

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
轻量化特征点及可变形描述符提取网络
引用本文
方宝富, 张克傲, 王浩, 袁晓辉. 轻量化特征点及可变形描述符提取网络. 模式识别与人工智能, 2024,37(12): 1107-1120
FANG Baofu, ZHANG Keao, WANG Hao, YUAN Xiaohui. LKDD-Net: Lightweight Keypoint and Deformable Descriptor Extraction Network. PATTERN RECOGNITION AND ARTIFICIAL INTELLIGENCE, 2024,37(12): 1107-1120.
Doi: 10.16451/j.cnki.issn1003-6059.202412006
FANG Baofu, ZHANG Keao, WANG Hao, YUAN Xiaohui. LKDD-Net: Lightweight Keypoint and Deformable Descriptor Extraction Network. PATTERN RECOGNITION AND ARTIFICIAL INTELLIGENCE, 2024,37(12): 1107-1120.
Permissions
Copyright©2024, 《模式识别与人工智能》编辑部
《模式识别与人工智能》编辑部
轻量化特征点及可变形描述符提取网络

方宝富,博士,副教授,主要研究方向为智能机器人系统.E-mail:fangbf@hfut.edu.cn.
作者简介:

张克傲,硕士研究生,主要研究方向为视觉SLAM.E-mail:1835430535@qq.com.

王浩,博士,教授,主要研究方向为分布式智能系统、机器人.E-mail:jsjxwangh@hfut. edu.cn.

袁晓辉,博士,教授,主要研究方向为计算机视觉、机器学习、人工智能.E-mail:xiaohui.yuan@unt.edu.
摘要
特征点提取是视觉同时定位与建图(Visual Simultaneous Localization and Mapping, VSLAM)的重要步骤之一,近年来出现的基于深度学习的特征点提取方法通常效率较低,无法满足实时性要求,也不能提供描述符所需的几何不变性.为此,文中提出轻量化特征点及可变形描述符提取网络(Lightweight Keypoint and Deformable Descriptor Extraction Network, LKDD-Net),在主干网络中引入轻量化网络模块,提高特征提取效率.LKDD-Net可同时获取特征点位置和可变形描述符.为了验证LKDD-Net的有效性,设计视觉里程计系统.在HPatches、TUM RGB-D公共数据集上的实验表明,LKDD-Net可在GPU上实时运行,特征点提取时间仅为8.3 ms,同时在各种场景中保持高精度和强鲁棒性,而且其构成的视觉里程计系统性能较优.
关键词:
特征点提取; 描述符; 轻量化网络; 视觉里程计
中图分类号:TP399
LKDD-Net: Lightweight Keypoint and Deformable Descriptor Extraction Network
FANG Baofu, Ph.D., associate professor. His research interests include intelligent robot systems.
About Author:
ZXHANG Keao, Master student. His research interests include visual SLAM.
WANG Hao, Ph.D., professor. His research interests include distributed intelligent systems and robots.
YUAN Xiaohui, Ph.D., professor. His research interests include computer vision, machine learning and artificial intelligence.
Abstract
Keypoint extraction is a crucial step in visual simultaneous localization and mapping(VSLAM). Existing deep learning based keypoint extraction methods suffer from low efficiency and fail to meet real-time requirements. Furthermore, they do not provide the geometric invariance required by descriptors. To address this issue, a lightweight keypoint and deformable descriptor extraction network(LKDD-Net) is proposed. A lightweight network module is introduced in the backbone network to improve the efficiency of feature extraction, and then the deformable convolution module is applied to the descriptor decoder to extract deformable descriptors. LKDD-Net is capable of simultaneously obtaining both keypoint locations and deformable descriptors. To study the effectiveness of LKDD-Net, a visual odometry system based on LKDD-Net is designed. Experiments on HPatches public dataset and TUM public dataset show that LKDD-Net can run in real-time on GPUs with keypoint extraction time being as low as 8.3 ms, while maintaining high accuracy in various scenarios. The performance of the visual odometry system composed of LKDD-Net is superior to traditional vision and VSLAM systems based on deep learning keypoint extraction. The proposed method successfully tracks all six sequences in TUM public dataset, demonstrating stronger robustness.
Key words:
Key Words Keypoint Extraction; Descriptor; Lightweight Network; Visual Odometry
图像特征点及描述符提取是视觉同时定位与建图(Visual Simultaneous Localization and Mapping, VSLAM)、SFM(Structure from Motion)和3D重建等任务的基础, 高质量的特征点应具有可区分性、可重复性, 并且对光照和视角变化保持不变, 同时描述符应具有一定的几何不变性.特征点匹配的本质是通过检测得到的特征点建立配对关系, 高质量的特征点可为特征点匹配提供重要信息, 从而提升整个系统的精度.
目前特征点提取方法主要分为两类.1)传统的特征点提取方法, 如ORB(Oriented FAST and Ro-tated BRIEF)[1].这些方法是基于先验知识设计的, 对旋转、尺度缩放具有一定不变性, 但在光照条件较差、视角变化较大时特征点匹配和跟踪效果较差.2)基于深度学习的特征点提取方法, 如Super-Point[2]、KP2D[3]、SiLK(Simple Learned Keypoints)[4]等.这些方法致力于提高特征点提取效果, 在光照条件较差和视角变化较大时仍具有一定的鲁棒性, 但提取的描述符缺乏几何不变性, 无法保证特征点匹配的准确性.同时, 基于深度学习的特征提取方法通常实时性较差.因此, 网络的轻量化设计和增强描述符的几何不变性具有重要意义.
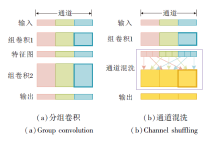
目前轻量化网络设计的方向主要分为两类.1)利用知识蒸馏、网络剪枝[5, 6]等.这类方法通用性较强, 但往往会损失精度, 或网络模型缩小时推理速度无法提高.2)强化卷积网络的卷积核, 可在一定程度提高网络的速度, 如MobileNetV3[7]、GhostNet[8]、ShuffleNet V2[9]等.这类方法普遍使用分组卷积提高效率.分组卷积可大幅提升网络速度, 但不同分组之间信息通常无法互相交流, 某个通道的输出只来自部分输入通道, 阻碍通道之间的信息交流, 削弱神经网络表达能力, 导致网络精度下降.
目前增强描述符几何不变性主要通过数据增强的方式, 如在训练数据中引入各种视角的变换(平移、缩放、翻转等), 让网络学到不同视角下的图像特征, 但这种对描述符几何不变性的增强方式受限于训练数据集, 面对复杂的几何特征时, 无法满足要求.
近年来, 深度学习在VSLAM领域发展迅速.王浩等[10]提出基于延迟语义的RGB-D SLAM算法(RGB-D SLAM Algorithm Based on Delayed Semantic Information in Dynamic Environment, DSV-SLAM), 将分割网络与VSLAM结合, 基于延迟的语义信息, 取得较优性能.
特征点提取是VSLAM前端里程计设计的重要步骤, 传统的特征点提取方法已较成熟.SIFT(Scale-Invariant Feature Transform)[11]特征点对于旋转、缩放和光照变化是不变的, 但太耗时, 无法应用于实时系统.SURF(Speeded Up Robust Features)[12]特征点是SIFT特征点的快速版本, 但仍无法实时运行.ORB特征点具有较高效率, 同时具有一定的尺度不变性和旋转不变性, 广泛应用于无需GPU加速的低功耗实时系统.上述特征点在一般环境下是有效的, 但部署到光照变化或快速旋转的场景中时, 性能会显著下降.因此, 研究者开始转向基于深度学习的特征点提取方法.GCNv2[13]依据相机的真实轨迹优化特征点提取网络, 但在一些复杂的场景中真实轨迹并不可靠.最近学者们开始提出自监督学习的方法, 采用自监督的训练方式, 并不需要真实的轨迹.Ono等[14]提出LF-Net(Local Features Network), 引入一种端到端网络, 在单个模块中联合优化特征点位置和描述符.Christiansen等[15]提出UnsuperPoint, 不需要任何标签, 也不需要真实轨迹进行优化, 只需要一次训练, 可同时输出特征点分数、特征点位置偏移、特征点描述符, 但是UnsuperPoint较耗时, 无法实时运行.
还有一些工作致力于提高特征点网络的效率, Yu等[16]基于深度可分离卷积, 设计特征点提取网络, 并以此构建视觉里程计系统, 在无人机平台中验证网络的效率和有效性.Kanakis等[17]提出Zippy-Point, 采用二进制描述符归一化层及混合精度网络, 保证网络效率.Potje等[18]提出XFeat, 是一个半密集匹配的特征点提取模型, 应用基于粗略局部描述符的新型匹配细化模块, 适用于资源受限的设备.
但是, 上述大多数方法仍比传统的特征点提取方法需要更多的执行时间, 无法实时运行, 同时提取的描述符不具备几何不变性, 无法满足特征点提取的实时性和高精度的要求.
针对上述问题, 本文提出轻量化特征点及可变形描述符提取网络(Lightweight Keypoint and Defor-mable Descriptor Extraction Network, LKDD-Net), 提取特征点和可变形描述符, 不需要标签和真实轨迹.特征点位置模块和可变形描述符模块共享轻量化主干网络的计算.采用一轮训练的方式, 可同时获取特征点位置和可变形描述符.实验表明, LKDD-Net可提高特征点提取的效率并增强描述符的几何不变性, 保证特征点提取精度.
1 轻量化特征点及可变形描述符提取网络
1.1 总体框架
本文提出轻量化特征点及可变形描述符提取网络(LKDD-Net), 具有一个轻量化主干网络、特征点位置模块和可变形描述符模块.主干网络基于轻量化网络模块, 同时在可变形描述符模块中引入可变形卷积[19].每帧彩色图像输入网络中, 网络输出类似于传统的特征点提取方法, 输出分数前N高的特征点位置及其可变形描述符.LKDD-Net的网络架构如图1所示.
 | 图1 LKDD-Net结构图Fig.1 Architecture of LKDD-Net |
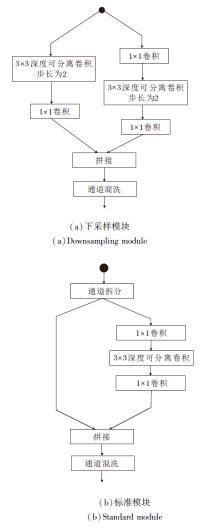
四组轻量化网络模块构成轻量化主干网络, 每组轻量化网络模块包含一个标准模块和一个下采样模块.轻量化网络模块采用通道混洗的方式, 实现高效的特征提取.
标准卷积模块可提取图像特征, 一定量的卷积模块可保证网络的计算量和参数, 提升网络精度.通过两次卷积模块后得到特征点分数.同样经过两次卷积模块后得到特征点位置偏移.特征点位置偏移和特征点分数结合后可得到最终特征点的位置.
可变形描述符模块由两个标准卷积模块和两个可变形卷积模块组成, 通过可变形卷积生成特征点的可变形描述符, 确保描述符在目标移动、旋转和缩放时具有鲁棒性.传统的特征点提取方法在一些复杂场景, 如光照条件较差、视角变化较大时, 很难完成准确的跟踪定位, 基于深度学习的特征点提取方法在这些复杂场景上具有一定的鲁棒性, 但实时性较差, 同时提取的描述符不具有几何不变性.LKDD-Net利用深度学习在特征点提取方面的优势, 结合可变形描述符, 同时采用轻量化主干网络, 提高特征点提取的效率和精度.
1.1.1 轻量化主干网络
主干网络提取图像特征, 为了保证特征点提取的实时性, 对主干网络进行轻量化处理.常规的轻量化方法会使用分组卷积的操作, 大幅减少网络的参数量, 但不同分组之间无任何联系.
如图2(a)所示, 分组卷积学到的特征非常有限, 也容易导致信息丢失.为了在保证实时性的同时, 保证网络精度, 采用通道混洗的方式.
 | 图2 分组卷积和通道混洗Fig.2 Grouping convolution and channel shuffling |
如图2(b)所示.通道混洗可保证不同通道分组之间的联系, 提升网络精度.
轻量化网络模块由一个下采样模块和一个标准模块组成, 结构如图3所示.此模块可看作是分组卷积的一种特殊情况, 即进行分组卷积(分组数为2)时, 一组保留特征不做计算, 另一组进行卷积.
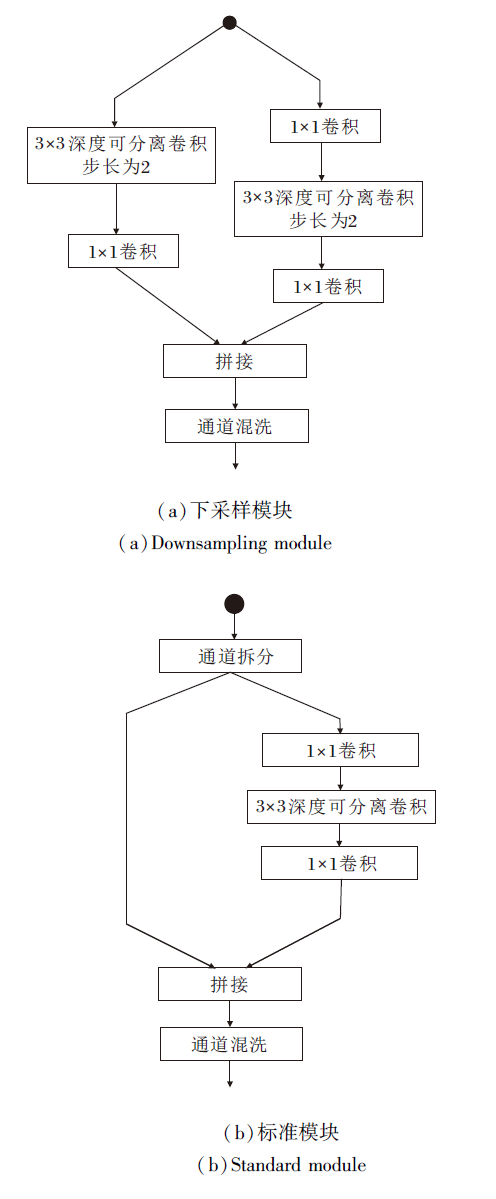 | 图3 轻量化网络模块结构图Fig.3 Structure of lightweight network module |
轻量化主干网络具有4对轻量化网络模块, 每对轻量化网络模块包含一个标准模块和一个下采样模块, 8个模块的通道数为16, 16, 32, 32, 64, 64, 128, 128.每个下采样模块将特征图高度和宽度下采样2倍, 而整个主干网络将特征图下采样8倍.最终输出图像中的条目对应输入图像中 8× 8 区域.例如:输入图像320× 240, 网络返回
条目, 每个条目包括特征点描述符、特征点分数和位置, 有效创建1 200个特征点.
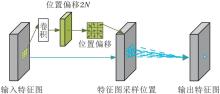
1.1.2 特征点位置模块
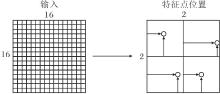
为了进行图像特征点匹配, 需要得到特征点位置, 最终输出分数前N高的特征点位置.特征点位置由特征点分数及特征点位置偏移共同得到.特征点位置偏移示意图如图4所示, 网络在每个8× 8区域预测特征点位置, 黑色箭头所指位置为特征点在每个8× 8区域的具体位置.对于16× 16的输入图像, 网络预测2× 2=4个特征点位置.单元格的中心为8× 8区域的中心位置, 可得到图像单元格的中心坐标集合C={c1, c2, …, cm}.首先将图像I输入LKDD-Net中, 同时输出特征点分数集合S={s1, s2, …, sm}和位置偏移集合P'={p'1, p'2, …, p'm}.通过位置偏移集合求解特征点最终位置, 并通过分数集合选取前N高的特征点位置.假设该解码器输出特征点偏移:
p'i=[u'i, v'i], v'i∈ (-1, 1), u'i∈ (-1, 1).
每个特征点位置偏移对应特征点位置:
pi=[ui, vi]=[ri, ci]+[u'i, v'i]
其中, σ 2表示单元格大小, σ 1表示与单元格大小之间的比率, [ri, ci]表示每个单元格中心坐标.
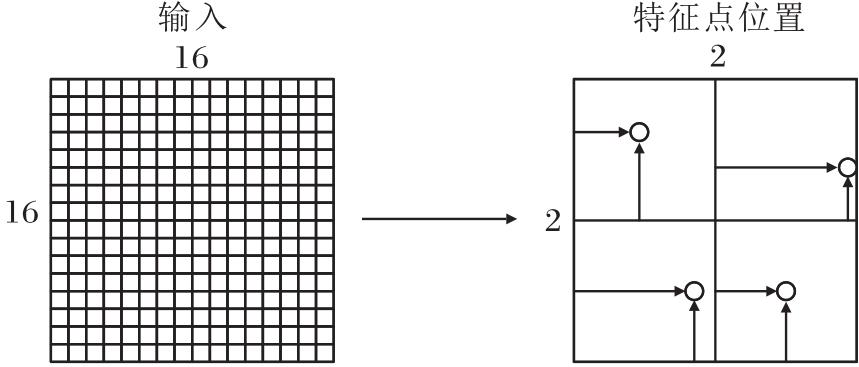 | 图4 特征点位置偏移示意图Fig.4 Schematic map of keypoint position offset |
通过式(1)可得到特征点位置集合:
P={p1, p2, …, pm}.
最后选取集合P中分数前N高的特征点位置, 作为图像I的特征点位置.
1.1.3 可变形描述符模块
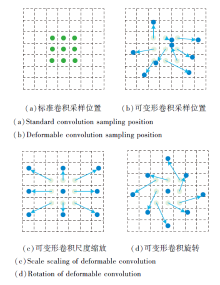
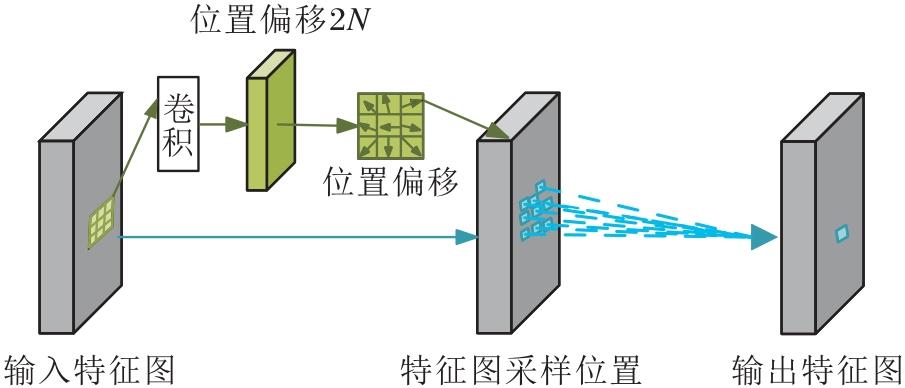
首先对低分辨率特征图进行上采样, 再通过可变形卷积模块, 输出可变形描述符.传统的卷积运算无法提供描述符所需的几何不变性, 可变形卷积模块添加二维偏移, 使卷积核能自由变形.标准卷积和可变形卷积采样位置示例如图5所示.在图中, 绿点表示标准卷积采样位置, 蓝点表示可变形卷积采样位置, 添加偏移量后可应对诸如目标移动、尺度缩放、旋转等各种情况.由图可知, 可变形卷积模块可有效地从非均匀形状中提取特征, 保证描述符的几何不变性.
 | 图5 标准卷积和可变形卷积采样位置示例Fig.5 Examples of sampling positions of standard convolution and deformable convolution |
两层标准卷积和两层可变形卷积采样位置示例如图6所示.顶部特征图上的两个激活单元位于不同尺度和形状的两个对象上, 中间图像为3× 3滤波器在顶部特征图上的采样位置, 底部图像为两层3× 3滤波器在中间特征图上的采样位置.
 | 图6 两层标准卷积和两层可变形卷积采样位置示例Fig.6 Examples of sampling positions of two-layer standard convolution and two-layer deformable convolution |
当可变形卷积堆叠时, 复合变形可更好地提取特征.标准卷积中的感受野和采样位置在整个顶部特征图上都是固定的, 传统描述符无法较好地描述特征点.可变形卷积可自适应调整采样位置, 更好地描述物体.
可变形卷积由两个特征预处理通道组成, 结构如图7所示, 上部卷积学习卷积核的采样位置.在膨胀为1的标准3× 3卷积核中, 卷积网格R可形式化为
R=
因此可通过
$y\left(l_{0}\right)=\sum_{p_{r} \in R} w\left(l_{r}\right) x\left(l_{0}+l_{r}\right)$
获得标准卷积在位置l0上的输出特征图, 其中, w(· )表示卷积权重, x(· )表示输入特征图, lr表示R中的位置.
 | 图7 可变形卷积结构图Fig.7 Structure of deformable convolution |
在可变形卷积中, 将偏移
{Δ lr|r=1, 2, …, |R|}
添至R中, 偏移位置lr+Δ lr使卷积核形成不规则形状.因此, 可变形卷积在p0上的输出特征图为:
$y\left(l_{0}\right)=\sum_{p_{r} \in R} w\left(l_{r}\right) x\left(l_{0}+l_{r}\right)$
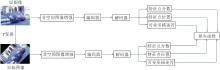
1.2 自监督模型训练
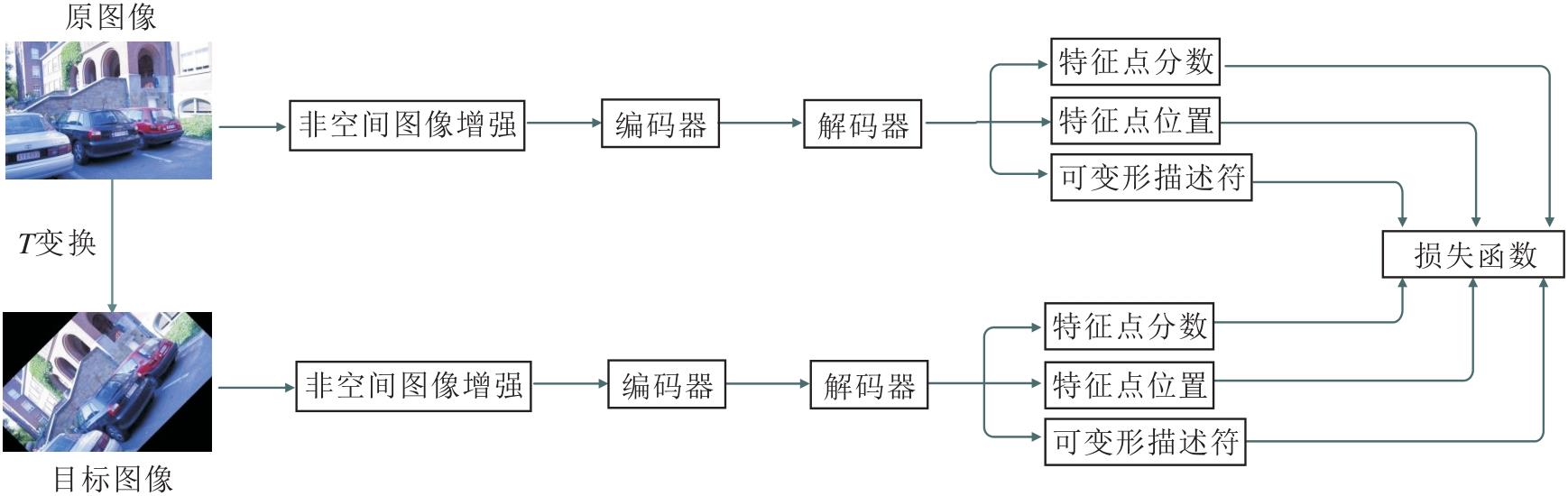
LKDD-Net使用自监督训练框架同时学习特征点分数、特征点位置偏移和可变形卷积, 过程如图8所示.在孪生网络中使用相同网络预测同幅输入图像的特征点.上半分支输入图像的原始版本, 下半分支输入图像的变换版本.下半分支的图像通过随机单应性变换T(旋转、缩放、倾斜和透视变换)进行空间变换.然后分别经过相互独立的随机非空间图像增强(如亮度)处理每个分支的图像.LKDD-Net从每个分支上预测图像的特征点及描述符.上半分支的特征点位置通过T进行变换, 在空间上对齐下半分支的点.
 | 图8 LKDD-Net训练过程Fig.8 Training process of LKDD-Net |
在自监督训练中, 对单应性变换T设定一定限制, 目的是保证图像的几何合理性和数值稳定性.缩放因子范围为 [0.9, 1.1], 避免特征点过度集中或稀疏.旋转角度范围为[-π /4, π /4], 覆盖常见的视角变化.透视变换参数范围为 [-0.2, 0.2], 避免严重扭曲导致训练不稳定.较小范围的T在训练初期有助于损失函数的快速收敛, 而逐渐增大的T能提升网络对复杂变换的鲁棒性.较大范围的T会导致源图像与目标图像的对应点分布差异显著, 如果T过于复杂(如过大的透视变换), 可能使描述符学习难度增加, 导致负样本和正样本的区分能力下降.此外, 为了避免特征点超出视野范围, 对于落在图像边界之外的特征点, 采取剔除策略, 不将其纳入损失计算中.最后, 在损失函数中通过对应特征点对训练模型.
1.3 损失函数
将特征点位置偏移损失、源图像Is和目标图像 It分别输入网络, 输出位置偏移:
p's=[u's, v's], p't=[u't, v't].
利用式(1)找到原始图像中对应的特征点:
ps=[us, vs], pt=[ut, vt].
下面通过给定的单应性变换T将源图像的特征点ps变换到目标图像中, 并得到扭曲的特征点:
通过欧氏距离找到目标图像中特征点pt中与扭曲特征点最接近的特征点:
最终特征点位置损失函数为:
$L_{\mathrm{pos}}=\sum_{i}\left\|p_{t}^{*}[i]-\hat{p}_{t}[i]\right\|_{2}, $
其中,
定义源图像中pi和目标图像中对应特征点
$\begin{array}{l}L_{\text {score }}= \\\qquad \sum_{i}\left[\left(\frac{s_{i}+\hat{s}_{i}}{2}\right) \cdot\left(d\left(\boldsymbol{p}_{i}, \hat{\boldsymbol{p}}_{i}\right)-\bar{d}\right)+\left(s_{i}-\hat{s}_{i}\right)^{2}\right], \end{array}$
其中,
$\bar{d}=\sum_{i=1}^{L}\left(\frac{d\left(\boldsymbol{p}_{i}, \hat{\boldsymbol{p}}_{i}\right)}{L}\right), $
表示平均重投影误差, d(· )表示特征点对的欧氏距离, L表示特征点对的数量.Lscore的前半部分可保证高质量的特征点对分数更高, 较低质量的特征点对分数更低; 后半部分可保证对应特征点有一致的分数.
ji表示源图像上特征点pi对应的描述符,
$L_{\mathrm{desc}}=\sum_{i} \max \left(0, \left\|j_{i}, j_{i, +}^{*}\right\|_{2}-\left\|j_{i}, j_{i, -}^{*}\right\|_{2}+m\right), $ (2)
其中m表示不同描述符的最大距离阈值.Ldesc可最小化对应特征点描述符之间的欧氏距离, 最大化非对应特征点描述符之间的欧氏距离.
最终损失函数为:
L=α Lpos+β Ldesc+γ Lscore,
采用α 、 β 、γ 平衡不同损失.
1.4 视觉里程计系统
本文提出的视觉里程计系统是基于LKDD-Net的视觉里程计系统, 采用LKDD-Net提取自监督特征点和可变形描述符.
基于传统的特征点提取方法的视觉里程计方法在一些复杂场景, 如光照条件较差、视角变化较大时, 很难完成准确的跟踪定位.基于深度学习的特征点提取方法的里程计在这些复杂场景中具有一定的鲁棒性, 但实时性较差, 提取的描述符不具有几何不变性.本文利用深度学习在特征点提取方面的优势, 采用轻量化主干网络, 结合可变形描述符, 提高视觉里程计系统的准确性和鲁棒性, 同时LKDD-Net也可在视觉里程计中实时运行.
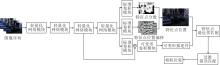
具体视觉里程计框架如图9所示, 图像序列持续输入LKDD-Net中, 通过网络输出特征点位置和可变形描述符, 选择分数最高的前300个特征点作为图像的特征点.
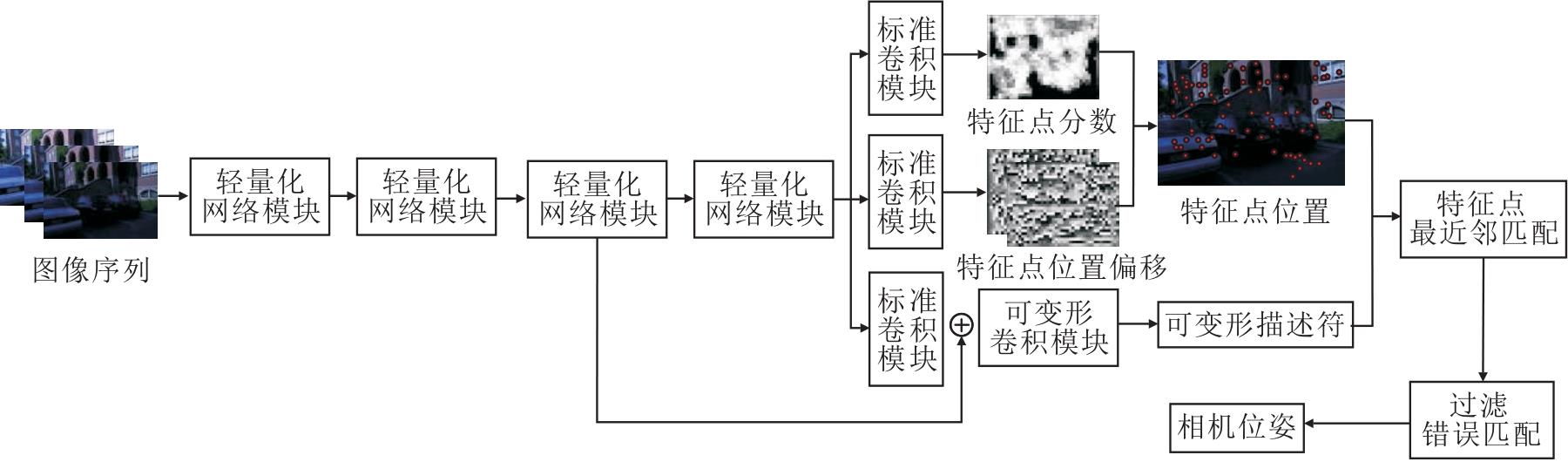 | 图9 视觉里程计框架图Fig.9 Framework of visual odometry |
为了保证系统的实时性, 本文采用最近邻匹配方法进行特征点匹配.由于图像的局部性质, 可能会出现误匹配, 降低位姿估计的精度, 所以在特征点匹配后需要剔除错误匹配对.在过滤错误匹配阶段使用随机采样一致性(Random Sample Consensus, RANSAC)优化匹配结果, 去除错误的特征点匹配对.最后根据匹配的特征点对求解相机运动.
本文实验所用相机的帧率约为30 fps.数据集相邻帧图像平均重合度约为85%.相机帧率主要由特征点提取速度决定, 较高的帧率可体现网络的实时性.高重合度则保障特征点的稳定性和匹配成功率.
2 实验及结果分析
实验平台如下:Intel i7 处理器, 32 GB内存, GTX3070显卡, ubuntu18.04操作系统.
2.1 实验数据集
本文选择COCO(Common Objects in Context)数据集[20]训练LKDD-Net, 训练时LKDD-Net完全自我监督, 仅使用图像, 无任何训练标签.
COCO数据集是一个广泛用于计算机视觉研究的大型图像数据集, 包含80个不同的物体类别, 共118 287幅训练图像, 图像涵盖多种场景, 包括室内、室外、城市、农村等.
本文选择HPatches数据集[21]的完整图像序列进行特征点评估.HPatches数据集包含57个光照场景和59个视角场景.每个场景包含6幅图像, 包括1幅参考图像、5幅目标图像和5个变换矩阵.变换矩阵将参考图像映射到5幅目标图像中的每幅图像.每种评估算法都提取每帧的点, 并将参考图像与每幅目标图像匹配, 总共产生57× 5+59× 5=580个图像对.计算所有图像对的指标并取其平均值.
对于视觉里程计系统, 选用TUM RGB-D公共数据集[22]进行评估.TUM RGB-D数据集包含多种场景, 包括对桌子的扫描、快速旋转以及绕着几乎无纹理和结构的办公柜转一圈等, 最终选用5个序列:fr1_desk、fr1_360、fr3_large_cab、fr3_nst、fr3_ office、fr3_nnf.这5个序列包含一些复杂的场景, 如快速旋转、无纹理或模糊的场景.
2.2 评价指标
重复率可衡量特征点的质量, 是两个视角观察的点数与总点数之间的比率.对于平面场景, 可使用单应性矩阵将点从一个视角简单映射到另一个视角, 建立两个摄像机视角之间的点对应关系.考虑两个对应点之间的定位误差, 如果低于ρ 像素, 定义为对应的点.为了只评估在两个视角中均可观察到的点, 重复率只包括两个视角共享区域中的点.
定位误差是指在两个相机视角中对应点的平均误差, 计算时仅包含距离低于ρ 像素的点对.
单应性准确度评估整个验证集上单应性的平均准确性, 是正确的单应性估计数量与单应性估计总数的比率.正确的单应性是指估计值与真实值的单应性误差小于给定的误差ε .
匹配分数衡量描述符的匹配精度, 即描述符采用最近邻方法匹配成功的特征点与共享区域中所有特征点之间的比率.
视觉里程计系统的评估方式采用绝对轨迹误差(Absolute Trajectory Error, ATE), 测量里程计的精度.
2.3 对比实验
LKDD-Net采用PyTorch进行训练.使用来自COCO数据集的11 8287幅训练图像, 训练的输入图像分辨率为320× 240.训练时设置批量大小为16, 总迭代次数为20.采用学习率为0.001的Adam(Adaptive Moment Estimation)[23]优化网络.设置式(1)中的σ 1=2, 式(2)中的m=0.2.总训练损失权重设置为α =1.0, β =1.0, γ =1.0.执行的单应性变换包括旋转、缩放和透视变换.对图像进行尺度[0.9, 1.1]、旋转[-π /4, π /4]和透视[-0.2, 0.2]的变换, 非空间图像增强包括亮度[0.5, 1.5]的颜色增强, 并以0.5的概率将彩色图像转换为灰度图像.
在HPatches数据集上进行实验, 选择如下对比方法.
1)传统的特征提取方法:ORB[1]、SIFT[11]、SURF[12].
2)基于深度学习的特征点提取方法:Super-Point[2]、KP2D[3]、LF-Net[14]、ZippyPoint[17]、 XFeat[18]、R2D2(Repeatable and Reliable Detector and Des-criptor)[24].
SIFT对尺度和旋转变化具有较强的鲁棒性, 但计算复杂度较高.SURF改进SIFT的速度, 但仍较耗费资源.ORB效率较高, 适合实时应用.LF-Net引入端到端网络, 联合优化特征点位置和描述符, 提升特征点的质量.SuperPoint通过共享编码器降低计算量, 但需要两轮训练.R2D2专注于鲁棒性和可重复性, 适合视觉任务中的关键场景.KP2D利用特征点与描述符的联合学习, 增强特征点的表达能力.ZippyPoint采用二进制描述符和混合精度网络, 提升效率.XFeat提供半密集匹配能力, 设计新的匹配细化模块, 适合资源受限设备.
在每幅图像中提取特征点, 低分辨率图像选择分数最高的前300个特征点作为图像特征点, 高分辨率图像选择前1 000个特征点作为图像特征点, 设置ρ =3, 误差ε =3.除了定位误差之外, 其它指标值越高方法性能越优.
网络生成两幅图像的特征点和描述符, 使用最近邻方法匹配描述符, 使用RANSAC匹配特征点位置以估计单应性矩阵.
分别选取图像分辨率为320× 240和640× 480, 各方法的指标值结果如表1和表2所示, 表中黑体数字表示最优值, 斜体数字表示次优值.
| 表1 图像分辨率为320× 240时各方法的指标值对比 Table 1 Comparison of metric values for different methods at an image resolution of 320× 240 |
| 表2 图像分辨率为640× 480时各方法的指标值对比 Table 2 Comparison of metric values for different methods at an image resolution of 640× 480 |
由表1和表2可得, 基于深度学习的特征点提取方法在大多数指标上都优于传统的特征点提取方法.传统的特征点提取方法中SIFT表现最优, 基于深度学习的特征点提取方法中XFeat最优, 但LKDD-Net在定位误差、单应性准确度和匹配分数上都优于两者, 由此验证其在特征点提取任务中的有效性.
LKDD-Net在320× 240分辨率图像上表现更优, 这是由于LKDD-Net训练时采用320× 240分辨率, 更适合320× 240分辨率图像.
ORB、SIFT、SuperPoint、KP2D、ZippyPoint、XFeat、LKDD-Net在HPatches数据集上的可视化结果如图10所示, 选取Hpatches数据集上光照变化、光照条件较差和视角变化较大的场景, 这些复杂的情况是传统的特征点提取方法无法应对的.
 | 图10 各方法在不同场景下的特征点匹配可视化结果Fig.10 Visualization results of feature point matching for different methods in different scenarios |
由图10可知, 在这3种情况下, 传统的特征点提取方法性能都弱于基于深度学习的特征点提取方法, 传统的特征点提取方法在光照条件较差、视角变化较大时, 存在大量误匹配的情况, 这是由于其不具备处理场景光照条件较差和视角变化较大的能力.基于深度学习的特征点提取方法在训练时采用光照图像, 增强光照鲁棒性, 同时提取特征点的重复率更高, 因此在光照条件较差和视角变化较大时具有更好的鲁棒性.相比其它基于深度学习的特征点提取方法, LKDD-Net性能更优, 这是由于LKDD-Net提取可变形描述符, 描述符采样的位置是可变的, 因此具有较好的几何不变性, 能在这三种场景中产生更优表现.
2.4 消融实验
LKDD-Net的主要改进为轻量化主干网络及可变形描述符模块.本节定义如下网络.1)V0.未使用轻量化网络模块和可变形卷积模块的网络, 为了保证网络的完整性, 主干网络和描述符解码器设为标准卷积模块, 输入输出的通道数与LKDD-Net保持一致.2)V1.在V0的基础上将主干网络的标准卷积模块替换为轻量化网络模块.3)V2.在V0的基础上将描述符解码器的标准卷积替换为可变形卷积.
4种网络的消融实验结果如表3所示, 表中黑体数字表示最优值, 斜体数字表示次优值.
| 表3 不同变体的消融实验结果 Table 3 Results of ablation experiment on different variants |
由表3可见, 相比V0, V1采用更高效的主干网络, 提高系统效率, 同时性能与V0接近.相比V0, V2采用可变形描述符, 性能更优.LKDD-Net在定位误差、单应性准确度和匹配分数中取得最优值, 表明其比V2更高效.
2.5 里程计评估
本文基于LKDD-Net提取特征点构建里程计系统, RANSAC迭代次数统一设为100.选择如下对比方法.1)传统的特征点提取方法:ORB-SLAM2[25].2)直接法:ElasticFusion[26].3)基于深度学习提取特征点的VSLAM系统:GCNv2[13]、DXSLAM[27]、DPVO(Deep Patch Visual Odometry)[28].DPVO是目前最先进的基于深度学习的视觉里程计算法之一.
各方法在TUM RGB-D数据集上5个序列轨迹误差对比结果如表4所示.在表中, -表示方法在该序列中定位失败, 黑体数字表示最优值, 斜体数字表示次优值.
| 表4 各方法的绝对轨迹误差对比 Table 4 Comparison of absolute trajectory errors among different methods m |
由表4可见, 对比方法都在一些序列中遇到定位失败的问题, 而LKDD-Net在所有测试序列中都跟踪良好, 这是由于里程计采用LKDD-Net进行特征点提取, 具有高效的主干网络及可变形描述符.
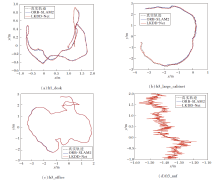
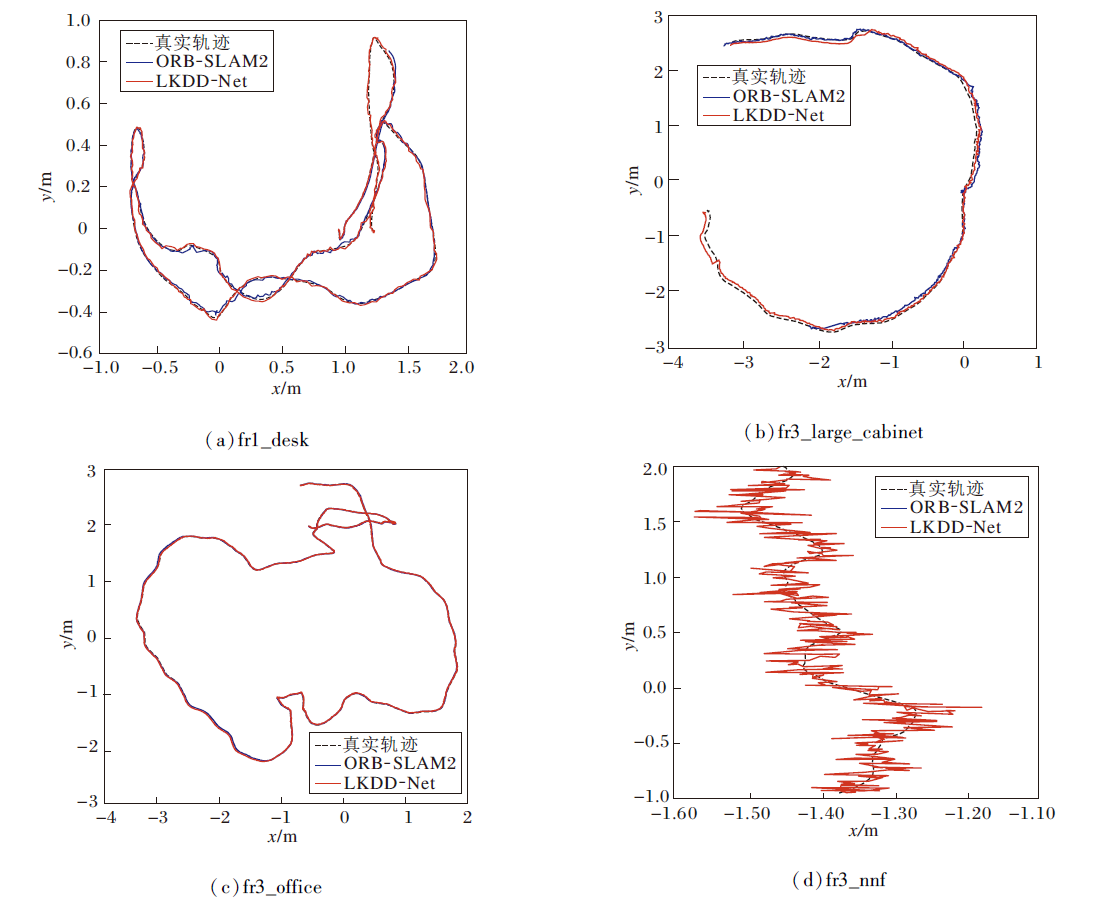
LKDD-Net和ORB-SLAM2可视化轨迹对比如图11所示.
 | 图11 LKDD-Net与ORB-SLAM2的轨迹对比Fig.11 Comparison of trajectories between LKDD-Net and ORB-SLAM2 |
fr1_desk序列为相机绕着一台桌子转了一圈, 存在快速旋转的场景, ORB-SLAM2的特征点质量较差, 最终定位失败, LKDD-Net取得较优效果.fr3_ large_cabinet序列为相机绕着一个大型柜子转了一圈, 该柜子几乎无纹理和结构, 大部分是平面和直角, LKDD-Net在弱纹理的场景下轨迹优于ORB-SLAM2.fr3_office序列为相机穿过具有许多纹理和结构的家庭和办公室场景, 轨迹的终点与起点重叠, 因此存在一个大的回环, 本文里程计并不包含回环检测, 但仍取得与ORB-SLAM2接近的轨迹.fr3_nnf序列为相机沿着平面木制表面移动大约2 m, 几乎没有可见的结构和纹理, LKDD-Net仍实现定位, 这主要依靠其高质量的特征点及描述符, x轴方向产生的波动是因为图(d)中y轴的尺度为x轴的10倍, 所以x轴波动更明显.
由图11可见, LKDD-Net实现全部序列的跟踪, 而ORB-SLAM2在其中三个序列都定位失败, 由此验证LKDD-Net特征点提取网络的有效性和鲁棒性.
2.6 运行时间
特征点提取作为一种面向实际应用的技术, 实时性是其重要评价指标之一.本文基于深度学习的方法提取特征点, 所以选择如下特征点提取方法进行对比:SuperPoint、R2D2、KP2D、LF-Net、ZippyPoint、X-Feat.对于每种方法, 输入图像分辨率为320× 240, 并提取300个特征点.评价指标包括参数量、点乘累加计算量(Giga Multiply-Accumulation Opera-tions per Second, GMACs).具体结果如表5所示, 表中黑体数字表示最优值, 斜体数字表示次优值.由表可见, R2D2的参数数量最少, 但计算量较大.相比其它方法, LKDD-Net保持少量的参数量和最低的计算量.
| 表5 各方法的参数量和计算量对比 Table 5 Comparison of parameter count and computational complexity among different methods |
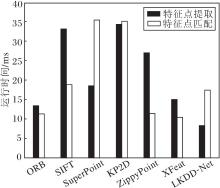
各方法特征点提取和特征点匹配耗时对比如图12所示, 实验图像选取Hpathes数据集上分辨率为320× 240的彩色图像, 每次提取 300个特征点, 运行时间为每种方法在所有图像上提取300个特征点时间之和的平均值.特征点匹配采用Hpathes数据集上同个场景中的两幅图像, 首先使用该方法提取特征点, 再计算两幅图像的匹配时间, 所有方法统一采用最近邻方法进行匹配, 最终的匹配时间为所有图像对匹配时间相加求平均值.
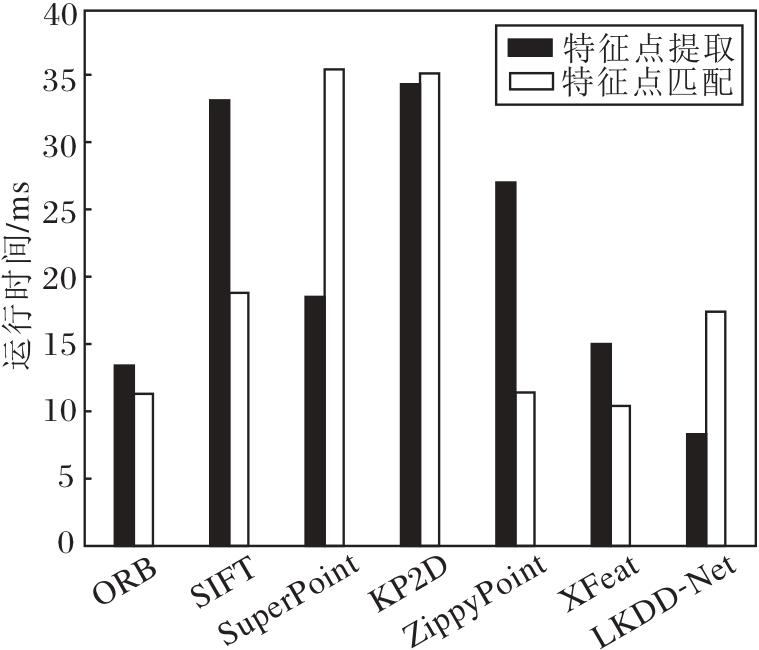 | 图12 各方法的特征点效率对比Fig.12 Keypoint efficiency comparison of different methods |
由图12可见, ORB作为常用方法, 具有较好的实时性.SIFT由于较大的计算量导致特征点提取时间较长, 无法实时运行.SuperPoint和KP2D由于采用256位的浮点描述符, 导致匹配时间远超其它方法.ZippyPoint由于采用二进制描述符, 匹配时间与ORB相近, 但特征点提取时间远超ORB.XFeat由于采用64位的描述符, 特征点匹配时间最低.LKDD-Net的特征点提取时间最低, 这是因为其采用轻量化主干网络, 大幅减少参数量和计算量.LKDD-Net特征点匹配时间略高于ORB和Zippy-Point, 这是因为ORB和ZippyPoint都采用256位二进制描述符, 而LKDD-Net采用128位浮点描述符, 浮点描述符采用欧氏距离计算两个描述符的距离, 二进制描述符采用汉明距离计算两个描述符的距离, 相比汉明距离, 欧氏距离的计算更耗时.ORB特征点能在ORB-SLAM2系统中实时运行, LKDD-Net在GPU的环境下能接近ORB特征点的速度, 满足特征点提取实时运行的要求.
3 结束语
针对基于深度学习的特征点提取方法无法实时运行以及其描述符不能满足几何不变性的缺点, 本文提出轻量化特征点及可变形描述符提取网络(LKDD-Net), 提取自监督特征点, 可同时获得特征点位置和可变形描述符.将轻量化网络模块引入主干网络中, 采用通道混洗, 增强分组卷积之间的信息交流, 提高网络效率, 同时采用可变形描述符, 增强描述符的几何不变性.在HPatches、TUM RGB-D数据集上的对比实验表明, LKDD-Net提取的特征点能在复杂环境下表现较优, 构成的视觉里程计系统具有较好的鲁棒性, 同时可实时运行.今后将继续优化LKDD-Net, 并应用于无人机等嵌入式设备中.
本文责任编委 李贻斌
Recommended by Associate Editor LI Yibin
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|