{kind=link}
{kind=link}
{kind=link}
动态融入 k近邻知识的领域机器翻译方法
[黄于欣1, 2  , 申涛
, 申涛1, 2 , 江姝婷1, 2 , 曾豪1, 2 , 赖华1, 2 ]
, 申涛, 江姝婷, 曾豪, 赖华]
|
|



作者简介: 
黄于欣,博士,副教授,主要研究方向为自然语言处理、文本摘要.E-mail:huangyuxin2004@163.com. 
申 涛,硕士研究生,主要研究方向为自然语言处理、机器翻译.E-mail:glosts@163.com. 
江姝婷,博士研究生,主要研究方向为自然语言处理、神经机器翻译.E-mail:shuting_jiang22@163.com. 
曾 豪,硕士研究生,主要研究方向为自然语言处理、机器翻译.E-mail:407536543@qq.com.
基于 k近邻检索的领域机器翻译方法通过解码器预测分布与 k近邻知识的融合提升翻译性能,但检索知识的不准确性可能会对模型预测产生干扰.为此,文中提出动态融入 k近邻知识的领域机器翻译方法.首先,通过评估解码器输出分布的置信度,结合门控机制,动态判断是否融合 k近邻结果,灵活调整 k近邻知识的融合程度.然后,引入自适应 k值模块,减少错误知识干扰.同时,设计分布引导损失,引导模型输出逐步逼近目标分布,提高翻译的准确性.最后,在四个德语-英语领域机器翻译数据集上的实验表明文中方法的性能具有一定提升.
About Author:
HUANG Yuxin, Ph.D., associate profe-ssor. His research interests include natural language processing and text summarization.
SHEN Tao, Master student. His research interests include natural language processing and machine translation.
JIANG Shuting, Ph.D. candidate. Her re-search interests include natural language processing and neural machine translation.
ZENG Hao, Master student. His research interests include natural language processing and machine translation.
Domain machine translation methods based on k-nearest neighbour retrieval improve translation quality by incorporating translation knowledge retrieved from a translation knowledge base. Existing methods enhance translation performance by fusing the decoder prediction distribution with k-nearest neighbour knowledge. However, the inaccuracy of the retrieved k-nearest neighbor knowledge may interfere with the prediction results of the model. To address this issue, a domain machine translation method with dynamic incorporation of k-nearest neighbor knowledge is proposed. The confidence of the decoder output distribution is first assessed. With the combination of gating mechanism, the proposed method dynamically decides whether to incorporate the k-nearest-neighbor retrieval results, thereby adjusting the degree of incorporation of k-nearest neighbor knowledge flexibly. The adaptive k-value module is introduced to reduce the interference caused by incorrect k-nearest neighbor knowledge. Besides, the distribution-guided loss is designed to steer the model output approach the target distribution gradually. On four domain-specific German-English machine translation datasets, the proposed method achieves improvements.
领域翻译(Domain Translation)[1, 2, 3]是指在法律、医学、生物等特定领域中, 将源语言准确转换为目标语言的一项机器翻译技术.不同领域的文本在词汇和句法结构上存在显著差异, 传统神经机器翻译(Neural Machine Translation, NMT)[1]模型通常基于大规模通用数据进行训练, 难以有效捕捉特定领域的语言特性, 从而导致翻译过程中出现幻觉(Hallucination)、术语误译等问题[1].
k近邻方法(k-Nearest Neighbor, kNN)已广泛应用于多个领域[4, 5, 6, 7], 其中, 基于k近邻检索的领域翻译已成为机器翻译任务的重要研究方向之一[7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29].Khandelwal等[7]提出kNN-MT(k-Nearest Neighbor Machine Translation), 将翻译知识整合到解码算法中, 提升特定领域的翻译性能.kNN-MT使用通用的预训练机器翻译模型, 将训练数据中的平行句对转换为翻译知识库中的键值对, 构建特定领域的翻译知识库.在解码过程中, 根据当前上下文向量, 在翻译知识库中检索与之最相关的k个目标词, 并融合为k近邻知识, 与模型输出分布结合, 最终生成目标词预测.kNN-MT的创新在于无需额外训练步骤, 通过直接融合领域相关知识提升特定领域NMT模型的翻译质量.然而在实际应用中, 若待翻译的句子与翻译知识库差异较大, 模型在解码时可能会过度依赖k近邻知识, 导致翻译错误.因此, 如何有效融入k近邻知识以提升kNN-MT的领域适应能力, 成为一个亟待解决的问题.
当前提升kNN-MT性能的研究主要集中在如下两个方向.
1)检索优化方法.现有研究调整k近邻知识的分布与融合权重提升翻译性能.Zheng等[8]动态调整不同阶段的k近邻知识, 提高模型的整体性能.Jiang等[9]提出动态校准策略, 细化k近邻分布并引入额外的超参数控制, 更精准地结合检索知识.Stap等[10]利用M2M100[30]构建以英语为枢纽语言的多语言翻译知识库, 显著提升跨语言翻译效果.Nishida等[11]提出基于扰动的kNN-MT, 生成多样化的翻译候选并调整扰动幅度, 缓解训练数据与测试数据分布差异引发的过度修正问题.然而, 上述方法依赖预训练NMT模型构建翻译知识库[7], 并且主要关注检索结果的准确性[8, 9, 10, 11], 未充分考虑模型翻译的正确性, 导致kNN-MT的融合策略可能会引发连锁反应.当检索的知识包含噪声或与当前翻译内容不相关时, 会导致翻译结果出现错误叠加, 从而显著降低翻译的性能[12].
2)知识融入的方法.现有研究通过知识蒸馏或添加额外的域适配器学习k近邻知识[13, 14, 15].Yang等[13]提出kNN-KD(k-Nearest Neighbor Knowledge Distillation), 整合不同k值下获取的k近邻知识, 扩充为额外的训练信息.Zhu等[14]提出INK, 优化k近邻知识的表示, 使其更平滑, 从而改善翻译模型的表征能力.Wang等[15]进一步提出利用翻译知识库辅助预训练模型微调, 通过多样化的微调策略提升翻译性能.然而, 低资源翻译知识库难以精确表征目标领域的语义分布, 表示空间的质量通常较欠缺[16], 导致不同k值下的k近邻知识往往差异过大, 影响模型性能.
本文提出动态融入k近邻知识的领域机器翻译方法, 旨在提升模型对k近邻知识的整合能力.引入置信度模块, 评估NMT翻译的可靠性, 动态调整k近邻知识的融合程度.同时, 设计基于置信度阈值的门控机制, 避免对k近邻知识的过度依赖, 确保模型在必要时依赖自身生成的翻译结果.针对k值的敏感性问题[8], 引入自适应k值模块, 减少噪声干扰.此外, 在损失函数中加入分布引导损失, 缩小最终融合分布、真实分布及NMT生成分布之间的差异, 提升模型的翻译准确性和稳健性.为了进一步增强模型的学习能力, 通过奖励机制激励模型, 使其在融合结果更接近真实分布时, 更好地适应不同领域的语言特性, 提升模型对k近邻知识的整合能力.在4个德语-英语机器翻译数据集上的实验表明, 相比其它基线模型, 本文方法展现出更强的竞争力, 在BLEU分数上提升0.58~1.22, 表明方法的有效性.
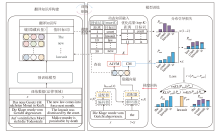
本文提出动态融入k近邻知识的领域自适应机器翻译方法, 整体架构如图1所示.方法包括两个主要任务模块:翻译知识库构建和模型训练.在知识库构建阶段, 利用预训练模型将领域训练数据转换为对应的翻译知识库.
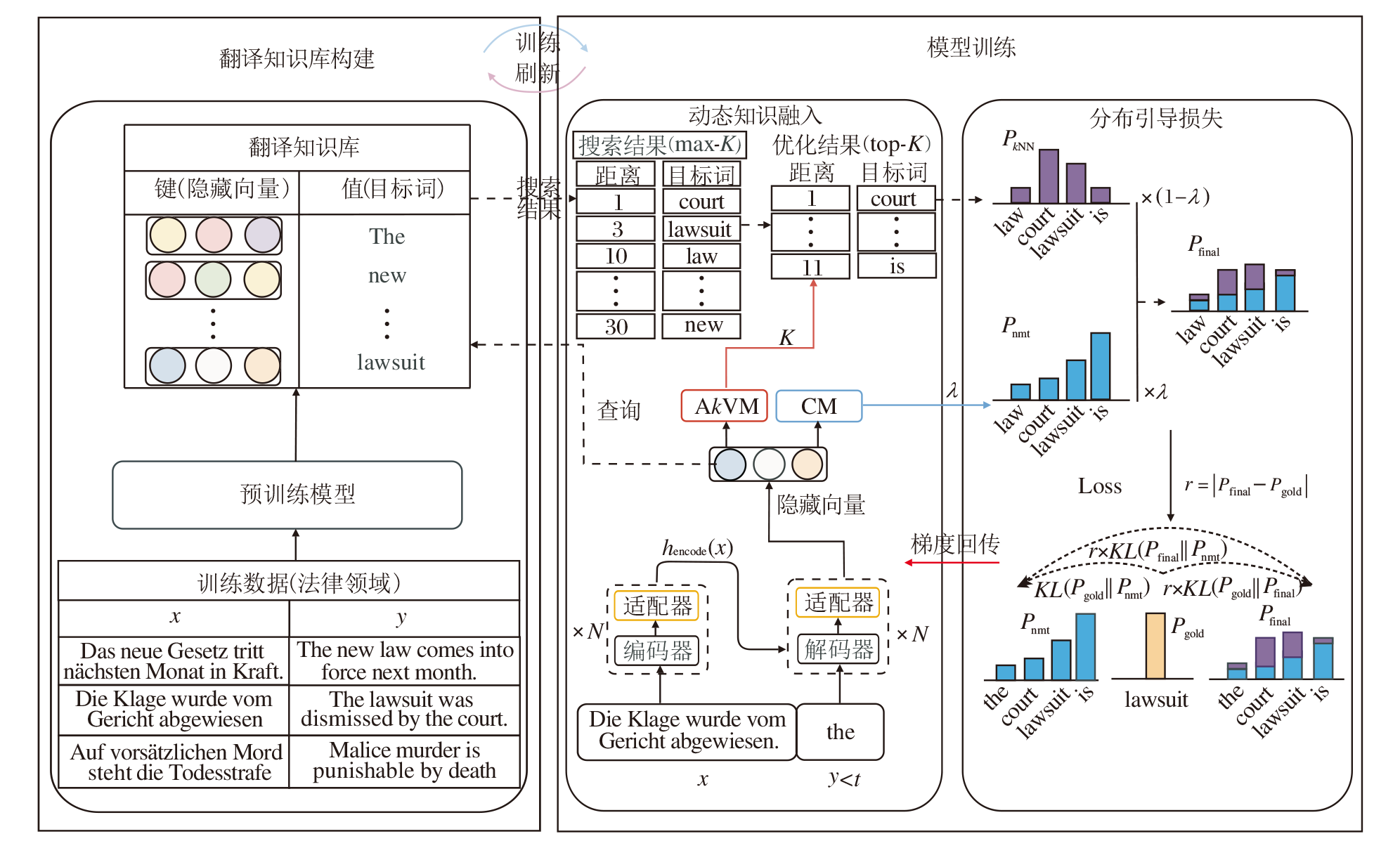 | 图1 本文方法整体构架Fig.1 Framework of the proposed method |
随后, 在模型训练阶段, 引入置信度模块(Con-fidence Module, CM)、自适应k值模块(Adaptive k-Value Module, AkVM)以及适配器, 实现对k近邻知识的有效整合.此外, 在解码器阶段引入分布引导损失函数, 缓解错误k近邻知识对模型性能的负面影响, 提高NMT模型的翻译质量.
Kandelwal等[7]提出kNN-MT, 使用预训练的翻译模型将平行句对转化为可存储的翻译知识库.基于k近邻思想, 在解码过程中融入与待翻译输入相似的k近邻知识, 结合NMT模型生成的下一个词的预测分布与k近邻知识的检索分布, 共同决定最终的翻译结果, 提升翻译性能.kNN-MT通常分为两个过程:翻译知识库的构建和融合推理.
1)翻译知识库的构建.翻译知识库将双语句子对转换为一组键值对进行存储.在现有的训练集上选择一个平行的双语句子对(x, y)∈ (X, Y), 输入预先训练的NMT模型中, 获得在每个时间步长t生成的上下文表示f(x, y< t), 即时刻t的翻译上下文的隐藏向量表示.此时, 预测对应的下一个目标词的真值为yt, 通过将输出的隐藏状态f(x, y< t)作为键, yt作为值, 循环遍历整个训练集, 构建翻译知识库(K, V).利用这种方法可完成翻译知识库的构建:
$(K, V)={{\cup }_{\left( x, y \right)\in \left( X, Y \right)}}\{(f(x, {{y}_{< t}}), {{y}_{t}}), \forall {{y}_{t}}\in y\}$.
2)融合推理.在推理过程中, 输入句子x被用于生成相应的翻译结果y.在第t个解码步骤中, 基于当前已生成的句子
Nt={(hi, vi), i∈ {1, 2, …, k}}.
最后, 将检索到的邻居映射为词表上的概率分布:
${{P}_{kNN}}\left( {{y}_{t}}|x, {{{\hat{y}}}_{< t}} \right)\propto \sum\limits_{\left( {{h}_{i}}, {{v}_{i}} \right)}{{{1}_{{{y}_{t}}={{v}_{t}}}}\exp }\left( -\frac{d\left( {{h}_{i}}, ~f\left( x, {{{\hat{y}}}_{t}} \right) \right)}{T} \right)$,
其中, d(· )表示欧氏距离函数, T表示温度超参数.最终的融合分布由检索到的分布PkNN和NMT生成的分布Pnmt融合而成:
${{P}_{\text{final}}}\left( {{y}_{t}}|x, {{{\hat{y}}}_{< t}} \right)=\lambda {{P}_{kNN}}\left( {{y}_{t}}|x, {{{\hat{y}}}_{< t}} \right)+(1-\lambda ){{P}_{\text{nmt}}}\left( {{y}_{t}}|x, {{{\hat{y}}}_{< t}} \right)$, (1)
其中λ 表示融合的权重.上述方法相当于针对NMT模型预测结果执行一次向量投影, 将模型表示映射至更适合领域特定数据的空间, 从而实现隐式微调, 提高翻译性能[17].
在模型训练过程中, 引入置信度模块(CM).CM设计为前馈神经网络, 用于评估模型在时刻t对当前翻译词的置信度, 置信度值直接决定最终融合概率中的权重分配.当置信度高于预设阈值τ 时, 可视为模型的翻译准确性已较高, 因此可跳过翻译知识库的检索步骤[18].此时, 在模型生成的概率分布上加入极小的扰动值ε , 代替当前时刻的融合分布.如果置信度低于设定阈值τ , 正常进行翻译知识库的检索.如式(1)所示, 通过将检索的k近邻知识与NMT的分布进行置信度加权融合, 获得最终的融合分布:
本文方法中NMT分布的权重由置信度分数
λ =σ (w2(RELU((w1ht)+b1))+b2)
决定, 而k近邻知识的权重为1-λ .其中:ht表示输入句子x经过NMT模型后, 获得解码器在时刻t的最后特征向量; w1表示置信度模块第1个前馈层的权重矩阵, b1表示其偏置向量; RELU(· )表示激活函数; w2表示置信度模块第2个前馈层的权重矩阵, b2表示其偏置向量; σ (· )表示sigmoid激活函数.
自适应k值模块(AkVM)是一个前馈网络, 旨在提高模型检索k近邻知识的准确性.在检索过程中, AkVM动态调整不同时刻检索的k值, 自适应优化最终的检索结果[8].具体而言, 首先根据输入特征和设定的最大值max k, 为每个样本检索近邻向量:对于置信度较高的输入特征, 选择较小的k值以减少噪声干扰; 对于置信度较低的输入特征, 选取较大的k值以增强结果的多样性与鲁棒性.如图1所示, 最后经过归一化缩放得到最终k值用于处理搜索得到的近邻向量, 从而生成更准确的k近邻知识.k值的计算公式如下:
$k=\exp \left( 1-\frac{{{\lambda }_{t}}}{{\bar{\lambda }}} \right)\sigma ({{q}_{2}}(RELU(({{q}_{1}}{{h}_{t}})+{{z}_{1}}))+{{z}_{2}})$,
其中, λ t表示时刻t的置信度,
最终将k扩展至1至max k之间, 使用扩展后的k计算得到最终的检索结果.通过这种方式, 模型能更好地适应不同输入特征的变化, 提高检索结果的准确性.
kNN-MT的成功在于其能在无需额外训练的情况下, 通过融合翻译知识增强领域适应能力, 从而在翻译质量上优于传统的NMT模型.具体而言, k近邻检索可作为翻译预测的隐式微调过程, 利用翻译预测状态ht, 从翻译记忆库中检索对应的k近邻知识PkNN, 并生成最终的融合分布Pfinal.在此过程中, 模型的参数可视为一种策略, 而k近邻知识的融合过程则体现一种学习机制.这一特性与生成式自然语言模型中的结构化预测方法密切相关, 并与强化学习(Reinforcement Learning, RL)框架高度契合.强化学习包括初始化、交互、环境反馈、学习和循环五个阶段, 已被广泛应用于模型训练[31, 32], 并在多项任务中证实其有效性.
不同于常规翻译任务中将BLEU[33]作为奖励设定, 在kNN-MT中, 由于k近邻检索是针对每个单词在不同时刻进行的, 因此模型的奖励机制可设定为每个时刻的最终融合检索分布与真实分布之间的差异, 此设定能有效减少错误k近邻知识对模型性能的负面影响.计算模型在时间步t生成的最终融合分布与真实目标词分布之间的差异, 定义为中间奖励:
r=where(Pfinal(yt)=Pgold(yt)).
其中:Pfinal(yt)表示在时刻t, 融合k近邻知识的检索分布与NMT模型的预测分布, 生成的最终融合分布; Pgold(yt)表示对应的真实目标词分布; where(· )用于评估两个分布中最大候选词的一致性, 并将其作为最终输出, 如果候选词相同, 输出值为1, 若不一致, 输出值为0.中间奖励项为:
当中间奖励r=1时, 表示融合后的分布与真实分布一致, 若直接将奖励项设为0, 会导致模型训练波动过大, 影响收敛性, 因此, 本文将奖励分别设定为1/k和1/n.当r=0时, 表示此时融合分布存在偏差, 此时引入惩罚项, 分别设定为1/j和1/m.其中k、n、 j、m表示可调超参数.
为了进一步优化模型与k近邻知识的融合精度, 本文采用KL散度(Kullback-Leibler Divergence)作为损失函数, 拉近两个分布之间的差距, 优化目标是最小化预期奖励.具体形式如下所示:
${{L}_{fg}}=\frac{1}{\left| D \right|}\cdot \sum\limits_{\left( x, y \right)\in D}{{{r}_{g}}{{D}_{KL}}\left[ {{P}_{\text{gold}}}\left( {{y}_{t}}|x, {{{\hat{y}}}_{t}} \right)||{{P}_{\text{final}}}({{y}_{t}}|x, {{{\hat{y}}}_{t}}) \right]}$, (2)
其中, rg表示模型在时刻t预测时的中间奖励, x表示源句子, y表示对应的目标句子, D表示训练集上平行句对的集合, ${{P}_{\text{gold}}}\left( {{y}_{t}}|x, {{{\hat{y}}}_{t}} \right)$表示时刻t真实目标词的分布, ${{P}_{\text{final}}}({{y}_{t}}|x, {{\hat{y}}_{t}})$表示时刻t检索分布与NMT模型的预测分布融合后的最终分布, KL(· )表示KL散度, 通过最小化目标分布Pgold和最终融合分布Pfinal之间的KL散度以优化最终融合分布, 使其向真实分布Pgold靠拢.同时, 通过最小化最终融合分布Pfinal和NMT模型分布Pnmt之间的KL散度, 可进一步优化NMT的预测分布, 即
${{L}_{fn}}=\frac{1}{\left| D \right|}\cdot \sum\limits_{\left( x, y \right)\in D}{{{r}_{n}}{{D}_{KL}}\left[ {{P}_{\text{final}}}\left( {{y}_{t}}|x, {{{\hat{y}}}_{< t}} \right)||{{P}_{\text{nmt}}}({{y}_{t}}|x, {{{\hat{y}}}_{< t}}) \right]}$, (3)
其中, rn表示模型在时刻t预测时的中间奖励, ${{P}_{\text{nmt}}}({{y}_{t}}|x, {{\hat{y}}_{< t}})$表示时刻t对应的NMT的预测分布, 通过最小化NMT的预测分布Pnmt与最终融合分布Pfinal之间的KL散度, 可引导NMT分布逐步向融合分布Pfinal靠拢, 进一步提高模型的预测质量和一致性.
神经机器翻译任务要求在输入源语言句子时, 预测目标语言句子, 损失函数如下:
${{L}_{nmt}}=\underset{i=1}{\overset{n}{\mathop \sum }}\, \left( -\ln P\left( {{y}_{i}}|{{x}_{i}}; \theta \right) \right)$,
其中, $P\left( {{y}_{i}}|{{x}_{i}}; \theta \right)$表示源句子xi翻译为目标句子yi的概率, n表示句子数量, θ 表示模型参数.
本文方法不仅优化k近邻知识的表示, 还使模型能选择最合适的k近邻知识.具体而言, 设计一个结合三种学习目标的适配器, 目标是最小化最终训练目标:
L=Lnmt+rnLfn+rgLfg,
其中, Lnmt表示翻译损失, rn、rg表示平衡不同损失函数权重的超参数, Lfn表示最小化最终融合分布与NMT的预测分布之间差异的损失, Lfg表示最小化最终融合分布与真实目标词的分布之间差异的损失.
为了评估本文方法的有效性, 针对领域机器翻译任务, 本文采用与之前kNN-MT研究相同的设置[7, 8, 9, 14], 并在德语-英语公开数据集进行实验.
本文使用4个标准的德语-英语数据集, 涵盖Medical、Law、IT、Subtitles领域[34], 其中, Medical、Law、IT领域的数据直接采用Zheng等[8]发布的预处理数据.为了评估模型在低资源场景下的表现, 本文从清洗后的字幕数据集中抽取34 000个句对作为低资源领域的样本.实验数据集详情如表1所示.
| 表1 实验数据集 Table 1 Experimental Dataset |
为了确保实验的一致性, 本文采用2019年WMT德语-英语新闻翻译任务的获胜方法[35]作为预训练的NMT模型, 用于翻译任务和数据存储构建, 该方法基于Transformer架构, 并通过Fairseq工具包实现.
本文方法以文献[35]方法为初始化基础, 采用β 1=0.9, β 2=0.98的Adam(Adaptive Moment Es-timation)优化器, 设置学习率为5e-04, 最大词元数为1 024, 学习率预热更新步数为6 000, 标签平滑值为0.1, 失活率为0.1.在适配器大小方面, Medical、Law、IT、Subtitles分别设置为8 192、4 096、2 048、1 024.对于超参数的设置, rn中k=2, j=1, rg中的n=2.5, m=5.
在每轮训练完成后, 使用更新后的NMT模型权重重新构建数据存储.重复此过程直至模型收敛.
所有方法均是在单张NVIDIA GEFORCE RTX 3090 GPU上进行训练.
为了验证本文方法的有效性, 选择如下kNN-MT基线方法进行对比, 包括检索优化方法和知识融合策略的相关方法.
1)kNN-MT[7].基于WMT-2019德语-英语新闻任务的冠军模型生成翻译知识库, 并在解码阶段将其融入模型.
2)Adaptive kNN-MT[8].kNN-MT的高级变体, 动态决定k近邻检索结果的使用并获得更稳定的性能.
3)Robust kNN-MT[9].检索优化中先进的kNN-MT变体, 通过动态校准k近邻结果和引入超参数提升性能.
4)INK[14].引入少量新参数, 平滑k近邻检索结果的表示空间.
5)文献[35]方法.WMT2019在德语-英语新闻任务上最终的冠军模型.
6)Adapter[36].添加额外的适配器模块, 对齐上下文表示和词嵌入, 优化模型的表示能力.
在4个德语-英语数据集上进行对比实验, 保留原基线模型的参数设置, BLEU值如表2所示, 表中黑体数字表示最优值.由表可得如下结论.
| 表2 各方法在德语-英语翻译任务上的BLEU指标 Table 2 BLEU of different methods on German to English translation task |
1)本文方法在多领域翻译任务中表现出色.平均BLEU值达到51.24, 显著优于现有主流方法和其它增强方法, 充分展现其在领域翻译任务中的强大适应能力.在Medical、IT等高资源领域, 本文方法的BLEU值分别达到58.03和49.79.然而, 在Law领域的表现略显不足, 这可能是由于该领域知识库庞大且蕴含丰富的信息, 适配器的学习能力存在一定局限性, 仅依靠两层适配器难以全面捕获其复杂领域知识.
2)本文方法在低资源的情况下能取得较优值.在仅包含30 000条数据的低资源Subtitles领域, BLEU值达到34.99, 充分体现其在数据匮乏场景中的适应性和对有限知识库的高效利用能力[37, 38]. 这得益于置信度、自适应k值及分布约束损失的引入, 使方法能调节k近邻知识的融合程度, 降低噪声干扰的影响, 并进一步优化知识库的质量以满足特定领域需求, 从而提升领域术语翻译的准确性.
为了进一步探究本文方法的有效性, 进行一系列消融实验, 逐步移除方法中的不同模块, 研究每个模块对整体性能的贡献.在IT领域的数据集上进行实验, 分别对如下模块做消融实验.
1)AkVM.在解码时检索不同数量的k近邻知识.
2)CM.决定最终的插值权重及门控机制.
3)RL模块.给模型合适的奖励从而学习到更好的知识.
4)损失函数.包含Lfn和Lfg.Lfn表示最小化最终融合分布与NMT预测分布之间的差异, Lfg表示最小化最终融合分布与真实目标词分布之间的差异.
最终消融实验结果如表3所示, 表中-表示方法在训练过程中去除相应部分.
| 表3 各模块消融实验结果 Table 3 Results of ablation experiment of different modules |
由表3可知, 当分别去除AkVM、CM、RL模块时, 在德语-英语的IT领域测试集上的BLEU评分降幅为0.33~0.54, 这进一步表明模块在提升模型性能方面的重要性.去除Lfg和Lfn以后, 性能降幅为0.51~1.36, 这验证了各损失项设计的有效性.k近邻知识融合本质是在投影层上进行额外映射[17].消融实验进一步表明, 缩小投影层与NMT模型表示之间的差距能促进方法对k近邻知识的学习.
为了进一步验证本文方法在面对带噪声的k近邻知识时的鲁棒性表现, 对每个德语-英语领域的k近邻知识进行噪声插入.具体噪声类型如下.
1)填充.从查询的k近邻分布概率中, 选取前8个最大值的k近邻预测概率, 随机选择其中一个的预测概率值, 设置为k近邻分布概率中的最大概率值, 并对所有概率进行归一化处理, 扰动率设定为0.1.
2)交换.同样从查询的k近邻分布概率中, 选取8个最大值的k近邻预测概率, 随机选择2个概率进行交换, 并对所有概率进行归一化处理, 扰动率设定为0.5.
3)高斯噪声.在查询的k近邻分布概率中引入高斯噪声, 增强模型的鲁棒性.噪声的标准差分别设置为0.002和0.01并进行测试, 扰动率设定为1.
为了进一步分析本文方法对不同类型k近邻知识噪声的鲁棒性, 使用如下鲁棒性评估指标[39]:
其中, M表示翻译模型, x表示源句子, y表示参考翻译, y'δ 表示扰动句子x'δ 的翻译结果, y'表示源句子x的翻译结果, TQ(· )表示测量翻译质量的指标.本文将扰动句子x'δ 替换为扰动k近邻知识
鲁棒性评价指标用于衡量模型在噪声输入下翻译质量的退化程度.值越接近1, 表明模型对此类噪声输入表现出的鲁棒性越好; 值越接近0, 表明模型在噪声影响下翻译质量退化越严重.
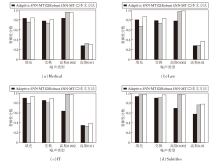
Adaptive kNN-MT、Robust kNN-MT和本文方法在不同类型噪声上的鲁棒性如图2所示.
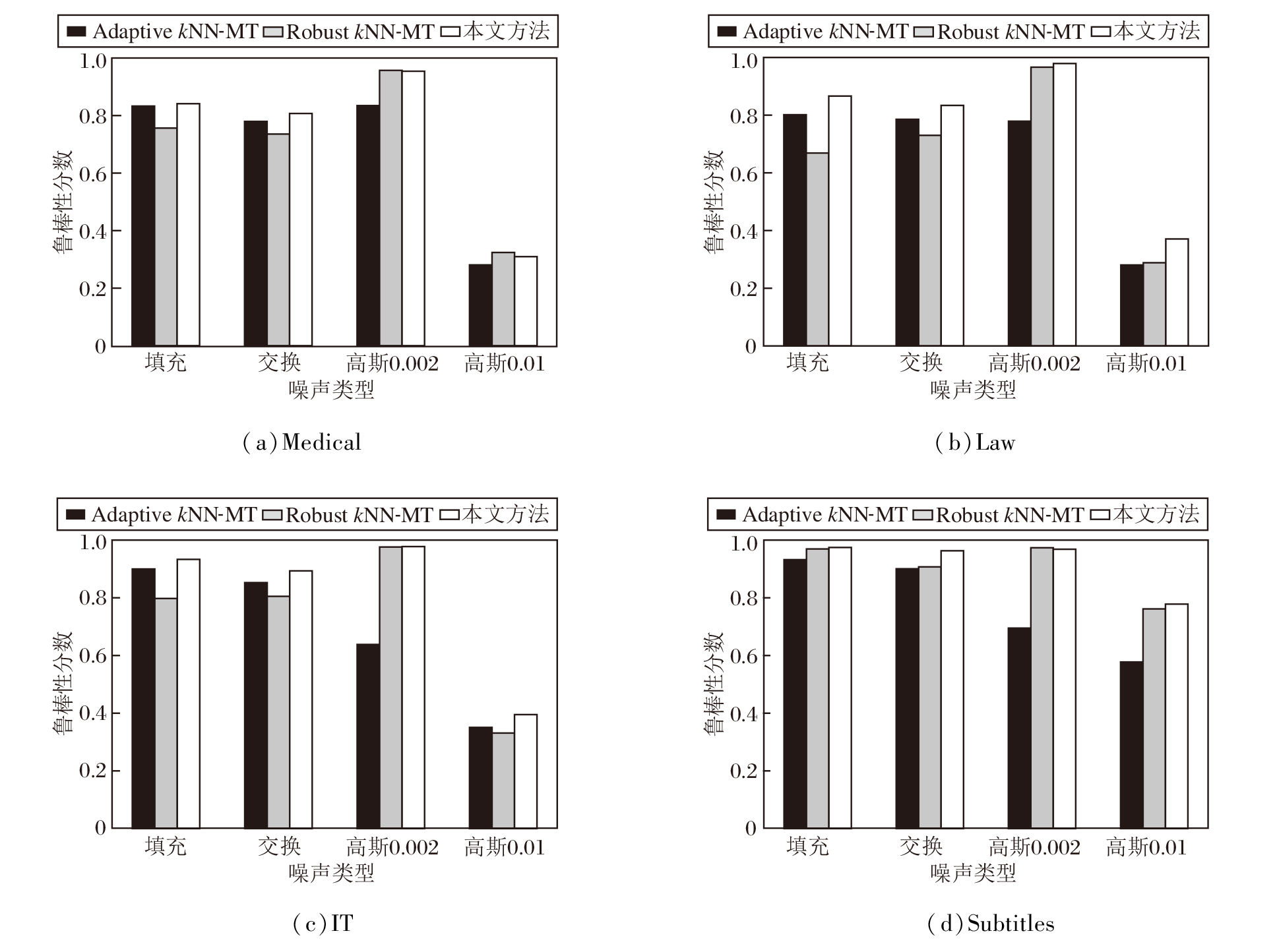 | 图2 各方法在不同噪声类型下的鲁棒性分数Fig.2 Robustness indicators of 3 methods with different types of noise |
由图2可知, 方法对噪声的敏感性受k近邻知识准确性的影响, 尤其在高资源领域, k近邻知识通常包含更丰富的信息.例如:在Law领域, 当k近邻知识占主导地位时, 模型在强噪声下的鲁棒性显著下降, 从弱噪声的效果可看出适度引入噪声可在一定程度上提升模型的鲁棒性.本文方法在各领域, 尤其是Subtitles和IT领域, 展现出更强的鲁棒性.在填充和强噪声条件下, 本文方法的鲁棒性分数显著高于其它方法, 表明其在噪声干扰下具有更强的适应能力, 能有效减缓噪声对k近邻知识融合的影响.
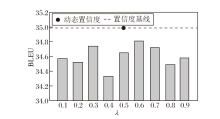
为了进一步探索本文方法的有效性, 选取固定权重 λ =0.1, 0.2, …, 0.9, 在Subtitles领域中进行实验.针对每个固定权重均从头训练直至收敛.
本文方法在不同 λ 值下BLEU分数如图3所示.
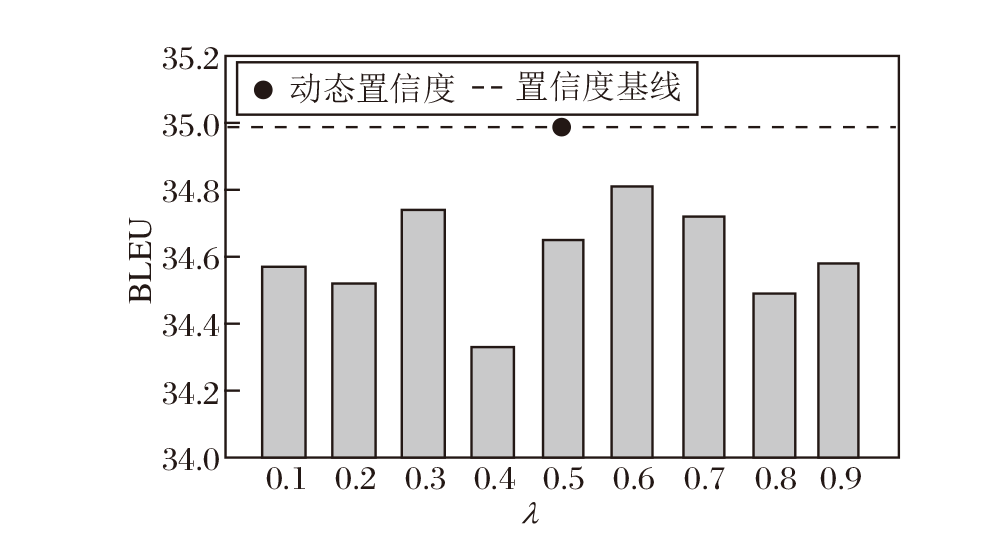 | 图3 λ 对本文方法的性能影响Fig.3 Effect of λ on performance of the proposed method |
由图3可见, λ 的变化对本文方法性能产生一定影响, 不同设置下BLEU分数存在小幅波动.总体而言, λ 值处于中间范围时, 方法性能相对较优, 而极端值往往导致性能下降.相比之下, 本文方法通过动态调整λ 值, 能更好地适应不同输入, 显著提升翻译质量, 表现出优于固定λ 的鲁棒性和灵活性.实验结果进一步验证动态策略在优化翻译性能方面的潜力.
为了验证本文方法在领域翻译中的性能, 选取两个具体的翻译实例, 验证其有效性.为了简化对比, 仅保留实验变体进行对比说明.实例1来自IT领域, 实例2来自Subtitles领域, 中文释义均采用Deepl翻译生成.具体翻译实例对比如表4所示, 在表中, 单下划线+加粗表示错误部分, =表示漏翻.
| 表4 翻译实例 Table 4 Translation examples |
由表4可见, 在实例1中, 文献[35]方法、Adaptive kNN-MT和Robust kNN-MT均未提及“ dialogue box” , 导致重要的上下文信息丢失.此外, Robust kNN-MT的翻译使用“ contains the names” , 导致翻译内容模糊, 未能准确表达“ 列出” 的含义.INK在翻译中引入“ tab page” , 偏离原文中的“ dialogue box” , 造成语境不符.在实例2中, 文献[35]方法的翻译将“ Wanne” 误译为“ tub of cauliflower” , 引入与原文无关的“ cauliflower” , 产生信息偏差.AdaptivekNN-MT虽然保留部分语义, 但同样使用“ cau” .Robust kNN-MT漏翻最后一句, INK在翻译时出现漏译及使用“ cau” 的情况.相比之下, 本文方法在准确传达源文本情感和信息方面表现出更高水平.
上述分析表明, 本文方法在保持语义一致性方面表现优异, 同时有效减少过度依赖外部知识导致的误译现象, 展现出较高的翻译质量.
本文提出动态融入k近邻知识的领域机器翻译方法, 旨在通过引入k近邻知识提升领域翻译的准确性和连贯性.实验表明, 本文方法可有效减少错误k近邻知识对模型的干扰, 提升低资源领域的翻译性能, 同时在高资源领域中也具有一定的竞争力. 消融实验进一步验证引入模块的有效性.置信度模块与门控机制能有效控制k近邻知识的融合程度, 避免对k近邻知识的过度依赖; 自适应k值模块降低模型对噪声的敏感性, 而分布引导损失提升领域术语翻译的准确性.今后将聚焦于优化计算效率, 并探索如何在大规模翻译知识库和大模型场景下进一步提升kNN-MT的性能.
本文责任编委 马少平
Recommended by Associate Editor MA Shaoping
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|