

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于领域知识融合和短语结构约束的冶金文献命名实体识别方法
引用本文
陈玮, 余正涛, 王振晗. 基于领域知识融合和短语结构约束的冶金文献命名实体识别方法. 模式识别与人工智能, 2024,37(12): 1094-1106
CHEN Wei, YU Zhengtao, WANG Zhenhan. Named Entity Recognition Method for Metallurgical Literature Based on Domain Knowledge Fusion and Phrase Structure Constraints. PATTERN RECOGNITION AND ARTIFICIAL INTELLIGENCE, 2024,37(12): 1094-1106.
Doi: 10.16451/j.cnki.issn1003-6059.202412005
CHEN Wei, YU Zhengtao, WANG Zhenhan. Named Entity Recognition Method for Metallurgical Literature Based on Domain Knowledge Fusion and Phrase Structure Constraints. PATTERN RECOGNITION AND ARTIFICIAL INTELLIGENCE, 2024,37(12): 1094-1106.
Permissions
Copyright©2024, 《模式识别与人工智能》编辑部
《模式识别与人工智能》编辑部
基于领域知识融合和短语结构约束的冶金文献命名实体识别方法

余正涛,博士,教授,主要研究方向为自然语言处理、机器翻译.E-mail:ztyu@hotmail.com.
作者简介:

陈 玮,博士,讲师,主要研究方向为自然语言处理、文本挖掘、信息检索.E-mail:chenwei1983@kust.edu.cn.

王振晗,博士,讲师,主要研究方向为自然语言处理、机器翻译.E-mail:wangzhenhan93@gmail.com.
摘要
冶金命名实体识别旨在识别冶金领域文本中的冶金技术、冶金工艺、术语、金属元素、冶金机构等相关实体,是冶金领域知识获取与整理、热点识别、信息检索的基础.但是,标注数据稀缺,实体类型与通用领域差异显著,包含较多长实体,这些使通用领域命名实体识别模型难以迁移至冶金领域.因此,文中提出基于领域知识融合和短语结构约束的冶金文献命名实体识别方法,利用少量冶金领域的实体标注语料微调模型,增强迁移模型对冶金领域实体结构和相关知识的理解.在微调过程中:一方面,利用冶金领域词典,通过字词匹配词典信息,将字词相关的领域知识融入表示层,增强迁移能力.另一方面,针对长实体匹配问题,设计短语结构约束模型,将字符级输入序列与冶金领域特定的实体规则匹配,识别符合冶金领域特有命名实体结构的实体.在冶金数据集上的实验表明文中方法的准确率有所提升.
关键词:
中文命名实体识别; 冶金文献挖掘; 迁移学习; 领域知识融入; 短语结构约束
中图分类号:TP39
Named Entity Recognition Method for Metallurgical Literature Based on Domain Knowledge Fusion and Phrase Structure Constraints
YU Zhengtao, Ph.D., professor. His research interests include natural language processing and machine translation.
About Author:
CHEN Wei, Ph.D., lecturer. His research interests include natural language processing, text mining and information retrie-val.
WANG Zhenhan, Ph.D., lecturer. His research interests include natural language processing and machine translation.
Abstract
Metallurgical named entity recognition(NER) aims to identify relevant entities such as metallurgical techniques, processes, terminologies, metallic elements and institutions in the texts of metallurgical domain. Metallurgical NER serves as the foundation for knowledge extraction and organization, hotspot detection, and information retrieval in this field. However, the scarcity of annotated data, the significant differences in entity types compared to general domains and long entities make the transfer of general domain NER models to the metallurgical field challenging. A named entity recognition method for metallurgical literature based on domain knowledge integration and phrase structure constraints is proposed. By fine-tuning the model with a small amount of annotated metallurgical data, the understanding of entity structures and related knowledge in the metallurgical domain is enhanced. During fine-tuning, a metallurgical domain dictionary is leveraged at the representation layer. Through character-word matching, domain-specific knowledge is incorporated into the representation layer to improve the transferability of the model. A phrase structure constraint module is designed to address the challenge of recognizing long entities. Character-level input sequences are matched with metallurgical-specific entity rules, and thus the entities conforming to the unique structures of metallurgical named entities are recognized. Experiments on metallurgical datasets indicate an accuracy improvement for the proposed method.
Key words:
Key Words Chinese Named Entity Recognition; Metallurgical Literature Mining; Transfer Learning; Domain Knowledge Integration; Phrase Structure Constraint
冶金领域命名实体识别旨在识别和提取冶金学领域文本中的冶金技术、冶金工艺、术语、金属元素、冶金机构等命名实体, 是进行冶金实体关系识别的基础, 也是冶金领域知识获取与整理、热点识别、信息检索的基础, 在冶金学研究和应用中具有重要价值, 不仅对研究者和工程师帮助巨大, 也对整个冶金行业的发展与创新起到积极推动作用.
冶金命名实体可分为金属元素类、矿石矿物类、冶金材料类、冶金产品类、冶金工艺类、冶金环保类、冶金技术类、冶金企业和机构类、冶金设备类、冶金专业术语类.冶金领域的命名实体识别(Named Entity Recognition, NER)面临诸多挑战.1)冶金领域类别标注体系与通用领域之间具有显著差异, 冶金领域具备高度专业化的术语和分类体系, 而常见的机器学习模型或自然语言处理工具主要是针对通用文本进行训练, 在识别冶金领域特定类别时准确率较低.冶金分类的细致程度远超过通用领域(如人名、地点等简单实体), 需要更复杂的标注体系, 增加模型的设计和实现难度.2)冶金领域专有术语量大、变化快, 相比通用语言, 许多词汇是行业特定的, 这要求模型具备一定的领域知识.3)冶金命名实体包含许多由多个词汇组合的长实体, 模型在识别时难以判断实际边界和结构, 需要结合领域知识, 利用迁移学习、深度学习等技术提升模型在冶金领域中的识别能力.由此可见, 冶金领域的命名实体识别面临诸多挑战, 包括类别标注体系的复杂性、长实体和组合实体的存在以及领域专业术语的丰富性等.这些特点使冶金领域的命名实体识别难以直接采用通用领域的模型, 需要进行特定的优化和调整.
现阶段通用中文命名实体识别工作已较成熟, 面向特定领域的研究也逐步开展.冶金命名实体识别属于领域命名实体类别.目前主要的领域命名实体识别的方法有:领域知识融入的方法、基于预训练模型的实体识别方法和基于迁移学习的方法.
面向领域的NER模型常需要利用特定领域的知识, 提高模型在特定领域内的识别效果.基于领域知识融入的NER通常通过融合外部知识库、特征工程、预训练语言模型等手段, 将特定领域的背景知识引入模型, 提高对相关实体的识别能力.Zhu等[1]提出针对中文电子病历中BNER(Biomedical Named Entity Recognition)的DGAN(Dictionary-Guided Atten- tion Network), 将电子病历文本与生物医学词典匹配, 使相关的生物医学词典信息融入命名实体识别网络中, 提高医学NER的效果.Nie等[2]将领域知识图谱融入领域命名实体识别模型中, 提高小样本框架下命名实体识别的准确率.Tian等[3]在多任务学习框架下将过滤算法融入领域词汇, 提高面向领域的中文命名实体识别效果.尽管基于领域知识融入的面向领域的命名实体识别方法在识别效果上具有一定提升, 但单一的领域知识融入不能较好地发挥领域知识的作用, 也未能很好体现领域实体边界、子词结构等信息, 识别效果还有待提高.
Qiu等[4]提出基于深度学习的中文工程地质命名实体识别方法, 使用GeoBERT(Geological Bidi-rectional Encoder Representation from Transformers), 并结合拼音、部首和位置向量等多特征, 生成字节序列的表示, 随后被融合并通过BiLSTM-Attention进行训练, 最后使用CRF(Conditional Random Fields)获得较优实体分类结果.Liang等[5]在预训练语言模型BERT-SNER中使用UMLS(Unified Medical Language System), 对标注数据进行提示标记后采用迁移学习的方式, 在德语临床医学文本的实体识别中取得较优性能.陈娜等[6]提出结合注意力机制的BERT-BiGRU-CRF, 提升中文电子病历命名实体识别的能力, 利用BERT(Bidirectional Encoder Repre-sentation from Transformers)预训练模型获取动态字向量, 通过BiGRU(Bidirectional Gate Recurrent Unit)提取全局语义特征, 并引入注意力机制, 增强语义特征, 最后通过CRF输出全局最优标签序列.预训练模型虽然在通用语言理解方面表现出色, 但面对特定领域的文本时, 可能需要额外的调整和优化以更好地捕捉领域相关的术语和表达方式[7].
学者们不断深入研究预训练模型、微调技术及领域适应方法, 逐步提升特定领域的NER性能.迁移学习[8]的一个主要优势是在目标任务上只需要少量的标注数据.Sun等[9]改进预训练模型, 使用改进后的BERT进行迁移学习, 实现在西班牙语上的生物医学领域的命名实体识别.吴炳潮等[10]动态融合跨域共享的实体块信息, 提出动态迁移实体块信息的跨领域中文实体识别模型(Cross-Domain Chinese NER Model by Dynamically Transferring Entity Infor-mation, TES-NER), 实现实体块信息的动态迁移, 以通用域(源域)数据集为标注语料, 以充足的新闻域数据为训练数据, 在其它域数据集上迁移后, 实体识别率有所提高, 进一步验证领域自适应的有效性.Smă du等[11]创建领域自适应的多任务学习框架, 进行联合学习与迁移学习, 在司法领域的命名实体识别上取得一定效果.迁移学习是今后解决领域内数据稀缺问题的一种有效但较困难的方法.
冶金命名实体识别是一个特定领域的实体识别任务, 也面临标记数据稀缺、长实体难以识别的问题.传统的数据迁移方法很难直接应用于冶金命名实体识别.冶金领域知识专业性强、领域特征明显, 而且实体丰富、长实体较多.通用模型中使用的标记语料库与冶金领域的标记数据域差异较大, 导致转移困难.鉴于领域命名实体识别的前期研究, 冶金命名实体识别面临标记的训练数据不足的核心问题, 通用的NER模型无法较好适应冶金领域的特定术语和实体, 冶金领域的知识不能在通用模型中发挥作用、冶金领域长实体未能准确标识等问题导致迁移学习较困难.
针对上述问题, 本文提出基于领域知识融合和短语结构约束的冶金文献命名实体识别方法, 旨在将标记数据丰富的通用领域实体识别模型迁至标记数据稀缺的冶金领域, 在迁移模型表示层进行冶金领域知识的融入, 提高模型对冶金知识的理解, 实现知识的有效迁移.同时对迁移模型进行短语结构约束, 提高模型对冶金领域专有术语和复杂长实体的识别能力.一方面, 设计领域知识双层融入机制, 在字符层面和词层面注入领域知识; 另一方面, 根据冶金长实体的特征, 设计短语结构约束, 约束迁移模型识别长实体, 共同提升模型对冶金命名实体的理解能力.迁移学习可实现将标记数据丰富的通用领域的实体识别模型迁至标记数据稀缺的冶金领域进行命名实体识别, 达到使用少量冶金领域标记数据进行实体识别的目的.向迁移模型融入冶金领域知识可提高模型对领域术语和实体的识别能力, 增强模型对领域文本的语义结构的理解, 提高识别效果.向迁移模型融入符合冶金实体长实体特性的特征模板可进一步增强模型对复杂长实体结构的理解, 提高复杂长实体识别的效果.为了进一步验证模型的有效性, 利用少量标注的冶金领域命名实体语料进行再次训练以完成微调, 从而实现对冶金领域特性的优化.
1 基于领域知识融合和短语结构约束的冶金文献命名实体识别方法
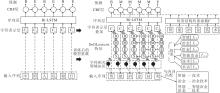
本文提出基于领域知识融合和短语结构约束的冶金文献命名实体识别方法, 旨在通过迁移学习和微调增强模型对冶金领域实体结构及知识的理解.方法整体框架如图1所示.首先基于迁移学习的预训练模型(BiLSTM-CRF), 在通用领域的NER数据集上进行预训练, 获得较强的泛化能力.在微调过程中, 通过领域知识融合和短语结构约束增强对冶金领域的适应性.使用冶金领域的基础词典, 将输入文本中的字词与词典进行匹配, 将与输入词相关的领域信息注入表示层, 使模型在特征表达上具备对冶金领域术语的感知能力.这种知识融合机制增强模型对冶金领域实体的理解能力, 特别是在特定术语和短语的识别上效果显著.同时, 设计短语结构约束模块, 针对冶金领域长实体的识别难题, 通过字符级输入序列与特定的实体规则进行匹配.短语结构约束模型结合冶金领域的命名规则, 将输入的字符序列与预定义的实体模板进行匹配, 确保识别符合冶金特性和命名结构的长实体.通过迁移学习、领域知识融合和短语结构约束的结合, 本文方法有效提升冶金领域NER任务的识别准确率, 在冶金技术、工艺等复杂命名结构上的识别效果尤为突出.
 | 图1 本文方法框架图Fig.1 Architecture of the proposed method |
1.1 问题定义
设Y为冶金领域数据集
Dtarget=X={s1, …, si, …, sn}
中句子集X对应的标签集合, 其中
si={char1, …, charj, …, charn}
表示文档中第i个句子, charj表示句子si的第j个字符.给定预训练源数据集Dsource, 对命名实体识别模型f0进行预训练, 构建通用命名实体模型f'0.
本文目标是在目标冶金领域数据集Dtarget下, 微调根据冶金领域实体特性修改后的通用命名实体识别模型f'0, 获取冶金命名实体识别模型:
$f_{0} \xrightarrow[D_{\text {source }}]{\text { 训练 }} f_{0}^{\prime} \xrightarrow[D_{\text {target }}]{\text { 微调 }} f, $
使标签集合Y中的标签为正确的冶金命名实体标签, 即
Y=f(X)=f(s1, s2, …, sn).
本文首先使用BiLSTM-CRF进行迁移学习, 再对迁移模型进行领域知识的融入和短语结构的约束, 在使用少量冶金领域训练数据进行微调后, 完成冶金领域命名实体识别模型的构建.
1.2 迁移模型的领域知识融入方法
基于字符级的命名实体识别往往忽略词级的信息, 基于词级的命名实体识别往往忽略词相关领域知识的导向作用.借鉴SoftLexicon(LSTM)[12]、La- ttice LSTM[13]的思想, 即通过将词典中的词汇匹配到文本中的字符上实现SoftLexicon特征提取.每个字符根据其所在词汇中的位置标记为B(开始)、M(中间)、E(结束)或S(单独).这种在字符嵌入中加入标签信息, 可提升字符的语境表示.再通过序列编码器Bi-LSTM(Bi-directional Long Short-Term Me-mory)处理这些增强的嵌入, 提升在NER任务中的精确性.本文将基于字符相关的领域知识融入命名实体识别迁移模型中.
本文的字符相关的领域知识分为两部分:1)字符chari的领域知识向量; 2)字符在输入序列中形成的字符相关边界词向量及边界词的领域知识向量的融合.
1.2.1 字符的领域知识向量表示
与字符语义相似的冶金领域词汇对应的向量通过加权求和的形式组成输入序列中的字符领域知识向量.通过字符向量与词向量相似度算法, 在冶金基础词典中寻找与输入序列中字符相似的词.找出与目标字符最相关前N个领域词wj.字符和词使用同一个Gensim库(https://github.com/piskvorky/gensim)中的Word2Vec模型转换成向量, 在Gensim中, 使用most_similar函数获取与查询词语义相似的前N个词, 分别计算这前N个词和chari的语义相似度:
si
词wordj对字符chari的相关性系数如下所示:
$\begin{aligned}\alpha_{i j}^{\text {char }}= & \operatorname{softmax}_{j}\left(\operatorname{sim}_{i j}^{\text {char }}\right)= \\& \frac{\exp \left(\sigma\left(\operatorname{sim}_{i j}^{\text {char }}\left(\boldsymbol{e}\left(\operatorname{char}_{i}\right), \boldsymbol{e}\left(w_{j}\right)\right)\right)\right)}{\sum_{k \in N_{i}} \exp \left(\sigma\left(\left(\operatorname{sim}_{i k}^{\text {char }}\left(\boldsymbol{e}\left(\operatorname{char}_{i}\right), \boldsymbol{e}\left(w_{k}\right)\right)\right)\right)\right)}, \end{aligned}$
其中, σ =sigmoid()函数, 以便向量各维度数据在0和1之间归一化数据.
字符chari的领域知识向量为:
$\boldsymbol{e}^{c}\left(\operatorname{char}_{i}\right)=\sigma\left(\sum_{j \in N_{i}} \alpha_{i j}^{\text {char }} \boldsymbol{e}\left(w_{j}^{\mathrm{sim}}\right)\right), $
该向量通过与输入序列中的字符chari语义相关的词向量加权形成, 其中
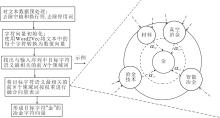
领域知识向量融合邻居信息过程如图2所示, 对字符“ 金” 进行领域知识向量化表示时, 与该字符相关的词“ 冶金技术” 、“ 材料” 、“ 真空冶金” 、“ 智能冶金” 按照融合公式乘以相关性比例进行信息融合.
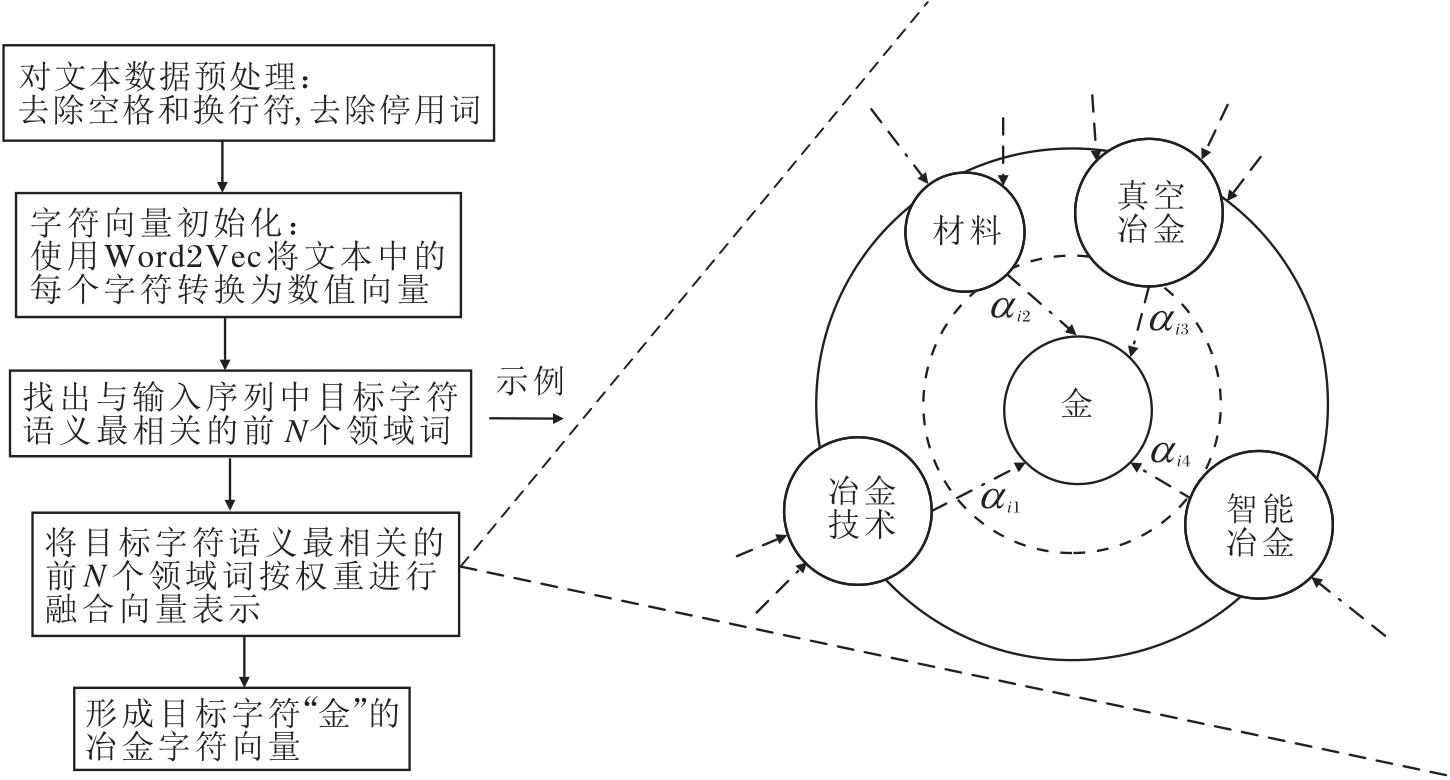 | 图2 领域知识向量融合邻居信息过程示例Fig.2 Process of fusing neighborhood information with domain knowledge vectors |
1.2.2 字符相关边界词向量及边界词的领域知识向量的融合
文献[12]和文献[13]的实验说明, 融入字符相关边界词信息有助于命名实体识别任务效果的提升.借鉴Zhang等[13]的思想, 本文融合字符相关边界词向量及边界词的领域知识向量, 并最终融入字符信息中.对于任意一个输入序列
s={char1, char2, …, charn},
wordij为其子序列{chari, chari+1, …, charj}即序列s中的词.
对匹配的边界词进行分类.每个字符均存在相关的几个词.本文将字符对应的边界词进行分类, 对于在输入序列
s={char1, char2, …, charn}
中的每个字符chari, 分成与分词标签“ BMES” 对应的四类词:
B(chari)={wi, k, ∀ wi, k∈ L, i< k≤ n},
M(chari)={wj, k, ∀ wj, k∈ L, 1≤ j< i< k≤ n},
E(chari)={wj, i, ∀ wj, i∈ L, 1≤ j< i},
S(chari)={chari, ∃chari∈ L},
其中, L表示所有输入序列经文本解析构成的词典, B(chari)表示与chari相关的所有标记为开始标签的词集合, M(chari)表示与chari相关的所有标记为中间标签的词集合, E(chari)表示与chari相关的所有标记为结尾标签的词集合, S(chari)表示与chari相关的所有标记为单独词标签的词集合.
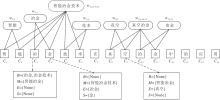
本文方法就是将与chari相关的分词标签“ BMES” 对应的四类词及该词相关的领域知识进行融合.如图3所示, 在“ 智能冶金技术在真空冶金中的应用” 这句有15个字的句子中, 存在词w1, 2(智能)、w3, 4(冶金)、w1, 2, 3, 4, 5, 6(智能冶金技术)、w4, 5(技术)等, 同时根据分词标签“ BMES” 的标记规则, 句子中的每个字符都可产生对应的词组.
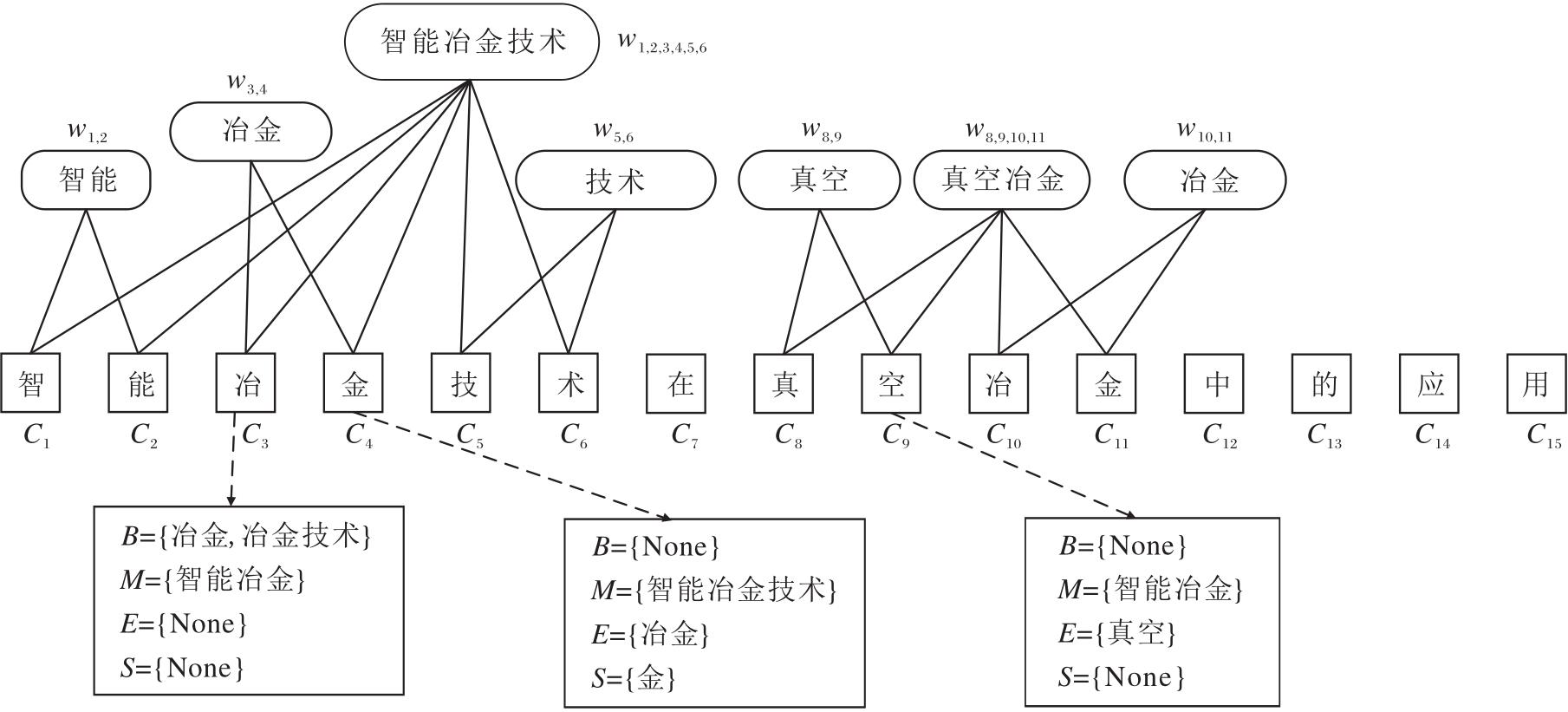 | 图3 模型字符输入序列的字符相关词汇解析示例Fig.3 Example of character-related vocabulary parsing for sequence of model character input |
例如:字符C3“ 冶” 对应的词组为
B={冶金, 冶金技术}, M={智能冶金},
E={None}, S={None}.
根据后续字符相关词语融合规则, 可将标记规则“ BMES” 的词进行融合.
对匹配到的词进行向量化.与chari相关的分词标签“ BMES” 对应的四类词的信息需要进行编码方能融入对应字符的表示信息中.每一类型的词的表示信息编码到固定维度的向量中.与字符相关的一类边界词的向量化表示如下所示:
$\begin{array}{l}\boldsymbol{e} \mathbf{2} \boldsymbol{c}(\text { words })= \frac{4}{N_{w \in w o r d s}} \sum^{n} n(w) \boldsymbol{e}^{w}(w) \text { where } N \in \sum_{w \in B \cup M \cup E \cup S} n(w), \end{array}$
上式将词统一映射到对应字符chari的固定维度向量中, 其中, words表示某一种标记类型的词集合, w表示具体的某一个词, ew(w)表示边界词w融合领域知识后的词向量化表示, 即边界词w的领域知识向量, n(w)表示词w在输入序列中出现的频率.第i个词w融合领域知识后的词向量化表示:
$\boldsymbol{e}^{w}(w)=\boldsymbol{e}\left(\text { word }_{i}\right) \| \sigma\left(\sum_{j \in N_{i}} \alpha_{i j} \boldsymbol{e}\left(\text { word }_{j}\right)\right), $
其中
$\begin{array}{l}\alpha_{i j}=\operatorname{softmax}_{j}\left(\operatorname{sim}_{i j}\right)= \\\frac{\exp \left(\sigma\left(\operatorname{sim}_{i j}\left(\boldsymbol{e}\left(\operatorname{word}_{i}\right), \boldsymbol{e}\left(\operatorname{word}_{j}\right)\right)\right)\right)}{\sum_{k \in N_{i}} \exp \left(\sigma\left(\left(\operatorname{sim}_{i k}\left(\boldsymbol{e}\left(\operatorname{word}_{i}\right), \boldsymbol{e}\left(\operatorname{word}_{k}\right)\right)\right)\right)\right)}, \\\operatorname{sim}_{i j}=\operatorname{similar}\left(\boldsymbol{e}\left(\operatorname{word}_{i}\right), \boldsymbol{e}\left(\operatorname{word}_{j}\right)\right) .\end{array}$
σ 表示sigmod()函数, 以便向量各维度数据在0和1之间归一化.ew(w)的领域知识向量的算法与字符的领域知识向量算法相似, 可参照字符chari的领域知识向量计算方法.
将与chari相关的分词标签“ BMES” 对应的四类词融合后进行向量化表示:
e2c(B, M, E, S)=
[e2c(B)‖ e2c(M)‖ e2c(E)‖ e2c(S)].
1.2.3 输入序列中以字符为单位的向量化表示
输入序列是以字符为单位进行模型输入, 此时以字符为单位的融合领域知识和边界词信息的输入向量为:
e(inputchar)=e(char)‖ ec(char)‖ e2c(B, M, E, S),
该向量是由字符本身的向量e(char)、字符char的领域知识向量ec(char)、字符char相关边界词向量及边界词的领域知识向量e2c(B, M, E, S)进行向量拼接而成.
1.3 迁移模型的短语结构约束方法
冶金领域的命名实体大致分为金属元素类、矿石矿物类、冶金材料类、冶金产品类、冶金工艺类、冶金环保类、冶金技术类、冶金企业和机构类、冶金设备类、冶金专业术语类.每类命名实体都较长, 存在的子词结构对于命名实体识别都有一定影响作用.例如:冶金技术类中的实体中一般结构为前缀修饰词+动词+后缀“ 技术” 的情况.
本文将10类命名实体的短语结构信息进行总结, 利用n-gram特征捕捉短语结构, 将特征信息写入原模型CRF部分的特征模板中, 将模板信息分为词级模板和字符级模板, 进一步提高对冶金命名实体的识别能力.
本文方法基于字符模板(基于词的模板定义方法类似)即字符的特征函数fi的定义如下.
设句子
S={char1, char2, …charn},
charn表示句子S的第n个字符.字符特征函数:
f=f(S)=f(char1, char2, …, charn)=
{f(char1), f(char2), …, f(charn)},
其中,
f(chari)=[score1, score2, …, scorem],
变量scorej表示字符chari的特征函数f(chari)对应的第j类冶金实体类别的打分.
基于字符的特征函数获取过程如下.
算法1 char_ features()
输入 sentence S={char1, char2, …, charn},
输出 Categories Score List[score1, score2, …
scorem] for each char
for chari∈ S do
featur
ScoreLis
ScoreListsentence← {ScoreLis
end for
return ScoreListsentence
算法1中Markfeature(chari, S)表示对字符chari进行特征标记, 包括一些基础特征的标记, 如词性判断、是否是前缀词等, 还有一些复合特征的判断, 如是否符合“ 冶金技术类” 的字符, 即符合前缀修饰词+动词+后缀“ 技术” 的情况, 如本字符是技术的“ 技” , 则前一个字符应是动词属性的一个字符.命名实体的10种类型的特征模型情况很多, 篇幅有限, 不再赘述.
1.4 迁移模型的标签概率函数和损失函数
迁移模型的标签预测的输入由冶金领域知识融入模型Bi-LSTM输出的标签概率和短语结构特征函数模型输出的特征分数共同作为输入信息.结合Bi-LSTM与基于短语结构约束的CRF模型的输出, 在CRF解码端共同计算得出冶金实体类别的概率.由少量冶金标记语料对迁移模型进行微调训练后获得分数的预测.
在输入的句子序列为X时产生标签Y的概率:
p(Y|X)=$\frac{1}{Z\left(x_{e}, x_{f}\right)} \exp \left(\sum_{j=1}^{n} \sum_{i=1}^{m} \lambda_{i} f_{i}\left(y_{j-1}, y_{j}, x_{e}, x_{f}\right)\right)$.
其中:
$Z\left(x_{e}, x_{f}\right)=\sum_{y} \exp \left(\sum_{j=1}^{n} \sum_{i=1}^{m} \lambda_{i} f_{i}\left(y_{j-1}, y_{j}, x_{e}, x_{f}\right)\right)$
表示归一化因子, 是所有输出序列标签结果的分值相加; xe表示以字符ec(char)的序列作为输入, 经过Bi-LSTM计算后的输出; xf表示字符输入序列经过特征函数char_ features()计算后的字符特征分数序列; $\sum_{j=1}^{n}$表示对序列中字符情况的汇总, $\sum_{i=1}^{n}$表示对每个字符的特征情况的汇总; λ i表示特殊函数的权重; fi表示字符的特征函数.
损失函数如下所示:
$\begin{aligned}L= & -\ln p(Y \mid X)= \\& -\ln \left(\frac{\exp \left(\sum_{j=1}^{n} \sum_{i=1}^{m} \lambda_{i} f_{i}\left(y_{j-1}, y_{j}, x_{e}, x_{f}\right)\right)}{\sum_{y} \exp \left(\sum_{j=1}^{n} \sum_{i=1}^{m} \lambda_{i} f_{i}\left(y_{j-1}, y_{j}, x_{e}, x_{f}\right)\right)}=\right. \\& \sum_{j=1}^{n} \sum_{i=1}^{m} \lambda_{i} f_{i}\left(y_{j-1}, y_{j}, x_{e}, x_{f}\right)+ \\& \sum_{y} \exp \left(\sum_{j=1}^{n} \sum_{i=1}^{m} \lambda_{i} f_{i}\left(y_{j-1}, y_{j}, x_{e}, x_{f}\right)\right)\end{aligned}$.
2 实验及结果分析
2.1 实验环境
冶金领域文献数据集上的命名实体共分为10类, 具体如表1所示.冶金命名实体领域特性明显, 实体内短语结构与子词结构特征明显, 传统的命名实体方法在少量标记语料下识别能力较弱.
| 表1 冶金领域实体分类 Table 1 Entity classification of metallurgical domain |
本文使用Resume数据集(https://github.com/nirajkale/ResumeNER)和自行标注的冶金领域文献数据集(简记为Metallurgical)进行实验.Resume数据集包含1.2× 105个字符标注训练数据, 1.5× 104个字符标注测试数据, 用于训练通用模型.Metallurgical数据集包含8 000多个字符标注数据, 用于对迁移模型进行修正后的训练调整, 从而使模型在使用少量的冶金命名实体标注数据的情况下, 能识别冶金文献的命名实体.
使用通用语料训练通用模型时, 设置迭代次数为100, 字符嵌入大小为250, 隐层大小为300, 模型的学习率为0.001 5, 优化器选择Adam(Adaptive Moment Estimation), 失活率设为0.5.
2.2 对比实验
2.2.1 对比方法
本文选择如下对比方法.
1)SoftLexicon(LSTM)[12].基于词典的中文命名实体识别方法.将词汇信息融入字符向量中, 融合基于字符和基于词汇的命名实体识别方法, 有效提升NER的准确性.
2)Lattice LSTM[13].中文NER的LSTM的经典方法.相比基于字符的方法, 该方法显性利用词和词序信息.相比基于词的方法, 该方法完整嵌入词语信息, 不会出现分词错误.
3)文献[14]方法.命名实体识别领域一种常用的序列标注模型, 目前常用的基于词级别的NER模型之一.因其在长距离依赖和标签依赖关系上的优势而被广泛应用于命名实体识别任务, 不仅提高实体识别的准确率, 也能处理复杂的输入序列.文本数据中的每个词通过预训练的词嵌入, 如Word2Vec, 转换成的词向量并作为输入数据.每个词的实体标签作为输出.
4)文献[15]方法.相比基于词级别的模型, 字符级模型直接从字符序列中学习, 可更好地处理拼写错误、新词和其它语言特异性问题.该方法适合处理多样化的文本数据, 减少对预处理步骤(如分词)的依赖, 性能更健壮.该方法在资源较少的语言或专业领域中表现较优.
选择这4种命名实体识别方法基于如下考虑.
1)对输入数据处理后特征表示的多样性. 这4种方法涵盖基于词级别和字符级别的不同粒度的数据处理方式, 在文本处理上采取不同的特征表示和序列建模方法.
2)技术的代表性.每种方法代表命名实体识别领域的一种主流技术路线.Lattice LSTM引入词汇和字节点构建的格结构, 显式利用词和词序信息, 提升中文NER的效果.SoftLexicon(LSTM)整合词典信息, 将词汇信息融入字符向量中, 代表一种将外部知识引入模型的思路.
3)基准性能的考虑.这4种方法已在许多命名实体识别任务中被广泛应用, 并且在多个基准数据集上表现出色, 因此可作为本文方法的性能衡量基准.
4)促进知识的融入与提升.SoftLexicon(LSTM)融入词汇信息, 代表一种知识增强的策略, 而其它方法在不同层次上强调深度学习模型对文本序列的建模能力.通过这种对比, 可探讨知识增强与深度学习方法之间的协同效应.
2.2.2 不同数据集上对比结果
首先使用通用语料训练对比方法并测试, 然后使用冶金语料对其测试, 结果如表2所示.
| 表2 各方法在2个数据集上的指标值对比 Table 2 Metric value comparison of different methods on 2 datasets % |
由表2可知, 基于字符级别的方法性能优于基于词级别的方法, 说明在Resume、Metallurgical数据集上更细粒度的字符向量有助于提升命名实体识别的效果, 由此验证本文采用基于字符的迁移模型是合理的.
4种对比方法在Resume数据集的效果优于在Metallurgical数据集上的效果, 说明直接在Meta-llurgical数据集上使用4种方法是不适用的.Lattice LSTM、SoftLexicon(LSTM)在2个数据集上的性能优于文献[14]方法和文献[15]方法, 说明句子中词或字符之间的关联关系, 以及将词汇信息融入字符信息中对命名实体识别模型都有效.因此, 在迁移模型微调时采用冶金领域知识融入(多种词汇融入方法)的策略是合理的.
本文方法(Without Transfer Learning)和本文方法在Metallurgical数据集上的性能均最优, 说明本文方法对于冶金命名实体识别是有效的.Without Transfer Learning是指对通用模型不进行数据的预训练, 根据领域特性, 直接修改模型后, 使用领域数据进行训练和预测.
在冶金命名实体标注语料稀缺、语料规模较小的条件下, 未使用迁移学习而借用通用模型中信息的本文方法的效果也不明显, 然而使用迁移学习后的本文方法性能有了提升, 这说明借用通用模型的信息进行迁移学习是有效的, 采取知识融入和短语结构约束的方法也是有效的.
本文方法在通用数据集上的表现受到领域知识融合和短语结构约束模块的影响.这些模块专注于冶金领域的特性, 在通用数据集上的表现略差.
2.2.3 SoftLexicon(LSTM)和本文方法结果对比
在Metallurgical数据集上对比SoftLexicon(LSTM)和本文方法, 具体指标值如表3所示.由表可知, 本文方法在性能上明显优于SoftLexicon(LSTM).金属元素类、矿石矿物类、冶金材料类和冶金产品类的粒度较细, 较少包含冗长的冶金实体, 采用两种方法均可进行识别, 而对于冶金设备类、冶金术语类、冶金环保类及冶金企业与机构类, 充满复杂结构的长实体, SoftLexicon(LSTM)识别效果较差.本文方法由于加入短语结构约束模型, 可解析冶金长实体的结构信息, 因此解决上述问题.总之, 本文方法在识别较短的实体方面表现出色, 相比其它方法和缺乏短语约束的消融方法, 本文方法在识别较长实体时性能也有显著提升.如何进一步提高对冗长冶金实体的识别效果是值得探索的研究方向之一.
| 表3 SoftLexicon(LSTM)和本文方法在冶金数据集上针对不同实体类别的性能对比 Table 3 Performance comparison between SoftLexicon(LSTM) and the proposed method on different entity categories on metallurgical dataset % |
2.2.4 不同批次对性能的影响
为了更好地理解各方法在不同批次大小下的表现, 在Metallurgical数据集上进行实验, 具体结果如图4所示.由图可见, 本文方法在批次大小为32时表现最佳.本文方法是一种基于迁移学习的命名实体识别模型, 专为冶金领域样本数据稀少的情况设计.在迁移学习的少样本NER任务中, 由于数据有限, 容易出现过拟合, 因此批次大小的选择至关重要.一般而言, 较小的批次大小有助于方法更好地捕捉样本特征并实现稳定收敛.因此, 推荐批次大小在16至32之间.由图可见, Lattice LSTM和SoftLexicon(LSTM)在批次大小为32时表现良好, 而文献[14]方法和文献[15]方法在批次大小为64时表现更佳.这表明传统的NER模型可以从稍大一些的批次大小中获益, 但仍需注意模型的泛化能力和过拟合的风险.
 | 图4 Metallurgical数据集上批次大小对方法性能的影响Fig.4 Effect of batch size on method performance on Metallurgical dataset |
2.3 消融实验
本文方法包括3个重要部分:迁移学习、领域知识、短语结构, 不同配置下方法在Metallurgical数据集上的性能如表4所示.
| 表4 各模块在Metallurgical数据集上的消融实验结果 Table 4 Ablation experiment results on metallurgical datasets % |
由表4可见, 未使用迁移学习且仅依靠有限的标注语料进行重新训练的通用方法表现不佳.此外, 当仅使用通用语料进行训练且未融入领域知识和短语结构约束时, 性能最差.加入短语结构约束但未融入领域知识的方法在迁移学习中表现较优, 但仍不及仅融入领域知识而未加入短语结构约束的配置.这一结果表明, 对于本文方法而言, 领域知识的融入比短语结构约束更重要.最终, 同时融入领域知识和短语结构约束的本文方法在冶金命名实体识别任务上取得最优值.
2.4 案例分析
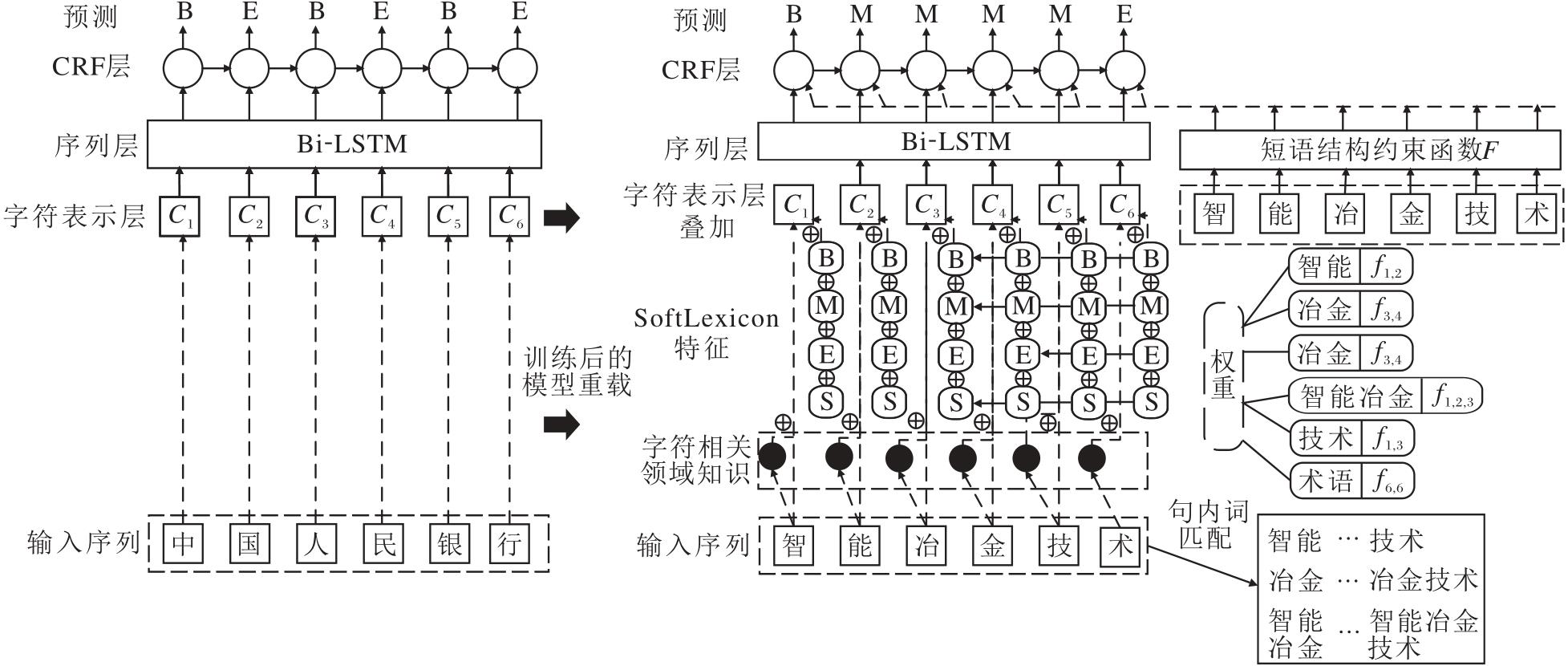
本节给出本文方法在冶金命名实体识别上的应用案例.案例1如图5(a)所示, 图中提到的“ 智能冶金技术在真空冶金中的应用” 涉及诸如智能、真空冶金、冶金技术等相关术语, 也包含智能、冶金、技术、真空、应用等词汇, 以及人工智能、机器学习、自适应控制、专家系统、冶炼、提纯、铸造、锻造、自动化技术、控制技术、监测技术、信息技术、智能冶金技术、智能冶炼系统、智能监控与控制、智能数据分析、智能决策支持、冶炼炉、精炼炉、铸造机、锻造机等词汇相关的词语.将这些词汇融入命名实体识别模型中, 可增强方法对“ 智能冶金技术” 这一实体的理解和识别能力, 包括对智能技术在冶金过程中应用的各个方面的认识, 以及对相关工艺、设备、质量控制、环境与安全、材料科学等方面的深入理解.
 | 图5 本文方法在冶金命名实体识别上的应用案例Fig.5 Cases of the proposed method for metallurgical named entity recognition |
这种知识融入有助于提高模型在冶金领域的命名实体识别的准确性和相关性.再通过设定的短语结构模版进行匹配, 可匹配到“ [修饰词]+冶金+[领域]” 这个模版, 从而确认“ 智能” 、“ 冶金” 、“ 技术” 三个词汇连接在一起是合理的.同时通过n-gram等其它短语结构约束条件再次判断(实体符合的短语结构约束越多, 说明该组合连接在一起的可能性就越大), 最终识别长实体.通过这些短语结构约束, 命名实体识别模型能更准确地识别和理解“ 智能冶金技术” 这一长实体的结构和含义, 尤其是在冶金领域的特定语境中, 有助于提高模型对复杂长实体的识别能力, 特别是在领域知识融入的基础上.
案例2的模型输出基于案例1, 因此不再赘述.从案例2可看出, 对于一些较长的冶金实体, 如果不结合领域知识和短语结构约束, 实体的粒度会被分割.例如:“ 电弧炉” 可能被识别为“ 电弧” , 而“ 熔炼技术” 分为“ 熔炼” 和“ 技术” .引入领域知识后, 能正确识别“ 熔炼技术” , 避免将其误认为两个独立的词.
然而, 方法仍未能捕捉“ 快速” 与“ 熔炼技术” 之间的关系.通过应用短语结构约束, 可识别“ 快速” 和“ 熔炼技术” 之间的关联, 及“ 电弧炉” 与“ 快速熔炼技术” 的相关性, 从而完整识别“ 电弧炉快速熔炼技术” .2个案例表明, 冶金实体识别模型需要结合领域知识和短语结构约束以提高准确性.
3 结束语
针对冶金命名实体的独特性, 本文提出基于领域知识融合和短语结构约束的冶金文献命名实体识别方法, 在迁移学习的基础上, 融合冶金领域知识和短语结构约束, 优化通用命名实体识别模型, 使其在仅有少量冶金标注语料的情况下, 准确识别冶金命名实体, 缓解冶金命名实体识别中因标注数据有限和通用模型在迁移学习中识别不准的难题.实验表明, 本文方法提高在冶金领域的识别准确率和鲁棒性, 领域知识与短语结构的结合在命名实体识别任务中是有效的.同时也表明, 本文方法在不同类型的冶金实体分类中表现优异, 具备良好的推广应用潜力.
本文责任编委 马少平
Recommended by Associate Editor MA Shaoping
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|