{kind=link}
角色增强的共情回复生成
引用本文
吴运兵, 叶成龙, 阴爱英, 陈开志, 杨州. 角色增强的共情回复生成. 模式识别与人工智能, 2024,37(12): 1043-1055
WU Yunbing, YE Chenglong, YIN Aiying, CHEN Kaizhi, YANG Zhou. PERG: Persona-Enhanced Empathetic Response Generation. PATTERN RECOGNITION AND ARTIFICIAL INTELLIGENCE, 2024,37(12): 1043-1055.
Doi: 10.16451/j.cnki.issn1003-6059.202412001
WU Yunbing, YE Chenglong, YIN Aiying, CHEN Kaizhi, YANG Zhou. PERG: Persona-Enhanced Empathetic Response Generation. PATTERN RECOGNITION AND ARTIFICIAL INTELLIGENCE, 2024,37(12): 1043-1055.
Permissions
Copyright©2024, 《模式识别与人工智能》编辑部
《模式识别与人工智能》编辑部
角色增强的共情回复生成

吴运兵,硕士,副教授,主要研究方向为知识表示、情感分析.E-mail:wyb5820@fzu.edu.cn.
作者简介:

叶成龙,硕士研究生,主要研究方向为共情对话生成.E-mail:231020027@fzu.edu.cn.

阴爱英,硕士,副教授,主要研究方向为文本检索、数据挖掘.E-mail:43547598@qq.com.

陈开志,博士,副教授,主要研究方向为计算机视觉、自然语言处理.E-mail:ckz@fzu.edu.cn.

杨州,博士研究生,主要研究方向为共情对话生成、情感分析.E-mail:200310007@fzu.edu.cn.
摘要
共情回复生成旨在理解对话中用户的经历与感受并表达出合理的回复.心理学理论认为,角色是人格的外在表现,与共情密切相关.然而,现有工作主要关注共情的认知因素和情绪因素,忽略有益于共情的角色因素,导致缺少个性化的共情回复.为了解决该问题,文中提出角色增强的共情回复生成模型(Persona-Enhanced Empathetic Response Generation Model, PERG).首先,为了有效利用角色信息,提出角色增强编码模块,通过编码器捕获上下文、情境及角色信息的深层语义关系,结合上下文和情境筛选角色信息,提升模型对说话者与回应者角色的理解,增强共情能力.然后,在角色调控解码模块中,设计基于多解码器融合的调控机制,有效结合角色信息,调节上下文和情境对共情回复的影响,生成高度个性化的共情回复.在公开的共情回复EmpatheticDialogues数据集上的实验表明,PERG在多个指标上均取得较优值.
关键词:
自然语言处理; 对话系统; 共情回复; 角色增强; 角色调控
中图分类号:TP391.1
PERG: Persona-Enhanced Empathetic Response Generation
WU Yunbing, Master, associate professor. His research interests include knowledge representation and sentiment analysis.
About Author:
YE Chenglong, Master student. His research interests include empathetic dialogue generation.
YIN Aiying, Master, associate professor. Her research interests include text retrieval and data mining.
CHEN Kaizhi, Ph.D., associate profe-ssor. His research interests include computer vision and natural language processing.
YANG Zhou, Ph.D. candidate. His research interests include empathetic dialogue generation and sentiment analysis.
Abstract
Empathetic response generation aims to understand the experiences and feelings of users in conversations and provide appropriate responses. Psychological theories suggest that roles serve as an external manifestation of personality and are closely related to empathy. However, existing research primarily focuses on the cognitive and emotional factors of empathy while neglecting role factors that are beneficial to empathy, resulting in a lack of personalized empathetic responses. To address this issue, a persona-enhanced empathetic response generation model(PERG) is proposed. A persona-enhanced encoding module is introduced to capture deep semantic relationships among context, situation and role information through an encoder. By filtering role information based on context and situation, the understanding of the speaker's and responder's roles by the model is significantly improved, and thereby enhancing its empathetic capabilities. In the persona control decoding module, a multi-decoder control fusion mechanism is designed. The role information is effectively combined to regulate the impact of context and situation on empathy responses , generating highly personalized empathetic responses. Experiments on EmpatheticDialogues dataset indicate that PERG achieves superior performance in multiple metrics.
Key words:
Key Words Natural Language Processing; Dialogue System; Empathetic Response; Persona Enhancement; Persona Regulation
共情是指理解他人感受, 并合理做出回复的能力[1].共情回复生成任务是人机对话回复中提高对话质量的一项重要任务, 主要关注用户情绪的自动感知和共情回复的生成, 旨在通过理解对话中的用户感受, 生成适当的同理性回复, 从而使对话更自然和人性化[2, 3, 4, 5].在该任务中, 生成式模型通常作为倾听者, 通过对话持续深入了解用户的内心世界, 并生成具有共情力的回复, 使用户获得愉悦、满足的心理体验.共情回复生成任务在心理健康、教育及医疗健康等领域的对话机器人方面发挥重要作用[6, 7].
在共情回复生成研究中, 早期的工作仅关注情绪因素对共情的影响.Rashkin等[4]通过预训练的情绪分类器识别用户情感, 并注入生成模型中, 生成共情回复.Xie等[5]提出MEED(End-to-End Multi-turn Emotionally Engaging Dialog Model), 引入LIWC(Linguistic Inquiry and Word Count)[8], 为对话的每个句子构建情感向量, 并使用门控循环单元(Gated Recurrent Unit, GRU)结构学习多个句子的情感表示, 获得话语级的情绪.Shin等[9]认为现有工作是依据用户当前的情绪状态进行回复, 而共情回复应着眼于用户的未来感受, 提出模拟用户未来的情绪状态以生成更优的共情回复方法.
上述方法仅关注对话整体的单一情绪, 而对话中的情绪往往是混杂的.因此, Lin等[10]提出MoEL(Mixture of Empathetic Listeners), 针对用户的不同情绪分别设计相应的专家解码器, 并融合多个专家解码器的输出, 以此生成共情回复.Majumder等[11]将用户情绪划分为积极和消极两类, 基于“ 共情回复通常会模仿用户情绪” 这一假设提出MIME(MIMicking Emotions), 同时设计多种机制, 促使回复模仿用户情绪.
此外, 一些研究者认为感知对话中的细微情绪能更好地理解共情.Li等[12]意识到已有方法针对用户细粒度情感的建模能力较弱, 提出EmpDG, 为对话上下文中的多粒度情感因素进行建模.Zhong等[13]关注对话中具有细微情绪的情绪词, 注重否定词与词强度的作用.
虽然上述方法在共情回复生成研究中取得较优效果, 但仅关注情绪因素以增强模型的共情能力, 忽略认知因素对共情的影响, 致使回复的共情效果欠佳.因此, 有些研究者开始同时考虑情绪和认知两方面对共情的影响.Zhong等[14]提出CARE(Common-sense-Aware Response Generation with Specified Emo-tions), 通过常识, 从认知上增强共情的理解.Li等[15]提出KEMP(Knowledge-Aware Empathetic Dia-logue Generation Method), 认为常识有助于理解对话中的隐含情绪, 借助常识构建情绪语境图, 理解用户的隐藏情绪和学习情绪交互.Sabour等[16]提出CEM(Commonsense-Aware Empathetic Chatting Machine), 考虑利用常识性知识获取更多关于用户状态的信息, 促进对用户状态的深度理解, 同时利用这些外部信息增强回复中的共情表现.Wang等[17]提出SEEK(Serial Encoding and Emotion-Knowledge Interaction), 通过常识性知识和情绪之间的双向交互选择过程建模, 提高识别的情绪和过滤不合理外部知识的能力, 产生更合理的共情回复.Zhao等[18]提出EmpSOA(Empathetic Response with Explicit Self-Other Aware-ness), 利用常识性知识表现自我意识和他人意识的细粒度情绪和认知状态, 同时将其注入共情回复的生成过程中.Wang等[19]提出CTSM(Combining Trait and State Emotions for Empathetic Response Model), 在生成回复和上下文之间对齐特征情绪和状态情绪, 并结合外部知识, 增强模型的共情能力.Yang等提出IAMM(Iterative Associative Memory Model)[20]和SDAM(Situation-Dialogue Association Model)[21], 引入情境信息增强认知.Zhou等[22]提出CASE(Cog- nition and Affection for Responding Empathetically), 先建立常识认知图和情绪概念图, 再在粗粒度级别和细粒度级别上分别对齐用户的认知和情绪, 实现共情回复.
此外, 一些研究者考虑借助大模型提升共情能力.Cai等[23]提出一种常识知识选择范式, 动态选择与用户认知最相关的常识, 增强共情回复的生成.Bi等[24]提出DIFFUSEMP, 统一对话上下文和控制信号的使用, 进而调控共情的表达.尽管这些工作能更全面考虑情绪因素和认知因素的影响, 提升共情回复的效果, 但均忽略对于共情回复生成十分重要的个性化因素— — 角色信息, 导致共情回复模型的性能受限.
在心理学中, 角色可被认为是人格的一种外在表达[25], 并且与共情密切相关[26, 27, 28, 29, 30].因此, 将角色信息融入共情回复生成任务中, 能增强回复的共情能力, 同时也使其更具个性化.因此, 为了提升共情回复生成任务中的个性化因素和模型的共情能力, 本文提出角色增强的共情回复生成模型(Persona-Enhanced Empathetic Response Generation, PERG), 在共情回复中引入角色信息, 提升共情回复的性能.首先, 提出角色增强编码模块, 利用编码器捕捉上下文、情境与角色信息之间的深层次语义关联.同时, 结合上下文和情境对角色信息进行筛选与强化, 增强其与上下文和情境的关联性, 确保角色信息高度的一致性与完整性.然后, 在角色调控解码模块上, 采用基于多解码器融合的调控机制, 在理解角色信息的基础上, 精准调控上下文和情境在共情回复中的影响, 生成更加个性化和人性化的共情回复, 大幅提升模型的共情表达能力和交互质量.Empathetic-Dialogues数据集[4]上的实验验证PERG的有效性.
1 角色增强的共情回复生成模型
本文提出角色增强的共情回复生成模型(PERG), 可融合上下文、情境及角色信息, 实现更深层次的对话理解, 并生成个性化的共情回复.PERG架构如图1所示.PERG由三部分组成.1)角色增强编码模块, 编码多种信息, 充分理解对话, 并结合上下文和情境强化对角色的理解.2)情绪预测模块, 基于理解的信息进行情绪预测.3)角色调控解码模块, 将多解码器融合的调控机制用于共情回复生成, 使回复更具人性化和共情能力.
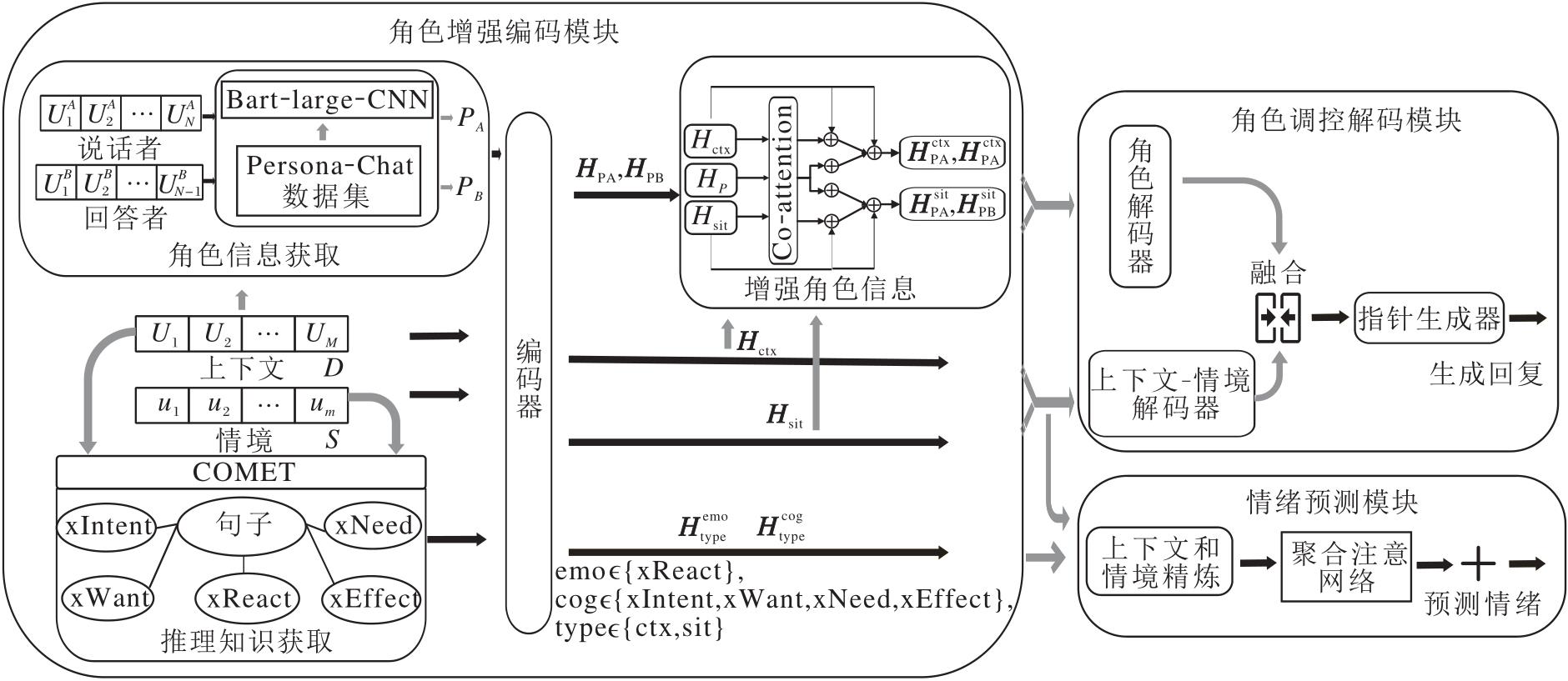 | 图1 PERG架构图Fig.1 Architecture of PERG |
1.1 形式化定义
形式上, 共情回复生成的任务描述如下.
给定上下文
D=[U1, …, Ui, …, UM],
m个单词组成的情境描述
S=[
说话者角色信息
PA=[
回答者角色信息
PB=[
其中
Ui=[
表示包含mi个单词的第i个话语,
$ p_{i}^{B}=\left[w_{1}^{i}, w_{2}^{i}, \cdots, w_{m_{B i}}^{i}\right], $
分别表示包括mAi和mBi个单词的角色信息的句子.
在理解对话情绪E的基础上, 生成N个单词组成的个性化的共情回复序列:
Y=[y1, y2, …, yN].
1.2 角色增强编码模块
角色信息是共情的关键因素[27, 28, 29], 以往的方法[14, 15, 16, 17, 18, 19, 20, 21]仅关注共情的情绪和认知因素, 忽略个性化因素, 难以结合对话者的个人特点更全面理解共情.为了弥补这一缺陷, 本文提出角色增强编码模块, 分别对上下文、情境、推理知识和角色信息进行编码, 以便更好地理解对话内容和背景.同时, 结合上下文和情境筛选角色信息, 并通过精炼编码器, 增强对角色信息的理解, 提升角色信息的正确性和完整性.
1.2.1 信息获取
1)角色信息获取.在对话系统中, 角色信息是指对话者的特征、偏好和上下文信息.在共情回复生成任务中, 合理利用角色信息有助于提升与用户的交流效果.由于在对话前难以准确预测说话者和回答者的角色信息, 因此, 有必要通过其言语内容推断这些信息.假设说话者A和回答者B之间的对话(上下文)如下:
D=[
首先连接A、B的历史话语,
DA=
$D_{B}=U_{1}^{B} \oplus U_{2}^{B} \oplus \cdots \oplus U_{n-1}^{B} .$
运用文献[29]中借助Persona-Chat数据集[31]进行预训练的角色信息提取模型(经过微调的bart-large-CNN模型), 分别从DA和DB中推断说话者角色信息和回答者角色信息:
PA=[
$\boldsymbol{P}_{B}=\left[p_{1}^{B}, \cdots, p_{i}^{B}, \cdots, p_{m B}^{B}\right] .$
此外, 若不存在回答者历史话语, 回答者角色信息为空.
2)推理知识获取.推理知识属于人类社会的常识性知识, 合理运用推理过程, 可促进对事物更深入的认知和理解.在对话系统交互时, 用户可能不会明确分享他们的处境和感受的所有信息, 而对话系统可模仿人类思维, 利用推理知识, 在用户明确提到的信息和隐含信息之间建立联系, 进一步理解用户的处境和感受.
依据CEM[16]和IAMM[20], 本文使用在ATOMIC(An Atlas of Machine Commonsense)常识性推理数据集[32]上预训练的COMET[33], 为上下文D中的最后一个句子和情景S生成5种常识性关系的推理知识:事件对人们的影响(xEffect)、人们对事件的反应(xReact)、人们在事件发生前的意图(xIntent)、事件发生需要人们做什么(xNeed)、在事件发生后人们想要什么(xWant), 并将这些推理知识连接成序列.这5种常识性关系被分为两类:
emo=[xReact]
表示情绪状态;
cog∈ {[xWant], [xNeed], [xIntent], [xEffect]}
表示认知状态.
1.2.2 信息编码
信息编码包括上下文编码、情境编码、推理知识编码和角色信息编码四个部分.
上下文编码通过Transformer编码器处理上下文信息, 使模型更好地理解文本的含义与语义关系.借鉴CEM[16]和SEEK[17], 首先连接上下文话语, 并在前面加上起始标记[CLS], 形成上下文序列:
C=[CLS]⊕u1⊕u2…⊕un-1,
其中, [CLS]表示整个文本的语义特征向量, ⊕表示连接操作.
然后, 将该上下文序列C转换为词嵌入, 并与位置嵌入及发言状态嵌入相加, 得到上下文嵌入EC, 发言状态嵌入用于区分对话中的说话者和回答者.
最终, 将该嵌入送入Transformer编码器, 生成上下文表示:
Hctx=TRSEnc(EC)∈ RM× d,
其中, TRSEnc(· )表示Transformer编码器, M表示上下文表示的长度, d表示Transformer编码器的隐藏大小.
情境是对话产生的特定场景[20, 21], 旨在更高效地处理、分析和利用与情境相关的信息.首先, 将情境序列S转换为词嵌入, 并与位置嵌入相加, 得到情境嵌入ES.然后, 将ES输入Transformer编码器, 生成情境表示:
Hsit=TRSEnc(ES)∈ Rm× d,
其中m表示情境表示的长度.
推理知识编码旨在有效理解生成的常识性文本知识.根据推理知识获取部分, 推理知识序列划分为认知状态序列
$\boldsymbol{H}_{\text {type }}^{\mathrm{emo}}=T R S_{\text {Enc }}\left(\boldsymbol{E}_{\text {type }}^{\mathrm{emo}}\right) \in \mathbf{R}^{L_{\mathrm{emo}} \times d}, $
其中, Lcog表示认知状态的文本描述长度, Lemo表示情绪状态序列的文本描述长度, type∈ {ctx, sit}表示上下文或情境.
角色信息编码的目的是准确理解并处理说话者角色信息和回答者角色信息.首先, 将角色信息PA和PB转换为词嵌入, 并与位置嵌入和发言状态嵌入相加, 得到角色嵌入EPA和EPB.然后, 输入Transfor-mer编码器, 生成对应的角色信息表示:
HPA=TRSEnc(EPA)∈ RmA× d,
HPB=TRSEnc(EPB)∈ RmB× d,
其中, mA表示说话者角色表示的长度, mB表示回答者角色表示的长度.
1.2.3 角色信息增强
角色信息增强包括上下文增强和情境增强两个方面.上下文增强通过处理说话者和回答者的上下文信息, 确保其角色信息的完整性和准确性.情境增强关注在特定情境下对角色信息的调整, 保证角色信息的适当性和一致性.这两种方法共同作用, 旨在提升系统对角色信息的理解和处理能力.
在上下文增强角色信息方面, 为了突出与说话者角色信息更相关的上下文, 运用Co-attention机制, 即在上下文表示Hctx上计算额外的注意力关注:
Zctx=softmax(Hctx·
其中, softmax(· )表示softmax激活函数, · 表示矩阵相乘.
将Hctx和Zctx在最后一维上拼接, 并应用层归一化(Layer Normalization, LN)操作, 得到增强后的上下文表示:
同样, 为了使说话者角色信息与提供的上下文更一致, 基于上述步骤获得新的说话者角色表示:
其中
ZPA=softmax(HPA·
表示在说话者角色信息表示上计算的额外注意力关注.
这一过程有助于忽略那些不准确或与上下文无关的说话者角色信息, 提高对说话者角色信息的理解.此外, 鉴于推断的说话者角色信息可能不完整, 先将
其中
$\lambda_{i}=\frac{e^{w_{i}}}{\sum_{j} e^{w_{j}}}, i=1, 2, 3, j=1, 2, 3, $ (6)
表示对应权重, w1、w2、w3表示初始值相同的模型参数.
为了有效压缩和筛选上下文增强的说话者角色信息, 并过滤次要信息, 将
其中, Encref(· )表示基于Transformer编码器构建的精炼编码器.
针对回答者角色信息
情境增强角色信息的处理方法与上下文增强角色信息的处理方法类似, 采用相同的增强模块处理说话者角色信息和回答者角色信息, 获得精炼的、情境增强的说话者和回答者角色信息表示
1.3 情绪预测模块
情绪预测模块由上下文和情境精炼、情绪预测两个部分组成, 通过推理知识对上下文和情境进行精炼, 并采用聚合注意网络(Aggregation Attention Networks)[21]提取其中重要的情绪相关信息, 从而提升说话者情绪预测的准确性.
1.3.1 上下文和情境精炼
上下文和情境精炼目的是利用推理知识提炼上下文和情境中的关键信息, 同时过滤无关的次要信息, 更准确地理解上下文和情境.
首先, 使用认知状态序列的隐藏表示[CLS]和情绪状态序列的平均隐藏表示, 作为这两个序列的整体语义表示:
$\boldsymbol{h}_{\text {type }}^{\text {emo }}=\operatorname{Average}\left(\boldsymbol{H}_{\text {type }}^{\text {emo }}\right) \in \mathbf{R}^{d}, $
其中type∈ {ctx, sit}表示上下文或情境.
接下来, 先将
$\widetilde{\boldsymbol{H}}_{\text {type }}^{\text {emo }}=E n c_{\text {ref }}\left(\boldsymbol{U}_{\text {type }}^{\text {emo }}\right) \in \mathbf{R}^{L_{\text {type }} \times d}, $
其中
$\boldsymbol{U}_{\text {type }}^{\text {cog }}=\boldsymbol{H}_{\text {type }} \oplus \boldsymbol{h}_{\text {type }}^{\text {emo }} \in \mathbf{R}^{L_{\text {type }} \times 2 d}, $
Encref(· )表示精炼编码器, ⊕ 表示连接操作.
相比在序列级连接(即在序列末尾添加附加信息), 单词级别连接能融合序列中每个单词内的附加知识.
为了综合情绪和认知两种状态的推理知识, 在单词级别上连接两种状态的精炼上下文或情境表示.首先将认知状态中的4种关系在单词级别上连接, 再与情绪状态融合, 得到5种关系精炼的上下文或情境表示
其中
$\widetilde{\boldsymbol{H}}_{\text {type }}^{\mathrm{COG}}=\bigoplus_{\text {cog } \in\{\mathrm{xWant}, \mathrm{xNeed}, \text {, Intent, xEffect }\}} \widetilde{\boldsymbol{H}}_{\text {type }}^{\mathrm{cog}}, $
σ (· )表示sigmod激活函数, ☉表示逐元素相乘.
1.3.2 情绪预测
情绪预测旨在准确捕捉对话中说话者的情绪, 并在回复中恰当地表达出来.为了提高情绪预测的准确性, 本文使用两个结构相同但参数不同的聚合注意网络, 从精炼的上下文和情境中提取有效的信息进行情绪预测, 对应的情绪概率如下:
$\boldsymbol{P}_{\mathrm{ctx}}^{e}=A t t_{\mathrm{ctx}}\left(\widetilde{\boldsymbol{H}}_{\mathrm{ctx}}\right)$
$\boldsymbol{P}_{\text {sit }}^{e}=A t t_{\text {sit }}\left(\widetilde{\boldsymbol{H}}_{\text {sit }}\right), $
其中, Attctx(· )表示精炼的上下文聚合注意网络, Attsit(· )表示精炼的情境聚合注意网络.
为了说明聚合注意网络的结构, 以精炼的上下文聚合注意网络Attctx(· )为例.首先计算精炼的上下文表示
$\boldsymbol{P}_{S}=\operatorname{Softmax}\left(\boldsymbol{w}_{1}^{s} \boldsymbol{H}_{1}^{a}+\boldsymbol{b}_{1}^{s}\right) \in \mathbf{R}^{N}, $
并将所有单词概率相加, 得到注意力隐藏表示
$\boldsymbol{H}_{2}=\sum_{j=1}^{L} \boldsymbol{P}_{S}[j] \cdot \widetilde{\boldsymbol{H}}_{\mathrm{ctx}}[j] \in \mathbf{R}^{d}$,
其中,
$\boldsymbol{H}_{1}^{a}=\operatorname{Tanh}\left(\boldsymbol{w}_{1}^{a} \widetilde{\boldsymbol{H}}_{\mathrm{ctx}}+\boldsymbol{b}_{1}^{a}\right) \in \mathbf{R}^{N \times d}, $
接着, 使用一个非线性层和线性层对精炼的上下文进行学习, 预测上下文情绪概率:
其中,
de表示情绪类别的数量, 设为32,
最后, 将从上下文和情境中得到的两种情绪概率相加, 得到整体对话的情绪概率:
Pe=
并通过情绪概率Pe预测对话的情绪类别.此外, 在训练过程中, 分别计算真实情绪标签e* 和两种预测的情绪类别之间的负对数似然损失, 并将这两个损失合并, 形成整体情绪损失:
Le=-ln(
从而对模型进行优化.
1.4 角色调控解码模块
在对话中, 仅有部分关键的信息能代表角色信息[29].为了挖掘关键信息并以合理的方式表达到回复中, 本文提出角色调控解码模块, 借助上下文-情境解码器以及角色解码器, 从上下文、情境和角色信息中提取关键内容.同时, 采用基于多解码器融合的调控机制融合这些解码结果, 以调控上下文和情境中角色信息对回复的影响, 进而生成个性化的共情回复.
1.4.1 上下文、情境和角色信息解码
上下文、情境和角色信息解码的目标是通过上下文-情境解码器和角色解码器分别对上下文、情境及角色信息进行解码, 从而理解这三类文本的语义和语境, 并利用这些信息生成相应的输出.
为了生成与上下文和情境相关的回复, 首先, 使用上下文-情境解码器对输入的上下文表示Hctx和情境表示Hsit进行解码:
$\boldsymbol{H}_{\mathrm{sit}}^{\mathrm{dec}}=\operatorname{Dec} c_{\mathrm{ctx}-\mathrm{sit}}\left(\boldsymbol{H}_{\mathrm{sit}}\right) \in \mathbf{R}^{d_{t} \times d}, $
其中, Decctx-sit(· )表示基于Transform解码器构建的上下文-情境解码器, dt表示第t步解码的回复长度.
对于角色信息的解码, 通过角色解码器对输入的上下文增强的说话者角色信息和回答者角色信息表示
$\begin{array}{l}\widehat{\boldsymbol{H}}_{\mathrm{PA}}^{\mathrm{ctx}}=D e c_{\text {persona }}\left(\widetilde{\boldsymbol{H}}_{\mathrm{PA}}^{\mathrm{ctx}}\right) \in \mathbf{R}^{d_{t} \times d}, \\\widehat{\boldsymbol{H}}_{\mathrm{PB}}^{\mathrm{ctx}}=D e c_{\text {persona }}\left(\widetilde{\boldsymbol{H}}_{\mathrm{PB}}^{\mathrm{ctx}}\right) \in \mathbf{R}^{d_{t} \times d} .\end{array}$
其中Decpersona(· )表示基于Transformer解码器构建的角色解码器.
同样地, 对情境增强的说话者角色信息和回答者角色信息表示
$\begin{array}{l}\widehat{\boldsymbol{H}}_{P A}^{\text {sit }}=D e c_{\text {persona }}\left(\widetilde{\boldsymbol{H}}_{P A}^{\text {sit }}\right) \in \mathbf{R}^{d_{t} \times d}, \\\widehat{\boldsymbol{H}}_{P B}^{\text {sit }}=D e c_{\text {persona }}\left(\widetilde{\boldsymbol{H}}_{P B}^{\text {sit }}\right) \in \mathbf{R}^{d_{t} \times d} .\end{array}$
1.4.2 回复生成
回复生成的任务是采用基于多解码器融合的调控机制, 融合上下文-情境解码器以及角色解码器的输出结果, 并借助指针生成器[34]生成最终的共情回复.为了实现对上下文、情境和角色信息的灵活调控, 本文首先整合上下文和角色信息, 结合情境和角色信息, 最终通过融合结果生成个性化的共情回复.
首先, 在单词级别上连接上下文解码信息
$\boldsymbol{H}_{1}=\boldsymbol{H}_{\mathrm{ctx}}^{\mathrm{dec}} \oplus \widehat{\boldsymbol{H}}_{P A}^{\mathrm{ctx}} \in \mathbf{R}^{L_{t} \times 2 d}, $
其中, ⊕ 表示连接操作, ctx表示上下文信息, 并通过sigmod门控网络计算权重.
然后, 结合上下文增强的回答者角色信息
其中
g1=σ (wH1+b),
σ (· )表示sigmod激活函数, w、b表示可学习的参数, w1、w2表示模型参数.
在情境和角色信息的整合方面, 采用类似的步骤, 在单词级别上连接情境解码信息
$\boldsymbol{H}_{2}=\boldsymbol{H}_{\mathrm{sit}}^{\mathrm{dec}} \oplus \widehat{\boldsymbol{H}}_{P B}^{\mathrm{sit}} \in \mathbf{R}^{L_{t} \times 2 d}, $
其中sit表示情境信息.而后得到融合结果:
其中
g2=σ (wH2+b).
最后, 在单词级别上连接
$\boldsymbol{H}=\widetilde{\boldsymbol{H}}_{1} \oplus \widetilde{\boldsymbol{H}}_{2} \in \mathbf{R}^{L_{t} \times 2 d}, $
生成最终的融合结果
平衡上下文、情境和角色信息对共情回复的影响, 其中
g=σ (wH+b).
该融合结果
$P\left(y_{t} \mid E_{y< t}, \text { ctx }, \text { sit }, \text { per }\right)=\operatorname{PoGen}(\widetilde{\boldsymbol{H}}), $
其中, Ey< t表示截至时间步长t-1生成回复的嵌入, per表示角色信息, PoGen(· )表示指针生成器网络模块[33].
在模型优化方面, 使用交叉熵损失作为生成损失:
$L_{\operatorname{gen}\left(y_{t}\right)}=-\sum_{t=1}^{T} \ln \left(P\left(y_{t} \mid y< t, \text { ctx }, \text { sit, per }\right)\right), $,
为了提升回复的多样性, 结合Sabour等[16]提出的多样性损失Ldiv, 模型的总损失为情绪损失、生成损失和多样性损失的加权和:
L=r1Le+r2
其中r1、r2、r3表示模型参数.
2 实验及结果分析
2.1 实验数据集
本文在EmpatheticDialogues数据集[4]上进行实验.EmpatheticDialogues数据集是在Amazon Mechanical Turk上收集的大型多回合共情对话数据集, 包含约25 000个一对一的开放域对话.Rashkin等[4]将两名众包工作者配对: 一名工作者作为说话者, 另一名工作者作为回答者, 并在预定情境下开始对话.说话者要求谈论个人的情绪感受, 而回答者根据说话者的话语推断潜在的情绪, 并做出共情回复.该数据集提供32个均匀分布的情绪标签, 在训练过程中, 对话历史的情绪标签(即说话者的情绪)作为监督信号.在测试阶段, 隐藏情绪标签, 评估模型的共情能力.模型输入为对话历史, 输出为回答者的回复.
本文在训练集上使用17 802个对话, 验证集上使用2 628个对话, 测试集上使用2 494个对话.对话历史和回复的平均长度分别为2.1个句子和13.5个单词.
具体训练集对话样例如下所示.
Label: Terrified
Situation: Speaker felt this when "I got home for lunch and found a bat outside on my front porch."
Conversation:
Speaker: I got home for lunch and found a bat outside on my front porch. It probably has rabies. Bats shouldn't be out during the day.
Listener: Doesn't rabies cause sensitivity to light? Either way I would freak out.
Speaker: It can but, it also causes animals to behave erratically like bats wandering around in the middle of the day.
Listener: Oh yeah, gotcha. I really don't like animals that are small and move quickly.
Speaker: Generally yes.
2.2 实验参数
本文采用PyTorch框架实现PERG, 并用预训练的300维的GloVe(Global Vectors)向量[35]初始化词嵌入, 在模型的各个组件中, 设置隐藏维度d=300.模型的批处理大小设为16, 并采用早停机制防止过拟合.在训练阶段, 学习率初始化为0.000 1, 并参照文献[36]方法对学习率进行调整.在NVIDIA GeForce RTX3090上使用Adam(Adaptive Moment Estimation)[37]优化器, 设置β 1=0.9, β 2=0.98, 用于优化模型并更新参数.PERG的损失函数由生成损失、情绪损失和多样性损失组成, 取权重r1=1.0, r2=1.0, r3=1.5.经过大约19 000次迭代, 方法收敛.Transformer编码器中嵌入层和隐藏层大小均为300, 层数为1, 注意力头数为2, K和V最后维度均为40, 前馈网络中间层的隐藏层大小为50, 最大序列长度为1 000.
2.3 评价指标
为了全面评估PERG的性能, 使用的评价指标包括自动评价和人工评价.由于共情回复生成模型较灵活, 一般采用人工评价结合自动评价的方式评估性能.
在自动评价方面, 从如下三个方面评估方法的语言质量.
1)在流利度方面, 采用困惑度(Perplexity, PPL)[38], 预测句子出现的概率.具体公式如下:
PPL=
其中, M表示生成回复的词个数, P(· )表示概率.可以看出, 句子出现的概率越大, 困惑度越低, 回复越流畅.因此PPL值越小, 方法性能越优.
2)在多样性方面, 选择Dist-1和Dist-2指标[39].该指标主要用于计算模型生成的回复在单粒度方面词和双粒度方面词的不重复率, 得分越高, 多样性越优.具体公式如下:
$\text { Dist-n }=\frac{\text { Distinct }\left(\sum_{i=1}^{N} n \text {-gram }\right)}{\sum_{i=1}^{N} n \text {-gram }}$.
其中:n表示粒度, 文中n的取值为延用基准实验的1和2, 1表示单粒度, 2表示双粒度; 分子表示生成回复中该粒度的词组不重复个数; 分母表示生成回复中所有该粒度词的个数; N表示词组个数.为了同之前的工作一致[15, 16, 17, 18], 文中这两个指标的值均是乘以100以后的值.
3)在情绪预测方面, 通常采用准确度(Accu-racy, Acc)衡量模型对回复情感的预测准确性.准确度是指预测分类正确的样本数在总样本数中所占比例, 值越大, 模型性能越优.具体公式如下:
Acc=
在人工评价方面, 本文邀请三位专业的测试人员, 评估不同模型回复的质量.依据文献[20]和文献[21]的工作, 采用A/B测试对比基准模型和PERG.如果测试人员认为PEDG的回复更优, Win加一; 如果更差, Lose加一, 否则就是平局.最终如果Win值大于Lose值, 说明模型效果较优, 否则, 说明模型效果较差.
在评判回复质量方面, 本文考虑共情(Emp)、相关性(Rel)和流畅性(Flu).共情衡量回复中的情绪是否恰当, 相关性衡量回复是否与对话主题和内容相关, 流畅性衡量回复的语言是否自然通顺.
2.4 对比实验
为了评估PERG的性能, 选择如下对比模型.
1)EmpDG[12].考虑细粒度的情绪因素和用户反馈对共情回复的影响.
2)KEMP[15].利用来自ConceptNet[40]的外部知识, 增强对话中的内隐情绪.
3)CEM[16].利用来自COMET的推理知识, 作用于共情回复中的情绪和认知两个方面.
4)SEEK[17].情绪流模型, 涉及共情回复生成任务中的动态情绪过程.
5)EmpSOA[18].通过外显的自我和他人意识产生共情回复.
6)CASE[22].从细粒度和粗粒度两个角度对齐共情回复中的情绪因素和认知因素.
在自动评价方面, 各模型的指标值对比结果如表1所示, 表中黑体数字表示最优值.由表可得如下结论.
| 表1 各模型的自动评估结果 Table 1 Automatic evaluation results of different models |
1)在情绪预测准确性方面, PERG显著优于对比模型, 相比性能最佳的EmpSOA, Acc指标提升2.91%.这充分说明引入角色信息有助于增强对对话的深层次理解.因为模型关注上下文和情境中的推理知识, 所以能提高情绪检测的准确性.
2)在多样性方面, PERG同样超越对比模型, 相比性能最佳的CASE, 在Dist-1和Dist-2指标上分别提升0.69和1.21.这是因为通过角色信息整合上下文和情境, 提供丰富的背景信息, 同时利用角色信息提升回复的个性化, 进一步推动多样性回复的产生.
3)在困惑度方面, PERG超过大多数对比模型, 这说明角色信息提供有利于回复的关键信息, 而上下文-情境解码器和角色解码器也为高质量回复提供优势.PERG的结果略低于EmpSOA, 其原因是个性化的共情回复需要更多的细节和背景信息, 以便更好地理解对方的情感和经历, 这导致回复长度的增加, 从而降低PPL值.
PERG、CASE、SEEK和EmpSOA在共情、相关性和流畅性的评估结果如表2所示, 表中κ 为Fleiss的Kappa系数[41], 表示测量测试者一致性程度, 0.4 < κ ≤ 0.6表示中等的一致性.
| 表2 各模型的人工评估结果 Table 2 Manual evaluation results of different models |
由表2可得如下结论.
1)PERG在共情方面呈现优越性, 原因在于其能借助角色信息, 结合上下文和情境, 准确感知更广泛的感受, 并通过解码器生成合适的个性化回复.
2)PERG在相关性方面的优势表明, 当考虑角色信息后, 模型能精准全面地了解对话的主题和背景知识, 生成更具相关性的回复.
3)PERG在流畅性上提高则显示其利用角色信息充分理解上下文和情境信息, 并依据这三种信息形成自然流利的回复.
2.5 消融实验
本文设定如下模型以验证角色信息和推理知识的有效性.
1)w/o ctx_s.去除上下文增强的说话者角色信息.
2)w/o sit_s.去除情境增强的说话者角色信息.
3)w/o ctx_r.去除上下文增强的回答者角色信息.
4)w/o sit_s.去除情境增强的回答者角色信息.
5)w/o all_per.去除所有增强的角色信息.
6)w/o ctx_k.去除上下文中的推理知识.
7)w/o sit_k.去除情境中的推理知识.
8)w/o all_k.去除上下文和情境中推理知识.
各模型消融实验结果如表3所示, 表中黑体数字表示最优值.
| 表3 各模型的消融实验结果 Table 3 Ablation experiment results of different models |
由表3可得如下结论.
1)分别去除这四种不同的角色信息, 均对情绪预测准确性和多样性指标有较大影响, 并且去除所有角色信息, 4个指标值都大幅下降, 这说明引入角色信息对提升模型的共情回复效果能有所帮助, 通过角色信息可针对不同主题的对话生成个性化的共情回复, 增强回复的多样性.利用角色信息还可挖掘上下文和情境中的关键信息, 进行有效结合, 进一步增强共情回复.在困惑度指标方面, 相比去除一种角色信息的模型, PERG的指标值略高, 原因是生成的回复中包含稍多的通用性句子, 从而具有更好的困惑度, 但会降低共情程度和多样性.
2)分别去除上下文和情境中的推理知识, 情绪预测准确率和多样性指标都有不同程度的下降.此外, 去除所有的推理知识, 4个指标值均有影响, 特别是情绪预测准确率大幅下降.这表明推理知识在模型识别用户感受的过程中作用显著, 并且引入外部知识, 能更好地把握用户情况, 提升回复的多样性, 让回复更自然流畅.
2.6 参数分析
为了进一步研究模型参数的有效性, 定义多样性损失权重参数r3=1.0, 1.5, 2.0, 分析其对PERG的影响, 具体结果如表4所示, 表中黑体数字表示最优值.由表可见, 当情绪损失、生成损失和多样性损失的权重均设置为1.0时, 模型对通用回复的惩罚力度不足, 倾向于生成通用的共情回复, 导致模型的Dist-1和Dist-2指标表现不佳, 而PPL指标却有所改善.当多样性损失的权重增至2.0时, 尽管提升模型回复的多样性(表现为Dist-1和Dist-2指标的提升), 但却在PPL和Acc方面产生负面影响.综合考虑之后, 将多样性损失的权重设置为1.5, PERG在多样性、困惑度和情绪预测准确性之间实现较好的平衡, 整体性能得以提升.
| 表4 不同r3对PERG性能的影响 Table 4 Effect of r3 on PERG performance |
2.7 案例分析
本文选取案例1和案例2, 对比CASE、SEEK、EmpSOA和PERG, 具体结果如表5和表6所示.
| 表5 案例1 Table 5 Case 1 |
| 表6 案例2 Table 6 Case 2 |
在案例1中, CASE表达对女儿的称赞(That is awesome!), 但后一句话与上下文语境严重不符(I bet she is going to be a great parent!), 而SEEK未表达出骄傲的情绪.EmpSOA虽对说话者的女儿进行称赞(That is awesome!), 与对话中说话者骄傲的情绪有所回应, 但What is the first step in the future?这部分内容偏离当下说话者主要表达的骄傲以及对女儿天赋的感慨.PERG结合说话者作为父亲对女儿的骄傲这一角色信息, 不仅表达对孩子获胜这一事件的称赞(Wow, that is awesome!), 还进一步推测孩子自身也会感到骄傲(I bet she was very proud of her.), 从而更全面深入地与说话者对女儿成就的骄傲产生共情.
在案例2中, CASE虽然表达激动的情绪, 但后续的回答与前文的已知信息存在差异.SEEK和EmpSOA都仅使用通用的回复表达对说话者养狗这一事件的高兴, 未能与说话者产生更深层次的共鸣, 并且忽视事件的后续进展.PERG通过That is great!契合说话者兴奋的情绪, 并利用说话者角色信息中的I now have a puppy of my own.这一说话者拥有小狗的前提以及回答者想要询问更多信息的性格特点, 进一步通过询问小狗的种类(What kind of puppy did you get?), 与说话者兴奋的情绪和经历产生共鸣.总之, PERG借助角色信息有助于更细致地理解对话, 进而产生更丰富相关的个性化回复.
3 结束语
本文提出角色增强的共情回复生成模型(PERG), 通过增强说话者和回答者的角色信息, 深度理解对话中的情绪和认知, 提升模型的共情能力以及回复的个性化程度.PERG编码角色信息, 获取说话者和回答者的背景与性格特点, 结合上下文和情境筛选角色信息, 更全面深入地理解角色信息.在此基础上, 利用推理知识精炼上下文和情境, 获取其中重要的情绪信息, 进一步增强模型的情绪感知能力.最后, 通过多解码器融合的调控机制, 借助角色信息, 调节上下文和情境对回复的影响, 生成个性化的共情回复.自动评估结果与人工评估结果均验证PERG在共情回复生成任务中的有效性.今后将进一步探索角色信息在大模型中的应用, 充分利用大模型丰富的先验知识和强大的拟合能力, 实现更具个性化的共情回复.
本文责任编委 梁吉业
Recommended by Associate Editor LIANG Jiye
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|