{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于自适应组合滤波器的谱图神经网络
引用本文
李伟诺, 黄梅香, 卢福良, 屠良平. 基于自适应组合滤波器的谱图神经网络. 模式识别与人工智能, 2024,37(12): 1069-1082
LI Weinuo, HUANG Meixiang, LU Fuliang, TU Liangping. Spectral Graph Neural Network Based on Adaptive Combination Filters. PATTERN RECOGNITION AND ARTIFICIAL INTELLIGENCE, 2024,37(12): 1069-1082.
Doi: 10.16451/j.cnki.issn1003-6059.202412003
LI Weinuo, HUANG Meixiang, LU Fuliang, TU Liangping. Spectral Graph Neural Network Based on Adaptive Combination Filters. PATTERN RECOGNITION AND ARTIFICIAL INTELLIGENCE, 2024,37(12): 1069-1082.
Permissions
Copyright©2024, 《模式识别与人工智能》编辑部
《模式识别与人工智能》编辑部
基于自适应组合滤波器的谱图神经网络

黄梅香,博士,讲师,主要研究方向为图像处理、深度学习.E-mail:mxiang_huang@163.com.
作者简介:

李伟诺,硕士研究生,主要研究方向为机器学习、图神经网络.E-mail:mnwnli@163.com.

卢福良,博士,教授,主要研究方向为图论及其应用.E-mail:flianglu@163.com.

屠良平,博士,教授,主要研究方向为机器学习、人工智能.E-mail:tuliangping@ustl.edu.cn.
摘要
谱图神经网络(Spectral Graph Neural Networks, SGNNs)在处理同配图数据时性能较优.然而,现有的SGNNs大多基于拉普拉斯矩阵的多项式近似设计滤波器,难以有效捕获图谱信号中的高频部分,进而限制其在异配图数据上的应用.此外,基于拉普拉斯矩阵设计的滤波器仅反映图拓扑的全局结构特征,无法灵活适应图数据中复杂的局部模式.为此,文中提出基于自适应组合滤波器的谱图神经网络(Spectral Graph Neural Network Based on Adaptive Combination Filters, ACGNN),从非多项式基的角度出发,组合图拉普拉斯矩阵的特征向量和特征值,设计根据节点邻域模式进行划分的组合滤波器,有效捕捉和学习不同节点的邻域结构模式.同时,在滤波器函数中加入与节点特征相关的参数矩阵,使滤波器能根据节点特征自适应调整权重.在5个同配图数据集和3个异配图数据集上的实验表明ACGNN的有效性和优越性.
关键词:
谱图神经网络; 异配图; 组合滤波器; 节点分类
中图分类号:TP391
Spectral Graph Neural Network Based on Adaptive Combination Filters
HUANG Meixiang, Ph.D., lecturer. Her research interests include image processing and deep lear-ning.)
About Author:
LI Weinuo, Master student. His research interests include machine learning and graph neural network.
LU Fuliang, Ph.D., professor. His research interests include graph theory and applications.
TU Liangping, Ph.D., professor. His research interests include machine learning and artificial intelligence.
Abstract
Spectral graph neural networks(SGNNs) exhibit strong performance in processing homophilic graph data. However, most existing SGNNs design filters based on polynomial approximations of Laplacian matrix, which struggle to effectively capture high-frequency components of graph signals. Consequently, their performance on heterophilic graphs is limited. Additionally, filters based on Laplacian matrix can only capture global structural features of graph topology, limiting their adaptability to complex local patterns in graph data. To overcome these limitations, a spectral graph neural network based on adaptive combination filters(ACGNN) is proposed. Instead of using polynomial bases, eigenvectors and eigenvalues of Laplacian matrix are combined to design a filter by partitioning node neighborhood patterns, and the filter can effectively capture and learn diverse node neighborhood structural patterns. Moreover, the filter can adaptively adjust weights based on node characteristics by integrating a parameter matrix associated with node features into the filter function. Experimental results on both homophilic and heterophilic graph datasets validate the effectiveness and superior performance of ACGNN.
Key words:
Key Words Spectral Graph Neural Network; Heterophilic Graph; Combination Filters; Node Classification
图神经网络(Graph Neural Networks, GNNs) 作为分析图数据的有效工具, 在与图相关的应用领域表现出色, 如社交网络分析[1, 2]、推荐系统[3, 4]、药物发现[5, 6]、交通流量预测[7]等.图机器学习领域的一个常见假设是同配性[8, 9], 即连接的节点倾向于彼此共享相似的属性, 这种假设也是GNNs在部分图数据上取得优秀表现的关键因素之一.
然而, 越来越多的工作发现, GNNs在面对现实世界图数据时并不总是优于传统的神经网络[10, 11].这主要是因为在现实中存在大量的异配图, 这类图由多种不同类型的节点和边构成.在异配图中, 节点和边不仅在结构上有差异, 还可携带不同的属性或表示不同的关系.以知识图谱为例[12], 节点可表示人物、地点、事件、概念等不同类型的实体, 边可表示实体之间的各种关系, 如“ 某人出生在某地” 、“ 某事件发生在某时间” 等.对于一个固定的图拓扑结构, 当结合不同下游任务的不同标签分布时, 图的同配性可能会有所不同.以社交网络为例, 用户通常会与具有相似兴趣的其他用户建立连接.因此, 如果以用户的兴趣爱好作为标签, 社交网络图可能会表现出较高的同配性.然而, 如果以用户年龄作为标签, 则社交网络图可能会表现出异配性或随机性, 因为不同年龄的用户混合后, 可能没有明显的聚集趋势.
由于下游任务与图结构之间相关性的不可预测, 不同区域之间可能存在不同的子图模式.即使是强同配图也会有少量随机或异配的局部模式, 即某些节点的邻居标签分布可能是随机或异配的[13].因此, 同配性假设阻碍GNNs对异配图等更普遍的图数据的发展[14].
现有的GNNs大致可分为空间域GNNs[15, 16, 17, 18]和谱域GNNs[19, 20, 21].空间域GNNs通过消息传递范式或注意力网络结构学习图节点表示.谱域GNNs基于谱图理论[22]和图信号处理[23], 对图拉普拉斯矩阵进行谱分析, 利用卷积定理定义谱图滤波器.空间域GNNs在给定图拓扑结构下从邻居节点聚合特征, 但面对异配图中复杂的子图模式, 直接聚合邻居节点的信息可能会降低模型的表达能力[10].
近年来, 图的异配性问题受到学者们的关注, 越来越多的研究在打破以往GNNs的同配性限制方面进行探索.空间域GNNs主要集中在各种聚合方案设计[24, 25]和关系重估计(即图重布线)[26, 27, 28]上, 以此增强对异配图的处理能力.尽管这些方法取得一定进展, 但往往会引入额外的计算复杂度[29].另一方面, 谱域GNNs主要通过组合系数自适应学习滤波器模型[30]和通过高阶多项式近似学习适合的全局滤波器[31, 32, 33], 不仅扩展GNNs对不同类型图数据的适用性, 还具备更好的可解释性.然而, 大多数基于多项式近似的方法在拟合高频信号方面存在局限性[34], 主要贡献通常集中在前几项, 更倾向于学习中低通滤波器, 难以应对异配图上复杂的谱信号频率变化[35].此外, 全局滤波器建模无法捕捉局部结构模式的变化, 对于包含复杂局部结构模式的图数据, 效果仍待提升[13].
不论是同配图还是异配图, 图中均存在复杂的子图模式, 而这些子图的同配性和结构模式在局部上并不一致.为此, 本文提出基于自适应组合滤波器的谱图神经网络(Spectral Graph Neural Network Based on Adaptive Combination Filters, ACGNN).将每个节点的局部邻域视为子图, 从局部子图角度分析图数据.使用非多项式基学习滤波器, 精准捕获信号变化.分析拉普拉斯矩阵的特征向量和特征值, 设计基于节点邻域模式划分的组合滤波器, 有效区分不同节点的邻域子图模式.此外, 在滤波器函数中引入与节点特征相关的参数矩阵, 使滤波器可根据节点特征自适应调整权重.实验表明, ACGNN在基于8个真实世界数据集的节点分类任务上取得较优性能, 在大多数任务上获得一定的性能提升.
1 相关知识
1.1 符号定义
给定图G=(V, E), 其中, V表示节点集合, E表示边集合.若ei, j∈ E, 则节点vi、vj之间有边相连.A表示图G的邻接矩阵, 若节点vi、vj之间有连边, Aij=1, 否则Aij=0, 即A描述图G的拓扑结构信息.
对于每个节点v, Np(v)表示第p阶邻域, N≤ p(v)表示p阶内邻域.
通常, 归一化邻接矩阵
其中D表示度矩阵.因此, 图G的归一化拉普拉斯矩阵定义为
L=I-
其中I表示单位矩阵.由于L的实对称性, 可特征分解为UΛ UT, 其中特征向量矩阵
U=[u1, u2, …, un]T,
特征值构成的对角矩阵
Λ =diag[λ 1, λ 2, …, λ n],
λ i∈ [0, 2], i∈ {1, 2, …, n}.
给定图G上的节点特征矩阵(信号)
X=[x1, x2, …, xn]T, i∈ {1, 2, …, n},
其中xi表示第i个节点vi的特征属性.
此外, 对于节点分类任务, 节点v的类标签
yv={1, 2, …, C}∈ Y,
其中, Y表示类标签集合, C表示类的个数.
1.2 图傅里叶变换
根据谱图理论和图信号处理, 图拉普拉斯矩阵的特征值λ 表示图G拓扑结构信号的频率.给定一个图信号x, 其图傅里叶变换定义为
傅里叶逆变换[36]定义为
x=U
根据图傅里叶变换和拉普拉斯矩阵的特征分解, 作用于信号x的谱滤波器为:
$\hat{\boldsymbol{g}}(\boldsymbol{L}) \boldsymbol{x}=\sum_{i=1}^{n} \hat{\boldsymbol{g}}\left(\lambda_{i}\right) \boldsymbol{u}_{i} \boldsymbol{u}_{i}^{\mathrm{T}} \boldsymbol{x}=\boldsymbol{U} \hat{\boldsymbol{g}} \boldsymbol{U}^{\mathrm{T}} \boldsymbol{x}$, (1)
其中
$\begin{array}{l}\hat{\boldsymbol{g}}=\hat{\boldsymbol{g}}(\boldsymbol{\Lambda})=\operatorname{diag}\left[\hat{\boldsymbol{g}}\left(\lambda_{1}\right), \hat{\boldsymbol{g}}\left(\lambda_{2}\right), \cdots, \hat{\boldsymbol{g}}\left(\lambda_{n}\right)\right], \\\boldsymbol{g}=\boldsymbol{U} \hat{\boldsymbol{g}} .\end{array}$
根据卷积定理, 式 (1) 可改写为空间图卷积的形式:
x* G g=U((UTg)☉(UTx)),
其中, * G表示图卷积算子, ☉表示哈达玛乘积.
1.3 基于多项式的频谱滤波
早期的谱域GNNs直接对拉普拉斯矩阵进行特征分解, 并使用特征向量作为傅里叶基.然而, 谱分解的计算成本较高, 尤其在处理大规模图时问题更突出.为了避免拉普拉斯特征向量的显式计算, 随后的研究尝试使用各类多项式逼近图谱滤波器.可利用切比雪夫多项式将滤波器逼近为[20]:
$\hat{g}\left(\lambda_{i}\right) \approx \widehat{P}_{K}\left(\lambda_{i}\right)=\sum_{k=0}^{K-1} \alpha_{k} \hat{p}_{k}\left(\lambda_{i}\right)$, (2)
其中,
$\hat{\boldsymbol{g}}(\boldsymbol{L}) \boldsymbol{x} \approx \sum_{k=0}^{K-1} \alpha_{k} \boldsymbol{U} \hat{p}_{k}(\boldsymbol{\Lambda}) \boldsymbol{U}^{\mathrm{T}} \boldsymbol{x}=\sum_{k=0}^{K-1} \alpha_{k} \hat{p}_{k}(\boldsymbol{L}) \boldsymbol{x}, $
1.4 图的随机性指标
节点同配比[11]和边同配比[24]是衡量图同配性的常用指标.本文主要关注节点分类任务, 因此仅考虑节点邻域的标签一致性, 故选择节点同配比度量图的同配性.对于图G, 其节点同配比为:
$H_{G}=\frac{1}{V} \sum_{v \in V} h_{N_{1}}(v)$,
其中
其中, ym表示节点m的类标签, yv表示节点v的类标签.
HG是面向整个图数据的总体评价指标, hN≤ p(v)作为节点级指标, 用于衡量单个节点的局部邻域同配性.对于图G, 将每个节点的邻域作为一个子图, hN≤ p(v)能反映图中包含的不同子图模式.然而, hN≤ p(v)仅考虑邻域标签的一致性, 忽略邻域标签的随机性.
为了研究局部邻域子图的标签随机性, Zheng等[13]提出标签熵的概念, 用于度量节点v的邻域标签分布, 定义如下:
$\begin{array}{l}S_{N_{\leqslant p}}(v)= \\\quad-\sum_{y \in Y}\left(\frac{\left|N_{\leqslant p}^{(y)}(v)\right|}{\left|N_{\leqslant p}(v)\right|}+\varepsilon\right) \log _{2}\left(\frac{\left|N_{\leqslant p}^{(y)}(v)\right|}{\left|N_{\leqslant p}(v)\right|}+\varepsilon\right), \end{array}$
其中
显然, 邻居节点的标签分布均匀时, 标签熵趋于最大.相反, 如果给定节点的邻居标签都属于同一类别, 标签熵最小.
1.5 多分辨率分析
多分辨率分析(Multiresolution Analysis, MRA)是一种将信号分解为不同分辨率层次的方法, 核心思想是利用逐级细化的子空间序列{Vj}j∈ Z分割有限能量空间L2(R), 其中
V0⊂V1⊂…⊂Vj⊂Vj+1⊂…⊂L2(R).
∀ j, {Wj}j∈ Z表示正交补空间序列, 满足
Vj+1=Vj⊕ Wj,
则L2(R)可分解为基础空间V0和正交补空间{Wj}j∈ Z的直和:
$L^{2}(\mathbf{R})=V_{0} \oplus W_{0} \oplus W_{1} \oplus \cdots$
对于信号函数f(t)∈ L2(R), 以二进制小波为例, MRA展开可通过尺度小波
Φ j, k(t)=Φ (2jt-k)∈ L2(R)
和母小波
Ψ j, k(t)=Ψ (2jt-k)∈ L2(R)
唯一表示为
$\begin{aligned}f(t)= & f_{0}(t)+\sum_{j=0}^{\infty} \omega_{j}(t)= \\& \sum_{k} a_{k} \Phi(t-k)+\sum_{j=0}^{\infty} \sum_{k} b_{j k} \Psi\left(2^{j} t-k\right), \end{aligned}$
其中, j表示缩放参数, k表示平移参数, f0(· )表示f(t)在V0中的信息分量, ω j(· )表示f(t)在Wj中的信息分量[37], ak表示信号在V0中的投影系数,
ak=< f(t), Φ (t-k)> ,
bjk表示信号在Wj中的投影系数,
bjk=< f(t), Ψ (2jt-k)> .
由于Vj-1⊂Vj⊂Vj+1属于严格包含关系, Vj中的尺度小波和Wj中的母小波可通过Vj+1中的尺度小波表示[35].所以正交补空间Wj的生成母小波Ψ j, k(· )可用尺度小波Φ j+1, k(· )替换表示为
$f(t)=\sum_{k} a_{k} \Phi(t-k)+\sum_{j=0}^{\infty} \sum_{k} b_{j k} \Phi\left(2^{j+1} t-k\right) .$ (3)
因此, 对于定义在空间L2(R)中的信号f(t), 通过多分辨率分析可对其进行逐层分解和重建.
2 基于自适应组合滤波器的谱图神经网络
2.1 基于节点邻域模式的组合滤波器
图上信号的平滑度是图信号处理中的一种有效度量方法, 用于衡量图中相邻节点间信号相似的可能性[36, 37, 38].拉普拉斯矩阵的特征值
λ i=
反映其相关特征向量ui在图上的平滑度[39], 即与较小特征值关联的特征向量表示具有缓慢变化的低频信号, 而与大特征值关联的特征向量表示具有快速变化的高频信号.
给定图上的信号x, 经过图傅里叶变换UTx, 有
其中{α i
ui
故{ui
对于具有相似邻域结构模式的局部子图, 频谱变化也趋于相似[40].通过节点邻域同配比
鉴于这些局部邻域模式的类型数量有限, 本文利用多分辨率分析的思想重建图谱滤波器, 提出简单的分段函数Se
Se
其中, s表示控制分割区间个数的缩放参数, k表示确定区间位置的平移参数.
分段函数Se
使用Se
$\begin{aligned}\hat{g}(\lambda)= & \sum_{k} a_{k} \operatorname{Seg}_{0}^{k}(\lambda)+\sum_{s=0}^{\infty} \sum_{k} b_{s k} \operatorname{Seg}_{s+1}^{k}(\lambda)= \\& \sum_{s=0}^{\infty} \sum_{k}\left\langle\hat{g}(\lambda), \operatorname{Seg}_{s}^{k}(\lambda)\right\rangle \operatorname{Seg}_{s}^{k}(\lambda) .\end{aligned}$
实际上, 每个图数据的局部邻域子图模式数量是有限的, 因此无需对滤波器进行无限细化, 只需选择合适的缩放参数s对其分割.此外, 由于系数<
$\begin{aligned}\hat{g}(\lambda) \approx & \sum_{k}\left\langle\hat{g}(\lambda), \operatorname{Seg}_{s}^{k}(\lambda)\right\rangle \operatorname{Seg}_{s}^{k}(\lambda)= \\& \sum_{k} \theta_{k} \operatorname{Seg}_{s}^{k}(\lambda)\end{aligned}$,
其中, θ k表示通过神经网络学到的权重参数, 对应组合滤波器在第k个频段的权重参数.
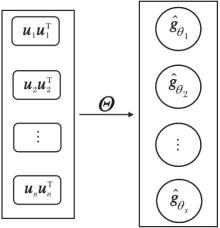
组合滤波器示意图如图1所示.基础滤波器{ui
1)当i≠ j时,
2)
 | 图1 组合滤波器示意图Fig.1 Schematic diagram of combination filters |
每个滤波器子集
$\hat{\boldsymbol{g}}_{\theta}=\sum_{k=1}^{s} \Theta_{k k} \operatorname{Seg}_{s}^{k}(\boldsymbol{\Lambda})$, (5)
其中
Θ =diag[θ 1, θ 2, …, θ s]
表示网络可学习参数.对于信号x,
$\boldsymbol{U} \hat{\boldsymbol{g}}_{\theta} \boldsymbol{U}^{\mathrm{T}} \boldsymbol{x}=\boldsymbol{U} \sum_{k=1}^{s} \Theta_{k k} \operatorname{Seg}_{s}^{k}(\boldsymbol{\Lambda}) \boldsymbol{U}^{\mathrm{T}} \boldsymbol{x} .$(6)
2.2 融合节点特征的自适应组合滤波器
当s→ +¥ , 式(4)可表示为
U
其等价于式(1).因此, 其本质上仍是一组针对图的拓扑结构信息进行学习的滤波器, 这些滤波器的参数是在整个图上训练的固定值.实际应用中的图数据通常包括节点特征和图的拓扑结构信息, 而式(6)构造的滤波器组仅针对图的拓扑结构信息进行学习, 并未融合图的节点特征.
图的拓扑结构通过边记录节点之间的连接关系, 这些边也可能因为不同的节点特征而具有不同的属性.因此, 在式(6)构造的组合滤波器的基础上引入节点特征, 学习节点之间的潜在关系, 有助于提高滤波器组在适应局部模式的变化方面的有效性和灵活性.
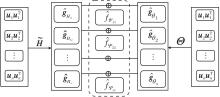
为了在滤波器的学习过程中整合图的节点特征与拓扑结构信息, 本文在滤波函数中引入一个非线性变换的节点特征矩阵H, 用于自适应引导滤波器组更新权重, 定义如下:
H=σ (XW* )T,
其中, W* ∈ Rn× s表示网络可学习参数矩阵, σ (· )表示激活函数.因此, 式(5)中的谱滤波函数
$\widehat{f}_{\Psi}=\sum_{k=1}^{s} \Psi_{k k} \operatorname{Se}_{s}^{k}(\boldsymbol{\Lambda})$, (7)
其中
Ψ =
$\widetilde{\boldsymbol{H}}=\operatorname{diag}\left[\sum_{j=1}^{n} h_{1 j}, \sum_{j=1}^{n} h_{2 j}, \cdots, \sum_{j=1}^{n} h_{s j}\right] .$
因此, 式(7)中
$\begin{array}{l}\widehat{\boldsymbol{U} f_{\Psi}} \boldsymbol{U}^{\mathrm{T}} \boldsymbol{x}=\boldsymbol{U} \sum_{k=1}^{s} \Psi_{k k} S e g_{s}^{k}(\boldsymbol{\Lambda}) \boldsymbol{U}^{\mathrm{T}} \boldsymbol{x}= \\\quad \boldsymbol{U} \sum_{k=1}^{s} \widetilde{H}_{k k} S e g_{s}^{k}(\boldsymbol{\Lambda}) \boldsymbol{U}^{\mathrm{T}} \boldsymbol{x}+\boldsymbol{U} \sum_{k=1}^{s} \Theta_{k k} \operatorname{Seg}_{s}^{k}(\boldsymbol{\Lambda}) \boldsymbol{U}^{\mathrm{T}} \boldsymbol{x} .\end{array}$(8)
自适应组合滤波器框架如图2所示.在式(8)中, Ψ 可分解为两组滤波器参数Θ 和
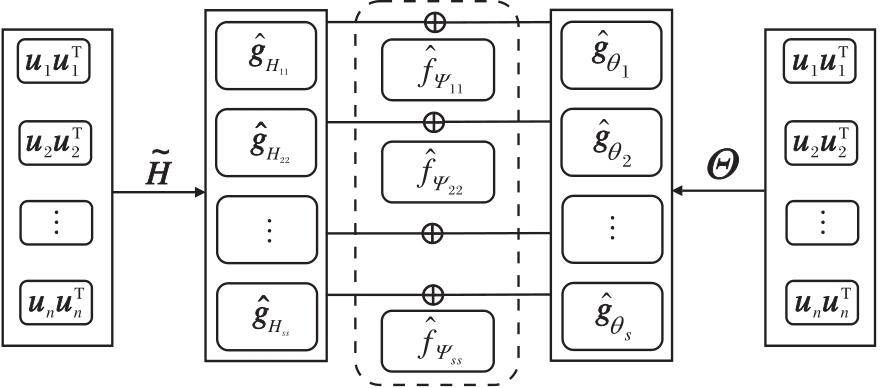 | 图2 自适应组合滤波器框架图Fig.2 Flowchart of adaptive combination filters |
2.3 方法架构
基于2.2节中描述的自适应组合滤波, 描述ACGNN的结构.
首先, 设X(0)∈ Rn× d为图节点特征矩阵, 对其进行两次独立的非线性变换, 分别得到
H=σ (X(0)W(1))T∈ Rn× s,
$\widetilde{\boldsymbol{X}}^{(0)}=\sigma\left(\boldsymbol{X}^{(0)} \boldsymbol{W}^{(2)}\right) \in \mathbf{R}^{n \times q}, $
其中, σ (· )表示激活函数, W(1)∈ Rd× s、W(2)∈ Rd× q表示网络可学习参数矩阵, s表示Se
节点特征矩阵在隐藏空间中的信息传播过程描述如下:
其中σ (· )表示激活函数.网络输出层为:
Z=softmax(
其中
$\operatorname{softmax}\left(\boldsymbol{x}_{i}\right)=\frac{\exp \left(\boldsymbol{x}_{i}\right)}{\sum_{j} \exp \left(\boldsymbol{x}_{j}\right)}$.
在训练过程中, 通过最小化所有标记节点的交叉熵误差更新网络参数, 即
$\text { Loss }=-\sum_{i \in y_{L}} \sum_{j=1}^{C} Y_{i j} \ln Z_{i j}, $
其中, yL表示标记节点的集合, Zij表示模型将第i个节点分配给j类的预测概率.
2.4 复杂度分析
ACGNN由组合滤波器和节点特征融合两个模块组成.组合滤波器的计算消耗主要集中在拉普拉斯矩阵的特征分解, 时间复杂度为O(n3), 但在模型处理中将其作为预处理步骤, 有效降低后续计算量.在节点特征融合模块中, 计算的主要开销集中在特征矩阵H的构建, 时间复杂度为O(nds), 其中, n表示节点数, d表示节点的特征维度, s表示缩放参数.由于s≪n, 故节点特征融合模块对整体模型的时间复杂度影响较小.
3 实验及结果分析
3.1 实验设置
为了全面评估ACGNN, 在如下8个不同规模的基准数据集上进行实验.1)5个同配图数据集:引文网络数据集Cora、CiteSeer、PubMed[41], 亚马逊联合采购关系图数据集Computers、Photo[42].2)3个异配图数据集:维基百科图谱数据集Chameleon、Squirrel[43], 演员共现网络数据集Actor[11].数据集统计信息如表1所示.
| 表1 实验数据集统计信息 Table 1 Statistical information of experimental datasets |
Cora、CiteSeer、PubMed数据集是3个标准的引文网络数据集, 每个节点表示一篇文章, 边表示节点间存在引用关系.节点特征对应每篇文章的描述词汇, 使用词袋模型编码.
Computers、Photo数据集是亚马逊共同购买图的两个导出子图, 在该类图中, 节点表示商品, 边表示两个商品经常被一起购买, 节点特征对应于产品评价, 使用词袋模型编码, 类别标签由产品类别决定.
Chameleon、Squirrel数据集是2个分别关于变色龙和松鼠主题的维基百科页面网络.节点表示2018年12月的英文维基百科文章, 边表示它们页面之间的相互引用链接.节点特征对应于文章中特定名词的出现情况和平均月流量(2017年10月至2018年11月).
Actor数据集是从电影-导演-演员-编剧网络中导出的仅包含演员的子图, 每个节点表示一个演员.若两个节点之间存在边, 表示二者在同一维基百科页面上共同出现.节点特征对应于维基百科页面中的部分关键词.
本文采用准确率(Accuracy)作为性能评价指标, 定义如下:
Accuracy=
其中, TP表示模型将正类样本正确分类为正类, TN表示模型将负类样本正确分类为负类, FP表示模型将负类样本错误分类为正类, FN表示模型将正类样本错误分类为负类.
在8个现实世界数据集上, 采用6∶ 2∶ 2的分割比例, 将节点集随机分成训练集、验证集和测试集, 对每种方法进行全监督学习.通过随机种子随机生成10个随机分裂, 并在相同的分裂上进行评估, 最后, 以95%的置信区间记录每种方法的平均准确率.
为了确保公平性, 所有方法都使用两个卷积单元和一个线性输出层, 用Pytorch进行训练, 权重的初始化遵循Xavier初始化, 使用NVIDIA RTX 4090 GPU加速训练.采用权值衰减L2的Adam(Adaptive Moment Estimation)作为ACGNN训练的优化器.最大训练次数设为1 000, 当验证集损失函数连续200次不下降提前停止训练.所有数据集的失活率设为0.5.对于每个数据集, 在{0.001, 0.005, 0.01, 0.05, 0.1}内搜索最优学习率, 在{16, 32, 64, 128, 256}内搜索最优隐藏层维度, 在{0.000 1, 0.000 5, 0.001}内搜索最优衰减系数.
3.2 对比实验
本文选择如下基线方法进行对比实验.
1)MLP(Multilayer Perceptron).前馈神经网络, 通常包括一个输入层、一个或多个隐藏层以及一个输出层.每层由若干神经元构成, 层与层之间通过全连接的方式相互连接.
2)文献[20]方法.定义图卷积运算, 使用切比雪夫多项式参数化卷积核.
3)GPRGNN[30].结合自适应广义PageRank与GNN, 将特征传播的每步与可学习的权重关联.
4)BernNet[31].通过K阶Bernstein多项式逼近图谱滤波器, 并通过设置Bernstein基的系数设计其属性.
5)ChebNetII[33].基于切比雪夫插值的新型GNNs, 重新考虑切比雪夫多项式近似谱图卷积的问题, 增强原始的切比雪夫多项式近似.
6)GCN(Multi-layer Graph Convolutional Net-work)[44].通过一阶多项式局部近似谱图卷积, 建立谱方法和空间方法的统一框架.
7)APPNP(Approximate Personalized Propaga-tion of Neural Predictions)[45].结合PageRank[46]和神经网络预测, 通过个性化的传播机制, 提高节点分类性能.
8)GATs(Graph Attention Networks)[47].在节点的单跳邻域中引入多头注意机制, 获得节点表示.
9)FAGCN(Frequency Adaptation Graph Convo-lutional Networks)[48].频率自适应的图卷积网络, 具有自适应机制, 可在消息传递过程中自适应集成不同信号.
10)Diag-NSD[49].从拓扑角度, 利用细胞束理论, 为图赋予几何结构, 缓解现有GNNs在处理异配性和过平滑问题时的局限性.
11)GREET(Unsupervised Graph Representa-tion Learning Method with Edge Heterophily Discri-minating)[50].区分同性边和异性边以学习图表示, 从特征和结构信息中推断边缘同配或异配, 并使用低通滤波器和高通滤波器捕获相应信息.
各方法在8个现实世界数据集上的平均准确率如表2所示, 表中数值表示平均准确率± 95%置信区间, 黑体数字表示最优值, 斜体数字表示次优值.由表可见, ACGNN在Cora、PubMed、Photo、Chameleon、Squirrel数据集上表现最优, 在Computers数据集表现次优, 在CiteSeer、Actor数据集上也表现出与对比方法相当的性能.
| 表2 各方法在8个数据集上的节点分类准确率对比 Table 2 Comparison of node classification accuracy of different methods on 8 datasets % |
在异配图上, 不同方法之间的性能差异较大, 特别是在Chameleon、Squirrel数据集上, ACGNN表现出明显优势, 相比次优方法ChebNetII, 准确率分别提升约2.04%和7.46%.这说明ACGNN在处理复杂局部结构模式和图谱信号方面具有明显优势.在同为异配图的Actor数据集上, 各方法的表现都不够理想, 而在同配图数据集上, ACGNN取得3个最优值和1个次优值, 这说明基于特定局部邻域模式和节点特征学习图谱滤波器的方法在同配图数据集上仍然有效.
下面讨论各方法在除了Actor数据集以外的7个数据集上的性能表现.相比MLP, 其余方法在除了Actor数据集以外的7个数据集上均有更优性能, 这归功于GNNs是端到端的训练方式, 并在标签的指导下通过图结构更新节点表示.
另外, 相比基于多项式逼近滤波器的方法(文献[20]方法, GPRGNN, BernNet), ChebNetII在多个数据集取得次优值, 特别是在异配图数据集上具有明显优势.ChebNetII在Chameleon、Squirrel数据集上的准确率分别比文献[20]方法提升11.63%和17.01%, 比GPRGNN提升4.09%和7.57%, 比BernNet提升3.08%和6.37%, 这说明单纯依赖多项式基构造图谱滤波器存在局限性.
虽然ChebNetII使用切比雪夫插值增强多项式逼近性能, 但在Chameleon、Squirrel数据集上的性能仍明显低于ACGNN, 准确率分别降低2.04%和7.46%.这意味着基于多项式的模型在面对异配图数据中的高频信号时存在固有缺陷.
ACGNN在除了Actor数据集以外的7个数据集上的性能均优于Diag-NSD和GREET, 尤其在异配图数据集上具有明显优势.在Chameleon数据集上, ACGNN的准确率分别比DiagNSD和GREET提升4.73%和5.20%, 在 Squirrel数据集上, ACGNN的准确率分别比Diag-NSD和GREET提升10.40%和10.55%.
这表明, ACGNN对基础滤波器进行分段组合设计, 并在滤波器学习过程中融入节点特征, 有利于模型识别局部邻域模式, 捕捉更细致的高频信号, 因此在处理复杂的异配图时表现出一定优势, 具有良好的有效性.
3.3 消融实验
为了验证ACGNN中各模块的有效性, 设计如下3种变体.
1)ACGNN-base.同时移除滤波器组合模块和自适应节点特征模块后的ACGNN变体, 即关闭图2中左右两边的滤波器模块.
2)ACGNN/comb.只移除考虑局部邻域模式的滤波器组合模块后的ACGNN变体, 即关闭图2中右边的滤波器组合模块.
3)ACGNN/adapt.只移除关联节点特征的自适应模块后的ACGNN, 即关闭图2中左边的模块.
为了验证ACGNN各模块面对同配图和异配图时的贡献, 选用3个同配图数据集Cora、CiteSeer、PubMed和3个异配图数据集Chameleon、Squirrel、Actor, 进行消融实验.因为ACGNN-base和ACGNN/comb都移除组合滤波器, 故s设为1, 其它实验参数设置与ACGNN一致, 均采用准确率作为评价指标.
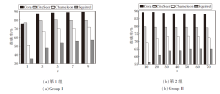
不同变体在6个数据集上的消融实验结果如表3所示, 表中数值表示平均准确率± 95%置信区间, 黑体数字表示最优值, 斜体数字表示次优值.
| 表3 各模块消融实验结果 Table 3 Ablation experiment results of different modules % |
观察表3发现, ACGNN在各数据集上均为最优值.具体地, 在Chameleon、Squirrel、Actor异配图数据集上, ACGNN的准确率比只移除滤波器组合模块的ACGNN/comb分别提升0.76%、3.07%和2.30%, 比只移除节点特征融合模块的ACGNN/adapt分别提升0.6%、3.7%和2.0%.
在Cora、CiteSeer、PubMed同配图数据集上, ACGNN的准确率比ACGNN/comb分别提升0.87%、0.97%和2.16%, 比ACGNN/adapt分别提升0.39%、1.98%和1.29%.由此表明滤波器组合和节点特征融合这两个模块对整体模型性能的提升均具有重要贡献.
更进一步, ACGNN/comb和ACGNN/adapt在除了Actor数据集以外的5个数据集上均优于同时移除两个模块的ACGNN-base.特别是在Chame-leon、Squirrel异配图数据集上, ACGNN/comb的准确率分别比ACGNN-base提升约22.58%、25.51%, 这一提升得益于在滤波器的学习过程中充分考虑节点特征, 能帮助模型准确识别具有对应局部邻域模式的节点, 进行节点级的参数调整, 从而具有更好的节点嵌入表现.在Chameleon、Squirrel数据集上, ACGNN/adapt的准确率分别比ACGNN-base提升约22.62%、27.63%, 这说明对滤波器进行组合后, 方法能考虑异配图中复杂的节点局部邻域模式, 调整不同频率的滤波器, 处理图谱信号, 提高节点嵌入的效果.
需要注意的是, 在Actor数据集上, ACGNN/comb和ACGNN/adapt并未取得令人满意的结果, 甚至ACGNN/adapt的表现低于ACGNN-base.
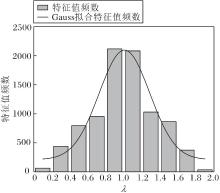
图3描述Actor数据集上拉普拉斯矩阵特征值的分布情况.观察图3可发现, 特征值的分布主要集中在λ =1附近, 而较大特征值或较小特征值占比很少.此外, 在所有特征值中, 有1 135个特征值等于1, 约占特征值总数的15%.这说明Actor数据集对应于一个高度同构的图, 大部分节点具有类似或相同的邻域结构模式[40].而ACGNN未能充分利用图的同构性特征, 组合滤波器无法通过特征值区分高度同构图的节点邻域结构模式, 从而导致性能受限.
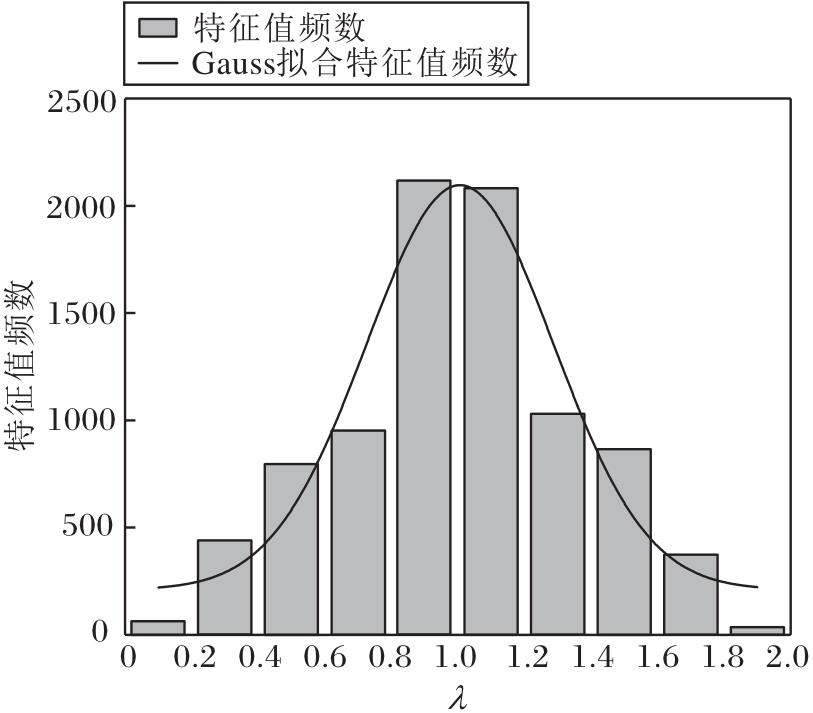 | 图3 Actor数据集的特征值分布图Fig.3 Eigenvalue distribution of Actor dataset |
下文从图数据的边稠密程度和节点特征维度进行分析.通过计算边密度[51]
ρ =|E|/|V|,
其中, |E|表示边数, |V|表示节点数, 反映边稠密程度.由表1可知, Actor数据集的边密度为3.5, 略高于Cora等同配图数据集, 但远低于Chameleon、Squirrel等异配图数据集.较低的边密度会限制节点聚合的邻域信息量, 削弱方法在信息聚合中的学习能力.而且, 由表1可知, Actor数据集的特征维度为932, Chameleon、Squirrel数据集的特征维度分别为2 325和2 089, 而较低的特征维度可能使方法更容易出现过平滑问题[52], 从而影响分类性能.总之, 低边密度、较低的特征维度及高同构特性共同制约GNN模型在Actor数据集上的表现.
3.4 参数敏感性分析
本文的缩放参数s决定分割区间数, 可根据图信号的频率分布特性进行调整.通常情况下, 同配图的节点邻域模式数量较少, 可通过较少分割区间数拟合, 而对于异配图, 更多的分割区间数有助于方法拟合更复杂的节点邻域模式, 捕捉更多的细节[13].
为了验证缩放参数s对ACGNN性能的影响, 实验选取{1, 3, 5, 7, 9}和{10, 20, 30, 40, 50, 60, 70}两组参数, 旨在通过对比不同区间分割数, 分析ACGNN在处理同配图和异配图时, 性能随参数变化的趋势.在Cora、CiteSeer、Chameleon、Squirrel数据集上进行实验, 采用控制变量法, 除了s, 其它实验设置和评价指标与ACGNN一致.具体结果如图4所示.
 | 图4 s对ACGNN性能的影响Fig.4 Effect of s on ACGNN performance |
观察图4(a) 发现, 随着s的增加, 性能呈现上升趋势.在Cora、CiteSeer同配图数据集上的增加趋势相对平缓, 在Cora数据集上, 准确率在s=9附近达到峰值(88.82%), 在CiteSeer数据集上, 准确率在s=5附近达到峰值(80.32%).在Chameleon、Squirrel异配图数据集上的提升则更加明显, 在Chameleon数据集上, 准确率在s=50附近达到峰值(73.41%), 在Squirrel数据集上, 准确率在s=50附近达到峰值(65.18%).这表明, 通过增大s调节组合滤波器, 可更好地区分不同节点的邻域结构模式, 学到更复杂的滤波器, 从而提升性能.
结合图4(b)发现, 当s≥ 10, 方法在同配图数据集上的性能波动变得很小并很快呈现略微下降的趋势, 而在异配图数据集上的性能在s≥ 10后仍保持明显提升趋势, 但在s≥ 50后也出现略微下降.这种现象与预期一致, 因为同配图数据的节点邻域模式相对简单, 多依赖平滑信息, 而基于过多的分割区间数学习的组合滤波器可能会降低平滑信号的权重, 导致性能下降.相比之下, 异配图数据具有更复杂的节点邻域模式, 对s的变化更敏感, 相对复杂的滤波器能更好地适应这类数据的多样性和复杂性, 但过多的分割区间数也会导致过拟合, 影响方法性能.这种现象表明, 在处理异配图数据时, 选择合适的模型和滤波器组合对于提升方法的泛化能力和实际应用效果具有重要意义.
3.5 滤波器可视化
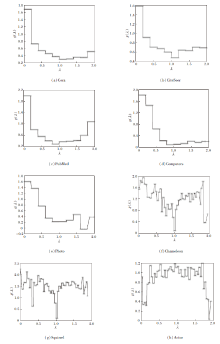
本节通过可视化 ACGNN 在现实世界数据集上学到的滤波器, 进一步验证其有效性.在8个数据集上的滤波器参数可视化结果如图5所示.
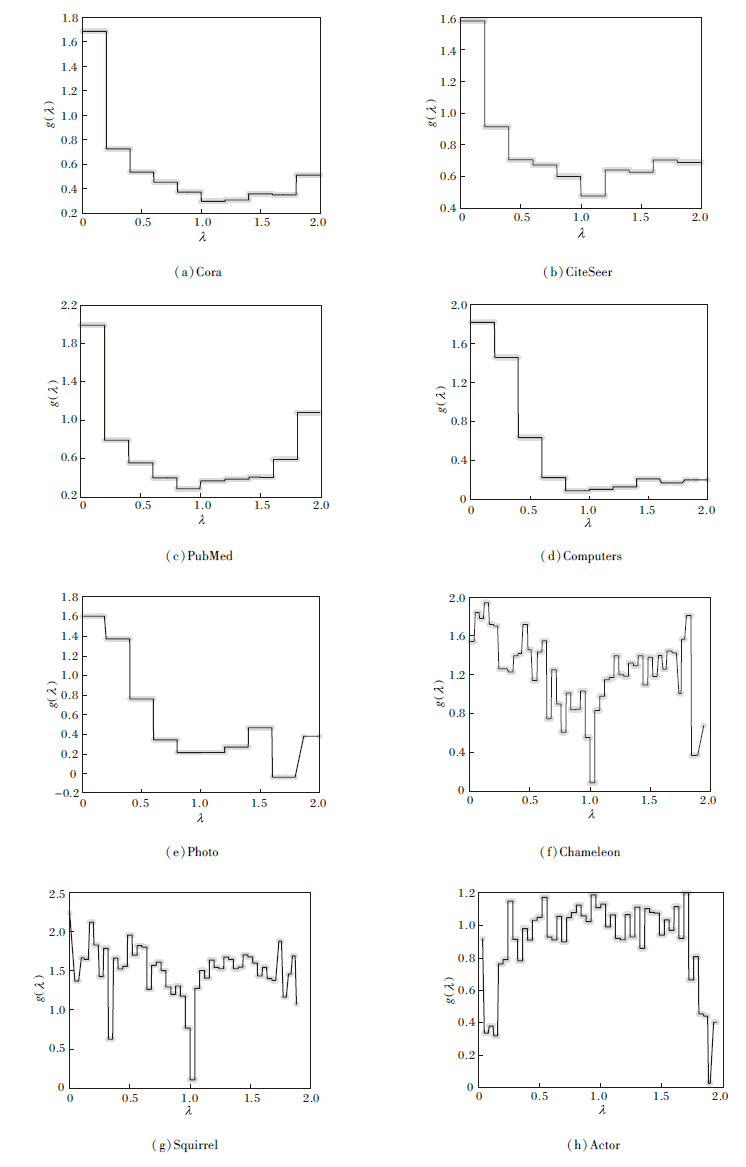 | 图5 滤波器参数可视化结果Fig.5 Visualization results of filter parameters |
由图5可知, 在同配图数据集上, 学到的滤波器整体表现出较强的低通特性.然而, 在同配图上滤波器仍捕捉到部分的高频变化.
结合ACGNN取得的优异性能, 上述情况说明现实世界数据集的滤波器存在局部突变, 而ACGNN的自适应滤波器能有效捕获这些局部突变, 学到更复杂的滤波器.在异配图数据上, 学到的滤波器呈现不同的特点.
在Chameleon、Squirrel数据集上, ACGNN学到类似梳状结构的滤波器.由于ACGNN在这两个数据集上的表现明显优于所有对比方法, 这表明复杂的梳状滤波器能更好地捕捉异配图数据中存在的复杂邻域模式, 捕捉有效的高频信号, 从而提升性能.
综上所述, ACGNN不仅能拟合同配图数据的平滑信号, 而且能在异配图数据中捕捉更复杂的高频信息.
4 结束语
本文提出基于自适应组合滤波器的谱图神经网络(ACGNN), 旨在解决图数据特别是异配图中节点特征多样性和邻居结构模式复杂性的问题.通过分析归一化拉普拉斯矩阵的特征向量和特征值, 提出基于节点邻域模式进行组合的组合滤波器设计方法, 通过分割函数将基础滤波器划分为不同频段的滤波器组, 从而有效捕捉和学习复杂的节点邻域结构.在此基础上, 进一步探讨融合节点特征的自适应组合滤波器, 引入节点特征参数矩阵, 使滤波器能根据节点特征自适应调整权重.实验表明, ACGNN可在多个现实世界数据集上取得较优性能, 特别是在处理异配图数据时, 能有效学习复杂的滤波器结构, 在捕获图数据中局部突变和复杂特征模式方面具有一定的优越性.
综上所述, ACGNN不仅在理论上丰富图神经网络的滤波器设计, 也在实验中展示其在处理复杂图数据和多样节点特征上的潜力和有效性.今后可考虑进一步降低组合滤波器的计算复杂度, 在更广泛的图数据应用场景中验证和推广ACGNN的适用性.
本文责任编委 梁吉业
Recommended by Associate Editor LIANG Jiye
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|
| [47] |
|
| [48] |
|
| [49] |
|
| [50] |
|
| [51] |
|
| [52] |
|