





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于扩散模型的无条件反事实解释生成方法
[仲智1  , 王宇
, 王宇2 , 祝子烨1 , 李云1 ]
, 王宇, 祝子烨, 李云]
|
|



作者简介: 
仲 智,硕士研究生,主要研究方向为机器学习.E-mail:1022040906@njupt.edu.cn. 
王 宇,博士,讲师,主要研究方向为机器学习、自然语言处理.E-mail:wangyu@cpu.edu.cn. 
祝子烨,博士,讲师,主要研究方向为机器学习、自然语言处理.E-mail:zhuziye@njupt.edu.cn.
反事实解释通过对输入数据实施最小且具解释性的改动改变模型输出,揭示影响模型决策的关键因素.现有基于扩散模型的反事实解释方法依赖条件生成,需要额外获取与分类相关的语义信息,难以保证语义信息质量并增加计算成本.针对上述问题,文中基于生成扩散模型中的DDIMs(Denoising Diffusion Implicit Models),提出基于扩散模型的无条件反事实解释生成方法.首先,利用隐式去噪扩散模型在反向去噪过程中展现的一致性,将噪声图像视为隐变量以控制输出生成,从而使扩散模型适用于无条件的反事实解释生成流程.然后,充分利用隐式去噪扩散模型在过滤高频噪声和分布外扰动方面的优势,重塑无条件的反事实解释生成流程,生成具有解释性的语义改动.在不同数据集上的实验表明,文中方法的多项指标值较优.
About Author:
ZHONG Zhi, Master student. His research interests include machine learning.
WANG Yu, Ph.D., lecturer. His research interests include machine learning and natural language processing.
ZHU Ziye, Ph.D., lecturer. Her research interests include machine learning and natural language processing.
Counterfactual explanations alter the model output by implementing minimal and interpretable modifications to input data, revealing key factors influencing model decisions. Existing counterfactual explanation methods based on diffusion models rely on conditional generation, requiring additional semantic information related to classification. However, ensuring semantic quality of the semantic information is challenging and computational costs are increased. To address these issues, an unconditional counterfactual explanation generation method based on the denoising diffusion implicit model(DDIM)is proposed. By leveraging the consistency exhibited by DDIM during the reverse denoising process, noisy images are treated as latent variables to control the generated outputs, thus making the diffusion model suitable for unconditional counterfactual explanation generation workflows. Then, the advantages of DDIM in filtering high-frequency noise and out-of-distribution perturbations are fully utilized, thereby reconstructing the unconditional counterfactual explanation workflow to generate semantically interpretable modifications. Extensive experiments on different datasets demonstrate that the proposed method achieves superior results across multiple metrics.
深度神经网络(Deep Neural Networks, DNN)因其卓越的预测能力受到学术界广泛关注, 目前已在诸如人脸识别和医疗检测等领域得到广泛应用.然而, 现有的深度模型在训练过程中难以保证其所学特征与数据的真实相关性, 从而降低模型决策的可信度.这一问题引发工业界对模型学习内容及预测机制的关注, 即要求深度学习模型在预测过程中利用正确特征并避免虚假关联.然而, 由于深度模型高度非线性且参数化程度过高, 解释其决策机制非常困难.为了应对这一挑战, 学者们提出解释性人工智能(Explainable Artificial Intelligence, XAI), 旨在“ 打开黑箱” , 解读模型诱导的偏见, 进而提高模型的可信度.目前深度学习模型的黑箱特性及其可解释性问题受到广泛关注, 开发解释性方法以提升其可信度已成为研究重点.
在这一背景下, 反事实解释(Counterfactual Explanations, CE)作为一种新兴方法, 近年来备受关注.反事实解释为模型的决策过程提供关键洞察[1, 2, 3], 核心思路是通过对输入样本施加最小但有意义的扰动, 改变模型的原始决策.反事实解释必须满足如下要求.1)解释必须有效, 能成功改变模型的预测结果.2)生成的反事实样例应当与原始输入保持邻近关系, 即通过最小的扰动生成实例, 从而提供简单且直接的解释.3)解释必须现实且容易理解, 即引入的语义变化应当符合现实语境.当反事实解释方法在输入图像中引入分布之外的伪像时, 可能难以明确决策的翻转是由伪像本身还是分布偏移导致的, 从而降低解释的清晰性.
虽然现有方法可在视觉系统中实现反事实解释生成, 如添加对抗性噪声[4], 但无法满足对图像的改动应尽可能小, 并涵盖所有关键特征, 以提供对模型决策依据的深入理解的要求.为此, 大多数反事实解释研究采用生成模型, 如生成对抗网络(Genera-tive Adversarial Network, GANs)[5]或变分自编码器(Variational Autoencoder, VAE)[6].这些模型通过隐变量提供一种直观的方式, 能捕捉图像的形状和结构, 并在生成过程中约束图像的变化区域.最近, DDPM(Denoising Diffusion Probabilistic Models)[7]的出现进一步提高生成模型的生成质量.
在现有的反事解释方法中, 基于扩散模型的生成方式通常依赖条件生成, 即需要模型额外获取与分类相关的语义信息.与传统的GANs或VAE的编码器和解码器架构不同, DDPM包含加噪与去噪两个步骤.在去噪过程中, 通过上一时刻的均值和方差进行随机采样, 因此针对相同的噪声输入会生成不同的输出.这种随机性导致DDPM无法重构需要解释的输入样例, 因此不适用于无条件的反事实样例生成任务.
为了解决上述问题, 本文提出基于扩散模型的无条件反事实解释生成方法(Diffusion Models Based Unconditional Counterfactual Explanations Generation, DICE), 采用DDIMs(Denoising Diffusion Implicit Mo-dels)[8]作为生成模型, 结合无条件生成流程和扩散模型具有的正则化效果, 无论被解释分类器在面对干扰或噪声时的鲁棒性如何, 均能生成高质量的反事实解释样例.首先, 利用DDIMs反向去噪过程的一致性, 将噪声图像视为隐变量, 使去噪扩散模型适用于无条件的反事实解释生成流程, 达到较优的生成效果.然后, 提出基于DDIMs的正则化工具, 用于辅助解释非鲁棒分类器, 减少高频噪声和分布外扰动的影响, 从而在反事实解释样例中生成可解释的语义改动.DICE能有效支持分类器的鲁棒性差异, 实现对鲁棒分类器和非鲁棒分类器的统一反事实解释生成.在多个数据集和分类任务上的测评表明, DICE生成的反事实解释样例在生成效果上优于现有的先进方法, 并在多项定量评价指标上取得更优表现.
可解释人工智能的方法主要分为内在可解释性方法和事后可解释性方法.内在可解释性方法在模型设计阶段注重构建具有可解释性的架构[9, 10, 11, 12], 而事后可解释性方法关注分析现有模型.事后可解释性方法可进一步划分为全局解释和局部解释.全局解释阐明分类器的整体行为, 而局部解释聚焦于单个实例的具体决策机制.局部解释方法包括显著性图[13, 14, 15, 16, 17, 18]、概念归因[19, 20, 21]和模型蒸馏[22, 23]等, 这些方法通常通过分析模型决策的依据揭示其运行机制.一些自称为反事实方法的研究[24, 25, 26, 27]实际上仅在两个图像之间突出变化区域, 并未对图像进行实质性修改, 与真正的反事实解释存在显著差异.
近年来, 反事实解释在解释模型决策方面取得显著进展.如图1所示, 左图为给定的输入查询图像, 被解释的分类器判定该图像中人物没有笑容.右图为反事实解释样例, 分类器判定该图像中人物存在笑容.对比两幅图像可观察到, 相比左图, 右图人物出现嘴角上扬、颧骨突出及泛起腮红等特征.由此可见, 这些特征是分类器判定人物是否微笑的重要依据.此外, 这些特征变化符合人类认知, 进一步验证该分类器的可信性.
 | 图1 反事实解释样例Fig.1 Counterfactual explanation example |
目前, 部分研究方法依赖于原型[28]或深度反转[29], 另一些方法则探索不同分类模型在结合CE进行解释时的表现, 如可逆卷积神经网络[30]和鲁棒网络[31, 32].生成方法因其在生成CE时的多重优势, 已成为研究的主流方向之一.生成技术能在数据流形上生成更符合分布特性的解释样本.
具体而言, 生成方法可分为两种模式:1)条件生成方法[33, 34], 通过适配分类模型的学习内容或控制扰动以生成CE; 2)无条件生成方法[35, 36, 37, 38, 39, 40], 更注重对潜在空间向量的优化.
Jeanneret等[35]在反事实解释生成中引入扩散模型, 提出DiME(Diffusion Models for Counterfactual Explanations), 通过条件扩散模型, 在每步去噪过程中借助分类器引导生成, 但其依赖DDPM生成过程, 受其随机性限制, 生成效果略显不足.
在近期方法中, ACE(Adversarial Counterfactual Visual Explanations)[41]虽同样基于DDPM, 但主要将其用作正则化器.ACE在图像空间中通过对抗性攻击生成语义变化, 随后利用DDPM进行后续细化处理.尽管ACE是一种无条件反事实解释生成方法, 生成流程与典型无条件方法存在差异, 却依然受限于DDPM的随机性, 需要额外的细化步骤以突出与分类标签变化最相关的部分.
在将扩散模型应用于无条件方法的过程中, 找到适合扩散模型的潜在变量是关键问题之一.DDIMs成功实现反事实解释的生成.在DDIMs中, 由于反向去噪过程的确定性, 相同的噪声种子始终生成相同图像.DDIMs通过编码噪声图像的高级特征, 展现类似于其它隐式概率模型的语义插值效应.由此噪声图像可被视为潜在变量, 用于直接调控生成图像的特性.这种机制与DDPM显著不同:DDPM因生成过程中的采样随机性, 相同的噪声图像可能生成不同的干净图像; DDIMs的确定性和语义插值效应使其能通过潜在变量的控制, 在高层次上精确调控生成图像的特性.
鉴于对反事实解释的论述, 本文提出基于扩散模型的无条件反事实解释生成方法(DICE), 旨在将扩散模型应用于反事实解释的无条件生成流程中, 从而实现更优质的生成效果.
扩散模型作为生成模型的一种, 利用噪声辅助学习数据分布, 包含前向加噪过程与反向去噪过程.加噪过程旨在逐步向图像中注入噪声, 扩展数据分布的覆盖范围, 从而使原本高密度的数据区域“ 膨胀” , 在采样早期能更准确地估计梯度值.去噪过程利用当前数据分布的梯度, 从噪声图像逐步还原加噪前的原始图像.近年来的研究进一步表明, 不同的去噪过程可赋予扩散模型不同的特性, 满足多样化的生成任务需求.
针对反事实解释的生成需求, 本文基于DDIMs提出DICE, 充分利用隐式扩散模型的一致性特点, 即确定的噪声输入可生成一致的干净图像.通过将噪声图像视为隐变量, DICE有效控制生成过程, 生成符合目标语义的反事实解释样例.
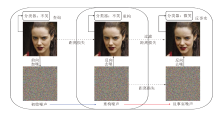
DICE整体架构如图2所示, 包括两个关键步骤:重构噪声获取和反事实解释构建.
 | 图2 DICE整体架构Fig.2 Framework of DICE |
在重构噪声获取步骤中, DICE提取与输入图像对应的噪声图像隐变量, 操控该隐变量实现输入图像的语义变化, 为反事实解释的生成奠定基础.反事实解释构建步骤以提取的噪声图像隐变量为起点, 依次计算去噪后图像与输入图像的距离损失以及与目标分类标签的交叉熵损失, 并将两者的加权和用于优化噪声变量, 优化后的噪声作为新起点.其中, 分类损失引导隐变量生成语义变化, 同时利用距离损失限制变化幅度, 确保语义改动的合理性与最小化.最终通过迭代优化, 噪声图像能生成反事实解释样例.
DICE的伪代码如下所示.
算法1 DICE
输入输入图像x, 输入图像的重构噪声z',
输入图像的反事实解释噪声z″,
目标分类标签y
输出输入图像的反事实解释xc
z'=forward Process(x)
for i=1, 2, …, n do
arg
end for
z″=z'
for i=1, 2, …, m do
arg
end for
xc=backward Process(z″)
优化重构模块旨在获得能重构查询图像的噪声图像隐变量.在DDIMs中, 由于反向去噪过程的确定性特性, 噪声图像可被视为隐变量.当噪声图像隐变量确定后, 反向去噪过程生成的干净图像也随之确定.因此, DICE利用DDIMs的这一特性实现查询图像的重构.
优化重构步骤包括前向加噪过程和迭代优化并去噪的过程.对于输入的查询图像, 前向加噪过程将其逐步转化为噪声图像, 作为隐变量的初始状态.然后, 在迭代优化过程中, 依据特定的损失函数优化隐变量.通过该优化过程, 最终利用反向去噪将隐变量还原为与输入查询图像一致的生成图像, 实现重构目标.
2.2.1 初始噪声确定
为了确定初始噪声, 给定输入查询图像x, 利用扩散模型的前向加噪过程, 通过迭代采样z1, z2, …, zT, 逐步使用白噪声替换部分信号.具体地, 设β t为预定的方差, 前向过程遵循如下递归表达式:
${{z}_{t}}\tilde{\ }N(\sqrt{1-{{\beta }_{t}}}{{z}_{t}}_{-1}, {{\beta }_{t}}I)$,
其中, N(· )表示正态分布, I表示单位矩阵, z0=x.实际上, 可直接从原始样本模拟这个过程, 即
${{z}_{t}}\tilde{\ }N(\sqrt{{{\alpha }_{t}}}x, (1-{{\alpha }_{t}})I)$,
其中
${{\alpha }_{t}}\, \!:=\underset{k=1}{\overset{t}{\mathop \prod }}\, (1-{{\beta }_{k}})$.
为了明确起见, 在后文中使用x表示干净的图像, 使用z表示有噪声的图像.
为了确保初始噪声生成的图像尽可能接近输入图像, 对输入图像添加的噪声强度为T.在Celeba-HQ数据集上, T=500; 在ImageNet数据集上, T=100.在实验设置的噪声强度下, 生成图像的数据点在分布上接近于输入图像的数据点.因此, 选择该噪声强度下生成的噪声图像z作为初始噪声, 减少后续迭代优化的步骤.
2.2.2 重构噪声优化
确定初始噪声图像z后, 其反向去噪后生成的图像接近输入图像.在反向去噪过程中, 神经网络对zT逐步去噪, 以恢复之前的样本zT-1, zT-2, …, z0.该网络以当前时间步t和一个有噪声的样本zt作为输入, 产生一个均值μ (t, zt)和一个协方差矩阵Σ (t, zt), 分别简写为μ (zt)和Σ (zt).然后, zt-1被采样为
zt-1~N(μ (zt), Σ (zt)).
上式可具体展开为高斯噪声的线性变换:
${{z}_{t}}_{-1}=\sqrt{{{\alpha }_{t-1}}}\left( \frac{{{z}_{t}}-\sqrt[]{1-{{\alpha }_{t}}} \ \ \ \epsilon _{\theta }^{\left( t \right)}\left( {{z}_{t}} \right)}{\sqrt[]{{{\alpha }_{t}}}} \right)+\sqrt[]{1-{{\alpha }_{t-1}}-\sigma _{t}^{2}}\epsilon _{\theta }^{\left( t \right)}~({{z}_{t}})+{{\sigma }_{t}}{{\epsilon }_{t}}$,
其中, 右式第1项是根据zt推测的当前噪声强度下的干净图像z0, 第2项为指向zt的方向, 最后一项是随机噪声, ${{\epsilon }_{t}}\tilde{\ }N(0, 1)$表示与zt无关的标准高斯噪声.无需重新训练模型, 在${{\epsilon }_{t}}$预测相同的情况下, 不同的σ t取值对应不同的生成过程.当对所有t的取值都设置σ t=0时, 给定zt反向的去噪过程变得明确, 即体现DDIMs的一致性.
最终, z被恢复为干净图像.根据z对应的生成图像及输入图像x, 计算两者间的距离损失作为优化目标:
arg
其中:z'表示通过优化损失函数后得到的噪声图像, 能使初始噪声图像z重构输入图像x; 损失函数Ldist(· )采用L2均方误差; G(z')表示通过生成模型将z'转换为图像的过程.上式确保z'生成的图像能重构输入查询图像x.
经过一定次数的迭代, 隐变量噪声图像z'通过反向去噪过程还原输入的查询图像, 同时能有效控制查询图像的特征变化.最终, 将优化后的隐变量噪声图像z'保存为副本.
综上所述, 在 DICE的第一步中, 成功获得能重构查询图像的隐变量噪声图像, 并有助于后续构建反事实解释.
构建反事实部分旨在得到查询图像的反事实解释.反事实解释与查询图像之间存在确保两者标签相悖的语义变化, 对于扩散模型来说, 包含一个前向加噪及反向去噪的扩散过程, 可过滤使标签改变的高频噪声, 并保留语义变化.然后, 利用过滤后的图像计算分类损失函数迭代扰动隐变量.最终通过去噪隐变量得到的图像即为反事实解释样例.
2.3.1 正则化
为了避免生成对抗性噪声并确保产生有意义的语义, 过滤操作需满足如下两点关键要求.1)应去除传统对抗性攻击中生成的高频信息.这类扰动虽然可能影响分类器的决策, 但对人类而言既不可操作也难以理解.2)应生成分布内的图像而不扭曲输入图像, 以便尽可能保留与决策无关的图像结构, 同时避免提供误导性信息.
在DICE中, 设置加噪强度T, 将扩散模型的前向加噪和反向去噪过程整合为扩散过滤过程.在这一过程中, 首先对重构噪声z'去噪后得到查询图像.然后, 对图像实施过滤操作, 其中噪声强度T与2.2.1节确定初始噪声中强度保持一致, 过滤后的图像与查询图像相近, 并且具有相同的分类标签.
2.3.2 反事实解释生成
将过滤后的图像输入需要解释的分类器m, 计算其对于反事实解释目标分类的分类损失, 再计算当前隐变量噪声图像与z'距离损失, 通过这两个损失函数的加权求和对隐变量噪声图像进行迭代优化, 公式如下:
arg
其中:Fτ (G(z″))表示对由隐变量生成的图像进行过滤操作, 并计算其对于目标标签y的分类损失.公式第1项用于确保反事实噪声z″最终生成的图像分类与输入查询图像分类结果相悖; 第2项中z″与z'的距离损失Ldist采用L2均方误差, 用于约束反事实图像与输入图像间存在的语义变化的幅度, 确保这种变化是导致分类改变的充分必要条件.
经过多次迭代优化后, 最终得到的反事实噪声图像z″可通过反向去噪过程构建反事实解释图像.相比查询图像, 该图像呈现出最小但有意义的语义变化, 并且其分类标签为反事实解释的目标标签.
综上所述, DICE通过两个步骤生成查询图像的反事实解释.对比查询图像与反事实解释图像, 可识别分类器在决策中关注的关键特征, 评估分类器的可信性.
基于近期关于反事实解释的研究成果[42], 首先, 在CelebA-HQ[21]数据集上评估DICE, 使用的图像分辨率为256 × 256, 选择DenseNet121[43]分类器作为决策模型, 测试主要集中在“ 微笑” 和“ 年龄” 这两个分类标签上.然后, 在ImageNet数据集[44]上继续开展实验, 使用的图像分辨率为256 × 256, 决策模型选用ResNet50[45]分类器, 目标分类标签是“ 斑马” 和“ 棕马” 、“ 猎豹” 和“ 美洲狮” 、“ 埃及猫” 和“ 波斯猫” .
针对需要生成反事实解释的分类器, 采用来自STEEX(Steering Counterfactual Explanations with Semantics)[46]的DenseNet121预训练权重, 并遵循ACE的实验设置, 使用PyTorch提供的ResNet50预训练权重以确保公平对比.
对于扩散模型的选择, 在CelebA-HQ数据集上采用面向Hugging Face预训练的DDIMs.针对Image- Net数据集, 沿用ACE的实验设定, 选用OpenAI提供的扩散模型, 并将反向去噪的过程设置为DDIMs中的确定性过程.
对于评价指标, 反事实解释的有效性通常通过FR(Flip Rate)指标衡量, 即反事实解释被分类为目标标签的概率.在面部图像及其属性的评估中, 已有多种指标用于量化反事实解释与输入查询图像之间的相似程度.首先, MNAC(Mean Number of Attributes Changed)指标衡量输入图像与反事实解释之间的特征最小变化量, 利用在VGGFace2数据集[47]上预训练的Orcale网络并在数据集上微调后计算得出.然而, ACE揭示MNAC的局限性, 并提出CD(Corre-lation Difference)指标作为改进.其次, 为了评估反事实解释是否改变输入图像的身份信息, FVA(Face Verification Accuracy)指标通过面部验证网络量化面部识别的准确性.然而, ACE指出FVA指标仅适用于面部相关问题并且仅关注最小扰动.为此, ACE建议跳过阈值设定, 转而使用编码器层面上的平均余弦距离度量输入图像与反事实解释之间的相似性, 并将这一度量称为FS(Face Similarity).为了处理非面部图像, ACE通过自监督学习对图像对进行编码以扩展FS.其中, 利用SimSiam作为编码网络测量余弦相似度, 称为S3(SimSiam Similarity)指标.此外, COUT(Counterfactual Transition)指标[36]用于量化输入与反事实之间的过渡概率.最后, 通常通过原始样本集合与反事实解释样本集合之间的FID(Fré chet Inception Distance)[48]指标评估反事实解释的真实性.
实验设置如下所述.在CelebA-HQ数据集上, DICE的加噪强度设为500, 以实现较优的生成效果.在获取重构噪声步骤中, 迭代次数设为80次, 采用Adam(Adaptive Moment Estimation)[49]优化器, 初始学习率设为0.01, 并在第20次迭代和第70次迭代时分别将学习率调整为0.005和0.001.逐步降低学习率的方法能在损失函数接近收敛时提高优化精度.在构建反事实解释过程中, 迭代次数设为20, 每次迭代包括一次过滤操作和一次生成操作, 共计40次反向去噪步骤, 整个流程累计120次去噪操作.学习率设为固定值0.05, 距离损失的系数设为0.5, 以平衡特征变化的幅度与标签修改之间的关系.在ImageNet数据集上, 基于生成模型的性能表现, 加噪强度设为100.在获取重构噪声步骤中, 迭代次数设为200, 同样使用Adam优化器, 初始学习率设为0.1, 并在第100次迭代时, 降至0.01.在构建反事实解释过程中, 迭代次数设为25, 累计250次去噪步骤.学习率固定设为0.008, 距离损失的系数设为0.001.
在CelebA-HQ、ImageNet数据集上进行定性实验.
笑容标签的反事实图像样例如图3所示.由图可知:从“ 不笑” 到“ 微笑” 的变化过程中, 观察到颧骨上升、嘴角上扬及法令纹加深等面部特征的变化; 从“ 微笑” 到“ 不笑” 的过程中, 面部图像表现为颧骨下降、嘴唇闭合及法令纹减少.
 | 图3 笑容标签的反事实图像样例Fig.3 Counterfactual image examples for smile labels |
年龄标签的反事实图像样例如图4所示.由图可知:从“ 年轻” 到“ 年迈” 的变化中, 伴随着面部皱纹增多、肤色由黄变白及法令纹加深; 从“ 年迈” 到“ 年轻” 的过程中, 面部图像表现为皱纹减少、肤色由白变黄及法令纹减淡.这些变化均符合人类直觉, 表明分类器在年龄标签上的判别是可信的.
 | 图4 年龄标签的反事实图像样例Fig.4 Counterfactual image examples for age labels |
动物标签的反事实图像样例如图5所示.由图可知:从“ 棕马” 到“ 斑马” 的变化过程中, 条纹特征显著增加, 尤其是在脸部和四肢区域; 从“ 美洲狮” 到“ 猎豹” 的变化中, 斑点特征开始增多; 从“ 波斯猫” 到“ 埃及猫” 的变化中, 同样伴随着斑点特征的增加.这些图像表明:对于“ 斑马” 标签, 分类器更关注条纹特征; 对于“ 猎豹” 和“ 埃及猫” 标签, 分类器更重视斑点特征.上述特征变化符合人类直觉, 说明分类器在这些分类任务上的决策是可信的.
 | 图5 动物分类的反事实图像样例Fig.5 Counterfactual image examples for animal classification |
从属性特征的分布来看, 某些特征表现为更稀疏或更粗糙的模式, 而另一些特征具有更广泛的覆盖.例如:在人脸数据集上, 年龄特征涉及更广泛的面部区域, 而微笑特征集中在较小的局部区域.在动物数据集上, 这些特征广泛分布于动物身体的不同区域, 如条纹或斑点分布于面部、四肢或躯干等区域.
本文选择如下对比方法:DiME[35], DiVE(Diverse Valuable Explanations)[38], ACE[41], STEEX[47], LDCE(Latent Diffusion Counterfactual Explanations)[50]、TIME(Text-to-Image Models for Counterfactual Explanations)[51].
在CelebA-HQ数据集上关于笑容标签和年龄标签的分类指标结果如表1和表2所示.由表可见, DICE在处理年龄标签及微笑标签的数据时, 在大多数指标上优于现有方法, 同时展现较高的稳定性.
| 表1 各方法在笑容标签上的分类指标值 Table 1 Classification metric values of different methods on smile labels |
| 表2 各方法在年龄标签上的分类指标值 Table 2 Classification metric values of different methods on age labels |
TIME在部分指标上性能优越的原因可能在于其依赖条件生成, 即通过训练模型额外获取与分类相关的语义信息.然而, 本文认为这一策略难以保证语义信息的质量并且增加计算成本.相比之下, DICE在MNAC和FVA等指标上均优于TIME, 显示出更高的分类语义信息质量.但是在图像分布相似度FID指标上, DICE表现相对较弱, 可能是由于生成过程中引入更多的语义信息变化.
ACE在部分指标上的优势可能得益于其引入额外的细化步骤, 更有效保留反事实解释样例中与分类变化最相关的特征.DICE在无需额外细化步骤的情况下, 已实现与ACE相当的生成效果, 并在与去除细化步骤的ACE* 的对比中展现显著优势.ACE* 仅在COUT和FR指标上优于DICE, 但在其它主要指标上, DICE的表现仍然相当或更优.
综上所述, DICE采用无条件生成策略, 无需额外计算开销或细化步骤, 便可达到与现有方法相当的效果, 并在部分指标上实现更优.
在ImageNet数据集上进行定量对比, 结果如表3所示.
| 表3 各方法在动物标签上的分类指标值 Table 3 Classification metric values of different methods on animal labels |
由表3可见, DICE在各项指标上与当前先进方法表现相当.由于实验设置中对特征变化的限制, DICE在FID指标上表现更优, 但该限制也在一定程度上抑制FR指标的提升.
上述结果表明, DICE在生成反事实解释方面具有一定优势, 是一种有效且可靠的反事实生成方法.
为了验证构建的反事实解释步骤中过滤操作的有效性, 设计消融实验, 对比是否添加过滤操作后生成反事实解释样例之间的差异.实验以CelebA-HQ数据集的非鲁棒分类器为对象, 保持参数和流程不变, 仅使用未经过滤的图像计算分类损失.具体笑容标签和年龄标签的分类图像样例如图6和图7所示.在图中:过滤操作表示通过DDIMs的前向加噪与反向去噪过程过滤后计算分类损失, 并通过迭代优化后生成的图像; 无过滤操作则是表示省略过滤过程后的生成图像.由图6和图7可见, 两种情况下的分类均发生改变, 但生成的反事实样例存在显著差异.经过过滤后操作后, 图像可呈现明显的语义变化, 如嘴角上扬、脸颊泛红等特征, 能清晰反映分类器在判断笑容分类时关注的关键特征, 从而为用户提供有效的分类解释.相比之下, 未经过滤操作后的图像与原始图像几乎无异, 缺乏显著的语义变化, 即使分类结果改变, 也无法为用户提供可靠的解释.上述结果验证DICE在抑制高频噪声和分布外扰动方面的显著优势.
 | 图6 笑容标签分类消融实验样例Fig.6 Samples for smile label classification in ablation experiment |
 | 图7 年龄标签分类消融实验样例Fig.7 Samples for age label classification in ablation experiment |
本文的消融实验旨在验证DICE在过滤高频噪声和分布外扰动方面的设计优势.实验选择的Den- seNet121分类器存在非鲁棒性, 这类分类器易受高频噪声和分布外扰动的影响.通过对比过滤前后的生成样例, 证实DICE可抑制高频噪声和分布外扰动, 在鲁棒分类器和非鲁棒分类器下均能生成具有可解释性的语义改动.
消融实验表明, 过滤操作可有效辅助非鲁棒分类器生成具有显著语义变化的反事实解释, 而省略过滤操作使生成过程更接近于对抗攻击.此外, 无论针对鲁棒分类器还是非鲁棒分类器, DICE均可通过过滤操作生成具有解释性的反事实样例.
本文提出基于扩散模型的无条件反事实解释生成方法(DICE).首先, 基于隐式扩散模型的去噪一致性, 将噪声图像视为隐变量, 使扩散模型能沿用传统生成模型的无条件反事实解释生成流程.其次, DICE将隐式去噪扩散概率模型视为正则化器, 增强目标分类器的鲁棒性, 即使分类器本身不具备鲁棒性, DICE也能生成具有解释性的语义变化.在反事实评价指标方面, DICE表现较优, 能生成更自然的特征变化, 即稀疏且现实可行的修改, 具有较好的可解释性.今后的工作将集中于如下方向.1)鉴于多次去噪过程限制DICE在反事实生成速率上的性能提升, 计划探索最新的扩散生成模型, 进一步提高方法的生成效率.2)进一步研究噪声图像作为隐变量的应用, 期望实现其与生成图像之间更强的解耦效果.3)本文实验基于多分类数据集并验证DICE在有限分类标签下的有效性, 可考虑扩展至更多分类标签, 进一步评估方法的适用性.
本文责任编委 封举富
Recommended by Associate Editor FENG Jufu
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|
| [47] |
|
| [48] |
|
| [49] |
|
| [50] |
|
| [51] |
|