
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
融合级联频域特征的信息微观扩散预测模型
引用本文
赖雨阳, 朱小飞. 融合级联频域特征的信息微观扩散预测模型. 模式识别与人工智能, 2024,37(12): 1056-1068
LAI Yuyang, ZHU Xiaofei. Information Microscopic Diffusion Prediction Integrating Cascaded Frequency Domain Features. PATTERN RECOGNITION AND ARTIFICIAL INTELLIGENCE, 2024,37(12): 1056-1068.
Doi: 10.16451/j.cnki.issn1003-6059.202412002
LAI Yuyang, ZHU Xiaofei. Information Microscopic Diffusion Prediction Integrating Cascaded Frequency Domain Features. PATTERN RECOGNITION AND ARTIFICIAL INTELLIGENCE, 2024,37(12): 1056-1068.
Permissions
Copyright©2024, 《模式识别与人工智能》编辑部
《模式识别与人工智能》编辑部
融合级联频域特征的信息微观扩散预测模型

朱小飞,博士,教授,主要研究方向为自然语言处理、数据挖掘、信息检索.E-mail:zxf@cqut.edu.cn.
作者简介:

赖雨阳,硕士研究生,主要研究方向为社交网络.E-mail:laiyy@stu.cqut.edu.cn.
摘要
微观扩散预测对于深入理解信息在社会网络中的传播具有关键意义.为了进一步提升信息传播预测的精准度,文中提出融合级联频域特征的信息微观扩散预测模型.首先,基于用户友谊关系和历史级联,分别构建社交图和信息扩散超图,并利用图卷积神经网络提取用户在社交关系和转发行为上的表征.然后,应用傅立叶变换,将级联的时域特征映射至频域,通过高频分量与低频分量捕捉级联的短期波动和长期趋势.最后,为了生成更具表现力的用户表示,设计注意力融合层,有效避免特征冗余和信息缺失的问题,进一步优化性能.在四个公开数据集上的实验表明,文中模型在Hits@ K和mAP@ K指标上都有所提升,由此表明模型的有效性.
关键词:
社交网络; 信息传播预测; 级联预测; 傅立叶变换; 多头注意力机制
中图分类号:TP399
Information Microscopic Diffusion Prediction Integrating Cascaded Frequency Domain Features
ZHU Xiaofei, Ph.D., professor. His research interests include natural language processing, data mining and information retrieval.
About Author:
LAI Yuyang, Master student. Her research interests include social network.
Abstract
The research on microscopic diffusion prediction is of great significance for understanding the propagation of information in social networks. To improve the accuracy of information diffusion predictions, an information microscopic diffusion prediction model integrating cascaded frequency domain features is proposed. First, a social graph and an information diffusion hypergraph are constructed separately based on user friendship relationships and historical cascades. Graph convolutional neural networks are utilized to capture user representations in social relationships and forwarding behaviors. Next, Fourier Transform is applied to map the time-domain cascade features to the frequency domain, effectively capturing both short-term fluctuations and long-term trends in the cascade through high-frequency and low-frequency components. Finally, an attention fusion layer is designed to generate a more expressive user representation, effectively addressing the issues of feature redundancy and information loss. Thus, the performance of the proposed model is further optimized. Experiments on four public datasets show the proposed model improves Hits@ K and mAP@ K, demonstrating the effectiveness of itself.
Key words:
Key Words Social Network; Information Diffusion Prediction; Cascade Prediction; Fourier Transform; Multi-head Attention Mechanism
社交网络的兴起深刻改变人们的生活方式和交流模式, 微博、Facebook等在线社交媒体的出现使网络平台上信息传播的方式发生巨大变化.然而, 社交网络的发展具有两面性:从积极角度上看, 它凭借强大的传播能力, 在用户个性化分析[1, 2]、社会推荐[3, 4]等领域发挥着不可或缺的作用; 从消极角度上看, 虚假新闻发布[5, 6]和谣言传播[7, 8]也愈演愈烈.针对信息的微观扩散预测为监测和控制信息动态传播提供基础支持, 因此具有重要的现实意义和社会价值.
信息级联微观扩散预测任务旨在探索信息传播过程中下一个即将被感染的节点[9].网络用户每天都会接收大量的信息, 但是否会转发这些信息却是不确定的, 即信息的传播并非简单的单向流动, 而是与诸多因素关联, 如个人兴趣偏好、社交同质性、社会影响等.这些因素共同作用, 决定信息在网络上的传播路径和规模.
近年来, 信息扩散预测问题得到学者们的广泛关注和深入研究, 已有诸多方法被提出用于建模和预测信息传播的扩散过程.早期的方法主要基于预定义的扩散模型.独立级联模型[10, 11]直接计算用户被感染的概率参数, 实现预测.基于特征工程的方法[12, 13]手工提取时序、结构及用户等特征, 并结合机器学习算法预测级联的潜在被感染用户.然而, 现实世界中的信息传播模式高度动态且多样化, 使得此类方法容易受到局限性假设的约束, 或因繁琐的特征提取过程而受到限制, 难以全面刻画复杂的传播规律[14].
随着深度神经网络的兴起与发展, 越来越多的研究者基于深度学习提出高效精准的端到端预测方法.Yang等[15]提出NDM(Neural Diffusion Model), 采用注意力机制和卷积神经网络对级联进行建模, 引入宽松的独立性假设, 缓解长期依赖问题.针对级联扩散的时序特性, 一些研究者提出基于递归神经网络及其变体的模型.Wang等[16]提出Topo-LSTM(Topological LSTM), 基于序列级联重构数据结构, 并利用拓扑信息与长短时记忆网络(Long Short-Term Memory, LSTM)预测信息传播过程中节点的动态感染, 进一步提高预测的准确性.Islam 等[17]提出DeepDiffuse, 结合长短期记忆网络和注意力机制, 学习级联序列的时间信息.Wang等[18]提出SNIDSA(Sequential Neural Information Diffusion Model with Structure Attention), 将结构注意力模块和门控机制集成到递归神经网络中, 整合结构和序列信息.Li等[19]提出GRASS(GRU-Like Attention Unit and Struc-tured Spreading), 将注意力机制融入循环神经网络, 挖掘级联传播中的跳变信息, 解决时空特征缺失的问题.相比传统方法, 上述模型在信息传播预测的精度方面取得显著提升, 但只关注级联扩散序列中的依赖关系, 忽略社会影响.
为了捕获同一级联中受感染用户之间的相关性, Wang等[20]提出CE-GCN(Cascade-Enhanced Graph Convolutional Networks), 构建包含社交图节点和传播图节点的增强异构图, 同时学习用户的社会关系和级联的传播结构.Wang等[21]提出DyDiff-VAE, 基于变分自编码器框架学习社会同质性和时间信息, 较好地学习信息级联的表示并实现更高的效率.Yuan等[22]提出DyHGCN(Dynamic Heterogeneous Graph Convolutional Network), 将时间信息编码至异构图中, 并从若干根据时间戳划分的异构图中学习用户的社会关系和动态偏好.Sun等[23]提出MS-HGAT(Memory-Enhanced Sequential Hypergraph Atten-tion Networks), 基于历史级联构建扩散超图, 通过超边和注意力机制描述用户与级联之间的动态交互.Yang等[24]基于强化学习, 提出FOREST(Reinforced Recurrent Networks with Structural Context).Jiao等[25]在此基础上提出MINDS(Streamlined and Effi-cient Model for Multi-scale Information Diffusion Pre-diction), 引入对抗训练和正交约束, 增强用户表示.Qiao等[26]提出RotDiff(Hyperbolic Rotation Repre-sentation Model), 在双曲空间中对扩散级联和社会图进行联合建模.
基于深度学习的方法进一步提升信息微观扩散预测的准确率, 但仍存在局限性.首先, 信息的传播过程通常是动态复杂的, 基于时域信息直接建模时通常需要额外的多尺度设计, 如子图划分[22, 23, 25]等, 以此捕捉信息级联的局部动态特性, 然而切割子图的方法可能导致全局信息丢失.傅立叶分析在研究神经网络的普遍近似性方面具有重要作用, 有助于缓解现有限制.在实际应用中, 离散傅立叶变换, 特别是快速傅立叶变换, 已广泛应用于信号处理中, 如将神经网络拟合到心电图信号[27, 28, 29]或求解进化偏微分方程[30].傅立叶变换实现时域与频域之间的转换, 可应用于不同场景, 如社会推荐[31]、时序预测[32]等.然而, 在级联预测领域, 傅立叶变换的相关研究仍较稀缺.此外, 现有方法通常对不同数据成分分别建模, 独立地从社交图和扩散图中学习用户的嵌入表示, 再通过简单的门控机制进行融合.这种方式可能导致在融合过程中保留冗余信息、丢弃关键信息[26], 从而限制模型性能.
为了解决上述问题, 本文提出融合级联频域特征的信息微观扩散预测模型(Information Microsco-pic Diffusion Prediction Integrating Cascaded Frequency Domain Features, IMDP_ICF), 通过傅立叶变换将级联的时域特征映射到频域, 充分利用信息传播中的频率特性, 结合低频分量和高频分量, 精准捕获级联的长期趋势与短期波动.此外, 为了更准确地刻画基于社交关系的用户特征与级联层面用户特征之间的相关性, 设计注意力融合层, 有效整合用户特征.相比传统的拼接操作和门控融合方法, IMDP_ICF引入注意力融合策略, 计算两个向量的相关性得分以提取和保留关键信息, 进一步提升预测的准确性.在4个真实数据集上的实验表明, IMDP_ICF的Hits@K得分和mAP@K指标都有所提升.
1 任务定义
用户的转发行为会受到社交同质性影响, 社交同质性是指在社交网络中相互关联的用户表现出相似的偏好特征.针对社交同质性, 本文基于用户的友谊关系, 构建社交友谊图GS=(U, ES), 其中, U表示用户节点集合, ES表示社交边的集合, 如果用户ui∈ U, uj∈ U之间存在社交关系, 将边eij保存至ES.一条级联
cm={(u1, t1), (u2, t2), …, (
记录信息m的顺序扩散过程, 其中ti表示用户被感染的时刻.历史级联的集合C={c1, c2, …, cM}, 其中, M表示级联个数.根据观察到的级联, 构建扩散超图HGD(U, ED), ED表示信息在用户间传播的超边集合, 一条超边包含参与同一个级联的所有用户.
级联扩散预测任务可定义为:给定社交图、扩散超图和目标级联, 预测未感染用户在下一时刻被感染的概率, 并根据概率进行排序.
2 融合级联频域特征的信息微观 扩散预测模型
本文提出融合级联频域特征的信息微观扩散预测模型(IMDP_ICF), 整体架构如图1所示.
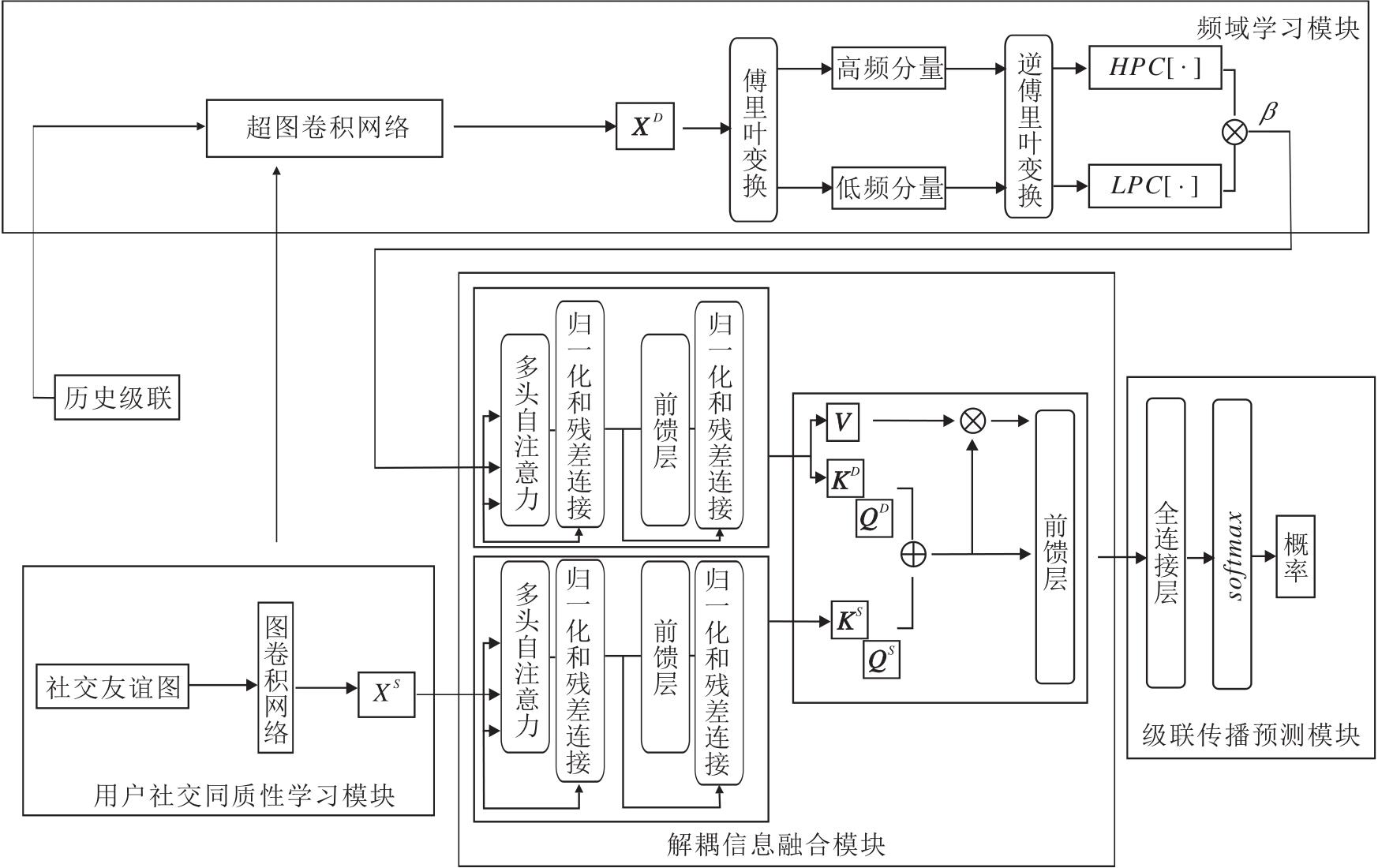 | 图1 IMDP_ICF总体框架图Fig.1 Overall framework of IMDP_ICF |
IMDP_ICF主要由四个模块组成.1)用户社交同质性学习模块.构建友谊图, 通过图卷积神经网络学习基于社交关系的用户表示.2)频域学习模块.通过扩散超图获得基于转发行为的用户表示, 在傅立叶域中学习级联的长期趋势与短期波动.3)解耦信息融合模块.学习级联内部的上下文交互特征, 融合两个层面的用户嵌入, 最大限度保留有效信息.4)级联传播预测模块.根据最终的用户表示, 计算候选节点被感染概率.
2.1 用户社交同质性学习模块
用户倾向于与兴趣相似的个体进行社交互动, 这体现社交同质性原则, 即关系亲密的朋友通常拥有共同的兴趣爱好.因此, 可通过友谊关系学习用户的社交同质性.对于未参与任何级联的用户, 通过社交友谊图探索其邻居特征, 从而推测其偏好, 可有效缓解冷启动问题.为此, 采用图卷积网络, 在社交友谊图上学习用户的社交同质性.经过两层图卷积神经网络得到所有用户的社交同质性表征:
US=[U
其中, 通过正态分布随机初始化获得用户的初始表示U
$ \boldsymbol{U}_{S}^{l+1}=\operatorname{ReLU}\left(\widetilde{\boldsymbol{D}}_{S}^{-\frac{1}{2}} \widetilde{\boldsymbol{A}}_{S} \widetilde{\boldsymbol{D}}_{S}^{-\frac{1}{2}} \boldsymbol{U}_{S}^{l} \boldsymbol{W}_{S}\right), l=0, 1, \cdots, L-1, $
WS表示可训练的参数矩阵,
2.2 频域学习模块
由于社交同质性不能准确体现用户交互偏好, 本节基于历史级联, 构建传播超图, 在级联层面学习用户交互信息, 并利用傅立叶变换捕获级联长期趋势与短期波动.
2.2.1 扩散超图卷积
超图包含用户与级联的交互信息, 首先利用超图注意力网络获取全局信息.超图卷积分为两个阶段:超节点到超边、超边到超节点.聚合超边ej中的所有超节点在l层的表示ui, 更新该条超边在l+1层的特征:
$ \boldsymbol{e}_{j}^{l+1}=\operatorname{ReLU}\left(\sum_{u_{i} \in e_{j}} \alpha_{i j} \boldsymbol{W}_{1} \boldsymbol{u}_{i}^{l}\right)$
其中:W1∈ Rd× d表示可训练的权重矩阵, d表示嵌入维度.为了提高模型的表达能力, 超图注意力网络使用从友谊图中学到的用户表示US作为初始输入, 而不是从正态分布中初始化用户表示;
$\alpha_{i j}=\frac{\exp \left(-\operatorname{dis}\left(\boldsymbol{W}_{1} \boldsymbol{u}_{i}, \boldsymbol{W}_{1} \boldsymbol{r}_{j}\right)\right.}{\sum_{u_{k} \in e_{j}} \exp \left(-\operatorname{dis}\left(\boldsymbol{W}_{1} \boldsymbol{u}_{k}, \boldsymbol{W}_{1} \boldsymbol{r}_{j}\right)\right)}, $
表示ui在ej中的注意力分数, ui、uj为超节点的表示, rj为第一个参与超边ej的节点, 因为该节点可部分反映级联的内容, 所以卷积过程保留该节点的信息, 并通过dis(· )计算超边ej中其它节点与rj的欧氏距离, 作为注意力分数.
然后, 将用户ui参与的所有超边信息聚合到用户ui, 以超边特征更新超节点, 过程可定义为
$ \boldsymbol{u}_{i}^{l+1}=\operatorname{Re} L U\left(\sum_{e_{p} \in \chi_{u_{i}}} \boldsymbol{W}_{2} \boldsymbol{e}_{j}^{l+1}\right), $
其中,
经过超图注意力卷积网络学到基于转发行为的用户表征UD∈ RN× d.
2.2.2 级联长期与短期趋势学习
傅立叶变换是数字信号处理的关键步骤之一, 它将一系列值投射到频域.给定目标级联cm, 从UD中查找参与级联cm的用户表示
其中|cm|表示级联cm的真实长度.再通过傅立叶变换, 将级联序列表示矩阵
fj=
组成, 其中, i表示虚数单位, j表示第j行.
F(
低频分量是指传播信号中变化缓慢的部分, 反映级联传播的全局趋势和宏观行为, 对应传播过程中的长期特征或整体扩散模式.例如:长期关注某一主题的核心用户群体或信息在较长时间内缓慢扩散, 形成稳定的传播路径, 这种情况下的传播信号在频域中表现为低频成分.高频分量是指传播信号中变化快速的部分, 反映级联传播的局部特性和细节行为, 对应传播中的短期波动或局部活跃现象.相比高频信号, 低频信号更稳定, 然而如果只使用低频分量会导致过平滑的问题, 因此IMDP_ICF选择性地利用高频信号, 并学习如何更好地融合低频分量与高频分量.提取的目标级联cm的低频信号(共同信号)为:
LPC[
提取的高频信号(局部波动信号)为:
HPC[
其中:
为了更好地融合低频分量和高频分量, 设置可训练的参数β , 调整频率比例, 融合级联频域特征的用户表示
2.3 解耦信息融合模块
2.3.1 级联上下文注意力增强模块
基于图的表示学习虽然能捕获用户之间的协同关系, 但在分析级联内部上下文交互信息方面存在不足.鉴于Transformer在序列推荐等顺序任务中的出色表现, IMDP_ICF使用多头自注意力模块, 进一步捕获目标级联中的上下文信息, 增强用户表示.以
作为级联上下文注意力增强模块的输入, 则
其中,
$\operatorname{Att}(\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V})=\operatorname{softmax}\left(\frac{\boldsymbol{Q} \boldsymbol{K}^{\mathrm{T}}}{\sqrt{d h_{1}^{-1}}}+\text { Mask }\right) \boldsymbol{V}$,
h1表示多头注意力的头数, Mask表示为了避免信息泄露引入的掩码矩阵, 当i≤ j时为0, 否则为-¥ , W
最后, 使用两层的全连接神经网络作为前馈层, 获得增强的用户表示:
其中, W3、W4表示可学习的参数矩阵, b1、b2表示偏置参数.
类似地, 也以同样的方式获得
2.3.2 注意力融合模块
为了获得最终的用户表示, 融合
$\begin{array}{l}\boldsymbol{a t t t}_{i}^{D}=\left(\boldsymbol{X}_{m}^{D^{\prime}} \boldsymbol{W}_{i}^{Q_{2}}\right)\left(\boldsymbol{X}_{m}^{D^{\prime}} \boldsymbol{W}_{i}^{K_{2}}\right)^{\mathrm{T}}, \\\boldsymbol{a t t}_{i}^{S_{i}}=\left(\boldsymbol{X}_{m}^{S^{\prime}} \boldsymbol{W}_{i}^{Q_{3}}\right)\left(\boldsymbol{X}_{m}^{S^{\prime}} \boldsymbol{W}_{i}^{K_{3}}\right)^{\mathrm{T}}, \end{array}$
其中W
fus-atti=at
最后, 拼接所有注意力头的输出并送入前馈层, 在前馈神经网络中结合多层感知器和ReLU激活函数, 进一步捕获非线性特征:
Xm=ReLU(fus_hmW5+b3)W6+b4,
其中
fus_hm=[h1, m, h2, m, …,
$\boldsymbol{h}_{i, m}=\operatorname{softmax}\left(\frac{\boldsymbol{f u s}_{\boldsymbol{u}} \boldsymbol{a} \boldsymbol{t t}_{i}}{\sqrt{d h_{2}^{-1}}}\right)\left(\boldsymbol{X}_{m}^{D^{\prime}} \boldsymbol{W}_{i}^{V_{2}}\right), $
W
注意力融合模块不仅有效解决特征冗余和关键信息丢失的问题, 还避免由异构嵌入的混合关联引起的不必要的注意力随机性, 实现合理稳定的自关注, 提高模型的表达能力.
2.4 级联传播预测模块
将融合的特征表示Xm通过全连接层, 计算用户参与级联的概率:
其中, Wp表示将Xm映射到特定空间的参数矩阵, Maskp表示用于屏蔽预测之前被激活的用户.本文采用交叉熵损失函数作为约束, 定义如下:
$L_{\mathrm{CE}}(\theta)=-\sum_{i=2}^{\left|c_{m}\right|} \sum_{j=1}^{|U|} y_{i j} \ln \left(p_{i j}\right)$,
其中, θ 表示所有可训练的参数集合, pij表示第i个参与级联cm的用户为uj的概率, yij表示真实标签, 如果uj为第i个参与级联cm的用户, yij=1, 否则yij=0.
3 实验及结果分析
3.1 实验设置
3.1.1 实验数据集
本文选择在Douban、Android、Memetracker、Chris-tianity这4个公开数据集上评估模型性能, 数据集的统计信息如表1所示.
| 表1 实验数据集 Table 1 Experimental datasets |
1)Douban数据集.从豆瓣网站收集, 在该网站上用户可关注其他用户, 还可分享、转发、评论他们喜爱的书籍或电影.一本书或一部电影被视为一个信息项, 如果用户标记阅读或观看它, 认此用户参与这条信息的传播.
2)Android数据集.从社区问答网站Stack Ex-change收集, 包含用户关于安卓主题在不同渠道的互动.
3)Memetracker数据集.收集在线网站上2008年8月至10月的新闻故事和博客文章, 将使用最频繁的引用和短语视为模因.每个模因都是一个信息项, 网站的每个URL被视为一位用户, 没有潜在的社交图谱.
4)Christianity数据集.来源同Android数据集, 包含用户就基督教主题在Stack Exchange网站的互动.
3.1.2 评价指标
根据定义, 信息微观扩散预测任务可视为一种检索问题.因此, 本文采用信息检索任务中常用的模型排序性能评价指标mAP@K和Hits@K进行评估, K=10, 50, 100, 指标值越高, 模型预测性能越优.
1)mAP@K.计算前K个预测结果的平均精度, 并考虑用户在排名预测结果中的顺序.具体公式如下:
$m A P @ K=\frac{1}{\sum_{c_{m} \in C}\left|c_{m}\right|} \sum_{j=2}^{\left|c_{m}\right|} A P @ K(j), $
其中,
$ A P @K=\sum_{k=1}^{K}\left(\frac{n}{k} \cdot \operatorname{rel}(k)\right)$,
AP@K(j)表示级联cm第j个位置的AP@K, n表示被感染用户的真实个数, rel(k)表示二值函数, 若排名第k的用户被准确预测, rel(k)=1, 否则, rel(k)=0.
2)Hits@K.计算前K个预测结果中包含实际被感染用户的概率, 不考虑排名顺序.具体公式如下:
$ \text { Hits@} K=\sum_{c_{m} \in C}\left(\frac{1}{K} \sum_{i \in c_{m}} I\left[r_{i}^{m}< K\right]\right), $
其中, I[· ]表示指示函数, 若括号中条件满足, 返回1, 否则返回0,
3.1.3 实验环境
所有实验在Linux操作系统上进行, GPU为GeForce GTX 4070Ti, 内存为12 GB.利用PyTorch框架实现IMDP_ICF, 参数更新使用Adam(Adaptive Moment Estimation)优化器, 设置学习率为0.001, 丢弃率为0.3, 批大小为64, 嵌入维数为64, 多头注意力机制的头数量为14.由于级联长度存在显著差异, 为了便于训练, 并确保进行公正对比, 总体实验部分将级联长度标准化为200.此外, 使用两层图卷积网络学习用户社交同质性, 并利用单层超图注意力卷积网络学习级联层面的用户表示.每个数据集随机选择80%级联用于训练, 10%级联用于验证, 剩余10%级联用于测试.对于所有基线模型, 保留原文献中建议的参数设置.
3.2 对比实验
为了验证IMDP_ICF的有效性, 选择如下模型进行对比.
1)NDM[15].简化复杂的信息扩散机制, 采用注意力机制和卷积网络建模级联, 提高模型泛化能力.
2)Topo-LSTM[16].将顺序级联重构为有向无环图, 并扩展标准长短期记忆网络, 模拟信息扩散过程.
3)DeepDiffuse[17].利用循环神经网络和注意力机制, 对受影响的级联用户进行顺序建模.
4)SNIDSA[18].通过循环神经网络学习级联的顺序信息, 计算扩散路径的结构注意力, 共同学习异构信息表征, 从而探索扩散路径和社会网络.
5)DyHGCN[22].将时间信息编码到社交图和动态扩散图中构建异构图, 动态学习用户偏好.
6)MS-HGAT[23].构建一系列超图, 动态描述用户与级联之间的交互, 并利用记忆和门控机制有效存储和融合特征.
7)FOREST[24].利用门控循环单元学习序列特征, 通过图卷积网络提取网络结构信息, 实现对信息扩散过程的有效预测.
8)MINDS[25].利用宏观预测结果指导微观预测, 增强两个任务的内在联系, 并引入对抗训练和正交性约束, 减轻特征冗余并确保共享特征的完整性.
9)Inf-VAE(Variational Autoencoder Frame-work)[35].通过图神经网络嵌入社会同质性, 并基于变分自编码器设计一个共同关注的融合网络, 整合社会和时间变量.
各模型在4个公开数据集上的指标值结果如表2和表3所示, 表中黑体数字表示最优值, 斜体数字表示次优值.由表得出如下结论.IMDP_ICF在Hits@K和mAP@K指标上明显优于对比模型.相比排名次优的MS-HGAT和MINDS, IMDP_ICF并未采用划分子图的方式获取局部信息和全局信息, 而是构建全局扩散图, 从频域角度学习级联与用户之间的深层关系, 并利用注意力机制有效融合特征.
| 表2 各模型在4个数据集上的mAP@K值对比 Table 2 mAP@K value comparison of different models on 4 datasets % |
| 表3 各模型在4个数据集上的Hits@K对比 Table 3 Hits@K value comparison of different models on 4 datasets % |
总之, 基于图的方法(FOREST和Inf-VAE)在性能上优于依赖卷积神经网络和注意力机制的方法(NDM), 而仅关注静态用户关系的模型(SNIDSA)或仅侧重于传播序列信息建模的模型(Topo-LSTM和DeepDiffuse)的表现均不及能同时建模社交关系和信息级联的方法(DyHGCN).实验表明, 从扩散图中学习用户表示能更加有效提升预测精度.IMDP_ICF综合两方面的优势:一方面从用户友谊关系中挖掘社交同质性因子, 另一方面从级联信息中提取社会影响因子, 从而更精准预测目标用户未来的转发行为.
此外, 现有方法通常仅关注级联的时域信息, 而未充分利用频域特性.相比基于时域建模的方法(MS-HGAT和MINDS), 融合级联频域特征的方法分析级联的频谱, 能同时捕获级联的长期趋势与短期波动, 具备更强的表现力.在Douban、Android、Memetracker数据集上, IMDP_ICF在mAP@K和Hits@K指标上平均提升超12%和5%.尤其在Douban数据集上, IMDP_ICF在mAP@10指标上提升23%.即使在缺少社交图的Memetracker数据集上, IMDP_ICF通过对扩散图的建模, 性能仍优于对比模型, 表现出较强的灵活性.在Christianity数据集上, 尽管IMDP_ICF在mAP@100指标上比MINDS降低2%, 但在其它指标上更具有竞争力.
上述实验结果验证IMDP_ICF在扩散预测任务中的有效性, 总体性能优于对比模型, 反映其在信息扩散预测任务中的优势.
3.3 消融实验
为了验证IMDP_ICF每个模块的有效性, 在4个数据集上进行消融实验.IMDP_ICF的7个变体如下.
1)w/o GF.移除社交图, 仅在扩散超图上学习用户表示, 不再考虑社交同质性对用户的影响.
2)w/o GD.移除扩散超图, 仅在友谊图上学习用户表示, 不再考虑社会影响对用户的影响.
3)w/o FFT.移除傅立叶变换, 扩散图经过超图卷积后, 不再进行傅立叶变换, 直接进行级联内部上下文信息学习.
4)w/o AF.移除注意力融合机制, 使用门控融合机制融合两方面的用户特征.
5)w/o LP.不使用低频分量, 仅使用高频分量.
6)w/o HP.不使用高频信息, 仅使用低频分量.
7)w FFT.使用傅立叶变换.
具体消融实验结果如表4和表5所示, 表中黑体数字表示最优值.由表可见, 社交图和扩散超图在用户依赖建模中起到基础性作用, 移除社交图或扩散超图后, 在4个数据集上模型性能均明显下降.在Christianity、Android数据集上, 仅对扩散超图建模比仅对社会联系建模得分更高, 这表明扩散依赖比社会联系作用更显著.上述情况在Douban数据集上则相反, 这是因为在豆瓣数据集上, 只有交互超过二十次的用户才被认为存在朋友关系, 所以该数据集的社会关联包含更多的有效信息.由于Memetracker数据集没有潜在社交图, 故去掉扩散超图后通过随机初始化获得用户表示.当同时构建社交图和扩散超图但不再利用傅立叶变换时, 模型性能依然低于IMDP_ICF, 这是因为频域信息的缺失导致模型无法准确获取用户行为的全貌, 难以有效区分重要的传播模式与偶然的波动, 从而导致性能下降.相比门控融合机制, 注意力融合策略通过动态权重分配捕捉复杂的依赖关系, 能实现更精细的信息融合.将注意力融合机制替换为门控融合机制后模型性能出现下降, 这验证本文的假设:门控机制容易导致信息冗余和重要特征的丢失, 而注意力融合机制则有效避免这一问题.
| 表4 各模块在4个数据集上的mAP@K值对比 Table 4 mAP@K value comparison of different modules on 4 datasets % |
| 表5 各模块在4个数据集上的Hits@K值对比 Table 5 Hits@K value comparison of different modules on 4 datasets % |
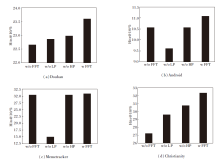
为了进一步验证频域信息的有效性, 分别对高频分量和低频分量进行实验, 具体Hits@10值如图2所示.
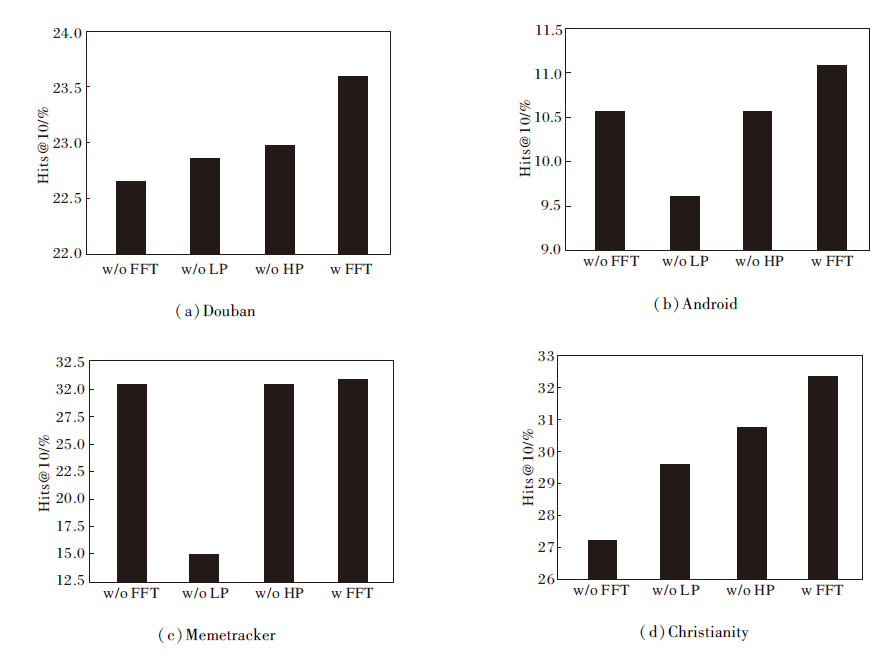 | 图2 高频分量和低频分量对IMDP_ICF性能的影响Fig.2 Effect of high-frequency and low-frequency components on IMDP_ICF performance |
级联的低频信息和高频信息共同构成一个完整的传播动态图景, 忽视其中任何一部分都会降低模型对信息传播过程的理解与预测能力, 进而影响预测精度和可靠性.低频分量通常包含信息传播的长期趋势、渐进性和核心模式, 这些特征对于深入理解信息传播过程至关重要.如果缺失低频信息, 模型可能失去对长期影响的把握, 导致显著的性能下降.相比之下, 高频信息更多地反映传播过程中的短期波动, 尽管它的缺失会影响短期预测的精度, 但对整体性能的影响通常不如低频信息的缺失显著.因此, 在4个数据集上, 缺失低频分量时, IMDP_ICF性能下降明显高于缺失高频分量的情况.特别是在Memetracker数据集上, 当低频信息被丢弃时, 模型性能骤降, 这可能是因为高频信息中包含大量噪声, 而这些噪声会干扰预测精度.
3.4 超参数敏感性分析
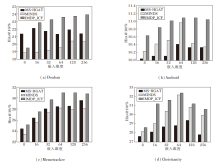
本节进一步对IMDP_ICF的关键参数进行敏感性分析实验, 确定它们对预测性能的影响, 选择的对比模型为MS-HGAT[23]和MINDS[25].
定义嵌入维度为8, 16, 32, 64, 128, 256, 研究其对模型性能的影响, 具体Hits@10值如图3所示.由图可见, 相比MS-HGAT和MINDS, IMDP_ICF在不同维度上都具有更优的表征能力.
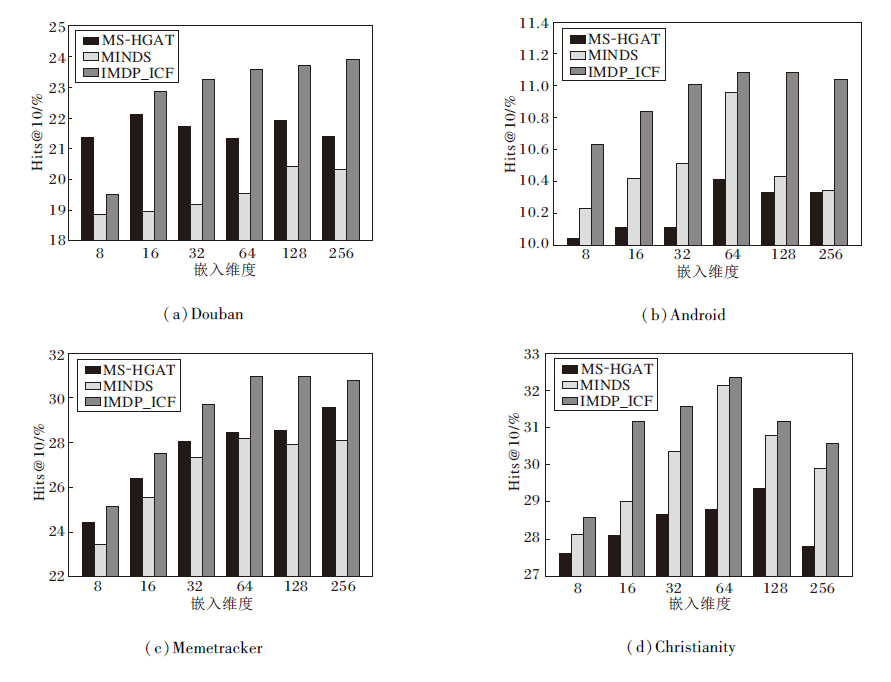 | 图3 嵌入维度对模型性能的影响Fig.3 Effect of embedding dimension on model performance |
在Douban数据集上IMDP_ICF的Hits@10分数随维度的增加而持续增加, 因为更大的维度可能更准确表示复杂的扩散关系.当维度超过128时, MS-HGAT和MINDS的性能达到饱和, 甚至过拟合, 导致模型性能下降, 这表明IMDP_ICF具有更强的学习能力.
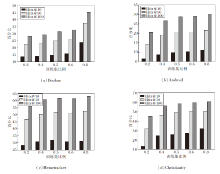
为了探讨级联长度对性能的影响, 定义级联最大长度为50, 100, 200, 300.由于级联长度增加会提高预测难度, 模型性能通常会随着级联长度的增加而下降.3种模型的Hits@10值对比结果如图4所示.由图可知, MS-HGAT在Douban、Memetracker数据集上的表现优于MINDS, 而MINDS在Android、Christianity数据集上的表现优于MS-HGAT, 但IMDP_ICF的表现始终优于对比模型, 且MS-HGAT和MINDS的性能随级联长度增加出现大幅下降, 而IMDP_ICF的性能下降到一定程度后表现稳定, 表明IMDP_ICF具有较强的鲁棒性.
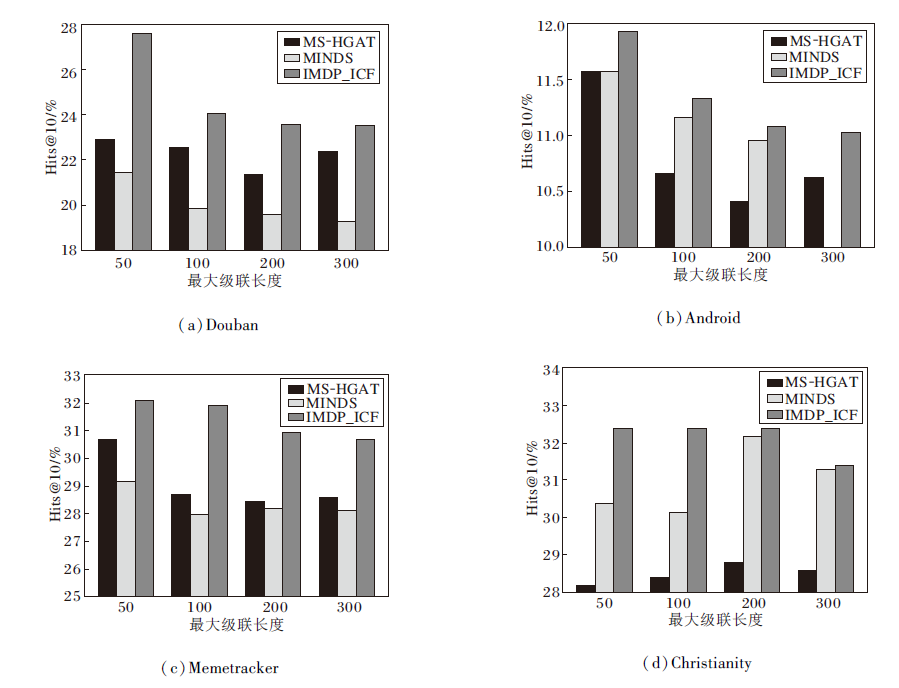 | 图4 最大级联长度对模型性能的影响Fig.4 Effect of maximum cascade length on model performance |
用户社交图是基于训练集构建的, 因此训练集的数量和质量对模型性能具有重要影响.本节进一步探讨当训练集比例在{0.2, 0.4, 0.5, 0.6, 0.8}范围内变化时对预测性能的影响, 其中0.2表示使用训练集上20%的数据构建用户友谊图和扩散超图.选取Hits@K作为评价指标, 在4个数据集上的结果如图5所示.由图可见, 在Douban数据集上, 用户之间的朋友关系需要多次互动才能建立, 社交关系的形成和信息传播的过程是渐进的.这种长期互动的模式需要较大的数据量来学习, 尤其是在使用频谱分析方法时, 需要通过长时间的历史数据识别和捕捉长期的传播趋势和规律.
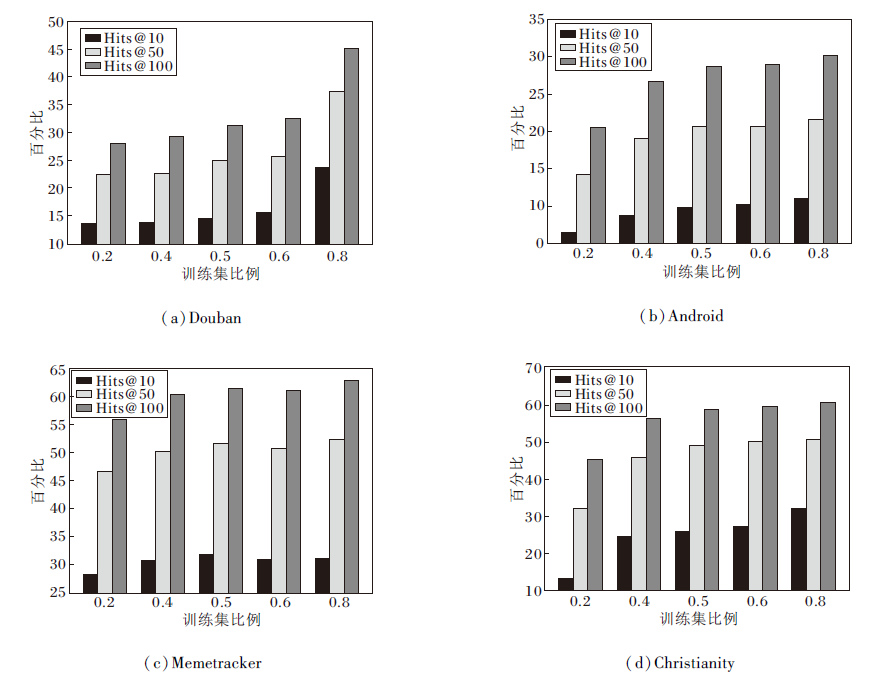 | 图5 训练集比例对IMDP_ICF性能的影响Fig.5 Effect of training proportion on IMDP_ICF performance |
当训练数据量不足时, 模型可能难以识别这些长期模式, 导致预测性能较低.因此, 在Douban数据集上, 需要使用80%的训练数据才能显著提升模型性能.
Android、Christianity数据集上基于真实社交关系构建用户友谊关系, 仅需50%的训练数据, IMDP_ICF就能达到较优性能, 并保持较高的稳定性, 而对于没有潜在社交图的Memetracker数据集, 训练集比例对模型性能的影响较小.
4 结束语
本文提出融合级联频域特征的信息微观扩散预测模型(IMDP_ICF), 通过独特的频谱表示, 准确有效捕捉信息传播过程中的全局趋势与局部波动, 从而确保模型既能进行长期预测, 又能精准进行短期预测.此外, 注意力融合策略有效过滤冗余信息并保留关键信息, 有助于精确进行信息微观扩散预测.最后, 在4个公开数据集上与多个基准模型的对比实验验证IMDP_ICF的先进性.今后将进一步探索基于频率的深层次机制, 深入研究频谱在信息级联预测中的有效性和可解释性.
本文责任编委 林鸿飞
Recommended by Associate Editor LIN Hongfei
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|