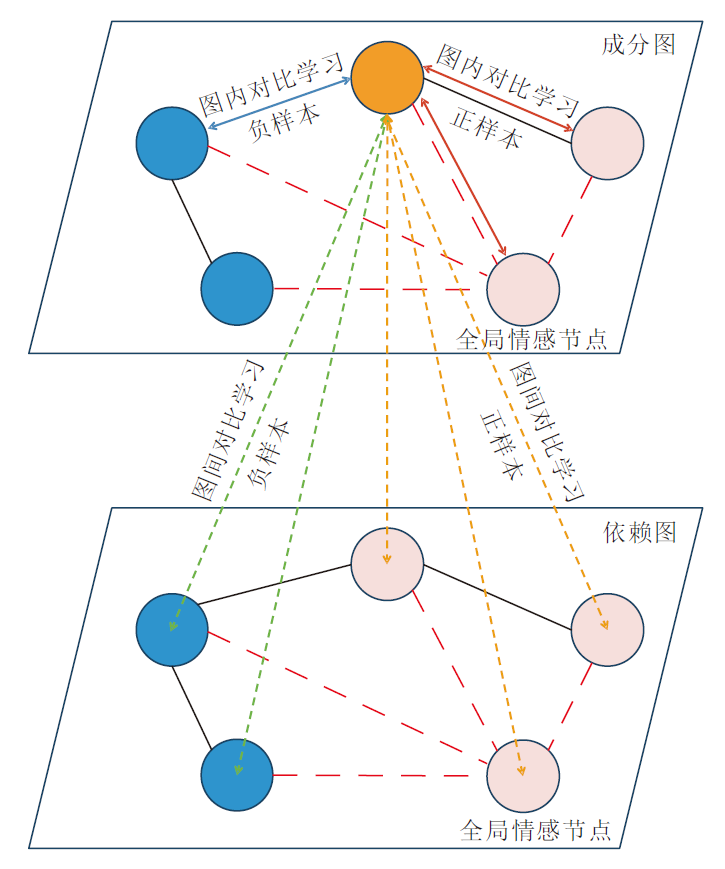 | 图2 对比学习模块结构图Fig.2 Structure of contrastive learning module |
2.4.1 图内对比学习
以成分图的视角为例, 在图内对比学习过程中, 先将成分图中的方面项节点定义为锚节点ua, 即图2中的橙色节点.然后, 将成分图中与方面项相关的节点作为正样本(图2中成分图的粉色节点), 成分图中其它节点作为负样本(图2中成分图的蓝色节点), 遵循InfoNCE函数[28]计算图内对比学习损失:
$\begin{array}{l} L_{\text {intra }}^{U}\left(\boldsymbol{u}_{a}, \boldsymbol{S}^{u}\right)= \\ -\ln \left(\frac{\sum_{\boldsymbol{u}_{j} \in S^{u}} \exp \left(\frac{\operatorname{sim}\left(\sigma\left(\boldsymbol{u}_{a}\right), \sigma\left(\boldsymbol{u}_{j}\right)\right)}{\tau}\right)}{\sum_{\boldsymbol{u}_{k} \notin S^{u}} \exp \left(\frac{\operatorname{sim}\left(\sigma\left(\boldsymbol{u}_{a}\right), \sigma\left(\boldsymbol{u}_{k}\right)\right)}{\tau}\right)} .\right. \end{array}$ (2)
其中:uj为成分图中与方面项节点相关的节点, j≠ a; uk为成分图中其它节点, k≠ a; τ 为温度参数; 函数sim(· , · )为余弦相似度, σ (· )为非线性映射函数ReLU.
使用与式(2)相同的方式计算依赖图的图内对比损失
$L_{\text {intra }}=\frac{1}{N_{B}} \sum_{\substack{\boldsymbol{u}_{a} \in \boldsymbol{B} \\ \boldsymbol{v}_{a} \in \boldsymbol{B} \\ \boldsymbol{S}^{u} \in \boldsymbol{B} \\ \boldsymbol{S}^{v} \in \boldsymbol{B}}}\left(L_{\text {intra }}^{U}\left(\boldsymbol{u}_{a}, \boldsymbol{S}^{u}\right)+L_{\text {intra }}^{V}\left(\boldsymbol{v}_{a}, \boldsymbol{S}^{v}\right)\right), $
其中, B为训练时的一个批次, NB为批次的大小, va为Hdep中的方面项节点表示.
2.4.2 图间对比学习
图间对比学习可捕捉不同图之间的相关性, 进一步将方面项表示与相关单词的表示靠近, 与无关单词的表示远离, 减少无关上下文的干扰.
同样以成分图的视角为例, 在图间对比学习过程中, 仍将成分图的方面项节点定义为锚节点ua.然后, 将依赖图中的方面项节点及方面项相关节点作为正样本(图2中依赖图的粉色节点), 依赖图中的其它节点作为负样本(图2中依赖图的蓝色节点), 计算图间对比学习损失:
$l\left(\boldsymbol{u}_{a}, \boldsymbol{v}_{a}, \boldsymbol{S}^{v}\right)=-\ln \left(\frac{\sum_{\boldsymbol{v}_{j} \in S^{v}} \exp \left(\delta\left(\frac{\operatorname{sim}\left(\sigma\left(\boldsymbol{u}_{a}\right), \sigma\left(\boldsymbol{v}_{j}\right)\right)}{\tau}\right)\right)+\exp \left(\frac{\operatorname{sim}\left(\sigma\left(\boldsymbol{u}_{a}\right), \sigma\left(\boldsymbol{v}_{a}\right)\right)}{\tau}\right)}{\sum_{\boldsymbol{v}_{k} \notin S^{v}} \exp \left(\frac{\operatorname{sim}\left(\sigma\left(\boldsymbol{u}_{a}\right), \sigma\left(\boldsymbol{v}_{k}\right)\right)}{\tau}\right)}\right) .$ (3)
其中:δ =sim(· , · ), 表示给两种正样本分配不同权重; vj为依赖图中与方面项相关的节点, j≠ a; vk为依赖图中其它节点, k≠ a.
由于成分图和依赖图这两种视角是对称的, 因此, 与式(3)类似, 可得到依赖图视角的图间对比学习损失l(va, ua, Su).将两个图间对比损失相加, 可得到完整的图间对比损失:
$L_{\text {inter }}=\frac{1}{2 N_{B}} \sum_{\substack{\boldsymbol{u}_{a} \in \boldsymbol{B} \\ \boldsymbol{v}_{a} \in \boldsymbol{B} \\ \boldsymbol{S}^{u} \in \boldsymbol{B}}}\left(l\left(\boldsymbol{u}_{a}, \boldsymbol{v}_{a}, \boldsymbol{S}^{v}\right)+l\left(\boldsymbol{v}_{a}, \boldsymbol{u}_{a}, \boldsymbol{S}^{u}\right)\right) .$
最后, 将图内对比学习损失和图间对比学习损失相加, 得到完整的对比学习损失:
Lcl=Lintra+Linter.
相似的句法表示和语义表示可能会降低情感特征的丰富程度, 不利于不同表示之间情感信息的互补.因此, 有必要对句法表示和语义表示进行相似度分离, 让不同类型的表示能学到具有一定差异的特征.本文提出基于KL散度(Kullback-Leibler Diver-gence)的相似度分离方法, 让模型能更有效地学习句法和语义这两种不同视角的情感特征.语义表示和依赖图句法表示的相似度分离损失如下所示:
$L_{k l}^{\prime}\left(\boldsymbol{H}^{\mathrm{sem}}, \boldsymbol{H}^{\mathrm{dep}}\right)=\sum_{i=1}^{N_{B}} \ln \left(1+\frac{2}{\left|K L\left(\boldsymbol{H}_{i}^{\mathrm{dep}} \| \boldsymbol{H}_{i}^{\mathrm{sem}}\right)\right|+\left|K L\left(\boldsymbol{H}_{i}^{\mathrm{sem}} \| \boldsymbol{H}_{i}^{\mathrm{dep}}\right)\right|}\right), $
其中
$\begin{array}{l} K L\left(\boldsymbol{H}_{i}^{\mathrm{dep}} \| \boldsymbol{H}_{i}^{\mathrm{sem}}\right)=\sum_{j=0}^{n} \varphi\left(\boldsymbol{h}_{i j}^{\mathrm{dep}}\right) \ln \left(\frac{\varphi\left(\boldsymbol{h}_{i j}^{\mathrm{dep}}\right)}{\varphi\left(\boldsymbol{h}_{i j}^{\mathrm{sem}}\right)}\right), \\ K L\left(\boldsymbol{H}_{i}^{\mathrm{sem}} \| \boldsymbol{H}_{i}^{\mathrm{dep}}\right)=\sum_{j=0}^{n} \varphi\left(\boldsymbol{h}_{i j}^{\mathrm{sem}}\right) \ln \left(\frac{\varphi\left(\boldsymbol{h}_{i j}^{\mathrm{sem}}\right)}{\varphi\left(\boldsymbol{h}_{i j}^{\mathrm{dep}}\right)}\right), \end{array}$
φ (· )为softmax函数,
$L_{k l}^{\prime}\left(\boldsymbol{H}^{\mathrm{sem}}, \boldsymbol{H}^{\mathrm{con}}\right)=\sum_{i=1}^{N_{B}} \ln \left(1+\frac{2}{\left|K L\left(\boldsymbol{H}_{i}^{\mathrm{con}} \| \boldsymbol{H}_{i}^{\mathrm{sem}}\right)\right|+\left|K L\left(\boldsymbol{H}_{i}^{\mathrm{sem}} \| \boldsymbol{H}_{i}^{\mathrm{con}}\right)\right|}\right) .$
最后, 得到相似度分离损失:
$L_{\mathrm{kl}}=L_{\mathrm{kl}}^{\prime}\left(\boldsymbol{H}^{\mathrm{sem}}, \boldsymbol{H}^{\mathrm{dep}}\right)+L_{\mathrm{kl}}^{\prime}\left(\boldsymbol{H}^{\mathrm{sem}}, \boldsymbol{H}^{\mathrm{con}}\right) .$
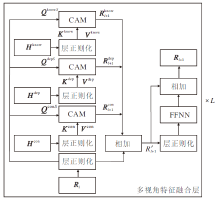
由于Hdep、Hcon、Hsem、Hknow是从不同视角得到的特征, 直接使用拼接的方式聚合可能难以充分利用它们蕴含的情感信息, 因此, 本文设计多视角特征融合模块, 让这些特征相互融合补充.该模块的结构如图3所示.
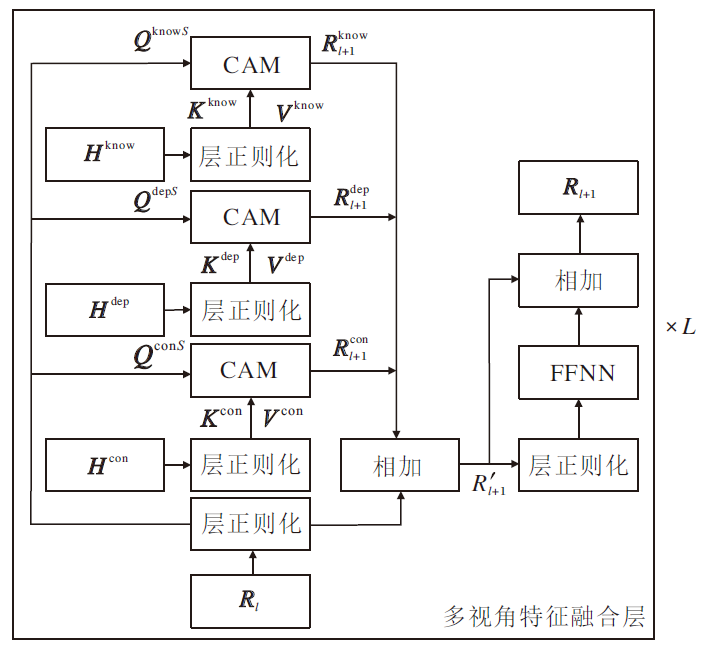 | 图3 多视角特征融合模块结构Fig.3 Structure of Multi-view feature fusion module |
多视角特征融合模块由L个多视角特征融合层构成, 第l层的输入为Rl、Hdep、Hcon、Hknow.当l=0时, R0=Hsem.先将输入的Rl、Hdep、Hcon、Hknow各自进行层正则化, 然后使用交叉注意力机制(Cross Attention Mechanism, CAM)进行特征融合, 具体过程如下:
$\begin{aligned} \boldsymbol{R}_{l+1}^{x}= & \operatorname{CAM}\left(\boldsymbol{Q}^{x S}, \boldsymbol{K}^{x}, \boldsymbol{V}^{x}\right)= \\ & \operatorname{softmax}\left(\frac{\left(\boldsymbol{Q}^{x S} \boldsymbol{W}_{Q}^{x}\right)\left(\boldsymbol{K}^{x} \boldsymbol{W}_{K}^{x}\right)^{\mathrm{T}}}{\sqrt{d_{m}}}\right)\left(\boldsymbol{V}^{x} \boldsymbol{W}_{v}^{x}\right), \end{aligned}$
其中
$\begin{array}{l} \boldsymbol{Q}^{x S}=\operatorname{LayerNorm}\left(\boldsymbol{R}_{l}\right), \\ \boldsymbol{K}^{x}=\operatorname{LayerNorm}\left(\boldsymbol{H}^{x}\right), \\ \boldsymbol{V}^{x}=\operatorname{LayerNorm}\left(\boldsymbol{H}^{x}\right), \\ x \in\{\operatorname{dep}, \operatorname{con}, \mathrm{know}\}, \end{array}$
S为sem, LayerNorm(· )为层正则化, W
然后, 将
$\boldsymbol{R}_{l+1}^{\prime}=\boldsymbol{R}_{l+1}^{\mathrm{dep}}+\boldsymbol{R}_{l+1}^{\mathrm{con}}+\boldsymbol{R}_{l+1}^{\mathrm{know}}+\text { LayerNorm }\left(\boldsymbol{R}_{l}\right) .$
最后, 对R'l+1使用层正则化, 再输入前馈神经网络中, 并进行残差连接, 第l+1层输出为:
$\boldsymbol{R}_{l+1}=\operatorname{FFNN}\left(\operatorname{LayerNorm}\left(\boldsymbol{R}_{l+1}^{\prime}\right)\right)+\boldsymbol{R}_{l+1}^{\prime} \in \mathbf{R}^{(n+1) \times d_{m}}, $
其中FFNN(· )表示前馈神经网络.
将多视角特征融合模块最后一层的输出记为多视角特征增强表示z=RL.
情感分类模块可预测情感极性.首先, 将多视角特征增强表示z中的方面项单词表示进行均值池化, 得到局部情感表示:
$\boldsymbol{h}^{\text {local }}=\operatorname{AvgPooling}\left(\boldsymbol{z}_{a_{1}}, \boldsymbol{z}_{a_{2}}, \cdots, \boldsymbol{z}_{a_{m}}\right), $
其中
$\hat{y}_{(s, a)}=\operatorname{softmax}\left(\boldsymbol{W}_{p}\left(\left[\boldsymbol{h}^{\text {global }} ; \boldsymbol{h}^{\text {local }}\right]\right)+\boldsymbol{b}_{p}\right) \in \mathbf{R}^{d_{p}}, $
其中, $ \boldsymbol{W}_{p} \in \mathbf{R}^{d_{p} \times 2 d_{m}} 、 \boldsymbol{b}_{p} \in \mathbf{R}^{d_{p}}$分别为可训练的权重和偏置, dp为情感极性标签的维度.将预测结果和真实标签之间的交叉熵损失定义如下:
$L_{p}=\sum_{(s, a) \in D} y_{(s, a)} \ln \hat{y}_{(s, a)}, $
其中, D包含所有的句子-方面项序列, y(s, a)为情感极性的真实分布.
通过优化情感分类损失Lp、对比学习损失Lcl和相似度分离损失Lkl进行训练, 模型的整体损失如下:
$L(\Theta)=L_{p}+\alpha L_{\mathrm{cl}}+\beta L_{\mathrm{kl}}, $
其中, Θ 为所有需要学习的模型参数, α 、 β 为超参数.
本文采用的实验环境如下:CPU为Intel Core i7 7700K, 内存大小为DDR4 8 GB, GPU为GeForce GTX 3060Ti, 操作系统为win10 64位, 开发环境为Python 3.8.0和Pytorch 2.0.0.
本文使用SemEval 2014任务中的Laptop、Res-taurant数据集以及Dong等[29]构建的Twitter数据集进行实验.Laptop数据集包含笔记本电脑的评论, Restaurant数据集包含餐厅的在线评论, Twitter数据集包含Twitter上的推文.表1统计数据集上3种情感极性的训练集样本数量和测试集样本数量.3个数据集的训练集和测试集均由原始数据集提供, 在此基础上, 本文随机将训练集上20%数据作为验证集.另外, 遵循Li等[3]的工作, 删除数据集上含有冲突标签的方面项和不含任何方面项的句子.
| 表1 实验数据集统计信息 Table 1 Statistical information of experimental datasets |
本文使用SuPar(https://github.com/yzhangcs/parser)解析输入句子, 从而得到依赖树和成分树.BERT的版本为bert-base-uncased, 特征维度dm=768, 失活率为0.3.使用Zhong等[12]提出的外部知识嵌入, 特征维度dek=400.训练模型时批次大小为16, 使用Adam(Adaptive Moment Estimation)优化器, 初始学习率设置为2× 10-5.在Laptop、Res-taurant数据集上, 依赖图卷积网络、成分图卷积网络和语义图卷积网络的层数均为3层, 在Twitter数据集上均为4层.设置损失中超参数α =β =0.15, 对比学习模块中温度参数τ =0.12.此外, 在Laptop、Restaurant数据集上, 多视角特征融合模块层数为3, 在Twitter数据集上层数为4.
评估指标选用常用的准确率(Accuracy, Acc)和Macro-F1(F1).
本文选择如下对比模型.
1)基于注意力机制的方法.
(1)MGAN[16].通过多粒度的注意力机制获得方面项和上下文之间的词级交互.
(2)AEN[17].使用注意力编码器建模上下文和方面项之间的关系.
(3)AOAN[18].利用相邻跨度增强和多视角注意力机制对齐方面项与相应观点项.
2)基于句法的方法.
(1)R-GAT(Relational Graph Attention Net-work)[9].重塑依赖树, 并用关系图注意力网络编码树结构.
(2)CDT[19].结合神经网络和依赖树学习情感特征.
(3)T-GCN[22].结合依赖关系和依赖类型信息, 分析上下文和方面项之间关系.
(4)WGAT[23].根据不同依赖关系的重要度差异, 构造依赖加权邻接矩阵.
3)多图结合的方法.
(1)MGFN(Multi-graph Fusion Network)[1].利用句法依赖关系标签信息和语义信息学习情感特征.
(2)DualGCN(Dual Graph Convolutional Net-works)[3].让句法信息和语义信息互补, 改善情感分类效果.
(3)A2SMvCL[10].通过方面到范围的多视角对比学习减少无关上下文的干扰.
(4)EMGF[11].融合多种粒度的特征, 产生累积效应.
(5)KGAN(Knowledge Graph Augmented Net-work)[12].为情感特征添加外部知识信息.
(6)DAGCN[25].结合句法权重图和方面融合注意力机制, 对齐方面项与观点项.
(7)S2GSL[26].利用段落感知的语义图和基于句法的潜在图捕捉情感特征.
(8)TextGT(Double-View Graph Transformer on Text )[30].设计图Transformer, 紧密耦合图视角和序列视角的编码过程, 缓解过平滑问题.
各模型在3个数据集上的指标值如表2所示.表中黑体数字表示最优值, 斜体数字表示次优值, 对比模型的实验结果均引用自原论文.
| 表2 各模型在3个数据集上指标值对比 Table 2 Metric value comparison of different models on 3 datasets % |
由表2可见, CLMVFF在3个数据集上的指标值均最优, 这表明其在ABSA任务中的有效性.相比次优值, CLMVFF在Laptop、Restaurant数据集上提升较大, 在Twitter数据集上提升较小, 这可能是因为Twitter数据集上句子结构比其它两个数据集更复杂, 情感分析的难度更大.
相比MGAN等基于注意力机制的方法, CLMV-FF在3个数据集上的指标值提升较显著, 因为CLMVFF通过对比学习减少注意力机制对无关上下文的关注.此外, 相比CDT等基于句法的方法, CL-MVFF的指标值也有显著改善, 这表明结合多种句法和语义信息可有效丰富情感特征.同时在对比学习的帮助下, 依赖树中的噪声干扰也得到有效抑制, 可提高ABSA性能.在多图结合的方法中, CLMVFF取得最优值, 这表明通过引入全局情感节点, 能更有效地处理被隐含表达的方面项情感, 增强模型的情感分析能力.通过改进对比学习模块和增加相似度分离模块, CLMVFF具有比A2SMvCL更好的抗噪声干扰能力和特征学习能力.
从整体上看, 相比基于注意力机制的方法, 基于句法的方法在性能上有一定提升, 这可能是因为依赖树可减少方面项与观点项之间的距离, 更有利于捕捉情感特征.此外, 多图结合的方法性能优于基于注意力机制的方法和基于句法的方法, 这是因为多图结合的方法同时利用多种情感特征.
为了研究CLMVFF中各模块的有效性, 设计如下变体进行消融实验.
1)w/o Lcl:去除对比学习模块.
2)w/o global:去除全局情感节点.
3)w/o Lkl:去除相似度分离模块.
4)w/o MVFF:去除多视角特征融合模块, 改为拼接.
此外, 为了探究利用多视角特征进行情感分析的必要性, 还设计如下变体.
1)CLMVFF-dep:保留依赖图卷积网络模块, 去除成分图卷积网络模块、语义图卷积网络模块和外部知识模块.
2)CLMVFF-con:保留成分图卷积网络模块, 去除依赖图卷积网络模块、语义图卷积网络模块和外部知识模块.
3)CLMVFF-sem:保留语义图卷积网络模块, 去除成分图卷积网络模块、依赖图卷积网络模块和外部知识模块.
4)CLMVFF-know:保留外部知识模块, 去除成分图卷积网络模块、语义图卷积网络模块和依赖图卷积网络模块.
在上述四个变体中, 由于只存在一种视角下的特征, 对比学习模块、相似度分离模块和多视角特征融合模块缺少必要的输入, 无法运作, 所以在这4个变体中, 也去除对比学习模块、相似度分离模块和多视角特征融合模块.
各模块具体消融实验结果如表3所示, 表中黑体数字表示最优值.从前4个变体的指标值可看出, 在去除相应模块后, CLMVFF的性能都出现不同程度的下降, 这表明各模块对ABSA任务都是有效的.在去除对比学习模块后, 性能出现大幅下降, 这表明对比学习模块可有效抑制无关上下文的干扰.全局情感节点的去除也对性能造成一定影响, 这说明全局情感节点在处理方面项情感被隐含表达的样本时可起到帮助作用.从表3中还可看出, 去除相似度分离模块后, 模型的情感分析能力也受到一定削弱, 这验证相似度分离模块可增强情感特征, 从而提升ABSA效果.将多视角特征融合模块替换为拼接对模型性能产生较大的负面影响, 这表明多视角特征融合模块可有效聚合不同表示中的情感特征.总之, CLMVFF中各模块在ABSA任务中都发挥重要作用.
| 表3 各模块消融实验结果 Table 3 Ablation experiment results of different modules % |
相比CLMVFF, 后四个变体在3个数据集上的指标值都出现大幅下降, 在难度较大的Twitter数据集上下降最多, 这表明依靠单个视角下的特征进行情感分析的效果有限, 尤其是在处理具有复杂结构的句子时.因此, 在进行情感分析时, 有必要从多个视角学习句子的情感特征.
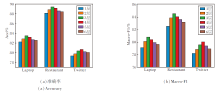
为了评估不同的多视角特征融合模块层数对模型性能的影响, 设置多视角特征融合模块的层数L=1, 2, 3, 4, 5, 6, 并在Laptop、Restaurant和Twitter数据集上进行实验, 结果如图4所示.由图可知, 在Laptop、Restaurant数据集上, 当L=3时, 模型性能最佳.在Twitter数据集上, 当L=4时, 模型表现最优.这可能是因为Twitter数据集的难度较大, 需要更多的层数整合信息.当层数不断增加后, 在3个数据集上, 模型性能都出现一定的下降, 这可能是因为过多的层数使模型变得过拟合, 影响其情感分析能力.
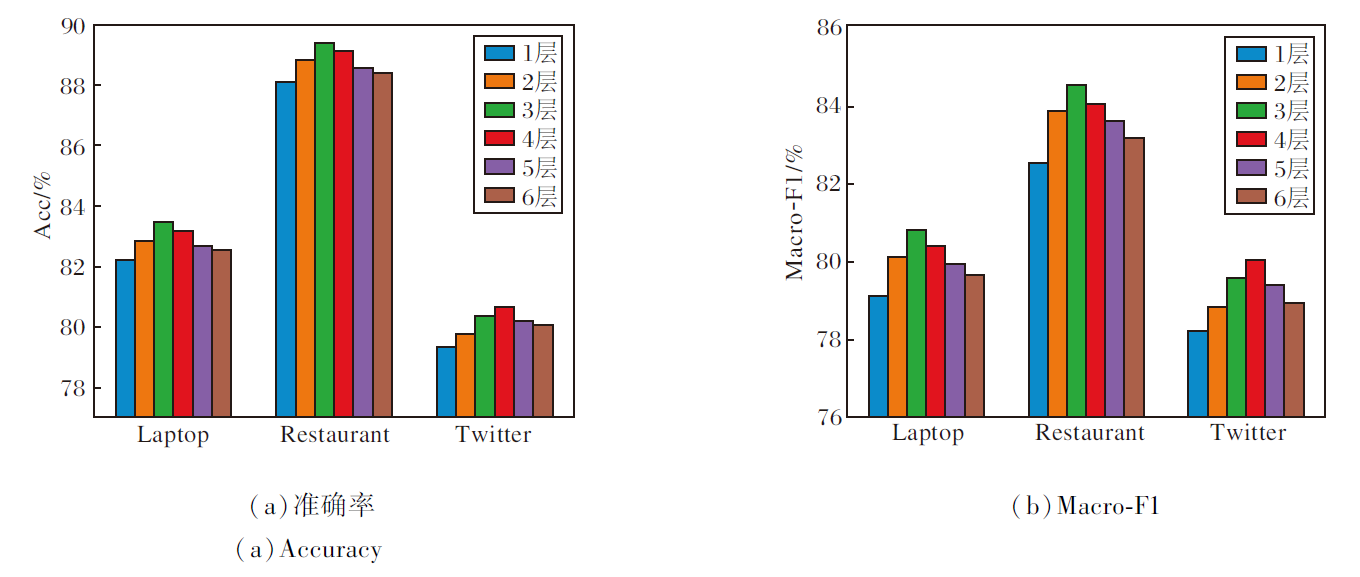 | 图4 多视角特征融合模块层数对CLMVFF性能的影响Fig.4 Effect of the number of multi-view feature fusion module layers on performance of CLMVFF |
为了分析CLMVFF处理各类样本的能力, 从3个数据集上挑选具有代表性的样本进行案例研究, 并与AOAN[18]、A2SMvCL[10]和T-GCN[22]进行对比, 结果如表4所示.在表中, []中内容为方面项, []的下标表示方面项的情感极性标签, p、n、o分别表示积极、消极及中性, √ 、× 分别表示模型预测正确和预测错误.
| 表4 案例研究结果 Table 4 Results of case study |
由表4可见, 在第1个样本中, 方面项food和service具有相反的情感极性, 可能是因为样本句子结构较简单, 所有模型都预测正确.第2个样本对方面项usb ports的情感无明确描述, 可验证模型是否捕捉到全局情感特征.由于AOAN、T-GCN、A2SMvCL并未对全局情感特征进行建模, 所以未能正确分析句子的整体情感, 都预测错误.第3个样本是一个非正式的句子, 无严格的句法结构.对于这类句子, 依存分析难以得到正确结果, 所以只依靠句法信息的T-GCN做出错误预测.第4个样本是包含多个方面项的复杂句子, 可检验模型分析复杂句式的能力, AOAN、T-GCN、A2SMvCL都未能完全正确预测所有方面项的情感极性.对于这4个样本, CLMVFF都可以正确预测, 这表明CLMVFF不仅可有效处理含有多种情感极性的句子, 还可捕捉句子的全局情感特征.此外, 在处理带有非正式结构及复杂结构的句子时, CLMVFF也可利用多种句法和语义信息对情感进行准确预测.
所有模型都错误预测第5个样本的情感, 这可能是因为隐式方面项干扰显式方面项的情感分析.通过分析句义可知, fast应该表达对某种电脑的积极情感, 但是由于句子中未明确出现这个方面项, CLMVFF无法将fast与正确的方面项配对, 这就让fast误导对显式方面项programs的情感分析.因此, CLMVFF缺乏有效处理隐式方面项的能力.这导致在分析含有隐式方面项的句子情感时, CLMVFF表现不佳.
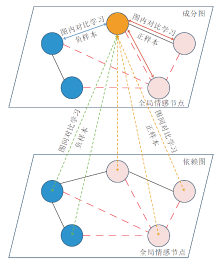
为了研究CLMVFF减少噪声干扰的效果, 选择Restaurant数据集上含有多个方面项的样本进行实验, 并在图5中对方面项与句子中其它单词之间的注意分数进行可视化.图5案例1中方面项与相应观点项为(food, Great)、(service, dreadful), 案例2中方面项与相应观点项为(food, good and popular)、(waiting, nightmare), 图中无数字部分表示将方面项与自身之间的注意力分数屏蔽, [global]表示全局情感节点.
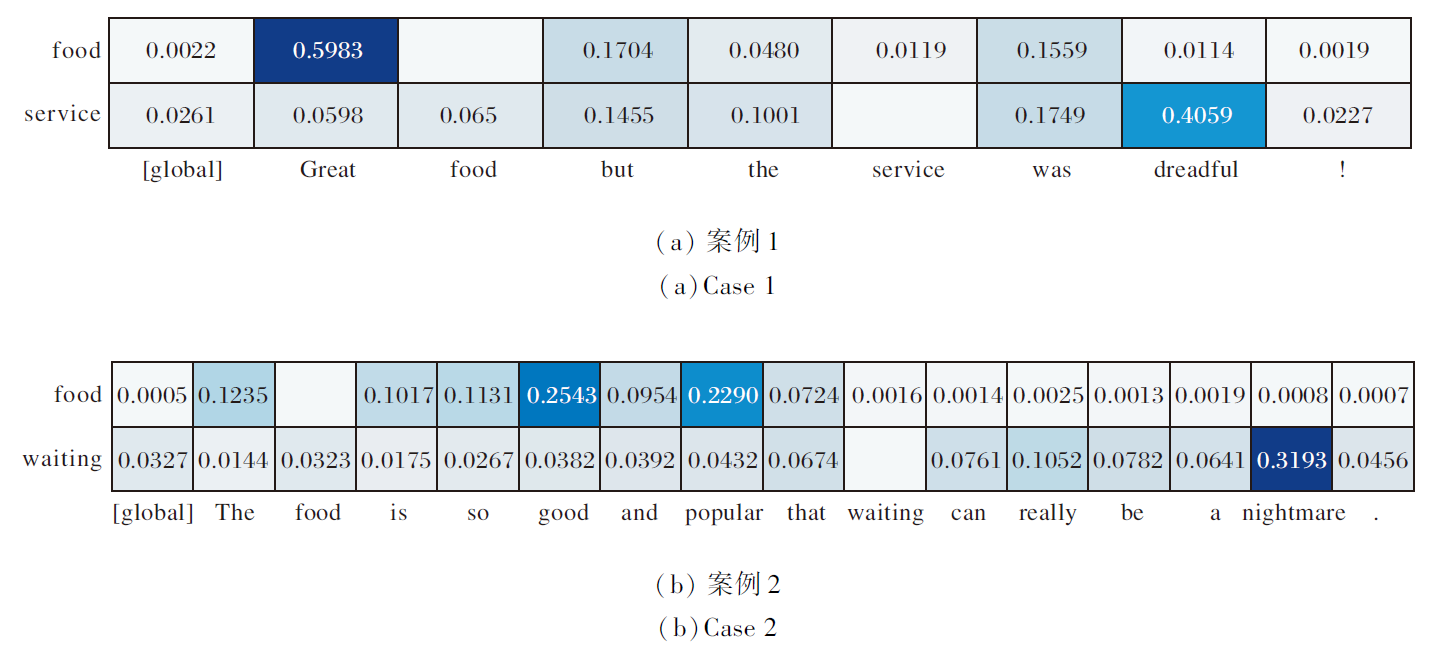 | 图5 多方面项样本注意力分数可视化结果Fig.5 Attention score visualization results of samples with multiple aspects |
从两个案例可发现, 方面项与相应观点项之间的注意力分数明显高于方面项与其它单词之间的注意力分数.这表明CLMVFF确实可有效减少无关单词的干扰, 准确对齐方面项与相应观点项, 提高ABSA性能.
本文改进当前方面级情感分析模型中的缺陷, 提出基于对比学习的多视角特征融合方面级情感分析模型(CLMVFF).CLMVFF使用多视角特征融合模块融合依赖图句法信息、成分图句法信息、语义信息及外部知识信息, 并利用对比学习减少无关上下文的干扰, 同时对句法表示和语义表示进行相似度分离以增强情感特征.考虑到方面项情感存在被隐含表达的情况, 还对全局情感特征进行学习, 这提升CLMVFF的情感分析能力.在3个公共基准数据集上的实验结果表明, CLMVFF性能较优.此外, 消融实验也验证CLMVFF各模块的有效性.今后将考虑增强模型处理隐式方面项的能力, 并拓展模型功能, 使其可同时提取句子中的方面项、观点项及情感极性.
本文责任编委 林鸿飞
Recommended by Associate Editor LIN Hongfei
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|