
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于场景图知识的文本到图像行人重识别
[王晋溪1  , 鲁鸣鸣
, 鲁鸣鸣1 ]
, 鲁鸣鸣]
|
|



作者简介: 
王晋溪,硕士研究生,主要研究方向为深度学习、计算机视觉.E-mail:224711027@csu.edu.cn.
现有的大多数文本到图像的行人重识别方法对CLIP(Contrastive Language-Image Pretraining)等视觉语言模型进行微调以适应行人重识别任务,并获得预训练模型的强大视觉语言联合表征能力,然而,这些方法通常只考虑对下游重识别任务的任务适应,却忽视由于数据差异所需的数据域适应,难以有效捕获结构化知识(理解对象属性及对象间关系).针对这些问题,基于CLIP-ReID,文中提出基于场景图知识的文本到图像行人重识别方法,采用两阶段训练策略.在第一阶段,冻结CLIP的图像编码器和文本编码器,利用提示学习优化可学习提示词,实现下游数据域与CLIP原始训练数据域的适配,解决数据域适应的问题.在第二阶段,微调CLIP的同时引入语义负采样和场景图编码器模块,先通过场景图生成语义相近的难样本,并引入三元组损失作为额外优化目标,再引入场景图编码器,将场景图作为输入,增强CLIP在第二阶段对结构化知识的获取能力.在3个广泛使用的数据集上验证文中方法的有效性.
About Author:
WANG Jinxi, Master student. His research interests include deep learning and computer vision.
Most existing text-to-image person re-identification methods adapt to person re-identification tasks and obtain strong visual language joint representation capabilities of pre-trained models by fine-tuning visual language models, such as contrastive language-image pretraining(CLIP). These methods only consider the task adaptation for downstream re-identification task, but they ignore the required data adaptation due to data differences and it is still difficult for them to effectively capture structured knowledge, such as understanding object attributes and relationships between objects. To solve these problems, a scene graph knowledge based text-to-image person re-identification method is proposed. A two-stage training strategy is employed. In the first stage, the image encoder and the text encoder of CLIP model are frozen. Prompt learning is utilized to optimize the learnable prompt tokens to make the downstream data domain adapt to the original training data domain of CLIP model. Thus, the domain adaptation problem is effectively solved. In the second stage, while fine-tuning CLIP model, semantic negative sampling and scene graph encoder modules are introduced. First, difficult samples with similar semantics are generated by scene graph, and the triplet loss is introduced as an additional optimization target. Second, the scene graph encoder is introduced to take the scene graph as input, enhancing CLIP ability to acquire structured knowledge in the second stage. The effectiveness of the proposed method is verified on three widely used datasets.
随着监控技术的进步和对公共安全需求的增加, 主题公园、机场、街道及大学校园等公共场所每日都会产生海量的监控视频.传统的行人重识别(Person Re-identification, ReID)技术[1]通常需要目标人物的图像作为查询对象, 但在实际应用中, 获取目标人物的图像往往具有一定的挑战性.例如:在火灾、交通事故等紧急情况中, 监控设备可能因损坏或现场混乱而无法正常工作, 难以及时获取目标人物的图像.此外, 当目标人物首次出现在监控画面时, 可能由于其突然出现或迅速移动, 监控系统未能及时捕捉清晰图像, 或者目击者无法立即提供高质量的图像信息.相比之下, 使用行人的文本描述作为查询对象显得更加灵活和高效, 因为文本描述可通过目击者的口述或其它非侵入性手段轻松获得, 并且不受图像质量或实时捕捉的限制.
近年来, 基于文本到图像的行人重识别(Text-to-Image Person Re-identification, T2IReID)技术受到广泛关注.通过结合自然语言描述与图像特征, T2IReID 实现更直观灵活的行人匹配, 尤其在图像不足或环境复杂时具有显著优势, 因此已在智能城市和安全监控领域展现出重要的应用前景.
但是, T2IReID任务仍面临挑战, 主要原因是不同模态之间固有的异质性差距和外观属性冗余.这些异质性差距体现在图像和文本在数据形式和特征表达上的差异, 而外观属性冗余是指行人图像中存在大量无关或重复的视觉信息.这些因素都增加准确匹配图像和文本的难度.为了解决这些问题, 大多数现有的方法尝试通过全局和局部匹配对齐学习用于行人重识别的准确相似性度量.具体而言, 一些全局匹配方法[2, 3, 4]利用视觉语言模型的骨干网络提取模态特定的特征, 并利用对比学习实现全局视觉语义对齐.为了捕捉细粒度的信息, 一些局部匹配方法尝试将局部身体区域与文本描述的实体明确对齐, 提高行人特征的可分辨性.
在此背景下, 最近提出的大规模视觉语言预训练(Vision-Language Pre-training, VLP)为T2IReID任务提供新的解决方案, 可利用预训练模型, 如BERT(Bidirectional Encoder Representations from Transformers)[5]、ViT(Vision Transformer)[6]和CLIP(Contrastive Language-Image Pretraining)[7], 学习视觉与语义的丰富知识, 实现显式的全局对齐或发现更细粒度的局部对齐, 提高重识别性能.
尽管上述方法取得一定进展, 但在实际应用中仍存在问题.Lin等[8]指出, CLIP在细粒度语义捕捉上存在与词袋模型相似的局限性.Huang等[9]提到, CLIP在理解文本的结构信息方面存在局限性, 无法准确区分文本中的歧义表达.因此, 现有的这些基于CLIP的T2IReID在理解句子的细粒度语义, 尤其是对象属性和对象之间关系的能力方面仍有待进一步验证.
此外, 基于CLIP的T2IReID通常依赖对整个网络的直接微调, 使CLIP适应T2IReID任务.虽然这些方法在这一任务上表现出很强的竞争力, 但值得注意的是, 当将VLP应用于下游任务时, 除了任务自适应之外, 还需要进行域自适应.具体而言, 在T2IReID任务中, 图像和文本描述的内容与CLIP原始训练数据域ImageNet之间存在显著差异.Image- Net的训练数据主要包括各种物体图像和动物图像, 文本描述风格广泛, 而行人重识别任务中的数据更专注于人类外观和行为细节.这种差异意味着直接应用CLIP可能会导致损失一些原有的有价值知识, 从而影响模型性能.因此, 尽管现有研究尝试将CLIP捕捉的丰富跨模态知识直接应用于T2IReID任务, 但可能未能充分适应领域特定需求, 从而限制模型性能的进一步提升.
为了解决上述问题, 本文提出基于场景图知识的文本到图像行人重识别, 采用与CLIP-ReID[10]相似的两阶段训练策略, 将领域适应与任务适应分开.在第一阶段, 不同于CLIP-ReID为了获取文本标签以学习提示词, 在文本编码器的输入序列中引入可学习的提示词, 并冻结图像编码器和文本编码器, 仅对提示词进行学习.不仅继承CLIP强大的视觉语言联合表征能力, 还通过学习领域特定的提示词, 实现对目标领域的适配, 有效反映行人目标域的标签分布.在第二阶段, 冻结已学到的提示词, 并对文本编码器和图像编码器进行微调.为了在微调过程中保持原有预训练知识, 采用如下策略:先引入语义负采样的方式, 帮助模型在训练中保持对原始特征的敏感性, 再在微调过程中使用较小的学习率, 减少对预训练权重的干扰, 使模型能在保持预训练知识的基础上, 更专注地适应特定重识别任务中的细粒度信息.此外, 引入场景图编码器, 利用场景图知识作为输入, 增强CLIP对结构化知识的获取能力.在3个主流的T2IReID数据集上的广泛实验表明, 本文方法具有一定的性能提升.
行人重识别是利用计算机视觉技术判断图像或视频序列中是否存在特定行人的技术, 而文本到图像的行人重识别是由Li等[1]提出的一项跨模态行人检索任务, 该任务的核心挑战在于捕捉行人的细粒度特征并在潜在空间中实现跨模态特征的对齐.
早期的工作主要采用单模态编码器, 分别从文本和图像中提取特征, 再利用投影层将这些特征投影到共享的潜在空间, 实现全局特征或局部特征对齐.Zhang等[2]提出CMPM(Cross-Modal Projection Matching)和CMPC(Cross-Modal Projection Classifica-tion), 但在对齐全局特征时牺牲大量细粒度特征, 这对于细粒度的跨模态检索任务来说是次优的, 限制模型性能的提升.相比之下, 为了实现细粒度的对齐, 基于局部匹配的方法[11, 12, 13]探索身体区域和文本实体之间的显式局部对齐, 从而实现更高精度的匹配.
最近, 像CLIP这样的VLP联系视觉表示与其相应的高级语言描述, 为T2IReID任务引入新的解决方案.预训练视觉语言模型的目的是利用大规模的文本图像数据集, 获得具有强大表示能力的多模态模型, 这种预训练模型随后可进行微调或直接用于下游任务[14].Han等[15]将CLIP应用于T2IReID任务, 提出CM-MoCo(Cross-Modal Momentum Con-trastive Learning), 能在相对较小的T2IReID数据集上学到更具辨别性的特征.Yan等[16]提出CFine(CLIP-Driven Fine-Grained Information Excavation Frame-work), 从文本和图像中挖掘细粒度信息, 从而实现更精确的检索.Jiang等[11]提出IRRA(Cross-Modal Implicit Relation Reasoning and Aligning Framework), 通过未被掩蔽的文本标记和视觉标记预测掩蔽标记, 对齐图像和文本的上下文表示, 并建立局部依赖关系模型.
尽管上述方法已取得较优性能, 但都忽略CLIP在捕捉结构化知识(对象属性和对象之间关系)方面的缺陷.
最初学者在自然语言处理领域提出提示学习[17], 目的是在预训练语言模型的输入中加入特定的提示, 这些提示通常是为引导模型理解特定任务设计的文本片段或问题格式, 从而帮助模型更好地适应和理解下游任务.
在早期阶段, 通常通过人工定义的提示[18]提升下游任务的性能, 然而, 这种提示的设计需要大量的专家知识和人力资源, 并且由于提示的固定性和任务的依赖性, 难以充分发挥语言模型的自适应性和泛化能力.
为了解决上述问题, 一些研究者将提示词设计成可学习的连续向量, 可根据特定任务通过梯度反向传播直接优化.Zhou等[19]提出CoOp(Context Opti-mization), 通过优化其语言分支的连续提示向量集以微调CLIP, 实现少样本迁移.Zhou等[20]提出Co-CoOp(Conditional Context Optimization), 指出CoOp在处理新类别上的性能不足, 并为每个图像实例生成动态提示(即生成与输入图像实例相关的条件化提示), 使提示能适应每个实例的独特特征, 从而提升视觉语言模型的泛化能力.Ge等[21]提出DAPL(Domain Adaptation via Prompt Learning), 相比Co-CoOp, 其核心思想是在提示中嵌入领域信息, 再用于分类任务, 从而根据不同领域动态调整分类器.
得益于上述工作的努力, 提示学习技术目前已广泛应用于多种下游任务, 如目标检测[22]、语义分割[23]和图像检索[24]等.CLIP-ReID是首个将CLIP应用于行人重识别任务的方法, 通过学习与特定身份相关的文本提示, 对齐文本编码器生成的文本表示与图像编码器生成的图像表示, 提取更具鉴别力的全局特征.然而, CLIP-ReID的文本提示学习主要用于生成文本标签, 这在一定程度上忽略模型对不同数据域的适应能力.
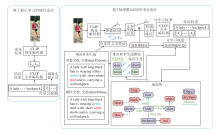
本文提出基于场景图知识的文本到图像行人重识别, 架构如图1所示.使用CLIP-ViT-B/16[7]作为主干网络, 包含一个图像编码器 I(· )和一个文本编码器T(· ), 两个编码器均采用12层的Transformer[25]架构.采用两阶段的训练策略, 第一阶段将固定图像编码器和文本编码器只学习提示, 第二阶段将固定学习完成的提示只对图像编码器和文本编码器进行微调.
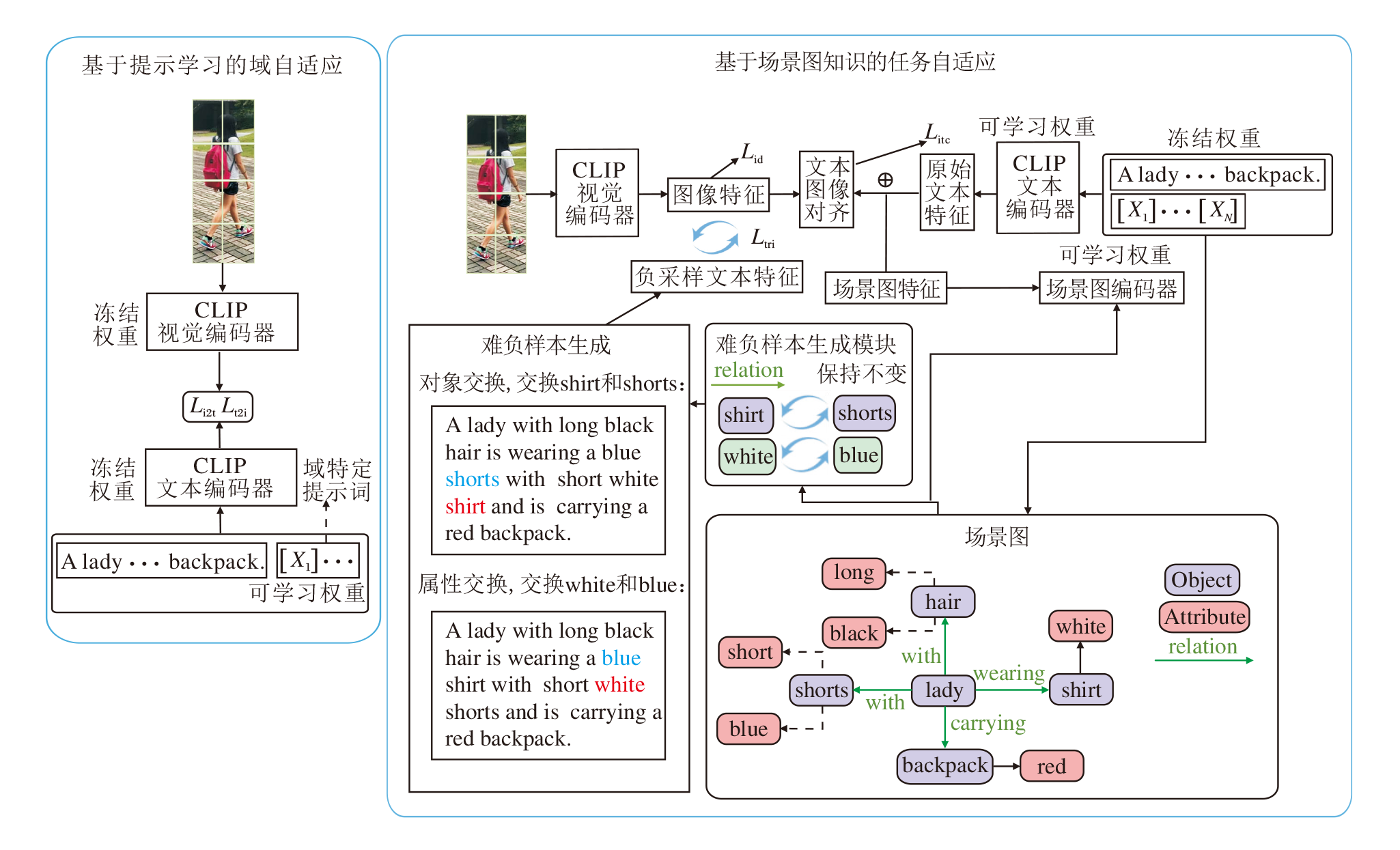 | 图1 本文方法架构图Fig.1 Architecture of the proposed method |
如图1左图所示, 给定一幅图像I∈ RH× W× C.首先, 将I分割成一系列 Nv=HW/P2的固定大小、不重叠的图像块, 其中, (H, W)表示图像分辨率, C表示通道数, P表示块的大小, 再通过一个可训练的线性投影将块序列映射成一系列的视觉标记
{
每个视觉标记表示一个非重叠局部标记或可学习的[CLS]嵌入.然后, 视觉标记输入视觉编码器I(· )模块中, 学习每个图像块之间的相关性, 每个图像块都有一个对应的输出值, 用于表示该图像块的特征.最后, 采用线性投影法将
V={Vcls, V1, V2…,
其中Nv表示视觉标记的数量.
同样, 文本编码器T(· )从输入文本中生成文本标记序列并提取文本表示.对于给定文本T, 使用文本编码器T(· )提取文本表示.遵循CLIP, 首先使用小写字节对编码[26]进行分词, 词汇量为49 152.文本描述的开始和结束分别用[SOS]和[EOS]标记标识, 表示序列的起点和终点.然后, 将文本标记
{
输入T(· )模块中, 并通过掩码自注意机制学习每个标记的相关性.最后, 采用线性投影法将
T={Tsos, T1, T2, …,
其中Nt表示文本标记的数量.
当将CLIP引入下游任务时, 不仅需要进行任务自适应, 还需要进行域自适应, 本文采用提示学习的方法实现域自适应.如图1左图所示, 在文本编码器的输入序列中添加可学习的提示词, 学习如何适应下游数据与原始CLIP训练数据之间的领域差距.提示被定义为连续的特定于ID的可学习向量, 维度与Transformer块的嵌入空间保持一致.值得注意的是, 位置嵌入不会添加到提示中, 因此插入位置并不重要.本文直接将可学习的提示词添加到文本序列的末尾, 文本提示
Ptxt={[X1], [X2], …, [XN]}={
其中, 每个提示的上标表示它被添加到文本编码器中, 下标XT表示文本提示词的长度.Ptxt直接添加到文本序列末尾, 因此文本标记变为
{
提示词添加到[EOS]标记之后是因为模型可在保持原始句子完整性的同时, 引入额外的上下文信息或指导信息.只学习文本提示而不学习视觉提示的原因在于, 文本提示的学习更灵活, 通过调整输入的文本序列以适应新的领域变化, 而不调整其它模型参数.这种方式可有效避免对视觉特征的过度调优, 降低模型过拟合的风险.
在这一阶段, 固定图像编码器I(· )和文本编码器T(· )的参数, 只优化可学习的提示词.与CLIP类似, i∈ {1, 2, …, B}表示一个批次(B个图像)中第i个图像的索引.令Vcls为图像特征的[CLS]标记嵌入, 而Teos为相应文本特征的[EOS]标记嵌入, 使用对比学习作为目标损失, 旨在拉近相似样本(正样本)之间距离的同时推远不相似样本(负样本)之间距离, 学习有效的表征.具体而言, 通过映射Teos和Vcls分别得到最终的文本表征
${{L}_{t2i}}\left( {{y}_{i}} \right)=\frac{-1}{\left| P\left( {{y}_{i}} \right) \right|}\underset{p\in P\left( {{y}_{i}} \right)}{\mathop \sum }\,\ln \left( \frac{\exp \left( s\left( {{f}^{txt}}_{p},~f{{~}^{img}}_{{{y}_{i}}} \right) \right)}{\mathop{\sum }_{a=1}^{B}\exp \left( s\left( {{f}^{txt}}_{a},~{{f}^{img}}_{{{y}_{i}}} \right) \right)} \right)$. (1)
其中:s(· , · )表示计算文本和图像之间距离的余弦相似度函数;
P(yi)={p∈ 1, 2, …, B∶ yp=yi},
表示这一批次中所有与
同理, 图像到文本的对比损失可依据式(1)用同样的方法表示, 因此, 第一训练阶段使用的损失为:
Lstage1=Litc=Lt2i+Li2t. (2)
梯度通过I(· )和T(· )反向传播, 以优化提示, 通过这种方式, 缩小下游数据域与CLIP原始训练数据域之间的差距.因此, 在随后的微调阶段, CLIP可专注于任务自适应.
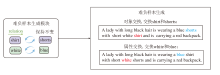
在完成第一阶段的数据域适应后, 针对现有基于CLIP的T2IReID在理解句子的细粒度语义, 尤其是对象属性和对象之间关系方面仍需进一步验证的问题, 开展相关实验, 结果如图2所示, 通过交换文本描述中颜色信息, 并使用IRRA[11]评估图像和对齐、未对齐描述之间的CLIP分数(语义相似度).图像与正确匹配描述之间的CLIP分数反而低于图像与不匹配描述之间的分数, 这表明在两个对象之间交换属性会增加模型准确区分其语义的难度.
 | 图2 图像和对齐/未对齐描述之间的CLIP分数Fig.2 CLIP score between image and aligned or unaligned description |
此外, 基于CLIP的模型生成的通用表示无法有效区分包含相同单词但在结构化知识上存在差异的文本片段.因此, 当输入文本发生细微变化(如简单的属性交换)时, 模型可能产生错误判断, 导致其在文本行人检索任务中的准确率下降.这种准确率的降低不仅影响模型在训练集上的表现, 还限制其在实际应用场景中的泛化能力.
针对上述问题, 如图1右图所示, 在第二阶段保持之前学到的文本提示词和原始的文本序列不变, 仅优化两个编码器的参数, 这样模型在保留已有知识的基础上, 能进一步细化对关键特征的学习, 更专注于细粒度信息, 提高模型在重识别任务中的适应性和泛化能力.
此外, 为了克服CLIP在捕获结构化知识方面的不足, 首先, 引入场景图生成模块, 生成具有相同词组但详细语义不同的语义负样本, 增强细粒度结构化表示.然后, 提出场景图编码器, 使用场景图作为输入, 将场景图的结构化知识整合到结构化表示中, 再与文本表示整合.通过这种方式, 文本表示不仅包含整个句子承载的单词信息, 还融入句子中的详细语义构成的结构化知识, 从而丰富模型的语义理解能力.
2.2.1 场景图生成和语义负采样
通常来说, 详细的语义信息, 包括对象、对象属性及对象之间的关系, 对于理解结构化知识至关重要.这些信息对于跨模态学习也非常关键, 跨模态学习旨在增强视觉和语言的联合表征.本文采用Johnson等[27]的场景图解析器将文本解析成场景图.值得注意的是, 这里的场景图是从自然语言文本中提取的对象、属性及它们之间语义关系的结构化表示, 而非生成具体的图像或场景.
给定文本句子T, 解析成一个场景图:
G(T)=< O(T), E(T), K(T)> .
其中:O(T)表示T中的对象集合;
E(T)⊆O(T)× R(T)× O(T)
表示对象之间实际关系的超边集合, R(T)表示关系节点的集合;
K(T)⊆O(T)× A(T)
表示属性对的集合, A(T)表示与对象相关联的属性节点的集合.
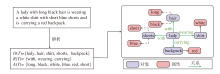
基于原始文本描述“ A lady with long black hair is wearing a white shirt with short blue shorts and is carrying a red backpack.” 生成的场景图范例如图3所示, 图中, “ lady” 是基础对象, “ black” 和“ long” 为对象“ hair” 相关属性, 描述对象颜色或其它属性, “ wearing” 表示对象之间的关系.
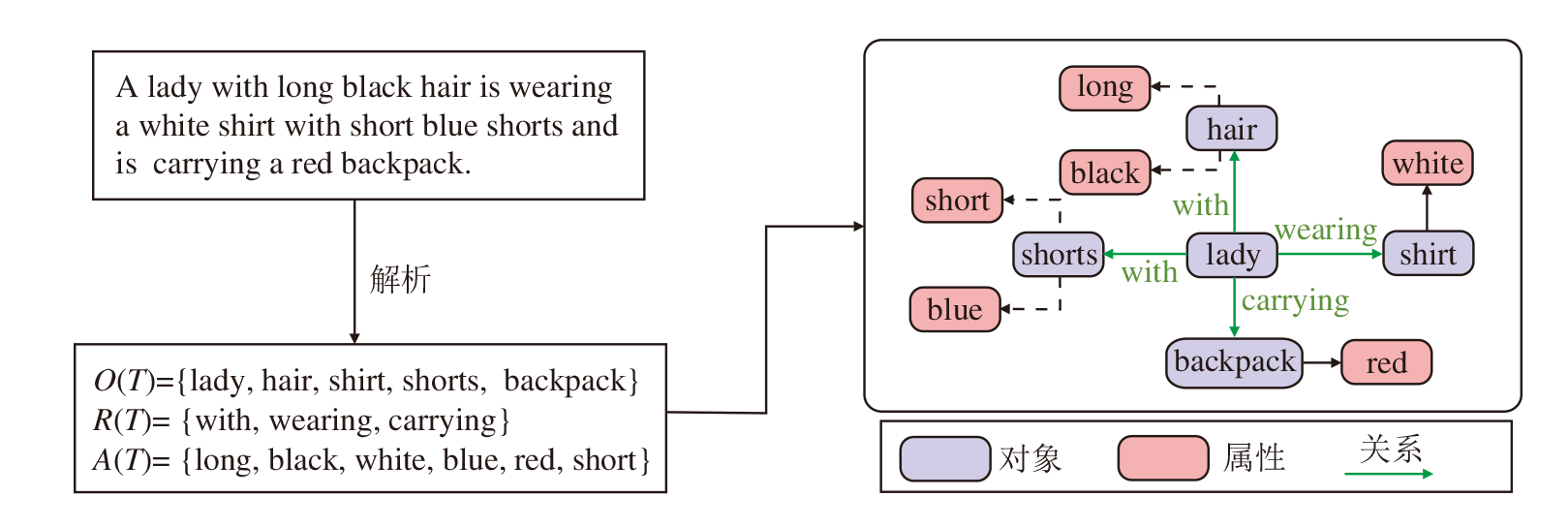 | 图3 场景图生成示例Fig.3 Scene graph generation example |
得到场景图之后, 本文目标是构建具有相似构成但不同语义的负样本, 以增强CLIP理解对象属性和对象之间关系的能力.
给定一个图像文本对(I, T)和由文本T生成的场景图G(T), 考虑到ReID任务对应的场景是以人为中心, 场景图中的三元组可表示为
(person, relation, object).
那么可通过对象交换的方式生成语义负样本T-.
给定场景图中的任意两对对象关系对(P, R, Oi)和(P, R, Oj), 对象交换可形式化描述为
T-=Swap((P, R, Oi), (P, R, Oj))=(P, R, Oj), (P, R, Oi),
其中, Swap(· , · )表示交换句子成分的函数, P表示以人为中心的主语, R表示关系词, Oi、Oj表示对象.
类似地, 对于场景图中的任意属性对(Am, Oi)和(An, Oj), 通过属性交换的方式生成T-:
T-=Swap((AmOi), (AnOj))=
以原始描述“ A lady with long black hair is wearing a white shirt with short blue shorts and is carrying a red backpack.” 为例, 生成的难负样本如图4所示.
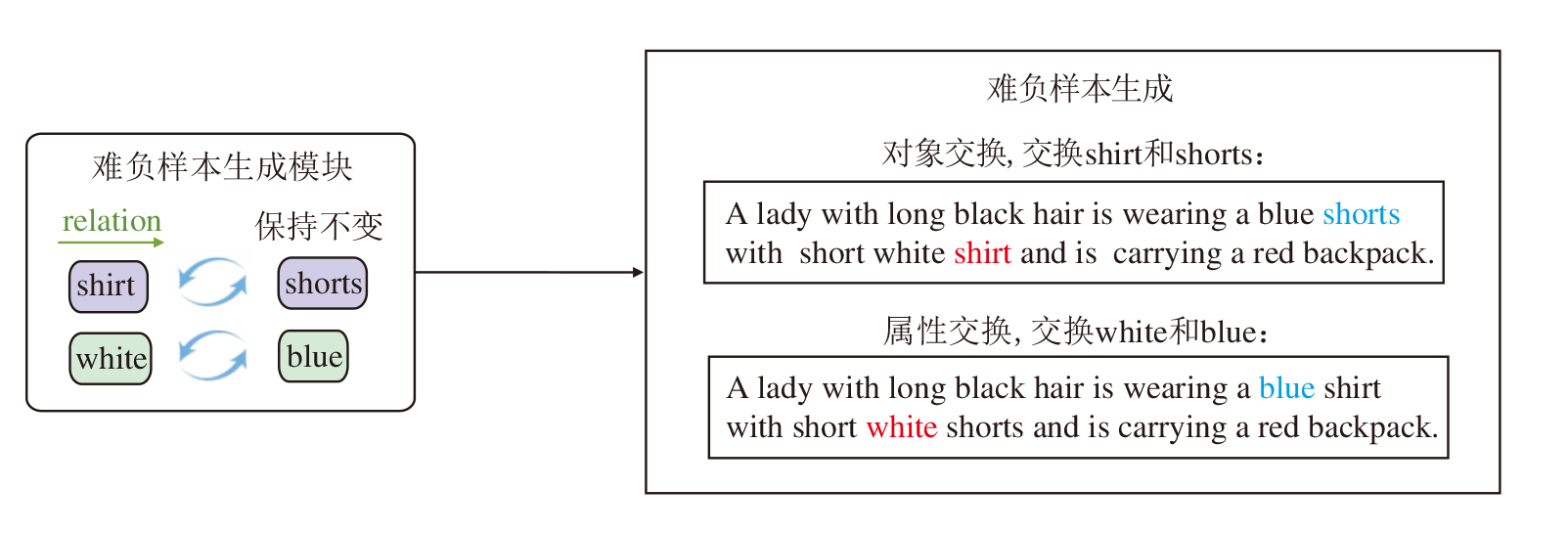 | 图4 难负样本生成示例Fig.4 Example of hard negative sample generation |
这些通过对象交换生成的负样本, 与原始正样本一起用于三元组损失的优化, 其目的是通过拉近正样本对的距离、推远负样本对的距离, 优化模型的嵌入空间, 增强其对图像中对象属性及语义关系的理解能力, 提高对表面相似但语义错误样本的区分能力.
2.2.2 场景图编码器
CLIP以“ 词袋” 方式处理文本输入, 忽略文本的详细语义.相比之下, 引入场景图可捕获句子中的关键结构信息, 使模型深入观察文本的细粒度语义.因此, 本文设计场景图编码器, 显式建模对象、属性、对象之间的关系以及对象与属性的关系, 将这些结构化信息作为模型输入, 增强模型对细粒度语义的理解能力.
将关系对和三元组这两种结构化知识统一视作三元组处理, 在关系对中添加连接词“ is” , 实现统一的表示形式.例如:属性-对象关系对(white, shirt)在这种方式下会处理为三元组(shirt, is, white).通过这种方法, 得到一组三元组:
Tin={(hj, rj, tj)∣j∈ [1, K]},
其中, hj表示头实体, rj表示关系实体, tj表示尾实体.对于Tin中的每个三元组(hj, rj, tj), 使用来自BERT的分词器和词汇嵌入, 得到每个实体的嵌入
其中ENCtriple(· )表示三元组编码函数.
这样设计的原因是为了区分三元组的位置信息.例如:两个三元组(shirt, is, white)和(white, is, shirt)虽然组成元素相同但顺序不同, 通过简单的累加方法得到的最终嵌入结果将是一样的, 这会影响模型区分这些三元组的能力.因此, 引入三元组编码函数式(3), 确保模型能有效识别和处理不同的三元组结构.这样, K个三元组可处理成K个语义嵌入.然后, 将三元组输入多个Transformer层, 得到场景图表示.最后, 整合文本表示和场景图表示, 得到最终的融入结构化知识的文本表示:
其中, λ 表示超参数, etext表示文本嵌入, eKE表示结构知识嵌入.这两种嵌入共同构成文本表示.这样的设计使本文方法不仅能捕捉整个句子承载的单词信息, 更重要的是, 它能理解和利用句子中的详细语义构成的结构化知识.
2.2.3 损失函数设计
为了提高类内紧凑性, 遵循ReID领域中广泛认可的方法[28], 采用带标签平滑的ID损失:
${{L}_{\text{id}}}=\underset{k=1}{\overset{N}{\mathop \sum }}\,\left( -{{q}_{k}}\text{ln }\!\!~\!\!\text{ }{{p}_{k}} \right)$,
其中
$ q_k=(1-\epsilon) \delta_{k, y}+\frac{\epsilon}{N}$,
表示基本目标分布中的值, $\epsilon $表示超参数, ln pk表示类别k的ID预测对数, N表示实例总数.
利用2.1节中式(2)提到的Litc学习更好的特征表示.此外, 引入额外的对比学习目标, 提高结构化表示的性能.对比学习目标是拉近图像I与对应描述T(正样本)之间的距离, 并推远图像I与负样本T-之间的距离, 用于学习充分的表示, 即
Ltri=max(0, d'-d+α ),
其中, d'表示图像I与负样本描述T-之间的距离, d表示图像I与对应描述T之间的距离, α 表示边界超参数.
最终在第二阶段使用的损失如下所示:
Lstage2=Lid+Ltri+Litc.
算法1 基于场景图知识的文本到图像行人重识别
输入 一个批次(N个文本对)的图像xi, 对应的文本描述
参数 一组可学习的文本标记Ptxt, 长度为超参数XN, 图像编码器I, 文本编码器T, 场景图编码器K, 线性层gV、gT、gG
从预训练的CLIP初始化I、T、gV、gT, 随机初始化可学习文本标记Ptxt, 从BERT-base初始化场景图编码器K和gG
while in the 1st stage do
s(Vi,
s(· )表示相似性的计算, 使用Litc优化Ptxt
End while
for yi= 1 to N do
tex
生成场景图
负样本采样
End for
while in the 2nd stage do
text
s(Vi,
使用Lid、Ltri和Litc优化I、T和K
End while
在算法1中, 第一阶段使用可学习的提示词学习CLIP的原始训练数据域的特征, 使CLIP保留其自身优势的同时完成数据域适应.在第二阶段, 对CLIP进行微调, 增强模型对细粒度信息的处理能力, 促进任务适应.另外还引入语义负采样和场景图知识编码器, 使用场景图知识作为输入, 增强CLIP在第二阶段对结构化知识的获取能力.
本文选择在CHUK-PEDES[1]、ICFG-PEDES[15]、RSTPReid[29]这3个主流的T2IReID数据集上进行实验.数据集的详细信息如表1所示.
| 表1 实验数据集 Table 1 Experimental datasets |
CUHK-PEDES数据集是第一个可获取的用于文本图像个人检索的数据集, 包含13 003个行人的40 206幅图像和80 412条文本描述, 每幅图像配有2条文本描述.遵循官方协议, 数据集划分为训练集、验证集和测试集.训练集包含11 003位行人的34 054幅图像和68 108条描述; 验证集包含1 000位行人的3 078幅图像和6 156条描述; 测试集包含1 000位行人的3 074幅图像和6 148条描述.
ICFG-PEDES数据集上所有的图像来源于MSMT17数据集[30], 相比CHUK-PEDES数据集, 包含更多身份和文本描述.ICFG-PEDES数据集包含4 102位行人的54 522条文本描述和54 522幅图像, 即每幅图像有一个对应的文本描述.数据集划分为训练集和测试集, 训练集包含3 102位行人的34 674个图像文本对, 测试集包含剩下的1 000个行人的19 848个图像文本对.
RSTPReid数据集上的图像同样收集自MSMT-17数据集, 包括4 101个行人的20 505幅图像和41 010条文本描述.每人对应由15个不同摄像头捕获的5幅图像, 每幅图像有2个对应的文本描述.训练集包含3 701位行人, 验证集和测试集分别包含200位行人.
本文采用T2IReID的标准评估指标:Rank-1、Rank-5和Rank-10准确率及均值平均精度(Mean Average Precision, mAP).给定一个文本描述的查询, 计算图库中所有图像与这个文本描述的相似度, 再根据相似度值进行排序.Rank-K是指真实匹配图像在相似度排序表中出现在前K个的概率.
在单个NVIDIA A100 GPU上使用PyTorch进行所有实验, 采用CLIP-ViT-B/16作为骨干模型.将模型初始化为BLIP(Bootstrapping Language Image Pre-training)的参数, 在1.29× 108个图像文本对上进行预训练.
对于文本编码器, 由于数据集上的文本描述不超过50个单词, 设置文本Transformer块的宽度为512, 注意力头的数量为8, 标记的最大长度为77, 可学习的提示长度为8, 并使用xavier[31]统一初始化方案随机初始化.
对于图像编码器, 图像调整为384× 128, 补丁大小为16× 16, 因此有193个(添加一个[CLS]标记)补丁.首先将视觉位置嵌入从197调整为193, 隐藏层大小为768, 最终将特征维度从768投影为512.
在训练过程中, 采用随机水平翻转、随机擦除和随机裁剪进行数据增强.基础学习率设为1e-5.在开始的5轮中采用预热策略, 使学习率从1e-6线性增长到1e-5.分类器的学习率设为基础学习率的5倍, 并使用带有余弦学习率衰减的Adam(Adaptive Moment Estimation)优化器进行模型优化.两个训练阶段的配置保持一致, 每个阶段训练轮数设为60轮, 以实现完全收敛.第二阶段结构知识嵌入的权重设为0.2.
本节选择多种在文本到图像行人重识别领域具有代表性的方法作为对比方法, 验证本文方法的有效性.
1)IVT(Implicit Visual-Textual)[4], 基于文本的人物检索的隐式视觉文本框架.
2)IRRA[11], 学习局部视觉与文本标记之间的关系, 增强全局图像与文本的匹配能力.
3)CFine[16], 利用CLIP等预训练视觉语言模型进行细粒度文本图像行人重识别的方法.
4)SRCF(Simple and Robust Correlation Fil-tering)[32], 鲁棒的相关滤波方法, 用于基于文本的行人搜索.
5)AXM-Net[33], 隐式跨模态特征对齐的行人重识别方法.
6)ASAMN(Adaptive Salient Attribute Mask Network)[34], 关注容易忽略、不明显的特征, 提升跨模态文本图像匹配的效果.
7)TransTPS[35], 通过多粒度匹配和Transformer架构实现更深层次的模态交互的基于文本的行人检索方法.
8)MMGCN(Multimodal Graph Convolutional Network)[36], 采用图卷积网络, 高效提取并融合多模态特征的基于文本的行人图像重识别方法.
9)SAL(Cross-Modal Semantic Alignment Lear-ning)[37], 有效促进学习具有高效、准确跨模态对齐的判别表征.
10)EESSO(Exploiting Extreme and Smooth Sig-nals via Omni-Frequency Learning)[38], 基于全频学习并利用极端平滑信号的文本驱动行人检索方法.
11)VGSG(Vision-Guided Semantic-Group Net-work)[39], 基于文本的人物搜索的方法, 提取和对齐细粒度的视觉和文本特征实现人物检索.
12)CFAM(Cross-Modal Fine-Grained Aligning and Matching Framework)[40], 融合跨模态共享粒度解码器与难负样本匹配机制, 实现不同模态数据的精确对齐与匹配.
此外, 还使用基线模型CLIP-ViT-B/16[7]作为参考.
各方法在3个广泛使用的基准数据集上的指标值如表2~表4所示.表中黑体数字表示最优值, “ -” 表示原文献无结果, w/o CLIP表示未使用CLIP作为预训练模型的方法, w/ CLIP表示使用CLIP作为预训练模型的方法.基线模型使用Info-NCE loss[41]直接对CLIP进行全局微调.
| 表2 各方法在CUHK-PEDES数据集上的指标值对比 Table 2 Metric value comparison of different methods on CUHK-PEDES dataset % |
| 表3 各方法在ICFG-PEDES数据集上的指标值对比 Table 3 Metric value comparison of different methods on ICFG-PEDES dataset % |
| 表4 各方法在RSTPReid数据集上的指标值对比 Table 4 Metric value comparison of different methods on RSTPReid dataset % |
由表2~表4可见, 本文方法在3个数据集上都取得较高的Rank-1和mAP值.在ICFG-PEDES数据集上, 本文方法的所有指标均最优.在RS-TPReid数据集上, 相比次优方法, 本文方法的Rank-5、Rank-10和mAP值提升1.30%、0.35%、0.13%.在CUHK-PEDES数据集上, 本文方法与IRRA存在一定的性能差距.本文分析认为, 这主要是由于CUHK- PEDES数据集上的文本描述比其它两个数据集更细致, 粒度更高, 在这种情况下, 第一阶段学到的域特定提示词包含的信息较有限, 性能提升相对较小.
上述结果表明, 本文方法在ICFG-PEDES、RST- PReid数据集上的性能具有一定竞争力, 并在保持甚至提升性能的同时, 可进一步增强模型的语义理解能力.
为了验证本文提出的可学习提示词、负样本采样和场景图编码器的有效性, 本节分析各部分对方法性能的具体贡献.在CUHK-PEDES数据集上进行消融实验, 结果如表5所示.由表可见, 每个模块都在不同程度上提升方法性能, 而结合可学习提示词、负样本采样和场景图编码器的多重优化策略达到最优性能.这表明本文对CLIP-ReID两个阶段做出的改进均有效, 并且在提高性能的同时为CLIP提供结构化知识.
| 表5 在CUHK-PEDES数据集上的消融实验结果 Table 5 Results of ablation experiments on CUHK-PEDES dataset % |
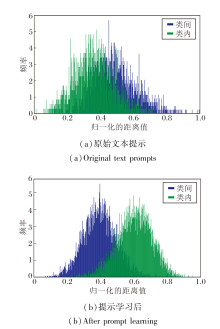
为了验证第一阶段学习的文本提示可有效完成数据域适应, 在CUHK-PEDES数据集上可视化原始行人文本序列与附加第一阶段学到文本提示后的类内和类间特征距离分布.对于两个不同的类别 Ω i和Ω j, 类内距离
$\text{d}\left( {{\text{ }\!\!\Omega\!\!\text{ }}_{\text{i}}} \right)=\frac{1}{{{N}_{i}}{{N}_{i}}}\underset{k=1}{\overset{{{N}_{i}}}{\mathop \sum }}\,\underset{l=1}{\overset{{{N}_{i}}}{\mathop \sum }}\,{{\text{d}}^{2}}\left( X_{k}^{\left( i \right)},X_{l}^{\left( i \right)} \right)$,
类间距离
$\text{d}\left( {{\text{ }\!\!\Omega\!\!\text{ }}_{\text{i}}},{{\text{ }\!\!\Omega\!\!\text{ }}_{\text{j}}} \right)=\frac{1}{{{N}_{i}}{{N}_{j}}}\underset{k=1}{\overset{{{N}_{i}}}{\mathop \sum }}\,\underset{l=1}{\overset{{{N}_{j}}}{\mathop \sum }}\,\text{d}\left( X_{k}^{\left( i \right)},X_{l}^{\left( j \right)} \right)$,
其中, Ni表示类别Ω i中的样本数量,
最终结果如图5所示.由图可较直观看到, 经过提示学习之后, 类内的平均距离减小, 类间的平均距离增大.这表明, 经过第一阶段学习后的提示相比原始文本序列更具有辨别力.原始文本序列未能适应CLIP的原始数据域, 导致类内和类间的平均距离差异较小.因此, 第一阶段学到的提示词能使文本特征更具有鉴别性, 更有效反映行人目标域的标签分布.
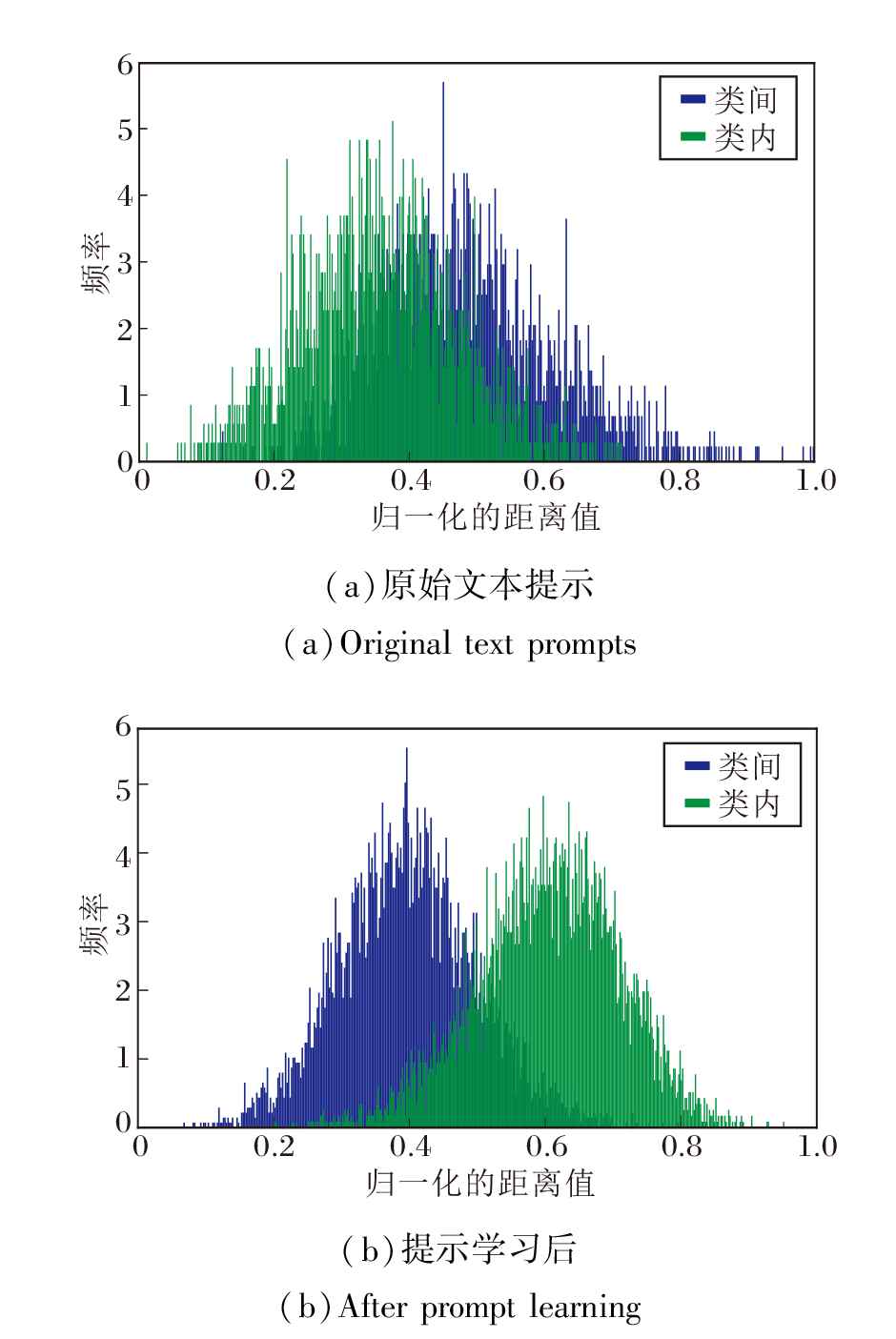 | 图5 CUHK-PEDES数据集上提示学习前后类内与类间的特征距离分布对比Fig.5 Distribution of intra-class and inter-class feature distances before and after prompt learning on CUHK-PEDES dataset |
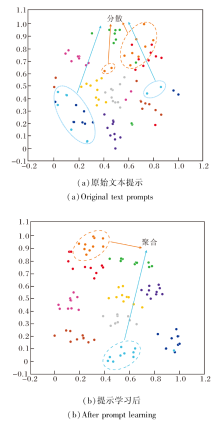
同时, 使用t-SNE(t-Distributed Stochastic Neigh-bor Embedding)[42]可视化文本编码器最后一层的特征分布.在CUHK-PEDES数据集上随机选择10位行人, 原始文本提示和经过提示学习后的样本分布对比如图6所示.
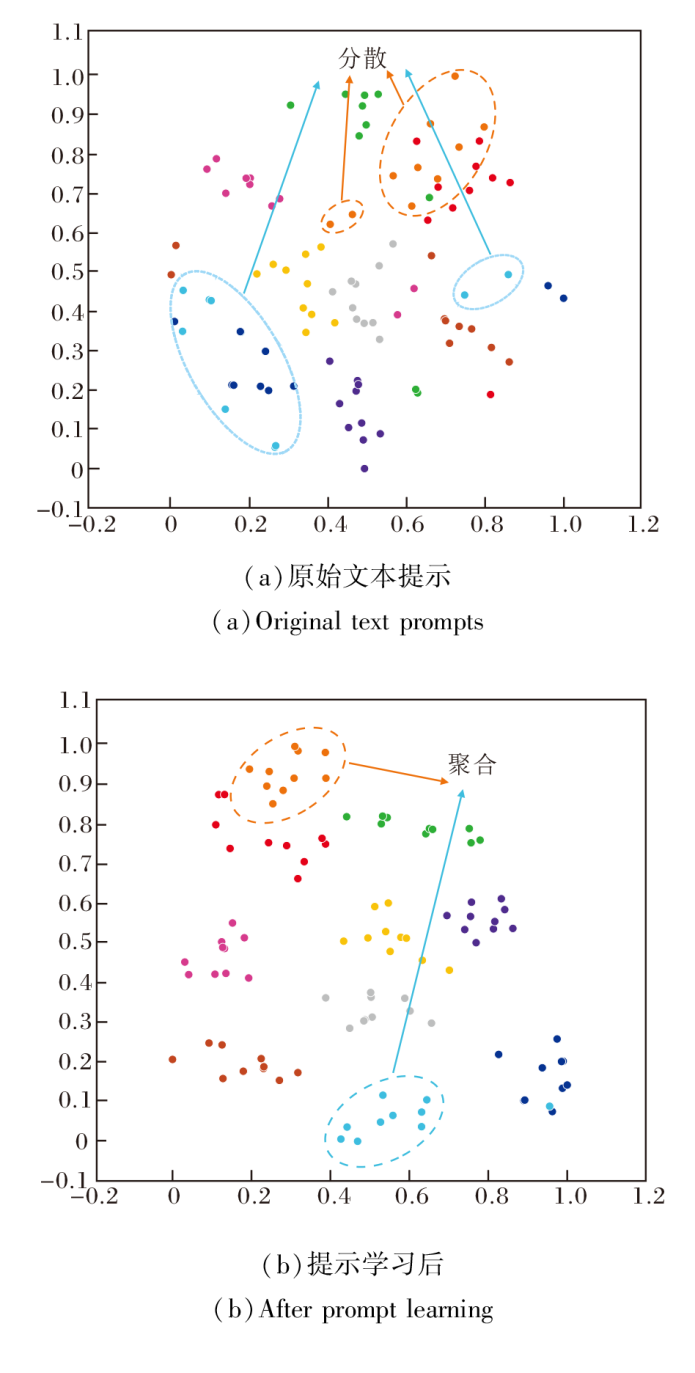 | 图6 CUHK-PEDES数据集上提示学习前后样本分布对比Fig.6 Sample distribution before and after prompt learning on CUHK-PEDES dataset |
在图6(a)中可看到, 同一行人的不同文本特征嵌入较分散.在(b)中经过提示学习后可有效聚合属于同一行人的特征嵌入, 有效减轻特征分散对模型准确率的负面影响.
使用2.2.1节中的语义负采样方法生成属性和对象交换的负样本案例, 本文方法和IRRA在CU-HK-PEDES、ICFG-PEDES数据集上的预测语义相似性得分如表6和表7所示.在表中, 文本后的“ √ ” 和“ × ” 分别表示图像和文本描述是否对应.
| 表6 各方法在CUHK-PEDES数据集上的CLIP得分 Table 6 CLIP score of different methods on CUHK-PEDES dataset |
| 表7 各方法在ICFG-PEDES数据集上的CLIP得分 Table 7 CLIP score of different methods on ICFG-PEDES dataset |
对于这些难负样本, 表6和表7结果表明, 未引入结构化场景图知识的IRRA无法正确区别两个属性或对象交换之后的文本描述与给定图像之间的语义相似性, 显示出其在捕捉结构化语义方面的不足.本文方法对细粒度语义的变化表现出高度的敏感性, 能以较大的余量有效区分对齐和未对齐的文本描述, 这表明基于场景图知识微调的模型具有一定的结构化知识, 并且在语义相似的难样本场景下性能良好.
因此, 上述分析表明, 本文方法在保证模型高性能的同时, 具备以往方法缺乏的结构化知识, 展现出对细粒度语义变化的高敏感性, 即使在文本描述语义相似的难样本情况下, 仍能获得可靠结果.
本文提出基于场景图知识的文本到图像行人重识别方法, 采用两阶段训练策略, 有效分离领域适应和任务适应的同时利用场景图知识增强结构化表征.在第一阶段, 使用提示学习优化可学习提示, 实现下游数据域与CLIP原始训练数据域的适配, 促进领域适应, 在第二阶段, 对CLIP进行微调, 增强模型对细粒度信息的处理能力, 促进任务适应.进一步提出语义负采样和场景图编码器模块, 使用场景图知识作为输入, 增强CLIP在第二阶段对结构化知识的获取能力.本文方法在三个广泛使用的数据集上取得有竞争力的效果, 证实其有效性.今后考虑进一步探讨所提出模块的可移植性, 评估在其它T2IReID模型中的应用潜力, 同时, 优化模型的效率和泛化能力, 更好地适应多样化的实际场景.
本文责任编委 黄华
Recommended by Associate Editor HUANG Hua
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|