

{kind=link}
{kind=link}
{kind=link}
基于局部对比学习与新类特征生成的小样本图像分类
[陈宁1  , 刘凡
, 刘凡1 , 董晨炜1 , 陈峙宇1 ]
, 刘凡, 董晨炜, 陈峙宇]
|
|



作者简介:

陈 宁,硕士研究生,主要研究方向为计算机视觉、图像分类、目标检测.E-mail:cn@hhu.edu.cn.

董晨炜,硕士研究生,主要研究方向为深度学习、噪声关联.E-mail:dongchenwei@hhu.edu.cn.

陈峙宇,硕士研究生,主要研究方向为计算机视觉、图像分类.E-mail:hhuczy@yeah.net.
现有的图像分类方法通常依赖于大规模的标注数据,但当数据有限时,方法在局部特征表示能力和样本数量上都存在不足.为了缓解此问题,文中提出基于局部对比学习与新类特征生成的小样本图像分类方法.首先,引入局部对比学习,将图像表示为多个局部特征并进行监督对比学习,增强模型的局部特征表示能力.然后,通过全局对比学习,确保图像整体特征的可分性.最后,在对比学习的基础上,提出特征生成方法,利用基类数据的类别原型生成新类别的样本特征,有效缓解小样本条件下的数据不足问题.在公共数据集上的实验表明,文中方法性能较优.
About Author:
CHEN Ning, Master student. His research interests include computer vision, image cla-ssification and object detection.
DONG Chenwei, Master student. His research interests include deep learning and noisy correspondence.
CHEN Zhiyu, Master student. His research interests include computer vision and image classification.
The existing image classification methods depend on large-scale manually annotated data. However, when data is limited, these methods suffer from deficiencies in both local feature representation and the number of samples. To address these issues, a method for few-shot image classification based on local contrastive learning and novel class feature generation is proposed. First, local contrastive learning is introduced to represent images as multiple local features and conduct supervised contrastive learning among these local features. Thus, the model capability to represent local features is enhanced. Second, global contrastive learning is employed to ensure the separability of the overall image features. Finally, a feature generation method is proposed to mitigate the data scarcity issue under few-shot conditions. Experiments on public datasets demonstrate the superiority of the proposed method.
深度学习现已在计算机视觉、语音识别、自然语言处理、数据挖掘、自动驾驶等领域取得突破.然而, 这些成功很大程度上依赖于大规模数据集和高性能计算资源.在实际应用中, 一些场景只能提供有限的数据或仅有极少的标注数据, 而对无标签数据进行标注需要耗费大量的时间和人力.在某些特殊领域, 甚至很难获取足够数量的样本.
研究表明, 人类只需观察几幅特定物体的图像就能识别该物体, 并且具备强大的泛化能力.受到人类学习能力的启发, 小样本学习旨在通过仿效人类学习的方式, 在仅有的少量训练样本的情况下, 挖掘关键特征并训练有效的深度预测模型.小样本图像分类作为小样本学习的主要分支之一, 在人脸识别[1]、目标检测[2]、语义分割[3]、目标追踪[4]、疾病诊断[5]等领域发挥重要作用.
近年来, 对比学习成为图像表示学习的一种新的训练范式, 其基本思想是将图像映射到高维的特征表示空间中, 在空间中使类别相同或语义相近的样本更接近, 类别不同或语义不相近的样本距离更远.对比学习最初采用自监督的训练方式, 通常使用图像增强方法构建正样本.诸多研究者指出, 相比使用交叉熵的训练方式, 对比学习能更好地进行图像特征提取, 有效提升模型的泛化性能.He等[6]提出MoCo(Momentum Contrast), 采用对比损失, 在Image-Net上的分类性能优于基于交叉熵损失的模型.Chen等[7]提出SimCLR(Simple Framework for Contrastive Learning of Visual Representations), 设计对比损失, 最大化特征空间下相同目标的空间距离相似度, 最小化不同目标的相似度, 进一步提升模型精度.
早期对比学习的方法和损失函数的设计还未统一, 研究者们进行多方尝试[8, 9], 如CMC(Contrastive Multiview Coding)[10].之后, 自监督的对比学习方法发展到第二阶段, 模型结构趋于统一.在MoCo和SimCLR的基础上, 又衍生出MoCo v2[11]和SimCLR-v2[12]等改进模型.随着Vision Transformer[13]的出现, 也有一些方法尝试使用Vision Transformer进行自监督训练, 如MoCo v3[14]和DINO[15].Khosla等[16]将自监督的对比学习方法拓展到有监督框架下, 提出SupCon, 以SimCLR为基础, 利用数据的标签信息, 在特征空间中拉近同一类别的样本, 同时推开不同类别的样本.对比学习起初应用于通用图像分类领域, 一些研究者发现其优秀的特征表示能力, 开始用于小样本图像分类中.
基于对比学习的小样本图像分类方法普遍采用监督对比学习的方式.相比自监督的对比学习方法, 监督对比学习能使模型充分学习基类数据的知识, 在新类上泛化效果更优.Das等[17]提出ConFT, 利用基类中不重叠类别样本, 为监督对比学习构建更好的负样本对.Liu等[18]提出InfoPatch, 将输入图像切割成多个局部块, 使用PatchMix合成新图像以构成困难样本对.Ouali等[19]提出空间与全局结合的对比学习方法, 使用空间注意力机制修正图像特征, 使提取的特征更鲁棒.Ma等[20]提出PAL(Partner-Assisted Learning), 使用蒸馏技术帮助网络更好的学习.总体来说, 现有方法通常基于图像的整体特征进行监督对比学习, 使模型仅关注图像的全局特征, 局部特征的表示不足.
尽管已有的对比学习方法通过改进模型结构、模型蒸馏等方式有效提升模型在新类上的泛化性能, 但是在极端的小样本条件下, 如样本只有1幅图像或5幅图像, 模型仍不能较好地描述新类类别特征, 类别原型表示存在偏差.Chawla等[21]提出SMOTE(Synthetic Minority Over-Sampling Technique), 在有限样本的条件下, 进行新样本生成.SMOTE的主要思想是在每个样本和它的K个最近邻之间进行线性插值, 但在样本过少时并不能直接用于小样本图像分类.Wang等[22]提出两个重要的概念:对齐性和均匀性.在对比学习中图像特征会经过正则化处理, 因此所有的图像特征被认为分布在一个超球面上.对齐性是指语义相近的样本其特征表示更相似, 在超球面上样本间的距离更近; 均匀性是指不相近的样本应当均匀分布在超球面上.其认为一个好的特征表示空间应当满足这两个条件, 而满足这两个条件的特征表示空间是线性可分的.监督对比学习能将样本特征映射到单位超球面上, 使特征空间满足文献[22]提出的对齐性和均匀性.这样不同类别的样本特征均匀分布在单位超球面上, 而同一类别的样本密集聚集在一个局部区域周围, 同一新类的样本与其相似基类之间的位置相近, 使用近邻的基类原型替代原样本进行插值成为一种可能.
针对现有方法局部特征表示不足和新类样本不足的问题, 本文提出基于局部对比学习与新类特征生成的小样本图像分类(Local Contrastive Learning and Novel Class Feature Generation, LCNFG)方法.首先引入局部对比学习, 确保每个局部特征都能保留类别信息, 增强局部特征的表示能力.然后, 结合全局对比学习与局部对比学习, 避免全局信息的丢失.在对比学习的基础上找到新类特征的近邻基类原型, 在基类原型和新类特征间进行线性插值, 生成大量样本特征, 缓解新类上样本不足的问题, 使类别原型的表示更准确.
本文提出基于局部对比学习与新类特征生成的小样本图像分类方法(LCNFG), 整体框架如图1所示.LCNFG主要分为两个阶段:基于全局和局部对比学习预训练和基于基类原型的新类特征生成.
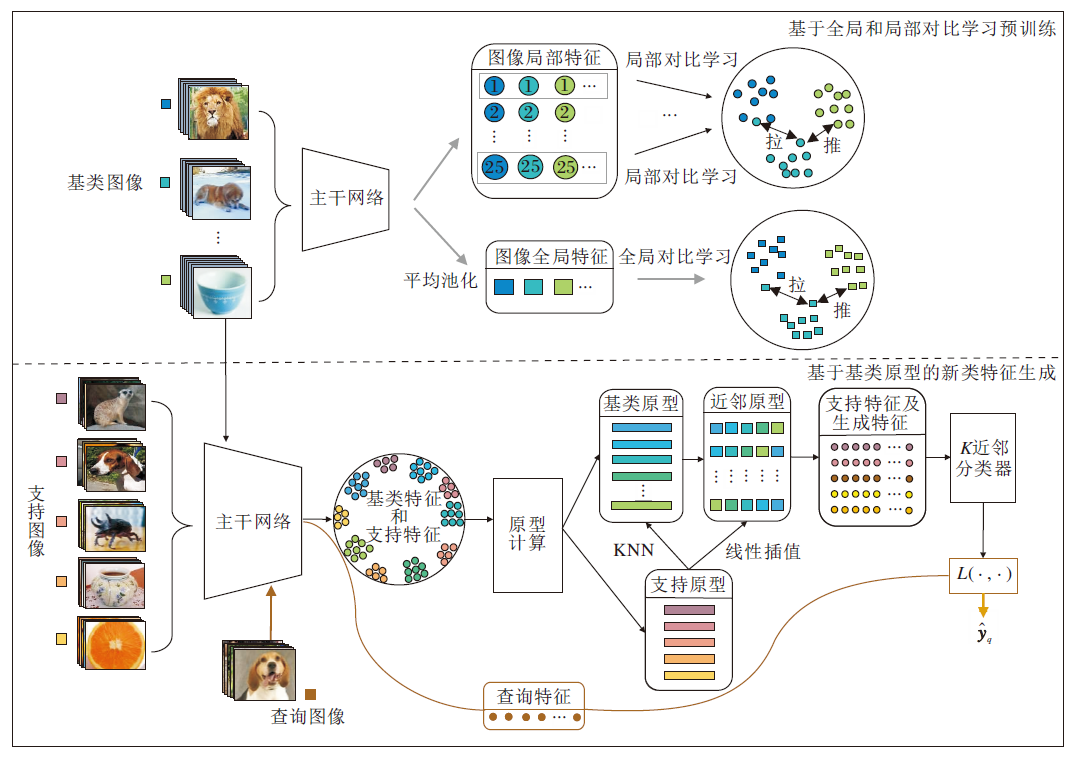 | 图1 LCNFG总体框架图Fig.1 Overall framework of LCNFG |
在预训练阶段, 局部对比学习将图像表示为多个局部特征, 使用监督对比学习使每个局部特征都尽可能保留图像类别的可鉴别信息, 从而使模型关注图像的局部变化.全局对比学习将图像的局部特征归纳为全局特征, 并使用监督对比学习, 保证图像整体特征的可分性.
在特征生成阶段, 基于预训练的主干网络, 提出基于基类原型的新类特征生成方法, 利用基类数据的类别原型, 生成新类样本特征, 缓解小样本条件下数据不足的问题.
最后, 基于支持特征和生成后的特征计算更准确的类别原型, 分类查询集中的未标注图像.
本文提出局部对比学习方法, 并设计相应的局部对比损失函数Llocal.Llocal将全局特征的单一特征空间拓展为多个局部特征空间.在每个局部特征空间中, Llocal通过拉近同类样本的局部特征、推远不同类样本的局部特征, 强化类别间的可区分性.最终, 图像的每个局部特征尽可能保留其对应类别的辨别信息, 从而增强主干网络对图像局部变化的敏感性.
首先获取局部特征.如图1上半部分所示, 对于给定的任一幅图像x, 输入主干网络E(· ), 原图像特征U∈ RC.去除主干网络最后一层的平均池化层, 可得到图像的局部特征图$\boldsymbol{u} \in \mathbf{R}^{C \times r}$, 其中r=h× w表示特征图的空间尺寸, $ \boldsymbol{u}^{i} \in \mathbf{R}^{C}$表示第i个位置的局部特征向量.之后, 单独考虑每个位置的局部特征向量, 在每幅图像相同位置的局部特征之间进行对比学习.
具体而言, 在基类数据集Dbase上随机采样一个批次, 共M幅图像, 将图像输入数据增强模块T(· ), 生成2M幅图像.对于其中的一幅样本, 记为xm.之后, 将样本输入主干网络E(· ), 得到图像的特征
$\boldsymbol{u}_{m}=E\left(\boldsymbol{x}_{m}\right) \in \mathbf{R}^{C \times r}, $
$\boldsymbol{u}_{m}=\left\{\boldsymbol{u}_{m}^{i}\right\}_{i=1}^{C}$表示该图像共有C个局部特征.
记A(m)={(xm, ym)
$L_{\text {local }}=-\frac{1}{r} \sum_{i=1}^{r}\left(\sum _ { m \in \boldsymbol { A } ( m ) } \left(\frac{1}{|\boldsymbol{P}(m)|} \sum_{\boldsymbol{p} \in \boldsymbol{P}(m)}\right.\left.\left(\frac{\exp \left(\frac{S_{m p}^{i}}{\tau}\right)}{\sum_{\boldsymbol{p} \in \boldsymbol{P}(m)} \exp \left(\frac{S_{m p}^{i}}{\tau}\right)+\sum_{a \in N(m)} \exp \left(\frac{S_{m a}^{i}}{\tau}\right)}\right)\right)\right), $
其中, τ ∈ i+表示温度超参数, p表示P(m)中的第p个样本, a表示N(m)中的第a个样本,
$S_{m p}^{i}=\frac{\left(\boldsymbol{u}_{m}^{i}\right)^{\mathrm{T}} \boldsymbol{u}_{p}^{i}}{\left\|\left(\boldsymbol{u}_{m}^{i}\right)^{\mathrm{T}}\right\|\left\|\boldsymbol{u}_{p}^{i}\right\|}, $
表示样本xm第i个位置的局部特征向量与其正样本集合中第p个正样本第i个位置的局部特征向量之间的余弦相似度,
$S_{m a}^{i}=\frac{\left(\boldsymbol{u}_{m}^{i}\right)^{\mathrm{T}} \boldsymbol{u}_{a}^{i}}{\left\|\left(\boldsymbol{u}_{m}^{i}\right)^{\mathrm{T}}\right\|\left\|\boldsymbol{u}_{a}^{i}\right\|}, $
表示样本xm第i个位置的局部特征向量与其负样本集合中第a个负样本第i个位置的局部特征向量之间的余弦相似度.因此, 对于样本xm, 其与正负样本之间的特征度量, 由每个位置的局部特征度量求平均得到.
仅使用局部对比学习可能会导致图像整体信息的丢失, 为了保证图像整体的可鉴别性, 本文结合全局对比学习和局部对比学习.全局对比学习保留主干网络E(· )最后的平均池化层, 因此记一幅图像为x, 图像的全局特征z∈ RC.
全局对比学习使用局部对比学习中随机采样并数据增强的2M幅图像, $ \boldsymbol{A}(m)=\left\{\left(\boldsymbol{x}_{m}, \boldsymbol{y}_{m}\right)\right\}_{m=1}^{2 M}$, 表示2M幅图像样本及其标签的集合.与局部对比学习相同, 给定一幅图像xm, 依据A(m)中的标签信息, 可得到与xm相同类别的正样本集合, 记为P(m), |P(m)|为集合中样本个数.A(m)中其余与xm不同类别的负样本集合记为N(m).计算全局的监督对比损失:
$L_{\text {global }}=\sum_{m \in \boldsymbol{A}(m)}\left(\frac{-1}{|\boldsymbol{P}(m)|} \sum_{p \in \boldsymbol{P}(m)}\left(\frac{\exp \left(\frac{S_{m p}}{\tau}\right)}{\sum_{p \in \boldsymbol{P}(m)} \exp \left(\frac{S_{m p}}{\tau}\right)+\sum_{a \in N(m)} \exp \left(\frac{S_{m a}}{\tau}\right)}\right) \right).$
在预训练阶段, 本文引入自监督任务中的旋转分类任务, 能在预训练过程中学到更通用的特征, 从而有效降低过拟合的风险.将图像xi旋转0° , 90° , 180° , 270° 后输入主干网络, 在主干网络后添加一个四类别分类器Cr(g), 预测图像的旋转角度.Cr(g)可使用矩阵$\boldsymbol{W}_{r}=\left\{\boldsymbol{w}_{r i}\right\}_{i=1}^{4}$表示, 因此, 对于图像xi, 旋转预测的类别分数如下:
$S_{i}^{r}=C_{r}\left(\boldsymbol{z}_{i}\right)=\boldsymbol{z}_{i}^{\mathrm{T}} \boldsymbol{W}_{r}=\boldsymbol{z}_{i}^{\mathrm{T}}\left[\boldsymbol{w}_{r 1}, \boldsymbol{w}_{r 2}, \boldsymbol{w}_{r 3}, \boldsymbol{w}_{r 4}\right] .$
之后, 使用Softmax函数, 得到第j类的预测概率:
$p_{i j}=\frac{\exp \left(\boldsymbol{z}_{i}^{\mathrm{T}} \boldsymbol{w}_{r j}\right)}{\sum_{k=1}^{4} \exp \left(\boldsymbol{z}_{i}^{\mathrm{T}} \boldsymbol{w}_{r k}\right)} .$
由此得到旋转预测的自监督损失(Self-Supervised Loss, SSL):
$\begin{aligned} L_{\mathrm{SSL}}= & -\sum_{i=1}^{m} \sum_{k=1}^{4} y_{i k} \ln p_{i k}=-\sum_{i=1}^{m} \ln p_{i j}= \\ & -\sum_{i=1}^{m} \ln \left(\frac{\exp \left(\boldsymbol{z}_{i}^{\mathrm{T}} \boldsymbol{w}_{r j}\right)}{\sum_{k=1}^{4} \exp \left(\boldsymbol{z}_{i}^{\mathrm{T}} \boldsymbol{w}_{r k}\right)}\right) . \end{aligned}$
在预训练过程中本文方法的整体损失为:
$L=\alpha L_{\text {local }}+\beta L_{\text {global }}+L_{\mathrm{SSL}}, $
其中α 、 β 为系数, 用于控制损失大小.
如图1下半部分所示, 第二阶段为新类特征生成阶段.在N-way K-shot的采样任务中, 每个任务包含一个支持集和一个查询集.基于基类原型的新类特征生成方法用于在支持集有限的情况下生成大量样本特征, 主要包括如下三部分.第一部分是使用预训练阶段主干网络获得的参数提取支持集和查询集样本的特征.第二部分是特征生成模块, 利用K近邻算法(K-Nearest Neighbors, KNN)计算与支持集特征最相似的基类原型, 并通过SMOTE在基类原型与支持特征之间进行线性插值, 从而生成新的样本特征.第三部分是KNN测试分类器, 通过支持特征和生成特征计算类别原型, 并基于查询样本特征与各类原型之间的余弦距离进行分类.
在二阶段的测试过程中, 需要进行N-way K-shot任务的采样.每个任务包含一个支持集
$\boldsymbol{D}_{\text {support }}=\left\{\boldsymbol{S}_{n}\right\}_{n=1}^{N}, \boldsymbol{S}_{n}=\left\{\left(\boldsymbol{x}_{s}, \boldsymbol{y}_{s}\right)\right\}_{s=1}^{K}$
和一个查询集
$\boldsymbol{D}_{\text {query }}=\left\{\boldsymbol{x}_{q}\right\}_{\substack{T \times N \\ q=1}} .$
对于支持集的一幅图像xs, 将其输入训练好的主干网络后, 得到d维的特征向量us.新类中每个类别的原型Pn由该类别中所有样本的特征求平均得到, 即
$\boldsymbol{P}_{n}=\frac{1}{K} \sum_{s \in S_{n}} \boldsymbol{u}_{s} .$
同时, 计算基类中共Cb个类别的原型, 记作
$\boldsymbol{J}_{B}=\left\{\boldsymbol{u}_{C}\right\}_{c=1}^{C_{b}} .$
对于Pn中每个新类类别的原型, 找到在基类原型JB中与其最近的L个邻居, 距离度量采用余弦相似度, 将这些邻居记为Jn={ul∈ JB
$\boldsymbol{u}_{\text {new }}=\boldsymbol{P}_{n}+\lambda\left(\boldsymbol{P}_{n}-\boldsymbol{u}_{l}\right), $
其中λ ∈ [0, 1]为一个随机数.通过不断改变λ 的数值, 并在Jn中反复随机选择原型数据, 每个新类都能获得大量的新特征.
在分类时, 将这些新生成的特征与支持集中的原特征合并, 进行平均求和操作, 计算每个新类类别的原型.将新类中第n个类别的新原型记为P'n.对于查询集中的样本, 计算其特征与每个类别原型之间的余弦距离, 选择距离最近的类别作为预测标签:
$\hat{\boldsymbol{y}}_{i}=\arg \min _{n} D\left(E\left(\boldsymbol{x}_{q}\right), \boldsymbol{P}_{n}^{\prime}\right), $
其中D(· , · )表示余弦距离函数.
为了更清晰地阐明全局与局部对比学习阶段以及新类特征生成阶段, 使用伪代码设计LCNFG.
算法1 LCNFG
输入 基类数据集Dbase,
支持集的图像及其标签Dsupport,
查询集Dquery, 数据增强模块T(· ),
主干网络E(· ), 批次大小M, 温度参数τ
输出 查询集中每个样本的预测分类
对于每轮epoch:
采样:从Dbase中采样一个批次
$\boldsymbol{D}_{\text {batch }}=\left\{\left(\boldsymbol{x}_{m}, \boldsymbol{y}_{m}\right)\right\}_{m=1}^{M}$
特征提取:取图像的局部特征
$\boldsymbol{u}_{m}=E\left(\boldsymbol{x}_{m}\right), \boldsymbol{u}_{m+M}=E\left(\boldsymbol{x}_{m+M}\right)$
计算损失Llocal
特征提取:取图像的全局特征
$z_{m}=E\left(\boldsymbol{x}_{m}\right), z_{m+M}=E\left(\boldsymbol{x}_{m+M}\right)$
计算损失Lglobal、LSSL和整体损失L, 更新参数
结束
对于支持集的每幅样本xS:
特征提取:zS=E(xS)
计算原型:计算类别n的原型Pn
结束
对于查询集的每幅样本xq:
特征提取:zq=E(xq)
查询样本预测分类标签
结束
本文在miniImageNet、tieredImageNet、CIFAR-FS这3个公共数据集上进行实验.
miniImageNet数据集包含100个类别, 每个类别有600幅图像, 依据MatchingNet中的划分方法, 将100类划分为64个训练类、16个验证类和20个测试类.
tieredImageNet数据集包含608个类别, 平均每个类别包含1 281幅图像, 在实验中划分为351个训练类、97个验证类和160个测试类.
CIFAR-FS数据集由CIFAR-100数据集随机划分而成, 其中64类用于训练, 16类用于验证, 20类用于测试.
实验中采用ResNet-12作为主干网络.在预训练过程中, 采用动量为0.9, 权重衰减系数为0.000 5的随机梯度下降算法进行优化.学习率初始化为0.125, 在所有的实验中, 批处理大小为64.在miniImageNet、CIFAR-FS数据集上, 迭代周期设为120, 每30个迭代周期学习率调整为原来的0.2.在CUB数据集上, 迭代周期设为280, 训练70个迭代周期后, 学习率每30个迭代周期调整为原来的0.2.
LCNFG由基分类器、旋转分类器和线性层组成, 分别由每个损失项进行优化.为了更好地评估计算效率, 有必要进行计算复杂度分析.假设训练周期数为T, 每个周期的图像数量为M, 基分类器的输出数量为Cb, 旋转分类器的输出数量为4, 线性层神经元数量为P.基于这3个组件的计算开销, LCNFG的整体计算复杂度为O((Cb+4+P) TM), 由此表明复杂度与图像数量M呈线性关系.随着图像数量的增加, 计算复杂度呈正比例增加, 但由于每个部分的输出维度相对固定, 整体复杂度增长较平稳.因此, 在大规模数据集上, LCNFG也能保持较高的计算效率.
本文选择如下对比方法.
1)基于元学习的方法:Prototypical Networks[23]、DeepEMD[24]、CC+rot[25]、BML(Binocular Mutual Learning)[26]、RENet(Relational Embedding Net-work)[27]、FRN(Feature Map Reconstruction Net-works)[28]、MeTAL(Meta-Learning with Task-Ada- ptive Loss Function)[29]、文献[30]方法、MCGN(Mutual CRF-GNN)[31]、IEPT(Instance-Level and Episode-Level Pretext Task)[32]、APP2S(Adaptive Po-incaré Point to Set)[33]、HGNN(Hybrid Graph Neural Networks)[34]、文献[35]方法、MCL(Mutual Cen-tralized Learning)[36]、STANet(Semantic and Target Attentions Network)[37]、ALFA(Adaptive Learning of hyperparameters for Fast Adaptation)[38]、FGFL(Fre-quency-Guided Few-Shot Learning Framework)[39] 、RN(Relation Network)[40] 、AFHN(Adversarial Feature Hallucination Networks)[41] 、Meta Navigator[42] 、CVET(Cross-View Episodic Training)[43].
2)基于迁移的方法:PAL(Partner-Assisted Lear-ning)[20]、Neg-Cosine[44] 、S2M2[45]、文献[46]方法、SKD(Two-Stage Self-Supervised Knowledge Distilla-tion)[47]、文献[48]方法、TPMN(End-to-End Task-Aware Part Mining Network)[49]、DeepBDC(Deep Brownian Distance Covariance)[50] 、MABAS(Model-Agnostic Boundary-Adversarial Sampling)[51].
在LCNFG中去除特征生成模块, 只保留局部对比学习(Local Contrastive Learning, LCL)、全局对比学习(Global Contrastive Learning, GCL)和自监督损失(SSL), 简记为LCL+GCL+SSL, 也放入对比实验中.
在5-way 1-shot和5-way 5-shot任务上分析各对比方法的分类准确率.各方法在CIFAR-FS数据集上的分类准确率对比如表1所示, 表中黑体数字表示最优值.
| 表1 各方法在CIFAR-FS数据集上分类准确率对比 Table 1 Classification performance comparison of different methods on CIFAR-FS dataset |
由表1可见, LCNFG在1-shot任务和5-shot任务上取得最高值.相比Meta Navigator, LCL+GCL+SSL在1-shot任务和5-shot任务上分别提升3%和2.66%.在基于迁移学习的方法中, 相比PAL, LCL+GCL+SSL在1-shot任务和5-shot任务上分别提升0.53%和1.11%.之后, 在LCL+GCL+SSL的基础上, LCNFG在1-shot任务将分类准确率提至78.41%, 5-shot任务将分类准确率提至89.28%, 为最优值.
各方法在miniImageNet、tieredImageNet数据集上的对比结果如表2所示, 表中黑体数字表示最优值.
| 表2 各方法在miniImageNet、tieredImageNet数据集上的分类准确率对比 Table 2 Classification performance comparison of different methods on miniImageNet and tieredImageNet datasets % |
由表2可见, 在miniImageNet数据集上, LCL+GCL+SSL在1-shot任务和5-shot任务中取得68.40%和83.69%的分类准确率.LCL+GCL+SSL在1-shot任务上比APP2S提高2.15%, 比文献[35]方法提高0.08%; 在5-shot任务上比APP2S提高0.27%, 比文献[35]方法提高0.98%.在LCL+GCL+SSL的基础上, 结合基于基类原型的LCNFG文献[35]方法进一步提升分类准确率.
在tieredImageNet数据集上, LCL+GCL+SSL同样表现优秀.在此基础上, LCNFG进一步提升分类准确率, 在1-shot任务上取得最高值, 在5-shot任务上略低于文献[35]方法.在5-shot任务上, LCNFG的分类效果略低于文献[35]方法, 其原因可能是5-shot任务的样本数据较多, 特征生成方法带来的提升效果有限.
消融实验包含局部对比学习(LCL)、全局对比学习(GCL)、全局和局部对比学习(LCL+GLC)、结合全局和局部自监督对比学习(LCL+GCL+SSL)、LCNFG.
在miniImageNet、CIFAR-FS数据集上进行消融实验, 选择5-way 1-shot和5-way 5-shot任务, 分类准确率如表3所示.由表可看出, LCL和GCL在两个数据集上都取得不错的分类准确率, LCL在所有的任务中的分类准确率都高于GCL, 由此验证在小样本条件下局部特征比全局特征具有更好的分类效果.在此基础上, 将二者结合的方法LCL+GCL性能更优.在LCL+GCL的基础上引入自监督损失函数的LCL+GCL+SSL进一步提升分类准确率.而LCNFG在LCL+GCL+SSL基础上加入特征生成模块, 获得最优值, 进一步验证其有效性和优势.
| 表3 在2个数据集上的消融实验结果 Table 3 Results of ablation experiment on 2 datasets % |
从miniImageNet数据集上随机抽取3幅图像, 分别输入使用全局对比学习和局部对比学习预训练的主干网络中.之后使用Grad-CAM(Gradient-Weigh-ted Class Activation Mapping)[52]对生成的特征图进行热力图可视化, 具体如图2所示.
 | 图2 在miniImageNet数据集上的Grad-CAM可视化结果Fig.2 Grad-CAM visualization results on miniImageNet dataset |
由图2可看出:全局对比学习主要关注物体整体, 在热力图中物体整体部分被高亮显示; 在局部对比学习中, 高亮部分可分散在物体的各个部位, 由此验证局部对比学习可捕获图像的局部特征, 对图像的局部变化敏感性更强.
此外, 为了验证特征生成算法的有效性, 将看不见的支持类样本的特征及其对应的生成特征可视化.在miniImageNet数据集上随机从测试集上选择5类, 每类抽取200幅样本图像.在CIFAR-FS数据集上同样从测试集上随机选择5类, 每类抽取35幅样本图像.计算5个类别的原型特征, 并对这些原型特征及其相应的生成特征进行可视化.每个类别生成特征的数量设为750.
将图像输入主干网络后, 使用t-SNE(t-Distri- buted Stochastic Neighbor Embedding)[53]进行可视化, 结果如图3所示.
 | 图3 在2个数据集上t-SNE可视化结果Fig.3 t-SNE visualization results on 2 datasets |
从图3左图可看出, 在miniImageNet、CIFAR-FS数据集上, 同类样本特征紧密聚集, 不同类别的特征相互远离, 类与类之间的边界清晰.在图3右图中, ★表示类别原型, ▲表示生成特征, 可以看出, 原型特征和生成特征的类边界是清晰的, 并且生成的样本特征同原型紧凑地靠在一起.这验证特征生成算法的有效性.
在小样本条件下, 图像分类方法仅关注图像的全局特征, 可能会导致模型缺乏对光照、遮挡、姿态等局部变化的敏感性, 泛化性能下降.为了有效改善此不足, 本文提出基于局部对比学习与新类特征生成的小样本图像分类方法(LCNFG), 包含局部对比学习、全局对比学习、特征生成三部分.局部对比学习将图像表示为多个局部特征向量, 在每个局部特征间进行监督对比学习.全局对比学习将图像表示为一个整体, 保证图像整体的类别可分性.特征生成将基类原型加以利用, 有效缓解新类样本不足的问题.LCNFG结合局部对比学习和全局对比学习, 使模型能更关注图像的局部信息, 同时避免全局信息的丢失, 在解决局部特征表示不足和新类样本不足等问题上具有明显优势.但是在局部对比学习中, 图像的局部部分可能为背景或噪声, 使用监督对比学习可能会对模型产生一定的偏差.因此, 今后可考虑引入近邻机制, 在同类中找出相似的局部图像进行监督对比学习, 避免无意义的背景或噪声对模型的影响.
本文责任编委 桑 农
Recommended by Associate Editor SANG Nong
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|
| [47] |
|
| [48] |
|
| [49] |
|
| [50] |
|
| [51] |
|
| [52] |
|
| [53] |
|