

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
无锚框关键点与注意力机制结合的自适应孪生网络目标追踪方法
[袁帅1, 2, 3  , 窦慧泽
, 窦慧泽1 , 耿金玉4 , 栾方军1, 2, 3 ]
, 窦慧泽, 耿金玉, 栾方军]
|
|



作者简介: 
窦慧泽,硕士研究生,主要研究方向为深度学习、计算机图像处理.E-mail:dhzyjwj@163.com. 
耿金玉,硕士研究生,主要研究方向为深度学习、计算机图像处理.E-mail:2678799403@qq.com. 
栾方军,博士,教授,主要研究方向为图像处理、模式识别、大数据管理与分析.E-mail:luanfangjun@sjzu.edu.cn.
目前孪生网络目标追踪算法在目标候选框的生成阶段计算复杂度较高,导致算法存在实时性较差以及在复杂场景中目标追踪精准度较低等缺陷.针对这些问题,文中提出无锚框关键点与注意力机制结合的自适应孪生网络目标追踪方法.首先,在孪生子网络的主干网络中设计大核卷积注意力模块,提取目标全局特征, 提升方法的精准度和泛化能力.然后,设计无锚框多关键点模块,学习目标的多关键点,采用自适应学习权重系数模块,筛选准确的目标关键点,进一步提升方法的精准度和鲁棒性.最后,将关键点转换成预测框,无需生成预定义的目标候选框,可减少计算复杂度,提升目标追踪的实时性.在4个数据集上的实验表明,文中方法在精准度和成功率上都有所提升.
About Author:
DOU Huize, Master student. His research interests include deep learning and computer image processing.
GENG Jinyu, Master student. His research interests include deep learning and computer image processing.
LUAN Fangjun, Ph.D., professor. His research interests include image processing, pattern recognition, and big data management and analysis.
The high computational complexity of current Siamese network based target tracking algorithm during the candidate box generation stage results in poor real-time performance and reduced accuracy in complex scenarios. To address these issues, an anchor-free RepPoints and attention mechanism based adaptive Siamese network for object tracking is proposed. First, a large-kernel convolutional attention module is introduced in the backbone network of the Siamese subnetwork to extract global features of the target, enhancing the precision and generalization ability of the model. Second, a module for anchor-free multi-RepPoints is utilized to learn multiple RepPoints of the target, and then an adaptive learning weight coefficient module is employed to filter out more accurate target RepPoints, further improving model precision and robustness. Finally, RepPoints are transformed into predicted boxes, thereby eliminating the need for predefined candidate boxes, reducing computational complexity and enhancing real-time tracking performance. Experiments indicate that the proposed method achieves significant improvements in precision and success rate on four datasets.
目标追踪是人工智能领域中的一项关键技术, 在物联网、大数据和云计算等技术的推动下, 应用越来越广泛, 对技术的要求也越来越高.特别是在智能监控、车辆追踪等领域, 目标追踪技术正发挥着重要作用.
目标追踪方法主要包括传统目标追踪方法和深度学习目标追踪方法, 传统目标追踪方法主要有卡尔曼滤波[1]、粒子滤波[2]、均值漂移[3]、光流法[4]等.然而, 这些方法在追踪目标时普遍存在泛化能力较差以及对复杂背景遮挡敏感等问题.在深度学习目标追踪方法出现之后, 追踪效果大幅提升.
基于深度学习的目标追踪网络主要包含卷积神经网络(Convolutional Neural Networks, CNN)[5]、孪生网络(Siamese Network)、循环神经网络(Recu-rrent Neural Network, RNN)、生成对抗网络(Genera-tive Adversarial Network, GAN)、注意力机制等网络类型.基于CNN的方法一般采用追踪网络框架的主干部分提取目标特征.基于孪生网络的方法通过计算两个输入样本之间的相似度进行目标追踪.基于RNN的方法将视频的连续帧看作一个时间序列, 利用之前帧的信息以及当前帧的特征, 预测目标在当前帧的位置和状态.GAN由生成器和判别器组成, 可生成类似目标的样本以优化跟踪, 用于应对目标遮挡、变形等情况.基于注意力机制的方法对目标特征进行加权处理, 突出目标的关键特征.
Song等[6]提出VITAL(Visual Tracking via Ad-versarial Learning), 将GAN引入目标追踪中, 让生成器生成与目标相似的样本, 训练判别器以区分真实目标和生成样本, 从而使追踪器更好地适应目标的外观变化和复杂的背景干扰.李雪等[7]提出结合双注意力与特征融合的孪生网络目标追踪算法, 引入由通道注意力机制和空间注意力机制组成的注意力模块, 抑制不重要的背景信息, 但双注意力机制的计算需要处理特征图的每个通道和空间位置, 增加算法的计算量和运行时间.Bewley等[8]提出SORT(Simple Online and Realtime Tracking), 采用轻量级的目标检测器YOLO(You Only Look Once), 结合卡尔曼滤波器进行目标运动状态的预测, 实现高效的目标追踪.由于SORT主要依赖轻量级目标检测器提取简单的特征以表示目标, 限制对目标复杂特征的捕捉.随后, Wojke等[9]改进SORT, 提出Deep SORT, 使用RNN建模目标的运动轨迹, 并使用卡尔曼滤波器对轨迹进行预测和更新, 提升在复杂场景下的目标区分能力和追踪准确性.Danelljan等[10]提出ATOM(Accurate Tracking by Overlap Maximization), 引入自适应的目标导向度量学习方法, 学习目标中心和背景样本之间的相似性度量, 有效提升目标的特征表示, 但是引入的复杂背景建模和自适应模型更新机制导致实时性降低.Zhang等[11]提出FairMOT, 联合训练目标检测和追踪模块, 提高对复杂场景下目标的准确检测和连续追踪能力.
随着深度学习技术的快速发展, 基于孪生网络的目标追踪方法已取得显著进展.这一切源于SiamFC(Siamese Fully-Convolutional)[12]的提出.Siam-FC包括两个完全相同的子网络, 一个子网络作为模板网络, 另一个作为搜索网络.模型通过计算参考帧与当前帧之间目标的相似度进行目标追踪.尽管相似度高的位置通常可表示目标位置, 但在实际应用中, 这个位置需要进一步提高精准度和鲁棒性, 特别是在面对目标尺寸变化、遮挡、光照变化、视角变化等复杂场景时, 目标的特征表示可能会发生变化以及网络可能无法提取完整的目标特征.
为了解决这些问题, 学者提出许多算法.Li等[13]提出SiamRPN, 通过孪生网络架构将目标追踪任务转化为目标检测任务, 引入RPN(Region Pro-posal Network), 用于准确回归目标的边界框, 提高目标追踪位置的精准度.在实时性要求高的应用场景(如视频监控、自动驾驶等)要求算法能及时处理和响应输入数据的领域, RPN的计算复杂度较高, 无法满足实时性的要求, 导致延迟较大或无法实现实时目标追踪.Zhu等[14]提出DaSiamRPN(Distractor- Aware Siamese RPN), 引入RPN模块, 改进训练方式, 针对追踪过程的干扰物, 设计干扰意识模块, 让追踪物体在连续帧之间尽可能保持稳定, 减小与上一帧的差异以消除类内干扰.随后, Zhang等[15]提出SiamDW, 同样在SiamRPN基础上提出CIR(Cro- pping-Inside Residual)单元, 引入旋转不变性和跨通道相关性, 提取目标特征.Hu等[16]提出Siam-Mask, 在SiamRPN的基础上引入一个目标分割分支, 负责生成目标的掩码, 使算法可输出目标的精确边界, 提升追踪结果.Li等[17]提出SiamRPN++, 引入更深层网络, 利用均匀采样, 使目标在中心点附近进行偏移, 缓解目标在中心点平移不变性的问题.Yang 等[18]提出RPDet(RepPoints Detection), 基于无锚框的目标追踪器, 通过可变形卷积, 学习一组关键点, 用于表示目标物体, 这些点能自适应分布在物体重要的局部语义区域, 精准捕捉物体的特征信息, 但对于具有复杂纹理、非规则形状的物体, 可能无法充分捕捉所有的关键几何信息.为了解决这个问题, Chen等[19]改进RPDet, 提出PepPoints v2, 增加角点预测分割与目标前景分割, 帮助模型更好地识别目标的轮廓和类别, 这两个分割分支同时也增加模型的计算复杂度和训练、推理的速度.
从传统方法到深度学习方法的转变, 使得在复杂场景下的目标检测和追踪能力具有显著提升, 但在实时性、算法复杂度和精准度等方面仍需进一步探索和优化.传统方法和深度学习技术的发展, 特别是基于孪生网络的目标追踪方法表现出的巨大潜力, 为复杂场景下的实时目标追踪提供新的可能性.
在上述分析的基础上, 本文提出基于无锚框关键点与注意力机制结合的自适应孪生网络目标追踪方法(Anchor-Free RepPoints and Attention Mecha-nism Based Adaptive Siamese Network for Object Tra-cking, AAASiam), 可在减少计算量的同时保持更好的精准度与实时性.改进孪生网络的主干网络, 提取具有更丰富语义的目标特征, 采用可变形卷积, 学习追踪目标相关的关键点, 拼接得到描述追踪目标内部与边缘的多关键点.再采用自适应学习权重系数模块, 剔除偏离目标的关键点, 通过最大-最小函数将关键点转换成预测框, 实现目标追踪.在多个数据集上的实验验证AAASiam的有效性.
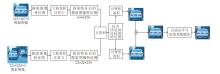
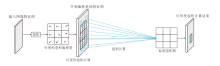
本文提出无锚框关键点与注意力机制结合的自适应孪生网络目标追踪方法(AAASiam), 结构如图1所示.首先, 通过孪生大核卷积注意力子网络提取当前帧图像(搜索图像)和参考帧图像(模板图像)中的特征信息, 进行互卷积操作, 计算相似度, 判断当前帧图像中是否包含参考帧图像中的待追踪目标.如果当前帧图像中不包含待追踪目标, 跳过5帧图像并重新初始化; 若包含待追踪目标, 无锚框多关键点模块会学习当前帧图像中目标的多关键点进行定位.
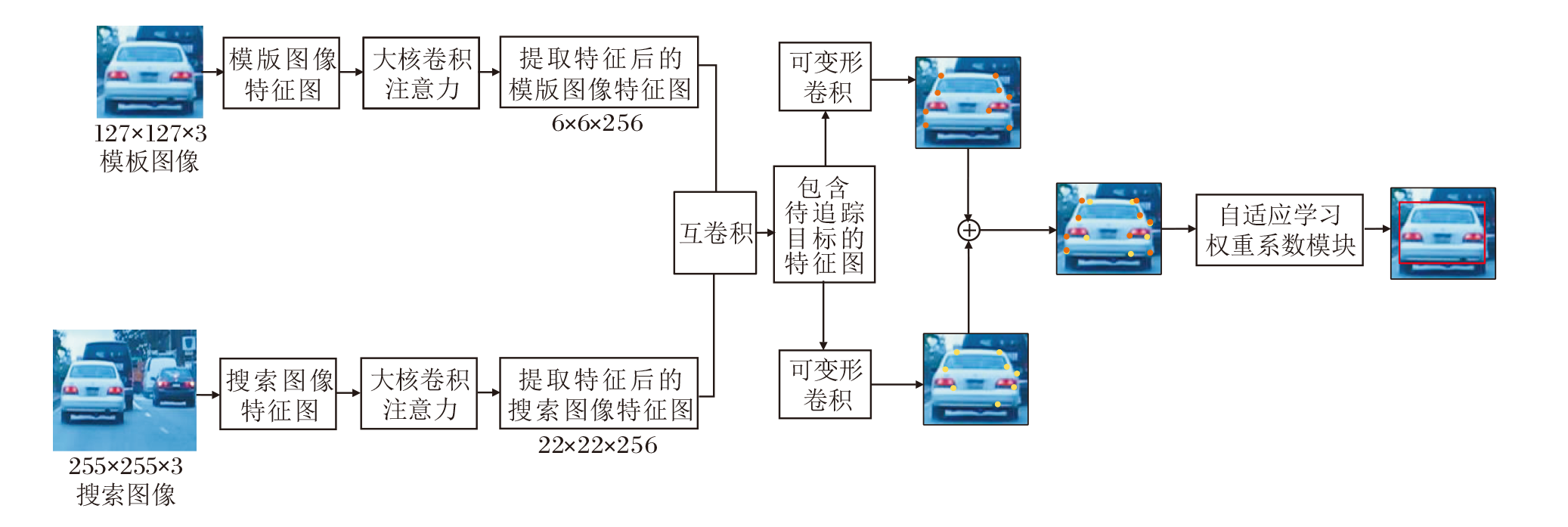 | 图1 AAASiam结构图Fig.1 Structure of AAASiam |
本文选择使用ResNet作为孪生大核卷积注意力子网络的骨干网络.ResNet 通常在大规模的图像数据集上进行预训练, 如 ImageNet.这种预训练使ResNet 学到通用的图像特征表示, 具有较强的泛化性.当ResNet作为骨干网络应用于孪生大核卷积注意力子网络时, 这些预训练的参数可提供良好的初始化, 加速网络的收敛速度, 提高性能.
无锚框多关键点模块首先会根据目标的中心点回归第一阶段的关键点, 再根据第一阶段的关键点, 采用最大-最小转换函数产生一个预测框, 并根据标签, 使用第一阶段的预测框进行目标追踪的训练.之后是第二阶段关键点的定位损失训练, 即在第一阶段得到的关键点的基础上通过可变形卷积继续回归, 再次得到偏移量, 产生更贴近目标的定位.重复上述操作, 并同时采用两组可变形卷积, 得到关于目标的多关键点, 通过自适应学习权重系数模块(Adaptive Learning Weight Coefficient, ALWC)筛选更准确的关键点.
自适应学习权重系数模块会根据损失函数不断反向传播, 更新第一阶段关键点与第二阶段关键点的权重系数, 用于保证关键点的准确性.最后, 将得到的更准确的关键点转换成预测框, 完成目标的最终定位.
注意力机制通过模仿人类视觉和认知系统的方式, 使深度学习模型选择性地关注输入中的重要信息, 提高模型的泛化能力.其中, 以ViT(Vision Trans- former)[20]为代表的自注意力机制在计算机视觉中开辟新的方向, 突破传统卷积神经网络无法关注全局信息的局限, 并在多种视觉任务中表现出色[21].
自注意力机制通过计算元素之间的相对重要性捕捉长距离依赖关系, 但随着序列长度的增加, 计算复杂度显著上升, 对具有实时性要求的任务构成挑战.传统的卷积操作能较好地捕获局部信息, 但受限于感受野尺寸, 可能会忽略全局信息.通过增大卷积核以扩展感受野可捕获更多的全局信息, 但也增加模型复杂度和训练难度.
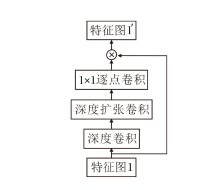
基于上述分析, 本文在孪生子网络的主干网络中集成大核卷积注意力, 帮助神经网络提取全局特征[22].大核卷积注意力将标准大卷积分解为深度卷积[23]、深度扩张卷积[24]和逐点卷积[25]三个独立的卷积操作, 实现广泛的感受野, 同时大幅减少计算量, 具体网络结构如图2所示.
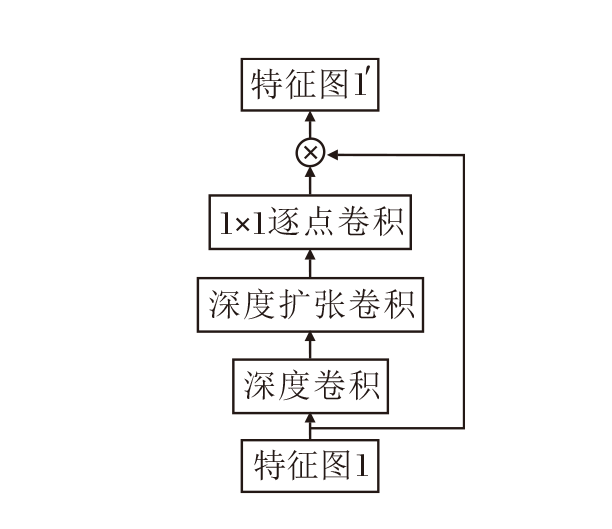 | 图2 大核卷积注意力网络结构Fig.2 Structure of large-kernel convolutional attention network |
标准大卷积分解方法如下.将一个 K× K的标准大卷积核分解为一个
卷积核为13× 13的标准大卷积与大核卷积注意力分解之后3种卷积操作的参数量之和的对比结果如表1所示.表中输入通道均为RGB3通道, 扩张率为3. 由表可见, 卷积核为13× 13标准大卷积的参数量是大核卷积注意力分解之后的参数量之和的4.2倍, 进一步验证这种分解方法有助于减少参数量和计算复杂度, 允许模型捕获更广泛的感受野和自适应关注输入数据中的重要部分.
| 表1 不同卷积的参数量对比 Table 1 Comparison of the number of parameters for different convolutions |
大核卷积注意力结合自注意力机制和卷积操作的优点, 避免二者的不足.深度卷积在输入数据的通道维度上进行卷积, 捕获局部信息.深度扩张卷积引入扩张率, 获得更大的感受野, 捕获全局信息.逐点卷积用于整合之前两部分卷积的输出, 自适应学习和选择性关注输入中的重要信息.
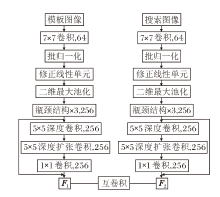
孪生大核卷积注意力子网络结构图如图3所示.搜索图像与模板图像在经过孪生大核卷积注意力子网络提取特征后[26], 分别生成特征图F1、F2.二者进行互卷积操作以计算相似度, 生成一个响应图, 其中每个像素值都表示搜索图像中对应位置与模板图像的相似度.然后, 在响应图中找到最大值, 该最大值对应的位置即为目标对象在搜索图像中的估计位置.通过这种方式, 孪生大核卷积注意力子网络能在特征空间中量化模板图像和搜索图像之间的相似度, 判断当前帧图像中是否包含待追踪目标.
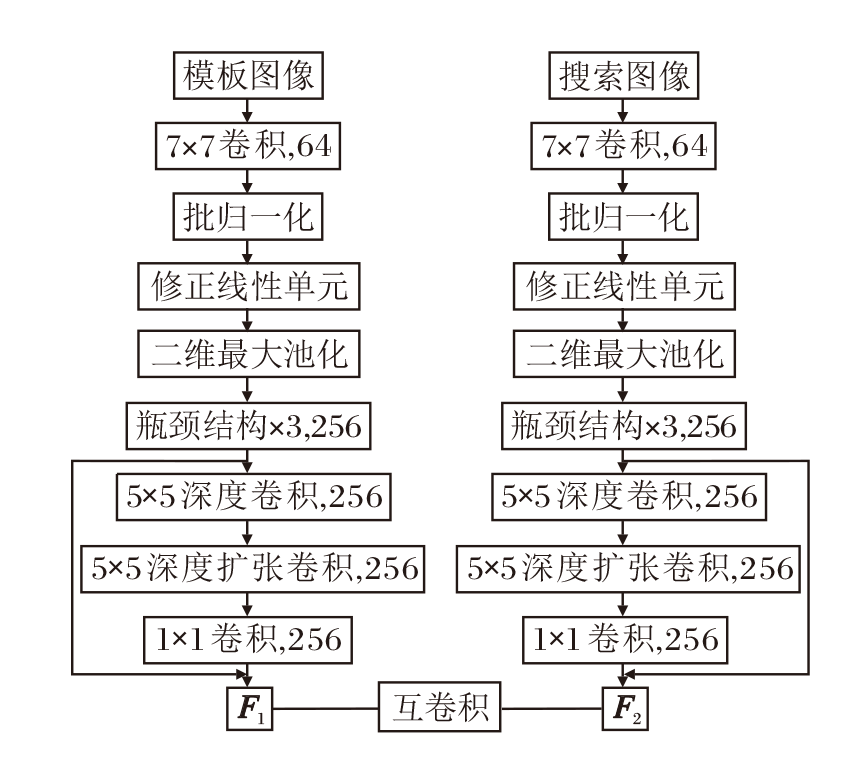 | 图3 孪生大核卷积注意力子网络结构Fig.3 Structure of Siamese large-kernel convolutional attention subnetwork |
有锚框(Anchor-Based)方法和无锚框(Anchor-Free)方法是两种不同的目标追踪方法[27], 区别在于是否使用预定义的锚框匹配真实框.
在传统的有锚框方法中, 效果往往受限于锚框的配置参数, 如锚框大小、正负样本采样和锚框宽高比等.这要求开发者深入了解数据, 正确配置锚框参数, 从而训练得到一个较好的模型.同时, 有锚框方法会产生大量预定义的锚框, 需要通过NMS(Non-maximum Suppression)[28]去除高度重叠的候选框, 保留置信度最高的框.最后, 使用分类器对筛选后的候选框进行目标分类, 判断每个框内是否包含目标, 并预测目标类别.这一系列操作无疑增加计算量和内存消耗, 降低追踪的实时性.
与之相比, 无锚框方法无需配置锚框参数, 即可训练得到一个较好的模型, 并减少训练前对数据复杂度的分析过程, 也不需要生成预定义的锚框, 从而大幅降低计算复杂度.
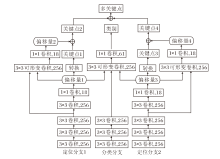
因此, 本文提出无锚框多关键点模块, 完成对追踪目标的精准定位工作, 模块结构如图4所示.
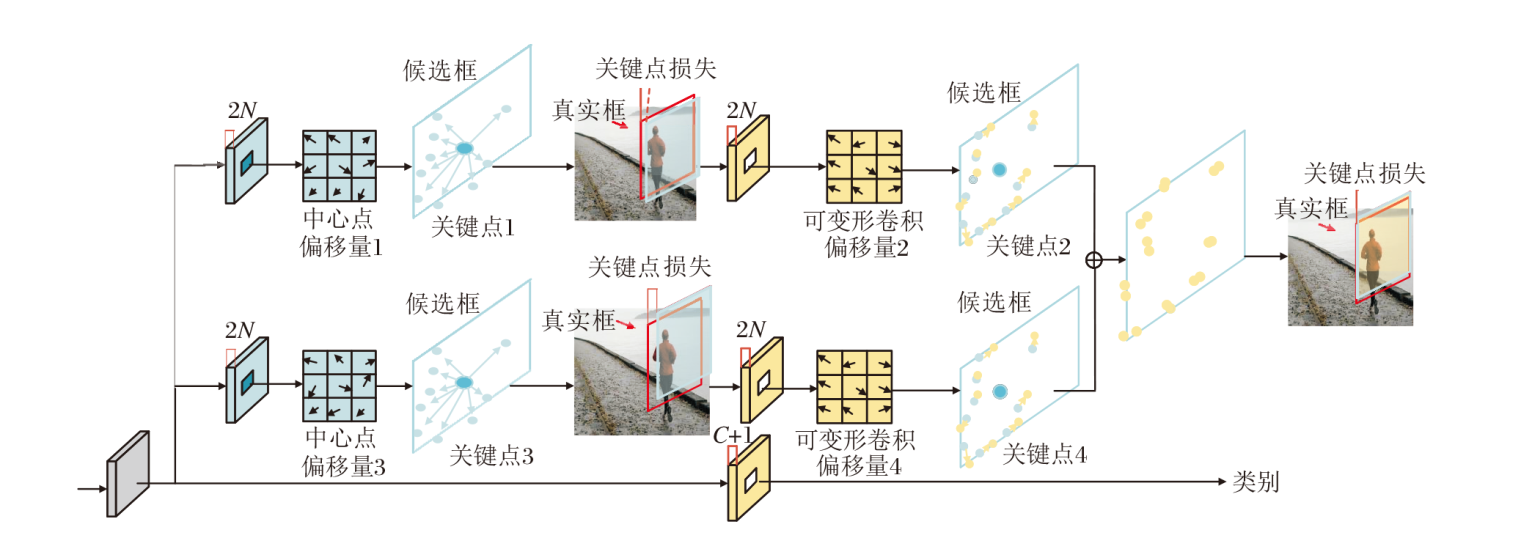 | 图4 无锚框多关键点模块结构图Fig.4 Structure of anchor-free multi-RepPoints module |
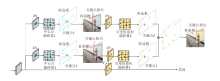
关键点是一组点集, 可通过约束目标空间范围的方式在目标上自适应定位, 并指示语义上重要的局部区域.首先, 中心点作为目标的原始表示, 通过回归中心点上的偏移量得到第一阶段关键点.然后, 通过两组可变形卷积[29, 30]自适应学习第二阶段关键点的偏移量, 得到第二批关键点的位置.可变形卷积计算过程如图5所示.
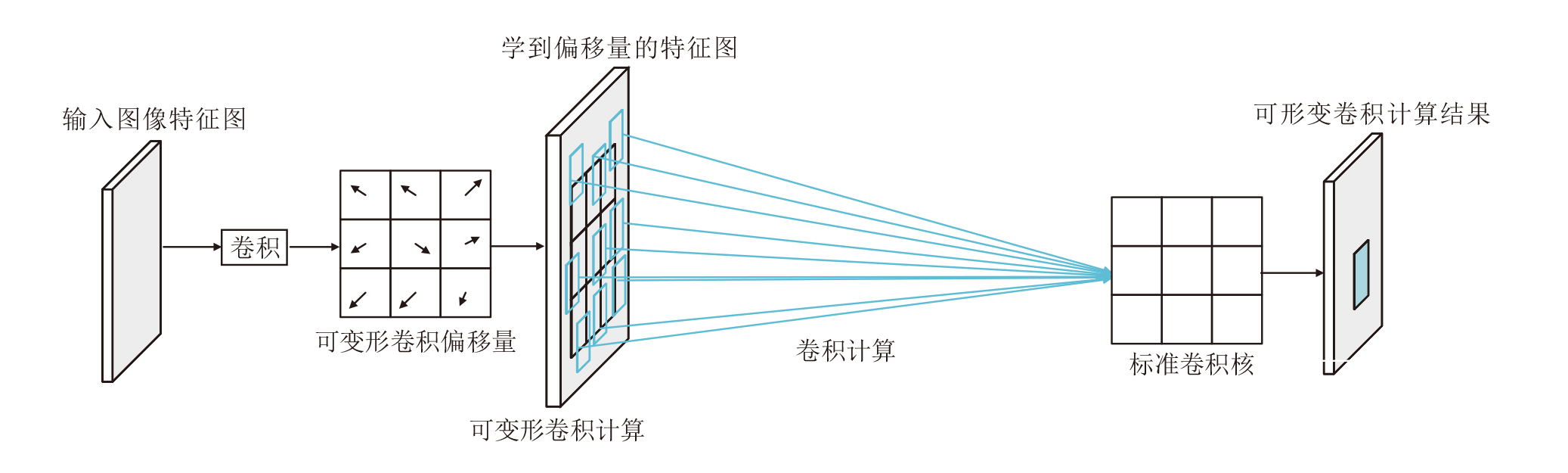 | 图5 可形变卷积计算过程Fig.5 Computing process of deformable convolution |
通过一个卷积层获得偏移量, 输入特征图后输出偏差.生成通道维度是2N, 其中的2分别对应X、Y方向的偏移量, N表示关键点的个数.整个过程一共有两种卷积核:标准卷积核和学习偏移量卷积核, 这两种卷积核通过双线性插值反向传播同时进行参数更新.图4中蓝点为初始关键点的预测位置, 黄点为基于偏移量进行精细调整后的最终关键点位置, 通过拼接得到目标的多关键点.
多关键点模块可表示为
其中, xk、yk分别为第k个关键点的横纵坐标, N表示使用的关键点数量, 本文中默认为18.
通过可变形卷积学到的预测偏移量设为Δ xk与Δ yk, 故Rep的细化表示如下:
最后, 采用最大-最小转换函数将关键点转换为预测框.该转换函数通过确定预测框的左下角和右上角的点, 生成一个可包含所有关键点的最小矩形框.通过Smooth L1 损失函数[31]计算预测框与真实框之间的Loss值.
SmoothL1损失表达式如下:
其中x表示预测值与真实值之间的差值.当|x|≤ 1时Smooth L1损失函数退化为平方损失; 当|x|> 1时Smooth L1损失函数退化为绝对值损失.因此Smooth L1损失函数可有效处理预测值与真实值之间的较大差异, 同时避免在接近0时的数值不稳定性.
无锚框多关键点模块采用两组可变形卷积自适应学习目标的关键点, 这些点集往往可描述物体的轮廓并将其与背景区分.每组可变形卷积可学习9个关键点, 通过对两组可变形卷积的结果进行拼接, 得到关于目标对象的多关键点.
同时, 本文也对比只使用一组可变形卷积及使用三组可变形卷积的结果.实验表明, 使用18个关键点结果优于9个关键点和27个关键点, 特别是在追踪纹理丰富或边缘形状复杂的目标时, 效果更明显.
无锚框多关键点模块结构如图6所示.
 | 图6 无锚框多关键点模块结构Fig.6 Structure of anchor-free multi-RepPoints module |
无锚框多关键点模块整体框架基于全卷积网络, 但与其它单阶段方法不同, 采用两次回归与一次分类, 确定最终的目标位置.此外, 分类和最后一次回归阶段采用可变形卷积, 允许卷积核在不同位置进行自适应的变形采样.
在训练过程中, 由第一次回归得出可变形卷积的偏移量, 因此偏移量是有监督的.这些偏移量可根据输入数据的特征动态调整卷积核的形状和位置, 从而确保特征质量和准确性.
由于引入大核卷积注意力与无锚框多关键点模块, AAASiam取得良好结果.然而, 通过多次实验发现, 结果存在一定的上下浮动.这是因为通过无锚框多关键点模块获取的多关键点, 最终被转换成预测框, 也就是说, 关键点位置的预测结果直接决定预测框的位置以及后续的追踪效果.虽然无锚框多关键点模块通常有助于更好地定位目标, 因为多关键点信息有利于描述物体的内部及轮廓边缘, 但在某些情况下也可能会带来负面效果, 即某些关键点可能会偏离目标对象, 对后续的目标定位和追踪产生极大影响.
因此, 本文提出自适应学习权重系数模块(ALWC), 负责整合无锚框多关键点模块学到的多关键点, 保留对目标描述更准确的关键点并转换成预测框, 从而提升目标追踪的精准度和鲁棒性.
无锚框多关键点模块采用两次回归定位目标的多关键点.第一次回归预测多关键点的初始位置, 第二次回归在第一次回归的基础上进行偏移, 定位多关键点的最终位置.因此, 第一次回归预测的关键点位置至关重要.为此神经网络新增两个权重信息:初始关键点位置权重和最终关键点位置权重.初始关键点位置权重系数设为0.8, 最终关键点位置权重系数设为0.2.
通过权重乘和的方式, 可以得到更准确的关键点信息, 并不断通过优化器随训练一起学习, 自适应更新权重系数并进行反向传播, 以优化关键点预测结果.
为了验证AAASiam的有效性, 选择在ImageNet数据集上训练模型, 并在VOT2019、VOT-2016、TC-128、OTB100数据集[32]上进行测试和验证.图7为VOT2019数据集上具有代表性的图像.
 | 图7 VOT2019数据集图像示例Fig.7 Image examples from VOT2019 dataset |
本文设定批次大小为32, 轮次为20, 学习率为0.38, 优化器使用随机梯度下降对模型进行训练.实验环境为pytorch1.10, python3.8, cuda11.3, gcc-8.1.0.同时, 采用随机裁剪、颜色扭曲、随机缩放、随机翻转和随机旋转等图像增强策略[33], 提升目标追踪的性能和鲁棒性.
测试评价指标选择精准度、鲁棒性、平均期望重叠率(Expected Average Overlap, EAO)和每秒帧数(Frames per Second, FPS).
根据追踪算法预测的目标边界框和标注的真实边界框面积重叠率计算得到精准度, 数值越大, 算法追踪效果越优.首先计算第i个追踪器第 t 帧的重叠率:
${{\phi }_{t}}(i)=\frac{1}{{{N}_{rep}}}\underset{k=1}{\overset{{{N}_{rep}}}{\mathop \sum }}\, \left( \frac{A_{t}^{k}\cap B_{t}^{k}}{A_{t}^{k}\cap B_{t}^{k}} \right)$,
其中,
${{\rho }_{A}}(i)=\frac{1}{{{N}_{valid}}}\underset{t=1}{\overset{{{N}_{valid}}}{\mathop \sum }}\, {{\phi }_{t}}(i)$,
其中Nvalid表示该视频序列的长度.
鲁棒性用于评价追踪器追踪目标稳定性, 数值越小, 追踪算法的稳定性越优.计算公式如下:
${{\rho }_{R}}(i)=\frac{1}{{{N}_{rep}}}\underset{k=1}{\overset{{{N}_{rep}}}{\mathop \sum }}\, F(i, k)$,
其中F(i, k)表示第i个追踪器重复k次时失败次数.
根据准确性和鲁棒性计算得到EAO, 可用于评价跟踪算法的综合性能.首先依据长度对全部视频序列分组, 再令跟踪器在序列长度为Ns的视频上运行算法, 获得序列准确率:
${{\Phi }_{{{N}_{s}}}}=\frac{1}{{{N}_{s}}}\underset{i=1}{\overset{{{N}_{s}}}{\mathop \sum }}\,{{\Phi }_{i}}$.
追踪器在所有长度为Ns的序列上的EAO值:
$\hat{\Phi }=\frac{1}{{{N}_{h}}-{{N}_{l}}}\underset{{{N}_{s}}={{N}_{l}}}{\overset{{{N}_{h}}}{\mathop \sum }}\, \hat{\Phi }{{~}_{{{N}_{s}}}}$.
最后计算其它长度的视频序列EAO值, 假设序列长度范围为[Nl, Nh], 求得追踪器的EAO值:
$\hat{\Phi }=\frac{1}{{{N}_{h}}-{{N}_{l}}}\underset{{{N}_{s}}={{N}_{l}}}{\overset{{{N}_{h}}}{\mathop \sum }}\, \hat{\Phi }{{~}_{{{N}_{s}}}}$.
为了验证大核卷积注意力、无锚框关键点模块、无锚框多关键点模块、自适应学习权重系数模块对目标追踪的影响, 进行消融实验, 选择SiamRPN++[17]作为基线方法, 观察每个模块对方法追踪结果的影响.具体消融实验结果如表2所示, 表中黑体数字表示最优值.
| 表2 各模块消融实验结果 Table 2 Ablation experiment results of different modules |
由表2可见, 相比SiamRPN++, 同时添加大核卷积注意力和无锚框关键点模块之后, 精准度提升1.3%, EAO提升2.4%, 鲁棒性同时也降低6.1%.由于自适应学习权重系数模块仅用于整合优化无锚框多关键点模块学到的结果, 故不能单独使用, 也不能与关键点模块或大核卷积注意力同时使用.相比SiamRPN++, AAASiam的精准度提升3.6%, EAO提升5.3%, 鲁棒性降低11.2%.鲁棒性的降低可有效避免追踪失败的问题.同时, 分别单独添加大核卷积注意力、无锚框关键点模块与无锚框多关键点模块, 发现无锚框多关键点模块在各项指标上都取得更优值, 这表明无锚框多关键点模块可帮助方法更好地追踪目标.
为了进一步验证AAASiam的检测性能, 选择多种对比方法:ATOM[10]、SiamRPN[13]、DaSiamRPN[14]、SiamMask[16]、SiamRPN++[17]、DiMP[34]、PrDiMP(Pro-babilistic DiMP)[35]、SiamBAN(Siamese Box Adaptive Network)[36]、ViPT(Visual Prompt Multi-Modal Tracking)[37]、文献[38]方法、基于元循环优化的多尺度感知孪生网络目标跟踪方法(Meta-cyclic Optimiza-tion Based Multiscale Perceptual Siamese Networks Method for Object Tracking, SiamMP-Meta)[39]、MEEM(Multiple Experts Entropy Minimization)[40]、Struck[41]、IKPCA-KCF(Incremental Kernel Principal Component Analysis-Based Kernelized Correlation Filter)[42]、ALPCA[43]、ECO[44]、文献[45]方法、文献[46]方法.
各方法在VOT2019数据集上的指标值结果如表3所示, 表中SiamMRep为使用27个关键点的AAASiam, 黑体数字表示最优值.
| 表3 各方法在VOT2019数据集上的测试结果对比 Table 3 Result comparison of different methods on VOT2019 dataset |
由表3可知, SiamMRep的鲁棒性很好但精准度和EAO并不理想.这是因为SiamMRep使用27个关键点描述目标, 增加训练过程的计算复杂度, 需要处理大量的关键点, 导致网络无法收敛或需要更多的训练轮次.因此, 这些关键点可能会在网络学习过程中偏离目标, 根据最大-最小函数, 这会导致最后生成的预测框大小超出目标实际真实框.而在VOT-2019数据集上, 根据目标追踪失败的次数衡量鲁棒性, 大的预测框容易与目标的真实框重叠, 因此可能被错误认为是成功追踪, 但这在实际应用中并不理想.
此外, SiamRPN++、SiamMask、SiamBAN 等孪生目标追踪方法的EAO值较优, 但由于引入目标检测或目标分割的组件, 在速度方面的表现并不突出.
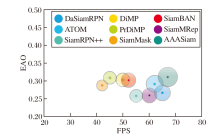
各方法的EAO气泡图如图8所示.由图可知, AAASiam气泡面积最大, 这表明其在相同环境下能更快地对目标进行追踪的同时保持较高的EAO值.
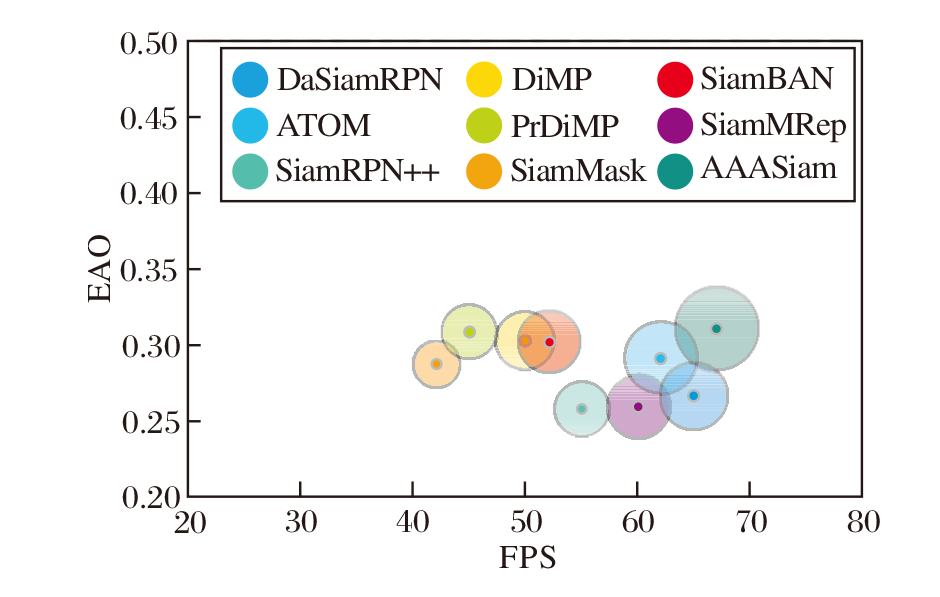 | 图8 EAO的气泡图Fig.8 Bubble chart of EAO |
DaSiamRPN、SiamRPN++、SiamMask、SiamRPN++_3(见2.3节)和AAASiam追踪可视化结果如图9所示.在图中, 绿框为标注框, 黄框为预测框.由图可看出, AAASiam的预测框较贴合目标的标注框, 由此表明其追踪目标时的准确性.
 | 图9 各方法在VOT2019数据集上追踪可视化结果Fig.9 Visualization results of tracking by different methods on VOT2019 dataset |
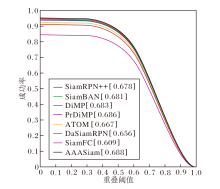
此外, 还在VOT2016、TC-128、OTB100数据集上进行单独评估, 各方法在VOT2016数据集上的测试结果如表4所示, 在TC-128数据集上的测试结果如表5所示, 表中黑体数字表示最优值.各方法在OTB100数据集上的追踪成功率对比如图10所示.
| 表4 各方法在VOT2016数据集上的测试结果对比 Table 4 Test result comparison of different methods on VOT2016 dataset |
| 表5 各方法在TC-128数据集上的测试结果对比 Table 5 Test result comparison of different methods on TC-128 dataset. |
 | 图10 各方法在OTB100数据集上追踪成功率对比Fig.10 Tracking success rate comparison of different methods on OTB100 dataset |
由表4、表5和图10可知:在VOT2016数据集上, 相比SiamRPN++, AAASiam精准度提升3.0%, EAO值提升4.9%, 鲁棒性降低2.8%, 同时FPS也提升19, 提升目标追踪的实时性.在OTB100、TC-128数据集上, 相比SiamRPN++, AAASiam成功率也分别提升1.0%与2.6%.这表明AAASiam在其它数据集上依然表现良好.
本文提出无锚框关键点与注意力机制结合的自适应孪生网络目标追踪方法(AAASiam), 解决目标候选框生成阶段计算复杂度较高导致实时性较差和在面对具有复杂形状的目标物体时难以追踪的问题.首先, 采用大核卷积注意力, 集成到孪生子网络中, 允许在特征图中处理全局信息, 同时避免过多计算.再将原有RPN模块替换成无锚框多关键点模块, 这样无需生成预定义锚框, 减少计算复杂度.然后, 通过自适应学习权重系数模块, 实现对更贴合目标对象的多关键点的保留.通过最大-最小函数, 将生成的关键点转换成预测框, 在减小计算量的同时提高目标追踪的实时性.最后, 在多个数据集上验证AAASiam的有效性.结果表明AAASiam可提高目标追踪实时性, 同时实现更高的精准度.由于本文未对目标的模板图像选择进行优化, 若复杂场景中目标特征发生较大改变时, 会导致将背景内容误识别为目标关键点, 从而引起后续追踪失败.如何选择更新模板图像, 避免目标追踪失败, 将是今后的研究重点之一.
本文责任编委 黄华
Recommended by Associate Editor HUANG Hua
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|