


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于文本图像互学习的换衣行人重识别方法
[葛斌1  , 卢洋
, 卢洋1 , 夏晨星1 , 官骏鸣2 ]
, 卢洋, 夏晨星, 官骏鸣]
|
|



作者简介: 
卢 洋,硕士研究生,主要研究方向为计算机视觉、深度学习.E-mail:2022201255@aust.edu.cn. 
夏晨星,博士,副教授,主要研究方向为计算机视觉、模式识别、机器学习.E-mail:cxxia@aust.edu.cn. 
官骏鸣,博士,副教授,主要研究方向为计算机视觉、模式识别.E-mail:105051@hsu.edu.cn.
针对行人重识别在换衣场景下的小数据集样本中识别精度较低的问题,结合大模型CLIP(Contrastive Language-Image Pre-training)生成伪文本的功能,提出基于文本图像互学习的换衣行人重识别方法.在训练第一阶段,设计伪文本生成器,交换同批次中的样本像素,生成多样性文本,增强文本差异性,并通过语义对齐损失约束文本特征的一致性.在第二阶段,设计局部全局融合网络,融合局部特征和全局特征,在第一阶段文本信息的指导下,增强视觉特征的判别性.在PRCC、Celeb-ReID、Celeb-Light、VC-Clothes数据集上的实验表明,文中方法可提升在小数据集样本中的性能.
About Author:
LU Yang, Master student. His research in-terests include computer vision and deep lear-ning.
XIA Chenxing, Ph.D., associate professor. His research interests include computer vision, pattern recognition and machine lear-ning.
GUAN Junming, Ph.D., associate profe-ssor. His research interests include computer vision and pattern recognition.
To address the issue of low recognition accuracy in pedestrian re-identification(Re-ID) tasks involving clothing changes, a method for clothes-changing person re-identification based on text-image mutual learning(TIML) is proposed. It leverages the ability of contrastive language-image pre-training to generate pseudo-texts. In the first training phase, a pseudo-text generator is designed to enhance text diversity by swapping pixel information among samples within the same batch, thereby augmenting text variability. Additionally, a semantic alignment loss LSA is introduced to ensure the consistency in text feature representation. In the second phase of training, a global and local fusion network is devised to bolster the discriminative power of visual features by fusing local and global features, guided by the textual information obtained in the first phase. Experiments on PRCC, Celeb-ReID, Celeb-Light and VC-Clothes datasets demonstrate that the proposed model significantly improves recognition accuracy in scenarios with small dataset samples.
行人重识别(Person Re-identification, ReID)任务旨在联系分布式摄像机网络中同一目标人物的多幅图像或同一摄像机在不同场合下拍摄的图像.对于大规模视频监控系统而言, 行人重识别技术弥补固定摄像机的视觉局限性, 在智慧城市、监控安全和司法调查等领域具有重要的应用价值.
目前ReID方法主要克服姿态、背景、遮挡等传统难题, 解决短期的行人识别任务.罗浩等[1]将人物ReID系统分为封闭世界系统和开放世界系统, 并从深度特征表示学习、深度度量学习和排序优化等方面对人物ReID技术进行全面评述和深入分析.文献[2]和文献[3]设计新的损失函数和框架, 解决行人重识别任务.文献[4]~文献[6]设计全新的网络结构, 用于捕获全局特征和局部特征.然而, 随着时间跨度的增加, 换衣问题无法避免, 如犯罪嫌疑人通常会更换衣服以避免被识别和追踪.因此, 换衣行人重识别(Clothes-Changing Person Re-identifi-cation, CC-ReID)在智慧城市和智能安防等场景越发重要, 近年来更是受到研究者们的关注和重视.
目前, CC-ReID面临的主要挑战在于服装变换带来的类内外观差异较大而类间外观差异较小的问题.一些研究者从数据驱动的角度出发, 为CCReID任务提供新的数据集, 如Celebrities-reID[7]、PRCC(Person Re-id under Moderate Clothing Change)[8]、VC-Clothes[9]和LTCC(Long-Term Cloth-Changing)[10]数据集.
研究者提出的方法通常可分为如下两个方向.
第一个方向是使用诸如步态[11]、轮廓[12]、姿势关键点[13]等辅助模态退化服装信息的影响.文献[14]和文献[15]中采用人体解析模型, 直接定位服装相关的区域, 并在模型训练的过程中减轻来自服装的影响.Yang等[8]使用人体轮廓草图和极坐标转化, 并与全局特征结合, 实现一定程度上的服装消解.Li等[16]考虑基于视频的场景, 结合步态和时间信息, 提出CCPG(Cloth-Changing Benchmark for Person Re-identification and Gait Recognition)视频数据集, 进行CC-ReID.Zhang等[17]提出MBUNet(Multi-bio-metric Unified Network), 使用身体关键点作为结构特征, 重点研究身份识别的软生物特征线索.
第二个方向是从单一图像中学习抗服装干扰的判别性特征, 深度挖掘潜藏在图像中的底层信息.Liu等[18]提出DLAW(Dual-Level Adaptive Weigh-ting), 定位每个身份的服装区域, 并在推理过程中自适应加权不同区域的特征.Zheng等[19]通过生成模型和判别模型, 进一步分离外观信息和结构信息, 在不使用生成数据的情况下显著改善性能.Huang等[20]使用载体神经元代替标量神经元, 设计ReIDCaps, 平衡多分支特征, 准确识别服装无关特征.Gu等[21]提出CAL(Clothes-Based Adversarial Loss), 制作服装标签, 并将服装类视为细化的身份类, 训练不同的分类器, 采用对抗学习, 强调与身份相关的信息.Kweon等[22]提出NPFM(Noisy Patch Filtering Mo- dule), 将图像分割为上部和下部, 计算各自的可靠分数, 筛选可靠的全局信息, 用于模型推理.Zhang等[23]通过重排序机制, 进一步筛选排序后的结果, 提高模型性能.
然而当前方法在Celeb-ReID、Celeb-Light等小数据集上表现出强烈的性能衰退, 难以满足通过小样本构建行人重识别系统的需求.传统行人重识别网络在图像空间进行网络优化, 限制网络学习的可能性, CLIP(Contrastive Language-Image Pre-training)[24]通过伪文本和图像的跨模态交互, 在跨模态空间中为网络优化提供更多的可能, 一定程度上缓解服装变换带来的图像层面的类内差异和类间相似问题.
鉴于传统模型提取的特征在小数据集上表现不佳的缺点, 本文引入CLIP, 提出基于文本图像互学习的换衣行人重识别方法(Clothes-Changing Person Re-identification Method Based on Text-Image Mutual Learning, TIML).
在第一阶段, 设计伪文本生成器(Pseudo-Text Generator, PTG)和语义对齐损失LSA.PTG通过交换像素增强同批次中样本的视觉差异性, 使用CLIP冻结的文本编码器和视觉编码器分别提取文本特征和视觉特征, 通过LSA约束PTG的训练, 进而生成对应图像, 消除服装信息的伪文本特征.
在第二阶段, 为了进一步提高视觉特征的判别性, 提出局部全局融合网络(Global and Local Fusion Net, GLFNet), 局部分支通过多尺度卷积核提取不同局部的行人特征, 全局分支通过多头自注意力机制增强全局特征的判别能力, 融合头通过全连接层融合局部视觉特征和全局视觉特征, 提高最终推理特征的判别能力.
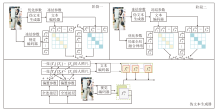
本文提出基于文本图像互学习的换衣行人重识别方法(TIML), 框架如图1所示.TIMI是一个双阶段模型, 用于提取判别性强的行人特征.在第一阶段, 通过交换同批次行人服装区域的像素和损失函数LSA训练PTG, 生成抗服装干扰的伪文本特征.在第二阶段, 设计双分支GLFNet, 在局部分支引入多尺度卷积核, 在全局分支引入多头自注意力, 训练视觉编码器, 提取判别性强的视觉特征.
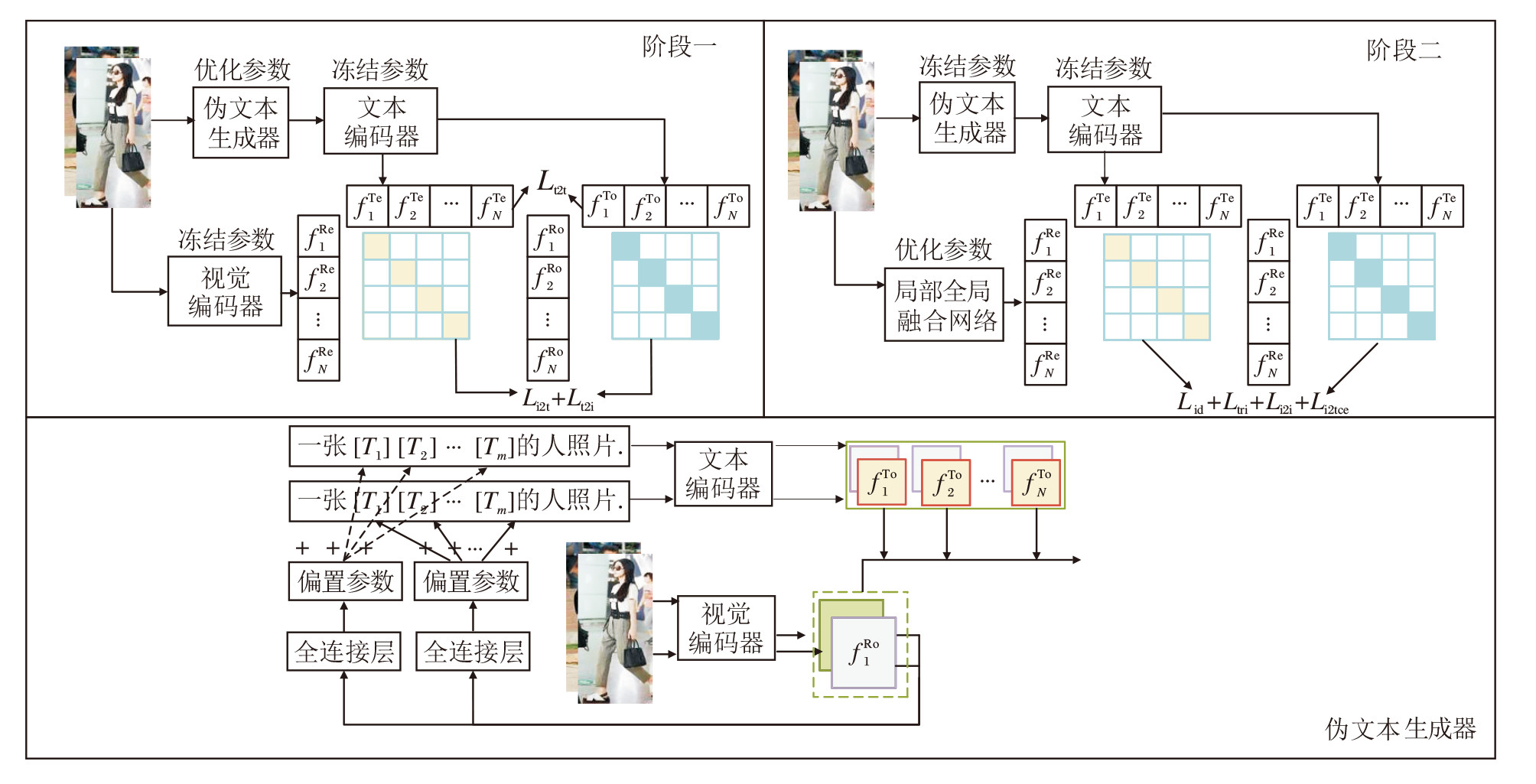 | 图1 TIML框架图Fig.1 Framework of TIML |
视觉-语言学习范式近年来颇受学者欢迎, CLIP作为一种具有代表性的视觉语言学习模式, 通过图像-文本对的相似性约束, 在自然语言和视觉内容之间建立联系.
本文考虑到小样本数据集的复杂性, 使用CLIP具有先验知识的视觉编码器V(· )和文本编码器T(· )提取视觉特征和文本特征.
一方面, CLIP的视觉编码器V(· )有ViT-B/16和CNN两种结构可供选择, 都能将图像归纳为跨模态嵌入中的特征向量.
另一方面, 文本编码器T(· )是以ViT-B/16的形式实现的, 用于从句子生成表示.
具体地, 给定一个句子, 例如:一张[T1][T2]…[TM][类别]的人照片, 其中, [类别]一般用具体的文本标签代替.T(· )首先会将每个[Tm](m=1, 2, …, M)转换成一个唯一的数字ID.然后, 将每个ID映射到512维的词嵌入中.为了实现并行计算, 每个文本序列的长度固定为77, 包括开始[SOS]标记和结束[EOS]标记.经过一个有8个注意头的12层模型后, [EOS]标记被视为文本的特征表示.之后进行层归一化, 线性投射到跨模态嵌入空间中.损失Li2t和Lt2i共同约束视觉编码器V(· )提取的视觉特征和文本编码器T(· )提取的文本特征, 确保其在跨模态空间中相互对应.Li2t和Lt2i的计算方式如下:
${{L}_{i2t}}=-\frac{1}{B}\underset{i=1}{\overset{B}{\mathop \sum }}\,{{\log }_{2}}\left( \frac{\exp \left( S\left( ~f{{~}^{V}}_{i},~f{{~}^{T}}_{i} \right) \right)}{\mathop{\sum }_{j=1}^{B}\exp \left( S\left( ~f{{~}^{V}}_{i},~f{{~}^{T}}_{j} \right) \right)} \right)$,
${{L}_{t2i}}=-\frac{1}{B}\underset{i=1}{\overset{B}{\mathop \sum }}\,{{\log }_{2}}\left( \frac{\exp \left( S\left( ~f{{~}^{V}}_{i},~f{{~}^{T}}_{i} \right) \right)}{\mathop{\sum }_{j=1}^{B}\exp \left( S\left( ~f{{~}^{V}}_{a},~f{{~}^{T}}_{i} \right) \right)} \right)$,
其中,
实验表明, CLIP通过对数以亿计的图文进行训练, 能对任意给定的图像和文本计算相关性分数.
鉴于Li等[25]发现文本模态有助于行人重识别网络提取具有判别性的行人特征.本文尝试将其应用在换衣场景下, 结果是性能显著下降.原因如下:CLIP虽然具有强大的图文匹配功能, 但对行人的文本描述更注重行人的穿着.在换衣场景下, 同一行人可能会有不同的服装, 不同行人可能有相似或相同的服装, 这导致直接使用CLIP的文本编码器无法学到独立于行人身份的文本特征, 不利于发挥CLIP强大的图文匹配功能[24].为此本文提出伪文本生成器(PTG)和语义对齐损失LSA, 通过PTG生成身份独立的伪文本特征, 并利用LSA约束PTG生成的伪文本特征兼顾语义一致性和差异性.
为了生成可靠的伪文本, 采用特定于ID的可学习标记学习伪文本描述.如图1所示, 输入文本编码器的文本描述被设计为“ 一张[T1][T2]…[TM][类别]的人照片” , 其中, 每个[Tm](m=1, 2, …, M)表示一个可学习的文本标记, 维度与单词嵌入相同, M表示可学习文本标记的数量.
在第一阶段, 固定视觉编码器和文本编码器的参数, 只优化标记[Tm].受Shu等[14]启发, 首先, 将同一批次的图像输入SCHP(Self-Correction for Hu-man Parsing)人体解析模型中, 获得人体(背景、头部、躯干、上臂、下臂、上腿、下腿)的语义分割图.将躯干语义图应用于图像, 获得人体服装部分.随机交换批次中原始图像服装区域的像素, 增加样本的视觉差异性.然后, 将原始图像和增强后图像依次输入冻结的视觉编码器中, 获得视觉特征(F1, F2), 其中, F1=f
同一批次中存在多幅属于同个行人的图像, 这些图像身份标签相同但视觉表现不同.如果只依赖身份标签获取的文本特征指导视觉特征学习, 由于相同身份标签的图像具有相同的文本特征, 优化中将无法利用CLIP的文本描述能力对应文本特征与视觉特征, 从而无法通过消除文本中服装干扰间接消除视觉特征中的服装干扰.因此本文将获得的视觉特征(F1, F2)依次通过一个映射层FC(768, 512), 映射为同文本标记[Tm]相同大小的512维偏置参数π , 并将π 与[Ti]相加, 增强文本对同一行人描述的差异性.
最后, 与CLIP类似, 伪文本描述的生成需要使用损失Li2t和Lt2i约束视觉特征和文本特征在跨模态空间进行交互, 但不同于CLIP的每个ID共享相同的文本描述.在CC-ReID场景下, 一个批次图像中的不同图像可能属于同一个人, 因此引入修改后的Li2t和Lt2i, 约束T1, T2后分别向F1, F2靠齐, 提高文本特征(T1, T2)的可靠性.修改后的Li2t和Lt2i如下所示:
${{L}_{i}}_{2t}=-\frac{1}{B}\underset{i=1}{\overset{B}{\mathop \sum }}\, \left( {{\log }_{2}}\left( \frac{\exp \left( S\left( ~f~_{i}^{Ro}, ~f~_{i}^{To} \right) \right)}{\mathop{\sum }_{j=1}^{B}\exp \left( S\left( ~f~_{i}^{Ro}, ~f~_{j}^{To} \right) \right)} \right)+{{\log }_{2}}\left( \frac{\exp \left( S\left( ~f~_{i}^{\operatorname{Re}}, ~f~_{i}^{Te} \right) \right)}{\mathop{\sum }_{j=1}^{B}\exp \left( ~S\left( ~f~_{i}^{\operatorname{Re}}~, ~f~_{j}^{Te} \right) \right)} \right) \right)$, (1)
${{L}_{t}}_{2i}=-\frac{1}{B}\underset{i=1}{\overset{B}{\mathop \sum }}\, \left( {{\log }_{2}}\left( \frac{\exp \left( S\left( ~f~_{i}^{Ro}, ~f~_{i}^{To} \right) \right)}{\mathop{\sum }_{j=1}^{B}\exp \left( S\left( ~f~_{j}^{Ro}, ~f~_{i}^{To} \right) \right)} \right)+{{\log }_{2}}\left( \frac{\exp \left( S\left( ~f~_{i}^{\operatorname{Re}}, ~f~_{i}^{Te} \right) \right)}{\mathop{\sum }_{j=1}^{B}\exp \left( S\left( ~f~_{j}^{\operatorname{Re}}, ~f~_{i}^{Te} \right) \right)} \right) \right)$, (2)
其中, S(· )表示相似度度量函数, B表示批量大小, f
PTG在训练过程中会产生两倍ID数量的伪文本描述, 一部分为对应原始图像的伪文本, 另一部分为对应增强图像的伪文本, 通过Li2t和Lt2i损失可在跨模态空间中对齐文本特征和视觉特征.本文发现, PTG虽然仅增强文本描述的差异性有助于提升性能, 但却忽略文本描述的一致性.由于伪文本本身的缺陷, 语义信息不具有完备性, 因此PTG需要多描述生成增强伪文本的数量, 但对于同一行人的文本描述应当是既有差异又具有共性.为此, 本文提出LSA, 在Li2t和Lt2i的基础上加入Lt2t损失, 进一步缩小文本特征T1、T2之间的距离, 减弱相同样本仅服装区域不同情况下的语义差距.LSA损失如下所示:
LSA=α (Li2t+Lt2i)+(1-α )Lt2t,
其中
${{L}_{t}}_{2t}=\sqrt{\underset{i=1}{\overset{l}{\mathop \sum }}\, {{\left( \frac{f~_{i}^{Te}-f~_{i}^{To}}{{{s}_{i}}} \right)}^{2}}}$, (3)
l表示特征fi的长度, si表示各个维度的标准差, 参数α 用于调控伪文本描述的差异性和一致性, 确保发挥文本的指导作用.
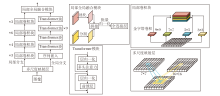
针对当前换衣行人重识别网络在整合局部信息与全局信息方面的不足, 本文进一步提出局部全局融合网络(GLFNet), 结构如图2所示.
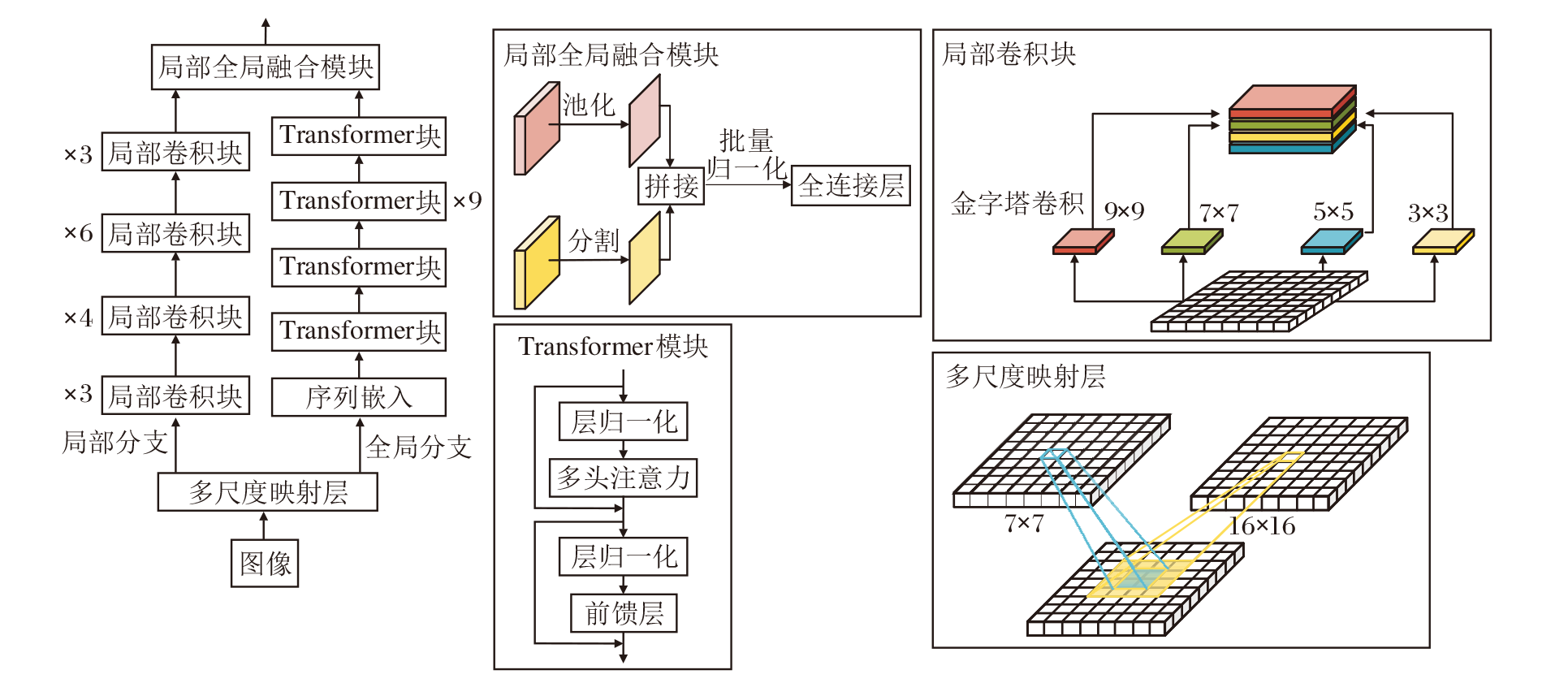 | 图2 GLFNet框架图Fig.2 Framework of GLFNet |
GLFNet网络架构由局部分支和全局分支组成, 旨在高效提取并融合图像中的多尺度特征和全局信息.
在局部分支中, 首先利用一组大小分别为9× 9、7× 7、5× 5、3× 3的卷积核, 捕捉图像中的多尺度特征.为了减轻多尺度卷积操作带来的计算压力, 引入分组卷积技术, 并按照8∶ 4∶ 2∶ 1的比例为不同大小的卷积核分配通道数.值得注意的是, 由于较大的卷积核计算量相对较小, 因此可分配更多的通道, 充分利用其捕捉大尺度特征的能力.
全局分支侧重于提取图像的全局信息.首先, 使用大小为16× 16、步长为16的卷积核将图像分割成128个补丁.然后, 通过序列嵌入技术, 将每个补丁映射为768维的序列, 并加入一个类嵌入补丁, 以便将数据格式从原始图像的尺寸(B, 3, 256, 128)转换为适用于序列学习的格式(B, 129, 768), 其中B表示批量大小.为了促进所有补丁之间的信息交互, 全局分支采用多头自注意力机制, 为每个头独立计算注意力权重, 并对对应的值(Value)进行加权求和, 得到每个头的输出.在最后一个维度上拼接所有头的输出, 并通过一个线性变换得到全局分支的最终输出.计算过程如下所示.
图像转换后的序列如下所示:
z0=[xclass;
其中:
经过注意力后的序列如下所示:
z'l=MHSA(LN(zl-1))+zl-1,
其中, MHSA(· )表示多头注意力, LN(· )表示层归一化, l=1, 2, …, L, L表示Transformer块的层数.
经过多层感知后的序列如下所示:
zl=MLP(LN(z'l))+z'l,
其中MLP(· )表示全连接层.
最终预测结果为:
y=LN(
其中
为了充分利用局部分支和全局分支提取的特征, GLFNet还引入一个局部全局融合模块.对于局部特征(B, 2 048, 16, 8), 首先, 采用自适应平均池化技术将其变形为(B, 2 048).对于全局特征(B, 129, 768), 从第二维使用类嵌入补丁, 分割全局信息(B, 768).然后, 将局部特征和全局特征拼接成新的特征向量feat(B, 2 816).最后, 通过批量归一化和全连接层处理, 将融合后的特征映射为类分数score(B, num_class), 用于后续的推理任务.
本文的损失函数分为两个阶段.
第一阶段的损失函数如下所示:
LSA=α (Li2t+Lt2i)+(1-α )Lt2t.
其中:Li2t+Lt2i表示第一阶段的视觉特征和文本特征的交叉熵损失, 用于拉近文本特征和视觉特征之间的距离, 计算方式如式(1)和式(2)所示; Lt2t表示文本对齐损失函数, 采用欧氏距离度量源图像对应文本和增强图像对应文本之间的距离, 计算方式如式(3)所示.
第二阶段的损失函数如下所示:
Lstage2=Lid+Ltri+Li2tce+Li2i.
身份损失函数
${{L}_{id}}=-\frac{1}{B}\underset{i=1}{\overset{B}{\mathop \sum }}\, {{q}_{i}}{{\log }_{2}}(W({{f}_{i}}))$,
计算基于模型预测身份和行人的身份标签, 其中, qi表示第i幅图像标签yi的标签平滑的编码值, W(· )表示分类器, 计算第i幅图像的类置信分数.
三元组损失
${{L}_{tri}}=\underset{i=1}{\overset{N}{\mathop \sum }}\, \max ({{d}_{p}}(i)-{{d}_{n}}(i)+m, 0)$,
其中,
表示正类之间的特征距离,
表示负类之间的特征距离, fi表示样本xi的特征, fp表示一个批量中与fi最不相似的正样本特征, fn表示一个批量中与fi最相似的负样本特征, N表示样本总数, ‖ · ‖ 2表示欧氏距离, m表示边界参数, 用于控制网络优化, 防止出现震荡.
由于传统方法仅注重视觉信息, 忽略语言的潜力, 本文定义图像到文本的交叉熵损失Li2tce, 利用第一阶段的伪文本指导视觉特征的学习, 增强视觉特征的抗服装干扰性, 则
${{L}_{i2tce}}=-\frac{1}{B}\underset{i=1}{\overset{B}{\mathop \sum }}\, {{q}_{i}}\left( {{\log }_{2}}\left( \frac{\exp \left( s\left( ~f~_{i}^{Ro}, ~f~_{i}^{To} \right) \right)}{\mathop{\sum }_{j=1}^{B}\exp \left( s\left( ~f~_{i}^{Ro}, ~f~_{j}^{To} \right) \right)} \right)+\log 2\left( \frac{\exp \left( s\left( ~f~_{i}^{\operatorname{Re}}, ~f~_{i}^{Te} \right) \right)}{\mathop{\sum }_{j=1}^{B}\exp \left( s\left( ~f~_{i}^{\operatorname{Re}}, ~f~_{j}^{Te} \right) \right)} \right) \right)$
针对源图像和增强图像的视觉特征, 本文进一步使用Li2i损失, 拉近相同身份间的距离:
${{L}_{i2i}}=\sqrt{\underset{i=1}{\overset{l}{\mathop \sum }}\, {{\left( \frac{f~_{i}^{\operatorname{Re}}-f~_{i}^{Ro}}{{{s}_{i}}} \right)}^{2}}}$,
其中l表示特征fi的长度.
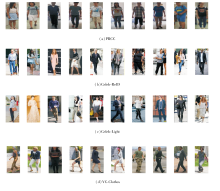
本文选择在PRCC、Celeb-ReID、Celeb-Light、VC-Clothes这4个常规的换衣ReID数据集上进行实验, 数据集上的图像示例如图3所示.
 | 图3 实验数据集示例Fig.3 Examples of experimental datasets |
PRCC数据集包含221个身份和33 698幅行人图像.Celeb-ReID数据集包含1 052个身份和34 186幅行人图像.Celeb-Light数据集包含590个身份和10 842幅行人图像.VC-Clothes数据集包含512个身份和19 060幅行人图像.VC-Clothes数据集来源于虚拟游戏GTA-V, 容易识别相同行人.Celeb-ReID、Celeb-Light数据集为小数据集, 来源于街头名人, 更符合实际情况, 也更复杂, 具有一定的挑战性.
本文采用的评价指标包括累积匹配特征(Rank-n)和平均精度(Mean Average Precision, mAP).Rank-n表示搜索结果中置信度最高的前n个结果中正确匹配的概率.mAP将行人重识别看作检索任务, 计算数据集上所有类的预测平均精度的均值, 计算公式如下:
$mAP=\underset{i=1}{\overset{q}{\mathop \sum }}\, \left( \frac{A{{P}_{i}}}{q} \right)$,
其中, APi表示类别的平均精度, q表示类别数.
所有实验都是在GTX4090GPU上进行, 输入图像统一调整为256× 128大小, 并采用随机翻转、填充和裁剪等数据增强策略.在训练第一阶段, PTG训练120轮, 初始学习率设为3× 10-4, 并根据余弦方案进行衰减.在第二阶段, GLFNet训练60轮, 在前10轮中, 学习率从3× 10-6线性增至3× 10-4, 在第20轮和第40轮训练中, 学习率以0.1的速率下降.批次大小设为64, 每个批次8位行人, 每位行人8幅RGB图像, 采用Adam(Adaptive Moment Estima-tion)动态优化器优化训练过程.
本节选择如下换衣行人重识别方法进行对比:文献[12]方法、FSAM(Fine-Grained Shape-Appea-rance Mutual Learning Framework)[13]、IGCL(Identity-Guided Collaborative Learning Scheme)[15]、CAL[21]、RCSANet(Regularization via Clothing Status Aware-ness Network)[26]、GI-ReID(Gait-Assisted Image-Based ReID Framework)[27]、IRANet(Identity-Relevance Aware Neural Network)[28]、文献[29]方法、MVSE(Multi-granular Visual-Semantic Embedding Algorithm)[30]、文献[31]方法、CAMC(Co-attention Aligned Mutual Cross-Attention)[32]、ADC(Attentive Decoupling)[33]、CCIL(Causal Clothes-Invariant Learning)[34]、AIM(Causality-Based Auto-Intervention Model)[35]、ACID(Auxiliary-Free Competitive Identification)[36]、DCR-ReID(Deep Component Reconstruction ReID)[37]、CCFA(Clothing-Change Feature Augmentation)[38]、SC-ReID[39]、文献[40]方法.
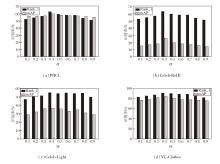
各方法在PRCC、Celeb-ReID、Celeb-Light、VC-Clothes数据集上的指标值对比结果如表1所示, 表中黑体数字表示最优值, 斜体数字表示次优值, -表示原文献未在该数据集上进行相关实验.由表可看出, TIML在Celeb-ReID、Celeb-Light、VC-Clothes数据集上取得最优值, 在PRCC数据集的换衣场景下, 取得次优值.相比ACID和IGCL, 在PRCC数据集的换衣场景下, TIML在Rank-1指标上比ACID提升8.4%, 在mAP指标上比IGCL提升1.1%.虽然相比ACID在mAP指标上和IGCL在Rank-1指标上, TIML未能取得优势, 但在Celeb-Lgiht、Celeb-ReID数据集上的表现优于ACID和IGCL, 在Celeb-ReID数据集上, Rank-1和mAP值分别比ACID提升15.2%和16.9%, 在Celeb-Light数据集上, Rank-1和mAP值分别比IGCL提升20.9%和20.4%, 这说明TIML更能提取判别力强的特征, 也更适用于在小数据场景下构建行人重识别系统.
| 表1 各方法在4个数据集上的指标值对比 Table 1 Metric value comparison of different methods on 4 datasets % |
相比目前主流的换衣行人重识别方法, TIML引入文本模态指导视觉特征的学习.相比图像信息中服装区域占据行人的大部分区域, 难以准确分离其中的服装信息和行人身份信息, 语言描述更具体, 可准确消除服装因素造成的干扰, 并且由于PTG提供充满差异性和一致性的文本描述, 使得在小数据集上视觉特征的学习能从文本特征中得到帮助, 提高其在小数据集上的表现.
本节首先验证TIML中PTG和GLFNet的性能.基准方法使用ResNet50, TIML(v1)表示第二阶段不使用图像到文本的交叉熵损失Li2tce, TIML(v2)表示使用图像到文本的交叉熵损失Li2t, TIML(v3)表示使用增加标签平滑qi的图像到文本的交叉熵损失Li2tce, 即TIML.
各模块在PRCC、Celeb-ReID、Celeb-Light数据集上的消融实验结果如表2所示, 表中黑体数字表示最优值.由表可见, Li2t和Li2tce能提升方法性能, 同时证实加入qi的有效性.在PRCC、Celeb-ReID、Celeb-Light数据集上, 相比ResNet50, TIML-1的Rank-1分别提升7.7%, 13.6%和37.3%, mAP分别提升11.0%, 17.4%和27.4%.这说明TIML-1能帮助在小样本场景下构建行人重识别系统.当在第一阶段添加PTG时, 相比TIML-1, 在PRCC、Celeb-ReID、Celeb-Light数据集上, TIML-2的Rank-1分别提升9.2%, 0.8%和0.3%, mAP分别提升6.9%, 0.5%和0.2%, 这说明PTG能提供具有指导意义的伪文本信息, 也更具有泛化性.当仅在第二阶段添加GLFNet, 相比TIML-1, 在PRCC、Celeb-ReID、Celeb-Light数据集上, TIML-3的Rank-1分别提升7.8%, 0.1%和0.1%, mAP分别提升7.2%, 0.4%和0.1%, 这验证GLFNet融合局部特征和全局特征的方式更有利于提取具有判别性的视觉特征.加入PTG和GLFNet后, TIML达到最优值, 这表明本文设计组件的有效性.同时, 相比ResNet50, TIML在Celeb-ReID、Celeb-Light数据集上取得最优值, 这表明其有利于在小数据集上构建行人重识别系统.
| 表2 各模块的消融实验结果 Table 2 Ablation experiment results of different modules % |
是否添加PTG或GLFNet模块后的热力图如图4所示.
 | 图4 各模块的可视化热力图Fig.4 Visual heatmaps of different modules |
由图4可见, 未添加任何模块时, 方法识别行人身份时对服装区域依赖较大.当添加PTG后, 将注意力转移向头部、脚部等微小却具有独立代表行人身份的区域.当进一步添加GLFNet后, 方法一定程度上减弱对服装区域的依赖, 增强对非服装区域的关注.值得注意的是, 方法对行人身份的识别是综合考虑图像的所有因素, 并且由于伪文本的引入, 可能学到人们无法理解的识别模式.例如:图中ID2虽然降低对脸部区域关注, 但仍能准确识别行人, 其内在原因是ID2存在有比面部更重要的判别信息.
为了验证PTG的合理性, 在PRCC、Celeb-ReID、Celeb-Light数据集上展开实验, 针对PTG中偏置参数、增强伪文本、源伪文本进行消融实验, 结果如表3所示, 表中黑体数字表示最优值.由表可见, 添加偏置参数后取得更优值, 说明偏置参数能增添伪文本的差异性.综合考虑增强伪文本和源伪文本的方式能丰富对行人的描述, 由此说明本文设计的合理性.
| 表3 PTG模块内部设计合理性的实验结果 Table 3 Experimental results of internal design rationalization for PTG module % |
定义超参数α =0.1, 0.2, …, 0.9, 验证不同α 对TIML性能的影响. 在PRCC、Celeb-ReID、Celeb-Light、VC-Clothes数据集上进行实验, 识别率结果如图5所示.由图可看出, 第一阶段用于平衡文本差异性和一致性的超参数α 的最优值为0.4.
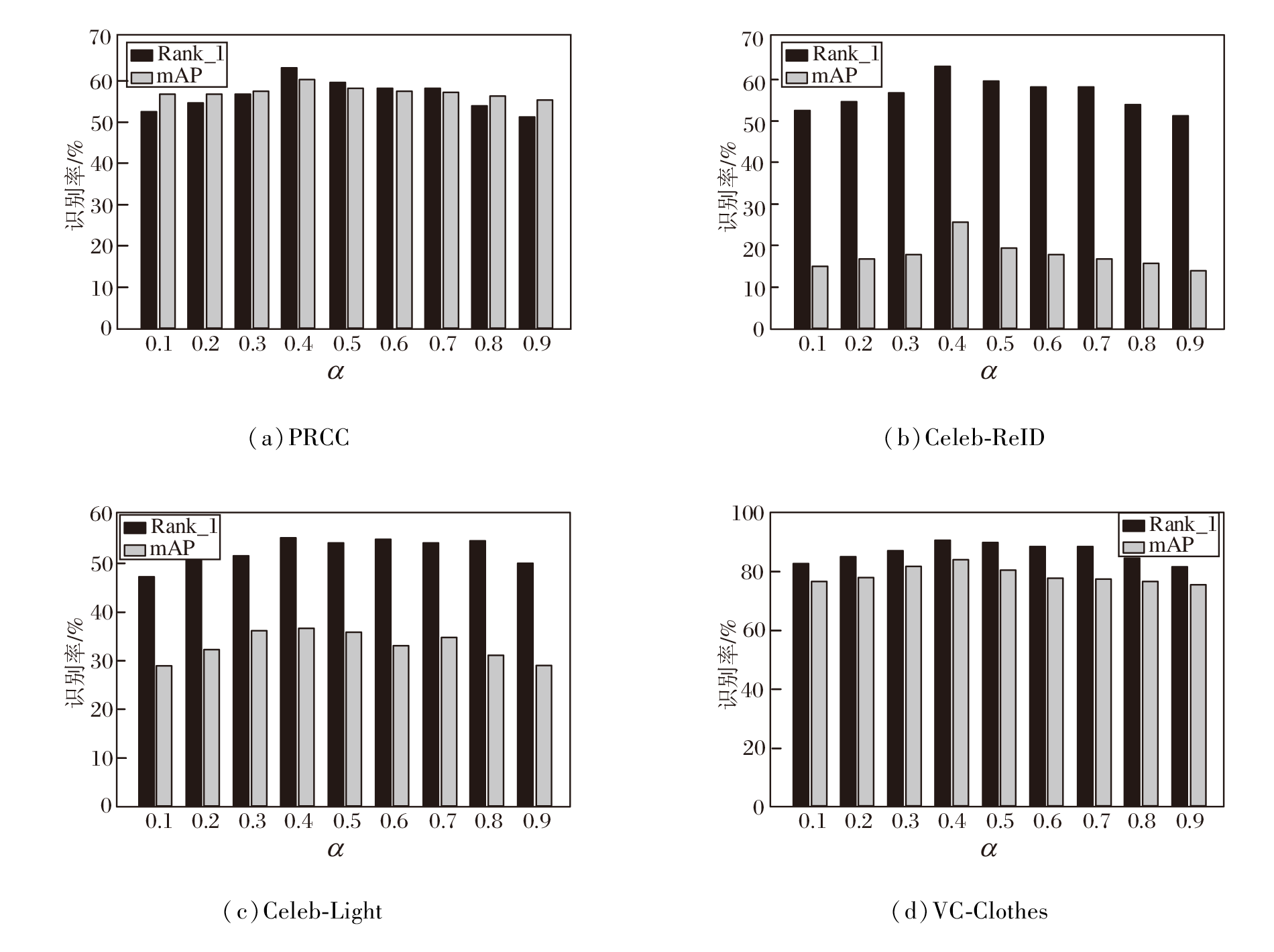 | 图5 α 对TIML性能的影响Fig.5 Effect of α on TIML performance |
为了验证GLFNet的优越性, 分别对比如下以ResNet(Residual Networks)、DenseNet(Densely Con-nected Convolutional Networks)、ViT(Vision Trans-former)为骨干网络的方法:FSAM[13]、CAL[21]、RCSANet[26]、GI-ReID[27]、MVSE[30]、文献[31]方法、MGN(Multiple Granularity Network)[41]、ResNet-50(50-Layers Residual Network)[42]、DenseNet-121[43].
各方法的指标值结果如表4所示, 表中黑体数字表示最优值.
| 表4 GLFNet的消融实验结果 Table 4 Ablation experiment results of GLFNet |
由表4可见:对比以ResNet为骨干网络的方法, GLFNet的Rank-1和mAP指标比CAL提升8.2%和4.8%.对比以DenseNet为骨干网络的方法, GLF-Net的Rank-1和mAP指标比MVSE提升15.8%和8.1%.对比以ViT为骨干网络的方法, GLF-Net的Rank-1指标比文献[31]方法提升16.5%.这些表明GLFNet能提高视觉特征的判别性.
对比表4后三行可看出, 混合使用局部分支和全局分支更能提高GLFNet的特征提取能力, 这表明GLFNet设计的合理性.GLFNet的局部分支采用金字塔卷积结构, 通过多尺度卷积核充分提取多尺度的局部信息, 全局分支采用传统的ViT结构, 将图像划分为多个补丁, 并映射为序列, 再通过多头自注意力层, 交互学习各部分之间的信息, 并在[类别]序列集中提取全局信息.在融合头中, 对局部特征使用池化操作, 对全局特征使用分割操作, 同时拼接局部特征和全局特征, 再经过批量归一化和全连接层, 融合局部信息和全局信息, 提高最终特征的鉴别能力.
本文提出基于文本图像互学习的换衣行人重识别方法(TIML), 缓解行人重识别方法在小数据集上性能较差的问题.从多模态的角度出发, 直接面对由小样本数据集带来的挑战.不同于以往方法只考虑单模态的视觉输入, 引入大模型CLIP的先验文本知识, 缓解小样本数据分布差异较大的问题.同时为了提高CLIP在换衣行人重识别领域的性能, 设计伪文本生成器(PTG), 将伪文本引入跨模态空间中, 固定原CLIP的视觉编码器和文本编码器, 并增加多种伪文本描述, 增强文本描述的差异性, 在不显著增加额外训练成本的情况下显著提升性能.为了进一步提升方法的判别能力, 设计局部全局融合网络(GLF-Net), 通过多尺度卷积核和多头自注意力机制, 增强方法对局部特征和全局特征的提取能力.
今后工作主要包括如下三个方面.1)考虑到伪文本的不稳定性, 使用图文生成模型为图像生成真实的文本描述.2)考虑到换衣场景和其它场景的差异, 拟改进方法, 提高域泛化性.3)考虑多种数据增强方式, 扩充伪文本描述的差异性.
本文责任编委 张军平
Recommended by Associate Editor ZHANG Junping
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|