


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
面向皮肤镜图像识别的内卷胶囊网络
[王凌翔1  , 张莉
, 张莉1 ]
, 张莉]
|
|



作者简介:
王凌翔,硕士研究生,主要研究方向为图像处理.E-mail:1154595901@qq.com.
皮肤镜图像识别能区分皮肤病变,有助于皮肤癌的早期诊断.为了提高皮肤镜图像识别效率,文中提出面向皮肤镜图像识别的内卷胶囊网络(Involutional Capsule Network, InvCNet),融合内卷操作和全局注意力机制(Global Attention Mechanism, GAM),并去除重构部分.内卷操作融合特征图在通道上的信息,提供丰富的细节,增强皮肤镜图像特征.GAM减轻卷积和池化操作引起的空间信息损失,放大跨维度交互.在4个皮肤镜图像数据集上的实验表明,InvCNet大幅减少网络参数量,并在多数数据集上性能较优.
About Author:
WANG Lingxiang, Master student. His research interests include image processing.
Dermoscopy image recognition can distinguish skin lesions and it is helpful for the early diagnosis of skin cancer. To enhance the efficiency of dermoscopy image recognition, an involutional capsule network(InvCNet) is proposed. InvCNet combines an involutional operation and a global attention mechanism(GAM), while the reconstruction part is removed. The involution operation provides rich minutiae to enhance the dermoscopy image features by fusing information of feature maps across channels. Meanwhile, GAM is employed to mitigate the loss of spatial information induced by the convolution and pooling operations and amplify the cross-dimensional interactions. Experiments on four public datasets demonstrate that InvCNet significantly reduces the number of network parameters while achieving superior performance on most datasets.
随着人口的不断增长, 皮肤癌的发病率也在不断上升.在未得到及时诊断和治疗的情况下, 皮肤癌会严重影响患者的健康, 产生一些并发症, 甚至导致患者死亡.Rogers等[1]的报告显示, 黑色素瘤皮肤癌非转移期患者的5年生存率高达99%, 与之形成鲜明对比的是, 转移期患者的生存率仅为20%.
皮肤镜图像的检测和分类在皮肤癌的早期诊断中发挥重要作用.起初, 医生仅依靠肉眼观察并辅以皮肤镜成像进行诊断, 这种诊断方式很大程度上依赖医生的经验和直觉, 不可避免地会产生误诊、漏诊现象.近年来, 随着人工智能在医疗领域的发展, 深度学习已成为医疗图像检测和分类的重要工具.
作为一种普遍使用的深度学习方法, 卷积神经网络(Convolution Neural Network, CNN)已广泛应用于医学图像分析.最直接的应用方式是利用迁移学习的思想, 将成熟的CNN模型直接处理皮肤镜图像识别任务.Esteva等[2]将GoogleNet预训练模型应用到皮肤病变领域中, 对整合多个皮肤病变图像数据集进行分类, 准确率超过两位皮肤科医生完成相同分类任务的平均准确率.为了提高分类网络的泛化能力, 研究者使用迁移学习和生成对抗网络(Generative Adversarial Network, GAN), 并取得令人满意的结果[3, 4].
另一种应用方式是对CNN结构进行合理变形, 再应用到皮肤镜图像识别领域中[5, 6, 7, 8, 9, 10].这些变形方法都是在基础模型上融入某些元素, 如融入软注意力机制的IRv2+SA(Inception ResNet v2 with Soft Atten-tion)[5].Xie等[6]提出SSAC(Semi-supervised Adver-sarial Classification), 由基于自编码器的无监督对抗重建模块和分类模块组成, 可充分利用有标签数据和无标签的数据, 避免在小样本医学数据集上出现过拟合现象, 最终提升分类性能.Zhang等[7]提出SDL(Synergic Deep Learning), 使用协同策略, 使多个CNN相互学习.Wan等[10]结合多尺度信息和长时间注意力, 提出MSLANet(Multi-scale Long Atten-tion Network).
由于卷积运算固有的局部性, CNN的浅层部分难以从图像模态中提取上下文信息.为此, 研究者将Transformer应用到皮肤镜图像识别任务中, 获得对全局特征的关注.在这些方法中, 包括直接利用Transformer的方法[11, 12], 也有采用视觉Transformer(Vision Transformer, ViT)的方法[13, 14, 15, 16].
直接利用Transformer的方法联合CNN和Trans- former一起执行任务.Wu等[12]提出ScATNet(Scale-Aware Transformer Network), 对多个输入尺度的斑块间和尺度间表征进行建模, 诊断活检图像中黑色素细胞的病变.采用ViT的方法是独立的Transformer模型, 不需要CNN辅助.Pedro等[16]采用ViT架构对皮肤癌图像进行分类.相比基于CNN的方法, 基于Transformer的方法往往缺乏对局部信息的关注.
基于CNN的方法和基于Transformer的方法都会随网络层数的增加带来巨量的网络参数, 不仅延长网络的训练时间, 也加大网络的训练难度.因此, Sabour等[17]提出CapsNet(Capsule Network).与CNN和Transformer不同, CapsNet是在“ 胶囊” 中处理数据.“ 胶囊” 是一小组神经元, 能提取图像纹理、形状或方向等特征.CapsNet能兼顾图像的局部信息和全局信息, 对图像中的空间层次结构进行有效识别, 已应用到脑肿瘤图像分类[18]、植物疾病检测[19]、细胞分类[20]等.
研究者也从不同角度探索CapsNet.Xiang等[21]提出MS-CapsNet(Multi-scale Capsule Network), 在Fashion MNIST[22]、CIF-AR10数据集[23]上的鲁棒性比原始CapsNet更强.Rajasegaran等[24]利用残差学习, 开发DeepCaps, 大幅减少参数量.该方法的成功为CapsNet提供一种深度架构.Sharifi等[25]提出PrunedCaps, 设计基于泰勒分解的修剪层, 丢弃无用的初级胶囊.
目前, 胶囊网络在皮肤病变识别方面的应用较少.Lan等[26]将大核卷积引入CapsNet, 提出Fix-Caps, 为网络提供更大的感受野.Goceri[27]提出AFConvCapsNet, 学习胶囊向量之间空间关系的编码和建模, 并保持向量方向.李励泽等[28]改进原始胶囊网络激活函数, 将胶囊网络应用到皮肤图像分类领域, 在ISIC2017数据集上性能较优.林凯迪等[29]提出基于矩阵胶囊网络的皮肤镜图像分类识别算法, 将向量胶囊替换为矩阵胶囊, 修改原始CapsNet的路由机制, 在ISIC2017数据集[30]上达到98.2%的平均精度.因此, 基于胶囊网络的分类方法在皮肤癌诊断领域具有较大的发展潜力.
CapsNet虽然能有效捕捉图像中的空间层次结构, 但经典CapsNet的底层部分只包含一个简单的卷积层, 提取浅层特征的能力较差.因此, 本文提出面向皮肤镜图像识别的内卷胶囊网络(Involutional Capsule Network, InvCNet), 在底层引入内卷操作, 可学习感受野的大小和位置, 在不同位置和尺度上实现自适应特征捕捉, 增强模型的表现力.此外, 引入全局注意力机制(Global Attention Mechanism, GAM), 增强跨维度的交互作用, 可同时捕捉三个维度的特征, 减少信息丢失.在ISIC2017[30]、HAM-10000[31]、ISIC2018[32]、ISIC2019[33]数据集上的实验验证InvCNet在皮肤癌诊断中的可行性和有效性.
胶囊网络通过编码特征的位姿(Position)和空间(Spatial)关系, 提升对图像分类任务的性能.考虑到皮肤镜图像的特点, 本文在胶囊网络的基础上提出面向皮肤镜图像识别的内卷胶囊网络(InvCNet), 识别皮肤镜图像中的皮肤病变.InvCNet通过内卷操作, 提取皮肤镜图像的细节信息, 如边缘特征, 增强模型提取特征的能力.
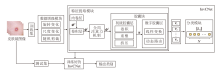
InvCNet的训练和测试过程如图1所示.以单幅图像为例, 设输入的皮肤镜图像X∈ R3× w× h, 其中, w表示图像宽度、h表示图像高度.
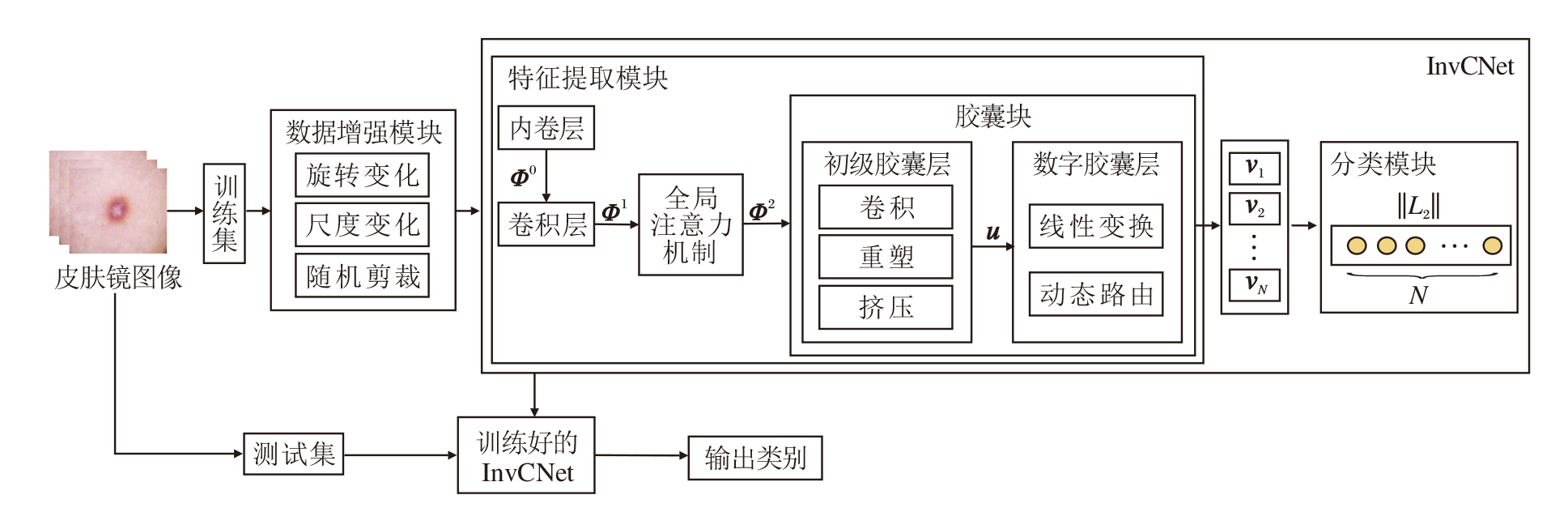 | 图1 InvCNet的训练和测试过程Fig.1 Training and test processes of InvCNet |
在训练过程中, 数据增强模块用于扩展输入数据的数量或解决数据不平衡问题.模块采用3种数据变化方式:旋转变化、尺度变化、随机剪裁.数据增强模块的输出直接输入InvCNet中.
InvCNet包含特征提取模块和分类模块.经典CapsNet的特征提取模块包含卷积层、初级胶囊层、数字胶囊层.InvCNet的特征提取模块由5个关键部分组成:内卷层、卷积层、全局注意力机制(GAM)、初级胶囊层和数字胶囊层.
对于给定的输入图像, 特征提取模块首先通过内卷层提取内卷层特征Φ 0∈
在测试过程中, 将待分类的皮肤镜图像输入已训练好的InvCNet中, 可由分类模块输出预测类别.测试过程中的输入图像不需要经过数据增强模块.
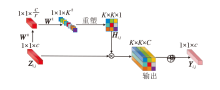
本文在特征提取模块中引入内卷操作.内卷是一种神经网络算子, 引入自适应感受野, 能较好地处理图像细节和局部特征[33].内卷运算可看作是卷积运算的逆运算, 具有空间特异性和通道不变性.
假设Zi, j∈ RC是位于位置(i, j)的C通道像素向量, 则经过内卷操作后得到的输出特征映射Yi, j∈ RC, 其中
${{Y}_{i}}_{, j, k}=\sum\limits_{\left( u, v \right)\in {{\Delta }_{K}}}{{{H}_{i}}_{, j, u+\left\lfloor K/2 \right\rfloor , v+\left\lfloor K/2 \right\rfloor , \left\lceil kG/C \right\rceil }{{Z}_{i}}_{, j, k}}$,
Zi, j, k表示Zi, j的第k个元素,
Δ K=[-⌊K/2」, …, ⌊K/2」]☉[-⌊K/2」, …, ⌊K/2」],
表示对像素进行卷积的邻域偏移量集合, ⌊· 」表示下取整, 「· ⌉表示上取整, ☉表示笛卡尔乘积, K表示内卷核大小, G表示共享相同内卷核的组数.
位置(i, j)的内卷核为:
Hi, j=R(W1g(W0Zi, j))∈ RK× K× G,
其中, R(· )表示Reshape操作, g(· )表示批量归一化和非线性激活的联合处理函数, 权重矩阵W0∈
内卷操作过程如图2所示, G=1.对于Zi, j, 经过线性变换后, 得到长度为1× 1× K2的向量.再对得到的内卷核进行展开操作, 生成的内卷核Hi, j大小为K× K× 1, 这意味着同一组像素集合将使用相同的内卷核.然后, 将内卷核应用于Zi, j, 进行矩阵相乘操作, 生成K× K× C的输出.最后, 通过求和运算, 将来自K× K邻域的信息汇总, 输出长度为C的像素向量Yi, j.内卷操作的计算复杂度与特征通道的数量呈线性增长.
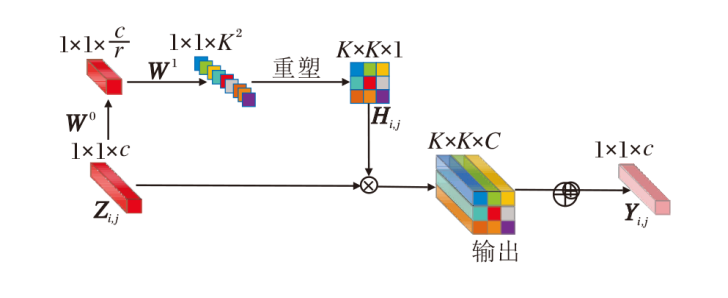 | 图2 内卷操作过程Fig.2 Involution operation |
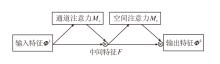
InvCNet的特征提取模块还引入全局注意力机制(GAM).全局注意力机制增强跨维度的交互作用, 可同时捕捉三个维度的特征, 减少信息弥散, 提升神经网络的性能[34].考虑到内卷和卷积的特殊性以及皮肤癌图像的特征, 全局注意力机制被添入卷积层和初级胶囊层之间, 用于减少卷积和池化操作带来的特征图信息损失.
全局注意力机制的流程图如图3所示.GAM包含通道注意力子模块和空间注意力子模块.给定输入特征图Φ 1∈
F=Mc(Φ 1)☉Φ 1,
其中, Mc(· )表示通道注意力操作, ☉表示元素相乘.
输出
Φ 2=Ms(F)☉F,
其中Ms(· )表示空间注意力操作
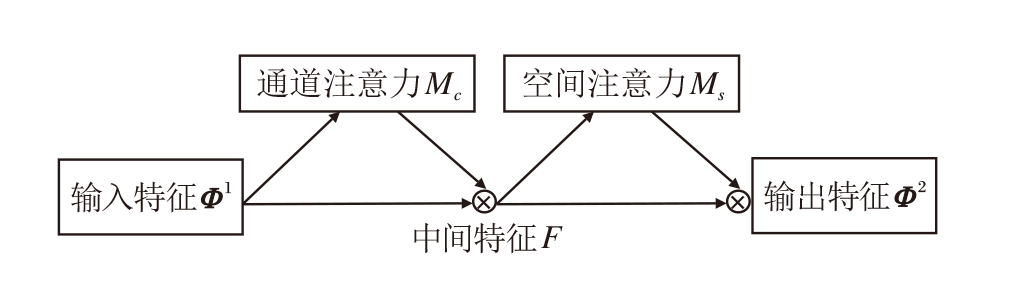 | 图3 全局注意力机制流程图Fig.3 Flowchart of GAM |
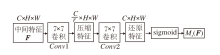
通道注意子模块流程图如图4所示.模块首先使用三维排列保留三维信息(通道深度、空间宽度及高度), 即通过置换得到
Mc(Φ 1)=σ (P(MLP(MLP(
其中, σ (· )表示sigmoid函数, P(· )表示置换函数, 用于调整中间特征的三维排列, MLP(· )表示感知器层.
 | 图4 通道注意力子模块流程图Fig.4 Flowchart of channel attention submodule |
为了关注空间信息, 空间注意子模块使用两个卷积层进行空间信息融合.由于最大池化减少信息, 并会产生负面影响, 因此空间注意力模块不采用池化操作, 以进一步保留特性映射, 但有时会显著增加参数量.空间注意子模块流程图如图5所示.模块计算公式如下:
Ms(F)=σ (Conv2(Conv1(F))),
其中, Conv1(· )表示卷积核大小为7× 7、通道缩减比为r的卷积操作, Conv2(· )表示卷积核大小为7× 7, 还原通道数量的卷积操作.
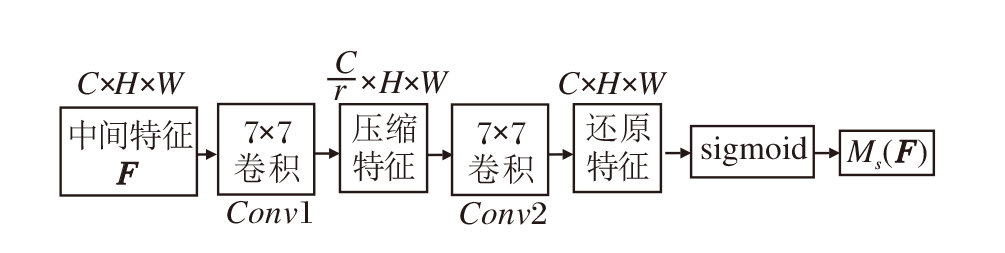 | 图5 空间注意力子模块流程图Fig.5 Flowchart of spatial attention submodule |
初级胶囊层和数字胶囊层都属于胶囊层.与CapsNet一样, InvCNet在初级胶囊层使用卷积、重塑和挤压, 生成初始胶囊向量u∈ Rn× d.数字胶囊层包含线性变换和动态路由两个子模块.线性变换子模块提供变换权重矩阵W
${{s}_{j}}=h\left( {{{\hat{u}}}_{ij}} \right)=\sum\limits_{i}{{{c}_{ij}}}{{\hat{u}}_{ij}}\in {{R}^{n}}^{\times D}$,
其中cij为耦合系数, 表示初级胶囊i与数字胶囊j之间的相对强度.则数字胶囊向量为:
vj=squash(sj)=
其中squash(· )表示挤压函数.
动态路由具体过程如算法1所示.
算法1 动态路由过程
输入 (
输出vj
对第l层所有胶囊i和第l+1层所有胶囊j,
bij← 0
进行r次迭代:
对第l层所有胶囊i, ci← softmax(bi)
对第l+1层所有胶囊$j, {{s}_{j}}\leftarrow \sum\limits_{i}{{{c}_{ij}}{{{\hat{u}}}_{ij}}}$
对第l+1层所有胶囊j, vj← squash(sj)
对所有的胶囊i和胶囊j, bij← bij+
返回 vj
分类器模块计算数字胶囊的L2范数, 即
${{v}_{j}}_{2}=\sqrt{v_{j1}^{2}+v_{j2}^{2}+\ldots +v_{jD}^{2}}$.
然后, 将模长最大胶囊的索引号作为预测的分类标签y, 即
InvCNet使用间隔(Margin)损失函数提高正确类别的概率.对于第k类, 损失函数为:
Lk=T(y, k)max(0, m+-
其中:λ 表示非负正则参数; m+和m-表示非负实数, m++m-=1; T(y, k)表示类别指示函数, 如果y=k, T(y, k)=1, 否则T(y, k)=0.
总损失是所有数字胶囊的损失之和.
本文采用ISIC2017[30]、HAM10000[31]、ISIC- 2018[32]、ISIC2019数据集, 分别用于验证InvCNet在多分类任务及两分类任务上的有效性.
HAM10000数据集包含10 015幅皮肤镜图像, 每幅图像尺寸为450× 600.数据集共包括7类皮肤病变:AKIEC(Actinic Keratosis/Intra Epithelial Ca- rcinoma)、BCC(Basal Cell Carcinoma)、BKL(Benign Keratosis)、DF(Dermatofibroma)、MEL(Melanoma)、NV(Melanocytic Nevi)和VASC(Vascular Lesions), 示例如图6所示.
 | 图6 HAM10000数据集上7种皮肤病变图像示例Fig.6 Seven types of skin lesion images on HAM10000 dataset |
ISIC 2017、ISIC2018、ISIC2019数据集是由ISIC(International Skin Imaging Collaboration)发布的大规模皮肤镜图像数据集.ISIC2017数据集包含2 000幅训练图像、150幅验证图像和600幅测试图像.图像尺寸为767× 576至6 621× 4 441不等.数据集包括3类疾病:黑色素瘤(Melanoma, MEL)、脂溢性角化病(Seborrheic Keratosis, SEB)、良性痣(Nevus, NV).通常可利用ISIC2017数据集进行两分类任务, 即黑色素瘤-良性痣(MEL-NV)两分类任务和脂溢性角化病-良性痣(SEB-NV)两分类任务.ISIC2018数据集包含10 015幅训练图像、193幅验证图像和1 512幅测试图像, 类别与HAM10000数据集一致, 包含7类疾病数据.ISIC2019数据集包含25 533幅图像, 并在ISIC2018数据集的基础上增加鳞状细胞癌(Squamous Cell Carcinoma, SCC)类别.
皮肤镜图像数据存在严重的类别不平衡现象, 导致模型在进行分类时会倾向于预测样本数量较多的类别, 因此, 需要采用数据增强技术对训练集上的少数类数据进行扩充.
在HAM10000数据集上, 遵循文献[5]的数据处理方式, 对数据集进行训练-验证-测试划分, 提取828幅图像作为测试集.为了便于对比, 使用与文献[5]一致的数据增强方法增加训练集上的样本数量, 并将处理后的数据图像保存为224× 224的PNG格式.
由于ISIC2019数据集未提供训练-验证-测试的划分, 本文考虑采用训练集∶ 验证集∶ 测试集为8∶ 1∶ 1的比例划分原始数据集.在ISIC系列数据集上, 也采用与文献[5]一致的数据增强方法扩充训练集, 并将处理后的图像保存为224× 224的PNG格式.
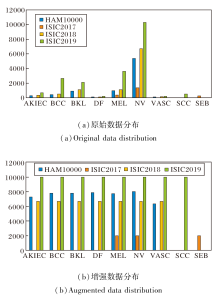
经过数据增强后, HAM10000、ISIC2017、ISIC-2018、ISIC2019数据集的训练数据集数量分别增至53 639幅、6 000幅、46 900幅、80 000幅.各数据集增强前后各子集数据分布情况如图7所示.
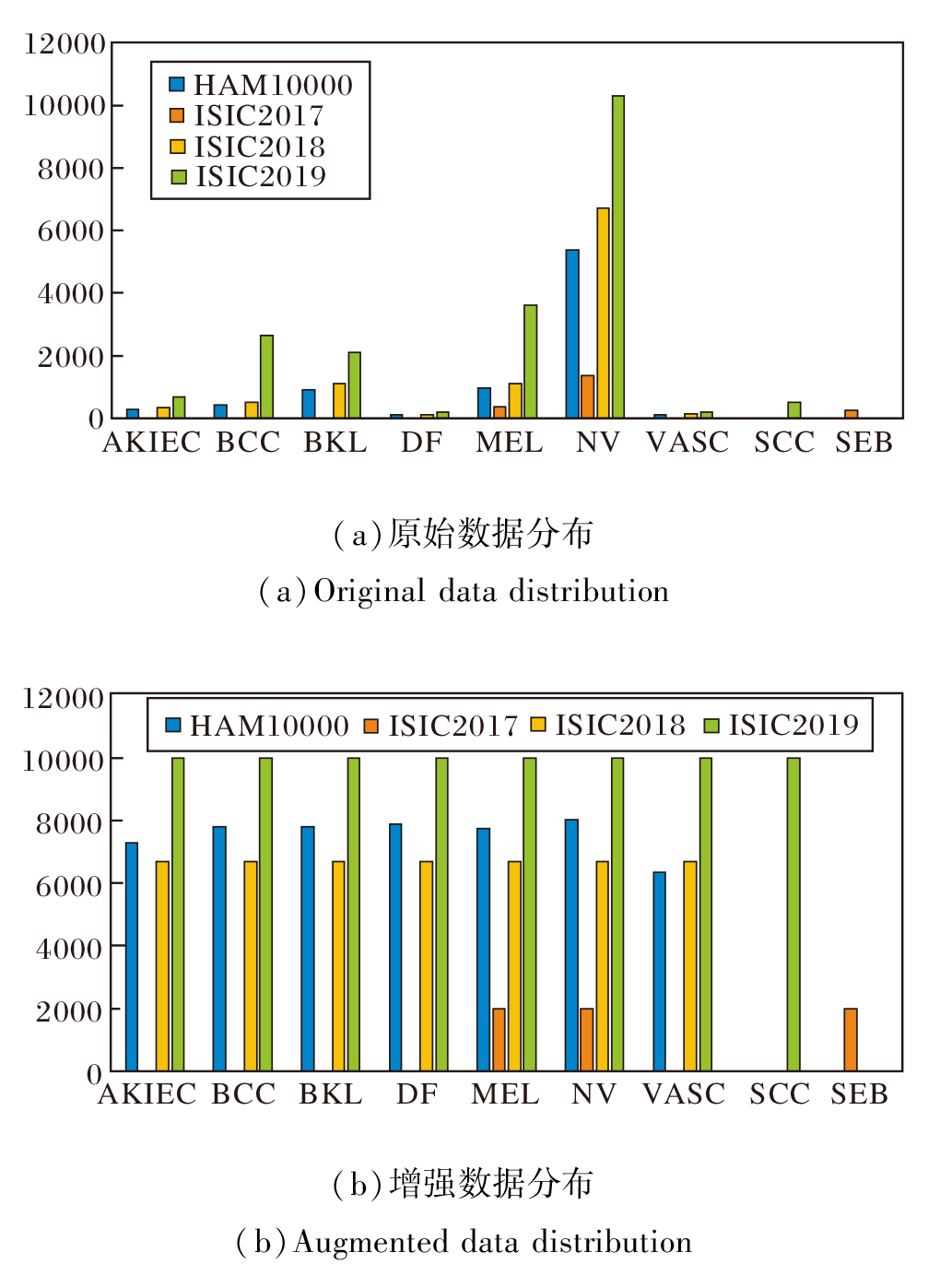 | 图7 数据增强前后4个数据集的分布情况Fig.7 Distribution of 4 datasets before and after augmentation |
实验环境配置如下:操作系统为Ubuntu18.04, 显卡配置为NVIDIA GeForce RTX 3090, 显存为24 GB; 软件平台为Python3.9, CUDA 10.2, Pytorch 1.10.2.
使用准确率(Accuracy, Acc)、精确率(Precision, Pre)、召回率(Recall, Rec)、特异性(Specificity, Spe)和F1分数(F1-Score)进行评估, 具体公式如下:
其中, TN表示真阴性, TP表示真阳性, FP表示假阳性, FN表示假阴性, T表示样本总数.
在处理多分类问题时, 精确度衡量的是对总体样本的预测, F1分数和召回率表示对某一类别的预测, 因此, 必须单独计算每类的F1分数和召回率.
在InvCNet中, 设置内卷层滤波器尺寸为7× 7, 内卷层的滤波器层数为1层, 卷积层滤波器尺寸为10× 10.在训练阶段, 在HAM10000、ISIC2018数据集上共训练125个迭代周期, 初始学习率设为0.1.在ISIC2017数据集上, 共训练100个迭代周期, 初始学习率设为0.01.在ISIC2019数据集上共训练120个迭代周期, 学习率设为0.1.使用Adam(Adaptive Moment Estimation)作为训练网络的优化器, 设置指数衰减率β 1=0.9, β 2=0.999.训练过程采用余弦退火算法调整学习率, 批次大小设为32.在InvCNet中, 设置边际损失函数的超参数m+=0.9, m-=0.1, λ =0.5.
为了验证InvCNet的有效性, 进行对比实验.
首先在ISIC2017数据集上进行实验, 对比方法包括:DenseNet-201(Dense Convolutional Network with 201 Layers)[35]、Inception-v3[36]、ResNet-50(50- Layers Residual Network)[37]、MobileNetV3[38].另外, 为了考察数据增强的效果, 在数据增强前和数据增强后都训练InvCNet.为了区分, 使用InvCNet(No-Aug)表示InvCNet只对未增强数据进行训练.
考虑到在ISIC2017数据集开展的是两个两分类任务, 采用准确率、召回率、特异性衡量网络的分类性能, 此外还采用模型复杂度(参数量)和运算量(浮点数运算数(Floating-Point Operations, FLOPs), 衡量网络运行效率.
各方法在ISIC2017数据集的MEL-NV、SEB-NV两分类子任务上的性能对比如表1所示, 表中黑体数字表示最优值.由表可见, InvCNet在多数指标上取得最优值.通常较高的召回率会带来较低的特异性, 较高的特异性会带来较低的召回率, 但是, InvCNet在MEL-NV子任务上取得较好的平衡.对于SEB-NV分类任务, InvCNet在准确率和特异性上取得最优值.值得注意的是, InvCNet(NoAug)在召回率上表现更优.一个可能的原因是数据增强虽在一定程度上提升网络性能, 但造成过拟合, 使InvCNet在多数类(NV)上表现出更好的分类结果.此外, InvCNet不仅在准确性上明显优于对比方法, 而且在模型复杂度上远低于对比方法.虽然InvCNet的FLOPs为11.3 G, 略高于MobileNetV3, 但InvCNet只有0.58 M个参数, 约为MobileNetV3(1.53 M个参数)的38%.
| 表1 各方法在ISIC2017数据集上的性能对比 Table 1 Performance comparison of different methods on ISIC2017 dataset |
HAM10000、ISIC2018、ISIC2019数据集均为多分类数据集, 各方法在这3个数据集上的分类性能对比如表2所示, 表中黑体数字表示最优值.由表可看到, InvCNet在分类准确率上明显优于其它方法.在ISIC2018数据集上, InvCNet在所有指标上都取得最优值.值得注意的是, InvCNet仅用简单的内卷-卷积结构便取得有竞争力的结果, 表明其在多分类任务上的有效性.
| 表2 各方法在3个数据集上的性能对比 Table 2 Performance comparison of different methods on 3 datasets % |
在ISIC2017数据集上, 选择如下SOTA(State- of-the-Art)方法:IRv2-SA[5]、SSAC[6]、SDL[7]、GP CN-NDTEL(Global-Part CNN Model with Data-Trans-formed Ensemble Learning)[8]、ARLCNN(Attention Residual Learning CNN)[9]、MSLANet[10]、ResNet152-HRL(ResNet152 with Hierarchical Representation Learning)[39].
各方法的性能对比如表3所示, 表中黑体数字表示最优值.
| 表3 InvCNet和SOTA方法在ISIC2017数据集上的性能对比 Table 3 Performance comparison of InvCNet and SOTA methods on ISIC2017 dataset % |
由表3可知, 在MEL-NV子任务上, Inv-CNet的性能与SOTA方法性能相当.在SEB-NV子任务上, InvCNet取得最好的特异性(100%).
在HAM10000、ISIC2018、ISIC2019数据集上, 选取的SOTA方法如下.
1)HAM10000数据集上:IRv2-SA[5]、AFConv-CapsNet[27]、FixCaps[26]、文献[40]方法、IM-CNN(Interpretability-Based Multimodal CNN)[41].
2)ISIC2018数据集上:MSRNet[42]、文献[43]方法.
3)ISIC2019数据集上:文献[44]方法、SCDNet[45]、Spiking VGG-13[46]、wide-ShuffleNet[47].
InvCNet和SOTA方法在3个数据集上的性能对比如表4所示.表中黑体数字表示最优值.由表可知, 在HAM10000数据集上, InvCNet在准确率上取得最高值(95.65%).同时, FixCaps和InvCNet的网络参数量相当, 但是相比FixCaps, InvCNet在准确率、精确率、召回率、F1分数上分别提高1.57%、1.87%、4.00%、3.30%.在ISIC2018数据集上, InvCNet取得最高的精确度(82.86%), 其它指标取得次优.InvCNet在ISIC2019数据集上的表现并不理想.主要原因是该数据集的数量相对更多, 图像更复杂多变.相比深层的网络结构, InvCNet仅凭简单的内卷-卷积浅层结构提取特征能力是有限的, 导致其未获得较优的分类性能.
| 表4 InvCNet和SOTA方法在3个数据集上的性能对比 Table 4 Performance comparison of InvCNet and SOTA methods on 3 datasets |
总之, InvCNet在皮肤镜图像的分类任务上有一定优势.这主要取决于两个方面:一方面, InvCNet是基于胶囊网络的, 不仅能学习用于特征提取和图像分类的优秀权重, 还能学习如何编码皮肤镜图像特征的姿势和空间关系.另一方面, InvCNet引入内卷算子和全局注意力机制, 能利用图像的通道信息, 并利用通道信息和空间信息之间的相互作用.
在设计InvCNet网络结构时, 需要考虑内卷层滤波器尺寸、内卷层数量、卷积层滤波器尺寸对性能的影响.2.3节给出这些参数的设置.本节将进一步在HAM10000数据集上分析这些参数.
在InvCNet其它参数不变的条件下, 首先验证内卷层中滤波器尺寸变化对分类准确率的影响.实验为内卷滤波器设置4种尺寸:3× 3、5× 5、7× 7、9× 9.在4种尺寸下, InvCNet的分类准确率分别为86.47%, 91.91%, 95.65%, 93.84%.InvCNet在滤波器尺寸为7× 7时达到最优值, 即95.65%, 因此将InvCNet的滤波器尺寸设为7× 7.
InvCNet内卷层数量表示在早期阶段使用图像通道信息的能力.在InvCNet其它参数不变的条件下, 验证内卷层数量对分类准确率的影响.令内卷层的数量为1, 2, 3, 相应InvCNet的分类准确率为95.65%, 92.27%, 93.59%.可明显看出, 增加内卷层深度并不能提高模型的分类性能, 并且只使用1层内卷就能获得最优分类精度.
虽然3层内卷比2层内卷显示出更高的准确率, 但时间成本会明显增加.此外, 当进一步增加层数时, 损失也不会收敛.因此, InvCNet的内卷层数设为1是较合理的.
下面在InvCNet其它参数不变的条件下验证卷积层滤波器尺寸对分类准确率的影响.在实验中, 将卷积层滤波器尺寸从5× 5调整为21× 21.InvCNet的分类准确率随卷积层滤波器尺寸变化情况如表5所示.
| 表5 卷积层滤波器尺寸对InvCNet性能的影响 Table 5 Classification accuracy of InvCNet with different convolution kernel sizes % |
由表5可看出, InvCNet在卷积层滤波器尺寸等于10× 10时达到最优值.在一定范围内, 随着卷积层滤波器尺寸的变化, 分类准确率先上升后下降.这些结果表明, 使用中等尺寸的卷积核比使用小尺寸卷积核和大尺寸卷积核更好.本文推测, 扩大感受野可使方法有效利用更多的空间信息, 但过大的感受野可能会引入无关信息或噪声, 从而影响分类准确率.
InvCNet涉及两个模块:内卷层和全局注意力机制.为了验证这两个模块的有效性, 进行相关的消融实验.
2.6.1 内卷层
为了确定引入内卷层的有效性, 设计InvCNet的两个变形.
1)InvCNet-1.不包含内卷的InvCNet, 2)InvCNet-2.内卷层和卷积层位置交换的InvCNet.
InvCNet-1、InvCNet-2、InvCNet的分类准确率分别为91.42%, 93.84%, 95.65%.InvCNet具有最优性能, 交换内卷和卷积位置的InvCNet-2次优, 没有内卷层的InvCNet-1最低.因此可认为, 在早期阶段嵌入内卷层可提高方法性能, 而且内卷和卷积的位置不能互换.
为了进一步验证内卷层的作用, InvCNet-1和InvCNet在卷积层后的5个通道特征图如图8所示.由图可看出, 有内卷操作的InvCNet利用内卷提供丰富的细节信息和语义特征, 可强调目标部分的边缘和勾勒前景与背景等.内卷操作对每个像素生成不同的内卷核, 可通过所有通道从该像素学习权重.这个属性允许内卷在单幅特征图中提供各种模式和丰富的特征.此外, 内卷通过所有通道将内卷核应用于一个单个像素及其近邻, 并再次求和(内卷操作见图2).由于该内卷核的权重是从该像素生成的, 因此将该内卷核应用于其近邻并对其求和可聚合上下文关系, 从而对长范围依赖性进行建模.由此, 内卷层对于生成具有区分度的特征十分重要.
 | 图8 InvCNet-1和InvCNet在卷积层后的特征图对比Fig.8 Comparison of feature maps after convolution layer obtained by InvCNet-1 and InvCNet |
2.6.2 全局注意力机制
目前, 在深度学习中已提出多种注意机制, 常用的包括SENet[48]、CBAM(Convolutional Block Atten- tion Module)[49]、BAM(Bottleneck Attention Modu- le)[50]、Triplet Attention[51]及本文提出的全局注意力机制(GAM).SENet通过挤压和激励操作建模图像通道之间的关系, 自适应学到每个通道的重要性, 但会忽略图像的位置信息, 出现过拟合现象.CBAM是一种将通道注意力操作和空间注意力操作顺序放置的注意力机制, 而BAM 则是并行排列.但这两种方法都忽略通道与空间之间的相互作用, 丢失跨维度信息.TAM利用通道、空间宽度和空间高度这三个维度中每对之间的注意力权重提高效率.然而, 注意力操作每次仍应用于其中两个维度, 而不是所有三个维度.
在上述注意力机制中, CBAM与GAM整体结构类似, 均由通道注意力操作及空间注意力操作顺序排列组成, 但两种方法在子模块的设计上有所区别.
给定输入特征图Fc∈ RC× w× h, CBAM的通道注意力模块和空间注意力模块计算公式如下:
$M_{c}^{1}({{F}^{c}})=\sigma (MLP(F_{\text{Avg}}^{c})+MLP(F_{\text{Max}}^{c})))$,
$M_{s}^{1}({{F}^{c}})=\sigma ({{f}^{7\times 7}}([F_{\text{Avg}}^{s}; F_{\text{Max}}^{s}]))$.
其中:
在通道注意力模块中, GAM对输入图像进行置换及还原增强跨维度的信息交互, 同时考虑三个维度的信息, 而CBAM采用全局池化, 忽略跨维度信息的相互作用.在空间注意力模块中, GAM去除池化操作, 采用一个通道压缩卷积和一个通道还原卷积进行空间信息融合, 而CBAM只采用一个卷积操作对拼接的池化特征图进行压缩.
为了验证InvCNet引入GAM的有效性, 另外设计7种InvCNet的变体(InvCNet-3~InvCNet-9), 用不同的注意力模块替换GAM或不用注意力模块.这些变体的具体设计如表6所示.值得注意的是, InvCNet-8及InvCNet-9采用的注意力机制为GAM的变体, InvCNet-8采用通道注意力和空间注意力并行的排列方式, InvCNet-9采用先空间注意力后通道注意力的排列方式, 分别用GAM-P和GAM-R表示两种方法的注意力机制.
| 表6 注意力机制的消融实验结果 Table 6 Ablation experiment results of attention mechanisms % |
由表6可见, 经典的CapsNet没有内卷层也没有注意力机制, 性能最差.对比InvCNet-1和Inv- CNet-3可知, 内卷和注意力机制任一模块的引入能有效且相似地提升方法性能, 当然两个模块同时引入更能大幅提升准确率.在保持引入内卷层的情况下, 加入其它注意力机制均能在不同程度上提升方法性能, 但仍比不上全局注意力机制.此外, 本文发现, GAM子模块的排列方式对方法性能也有影响.顺序注意力比并行注意力性能更优, 并且通道一阶的性能优于空间一阶.本文推测造成这种结果的原因可能是:从空间的角度上看, 通道注意力是全局应用的, 而空间注意力是局部的, 在早期利用全局信息对于高质量特征图的生成具有积极贡献.
本文提出面向皮肤镜图像识别的内卷胶囊网络(InvCNet).相比经典胶囊网络CapsNet, InvCNet引入内卷操作和全局注意力机制(GAM).InvCNet利用内卷层, 可捕捉更多的位置和尺度特征, 采用全局注意力机制, 减少空间信息的损失, 扩大维度间的相互作用.在HAM10000、ISIC2017、SIC2018、SIC2019数据集上评估InvCNet.实验表明:在HAM10000数据集上, 相比现有方法, InvCNet可用更少的计算量提高检测精度, 准确率达到95.65%, 优于对比方法.在ISIC2017数据集上, 相比SOTA方法, InvCNet在2个两分类子任务上都表现出具有竞争力性能.在ISIC2018数据集上也表现出较优的性能.InvCNet是一个高轻量级网络, 相比轻量级的MobileNetV3, 参数量减少62%, 具备较好的分类能力, 因此InvCNet在一定程度上可为医生(尤其是经验不足的医生)提供有效的辅助诊断.
尽管如此, 观察InvCNet在4个数据集上的表现还是可看到其存在的一些不足.在数量较多、复杂多变的ISIC2019皮肤癌图像数据集上, InvCNet的简单网络结构不能提取有效的判别特征, 导致性能不佳, 因此提升InvCNet在此类型数据上的性能是今后将要开展的工作之一.另外, 虽然相比深度网络方法, InvCNet的参数量大幅减少, 但是内卷层和胶囊层的动态路由机制妨碍InvCNet的快速训练, 因此优化网络的运行时间也是一个可能的改进方向.
本文责任编委 陈松灿
Recommended by Associate Editor CHEN Songcan
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|
| [47] |
|
| [48] |
|
| [49] |
|
| [50] |
|
| [51] |
|